KLASIFIKASI ANOMALI INTRUSION DETECTION
SYSTEM (IDS) MENGGUNAKAN NAÏVE BAYES
DENGAN WRAPPER SUBSET EVALUATION (WRP)
TUGAS AKHIR
Oleh :
Edi Kurniawan 3311401019
Disusun untuk memenuhi syarat kelulusan Program Diploma III (DIII)
PROGRAM STUDI TEKNIK INFORMATIKA POLITEKNIK NEGERI BATAM
BATAM 2017
HALAMAN PERNYATAAN
Dengan ini, saya:
NIM : 3311401019 Nama : Edi Kurniawan
adalah mahasiswa Teknik Informatika Politeknik Batam yang menyatakan bahwa tugas akhir dengan judul:
KLASIFIKASI ANOMALI INTRUSION DETECTION SYSTEM (IDS) MENGGUNAKAN NAÏVE BAYES DENGAN WRAPPER SUBSET
EVALUATION (WRP)
disusun dengan:
1. tidak melakukan plagiat terhadap naskah karya orang lain 2. tidak melakukan pemalsuan data
3. tidak menggunakan karya orang lain tanpa menyebut sumber asli atau tanpa ijin pemilik
Jika kemudian terbukti terjadi pelanggaran terhadap pernyataan di atas, maka saya bersedia menerima sanksi apapun termasuk pencabutan gelar akademik.
Lembar pernyataan ini juga memberikan hak kepada Politeknik Batam untuk mempergunakan, mendistribusikan ataupun memproduksi ulang seluruh hasil Tugas Akhir ini.
Batam, 5 Januari 2017
Edi Kurniawan 3311401019
iv
KATA PENGANTAR
Puji syukur penulis panjatkan ke hadirat Tuhan Yang Maha Esa , atas rahmat dan hidayah kepada penulis ,sehingga penulis dapat menyelesaikan Tugas Akhir yang berjudul ”Klasifikasi Anomali Intrusion Detection System (IDS) Menggunaka n Naïve Bayes Dengan Wrapper Subset Evaluation (WRP)”.
Pada kesempatan ini, penulis hendak mengucapkan ungkapan terima kasih kepada pihak-pihak yang telah membantu proses penyelesaian Tugas Akhir ini yaitu : 1. Tuhan Yang Maha Esa , yang senantiasa memberikan anugerah dan nikmat- N ya
berupa nikmat kesehatan yang selalu diberikan kepada penulis.
2. Bapak Dwi Ely Kurniawan M.Kom selaku dosen koordinator Tugas Akhir. 3. Bapak Sudra Irawan M.Sc , selaku dosen wali Teknik Informatika angkatan
2014 yang selalu memberikan motivasi bagi Penulis agar menyelesaikan Tugas Akhir I dengan baik.
4. Bapak Tri Ramadhani Arjo selaku dosen pembimbing Tugas Akhir.
5. Keluarga penulis yang telah memberi banyak motivasi kepada penulis dalam penyelesaikan pembuatan laporan Tugas Akhir.
6. Sahabat dan teman-teman yang tidak dapat disebutkan satu per satu yang telah membantu penyusunan dalam menyelesaikan Tugas Akhir ini.
7. Seseorang yang selalu memberi semangat T.P dengan NIM 4121401025 Penulis menyadari selama pembuatan Tugas Akhir ini masih banyak terdapat kekurangan dalam penyusunan Tugas Akhir. Karena itu kami mengucapkan mohon maaf atas kesalahan dan kekurangan laporan ini .Diharapkan kritik dan saran pembaca kepada penulis untuk laporan ini. Semoga laporan Tugas Akhir ini dapat bermanfaat dan bisa digunakan sebaik-baiknya oleh pembaca.
Batam, 5 Januari 2016 Penulis
v
ABSTRAK
KLASIFIKASI ANOMALI INTRUSION DETECTION SYSTEM (IDS) MENGGUNAKAN NAÏVE BAYES DENGAN WRAPPER SUBSET
EVALUATION (WRP)
Intrusion Detection System (IDS) merupakan sistem yang dapat mendeteksi adanya intrusi atau gangguan pada suatu jaringan atau sistem informasi. Salah satu jenis IDS adalah anomaly detection. anomaly detection dapat mendeteksi serangan yang menyimpang dari aktivitas normal berdasarkan probalitas statistika. Statistical anomaly detection tidak memiliki model intelligent learning yang mungk in menyebabkan false alarm memiliki tingkat deteksi tinggi. Dalam penelitian ini digunakan Naïve bayes sebagai intelligent learning karena Naïve bayes dikenal baik dalam algoritma klasifikasi. Atribut yang diteliti yaitu dataset NSL KDD tahun 2012 yang direduksi datanya dari 41 atribut menjadi 3 atribut menggunaka n algoritma wrapper subset evaluation (WRP). Sebuah sistem dibangun untuk mengklasifikasi jenis serangan berupa normal dan abnormal pada IDS menggunakan naïve bayes dengan seleksi atribut WRP. Pengujian yang dilakukan dengan data pertambahan bertahap dan 5-fold cross validation dengan data training sebanyak 900 data. Dalam sistem ini, data training merupakan hal yang sangat penting untuk menentukan akurasi. Hasil pengujian data uji dengan data pertambahan bertahap dari 10,20,30,40,50,100 didapatkan akurasi rata-rata 92% dan hasil pengujian data uji dengan cross validation didapatkan akurasi 94,6%. Sistem analisis data jaringan ini dapat mengklasifikasikan data jaringan berupa anomaly atau normal menggunakan naïve bayes dengan seleksi atribut WRP dengan benar, walaupun dengan atribut yang sedikit tidak mengurangi kualitas data.
Kata Kunci : Naive bayes, Intrusion Detection System, anomaly Detection, Klasifikasi, Wrapper subset Evaluation
vi
ABSTRACT
CLASSIFICATION OF ANOMALY INTRUSION DETECTION SYSTEM (IDS) USING NAÏVE BAYES WITH WRAPPER SUBSET EVALUATION
(WRP)
Intrusion Detection System (IDS) is a system that can detect any intrusion or interference on a network or information system. One type of IDS is an anomaly detection. anomaly detection can detect attacks that deviate from normal activit y based on statistical probabilities. Statistical anomaly detection doesn’t have an intelligent learning model that may cause false alarm to have a high detection rate.
In this study used Naïve bayes as intelligent learning because Naïve bayes are well known in the classification algorithm. The attributes studied are the KSD NSL dataset of 2012 which is reduced from 41 attributes to 3 attributes using the wrapper subset evaluation (WRP) algorithm. A system is built to classify normal and abnormal types of attacks on IDS using naïve bayes with WRP attribute selection. Tests conducted with gradual increment data and 5-fold cross validation with 900 training set. In this system, training data is very important to determine accuracy. Test results of test set with gradual increment data from 10, 20, 30, 40, 50, 100 obtained average accuracy 92% and result of test set with cross validation got accuracy 94,6%.This network data analysis system can classify anomaly or normal network data using naïve bayes with proper WRP attribute selection, although with few attributes does not reduce data quality.
Keywords : Naive bayes, Intrusion Detection System, anomaly Detection, Classification, Wrapper subset Evaluation
vii
DAFTAR ISI
Halaman Judul ...i
HALAMAN PEN GESAHAN ... ii
HALAMAN PERNYATAAN ... iii
KATA PENGANTAR... iv ABSTRAK ...v ABSTRACT ... vi BAB I PENDAHULUAN ... 1 1.1 Latar Belakang ... 1 1.2 Rumusan Masalah... 2 1.3 Batasan Masalah ... 3 1.4 Tujuan Penelitian ... 3 1.5 Manfaat Penelitian ... 3 1.6 Tinjauan Pustaka... 3 1.7 Sistematika Penulisan ... 4
BAB II LANDASAN TEORI ... 7
2.1 Intrusion Detection System... 7
2.1.1 Teknologi IDS ... 7
2.1.2 Jenis-jenis Pendeteksian ... 8
2.1.3 Pendeteksian Intrusi dengan Data Mining... 9
2.2 Data Mining ... 11
2.3 Konsep K lasifikasi ... 13
2.4 Metode Naive bayes... 14
2.5 Karakteristik Naïve Bayes ... 17
2.7 Seleksi Fitur Berbasis Wrapper ... 17
2.8 Confusion Matrix ... 18
2.9 K-fold cross validation ... 19
2.10 Java ... 20
2.11 UML ... 20
2.12 Weka ... 20
viii
BAB III AN ALISIS DAN PERANCANGAN... 23
3.1 Desain Penelitian ... 23 3.2 Studi Literatur ... 23 3.3 Pengumpulan Data ... 23 3.4 Preprocessing ... 25 3.4.1 Reduksi Data... 25 3.5 Pemodelan Data ... 27
3.6 Pengujian dan Evaluasi ... 29
3.6.1 Confusion Matrix ... 29
3.6.2 Cross Validation ... 31
3.7 Deskripsi Umum Sistem ... 31
3.8 Kebutuhan Fungsional ... 32
3.9 Kebutuhan Non Fungsional ... 33
3.10 Use Case Diagram ... 33
3.11 Skenario Use Case ... 34
3.12 Activity Diagram... Error! Bookmark not defined. 3.13 Class Diagram ... 41
3.14 Perancangan Antarmuka ... 42
BAB IV IMPLEMENTASI DAN PENGUJIAN ... 47
4.1 Implementasi Daftar File ... 47
4.2 Implementasi Antarmuka... 47
4.3 Hasil Pengujian ... 58
4.3.1 Hasil Pengujian Data Uji ... 58
4.3.2 Hasil Pengujian Sistem ... 61
BAB V K ESIMPULAN DAN SARAN ... 64
5.1 Kesimpulan ... 64
5.2 Saran ... 64
DAFTAR PUSTAKA ... 65
ix
DAFTAR GAMBAR
Gambar 2.1 Pemrosesan data koneksi jaringan dengan data mining (Han) . 10
Gambar 2.2 Tahap-tahap Knowledge Discovery from Data (KDD) ... 12
Gambar 2.3 Proses Pekerjaan Klasifikasi... 14
Gambar 2.4 Alur Metode Naïve Bayes... 15
Gambar 2.5 Algoritma Forward Selection ... 18
Gambar 2.6 Ilustrasi proses k-fold cross validation (k=3) ... 19
Gambar 2.7 Tampilan Aplikasi Weka Data Mining Tool ... 21
Gambar 3.1 Metode Pengerjaan……… 23
Gambar 3.2 Data NSL-KDD ... 24
Gambar 3.3 Seleksi Atribut dengan WEKA... 26
Gambar 3.4 Hasil Seleksi Atribut ... 27
Gambar 3. 5 Pembagian Dataset ... 31
Gambar 3.6 Deskripsi Umum Sistem ... 32
Gambar 3.7 Use Case Diagram ... 33
Gambar 3. 8 Activity Diagram Mengimpor Data ... 37
Gambar 3. 9 Activity Diagram Mengekspor Data... 38
Gambar 3. 10 Activity Diagram Menambah Baris... 38
Gambar 3. 11 Activity Diagram Mengubah Baris ... 39
Gambar 3. 12 Activity Diagram Menghapus Baris ... 39
Gambar 3. 13 Activity Diagram Melakukan Klasifikasi ... 40
Gambar 3. 14 Class Diagram ... 41
Gambar 3. 15 User Interface Halaman Utama ... 42
Gambar 3. 16 User Interface Halaman Awal ... 43
Gambar 3. 17 User Interface Halaman Pola Data ... 43
Gambar 3. 18 User Interface Halaman Editor Class ... 44
Gambar 3. 19 User Interface Halaman Klasifikasi ... 45
Gambar 4. 1 Antarmuka import data training………. 48
Gambar 4. 2 Source Code import data training ... 49
x
Gambar 4. 4 Source code me masukkan class ... 50
Gambar 4. 5 Antarmuka ekspor data training ... 51
Gambar 4. 6 Source code ekspor data training ... 51
Gambar 4. 7 Source code menambahkan baris baru ... 52
Gambar 4. 8 Source code menghapus baris... 52
Gambar 4. 9 Source code klasifikasi... 54
Gambar 4. 10 Antarmuka evaluasi... 54
Gambar 4. 11 Source code evaluasi ... 55
Gambar 4. 12 Antarmuka import data testing ... 55
Gambar 4. 13 Source code import data testing ... 56
Gambar 4. 14 Antarmuka Hasil klasifikasi ... 56
xi
DAFTAR TABEL
Tabel 1.1 Perbandingan Hasil Penelitian ... 4
Tabel 2.1 Data Cuaca dan Keputusan Main atau Tidak (Santosa, 2007)….. 16
Tabel 2.2 Confusion Matrix 2 kelas ... 18
Tabel 3.1 Deskripsi Atribut Hasil Seleksi Atribut……… 27
Tabel 3.2 Sebagian Data NSL-KDD ... 28
Tabel 3.3 Probabilitas kemunculan setiap nilai untuk atribut service (a1) ... 28
Tabel 3.4 Probabilitas kemunculan setiap nilai untuk atribut flag (a2) ... 29
Tabel 3.5 Probabilitas kemunculan setiap nilai untuk atribut class (a4)... 29
Tabel 3.6 Data untuk pengujian model ... 30
Tabel 3.7 Confusion Matrix Pengujian Data ... 30
Tabel 3.8 Skenario Use Case Mengimpor Data ... 34
Tabel 3.9 Skenario Use Case Mengekspor Data ... 35
Tabel 3.10 Skenario Use Case Menambah Baris ... 35
Tabel 3.11 Skenario Use Case Mengubah Baris ... 36
Tabel 3. 12 Skenario Use Case Menghapus Baris ... 36
Tabel 3. 13 Skenario Use Case Melakukan Klasifikasi... 36
Tabel 3. 14 Penjelasan User Inte rface Halaman Utama ... 42
Tabel 3. 15 Penjelasan User Inte rface Halaman Awal ... 43
Tabel 3. 16 Penjelasan User Inte rface Halaman Pola Data... 44
Tabel 3. 17 Penjelasan User Inte rface Halaman Editor Class ... 45
Tabel 3. 18 Penjelasan User Inte rface Halaman Klasifikasi ... 45
Tabel 4. 1 Imple mentasi Daftar File………...47
Tabel 4. 2 Hasil Pengujian 10 Dataset ... 58
Tabel 4. 3 Hasil Pengujian 20 Dataset ... 58
Tabel 4. 4 Hasil Pengujian 30 Dataset ... 58
Tabel 4. 5 Hasil Pengujian 40 Dataset ... 59
Tabel 4. 6 Hasil Pengujian 50 Dataset ... 59
Tabel 4. 7 Hasil Pengujian 100 Dataset ... 59
xii
Tabel 4. 9 Hasil pengujian pertama cross validation ... 60
Tabel 4. 10 Hasil pengujian kedua cross validation ... 60
Tabel 4. 11 Hasil pengujian ketiga cross validation ... 60
Tabel 4. 12 Hasil pengujian keempat cross validation... 61
Tabel 4. 13 Hasil pengujian kelima cross validation... 61
Tabel 4. 14 Rata-rata pengujian Cross Validation ... 61
1 BAB I PENDAHULUAN
1.1 Latar Belakang
Internet meningkat secara signifikan, kenaikan berupa gangguan atau serangan dari cracker menemukan kekurangan pada protokol internet, sistem operasi dan software aplikasi. Browser menjadi alat utama dalam mengekploitasi diantara sebagian besar pengguna komputer pada tahun 2015. Kaspersky Lab pada tahun 2015 mengeluarkan laporan survei untuk ancaman-ancaman serangan dari beberapa sumber yakni android mendapatkan 14 %, java 13 %, adobe flash player 4%, office 4%, adobe reader 3%, dan browser mendapat persentase terbesar yaitu 62% (Garnaeva, 2015). Keamanan jaringan menjadi kunci untuk variasi dari ancaman serangan. Hal tersebut dianggap aman jika keamanan jaringan tidak hanya berfokus pada keamanan di komputer tersebut melainkan ketika transmisi data, pada saat itulah serangan mudah terjadi. Hacker akan menyerang pada saat itu mengamb il data, dekripsi data dan mengisi kembali dengan pesan palsu.(Daya, 2015)
Intrusion Detection System (IDS) diindisikasikan dengan instrumen yang berkembang untuk mendeteksi pelanggaran terhadap kebijakan keamanan sistem. Fokus utama IDS terletak pada sistem pertahanan untuk mengidentifikas i kemungkinan masalah, informasi logging. IDS dibagi menjadi 2 yaitu misuse-based dan anomaly-based. Model Misuse Detection mengeksekusi teknik pencocokan pola sederhana untuk mencocokkan serangan berdasarkan pola serangan yang berada dalam database dan menghasilkan banyak false positif rendah. anomaly detection dapat mendeteksi serangan yang menyimpang dari aktivitas normal berdasarkan probalitas statistika.. anomaly detection mendeteksi dengan mencari abnormal di dalam jaringan. (Jabez, 2015).
Pengujian algoritma pemilihan atribut dilakukan pada algoritma naïve bayes dan C4.5. Dilakukan seleksi atribut dengan menggunakan Information Gain (IG), Relief (RLF), Principal Component (PC), Consistency-Based Subset Evaluation (CNS),
2 Correlation-Based Feature Selection (CFS) dan Wrapper Subset Evaluation (WRP). Setelah seleksi atribut pada 25 dataset yang berasal dari weka, klasifikas i menggunakan algoritma naïve bayes dan C4.5. Hasil penelitian menjelaskan WRP lebih unggul daripada teknik seleksi atribut lainnya (Yuniar, 2013). Algoritma naïve bayes merupakan dasar dari kebanyakan machine learning dan metode data mining. Naïve bayes merupakan metode supervised learning. Algoritma ini digunaka n untuk menciptakan model dengan kemampuan klasifikasi. Sehingga menjadika n naïve bayes menjadi sebuah cara baru untuk eksplorasi dan mengerti data. Penelitian penggunaan naïve bayes pada klasifikasi besar penggunaan listrik rumah tangga dijelaskan bahwa dengan penerapan naïve bayes hasil persentasi 78.3% untuk keakuratan prediksi, dimana dari 60 data terdapat 47 data diklasifikasi dengan benar (Saleh, 2015) .
Sistem pemantauan suatu jaringan biasanya adalah dengan memantau traffic jaringan secara manual. Serangan yang terjadi pada jaringan menjadi tanggung jawab seorang system administrator. Mengetahui adanya anomali pada jaringa n dapat mempersingkat waktu system administrator, permasalahan yang terjadi pada IDS adalah tidak mudahnya untuk membedakan request paket data yang terjadi pada jaringan, dikarenakan banyaknya log traffic jaringan sehingga menyulitka n administrator mendeteksi ada tidaknya anomali dalam jaringan.
Dalam tugas akhir ini, diusulkan suatu topik “Klasifikasi Anomali Intrusion Detection System (IDS) Menggunakan Naïve bayes dengan Wrapper Subset Evalution (WRP)” dengan menggunakan data mining untuk mengklasifikas i anomali pada IDS.
1.2 Rumusan Masalah
Berdasarkan latar belakang dapat dirumuskan permasalahan yang akan diselesaika n dalam hal ini adalah :
1. Bagaimana cara mengklasifikasi jenis serangan berupa normal atau anomali pada IDS menggunakan metode naïve bayes?
2. Bagaimana merancang bangun sistem analisis data jaringan menggunaka n metode naïve bayes ?
3 1.3 Batasan Masalah
Ruang lingkup masalah yang akan ditangani adalah sebagai berikut:
1. Data yang digunakan NSL-KDD tahun 2012. Dari data awal sebanyak 25193 record diambil sampling sebanyak 900 data.
2. Analisis pengujian algoritma naive bayes untuk IDS tidak termasuk dalam hal implementasi ke dalam suatu sistem jaringan.
3. Tidak melakukan monitoring serangan secara real time.
1.4 Tujuan Penelitian
Tujuan pembuatan tugas akhir ini adalah menemukan model yang digunakan untuk mengklasifikasi jenis serangan berupa normal atau anomali pada IDS menggunaka n metode naive bayes, serta sistem analisis data jaringan yang dapat mengenali tipe jaringan.
1.5 Manfaat Penelitian
Manfaat dari penelitian ini adalah dapat memberikan kejelasan dan pemahama n terhadap cara kerja dan pemanfaatan algoritma naïve bayes dalam proses pengklasifikasian serangan pada IDS. Sehingga beberapa manfaat diperoleh dari penelirian ini yaitu:
1. Membantu system administrator dalam mengenali request paket yang keluar masuk ke dalam jaringan.
2. Mengenal dan memahami kinerja algoritma naïve bayes pada proses klasifikasi dalam IDS.
3. System administrator dapat mengetahui cara-cara mana saja yang digunakan intruder agar dilakukan pencegahan terhadap cara tersebut.
1.6 Tinjauan Pustaka
Penelitian ini dikembangkan dari hasil beberapa penelitian terkait dengan IDS. Diharapkan dapat membuat suatu analisis baru yang belum pernah ada pada referensi sebelumnya.
4 Adapun perbedaan penelitian ini dapat dilihat dari tabel 1.1:
Tabel 1.1 Perbandingan Hasil Penelitian Aspek
Perbandingan
Bekti Maryuni Susanto
Trisna, dkk Tugas Akhir Permasalahan Naïve Bayes untuk
mendeteksi gangguan jaringan komputer dengan seleksi atribut berbasis korelasi. Penerapan Naïve Bayes Pada Intrusion Detection System dengan Diskritisasi Variabel. Klasifikasi Anomali Intrusion Detection System (IDS) Menggunakan Naïve Bayes dengan Wrapper Subset Evaluation (WRP)
Algoritma Naïve Bayes Naïve Bayes Naïve Bayes
Seleksi atribut Korelasi (CFS) Korelasi (CFS) Wrapper Subset Evaluation (WRP) Data yang digunakan KDD 99 NSL-KDD 99 NSL-KDD 99 Akurasi 81.89%` 88.20 % 1.7 Sistematika Penulisan
Sistematika penulisan menggambarkan secara singkat organisasi penulisan laporan beserta ringkasan isi dari setiap bagiannya.
Bab I Pendahuluan
Berisi tentang latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, tinjauan pustaka dan sistematika penulisan.
Bab II Landasan Teori
Berisi tentang teori-teori yang berhubungan dengan penelitian yang dilakukan yaitu Klasifikasi Anomali Intrusion Detection System (IDS) Menggunakan Naïve Bayes dengan Wrapper Subset Evaluation (WRP).
5 Bab III Analisis Dan Perancangan
Berisi tentang analisa dan langkah-langkah penyelesaian masalah dalam mengklasifikasi jenis serangan berupa normal atau anomali pada IDS menggunakan naïve bayes serta perancangan sistem analisis data jaringan.
Bab IV Hasil dan Pembahasan
Bagian ini berisi hasil implementasi fungsional serta pengujia n aplikasi. Bagian ini juga terdapat pembahasan mengenai pengujia n yang telah dilakukan.
Bab V Kesimpulan dan Saran
Berisi tentang kesimpulan dari penelitian dan pengujian yang telah dilakukan, serta saran mengenai pengembangan dari penelitian yang telah dilakukan.
6 BAB II
LANDASAN TEORI
2.1 Intrusion Detection System
Intrusion Detection System (IDS) merupakan suatu tindakan untuk mendeteksi adanya trafik paket yang tidak diinginkan dalam sebuah jaringan atau device. Sebuah IDS dapat diimplementasikan melalui software atau aplikasi yang ter-install dalam sebuah device dan aplikasi tersebut dapat memantau paket jaringan untuk mendeteksi adanya paket-paket illegal seperti paket yang merusak kebijakan rules keamanan, dan paket yang ditujukan untuk mengambil hak akses suatu pengguna (Wu, 2009).
Pendeteksian intrusi merupakan proses pemantauan dan analisis kejadian yang terjadi pada sebuah komputer dan atau jaringan untuk mendeteksi tanda-tanda terjadinya permasalahan security. Umumnya, sebuah IDS memberi notifikas i kepada analis (system administrator) ketika terdapat kemungkinan terjadinya intrusi. Adapun tantangan yang dihadapi oleh IDS (Lazarevic ,2003) adalah sebagai berikut:
1. Ukuran data yang sangat besar. 2. Data berdimensi tinggi.
3. Data yang berdekatan waktunya umumnya berhubungan.
4. Distribusi kelas yang tidak seimbang (data intrusi umumnya sangat jarang) 5. Memerlukan preprocessing dari data yang dikumpulkan sehingga dapat dianalisis. Misalnya, untuk mengambil informasi dasar mengenai alamat asal tujuan data koneksi yang telah dikumpulkan dengan memeriksa bagian header paket data, sampai memeriksa bagian pesan dari paket data untuk mengetahui informasi lebih lanjut seperti jumlah usaha login yang gagal. 6. High performance computing sangat penting terutama untuk IDS yang
7 2.1.1 Teknologi IDS
Beberapa jenis dari teknologi IDS adalah Network-Based, Wireless IDS, Network Behavior, anomaly Detection dan Host-Based. Pengembangan dan implementas i teknologi IDS ke dalam sebuah sistem jaringan tergantung dari variasi konfiguras i jaringan itu sendiri. Pada dasarnya setiap jenis teknologi IDS mempunya i keuntungan dan kekurangan dalam hal pendeteksian, konfigurasi dan biaya, tetapi secara umum teknologi IDS yang paling sering digunakan adalah Network-Based dan Host-Based. Secara spesifik berikut penjelasan dari masing-masing tipe teknologi IDS (Wu, 2009).
a. Network-Based
Network Intrusion Detection System (NIDS) adalah salah satu tipe IDS yang populer atau paling banyak diimplementasikan kedalam sebuah sistem 6 jaringa n. Tipe ini menganalisa paket-paket jaringan pada semua lapisan Open System Interconnection (OSI) dan membuat sebuah tindakan kepada paket tersebut. Kebanyakan NIDS lebih mudah diterapkan kedalam suatu jaringan dan dapat memantau paket dari banyak sistem sekaligus (Wu, 2009).
b. WLAN IDS
Wireless Local Area Network (WLAN) IDS menyerupai NIDS yang dapat menganalisa paket-paket jaringan. WLAN ini dapat menganalisa paket wireless secara spesifik, termasuk pemindaian pengguna eksternal yang mencoba untuk terhubung ke Access Point (AP). Karena WLAN IDS sendiri sebenarnya adalah NIDS dengan menggunakan wireless maka aturan-aturan keamanan yang diterapkan lebih luas (Wu, 2009).
c. Network Behavior anomaly Detection
Network Behavior anomaly Detection (NBAD) memantau paket pada segmen-segmen jaringan untuk menentukan anomali-anomali dalam jumlah paket atau tipe paket. Segment yang biasanya melihat paket yang sangat kecil atau segmen yang hanya melihat paket tertentu yang dapat mengubah jumlah atau jenis paket jika suatu kejadian yang tidak diinginkan terjadi (Wu, 2009).
8 d. Host-Based
Host-based Intrusion Detection System (HIDS) menganalisa paket jaringan dan pengaturan sistem secara spesifik seperti software calls, local security policy, local log audits, dll. HIDS harus diinstal di setiap mesin dan membutuhkan konfiguras i secara spesifik pada sistem operasi dan software (Wu, 2009).
2.1.2 Jenis-jenis Pendeteksian
Menurut Wu dalam bukunya Information Assurance Tools Report yang diterbitka n pada tahun 2009 terdapat beberapa jenis-jenis pendeteksian dalam implementas i IDS. Jenis-jenis tersebut adalah Signature-Based Detection, anomaly-Based Detection, dan Stateful Protocol Inspection. Berikut penjelasan mengenai macam-macam jenis pendeteksian.
a. Signature-Based Detection
Sebuah IDS dapat menggunakan pendeteksian Signature-Based Detection dari sebuah paket, bergantung data paket yang diketahui untuk menganalisa potensi terjadinya paket ilegal. Tipe pendeteksi ini sangat cepat dan mudah dikonfiguras i. Bagaimanapun juga seorang penyerang dapat dengan mudah memodifikasi sebuah serangan untuk menyiasati agar tidak terkenali oleh Signature-Based IDS. Meskipun kemampuan tipe ini terbatas dalam mendeteksi banyaknya serangan, tipe ini mempunyai kelebihan dalam hal keakuratan (Wu, 2009).
b. anomaly-Based Detection
IDS yang dapat memantau paket jaringan dan mendeteksi data yang tidak valid, atau umumnya tidak normal menggunakan jenis deteksi anomaly-Based. Metode ini berguna untuk mendeteksi paket-paket yang tidak diinginkan (Wu, 2009). c. Stateful Protocol Inspection
Stateful Protocol Inspection menyerupai pendeteksi berbasis anomali, tetapi jenis ini dapat menganalisa paket lapisan 3 OSI yaitu lapisan Network dan lapisan 4 yaitu lapisan protokol.
9 2.1.3 Pendeteksian Intrusi dengan Data Mining
Pendeteksian intrusi dengan data mining dilakukan melalui outlier analysis. Pada dataset, sering kali terdapat data yang tidak sesuai dengan general behavior atau model data. Data seperti ini berbeda dan tidak konsisten dengan data yang lain dan disebut dengan outlier. Outlier mining dapat dipandang dalam dua bagian permasalahan yaitu mendefinisikan data yang dianggap tidak konsisten dan bagaimana cara yang efisien untuk mining outlier yang sudah didefinikan. Oleh karena itu pendeteksian intrusi sering juga dipandang sebagai pendeteksian outlier. Menurut Hsu , terdapat beberapa alasan mengapa data mining dapat digunaka n untuk mendeteksi intrusi yaitu:
1. Data mining menerapkan algoritma tertentu untuk mengekstrak pattern dari data .
2. Aktivitas normal maupun intrusi meninggalkan jejak (evidence) pada data yang diaudit.
3. Dari sudut pandang data, pendeteksian intrusi merupakan proses analisis data.
4. Data mining sudah berhasil diaplikasikan pada domain aplikasi terkait seperti fraud detection dan fault/alarm management
5. Proses pembelajaran dapat dilakukan terhadap data traffic. Dengan pendekatan supervised learning melalui pembelajaran dapat dibangun model dari data intrusi yang sudah pernah terjadi. Dengan pendekatan unsupervised learning proses pembelajaran dapat mengidentifikas i aktrivitas-aktivitas yang mencurigakan.
6. Data mining dapat digunakan untuk mengubah atau me-maintain model terhadap data yang bersifat dinamis.
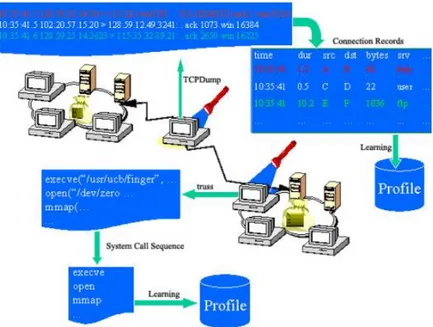
Contoh data yang akan di-mining untuk pendeteksian intrusi dapat dilihat pada gambar 1. Data yang digunakan umumnya merupakan data koneksi jaringan dalam bentuk TCPDump. Data ini merupakan data mentah yang masih harus dipreprocess terlebih dahulu menjadi connection records. Untuk dapat memperoleh
atribut-10 atribut koneksi data ke jaringan dapat digunakan perangkat lunak TCPtrace seperti yang digunakan pada (Lazarevic, 2003).
Teknik data mining yang dapat diterapkan dalam pendeteksian intrusi dapat berupa supervised learning maupun unsupervised learning. Teknik supervised learning memerlukan dataset yang diberi label data normal atau data intrusi sesuai dengan jenisnya. Namun, dataset yang mememiliki label cukup sulit untuk diperoleh dalam aplikasi yang sebenarnya. Selain itu, sulit untuk memastikan apakah semua label yang telah diberikan mewakili semua jenis intrusi. Oleh karena itu, unsupervised learning juga banyak digunakan, tetapi pada teknik ini yang dideteksi tidak diketahui jenisnya seperti pada supervised learning.
Gambar 2.1 Pemrosesan data koneksi jaringan dengan data mining (Han) Berdasarkan metode yang digunakan, pendeteksian intrusi dapat dibagi menjadi dua kategori yaitu misuse detection (signature-based) dan anomaly detection (noise characterization). Kedua metode ini mememliki kelebihan dan kekurangan. Dalam pendekatan misuse detection yang menggunakan teknik data mining, pendeteksian intrusi dilakukan dengan cara membuat model data intrusi dari data set yang sudah diberi label intrusi. Hal ini berbeda dengan pendekatan misuse detection yang menggunakan basis data untuk menyimpan signature dari intrusi yang diketahui secara manual. Perbedaannya, dengan data mining, model signature (pattern) dari
11 intrusi dibangun secara otomatis lewat pelatihan. Selanjutnya, model dari hasil pelatihan dapat digunakan untuk mendeteksi intrusi. Jadi teknik klasifikasi dalam pendeteksian intrusi merupakan pendekatan misuse detection. Kelebihan utama dari pendekatan ini adalah mampu memdeteksi intrusi yang sudah diketahui secara akurat, tetapi tidak dapat mendeteksi jenis intrusi yang belum diketahui (benar-benar baru dan belum pernah dilihat sebelumnya).
Dalam pendekatan yang kedua yaitu anomaly detection, deteksi intrusi dilakukan dengan cara membuat model dari data normal, kemudian mendeteksi deviasi antara model normal dengan data yang diobservasi. Kelebihan dari anomaly detection adalah dapat mendeteksi intrusi jenis baru sebagai deviasi dari data normal. Akan tetapi, intrusi yang dideteksi dengan metode ini tidak dapat diketahui jenisnya seperti pada misuse detection dan cenderung menghasilkan false positive yang tinggi.
anomaly detection dapat diimplementasikan dalam bentuk supervised anomaly detection atau unsupervised anomaly detection. Dalam pendekatan yang pertama, digunakan data pelatihan yang hanya mengandung data normal, sedangkan pada pendekatan kedua tidak diketahui informasi apapun dari data penelitia n. Pendekatan kedua juga banyak diteliti karena jika data pelatihan sangat besar maka akan sulit memastikan semua data tersebut adalah data normal.
2.2 Data Mining
Data mining merupakan disiplin ilmu yang mempelajari metode untuk mengekstrak pengetahuan atau menemukan pola dari suatu data (Han dan Kamber, 2006). Data mining sering juga disebut knowledge discovery in database (KDD), adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemuka n keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan (Santosa, 2007). Adapun proses KDD ditunjukkan pada Gambar 2.2.
12 Gambar 2.2 Tahap-tahap Knowledge Discovery from Data (KDD) Proses dalam KDD secara runtut adalah sebagai berikut (Han, J., et al, 2012) : 1. Pembersihan Data (Data Cleaning)
Pembersihan data bertugas untuk menghilangkan noise dan data yang tidak konsisten. Pada tahap ini dilakukan penghapusan pada data yang tidak memilik i kelengkapan atribut sesuai yang dibutuhkan.
2. Integrasi Data (Data Integration)
Integrasi data merupakan proses kombinasi beberapa sumber data. Pada tahap ini dilakukan penggabungan data dari berbagai sumber untuk dibentuk penyimpa na n data yang koheren.
3. Seleksi Data (Data Selection)
Seleksi data merupakan proses pengambilan data yang berkaitan dengan tugas analisis dari basis data. Pada tahap ini dilakukan teknik perolehan sebuah pengurangan representasi dari data dan meminimalkan hilangnya informasi data. Hal ini meliputi metode pengurangan atribut dan kompresi data.
4. Transformasi Data (Data Transformation)
Pada tahap ini data diubah dan dikonsolidasikan ke dalam bentuk yang sesuai untuk penambangan (mining) dengan melakukan ringkasan atau penggabungan operasi. 5. Penambangan Data (Data Mining)
Data mining adalah inti pada proses KDD. Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik tertentu.
13 Pemilihan teknik dan algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
6. Evaluasi Pola (Pattern Evaluation)
Tahap ini merupakan identifikasi kebenaran pola yang merupakan pengetahua n dasar pada langkah-langkah yang diberikan.
7. Representasi Pengetahuan (Knowledge Presentation)
Pada tahap ini penemuan pengetahuan direpresentasikan secara visual kepada pengguna untuk membantu dalam memahami hasil data mining juga disertakan penyajian pengetahuan mengenai metode yang digunakan untuk memperole h pengetahuan yang diperoleh pengguna.
2.3 Konsep Klasifikasi
Klasifikasi merupakan pekerjaan menilai objek data untuk memasukkannya ke dalam kelas tertentu dari sejumlah kelas yang tersedia. Dalam klasifikasi ada dua pekerjaan utama yang dilakukan, yaitu (1) pembangunan model sebagai prototipe untuk disimpan sebagai memori dan (2) penggunaan model tersebut untuk melakukan pengenalan/ klasifikasi/ prediksi pada suatu objek data lain agar diketahui di kelas mana objek data tersebut dalam model yang sudah disimpannya (Prasetyo, 2012).
Klasifikasi adalah metode data mining yang dapat digunakan untuk proses pencarian sekumpulan model (fungsi) yang dapat menjelaskan dan membedakan kelas-kelas data atau konsep, yang tujuannya supaya model tersebut dapat digunakan memprediksi objek kelas yang labelnya tidak diketahui atau dapat memprediksi kecenderungan data-data yang muncul di masa depan. Metode klasifikasi juga bertujuan untuk melakukan pemetaan data ke dalam kelas yang sudah didefinisikan sebelumnya berdasarkan pada nilai atribut data (Han dan Kamber, 2006). Proses klasifikasi tersebut seperti terlihat pada gambar 2.3.
14 Gambar 2.3 Proses Pekerjaan Klasifikasi
2.4 Metode Naive bayes
Naive bayes merupakan teknik prediksi berbasis probabilistik sederhana yang berdasar pada penerapan teorema Bayes (aturan Bayes) dengan asumsi independensi (ketidaktergantungan) yang kuat (naif). Dengan kata lain, dalam Naive bayes model yang digunakan adalah “model fitur independen” (Prasetyo, 2012).
Naive bayes adalah salah satu algoritma pembelajaran induktif yang paling efekt if dan efisien untuk machine learning dan data mining. Performa Naive bayes yang kompetitif dalam proses klasifikasi walaupun menggunakan asumsi keindependenan atribut (tidak ada kaitan antar atribut). Asumsi keindependenna n atribut ini pada data sebenarnya jarang terjadi, namun walaupun asumsi keindependenan atribut tersebut dilanggar performa pengklasifikasian Naive bayes cukup tinggi, hal ini dibuktikan pada berbagai penelitian empiris (Shadiq, 2009). Dari definisi di atas dapat diambil kesimpulan bahwa Naive bayes adalah sebuah teknik klasifikasi probabilistik yang berdasarkan teorema bayes yang menggunaka n asumsi keindependenan atribut (tidak ada kaitan antar atribut) dalam proses pengklasifikasiannya.
Dalam sebuah aturan yang mudah, sebuah klasifikas i Naive bayes diasumsika n bahwa ada atau tidaknya ciri tertentu dari sebuah kelas tidak ada hubungannya dengan ciri dari kelas lainnya. Untuk contohnya, buah akan dianggap sebagai sebuah apel jika berwarna merah, berbentuk bulat dan berdiameter sekitar 6 cm. Walaupun jika ciri-ciri tersebut bergantung satu sama 9 lainnya, dalam Bayes hal
15 tersebut tidak dipandang sehingga masing- masing fitur seolah tidak memilik i hubungan apapun. Berdasarkan ciri alami dari sebuah model probabilita s, klasifikasi Naive bayes bisa dibuat lebih efisien dalam bentuk pembelajaran. Dalam beberapa bentuk praktiknya, parameter untuk perhitungan model Naive bayes menggunakan metode maximum likehood, atau kemiripan tertinggi.
Dasar dari teorema Naïve Bayes yang dipakai dalam pemrograman adalah rumus bayes yaitu sebagai berikut (Han and Kamber, 2006):
𝑃(𝐻|𝑋) = 𝑃(𝑋𝑃(𝑋)|𝐻)𝑃(𝐻)……….(1) dimana P(H|X) merupakan probabilitas H di dalam X atau dengan bahasa lain P(H|X) adalah persentase banyaknya H di dalam X, P(X|H) merupakan probabilita s X di dalam H, P(H) merupakan probabilitas prior dari H dan P(X) merupakan probabilitas prior dari X.
Alur dari metode Naïve Bayes dapat dilihat pada gambar 2.4 sebagai berikut:
Start
Baca Data Training
Jumlah dan Probabilitas
Tabel Probabilitas
Solusi
Stop
16 Adapun keterangan dari gambar 2.4 sebagai berikut:
1. Baca data training
2. Hitung Jumlah dan Probabilitas
3. Cari nilai probabilistic dengan cara menghitung jumlah data yang sesuai dari kategori yang sama dibagi dengan jumlah data pada kategori tersebut.
4. Solusi kemudian dihasilkan.
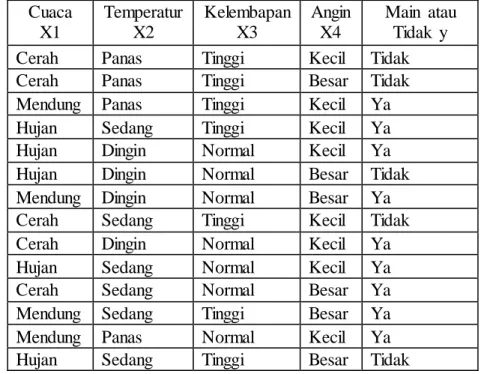
Konsep dari perhitungan Naive bayes dapat dijelaskan dengan menggunaka n contoh yang terdapat pada data sebagai berikut:
Tabel 2.1 Data Cuaca dan Keputusan Main atau Tidak (Santosa, 2007) Cuaca X1 Temperatur X2 Kelembapan X3 Angin X4 Main atau Tidak y
Cerah Panas Tinggi Kecil Tidak
Cerah Panas Tinggi Besar Tidak
Mendung Panas Tinggi Kecil Ya
Hujan Sedang Tinggi Kecil Ya
Hujan Dingin Normal Kecil Ya
Hujan Dingin Normal Besar Tidak
Mendung Dingin Normal Besar Ya
Cerah Sedang Tinggi Kecil Tidak
Cerah Dingin Normal Kecil Ya
Hujan Sedang Normal Kecil Ya
Cerah Sedang Normal Besar Ya
Mendung Sedang Tinggi Besar Ya
Mendung Panas Normal Kecil Ya
Hujan Sedang Tinggi Besar Tidak
Naive bayes akan menentukan kelas dari data baru berikut:
(Cuaca = Cerah, Temperatur = Dingin, Kelembapan = Tinggi, Angin = Besar) P(main) = 149 = 0.64 P(tidak) = 145 = 0.36
P(Angin = Besar | main) = 39= 0.33 P(Angin = Besar | tidak) = 3
5= 0.60
P(main) P(Cerah/main) P(Dingin/main) P(Tinggi/main) P(Besar/main) = 9 14 ⁄ ∗ 2 9 ⁄ ∗ 3 9 ⁄ ∗ 3 9 ⁄ ∗ 3 9 ⁄ = 0.0053
17 P(tidak) P(Cerah/ tidak) P(Dingin/ tidak) P(Tinggi/ tidak) P(Besar/ tidak)
= 5 14 ⁄ ∗ 3 5 ⁄ ∗ 1 5 ⁄ ∗ 4 5 ⁄ ∗ 3 5 ⁄ = 0.0206
Dari data baru tersebut dapat disimpulkan tidak main, berdasarkan estimas i probabilitas yang dipelajari dari data training.
2.5 Karakteristik Naïve Bayes
Klasifikasi dengan Naïve Bayes bekerja berdasarkan teori probabalitas yang memandang semua fitur dari data sebagai bukti dalam probabilitas. Hal ini memberikan karakteristik Naïve Bayes sebagai berikut:
1. Metode Naïve Bayes bekerja teguh (robust) terhadap data-data yang terisolasi yang biasanya merupakan data dengan karakteristik berbeda (outliner). Naïve Bayes juga bisa menangani nilai atribut yang salah dengan mengabaikan data latih selama proses pembangunan model dan klasifikasi. 2. Tangguh menghadapi atribut yang tidak relevan.
3. Atribut yang mempunyai korelasi bisa mendegradasi kinerja klasifikas i Naïve Bayes karena asumsi independensi atribut tersebut sudah tidak ada. 2.7 Seleksi Fitur Berbasis Wrapper
Seleksi fitur berbasis wrapper menggunakan classifier untuk mengevaluasi subset fitur dengan mengukur cross-validasi. Pada penelitian ini menggunakan forward selection untuk metode seleksi fitur berbasis wrapper. Algoritma forward selection dimulai dengan subset fitur kosong. Dalam setiap iterasi, menambahkan satu fitur setiap langkah ke depan sampai sejumlah standar fitur tercapai. Untuk satu langkah, setiap fitur kandidat secara terpisah ditambahkan ke bagian saat ini dan kemudian dievaluasi. Fitur yang diinduksi peningkatan tertinggi disertakan dalam hasil bagian seperti pada gambar 2.5.
18 Gambar 2.5 Algoritma Forward Selection
2.8 Confusion Matrix
Confusion matrix adalah tool yang digunakan untuk evaluasi model klasifikas i untuk memperkirakan objek yang benar atau salah (Gorunescu, 2011). Sebuah matrix dari prediksi yang akan dibandingkan dengan kelas yang asli dari inputan atau dengan kata lain berisi informasi nilai aktual dan prediksi pada klasifikas i. Tabel 2.2 menunjukkan confusion matrix 2 kelas.
Tabel 2.2 Confusion Matrix 2 kelas
Classification Predicted Class
Class = Yes Class = No
Class = Yes a (true positive- TP) b (false negative –FN) Class = No c (false positive- FP) d (true negative –TN) Rumus untuk menghitung tingkat akurasi pada matrik adalah :
19 2.9 K-fold cross validation
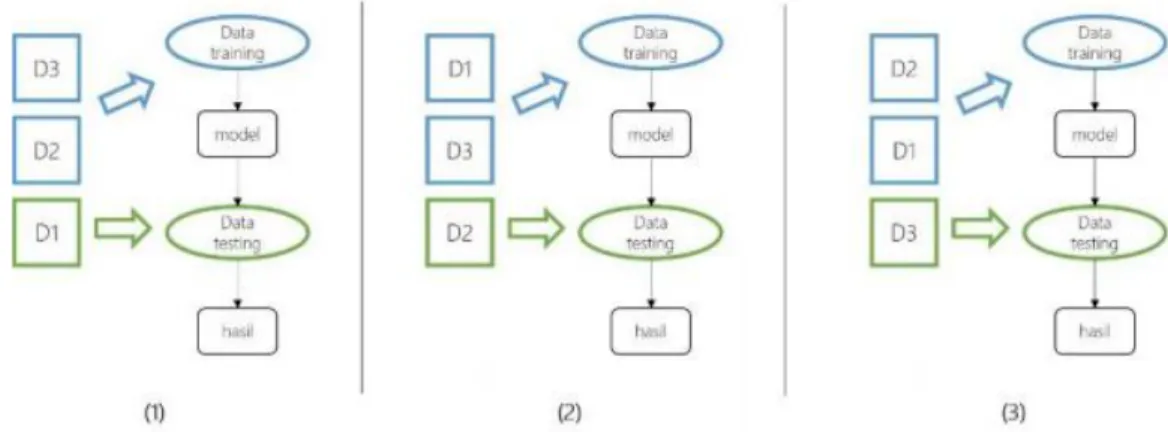
Untuk melakukan pengujian terhadap model yang dibangun, dilakukan dengan suatu skenario pengujian. Skenario pengujian dilakukan dengan menggunakan k-fold cross validation. K-k-fold cross validation adalah teknik untuk melakuka n pengujian dimana dataset D dibagi menjadi k bagian secara acak dengan ukuran yang sama (Kohavi, 1995). Dataset D yang telah terbagi menjadi k bagian, dapat dituliskan dengan 𝐷1, 𝐷2, 𝐷3,..., 𝐷𝑘. Proses pengujian dilakukan sebanyak k kali, dimana pada pengujian ke-i, dataset 𝐷𝑖 akan menjadi data testing dan sisanya akan menjadi data training.
Gambar 2.6 Ilustrasi proses k-fold cross validation (k=3)
Pada gambar 2.6 ditampilkan contoh dari tahapan k-fold cross validation, dimana nilai k=3, artinya dataset D dibagi menjadi 3 bagian yaitu 𝐷1, 𝐷2 dan 𝐷3 dan 20 pengujian dilakukan sebanyak 3 kali. Pada pengujian pertama (1), 𝐷1 menjadi data testing, sedangkan 𝐷2 dan 𝐷3 menjadi data training. Pada pengujian kedua (2), 𝐷2 menjadi data testing, sedangkan 𝐷3 dan 𝐷1 menjadi data training. Pada pengujian ketiga (3), 𝐷3 menjadi data testing, sedangkan 𝐷1 dan 𝐷2 menjadi data training. Masing-masing dari data training dilakukan proses training dan data testing dilakukan proses testing dengan algoritma naive bayes.
Dari pengujian yang dilakukan dengan metode k-fold cross validation dievaluas i dengan menggunakan confussion matrix untuk mengetahui tingkat akurasi dari setiap pengujian yang dilakukan.
20 2.10 Java
Supardi dalam bukunya menyebutkan bahwa Java merupakan perangkat lunak produksi Sun Microsystem Inc untuk pemrograman multipurpose, multiplatform, mudah dipelajari dan powerful. Aplikasi-aplikasi yang dapat dibuat dari Java meliputi Web Programming, Desktop Programming, dan Mobile Programming. Aplikasi yang berjalan pada Android juga dibangun berdasarkan bahasa pemrograman Java. Pengetahuan tentang Java dan konsep OOP (Object Oriented Programming).
2.11 UML
Unified Modeling Language ( UML ) adalah “suatu bahasa yang telah menjadi standar dalam industri untuk merancang, visualisasi dan mendokumentasika n sistem perangkat lunak”. UML diaplikasikan untuk penyelesaian masalah dengan menggunakan konsep object oriented. Siapapun yang akan mempelajari UML harus mengenal prinsip-prinsip yang digunakan dalam penyelesaian masalah object oriented, dimana semuanya dimulai dengan pembuatan model. Sebuah model adalah abstraksi dari sebuah masalah. Model terdiri dari objek-objek yang berinteraksi dengan mengirim message satu sama lain. Objek memiliki hal-hal yang mereka ketahui (attrribute) dan hal-hal yang dapat mereka lakukan (behavior atau operation). Nilai dari atribut-atribut sebuah objek digambarkan dalam bentuk state. Class merupakan ‘blueprints’ dari objek. Class membungkus atribut-atribut (data) dan behavior (method dan fungsi) dalam sebuah entiti tunggal yang jelas (Aliya h, 2009).
2.12 Weka
Weka merupakan aplikasi data mining yang berbasis open source (GPL) dan ber-engine Java. Weka terdiri dari koleksi algoritma machine learning yang dapat digunakan untuk melakukan generalisasi atau formulasi dari sekumpulan data sampling. Kekuatan Weka sebenarnya terletak pada algoritma yang makin lengkap dan canggih, kesuksesan data mining tetap terletak pada faktor pengetahua n manusianya itu sendiri. Hal tersebut bisa dilakukan jika adanya pengumpulan data yang berkualitas tinggi pengetahuan pemodelan dan penggunaan algoritma yang
21 tepat, sehingga akan menjamin keakuratan formulasi yang diharapkan. Weka mendukung beberapa format file untuk masukannya, diantaranya :
a. Comma Separated Values (CSV) : Merupakan file teks dengan pemisah tanda koma (,) yang cukup umum digunakan. Anda bisa membuat file ini dengan menggunakan Microsoft Excel atau membuatnya sendiri dengan menggunakan notepad.
b. Format C45 : Merupakan format file yang bisa diakses dengan menggunakan aplikasi Weka.
c. Attribute-Relation File Format (ARFF) : Merupakan tipe file teks yang berisi berbagai instance data yang berhubungan dengan suatu set atribut data yang dideskripsikan juga dalam file tersebut.
Gambar 2.7 Tampilan Aplikasi Weka Data Mining Tool 2.13 Netbeans
NetBeans IDE adalah sebuah lingkungan pengembangan - sebuah kakas untuk pemrogram menulis, mengompilasi, mencari kesalahan dan menyebarkan program. Netbeans IDE ditulis dalam Java namun dapat mendukung bahasa pemrograma n lain. Terdapat banyak modul untuk memperluas Netbeans IDE.Netbeans IDE adalah sebuah produk bebas dengan tanpa batasan bagaima na digunakan(Wahyudin, 2011). Adapun kelebihan Netbeans IDE antara lain :
22 2. Berjalan pada multiplatform sistem operasi termasuk Windows, Linux, Mac
OS, Solaris.
3. Berfungsi untuk pengembangan aplikasi mobile menggunakan bahasa Java. 4. Mendukung untuk pengembangan aplikasi web menggunakan PHP.
5. Mendukung permodelan perangkat lunak menggunakan UML. 6. Terdapat banyak modul untuk mengembangkan lebih lanjut. 7. Merupakan produk free tanpa ada batasan penggunaannya. 8. Merupakan produk open source.
23 BAB III
ANALISIS DAN PERANCANGAN 3.1 Desain Penelitian
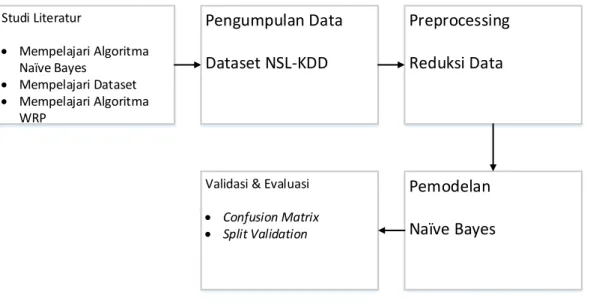
Desain penelitian merupakan tahapan yang akan dilakukan penulis untuk memberikan gambaran serta kemudahan dalam melakukan penelitian. Gambar 3.1 merupakan tahapan penelitian yang digunakan:
Pengumpulan Data Dataset NSL-KDD Studi Literatur Mempelajari Algoritma Naïve Bayes Mempelajari Dataset Mempelajari Algoritma WRP Preprocessing Reduksi Data Pemodelan Naïve Bayes
Validasi & Evaluasi
Confusion Matrix
Split Validation
Gambar 3.1 Metode Pengerjaan 3.2 Studi Literatur
Tahap pertama penelitian ini adalah studi literatur yang dilakukan untuk mengga li teori-teori untuk memperoleh permasalahan yang timbul. Data atau informasi dapat dikumpulkan dengan membaca buku dan jurnal sebagai referensi yang dijadikan acuan pembahasan. Pembelajaran yang dilakukan yaitu mempelajari algorit ma Naïve Bayes, WRP, dan dataset yang digunakan.
3.3 Pengumpulan Data
Penelitian mengusulkan penggunaan dataset NSL-KDD tahun 2012 untuk pengujian metode pada IDS. NSL-KDD Cup 99 merupakan data yang diusulka n untuk mengurangi masalah mendasar pada KDD 99. KDD 99 sangat mempergar uhi kinerja dari sebuah sistem dan hasil estimasi dari pendekatan anomaly detection.
24 Untuk mengatasi masalah ini, dataset yang akan digunakan adalah NSL-KDD99 yang terdiri dari record yang dipilih dari dataset KDD Cup 99. Keuntunga n menggunakan dataset ini adalah :
a. Tidak ada record yang berlebihan di dalam train set, jadi classifier tidak akan menghasilkan hasil yang bias.
b. Tidak ada duplikat record pada test set yang memiliki reduction rates yang lebih baik.
Data tersebut berjumlah 25193 baris dengan 41 atribut yang terdapat pada NSL-KDD, yaitu duration, protocol_type, service, flag, src_bytes, dst_bytes, land, wrong_fragment, urgent, hot, num_failed_logins, logged_in, num_compromised, root_shell. su_attempted, num_root, num_file_creations, num_shells, num_access_files, num_outbound_cmds, is_host_login, is_guest_login, count, srv_count, serror_rate, srv_serror_rate, rerror_rate, srv_rerror_rate, same_srv_rate, diff_srv_rate, srv_diff_host_rate, dst_host_count, dst_host_srv_count, dst_host_same_srv_rate, dst_host_diff_srv_rate, dst_host_same_src_port_rate, dst_host_srv_diff_host_rate, dst_host_serror_rate, dst_host_srv_serror_rate, dst_host_rerror_rate, dst_host_srv_rerror_rate, class.
Berikut tampilan sejumlah data yang diambil dari data log IDS pada gambar 3.2.
25 3.4 Preprocessing
Preprocessing adalah suatu proses atau langkah yang dilakukan untuk membuat data mentah menjadi data yang berkualitas. Preprocessing yang dilakukan melip ut i reduksi data.
3.4.1 Reduksi Data
Reduksi data yaitu suatu cara mengurangi ukuran data tetapi menghasilkan hasil analisis yang sama (hampir sama). Reduksi data dapat dilakukan dengan banyak cara, salah satunya adalah seleksi atribut. Seleksi atribut merupakan proses pemilihan atribut dalam suatu dataset yang memiliki kaitan terhadap kelasnya. Seleksi atribut yang digunakan dalam penelitian ini yaitu wrapper subset evalution. Dalam proses seleksi atribut yang dilakukan adalah mengurangi atribut yang dianggap tidak perlu, proses tersebut dibantu oleh aplikasi WEKA seperti pada gambar 3.3.
26 Gambar 3.3 Seleksi Atribut dengan WEKA
27 Pemangkasan atribut dilakukan oleh WEKA. Dataset awal yang mememiliki 41 atribut kemudian dengan Wrapper Subset Evaluation (WRP) dengan search method bestfirst dan metode naïve bayes dengan iterasi sebanyak 10 kali menggunaka n cross validation. Sehingga hasil seleksi atribut meninggalkan 3 atribut yaitu service (100%) , flag(100%), dan logged_in(80%). Gambar 3.4 merupakan hasil seleksi atribut
Gambar 3.4 Hasil Seleksi Atribut Dengan penjelasan setiap atributnya pada tabel 3.1 :
Tabel 3.1 Deskripsi Atribut Hasil Seleksi Atribut
No Nama Atribut Deskripsi Tipe Data
1 Service Layanan jaringan pada tujuan koneksi seperti http, telnet, dan lain sebagainya.
Continuous 2 Flag Status normal atau error koneksi. Continuous 3 Logged_in Bernilai 1 jika berhasil login, 0 jika
sebaliknya
Discrete
3.5 Pemodelan Data
Tahap ini peneliti akan memanfaatkan metode algoritma klasifikasi naïve bayes untuk melakukan klasifikasi terhadap IDS. Penghitungan dengan algoritma naïve bayes dilakukan secara manual. Berikut contoh data yang akan dihitung :
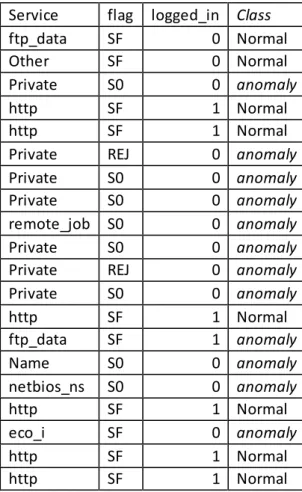
28 Misalnya ingin diketahui apakah suatu data log masuk dalam kategori dalam jaringan dipilih untuk normal atau intrusi dengan algoritma naïve bayes. Untuk menetapkan 20 data akan menjadi patokan. Ada 4 atribut yang digunakan seperti terlihat pada tabel 3.2.
4. Service (a1), 5. Flag (a2),
6. Logged_in (a3), dan 7. Class (a4)
Tabel 3.2 Sebagian Data NSL-KDD Service flag logged_in Class ftp_data SF 0 Normal Other SF 0 Normal Private S0 0 anomaly
http SF 1 Normal
http SF 1 Normal
Private REJ 0 anomaly Private S0 0 anomaly Private S0 0 anomaly remote_job S0 0 anomaly Private S0 0 anomaly Private REJ 0 anomaly Private S0 0 anomaly http SF 1 Normal ftp_data SF 1 anomaly Name S0 0 anomaly netbios_ns S0 0 anomaly http SF 1 Normal eco_i SF 0 anomaly http SF 1 Normal http SF 1 Normal
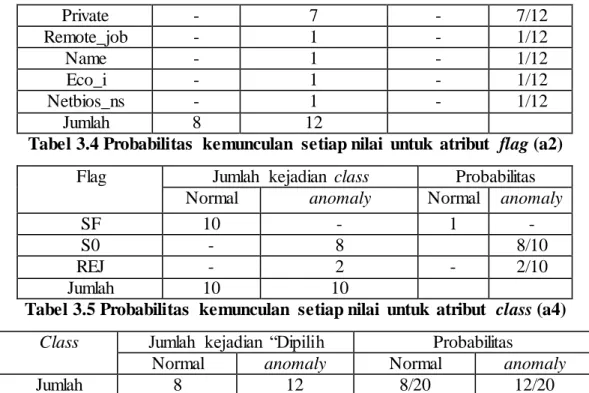
Probababilitas atribut service dan flag terlihat pada tabel 3.3 dan tabel 3.4. Tabel 3.3 Probabilitas kemunculan setiap nilai untuk atribut service (a1)
Service Jumlah kejadian class Probabilitas
Normal anomaly Normal anomaly
ftp_data 1 1 1/8 1/12
Other 1 - 1/8 -
29 Private - 7 - 7/12 Remote_job - 1 - 1/12 Name - 1 - 1/12 Eco_i - 1 - 1/12 Netbios_ns - 1 - 1/12 Jumlah 8 12
Tabel 3.4 Probabilitas kemunculan setiap nilai untuk atribut flag (a2)
Flag Jumlah kejadian class Probabilitas
Normal anomaly Normal anomaly
SF 10 - 1 -
S0 - 8 8/10
REJ - 2 - 2/10
Jumlah 10 10
Tabel 3.5 Probabilitas kemunculan setiap nilai untuk atribut class (a4) Class Jumlah kejadian “Dipilih Probabilitas
Normal anomaly Normal anomaly
Jumlah 8 12 8/20 12/20
Dari data diatas apabila diberikan a1= http, a2= SF, a3=1, maka : Sehingga :
Nilai Normal= 6/8 x 1 x 6/8 x 8/20 = 0,225 Nilai anomaly= - x – x 1/12 x 12/20 = 0,05
Dari data baru tersebut dapat disimpulkan Normal, berdasarkan estimas i probabilitas yang dipelajari dari data training.
3.6 Pengujian dan Evaluasi
Dalam tahapan ini akan dilakukan validasi serta pengukuran keakuratan hasil yang dicapai oleh model menggunakan Confusion Matrix untuk pengukuran tingkat akurasi model, dan Cross Validation untuk validasi.
3.6.1 Confusion Matrix
Confusion matrix adalah tool yang digunakan untuk evaluasi model klasifikas i untuk memperkirakan objek yang benar atau salah.
Contoh perhitungan akurasi confusion matrix Diberikan 20 data untuk pengujian model.
30 Tabel 3.6 Data untuk pengujian model
Service Flag logged_in
http SF 1 eco_i SF 0 Finger S0 0 http SF 1 private REJ 0 domain_u SF 0 private SF 0 domain_u SF 0 supdup S0 0 http SF 1 uucp_path S0 0 ftp_data S0 0 Z39_50 S0 0 Smtp SF 1 Other SF 0 http SF 1 csnet_ns S0 0 Private SF 0 http SF 1 ftp_data SF 1
Perhitungan accuracy pada data tabel 3.6 .
Tabel 3.7 Confusion Matrix Pengujian Data
Classification Predicted Class
Class = Normal Class = anomaly
Class = Normal 7 3
Class = anomaly 1 9
Perhitungan Accuracy berdasarkan tabel 3.7. = 7+9
7+1+3+9𝑥 100% = 16
20 x 100% = 80 %
31 3.6.2 Cross Validation
Data yang digunakan sebagai masukan adalah sampling dari data NSL KDD 12. Data terdiri dari data normal dan data intrusi. Jumlah record data input adalah 900 record, namun komposisi data baik intrusi maupun normal berbeda-beda. Pembagian terlihat pada gambar 3.5.
Gambar 3. 5 Pembagian Dataset 3.7 Deskripsi Umum Sistem
Sistem Analisis Data Jaringan ialah aplikasi berbasis desktop yang dapat digunaka n oleh administrator jaringan untuk membantu dalam mengklasifikasikan data jaringan. Aplikasi ini juga diharapkan dapat mengurangi lemahnya kemampua n identifikasi data jaringan. Dan juga diharapkan menjadi solusi bagi pengklasifikasian data jaringan.
Dalam aplikasi hanya digunakan oleh administrator jaringan itu sendiri. Hak akses diberikan sepenuhnya kepada administrator jaringan. Dengan adanya sistem analisis ini, data jaringan dapat diklasifikan sesuai dengan jenisnya.
32 Gambar 3.6 Deskripsi Umum Sistem
Gambar 3.6 menjelaskan deskripsi umum sistem yang mengambarkan aksi yang dapat dilakukan aplikasi dan jalur data yang terjadi di aplikasi. Sudah tertera dengan jelas pembagian data diakses oleh administra tor jaringan. Administrator jaringa n dapat memasukkan data jaringan, melihat hasil evaluasi, mengklasifikasi data jaringan. Dengan adanya sistem analisis data jaringan ini diharapkan dapat membantu dan mempermudah pekerjaan dalam ruang lingkup administrato r. 3.8 Kebutuhan Fungsional
Kebutuhan fungsional dari sistem analisis data jaringan ialah sebagai berikut : F001. Pengguna harus dapat menambah data training.
F002. Pengguna harus dapat memasukkan data model klasifikasi F003. Aplikasi harus dapat mengekspor data training.
F004. Pengguna harus dapat menambahkan baris baru pada data training. F005. Pengguna harus dapat menghapus data jaringan pada data training. F006. Pengguna harus dapat mengubah data jaringan pada data training. F007. Aplikasi harus dapat melakukan pengklasifikasian jaringan
berdasarkan model klasifikasi menggunakan Algoritma Naïve Bayes F008. Aplikasi harus dapat menampilkan evaluasi model klasifikasi
F009. Pengguna harus dapat memasukkan data testing.
33 3.9 Kebutuhan Non Fungsional
Sementara itu, kebutuhan non fungsional dari sistem analisis data jaringan ini adalah sebagai berikut :
NF001. Aplikasi dapat digunakan dengan mudah dan tampilan mudah dimengerti
NF002. Aplikasi dapat membagi hak akses pengguna sesuai dengan fungs i yang dijalankan.
NF003. Aplikasi berbasis desktop 3.10 Use Case Diagram
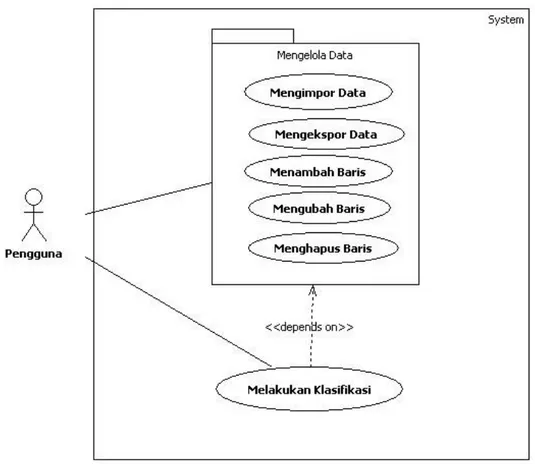
Gambar 3.7 Use Case Diagram
Diagram use case sistem ini seperti pada Gambar 3.7. Aktor atau pengguna dari sistem ini hanya satu, yaitu Pengguna. Terdapat dua fungsi utama yang dilakukan
34 pengguna terhadap sistem, yaitu melakukan pengelolaan data, dan melakuka n klasifikasi. Pengelolaan data merupakan fungsi yang dijalankan oleh penggu na untuk mengelola data jaringan, seperti import data, ekspor data, input data secara manual kedalam sistem, tambah baris tabel, hapus baris tabel.
Fungsi lainnya dari sistem ini adalah melakukan klasifikasi. Ketika fungs i dijalankan, sistem akan melakukan proses training untuk algoritma Naïve Bayes, menghitung akurasi, kemudian menampilkan hasilnya dan memunculka n klasifikasi data jaringan. Output dari fungsi ini adalah hasil klasifikasi algorit ma, data training dan testing , model yang dihasilkan oleh algoritma, dan akurasi algoritma.
3.11 Skenario Use Case
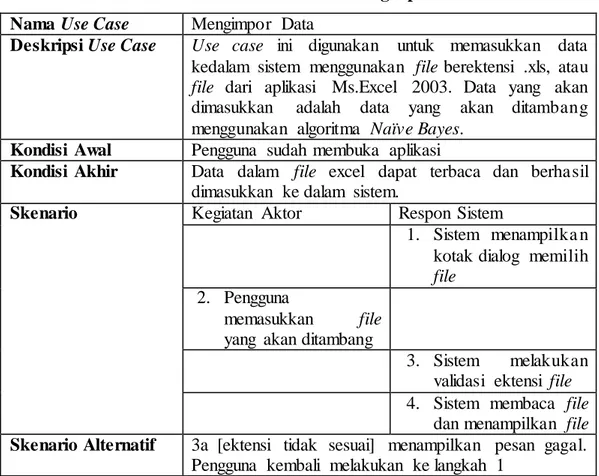
Tabel 3.8 Skenario Use Case Mengimpor Data Nama Use Case Mengimpor Data
Deskripsi Use Case Use case ini digunakan untuk memasukkan data kedalam sistem menggunakan file berektensi .xls, atau file dari aplikasi Ms.Excel 2003. Data yang akan dimasukkan adalah data yang akan ditambang menggunakan algoritma Naïve Bayes.
Kondisi Awal Pengguna sudah membuka aplikasi
Kondisi Akhir Data dalam file excel dapat terbaca dan berhasil dimasukkan ke dalam sistem.
Skenario Kegiatan Aktor Respon Sistem
1. Sistem menampilka n kotak dialog memilih file
2. Pengguna
memasukkan file yang akan ditambang
3. Sistem melakukan validasi ektensi file 4. Sistem membaca file
dan menampilkan file Skenario Alternatif 3a [ektensi tidak sesuai] menampilkan pesan gagal.
35 Tabel 3.9 Skenario Use Case Mengekspor Data
Nama Use Case Mengekspor Data
Deskripsi Use Case Use case ini digunakan untuk menyimpan data dari sistem kedalam file Ms.Excel
Kondisi Awal Pengguna sudah membuka aplikasi
Kondisi Akhir Data dalam sistem berhasil disimpan kedalam file excel
Skenario Kegiatan Aktor Respon Sistem
1. Sistem menampilka n kotak dialog menyimpan file 2. Pengguna memasukkan lokasi penyimpanan 3. Sistem menyimpa n data ke dalam file excel
Skenario Alternatif -
Tabel 3.10 Skenario Use Case Menambah Baris Nama Use Case Menambah Baris
Deskripsi Use Case Use case ini digunakan untuk menambah baris baru kedalam tabel. Baris baru yang ditambahkan tidak berisi data(null) dan baris yang akan ditambahkan pada tabel diurutan paling akhir
Kondisi Awal Pengguna sudah membuka aplikasi
Kondisi Akhir Data dalam sistem berhasil menghasilkan baris baru pada tabel.
Skenario Kegiatan Aktor Respon Sistem
1. Sistem
menambahkan baris baru yang kosong 2. Pengguna
memasukkan data baru
3. Sistem menyimpa n data baru dalam tabel Skenario Alternatif -
36 Tabel 3.11 Skenario Use Case Mengubah Baris
Nama Use Case Mengubah Baris
Deskripsi Use Case Use case ini digunakan untuk memasukkan atau mengubah data kedalam tabel secara manual.
Kondisi Awal Pengguna sudah membuka aplikasi
Kondisi Akhir Data dalam sistem berhasil dimasukkan/diubah dari dalam tabel
Skenario Kegiatan Aktor Respon Sistem
1. Pengguna memilih cell dari tabel dan memasukkan data
2. Sistem menyimpa n data yang dimasukkan pengguna
Skenario Alternatif -
Tabel 3. 12 Skenario Use Case Menghapus Baris Nama Use Case Menghapus Baris
Deskripsi Use Case Use case ini digunakan untuk menghapus baris dalam tabel. Baris yang akan dihapus adalah baris yang dipilih oleh pengguna.
Kondisi Awal Pengguna sudah membuka aplikasi
Kondisi Akhir Data dalam sistem berhasil dihapus dari dalam tabel
Skenario Kegiatan Aktor Respon Sistem
1. Pengguna memilih 1 baris yang akan dihapus dari tabel.
2. Sistem menghapus data yang dimasukkan pengguna
Skenario Alternatif -
Tabel 3. 13 Skenario Use Case Melakukan Klasifikasi Nama Use Case Melakukan Klasifikasi
Deskripsi Use Case Use case ini digunakan untuk melakukan proses klasifikasi.
Kondisi Awal Pengguna sudah memasukkan use case mengimpor data Kondisi Akhir Model terbentuk dan berhasil diklasifikasikan
Skenario Kegiatan Aktor Respon Sistem
1. Pengguna
memasukkan atribut data yang akan diujikan
37 2. Sistem melakukan
proses klasifikasi. 3. Sistem menampilka n
hasil klasifikasi. Skenario Alternatif 2a [data tidak lengkap] klasifikasi bernilai 0, menuju
langkah 3 3.12 Activity Diagram
Gambar 3. 8 Activity Diagram Mengimpor Data
Pada gambar 3.8 menjelaskan proses bagaimana sistem menjalankan proses impor data. Dari sistem menampilkan kotak dialog memilih file, lalu pengguna memasukkan file yang akan ditambang, ketika berhasil maka sistem membaca file dan menampilkan file. Namun bila gagal, maka sistem menampilkan pesan gagal dan sistem kembali menampilkan kotak dialog memilih file.
38 Gambar 3. 9 Activity Diagram Mengekspor Data
Sementara, pada activity diagram gambar 3.9, dimulai dari sistem menampilka n kotak dialog menyimpan file. Lalu pengguna memasukkan lokasi untuk penyimpanan file lalu sistem menyimpan data ke dalam file csv.
Gambar 3. 10 Activity Diagram Menambah Baris
Untuk activity diagram menambah baris terlihat pada gambar 3.10. Dimulai dari sistem menambahkan baris baru yang kosong pada tabel lalu pengguna
39 memasukkan data baru pada baris yang terbentuk. Maka sistem pun menyimpa n data baru dalam tabel.
Gambar 3. 11 Activity Diagram Mengubah Baris
Gambar 3.11 menjelaskan proses mengubah baris yang dimulai ketika pengguna memilih cell dari tabel yang datanya ingin diubah dan memasukkan data baru kemudian sistem menyimpan data yang dimasukkan pengguna.
Gambar 3. 12 Activity Diagram Menghapus Baris
Sementara untuk menghapus baris dari tabel, gambar 3.12 menggambarka n pengguna dan sistem. Pengguna memilih 1 baris yang akan dihapus dari tabel kemudian sistem menghapus data yang dimasukkan pengguna tersebut.
40 Gambar 3. 13 Activity Diagram Melakukan Klasifikasi
Untuk melakukan klasifikasi, Pengguna memasukkan atribut data yang akan diuji, kemudian sistem melakukan proses klasifikasi dan sistem menampilkan hasil klasifikasi. Namun bila data tidak lengkap, klasifikasi akan bernilai 0 dan sistem menampilkan nilai tersebut.
41 3.13 Class Diagram
Gambar 3. 14 Class Diagram
Dalam sistem analisis data jaringan ini, terdapat berbagai class berdasarkan pengerjaannya. Class yang ada dalam Gambar 3.14 dibagi menjadi boundary dan controller dimana jenis class ini mewakilkan dari kebutuhan sistem analisis yang diinginkan. Class ini juga hadir untuk menunjang data yang dibutuhkan dalam sistem analisis ini. Kebutuhan data, proses maupun antarmuka tiap fungsi saling bersingkron dengan class yang ada dan menciptakan suatu sistem persebaran class.