6 BAB II
LANDASAN TEORI
2.1 Suara ( Speech )
Suara atau bunyi biasanya merambat melalui udara dan akan memantul apabila ada dinding, suara atau bunyi tidak dapat merambat melalui ruang hampa. Suara dihasilkan oleh getaran suatu benda. Selama bergetar, perbedaan getaran, perbedaan tekanan terjadi di udara sekitarnya. Pola asilasi yang terjadi disebut dengan gelombang, gelombang mempunyai pola sama dan berulang pada interval tertentu, yang disebut periode.
Suara dapat dibagi menjadi dua yaitu :
a. Frekuensi adalah standar pengukuran suara jumlah satu siklus per detik (Jumlah pitch atau Amplitudo terbesar yang terdengar oleh telinga).
b. Amplitudo adalah intensitas atau keras lemahnya suara, semakin keras suara maka semakin besar pula amplitudonya.
2.2 Pengenalan Suara (Speech Recognition)
Pengenalan suara atau yang biasa disebut speech recognition adalah proses mengubah sinyal suara ke kalimat text atau bisa dibilang proses yang dilakukan oleh komputer untuk mengenali kata tanpa mempedulikan identitas orang terkait. Penelitian dibidang pengenalan suara (speech recognition) oleh mesin telah dilakukan hampir selama lima dekade, dimana percobaan awal oleh mesin dibuat sekitar tahun 1950-an, yaitu pada saat berbagai penelitian mencoba untuk mengeksploitasi ide-ide mereka. Dengan kata lain proses yang dilakukan komputer untuk mengenali kata yang diucapkan oleh seseorang tanpa mempedulikan identitas orang terkait, proses identifikasi suara berdasarkan kata yang diucapkan. Parameter yang dibandingkan adalah tingkat penekanan suara yang kemudian akan dicocokan dengan database yang sudah tersedia. 2.2.1 Mode Sistem Pengenalan Suara
Terdapat dua mode pada sistem pengenalan suara antara lain : a. Mode diktasi.
Pada mode ini user mengucapkan kata atau kalimat yang selanjutnya akan dikenali oleh komputer dan diubah menjadi data teks. Jumlah kata yang dikenali dibatasi oleh jumlah kata yang ada pada database. Keakuratan mode ini bergantung pada pola suara dan aksen pembicara serta pelatihan yang telah dilakukan.
b. Mode Command and Control.
Pada mode ini user mengucapkan kata atau kalimat yang sudah terdefinisi terlebih dahulu pada database dan selanjutnya digunakan untuk menjalankan perintah tertentu pada aplikasi komputer. Jumlah perintah yang dikenali tergantung dari aplikasi yang telah didefinisikan terlebih dahulu pada database. Mode ini jumlah katanya terbatas dan ada
kemungkinan pembicara tidak perlu melakukan pelatihan pada sistem sebelumnya.
Terdapat empat proses pada sistem utama pengenalan pembicaraan ini, baik pada mode diktasi ataupun command and control yakni : pencocokan kata, pemisahan kata, pengenalan pembicara, dan perbendaharaan kata.
2.2.2 Pencocokan Kata
Pencocokan kata adalah proses untuk mencocokan kata atau ucapan yang berhasil diidentifikasi dengan database yang dimiliki oleh sistem. Terdapat dua metode yang dapat dipakai pada proses pencocokan kata ini antara lain : whole-word matching dan phoneme matching.
a. Pada whole-word matching, sistem akan mencari di dalam database kata yang tepat dan persis dengan kata hasil ucapan user.
b. Sedangkan pada phoneme matching, sistem mempunyai kamus fonem (fonem adalah bagian terkecil dan unik dari suara yang membentuk sebuah kata).
2.2.3 Pemisahan Kata
Pemisahan kata adalah proses untuk memisahkan suara yang diucapkan oleh pengguna menjadi beberapa bagian. Masing-masing bagian dapat berupa kalimat atau satu kata. Terdapat tiga macam metode yang digunakan pada proses pemisahan kata ini yaitu : discrete speech, word spotting, dan continuous speech.
a. Pada discrete speech, pengguna diharuskan mengucapkan kalimat secara terpenggal dengan adanya jeda sejenak diantara kata. Jeda tersebut digunakan oleh sistem untuk mendeteksi
awal dan akhir sebuah kata. Discrete speech ini mempunyai kelebihan yaitu sedikit resource (memori komputer,waktu proses) yang digunakan oleh sistem untuk mendeteksi suara, tetapi mempunyai kelemahan yaitu ketidaknyamanan pengguna dalam mengucapkan sebuah kalimat.
b. Pada word spotting, dalam sebuah kalimat yang diucapkan pengguna sistem hanya mendeteksi kata yang terdapat dalam perbendaharaan yang dimilikinya, dan mengabaikan kata lain yang tidak dimilikinya. Sehingga walau pengguna mengucapkan kalimat yang berbeda, bila di dalam kalimat tersebut terdapat sebuah kata yang sama dan terdapat di perbendaharaan sistem, maka hasil pengenalan akan sama. Kelemahan metode ini besar kemungkinan sistem melakukan kesalahan arti pengenalan dalam bentuk kalimat. Tetapi metode ini mempunyai kelebihan yaitu pengguna dapat mengucapkan kalimat secara normal tanpa harus berhenti diantara kata.
c. Pada metode continuous speech, sistem akan mengenali dan memproses setiap kata yang yang diucapkan. Metode ini cukup akurat dalam mengenali ucapan pengguna. Tetapi di samping itu metode ini memerlukan resource yang besar dalam prosesnya. Pada metode ini, sistem harus dapat mendeteksi awal dan akhir setiap kata dalam kalimat tanpa adanya jeda diantara kata tersebut, dan setelah berhasil memisahkan kata, langkah selanjutnya adalah mencocokan dengan perbendaharaan kata yang dimilikinya.
2.2.4 Pengenalan Pembicaraan
Sistem pengenalan pembicaraan mempunyai beberapa sifat dilihat dari ketergantungan terhadap pengguna yaitu speaker dependent, speaker independent dan speaker adaptive.
a. Pada speaker dependent, sistem membutuhkan pelatihan untuk setiap pengguna yang akan menggunakan sistem tersebut. Sistem tidak akan dapat mengenali pengguna yang belum pernah melakukan pelatihan.
b. Pada speaker independent, pengguna tidak perlu melakukan pelatihan sebelum dapat menggunakan sistem, karena sistem mampu mengenali suara pengguna baik perempuan maupun laki-laki dan dialek yang digunakan.
c. Pada speaker adaptive, merupakan perpaduan dari speaker dependent dan speaker independent, dimana pengguna tidak perlu melakukan pelatihan dan keakuratan pengenalan sistem akan makin meningkat jika pengguna yang sama bekerja terus menerus selama beberapa waktu tertentu.
2.2.5 Perbendaharaan Kata
Perbendeharaan kata adalah bagian terakhir dalam sebuah sistem pengenalan pembicaraan. Terdapat dua hal yang perlu diperhatikan pada perbendaharaan kata, yaitu ukuran dan keakuratan. Jika perbendaharaan kata berjumlah banyak maka sebuah sistem akan mudah dalam melakukan pencocokan kata, tetapi dengan makin meningkatnya jumlah perbendaharaan kata, maka jumlah kata yang mempunyai ucapan hampir sama juga meningkat, hal ini akan menurunkan keakuratan pengenalan suara, dan sebaliknya, jika sebuah sistem mempunyai perbendaharaan kata sedikit, maka keakuratan pengenalan suara akan tinggi karena sedikitnya kata yang hampir sama, tetapi semakin banyak kata yang tidak terkenali. Untuk sistem pengenalan mode command and
control, akan lebih baik jika menggunakan jumlah perbendaharaan kata sedikit (kurang dari 100 kata), tetapi untuk mode diktasi akan membutuhkan jumlah perbendaharaan kata yang banyak.
2.2.6 Interaksi Manusia dan Komputer
Human Computer Interaction (HCI) atau yang biasa disebut interaksi manusia dan komputer merupakan satu disiplin ilmu yang mengkaji tentang komunikasi atau interaksi diantara pengguna dengan sistem. Sistem disini yang dimaksud adalah tidak terhadap kepada sistem-sistem berkomputer saja, akan tetapi produk-produk yang biasa digunakan oleh user seperti kendaraan, peralatan rumah tangga, dan lain sebagainya. Peranan interaksi manusia dan komputer adalah untuk menghasilkan sebuah sistem yang berguna, berkesan dan efektif. Model interaksi diantara pengguna dengan sistem melibatkan tiga komponen yaitu pengguna, interaksi dan sistem itu sendiri. Kunci utama dalam HCI adalah usability, yaitu suatu sistem harus mudah digunakan, memberi keleluasan pada pengguna, serta mudah untuk dipelajari.
Interaksi juga dapat dilihat sebagai dialog antara komputer dengan pengguna (Alan Dix et al. 136). Pemilihan tipe interaksi yang tepat dapat memberikan efek yang baik terhadap dialog antara pengguna dan komputer. Terdapat beberapa tipe interaksi yang digunakan, diantaranya meliputi antarmuka baris perintah, menu, bahasa alami, dialog dengan tanya jawab terstruktur, formulir isian dan kertas kerja serta WIMP.
1. Antarmuka Baris Perintah (command line interface)
Merupakan bentuk dialog intraktif yang pertama digunakan dan masih dipakai hingga saat ini. Dengan antarmuka baris perintah, pengguna memberikan instruksi secara langsung kepada komputer dengan menggunakan tombol fungsi, karakter tunggal, perintah dalam bentuk singkat maupun
panjang. Antarmuka baris perintah memungkinkan pengguna mengakses dengan cepat fungsi sistem.
2. Menu
Merupakan sekumpulan pilihan yang tersedia bagi pengguna yang ditampilkan pada layar dan dapat dipilih menggunakan mouse atau tombol numerik maupun alfabetik. Pilihan pada menu harus mempresentasikan arti dan dikelompokkan berdasarkan suatu katagori agar mudah dikenali dan memudahkan pengguna memilih sesuai dengan tugas yang akan dilaksanakan.
3. Bahasa Alami (natural language)
Merupakan mekanisme komunikasi yang atraktif. Umumnya, komputer tidak dapat mengerti instruksi yang dituliskan dalam bahasa sehari-hari. Bahasa alami dapat mengerti masukan tertulis (written input) dan masukan ucapan (speech input). Namun masih ada kekurangan dalam hal kerancuan (ambiguity) pada aspek sintaksis dan semantik.
4. Dialog dengan Tanya Jawab Terstruktur (question/answer and query dialogue)
Merupakan mekanisme sederhana untuk masukan pada beberapa aplikasi. Pengguna diberikan serangkaian pertanyaan, umumnya dalam bentuk jawaban ya atau tidak (Y/N). pilihan ganda atau dalam bentuk kode, dan bimbingan tahap demi tahap selama proses interaksi. Antarmuka ini mudah dipelajari namun terbatas fungsinya.
5. Formulir Isian (form fills)
Utamanya digunakan untuk aplikasi pemasukan data (data entry) dan pencarian data (data retrieval). Bentuk formulir isian adalah berupa tampilan yang menyerupai selembar kertas dengan beberapa celah (slot/field) untuk diisi. Kertas kerja
(spreadsheet) adalah variasi dari formulir isian kertas kerja terdiri dari sel yang dapat berisi nilai atau formula.
6. WIMP (Windows Icon Menu Pointer)
Merupakan antarmuka standar untuk sebagian besar sistem komputer interaktif yang digunakan saat ini terutama pada komputer pribadi dan desktop workstation. Window merupakan area layar yang berperilaku seperti terminal tersendiri dan berisi grafik/teks yang dapat dipindahkan dan diubah ukurannya. Satu layar dapat terdiri dari satu dan lebih window yang memungkinkan lebih dari satu tugas aktif pada saat yang bersamaan. Icon merupakan sebuah gambar kecil yang digunakan untuk mempresentasikan window yang sedang berada dalam keadaan tertutup (closed). Window dapat diaktifkan atau diperbesar dengan melakukan klik icon yang bersangkutan, dan sebaliknya jika pengguna menggunakan atau mengerjakan tugas pada satu window tertentu maka dia dapat menonaktifkan wndow menjadi icon yang disebut sebagai iconifying. Menu adalah teknik interaksi yang umum digunakan bahkan oleh sistem yang bukan window sekalipun. Menu menampilkan pilihan operasi atau layanan yang diberikan atau tersedia oleh sistem. Pengguna dapat memperoleh petunjuk mengenai operasi apa saja pada sistem melalui menu. Oleh karena itu penamaan pada menu haruslah memiliki arti dan informatif. Pointer merupakan komponen yang penting dalam sistem WIMP karena interaksi pada sistem ini memerlukan aktifitas menunjuk (pointing) dan memilih (selecting). Pengguna diberikan cursor pada layar yang dapat dikendalikan oleh peralatan masukan seperti mouse, joystick atau trackball.
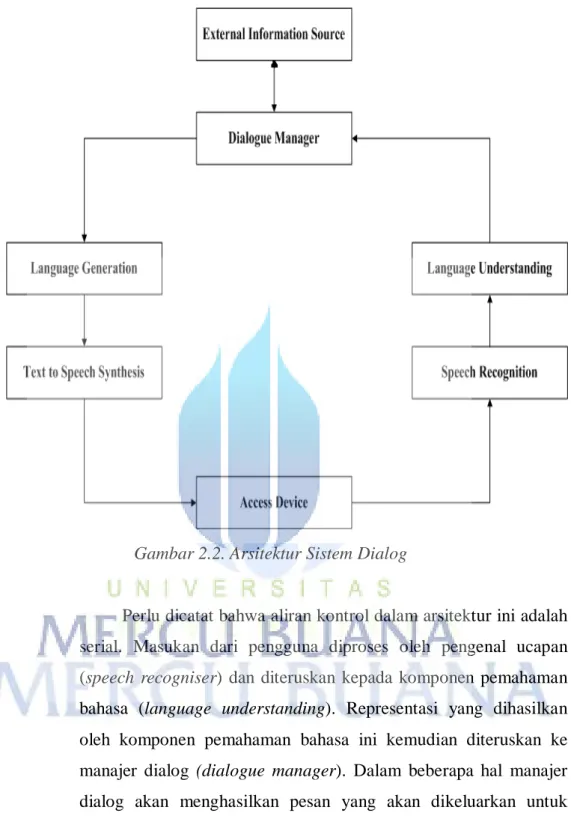
2.2.7 Komponen Sistem Dialog Lisan
Sistem dialog lisan terdiri dari beberapa komponen yang dibutuhkan agar sistem dapat berfungsi dengan baik, diantaranya pengenalan ucapan (speech recognition) dan teks ke ucapan (text to speech) (Michael F. Mctear 79). Gambaran berikut menjelaskan komponen yang fokus dengan proses masukan dari pengguna ke dalam sistem dan keluaran dari sistem kepada pengguna, yaitu pengenalan ucapan (speech recognition), pemahaman bahasa (language understanding), pembangkitan bahasa (language generation) dan keluaran ucapan (speech output).
Dialog berikut dapat digunakan untuk memperkenalkan berbagai komponen dari sistem dialog lisan dan untuk menjelaskan peran setiap komponen di dalam sistem.
Sistem : Selamat Datang di Informasi Pelayanan Penerbangan. Kemana Tempat Tujuan Anda?
Penelpon : Saya Ingin Pergi ke Bali Hari Sabtu Pada Jam 10.00 Pagi.
Sistem : Ada Penerbangan Kami Menuju Bali Pada Hari Sabtu jam 09.30.
Dialog tersebut dimulai dengan ucapan salam sistem kepada pengguna dan penyampaian informasi kepada pengguna. Penelpon merespon dengan ucapan. Untuk proses ucapan ini sistem harus terlibat dalam proses berikut :
1. Mengenali kata-kata yang diucapkan oleh penelpon (speech recognition).
2. Menetapkan arti dari masing-masing kata (language understanding).
3. Menentukan bahwa dialognya sesuai dan memutuskan apa yang harus dilakukan selanjutnya, misalnya memperjelas
ucapan yang tidak jelas, melakukan konfirmasi, meminta informasi lebih lanjut atau mencari sumber informasi (dialogue manager).
4. Mengambil penerbangan yang sesuai dengan kebutuhan penelpon (external communication).
5. Memilih kata frasa untuk digunakan dalam menanggapi (language generation).
6. Mengucapkan tanggapan (text to speech synthesis).
Proses ini menggambarkan peran setiap komponen dari sistem dialog lisan. Dalam contoh ini masing-masing proses berjalan dengan lancar. Namun pada kondisi yang sesungguhnya mungkin ada masalah pada setiap tahap. Komponen pengenalan ucapan mungkin gagal untuk mengenali kata-kata penelepon secara benar, komponen pemahaman bahasa bisa menetapkan arti yang salah satu tidak bisa memilih arti yang benar jika ucapannya itu ambigu dan sebagainya. Pengaturan dialog mungkin menempatkan sistem pada posisi mengambil informasi dari luar atau mengklarifikasi masukan dari pengguna. Keluaran yang bersanngkutan dan komponen pembangkitan bahasa perlu merumuskan ucapan sistem sedemikian rupa sehingga informasi yang disajikan tidak ambigu dan jelas ketika komponen sintesis teks ke ucapan mengucapkan kata-kata sehingga kalimatnya benar supaya pesan tersebut dipahami. Arsitektur dasar dari sistem dialog lisan yang mendukung fungsi tersebut ditunjukan dalam gambar berikut.
Gambar 2.2. Arsitektur Sistem Dialog
Perlu dicatat bahwa aliran kontrol dalam arsitektur ini adalah serial. Masukan dari pengguna diproses oleh pengenal ucapan (speech recogniser) dan diteruskan kepada komponen pemahaman bahasa (language understanding). Representasi yang dihasilkan oleh komponen pemahaman bahasa ini kemudian diteruskan ke manajer dialog (dialogue manager). Dalam beberapa hal manajer dialog akan menghasilkan pesan yang akan dikeluarkan untuk pengguna. Pesan ini akan melewati pembangkitan bahasa dan komponen sistesis teks ke ucapan sehingga sudah dalam bentuk yang akan diucapkan kepada pengguna. Manajer dialog juga akan berinteraksi dengan sumber pengetahuan luar (external information service) yang memberikan informasi untuk menjadi keluaran bagi
pengguna. Beberapa pesan yang lewat melalui sistem mungkin dibutuhkan untuk melengkapi dialog. Sebgai contoh manajer dialog perlu untuk mengklarifikasi beberapa hal atau mungkin perlu untuk mengajukan pertanyaan tambahan sebelum dapat mengambil informasi yang diperlukan dari sumber pengetahuan luar (external information service).
Sebagian besar sistem dialog lisan, terutama yang dikembangkan secara komersial dirancang menggunakan kontrol aliran serial. Sistem yang lebih canggih seperti yang sedang dikembangkan di laboratorium riset, mungkin melibatkan arsitektur yang berbeda dimana manajer dialog memerankan fungsi pengawasan pusat dan berinteraksi secara langsung dengan komponen lainnya. Sebagai contoh jika ada masalah pada tingkat pengenalan ucapan manajer dialog mungkin bisa membawa beberapa pengetahuan kontekstual untuk menanggung yang tidak tersedia dalam komponen pengenalan ucapan.
2.2.8 Antarmuka Pengguna
Salah satu yang terpenting dalam HCI adalah antarmuka pengguna. Antarmuka pengguna merupakan bagian sistem yang akan dikendalikan oleh pengguna, untuk mencapai dan melaksanakan fungsi-fungsi suatu sistem. Ia juga dianggap sebagai jumlah keseluruhan keputusan reka bentuk. Antarmuka juga secara tidak langsung menunjukkan kepada pengguna tentang kefungsian sistem. Dengan kata lain, antarmuka bagi suatu sistem menggabungkan elemen-elemen dari pengguna dan juga kaedah komunikasi atau interaksi diantara keduanya. Pengguna hanya boleh berinteraksi dengan produk tersebut melalui antarmuka pengguna. Sebuah sistem antarmuka pengguna meliputi isi itu sendiri, alat input (keyboard, mouse, dan touchscreen), dan alat output (monitor, sound dan printer). Pengguna komputer pada masa sekarang tidak terhalang pada golongan tertentu yang terlibat dalam
bidang komputer secara langsung. Komputer telah menjadi salah satu keperluan penting yang digunakan oleh para user pada tahap mahir yang berbeda-beda. Kita tidak boleh lagi menganggap bahwa semua pengguna komputer mahir menggunakan komputer. Oleh karena itu, antarmuka pengguna perlu direka bentuk supaya ia lebih mudah dan jelas peranan antarmuka pengguna dalam kegunaan suatu sistem adalah amat penting. Reka bentuk antarmuka pengguna merupakan suatu proses yang kompleks. Ia memerlukan daya kreatifitas yang tinggi, pengalaman, analisa tugas terperinci dan kepahaman terhadap keperluan pengguna. Antarmuka pengguna boleh direka oleh pengatur cara komputer, penganalisa sistem, pakar antarmuka pengguna atau pengguna sendiri. Walau bagaimanapun, kebanyakan antarmuka direka dan dibangun oleh pengatur cara berkomputer.
2.2.9 Sejarah Pengenalan Suara
Berikut merupakan sejarah penelitian dibidang pengenalan suara (speech recognition) antara lain :
a. Tahun 1952, di Lab. Bell, Davis, Bidullph, Balashek membuat suatu sistem pengenalan digit terisolasi untuk seorang pembicara. Sistem tersebut sangat tergantung kepada pengukuran resonasi spectral di daerah vokal dari setiap digit. b. Tahun 1956, sebuah usaha mandiri pada Lab. RCA, Oison dan
Belar berusaha untuk mengenali sepuluh suku kata yang berbeda dari setiap pembicara yang juga bergantung pada pengukuran spectral pada area vokal.
c. Tahun 1959, Univ. Collage di inggris , Fry dan Danes mencoba untuk membuat suatu pengenalan fonem untuk mengenali empat vokal dan sembilan konsonan. Mereka menggunakan keputusan dari pengenalan.
d. Masih pada tahun 1959, dikonstruksikan di Lab. MIT, Forgie mencoba sepuluh vokal disisipkan dalam format a, b, -vokal, t dapat dikenali. Sebuah filter bank analyzer digunakan untuk menyediakan informasi spectral dan pengukuran waktu yang dipakai.
e. Pada tahun 1960, sejumlah ide fundamental dalam speech recognition muncul kepermukaan. Dimulai dengan beberapa laboratorium Jepang yang memasuki arena pengenalan dan membangun special-purpose hardware sebagai bagian dari sistem mereka. Suzuki dan Nakata meneliti hardware pengenalan huruf vokal.
f. Usaha lainnya dilakukan oleh Sakai dan Doshita dari Universitas Kyoto tahun 1962, yang membangun sebuah hardware pengenalan fonem. Usaha yang ketiga merupakan hardware pengenalan digit oleh nagata dan rekan kerjanya di Lab.NEC pada tahun 1963. Usaha ini mungkin yang paling dikenali sebagai percobaan perdana dari speech recognition pada NEC dan menjadi awal bagi sebuah program penelitian yang produktif.
g. Di era 60-an terdapat tiga proyek penelitian kunci yang pertama adalah usaha yang dilakukan oleh Martin dan rekannya pada laboratorium RCA, untuk membangun solusi realistik bagi problem yang berkaitan dengan ketidakseragaman dalam interval waktu, dari speech event. Martin membangun sistem dengan dasar pada kemampuan untuk mendeteksi awal dan akhir dari suatu speech. Martin membangun metodenya dan mendirikan satu perusahaan bernama Threshold Technology yang membuat, memasarkan, dan menjual produk-produk speech recognition. Sementara pada waktu yang bersamaan di Uni Sovyet, vintsyuk
mengajukan penggunaan dari metode dynamic programming untuk penyamaan waktu dari sepasang pengaturan speech. h. Pencapaian diakhir tahun 1960-an merupakan penelitian
pioneer dari Reddy dalam bidang continues speech recognition dan dynamic tracking dari fonem.
i. Pada tahun 1970-an penelitian speech recognition meraih sejumlah batu pijakan yang signifikan. Pertama, area dari kata terisolasi atau pengenalan ucapan diskrit menjadi suatu teknologi yang mungkin dan berguna berdasarkan pada pembelajaran fundamental oleh Velicho dan Zagoruyko di rusia, sakoe dan chiba di jepang, dan itakura di amerika. Pembelajaran di rusia membantu memajukan penggunaan dari ide pattern recognition dalam speech recognition. Penelitian di jepang memajukan bagaimana metode dynamic programming dapat diterapkan dengan sukses dan penelitian di amerika menunjukan bagaimana ide dari Linear Predictive Logic (LPC) yang mana telah digunakan dengan sukses pada pengkodean speech ber-bit rendah.
j. Hingga pada tahun 1980-an bercirikan pada pergeseran teknologi dari pendekatan berbasis template menjadi statistik modeling, terutama pendekatan model Hidden Markov Model. Ide lain diperkenalkan pada akhir 1980-an adalah penerapan neural network pada speech recognition. neural network pertama kali diperkenalkan pada tahun 1950, akan tetapi tidak terbukti berguna pada awalnya karena terlalu banyak masalah praktikal.
2.3 Mengenal C Sharp (C#)
C Sharp (C#) adalah sebuah bahasa perograman berorientasi objek yang dikembangkan oleh Microsoft sebagai bagian dari inisiatif kerangka .NET Framework. Bahasa pemrograman ini dibuat berbasiskan bahasa C++ yang telah dipengaruhi oleh aspek-aspek ataupun fitur bahasa yang terdapat pada bahasa-bahasa pemrograman lainnya seperti Java, Delphi, Visual Basic serta bahasa lainnya dengan beberapa penyederhanaan. Menurut standar ECMA-334 C# Language Specification, nama C# terdiri dari sebuah huruf latin C (U+0043) yang diikuti oleh tanda pagar yang menandakan angka # (U+0023). Tanda pagar (#) yang digunakan memang bukan tanda kres dalam seni musik melainkan digunakan karena karakter kres dalam seni musik tidak terdapat di dalam keyboard standar.
Pada akhir tahun 1990, Anders Helsberg, adalah seorang mantan karyawan Borland serta pembuat bahasa Turbo Pascal dan Borlan Delphi direkrut oleh Microsoft yang juga mendesain Windows Foundation Classes (WFC) yang digunakan dalam J++ untuk menangani proyek pengembangan J++. Sebagai hasil dari usaha tersebut, C# pun pertama kali diperkenalkan pada bulan juli 2000 sebagai sebuah bahasa pemrograman modern berorientasi objek yang menjadi sebuah bahasa pemrograman utama di dalam pengembangan pada platform Microsoft .Net Framework.
Pengalaman Helsberg dalam mendesain bahasa pemrograman seperti Visual J++, Delphi, Turbo Pascal dengan mudah dilihat dalam sintaksis bahasa C#, begitu pula halnya pada inti Common Language Runtime (CLR). Dalam makalah-makalah teknisnya ia menyebutkan kelemahan-kelemahan yang terdapat pada bahasa pemrograman yang umum digunakan saat ini, misal C#, Java, Delphi, ataupun Smalltalk. Kelemahan-kelemahan itulah yang menjadi basis CLR sebagai bentukan baru yang menutupi kelemahan-kelemahan tersebut, dan akhirnya mempengaruhi desain pada bahasa C# itu sendiri. Ada kritik yang menyatakan C# sebagai bahasa yang berbagi akar dari bahasa-bahasa pemrograman lain. Fitur-fitur yang diambilnya dari bahasa C++ dan Java adalah desain berorientasi objek, seperti garbage collection, reflection,
root class, dan juga penyederhanaan terhadap pewarisan multiple inheritance. Fitur tersebut di dalam C# kini telah diaplikasikan terhadap iteresi, properti, event, metadata dan konversi antara tipe-tipe sederhana dan juga objek.
C# didesain untuk memenuhi kebutuhan akan sintaksis C++ yang lebih ringkas dan Rapid Application Development yang tanpa batas tidak seperti yang terdapat pada Delphi dan Visual Basic.
Agar dapat mempromosikan penggunaan dari bahasa C#, Microsoft, dengan dukungan dari Intel Corporation dan Hewlett-Packard, mencoba mengajukan standarisasi terhadap bahasa C#. dan akhirnya, pada bulan desember 2001, standar pertama pun diterima oleh Europan Computer
Manufactures Association atau Ecma International (ECMA), dengan
nomer standar ECMA=334. Pada desember 2002, standar kedua pun diadopsi oleh ECMA, dan tiga bulan kemudian diterima oleh International Organitation for Standardization (ISO), dengan nomor standar ISO/IEC 23270:2006.
2.3.1 C Sharp (C#)
Microsoft Visual C# adalah sebuah program alat bantu pemrograman atau yang biasa disebut RAD (Rapid Application Development tool) yang dibuat oleh Microsoft Corporation dan dapat digunakan untuk membuat program berbasis grafis dengan menggunakan bahasa pemrograman mirip C++. Program ini telah dimasukan ke dalam produk Microsoft Visual Studio, bersama-sama dengan Visual C++, Visual Basic, Visual FoxPro, serta Visual J#. sejauh ini, program ini merupakan program yang paling banyak digunakan oleh programmer untuk membuat program dalam bahasa C#.
2.4 GUI (Grapichal User Inteface)
Antarmuka bergrafik atau yang biasa disebut Graphical User Interface (GUI), merupakan interface pengguna yang menggunakan
perwakilan-perwakilan visual seperti grafik, ikon dan animasi untuk mewakili komponen-komponen GUI tersebut. Melalui GUI, user dapat memberikan perintah yang akan dijalankan oleh program. Pembuatan GUI dilakukan pada form yang telah disediakan. User dapat menambahkan objek kontrol ke dalam form seperti button, text, label, image dan lain sebagainya.
Interaksi di dalam GUI merupakan sebuah interaksi secara manipulasi langsung dimana user berinteraksi dengan perwakilan-perwakilan visual objek melalui mouse atau piranti-piranti pointer yang lain. Point and click, drag and drop, dan menggerakan objek merupakan ciri-ciri utama dalam GUI itu sendiri.
2.5 Net Technology
.NET Platform merupakan sekumpulan teknologi yang
memungkinkan teknologi internet ditransformasikan dalam distributed computing transform dengan skalabilitas dan kompabilitas yang tinggi. Secara teknis, .NET Platform menyediakan konsep pemrograman dengan library dan modul-modul baru yang konsisten, terlepas dari jenis bahasa pemrograman yang digunakan..NET Platform menyediakan hal-hal berikut bagi para developer antara lain :
a. Language Independent, dengan programing model yang konsisten disemua tier aplikasi yang dibangun.
b. Interopabilitas dan kompabilitas antar aplikasi. c. Kemudahan migrasi dari teknologi yang ada saat ini.
d. Dukungan penuh terhadap berbagai teknologi standar yang digunakan dalam platform internet, antara lain HTTP, XML dan HTML.
1. .Net Framework
NET Framework adalah teknologi inti yang menyediakan berbagai library untuk digunakan oleh aplikasi diatasnya. Komponen inti .NET Framework adalah CLR (Common Language Runtime) yang menyediakan runtime environment untuk aplikasi yang dibangun menggunakan Visual Studio .NET, terlepas dari jenis bahasa pemrogramannya. Dengan adanya CLR tersebut, programmer dapat menikmati consistent object model dalam mengakses berbagai komponen library.
Dengan demikian penggunaan bahasa pemrograman dalam dunia .NET adalah lebih ke masalah selera dan bukan pada kelebihan maupun kekurangan masing-masing bahasa karena semua bahasa pemrograman yang mendukung .NET mengakses library yang sama dalam .NET Framework, dengan objek model yang konsisten, dengan runtime file yang sama. Bahasa adalah sekedar skin atau theme. Bagi seorang .NET developer, pemahaman terhadap konsep dan objek model .NET Framework adalah jauh lebih penting dari pada bahasa pemrograman itu sendiri.
2. .NET Building Block Service
Building block merupakan sekumpulan service yang bersifat programmable yang dapat diakses secara offline maupun online. Service tersebut merupakan modul-modul yang terdapat di suatu komputer, server dalam jaringan, maupun di suatu server di internet. Service ini merupakan suatu idealisasi di masa depan, dimana sebuah aplikasi bersifat terdistribusi dengan modul-modul yang tersimpan di berbagai tempat, tetapi dapat diintegrasikan membentuk suatu aplikasi. Konsep ini merupakan arah pengembangan subcription based software, yang saat ini mulai banyak berkembang dan dikenal sebagai ASP (Application Service Provider). Service tersebut dapat diakses oleh berbagai platform,
asalkan platform tersebut mendukung protokol SOAP, yang merupakan protokol standar dalam mengakses web services.
Peranan XML sebagai media definisi data menjadi sangat pentinng dalam hal ini XML juga menjadi pusat perubahan besar dalam platform .NET. semua data dalam .NET selalu direpresentasikan dalam bentuk XML.
3. Visual Studio .NET
Visual Studio .NET menyediakan tools bagi para developer untuk membangun aplikasi yang berjalan di .NET Framework. Visual Studio .NET membawa perubahan besar dalam gaya pemrograman, karena setiap programmer dituntut untuk memahami
.NET object model dan Object Oriented Programming (OOP)
dengan baik, jika tidak ingin menghasilkan aplikasi dengan performa rendah.
Visual Studio .NET juga semakin mempertipis jarak antara Windows Programmer dan Web Programmer. Dunia scripting yang akrab bagi programmer web akan sulit ditemukan dalam .NET karena perograman web sudah bersifat full object oriented, dengan fasilitas event-driven programming sebagaimana layaknya windows programming. Pemrograman web menjadi lebih mudah dan menyenangkan bagi para programmer windows. Bahasa pemrograman yang terdapat dalam Visual Studio .NET adalah VB.NET, C#, C++, J# dan Jscript. Dalam masa mendatang akan terus ditambah dengan berbagai macam bahasa pemrograman lain. 2.6 SPEECH APPLICATION PROGRAMMING INTERFACE
Salah satu ekstensi terbaru untuk sistem operasi windows 95 adalah Speech Aplication Programming Interface (SAPI). Ekstensi windows ini memberikan workstation kemampuan untuk mengenali ucapan manusia sebagai masukan, dan menciptakan keluaran audio seperti ucapan manusia dari teks. Kemampuan ini menambahkan dimensi baru bagi interaksi
antara manusia dan komputer. Layanan pengenalan ucapan (speech recgnition) dapat digunakan untuk memperluas penggunaan komputer bagi pengguna yang menemukan kesulitan dalam mengetik atau butuh waktu lama dalam mengetik.
Layanan teks ke ucapan (text to speech) dapat digunakan untuk menyediakan representasi suara dari dokumen teks bagi mereka yang tidak dapat tampilan layar karena keterbatasan fisik atau karena sifat pekerjaan mereka. Speech API (SAPI) merupakan bagian dari model Windows Open Service Architecture (WOSA). Layan pengenalan suara ucapan Speech Recognition (SR) dan text to speech (TTS) disediakan modul terpisah yang disebut mesin (engine). Pengguna dapat memilih mesin pengenalan ucapan yang lebih disukai untuk digunakan, asalkan tetap sesuai dengan antarmuka SAPI.
Antarmuka utama yang digunakan oleh aplikasi ialah ISpRecoContext. Antarmuka ini merupakan sebuah ISpEventSource, yang berarti ISpRecoContext tersebut adalah antarmuka aplikasi untuk menerima notifikasi dari sebuah event pengenalan ucapan. Aplikasi menggunakan engine pengenalan pembicaraan (ISpRecognizer). Dengan menggunakan shared recognizer yang memungkinkan untuk berbagi resource dengan aplikasi pengenalan ucapan yang lain. Untuk membuat ISpRecoContext untuk shared ISpRecognizer, aplikasi hanya membutuhkan pemanggilan terhadap CoCreateInstance (COM) pada komponen CLSID_SpSharedRecoContext. Dimana SAPI akan mengatur audio input stream sesuai dengan pengaturan standar SAPI. Shared ISpRecognizer ini paling banyak digunakan pada aplikasi pengenalan ucapan secara umum. Langkah berikut pembuatan sistem pengenalan ucapan adalah mengatur notifikasi untuk event yang dibutuhkan oleh aplikasi. Karena ISpRecognizer adalah ISpEventSource yang juga merupakan ISpNotifySource dari ISpRecoContext untuk memberitahukan dimana terdapat sebuah event dari ISpRecoContext, kemudian aplikasi juga harus memanggil ISpEventSource::SetInterest untuk menyatakan event mana yang perlu dinotifikasikan. Event yang paling penting adalah
SPEI_RECOGNITION, yang berfungsi untuk menyatakan bahwa ISpRecognizer telah mengenali suara tertentu dari ISpRecoContext.
Langkah terakhir pembuatan sistem pengenalan ucapan ini, aplikasi harus membuat, meletakan di memori (load) dan mengaktifkan ISpRecoGrammar, sesuai dengan mode pengenalan ucapan, misal : dikatasi atau command and control. Aplikasi harus membuat ISpRecoGrammar menggunakan ISpRecoContext::CreateGrammar. Kemudian aplikasi harus meletakan grammar yang telah dibuat pada memori yaitu dengan memanggil ISpRecoGrammar::LoadDictation untuk mode diktasi atau ISpRecoGrammar::LoadCmd untuk mode command and control. Untuk mengaktifkan grammar sehingga sistem pengenalan ucapan
dapat bekerja, aplikasi harus memanggil
ISpRecoGrammar::SetDictationState untuk mode diktasi atau ISpRecoGrammar::SetRuleState atau ISpRecoGrammar::SetRuleIdState untuk mode command and control.
Ketika terjadi notifikasi pada saat pengenalan ucapan bekerja, maka Iparam yang merupakan variabel anggota dari struktur SPEVENT akan menjadi ISpRecoResult yang kemudian digunakan oleh aplikasi untuk dapat menentukan apa yang telah terkenali dan sekaligus menentukan IspRecoGrammar mana yang harus digunakan. ISpRecognizer, baik shared ataupun InProc, dapat mempunyai ISpRecoContext lebih dari satu dan masing-masing ISpRecoContext dapat mempunyai lebih dari satu ISpRecoGrammar dimana masing-masing ISpRecoGrammar tersebut digunakan untuk mengenali tipe grammar yang berbeda (Muhamad Zaenal, 27).
2.6.1 Text to Speech SAPI
Tipe kedua layanan suara menyediakan kemampuan untuk mengubah teks tertulis ke dalam kata-kata yang diucapkan. Hal ini disebut Text to Speech (TTS). Seperti halnya terdapat sejumlah faktor yang perlu dipertimbangkan ketika mengembangkan mesin speech recognition, ada beberapa hal pula yang harus diperhatikan
saat membuat dan menerapkan aturan untuk mesin Text to Speech. Terdapat empat hal yang harus diatasi ketika membuat mesin TTS antara lain :
1. Fonem (phonemes)
2. Kualitas Suara (voice quality)
3. Teks ke Ucapan Sintesis (TTS synthesis) 4. TTS diphone concatenation
Berikut merupakan penjelasan dari masing-masing bagian yang harus diatasi ketika membuat mesin TTS.
1. Fonem (phonemes)
Fonem adalah bagian suara yang membentuk kata-kata. Ahli bahasa menggunakan fonem untuk merekam suara secara akurat suara vokal yang diucapkan oleh manusia ketika berbicara. Fonem yang sama juga dapat digunakan untuk menghasilkan suara terkomputerisasi.
Mesin TTS menggunakan pengetahuan ahli bahasa tentang aturan tata bahasa (grammer rule) dan fonem untuk memindai teks tercetak dan menghasilkan keluaran audio. Model desain SAPI mengenali dan memungkinkan penggabungan fonem sebagai metode untuk membuat keluaran suara. Microsoft telah mengembangkan sebuah ekspresi dari International Phonetic Alphabet (IPA) dalam bentuk String Unicode. Pemrograman dapat menggunakan string untuk meningkatkan kemampuan pengucapan dari mesin TTS, atau untuk menambahkan kata-kata baru ke dalam pembendaharaan kata.
2. Kualitas Suara (voice quality)
Kualitas suara terkomputerisasi secara langsung berkaitan dengan kecanggihan dari aturan yang mengidentifikasi dan
mengkonversi teks ke sinyal audio. Tidak terlalu sulit untuk membangun sebuah mesin TTS yang dapat membuat suara yang dikenali, namun sangat sulit untuk membuat mesin TTS yang tidak terdengar seperti suara buatan komputer. Ada tiga faktor dalam ucapan manusia yang sangat sulit untuk dihasilkan dengan komputer, yaitu :
1. Prosodi (prosody) 2. Emosi (emotion)
3. Anomali Pengucapan (pronunciation anomalies)
Ucapan manusia memiliki irama khusus atau prosodi (pola jeda), infleksi, dan penekanan yang merupakan bagian integral dari bahasa. Komputer dapat melakukan pekerjaan dengan baik jika hanya melakukan pengucapan kata-kata individual, tetapi sulit membuat akurat meniru nada dan irama ucapan manusia. Untuk alasan ini, selalu cukup mudah untuk membedakan suara yang dihasilkan komputer dengan komputer memutar ulang rekaman suara manusia.
Faktor lain dari ucapan manusia yang masih membuat komputer memiliki kesulitan dalam menterjemahkan adalah emosi (emotion). Meskipun mesin TTS mampu membedakan pernyataan deklaratif dari pertanyaan atau seruan, komputer masih belum mampu menyampaikan kualitas emotif ketika menterjemahkan teks ke ucapan. Selain itu setiap bahasa memiliki anomali pengucapan (pronunciation anomalies) sendiri yang tidak dimainkan dengan aturan ketika mengubah teks menjadi ucapan. Beberapa contoh umum dalam bahasa inggris adalah dough dan tough atau comb dan home.
Sistem teks ke ucapan biasanya menawarkan beberapa cara untuk mengoreksi jenis masalah. Salah satu solusi yang khas
adalah menyertakan kemampuan untuk memasukan ejaan fonetik dari sebuah kata dan menghubungkan ejaan tersebut ke dalam versi teks. Penyesuaian lainnya yang umum adalah mengizinkan pengguna untuk memasukan tags kontrol dalam teks untuk menginstruksikan mesin teks ke ucapan untuk menambahkan penekanan atau infleksi, atau mengubah kecepatan atau pitch dari keluaran audio.
3. Text to Speech Synthesis (TTS synthesis)
Setelah TTS mengetahui fonem yang digunakan untuk memproduksi kata, ada dua metode yang mungkin untuk menciptakan keluaran audio, yaitu sistesis atau diphone concatenation. Metode sistesis menggunakan perhitungan dari bibir seseorang dan posisi lidah, kekuatan nafas, dan faktor lainnya untuk mensintesis ucapan manusia. Metode ini biasanya tidak seakurat metode diphone. Namun jika TTS menggunakan metode sintesis untuk menghasilkan keluaran, sangat mudah untuk memodifikasi beberapa parameter, dan kemudian membuat suara baru. Sintesis berbasis mesin TTS secara keseluruhan memerlukan sumber daya komputasi yang sedikit dan kapasitas penyimpanan yang rendah. Sistem berbasis sintesis yang sedikit lebih sulit untuk dimengerti pada awalnya, tetapi biasanya menawarkan pengguna kemampuan untuk menyesuaikan nada, kecepatan, dan infleksi suara yang agak mudah.
4. TTS diphone concatenation
Metode diphone concatenation dalam pembangkitan suara menggunakan pasangan fonem untuk memproduksi masing-masing suara. Diphone ini merupakan awal dan akhir setiap bagian suara individu. Misalnya, kata “pig” berisi diphone silence –p, p-i, i-g, dan g-silence. Sistem TTS diphone meneliti kata dan kemudian menyusun pasangan fonem yang benar untuk mengucapkan kata
tersebut. Pasangan fonem ini diproduksi bukan oleh sintesis komputer, tapi dari rekaman sebenarnya suara manusia yang telah dipecah menjadi unsur-unsur terkecil dan dikelompokkan ke dalam berbagai pasangan diphone. Karena sistem TTS yang menggunakan diphone menggunakan elemen dari ucapan manusia yang sebenarnya, sehingga dapat menghasilkan keluaran lebih menyerupai manusia. Namun, karena pasangan diphone sangat bersifat bahasa spesifik, sistem diphone TTS biasanya didedikasikan untuk memproduksi satu bahasa. Karena itu, sistem diphone tidak bisa diterapkan dengan baik dalam lingkungan di mana ada kata-kata asing yang banyak, atau dimana TTS mungkin diperlukan untuk menghasilkan keluaran lebih dari satu bahasa.
2.7 Aturan Tata Bahasa
Elemen terakhir dari mesin pengenalan ucapan adalah aturan tata bahasa (grammar rule). Aturan tata bahasa digunakan oleh perangkat lunak pengenalan ucapan untuk menganalisis masukan ucapan manusia dan di dalam proses berupaya untuk memahami apa yang seseorang katakan. Ada banyak tata bahasa, masing-masing terdiri dari satu set aturan pengucapan. Sama seperti manusia yang harus belajar memakai tata bahasa umum agar dapat dipahami, komputer juga harus memakai tata bahasa yang sama dengan pembicara untuk mengkonversi informasi audio ke dalam teks. Tata bahasa dibagi dalam tiga jenis, yaitu :
a. Tata bahasa bebas konteks (context-free grammars). b. Tata bahasa dikte (dictation grammars).
c. Tata bahasa domain terbatas (limited domain grammars).
Tata bahasa bebas konteks menawarkan tingkat terbesar fleksibilitas ketika menafsirkan ucapan manusia. Tata bahasa dikte menawarkan tingkat akurasi terbesar saat mengubah kata yang diucapkan menjadi teks. Tata bahasa domain terbatas menawarkan kompromi antara tata bahasa bebas konteks yang sangat fleksibel dan tata bahasa dikte yang terbatas.
2.7.1 Tata Bahasa Bebas Konteks
Tata bahasa bebas konteks (context-free grammars) bekerja pada prinsip aturan-aturan berikut yang ditetapkan untuk menentukan kandidat yang paling mungkin untuk kata berikutnya di dalam kalimat. Context-Free Grammars (CFG) tidak bekerja pada pemikiran bahwa setiap kata harus dipahami dalam konteks. Sebaliknya, mereka mengevaluasi hubungan dari setiap kata dan frasa kata untuk mengetahui satu set aturan tentang kata apa yang mungkin pada suatu waktu tertentu. Unsur-unsur utama CFG antara lain :
a. Kata-kata (words), sebuah daftar kata yang valid untuk diucapkan.
b. Aturan-aturan (rules), satu set struktur ucapan dimana kata-kata digunakan.
c. Daftar lis (list), satu atau lebih set kata untuk digunakan dalam aturan.
CFG baik untuk sistem yang berurusan dengan dengan berbagai masukan. CFG juga mampu menangani perbendaharaan kata yang berubah-ubah. Hal ini karena sebagian besar bangunan aturan dilakukan CFG untuk menyelesaikan daftar deklarasi dan kelompok kata yang sesuai dengan pola umum atau atauran umum. Selain mesin pengenalan ucapan memahami aturan, sangat mudah untuk memperluas perbendaharan kata dengan memperluas daftar kemungkinan anggota kelompok.
2.7.2 Tata Bahasa Dikte
Tidak seperti CFG yang beroperasi menggunakan aturan, tata bahasa dikte (dictation grammars) berdasarkan evaluasi pada perbendaharaan kata. Fungsi utama dari suatu bahasa dikte adalah mengkonversi ucapan manusia ke dalam teks seakurat mungkin. Dalam rangka melakukan ini, tata bahasa dikte tidak hanya
membutuhkan perbendaharaan kata yang banyak untuk bekerja, tetapi juga contoh keluaran untuk digunakan sebagai model ketika menganalisis masukan ucapan. Aturan pengucapan tidak penting untuk suatu sistem yang hanya mengkonversi masukan suara manusia menjadi teks. Elemen dari tata bahasa dikte adalah : a. Topik (topic), mengidentifikasi topik dikte (misal, medis dan
hukum)
b. Umum (common),satu set kata yang biasa digunakan dalam dikte. Biasanya kelompok umum berisi teknis atau kata-kata khusus yang diharapkan muncul selama dikte yang biasanya tidak ditemukan dipercakapan reguler.
c. Grup (group), satu set kata terkait yang diharapkan, tetapi yang tidak langsung berkaitan dengan topik dikte. Grup biasanya memiliki seperangkat kata yang diharapkan sering terjadi selama dikte. Model tata bahasa bisa mengandung lebih dari satu grup.
d. Contoh (sample), contoh teks yang menunjukan gaya penulisan pembicara atau format umum dikte. Teks ini digunakan untuk membantu mesin pengenalan ucapan dalam menganalisis masukan ucapan.
Keberhasilan tata bahasa dikte tergantung pada kualitas dari perbendeharaan kata. Semakin banyak item pada daftar, semakin besar peluang mesin pengenalan ucapan salah antara satu item dengan yang lain. Namun, semakin terbatas perbendaharaan kata, semakin besar jumlah kata yang tidak diketahui yang akan selama dikte. Sistem dikte yang paling sukses dengan adanya keseimbangan ke dalaman perbendaharaan kata dan keunikan kata-kata dalam basis data. Untuk alasan ini, sistem dikte biasanya disetel untuk satu topik, seperti dikte hukum atau medis. Dengan membatasi perbendaharaan kata kepada kata yang paling mungkin terjadi diperjalanan dikte, akurasi penerjemahan meningkat.
2.7.3 Tata Bahasa domain Terbatas
Tata bahasa domain terbatas (limited domain grammars) menawarkan kompromi antara fleksibilitas CFG dan keakuratan tata bahasa dikte. Tata bahasa domain terbatas memiliki unsur-unsur berikut :
a. Kata-kata (words), ini adalah daftar kata khusus yang mungkin terjadi selama sesi.
b. Grup (group), ini adalah satu set kata terkait yang dapat terjadi selama sesi. Tata bahasa dapat berisi beberapa kelompok kata. Sebuah frasa tunggal akan diharapkan untuk memasukkan salah satu kata dalam kelompok.
c. Contoh (sample), contoh yang menunjukan gaya penulisan pembicara atau format umum dikte. Teks ini digunakan untuk membantu mesin pengenalan ucapan dalam menganalisis masukan ucapan.
Tata bahasa domain terbatas berguna dalam situasi dimana perbendaharaan kata sistem tidak perlu sangat besar. Contohnya sistem yang menggunakan bahasa alami untuk menerima pernyataan perintah. Tata bahasa domain terbatas juga bekerja dengan baik untuk mengisi formulir atau untuk masukan teks sederhana.
2.8 Application Programming Interface (API) SAPI 5.1
Application Programming Interface (API) SAPI secara dramatis mengurangi pemakaian berlebihan kode yang diperlukan sebuah aplikasi untuk menggunakan pengenalan ucapan dan teks ke ucapan, sehingga membuat teknologi mesin ucapan lebih mudah diakses dan baik untuk berbagai aplikasi. API SAPI menyediakan antarmuka tingkat tinggi antara aplikasi dan mesin ucapan. SAPI menerapkan semua detil tingkat rendah (low-level) yang dibutuhkan untuk mengendalikan dan mengelola opersi secara langsung (real-time) dari berbagai mesin ucapan.
Dua tipe dasar mesin SAPI adalah sistem teks ke ucapan (Text-to-Speech) dan pengenalan ucapan (Speech Recognition). Sistem TTS mensintesis string teks dan file ke dalam audio ucapan menggunakan suara sintetik. Pengenalan ucapan mengkonversi audio yang diucapkan manusia ke dalam string teks yang dapat dibaca oleh file.
2.9 UML (Unified Modeling Language)
Unified Modeling Language adalah bahasa standar yang digunakan untuk menjelaskan dan memvisualisasikan dalam proses analisis dan desain berorientasi obyek. UML menyediakan standar pada notasi dan diagram yang bisa digunakan untuk memodelkan sistem. Adapun diantaranya adalah sebagai berikut :
1. Use Case Diagram
Menjelaskan apa yang akan dilakukan oleh sistem yang akan dibangun dan siapa yang berinterakasi dengan sistem. Pengguna menggunakan use case diagram ini untuk memahami sistem dan mengevaluasi bahwa benar yang dilakukan sistem adalah untuk memecahkan masalah yang pengguna ajukan atau sedang dihadapi. Use case diagram ini memberikan gambaran statis dari sistem yang sedang dibangun dan merupakan gambaran dari proses analisis.
2. Activity Diagram
Merupakan diagram yang memodelkan aliran kerja (workflow) dari urutan aktivitas dalam suatu proses yang mengacu pada use case diagram.
3. Sequence Diagram
Menjelaskan secara detil urutan proses yang dilakukan dalam sistem untuk mencapai tujuan dari Use Case, interaksi yang terjadi antar Class, operasi apa saja yang terlibat, urutan antar operasi, dan informasi yang diperlukan oleh masing-masing operasi. Pembuatan sequence diagram merupakan aktivitas yang paling kritikal dari
proses desain karena menjadi pedoman dalam proses pemrograman nantinya dan berisi aliran kontrol dari program
2.10 Proses Pengenalan Suara (Speech Recognition)
Semua metode dasar proses pengenalan suara terdiri dari dua fase operasi, pertama adalah proses training, pada proses ini sistem belajar dari referensi pola yang berupa perbedaan pola sinyal suara misal frase, kata, fonem yang akan mengisi arti kata dari sistem, setiap referensi dipelajari dari yang dikatakan dan kemudian disimpan dalam template dan telah mengalami metode untuk merata-rata dan karakteristik statistik dan parameter statistik. Yang kedua adalah proses recognition yaitu pada proses ini sistem akan diberi inputan yang belum diketahui dan akan diidentifikasi berdasarkan pola template yang telah didapatkan pada proses training.
Gambar 2.3 Spektrum Suara
Secara umum, speech recognizer memproses sinyal suara yang masuk dan menyimpannya dalam bentuk digital. Hasil proses digitalisasi tersebut kemudian dikonversi dalam bentuk spektrum (serangkaian gelombang-gelombang) suara yang akan dianalisa dengan membandingkannya dengan template suara pada database sistem. Sebelumnya, data suara masukan dipilah-pilah dan diproses satu per satu berdasarkan urutannya.
2.11 Microphone
Mikrofon (microphone) adalah suatu jenis transduser yang mengubah energi-energi akustik (gelombang suara) menjadi sinyal listrik. Mikrofon merupakan salah satu alat untuk membantu komunikasi manusia agar dapat berinteraksi langsung dengan komputer atau jenis lainnya seperti telepon, alat perekam, pengudaraan radio, alat bantu dengar serta televisi.
Secara umum terdapat tiga jenis mikrofon dengan sifat yang berbeda-beda antara lain Ribbon Microphone, Dynamic Microphone, dan Condensor Microphone.
1. Ribbon Microphone
Jenis ini kualitasnya tidak/kurang baik, karena daya serap suaranya sangat rendah sehingga penggunaannya harus memerlukan tambahan kekuatan
2. Dynamic Microphone
Mikrofon jenis ini sering juga disebut ball microphone. Daya serap jenis mikorfon ini sangat tinggi. Artinya mikrofon ini sangat sensitif karena mampu menyerap seluruh suara.
3. Condensor Microphone
Seperti halnya jenis ball micrphone, condensor microphone juga mampu menerima suara dari segala arah, meskipun harus memerlukan tambahan kekuatan. Microphone jenis inilah yang digunakan dalam mengerjakan soal-soal speaking.
2.12 RAD (Rapid Applications Development)
Model RAD adalah model proses pembangunan perangkat lunak yang tergolong dalam teknik incremental (bertingkat). RAD menekankan pada siklus pembangunan yang singkat, cepat dan pendek. Waktu yang singkat adalah batasan yang penting untuk model ini. Adapun tahap-tahap
menggunakan metode RAD ini meliputi perencanaan, perancangan, implementasi serta pengujian.
1. Perencanaan
Pada tahap perencanaan ini dilakukan pengidentifikasian tujuan aplikasi atau sistem tersebut. Apabila pengetahuan diformulasikan secara lengkap, maka tahap implementasi dapat dimulai dengan membuat garis besar masalah kemudian memecahkan masalah tersebut.
2. Perancangan
Pada tahap ini dilakukan perancangan proses, yaitu perancangan proses-proses yang akan terjadi di dalam sistem.
3. Implementasi
Pada tahap ini setelah sistem dirancang kemudian diimplementasikan atau dibuat berupa sebuah aplikasi.
4. Pengujian
Pada tahap ini dilakukan pengujian terhadap sistem untuk mengetahui apakah program dapat berjalan dengan baik dan menghasilkan keluaran yang sesuai dengan respon yang diberikan. Pada tahap ini pula dapat diketahui kesalahan-kesalahan apa yang terjadi, sehingga dapat diperbaiki dalam pengembangan selanjutnya.