MAKALAH
ANALISIS SENTIMEN TWEET
Oleh :
Agung Sulistyo (14.01.53.0037) Tidy Yuniardy S (14.01.53.0003)
Indra Dwi H (14.01.53.0049)
FAKULTAS TEKNOLOGI INFORMASI UNIVERSITAS STIKUBANK (UNISBANK)
BAB I PENDAHULUAN
1.1 LATAR BELAKANG
Twitter adalah layanan jejaring sosial dan mikroblog yang memungkinkan penggunanya untuk mengirim dan membaca pesan atau informasi berbasis teks hingga 140 karakter, yang dikenal dengan sebutan kicauan (tweet).Sebuah tweet dapat mengekspresikan sebuah perasaan atau keadaan dari pengguna Twiter.Informasi yang beredar juga sangat banyak mulai dari berita, opini, komentar, kritik dan semuanya ada yang bersifat positif, negatif dan netral. Pada Twitter terdapat istilah bernama tweet yang merupakan sebuah pesan atau status yang dibuat oleh penggunanya.
Analisis sentimen merupakan bagian dari Natural Language Processing (NLP) dan Machine Learning. Cara kerjanya adalah dengan melakukan klasifikasi terhadap opini positif maupun negatif. Analisis sentimen menganalisa pendapat orang, evaluasi,sikap, penilaian, sentimen, dan emosi terhadap entitas sepertimasalah, produk, jasa, organisasi, individu, peristiwa atau suatu topik.Sentimen analisis ini memiliki tujuan untuk menentukan sentimen publik terhadap suatu objek tertentu yang disampaikan melalui twitter dengan menggunakan bahasa indonesia agar dapat membantu usaha untuk melihat opini publik terkait dengan objek tersebut sebagai bahan
BAB II
TINJAUAN PUSTAKA
2.1 KAJIAN DEDUKTIF 2.1.1 Analisis Sentimen
Analisa sentimen atau biasa disebut opinion mining merupakan salah satu cabang penelitian Text Mining. Opinion mining adalah riset komputasional dari opini, sentimen dan emosi yang diekspresikan secara tekstual. Jika diberikan suatu set dokumen teks yang berisi opini mengenai suatu objek, maka opinion mining bertujuan untuk mengekstrak atribut dan komponen dari objek yang telah dikomentasi pada setiap dokumen dan untuk menentukan apakah komentar tersebut bermakna positif atau negatif.
Sentiment Analysis dapat dibedakan berdasarkan sumber datanya, beberapa level yang sering digunakan dalam penelitian Sentiment Analysis adalah Sentiment Analysis pada level dokumen dan Sentiment Analysis pada level kalimat. Berdasarkan level sumber datanya Sentiment Analysis terbagi menjadi 2 kelompok besar yaitu :
a. Coarse-grained Sentiment Analysis
Pada Sentiment Analysis jenis ini, Sentiment Analysis yang dilakukan adalah pada level dokumen. Secara garis besar fokus utama dari Sentiment Analysisjenis ini adalah menganggap seluruh isi dokumen sebagai sebuah sentiment positif atau sentiment negatif.
b. Fined-grained Sentiment Analysis
Fined-grained Sentiment Analysis adalah Sentiment Analysis pada level kalimat. Fokus utama fined-greined Sentiment Analysis adalah menentukan sentimen pada setiap kalimat.
2.1.2 Analisis Opini atau Sentimen
paling terbantu, yaitu dalam dunia web-online (mengenai pelayan, maupun bagaimana kita dalam melihat suatu peristiwa dan mengambil keputusan atau opini pribadi mengenai suatu kejadian. Dalam sosial media data yang ditampung mengenai opini berkembang sangat pesat, karena opini lebih cepat disalurkan dan mudah melakukan akses ke opini orang lain oleh karena itu analisis sentiment sangat diperlakukan. Analisis sentiment merupakan tipologi area dari ilmu Natural Language Processing yang bergerak secara kontinum mulai dari level/tahap klasifikasi teks, sampai mereview polaritasnya. Riset yang paling sering dilakukan terhadap analisis Twitter adalah pada tahap klasifikasi.
2.2 KAJIAN INDUKTIF
Setelah klasifikasi, dibuat web framework pembuatan visualisasi berupa wordcloud dan grafik streamgraph yang ditampilkan secara interaktif dengan aplikasi berbasis web yaitu R Shiny.
BAB III
METODE PENELITIAN
3.1 OBJEK PENELITIAN
Objek dari analisis sentimen tweet adalah Starbucks
3.2 METODE PENGUMPULAN DATA
Berikut adalah metode pengumpulan data dalam penelitian ini 3.2.1 Studi Literatur
Pengumpulan data dilakukan dengan cara mempelajari, meneliti dan menelaah berbagai literatur yang bersumber dari buku, situs internet, jurnal ilmiah, dan sumber – sumber lainnya yang berkaitan dengan penelitian yang dilakukan.
3.2.2 Pengumpulan Data Twitter
Pengumpulan data twitter dilakukan dengan menggunakan sumber data primer yang diambil menggunakan Twitter Search API dengan memasukan keyword yang berhubungan dengan objek
3.2.3 Observasi
Observasi yang dilakukan ialah mengamati data tweet yang akan di analisis yang bersinggungan dengan objek penelitian.
3.3 JENIS DATA
Jenis data yang digunakan dalam penelitian ini adalah data primer yaitu tweet yang berhubungan dengan objek penelitian (Starbucks) dari sosial media Twiitter. Pengumpulan data menggunakan Twitter Search API dengan memasukan keyword – keyword yang berhubungan dengan objek yang dikombinasikan dengan kata – kata sentimen.
3.4 ALUR PENELITIAN
Gambar 3.1 Alur Analisis Sentimen
Berikut penjelasan dari alur analisis sentimen diatas : 1. Identifikasi Tweet
Identifikasi tweet merupakan tahapan awal yang dilakukan pada penelitian ini. Pada tahap ini yang dilakukan adalah melakukan pengidentifikasian tweet yang akan di analisis yaitu tweet yang bersinggungan dengan Starbucks
2. Penerapan Metode Algoritma Information Retrieval
Pada tahap ini tweet yang sudah diidentidikasi kemudian diterapkan algoritma information retrieval untuk mengetahui tweet mana yang mengandung sentimen dengan yang tidak, yang nantinya akan digunakan untuk perhitungan pada penerapan metode algoritma extraxtion
3. Penerapan Metode Algoritma Extraction
Pada tahap ini tweet yang sudah di-retreve kemudian diekstrak menggunakan algoritma extrction berupa klasifikasi yang sudah ditentukan
4. Pengujian Tingkat Akurasi
Pada tahap ini tweet yang sudah memiliki kelas masing – masing diuji
BAB IV
HASIL DAN PEMBAHASAN
4.1 IMPLEMENTASI
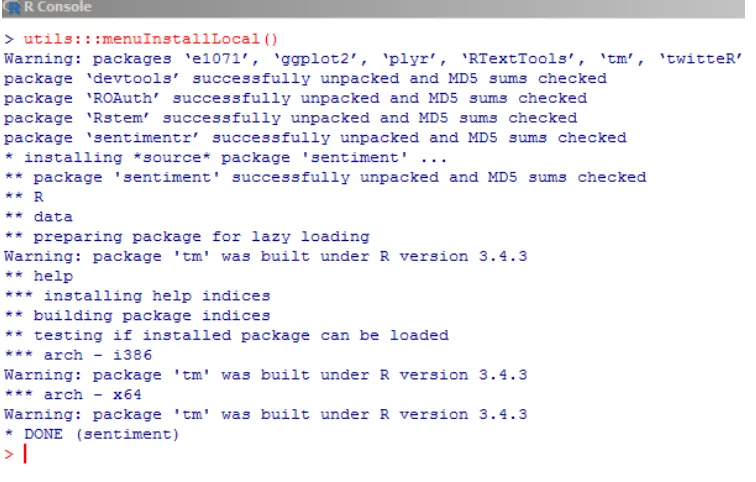
Dalam menjalankan program kita perlu melakukan Installasi package – package yang dibutuhkan sesuai kebutuhan pada penelitian ini.
install.packages("twitteR")
Gambar 1 (R Console)
Proses installasi package dari local filesGambar 1 (R Console), file dapat di download melalui mirror atau dari repositori yang tersedia. Setelah terinstall panggil library yang dibutuhkan.
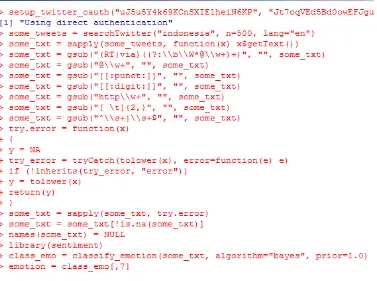
Untuk dapat mengakses data dari twitter kita perlu memasukan(“consumer key”, “consumer secret key”, “access token”,”access token key”) dari aplikasi yang dibuat di apps.twitter.com
setup_twitter_oauth("uJ5u5Y4k69KCnSXIE1heiN6KP",
"Jt7oqVEd5Bd0owEFJguiY4gtMv3P8E8P6SHLMfphI3s4IHT3cN",
"514460550-BTjSyvVg01i9l7ADeWRRry1udTBWXa6ec2dcbx6q","OyGA7Q8uG bb8y2hay1Y71bwt1zprGZXTBT8NqVfyD1UQH")
Setelah memasukan Twitter Aouth, jalankan program satu persatu
# harvest some tweets
some_tweets = searchTwitter("starbucks", n=500, lang="en")
# get the text
some_txt = sapply(some_tweets, function(x) x$getText())
# remove retweet entities
some_txt = gsub("(RT|via)((?:\\b\\W*@\\w+)+)", "", some_txt)
some_txt = gsub("@\\w+", "", some_txt)
# remove punctuation
some_txt = gsub("[[:punct:]]", "", some_txt)
# remove numbers
some_txt = gsub("[[:digit:]]", "", some_txt)
# remove html links
some_txt = gsub("http\\w+", "", some_txt)
# remove unnecessary spaces
some_txt = gsub("[ \t]{2,}", "", some_txt)
some_txt = gsub("^\\s+|\\s+$", "", some_txt)
# define "tolower error handling" function
try.error = function(x)
{
# create missing value
y = NA
# tryCatch error
try_error = tryCatch(tolower(x), error=function(e) e)
# if not an error
# lower case using try.error with sapply
some_txt = sapply(some_txt, try.error)
# remove NAs in some_txt
some_txt = some_txt[!is.na(some_txt)]
names(some_txt) = NULL
# classify emotion
class_emo = classify_emotion(some_txt, algorithm="bayes", prior=1.0)
# get emotion best fit
emotion = class_emo[,7]
# substitute NA’s by "unknown"
emotion[is.na(emotion)] = "unknown"
# classify polarity
class_pol = classify_polarity(some_txt, algorithm="bayes")
# get polarity best fit
polarity = class_pol[,4]
# data frame with results
sent_df = data.frame(text=some_txt, emotion=emotion,polarity=polarity, stringsAsFactors=FALSE)
# sort data frame
sent_df = within(sent_df,emotion <- factor(emotion, levels=names(sort(table(emotion), decreasing=TRUE))))
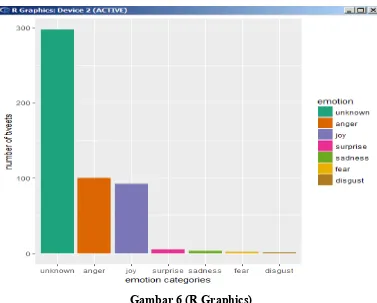
Untuk menampilkan Grafik Emotion CategoriesScript Programnya sebagai berikut: # plot distribution of emotions
ggplot(sent_df, aes(x=emotion)) + geom_bar(aes(y=..count..,
fill=emotion)) + scale_fill_brewer(palette="Dark2") + labs(x="emotion categories", y="number of tweets")
Gambar 6 (R Graphics)
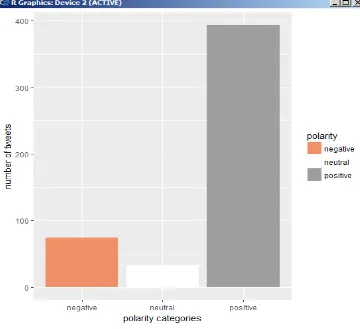
Gambar 7 (R Graphics)
# separating text by emotion
emos = levels(factor(sent_df$emotion))
nemo = length(emos)
emo.docs = rep("", nemo) for (i in 1:nemo)
{
tmp = some_txt[emotion == emos[i]] emo.docs[i] = paste(tmp, collapse=" ")
}
# remove stopwords
emo.docs = removeWords(emo.docs, stopwords("english"))
# create corpus
corpus = Corpus(VectorSource(emo.docs))
tdm = as.matrix(tdm) colnames(tdm) = emos
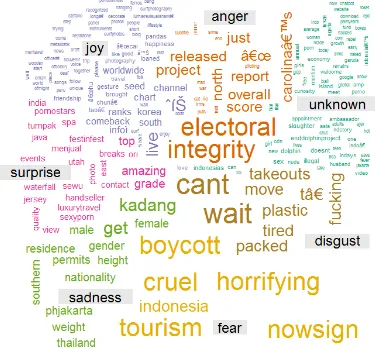
Untuk menampilkan World Cloud Script Programnya sebagai berikut: # comparison word cloud
comparison.cloud(tdm, colors = brewer.pal(nemo, "Dark2"),
scale = c(3,.5), random.order = FALSE, title.size = 1.5)
BAB V
KESIMPULAN DAN REKOMENDASI
5.1 KESIMPULAN
Penelitianmenggunakanmetode clustering inicukupefektifuntukmengetahui topic – topic apasaja yang sedangramai di perbincangkan
Dari penelitian / pembahasaninitentangmenganalisis dan mengklasifikasi sentimen melalui tweet di twitter dengan objek Indonesia, bahwa opinipositifnegatifatau sentiment masyarakatsangatbermacam – macam , darisegiemoticon yang ada sepertiyang terlihatpadaGrafik Emotion (Gambar 6), Grafik Polarity (Gambar 7), dantampilan GrafikWordCloud (Gambar 8).
5.2 REKOMENDASI
Untukperusahaan / instansi / komunitas yang sedangmencari data – data atauinformasimengenaitempat – tempat yang akandikunjungi , bisamenggunakanmetodeAnalisisSentimen Tweet melalui media Twitter, karenacukupefektifuntukmencari data - data yang di inginkan.
UntukpenelitianlanjutandanpembahasanlanjutandenganmetodeAnalisisSentime n Tweetinidiharapkanuntukterusmelakukanpembaruansistemdanpembaruan data – data yangakan di kerjakandalammetodeAnalisisSentimen Tweet ini,
karenaopiniatau sentiment
DAFTAR PUSTAKA
Eka Retnawijayati, F. E. (2016). Analisis Sentimen Pada Data Twitter dengan Menggunakan Text Mining terhadap Suatu Produk. Palembang: Universitas Bina Darma.
Nuke Y A Faradhillah, R. P. (2016). Eksperimen Sistem Klasifikasi Analisa Sentimen Twitter Pada Akun Resmi Pemerintah Kota Surabaya Berbasis Pembelajaran Mesin. Surabaya: Institut Teknologi Sepulih November.
Wibawa, B. (2018, Januari 8). Tugas Mata Kuliah Sistem Temu Kembali Informasi. Diambil kembali dari bachtiarwibawa.blogspot.co.id: http://bachtiarwibawa.blogspot.co.id/2016/12/tugas-mata-kuliah-sistem-temu-kembali.html
Kungfumas Wordpress. 2017. Analisa sentiment menggunakan R. (online)
LAMPIRAN
Source Code Analisa Sentiment Tweet
install.packages("twitteR")
some_tweets = searchTwitter("indonesia", n=500, lang="en")
# get the text
some_txt = sapply(some_tweets, function(x) x$getText())
# remove retweet entities
some_txt = gsub("(RT|via)((?:\\b\\W*@\\w+)+)", "", some_txt)
# remove at people
some_txt = gsub("@\\w+", "", some_txt)
# remove punctuation
some_txt = gsub("[[:punct:]]", "", some_txt)
# remove numbers
some_txt = gsub("[[:digit:]]", "", some_txt)
# remove html links
some_txt = gsub("http\\w+", "", some_txt)
# remove unnecessary spaces
some_txt = gsub("[ \t]{2,}", "", some_txt)
some_txt = gsub("^\\s+|\\s+$", "", some_txt)
# define "tolower error handling" function
try.error = function(x)
{
# create missing value
y = NA
# tryCatch error
# if not an error
if (!inherits(try_error, "error"))
y = tolower(x)
# result
return(y)
}
# lower case using try.error with sapply
some_txt = sapply(some_txt, try.error)
# remove NAs in some_txt
some_txt = some_txt[!is.na(some_txt)]
names(some_txt) = NULL
# classify emotion library(sentiment)
class_emo = classify_emotion(some_txt, algorithm="bayes", prior=1.0)
# get emotion best fit
emotion = class_emo[,7]
# substitute NA’s by "unknown"
emotion[is.na(emotion)] = "unknown"
# classify polarity
class_pol = classify_polarity(some_txt, algorithm="bayes")
# get polarity best fit
polarity = class_pol[,4]
# data frame with results
polarity=polarity, stringsAsFactors=FALSE)
# sort data frame
sent_df = within(sent_df,
emotion <- factor(emotion, levels=names(sort(table(emotion), decreasing=TRUE))))
# plot distribution of emotions ggplot(sent_df, aes(x=emotion)) +
geom_bar(aes(y=..count.., fill=emotion)) + scale_fill_brewer(palette="Dark2") +
labs(x="emotion categories", y="number of tweets") ---ggplot(sent_df, aes(x=polarity)) +
geom_bar(aes(y=..count.., fill=polarity)) +
scale_fill_brewer(palette="RdGy") +
labs(x="polarity categories", y="number of tweets") ---# separating text by emotion
emos = levels(factor(sent_df$emotion))
nemo = length(emos)
emo.docs = rep("", nemo)
for (i in 1:nemo)
{
tmp = some_txt[emotion == emos[i]]
emo.docs[i] = paste(tmp, collapse=" ")
}
# remove stopwords
emo.docs = removeWords(emo.docs, stopwords("english"))
corpus = Corpus(VectorSource(emo.docs))
tdm = TermDocumentMatrix(corpus)
tdm = as.matrix(tdm)
colnames(tdm) = emos
# comparison word cloud
comparison.cloud(tdm, colors = brewer.pal(nemo, "Dark2"),