ISBN : 978-979-16353-1-8
PROSIDING
SEMINAR NASIONAL
MATEMATIKA DAN PENDIDIKAN MATEMATIKA
“Peningkatan Kualitas Penelitian dan Pembelajaran
Matematika untuk Mencapai World Class University”
Yogyakarta, 28 November 2008
Penyelenggara :
Jurusan Pendidikan Matematika FMIPA UNY
Kerjasama dengan
Himpunan Matematika Indonesia (Indo-MS)
wilayah Jateng dan DIY
Jurusan Pendidikan Matematika
Fakultas Matematika dan Ilmu Pengetahuan Alam
Universitas Negeri Yogyakarta
PROSIDING SEMINAR NASIONAL
MATEMATIKA DAN PENDIDIKAN
MATEMATIKA
28 November 2008 FMIPA Universitas Negeri Yogyakarta
Artikel
‐
artikel dalam prosiding ini telah dipresentasikan dalam
Seminar Nasional Matematika dan Pendidikan Matematika
pada tanggal 28 November 2008
di Jurusan Pendidikan Matematika
Fakultas Matematika dan Ilmu Pengetahuan Alam
Universitas Negeri Yogyakarta
Tim Penyunting Artikel Seminar :
1. Prof. Dr. Rusgianto HS 2. Dr. Hartono
3. Dr. Djailani 4. Sahid, M.Sc.
Jurusan Pendidikan Matematika
Fakultas Matematika dan Ilmu Pengetahuan Alam
Universitas Negeri Yogyakarta
KATA PENGANTAR
Puji Syukur ke Hadirat Tuhan Yang Maha Esa atas segala Karunia dan
RahmatNya sehingga prosiding ini dapat diselesaikan. Prosiding ini merupakan
kumpulan makalah dari peneliti, dosen dan guru yang berkecimpung di bidang
Matematika dan Pendidikan Matematika yang berasal dari berbagai daerah di
Indonesia. Makalah yang dipresentasikan meliputi 1 makalah utama dan 65 makalah
pendamping yang terdiri dari 4 makalah bidang Aljabar, 1 makalah bidang Analisis,
25 makalah bidang Statistika, 9 makalah bidang Terapan dan Komputer, dan 28
makalah bidang Pendidikan Matematika
Pada kesempatan ini panitia mengucapkan terimakasih kepada semua pihak
yang telah membantu dan mendukung penyelenggaraan seminar ini. Kepada seluruh
peserta seminar diucapkan terimakasih atas partisipasinya dan selamat berseminar
semoga bermanfaat.
DAFTAR ISI
Cover Prosiding i
Kata Pengantar iii
Daftar Isi iv
1. Makalah Bidang Matematika
Kode Judul Hal
M - 1. Generalized Non-Homogeneous Morrey Spaces And Olsen Inequality (I.
Sihwaningrum, H. Gunawan, Y. Soeharyadi, W. S. Budhi)
1 – 1
M - 2. Nilai Eigen dan Vektor Eigen Matriks atas Aljabar Max-Plus Interval (M. Andy Rudhito, Sri Wahyuni, Ari Suparwanto, F. Susilo)
1 – 8
M - 3. Keterbatasan Operator Integral Fraksional Di Ruang Lebesgue Tak Homogen
(Herry Pribawanto Suryawan)
1 – 19
M - 4. Solusi Periodik Tunggal Suatu Persamaan Rayleigh (Sugimin) 1 – 28
M - 5. Ruang Barisan Selisih
( )
,1p Δ < < ∞p
l Dan Beberapa Permasalahan
Karakterisasi Produk Tensor lp
( )
Δ ⊗lq( )
Δ (Muslim Ansori)1 – 33
M - 6. Menampilkan Penaksir Parameter Pada Model Linear ( Mulyana ) 1 – 40
M - 7. Simulasi Radius Jarak Pengaruhnya Terhadap Kebaikan Model Regresi Logistik Spasial (Utami Dyah Syafitri, Agus M Sholeh, Poppy Suprapti)
1 – 45
M - 8. Estimasi Bayesian untuk Penentuan Besarnya Pengaruh Genetik Terhadap Sifat Fenotip Dan Studi Simulasinya (Adi Setiawan)
1 – 50
M - 9. Penduga Maksimum Likelihood Untuk Parameter Dispersi Model Poisson-Gamma Dalam Konteks Pendugaan Area Kecil (Alfian F. Hadi, Nusyirwan,
Khairil Anwar Notodiputro)
1 – 63
M - 10. Penentuan Sampling Minimal Dalam Eksperimen Life-Testing menggunakan
Order Statistics (Budhi Handoko)
1 – 78
M - 11. Analisis Conjoint Sebagai Alat Menentukan Model Preferensi Nasabah Menabung Di Bank (Budiono, Nani Hidayati)
1 – 90
M - 12. Evaluasi Tingkat Validitas Metode Penggabungan Respon ((Indeks Penampilan Tanaman, IPT) (Gusti N Adhi Wibawa, I Made Sumertajaya, Ahmad Ansori
Mattjik)
M - 13. Pemodelan Persamaan Struktural Dengan Partial Least Square (I Gede Nyoman
Mindra Jaya,I Made Sumertajaya)
1 – 118
M - 14. Penggerombolan Model Parameter Regresi dengan Error-Based Clustering
(I Made Sumertajaya, Gusti Adhi Wibawa, I Gede Nyoman Mindra Jaya)
1 – 133
M - 15. Koreksi Metode Connected Ammi dalam Pendugaan Data Tidak Lengkap (Made
Sumertajaya, Ahmad Ansori Mattjik, I Gede Nyoman Mindra Jaya)
1 – 145
M - 16. Pendekatan Metode Pemulusan Kernel Pada Pendugaan Area Kecil (Small
Area Estimation) (Indahwati, Kusman Sadik, Ratih Nurmasari)
1 – 162
M - 17. Penerapan Metode Pemulusan Kernel Pada Pendugaan Area Kecil
(Studi Kasus Pendugaan Pengeluaran Per Kapita Di Kota Bogor Tahun 2005)
(Indahwati, Utami Dyah Syafitri, Renita Sukma Mayasari)
1 – 173
M - 18. Zero Inflated Negative Binomial Models In Small Area Estimation (Irene
Muflikh Nadhiroh, Khairil Anwar Notodiputro, Indahwati)
1 – 183
M - 19. Aplikasi Multidimensional Scaling Untuk Peningkatan Pelayanan Proses Belajar Mengajar (PBM). (Irlandia Ginanjar)
1 – 194
M - 20. Peranan Formulasi Inversi Pada Fungsi Karakteristik Suatu Variabel Acak
(John Maspupu)
1 – 202
M - 21. Pendugaan Berbasis Model Untuk Kasus Biner Pada Small Area Estimation
(Kismiantini)
1 – 209
M - 22. Pendugaan Komponen Utama Pada Pengaruh Acak Model Linear Campuran Terampat (Mohammad Masjkur)
1 – 216
M - 23. Distribusi Poisson Tergeneralisasi Tak Terbatas Dan Beberapa Sifat-Sifatnya
( Suatu Pengembangan Teori Statistika Matematika) (Mutijah)
1 – 237
M - 24. Regresi Rasio Prevalensi Dengan Model Log-Binomial: Isu Ketakkonvergenan
(Netti Herawati, Alfian Futuhul Hadi, Nusyirwan, Khoirin Nisa)
1 – 249
M - 25. Pengujian Autokorelasi TerhadapSisaan Model Spatial Logistik (Utami Dyah
Syafitri, Bagus Sartono, Salamatuttanzil)
1 – 264
M - 26. Penerapan Analisis Survival Untuk Menaksir Waktu Bertahan Hidup Bagi Penderita Penyakit Jantung (Yani Hendrajaya,Adi Setiawan dan Hanna A.
Parhusip)
1 – 269
M - 27. Pendekatan Analisis Multilevel Respon Biner dalam Menentukan Faktor-Faktor yang Memengaruhi Imunisasi Lengkap (Bertho Tantular, I Gede Nyoman Mindra
Jaya)
1 – 281
M - 28. Optimasi Bobot Portofolio Dan Estimasi Var (Portfolio Weighted Optimization
And Var Estimation) (Sukono, Subanar, Dedi Rosadi )
1 – 292
M - 29. Estimasi Var Dengan Pendekatan Extreme Value (Estimation Of Var By Extreme
Value Approach) (Sukono, Subanar, Dedi Rosadi )
1 – 304
M - 30. Activities In Sunspot Group NOAA 9393 (Bachtiar Anwar, Bambang Setiahadi) 1 – 315
M - 31. Penyelesaian Asymmetric Travelling Salesman Problem
Dengan Algoritma Hungarian Dan Algoritma Cheapest Insertion Heuristic
(Caturiyati)
1 – 324
M - 32. Studi Model Variasi Harian Komponen H Berdasarkan Pola Hari Tenang
(Habirun)
1 – 335
M - 33. Pemodelan Perembesan Air dalam Tanah (Muhammad Hamzah, Djoko S,
Wahyudi W.P, Budi S)
1 – 346
M - 34. Eksistensi Dan Kestabilan Solusi Gelombang Jalan Model Kuasiliner Dissipatif Dua Kanal (Sumardi)
1 – 354
M - 35. Minimal Edge Dari Graf 2-Connected dengan Circumference Tertentu (On Edge Minimal 2-Connected Graphs With Prescribed Circumference)
(Tri Atmojo Kusmayadi)
1 – 365
M - 36. Model Sis dengan Pertumbuhan Logistik (Eti Dwi Wiraningsih, Widodo, Lina
Aryati, Syamsuddin Toaha)
1 – 373
M - 37. Aplikasi Model Dinamik Pada Bursa Efek (Joko Purwanto) 1 – 386
M - 38. Analisis Fraktal Emisi Sinyal ULF Dan Kaitannya Dengan Gempa Bumi di Indonesia (Sarmoko Saroso)
1 – 400
M - 39. Pengujian Hipotesis Rata-Rata Berurut untuk Membandingkan Tingkat kebocoran di Daerah Dinding Gingival menggunakan Tiga Macam Bahan Tambalan Sementara (Pendekatan Parametrik) (H. Bernik Maskun)
2. Makalah Bidang Pendidikan Matematika
Kode Judul Hal
P- 1 Pengembangan Model Creative Problem Solving Berbasis Teknologi Dalam Pembelajaran Matematika Di SMA (Adi Nur Cahyono)
2 - 1
P – 2 Mengembangkan Soal Terbuka (Open-Ended Problem) dalam Pembelajaran Matematika (Ali Mahmudi)
2 - 12
P – 3 Pengaruh Pemberian Tugas Creative Mind Map Setelah Pembelajaran Terhadap Kemampuan Kreativitas Dan Koneksi Matematik Siswa (Ayu Anzela Sari,
Jarnawi Afgani D)
2 - 23
P – 4 Kontribusi Matematika Dan Pembelajarannya bagi Pendidikan Nilai
(Gregoria Ariyanti )
2 - 38
P – 5 Mahasiswa Field Independent Dan Field Dependent dalam Memahami Konsep Grup * (Herry Agus Susanto)
2 - 64
P – 6 Peningkatan Pembelajaran Konsep Pengolahan Data Melalui Tutor Sebaya Dengan Komputer (Endah Ekowati )
2 - 78
P - 7 Pembelajaran Matematika Untuk Meningkatkan Kemampuan Pemecahan Masalah Matematis Siswa Sekolah Menengah Atas (Ibrahim)
2 - 90
P – 8 Strategi Pembelajaran Kolaboratif Berbasis Masalah (Djamilah Bondan
Widjajanti)
2 - 101
P – 9 Pembelajaran Matematika dengan Pendekatan Kooperatif Tutor Sebaya Bertingkat dalam Persiapan Menghadapi UN 2009 (Kukuh Guntoro)
2 - 111
P – 10 Melatih Kemampuan Metakognitif Siswa dalam Pembelajaran Matematika
(Risnanosanti, M.Pd)
2 - 115
P – 11 Teori Van Hiele Dan Komunikasi Matematik (Apa, Mengapa Dan Bagaimana)
( Hj.Epon Nur’aeni)
2 - 124
P – 12 Meningkatkan Kemampuan Berpikir Matematis Tingkat Tinggi Calon Guru Matematika Melalui Pembelajaran Berbasis Komputer Pada Perguruan Tinggi Muhammadiyah (Bambang Priyo Darminto)
2 - 139
P – 13 Pembelajaran Matematika dengan Konflik Kognitif (Dasa Ismaimuza) 2 - 155
P – 14 Peran Penalaran dalam Pemecahan Masalah Matematik(E. Elvis Napitupulu) 2 - 167
P – 15 Meningkatkan Hasil Belajar Matematika Dengan Menerapkan Pembelajaran Kooperatif Tipe STAD Pada Materi Pokok Aljabar Dan Aritmatika Sosial di Kelas 7C SMPN I Pringsurat Tahun Pelajaran 2008/2009 (Hidayati)
2 - 181
P – 16 Rekonstruksi Tingkat-Tingkat Berpikir Probabilistik Siswa Sekolah Menengah Pertama (Imam Sujadi)
2 - 187
P – 17 Mengembangkan Board Game Labirin Matematika Bagi Siswa Kelas Rendah Guna Menghindari Mind In Chaos Terhadap Matematika (Maman
Fathurrohman, Hepsi Nindiasari, Dan Ilmiyati Rahayu)
2 - 209
P – 18 Pemahaman Konsep Matematik Dalam Pembelajaran Matematika (Nila
Kesumawati)
2 - 229
P – 19 Meningkatkan Pemahaman Mahasiswa Pendidikan Matematika Fkip Ups Tegal Pada Konsep Distribusi Peluang Khusus melalui Pembelajaran Kooperatif Model STAD (Nina R. Chytrasari,Eleonora D. W.)
2 - 236
P –20 Pembelajaran Kooperatif Tipe Teams-Games-Tournaments (Tgt) guna
Meningkatkan Kemandirian Belajar Mahasiswa Statistika Matematika Program Studi Pendidikan Matematika FKIP UNTIRTA (Nurul Anriani, Novaliyosi,
Maman Fathurahman)
2 - 248
P –21 Pengembangan Bahan Ajar Berdasarkan Perkembangan Kognitif Untuk Meningkatkan Hasil Belajar Matematika Siswa SD (Rasiman)
2 - 257
P –22 Problem-Based Learning dan Kemampuan Berpikir Reflektif dalam Pembelajaran Matematika (Sri Hastuti Noer)
2 - 267
P –23 Pengaruh Penilaian Portofolio Dan Kecerdasan Emosional Terhadap Hasil Belajar Matematika Topik Dimensi Tiga Siswa Kelas X Sma Negeri 4 Kendari Tahun 2006 (Sunandar)
2 - 281
P –24 Proses Pembelajaran Student Centered Pada Mata Kuliah Statistik Nonparametrik (Penerapan Strategi Instant Assessment, Index Card Match, Practice Rehearsal
Pairs, Dan Case Study) (Yuliana Susanti)
2 - 200
P –25 Mengembangkan Keterampilan Berfikir Matematika ( Sehatta Saragih) 2 - 310
P –26 Pembelajaran Matematika Dengan Melibatkan Manajemen Otak (Suatu Alternatif Pembelajaran Interaktif) (Somakim)
2 - 327
P –27 Kemampuan Komunikasi Matematik Dan Keterampilan Sosial Siswa Dalam Pembelajaran Matematika(Kadir)
2 - 339
P –28 Pengaruh Bimbingan Belajar terhadap Hasil Belajar Mahasiswa (Studi Kasus Terhadap Mata Kuliah Analisis II) (Sugimin)
P – 29 Keterbatasan Memori dan Implikasinya dalam Mendesain Metode Pembelajaran Matematika (Endah Retnowati)
2 - 359
Estimasi Bayesian
untuk Penentuan Besarnya Pengaruh Genetik terhadap Sifat Fenotip dan Studi Simulasinya
Adi Setiawan ([email protected])
Program Studi Matematika, Fakultas Sains dan Matematika Universitas Kristen Satya Wacana
Jl. Diponegoro 52-60 Salatiga 50711, Indonesia
Abstract
Twins that have a particular categorical trait can be used to determine the genetic contribution to the trait. In this paper it is described a simulation study to generate a particular categorical data trait in MZ and DZ twin. The data is then used to find the genetic contribution to the trait by using Bayesian method.
Key-words: twin, genetic contribution, Bayesian method.
A. Pendahuluan
Dalam upaya menentukan besarnya pengaruh genetik terhadap sifat fenotip
(trait) dapat digunakan metode momen dan metode maksimum likelihood yang
menggunakan data trait pada pasangan kembar hasil simulasi (lihat dalam makalah
Setiawan (2008)). Dalam makalah ini akan dijelaskan metode lain yang menggunakan
pendekatan Bayesian.
B. Dasar Teori
Misalkan dimiliki suatu trait kuantitatif X dari suatu individu yang dipilih secara
random dari suatu populasi. Trait X dapat dianggap mengikuti model
X = A + E,
dengan A dan E masing-masing adalah faktor genetik dan faktor lingkungan yang saling
bebas. Dua individu yang diambil secara random dari suatu populasi masing-masing
dengan trait X1 dan X2 dapat dimodelkan sebagai
X1 = A1 + C + E1,
X2 = A2 + C + E2,
dengan (G1, G2), C, E1, E2 saling bebas dan E1, E2 berdistribusi identik. Dalam hal ini
C adalah faktor lingkungan bersama dan E adalah faktor lingkungan bukan bersama.
Apabila suatu trait yang didekomposisi sebagai X = A + C + E maka heritabilitas
(heritability) didefinisikan sebagai
) ( ) ( ) (
) ( )
( ) (
E V C V A V
A V X
V A V
+ +
= ,
yang dapat diestimasi berdasarkan dari data pengamatan X. Heritabilitas dapat
dipandang sebagai besarnya pengaruh faktor genetik terhadap sifat fenotip. Dalam
model ACE, variansi dan kovariansi dari trait X1 dan X2 antara dua individu yang
bersaudara dapat didekomposisi menjadi
2 2 2 2 2
1) ( )
(X =V X =σ =ν +η +κ
V , (1)
2 2 2
1, ) 2
(X X = Ψν +η
Cov ,
dengan ν2, η2 dan κ2 masing-masing adalah variansi faktor genetic A, variansi lingkungan bersama C dan variansi lingkungan bukan bersama E sedangkan Ψ
merupakan koefisien kinship yang tergantung pada hubungan antara dua saudara
tersebut (Lange, 2002). Untuk pasangan kembar MZ dan DZ masing-masing dapat
digunakan Ψ = 1/4 dan Ψ = 1/2. Dekomposisi variansi pada persamaan (1) tersebut
dapat diterapkan untuk trait kuantitatif maupun trait yang merupakan data kategori
(categorical trait). Trait ini dapat dianggap dipengaruhi oleh trait lain yang tidak
teramati (unobservable trait) yang dinamakan liabilitas (liability). Trait kategori yang
teramati (observable trait) seperti berpenyakit tertentu atau tidak, akan berkaitan dengan
suatu liabilitas yang melampaui batas (threshold). Hal tersebut dapat dijelaskan dalam
model matematika berikut ini.
Misalkan Y1 dan Y2 adalah ukuran dari suatu trait dikotomi pada 2 anggota pasangan
kembar. Kita menganggap bahwa vektor (Y1,Y2)t tergantung pada variabel laten (X1, X2)t
dan suatu batas b melalui persamaan Yi = 0 jika Xi ≤ b dan Yi = 1 jika Xi > b untuk i
=1,2. Diasumsikan bahwa (X1, X2)t mempunyai distribusi normal dan dapat
didekomposisi ke dalam komponen genetik A1, A2, komponen lingkungan bersama C
dan komponen lingkungan tidak bersama E1, E2 sebagai berikut :
⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ + ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ + ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ = ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛
2 1 2
1 2
1
E E C C A A X
X
(2)
dengan
⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ 2 2 2 2 2 2 1 , 0 0 ~ ν ν ν ν N A A
pada pasangan kembar MZ dan
⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ 2 2 2 2 2 2 1 5 , 0 5 , 0 , 0 0 ~ ν ν ν ν N A A
pada pasangan kembar DZ, sedangkan
⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ 2 2 2 2 2 , 0 0 ~ η η η η N C C , ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ 2 2 2 2 1 0 0 , 0 0 ~ κ κ N E E .
Dalam hal ini (A1,A2)t, (C,C)t dan (E1,E2)t saling bebas. Probabilitas bersyarat bahwa Y1
= 0 diberikan A1, A2 dan C adalah
) , , | ( ) , , | 0
(Y1 A1 A2 C P X1 b A1 A2 C
P = = ≤
=P(A1+C+E1≤b|A1,A2,C) =P(E1≤b−A1−C|A1,A2,C)
⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ − − Φ = 2 1 κ c a b
dan probabilitas bersyarat bahwa Y1 = 1 diberikan A1, A2 dan C adalah
) , , | ( ) , , | 1
(Y1 A1 A2 C P X1 b A1 A2 C P = = >
=P(A1+C+E1 >b|A1,A2,C) =P(E1>b−A1−C|A1,A2,C)
⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ − − Φ −
= 12
1 κ c a b .
Jika diberikan A1, A2 dan C maka Y1 dan Y2 variabel saling bebas. Probabilitas
bersyarat dari Y2 jika diberikan A1, A2 dan C dapat ditentukan dengan cara yang sama.
Batas b dapat distandardisasi menjadi
2 2 2 1) ( = ν +η +κ = ′ b X V b
Lebih jauh, heritabilitas atau komponen genetic Vg = σ2A dari status berpenyakit atau
tidak dapat ditentukan dengan
2 2 2 2 1 1 2 ) ( ) ( κ η ν ν σ = = + + = X V A V
Vg A ,
komponen lingkungan bersama Vs = σ2C dengan
2 2 2 2 1 2 ) ( ) ( κ η ν η σ = = + + = X V C V Vs C
dan komponen lingkungan tidak bersama Vu = σ2E dengan
2 2 2 2 1 1 2 ) ( ) ( κ η ν κ σ = = + + = X V E V
Vu E .
Misalkan pemetaan (y1, y2, a, c) → p(y1, y2, a, c) adalah fungsi densitas dari vektor (Y1,
Y2, A, C ) dan yj → p(yj | a, c) adalah densitas bersyarat dari Yj diberikan (A, C) untuk j
=1,2. Fungsi likelihood untuk pengamatan vektor dalam n pasangan kembar MZ yang
dipilih secara acak (dengan A := A1, A2) adalah
∏
= = n i i i i iMZ p y y a c
L
1
2
1, , , )
(
∏
= = n i i C i A i i ii y a c f a f c
y p
1
2
1, | , ) ( ) ( )
(
∏
= = n i i C i A i i i i ii a c p y a c f a f c
y p
1
2
1| , ) ( | , ) ( ) ( )
(
∏
= = n i i C i A i i i i ii a c q y a c f a f c
y q
1
2
1, , ) ( , , ) ( ) ( )
(
dengan fA dan fC masing-masing adalah fungsi densitas dari A dan C yang diberikan
oleh
⎥⎦ ⎤ ⎢⎣
⎡−
= 2 2
2 exp 2 1 ) ( ν πν i i A a a f , ⎥⎦ ⎤ ⎢⎣ ⎡−
= 2 2
2 exp 2 1 ) ( η πη i i C c c f , dan y y c a b c a b c a y q ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ − − Φ − ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ ⎟⎟⎠ ⎞ ⎜⎜⎝ ⎛ − − Φ = − 2 1 2 1 ) , , ( κ κ
=
[
Φ(
(b−a−c) θ1)
]
1−y[
1−Φ(
(b−a−c) θ1)
]
y dengan θ1= 1/κ2. Fungsi likelihood ini akan sebanding dengan( , , ) ( , , ) 2 exp 2 exp ] [ ]
[ 1 2
1 2 1 2 2 1 2 2 / 2 2 / 2 i i i i i i n i n i i n i i n n
MZ q y a c q y a c
c a
L
∑
∑
∏
= = = − − ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − ∝ν η ν η
Dengan kata lain, fungsi likelihood untuk n pasangan kembar MZ akan sebanding
dengan
( , , ) ( , , )
2 exp
2
exp 1 2
1 1 2 4 1 2 3 2 / 4 2 /
3 i i i i i i
n i n i i n i i n n
MZ q y a c q y a c
c a
L
∑
∑
∏
= = = − − ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − ∝θ θ θ θ
dengan θ3= 1/ν2 dan θ4= 1/η2.
Fungsi likelihood untuk pengamatan (Y1, Y2, A1, A2, C ) dalam m pasangan
kembar DZ yang dipilih secara acak diperoleh dengan cara yang sama dengan hanya
fungsi densitas bersama (A1, A2) yang berubah yaitu
∏
= = n i i i i i iDZ p y y a a c
L
1
2 1 2
1, , , , )
(
∏
= = n i i C i i i i i ii y a a c f a a f c
y p 1 2 1 2 1 2
1, | , , ) ( , ) ( )
(
∏
= = n i i C i i i i i i i ii a a c p y a a c f a a f c
y p 1 2 1 2 1 2 2 1
1| , , ) ( | , , ) ( , ) ( )
(
∏
= = n i i C i A i i i i i ii a c q y a c g a a f a f c
y q 1 2 2 1 2 2 1
1, , ) ( , , ) ( | ) ( ) ( )
(
dengan f adalah fungsi densitas bersama dari (A1, A2) dan g adalah fungsi densitas
bersyarat dari A1 jika diberikan A2 yang dinyatakan dengan rumus
(
)
⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ + − ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − − ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = 2 2 2 1 2 1 2 2 2 21 2(0,5)
2 1 1 2 1 exp 2 1 1 2 1 ) ,
(ai ai ai ai ai ai
f
⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − − ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ = 2 2 2 1 2 2 1 4 3 2 ) 5 , 0 ( exp 4 3 2 1 ) | ( ν ν π i i i i A a a a a g .
Hal itu berarti bahwa fungsi likelihoodnya sebanding dengan
[ ] [ ] exp
[ ]
( 1, 1, ) ( 2, 2, )1 2 / 2 2 / 2 i i i i i i n i n n
DZ x q y a c q y a c
L
∏
= − − − ∝ν η dengan 2 1 2 2 1 2 2 2 1 2 2 1 2 2 3 ) 5 , 0 ( 2 η ν ν∑
∑
∑
= − + = + = = m i i m i i mi ai ai a c
x .
Dengan kata lain, fungsi likelihood sebanding dengan
exp
[ ]
( 1, 1, ) ( 2, 2, )1 2
/ 4
3 i i i i i i
n
i m
m
DZ z q y a c q y a c
L
∏
= − ∝θ θ dengan 2 2 3 ) 5 , 0 (2 1 4 1 2
2 2 3 1 2 2 1
3
∑
=∑
=∑
=+ + − = m i i m i i m
i ai ai a c
z θ θ θ .
Kita memilih prior konjugat untuk parameter θ3, θ4, θ1 dari keluarga distribusi
gamma sehingga fungsi densitas priornya adalah
) exp(
) ( )
( 2 3
1 1 3 1 1 2 3
1 θ θ θ
π p p p p p − Γ = − , exp( ) ) ( )
( 3 31 4 4
3 3 4 4
2 θ θ θ
π p p p p p − Γ = − , exp( ) ) ( )
( 6 1
1 5 1 5 5 6 1
3 θ θ θ
π p p p p p − Γ = − ,
dan distribusi konjugat prior untuk parameter b dari keluarga distribusi normal, yaitu
fungsi densitas prior :
) 2 ) ( exp( 2 1 ) ( 8 2 7 8 4 p p b p
b = − −
π
π .
Dalam hal ini p1, p2, ..., p8 adalah parameter yang dipilih yang sesuai. Berdasarkan pada
anggapan bahwa parameter saling bebas maka fungsi densitas bersamanya adalah
) ( ) ( ) ( ) ( ) , , ,
(θ3 θ4 θ1 b π1 θ3 π2 θ4 π3 θ1 π4 b
π = .
Akibatnya fungsi densitasnya sebanding dengan
DZ
MZL
L b b) ( , , , ) ,
, ,
(θ3 θ4 θ1 →π θ3 θ4 θ1
Fungsi densitas posterior bersama π(θ1,θ3,θ4,b|data) memenuhi
2 1 1 5 1 ) 1 2 2 ( 4 ) 1 2 ( 3 4 3
1, , , | ) exp[ ]
( b data 1 3 p w w
m n p m n p − ∝θ + + − θ + + − θ − θ θ θ π , dengan 8 2 7 4 3 1 6 1 2 ) ( p p b v u p
w = θ + θ + θ + − ,
∏
=∏
= = n i m i i i i i i i i i i i ii a c q y a c q y a c q y a c
y q w 1 1 2 2 1 1 2 2 1 1
2 ( , , ) ( , , ) ( , , ) ( , , )
dan 2 3 ) 5 , 0 ( 2 2
1 1 1 22
2 2 1
1 2
2
∑
∑
∑
= = = + − + + = m i i m
i i i
n i i a a a a p u
∑
∑
= + = + = m i i n i i c c p v 1 2 2 1 2 1 4 2 1 2 1 .Berdasarkan pada fungsi densitas bersama, distribusi bersyarat penuh (full conditional
distribution) untuk masing-masing parameter dapat dinyatakan sebagai berikut :
∏
= − + + − ∝ m i i i i i i i m n p c a y q c a y q u p lain yang 1 2 2 1 1 3 ) 1 2 ( 33| ) exp [ ] ( , , ) ( , , )
(θ θ 1 θ
π ,
∏
= − + + − ∝ m i i i i i i i m n p c a y q c a y q v p lain yang 1 2 2 1 1 4 ) 1 2 2 ( 44| ) exp [ ] ( , , ) ( , , )
(θ θ 3 θ
π , 2 1 6 1 1
1| ) exp [ ]
( 5
w p p lain
yang θ p θ
θ π ∝ − − , 2 8 2 7 2 ) ( exp ) | ( w p p b lain yang b ⎥ ⎦ ⎤ ⎢ ⎣ ⎡− − ∝ π .
Untuk variabel laten, distribusi bersyarat penuh dapat ditentukan dengan
) , , ( ) , , ( 2 exp ) |
( 3 1 2
2 i i i i i i i
i q y a c q y a c
a lain yang a ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − ∝ θ π
untuk i=1,2, ..., n,
) , , ( ) , , ( 2 exp ) |
( 4 1 2
2 i i i i i i i
i q y a c q y a c
c lain yang c ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − ∝ θ π
) , , ( 2
) 5 , 0 ( 2 exp ) |
( 3 1 1
2 2 1
1 i i i
i i
i q y a c
a a
lain yang
a ⎥
⎦ ⎤ ⎢
⎣
⎡− −
∝ θ
π
untuk i=1,2, ..., m,
) , , ( 2
) 5 , 0 ( 2 exp ) |
( 3 2 2
2 1 2
2 i i i
i i
i q y a c
a a
lain yang
a ⎥
⎦ ⎤ ⎢
⎣
⎡− −
∝ θ
π
untuk i=1,2, ..., m.
Untuk mengkonstruksikan penyampel Markov Chain Monte Carlo (MCMC),
kita menggunakan algoritma Gibbs Sampler sebagai berikut :
1. Inisialisasi parameter [θ3]0, [θ4]0, [θ1]0, b0, [a1]0, [c1]0, ...…., [an]0, [cn]0, [a11]0,
[a12]0, [c1]0, ….,[am1]0 , [am2]0, [cm]0, dan diset j=1.
2. Dibangkitkan [θ3]j∼θ3→π(θ3 | yang lain) dengan yang lain berarti parameter
yang lain.
3. Dibangkitkan [θ4]j∼θ4→π(θ4 | yang lain).
4. Dibangkitkan θ1∼θ1→π(θ1 | yang lain).
5. Dibangkitkan bj∼ b →π(b | yang lain).
6. Dibangkitkan [ai]j∼ ai→π(ai | yang lain).
7. Dibangkitkan [ci]j∼ ci→π(ci | yang lain).
8. Dibangkitkan [ai1]j∼ ai1→π(ai1 | yang lain).
9. Dibangkitkan [ai2]j∼ ai2→π(ai2 | yang lain).
10. Langkah 2 sampai 9 untuk j = 1, 2, ... sampai rantai Markov (Markov chain)
menjadi konvergen.
Distribusi bersyarat di atas tidak ada yang merupakan anggota keluarga
standard. Untuk menyampelnya kita menggunakan algoritma Metropolis-Hasting yang
diusulkan sebagai berikut :
1. Distribusi eksponensial dengan rata-rata nilai θ3 sebelumnya untuk parameter θ3
yaitu
0 , exp
1 ) | (
3 3
3 ⎟⎟⎠ >
⎞ ⎜⎜⎝ ⎛−
= y y
y p
θ θ
θ ,
2. Distribusi eksponensial dengan rata-rata nilai θ4 sebelumnya untuk parameter θ4,
3. Distribusi eksponensial dengan rata-rata nilai θ1 sebelumnya untuk parameter θ1,
4. Distribusi normal dengan rata-rata nilai b sebelumnya dan variansi 1 untuk
variabel laten b,
5. Distribusi normal dengan rata-rata nilai ai sebelumnya dan variansi 1 untuk
variabel laten ai,
6. Distribusi normal dengan rata-rata nilai ci sebelumnya dan variansi 1 untuk
variabel laten ci,
7. Distribusi normal dengan rata-rata nilai ai1 sebelumnya dan variansi 1 untuk
variabel laten ai1,
8. Distribusi normal dengan rata-rata nilai ai2 sebelumnya dan variansi 1 untuk
variabel laten ai2.
C. Studi Simulasi, Hasil dan Pembahasan
Paket program R digunakan untuk membangkitkan data kategorikal pada sampel
pasangan kembar MZ dan DZ dengan menggunakan model pada persamaan (2). Dalam
simulasi ini, kami memilih menggunakan 400 pasangan kembar dan menggunakan input
pengaruh faktor genetik σ2A = 0,3, pengaruh lingkungan bersama σ2C = 0,4 dan
pengaruh lingkungan tidak bersama σ2E = 0,3 untuk memberikan gambaran bagaimana
metode ini digunakan. Tabel 1 dan Tabel 2 merupakan contoh dari hasil simulasi
tersebut. Dari tabel tersebut, terlihat bahwa terdapat 400 pasangan kembar. Tabel 1
berarti bahwa dari 400 pasang tersebut, terdapat 313 pasang yang keduanya tidak
berpenyakit tertentu yang menjadi perhatian (categorical trait), 30 pasang kembar
yang orang kembar 1 tidak berpenyakit sedangkan orang kembar 2 berpenyakit, 25
pasang kembar yang orang kembar 1 berpenyakit sedangkan orang kembar 2 tidak
berpenyakit, dan 32 pasang yang keduanya berpenyakit.
Tabel 1. Tabel kontingensi dari status berpenyakit tertentu (kategori 1) atau tidak (kategori 0) pada pasangan kembar MZ.
Kembar 2
Kembar 1 Kategori 0 Kategori 1
Kategori 0 313 30
Tabel 2. Tabel kontingensi dari status berpenyakit tertentu (kategori 1) atau tidak (kategori 0) pada pasangan kembar DZ.
Kembar 2
Kembar 1 Kategori 0 Kategori 1
Kategori 0 300 40
Kategori 1 34 26
Tabel 3. Data hasil simulasi dari status berpenyakit tertentu atau trait kategori (categorical trait) pada pasangan kembar MZ dan DZ serta estimasi kembali pengaruh faktor genetik σ2A, lingkungan bersama
σ2
C dan lingkungan tidak bersama σ2E dengan menggunakan metode Bayesian.
MZ DZ Metode Bayesian
No (0,0) (0,1) (1,0) (1,1) (0,0) (0,1) (1,0) (1,1) σ2
A σ2C σ2E
1 313 30 25 32 300 40 34 26 0.26 (0.10, 0.55) 0.36 (0.20, 0.49) 0.38 (0.28, 0.48) 2 298 33 29 40 306 34 38 22 0.34 (0.04, 0.63) 0.36 (0.12, 0.63) 0.30 (0.20, 0.42) 3 305 34 29 32 308 37 28 27 0.20 (0.06, 0.52) 0.47 (0.17, 0.63) 0.33 (0.22, 0.44) 4 292 27 36 45 296 44 37 23 0.56 (0.27, 0.75) 0.16 (0.02, 0.41) 0.27 (0.18, 0.38) 5 318 22 27 33 284 41 41 31 0.55 (0.10, 0.67) 0.19 (0.02, 0.50) 0.26 (0.16, 0.38)
Bila simulasi dilakukan n=5 kali maka akan diperoleh hasil lengkap seperti
dinyatakan pada Tabel 3. Berdasarkan data kategorikal pasangan kembar MZ dan DZ,
untuk mengestimasi besarnya komponen genetik Vg=σ2A, komponen lingkungan
bersama Vs=σ2C dan komponen lingkungan tidak bersama Vu=σ2E metode yang telah
dijelaskan di atas diimplementasikan dalam WinBUGS versi 1.4 (untuk gambaran
penggunaan WINBUGS versi 1.4 dalam estimasi Bayesian, lihat makalah Cowles,
2004). Untuk parameter 1/ν2, 1/η2 dan 1/κ2, dipilih prior Γ(1,1). Berdasarkan pada prior ini, variansi dari variabel laten X1 yang dinyatakan dengan V(X1) = ν2 + η2 + κ2 akan
memberikan probabilitas yang tinggi pada interval (2,20). Prior dari b′ digunakan
distribusi N(0,1) sehingga dalam pandangan persamaan (3), parameter b memberikan
probabilitas yang tinggi pada interval
( -3√(20-2), 3√(20-2))
sehingga prior distribusi N( 0 , 18) akan merupakan pemilihan yang beralasan untuk
parameter b. Dalam hal ini digunakan median dari rantai Markov dalam MCMC untuk
mengestimasi ketiga komponen tersebut. Nilai dalam tanda kurung memberikan
estimasi interval kredibel 95 % (credible interval) untuk metode Bayesian. Gambar 1
dan Gambar 2 masing-masing memberikan plot MCMC dan estimasi density (kernel
density estimation) untuk parameter-parameter yang diperlukan. Apabila digunakan
[image:19.595.85.486.286.351.2]input pengaruh faktor genetik σ2A = 0,8, pengaruh lingkungan bersama σ2C = 0,1 dan
pengaruh lingkungan tidak bersama σ2E = 0,1 akan dihasilkan Tabel 4 sedangkan bila
digunakan input pengaruh faktor genetik σ2A = 0,1, pengaruh lingkungan bersama
σ2
C = 0,4 dan pengaruh lingkungan tidak bersama σ2E = 0,3 akan dihasilkan Tabel 5.
Berdasarkan pada Tabel 3, Tabel 4 dan Tabel 5, terlihat bahwa metode Bayesian
memberikan estimasi yang relatif memuaskan karena sesuai dengan parameter yang
[image:20.595.84.487.314.393.2]digunakan untuk membangkitkan data pasangan kembar MZ dan DZ.
Tabel 4. Data hasil simulasi dari status berpenyakit tertentu atau trait kategori (categorical trait) pada pasangan kembar MZ dan DZ serta estimasi kembali pengaruh faktor genetik σ2A, lingkungan bersama
σ2
C dan lingkungan tidak bersama σ2E dengan menggunakan metode Bayesian. Dalam hal ini digunakan
input σ2A = 0,8, σ2A = 0,1 dan σ2A = 0,1.
MZ DZ Metode Bayesian
No (0,0) (0,1) (1,0) (1,1) (0,0) (0,1) (1,0) (1,1) σ2
A σ2C σ2E
1 313 17 21 49 285 46 40 29 0.77 (0.52, 0.89) 0.12 (0.03, 0.34) 0.12 (0.06, 0.19) 2 321 13 20 46 306 32 39 23 0.79 (0.57, 0.92) 0.11 (0.01, 0.29) 0.09 (0.05, 0.15) 3 323 19 21 37 302 42 35 21 0.68 (0.43, 0.85) 0.15 (0.02, 0.38) 0.17 (0.09, 0.26) 4 319 12 20 49 294 34 45 27 0.85 (0.57, 0.94) 0.07 (0.01, 0.32) 0.08 (0.04, 0.15) 5 320 16 13 51 288 36 46 30 0.81 (0.58, 0.91) 0.12 (0.03, 0.38) 0.07 (0.04, 0.17)
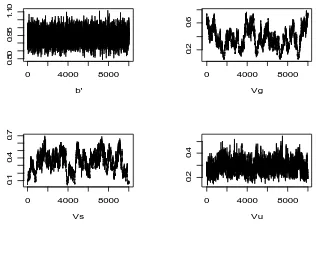
Gambar 1. Plot MCMC dengan ukuran sampel 10000 untuk batas b’ pengaruh faktor genetik Vg = σ2A,
lingkungan bersama Vs = σ2C dan lingkungan tidak bersama Vu = σ2E.
0 4000 8000
0
.80
0
.95
1.
10
b'
0 4000 8000
0.
2
0.
6
Vg
0 4000 8000
0.
1
0.
4
0
.7
Vs
0 4000 8000
0.
2
0
.4
[image:20.595.141.457.460.717.2]Tabel 5. Data hasil simulasi dari status berpenyakit tertentu atau trait kategori (categorical trait) pada pasangan kembar MZ dan DZ serta estimasi kembali pengaruh faktor genetik σ2A, lingkungan bersama
σ2
C dan lingkungan tidak bersama σ2E dengan menggunakan metode Bayesian. Dalam hal ini digunakan
input σ2A = 0,1, σ2A = 0,8 dan σ2A = 0,1.
MZ DZ Metode Bayesian
No (0,0) (0,1) (1,0) (1,1) (0,0) (0,1) (1,0) (1,1) σ2A σ 2
C σ
2 E
1 321 22 13 44 324 18 18 40 0.10 (0.01, 0.24) 0.80 (0.67, 0.89) 0.10 (0.05, 0.15) 2 318 20 19 43 301 27 31 41 0.19 (0.07, 0.45) 0.65 (0.42, 0.78) 0.14 (0.08, 0.22) 3 307 19 17 57 315 27 24 34 0.25 (0.06, 0.55) 0.65 (0.36, 0.82) 0.10 (0.05, 0.17) 4 320 20 18 42 321 15 21 43 0.05 (0.00, 0.16) 0.84 (0.72, 0.90) 0.11 (0.07, 0.17) 5 310 16 24 50 307 17 21 55 0.06 (0.02, 0.17) 0.84 (0.73, 0.90) 0.10 (0.06, 0.15)
Gambar 2. Estimasi densitas untuk batas b’ pengaruh faktor genetik Vg = σ2A, lingkungan bersama Vs = σ2
C dan lingkungan tidak bersama Vu = σ2E.
0.80 0.90 1.00 1.10
02
468
b'
0.0 0.2 0.4 0.6 0.8
0.
0
1.
0
2.
0
Vg
0.0 0.2 0.4 0.6
0.
0
1
.0
2
.0
Vs
0.1 0.2 0.3 0.4 0.5
02
4
6
Vu
Pendekatan Bayesian dengan bantuan MCMC dalam kasus ini merupakan
masalah yang relatif baru (Eaves dan Erkanli, 2003). Makalah atau hasil penelitian lain
yang terkait dengan pendekatan Bayesian dalam studi pasangan kembar (twin study)
sebagai contohnya adalah ditulis oleh Eaves et al. (2004), Eaves et al. (2005), van den
Berg et al. (2006) dan Setiawan (2007).
D. Kesimpulan
Dalam makalah ini telah dijelaskan bagaimana pendekatan Bayesian digunakan
untuk menentukan besarnya pengaruh genetik terhadap sifat fenotip tertentu dari data
yang diperoleh dengan cara simulasi. Penelitian ini dapat dikembangkan pada studi
simulasi yang menggunakan dua trait kategorikal pada pasangan kembar MZ dan DZ.
[image:21.595.150.450.280.484.2]E. Daftar Pustaka
[1] Lange, K. [2002], Mathematics and Statistical Methods for Genetic Analysis, Springer, New York
[2] Berg, S. M. van den, Setiawan, A., Bartels, M., Polderman, T.J.C., van der Vaart, A.W., Boomsma, D.I., (2006), Individual Differences in Puberty Onset in Girls : Bayesian Estimation of Heritabilities and Genetic Correlations, Behavior Genetics, 36 (2) : 261-270.
[3] Cowles, M. K., (2004), Review of WinBUGS 1.4, Am. Stat. 58:330-336.
[4] Eaves, L. J., and Erkanli, A. (2003). Markov Chain Monte Carlo approaches to analysis of genetic and environmental components of human developmental change and G × E interaction. Behav. Genet. 33:279-299·
[5] Eaves, L., Silberg, J., Foley, D., Bulik, C., Maes H., Erkanli A., Angold A., Costello E. J., Worthman C. (2004). Genetic and environmental influences on the relative timing of pubertal change, Twin Res. 7:471-481.
[6] Eaves, L., Erkanli, A., Silberg, J., Angold, A., Maes, H. H., Foley, D., (2005), Application of Bayesian Inference using Gibbs Sampling to Item Response Theory Modeling of Multi Sympton genetic Data, Behavior Genetics 35 (6) : 765-780.
[7] Setiawan, A. [2007] , Statistical Data Analysis of Genetic Data in Twin Studies and
Association Studies, Vrije Universiteit, Amsterdam, Ph.D Thesis, ISBN
978-90-9021728.
[8] Setiawan, A. [2008] , Penentuan Besarnya Pengaruh Faktor Genetik terhadap Sifat Fenotip dengan Metode Pasangan Kembar, Prosiding Seminar Basic Science V 2008