ISSN : 2502-8928 (Online) 151
Received June 1st,2012; Revised June 25th, 2012; Accepted July 10th, 2012
APLIKASI PREDIKSI PENJUALAN BARANG
MENGGUNAKAN METODE K-NEAREST NEIGHBOR
(KNN) (STUDI KASUS TUMAKA MART)
Hasmawati*1, Jumadil Nangi2, Mutmainnah Muchtar3 *1,2,3
Jurusan Teknik Informatika, Fakultas Teknik, Universitas Halu Oleo, Kendari e-mail:*[email protected], 2jumadilnangi87@ gmail.com,
3
Abstrak
Salah satu kegiatan usaha yang harus dilakukan agar perusahaan tetap berjalan dan berkembang adalah penjualan. Keputusan yang diambil pemegang tanggung jawab perusahaan akan mempengaruhi perusahaan dimasa depan. Salah satu keputusan yang harus ditentukan yaitu produk yang akan diproduksi dan dijual untuk periode selanjutnya. Dalam menentukan keputusan diperlukan metode agar keputusan yang akan diambil dapat tepat sasaran. Teknik yang digunakan untuk memperkirakan keadaan pada periode selanjutnya disebut prediksi. Penelitian ini mengusulkan pengembangan aplikasi prediksi penjualan barang. Adapun metode yang di usulkan adalah metode K-Nearest Neighbor dengan studi kasus Tumaka Mart. Hasil penelitian menunjukan metode yang diusulkan berhasil diimplementasikan untuk menyelesaikan kasus prediksi penjualan dengan tingkat error atau Mean Absolute Percentage Error sebesar 6 % dan akurasi 94 %.
Kata kunci—Penjualan, Prediksi, K-Nearest Neighbor.
Abstract
One of the business activities that must be done to keep the company running and growing is sales. Decisions taken by corporate responsibility holder will affect the company in the future. One of the decisions that must be determined is the product to be produced and sold for the next period. In determining the decision required method for decisions to be taken can be right on target. The technique used to estimate the situation in the next period is called prediction. This research proposes the development of sales prediction application of goods. The method proposed is K-Nearest Neighbor method with Tumaka Mart case study. The results showed that the proposed method was successfully implemented to solve sales prediction cases with error rate or Mean Absolute Percentage Error of 6% and 94% accuracy.
Keywords—Sales, Prediction, K-Nearest Neighbor.
1. PENDAHULUAN
erusahaan atau badan usaha didirikan dengan tujuan menghasilkan barang dan jasa yang ditujukan untuk kebutuhan konsumen sekaligus untuk mendapatkan keuntungan bagi perusahaan atau badan usaha tersebut. Selain itu dengan berdirinya perusahaan atau badan usaha juga dapat membantu mengurangi angka pengangguran melalui penyediaan lapangan pekerjaan,
sehingga mampu meningkatkan pertumbuhan ekonomi negara.
Kegiatan penjualan merupakan salah satu bagian utama dari kegiatan usaha dan juga merupakan salah satu indikator penting dalam dunia usaha. Penjualan berkaitan erat dengan laba dan rugi suatu badan usaha. Apabila tingkat penjualan yang dilakukan perusahaan bernilai besar maka keuntungan perusahaan tersebut juga besar, sehingga perusahaan atau badan usaha tersebut dapat bertahan menghadapi persaingan yang semakin ketat
dan dapat mengembangkan usahanya. Keputusan yang diambil oleh pemegang tanggung jawab perusahaan akan mempengaruhi perusahaan di masa yang akan datang. Seorang pimpinan atau pembuat keputusan juga harus dapat memprediksi permintaan atas produk yang diproduksi untuk periode berikutnya.
Prediksi atau forecasting merupakan seni dan ilmu yang dilakukan untuk mengetahui atau memperkirakan apa yang terjadi pada masa yang akan datang. Prediksi menjadi sangat penting karena penyusunan suatu rencana, di antaranya didasarkan pada suatu proyeksi atau ramalan. Oleh karena itu perusahaan atau badan usaha perlu mempredisikan apa yang terjadi pada masa yang akan datang yang digunakan sebagai landasan pembuatan keputusan atau kebijakan untuk kelangsungan perusahaan. Prediksi dilakukan perusahaan bertujuan untuk mengetahui dan memperkirakan jumlah penjualan yang akan datang dan jumlah kesalahan prediksi, sehingga dapat memenuhi kebutuhan konsumen dan manajemen perusahaan [1].
Permasalahan yang umum dihadapi oleh para pemilik perusahaan atau badan usaha adalah bagaimana memprediksi atau meramalkan penjualan barang di masa mendatang berdasarkan data yang telah direkam sebelumnya. Prediksi tersebut sangat berpengaruh pada keputusan pemilik perusahaan untuk menentukan jumlah barang yang harus disediakan, apabila memesan barang dalam jumlah yang cukup banyak dan ternyata penjualan barang tersebut hanya terjual beberapa saja. Oleh karenanya diperlukan aplikasi yang dapat membantu perusahaan atau badan usaha dalam memperkirakan jumlah permintaan barang, dengan menerapkan metode-metode peramalan tertentu. Tumaka Mart merupakan badan usaha yang bergerak pada bidang pengeceran (Retailing).Tumaka Mart masih menghadapi permasalahan yang umum di hadapi oleh pemilik badan usaha, misanya adanya kesulitan dalam penyediaan barang, seperti banyaknya stok barang yang kosong atau banyaknya barang yang tidak laku terjual. Ada banyak metode peramalan penjualan, salah satunya adalah metode K-Nearest Neighbor. Algoritma K-Nearest Neighbor digunakan karena memiliki akurasi
yang tinggi dengan rasio kesalahan kecil. K-Nearest Neighbor merupakan salah satu algoritma machine learning yang dianggap sederhana dalam implementasinya. Berdasarkan latar belakang tersebut mendorong peneliti untuk melakukan penelitian yang berjudul “APLIKASI
PREDIKSI PENJUALAN BARANG
MENGGUNAKAN METODE K-NEAREST NEIGHBOR (KNN) (Studi Kasus Tumaka Mart) “.
2. METODE PENELITIAN
2.1. Aplikasi Perangkat Lunak
Perangkat lunak dapat diaplikasikan ke berbagai situasi dimana serangkaian langkah prosedural (seperti algoritma) telah didefenisikan [2]. Berikut adalah area perangkat lunak yang menunjukan luasnya aplikasi potensial :
a. Perangkat Lunak Sistem
Perangkat lunak sistem merupakan sekumpulan program yang ditulis untuk melayani program-program yang lain. Banyak perangkat lunak sistem (misal kompiler, editor, dan utilitas pengatur file) memproses struktur-struktur informasi yang lengkap namun tetap. Perangkat lunak sistem ditandai dengan eratnya interaksi dengan perangkat keras komputer.
b. Perangkat Lunak Real-Time
Program-program yang
diperpanjang tanpa memberikan risiko kerusakan pada hasil.
c. Perangkat Lunak Bisnis
Sistem diskrit (contohnya payroll, account receivable/payable, inventory) telah mengembangkan perangkat lunak sistem informasi manajemen (MIS) yang mengakses satu atau lebih database besar yang berisi informasi bisnis. Aplikasi perangkat lunak bisnis juga meliputi penghitungan klien/server serta penghitungan interaktif (misal pemrosesan transaksi point-of-sale).
d. Perangkat Lunak Teknik dan Ilmu Pengetahuan
Perangkat lunak teknik dan ilmu pengetahuan ditandai algoritma number crunching. Perangkat lunak ini memiliki jangkauan aplikasi mulai dari astronomi sampai vulkanologi, dari analisis otomotif sampai dinamika orbit pesawat ruang angkasa, dan dari biologi molekuler sampai pabrik yang sudah diotomatisasi. Computer-aided design, simulasi sistem, dan aplikasi interaktif yang lain, sudah mulai memakai ciri-ciri perangkat lunak sistem genap dan real-time.
e. Embedded Software
Embedded software ada dalam read-only memory dan dipakai untuk mengontrol hasil serta sistem untuk keperluan konsumen dan pasar industri. Embedded software dapat melakukan fungsi yang terbatas serta fungsi esoterik (misal key pad control untuk microwave) atau memberikan kemampuan kontrol dan fungsi yang penting (contohnya fungsi dijital dalam sebuah automobil seperti kontrol bahan bakar, penampilan dash-board, sistem rem, dll).
f. Perangkat Lunak Komputer Personal Pengolah kata, spreadsheet, grafik komputer, multimedia, hiburan, manajemen database, aplikasi keuangan, bisnis dan personal, jaringan eksternal atau akses database hanya merupakan beberapa saja dari ratusan aplikasi yang ada.
g. Perangkat Lunak Kecerdasan Buatan Perangkat lunak kecerdasan buatan (Artificial Inteligent /AI) menggunakan algoritma non-numeris untuk memecahkan masalah kompleks yang tidak sesuai untuk perhitungan atau analisis secara langsung.
Perangkat lunak kecerdasan buatan adalah pengenalan pola (image dan voice), pembuktian teorema, dan permainan game. Di tahun-tahun terakhir, cabang perangkat lunak kecerdasan buatan yang baru, yang disebut artificial neural network, telah berkembang. Jaringan syaraf mensimulasi struktur proses-proses otak dan kemudian membawanya kepada perangkat lunak kelas baru yang dapat mengenali pola-pola yang kompleks serta belajar dari pengalaman-pengalaman masa lalu.
2.2. Data Mining
Data mining merupakan gabungan dari berbagai bidang ilmu, antara lain basis data, information retrieval, statistika, algoritma dan machine learning. Bidang ini telah berkembang sejak lama namun makin terasa pentingnya sekarang ini di mana muncul keperluan untuk mendapatkan informasi yang lebih dari data transaksi maupun fakta yang terkumpul selama bertahun-tahun. Data mining adalah cara menemukan informasi tersembunyi dalam sebuah basis data dan merupakan bagian dari proses Knowledge Discovery in Databases (KDD) untuk menemukan informasi dan pola yang berguna dalam data [3].
Kegiatan data mining biasanya dilakukan pada sebuah data warehouse yang menampung data dalam jumlah besar dari suatu organisasi. Proses data mining mencari informasi baru, berharga dan berguna di dalam sekumpulan data bervolume besar dengan melibatkan komputer dan manusia serta bersifat iteratif baik melalui proses otomatis ataupun manual [3]. Secara umum, data mining terbagi dalam 2 sifat :
1. Predictive: menghasilkan model berdasarkan sekumpulan data yang dapat digunakan untuk memperkirakan nilai data yang lain. Metode-metode yang termasuk Predictive Data Mining adalah:
a. Klasifikasi: pembagian data ke dalam beberapa kelompok yang telah ditentukan sebelumnya
b. Regresi: memetakan data ke suatu prediction variable
2. Descriptive: mengidentifikasi pola atau hubungan dalam data untuk menghasilkan informasi baru. Metode yang termasuk dalam Descriptive Data Mining adalah: a. Clustering: identifikasi kategori untuk
mendeskripsikan data
b. Association Rules: identifikasi hubungan antara data yang satu dengan lainnya.
c. Summarization: pemetaan data ke dalam subset dengan deskripsi sederhana
d. Sequence Discovery: identifikasi pola sekuensial dalam data
2.3. Prediksi
Forecasting adalah suatu usaha untuk meramalkan keadaan di masa mendatang melalui pengujian keadaan di masa lalu. Dalam kehidupan sosial segala sesuatu itu serba tidak pasti, sukar untuk diperkirakan secara tepat. Dalam hal ini perlu diadakan forecast. Forecasting yang dibuat selalu diupayakan agar dapat meminimumkan pengaruh ketidakpastian ini terhadap perusahaan. Dengan kata lain forecasting bertujuan mendapatkan forecast yang bisa meminimumkan kesalahan meramal (forecast error) yang biasanya diukur dengan mean squared error, mean absolute error, dan sebagainya [4].
2.4. K-Nearest Neigbor
K-Nearest Neighbor (K-NN) adalah suatu metode yang menggunakan algoritma supervised dimana hasil dari query instance yang baru diklasifikasikan berdasarkan mayoritas dari label class pada K-NN. Tujuan dari algoritma K-NN adalah mengklasifikasikan objek baru berdasarkan atribut dan training data. Algoritma K-NN bekerja berdasarkan jarak terpendek dari query instance ke training data untuk menentukan K-NN-nya. Salah satu cara untuk menghitung jarak dekat atau jauhnya tetangga menggunakan metode euclidean distance [5].
Ecludian Distance sering digunakan untuk menghitung jarak. Euclidian Distance berfungsi menguji ukuran yang bisa digunakan sebagai interpretasi kedekatan jarak antara dua obyek [5]. Persamaan (1) menunjukkan perhitungan Ecludian Distance.
(1)
Dimana,
xik = nilai x pada training data
xjk = nilai x pada testing data
m = batas jumlah banyaknya data
Jika hasil nilai dari Persamaan (1) besar maka akan semakin jauh tingkat keserupaan antara kedua objek dan sebaliknya jika hasil nilainya semakin kecil maka akan semakin dekat tingkat keserupaan antar objek tersebut. Objek yang dimaksud adalah training data dan testing data. Dalam algoritma ini, nilai k yang terbaik itu tergantung pada jumlah data. Ukuran nilai k yang besar belum tentu menjadi nilai k yang terbaik begitupun juga sebaliknya. Langkah-langkah untuk menghitung algoritma K-NN:
1) Menentukan nilai k.
2) Menghitung kuadrat jarak euclid (query instance) masing-masing objek terhadap training data yang diberikan.
Persamaan (1) menunjukkan perhitungan kuadrat jarak euclid (query instance) masing-masing objek terhadap training data yang diberikan.
3) Kemudian mengurutkan objek-objek tersebut ke dalam kelompok yang mempunyai jarak euclid terkecil.
4) Menghitung rata-rata dari nilai objek pada jangkauan K dengan menggunakan kategori Nearest Neighbor yang terdekat (jangkauan K), maka dapat diprediksi nilai query instance yang telah dihitung . Persamaan 2 menjukkan perhitungan rata-rata dari nilai objek pada jangkauan K. Persamaan (2) menunjukkan perhitungan rata-rata nilai objek pada jangkauan K.
(2)
2.5. Penjualan
Penjualan merupakan kegiatan ekonomis yang umum, dimana dengan penjualan sebuah perusahaan akan memperoleh hasil/laba sesuai dengan yang direncanakan atau memperoleh pengembalian atas biaya biaya yang dikeluarkan [6].
umumnya mempunyai 3 tujuan umum dalam penjualannya yaitu:
1. Mencapai volume penjualan tertentu, 2. Mendapatkan laba tertentu,
3. Menunjang pertumbuhan perusahaan.
2.6 Pemograman Java
Java adalah bahasa pemrograman yang berorientasi obyek (OOP) yang dapat dijalankan apada berbagai platform sistem operasi. Perkembangan java tidak hanya terfokus pada suatu sistem operasi, tetapi dikembangkan untuk berbagai sistem operasi dan bersifat open source [7]. Bahasa pemograman java sendiri terbagi menjadi 3 edition yaitu:
1. J2SE (Java 2 Standard Edition)
J2SE adalah inti dari bahasa pemrograman Java. JDK (Java Development Kit) adalah salah satu tool dari J2SE untuk mengompilasi dan menjalankan program java. Di dalamnya terdapat tool untuk mengompilasi dan JRE. Tool J2SE yang salah satunya adalah jdk 1.6, jdk merupakan tool open source dari Sun.
2. J2EE (Java 2 Enterprise Edition)
J2EE adalah sekelompok dari beberapa API (Application Programming Interface) dari java dan teknologi selain java.J2EE dibuat untuk membuat aplikasi yang kompleks. J2EE sering dianggap sebagai middleware atau teknologi yang berjalan di server, namun sebenarnya J2EE tidak hanya terbatas untuk itu.
3. J2ME (Java 2 Micro Edition)
Midlet untuk aplikasi mobile. J2ME merupakan edisi library yang dirancang untuk digunakan pada device tertentu seperti pagers dan mobile phone.
2.7. Mean Absolute Etor (MAE)
Mean Absolute Error (MAE). MAE bertujuan menghitung seberapa besar rata-rata selisih nilai prediksi rating yang dihasilkan oleh sistem dengan nilai rating yang sudah ada. Evaluasi MAE memanfaatkan teknik perhitungan yang sangat sederhana, yaitu dengan mencari selisih dari semua item yang di beri oleh sistem dengan item yang sudah ada. Nantinya selisih tersebut akan di absolute-kan (nilai positif) dan akhirnya di rata-rata. Dari hasil MAE, dapat terlihat jelas seberapa jauh selisih nilai prediksi rating yang
di berikan oleh sistem dengan nilai rating yang sebenarnya. Semakin besar nilai yang di dihasilkan oleh MAE maka dapat diartikan bahwa nilai prediksi yang dihasilkan semakin tidak akurat, sebaliknya jika nilai MAE yang di hasilkan mendekati 0 maka prediksi yang dihasilkan sistem semakin mendekati akurat [8]. Persamaan (3) menunjukkan perhitungan nilai MAE.
(3)
Dimana :
2.8. Mean Absolute Precentage Error (MAPE)
Mean Absolute Precentage Error (MAPE) dihitung dengan menggunakan kesalahan absolute pada tiap periode dibagi dengan nilai observasi yang nyata untuk periode itu. Kemudian, merata-ratakan kesalahan presentase absolute tersebut. MAPE merupakan pengukuran kesalahan yang menghitung ukuran presentase penyimpangan antara data aktual dengan data prediksi [9]. Persamaan (4) menunjukkan perhitungan nilai MAPE.
(4)
Dimana :
3. HASIL DAN PEMBAHASAN
Aplikasi prediksi penjualan barang yang telah dirancang merupakan sebuah aplikasi yang menggunakan bahasa pemograman Java NetBeans yang dibangun untuk memprediksi penjualan barang setiap bulannya di Tumaka Mart. Aplikasi ini menggunakan metode K-Nearest Neighbor (KNN).
Tebel 1 menunjukkan spesifikasi perangkat keras.
Tabel 1 Spesifikasi Perangkat Keras
No Nama Perangkat Spesifikasi
1. Processor Intel Core i3
2. Monitor Monitor 15,6 inch
4. Harddisk 1TB HDD
Tabel 2 menunjukkan spesifikasi perangkat lunak.
Tabel 2 Spesifikasi Perangkat Lunak
No Nama Perangkat Spesifikasi
1. Operating System Windows 7
2. NetBeans 8.0.2
3. Xampp 3.2.1
a. Flowchart Aplikasi
Flowchart aplikasi Prediksi Penjualan Barang Menggunakan Metode K-Nearest Neigbor (KNN). Gambar 1 menunjukkan flowchart aplikasi.
Gambar 1 Flowchart Aplikasi
b. Flowchart Metode K-Nearest Neigbor (KNN)
Gambar 2.menunjukkan flowchart metode KNN.
Gambar 2 flowchart Metode KNN.
c. Contoh Perhitungan Metode K-Nearest Neighbor (KNN) :
1. Pada kasus ini menggunakan data penjualan bulan 1 dan bulan 2 untuk meramalkan data penjualan pada bulan ke 3. Tabel 3 menunjukkan data penjualan barang.
Tabel 3 Data Penjualan Barang
Bulan 1 Bulan 2 Bulan 3 (Target)
103 129 112
119 133 125
133 140 139
120 137 129
2. Pada kasus ini diberikan nilai untuk menghitung nilai Bulan 3 dengan nilai Bulan 1 = 125 dan Bulan 2 = 134.
3. Menentukan nilai K. pada kasus ini nilai K = 2
Menghitung jarak Euclid data baru terhadap data yang ada. Tabel 4 menunjukkan perhitungan jarak Euclid.
Tabel 4 Menghitung Jarak Euclid
Bulan 1 Bulan 2
Squared distance to query distance
(125,134)
103 129 (103 - 125)
2 + (129 - 134) 2 = 17
119 133 (119 - 125)
2 + (133 - 134) 2 = 7
133 140 (133 - 125)
2 + (140 - 134) 2 = 14
120 137 (120 - 125)
2 + (137 - 134) 2 = 8
4. Mengurutkan jarak Euclid terkecil.
Tabel 5 menunjukkan urutan jarak Euclid terkecil
Tabel 5 Mengurutkan Jarak Euclid Terkecil
Bulan 1 Bulan 2
Squared distance to query distance
(125,134)
Urutan Jarak Terkecil
Apa termaksuk
Nearest Neighbor
(K)
103 129
(103 - 125) 2 +
(129 - 134) 2 =
17
4 Tidak
119 133
(119 - 125) 2 +
(133 - 134) 2 =
7
1 Iya
133 140
(133 - 125) 2 +
(140 - 134) 2 =
14
3 Tidak
120 137
(120 - 125) 2 + (137 - 134) 2 =
8
5. Menghitung rata-rata dari nilai object pada jangkauan nearest neighbor (K)
d. Pengujian Perbandingan Perhitungan Manual KNN dengan Perhitungan Aplikasi
Pengujian ini akan membandingkan perhitungan manual menggunakan metode K-Nearest Neigbor (KNN) dengan perhitungan aplikasi menggunakan metode K-Nearest Neighbor. Tabel 6 menunjukkan Perbandingan Perhitungan Manual dan perhitungan Aplikasi Menggunakan Metode KNN.
Tabel 6 Perbandingan Perhitungan Manual dan perhitungan Aplikasi Menggunakan Metode KNN
Perhitungan Manual Perhitungan Aplikasi
Nama
e. Pengujian Analisis Keakurasian Hasil Prediksi
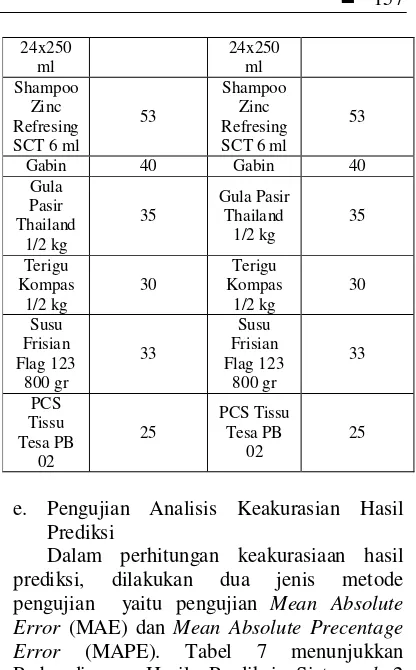
Dalam perhitungan keakurasiaan hasil prediksi, dilakukan dua jenis metode pengujian yaitu pengujian Mean Absolute Error (MAE) dan Mean Absolute Precentage Error (MAPE). Tabel 7 menunjukkan Perbandingan Hasil Prediksi Sistem k=2 dengan Hasil Sebenarnya.
Tabel 7 Perbandingan Hasil Prediksi Sistem k = 2 dengan Hasil Sebenarnya
Nama Barang
Hasil Prediksi dengan
k=2 Hasil yang Sebenarnya
Putih BAG 900 gr Sunlight
Anti Bacteria
250 gr
50 46 54 55 37 34 51 53
Lifebuoy BW Red
Ref 24x250
ml
66 72 71 70 54 37 29 42
Shampoo Zinc Refresin g SCT 6
ml
53 58 59 52 34 39 27 31
Gabin 40 41 32 34 31 36 25 28
Gula Pasir Thailand
1/2 kg
35 35 34 30 32 34 31 29
Terigu Kompas
1/2 kg
30 27 30 27 28 15 26 31
Susu Frisian Flag 123
800 gr
32 32 30 29 21 18 26 24
PCS Tissu Tesa PB
02
25 25 24 28 21 18 28 13
Perhitungan Mean Absolute Error (MAE) untuk Aqua Botol Tengah 600 ml dengan nilai k = 2.
Perhitungan Mean Absolute Precentage Error (MAPE) untuk Aqua Botol Tengah 600 ml dengan nilai k = 2.
4. KESIMPULAN
Berdasarkan studi literatur, analisis, perancangan, implementasi dan pengujian sistem ini, maka kesimpulan yang di dapat adalah sebagai berikut :
1. Aplikasi prediksi penjualan barang dengan studi kasus Tumaka Mart berhasil dibangun dengan menerapkan metode K-Nearest Neighbor (KNN).
2. Berdasarkan hasil pengujian yang dilakukan, Aplikasi prediksi penjualan barang menggunakan metode K-Nearest Neighbor (KNN) (studi kasus Tumaka Mart) mampu melakukan prediksi penjualan dengan nilai error
terkecil sebesar 0,001 % dan nilai error tertinggi adalah sebesar 1,231 %. Rata-rata nilai K yang menghasilkan error terkecil adalah nilai k = 2.
5. SARAN
Adapun saran yang dapat diberikan untuk pengembangan dan perbaikan aplikasi ini untuk selanjutnya yaitu diharapkan dapat dilakukan pengembangan pada aplikasi prediksi penjualan barang ini, dengan menambahkan jumlah sampel barang dan rentang waktu penjualan barang yang akan diprediksi.
DAFTAR PUSTAKA
[1] Indra Wibowo. 2010. “Analisis Permasalahan Penjualan Rokok Golden pada PT. Djitoe IndonesianTobacco Surakarta,”.
[2] Basu Swasta. 2001. Manajemen Penjualan. Yogyakarta: Badan Penerbit Fakultas Ekonomi, Universitas Gajah Mada.
[3] Jiawei Han and Kamber Micheline. 2006. Data Mining, Southeast Asia Edition: Concepts And Techniques. Morgan kaufmann.
[4] Bruce L., and Richard T. O’Connell Bowerman, 1993. Forecasting and time series: An Applied approach. 3rd.
[5] Lv Yisheng and Shuming Tang. 2009. “Real-time Highway Traffic Accident Prediction Based on the k-Nearest Neighbor Method, “in International Conference on Measuring Technology and Mechatronics Automation.
[6] Annastasya Liberty. 2015. “Sistem Informasi Meramalkan Penjualan Barang dengan Metode Double Exponential Smoothing”. Universitas Kristen Maranatha.
Pemograman Java”. Universitas Guna Darma.
[8] Nendang Kacikal. 2011. “Sistem Peramalan Dan Monitoring Persediaan Obat Di RSPG Cisaru Bogor Dengan Menggunakan Metode Single Exponential Smoothing Dan Reorder Point”. Universitas Komputer Indonesia.