THE ACCURACY OF MESSAGES RENDERING SEEN THROUGH THE KEYWORDS INTERPRETATION OF ENGLISH –INDONESIAN CONSECUTIVE
INTERPRETATION IN INTERPRETING CLASS OF ENGLISH LETTERS STUDY PROGRAMME OF SANATA DHARMA UNIVERSITY
AN UNDERGRADUATED THESIS
Presented as partial Fulfillment of the Requirements for the Degree of Sarjana Sastra
in English Letters
By
TAUFIQ JATI MURTAYA Student Number: 044214109
ENGLISH LETTERS STUDY PROGRAMME DEPARTMENT OF ENGLISH LETTERS
FACULTY OF LETTERS SANATA DHARMA UNIVERSITY
v
Why the head is above and feet is below, because we
Why the head is above and feet is below, because we
Why the head is above and feet is below, because we
Why the head is above and feet is below, because we
have a heart to place in the middle
have a heart to place in the middle
have a heart to place in the middle
have a heart to place in the middle
vii
For my beloved family, mother and father
For my beloved family, mother and father
For my beloved family, mother and father
For my beloved family, mother and father
viii
ACKNOWLEDGEMENTS
First of all, I would like to thank Alloh the Almighty, for the endless blessing and for giving me guidance in accomplishing this thesis. Also, I have to thank Muhammad SAW as the truth leader and messenger. Secondly, I would be glad to say that my mother and father are my biggest inspiration in my life, and I deeply thank them for that. My gratitude is also for my brother Sidiq, who always encourage me with their own way.
My special thanks goes to my advisor Adventina Putranti, S. S., M. Hum., for giving me her precious time and the patience in guiding me to finish this thesis. My gratitude also goes to Dewi Widyastuti, S. Pd., M. Hum., my co-advisor. A special appreciation also goes to all English Letters secretariat staff who have been so kind to help me during my study in Sanata Dharma University.
Afterwards, I would like to thank my best friend Oki, Agung ‘05, Adi and Aryk who always support and motivate me. I also thank to Mbah Roni for lending me the handycam; the Power Ranger Crew of Flattering Words; Mbakyu Ningsih, Ukerimash, and Sennyshimash; KD; and GMPG Sidomulyo. My special thank to FKM BUDI UTAMA; my dearest teachers and lovable friends mas Syamsi, The Ronald Company, Bang Fahmi, Bang Abdi, Mr. Rury, and Dugem Community. Last but not least is my gratitude for all my friends of the 2004 class that I could not mention one by one.
ix
TABLE OF CONTENT
TITLE PAGE ... i
APPROVAL PAGE ... ii
ACCEPTANCE PAGE ... iii
LEMBAR PERNYATAAN KEASLIAN KARYA ... iv
MOTTO PAGE ... v
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... vi
DEDICATION PAGE... vii
B. Review of Related Theories ... 15
1. Translation Theory of Omissions, Additions, and Substitutions and Errors ... 15
3. Translation Theory of Equivalence ... 23
C. Theoretical Framework ... 27
CHAPTER III METHODOLOGY 30
A. The English-Indonesian Keywords Interpretation ... 38
B. The Analysis of Omissions, Additions, and Substitutions and Errors ...42
C. The Influence of the Phenomenon of the Interpreting Result toward the Messages Rendering Process ... 50
1. Componential Analysis ... 50
xi ABSTRACT
TAUFIQ JATI MURTAYA (2011). The Accuracy of Messages Rendering Seen through the Keywords Interpretation of English-Indonesian Consecutive Interpretation in Interpreting Class of English Letters Study Programme of Sanata Dharma University. Yogyakarta: Department of English Letters, Faculty of Letters, Sanata Dharma University.
Language is developing from time to time as part of communication. In its development, a communication takes place not only within the same language user, but also between two or more different language user. Therefore, to build the bride of the differences, the present of an interpreter is needed in order to minimize such miscommunication. Recently, the study of the interpreting filed is developing. The studies are conducted not only in simultaneous interpreting, but also in consecutive interpreting. The research field of the study in interpreting is very wide. However, accuracy of the interpreting process get more attentions. As a matter of fact, to measure the accuracy of an interpretation, it usually refers to the whether the intention of the source sentence interpreted is transferred into the target text or not.
The discussion in this thesis is made based on the objectives of this research which are to find out how the keywords are interpreted by using consecutive method from English into Indonesian, and to find out the result of the keywords interpretation due to the messages rendering.
The two objectives were accomplished by doing data collecting and data analysis. The object of this research is the oral translation of the keywords from consecutive English-Indonesian test in interpreting class of English Letters Study Programme of Sanata Dharma University. After writing down all of the oral translation that has recorded before, then the researcher is looking for the keywords and juxtaposing them between the source and the target text. The next step is analyzing the keywords interpretation using the theory in translation of omissions, additions, and substitutions and errors. Final step is making an analysis of the phenomenon resulted from the previous analysis by considering the messages rendering process by using componential analysis and translation theory of equivalence.
Based on the analysis in this research, the phenomenon of interpretation found are skipping omission, comprehension omission, elaboration addition, mild semantics error, stemming error, error of false reference, and error of meaning. After conducting an analysis of those phenomena by using componential and translation theory of equivalence, there are two major results. Firstly, skipping omission and mild semantics error phenomena are considered as the less accurate interpretation. Secondly, comprehension omissions, elaboration addition, stemming error, error of false reference, and error of meaning phenomena are considered to be inaccurate.
xii ABSTRAK
TAUFIQ JATI MURTAYA (2011). The Accuracy of Messages Rendering Seen through the Keywords Interpretation of English-Indonesian Consecutive Interpretation in Interpreting Class of English Letters Study Programme os Sanata Dharma University. Yogyakarta: Jurusan Sastra Inggris, Fakultas Sastra Universitas Sanata Dharma.
Bahasa selalu berkembang dari waktu ke waktu sebagai bagian dari komunikasi. Dalam perkembangannya, sebuah komunikasi dapat terjadi tidak hanya diantara orang yang menggunakan bahasa yang sama, tetapi juga terjadi antara dua pengguna bahasa yang berbeda atau lebih. Oleh karena itu, untuk menyelaraskan perbedaan-perbedaan dalam bahasa tersebut di butuhkan seorang alih bahasa agar dapat meminimalisir kesalahpahaman. Akhir-akhir ini, penelitian di bidang alih bahasa baru berkembang. Penelitian itu dilakukan tidak hanya pada model alih bahasa secara simultaneous tetapi juga dalam model consecutive. Penelitian dalam alih bahasa cakupannya sangatlah luas. Namun demikian, ketepatan dalam proses alih bahasa mendapat perhatian yang lebih. Dalam kenyataanya, untuk mengukur ketepatan dalam alih bahasa selalu merujuk pada apakah maksud dari kalimat daribahasa asal dapat terdapat dalam bahasa target.
Diskusi dalam skripsi ini dibuat berdasarkan tujuan dari penelitian ini, yaitu untuk mengungkapkan bagaimana kata kunci diterjemahkan melalui metode consecutive dari bahasa Inggris ke dalam bahasa Indonesia, dan untuk menemukan bagaimana hasil alih bahasa dari kata kunci tersebut dengan mempertimbangkan proses pesan yang dialihkan.
Kedua tujuan tersebut dapat dicapai dengan melakukan pengumpulan data dan analisa data. Obyek dari penelitian ini adalah terjemahan lisan dari kata kunci dalam tes metode consecutive di kelas Interpreting program studi Sastra Inggris, Universitas Sanata Dharma. Setelah menulis semua terjemahan lisan yang telah direkam sebelumnya, kemudian peneliti mencari kata kunci dari teks asal dan teks target lalu menjajarkannya. Langkah selanjutnya adalah menganalisis kata kunci itu mengunakan teori terjemahan seperti omissions, additions, dan subtitutions and errors. Langkah yang terakhir adalah membuat analisis dari fenomena yang ditemukan dalam analisa sebelumnya dengan mempertimbangkan proses perpindahan pesan dengan menggunakan teori componential analysis dan teori equivalence dalam Ilmu Penerjemahan.
1 CHAPTER I INTRODUCTION
A. Background of the Study
Language is a living thing. Literature lover often suggests that language is
alive because it can so powerfully move a reader and shape his or her ideals (taken
from: http//serendip.brynmawr.edu/exchange/ncde/1212). A living thing has the
relation with some general signs such as motion, movement, growth,
development, changes, etc, and so does language. In its development, which is
considered as one of the characteristics of a living thing, language undergoes
some changes as followed by the survival, extinction and new occurrence of the
words, the transformation in its structure and the changes of word meaning from
time to time. Since language has some changes, therefore Albert C. Baugh and
Thomas Cabel in their book entitled A History of the English Language also
mention an important statement about language.
Although we rarely think of language as something that possesses life apart from the people who speak it, as we can think of plants or animals, we can observe in speech something like the process of change that characterize the live of living thing. When a language ceases to change, we call it a dead language (2002:2).
As a living thing, language can also die whenever it is not used by people to
communicate. That is why; a study of language field is precious toward the
existence of language.
People use language as a way to communicate. According to Finnegan,
mediates the transfer of thought from one person to another, which is mentioned
as the term of communication (2004:8). All information and messages can be
delivered and understood through language (Hanafi, 1986:14). Communication
through language enables us to live effectively, to develop our capabilities, and to
satisfy our curiosity about our surroundings (Lehmann, 1983:1). To satisfy our
curiosity; language, viewed from the essential part of communication of rendering
messages, functions as the repository and means of knowledge transmission
(Carter, 1995: v). Since language as well as communication always develop
through time, a research in those fields will be important and worthwhile.
There will be no doubt that one of the essential goals of communication is
to understand the intentions conveyed. The understanding achievement should be
in both the speaker and the listener, or it could be called the mutual understanding.
Thus, during the mutual understanding, both the speaker and listener share the
information needed. In other word they will cooperate with each other (Yule,
1996: 36-37). In George Yule’s book entitled Pragmatics, this kind of cooperative
action named as cooperative principle. In such a principle, the responsibility for
understanding is shared by both parties, the speaker and listener (Hale, 2007: 15).
Commonly, it will be much easier to understand the intended meaning in the
communication for the people who speak the same language, because they merely
have the same pragmatic conventions.
A language that is used and understood as the same conception in a certain
society will minimize an understanding distortion (Hanafi, 1986: 15). Meanwhile,
demanded to cope the various objectives in their life. For instance, how people
from many different nations held their communication in a multilateral
conference, while they tend to use their own language to communicate rather than
English, and they do not understand each other language. Indeed, a big
misconception has a large space to appear since the communication carries not
only the different pragmatic conventions but also different language and culture.
However, what the writer wants to underline is that the communication between
two different languages is possible.
According to Hanafi, there are two models of communication in relation
with the number of the used language; there are intra-lingual communication
model, a communication which used one language. The other is inter-lingual
communication model, this communication uses more than one language (1986:
16-17).
From the statements mentioned above, it implies that cooperative principle
occurs in intra-lingual communication in order to decrease misunderstanding. The
question is, what if the communication uses inter-lingual communication. As
Sandra Beatriz Hale mentioned an important aspect of communication in her book
entitled Community Interpreting.
From the quotation above it shows that the greater chance of misunderstanding
will appear since the more languages are used in a communication, namely in
inter-lingual interpretation. It also implies that misunderstanding is undeniable.
Referring to the last sentence of the quotation, it is clearly said that, in order to
achieve the understanding of two speakers who use different language, an
interpreter is definitely needed.
Since an interpreter is needed in any occasion of inter-lingual
communication, namely an international conference, a scientific study is also
needed in purpose to develop a better method of interpretation training and
minimize the misinterpretation; and achieve the goal of messages delivery.
Interpretation which is commonly defined as the oral transfer of a message from
language into another has a very long history (Simpson, 1994: 1731). According
to The Encyclopedia of Language and Linguistics, it is described that
Interpretation is said to be the world’s second oldest trade, interpreting as a profession only developed after World War I, when conference interpretation made its appearance at international gatherings at which French and English were used concurrently. The first regular teams of interpreters were employed at the Paris Peace Conference in 1919, at which the consecutive interpretation mode was worked out (Simpson, 1994:1737).
Although the practice of interpretation is old, however the profession and
discipline of interpreter are very young. According to Daniel Geil an interpreter
expert and researcher who are the member of AAIC (Association Internationale,
des Interpretes de Conference) the study of interpretation has been largely
developing in recent decades, namely in the seventies there are about 180 studies
nineties (taken from: http//www.aiic.net/viewpage.cfm/article299.htm). Those
mean the range of the study will always expand and grow. That is what stimulates
the writer’s interest.
From the statement quoted above, the first method which is used in
interpretation is consecutive method. Generally, there are two models of
interpretation, namely consecutive and simultaneous interpretation. In
simultaneous interpretation, the interpreter gives the interpretation in the target
language at virtually the same as the source express the messages in the source
language. On the other hand, in consecutive interpretation, the interpreter provides
the interpretation of a message in the target language after the source has stopped
speaking in the original language (Simpson, 1994: 1732-1733). Therefore, in
consecutive interpreting, the interpreter is usually taking notes during the speech
before the pause, and it is quite helpful in rendering the messages in the target
language later.
The concern of this study is in the consecutive interpretation. Although
consecutive interpretation use note taking in its process, the data or the notes are
not going to be analyzed since those are not readable and structuralized for the
researcher. Nevertheless, it will be supported also by its recorded oral source.
Compared to simultaneous interpretation, consecutive interpretation considered as
the more accurate in rendering the messages, because the interpreter is not only
recalling his or her short or long term memories, but also consulting to the notes
understandable before the eye of the interpreter who wrote it, so that the
misinterpretation can be reduced.
Although note taking can minimize the misinterpretation, still some
mistakes are occurring and those make the messages in the target language less
accurate. Accuracy is the main concern in interpretation process. Therefore, it
becomes a big question to the writer, what factors do influence the accuracy,
especially in the linguistics range. The writer then makes a deeper analysis that
one of the linguistics factors, which is considered as the most influential and the
first important step in note taking and delivering messages in target language, is
the key words of the speech. Thus, this research tries to know how key words are
interpreted so that they can render the messages from the source language into the
target language.
In order to narrow the field and make the more focusing and detail
analysis, the writer conducts the study on English-Indonesian interpretation. The
object that is going to be observed are not interpretation experts, however they are
learners. Based on the topic, the learners are students who took interpreting class
in English Letters study Programme of Sanata Dharma University. The writer
specifies the field research by selecting the learners of interpreting because they
have valuable situations to observe through its interpreting processes. The writer
aims to find a scientific finding of messages rendering during the
English-Indonesian interpreting process which seen through the keywords that will be
By analyzing the data and finally finding the answer, generally this study
is aimed to give a contribution to the development of interpretation study in
Indonesia. Specifically, the aim this study is to give a guidance and or explanation
for interpreting learner from Indonesia in avoiding and minimizing the errors and
misinterpretations. Also this study is aimed to give explanation to the interpreting
expert about the phenomenon occurrence in message delivery during the
interpretation process which influences the accuracy; and as one of the references
for trainer and researcher in formulating the best method on consecutive
interpretation learning. In other words, it is expected that Indonesian interpreters
can improve their skill, especially using consecutive interpretation method.
B. Problem Formulation
According to the background mentioned above, there are two problems
which the writer tries to answer. The problems are formulated as follow:
1. How are the keywords interpreted in English-Indonesian consecutive
interpretation in the interpreting class of English Letters study
Programme of Sanata Dharma University?
2. How does the interpretation of the keywords affect the message
C. Objectives of the Study
This chapter explains some objectives that are related to the problems
formulation. According to first problem formulation above, first objective is to
find out how the key words are interpreted by using consecutive method from
English as the source language to Indonesian as the target language in interpreting
class of English Letters students of Sanata Dharma University. The second, which
is also the last objective, is to analyze the result of the keywords interpretation due
to the messages rendering in interpreting process.
D. Definition of Terms
In order to avoid a misleading of understanding and to give distinct
explanation and limitation of the analysis of the study, it is important to know
some explanation of linguistics terminologies. The terms that will be used in this
analysis are accuracy, message rendering, keywords, and consecutive
interpretation.
The first term to explain is accuracy. Considering the quality in
interpreting and translation, accuracy is the most essential part to discuss in the
scientific range. What is meant by accuracy in this research is the interpreter‘s
fidelity in interpreting a text, and also closely related to the concept of
equivalence in linguistic study of interpretation or translation. According to Mona
Barker’s Routledge Encyclopedia of Translation Studies mentions that the
proponents of equivalence-based theories of translation usually define equivalence
text to be considered as a translation of the source text in the first place (2001:77).
There also mentions that
...equivalence is commonly established on the basis of: the source language (SL) and target language (TL) words supposedly referring to the same thing in the real world, i.e. on the basis of their referential or denotative equivalence; the SL and the TL words triggering the same or similar association in the minds of native speakers of the two languages, i.e. their connotative equivalence; the SL and TL words being used in the similar contexts in their respective language,...(2001:77).
The second is message rendering. What is meant by messages rendering
here is the intention of the source language flawlessly transferred in the target
language. In the other word, concerning its implementation, the listener of the
target language understands the aim of the speaker of the source language. There
is no such a violation of the meaning conveyed in the source language when it is
translated into the target language. The message conveyed in the target language
must match the source language message in meaning, content and intent (taken
from:http://seattlecentral.edu/faculty/baron/Winter_courses/ITP163/ITP163CEU
Nit7Monitoring&Correction.htm).
The next term that needs to be explained is keywords. In Larson’s book, A
Guide to Cross Language Equivalent there is stated that key words are words
which are used over and over in the text and are crucial to the theme or topic
under discussion. Keywords are most often words which represent an essential or
basic concept of the text (1984:177). Since they are often thematic, it is very
important to find and determine what the keywords are presented on the text, in
order to gain the most adequate or accurate lexical equivalent from the source
The last term is Consecutive Interpretation. In its purest form, consecutive interpretation is a mode in which the interpreter begins their
interpretation of complete message after the speaker has stopped producing the
source utterance (taken from: http://home.erthlink.net/~terparto/id7.html).
According to Ginori and Scimone, consecutive interpreting consists of listening to
a speech in one language and translating or summarizing it orally into another
(2001:17). In consecutive interpreting, the interpreter has a longer time to think
before rendering the messages accurately, since there is a temporal pause during
the speech. During the pause, the consecutive interpreter takes notes that record
ideas to be used later in delivering messages in target language (taken
from:http//www.interpreters.net.cn/articles/interpreter_in_doing_bussiness_in_ch
11 CHAPTER II
THEORETICAL REVIEW
This chapter covers three parts; review of related study, review of related
theories, and theoretical framework. The first part mentions the review of other
study which also discuss similar topic with this analysis. They are the text
condensation in consecutive interpreting and also the analysis of form-based and
meaning-based interpreting in relation with the effect of source text difficulty on
lexical target text form in simultaneous interpreting. The second part contains
some theories that are will be applied in the analysis. The theories that will be
used in here are the theory in interpreting such as theory of omissions, additions,
and errors of interpreting; the theory in semantics field namely componential
analysis; and equivalent theory of interpreting.
A. Review of Related Studies
An expert in interpreting field, Helle V. Dam, in her Ph.D. dissertation
entitled Text Condensation in Consecutive Interpreting at first, in the superficial
finding, mentioned that
It implied that during the consecutive interpreting process there would be a
reduction of the target text compared to the source text. Thus, to propose a
framework for an empirical investigation of this phenomenon, further she
elaborated her analysis by using two major modules, namely formal analysis and
linguistic analysis. From her investigation of the texts by using formal analysis,
she found that the main contribution of formal analysis to the present study is to
have identified the relevant condensation operations or forms as deletion and
substitution. In her findings, deletion is reflected partly in the segments
categorized as selective, partly in the segments represented by full deletion in the
target texts. Meanwhile, substitution is reflected in three subcategories of
substituting segments, i.e. in the formal substituting, the generalizing and the
integrating segments. Going deeper in her next investigation of the formal
analysis finding, that are deletion and substitution, by using linguistic analysis
then she took two different levels of analysis, namely syntactic analysis and
semantics-pragmatic analysis. From the analysis of deletion, it was hypothesized
that
the phenomenon of deletion is probably mainly governed by semantic-pragmatic position of source text elements, this position is frequently, however not all the time, syntactically marked, in the sense that elements which are less important in terms of information value tend to appear as syntactic modifiers, whereas more important elements often appear as
constitutive parts of sentence or phrases (taken from:
http://download2.hermes.asb.dk/archive/download/H17_14.pdf).
Whereas the analysis of formal substitution described that the phenomenon of
substitution depended on the paradigmatic nature. It meant that those phenomenon
In the other work, an article, published in the proceedings of the ASLA
Symposium on Translation and Interpreting held in Stockholm in November
1998, Helle V. Dam scientifically explained about the two generalized
paradigmatic strategies in interpreting namely form-based and meaning-based
interpreting. Her work entitle On The Option between Form-Based and
Meaning-Based Interpreting: The Effect of Source Text Difficulty on Lexical Target Text
Form in Simultaneous Interpreting set out to test a prevailing hypothesis that the
more difficult the source text, the more the interpreter tend to deviate from the
meaning-based approach and to interpret on the basis on the basis of source text
form. Form-based interpreting was generally described as the direct transmission
of the source text in composing the target text. In other word, it constructed the
target text only by referring to the surface form of the source text as much as
possible. Meanwhile, meaning-based interpreting focused more in the
representation of the source text in transmitting and constructing it into the target
text. Derived from that hypothesis, a basic premise was set out, that were lexical
similarity between source and target texts was taken to reflect form-based
interpreting, whereas lexical dissimilarity was held to reflect meaning-based
interpreting.
Then she found three phenomena in her analysis, which while having
simultaneous activities there rapidly occurred omissions; additions; and
core-material or the substitution with respect to the source text core-material. Then she
specified the research scope in the additions field. In order to ease and give
segments consist of a series of words grouped around a finite verb. In most cases,
the segment therefore corresponded to a clause. According to her model of
analysis, she categorized the segments into five categories; those are similar
segments, dissimilar segments, similar (dissimilar) segment, dissimilar (similar)
segments, and similar/dissimilar segments. Then the addition phenomenon were
analyzed by using those models. In short, based on the lexical similarity and
dissimilarity concept she provided a finding that the meaning–based approach to
interpreting was more associated with non-difficult source texts, and the
form-based technique was more associated with difficult texts.
Since the two studies above are discussing about the analysis of
interpreting texts, weather the portion of analysis is more on the interpreting field
of simultaneous interpreting, which is the second study or linguistic scope of
consecutive interpreting, which is the first study; both studies analyzed the same
phenomenon in interpreting namely omission, addition, etc. Therefore, this
research is going to have two steps of analysis which is used theory on
interpreting and also theory in linguistic. What make the different from the other
two studies above is that this research is trying to explain the phenomenon in
interpreting and its affect to the messages rendering in consecutive interpreting.
Regarding on the development of the research’s topic, then the two studies will be
B. Review of Related Theories
1. Translation Theory of Omissions, Additions, and Substitutions and Errors According to Pӧchhacker (2004: 142) since the first experimental studies
of interpreting, researchers have sought to examine the interpreter’s output for
various types of lexico-semantic “deviations” from the source text. It implies that
research on the product of interpreting, namely the source text, is evident to be
done since there are some digressions. Therefore, Henri C. Barik conducted a
research on simultaneous interpreting based on the theory of omission, addition,
and error in translation; and he concluded that
In simultaneous interpretation, the interpreter’s version may depart from the general version in three ways: the interpreter (henceforth abbreviated T for “translator,” since it cannot conveniently be abbreviated “I”) may omit some material uttered by the speaker (abbreviated “S”), he may add some material to the text, or he may substitute material, resulting in his saying not quite the same thing as the S. If the substitution is at considerable variance with the original version we may speak of an “error” of translation (Lambert, 1994: 121)
Thus, he classifies some code schemes related to the three events above as
follows.
a. Omissions
Omissions refer to items present on the original version which are left out
of the translation by the translator. Omissions are determined on the basis of the
final content of the original message, so that is it not considered an omission if the
translator does not translate a lexically irrelevant repetition or “false start” on the
part of the speaker of the source language (Lambert, 1994: 122). There are four
1) Skipping omission
It is an omission of a single word or short phrase by interpreter, who seems to
skip over it. This type of omission usually refers to qualifying adjective but
not alter the grammatical structure. Therefore, cause a minimal loss of
meaning and most of them are probably acceptable within the context of
translating (Lambert, 1994: 122).
2) Comprehension Omission
This omission appears when the interpreter fails to comprehend or is unable
to interpret part of the text. Therefore, there is an interruption in the
translator. This type of omission also usually involves larger unit of material.
As a result, there is a definite loss in meaning and an uncorrelated speech on
the part of the translator which consist of “bits and pieces” of translation
(Lambert, 1994: 123).
3) Delay Omission
This is an omission which seems to be due in large part to the delay of the
translator in his translation, as judged from listening to the tape (Lambert,
1994: 123).
4) Compounding Omission
This omission associated with the translator’s compounding process of
elements from different clause units. As a result, the target text sentence has
slightly different meaning from the source text although the gist is retrained
In the other article entitled Simultaneous Interpreting Qualitative and Linguistic
Data which composed in the book of The Interpreting Studies Reader, Barik
explains the types of additions as follows.
b. Additions
Addition refers to the items which are added to the target text but not
found in the source text. There are four types of addition.
1) Qualifier Addition
It is the addition by the translator of a qualifier or short of qualifying
phrase not in the original version.
2) Elaboration Addition
This addition is quite similar with qualifier addition, but it is more
elaborate and more extraneous to the text (Pöchhacker, 2002: 81).
3) Relationship Addition
This is an addition of a connective or of other material which result in a
relationship of elements or of sentences not present in the original. It can
alter the meaning of the source text since it is introducing a causal
relationship not explicitly stated in the original. In other word, it
introduces some new meaning or relationship to what is being said, even if
the gist is retained (Lambert, 1994: 126).
4) Closure Addition
This is an addition which accompanies rephrasing, omission, or
“closure” to a sentence unit, without adding anything substantial to the
sentence (Lambert, 1994: 126).
Besides the addition types above, there are still several kinds of addition excluded
from those five types above, which are judged inconsequential and, in most case,
too view in number. There are explained as follows.
1) Addition of connective end between phrases or sentences, resulting in a
linking of separate units.
2) Addition of specification, substituting this/that for the or some similar
event, or specifying an item referred to pronominally in the original.
3) Translation of language-specific items not required in the target language.
For example, when the definite article carried over from French to English:
e.g. The President Kennedy.
4) Addition of preposition or other item resulting in an ungrammatical
structure, but not contributing to or affecting the meaning of the material.
5) Addition on the part of the interpreter of extraneous material or comment
not related to the text (Lambert, 1994: 127).
c. Substitutions and Errors
This category refers to the substitution of the translator for what is said by
the speaker. A substitution can be a single word or a whole clause. Some
substitutions considered change the meaning, while the others can be said as
“errors” of translation. Sometime, it involves a combination of omission and
1) Mild semantic error
This is error or inaccuracy of the translation of some lexical item, which
only slightly distorts the intended meaning. This error often associated
with an awkward interpretation. The inaccuracy limited only in the lexical
item or expression, and it is not influence the rest of the unit of which it is
part of (Lambert, 1994: 128).
2) Gross semantics error
This is an error of translation which substantially changes the meaning of
what is said. This error also limited to specific item and does not affect to
the rest of the unit. There are three kinds of errors of this type.
a) Error stemming from assumed misunderstanding by the interpreter of
some lexical item because of homonym or near homonym, or because of
confusion in reporting with near-sounding word.
b) Error of false reference. It is probably stemming from confusion and
having its basis in the text. Different from the previous type, it brings
extraneous elements into the target text.
c) Error of meaning which is not due to confusion. This error appears without
a basis of the source text and therefore no suitable explanation can be
found. In addition, this criteria contains an obvious unintelligible material
3) Mild phrasing change
This situation happen when the translator does not say quiet the same thing
of the source text, but the gist of what is said is not affected (Lambert,
1994: 129).
2. Componential Analysis
Componential analysis is an analysis of the basic components of meaning
of a given word. It is a kind of analysis that deals with a lexical meaning which is
based on sense and sense components (Palumbo, 2009: 22). Patrizia Violi stated
in her book entitled Meaning and Experience that most model of semantic
analysis is componential: it is considered possible to breakdown single term into
further, more basic unit of meaning (2001:53). Componential analysis is found on
the basic idea that the meaning of each term can be analyzed by a set of meaning
components or properties of a more general order, some of which will be common
to various terms in the lexicon (2001: 53). She explains further that in this
semantics filed, there are two significant concepts, namely semantics features or
properties and componential analysis itself, that need to be concerned as written in
the citation below.
However, the term componential analysis is often used to refer not only to simple decomposition into semantics components, but to model which much more powerful theoretical assumptions. It is therefore important to immediately draw and maintain a distinction between two different notions:
1) The compositional method of analysis; and
2) A semantics theory based on the notion of an exhaustive feature analysis, which I shall refer to hereafter as features semantics.
analysis, not a theory of meaning, and it does not involve any theoretical assumptions about the nature of the meaning of words, except the very general one already mentioned. Indeed it can be used within any theoretical framework, and is often combined with other representational formats. Feature semantics on the other hand, is a theoretical model (or models) based on two specific assumptions
1) The semantics features on which the decomposition is based on are a set of necessary and sufficient conditions (NSCs) for the definition of the meaning; and
2) The features constitute a limited number of primitive terms (Violi, 2001: 53-54).
Violi also mentions the examples of componential analysis as follows
Man : ANIMATE & HUMAN & MALE & ADULT
Woman : ANIMATE & HUMAN & NON MALE & ADULT
Boy : ANIMATE & HUMAN & MALE & NON ADULT
Girl : ANIMATE & HUMAN & NON MALE & NON ADULT (2001:
55):
Later, when it works together with the concept of semantic feature, namely the set
of necessary and sufficient conditions (NSCs), several results will be considered
as consequences’ that will be used in determining its meaning units.
In addition, Ruth M Kempson in the book entitled Semantics Theory refers
the systematic relation between words as the concern in the componential
analysis. Componential analysis, therefore, analyzed the meaning of word not as
unitary concepts but as complexes made up of components of meaning which are
themselves semantic primitives (1997: 18). To have a clearer description, then
1) The word spinster may be analyzed as a semantic complex made up of the
features or components such as [HUMAN], [FEMALE], [ADULT],
[NEVER MARIED].
2) In order to give an account kinship terminology in various cultures,
componential analysis provides an analysis such as in the words mother
and aunt. The distinction of those words will be explicit if they are
analyzed as contrasting complexes of the components [FEMALE],
[PARENT OF], [CHILD OF].
3) To make a distinction between similar words such as murder and kill.
Murder is analyzed as having a meaning which is a complex of
components representing intention, causation, and death; and kill as
having a complex of only the components representing causation and
death.
4) In the similar way, the words give and take can be shown to be distinct by
virtue of their contrasting complex of components representing causation
and change of ownership.
Componential analysis also can make a distinct and detail analysis of the
elements of words that have relation. There are several steps to take in doing
componential analysis for words that have relation. According to Nida, in making
a componential analysis of any group of related words there are five basic steps
(1964: 83):
2) Defining the term as precisely as possible, on the basis of the objects involved. For example, for the English kinship term uncle it would specify father’s brother, mother’s brother, father’s father’s brother, mother’s father’s brother, etc.
3) Identifying the distinctive features which define the various contrasts in meaning, e.g. differences of generations, of sex, of lineality, etc.
4) Defining each term by mean of the distinctive features. For example, father may be defined as the first ascending generation, male, and lineal (i.e. direct line).
5) Making an overall statement in the relationship between the distinctive features and the total number of symbols classified. This is often done by means of some “plotting” and “mapping” of the semantic space (Nida, 1964:83).
As mentioned above, there are semantic features in the componential
analysis. Here the researcher gives the example of semantic features within words
as below.
The same semantic feature may be shared by many words. “Female” is a semantic feature, sometime indicated by suffix –ess, that makes up part of the meaning of nouns, such as:
tigress hen aunt maiden
doe mare debutante widow
ewe vixen girl woman
The words of the last two columns are also distinguished by the semantic feature “human” which also found in:
doctor dean professor teenager
dachelor parent baby child
Another part of the meaning of the words baby and child is that they are “young”. (We will continue to indicate words by using italics and semantic features by double quote.) The word father has the properties “male” and “adult” as do uncle and bachelor (Fromkin, 2010: 201).
3. Translation Theory of Equivalence
In determining the accuracy of translation or interpretation, the most
proportional method to use is by applying equivalence theory in the analysis of
translation define equivalence as the relationship between a source text (ST) and a
target text (TT) that allows the TT to be considered as a translation of the ST in
the first place (Baker, 2005: 77). According to Hatim in the book entitled
Teaching and Researching Translation the equivalent of translation, which is also
as a requirement of interpreting equivalence, involves any or all of these following
levels:
1) Source Language and Target Language words having similar orthographic
or phonological features (formal equivalence);
2) Source Language and Target Language words referring to the same thing
in the real world (referential or denotative equivalence);
3) Source Language and Target Language words triggering the same or
similar associations in the minds of speakers of the two languages
(connotative equivalence);
4) Source Language and Target Language words being used in the same or
similar contexts in their respective languages (text normative equivalence);
5) Source Language and Target Language words having the same effect on
their respective readers (pragmatic or dynamic equivalence) (2001: 26).
Mona Barker in the book entitled Routledge Encyclopedia of Translation Studies
also provides other types of equivalence as follow.
1) Referential or Denotative Equivalence
This equivalence established when the source text and the target text
2) Connotative Equivalence
This equivalence established when the source and target text words
triggering the same or similar associations in the minds of native speakers
of the two languages.
3) Text-Normative Equivalence
This equivalence established when the source and target text words being
used in the same or similar contexts in their respective language.
4) Pragmatic or Dynamic Equivalence
This equivalence established when the source and target text words having
the same effect on their respective readers (Baker, 2001: 77).
Here also mentions the types of equivalence offered by Eugene A. Nida which can
be seen as follow.
1) Formal equivalence or Formal correspondence
This equivalence concept consists of a target text item which represents
the closest equivalent of a source text word or phrase.
2) Dynamic equivalence
This equivalence is defined as a translation, which is in this case refers to
an interpretation activity, principle according to which a translator or
interpreter seeks to translate the meaning of the original in such a way that
the target text wording will trigger the same impact on the audience as the
original wording did upon the source text audience (Taken from:
Last but not least, in order to gain a detail explanation, this research also involves
the equivalence classification given by Otto Kade in Anthony Pym’s book entitled
Exploring Translation Theories.
1) One-to-one Equivalence
This equivalence established when one source-language item corresponds
to one target-language item.
2) One-to-several or several-to-one Equivalence
This equivalence established when an item on one language corresponds to
several in the other language.
3) One-to-part Equivalence
This equivalence established when only partial equivalents are available,
resulting in “approximate equivalence”. For example, the English term
brother has no full equivalent in Chinese or Korea, since the
corresponding terms have to specify whether this is an older or younger
brother. Whichever choice is made, the equivalence will thus be
“approximate”.
4) One-to-no Equivalence
This equivalence established when no equivalent is available in the target
text. For example, most languages did not have the term computer in their
vocabulary. Therefore, when such word appeared in translation or
interpretation, then a circumlocution (a phrase to describe an object) would
borrow foreign terms, while the others prefer to generate new terms from
their own existing resources (Pym, 2010: 29).
C. Theoretical Framework
The translation theories of omissions, additions, and substitutions and
errors will analyze the source and the target text, which are English and
Indonesian. In order to have a more focused analysis and to have a clear limitation
about the research, then the analysis will concern on the keywords. Therefore,
determining the keywords is essential to do. The keywords of the source text is
already given or determined and bold typed in its written text. Meanwhile, the
researcher has to find or determine the keywords of the target text.
In the definition of terms of the previous chapter it is mentioned that
keywords represent an essential basic concept of a text. By referring the written
source text in the book entitled Selected Topics High-Intermediate Listening
Comprehension by Ellen Kisslinger where the keywords have already determined,
and also consulting the dictionary without neglecting the context of the text
indeed, the keywords of the target text are specified. After listing the keywords
from both the target and the source text, then the next step to take is contrasting or
juxtaposing them. In juxtaposing them, the keywords of the source text maybe has
then there will shown that one keywords of the source text may have more than
one interpretation in the target text, or in the contrary have no translation in the
target text at all. Those, the more-than-one and missing translation will be
phenomena in this research, namely omissions, additions, and substitutions and
errors.
Meanwhile, the componential analysis theory in semantics leads the next
step of analysis in whether those phenomena; such as omissions, additions, and
substitutions; influent the messages rendering from the source text into the target
text. By using componential analysis, it will explain how those phenomena affect
the messages transmission. In a deeper analysis, it will also explain how the
interpretation accuracy based on the conveyed components of the words from the
source text as well as the target text. To avoid a vast and various perception of
accuracy, then the term closely relevant with accuracy is equivalence. Meaning to
say, the keywords are accurately interpreted when they have equivalent translation
in the target text.
Finally, componential analysis will work in coherence with the translation
theory of equivalence to analyze the phenomena, in order to provide a degree of
the accuracy of the keywords interpretation concerning the affection of the
phenomenon toward the messages rendering process. In other words, this
equivalence theory will help the analysis in determining the accuracy of the
interpretation, based on the phenomena analyzed in the componential analysis.
D. Research Framework
The following page is the research framework that is used in doing this
research. This framework is aimed to show the research steps taken from the
30 CHAPTER III METODHOLOGY
This part gives the information on the research procedure. It contains the
information about the object of the study, method of the study, and research
procedure. This chapter also discusses data gathering and data analysis of the
study.
A. Object of the Study
The object of the study is the process of messages transfer of consecutive
interpreting. The research data is oral recorded data of the middle examination of
interpreting class. Since the research take place in a class, the learners or students
of interpreting class become the one who produce the data. The students are
commonly the seventh grade students and several are from the higher grade that
have not taken interpreting class of English Letters Study Programme of Sanata
Dharma University. The interpreting class students are chosen because the
interpreting subject is studied in the seventh semester, it means they have already
studied English deeper for six semesters. It implies that the knowledge of English
language has expanding. For instance, they have studied, at least, several lessons
such as listening; reading; writing; speaking; structure or grammar; translation;
semantics; pragmatics, which is studied at the same semester with interpreting;
etc, which are essential for the progress in learning English language and as the
they have adequate competence of interpreting. Secondly, since the concern of
this study is the interpreting process then the writer expects to find certain
linguistics phenomenon which can be scientifically analyzed.
Linguistically, the study is going to analyze the oral translation of the
source language, namely English language into the target language that is
Indonesian language. Since to analyze the whole text of the interpretation are too
miscellaneous regarding to the structure of the language, namely sentences,
phrases, etc; thus the writer narrowed down the scope in order to get the specific
and more focused study. To gain a detailed study, an analysis of the lexicon or
maybe phrase is taken. In the matter of fact, the lexicons selected are the
keywords of the interpreted text. It is more effective and easy way to understand
the aim of a text, concerning about the context indeed, by referring the keywords.
In other word, the translation of the keywords from the source language to the
target language will be the data of the study.
B. Approach of the Study
The approach that is used in this research is semantics approach.
Semantics is the study of meaning expression in words, phrases, and sentences.
When studying the meaning of word, there is a branch in semantics field which is
called componential analysis. Componential analysis is an analysis of the basic
components of meaning which compose a word. It tries to extract what are the
of the word consist of words, which mean that the meaning of a word is dependent
on the meaning of other words.
In this research, componential analysis will try to look how the
components of word have a relation with the messages rendering in interpreting
activity, and later will determine the accuracy of the interpretation. The researcher
starts from the notion that each word in any language has the components to give
a meaning in it. Two different words from the different language can have the
same or similar meaning, since they posses or share the same or similar
components. Therefore, based on this approach, an interpretation can be
inaccurate or accurate depends on the components which are shared among the
source and the target text. The more components of the word from two different
languages are shared the more accurate the interpretation can be, the intention of
the sentence can be delivered to the target text.
The researcher also applies a research method that will help the data
analysis process, namely qualitative research. This research is categorized as field
research. The main methods employed in qualitative research were observation,
interviews, and documentary analysis (taken from:
http://www.edu.plymouth.ac.uk/resined/qualitativemethods 2/qualrshm.htm). This
research uses qualitative research method because the sources of the data are
recorded speeches which are transcribed into texts. In the qualitative research the
data consist of words or actions of the participants which the researcher hears and
observes (Holloway, 1997:43). In conducting the research, the writer also uses a
said when having his dissertation in The University of Georgia, that this is a
working draft of a booklet on conducting qualitative research using a camcorder
(taken from: http://qualitativeresearch.ratcliffs.net/15methods.pdf 15methods).
Therefore, recording the object or activity, interpreting process in this case, can be
done for collecting the data. Moreover, since the results of the study are presented
in a description form, then this research is categorized as a descriptive analytical
study. The result of qualitative research usually presented in the form of
quotations, descriptions, or sometime in basic statistics.
C. Method of Study
1. Data Sampling
The sample of this research is the keywords. Since there are many
keywords in the text, and there are all considered to be vary in its type, therefore
the researcher need to specify the keywords which are suitable to the analysis in
the research. Thus, the keywords that are appropriate to use in the analysis are the
keywords that have such the phenomena of omissions, additions, or substitutions
and errors. The keywords from the source text are having a change when it is
transferred into the target text. For example, the keywords is not completely
interpreted or even gone, then this is classified as an omission; or the
interpretation of a single word from the source text becomes a phrase in order to
give elaboration in the target text, then it will be called an additions; or the
which causes the alteration of the intended meaning, then it can be said as
substitutions and errors.
2. Data Collection
The data in this research were taken from the test of interpreting class. The
test was practicing consecutive interpreting. It performed in 12th, 14th, 15th
October 2009. The participants of the test were divided into groups. Each group
consists of two until four students. The test used three different texts or speeches
with different theme, and each group only got one speech. The test consists of two
phases, the first was a short sentence or phrase and the second was the longer one.
Every student in the group had to interpret the sentences or phrases of the speech
in turn. The speech was played in a tape recorder, while the student listened for a
while carefully. They were allowed to take a note indeed. Then he or she would
orally translate it after the lecture stopped the tape recorder for each short phrase
or sentence. After one finished then went to the next student. It had the same
method for the longer version.
In order to ease the analysis, the writer recorded the students’
performances for the first step in collecting the data. The writer used a camera
recorder and voice recorder in recording the interpreting processes. After taking
the students’ action as an oral data sources, it needed to write down into a written
texts.
Writing down the oral data sources into written texts is absolutely
distinct and researchable text, the writer used an oblique line in every segment
regarded to the pause of the sentence or phrase.
After getting the written text, the next part to take was identifying the
keywords and then made a list as a raw data. The keywords of the source language
were easily to be found, because the oral sources which were played in the tape
recorder had the written version, and its keywords had already bold typed. In the
other hand, the writer had to search the most appropriate words or phrases to the
source language to consider as the keywords of the result of the interpretation as
the target language. Therefore, it also needed to refer to dictionaries.
A table was made to make a comprehensible data. The table’s contents
consist of the keywords from the source language and target language as a
comparison. One source language’s keyword might have more than one
interpretation in the source language. Thus it would count as a second data.
3. Data Analysis
The researcher combined two types of research procedure in conducting
the analysis, namely the library and field research. It took library research
considering the needs to go to the library to find proportional references from
many books. The other term here was the field research. It needed a field research
because the research had to observe the object of the study.
The first step in analyzing the data of the written text was examining all
parts of the text to find the keywords. Since the keywords of the source language
language by comparing to the source language and also consulting the
dictionaries. Indeed, considering the context was the part which could not be
neglected.
Next was making a list of the keywords of the both sources to compare
what were in the source language and what were in the target language. By
comparing the keywords, without ignoring the text’s context, the writer could see
the changes and the process of message delivery at first. Then, by using
translation theory of omissions, additions, and substitutions and errors, the
researcher could set an empirical analysis of the phenomenon found in the
interpretation of the keywords.
The findings of the first analysis by using the theory of translation above
then would be analyzed deeper by using semantic theory. One of the theories in
semantic that were going to be applied in this analysis was componential analysis.
The componential analysis then would provide an empirical description of those
findings in relation to the interpreting accuracy. In order to give more convincing
and plausible analysis, the researcher combined the componential analysis with
the translation theory of equivalence. Finally, it would result accuracy
37 CHAPTER IV
ANALYSIS
This chapter will cover the analysis of the message rendering of
English-Indonesian consecutive interpreting in interpreting class of English Letter Study
Programme of Sanata Dharma University which is seen through the keywords
interpretation. The analysis will be divided into two major parts based on the
problem formulation in chapter one. They are the interpretation of the keywords
from English into Indonesian and the affection of those interpretations toward the
messages rendering.
Firstly, in the analysis of keywords interpretation, it will elaborate the
comparison of the English keywords and its interpretation in Indonesian by
juxtaposing each of them. Then, as the comparison is presented in a table, an
analysis based on the theories of omission, addition, and error take their part to
give an explanation toward the phenomena which occur.
Secondly, based on the findings of the first analysis, then those will be
analyzed further in relation with the affection matters toward the messages
rendering process. In this part of analysis, the componential analysis theory will
be the tool to provide the explanation. Finally, in the last part of this analysis will
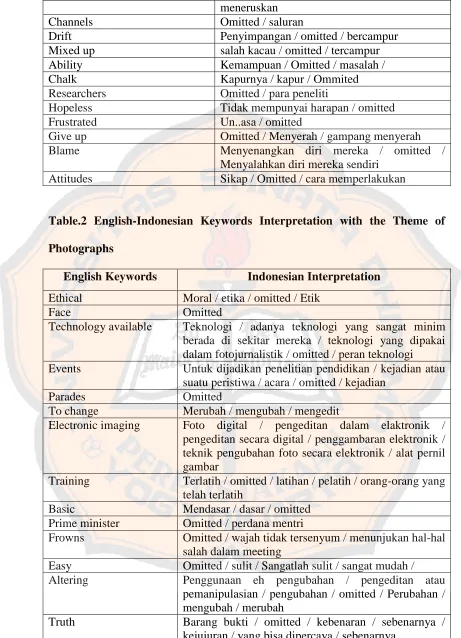
A. The English-Indonesian Keywords Interpretation
In this part, we will look at the English-Indonesian keywords interpretation
in the interpreting class of English Letters Study Programme of Sanata Dharma
University that was taken from the consecutive interpreting tests in 12th, 14th and
15th October 2009. As mentioned before that the keywords have already
determined in the printed text of the source language, namely English language,
since the recorded files has the written version. Therefore, it makes the researcher
easier in doing the analysis. However, based on the definition of keywords as
given in the chapter one before, then the researcher also includes some additional
keywords. Since the meaning of keywords in this research are the words which
are used over and over in the text and are crucial to the theme or topic under
discussion, and they are most often represent an essential or basic concept of the
text, then the researcher determined several additional keywords such as; 85 %,
Dyslexic Treatment Center, Upside-Down Kid, drift around, to change, Dr.
Harold Levinson, electronic imaging, easy, expressions, and summarized. These
founding, later will be included in the next analysis since their present in the
sentences have crucial effect of the message rendering process.
In order to give an understandable explanation of the keywords
interpretation, then the researcher makes a list in a table. The table will consist of
the source text keywords and the target text keywords. In the target text keywords
column, there will be divided into two columns based on the topic discussed,
namely Dyslexia and Photographs. One source text keyword might be interpreted