DIAGNOSA PENYAKIT DIABETES MELLITUS DENGAN METODE NAÏVE
DIAGNOSA PENYAKIT DIABETES MELLITUS DENGAN METODE NAÏVE
BAYES BERBASIS DESKTOP APPLICATION
BAYES BERBASIS DESKTOP APPLICATION
Al
Al mirmir a Sa Syayawli wli 1 1 , Gopi Yudoyo , Gopi Yudoyo 2 2 , M. Ali F, M. Ali F aahmi hmi 3 3 , S, Silil via Arvia Ar i Santhy i Santhy 4 4 , Zulkar, Zulkar naenaein in 55 1.
1. Teknik Informatika, Program Teknologi Informasi dan Ilmu Teknik Informatika, Program Teknologi Informasi dan Ilmu Komputer, Universitas Brawijaya,Komputer, Universitas Brawijaya, Malang, 65145, Indone
Malang, 65145, Indonesiasia 2.
2. Program Tek Program Teknologi Informasi dan nologi Informasi dan Ilmu Komputer, UIlmu Komputer, Universitas Bniversitas Brawijaya, Malang, 65145rawijaya, Malang, 65145,, Indonesia
Indonesia Email:
Email: [email protected]@gmail.com11 , , [email protected] [email protected] , , [email protected]@gmail.com33 , , silvia.aska@gma
[email protected] , , zulkhafourze@ [email protected]
Abstrak Abstrak Bidang kesehatan merupakan
Bidang kesehatan merupakan salah satu salah satu bidang yang bidang yang sudah menerapkan berbagai sudah menerapkan berbagai teknoloteknologi komputer.gi komputer. Untuk melakukan diagnosa penyakit yang diderita pasien pun sudah dilakukan dengan bantuan Untuk melakukan diagnosa penyakit yang diderita pasien pun sudah dilakukan dengan bantuan komputer. Salah satunya adalah untuk mendiagnosa penyakit diabetes mellitus yang dapat terjadi pada komputer. Salah satunya adalah untuk mendiagnosa penyakit diabetes mellitus yang dapat terjadi pada siapa pun. Penyakit diabetes mellitus merupakan salah satu jenis penyakit yang
siapa pun. Penyakit diabetes mellitus merupakan salah satu jenis penyakit yang sering ditemukan padasering ditemukan pada masyarakat. Penyakit ini juga merupakan penyebab kematian terbesar keempat di dunia, dan di masyarakat. Penyakit ini juga merupakan penyebab kematian terbesar keempat di dunia, dan di Indonesia terutama di kota-kota besar seperti Jakarta dan Surabaya sudah hampir 10 persen Indonesia terutama di kota-kota besar seperti Jakarta dan Surabaya sudah hampir 10 persen penduduknya mengidap
penduduknya mengidap diabetes. diabetes. Oleh Oleh karena itu, karena itu, penelitian penelitian ini ini bertujuan bertujuan untuk untuk mencegmencegah ah masalamasalahh tersebut dengan bantuan sistem pakar. Dalam hal ini, pasien dapat memasukkan berbagai gejala yang tersebut dengan bantuan sistem pakar. Dalam hal ini, pasien dapat memasukkan berbagai gejala yang mengindikasi penyakit Diabetes Mellitus. Dari gejala yang dimasukkan, dapat diketahui prediksi mengindikasi penyakit Diabetes Mellitus. Dari gejala yang dimasukkan, dapat diketahui prediksi bahwa
bahwa pasien pasien terkena terkena atau atau tidak tidak terkena terkena Diabetes Diabetes Mellitus Mellitus dengan dengan metode metode Naive Naive Bayes. Bayes. MetodeMetode Naïve Bayes ini
Naïve Bayes ini membamembantu kita ntu kita dalam menentukan probabilitas seorang pasien dengan gejala tertentudalam menentukan probabilitas seorang pasien dengan gejala tertentu dapat dikatakan terkena Diabetes mellitus atau tidak terkena Diabetes mellitus berdasarkan dari 22 dapat dikatakan terkena Diabetes mellitus atau tidak terkena Diabetes mellitus berdasarkan dari 22 gejala sebagai indikator kunci dari Diabetes Mellitus. Dari masukan tersebut akan dibandingkan gejala sebagai indikator kunci dari Diabetes Mellitus. Dari masukan tersebut akan dibandingkan dengan data training yang
dengan data training yang telah tervalidasi.telah tervalidasi. Kata Kunci
Kata Kunci : Diabetes mellitus, Teorema Bayes, Metode Naïve Bayes, Sistem Pakar : Diabetes mellitus, Teorema Bayes, Metode Naïve Bayes, Sistem Pakar
Abstract Abstract The health sector is
The health sector is one area that has one area that has been implementing a variety of computer technologies. To makebeen implementing a variety of computer technologies. To make a diagnosis of the patient's illness was already done with the help of computers. One is to diagnose a diagnosis of the patient's illness was already done with the help of computers. One is to diagnose diabetes mellitus that can be happened to anyone. Diabetes mellitus is a disease that is oftenly found diabetes mellitus that can be happened to anyone. Diabetes mellitus is a disease that is oftenly found in the community. This disease is also the fourth
in the community. This disease is also the fourth largest cause of death in the world, and ilargest cause of death in the world, and i n Indonesia,n Indonesia, especially in big cities such as Jakarta and Surabaya which are nearly 10 percent of the population especially in big cities such as Jakarta and Surabaya which are nearly 10 percent of the population have diabetes. Therefore, this study aims to avoid t
have diabetes. Therefore, this study aims to avoid t hese problems with the help of an hese problems with the help of an expert system. Inexpert system. In this case, the patient may enter a variety of symptoms that indicate Diabetes Mellitus disease. From this case, the patient may enter a variety of symptoms that indicate Diabetes Mellitus disease. From that symptoms, it can be seen the predictions of patients that exposed or not exposed to Diabetes that symptoms, it can be seen the predictions of patients that exposed or not exposed to Diabetes Mellitus with the
Mellitus with the Naive Bayes method. Naive Bayes method helps us in Naive Bayes method. Naive Bayes method helps us in determining the probability ofdetermining the probability of a patient with certain symptoms that can be said exposed or not exposed based on 22 symptoms as a a patient with certain symptoms that can be said exposed or not exposed based on 22 symptoms as a key indicator of Diabetes Mellitus. Furthermore, the input will be compared with training data that key indicator of Diabetes Mellitus. Furthermore, the input will be compared with training data that has been validated.
has been validated. Keywords: Dia
PENDAHULUAN
Diabetes Mellitus (DM) adalah penyakit yang akhir-akhir ini semakin banyak dijumpai. Penyakit Diabetes Melitus juga sering kita sebut dengan istilah kencing manis atau penyakit gula darah. Penyakit yang satu ini termasuk jenis penyakit kronis yang tanda awalnya yaitu meningkatnya kadar gula dalam darah sebagai akibat adanya gangguan sistem metabolisme dalam tubuh. Organ tubuh yang terganggu adalah pankreas yang mana sudah tidak berfungsi sebagaimana mestinya. Pankreas sudah tidak mampu memproduksi hormon insulin dalam memenuhi kebutuhan tubuh. Beberapa faktor yang menyebabkan seseorang menderita penyakit diabetes, yaitu [3] :
1) Banyak mengkonsumsi makanan yang mengandung gula
2) Kurang tidur
3) Makan terlalu banyak karbohidrat dari nasi atau roti
4) Merokok
5) Kurangnya Aktivitas Fisik 6) Faktor Keturunan
Penentuan mengenai terkena penyakit Diabetes Mellitus, dapat dikenali melalui beberapa gejala yang dirasakan seperti banyak kencing, dehidrasi, berat badan turun, penglihatan kabur, dan sebagainya. Prediksi seseorang mengidap penyakit ini dapat diketahui dari perhitungan probabilitas menggunakan metode Naïve Bayes. Metode ini memanfaatkan
teorema Bayes.
Teorema Bayes adalah sebuah pendekatan untuk sebuah ketidaktentuan yang diukur dengan probabilitas. Pendekatan bayes pada saat klasifikasi adalah mencari probabilitas tertinggi (VMAP) dengan masukan
atribut (a1, a2, a3, ..., an) seperti tampak pada
persamaan 1 berikut [2] :
VMAP = arg max P(v j |a1,a2,a3,...,an) (1)
v j
VTeorema Bayes sendiri berawal dari rumus persamaan 2 berikut :
P(A|B) =
(2)Dimana P(A|B) artinya peluang A jika diketahui keadaan B. Kemudian dari persamaan rumus 2 diatas didapat persamaan 3
seperti berikut :
P(B
A) = P( B | A) P(A) (3) Sehingga didapatkan teorema bayes seperti persamaan 4 berikut :P(A | B) =
|
(4)Yang mana :
A adalah hipotesis data A (class spesifik) B adalah data dengan class yang belum
P(A|B) adalah probabilitas hipotesis A
berdasar kondisi B (posterior | probability)
P(B|A) adalah probabilitas B berdasar
kondisi pada hipotesis A
P(A) adalah probabilitas hipotesis A
(prior probability)
P(B) adalah probabilitas dari B
Menggunakan teorema bayes ini, persamaan diatas dapat ditulis menjadi persamaan 5 berikut ini :
Vmap=arg max
|
(5)
Karena nilai P(a1, a2, a3, ..., an) konstan untuk
semua v j, maka persamaan ini dapat ditulis
menjadi persamaan 6 berikut ini :
VMAP = arg max P(a1,a2,a3,...,an | v j)P(v j)
v j
V(6)
Untuk menghitung P(a1, a2, a3, ..., an | v j) bisa
jadi semakin sulit karena jumlah term P(a1, a2,
a3, ..., an | v j) bisa jadi sangat besar [2]. Hal ini
disebabkan jumlah term tersebut
Permasalahannya adalah bagaimana cara memprediksikan bahwa seseorang terkena Diabetes Mellitus dengan menggunakan metode Naïve Bayes. Prediksi ini dapat menggunakan masukan berupa gejala – gejala Diabetes Mellitus yang dirasakan oleh pasien
seperti banyak kencing, dehidrasi, berat badan turun, penglihatan kabur, dan sebagainya.
Dalam prosesnya, diperlukan beberapa tahapan untuk menjadikan data mentah sebagai knowledge based bagi sistem pakar. Aktivitas yang dilakukan untuk memindahkan kepakaran adalah [3] :
1. Knowledge Acquistion (dari pakar atau sumber lainnya)
2. Knowledeg Representation (ke dalam komputer)
3. Knowledge Inferencing 4. Knowledge Transfering
Akuisisi pengetahun dilakukan sepanjang proses pembangunan sistem. Proses akuisisi pengetahuan dibagi kedalam enam tahap, yaitu
[5] :
1. Tahap Identifikasi
Tahap identifikasi meliputi penentuan komponen-komponen kunci dalam sistem yang sedang dibangun. Komponen kunci ini adalah knowledge
engineer , pakar, karakteristik masalah, sumber daya dan tujuan.
2. Tahap Konseptualisas
Tahap ini, memperjelas konsep – konsep kunci dan hubungannya yang telah didtemtukan pada tahap sebelumnya.
3. Tahap Formalisasi
Tahap ini, memetakan seluruh konsep – kosenp pengatahuan sebelumnya ke dalam representasi formal yang sesuai dengan permasalahan.
4. Tahap Implementasi
pengetahuan yang dipilih kemudian dibuatlah prototype dari sisem.
5. Tahap Pengujian
Tahap ini, melakukan pengujian terhadap sistem dengan memasukkan berbagai sampel masalah.
6. Revisi Protoype
METODE PENELITIAN
Pada penelitian ini, metode yang digunakan adalah metode klasifikasi dengan Naïve Bayes. Naïve Bayes menyederhanakan teorema bayes dengan asumsi bahwa fitur-fitur yang terdapat didalamnya saling tidak tergantung atau independen, setiap kata independen satu sama lain. Seperti tampak pada persamaan 7 berikut ini :
P(a1,a2,a3,...,an | v j) =
∏
|
(7)Dengan mensubstitusikan persamaan ini dengan persamaan diatas maka akan dihasilkan rumus seperti persamaan 8 berikut ini :
VMAP = arg max P(v j)
∏
|
(8)v j
VNaïve Bayes adalah model penyederhanaan dari metode bayes. Dimana:
VMAP = Nilai output hasil klasifikasi
Naïve Bayes
P(a1, a2, a3, …, an) = Peluang A Vj = Keadaan atau kategori j
Perancangan Sistem
Prosedur perancangan sistem secara umum terdiri atas beberapa tahap antara lain perancangan data, perancangan proses dan perancangan interface.
Tahap pertama adalah perancangan data meliputi data input, data output dan data training. Data training yang akan digunakan sebagai acuan untuk menentukan data output yang dihasilkan oleh sistem, diperoleh dari Departemen kesehatan dan kesejahteraan sosial RI 2001 sebanyak 18 data [4].
Tahap kedua adalah perancangan proses implementasi Naïve Bayes ke dalam
sistem. Pada tahap ini akan dijelaskan cara kerja sistem (perhitungan) dan proses-proses yang akan digunakan, mulai dari masuknya data input yang kemudian akan diproses oleh sistem hingga menjadi data output.
Pada tahap ini diambil beberapa data training untuk di tes. Kemudian diambil probabilitas kemunculan setiap nilai
masing-masing fitur per kelasnya.
Langkah pertama adalah dengan meng-generate data training yang telah diperoleh sebanyak 18 dataset. Dari data training yang diperoleh, kemudian dilakukan analisa mengenai gejala (fitur) dari penyakit Diabetes Mellitus. Setelah menganalisa, didapatkan 22 indikasi (bersifat diskrit) dari Diabetes Mellitus, yaitu :
a. Polituria b. Polidipsia
c. Polipagia d. Kesemutan e. Rasa tebal
f. Berat badan turun g. Kulit h. Gatal i. Bisul j. Infeksi k. Keputihan l. Luka m. Lapar n. Gemetar o. Lemah p. Konsentrasi q. Keringat r. Berdebar s. Pusing t. Gelisah u. Koma
Serta dua kelas utama yaitu kelas Ya (terkena Diabetes Mellitus) dan kelas Tidak (tidak terkena Diabetes Mellitus).
Langkah kedua yaitu melakukan testing dengan diberikan data sample. Dengan begitu dapat dihitung peluang terkena atau tidak terkena Diabetes Mellitus menggunakan Naïve Bayes. Dalam proses perhitungannnya dibutuhkan Prior yang merupakan probabilitas kemunculan kejadian tiap kelas yang tidak diketahui dengan pasti tetapi dapat diestimasi dari data yang tersedia. Prior dinyatakan dengan (P(h j)).
Variabel random diskrit yang didistribusikan bergantung pada kemunculan objek dan dinyatakan dengan P(x|h) yang menyatakan peluang muncul x jika diketahui h. Fungsi peluang P(x|h j) ini disebut juga dengan
istilah fungsi likelihood dari h j terhadap x.
Dari kedua fungsi diatas, dapat dilakukan perhitungan dengan metode Naïve Bayes seperti pada persamaan 9 berikut :
(
)∏
|
(9)Dimana j adalah jumlah kelas dan i adalah jumlah fitur yang ada.
Aturan bayes itu sendiri bisa ditetapkan sebagai berikut:
Misalkan terdapat kategori dua kelas P(h1) dan
P(h2).
|
<
|
, maka x diklasifikasikan sebagai h2.Pada pengamatan nilai x tertentu, ketika mengambil suatu keputusan maka probabilitas errornya seperti pada persamaan
10 berikut :
| {
|
|
(10)
Jadi jelasnya peluang error bisa diminimalkan jika diberikan nilai x dengan memutuskan h1
jika
|
>
|
dan memutuskan h2jika
|
>
|
[1]. Maka untuk memutuskan sesuatu atau decide dengan memilih nilai posterior yang paling besar.Tahap ketiga adalah perancangan interface. Tahap ini merupakan tahap pembuatan user interface sebagai fasilitator dalam berkomunikasi antar sistem dengan user .
HASIL DAN PEMBAHASAN
Eksperimen dilakukan untuk menguji kinerja sistem penentuan terkena Diabetes Mellitus. Pada proses pengujian ini, digunakan metode klasifikasi Naïve Bayes.
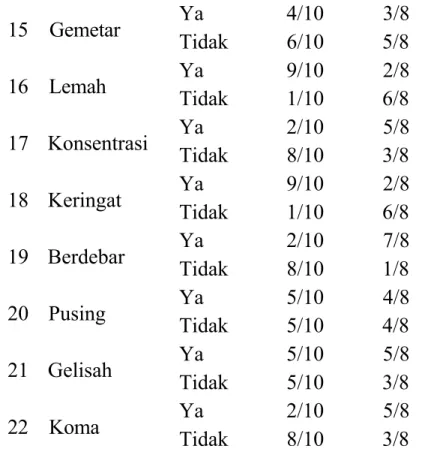
Langkah pertama yaitu menghitung probabilitas kemunculan dari setiap fitur (gejala) terhadap kelasnya. Berdasarkan perhitungan tersebut, diperoleh hasil seperti pada tabel 1 berikut :
Tabel 1. Likelihood tiap fitur dari semua kelas
Fitur
Kondisi
Diabetes Mellitus
Ya
Tidak
1 Poliuria Ya 7/10 3/8 Tidak 3/10 5/8 2 Polidipsia Ya 8/10 3/8 Tidak 1/10 5/8 3 Polipagia Ya 9/10 1/8 Tidak 1/10 7/8 4 Kram Ya 5/10 4/8 Tidak 5/10 4/8 5 Kesemutan Ya 6/10 2/8 Tidak 4/10 6/8 6 Rasa Tebal Ya 2/10 7/8 Tidak 8/10 1/8 7 Berat Badan Turun Ya 4/10 6/8 Tidak 6/10 2/8 8 Kulit Ya 2/10 7/8 Tidak 8/10 1/8 9 Gatal Ya 3/10 6/8 Tidak 7/10 2/8 10 Bisul Ya 1/10 6/8 Tidak 9/10 2/8 11 Infeksi Ya 2/10 7/8 Tidak 8/10 1/8 12 Keputihan Ya 4/10 5/8 Tidak 6/10 3/8 13 Luka Ya 7/10 1/8 Tidak 3/10 7/8 14 Lapar Ya 2/10 4/8 Tidak 8/10 4/8 15 Gemetar Ya 4/10 3/8 Tidak 6/10 5/8 16 Lemah Ya 9/10 2/8 Tidak 1/10 6/8 17 Konsentrasi Ya 2/10 5/8 Tidak 8/10 3/8 18 Keringat Ya 9/10 2/8 Tidak 1/10 6/8 19 Berdebar Ya 2/10 7/8 Tidak 8/10 1/8 20 Pusing Ya 5/10 4/8 Tidak 5/10 4/8 21 Gelisah Ya 5/10 5/8 Tidak 5/10 3/8 22 Koma Ya 2/10 5/8 Tidak 8/10 3/8Kemudian dilakukan analisis keakuratan data dengan memasukkan data sample melalui sistem seperti pada gambar 1 dan 2 berikut.
Gambar 1. Form input data user
Pengujian keakuratan dilakukan dengan memasukkan masalah yang sama dengan data training sebelumnya. Dari hasil pengujian tersebut, dapat dihitung tingkat keakuratan dengan cara pada persamaan 11 berikut :
Akurasi =
(11)
Adapun hasil pengujian dari setiap data training ditunjukkan pada tabel 2 berikut :
Tabel 2. Hasil pengujian
Data ke -Data Training Data Output (Hasil Pengujian) 1 ya ya 2 ya ya 3 tidak tidak 4 tidak tidak 5 tidak tidak 6 ya ya 7 ya ya 8 ya ya 9 tidak tidak 10 tidak tidak 11 ya ya 12 tidak tidak 13 ya ya 14 tidak ya 15 ya ya 16 ya ya 17 ya ya 18 tidak tidak
Dari pengujian tersebut, dapat diketahui tingkat keakurasiannya adalah :
Akurasi =
= 94,4%KESIMPULAN
Pada penelitian ini dapat disimpulkan bahwa semakin banyak jumlah data yang digunakan untuk training maka semakin tinggi keakuratannya. Selain itu, semakin sering juga dilakukan learning atau penambahan knowledge maka akan semakin cepat mendapatkan klasifikasi dengan benar.
Untuk langkah selanjutnya, akan berkonsentrasi pada pengembangan aplikasi seperti dapat menentukan nilai variasi konstanta bayes secara otomatis untuk mendapatkan akurasi yang tinggi dengan berapapun jumlah data trainingnya. Aplikasi juga dapat disempurnakan untuk meminimalisir waktu pemrosesan pada saat learning.
DAFTAR PUSTAKA
[1] Basuki, Achmad. 2006. Metode Bayes. Pens, Institut Teknologi Sepuluh November.
[2] Ferry Febrian, ” Analisis Komparasi Algoritma Klasifikasi Data Mining Pada Akseptasi Data Fakultatif Reasuransi Jiwa”, Tesis, Program Studi Teknik Informatika, Program Pasca Sarjana (S2) Magister Komputer, 2011. URL : http://edp.stmikpasim.ac.id/agoenthea/pub
-mp/01%20-%20research%20fields/data%20mining/th
esis/Ferry%20-%20Komparasi%20Klasifikasi%20DM% 20untuk%20Akseptasi%20Reas.pdf diakses tanggal 4 januari 2012.
[3] Suardin Yakub, “Sistem Pakar Deteksi Penyakit Diabetes Mellitus Dengan Menggunakan Pendekatan Naïve Bayesian Berbasis Web”, Skripsi, Jurusan Teknik Informatika, Fakultas Sains Dan Teknologi, 2008. URL : http://lib.uin- malang.ac.id/thesis/fullchapter/04550034-suardin-yakub.ps diakses tanggal 4 Oktober 2012.
[4] DEPKES RI. 2001. Pedoman Pengobatan Dasar Di Puskesmas Berdasarkan Gejala. Jakarta :
DEPKES.
[5] Firebaugh M.W., 1989, Artificial Intelligence: A knowledge-Based Approach, PWS-Kent Publishing