fungsi diskriminan cukup untuk memisahkan k buah kelompok.
Karena fungsi-fungsi diskriminan tidak saling berkorelasi, maka komponen aditif dari V masing-masing didekati dengan khi-kuadrat dengan
Vj = n-1- p+K
2 ln 1+λ j dengan :
𝑉𝑗 : statistik V-Bartlett untuk fungsi diskriminan ke-j
Pengujian secara berturut-turut dilakukan dengan mengurangi kumulatif V1, V2, ..., dari V. Berikut ringkasan statistik uji V-Bartlett : Tabel 1. Statistik V-Bartlett
Jumlah Fungsi Statistik Uji db
Satu Fungsi V p(K-1)
Dua Fungsi V-V1 (p-1)(K-2) Tiga Fungsi V-V1-V2 (p-2)(K-3)
dst Dst dst
Analisis Diskriminan Bertatar
Analisis diskriminan bertatar dilakukan dengan melibatkan peubah bebas satu persatu ke dalam model, dimulai dari peubah bebas yang paling dapat mendiskriminasi kelompok dengan baik, kemudian peubah bebas berikutnya yang bila dikombinasikan dengan peubah bebas awal dapat meningkatkan kemampuan diskriminasi model. Prosedur ini berlanjut sampai seluruh peubah bebas telah dipertimbangkan kombinasinya dengan kriteria perbaikan kemampuan diskriminasi model. Ada kemungkinan pada tahapan berikutnya, sebuah peubah bebas yang telah dimasukkan ke dalam model pada tahapan sebelumnya menjadi peubah yang harus dikeluarkan pada tahapan ini. (Hair et. al., 1995).
Tingkat Akurasi Fungsi
Untuk mengukur akurasi fungsi melalui ketepatan prediksi anggota kelompok ke dalam kelompok awalnya digunakan Correct Classification Rate (CCR). CCR merupakan persentase kebenaran (kesesuaian) nilai amatan dan dugaannya.
CCR = jumlah klasifikasi benar x 100%
jumlah amatan
Semakin besar persentase CCR yang dihasilkan, maka tingkat akurasi yang dihasilkan semakin tinggi (Hair et. al., 1995).
BAHAN DAN METODE
Bahan
Data yang digunakan dalam penelitian ini adalah data dari 208 kabupaten yang bersumber dari Kementrian Negara Pembangunan Daerah Tertinggal (KNPDT) tahun 2008. Data terdiri dari satu peubah respon dengan 33 peubah penjelas yang dapat dilihat pada Lampiran 1.
Perangkat lunak yang digunakan dalam penelitian ini yaitu SPSS 13.0 for Windows, Minitab® Release 14, dan Microsoft Office Excel 2007.
Metode
Metode penelitian ini yaitu : 1. Deskripsi peubah respon
2. Penyusunan fungsi diskriminan dengan menggunakan 80% amatan (166 kabupaten) yang diambil secara acak dan proporsional pada setiap kelompok status ketertinggalan. Pada tahapan ini dibentuk dua model yaitu :
a. Model 1. Menggunakan seluruh peubah penjelas untuk membentuk fungsi diskriminan.
b. Model 2. Melakukan analisis diskriminan bertatar dan menggunakan peubah terpilih sebagai dasar pembentukkan fungsi diskriminan.
3. Validasi model dilakukan dengan menggunakan 42 kabupaten yang tidak dipergunakan pada langkah kedua untuk menguji tingkat keberhasilan penempatan amatan ke dalam kelompok tertentu.
Tingkat keakuratan pendugaan model dapat dilihat dari jumlah pengamatan yang telah berhasil diklasifikasikan kedalam kelompok yang sebenarnya.
4. Memilih model yang terbaik dari langkah kedua berdasarkan ketepatan klasifikasinya.
HASIL DAN PEMBAHASAN
Eksplorasi Data
Berdasarkan data KNPDT tahun 2008 terdapat 208 kabupaten yang berstatus daerah tertinggal. KNPDT menentukan 4 kategori daerah tertinggal berdasarkan 6 kriteria utama yaitu 1) ekonomi, 2) sumber daya manusia, 3)
infrastruktur, 4) keuangan daerah, 5) aksesibilitas dan 6) karakteristik daerah.
Setiap kriteria memiliki indikator-indikator yang relevan untuk menggambarkan kriteria tersebut. Dari 208 kabupaten, 11 kabupaten (5.29%) dikategorikan sebagai daerah dengan status ketertinggalan yang sangat parah, 48 kabupaten (23.08%) termasuk dalam kategori daerah sangat tertinggal, 60 kabupaten (28.85%) termasuk dalam kategori daerah tertinggal, dan 89 kabupaten (42.79%) termasuk dalam kategori daerah agak tertinggal (Tabel 2).
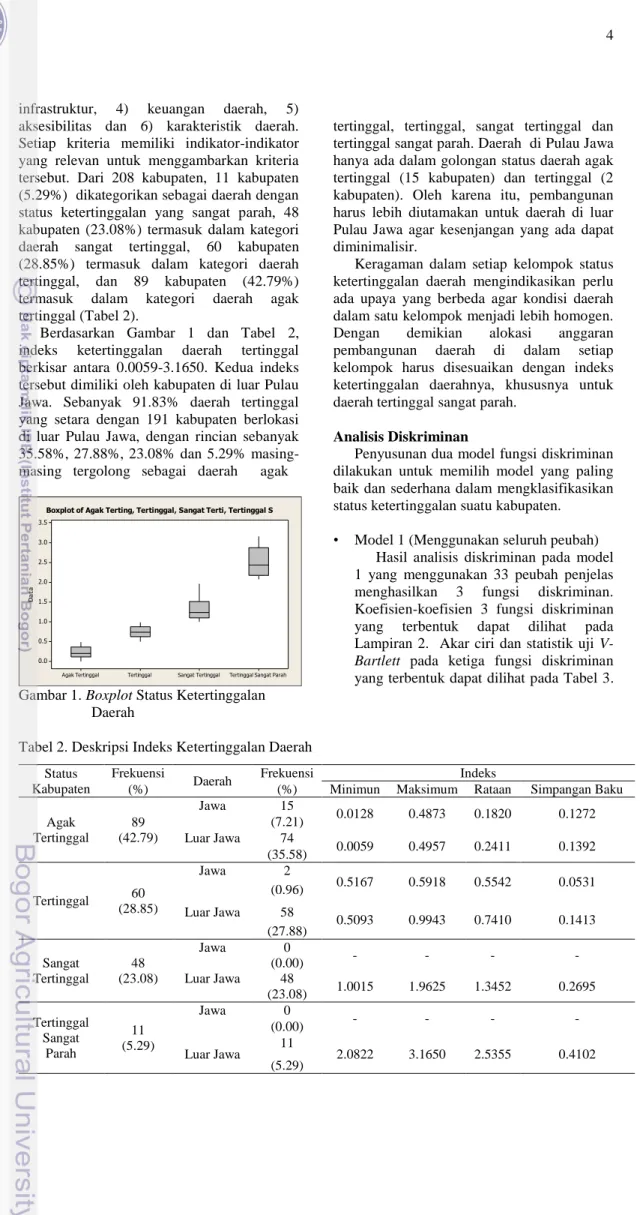
Berdasarkan Gambar 1 dan Tabel 2, indeks ketertinggalan daerah tertinggal berkisar antara 0.0059-3.1650. Kedua indeks tersebut dimiliki oleh kabupaten di luar Pulau Jawa. Sebanyak 91.83% daerah tertinggal yang setara dengan 191 kabupaten berlokasi di luar Pulau Jawa, dengan rincian sebanyak 35.58%, 27.88%, 23.08% dan 5.29% masing- masing tergolong sebagai daerah agak
Data
Tertinggal Sangat Parah Sangat Tertinggal
Tertinggal Agak Tertinggal
3.5 3.0 2.5 2.0 1.5 1.0 0.5 0.0
Boxplot of Agak Terting, Tertinggal, Sangat Terti, Tertinggal S
Gambar 1. Boxplot Status Ketertinggalan Daerah
tertinggal, tertinggal, sangat tertinggal dan tertinggal sangat parah. Daerah di Pulau Jawa hanya ada dalam golongan status daerah agak tertinggal (15 kabupaten) dan tertinggal (2 kabupaten). Oleh karena itu, pembangunan harus lebih diutamakan untuk daerah di luar Pulau Jawa agar kesenjangan yang ada dapat diminimalisir.
Keragaman dalam setiap kelompok status ketertinggalan daerah mengindikasikan perlu ada upaya yang berbeda agar kondisi daerah dalam satu kelompok menjadi lebih homogen.
Dengan demikian alokasi anggaran pembangunan daerah di dalam setiap kelompok harus disesuaikan dengan indeks ketertinggalan daerahnya, khususnya untuk daerah tertinggal sangat parah.
Analisis Diskriminan
Penyusunan dua model fungsi diskriminan dilakukan untuk memilih model yang paling baik dan sederhana dalam mengklasifikasikan status ketertinggalan suatu kabupaten.
• Model 1 (Menggunakan seluruh peubah) Hasil analisis diskriminan pada model 1 yang menggunakan 33 peubah penjelas menghasilkan 3 fungsi diskriminan.
Koefisien-koefisien 3 fungsi diskriminan yang terbentuk dapat dilihat pada Lampiran 2. Akar ciri dan statistik uji V- Bartlett pada ketiga fungsi diskriminan yang terbentuk dapat dilihat pada Tabel 3.
Tabel 2. Deskripsi Indeks Ketertinggalan Daerah Status
Kabupaten
Frekuensi
Daerah Frekuensi Indeks
(%) (%) Minimun Maksimum Rataan Simpangan Baku
Agak Tertinggal
89 (42.79)
Jawa 15
0.0128 0.4873 0.1820 0.1272 (7.21)
Luar Jawa 74
0.0059 0.4957 0.2411 0.1392 (35.58)
Tertinggal 60 (28.85)
Jawa 2
0.5167 0.5918 0.5542 0.0531 (0.96)
Luar Jawa 58
0.5093 0.9943 0.7410 0.1413 (27.88)
Sangat Tertinggal
48 (23.08)
Jawa 0
- - - -
(0.00) Luar Jawa 48
1.0015 1.9625 1.3452 0.2695 (23.08)
Tertinggal Sangat
Parah
11 (5.29)
Jawa 0
- - - -
(0.00) Luar Jawa 11
2.0822 3.1650 2.5355 0.4102 (5.29)
Akar ciri pertama, kedua dan ketiga menerangkan keragaman data masing- masing sebesar 93.25%, 4.90%, dan 1.85%. Hal ini menunjukkan bahwa sebagian besar keragaman antar kelompok terletak pada fungsi diskriminan pertama.
Tabel 3. Akar Ciri Fungsi Diskriminan dan Statistik Uji V-Bartlett model 1 Akar
Ciri
Keragaman
Statistik uji db Proporsi Kumulatif
15.6773 93.25 93.25 464.9687 99 0.8242 4.90 98.15 82.02108 64 0.3104 1.85 100.00 16.26366 31
Hipotesis nol yang menyatakan bahwa fungsi diskriminan pertama tidak diperlukan untuk membedakan keragaman antar kelompok status ketertinggalan daerah ditolak pada taraf α=0.05, demikian juga dengan yang menyatakan bahwa fungsi diskriminan kedua tidak diperlukan untuk membedakan keragaman antar kelompok status ketertinggalan daerah.
Hipotesis nol dalam pengujian fungsi diskriminan ketiga diterima pada taraf α=0.05, artinya fungsi diskriminan ketiga kurang mampu untuk membedakan keragaman antar kelompok status ketertinggalan daerah. Sehingga dari tiga fungsi yang dihasilkan hanya dua fungsi yang akan digunakan untuk mengklasifikasikan amatan. Dua fungsi yang digunakan dapat menjelaskan 98.15% keragaman antar kelompok.
Model 2 (Menggunakan analisis diskriminan bertatar)
Penyusunan model kedua dilakukan dengan melakukan analisis diskriminan bertatar untuk melihat peubah penjelas mana yang paling dapat mendiskriminasi kelompok dengan baik. Hasil analisis diskriminan bertatar menunjukkan dari 26 langkah terdapat 16 peubah yang terpilih untuk dimasukkan ke dalam model.
Peubah- peubah tersebut dapat dilihat pada Tabel 4.
Peubah pertama yang masuk ke dalam model adalah X35 (persentase rumah tangga pengguna listrik). Akan tetapi pada langkah ke 10 peubah tersebut dikeluarkan dari model, artinya peubah tersebut masih belum dapat mendiskriminasi kelompok dengan baik. Pada langkah selanjutnya peubah X12 masuk ke dalam model, artinya indeks kemiskinan paling menentukan status ketertinggalan suatu daerah.
Tabel 4. Hasil Analisis Diskriminan Bertatar
Langkah Peubah
Masuk Keluar
1 X35
2 X12
3 X39
4 X41
5 X64
6 X25
7 X11
8 X28
9 X62
10 X35
11 X211 12 X31
13 X39
14 X63
15 X51
16 X39
17 X21
18 X65
19 X66
20 X33
21 X39
22 X213
23 X28
24 X23
25 X62
26 X61
Peubah selanjutnya yang masuk ke dalam model adalah X25 angka harapan hidup. Peubah-peubah berikutnya yang masuk dalam model adalah peubah yang dapat menambah kemampuan fungsi dalam mendiskriminasi kelompok yang ada. Peubah X39 (jumlah desa yang mempunyai pasar tanpa bangunan permanen), X28 (rata-rata jarak pelayanan prasarana kesehatan) dan X62 (persentase jumlah desa yang rawan tanah longsor) yang masuk pada langkah ke 3, 8 dan 9 kemudian dikeluarkan kembali pada langkah ke 13, 23 dan 25, artinya ketiga peubah ini masih belum dapat meningkatkan kemampuan model untuk mendiskriminasi kelompok. Hingga langkah ke-26 peubah terakhir yang akan digunakan untuk membentuk fungsi diskriminan yaitu X61 (persentase jumlah desa yang rawan gempa bumi).
Hasil analisis diskriminan bertatar ini sesuai dengan pembobotan yang telah dilakukan oleh KNPDT sebelumnya.
Kriteria keuangan daerah (celah fiskal)
dan kriteria ekonomi yang terdiri dari indikator persentase kemiskinan dan indeks kemiskinan yang memiliki bobot terbesar menjadi salah satu peubah yang berperan dalam penyusunan fungsi diskriminan.
Sebanyak 16 peubah terpilih dalam analisis diskriminan bertatar digunakan sebagai dasar pembentukan fungsi diskriminan untuk model kedua. Hasil analisis diskriminan pada model 2 menghasilkan 3 fungsi diskriminan.
Koefisien-koefisien 3 fungsi diskriminan yang terbentuk dapat dilihat pada Lampiran 3.
Akar ciri dan statistik uji V-Bartlett dari ketiga fungsi diskriminan yang terbentuk dapat dilihat pada Tabel 5. Akar ciri pertama, kedua dan ketiga menerangkan keragaman data masing- masing sebesar 94.87%, 4.25%, dan 0.88%. Hal ini menunjukkan bahwa sebagian besar keragaman antar kelompok terletak pada fungsi pertama.
Tabel 5. Akar Ciri Fungsi Diskriminan dan Statistik Uji V-Bartlett model 2.
Akar Ciri
Keragaman
Statistik uji db Proporsi Kumulatif
12.6532 94.87 94.87 491.9464 48 0.5665 4.25 99.12 86.7799 30 0.1174 0.88 100.00 17.2073 14 Statistik uji V-Bartlett pada taraf α=0.05 menunjukkan bahwa hipotesis nol yang menyatakan bahwa fungsi diskriminan pertama tidak diperlukan untuk membedakan keragaman antar kelompok status ketertinggalan daerah ditolak, demikian juga dengan yang menyatakan bahwa fungsi diskriminan kedua tidak diperlukan untuk membedakan keragaman antar kelompok status ketertinggalan daerah. Hal ini berarti kedua fungsi diskriminan yang terbentuk
dapat digunakan untuk menerangkan keragaman antar kelompok.
Hipotesis nol dalam pengujian fungsi diskriminan ketiga diterima pada taraf α=0.05, artinya fungsi diskriminan ketiga kurang mampu untuk membedakan keragaman antar kelompok status ketertinggalan daerah. Sehingga dari tiga fungsi yang dihasilkan hanya dua fungsi yang akan digunakan untuk mengklasifikasikan amatan. Dua fungsi yang digunakan dapat menjelaskan 99.12% keragaman antar kelompok.
Ketepatan Klasifikasi
Dari model yang terbentuk, dengan menggunakan Correct Classification Rate (CCR), dilakukan evaluasi terhadap pengelompokan 80% data (166 kabupaten) terhadap model tersebut.
• Model 1
Dari 166 kabupaten, 97.0 % amatan (161 kabupaten) dapat diklasifikasikan dengan tepat sesuai dengan status ketertinggalan awalnya. Sisanya 3.0 % amatan (5 kabupaten) salah diklasifikasikan. Kesalahan klasifikasi terbesar terdapat pada kelompok daerah sangat tertinggal, yaitu sebesar 5.3 % amatan (2 dari 38 kabupaten) salah diklasifikasikan. Hasil klasifikasi dapat dilihat pada tabel 6.
• Model 2
Dari 166 kabupaten, 94.0 % amatan (156 kabupaten) dapat diklasifikasikan dengan tepat sesuai dengan status ketertinggalan awalnya. Sisanya 6.0 % amatan (10 kabupaten) salah diklasifikasikan. Kesalahan klasifikasi terbesar terdapat pada kelompok daerah sangat tertinggal, yaitu sebesar 8.5 % amatan (6 dari 71 kabupaten) salah diklasifikasikan. Hasil klasifikasi dapat dilihat pada tabel 7.
Tabel 6. Hasil Klasifikasi Daerah Tertinggal Model 1
Status KNPDT Status berdasarkan fungsi diskriminan
Total % benar
Kode Nama 1 2 3 4
1 Agak tertinggal 69 2 0 0 71 97.2
2 Tertinggal 1 47 0 0 48 97.9
3 Sangat Tertinggal 0 2 36 0 38 94.7
4 Tertinggal Sangat Parah 0 0 0 9 9 100.0
Total 70 51 36 9 166 97.0
Tabel 7. Hasil Klasifikasi Daerah Tertinggal Model 2
Status KNPDT Status berdasarkan fungsi diskriminan
Total % benar
Kode Nama 1 2 3 4
1 Agak tertinggal 65 6 0 0 71 91.5
2 Tertinggal 2 46 0 0 48 95.8
3 Sangat Tertinggal 0 2 36 0 38 94.7
4 Tertinggal Sangat Parah 0 0 0 9 9 100.0
Total 67 54 36 9 166 94.0
Validasi Model
Untuk melihat kemampuan fungsi diskriminan yang dibentuk dalam mengklasifikasikan suatu amatan ke dalam kelompok yang tepat dapat dilihat dari tingkat keberhasilan fungsi diskriminan tersebut dalam mengklasifikasikan amatan. Evaluasi terhadap pengelompokan yang didapatkan dengan menggunakan fungsi diskriminan dilakukan dengan menggunakan Correct Classification Rate (CCR).
Model 1
Berdasarkan fungsi diskriminan yang terbentuk diketahui bahwa dari 42 kabupaten yang digunakan sebagai gugus data uji, sebanyak 34 kabupaten (81.0%
amatan) berhasil diklasifikasikan dengan tepat, yaitu sesuai dengan status ketertinggalan awalnya. Sisanya, sebanyak 8 kabupaten (19.0% amatan) salah diklasifikasikan. Hasil validasi untuk model 1 dapat dilihat pada Tabel 6.
Dari hasil klasifikasi tersebut dapat diketahui bahwa kategori dengan tingkat kesalahan klasifikasi terkecil yaitu kategori daerah agak tertinggal, sebanyak 16 dari 18 kabupaten yang memiliki status
agak tertinggal dapat dikelompokkan dengan tepat.
Hasil pengelompokan tersebut juga menunjukkan bahwa kelompok dengan status daerah tertinggal sangat parah adalah kelompok yang mengalami paling banyak kesalahan klasifikasi. Tingkat kesalahan klasifikasi pada kelompok daerah tertinggal sangat parah yaitu 50%
(1 dari 2 amatan salah diklasifikasikan).
Hal ini juga dapat disebabkan oleh sedikitnya amatan yang ada pada kelompok status daerah tertinggal sangat parah.
Model 2
Dari hasil validasi pada Tabel 7 dapat diketahui bahwa kategori dengan tingkat kesalahan klasifikasi terkecil adalah kategori daerah agak tertinggal karena seluruh amatan dikelompokkan dengan tepat. Hasil pengelompokan tersebut juga menunjukkan bahwa kelompok dengan status daerah tertinggal sangat parah adalah kelompok yang mengalami paling banyak kesalahan klasifikasi. Tingkat kesalahan klasifikasi pada kelompok daerah tertinggal sangat parah yaitu 50.0%
(1 dari 2 amatan salah diklasifikasikan).
Tabel 8. Hasil Validasi Model 1
Status KNPDT Status berdasarkan fungsi diskriminan
Total % benar
Kode Nama 1 2 3 4
1 Agak tertinggal 16 2 0 0 18 88.9
2 Tertinggal 1 10 1 0 12 83.3
3 Sangat Tertinggal 0 3 7 0 10 70.0
4 Tertinggal Sangat Parah 0 0 1 1 2 50.0
Total 17 15 8 1 42 81.0
Tabel 9. Hasil Validasi Model 2
Status KNPDT Status berdasarkan fungsi diskriminan
Total % benar
Kode Nama 1 2 3 4
1 Agak tertinggal 18 0 0 0 18 100.0
2 Tertinggal 2 9 1 0 12 75.0
3 Sangat Tertinggal 0 1 9 0 10 90.0
4 Tertinggal Sangat Parah 0 0 1 1 2 50.0
Total 20 10 11 1 42 88.1
Berdasarkan fungsi diskriminan yang terbentuk diketahui bahwa dari 42 kabupaten, sebanyak 37 kabupaten (88.1%
amatan) berhasil diklasifikasikan dengan tepat, yaitu sesuai dengan status ketertinggalan awalnya. Sisanya, sebanyak 5 kabupaten (11.9% amatan) salah diklasifikasikan.
Untuk masing-masing model, kabupaten yang mengalami kesalahan klasifikasi untuk tiap-tiap status ketertinggalan dapat dilihat pada Lampiran 4. Berdasarkan indeks ketertinggalan yang dimiliki kabupaten- kabupaten tersebut, dapat diketahui bahwa umumnya kesalahan klasifikasi terjadi pada kabupaten-kabupaten yang indeks ketertinggalannya berada di sekitar batas kelas. Daerah dengan indeks ketertinggalan yang berada di sekitar batas bawah kelas akan diklasifikasikan ke dalam kelompok sebelumnya, sedangkan daerah dengan indeks ketertinggalan yang berada di sekitar batas atas kelas akan diklasifikasikan ke dalam kelompok sesudahnya.
Pemilihan model terbaik dilakukan dengan melihat sejauh mana fungsi yang dihasilkan oleh kedua model dapat mengklasifikasikan amatan dengan tepat. Berdasarkan hasil perhitungan kesalahan klasifikasi yang didapatkan diketahui bahwa kemampuan model 2 dalam menempatkan pengamatan ke dalam kelompok yang benar lebih baik dibandingkan dengan model 1. Pada model 2, dengan menggunakan 16 peubah penjelas ketepatan klasifikasinya mencapai 88.1%.
Dengan demikian model 2 merupakan model terbaik untuk menentukan status ketertinggalan daerah, karena dengan menggunakan peubah penjelas yang lebih sedikit, ketepatan klasifikasinya lebih tinggi dibandingkan dengan model yang menggunakan seluruh peubah penjelas.
Penggunaan peubah penjelas yang lebih sedikit akan lebih efektif dibandingkan dengan menggunakan seluruh peubah penjelas yang ada. Dua fungsi diskriminan yang menjelaskan 99.12% keragaman data dapat digunakan untuk menentukan status ketertinggalan kabupaten dengan menggunakan teritorial map yang dapat dilihat pada Lampiran 5.
SIMPULAN
Sebanyak 91.83% daerah tertinggal yang setara dengan 191 kabupaten berlokasi di luar Pulau Jawa sedangkan 8.17% kabupaten yang
berlokasi di Pulau Jawa hanya ada dalam golongan status daerah agak tertinggal (15 kabupaten) dan tertinggal (2 kabupaten).
Keragaman dalam setiap kelompok status ketertinggalan daerah mengindikasikan perlu ada upaya yang berbeda agar kondisi daerah dalam satu kelompok menjadi lebih homogen, khususnya untuk daerah yang tertinggal sangat parah.
Dengan menggunakan 80% data (166 kabupaten), didapatkan model 2 sebagai model terbaik. Fungsi diskriminan dibentuk dengan menggunakan 16 peubah penjelas dan menghasilkan dua fungsi yang dapat menjelaskan 99.12% keragaman data. Setiap kriteria yang ditentukan oleh Kementrian Negara Pembangunan Daerah Tertinggal terepresentasikan dalam model tersebut.
Kriteria Sumber Daya Manusia (SDM) hanya terwakili oleh 5 indikator (38.5%), kriteria infrastruktur terwakili oleh 2 indikator (22.2%), dan kriteria karakteristik daerah terwakili oleh 5 indikator (75.4%), sedangkan semua indikator pada kriteria ekonomi, keuangan daerah dan aksesibilitas ada dalam model. Penggunaan model tersebut terhadap 20% (42 kabupaten) yang berperan sebagai contoh uji menghasilkan ketepatan klasifikasi sebesar 88.1%.
SARAN
Deskripsi data menunjukkan bahwa terdapat karakteristik yang berbeda untuk kabupaten di daerah Jawa dan Luar Jawa. Hal ini menunjukkan bahwa kriteria untuk daerah bukan maju di Jawa dan luar Jawa perlu dibedakan dengan cara menyusun ulang indikator dan bobot untuk perhitungan indeks ketertinggalan daerah dan pemodelan yang lebih tepat.
DAFTAR PUSTAKA
Dillon WR. & Goldstein M. 1984.
Multivariate Analysis Methods and Applications. Canada : John Willey and Sons.
Hair JF et. al. 1995. Multivariate Data Analysis with Readings. New Jersey : Prentice Hall
Johnson RA. & Wichern D.W. 1988. Applied Multivariate Statistical Analysis. New Jersey : Prentice Hall.
Ramadhani, E. 2003. Fungsi Diskriminan Untuk Membedakan Keberhasilan