Sistem Pendukung Keputusan Pemilihan Pembimbing dan
Penguji Proyek Akhir di Politeknik Caltex Riau
Gunawan
1), Indah Lestari
2), Muhammad Ihsan Zul
3)1 ) Jurusan Teknik I n f o r ma t i k a , Politeknik Caltex Riau, Pekanbaru 28265, email: g u na wa n1 1 t i @ ma h a s i s w a . p c r . a c . i d
2)
Jurusan Sistem Informasi, Politeknik Caltex Riau, Pekanbaru 28265, email: i nd a h @p c r . a c . i d3)
Jurusan Teknik I n f o r ma t i k a , Politeknik Caltex Riau, Pekanbaru 28265, email: i h s a n @p c r . a c . i dAbstrak – Pada Politeknik Caltex Riau (PCR) penentuan dosen pembimbing dan penguji Proyek Akhir (PA) merupakan tugas dari koordinator PA. Penelitian ini bertujuan untuk membantu koordinator PA dalam menentukan dosen pembimbing dan penguji PA. Metode-metode yang digunakan untuk membangun sistem ini adalah Text Mining, k-Nea rest Neighbor (k-NN), dan Simple Additive Weighting (SAW). Text mining untuk melakukan preprocessing data, k-NN untuk melakukan pengklasifikasian KBK, sementara SAW untuk melakukan pembobotan kriteria dosen. Penelitian ini dapat merekomendasikan 5 nama dosen yang memiliki bobot tertinggi untuk menjadi pembimbing dan penguji PA berdasarkan KBK judul PA mahasiswa, dan memiliki nilai akurasi 83.3%.
Kata Kunci : Text Mining, SAW, k-NN, Proyek Akhir, Pembimbing, Penguji
Abstract - At the Polytechnic Caltex Riau (PCR) determination of final project (PA) adviser and reviewer is PA Coordinator duty. This research for assist PA Coordinator determine adviser and reviewer. The methods used to build this system are Text Mining, k-Nearest Neighbor (k-NN), and Simple Additive Weighting (SAW). Text mining for data preprocessing K-NN for KBK classification, while SAW for weighting the lecturer criteria. This research can recommend five name of lecturers who have the highest weight to be PA adviser and reviewer based of KBK, and has a 83.3% accuracy.
Keywords: Text Mining, SAW, k-NN, PCR, Final Project, Adviser, Reviewer
1. PENDAHULUAN
Politeknik Caltex Riau (PCR) merupakan sebuah institusi pendidikan yang berdiri sejak tahun 2001 di kota Pekanbaru. Sebagai salah satu politeknik terkemuka di Riau dan jumlah mahasiswa yang terus meningkat. Proyek Akhir (PA) merupakan salah satu syarat kelulusan di PCR. Proses pelaksanaan PA di PCR dilakukan selama satu tahun (2 semester) yaitu pada tahun tingkat akhir. Dalam proses pelaksanaan PA di PCR terdapat maksimal 3 orang dosen penguji dan 2 orang dosen pembimbing.
Pemilihan dosen pembimbing dan dosen penguji di PCR ternyata masih menggunakan cara manual. Cara manual yang dimaksud adalah pemilihan dosen pembimbing dan dosen penguji secara langsung oleh koordinator PA dan dipilih berdasarkan KBK dosen dan sesuaikan dengan judul PA mahasiswa. Proses pemilihannya yaitu:
1. Koordinator PA mengelompokkan semua judul PA mahasiswa yang diterima berdasarkan KBK dari program studi tersebut.
2. Koordinator PA mencocokkan KBK judul PA mahasiswa dengan KBK dosen yang akan dijadikan dosen pembimbing dan dosen penguji.
3. Apabila satu dosen telah melebihi kuota jadi dosen pembimbing dan dosen penguji dari yang ditentukan maka akan digantikan oleh dosen lain yang masih didalam satu KBK.
Masalah lain dari pemilihan manual oleh koordinator PA yaitu: dosen pembimbing dan dosen penguji yang tidak sesuai dengan judul PA mahasiswa, karena jumlah bidang peminatan mahasiswa dari tahun ke tahun berbeda sehingga jumlah dosen pembimbing dan dosen penguji dalam satu KBK ada yang berlebih dan ada yang tidak cukup. Untuk solusi KBK yang pembimbing dan penguji PA tidak cukup maka akan diambil dari dosen KBK lain sehingga banyak yang tidak sesuai dengan kompetensi PA yang akan dibuat mahasiswa.
Dalam membangun sistem ini menggunakan beberapa algoritma dan metode salah satunya adalah text mining. Penerapan text mining dapat digunakan untuk menganalisa data yang diperoleh dari judul-judul PA mahasiswa. Untuk menerapkan text mining, dibutuhkan judul mahasiswa yang sebelumnya sehingga dapat melihat pola-pola data yang terdahulu untuk menjadikan sebuah pengetahuan baru.
digunakan untuk menggambarkan kelas data penting atau untuk memprediksi tren data masa depan [1]. k-NN dilakukan dengan cara mencari kelompok k objek dalam data training yang paling dekat (mirip) dengan objek pada data baru atau data testing.
Chenometh merangkum perbandingan antara 5 algoritma yang sering digunakan dalam kategorisasi teks yaitu: Naïve Bayes (kinerja lebih rendah dari pada metode lain), Rocchio (kinerja rendah, terutama saat mengklasifikasi kedalam kategori dengan banyak term representatif), k-NN (kinerja baik, terutama untuk banyak kategori, tetapi lambat karena harus dibandingkan ke semua), Decision Tree (kinerja baik, tetapi memerlukan optimasi untuk menyelesaikan overfitting), Support Vector Machine (kinerja terbaik, tetapi sangat mudah terjadi error dalam data training), [2].
Selain klasifikasi, sistem ini juga menggunakan metode simple additive weighting. Metode ini digunakan untuk menentukan dosen pembimbing dan dosen penguji yang sesuai dengan KBK dosen dan merekomendasikan dosen yang memiliki kompetensi berbeda tetapi masih memiliki pengetahuan tentang kompetensi tersebut.
Berdasarkan alasan yang telah diuraikan, maka dilakukanlah penelitian untuk merancang sebuah sistem yang bisa merekomendasi nama dosen pembimbing dan dosen penguji PA mahasiswa PCR, adapun judul penelitian yang dibuat yaitu “Sistem pendukung keputusan pemilihan pembimbing dan penguji Proyek Akhir di Politeknik Caltex Riau”.
Terdapat 5 bagian utama pada tulisan ini. Bagian 1 membahas alasan mengapa dan bagaimana penelitian dilakukan, Bagian 2 berisi tentang penelitian terkait. Bagian 3 berisi perancangan sistem. Bagian 4 berisi analisa hasil pengujian penelitian, serta bagian 5 yang berisi dan kesimpulan dan saran penelitian.
2. PENELITIAN TERKAIT
Penelitian mengenai Sistem Pendukung Keputusan (SPK) sudah banyak dilakukan oleh berbagai kalangan termasuk mahasiswa. Berikut ini adalah beberapa penelitian yang berkaitan dengan sistem pendukung keputusan:
Tabel 1 Review penelitian terdahulu
Peneliti Metode Hasil
Pristiwanto (2014)
Simple Additive Weighting (SAW)
Nilai Bobot
Lukman (2012) Jaringan Syaraf Tiruan
Nama
pembimbing dan penguji
Sadhili (2011) - Nama pembimbing
Lukman (2012) Logika Fuzzy Nama pembimbing dan penguji Penelitian ini Simple Additive Rekomendasi
Weighting (SAW)
Berdasarkan tinjauan penelitian terdahulu, metode yang digunakan oleh penelitian 1 adalah SAW, penelitian 2 menggunakan jaringan syaraf tiruan, penelitian 3 tidak menggunakan metode, dan penelitian 4 menggunakan logika fuzzy. Proyek akhir yang akan dibuat ini menggunakan metode SAW karena membutuhkan pembobotan terhadap dosen-dosen yang akan menjadi pembimbing dan penguji. Sistem ini menggunakan teknik klasifikasi yaitu algoritma k-NN, fungsi k-NN di sistem ini untuk mengklasifikasikan data testing judul PA berdasarkan KBK yang berhubungan dengan judul tersebut. Sistem ini juga memiliki kemampuan lainnya yaitu mampu mendefinisikan KBK berdasarkan judul PA.
3. PERANCANGAN 3.1. Use Case Diagram
Pada Gambar 1 menjelaskan bahwa sistem ini terdapat 2 jenis pengguna yaitu:
1. Mahasiswa
Mahasiswa memiliki batasan dalam mengakses sistem ini, yang mana mahasiswa cuma bisa melakukan pengisian judul, edit data diri dan melihat informasi dari sistem.
2. Koordinator PA
Koordinator PA bertindak juga sebagai administrator sistem, di sini koordinator PA bisa mengelola judul yang telah dimasukkan oleh mahasiswa. Judul PA mahasiswa bisa diubah oleh koordinator apabila terdapat kesalahan.
Untuk mendapatkan nama pembimbing dan penguji koordinator PA terlebih dahulu judul PA harus dilakukan proses preprocessing yang terdiri dari 4 tahap yaitu:
a. Case Folding berfungsi untuk mengubah semua huruf menjadi huruf kecil (lower case) dan menghapus karakter selain huruf. b. Tokenizing merupakan proses untuk
memisahkan string menjadi per kata.
c. Filtering untuk menghapus kata-kata yang tidak penting seperti di, dan melalui, dll. d. Stemming merupakan proses untuk
mengubah kata berimbuhan menjadi kata dasar, pada penelitian ini menggunakan algoritma porter stemmer dengan menggabungkan bahasa inggris dan bahasa indonesia.
Jumlah tetangga terdekat yang digunakan pada penelitian ini adalah 20 karena dari hasil pengujian jumlah tetangga terdekat menunjukkan bahwa akurasi tetangga (k) =20 adalah akurasi yang tertinggi dibanding jumlah tetangga lainnya.
Dari hasil perhitungan algoritma k-NN maka didapatkan KBK judul tersebut, sehingga sistem bisa melanjutkan proses pemilihan dosen pembimbing dan penguji. Untuk mendapatkan nama-nama dosen pembimbing dan penguji sistem akan melakukan proses perhitungan alternatif menggunakan metode Simple Additive Weighting dengan rumus sebagai berikut:
Adapun kriteria yang akan dihitung oleh sistem ini adalah: pendidikan, kompetensi, jumlah membimbing atau menguji mahasiswa. Nilai-nilai dari kriteria tersebut bersifat dinamis dan tersimpan dalam database. Hasil dari perhitungan metode SAW adalah 5 nama dosen yang memiliki nilai alternatif tertinggi sehingga direkomendasikan ke koordinator PA untuk menentukannya. Selain fitur di atas koordinator PA juga bisa melakukan penambahan dosen, edit data dosen, dan penambahan mahasiswa.
Gambar 1 Use case diagram
4. HASIL DAN PEMBAHASAN
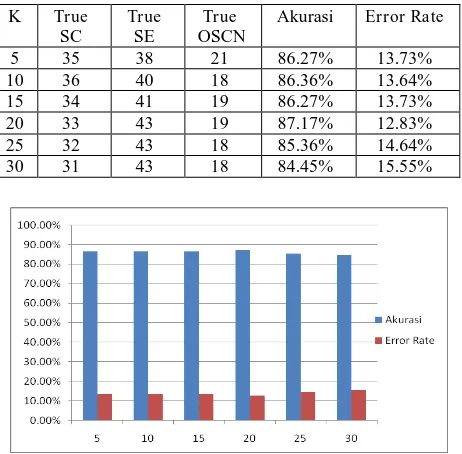
4.1. Pengujian Akurasi Jumlah Tetangga Terdekat Pengujian akurasi k-NN bertujuan untuk mengetahui kerja dari algoritma k-NN dalam mengklasifikasi data ke dalam label yang telah ditentukan. Pada pengujian ini sekaligus membandingkan keakuratan jumlah k yang digunakan dalam sistem. Untuk mendapatkan nilai akurasi menggunakan confusion matrix. Data training atau data judul PA mahasiswa PCR tahun 2009-2014 yang digunakan sebanyak 109 data dan jumlah data testing sama. Untuk melihat hasil pengujian bisa dilihat pada Tabel 2 dan Gambar 2.
Tabel 2 Perbandingan akurasi jumlah k
K True
SC
True SE
True OSCN
Akurasi Error Rate
5 35 38 21 86.27% 13.73%
10 36 40 18 86.36% 13.64%
15 34 41 19 86.27% 13.73%
20 33 43 19 87.17% 12.83%
25 32 43 18 85.36% 14.64%
30 31 43 18 84.45% 15.55%
Gambar 2 Grafik Akurasi Jumlah Tetangga Terdekat
4.2. Pengujian Akurasi k-NN
Pada tahap pengujian klasifikasi k-NN ini, data yang akan digunakan sebanyak 60 data dari data training antara lain: label Soft Computing (SC) sebanyak 20, label Software Engineering (SE) sebanyak 20, label Operating System and Computer Network (OSCN) sebanyak 20. Pengujian ini bertujuan untuk mengetahui unjuk kerja dari algoritma k-NN dalam mengklasifikasi data ke dalam kelas yang telah ditentukan. Hasil kinerja sistem diperoleh dengan memberikan nilai pada confusion matrix untuk menghitung nilai accuracy dari hasil pengujian.
Tabel 3 ConfusionMatrix pengujian akurasi k-NN
Predicted Class
Actual Class
SC SE OSCN
SC 16 0 1
SE 4 20 5
OSCN 0 0 14
Error Rate: 100% - 83.3% = 16.7% 4.3. Pembahasan
Dari hasil pengujian pada Tabel 4.1 dapat diketahui nilai akurasi untuk jumlah k = 5, 10, 15, 20, 25, 30. Pada penelitian ini menggunakan nilai k = 20 dengan nilai akurasi 87.17% dikarenakan dari 6 percobaan tersebut k dengan nilai 20 menunjukkan hasil akurasi yang tertinggi. Sedangkan pada pengujian akurasi dengan menggunakan 60 data dari data training menunjukkan hasil 83.3%. Nilai akurasi yang tidak maksimal dikarenakan oleh 2 faktor yaitu: jumlah data training setiap label yang berbeda-beda dan nilai penentu yang tidak konsisten.
Data training yang terdapat di sistem berjumlah 109 data yang terdiri dari: 38 data dengan label SC, 43 data dengan label SE, dan 28 data dengan label OSCN. Hal ini mempengaruhi nilai confidence setiap judul PA yang baru. Nilai confidence didapatkan dari jumlah label prediksi dibagi dengan jumlah nilai k.
Nilai penentu dalam training juga mempengaruhi nilai akurasi. Nilai penentu yang dimaksudkan adalah keyword-keyword yang terdapat dalam data training. Keyword merupakan kata-kata inti yang sama dengan keyword yang tersedia dalam sistem. Keyword yang tersedia dalam sistem sebanyak 28 kata dengan sub keyword 252 kata. Misalnya untuk keyword “Sistem”, dalam KBK SC, SE dan OSCN terkadang mengandung keyword tersebut sehingga nilai euclidean distance yang dihasilkan hampir sama.
Meskipun demikian, sistem ini hanyalah berupa decision support, yang berarti hanya memberikan option kepada user agar lebih mudah dalam menentukan pilihan. Keputusan terakhir dari pemilihan pembimbing dan penguji tetap pada keputusan koordinator PA atau administrator dari sistem
5. KESIMPULAN DAN SARAN 5.1. Kesimpulan
Dari hasil penelitian ini dapat disimpulkan bahwa: 1. Hasil klasifikasi menggunakan k-NN dapat
digunakan untuk mengklasifikasi judul PA
mahasiswa berdasarkan KBK dengan akurasi 83.3%.
2. Hasil perhitungan SAW bisa menghasilkan dosen yang memiliki kompetensi yang sama dengan KBK judul. Dosen yang direkomendasikan oleh sistem adalah 5 dosen dengan nilai bobot tertinggi.
5.2. Saran
Adapun saran yang dapat diberikan adalah:
1. Sistem ini dapat dikembangkan dengan menambah kriteria-kriteria penentuan dosen lainnya seperti sub kbk pada setiap dosen, sehingga dosen yang direkomendasi bisa lebih tepat.
2. Sistem ini dapat dikembangkan untuk jurusan selain jurusan komputer di PCR dengan jumlah data training yang lebih besar.
DAFTAR REFERENSI
[1] Han, Jiawei, Kamber, Micheline & Pei, Jian. (2012). Data Mining: Concepts and Techniques ( ed.) USA: Elsevier Inc.
[2] Darujati, Cahyo dan Gumelar, Agustinus Bimo, (2012). Pemanfaatan Teknik Supervised Untuk Klasifikasi Teks Bahasa Indonesia. Jurnal LINK, 1-5.
[3] Lukman, Andi. (2012), Optimasi Penentuan Pembimbing dan Penguji Skripsi Menggunakan Jaringan Syaraf Tiruan, Konferensi Nasional Ilmu Komputer (KONIK).
[4] Lukman, Andi. (2012), Penentuan Pembimbing dan Penguji Skripsi Berdasarkan Spesifikasi Keahlian Dosen Menggunakan Logika Fuzzy, Jurnal Informatika dan Multimedia (JIM) 1 (3)
[5] Pristiwanto, (2014). Sistem Pendukung Keputusan dengan Metode Simple Additive Weighting Untuk Menentukan Dosen Pembimbing Skripsi. Majalah Ilmiah Informasi dan Teknologi Ilmiah (INTI) 2 (1), 11-15.
[6] Sadhili, Rosi, Riza, Tengku Ahmad & Destiwati, Rita. (2011).