LAMPIRAN
DATA SET DIABETES
(700 Instances, 9 Attributes, 2 Classes)
Sumber: UCI Machine Learning Repository, yaitu: PIMA Indians Diabetes Dataset.
LISTING PROGRAM
<meta http-equiv="refresh" content="<?php echo $sec?>;URL='<?php echo $page?>'"> <?php
$time = microtime(); $time = explode(' ', $time); $time = $time[1] + $time[0]; $start = $time;
$sql_cek_iterasi = mysql_query("SELECT * FROM iterasi"); if(mysql_num_rows($sql_cek_iterasi) == 0){
$sql_akumulasi_jarak = mysql_query("SELECT * FROM akumulasi_jarak"); $array_akumulasi_jarak = mysql_fetch_array($sql_akumulasi_jarak);
mysql_query("INSERT INTO iterasi SET iterasi=1") or die(mysql_error());
$iterasi_tampil=1;
mysql_query("INSERT INTO iterasi SET iterasi='$iterasi'") or die(mysql_error()); }
$delete_jarak = mysql_query("DELETE FROM jarak");
$delete_akumulasi_jarak = mysql_query("DELETE FROM akumulasi_jarak"); //menentukan jumlah euclide distance
$sql_acak = mysql_query("SELECT * FROM nilai_acak ORDER BY id_nilai_acak ASC"); $i=1;
while($array_nilai_acak = mysql_fetch_array($sql_acak)){ $k = $i-1;
$sql_sampel = mysql_query("SELECT * FROM sampel ORDER BY id_sampel ASC"); while($array_sampel = mysql_fetch_array($sql_sampel)){
$cluser = sqrt(pow(($array_sampel['sampel_1'] - $array_nilai_acak['x1']),2) + pow(($array_sampel['sampel_2'] - $array_nilai_acak['x2']),2)
+ pow(($array_sampel['sampel_3'] - $array_nilai_acak['x3']),2) + pow(($array_sampel['sampel_4'] - $array_nilai_acak['x4']),2)
+ pow(($array_sampel['sampel_5'] - $array_nilai_acak['x5']),2) + pow(($array_sampel['sampel_6'] - $array_nilai_acak['x6']),2)
+ pow(($array_sampel['sampel_7'] - $array_nilai_acak['x7']),2) + pow(($array_sampel['sampel_8'] - $array_nilai_acak['x8']),2)) ;
$insert_jarak = mysql_query("INSERT INTO jarak VALUES ('','$array_sampel[id_sampel]','$cluser','$k')");
}
$i++; }
//menentukan jumlah euclide distanc
//perhitungan euclidean distancet terhadap centroid pada sampel
$sql_sampel = mysql_query("SELECT a.*,b.* FROM sampel a, jarak b where a.id_sampel=b.id_sampel ORDER BY a.id_sampel ASC");
while($array_sampel = mysql_fetch_array($sql_sampel)){
$sql_max_jarak = mysql_query("SELECT MIN(hasil) AS hasil_max, urutan, id_sampel FROM jarak WHERE id_sampel='$array_sampel[id_sampel]'");
$array_max_jarak = mysql_fetch_array($sql_max_jarak); if($array_max_jarak['hasil_max'] == $array_sampel['hasil']){
$insert_jarak = mysql_query("INSERT INTO akumulasi_jarak VALUES ('','$array_sampel[id_sampel]','$array_max_jarak[hasil_max]',$array_sampel[urutan])"); $insert_jarak = mysql_query("INSERT INTO akumulasi_jarak2 VALUES ('','$array_sampel[id_sampel]','$array_max_jarak[hasil_max]',$array_sampel[urutan])"); }
}
//perhitungan euclidean distancet terhadap centroid pada sampel //proses perpindahan centroids
$sql_num_sampel1 = mysql_query("SELECT a.*,b.* FROM sampel a, akumulasi_jarak b where a.id_sampel=b.id_sampel and b.urutan=0 ORDER BY a.id_sampel ASC");
$num_sampel1 = mysql_num_rows($sql_num_sampel1);
$sql_sampel_urutan_1 = mysql_query("SELECT SUM(a.sampel_1) AS nilai_1,SUM(a.sampel_2) AS nilai_2,
SUM(a.sampel_3) AS nilai_3,SUM(a.sampel_4) AS nilai_4,SUM(a.sampel_5) AS nilai_5,SUM(a.sampel_6) AS nilai_6,SUM(a.sampel_7) AS nilai_7
,SUM(a.sampel_8) AS nilai_8 FROM sampel a, akumulasi_jarak b where a.id_sampel=b.id_sampel and b.urutan=0 ORDER BY a.id_sampel ASC");
$sql_num_sampel2 = mysql_query("SELECT a.*,b.* FROM sampel a, akumulasi_jarak b where a.id_sampel=b.id_sampel and b.urutan=1 ORDER BY a.id_sampel ASC");
$num_sampel2 = mysql_num_rows($sql_num_sampel2);
$sql_sampel_urutan_2 = mysql_query("SELECT SUM(a.sampel_1) AS nilai_1,SUM(a.sampel_2) AS nilai_2,
SUM(a.sampel_3) AS nilai_3,SUM(a.sampel_4) AS nilai_4,SUM(a.sampel_5) AS nilai_5,SUM(a.sampel_6) AS nilai_6,SUM(a.sampel_7) AS nilai_7
,SUM(a.sampel_8) AS nilai_8 FROM sampel a, akumulasi_jarak b where a.id_sampel=b.id_sampel and b.urutan=1 ORDER BY a.id_sampel ASC");
$array_sampel_urutan_2 = mysql_fetch_array($sql_sampel_urutan_2) or die(mysql_error());
$update_1 = mysql_query("INSERT INTO nilai_acak VALUES ('','$sampel1_urutan_1','$sampel2_urutan_1',
'$sampel3_urutan_1','$sampel4_urutan_1','$sampel5_urutan_1','$sampel6_urutan_1','$sampel 7_urutan_1','$sampel8_urutan_1')");
$update_1 = mysql_query("INSERT INTO nilai_acak VALUES ('','$sampel1_urutan_2','$sampel2_urutan_2',
'$sampel3_urutan_2','$sampel4_urutan_2','$sampel5_urutan_2','$sampel6_urutan_2','$sampel 7_urutan_2','$sampel8_urutan_2')");
$sql_pilihan = mysql_query("SELECT * FROM akumulasi_jarak ORDER BY id_akumulasi_jarak ASC");
$array_pilihan = mysql_fetch_array($sql_pilihan);
$id_akumulasi_jarak = $array_pilihan['id_akumulasi_jarak'];
$sql_cek = mysql_query("SELECT * FROM akumulasi_jarak WHERE id_sampel='$array_pilihan[id_sampel]' and id_akumulasi_jarak='$id_akumulasi_jarak'"); $array_cek = mysql_fetch_array($sql_pilihan);
//proses perpindahan centroids
$total_time = round(($finish - $start), 4);
$sql_adult = mysql_query("select a.*,b.* from sampel a, akumulasi_jarak b where a.id_sampel=b.id_sampel
order by urutan asc ");
$sql_cek_akumulasi_jarak = mysql_query("SELECT * FROM akumulasi_jarak ORDER BY id_sampel ASC");
$array_cek_akumulasi_jarak = mysql_fetch_array($sql_cek_akumulasi_jarak); $cluster_pilihan = $array_cek_akumulasi_jarak['cluster_pilihan'];
$id_sampel_pilihan = $array_cek_akumulasi_jarak['id_sampel'];
$sql_num_akumulasi = mysql_query("SELECT * FROM akumulasi_jarak2 WHERE cluster_pilihan='$cluster_pilihan' and id_sampel='$id_sampel_pilihan'");
$num = mysql_num_rows($sql_num_akumulasi); if($num > 2){
$time = $time[1] + $time[0];
$sql_acak = mysql_query("SELECT * FROM testing ORDER BY id_testing DESC"); $i=1;
//proses perhitungan similiarity funtion pada algoritma KNN while($array_nilai_acak = mysql_fetch_array($sql_acak)){
$sql_sampel = mysql_query("SELECT * FROM sampel ORDER BY id_sampel ASC"); while($array_sampel = mysql_fetch_array($sql_sampel)){
$cluser = sqrt(pow(($array_sampel['sampel_1'] - $array_nilai_acak['x1']),2) + pow(($array_sampel['sampel_2'] - $array_nilai_acak['x2']),2)
+ pow(($array_sampel['sampel_3'] - $array_nilai_acak['x3']),2) + pow(($array_sampel['sampel_4'] - $array_nilai_acak['x4']),2)
+ pow(($array_sampel['sampel_5'] - $array_nilai_acak['x5']),2) + pow(($array_sampel['sampel_6'] - $array_nilai_acak['x6']),2)
+ pow(($array_sampel['sampel_7'] - $array_nilai_acak['x7']),2) + pow(($array_sampel['sampel_8'] - $array_nilai_acak['x8']),2)) ;
$insert_jarak = mysql_query("INSERT INTO jarak_knn VALUES ('','$array_sampel[id_sampel]','$cluser')") or die(mysql_error());
}
$i++; }
//proses perhitungan similiarity funtion pada algoritma KNN //nilai similiarity function pada sample
$sql_num = mysql_query("SELECT * FROM jarak_knn"); $sisa = mysql_num_rows($sql_num) - $k;
$sql_limit_atas = mysql_query("SELECT * FROM jarak_knn ORDER BY nilai DESC LIMIT $k") or die(mysql_error());
while($array_limit_atas = mysql_fetch_array($sql_limit_atas)){
$insert = mysql_query("INSERT INTO akumulasi_knn VALUES ('','$array_limit_atas[id_sampel]','Positif')");
}
$sql_limit_bawah = mysql_query("SELECT * FROM jarak_knn ORDER BY nilai ASC LIMIT $sisa");
while($array_limit_bawah = mysql_fetch_array($sql_limit_bawah)){
$insert = mysql_query("INSERT INTO akumulasi_knn VALUES ('','$array_limit_bawah[id_sampel]','Negatif')");
$total_time = round(($finish - $start), 4); //menghitung waktu eksekusi
?>
<div id="page_content">
<div id="page_content_inner">
<th>Umur(years) (age)</th>
$sql_adult = mysql_query("select a.*,b.* from sampel a, akumulasi_knn b where a.id_sampel=b.id_sampel
<td><?php echo $array_adult['sampel_8'];?></td>
if($nilai == $array_cek_knn['hasil'])
$ketepatan = 1;
} else {
$ketepatan = 0; }
$insert_ketepatan =
mysql_query("INSERT INTO cek_knn VALUES ('','$id_sampel','$ketepatan')"); }
$select_total = mysql_query("SELECT COUNT(*) AS jum_sampel FROM sampel");
$array_total = mysql_fetch_array($select_total);
$select = mysql_query("SELECT COUNT(*) AS jum_ketepatan FROM cek_knn WHERE ketepatan = '1'");
$array = mysql_fetch_array($select);
$ketepatan = ($array['jum_ketepatan'] / $array_total['jum_sampel']) * 100;
<h3 class="heading_b uk-margin-bottom">Hasil K-Means</h3> <div class="md-card">
$sql_adult = mysql_query("select a.*,b.* from sampel a, akumulasi_jarak b where a.id_sampel=b.id_sampel
and b.urutan='1'
order by a.id_sampel asc "); $string_positif = "";
while($array_adult = mysql_fetch_array($sql_adult)){
$string_positif .= "Sampel " . $array_adult['id_sampel'] . ', '; }
echo substr($string_positif, 0, strlen($string_positif) - 2); ?>
</div> </div>
</div>
$sql_adult = mysql_query("select a.*,b.* from sampel a, akumulasi_jarak b where a.id_sampel=b.id_sampel
and b.urutan='0'
order by a.id_sampel asc "); $string = "";
while($array_adult = mysql_fetch_array($sql_adult)){ $string .= "Sampel " . $array_adult['id_sampel'] . ', '; }
echo substr($string, 0, strlen($string) - 2); ?>
$sql_adult = mysql_query("select a.*,b.* from sampel a, akumulasi_knn b where a.id_sampel=b.id_sampel
and b.hasil='Positif'
order by id_akumulasi_knn asc "); $string_positif = "";
while($array_adult = mysql_fetch_array($sql_adult)){
$string_positif .= "Sampel " . $array_adult['id_sampel'] . ', '; }
echo substr($string_positif, 0, strlen($string_positif) - 2); ?>
$sql_adult = mysql_query("select a.*,b.* from sampel a, akumulasi_knn b where a.id_sampel=b.id_sampel
and b.hasil='Negatif'
order by a.id_sampel asc "); $string = "";
while($array_adult = mysql_fetch_array($sql_adult)){ $string .= "Sampel " . $array_adult['id_sampel'] . ', '; }
DAFTAR PUSTAKA
[AGU07] Agusta, Y. 2007. K-Means-Penerapan, Permasalahan dan Metode Terkait. Denpasar, Bali: Jurnal Sistem dan Informatika Vol.3, pp : 47-60.
[BUD13] Budiman, I. 2012. Data Clustering Menggunakan Metodologi CRISP- DM Untuk Pengenalan Pola Proporsi Pelaksanaan Tridharma. Tesis. Universitas Diponegoro.
[HUL13] Huliman.2013. Analisis Akurasi Algoritma Pohon Keputusan dan K-Nearest Neighbor (KNN).Tesis.Universitas Sumatera Utara.
[LAR05] Larose Daniel,T .2005. Discovering knowledge in data : an introduction to
data mining , John Wiley & Sons, Inc.
[MIR08] Mirza, M. 2008. Mengenal Diabetes Melitus. Kata Hati. Yogyakarta. [NUG11] Nugraheni, Y. 2011. Data Mining degan Metode Fuzzy Untuk Customer
Relationship Management (CRM) pada Perusahaan Retail. Universitas Udayana.
[NUR11] Nurjayanti B. 2011. Identifikasi shorea menggunakan K-Nearest Neighbor berdasarkan karakteristik morfologi daun. Skripsi. Institut Pertanian Bogor. [ONG13] Ong, J. O. 2013. Implementasi Algoritma K-Means Clustering Untuk
Menentukan Strategi Marketing President University(12):10-20.
[OSC13] Oscar Ong, J .2013. Implementasi Algoritma k-means Clustering untuk no. 1, pp. Menentukan Strategi Marketing President University. Jurnal Ilmiah
Teknik Industri. vol. 12,10-13.
[PAU12] Paulanda, Z. 2012. Model Profil Mahasiswa Yang Potensisal Drop Out Menggunakan Teknik Kernel-K-Mean Clustering Dan Decision Tree. Tesis. Universitas Sumatera Utara. 2013.
[RIS08] Rismawan, T & Kusumadewi, S. 2008. Aplikasi K-Means Untuk
Pengelompokkan Mahasiswa Berdasarkan Nilai Body Mass Index (BMI) & Ukuran Kerangka, SNATI. Yogyakarta.
[SAN07] Santosa, B. 2007. Data Mining : Teknik Pemanfaatan Data untuk Keperluan
Bisnis, Teori dan Aplikasi. Graha Ilmu. Yogyakarta.
[SOE04] Soegondo, S, dkk, 2004. Penatalaksanaan Diabetes Mellitus Terpadu. FKUI. Jakarta.
[SOR11] Soraya, Y. 2011. Perbandingan Kinerja Metode Single Linkage, Metode Complete Linkage dan Metode K-Means dalam Analisis Cluster. Universitas
81
[UTA10] Utami, D. D. P & Sutikno. 2010. Pengelompokan Zona Musim (ZOM) Dengan Fuzzy K-Means Clustering.
[VER09] Vercilles, Carlo. 2009. Business Intelligence: Data Mining and Optimazation for Decision Making. United Kingdom: Joh Wiley & Sons Ltd.
[ZAR13] Zarlis, M., Sitompul, O.S., Sawaluddin, Effendi, S., Sihombing, P. & Nababan, E.B.2013. Pedoman Penulisan Tesis. FasilkomTI. Universitas Sumatera Utara.
[MIR14] Mirkes EM. 2011. KNN and potential energy.
http://www.math.le.ac.uk/people/ag153/homepage/KNN/KNN3.html. (6 September 2014).
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
3.1 Pengumpulan Data Pelatihan
PIMA Indians Dataset adalah sebuah dataset yang didapat dari National Institute of
Diabetes and Digestive and Kidney Diseases dan pertama kali digunakan oleh
Smith,~J.~W., Everhart,~J.~E., Dickson,~W.~C., Knowler,~W.~C., \& Johannes,~R.~S pada tahun 1988 pada sebuah penelitian dengan judul memprediksi apakah sebuah sample terindikasi Diabetes Mellitus atau peramalan diabetes militus pada populasi di Phoenix, Arizona, USA. Dataset ini terdiri dari 12 kolom sehingga dalam penelitian ini diperlukan beberapa langkah pre-processing guna mengolah raw
data yang didapat sehingga menjadi data yang siap di training, adapun langkah- langkah nya adalah sebagai berikut:
1. Membuat rancangan data input dan output yang akan dimasukkan sebagai data penelitian
2. Memisahkan data penelitian menjadi dua bagian, yaitu data pelatihan dan data pengujian. Data pelatihan diguanakan untuk mengamati proses pengenalan pola (memorisasi), sedanga data pengujian digunakan untuk mengamati kemampuan algoritma dalam mengenali pola pada sample yang belum dipelajari oleh algoritma K - Nearest Neighbor dan K-Means sebelumnya.
PIMA Indians dataset terdiri dari beberapa tipe data, yaitu: integer, float, numeric,
Boolean sehingga pada masing-masing kolom memiliki karakteristik tersendiri
apakah itu nilai mean, fungsi distribusi nya, nilai maksimum dan minimum nya, pengetahuan menganai karakteriik masing-masing parameter dapat membantu proses pengolahan data input sehingga kita dapat melakukan penyaringan untuk mengetahui
sample yang mana saja yang layak diolah dan sample mana yang sebaiknya di hapus
atau dibuang, berikut disajikan dalam table 3.1 karakterisik pada masing-masing kolom dalam PIMA Indians dataset:
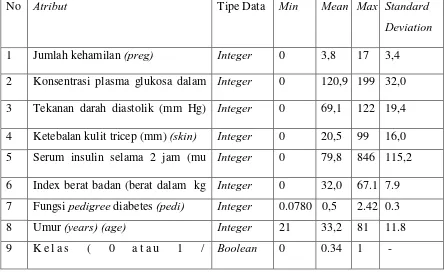
Tabel 3.1. Karakterisik pada masing-masing kolom dalam PIMA Indians dataset
No Atribut Tipe Data Min Mean Max Standard
Deviation
1 Jumlah kehamilan (preg) Integer 0 3,8 17 3,4
2 Konsentrasi plasma glukosa dalam Integer 0 120,9 199 32,0 3 Tekanan darah diastolik (mm Hg) Integer 0 69,1 122 19,4 4 Ketebalan kulit tricep (mm) (skin) Integer 0 20,5 99 16,0 5 Serum insulin selama 2 jam (mu Integer 0 79,8 846 115,2 6 Index berat badan (berat dalam kg Integer 0 32,0 67.1 7.9 7 Fungsi pedigree diabetes (pedi) Integer 0.0780 0,5 2.42 0.3
8 Umur (years) (age) Integer 21 33,2 81 11.8
9 K e l a s ( 0 a t a u 1 / Boolean 0 0.34 1 -
Pada dataset ini nama atribut pada PIMA Indians dataset diubah menjadi variabel sebagai berikut:
1. Jumlah kehamilan (preg) diubah menjadi �
2. Konsentrasi plasma glukosa dalam 2 jam diubah menjadi � 3. Tekanan darah diastolik (mm Hg) diubah menjadi � 4. Ketebalan kulit tricep (mm) (skin) diubah menjadi � 5. Serum insulin selama 2 jam diubah menjadi � 6. Index berat badan diubah menjadi �
7. Fungsi pedigree diabetes (pedi) diubah menjadi � 8. Umur (years) (age) diubah menjadi �
3.2. Proses Training pada Algoritma K-Means Clustering
Pada algoritma K-Means Clstering terjadi proses dalam 2 tahap utama yaitu: proses menghitung nilai rata-rata (mean) dan juga proses pergeseran centroids kearah mayoritas sample pelatihan. Pada bab ini akan dijelaskan masing-masing proses yang terjadi pada algoritma K-Means Clustering.
3.2.1. Menentukan jumlah cluster dan nilai centroids
Menentukan jumlah cluster dan centroids biasanya tergantung pada jenis permasalahan yang akan diselesaikan sehingga pada penelitian ini permasalahan yang akan diselesaikan berkaitan dengan diabetes mellitus sehingga hanya diperlukan dua buah centroid untuk mewakili dua buah cluster (kelompok) yaitu: postif (mengidap diabetes mellitus) dan negative (tidak mengidap diabetes mellitus) yang juga mewakili target pada data pelatihan, yaitu: 0 (negatif) dan 1 (positif).
Setelah menentukan jumlah cluster maka langkah selanjutnya adalah menetukan nilai centroids yang digunakan, namun dalam menentukan nilai centroids dilakukan secara random untuk menghindari terjadinya bottleneck dikarenakan nilai centroids
yang digunakan saling berdekatan ataupun terlalu jauh sehingga proses pemindahan
centroids pada langkah selanjutnya tidak dapat dilakukan ataupun makan waktu
terlalu lama. Pada penelitian kali ini penulis telah menentukan nilai centroids yang
di-generate secara random dapat dilihat pada Tabel 3.2 sebagai berikut.
Tabel 3.2. Nilai centroids yang akan digunakan
Centroids �1 �2 �3 �4 �5 �6 �7 �8 Target
centroids 1 1 87 78 27 32 34 0.1 22 0
centroids 2 5 187 76 27 207 43 1.03 53 1
Dalam penelitian ini juga terdapat sebagian sample yang akan digunakan dalam proses perhitungan ,dapat dilihat pada Tabel 3.3 sebagai berikut.
Tabel 3.3. Nilai sample
Sample Ke- �1 �2 �3 �4 �5 �6 �7 �8 Target
Sample 1 6 148 72 35 0 33.6 0.627 50 1
Sample 2 1 85 66 29 0 26.60 0.351 31 0
Sample 3 8 183 64 0 0 23.30 0.672 32 1
Sample 4 1 89 66 23 94 28.10 0.167 21 0
Sample 5 0 137 40 35 168 43.10 2.288 33 1
Sample ... .... .... .... .... ... .... .... .... ....
Sample 450 0 120 74 18 63 30.5 0.285 26 0
Sample 451 1 82 64 13 95 21.20 0.415 23 0
Sample 452 2 134 70 0 0 28.90 0.542 23 1
Sample 453 0 91 68 32 210 39.90 0.381 25 0
Sample ... .... .... .... .... .... .... .... .... ....
Sample 698 0 99 0 0 0 25 0.253 22 0
Sample 699 4 127 88 11 155 34.50 0.598 28 0
Sample 700 4 118 70 0 0 44.5 0.904 26 0
3.2.2. Menentukan jumlah Euclidean distance
Langkah kedua dalam proses pelatihan algoritma K-Means Clustering adalah menentukan nilai Euclidean distance pada masing-masing sample pelatihan. Dalam
algoritma K-Means Clustering terdapat beberapa pilihan dalam menentukan nilai
jarak pada antara masing-masing sample pelatihan seperti hamming distance dan
manhattan distance, namun pada penelitian kali ini penulis memilih untuk
menggunakan Euclidean distance dikarenakan alasan bahwa Euclidean distance
lebih sederhana dalam proses perhitungan dan memiliki running time yang lebih singkat namun tetap memiliki hasil yang cukup akurat jika dibandingan dengan
distance function yang lain seperti hamming distance dan manhattan distance.
Pada Euclidean distance nilai fungsi jarak yang didapat merupakan jarak antara sample pelatihan terhadap masing-masing centroids yang digunakan, dan pada algoritma K-Means Clustering yang harus diperhatikan adalah bahwa nilai
Euclidean distance yang memiliki nilai paling sedikit berarti sample tersebut adalah
anggota dari centroids terdekat dan pada akhirnya merupakan centroids yang mengalami shifting (pergeseran). Pada penelitian kali ini, penulis akan menjelaskan bagaimana proses perhitungan fungsi jarak pada algoritma K-Means Clustering
menggunakan Euclidean distance sebagai distance function-nya.
Perhitungan Euclidean distance untuk sample pada tabel 3.3 dengan nilai
centroids table 3.2 dengan menggunakan rumus Euclidean distance seperti yang
diuraikan sebagai berikut:
a. Hitung jarak data pertama ke pusat cluster pertama:
, = − + − + − + − + − +
, − + , − , + −
= 5654,43
b. Hitung jarak data pertama ke pusat cluster kedua:
, = − + − + − + − + − +
, − + , − , + −
= 44548,52
c. Hitung jarak data ke-450 ke pusat cluster pertama:
, = − + − + − + − + − +
, − + , − , + −
= 2176,284
d. Hitung jarak data ke-450 ke pusat cluster kedua:
, = − + − + − + − + − +
, − + , − , + −
= 26220,81
e. Hitung jarak data ke-700 ke pusat cluster pertama:
, = − + − + − + − + − +
, − + , − , + −
= 2913,896
f. Hitung jarak data ke-700 ke pusat cluster kedua:
, = − + − + − + − + − +
, − + , − , + −
= 49107,27
Tabel 3.4. Hasil Perhitungan Euclidean Distance Terhadap Centroids pada Sample
Sample Ke- Jarak Terhadap Centroid 1 Jarak Terhadap Centroid 2
Sample 1 5654,438 44548,52
Sample 2 1311,823 54126,42
Sample 3 11428,82 44576,22
Sample 4 4043,814 23751,75
Sample 5 22713,6 5807,593
Sample ... .... ....
Sample 450 2176,284 26220,81
Sample 451 4550,939 25300,62
Sample 452 4054,205 47531,05
Sample 453 31869,89 10133,03
Sample ... .... ....
Sample 698 8063,023 58408,6
Sample 699 17130,5 7402,437
Sample 700 2913,896 49107,27
= Centroids terdekat terhadap sample �n
Terlihat pada pada hasil Tabel 3.4 bahwa sample 5, 453 dan sample 699
memiliki nilai Euclidean Distance terkecil terhadap centroids 2, sedangkan sample
1, 2, 3, 4,450, 451, 452, 698 dan 700 memiliki nilai Euclidean Distance
terkecil terhadap centroids 1.
3.2.4.Proses perpindahan centroids
Pada proses selanjutnya dari K-Means Clustering adalah proses perpindahan centroids, proses ini merupakan sebuah proses yang bersifat iterative sehingga akan dilakukan secara berulang seiring dengan hasil yang didapat pada proses sebelumnya. Perpindahan centroids diawali dengan proses pencarian nilai mean pada masing- masing sample yang telah di-assignment pada setiap centroids untuk kemudian diketahui posisi pergeseran centroids berdasarkan pada nilai mean pada seluruh
sample ter-assignment pada centroids tersebut. Proses perhitungan perpindahan
centroids dapat dilihat sebagai berikut:
= [ . . ]+[ . . ]+[ . . ]
[ , . ]+[ . . ]+[ . . ]
[ . . ]+[ . ]+[ . . ]
= [ . . ]
= [ . . . . . . . ] =
[ . . ]+[ . . ]+[ . . ]
= [ . . ]
= [ . . . . . . . ]
Sesuai dengan hasil perhitungan yang diperoleh sebelumnya maka didapat posisi
centroids terbaru seperti dalam tabel 3.5 berikut:
Tabel 3.5. Hasil Pergeseran centroids
Centroid Centroid
Centroid awal [1 87 78 27 32 34 0.1 22]
[5 187 76 27 207 43 1.03 53]
Centroid baru [ . . . . . . . ]
[ . . . . . . . ]
3.3. Proses training pada algoritma K-Nearest Neighbor
Proses training pada K-Nearest Neighbor pada penerapannya hanyalah terdiri dari 5 proses yaitu proses perhitungan jarak menggunakan Euclidean Distance dalam menghitung tingkat kemiripan pada sample training dengan sample testing
dan kemudian diakhiri dengan proses pengelompokan dengan mempertimbangkan dan menghitung nilai ambang batas (threshold).
3.3.1. Proses perhitungan similarity function pada algoritma K-Nearest
Neighbor
Algoritma K-Nearest Neighbor menjadikan nilai similarity function sebagai
pertimbangan dalam proses clustering, ini berarti jika sebuah sample memiliki
kemiripan dengan sample yang lain maka besar kemungkinan bahwa sample
tersebut memiiki target ataupun berasal dari kelompok yang sama. Pada penelitian kali ini proses perhitungan similarity fuction dilakukan mengggunakan radial basis
function, dikarenakan radial basis function memiliki perhitungan yang cukup
sederhana jika digunakan pada dataset yang memiliki mayoritas tipe data integer
serta memiliki nilai similarity yang cukup akurat walaupun dibandingkan dengan
similarity function yang lain seperti: hamming distance dan manhattan distance.
Maka berikut perhitungan nilai similarity function berupa radial basis function
menggunakan Euclidean Distance yang dilakukan pada beberapa sample:
Pada Euclidean distance nilai fungsi jarak yang didapat merupakan jarak antara sample testing terhadap masing-masing sample training yang digunakan, dan pada algoritma K-Nearest Neighbor yang harus diperhatikan adalah bahwa nilai Euclidean distance yang memiliki nilai paling kecil berarti sample testing
tersebut adalah anggota dari sample training terdekat. Pada penelitian kali ini, penulis akan menjelaskan bagaimana proses perhitungan fungsi jarak pada
algoritma K-Nearest Neighbor menggunakan Euclidean distance sebagai distance
function-nya.
Pada proses perhitungan Euclidean Distance pada algoritma K-Nearest
Neighbor aplikasi data mining terdiri dari dua data,yaitu:
Data Testing
Data Testing yang akan digunakan seperti pada tabel 3.6 berikut:
Tabel 3.6. Nilai Data Testing yang akan digunakan
Sample testing �1 �2 �3 �4 �5 �6 �7 �8 Target
Sample 1 87 78 27 32 34.6 0.1 22 ?
Data Training
Data Training yang akan digunakan seperti pada tabel 3.7 berikut:
Tabel 3.7.Nilai Data Training
Sample Ke- �1 �2 �3 �4 �5 �6 �7 �8 Target
Sample 1 6 148 72 35 0 33.6 0.627 50 1
Sample 2 1 85 66 29 0 26.60 0.351 31 0
Sample 3 8 183 64 0 0 23.30 0.672 32 1
Sample 4 1 89 66 23 94 28.10 0.167 21 0
Sample 5 0 137 40 35 168 43.10 2.288 33 1
Sample 44 9 171 110 24 240 45,5 0,74 54 1
Sample 107 1 96 122 0 0 22,4 0,207 27 0
Sample 441 0 189 104 25 0 34,3 0,435 41 1
Sample 550 4 189 110 31 0 28,5 0,68 37 0
Sample 663 8 167 106 46 231 37,6 0,165 43 1
Sample 692 13 158 114 0 0 42,3 0,257 44 1
Perhitungan Euclidean distance untuk sebagian sample training pada tabel 3.7 dengan nilai data testing table 3.6 dengan menggunakan nilai K=5 seperti yang diuraikan sebagai berikut:
Seluruh hasil perhitungan Euclidean Distance pada sebagian sample
ditunjukkan pada Tabel 3.8 sebagai berikut:
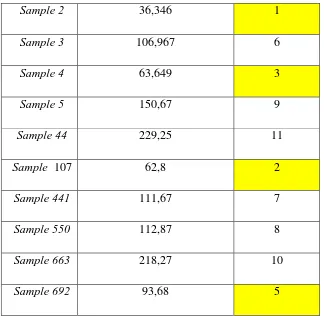
Tabel 3.8.Hasil Euclidean Distance Pada sebagian data training
Sample Ke- Euclidean Distance
Sample 1 75,201
Sample 2 36,346
Sample 3 106,967
Sample 4 63,649
Sample 5 150,67
Sample 44 229,25
Sample 107 62,8
Sample 441 111,67
Sample 550 112,87
Sample 663 218,27
Sample 692 93,68
Dari hasil perhitungan Euclidean Distance pada tabel 3.8, Kemudian mengurutkan objek-objek tersebut ke dalam kelompok yang mempunyai jarak Euclid terkecil dengan nilai K=5 pada tabel 3.9 sebagai berikut.
Tabel 3.9.Mengurutkan Objek ke dalam Kelompok ke Jarak Euclid Terkecil
Sample Ke- Euclidean Distance Jarak terkecil
Sample 1 75,201 4
Sample 2 36,346 1
Sample 3 106,967 6
Sample 4 63,649 3
Sample 5 150,67 9
Sample 44 229,25 11
Sample 107 62,8 2
Sample 441 111,67 7
Sample 550 112,87 8
Sample 663 218,27 10
Sample 692 93,68 5
Dari hasil pengelompokan objek pada tabel 3.9, Kemudian Mengumpulkan label
class (klasifikasi Nearest Neighbor) pada tabel 3.10 sebagai berikut.
Tabel 3.10 Label Class Y
Sample Ke- Euclidean Distance Jarak terkecil Target KNN
Sample 1 75,201 4 1 1
Sample 2 36,346 1 0 1
Sample 3 106,967 6 1
Sample 4 63,649 3 0 1
Sample 5 150,67 9 1
Sample 44 229,25 11 1
Sample 107 62,8 2 0 1
Sample 441 111,67 7 1
Sample 550 112,87 8 0
Sample 663 218,27 10 1
Sample 692 93,68 5 1 1
Dari hasil pengumpulkan label class (klasifikasi Nearest Neighbor) pada tabel 3.10, Kemudian Mencari Mayoritas Kategori seperti pada tabel 3.11 sebagai berikut.
Tabel 3.11 Hasil Akhir Mayoritas Kategori
Sample Ke- Euclidean Distance Jarak terkecil Target KNN
Sample 1 75,201 4 1 1
Sample 2 36,346 1 0 1
Sample 3 106,967 6 1
Sample 4 63,649 3 0 1
Sample 5 150,67 9 1
Sample 44 229,25 11 1
Sample 107 62,8 2 0 1
Sample 441 111,67 7 1
Sample 550 112,87 8 0
Sample 663 218,27 10 1
Sample 692 93,68 5 1 1
Seperti tampak pada Tabel 3.11, terdapat 11 data training. Ketika ada data testing, maka solusi yang akan diambil adalah hasil dari 5 sample terdekat dari data testing. Maka terlihat bahwa sample 1,2,4,107 dan 692 memiliki jarak lebih dekat dari pada sample lainya. Dengan demikian, mayoritas dari ke-5 sample yang terdekat adalah negatif.jadi data testing satu cluster dengan sample 2.
3.4. Struktur Tabel
Tabel merupakan tempat penyimpanan informasi dari sebuah aliran data dalam sebuah sistem. Berikut merupakan struktur dari beberapa tabel sistem yang akan dibangun.
1. Tabel akumulasi_jarak
Tabel akumulasi_jarak merupakan tabel yang berguna untuk menyimpan data akumulasi . Tabel akumulasi tersebut adalah seperti terlihat pada tabel 3.12 dibawah ini.
Tabel 3.12 Tabel akumulasi_jarak
Field Type Size Keterangan
id_akumulasi_jarak Int 10 id_akumulasi_jarak
id_sampel Int 10 id sampel
cluster_pilihan Double 10,3 nilai cluster pilihan
Urutan Int 2 urutan cluster
Primary Key : id_akumulasi_jarak Foreign Key : id_sampel
2. Tabel akumulasi_jarak2
Tabel akumulasi_jarak2 merupakan tabel yang berguna untuk menyimpan data akumulasi . Tabel akumulasi_jarak2 tersebut adalah seperti terlihat pada tabel 3.13 dibawah ini.
Tabel 3.13 Tabel akumulasi_jarak2
Field Type Size Keterangan
id_akumulasi_jarak2 Int 10 id_akumulasi_jarak
id_sampel Int 10 id sampel
cluster_pilihan Double 10,3 nilai cluster pilihan
Urutan Int 2 urutan cluster
Primary Key : id_akumulasi_jarak
3. Tabel akumulasi_knn
Tabel akumulasi_knn merupakan media untuk merekam data akumulasi knn. Struktur tabel akumulasi_knn adalah seperti terlihat pada tabel 3.14 dibawah ini.
Table 3.14. Tabel akumulasi_knn
Field Type Size Keterangan
id_akumulasi_knn Int 10 id akumulasi knn
id_sampel Int 10 id sampel
Hasil Varchar 10 hasil penilaian
Primary Key : id_akumulasi_knn Foreign Key : id_sampel
4. Tabel atribut
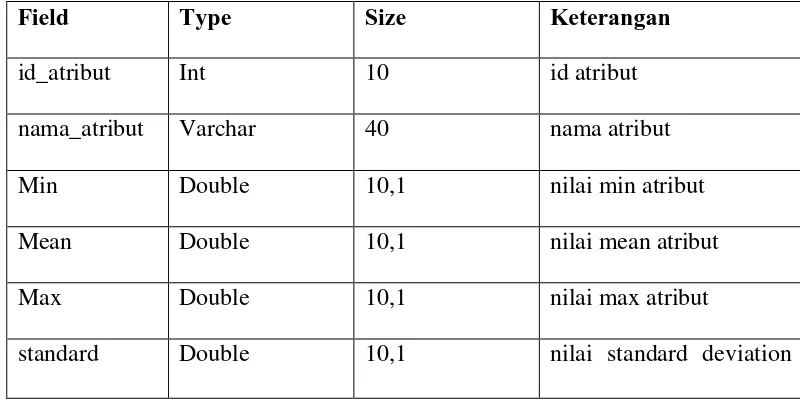
Tabel atribut merupakan media untuk merekam data atribut. Struktur tabel atribut adalah seperti terlihat pada tabel 3.15 dibawah ini.
Table 3.15. Tabel atribut
Field Type Size Keterangan
id_atribut Int 10 id atribut
nama_atribut Varchar 40 nama atribut
Min Double 10,1 nilai min atribut
Mean Double 10,1 nilai mean atribut
Max Double 10,1 nilai max atribut
standard Double 10,1 nilai standard deviation
Primary Key : id_atribut 5. Tabel iterasi
Tabel iterasi merupakan media untuk merekam data iterasi. Struktur tabel iterasi adalah seperti terlihat pada tabel 3.16 dibawah ini.
Table 3.16. Tabel iterasi
Field Type Size Keterangan
id_iterasi Int 10 id iterasi
Iterasi Int 10 nilai iterasi
Primary Key : id_iterasi 6. Tabel jarak
Tabel jarak merupakan media untuk merekam data jarak. Struktur tabel jarak adalah seperti terlihat pada tabel 3.17 dibawah ini.
Table 3.17. Tabel jarak
Field Type Size Keterangan
id_jarak Int 10 id jarak
id_sampel Int 10 id sampel
Hasil Double 10,3 hasil atribut
Urutan Int 2 urutan jarak
Primary Key : id_jarak Foreign Key : id_sampel 7. Tabel jarak_knn
Tabel jarak_knn merupakan media untuk merekam data jarak_knn. Struktur tabel jarak_knn adalah seperti terlihat pada tabel 3.18 dibawah ini
Table 3.18. Tabel jarak_knn
Field Type Size Keterangan
id_jarak Int 10 id jarak
id_sampel Int 10 id sampel
Nilai Double 10,3 nilai jarak
Primary Key : id_jarak Foreign Key : id_sampel
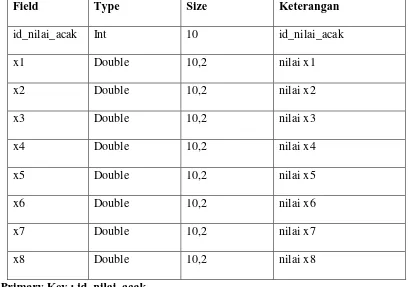
8. Tabel nilai_acak
Tabel nilai_acak merupakan media untuk merekam data nilai_acak. Struktur tabel nilai_acak adalah seperti terlihat pada tabel 3.19 dibawah ini.
Table 3.19. Tabel nilai_acak
Field Type Size Keterangan
id_nilai_acak Int 10 id_nilai_acak
x1 Double 10,2 nilai x1
x2 Double 10,2 nilai x2
x3 Double 10,2 nilai x3
x4 Double 10,2 nilai x4
x5 Double 10,2 nilai x5
x6 Double 10,2 nilai x6
x7 Double 10,2 nilai x7
x8 Double 10,2 nilai x8
Primary Key : id_nilai_acak 9. Tabel nilai_acak2
Tabel nilai_acak2 merupakan media untuk merekam data nilai_acak2. Struktur tabel nilai_acak2 adalah seperti terlihat pada tabel 3.20 dibawah ini
Table 3.20. Tabel nilai_acak2
Field Type Size Keterangan
id_nilai_acak2 Int 10 id_nilai_acak
x1 Double 10,2 nilai x1
x2 Double 10,2 nilai x2
x3 Double 10,2 nilai x3
x4 Double 10,2 nilai x4
x5 Double 10,2 nilai x5
x6 Double 10,2 nilai x6
x7 Double 10,2 nilai x7
x8 Double 10,2 nilai x8
Primary Key : id_nilai_acak
10. Tabel sampel
Tabel nilai_sampel merupakan media untuk merekam data sampel. Struktur table
sampel adalah seperti terlihat pada tabel 3.21 dibawah ini.
Table 3.21. Tabel sampel
Field Type Size Keterangan
id_sampel Int 10 id sampel
sampel_1 Double 10,2 nilai sampel 1
sampel_2 Double 10,2 nilai sampel 2
sampel_3 Double 10,2 nilai sampel 3
sampel_4 Double 10,2 nilai sampel 4
sampel_5 Double 10,2 nilai sampel 5
sampel_6 Double 10,2 nilai sampel 6
sampel_7 Double 10,2 nilai sampel 7
sampel_8 Double 10,2 nilai sampel 8
Primary Key : id_sampel 11. Tabel testing
Tabel testing merupakan media untuk merekam data testing. Struktur tabel testing
adalah seperti terlihat pada tabel 3.22 dibawah ini. Table 3.22. Tabel testing
Field Type Size Keterangan
id_testing Int 10 id testing
t1 Double 10,2 nilai t1
t2 Double 10,2 nilai t2
t3 Double 10,2 nilai t3
t4 Double 10,2 nilai t4
t5 Double 10,2 nilai t5
t6 Double 10,2 nilai t6
t7 Double 10,2 nilai t7
t8 Double 10,2 nilai t8
Primary Key : id_sampel
3.5. Perancangan system
3.5.1. Diagram Konteks
Diagram konteks adalah diagram yang mencakup masukan-masukan dasar, sistem
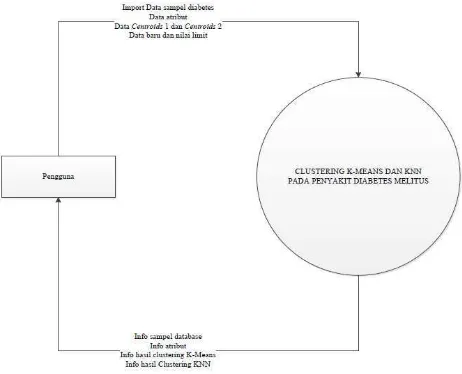
umum dan keluaran, diagram ini merupkan tingkatan tertinggi dalam diagram aliran data dan hanya memuat satu proses, menunjukan sistem secara keseluruhan, diagram tersebut tidak memuat penyimpanan dan penggambaran aliran data yang sederhana, proses tersebut diberi nomor nol. Semua entitas ekternal yang ditunjukan pada diagram konteks berikut aliran data-aliran data utama menuju dan dari system. Diagram kontek yang dirancang dapat dilihat pada gambar 3.1 di bawah ini
Gambar 3.1.Diagram Konteks
Diagram konteks di atas menjelaskan dimana pengguna menginputkan data
import data sampel database, data atribut, data Centroid 1 dan 2, dan data baru dan
nilai limit serta menerima informasi info sampel database, info atribut, info hasil
clustering K- Means, dan info hasil clustering K-Nearest Neighbor.
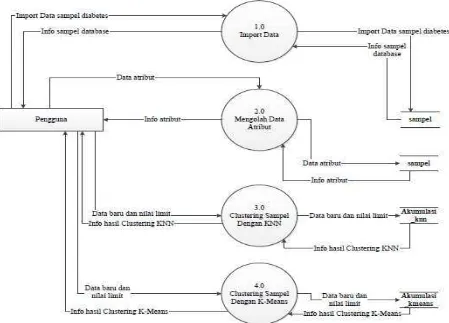
3.5.2. Data Flow Diagram
Data Flow Diagram (DFD) adalah suatu diagram yang menggunakan notasi-notasi
untuk menggambarkan arus dari data pada suatu sistem, yang penggunaannya sangat membantu untuk memahami sistem secara logika, tersruktur dan jelas. DFD sangat mirip dengan Flowchart. DFD dari system yang akan dirancang dapat dilihat pada gambar 3.2 di bawah ini
Gambar 3.2. Data Flow Diagram 3.5.3. Data Flow Diagram Level 2
Data Flow Diagram (DFD) Level 2 merupakan hasil dekomposisi dari Data Flow
Diagram (DFD) Level 1. DFD Level 2 dari system ini dapat dibagi menjadi 3 bagian
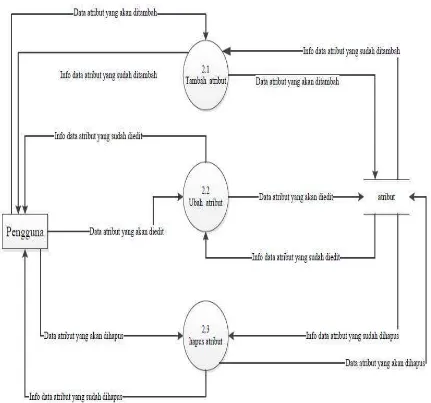
yang dapat dijelaskan pada gambar di bawah ini 1. DFD Level 2 olah data atribut
DFD Level 2 olah data atribut dari system yang akan dirancang dapat dilihat pada gambar 3.3 di bawah ini
Gambar 3.3. DFD Level 2 olah data atribut
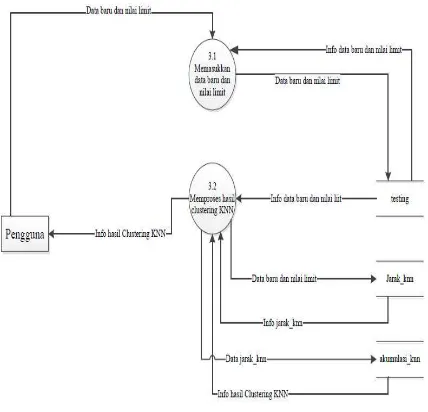
2. DFD Level 2 Proses Clustering sampel dengan KNN
DFD Level 2 Proses Clustering sampel dengan KNN dari system yang akan dirancang dapat dilihat pada gambar 3.4 di bawah ini
Gambar 3.4. DFD Level 2 Proses Clustering sampel dengan KNN
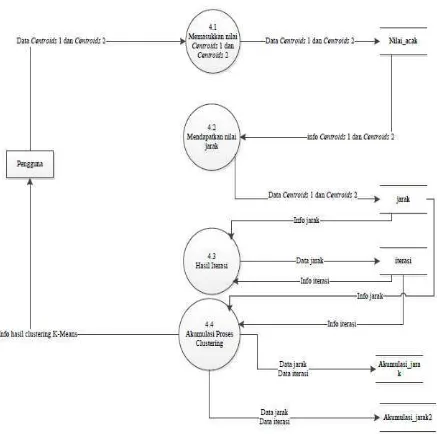
3. DFD Level 2 proses clustering dengan K-Means Clustering
DFD Level 2 proses clustering dengan K-Means dari system yang akan dirancang dapat dilihat pada gambar 3.5 di bawah ini
Gambar 3.5. DFD Level 2 proses clustering dengan K-Means Clustering
3.5.4. Entity Relation Diagram
Entity Relation Diagram merupakan salah satu pemodelan data konseptual
yang paling sering digunakan dalam proses pengembangan basis data bertipe relasional. Model E-R adalah rincian yang merupakan representasi logikan dari data pada satu organisasi atau area bisnis tertentu. ERD yang akan dibangun dapat dilihat pada gambar 3.6 di bawah ini
Gambar 3.6. Entity Relation Diagram
3.6. Flow Chart
Flow Chart merupakan gambar atau bagan yang memperlihatkan urutan dan
Dengan demikian setiap simbol menggambarkan proses tertentu. Sedangkan hubungan antar proses digambarkan dengan garis penghubung.
1. Flow Chart Menu
Flow Chart Menu dari system yang akan dirancang dapat dilihat pada gambar 3.7 di
bawah ini
Gambar 3.7. Flow Chart Menu
2.Flow ChartK-Means Clustering
Flow Chart K-Means Clustering dari system yang akan dirancang dapat dilihat pada
gambar 3.8 di bawah ini
Gambar 3.8. Flow Chart t K-Means
3. Flow ChartK-Nearest Neighbor
Flow Chart K-Nearest Neighbor dari system yang akan dirancang dapat dilihat pada
gambar 3.9 di bawah ini
Gambar 3.9. Flow Chart K-Nearest Neighbor
3.7. Perancangan User Interface
3.7.1. Perancangan Admin Interface Input (Pemasukan) Data
Perancangan input adalah spesifikasi pembuatan perancangan input yang nantinya akan berguna untuk mempermudah proses penginputan
1. Import Data Sampel Diabetes
Rancangan Import Data Sampel Diabetes dapat dilihat seperti pada Gambar 3.10.
Gambar 3.10. Import Data Sampel Diabetes Keterangan Gambar :
1. Link Home : Apabila diklik link ini, akan mengarah ke halaman home
2. Link Import Data : Apabila diklik link ini, akan mengarah ke halaman import data 3. Link Sampel Diabetes : Apabila diklik link ini, akan mengarah ke halaman sampel
Diabetes.
4. Link Algoritma K-Means : Apabila diklik link ini, akan mengarah ke halaman proses K-Means
5. Link Algoritma KNN : Apabila diklik link ini, akan mengarah ke halaman
proses KNN
6. Link Form Atribut : Apabila diklik link ini, akan mengarah ke halaman
form atribut
7. Link Data Atribut : Apabila diklik link ini, akan mengarah ke halaman data
atribut
8. Tombol Choose File : Tombol ini berfungsi untuk mengambil file yang akan diimport dari berkas yang ada dalam berkas Komputer pengguna
9. Tombol Import : Tombol ini berfungsi untuk melakukan proses import
setelah file berhasil diambil dari berkas komputer pengguna
2. Perancangan Input Nilai Data Baru dan Nilai Limit
Rancangan Input Nilai Data Baru dan Nilai Limit dapat dilihat pada Gambar 3.11.
Gambar 3.11. Perancangan Input Nilai Data Baru dan Nilai Limit
Keterangan Gambar :
1. Link Home : Apabila diklik link ini, akan mengarah ke halaman home
2. Link Import Data : Apabila diklik link ini, akan mengarah ke halaman import data 3. Link Sampel Diabetes : Apabila diklik link ini, akan mengarah ke halaman sampel
diabetes
4. Link Algoritma K-Means : Apabila diklik link ini, akan mengarah ke halaman proses K-Means
5. Link Algoritma KNN : Apabila diklik link ini, akan mengarah ke halaman KNN
6. Link Form Atribut : Apabila diklik link ini, akan mengarah ke halaman
form atribut
7. Link Data Atribut : Apabila diklik link ini, akan mengarah ke halaman data atribut
8. Textbox TI : Textbox ini berfungsi sebagai inputan dari nilai T1 9. Textbox T2 : Textbox ini berfungsi sebagai inputan dari nilai T2
10. Textbox T3 : Textbox ini berfungsi sebagai inputan dari nilai T3
11. Textbox T4 : Textbox ini berfungsi sebagai inputan dari nilai T4
12. Textbox T5 : Textbox ini berfungsi sebagai inputan dari nilai T5
13. Textbox T6 : Textbox ini berfungsi sebagai inputan dari nilai T6
14. Textbox T7 : Textbox ini berfungsi sebagai inputan dari nilai T7
15. Textbox T8 : Textbox ini berfungsi sebagai inputan dari nilai T8
16. Textbox Nilai K : Textbox ini berfungsi sebagai inputan dari nilai Limit dari K
17. Tombol Submit : Tombol ini berfungsi untuk melakukan proses submit
setelah semua data terisi
3. Perancangan Input Nilai Data Centroid 1 dan Data Centroid 2
Rancangan Input Nilai Data Centroid 1 dan Data Centroid 2 dapat dilihat pada Gambar 3.12.
Gambar 3.12. Perancangan Input Nilai Data Centroid 1 dan Data Centroid 2 Keterangan Gambar :
1. Link Home : Apabila diklik link ini, akan mengarah ke halaman home
2. Link Import Data : Apabila diklik link ini, akan mengarah ke halaman import data 3. Link Sampel Diabetes : Apabila diklik link ini, akan mengarah ke halaman sampel
diabetes
8. Textbox Centroid 1 X1 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
1 X1
9. Textbox Centroid 1 X2 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
1 X2
10. Textbox Centroid 1 X3 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
1 X3
11. Textbox Centroid 1 X4 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
1 X4
12. Textbox Centroid 1 X5 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
1 X5
13. Textbox Centroid 1 X6 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
1 X6
14. Textbox Centroid 1 X7 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
1 X7
15. Textbox Centroid 1 X8 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
1 X8
16. Textbox Centroid 2 X1 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
2 X1
17. Textbox Centroid 2 X2 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
2 X2
18. Textbox Centroid 2 X3 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
2 X3
19. Textbox Centroid 2 X4 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
2 X4
20. Textbox Centroid 2 X5 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
2 X5
21. Textbox Centroid 2 X6 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
2 X6
22. Textbox Centroid 2 X7 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
2 X7
23. Textbox Centroid 2 X8 : Textbox ini berfungsi sebagai inputan dari nilai Centroid
2 X8
24. Tombol Submit : Tombol ini berfungsi untuk melakukan proses submit
setelah semua data terisi 4. Perancangan Form Atribut
Rancangan Form Atribut dapat dilihat pada Gambar 3.13.
Gambar 3.13. Perancangan Form Atribut
Keterangan Gambar :
1. Link Home : Apabila diklik link ini, akan mengarah ke halaman home
2. Link Import Data : Apabila diklik link ini, akan mengarah ke halaman import data
3. Link Sampel Diabetes : Apabila diklik link ini, akan mengarah ke halaman sampel
diabetes
4. Link Algoritma K-Means : Apabila diklik link ini, akan mengarah ke halaman
proses K-Means
5. Link Algoritma KNN : Apabila diklik link ini, akan mengarah ke halaman proses
KNN
6. Link Form Atribut : Apabila diklik link ini, akan mengarah ke halaman
form atribut
7. Link Data Atribut : Apabila diklik link ini, akan mengarah ke halaman data atribut
8. Textbox nama atribut : Textbox ini berfungsi sebagai inputan dari nama atribut
9. Textbox min : Textbox ini berfungsi sebagai inputan dari nilai min
10. Textbox Mean : Textbox ini berfungsi sebagai inputan dari nilai Mean
11. Textbox Max : Textbox ini berfungsi sebagai inputan dari nilai Max
12. Textbox Standard deviation : Textbox ini berfungsi sebagai inputan dari nilai
Standard deviation
13. Tombol Submit : Tombol ini berfungsi untuk melakukan proses submit
setelah semua data terisi
3.7.2. Perancangan Admin Interface Output (Keluaran)
Perancangan output merupakan suatu bentuk keluaran yang dibutuhkan oleh admin dalam penyampaian informasi. Adapun maksud dari output disini adalah yang dihasilkan di layar monitor.
1. Perancangan Output Sampel Diabetes
Rancangan Output Sampel Diabetes dapat dilihat pada Gambar 3.14.
Gambar 3.14. Perancangan Output Sampel Diabetes Keterangan Gambar :
1. Link Home : Apabila diklik link ini, akan mengarah ke halaman home
2. Link Import Data : Apabila diklik link ini, akan mengarah ke halaman import data 3. Link Sampel Diabetes : Apabila diklik link ini, akan mengarah ke halaman sampel
diabetes
4. Link Algoritma K-Means : Apabila diklik link ini, akan mengarah ke halaman proses K-Means
5. Link Algoritma KNN : Apabila diklik link ini, akan mengarah ke halaman proses
KNN
6. Link Form Atribut : Apabila diklik link ini, akan mengarah ke halaman
form atribut
7. Link Data Atribut : Apabila diklik link ini, akan mengarah ke halaman data atribut
8. Tabel Sampel Diabetes : Tabel ini berisi dari data sampel diabetes yang teridiri dari kolom jumlah kehamilan, konsentrasi plasma glukosa, tekanan
diastolic, ketebalan kulit, index berat badan, fungsi pedigree, dan umur.
2. Perancangan Output Data Atribut
Rancangan Output Data Atribut dapat dilihat pada Gambar 3.15.
Gambar 3.15. Perancangan Output Data Atribut
Keterangan Gambar :
1. Link Home : Apabila diklik link ini, akan mengarah ke halaman home
2. Link Import Data : Apabila diklik link ini, akan mengarah ke halaman import data 3. Link Sampel Diabetes : Apabila diklik link ini, akan mengarah ke halaman sampel
diabetes
4. Link Algoritma K-Means : Apabila diklik link ini, akan mengarah ke halaman proses K-Means
5. Link Algoritma KNN : Apabila diklik link ini, akan mengarah ke halaman proses
KNN
6. Link Form Atribut : Apabila diklik link ini, akan mengarah ke halaman
form atribut
7. Link Data Atribut : Apabila diklik link ini, akan mengarah ke halaman data atribut 9. Tabel Sampel Diabetes : Tabel ini berisi dari data sampel diabetes yang teridiri
dari kolom nama atribut, min, mean, max, standard deviation, edit, dan delete
8
3. Perancangan Hasil Proses Clustering K-Nearest Neighbor
Rancangan Hasil Proses Clustering K-Nearest Neighbor dapat dilihat pada Gambar 3.16.
Gambar 3.16. Perancangan Hasil Proses Clustering K-Nearest Neighbor
Keterangan Gambar :
1. Link Home : Apabila diklik link ini, akan mengarah ke halaman home
2. Link Import Data : Apabila diklik link ini, akan mengarah ke halaman import data 3. Link Sampel Diabetes : Apabila diklik link ini, akan mengarah ke halaman sampel
diabetes
4. Link Algoritma K-Means : Apabila diklik link ini, akan mengarah ke halaman proses K-Means
5. Link Algoritma KNN : Apabila diklik link ini, akan mengarah ke halaman proses
KNN
6. Link Form Atribut : Apabila diklik link ini, akan mengarah ke halaman
form atribut
7. Link Data Atribut : Apabila diklik link ini, akan mengarah ke halaman data atribut
8. Tabel Algoritma KNN : Tabel ini berisi dari data hasil proses dari algoritma KNN yang teridiri dari kolom jumlah kehamilan, konsentrasi plasma glukosa, tekanan diastolik, ketebalan kulit, index berat badan, fungsi pedigree, umur,
sequare instance, dan status
4. Perancangan Hasil Proses Clustering K-Means
Rancangan Hasil Proses Clustering K-Means dapat dilihat pada Gambar 3.17.
Gambar 3.17. Perancangan Hasil Proses Clustering K-Means
Keterangan Gambar :
1. Link Home : Apabila diklik link ini, akan mengarah ke halaman home
2. Link Import Data : Apabila diklik link ini, akan mengarah ke halaman import data 3. Link Sampel Diabetes : Apabila diklik link ini, akan mengarah ke halaman sampel
diabetes
4. Link Algoritma K-Means : Apabila diklik link ini, akan mengarah ke halaman proses K-Means
5. Link Algoritma KNN : Apabila diklik link ini, akan mengarah ke halaman proses
KNN
8
6. Link Form Atribut : Apabila diklik link ini, akan mengarah ke halaman
form atribut
7. Link Data Atribut : Apabila diklik link ini, akan mengarah ke halaman data atribut
8. Tabel Algoritma K-Means : Tabel ini berisi dari data hasil proses dari algoritma
K-Means yang teridiri dari kolom jumlah kehamilan, konsentrasi plasma glukosa,
tekanan diastolik, ketebalan kulit, index berat badan, fungsi pedigree, umur,
sequare instance, dan status
10.Label Waktu penyelesaian : Label ini adalah label yang menampilkan hasil
waktu penyelesaian dari algoritma K-Means
69
BAB 4
IMPLEMENTASI DAN PENGUJIAN SISTEM
4.1 Pengertian Implementasi Sistem
Implementasi Sistem adalah langkah-langkah atau prosedur yang dilakukan dalam menyelesaikan desain sistem yang telah disetujui, menguji, dan memulai sistem baru yang telah disempurnakan.
4.2 Komponen Utama dalam Implementasi Sistem
Agar sistem perancangan yang telah dikerjakan dapat berjalan baik atau tidak, maka perlu kiranya dilakukan pengujian terhadap sistem yang telah dikerjakan. Oleh karena itu, dibutuhkan beberapa komponen untuk mencakup perangkat keras (Hardware), perangkat lunak (software), dan perangkat manusia (Brainware).
4.2.1. Perangkat Keras (Hardware)
Hardware merupakan komponen yang terlihat secara fisik yang saling bekerja sama dalam pengolahan data. Perangkat keras yang digunakan meliputi:
a. Monitor
b. CPU (Central Processing Unit)
c. Hardisk sebagai tempat sistem beroperasi dalam media penyimpanan d. Memori minimal 1GB
e. Keyboard dan Mouse 4.2.2 Perangkat Lunak (Software)
Software adalah instruksi atau program-program komputer yang dapat digunakan oleh komputer dengan memberikan fungsi serta penampilan yang diinginkan. Dalam hal ini perangkat lunak yang digunakan adalah:
a. Operating System Windows 7
b. Adobe Dreamwever CS5 sebagai tools editor untuk mendesain website
c. XAMPP 1.7.1 dimana terdapat Apache sebagai web server, PHP sebagai bahasa
pemrograman yang digunakan, dan MySQL sebagai software untuk server
database.
d. Mozilla Firefox 3.5+ untuk menjalankan program yang telah dirancang.
4.2.3. Unsur Manusia (Brainware)
Brainware merupakan faktor manusia yang menangani fasilitas komputer yang ada.
Faktor manusia yang dimaksud adalah orang-orang yang memiliki bagian untuk menangani sistem dan merupkan unsur manusia yang meliputi:
a. Analisa Sistem, yaitu orang membentuk dan membangun fasilitas rancangan sistem atau program.
b. Programmer, yaitu orang yang digunakan dalam membangun suatu program. c. Operator (Administrator), yaitu orang yang mengoperasikan sistem seperti
memasukkan data untuk dioperasikan oleh komputer dalam menghasilkan informasi dan lain sebagainya.
d. Public, yaitu orang yang memakai sistem yang telah dirancang untuk informasi yang dibutuhkan.
4.3 Tampilan Program
Sub bab ini akan menunjukkan tampilan program dan desain program website dari hasil perancangan yang telah dibangun pada bab sebelumnya sebelumnya.
4.3.1. Tampilan Import Data
Gambar di bawah ini adalah gambar untuk mengimport data sampel data diabetes . File yang diimport sendiri harus file berbentuk XLS. Gambar tampilan import data dapat dilihat pada gambar 4.1
Gambar 4.1 Tampilan Import Data
4.3.2. Halaman Data Sampel Diabetes
Gambar di bawah ini merupakan tampilan data sampel diabetes. Tampilan data ini sendiri menampilkan jumlah kehamilan, konsentrasi plasma, tekanan darah, ketebalan kulit, serum insulin, index berat badan, fungsi pedigree, dan umur. Halaman data sampel diabetes dapat dilihat pada Gambar 4.2
Gambar 4.2 Halaman Data Sampel Diabetes
4.3.3. Halaman Input Data Atribut
Gambar di bawah ini merupakan tampilan gambar Untuk Input data atribut.. Untuk form
penginputan data atribut, terdapat data-data yang wajib diisi oleh seorang administrator, yaitu nama atribut, min, mean, max, dan standar deviation. Gambar Input atribut dapat dilihat pada Gambar 4.3
Gambar 4.3 Input Data Atribut 4.3.4. Halaman Data Atribut
Gambar di bawah ini merupakan tampilan gambar untuk menampilkan data atribut dalam bentuk tabel. Data-data yang akan ditampilkan adalah nama
atribut, min, mean, max, standard deviation, edit, dan delete. Gambar halaman
data atribut dapat dilihat pada Gambar 4.4
Gambar 4.4 Input Data Bobot
4.3.5. Halaman Input nilai acak centroid
Gambar di bawah ini merupakan tampilan gambar Untuk Input data nilai acak centroid 1 dan centroid 2. Data yang diinput adalah nilai x dari masing-masing centroid sehingga akan mendapatkan hasil dari nilai K-Means dari inputan sebelumnya. Gambar input niai acak centroid dapat dilihat pada Gambar 4.5
Gambar 4.5 Halaman Input nilai acak centroid
4.3.6. Halaman Hasil Proses Clustering K-Means
Gambar di bawah ini merupakan tampilan gambar hasil clustering dari K-Means
yang mana akan ditampilkan hasil dari data diabetes, dan proses penginputan data acak dari form sebelumnya. Hasil tersebut berupa apakah positif atau tidaknya mengidap diabetes dari data yang sudah dilakukan proses clustering dengan menggunakan algortima K-Means. Gambar ini dapat dilihat pada Gambar 4.6
Gambar 4.6 Halaman Hasil Proses Clustering K-Means 4.3.7. Halaman Input data baru dan nilai limit
Gambar di bawah ini merupakan tampilan gambar Untuk Input data baru dan nilai limit, dimana kedua elemen ini dibutuhkan untuk proses mendapatkan clustering dari nilai knn. Gambar input data baru dan nilai limit dapat dilihat pada Gambar 4.8
Gambar 4.7 Halaman Input data baru dan nilai limit
4.3.8. Halaman Hasil Proses ClusteringK-Nearest Neighbor
Gambar 4.9 merupakan tampilan gambar hasil clustering dari KNN yang mana akan ditampilkan hasil dari data diabetes, dan proses penginputan data baru, dan nilai limit dari form sebelumnya. Hasil tersebut berupa apakah positif atau tidaknya mengidap diabetes dari data yang sudah dilakukan proses clustering dengan menggunakan algortima KNN
Gambar 4.8 Halaman Hasil Proses ClusteringK-Nearest Neighbor
BAB 5
KESIMPULAN DAN SARAN
5.1. Kesimpulan
Berdasarkan analisis dari sistem dan pengujian sistem secara menyeluruh yang telah dilakukan pada bab sebelumnya, maka kesimpulan pada penelitian ini antara lain:
1. Proses Cluster-isasi menggunakan k-Nearest Neighbor lebih cepat dibandingkan
k-Means Clustering karena k-Means Clustering melakukan sebanyak 11 iterasi sampai
nilai centroid-nya konstan sehingga waktu clusternya 11.6212 detik sedangkan waktu clusternya k-Nearest Neighbor0.4737 detik.
2. Akurasi dari Algoritma k-Nearest Neighbor terhadap data testing adalah 64.286 % sedangkan akurasi Algoritma k-Means Clustering adalah 67.143 % sehingga Algoritma k-Means Clustering lebih baik dalam melakukan Proses Cluster-isasi. 3. Hasil pengelompokan sample positive atau negative dengan menggunakan k-Means
Clustering dan k-Nearest Neighbor berhasil dilakukan.
5.2. Saran
Pada penelitian ini terdapat beberapa saran dalam pengembangan penelitian ini lebih lanjut, yakni:
1. Perlunya penelitian lebih lanjut dalam proses cluster-isasi, misalkan dengan menggunakan RapidMiner Studio, ML-Flex, MiningMart.
2. Perlu melakukan penelitian lebih lanjut sehingga menghasilkan akurasi yang lebih baik misalkan dengan algoritma Backpropagation dan Logistic Regression.
BAB 2
TINJAUAN PUSTAKA
2.1. Data Mining
Data Mining adalah suatu metode pengolahan data untuk menemukan pola yang
tersembunyi dari data tersebut. Hasil dari pengolahan data dengan metode Data
Mining ini dapat digunakan untuk mengambil keputusan di masa depan. Data Mining
ini juga dikenal dengan istilah pattern recognition (Ong, 2013).
Data Mining, sering juga disebut knowledge discovery in database (KDD),
adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam dataset berukuran besar. Keluaran dari Data Mining ini biasa dipakai untuk memperbaiki pengambilan keputusan di masa depan. Sehingga istilah pattern recognition sekarang jarang digunakan karena ia termasuk bagian dari Data Mining (Santosa, 2007).
Data Mining suatu proses kegiatan yang berulang-ulang pada analisis
database dalam jumlah besar, dengan tujuan untuk melakukan penggalian informasi
dan pengetahuan yang dapat membuktikan keakuratan dan potensi yang berguna bagi pengetahuan pekerja yang terlibat dalam pengambilan keputusan dan pemecahan masalah. Istilah data mining itu merujuk pada keseluruhan proses yang terdiri dari pengumpulan data analisis, pengembangan model pembelajaran induktif dan adopsi
keputusan praktis seta tindakan berdasarkan pengetahuan yang diperoleh (Vercilles,2009).Kegiatan data mining dapat dibagi kedalam dua inti penyelidikan utama, sesuai dengan tujuan utama dari analisis, yaitu: interpretasi dan prediksi
(Vercilles, 2009).
1. Interpretasi
Tujuan interpretasi adalah untuk mengidentifikasi pola yang teratur dalam data dan untuk mengekspresikan data melalui peraturan dan kriteria yang dapat dengan mudah dipahami oleh para ahli dalam domain aplikasi. Contoh; Clustering, Association Rules.