i
EFFECT SIZE PADA PENGUJIAN HIPOTESIS
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Sains
Program Studi Matematika
Oleh:
Reynaldo Kurnia Gazali NIM: 133114008
PROGRAM STUDI MATEMATIKA JURUSAN MATEMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
EFFECT SIZE ON HYPOTHESIS TESTING
Thesis
Presented as a Partial Fulfillment of the Requirements to Obtain the Degree of Sarjana Sains
in Mathematics
By:
Reynaldo Kurnia Gazali Student Number: 133114008
MATHEMATICS STUDY PROGRAM, DEPARTMENT OF MATHEMATICS FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
v
HALAMAN PERSEMBAHAN
Karya ini kupersembahkan untuk:
Tuhan Yesus Kristus, Bunda Maria yang senantiasa menyertaiku hingga saat ini,
vii ABSTRAK
Pengujian hipotesis seringkali digunakan dalam studi ataupun penelitian untuk memperoleh jawaban dari pertanyaan apakah ada perbedaan rata-rata populasi maupun apakah ada hubungan antar variabel. Pengujian hipotesis tidak memberikan makna yang lebih dari ada atau tidaknya perbedaan maupun hubungan tersebut. Oleh karena itu, penulis membahas effect size pada pengujian hipotesis, khususnya pada perbedaan rata-rata populasi. Effect size sangat penting untuk dipublikasikan pada penelitian/studi untuk melengkapi informasi pada pengujian hipotesis.
Penggunaan effect size banyak terdapat dalam analisis. Tujuan meta-analisis adalah untuk memperoleh estimasi effect size dari penggabungan beberapa/banyak studi. Penulis melakukan meta-analisis uji beda pada 5 skripsi di program studi Pendidikan Ekonomi dan Akuntansi Universitas Sanata Dharma, khususnya untuk sampel berpasangan dan 5 data hipotetik untuk sampel independen. Analisis data dilakukan dengan program R pada tingkat kepercayaan 95%.
Hasil akhir meta-analisis pada data berpasangan menunjukkan bahwa penggabungan 5 sampel skripsi memiliki perbedaan rata-rata distandardisasi sebesar 0.769. Hal ini berarti bahwa rata-rata pendapatan usaha kecil dan menengah sesudah mendapatkan kredit 0.769 kali lebih besar dari rata-rata pendapatan sebelum mendapatkan kredit. Nilai keseluruhan effect size pada data independen menunjukkan bahwa nilai perbedaan-rata distandardisasi yang diperoleh adalah 0.348. Hal ini berarti bahwa rata-rata kelompok eksperimen 0.348 kali lebih besar daripada rata-rata kelompok kontrol.
Kata kunci: pengujian hipotesis, perbedaan rata-rata yang distandardisasi,
viii ABSTRACT
Null hypothesis significance testing is often used in studies or research to get answers to the question of whether there is a difference in the population average and whether there is a relationship between variables. Null significance hypothesis testing doesn’t give more meaning rather than there is or no difference in the average population or relationship between variables. Therefore, the authors discuss the effect sizes on hypothesis testing, especially on the difference in the population average. The effect size is very important to be published in research/study to complete the information on hypothesis testing.
The use of effect sizes is found in the analysis. The purpose of meta-analysis is to obtain an estimate of the effect size of the combination of many studies. The authors perform meta-analysis of mean differences on 5 thesis in Economics and Accounting Education study program of Sanata Dharma University, especially for paired samples and 5 hypothetical data for independent sample. Data analysis was done with R program at 95% confidence intervals.
The final result of meta-analysis on paired data shows that the merging of 5 thesis samples has a standardized mean difference of 0.769. This means that the average income of small and medium businesses after obtaining credit is 0.769 times greater that the average income before getting credit. The final result of meta-analysis (summary effect) on independent data shows that the standardized mean difference obtained value is 0.348. This means that the experimental group average is 0.348 times greater than the control group average.
Keywords: hypothesis testing, standardized mean difference (SMD), Cohen’s d,
ix
KATA PENGANTAR
Puji dan syukur penulis panjatkan kepada Tuhan Yesus Kristus atas kasih karunia-Nya sehingga penulis dapat mengerjakan dan menyelesaikan skripsi ini dengan baik. Skripsi ini dibuat dengan tujuan memenuhi syarat untuk memperoleh gelar Sarjana Sains pada Program Studi Matematika, Fakultas Sains dan Teknologi, Universitas Sanata Dharma.
Penulis menyadari bahwa penulis melibatkan banyak pihak untuk membantu dalam menghadapi berbagai macam tantangan, kesulitan dan hambatan. Oleh karena itu, penulis mengucapkan terima kasih kepada:
1. Bapak Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D., selaku Dekan Fakultas Sains dan Teknologi.
2. Bapak Hartono, S.Si., M.Sc., Ph.D., selaku Ketua Prodi Matematika. 3. Ibu M.V. Any Herawati, S.Si., M.Si., selaku Dosen Pembimbing
Akademik.
4. Bapak Ir. Ignatius Aris Dwiatmoko, M.Sc., selaku Dosen Pembimbing Skripsi.
5. Romo, Bapak, dan Ibu Dosen yang telah banyak memberikan pengetahuan kepada penulis selama proses perkuliahan.
6. Kedua orang tua dan kedua adik yang telah mendukung saya selama proses pengerjaan skripsi.
7. Teman-teman Matematika 2013: Wahyu, Indra, Dion, Agung, Andre, Kristo, Ambar, Inge, Bintang, Lia, Tia, Yuni, Yui, Melisa, Sorta, Sisca, Natali, Yola, Sari, Dita, Ezra yang telah memberi masukan, kebahagiaan dan motivasi.
8. Kakak kos seperjuangan, khususnya Engger Zheng yang telah memberi kritik dan saran selama penulisan.
9. Kakak-kakak, teman-teman, adik kelas dan pihak lainnya yang telah membantu penulis dalam proses penulisan skripsi ini.
xii DAFTAR ISI
HALAMAN JUDUL………....i
HALAMAN PERSETUJUAN PEMBIMBING……….iii
HALAMAN PENGESAHAN………iv
HALAMAN KEASLIAN KARYA………v
HALAMAN PERSEMBAHAN……….vi
ABSTRAK……….vii
ABSTRACT………viii
KATA PENGANTAR………ix
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI…….………xi
DAFTAR ISI………..xii BAB I PENDAHULUAN………..…..1 A. Latar Belakang….………1 B. Rumusan Masalah...………..…4 C. Tujuan Penulisan……...………..…..4 D. Manfaat Penulisan…………...………...4 E. Metode Penulisan………...………..…4 F. Sistematika Penulisan……….……….……….5
BAB II UJI HIPOTESIS PERBEDAAN RATA-RATA..………...6
A. Statistika Inferensial………...…..6
B. Distribusi Sampling………....16
C. Pendugaan Parameter………..……...32
1. Selang Kepercayaan………...33
2. Selang Kepercayaan bagi Perbedaan Rata-rata Populasi……….39
3. Observasi Berpasangan………....48
D. Hipotesis Statistik………..51
1. Konsep Umum Hipotesis Statistik………...51
2. Pengujian Hipotesis Statistik………...55
xiii
E. Uji Hipotesis Rata-rata Satu Populasi…………..………..…....73
1. Uji Hipotesis Rata-rata Satu Populasi untuk Sampel Besar………….73
2. Uji Hipotesis Rata-rata Satu Populasi untuk Sampel Kecil………….80
F. Uji Hipotesis Rata-rata Dua Populasi……….………...83
1. Uji Normalitas dan Uji Homogenitas Variansi………83
2. Pengujian Hipotesis Rata-rata Dua Populasi dengan Variansi Populasi Diketahui…………...……….………..85
3. Pengujian Hipotesis Rata-rata Dua Populasi dengan Variansi Kedua Populasi Tidak Diketahui tetapi Sama Besar…………...…………....86
4. Pengujian Hipotesis Rata-rata Dua Populasi dengan Variansi Kedua Populasi Tidak Diketahui dan Variansi Tidak Sama...88
5. Uji Hipotesis Rata-rata Dua Populasi untuk Sampel Berpasangan….89 BAB III EFFECT SIZE COHEN………….…….………...………..…………...90
A. Dari Uji Signifikansi ke Effect Size………90
B. Jenis Effect Size...97
C. Perbedaan Rata-rata yang Distandardisasi………..……….101
1. Cohen’s 𝑑………….………..102
2. Selang Kepercayaan pada Effect Size 𝑑...113
D. Meta-Analisis pada 𝑑...116
1. Model Meta-Analisis………..116
2. Perhitungan Meta-Analisis pada 𝑑...123
3. Analisis Sensitifitas………125
Bab IV PENERAPAN EFFECT SIZE PADA HASIL-HASIL PENELITIAN..127
A. Meta-Analisis pada Data Berpasangan………...127
B. Meta-Analisis pada Data Independen……….140
BAB V KESIMPULAN………..156
A. Kesimpulan………..156
B. Saran………157 DAFTAR PUSTAKA
xiv
DAFTAR TABEL
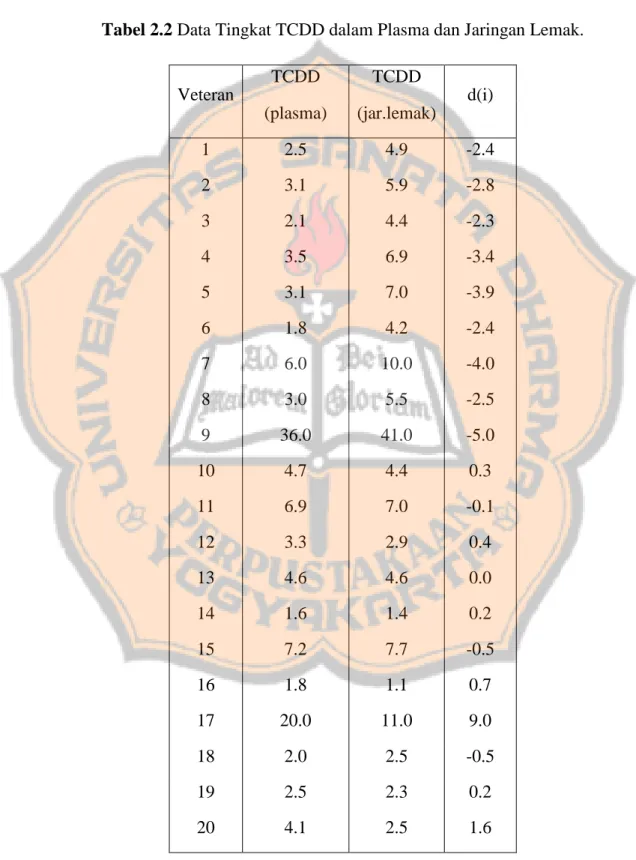
Tabel 2.1 Pengukuran Lamanya Waktu Perakitan Perangkat………..44 Tabel 2.2 Data Tingkat TCDD dalam Plasma dan Jaringan Lemak………50 Tabel 2.3 Kemungkinan Situasi dalam Pengujian Hipotesis Statistik………….60 Tabel 3.1 Nilai Kenyamanan untuk Dua Kelompok Independen………..105 Tabel 3.2 Nilai Kenyamanan untuk Pengujian Satu Kelompok Sebelum dan Sesudah Percobaan………….………112 Tabel 4.1 Nilai 𝑃 pada Data Berpasangan dengan Uji Kolgomorov-Smirnov..128 Tabel 4.2 Perhitungan Data Berpasangan dengan Model Efek Tetap...133 Tabel 4.3 Meta-analisis Rata-rata Selisih Pendapatan Usaha Kecil, Menengah Sebelum dan Sesudah Mendapatkan Kredit dengan Model Efek
Tetap……….…………..134 Tabel 4.4 Perhitungan Data Berpasangan dengan Model Efek Acak….……...137 Tabel 4.5 Meta-analisis Rata-rata Selisih Pendapatan Usaha Kecil, Menengah Sebelum dan Sesudah Mendapatkan Kredit dengan Model Efek
Acak……….………..138 Tabel 4.6 Uji Homogenitas Variansi dengan Uji Levenne…….………...141 Tabel 4.7 Uji 𝑡 dengan Tingkat Signifikansi 0.05……….142 Tabel 4.8 Perhitungan Data Independen dengan Model Efek Tetap……….…147 Tabel 4.9 Perbedaan Rata-rata (Standardized Mean Difference/ SMD) Kelompok Eksperimen dan Kelompok Kontrol dengan Model Efek Tetap...149 Tabel 4.10 Perhitungan Data Independen dengan Model Efek Acak…………151 Tabel 4.11 Perbedaan Rata-rata (Standardized Mean Difference/ SMD)
Kelompok Eksperimen dan Kelompok Kontrol dengan Model Efek Acak………...………..153
xv
DAFTAR GAMBAR
Gambar 2.1 Kriteria Keputusan untuk Menguji Hipotesis dengan Rata-rata Tertentu………...………...56 Gambar 2.2 Kurva Kemungkinan Hasil Data Kedua Jenis Pohon dari
Populasi yang Memiliki Dua Rata-rata Berbeda………65 Gambar 2.3 Daerah Kritis untuk Hipotesis Alternatif Dua Arah………...……75 Gambar 2.4 Nilai 𝑃 untuk Contoh 2.5.1………76 Gambar 3.1 Perbedaan Rata-rata Percobaan Insomnia Studi Lucky dan Noluck
dengan Selang Kepercayaan 95%...91 Gambar 3.2 Forest Plot yang Menggabungkan Hasil Lucky, Noluck
dan Kombinasi Meta-analisis (MA)…..…...………117 Gambar 3.3 Contoh Funnel Plot dengan Model Efek Acak……...…....…….125 Gambar 4.1 Gambar Funnel Plot Meta-analisis Data Berpasangan…...…….139 Gambar 4.2 Forest Plot Data Berpasangan untuk Model Efek Tetap dan Model
Efek Acak………...……….140 Gambar 4.3 Forest Plot Data Independen untuk Model Efek Tetap.……….154 Gambar 4.4 Forest Plot Data Independen untuk Model Efek Acak….….….154 Gambar 4.5 Funnel Plot Meta-analisis Perbedaan Rata-rata Kelompok
1 BAB I PENDAHULUAN
A. Latar Belakang
Ketika kita membaca tentang penelitian empiris, pertanyaan yang muncul pertama kali adalah seberapa penting efek yang dihasilkan. Dalam statistik, informasi tentang kekuatan efek tersebut dikenal dengan istilah effect size. Istilah
effect size pertama kali diungkapkan oleh Gene Glass (1976) di San Fransisco.
Glass menyebut istilah effect size sebagai suatu nilai standar yang dapat diberlakukan operasi hitung dan dapat dibandingkan antara pengaruh variabel satu dengan lainnya. Istilah ini muncul saat Glass menemukan kesalahan penelitian psikoterapi yang dilakukan H.J Eysenck. Eysenck mengklaim bahwa psikoterapi tidak efektif dan tidak ada data evaluatif untuk membuktikan sebaliknya. Glass membuktikan kesalahan tersebut dengan kemampuan statistik. Glass menghitung
effect size berdasarkan 375 studi untuk efek terapi: “ada perbedaan rata-rata pada
variabel hasil antara subjek perlakuan dan tanpa perlakuan dibagi dengan standar deviasi kelompok”. Effect size inilah yang dikenal dengan Cohen’s 𝑑.
Pada tahun 1999, istilah effect size mulai dikembangkan oleh American
Psychological Association (APA) sebagai ukuran kekuatan hubungan antara dua
variabel pada populasi statistik atau sampel berbasis perkiraan kuantitas. Olejnik dan Algina (2003) dalam jurnalnya menyatakan bahwa effect size merupakan ukuran mengenai besarnya efek suatu variabel pada variabel lain, besarnya perbedaan maupun hubungan yang bebas dari pengaruh besarnya sampel. Hunt (1997) melaporkan bahwa Glass mendeskripsikan hasil penelitian dalam langkah-langkah yang besar, yaitu penelitian tidak hanya berbicara tentang pengaruh terhadap subjek, melainkan seberapa besar pengaruh tersebut. Hal inilah yang merupakan tujuan penggunaan effect size.
Pengujian hipotesis dengan menggunakan teknik analisis statistik sering digunakan untuk mengetahui ada atau tidaknya pengaruh terhadap subjek pada penelitian. Ada beberapa pertimbangan dalam memilih teknik analisis statistik univariat (teknik analisis yang hanya melibatkan satu variabel) yaitu:
a. Berdasarkan masalah yang diuji, yaitu masalah rata-rata satu populasi, dua populasi dan lebih dari dua populasi, masalah asosiasi/relasi antar variabel yang skalanya sama/tidak sama.
b. Berdasarkan jenis sampel, yaitu pengambilan sampel independen dan pengambilan sampel berpasangan.
c. Berdasarkan pemenuhan asumsi, yaitu asumsi-asumsi tentang distribusi variabel populasi dipenuhi (statistika parametrik) dan tidak ada asumsi spesifik tentang distribusi variabel dalam populasi (statistika non parametrik).
Pengujian hipotesis rata-rata dua populasi digunakan untuk mengetahui apakah ada perbedaan atau tidak ada perbedaan rata-rata kedua populasi. Pengujian hipotesis rata-rata dua populasi menggunakan distribusi sampling dari 𝑡 yang dikenal dengan distribusi 𝑡. Distribusi ini menggunakan pendekatan distribusi Normal Standar. Kedua distribusi ini bergantung pada ukuran sampel. Oleh karena itu, pengujian hipotesis juga akan selalu bergantung pada ukuran sampel. Ini merupakan suatu kelemahan dalam uji hipotesis.
Penelitian empiris secara konsisten menunjukkan bahwa banyak peneliti tidak sepenuhnya memahami analisis data statistik untuk pengujian hipotesis (Schwab, 2011). Keputusan dari uji hipotesis hampir selalu dibuat berdasarkan uji signifikansi hipotesis nol tanpa memperhatikan metode statistik. Beberapa peneliti sering menginterpretasikan keputusan berupa hasil signifikansi secara statistik sebagai hasil yang penting. Padahal, signifikan di sini tidak dapat diartikan sebagai hasil yang penting, besar dan berguna bagi penelitian. Jika peneliti ingin mencari tahu seberapa besar pengaruh dan perbedaan yang dihasilkan pada penelitian, maka peneliti dapat menambahkan informasi tambahan pada pengujian
hipotesis. Informasi tersebut dapat berupa pengukuran terhadap besarnya efek atau dikenal dengan effect size.
Effect size sangat penting karena memungkinkan untuk membandingkan
besarnya efek penelitian pada pengujian hipotesis dari penelitian yang satu ke yang lainnya. Menurut Kirk (1996), pengukuran terhadap besarnya efek belum banyak dilakukan oleh peneliti-peneliti di bidang pendidikan, psikologi dan ilmu sosial. Oleh karena itu, penulis membahas pengukuran besarnya efek pada pengujian hipotesis dengan menggunakan effect size.
Effect size bergantung pada jenis parameter yang akan diuji di dalam
pengujian hipotesis. Jika parameter itu adalah perbedaan rata-rata populasi maka
effect size menunjukkan seberapa besar perbedaan itu. Effect size 𝑑 merupakan pengukuran effect size yang umum digunakan pada parameter tersebut. Permasalahan yang terkait dengan pengukuran besar kecilnya penggunaan effect
size 𝑑 adalah tidak adanya standar yang tetap.
Hedges (1988) menemukan bias pada pengukuran effect size 𝑑. Pada skripsi ini akan dilihat seberapa besar pengaruh bias tersebut pada 𝑑. Selain itu, selang kepercayaan diketahui dapat memberikan informasi tambahan bagi pengujian hipotesis. Dengan kata lain, adanya hubungan antara pengujian hipotesis dengan selang kepercayaan. Hubungan ini akan dilihat juga pada pembentukan selang kepercayaan bagi effect size 𝑑.
Penggunaan effect size banyak terdapat dalam meta-analisis, khususnya Cohen’s 𝑑. Larry Hedges (1987) menjelaskan meta-analisis sebagai teknik analisis statistik yang menggabungkan hasil dari penelitian berbeda untuk memberikan estimasi tunggal terbaik dengan selang kepercayaan di dalamnya. Meta-analisis menggunakan beberapa estimasi effect size karena pengukuran
effect size tidak dipengaruhi oleh ukuran sampel. Pada skripsi ini akan dilakukan
meta-analisis untuk sampel berpasangan pada 5 skripsi di program studi Pendidikan Ekonomi dan Akuntansi Universitas Sanata Dharma dan 5 data hipotetik untuk sampel independen.
B. Rumusan Masalah
Perumusan masalah yang akan dibicarakan pada tugas akhir ini adalah: 1. Apa yang dimaksud dengan effect size?
2. Bagaimana membentuk selang kepercayaan pada effect size 𝑑?
3. Bagaimana deskripsi effect size 𝑑 pada 5 skripsi di program studi Pendidikan Ekonomi, Akuntansi dan 5 data hipotetik?
C. Batasan Masalah
Tugas akhir ini dibatasi pada masalah-masalah sebagai berikut:
1. Efek statistik yang dibahas pada pengukuran effect size adalah effect size d. 2. Pengkajian effect size pada pengujian hipotesis untuk data yang dipilih secara
acak dan kontinu (data yang merupakan hasil pengukuran).
D. Tujuan Penulisan
Tujuan dari penulisan tugas akhir ini adalah untuk mengetahui seberapa besar effect size yang dihasilkan pada 5 skripsi di program studi Pendidikan Ekonomi dan Akuntansi, khususnya untuk sampel berpasangan dan 5 data hipotetik untuk sampel independen.
E. Manfaat Penulisan
Manfaat yang dapat diperoleh dari penulisan tugas akhir ini adalah memberi informasi kegunaan pelaporan effect size pada pengujian hipotesis.
F. Metode Penulisan
Metode yang digunakan penulis dalam tugas akhir ini adalah metode studi pustaka, yaitu dengan membaca atau mempelajari buku-buku atau jurnal-jurnal yang berkaitan dengan effect size, uji hipotesis, meta-analisis dan selang kepercayaan.
G. Sistematika Penulisan BAB I PENDAHULUAN A. Latar Belakang B. Rumusan Masalah C. Batasan Masalah D. Tujuan Penulisan E. Manfaat Penulisan F. Metode Penulisan G. Sistematika Penulisan
BAB II UJI HIPOTESIS PERBEDAAN RATA-RATA A. Statistika Inferensial
B. Distribusi Sampling C. Pendugaan Parameter D. Hipotesis Statistik
E. Uji Hipotesis Rata-rata Satu Populasi F. Uji Hipotesis Rata-rata Dua Populasi BAB III EFFECT SIZE COHEN
A. Dari Uji Signifikansi ke Effect Size B. Jenis Effect Size
C. Selang Kepercayaan pada 𝑑 D. Meta-Analisis pada 𝑑
BAB IV PENERAPAN EFFECT SIZE PADA HASIL-HASIL PENELITIAN A. Meta-Analisis pada Data Independen
B. Meta-Analisis pada Data Berpasangan BAB V PENUTUP
A. Kesimpulan B. Saran
DAFTAR PUSTAKA LAMPIRAN
6 BAB II
UJI HIPOTESIS PERBEDAAN RATA-RATA
A. Statistika Inferensial
Berdasarkan aktivitas yang dilakukan, statistika terbagi menjadi dua yaitu statistika deskriptif dan statistika inferensial. Pada bab ini akan dibahas tentang statistika inferensial yang berperan penting pada pengujian hipotesis dan pendugaan parameter. Statistikawan menggunakan hukum dasar probabilitas dan statistika inferensial untuk menarik kesimpulan tentang sistem ilmiah. Informasi dikumpulkan dalam bentuk sampel atau koleksi pengamatan. Sampel dikumpulkan dari populasi, yang merupakan kumpulan semua individu atau masing-masing item dari jenis tertentu. Suatu konstanta yang merupakan karakteristik populasi dinamakan parameter.
Definisi 2.1.1. Ruang sampel adalah himpunan yang terdiri dari semua kemungkinan titik sampel dalam suatu proses pengamatan.
Definisi 2.1.2. Variabel acak adalah fungsi bernilai real yang domainnya adalah ruang sampel.
Fungsi tertentu dari variabel acak yang diamati dalam sampel digunakan untuk menduga atau membuat keputusan tentang parameter populasi yang tidak diketahui. Misalnya, pendugaan rata-rata populasi 𝜇 dilakukan dengan mengambil sampel acak 𝑥1, 𝑥2, … , 𝑥𝑛 dari variabel acak 𝑋1, 𝑋2, … , 𝑋𝑛 dan rata-rata sampelnya
Variabel acak 𝑥̅ adalah fungsi dari variabel acak 𝑋1, 𝑋2, … , 𝑋𝑛 dan sampel berukuran 𝑛. Dengan kata lain, rata-rata sampel, yaitu 𝑥̅ adalah contoh statistik.
Definisi 2.1.3. Statistik adalah fungsi dari variabel acak yang diamati dalam sampel.
Sebagai contoh, dalam sebuah percobaan obat, sampel pasien diambil dan masing-masing diberi obat spesifik untuk mengurangi tekanan darah. Percobaan ini difokuskan pada penarikan kesimpulan tentang populasi pasien yang menderita hipertensi. Jadi, tujuan dari statistika inferensial adalah informasi yang terdapat dalam sampel digunakan untuk membuat kesimpulan tentang populasi di mana sampel diambil.
Definisi 2.1.4. Statistika inferensial adalah teknik analisis statistik yang terdiri dari beberapa metode statistik untuk dapat membuat kesimpulan atau generalisasi tentang populasi.
Definisi 2.1.5. Fungsi 𝑓(𝑥) adalah fungsi densitas probabilitas untuk variabel acak kontinu 𝑋, jika
1) 𝑓(𝑥) ≥ 0, untuk setiap 𝑥 ∈ ℝ. 2) ∫−∞∞ 𝑓(𝑥) 𝑑𝑥 = 1.
Fungsi Pembangkit Momen
Pada subbab ini akan dijelaskan fungsi pembangkit momen yang berkaitan dengan Teorema dalam distribusi sampling.
Definisi 2.1.6. Momen ke-𝑘 variabel acak 𝑋 diberikan oleh 𝜇′𝑘= 𝐸(𝑋𝑘) = { ∑ 𝑥𝑘𝑓(𝑥) 𝑥 , jika 𝑋 diskrit, ∫ 𝑥𝑘𝑓(𝑥) 𝑑𝑥 ∞ −∞ , jika 𝑋 kontinu.
Berdasarkan definisi 2.1.5, rata-rata dan variansi variabel acak 𝑋 adalah 𝜇′1 = 𝐸(𝑋) = 𝜇 dan 𝜇′2− 𝜇2 = 𝐸(𝑋2) − 𝜇2 = 𝜎2.
Definisi 2.1.7. Fungsi pembangkit momen dari variabel 𝑋 diberikan oleh 𝐸(𝑒𝑡𝑋) dan dinotasikan oleh 𝑚𝑋(𝑡). Dengan kata lain,
𝑚𝑋(𝑡) = 𝐸(𝑒𝑡𝑋) = { ∑ 𝑒𝑡𝑥𝑓(𝑥) 𝑥 , jika 𝑋 diskrit, ∫ 𝑒𝑡𝑥𝑓(𝑥) 𝑑𝑥 ∞ −∞ , jika 𝑋 kontinu.
Teorema 2.1.1. Misalkan 𝑋 adalah variabel acak dengan fungsi pembangkit momen 𝑚𝑋(𝑡). Didefinisikan
𝑑𝑘
𝑑𝑡𝑘𝑚𝑋(𝑡)|𝑡=0 = 𝜇′𝑘.
Bukti:
Misalkan 𝑚𝑋(𝑡) adalah fungsi pembangkit momen yang variabel acak 𝑋
terdiferensial 𝑘 kali. 𝑑𝑘 𝑑𝑡𝑘𝑚𝑋(𝑡) = 𝑑𝑘 𝑑𝑡𝑘∫ 𝑒 𝑡𝑥𝑓 𝑋(𝑥) 𝑑𝑥 ∞ −∞ = ∫ (𝑑 𝑘 𝑑𝑡𝑘𝑒 𝑡𝑥) 𝑓 𝑋(𝑥) 𝑑𝑥 ∞ −∞
= ∫ (𝑥𝑘𝑒𝑡𝑥)𝑓 𝑋(𝑥) 𝑑𝑥 ∞ −∞ = 𝐸(𝑋𝑘)𝑒𝑡𝑥. Dengan demikian, 𝑑𝑘 𝑑𝑡𝑘𝑚𝑋(𝑡)|𝑡=0= 𝐸(𝑋𝑘)𝑒𝑡𝑥|𝑡=0= 𝐸(𝑋𝑘) = 𝜇′𝑘. ∎
Contoh 2.1.1. Misalkan 𝑋 adalah variabel acak berdistribusi Normal dengan rata-rata 𝜇 dan variansi 𝜎2. Tentukan fungsi pembangkit momen untuk 𝑋.
Penyelesaian: Fungsi probabilitas Normal dengan rata-rata 𝜇 dan variansi 𝜎2
adalah
𝑓(𝑥) = 1
𝜎√2𝜋exp [− ( 1
2𝜎2) (𝑥 − 𝜇)2] , −∞ < 𝑥 < ∞
Fungsi pembangkit momen dari 𝑋 adalah
𝑚(𝑡) = 𝐸(𝑒𝑡𝑥) = ∫ 𝑒𝑡𝑥(exp [−(𝑥 − 𝜇) 2/2𝜎2] 𝜎√2𝜋 ) 𝑑𝑥. ∞ −∞ Misalkan 𝑢 = 𝑥 − 𝜇, 𝑑𝑢 = 𝑑𝑥, maka 𝑥 = 𝑢 + 𝜇, 𝑚(𝑡) = 1 𝜎√2𝜋∫ 𝑒 𝑡(𝑢+𝜇)𝑒−𝑢2/(2𝜎2) 𝑑𝑢 ∞ −∞ = 1 𝜎√2𝜋∫ exp [(𝑢 + 𝜇)𝑡 − 𝑢2 2𝜎2] 𝑑𝑢 ∞ −∞ = 1 𝜎√2𝜋∫ exp [ −𝑢2+ 2𝜎2(𝑢 + 𝜇)𝑡 2𝜎2 ] 𝑑𝑢 ∞ −∞
Kalikan dengan 𝑒𝑡2𝜎2/2/𝑒𝑡2𝜎2/2 dan melengkapkan kuadrat, 𝑚(𝑡) = 𝑒𝜇𝑡𝑒𝑡2𝜎2/2∫ exp [−(1/2𝜎 2)(𝑢2− 2𝜎2𝑡𝑢 + 𝜎4𝑡2)] 𝜎√2𝜋 𝑑𝑢 ∞ −∞ = 𝑒𝜇𝑡+(𝑡2𝜎2/2)∫ exp [−(𝑢 − 𝜎 2𝑡)2/2𝜎2] 𝜎√2𝜋 𝑑𝑢. ∞ −∞
Oleh karena integral tersebut adalah integral dari fungsi densitas Normal dengan rata-rata 𝜎2𝑡 dan variansi 𝜎2, maka integral tersebut bernilai 1. Jadi, fungsi
pembangkit momen dari 𝑋 adalah
𝑚(𝑡) = 𝑒𝜇𝑡+(𝑡2𝜎2/2).
Definisi 2.1.8. Variabel acak 𝑋 didefinisikan berdistribusi Gamma dengan parameter 𝛼 > 0 dan 𝛽 > 0 jika dan hanya jika fungsi densitas 𝑋 adalah
𝑓(𝑥) = { 𝑥𝛼−1𝑒− 𝑥 𝛽 𝛽𝛼Γ(𝛼) , 0 ≤ 𝑥 ≤ ∞ 0, selainnya, dengan Γ(𝛼) = ∫ 𝑥𝛼−1𝑒−𝑥 ∞ 0 𝑑𝑥.
Definisi 2.1.9. Misalkan 𝑣 adalah bilangan bulat positif. Variabel acak 𝑋 dikatakan berdistribusi Chi-Square dengan derajat bebas 𝑣 jika dan hanya jika 𝑋 adalah variabel acak berdistribusi Gamma dengan parameter 𝛼 = 𝑣/2 dan 𝛽 = 2.
Contoh 2.1.2. Misalkan 𝑋 adalah variabel acak berdistribusi Chi-Square dengan rata-rata 𝑣 dan variansi 2𝑣. Tentukan fungsi pembangkit momen untuk 𝑋.
Penyelesaian:
Fungsi probabilitas Chi-Square dengan rata-rata 𝑣 dan variansi 2𝑣 adalah
𝑓(𝑥) =𝑥
(𝑣/2)−1𝑒−𝑥/2
2𝑣/2Γ(𝑣/2) , 𝑥 > 0
Fungsi pembangkit momen dari 𝑋 adalah
𝑚(𝑡) = 𝐸(𝑒𝑡𝑥) = ∫ 𝑒𝑡𝑥𝑥(𝑣/2)−1𝑒 −𝑥/2 2𝑣/2Γ(𝑣/2) ∞ 0 𝑑𝑥 = 1 2𝑣/2Γ(𝑣/2)∫ 𝑒 − (1−2𝑡)𝑥2 𝑥(𝑣/2) 𝑥 ∞ 0 𝑑𝑥 Misalkan 𝑡 <1 2, 𝑢 = (1 − 2𝑡)𝑥 𝑑𝑢 = (1 − 2𝑡)𝑑𝑥 𝑚(𝑡) = 1 2𝑣/2Γ(𝑣/2)∫ 𝑒 − 𝑢2( 𝑢 1 − 2𝑡) 𝑣/2 ∞ 0 (1 𝑢) 𝑑𝑢 = (1 − 2𝑡)−𝑣/2∫ 𝑒 − 𝑢 2𝑢(𝑣/2)−1 2𝑣/2Γ(𝑣/2) ∞ 0 𝑑𝑢
Oleh karena integral tersebut adalah integral dari fungsi densitas Gamma dengan parameter 𝛼 = 𝑣/2 dan 𝛽 = 2, maka menurut definisi fungsi probabilitas (definisi 2.1.5), integral bersebut bernilai 1. Jadi, fungsi pembangkit momen dari 𝑋 adalah
Teorema 2.1.2. Teorema Ketunggalan: Misalkan 𝑚𝑋(𝑡) dan 𝑚𝑌(𝑡) adalah fungsi pembangkit momen dari variabel acak 𝑋 dan 𝑌. Jika kedua fungsi pembangkit momen ada dan 𝑚𝑋(𝑡) = 𝑚𝑌(𝑡), untuk setiap nilai 𝑡, maka 𝑋 dan 𝑌 mempunyai
distribusi probabilitas yang sama.
Bukti dapat dilihat pada skripsi Julie, Hongkie (1999) yang berjudul Teorema Limit Pusat dan Terapannya.
Contoh 2.1.3. Misalkan 𝑍 adalah variabel acak berdistribusi Normal dengan rata-rata 0 dan variansi 1. Gunakan metode fungsi pembangkit momen untuk menemukan distribusi probabilitas dari 𝑍2.
Penyelesaian:
Fungsi pembangkit momen dari 𝑍2 adalah
𝑚𝑍2(𝑡) = 𝐸(𝑒𝑡𝑍 2 ) = ∫ 𝑒𝑡𝑧2𝑓(𝑧) 𝑑𝑧 ∞ −∞ = ∫ 𝑒𝑡𝑧2𝑒 −𝑧2/2 √2𝜋 𝑑𝑧 ∞ −∞ = ∫ 1 √2𝜋𝑒 −(𝑧2/2)(1−2𝑡) 𝑑𝑧. ∞ −∞
Jika (1 − 2𝑡) > 0 (𝑡 < 1/2), integrand dari exp [− (𝑧2 2) (1 − 2𝑡)] √2𝜋 = exp [− (𝑧2 2) (1 − 2𝑡) −1 ⁄ ] √2𝜋
identik dengan fungsi probabilitas variabel acak Normal dengan rata-rata 0 dan variansi (1 − 2𝑡)−1. Untuk membuat integralnya sama dengan 1, kalikan dengan standar deviasinya, yaitu (1 − 2𝑡)−1/2, sehingga
𝑚𝑍2(𝑡) = 1 (1 − 2𝑡)1/2∫ 1 √2𝜋(1 − 2𝑡)−1/2exp [− ( 𝑧2 2) (1 − 2𝑡) −1 ⁄ ] 𝑑𝑧. ∞ −∞
𝑚𝑍2(𝑡) =
1
(1 − 2𝑡)1/2 = (1 − 2𝑡)−1/2.
Oleh karena fungsi pembangkit momen untuk 𝑍2 identik dengan fungsi pembangkit momen untuk variabel acak Chi-Square dengan derajat bebas 𝑣 = 1 (contoh 2.1.2), maka menurut Teorema Ketunggalan, 𝑍2 berdistribusi Chi-Square dengan derajat bebas 1. Dengan demikian, fungsi probabilitas untuk 𝑈 = 𝑍2 adalah
𝑓𝑈(𝑢) = {
𝑢−1/2𝑒−𝑢/2
Γ(1/2)√2 , 𝑢 ≥ 0 0, selainnya.
Contoh 2.1.4. Misalkan 𝑋 adalah variabel acak berdistribusi Normal dengan rata-rata 𝜇 dan variansi 𝜎2. Tunjukkan bahwa
𝑍 =𝑋 − 𝜇 𝜎
berdistribusi Normal Standar dengan rata-rata 0 dan variansi 1. Penyelesaian:
Dari contoh 2.1.1, fungsi pembangkit momen dari 𝑋 adalah 𝑒𝜇𝑡+(𝑡2𝜎2/2).
Dengan cara yang sama, fungsi pembangkit momen dari 𝑋 − 𝜇 adalah 𝑒𝑡2𝜎2/2,
sehingga 𝑚𝑍(𝑡) = 𝐸(𝑒𝑡𝑍) = 𝐸(𝑒(𝑡/𝜎)(𝑋−𝜇)) = 𝑚𝑋−𝜇( 𝑡 𝜎) = 𝑒 (𝑡/𝜎)2𝜎2/2 = 𝑒𝑡2/2.
Oleh karena 𝑚𝑍(𝑡) identik dengan fungsi pembangkit momen dari variabel acak Normal Standar, maka 𝑍 berdistribusi Normal Standar dengan 𝐸(𝑍) = 0 dan 𝑉(𝑍) = 1.
Teorema 2.1.3. Misalkan 𝑋1, 𝑋2, … , 𝑋𝑛 adalah variabel acak yang saling bebas dengan fungsi pembangkit momen 𝑚𝑋1(𝑡), 𝑚𝑋2(𝑡),…, 𝑚𝑋𝑛(𝑡). Jika 𝑈 = 𝑋1+ 𝑋2+ ⋯ + 𝑋𝑛, maka
𝑚𝑈(𝑡) = 𝑚𝑋1(𝑡) x 𝑚𝑋2(𝑡) x … x 𝑚𝑋𝑛(𝑡). Bukti:
Karena variabel acak 𝑋1, 𝑋2, … , 𝑋𝑛 saling bebas, maka
𝑚𝑈(𝑡) = 𝐸(𝑒𝑡(𝑋1+𝑋2+⋯+𝑋𝑛)) = 𝐸(𝑒𝑡𝑋1𝑒𝑡𝑋2… 𝑒𝑡𝑋𝑛) = 𝐸(𝑒𝑡𝑋1) x 𝐸(𝑒𝑡𝑋2) x … x 𝐸(𝑒𝑡𝑋𝑛).
Dengan definisi fungsi pembangkit momen,
𝑚𝑈(𝑡) = 𝑚𝑋1(𝑡) x 𝑚𝑋2(𝑡) x … x 𝑚𝑋𝑛(𝑡). ∎
Teorema 2.1.4. Misalkan 𝑋1, 𝑋2, … , 𝑋𝑛 adalah variabel acak saling bebas yang berdistribusi Normal dengan 𝐸(𝑋𝑖) = 𝜇𝑖, 𝑉(𝑋𝑖) = 𝜎𝑖2, untuk 𝑖 = 1,2, … , 𝑛 dan
𝑎1, 𝑎2,…, 𝑎𝑛 adalah konstanta. Jika
𝑈 = ∑ 𝑎𝑖𝑋𝑖 =
𝑛
𝑖=1
𝑎1𝑋1+ 𝑎2𝑋2 + ⋯ + 𝑎𝑛𝑋𝑛,
maka U adalah variabel acak berdistribusi Normal dengan
𝐸(𝑈) = ∑ 𝑎𝑖𝜇𝑖 𝑛 𝑖=1 = 𝑎1𝜇1+ 𝑎2𝜇2+ ⋯ + 𝑎𝑛𝜇𝑛 dan 𝑉(𝑈) = ∑ 𝑎𝑖2𝜎 𝑖2 𝑛 𝑖=1 = 𝑎12𝜎 12+ 𝑎22𝜎22+ ⋯ + 𝑎𝑛2𝜎𝑛2.
Bukti:
Dari contoh 2.1.1, fungsi pembangkit momen dari 𝑋 adalah 𝑒𝜇𝑡+(𝑡2𝜎2/2).
Karena 𝑋𝑖 berdistribusi Normal dengan rata-rata 𝜇𝑖 dan variansi 𝜎𝑖2, maka fungsi
pembangkit momen dari 𝑋𝑖 adalah
𝑚𝑋𝑖(𝑡) = exp (𝜇𝑖𝑡 +
𝜎𝑖2𝑡2
2 ). Fungsi pembangkit momen dari 𝑎𝑖𝑋𝑖 adalah
𝑚𝑎𝑖𝑋𝑖(𝑡) = 𝐸(𝑒𝑡𝑎𝑖𝑋𝑖) = 𝑚 𝑋𝑖(𝑎𝑖𝑡) = exp (𝜇𝑖𝑎𝑖𝑡 + 𝑎𝑖2𝜎𝑖 2 𝑡2 2 ).
Karena variabel acak 𝑋𝑖 saling bebas dan 𝑎𝑖𝑋𝑖 saling bebas, untuk 𝑖 = 1,2, … , 𝑛,
maka menurut teorema 2.1.3,
𝑚𝑈(𝑡) = 𝑚𝑎1𝑋1(𝑡) x 𝑚𝑎2𝑋2(𝑡) x … x 𝑚𝑎𝑛𝑋𝑛(𝑡) = exp (𝜇1𝑎1𝑡 +𝑎1 2𝜎 1 2 𝑡2 2 ) x … x exp (𝜇𝑛𝑎𝑛𝑡 + 𝑎𝑛2𝜎 𝑛 2 𝑡2 2 ) = exp (𝑡 ∑ 𝑎𝑖𝜇𝑖 𝑛 𝑖=1 +𝑡 2 2 ∑ 𝑎𝑖 2𝜎 𝑖2 𝑛 𝑖=1 ).
Oleh karena 𝑚𝑈(𝑡) identik dengan fungsi pembangkit momen dari distribusi
Normal, maka menurut Teorema Ketunggalan, 𝑈 mempunyai distribusi Normal dengan rata-rata ∑𝑛𝑖=1𝑎𝑖𝜇𝑖 dan variansi ∑ 𝑎𝑖2𝜎
𝑖2 𝑛
B. Distribusi Sampling
Fokus utama statistika inferensial berkaitan dengan generalisasi dan prediksi. Sebagai contoh, mesin minuman ringan dirancang untuk mengeluarkan minuman dengan rata-rata 240 mililiter per minuman. Perusahaan minuman tersebut menghitung rata-rata 40 minuman dan diperoleh rata-ratanya 𝑥̅ = 236 mililiter. Berdasarkan nilai tersebut, perusahaan memutuskan bahwa mesin masih mengeluarkan minuman dengan rata-rata 𝜇 = 240 mililiter. Empat puluh minuman mewakili sampel dari populasi tak hingga minuman yang akan dikeluarkan mesin.
Dari contoh di atas, statistik dihitung dari sampel yang dipilih dari populasi. Statistik juga menghasilkan berbagai pernyataan yang dibuat mengenai nilai-nilai parameter populasi yang mungkin atau mungkin tidak benar. Perusahaan minuman tersebut membuat keputusan bahwa minuman ringan mengeluarkan minuman dengan rata-rata 240 mililiter, meskipun rata-rata sampelnya 236 mililiter. Perusahaan tersebut membuat keputusan itu berdasarkan teori sampling.
Karena statistik adalah variabel acak yang bergantung hanya pada sampel yang diamati, maka statistik harus memiliki distribusi probabilitas. Distribusi probabilitas dari statistik inilah yang dinamakan distribusi sampling. Distribusi sampling dari statistik tergantung pada distribusi populasi, ukuran sampel dan metode pemilihan sampel. Distribusi sampling 𝑋̅ dinamakan distribusi sampling dari rata-rata. Distribusi sampling 𝑋̅ dengan ukuran sampel 𝑛 adalah distribusi yang terjadi ketika percobaan dilakukan berulang dan banyak nilai-nilai hasil 𝑋̅.
Distribusi sampling 𝑋̅ menggambarkan variabilitas rata-rata sampel sekitar rata-rata populasi 𝜇. Pada kasus mesin minuman ringan, pengetahuan tentang distribusi sampling 𝑋̅ memberikan perbedaan yang khas antara nilai 𝑥̅ yang diamati dan nilai rata-rata (𝜇) sebenarnya. Prinsip yang sama juga berlaku pada distribusi 𝑆2. Distribusi sampling ini menghasilkan nilai-nilai variabilitas variansi
Teorema 2.2.1. Misalkan 𝑋1, 𝑋2, … , 𝑋𝑛 adalah sampel acak saling bebas berukuran 𝑛 dari distribusi Normal dengan rata-rata 𝜇 dan variansi 𝜎2. Statistik
𝑋̅ =1 𝑛∑ 𝑋𝑖
𝑛
𝑖=1
akan berdistribusi Normal dengan rata-rata 𝜇𝑋̅ = 𝜇 dan variansi 𝜎𝑋̅2 = 𝜎2/𝑛.
Bukti: Karena 𝑋1, 𝑋2, … , 𝑋𝑛 adalah sampel acak dari distribusi Normal dengan rata-rata 𝜇, variansi 𝜎2 dan 𝑋𝑖, 𝑖 = 1,2, … , 𝑛 juga saling bebas dengan 𝐸(𝑋𝑖) = 𝜇 dan 𝑉(𝑋𝑖) = 𝜎2, maka 𝑋̅ =1 𝑛∑ 𝑋𝑖 𝑛 𝑖=1 = 1 𝑛(𝑋1) + 1 𝑛(𝑋2) + ⋯ + 1 𝑛(𝑋𝑛) = 𝑎1𝑋1+ 𝑎2𝑋2 + ⋯ + 𝑎𝑛𝑋𝑛, di mana 𝑎𝑖 = 1 𝑛, 𝑖 = 1,2, … , 𝑛.
Menurut teorema 2.1.4, karena 𝑋̅ dapat dinyatakan sebagai kombinasi linear dari 𝑋1, 𝑋2, … , 𝑋𝑛, maka 𝑋̅ berdistribusi Normal dengan
𝜇𝑋̅ = 𝐸(𝑋̅) = 𝐸[𝑎1𝑋1+ ⋯ + 𝑎𝑛𝑋𝑛] = 𝑎1𝐸(𝑋1) + ⋯ + 𝑎𝑛𝐸(𝑋𝑛) = 1 𝑛(𝜇) + ⋯ + 1 𝑛(𝜇) = 1 𝑛(𝑛𝜇) = 𝜇 dan 𝜎𝑋̅2 = 𝑉(𝑋̅) = 𝑉[𝑎1𝑋1+ ⋯ + 𝑎𝑛𝑋𝑛] = 𝑎1𝑉(𝑋1) + ⋯ + 𝑎𝑛𝑉(𝑋𝑛) = 1 𝑛2(𝜎 2) + ⋯ + 1 𝑛2(𝜎 2) = 1 𝑛2(𝑛𝜎 2) =𝜎2 𝑛 . ∎
Contoh 2.2.1. Sebuah mesin pengisi botol minuman dapat diatur sehingga debit rata-ratanya 𝜇 ons per botol. Telah diamati bahwa jumlah isian tiap botol berdistribusi Normal dengan standar deviasi 𝜎 = 1 ons. Sampel pengisian botol berukuran 𝑛 = 9 dipilih secara acak dari keluaran mesin pada hari tertentu (semua botol dengan pengaturan mesin yang sama) dan masing-masing botol diukur debitnya. Tentukan probabilitas bahwa rata-rata sampel akan berada dalam 0.3 ons rata-rata sebenarnya 𝜇 untuk pengaturan mesin yang dipilih.
Penyelesaian:
Misalkan 𝑋1, 𝑋2, … , 𝑋𝑛 adalah banyaknya botol yang akan diamati debitnya dan 𝑋𝑖, 𝑖 = 1,2, … ,9 berdistribusi Normal dengan rata-rata 𝜇 dan variansi 𝜎2 = 1. Berdasarkan teorema 2.2.1, 𝑋̅ memiliki distribusi sampling yang Normal dengan rata-rata 𝜇𝑋̅ = 𝜇 dan variansi 𝜎𝑋̅2 =
𝜎2 𝑛 = 1/9. 𝑃(|𝑋̅ − 𝜇| ≤ 0.3) = 𝑃[−0.3 ≤ 𝑋̅ − 𝜇 ≤ 0.3] = 𝑃 (−0.3 𝜎/√𝑛≤ 𝑋̅−𝜇 𝜎/√𝑛≤ 0.3 𝜎/√𝑛).
Karena (𝑋̅ − 𝜇𝑋̅)/𝜎𝑋̅ = (𝑋̅ − 𝜇)/(𝜎/√𝑛) berdistribusi Normal Standar, maka
𝑃(|𝑋̅ − 𝜇| ≤ 0.3) = 𝑃 (−0.3 1/√9≤ 𝑍 ≤ 0.3 1/√9) = 𝑃(−0.9 ≤ 𝑍 ≤ 0.9) = 1 − 2𝑃(𝑍 > 0.9) = 1 − 2(0.1841) = 0.6318.
Dengan demikian, probabilitas bahwa rata-rata sampel akan berada dalam 0.3 ons dari rata-rata populasi sebenarnya hanyalah 0.6318.
Teorema 2.2.2. Misalkan 𝑋 dan 𝑋1, 𝑋2, 𝑋3,… adalah variabel acak dengan fungsi pembangkit momen 𝑚(𝑡) dan 𝑚1(𝑡), 𝑚2(𝑡), 𝑚3(𝑡),…, 𝑚𝑛(𝑡).
Jika
lim
𝑛→∞𝑚𝑛(𝑡) = 𝑚(𝑡) , ∀𝑡 ∈ ℝ
maka fungsi distribusi dari 𝑋𝑛 konvergen ke fungsi distribusi dari 𝑋.
Bukti dapat dilihat pada buku Probability with Martingales karangan Williams, David (1991) halaman 185.
Teorema 2.2.3. Teorema Limit Pusat: Jika 𝑋̅ adalah rata-rata sampel acak berukuran 𝑛 yang diambil dari populasi dengan rata-rata 𝜇 dan variansi berhingga 𝜎2, maka bentuk limit dari distribusi
𝑍 = 𝑋̅ − 𝜇 𝜎/√𝑛,
konvergen ke fungsi distribusi Normal Standar 𝑛(𝑧; 0,1), ketika 𝑛 → ∞. Bukti: Misalkan 𝑈𝑛 = 𝑋̅ − 𝜇 𝜎/√𝑛 = 1 √𝑛( ∑𝑛𝑖=1𝑋𝑖− 𝑛𝜇 𝜎 ) = 1 √𝑛∑ 𝑍𝑖 𝑛 𝑖=1 , dengan 𝑍𝑖 = 𝑋𝑖 − 𝜇 𝜎 .
Karena variabel acak 𝑋𝑖 saling bebas dan berdistribusi Normal, maka menurut contoh 2.1.4, 𝑍𝑖, 𝑖 = 1,2, … , 𝑛 juga saling bebas dan berdistribusi Normal dengan rata-rata 𝐸(𝑍𝑖) = 0 dan variansi 𝑉(𝑍𝑖) = 1.
Karena fungsi pembangkit momen dari jumlahan variabel acak yang saling bebas adalah hasil kali masing-masing fungsi pembangkit momennya, maka
𝑚∑ 𝑍𝑖(𝑡) = 𝑚𝑍1(𝑡) x 𝑚𝑍2(𝑡) x … x 𝑚𝑍𝑛(𝑡) = [𝑚𝑍1(𝑡)] 𝑛 dan 𝑚𝑈𝑛(𝑡) = 𝑚∑ 𝑍𝑖( 𝑡 √𝑛) = [𝑚𝑍1( 𝑡 √𝑛)] 𝑛 .
Oleh karena deret Taylor di sekitar 0 dengan suku sisa bentuk Lagrange adalah
𝑚𝑍1(𝑡) = 𝑚𝑍1(0) + 𝑚′𝑍1(0)𝑡 + 𝑚′′𝑍1(𝜉)𝑡 2 2 , 0 < 𝜉 < 𝑡 dan karena 𝑚𝑍1(0) = 𝐸(𝑒 0𝑍1) = 𝐸(1) = 1 dan 𝑚′ 𝑍1(0) = 𝐸(𝑍1) = 0, 𝑚𝑍1(𝑡) = 1 + 𝑚′′𝑍1(𝜉) 𝑡2 2 sehingga 𝑚𝑈𝑛(𝑡) = [1 + 𝑚′′𝑍1(𝜉𝑛) 2 ( 𝑡 √𝑛) 2 ] 𝑛 = [1 +𝑚′′𝑍1(𝜉𝑛)𝑡 2/2 𝑛 ] 𝑛 , 0 < 𝜉𝑛 < 𝑡 √𝑛 . Ketika 𝑛 → ∞, 𝜉𝑛 → 0, maka 𝑚′′𝑍1(𝜉𝑛)𝑡2/2 → 𝑚′′ 𝑍1(0)𝑡 2/2 = 𝐸(𝑍 12)𝑡2/2 = 𝑡2/2, dengan 𝐸(𝑍12) = 𝑉(𝑍1) = 1. Dipandang lim 𝑛→∞𝑏𝑛 = 𝑏, maka lim 𝑛→∞(1 + 𝑏𝑛 𝑛) 𝑛 = 𝑒𝑏. (2.1)
Berdasarkan persamaan (𝟐. 𝟏) diperoleh lim 𝑛→∞𝑚𝑈𝑛(𝑡) = lim𝑛→∞(1 + 𝑚′′𝑍1(𝜉𝑛)𝑡2/2 𝑛 ) 𝑛 = 𝑒𝑡2/2.
Dari contoh 2.1.4, 𝑒𝑡2/2 identik dengan fungsi pembangkit momen untuk variabel
acak Normal Standar. Jadi, menurut teorema 2.2.2, fungsi distribusi 𝑈𝑛 konvergen ke fungsi distribusi dari variabel acak Normal Standar. ∎
Pendekatan distribusi Normal untuk 𝑋̅ akan bagus secara umum untuk ukuran sampel 𝑛 ≥ 30. Jika 𝑛 < 30, pendekatan baik hanya jika populasinya tidak terlalu berbeda dari distribusi Normal. Jika populasinya diketahui Normal, maka distribusi sampling dari 𝑋̅ akan mengikuti distribusi Normal persis, tidak peduli seberapa kecil ukuran sampel. Ukuran sampel 𝑛 = 30 adalah pedoman untuk menggunakan teorema 2.2.3 (Teorema Limit Pusat).
Contoh 2.2.2. Firma listrik memproduksi bola lampu yang memiliki waktu hidupnya mendekati distribusi Normal, dengan rata-rata sebesar 800 jam dan standar deviasi 40 jam. Tentukan probabilitas bahwa sampel acak dari 16 lampu akan memiliki rata-rata hidup kurang dari 775 jam.
Penyelesaian: Misalkan 𝑋̅ adalah lamanya hidup bola lampu yang berdistribusi Normal dengan 𝜇𝑋̅ = 800 dan 𝜎𝑋̅ =
40
√16= 10.
Probabilitas bahwa sampel acak dari 16 lampu akan memiliki rata-rata hidup kurang dari 775 jam adalah
𝑃(𝑋̅ < 775) = 𝑃 (𝑋̅ − 800 40/√16 <
775 − 800
10 ) = 𝑃(𝑍 < −2.5) = 0.0062. Gagasan umum distribusi sampling dan Teorema Limit Pusat sering digunakan untuk menghasilkan bukti tentang beberapa aspek penting dari distribusi, seperti parameter dari distribusi. Pada Teorema Limit Pusat, parameter yang menarik adalah rata-rata populasi 𝜇. Selain itu, penentuan nilai wajar dari rata-rata populasi 𝜇 adalah salah satu aplikasi yang paling penting dari Teorema Limit Pusat. Topik seperti pengujian hipotesis, pendugaan selang, kualitas kontrol dan lainnya memanfaatkan Teorema Limit Pusat. Contoh berikut menggambarkan penggunaan Teorema Limit Pusat yang berkaitan dengan rata-rata populasi serta penarikan kesimpulan menggunakan distribusi sampling dari 𝑋̅.
Contoh 2.2.3. Suatu proses manufaktur menghasilkan komponen silinder suku cadang untuk industri otomotif. Dalam proses tersebut diproduksi komponen yang memiliki diameter rata-rata 5 milimeter. Insinyur menduga bahwa rata-rata populasinya adalah 5 milimeter. Sebuah percobaan dilakukan pada 100 komponen yang dihasilkan oleh proses secara acak dan masing-masing komponen diukur diameternya. Diketahui bahwa standar deviasi populasi 𝜎 = 0.1 milimeter. Hasil percobaan menunjukkan diameter rata-rata sampel 𝑥̅ = 5.027 milimeter. Apakah informasi sampel ini muncul untuk mendukung atau menyangkal dugaan insinyur?
Penyelesaian: Contoh ini merefleksikan berbagai masalah yang sering diajukan dan diselesaikan dengan pengujian hipotesis. Pengujian hipotesis sendiri akan dibahas pada subbab selanjutnya. Untuk menyelesaikan masalah ini, prinsip distribusi sampling dan logika digunakan.
Jika probabilitas data menunjukkan bahwa nilai 𝑥̅ = 5.027 berbeda jauh dari rata-rata populasi (probabilitas mendekati 1), maka dugaan insinyur tersebut
tidak terbantahkan. Sebaliknya, jika probabilitas cukup kecil, maka data tidak mendukung dugaan bahwa 𝜇 = 5. Dengan kata lain, jika rata-rata populasi 𝜇 = 5, berapa probabilitas bahwa rata-rata sampel 𝑋̅ akan menyimpang sebanyak 0.027 milimeter?
Dengan Teorema Limit Pusat, probabilitasnya adalah
𝑃(|𝑋̅ − 5| ≥ 0.027) = 𝑃(𝑋̅ − 5 ≥ 0.027) + 𝑃(𝑋̅ − 5 ≤ −0.027)
= 2𝑃 (𝑋̅−50.1 √100
≥ 2.7) = 2𝑃(𝑍 ≥ 2.7)
= 2(0.0035) = 0.007.
Oleh karena itu, percobaan tersebut dengan 𝑥̅ = 5.027 tidak memberikan bukti pendukung untuk berspekulasi bahwa 𝜇 = 5. Jadi, dugaan insinyur tersebut dapat dibantah.
Teorema 2.2.4. Misalkan 𝑋1, 𝑋2, … , 𝑋𝑛 adalah sampel acak yang berdistribusi Normal dengan rata-rata 𝜇 dan variansi 𝜎2, maka statistik
𝑊 =(𝑛 − 1)𝑆 2 𝜎2 = 1 𝜎2∑(𝑋𝑖 − 𝑋̅)2 𝑛 𝑖=1
berdistribusi Chi-Square dengan derajat bebas (𝑛 − 1). Dengan demikian, 𝑋̅ dan 𝑆2 adalah variabel acak saling bebas.
Bukti: Pembuktian akan dilakukan secara khusus, yaitu untuk 𝑛 = 2. Untuk kasus 𝑛 = 2,
𝑋̅ = (1/2)(𝑋1+ 𝑋2) dan
𝑆2 = 1 2 − 1∑(𝑋𝑖 − 𝑋̅) 2 2 𝑖=1 = [𝑋1− ( 1 2) (𝑋1+ 𝑋2)] 2 + [𝑋2− ( 1 2) (𝑋1+ 𝑋2)] 2 = [1 2(𝑋1− 𝑋2)] 2 + [1 2(𝑋2− 𝑋1)] 2 = 2 [1 2(𝑋1− 𝑋2)] 2 = (𝑋1−𝑋2)2 2
Dengan demikian, untuk 𝑛 = 2,
𝑊 =(𝑛 − 1)𝑆 2 𝜎2 = (𝑋1− 𝑋2)2 2𝜎2 = ( 𝑋1− 𝑋2 √2𝜎2 ) 2 .
Menurut teorema 2.1.4, karena 𝑋1 − 𝑋2 adalah kombinasi linear yang saling bebas, maka variabel acak 𝑋1− 𝑋2 berdistribusi Normal (𝑋1 − 𝑋2 = 𝑎1𝑋1+𝑎2𝑋2, dengan 𝑎1 = 1 dan 𝑎2 = −1) dengan rata-rata
1𝜇 − 1𝜇 = 0 dan variansi (1)2𝜎2+ (−1)2𝜎2 = 2𝜎2. Oleh karena 𝑍 = 𝑋1− 𝑋2 √2𝜎2
berdistribusi Normal Standar, maka menurut Teorema Ketunggalan (lihat contoh 2.1.3), untuk 𝑛 = 2, 𝑊 =(𝑛 − 1)𝑆 2 𝜎2 = ( 𝑋1 − 𝑋2 √2𝜎2 ) 2 = 𝑍2
Untuk membuktikan 𝑋̅ dan 𝑆2 adalah variabel acak saling bebas, maka misalkan 𝑈1 = (𝑋1+ 𝑋2)/𝜎 dan 𝑈2 = (𝑋1− 𝑋2)/𝜎 adalah variabel acak saling
bebas, sehingga 𝑋̅ =𝑋1+𝑋2 2 = 𝜎𝑈1 2 dan 𝑆 2 = (𝑋1−𝑋2)2 2 = (𝜎𝑈2)2 2 .
Karena 𝑋̅ adalah fungsi dari 𝑈1 dan 𝑆2 adalah fungsi dari 𝑈2, maka bebas 𝑈1 dan 𝑈2 mengakibatkan 𝑋̅ dan 𝑆2 saling bebas. ∎
Asumsi pada Teorema Limit Pusat dan distribusi Normal adalah standar deviasi (𝜎) diketahui. Asumsi ini mungkin tidak masuk akal dalam situasi praktis. Namun, dalam banyak skenario percobaan, pengetahuan 𝜎 tentu tidak lebih masuk akal dari pengetahuan tentang rata-rata populasi 𝜇. Seringkali, pada kenyataannya, pendugaan 𝜎 harus diberikan oleh informasi sampel yang sama dalam menghasilkan rata-rata sampel 𝑥̅. Akibatnya, statistik yang digunakan untuk menarik kesimpulan pada 𝜇 adalah
𝑇 = 𝑋̅ − 𝜇 𝑆/√𝑛.
Definisi 2.2.1. Misalkan 𝑍 adalah variabel acak berdistribusi Normal Standar dan 𝑊 adalah variabel acak berdistribusi Chi-Square dengan derajat bebas 𝑣. Jika 𝑍 dan 𝑊 saling bebas, maka distribusi dari variabel acak 𝑇, dengan
𝑇 = 𝑍
√𝑊/𝑣 adalah distribusi 𝑡 dengan derajat bebas 𝑣 = 𝑛 − 1.
Teorema 2.2.5. Jika 𝑋1, 𝑋2, … , 𝑋𝑛 merupakan sampel acak dari populasi berdistribusi Normal dengan rata-rata 𝜇, variansi 𝜎2 dan
𝑋̅ =1 𝑛∑ 𝑋𝑖 𝑛 𝑖=1 dan 𝑆2 = 1 𝑛−1∑ (𝑋𝑖 − 𝑋̅) 2 𝑛 𝑖=1 ,
maka variabel acak 𝑇 = 𝑋̅−𝜇
𝑆/√𝑛 berdistribusi 𝑡 dengan derajat bebas 𝑣 = 𝑛 − 1.
Bukti: Misalkan
𝑍 = 𝑋̅ − 𝜇 𝜎/√𝑛 berdistribusi Normal Standar dan
𝑊 = (𝑛 − 1)𝑆
2
𝜎2
berdistribusi Chi-Square dengan derajat bebas 1.
Karena 𝑍 dan 𝑊 saling bebas, maka menurut teorema 2.2.4, 𝑋̅ dan 𝑆2 juga saling bebas. Jadi, dengan definisi 2.2.1 diperoleh
𝑇 = 𝑍 √𝑊/𝑣= (𝑋̅ − 𝜇)/(𝜎/√𝑛) √[(𝑛 − 1)𝑆2/𝜎2]/(𝑛 − 1)= 𝑋̅ − 𝜇 𝑆/√𝑛, berdistribusi 𝑡 dengan derajat bebas n-1. ∎
Jika ukuran sampel kecil, nilai-nilai 𝑆2 berfluktuasi dari sampel ke sampel
dan distribusi 𝑇 cukup menyimpang dari distribusi Normal Standar. Jika ukuran sampel cukup besar (𝑛 ≥ 30), maka distribusi 𝑇 tidak berbeda jauh dari distribusi Normal Standar. Namun, untuk 𝑛 < 30, penggunaan distribusi 𝑇 akan lebih akurat daripada distribusi Normal Standar.
Contoh 2.2.4. Seorang ahli kimia mengklaim bahwa rata-rata populasi hasil proses batch tertentu adalah 500 gram per mililiter bahan baku. Untuk memeriksa klaim ini, ahli tersebut mengambil sampel sebanyak 25 batch setiap bulan. Jika nilai 𝑡 jatuh antara −𝑡0.05 dan 𝑡0.05, ahli tersebut puas dengan klaimnya. Kesimpulan apa yang ia tarik dari sampel yang memiliki rata-rata 𝑥̅ = 518 gram per mililiter dan standar deviasi sampel 𝑠 = 40 gram? Asumsikan distribusi hasil mendekati Normal.
Penyelesaian: Dari tabel distribusi 𝑡 diperoleh 𝑡0.05= 1.711 dengan derajat
bebas 24. Ahli tersebut dapat puas dengan klaimnya jika sampel 25 batch menghasilkan nilai 𝑡 antara -1.711 dan 1.711. Jika 𝜇 = 500, maka
𝑡 =518 − 500
40/√25 = 2.25,
nilai tersebut di atas 1.711. Probabilitas nilai 𝑡, dengan 𝑣 = 24, sama atau lebih besar dari 2.25 adalah sekitar 0.02. Jika 𝜇 > 500, maka nilai 𝑡 yang dihitung dari sampel akan lebih masuk akal. Oleh karena itu, ahli tersebut cenderung menyimpulkan bahwa proses batch menghasilkan produk yang lebih baik daripada klaimnya.
Distribusi Sampling Perbedaan antara Dua Rata-Rata
Pada contoh sebelumnya, distribusi sampling hanya berpusat pada rata-rata tunggal 𝜇, khususnya untuk sampel berukuran besar (𝑛 ≥ 30) maupun sampel berukuran kecil (𝑛 < 30). Lebih jauh lagi, distribusi sampling tidak hanya berpusat pada rata-rata satu populasi, tetapi melibatkan dua populasi. Peneliti akan lebih tertarik dalam membandingkan percobaan yang melibatkan dua metode perbandingan. Dasar untuk perbandingannya adalah 𝜇1− 𝜇2, perbedaan pada rata-rata populasi.
Misalkan ada dua populasi, populasi pertama dengan rata-rata 𝜇1 dan variansi 𝜎12, populasi kedua dengan rata-rata 𝜇
2 dan variansi 𝜎22. Statistik 𝑋̅1
merepresentasikan rata-rata dari sampel acak berukuran 𝑛1 yang dipilih dari populasi pertama. Statistik 𝑋̅2 merepresentasikan rata-rata dari sampel acak berukuran 𝑛2 yang dipilih dari populasi kedua dan saling bebas dengan sampel
dari populasi pertama. Menurut Teorema Limit Pusat, variabel 𝑋̅1 mendekati
distribusi Normal dengan rata-rata 𝜇1 dan variansi 𝜎12/𝑛1 serta variabel 𝑋̅2
mendekati distribusi Normal dengan rata-rata 𝜇2 dan variansi 𝜎22/𝑛2.
Oleh karena 𝑋̅1 dan 𝑋̅2 saling bebas, maka
𝑋̅1− 𝑋̅2 = 𝑎1𝑋̅1+ 𝑎2𝑋̅2, dengan 𝑎1 = 1 dan 𝑎2 = −1
mendekati distribusi Normal dengan rata-rata
𝜇𝑋̅1−𝑋̅2 = 𝜇𝑋̅1− 𝜇𝑋̅2 = 𝜇1− 𝜇2 dan variansi 𝜎𝑋̅1−𝑋̅22 = 𝜎 𝑋̅1 2+ 𝜎 𝑋̅2 2 =𝜎1 2 𝑛1 + 𝜎22 𝑛2.
Teorema 2.2.6. Jika sampel berukuran 𝑛1 dan 𝑛2 yang saling bebas dan dipilih
secara acak dari dua populasi dengan rata-rata 𝜇1, 𝜇2 dan variansi 𝜎12, 𝜎
22, maka
distribusi sampling dari perbedaan rata-rata 𝑋̅1− 𝑋̅2 mendekati distribusi Normal
dengan rata-rata dan variansi diberikan oleh
𝜇𝑋̅1−𝑋̅2 = 𝜇1− 𝜇2 dan 𝜎𝑋̅1−𝑋̅22 = 𝜎12
𝑛1 +
𝜎22
Dengan kata lain,
𝑍 = (𝑋̅1 − 𝑋̅2) − (𝜇1− 𝜇2) √(𝜎12/𝑛1) + (𝜎22/𝑛2)
mendekati distribusi Normal Standar.
Bukti: Misalkan 𝑋11, 𝑋12,…, 𝑋1𝑛1adalah sampel acak saling bebas dari populasi dengan rata-rata 𝜇1, variansi 𝜎12 dan 𝑋
21, 𝑋22,…, 𝑋2𝑛2 adalah sampel acak saling bebas dari populasi dengan rata-rata 𝜇2, variansi 𝜎22.
Dipandang rata-rata sampel
𝑋̅1 =∑𝑛1𝑖=1𝑋1𝑖
𝑛1 dan 𝑋̅2 =
∑𝑛2𝑖=1𝑋2𝑖
𝑛2 . Fungsi pembangkit momen dari variabel acak 𝑋̅1 adalah
𝑚𝑋̅1(𝑡) = 𝐸 (𝑒 𝑡∑ 𝑋1𝑖 𝑛1 𝑖=1 𝑛1 ) = 𝐸 (𝑒 𝑡𝑋11 𝑛1 𝑒 𝑡𝑋12 𝑛1 … 𝑒 𝑡𝑋1𝑛1 𝑛1 ), menurut teorema 2.1.3, 𝑚𝑋̅1(𝑡) = 𝑚𝑋11( 𝑡 𝑛1) x 𝑚𝑋12( 𝑡 𝑛1) x … x 𝑚𝑋1𝑛1( 𝑡 𝑛1) = (𝑒𝜇1( 𝑡 𝑛1)+ 1 2𝜎 2 1( 𝑡 𝑛1) 2 ) 𝑛1 = 𝑒𝜇1𝑡+ 1 2 𝜎12 𝑛1𝑡 2 .
Dengan cara yang sama, fungsi pembangkit momen dari variabel acak 𝑋̅2 adalah
𝑚𝑋̅2(𝑡) = 𝑒
𝜇2𝑡+12𝜎22𝑛2𝑡2 . Dengan demikian, menurut teorema 2.1.3,
𝑚𝑋̅1−𝑋̅2(𝑡) = 𝑚𝑋̅1(𝑡)𝑚𝑋̅2(−𝑡) = 𝑒𝜇1𝑡+12𝜎12𝑛1𝑡2 𝑒−𝜇2𝑡+12𝜎22𝑛2(−𝑡)2 = 𝑒(𝜇1−𝜇2)𝑡+ 1 2( 𝜎12 𝑛1+ 𝜎22 𝑛2)𝑡 2 .
Oleh karena 𝑚𝑋̅1−𝑋̅2(𝑡) identik dengan fungsi pembangkit momen dari distribusi Normal, maka menurut Teorema Ketunggalan, 𝑋̅1− 𝑋̅2 mempunyai distribusi Normal dengan rata-rata 𝜇1−𝜇2 dan variansi 𝜎1
2
𝑛1 +
𝜎22
𝑛2. ∎
Jika 𝑛1 dan 𝑛2 lebih besar/sama dengan 30, maka pendekatan distribusi Normal untuk distribusi 𝑋̅1− 𝑋̅2 adalah baik ketika distribusi yang mendasarinya tidak terlalu jauh dari Normal. Bahkan, ketika 𝑛1 dan 𝑛2 kurang dari 30, pendekatan distribusi Normal juga cukup bagus, kecuali populasinya jelas tidak Normal. Jika populasinya Normal, maka distribusi 𝑋̅1− 𝑋̅2 akan berdistribusi Normal, tidak peduli berapapun ukuran sampel 𝑛1 dan 𝑛2.
Contoh 2.2.5. Dua percobaan independen (saling bebas) dijalankan untuk membandingkan dua jenis cat. Delapan belas spesimen dicat menggunakan cat jenis A dan waktu pengeringan direkam dalam jam. Hal yang sama juga dilakukan pada cat jenis B. Standar deviasi populasi keduanya adalah 1. Asumsikan rata-rata waktu pengeringan cat adalah sama untuk kedua jenis cat.
Tentukan 𝑃(𝑋̅𝐴− 𝑋̅𝐵> 1), dengan 𝑋̅𝐴 dan 𝑋̅𝐵 adalah rata-rata waktu pengeringan untuk sampel berukuran 𝑛𝐴 = 𝑛𝐵 = 18.
Penyelesaian: Distribusi sampling 𝑋̅𝐴− 𝑋̅𝐵 mendekati Normal dengan rata-rata 𝜇𝑋̅𝐴−𝑋̅𝐵 = 𝜇𝐴 − 𝜇𝐵 = 0.
dan variansi 𝜎𝑋̅𝐴−𝑋̅𝐵2 = 𝜎𝐴 2 𝑛𝐴 + 𝜎𝐵2 𝑛𝐵 = 1 18+ 1 18= 1 9. 𝑃(𝑋̅𝐴− 𝑋̅𝐵> 1) diberikan oleh 𝑃(𝑋̅𝐴− 𝑋̅𝐵 > 1) = 𝑃 ( 𝑋̅𝐴− 𝑋̅𝐵− 0 √1 9 > 3 ) = 𝑃(𝑍 > 3) = 1 − 𝑃(𝑍 < 3) = 1 − 0.9987 = 0.0013.
Mesin dalam perhitungan di atas didasarkan pada anggapan bahwa 𝜇𝐴 = 𝜇𝐵.
Percobaan sebenarnya dilakukan untuk tujuan menggambarkan kesimpulan tentang kesetaraan 𝜇𝐴 dan 𝜇𝐵, rata-rata waktu dua populasi pengeringan cat. Jika dua rata-rata berbeda sebanyak 1 jam (atau lebih), maka ini jelas merupakan bukti yang digunakan untuk menyimpulkan rata-rata populasi pengeringan cat tidak sama untuk kedua jenis cat.
Definisi 2.2.2. Distribusi non-sentral 𝑡 adalah distribusi sampling dari 𝑡 yang tidak terdistribusi di sekitar 0, tetapi di sekitar titik lain. Titik lain inilah yang dinamakan parameter non-sentral Δ. Parameter non-sentral Δ dapat dihitung sebagai
Δ =𝜇1− 𝜇 𝜎/√𝑛.
Dengan kata lain, distribusi non-sentral 𝑡 adalah distribusi sampling dari 𝑡 yang muncul ketika 𝜇1 benar dan variansi populasi (𝜎) diasumsikan tidak diketahui.
C. Pendugaan Parameter
Statistika inferensial dibagi atas dua bagian utama, yaitu pengujian hipotesis dan pendugaan parameter. Contoh berikut ini akan menjelaskan mengenai pendugaan parameter dan subbab berikutnya menjelaskan pengujian hipotesis. Seorang kandidat bupati ingin memperkirakan proporsi sebenarnya dari pemilih yang akan memilihnya dengan cara mengambil 100 orang secara acak untuk ditanyai pendapatnya. Proporsi pemilih yang menyukai kandidat tersebut dapat digunakan sebagai dugaan bagi proporsi populasi sebenarnya. Masalah ini jatuh di wilayah pendugaan.
Definisi 2.3.1. Suatu pendugaan titik dari beberapa parameter populasi 𝜃 adalah nilai tunggal 𝜃̂ dari statistik 𝛩̂. Nilai 𝑥̅ dari statistik 𝑋̅ yang dihitung dari sampel berukuran 𝑛 adalah penduga titik dari parameter populasi 𝜇.
Definisi 2.3.2. Misalkan 𝜃̂ adalah penduga titik untuk parameter 𝜃. Jika 𝐸(𝜃̂) = 𝜃, maka 𝜃̂ adalah penduga tak bias dan jika 𝐸(𝜃̂) ≠ 𝜃, maka 𝜃̂ dikatakan bias. Bias dari penduga titik 𝜃̂ diberikan oleh 𝐵(𝜃̂) = 𝐸(𝜃̂) − 𝜃.
Definisi 2.3.3. Suatu pendugaan selang dari parameter populasi θ adalah selang dalam bentuk 𝜃̂𝐿< θ < 𝜃̂𝑈, dengan 𝜃̂𝐿 (batas kepercayaan bawah) dan 𝜃̂𝑈 (batas kepercayaan atas) bergantung pada nilai dari statistik 𝛩̂ untuk sampel tertentu dan distribusi sampling 𝛩̂.
Berdasarkan metode pendugaan klasik, pendugaan parameter terbagi menjadi dua bagian, yaitu pendugaan titik dan pendugaan selang. Contoh berikut ini akan menjelaskan tentang pendugaan titik dan pendugaan selang. Misalnya,
ilmuwan ingin memperkirakan jumlah rata-rata merkuri (µ) yang dapat dipisahkan dari 1 ons batuan cinnabar diperoleh pada lokasi geografis. Pendugaan ini dapat dilakukan dengan dua bentuk yang berbeda. Pertama, 0.13 ons adalah penduga yang dekat dengan rata-rata populasi (µ) yang tidak diketahui. Jenis pendugaan ini adalah pendugaan titik karena nilainya tunggal. Kedua, rata-rata merkuri (µ) akan jatuh antara dua angka, misalnya, antara 0.07 dan 0.19 ons. Jenis pendugaan ini adalah pendugaan selang. Penduga titik tidak selalu tepat menduga parameter populasi sehingga digunakan pendugaan dalam bentuk selang (pendugan selang).
Informasi dalam sampel dapat digunakan untuk menghitung nilai pendugaan titik, pendugaan selang atau keduanya. Dalam kasus apapun, pendugaan yang sebenarnya dilakukan dengan menggunakan estimator (penduga) untuk parameter sasaran. Jadi, penduga adalah aturan yang dinyatakan sebagai rumus untuk menghitung nilai dugaan yang didasarkan pada pengukuran sampel.
1. Selang Kepercayaan
Penduga selang biasanya disebut selang kepercayaan. Titik ujung atas dan bawah dari selang kepercayaan masing-masing dinamakan batas atas dan bawah kepercayaan. Probabilitas bahwa selang kepercayaan (acak) akan memuat 𝜃 (kuantitas yang tetap) disebut koefisien kepercayaan. Dari sudut pandang praktis, koefisien kepercayaan menunjukkan proporsi, khususnya dalam pengambilan sampel berulang, selang yang dibentuk akan memuat parameter sasaran 𝜃.
Misalkan 𝜃̂𝐿 dan 𝜃̂𝑈 adalah batas bawah dan atas kepercayaan yang dipilih secara acak untuk parameter 𝜃. Jika
𝑃(𝜃̂𝐿 ≤ θ ≤ 𝜃̂𝑈) = 1 − 𝛼,
maka probabilitas 1 − 𝛼 adalah koefisien kepercayaan. Hasil dari selang kepercayaan yang diberikan oleh [𝜃̂𝐿, 𝜃̂𝑈] dinamakan selang kepercayaan dua sisi.
Bentuk selang kepercayaan satu sisi bagian bawah diberikan oleh 𝑃(𝜃̂𝐿 ≤ θ) = 1 − 𝛼.
Selang kepercayaan dalam bentuk di atas adalah [𝜃̂𝐿, ∞). Selang kepercayaan satu sisi bagian atas dapat dibentuk menjadi
𝑃(𝜃 ≤ 𝜃̂𝑈) = 1 − 𝛼.
Selang kepercayaan dalam bentuk di atas adalah (−∞, 𝜃̂𝑈].
Salah satu metode untuk mencari selang kepercayaan dinamakan metode Pivot. Metode ini bergantung pada suatu nilai yang disebut kuantitas Pivot serta mempunyai dua karakteristik, yaitu
a. Kuantitas Pivot merupakan fungsi dari pengukuran sampel dan parameter 𝜃 yang tidak diketahui.
b. Distribusi probabilitas dari kuantitas Pivot tidak bergantung pada parameter 𝜃.
Contoh 2.3.1. Misalkan variabel acak 𝑋 adalah observasi dari distribusi Normal dengan rata-rata 𝜇 yang tidak diketahui dan variansi 1. Tentukan selang kepercayaan 95% bagi 𝜇.
Penyelesaian:
Fungsi probabilitas bagi 𝜇 diberikan oleh
𝑓(𝑥) = 1
𝜎√2𝜋exp [− ( 1
2𝜎2) (𝑥 − 𝜇)
2] , −∞ < 𝑥 < ∞
Oleh karena 𝜇 tidak diketahui dan variansi 1, maka fungsi probabilitas dari 𝑈 =
𝑋−𝜇
𝑓𝑈(𝑢) = 1 √2𝜋exp [− 1 2𝑢 2] , −∞ < 𝑢 < ∞
Jelas bahwa 𝑈 berdistribusi Normal Standar dengan rata-rata 0 dan variansi 1. Karena 𝑈 adalah fungsi dari 𝑋 dan 𝜇, dan distribusi dari 𝑈 tidak bergantung pada 𝜇, maka 𝑈 dapat digunakan sebagai Pivot.
Koefisien kepercayaan adalah 1 − 𝛼 = 0.95, sehingga 𝑧𝛼/2= 𝑧0.025 = 1.96. Selang kepercayaan 95% bagi 𝜇 dapat dicari sebagai berikut,
𝑃(−1.96 < 𝑈 < 1.96) = 0.95
𝑃 (−1.96 < 𝑋 − 𝜇
𝜎 < 1.96) = 0.95, 𝜎 = 1 𝑃(𝑋 − 1.96 < 𝜇 < 𝑋 + 1.96) = 0.95
Jadi, selang kepercayaan 95% bagi 𝜇 adalah 𝑋 − 1.96 < 𝜇 < 𝑋 + 1.96.
Jika ukuran sampel besar, parameter sasaran 𝜃 adalah 𝜇 atau 𝜇1− 𝜇2 dan 𝜃̂ adalah penduga tak bias bagi 𝜃, maka untuk 𝑛 → ∞, Teorema Limit Pusat menjamin bahwa 𝜃̂ berdistribusi Normal dengan 𝐸(𝜃̂) = 𝜃 dan standar error 𝜎𝜃̂.
Akibatnya,
𝑍 = 𝜃̂ − 𝜃 𝜎𝜃̂
akan berdistribusi Normal Standar dan 𝑍 dapat digunakan sebagai Pivot. Dengan demikian,
𝑃(−𝑧𝛼/2≤ 𝑍 ≤ 𝑧𝛼/2) = 1 − 𝛼.
≡ 𝑃 (−𝑧𝛼/2 ≤
𝜃̂ − 𝜃
≡ 𝑃(−𝑧𝛼/2𝜎𝜃̂ ≤ 𝜃̂ − 𝜃 ≤ 𝑧𝛼/2𝜎𝜃̂) = 1 − 𝛼.
≡ 𝑃(−𝜃̂ − 𝑧𝛼/2𝜎𝜃̂ ≤ −𝜃 ≤ −𝜃̂ + 𝑧𝛼/2𝜎𝜃̂) = 1 − 𝛼.
≡ 𝑃(𝜃̂ − 𝑧𝛼/2𝜎𝜃̂ ≤ 𝜃 ≤ 𝜃̂ + 𝑧𝛼/2𝜎𝜃̂) = 1 − 𝛼.
Titik ujung untuk selang kepercayaan (1 − 𝛼)100% bagi 𝜃 diberikan oleh 𝜃̂𝐿 = 𝜃̂ − 𝑧𝛼/2𝜎𝜃̂ dan 𝜃̂𝑈 = 𝜃̂ + 𝑧𝛼/2𝜎𝜃̂,
dengan kata lain, 𝜃̂𝐿 dan 𝜃̂𝑈 adalah batas bawah dan batas atas selang kepercayaan (1 − 𝛼)100% bagi 𝜃.
Diberikan sampel acak 𝑛 (𝑛 ≥ 30) dari suatu populasi dengan rata-rata 𝜇 yang tidak diketahui dan variansi 𝜎2. Oleh karena rata-rata populasi tidak diketahui, maka 𝑥̅ (rata-rata sampel) adalah penduga bagi 𝜇.
Selang kepercayaan (1 − 𝛼)100% bagi 𝜇 diberikan oleh 𝑥̅ − 𝑧𝛼/2 𝜎
√𝑛< 𝜇 < 𝑥̅+𝑧𝛼/2 𝜎 √𝑛.
Statistik 𝜎/√𝑛 seringkali disebut standar error pendugaan 𝜇. Jika standar deviasi (𝜎) tidak diketahui, maka 𝑠 (standar deviasi sampel) adalah penduga bagi 𝜎.
Contoh 2.3.2. Nilai matematika di suatu negara dikumpulkan dengan cara mengambil sampel acak 500 sekolah. Masing-masing rata-rata sampel dan standar deviasinya adalah 501 dan 112. Tentukan selang kepercayaan 99% pada rata-rata nilai matematika tersebut.
Penyelesaian: Karena ukuran sampel besar, ini sangat memungkinkan untuk menggunakan pendekatan distribusi Normal. Misalkan 𝜇 adalah rata-rata nilai matematika di negara tersebut, sehingga 𝑥̅ adalah rata-rata sampelnya.
Selang kepercayaan 99% bagi rata-rata nilai matematika (𝜇) diberikan oleh 𝑥̅ − 𝑧𝛼/2 𝑠 √𝑛< 𝜇 < 𝑥̅+𝑧𝛼/2 𝑠 √𝑛. ≡ 𝑥̅ ± 𝑧𝛼/2 𝑠 √𝑛
Karena 1 − 𝛼 = 0.99, maka 𝛼 = 0.01. Dengan demikian, 𝑧𝛼/2= 𝑧0.005 = 2.575. Selang kepercayaan 99% bagi rata-rata nilai matematika adalah
501 ± 2.575 112
√500= 501 ± 12.9,
yang mengimplikasikan 488.1 < 𝜇 < 513.9. Selang 488.1 hingga 513.9 menunjukkan dapat dipercaya 99% memuat rata-rata nilai matematika yang sebenarnya.
Dipandang variabel acak di bawah ini
𝑇 =𝑋̅ − 𝜇 𝑆/√𝑛,
dengan 𝑛 adalah sampel berukuran kecil (𝑛 < 30), maka menurut teorema 2.2.5, variabel acak 𝑇 akan berdistribusi 𝑡 dengan derajat bebas 𝑣 = 𝑛 − 1.
Dari sifat-sifat distribusi 𝑡 yang menyerupai distribusi Normal untuk ukuran sampel yang besar, maka penggunaan distribusi 𝑡 dalam pembentukan selang kepercayaan bagi 𝜇 adalah
a. distribusi dari populasi mendekati Normal dengan standar deviasi dari populasi tidak diketahui.