1
Penerapan Algoritma Naive Bayes Untuk Penentuan Pelaksanaan
Promosi
(Studi Kasus: Biro Promosi FTI UKSW)
Artikel Ilmiah
Peneliti:
Rio Hanni Wowiling (672014189) Nina Setiyawati, S.Kom., M.Cs.
Program Studi Teknik Informatika
Fakultas Teknologi Informasi
Universitas Kristen Satya Wacana
6
1. Pendahuluan
Biro Promosi Fakultas Teknologi Informasi Universitas Kristen Satya Wacana (FTI-UKSW) merupakan salah satu unit kerja yang ada di FTI-UKSW yang memiliki peran penting dalam penyebaran informasi mengenai FTI-UKSW untuk meningkatkan jumlah mahasiswanya. Penyebaran informasi melalui media sosial maupun melakukan promosi secara langsung merupakan beberapa strategi yang telah dilakukan untuk memperkenalkan dan memberikan informasi tentang FTI-UKSW.
Promosi secara langsung dilakukan dengan membentuk beberapa tim yang dikirim atau ditempatkan di berbagai daerah di Indonesia yang sudah ditargetkan oleh Biro Promosi FTI-UKSW. Jumlah mahasiswa yang masuk di FTI-UKSW dari daerah satu dengan daerah yang lainnya berbeda-beda, sehingga hal yang perlu diketahui adalah efektifitas dari pelaksanaan promosi di tiap-tiap daerah yang sudah dilakukan sebagai dasar pengambilan keputusan untuk pelaksanaan promosi selanjutnya.
Berdasarkan latar belakang tersebut maka dilakukan penelitian untuk menentukan efektifitas dari pelaksanaan promosi di tiap-tiap daerah yang sudah dilakukan sebagai dasar pengambilan keputusan untuk pelaksanaan promosi selanjutnya. Dengan mengimplementasikan algoritma Naive Bayes yang merupakan salah satu metode klasifikasi dan yang memiliki kemampuan untuk memprediksi probabilitas di masa depan [1], diharapkan dapat menentukan efektifitas dari pelaksanaan promosi di tiap-tiap daerah sehingga dapat membantu Biro Promosi untuk menentukan pelaksanaan promosi selanjutnya serta strategi yang sesuai untuk setiap daerah.
Hasil analisis dari algoritma Naive Bayes terhadap data histori pelaksanaan promosi akan ditampilkan ke dalam aplikasi berbasis mobile yang bertujuan untuk menghasilkan laporan yang lebih informatif, sehingga memudahkan Biro Promosi FTI-UKSW sehubungan dengan pengambilan keputusan dan kebijakan-kebijakan terkait pelaksanaan promosi selanjutnya di suatu daerah. Aplikasi berbasis mobile
ini menggunakan format penulisan Java Script Objek Nation(JSON) untuk untuk pertukaran data.
Berdasarkan permasalahan di atas, maka dapat didapatkan rumusan masalah pada penelitian ini yaitu bagaimana melakukan analisis algoritma Naive Bayes
untuk menentukan efektifitas dari pelaksanaan promosi di tiap-tiap daerah yang sudah dilakukan sebagai dasar pengambilan keputusan untuk pelaksanaan promosi selanjutnya.
7
Pada penelitian mengenai “Klasifikasi Kayu Dengan Menggunakan Naive Bayes Classifier membahas tentang pengimplementasian algoritma Naive Bayes
dalam pengklasifikasian empat tipe kayu tertentu. Dan yang menjadi masalah dalam penelitian ini adalah bagaimana mengklasifikasikan empat tipe kayu tertentu tersebut hanya berdasarkan penampilan luarnya saja, dalam hal ini citra dari masing-masing tipe tersebut diambil dengan kamera digital. Selanjutnya dilakukan ekstraksi citra dengan menggunakan Local Binary Pattern (LBP) agar diperoleh citra gray-level yang kemudian dapat diolah lebih lanjut dalam image prossesing. Dan berdasarkan citra hasil LBP akan dapat diperoleh statistik-statistik yang dapat digunakan sebagai parameter untuk mengkarakterisasi suatu citra. Pada akhirnya, dengan menggunakan Naïve Bayes Classifier yang diimplementasikan pada perangkat lunak Matlab, akan menghasilkan informasi berupa klasifikasi yang sudah ditentukan sebelumnya [2].
Pada penelitian tentang “Data Mining Menggunakan Algoritma Naive Bayes untuk Klasifikasi Kelulusan Mahasiswa Universitas Dian Nuswantoro”
membahas masalah mengenai data mahasiswa dan data kelulusan mahasiswa Universitas Dian Nuswantoro yang menghasilkan data yang sangat berlimpah berupa data profil mahasiswa dan data akademik yang terjadi secara berulang yang menimbulkan penumpukan terhadap data mahasiswa sehingga mempengaruhi pencarian informasi terhadap data tersebut. Untuk menangani masalah tersebut, dilakukanlah proses pengklasifikasian terhadap data mahasiswa Universitas Dian Nuswantoro Fakultas Ilmu Komputer angkatan 2009 berjenjang D3 dan S1 dengan memanfaatkan proses data mining dengan menggunakan teknik klasifikasi. Metode yang digunakan adalah CRISP-DM dengan melalui proses business understanding, data understanding, data preparation, modeling, evaluation dan deployment. Algoritma yang digunakan untuk klasifikasi kelulusan adalah algoritma Naïve Bayes. Serta implementasi menggunakan RapidMiner 5.3 yang digunakan untuk membantu menemukan nilai yang akurat. Atribut yang digunakan adalah NIM, Nama, Jenjang, Progdi, Provinsi Asal, Jenis Kelamin, SKS, IPK, dan Tahun Lulus. Hasil dari penelitian ini digunakan sebagai salah satu dasar pengambilan keputusan untuk menentukan kebijakan oleh pihak Fasilkom [3].
Berbeda dengan penelitian sebelumnya, penelitian ini membahas tentang algoritma Naive Bayes untuk menentukan efektifitas dari pelaksanaan promosi di tiap-tiap daerah yang sudah dilakukan sebagai dasar pengambilan keputusan untuk pelaksanaan promosi selanjutnya. Dan yang menjadi masalah pada penelitian ini yaitu bagaimana menentukan efektifitas dari pelaksanaan promosi di tiap-tiap daerah yang sudah dilakukan sebagai dasar pengambilan keputusan untuk pelaksanaan promosi selanjutnya. Dengan menggunakan algoritma Naive Bayes, akan menghasilkan informasi efektifitas dari tiap-tiap daerah yang sudah dilakukan promosi dan informasi pelaksanaan promosi berikutnya.
8
1. Deskripsi
Terkadang peneliti dan analisis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecendrungan yang terdapat dalam data.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih ke arah numerik dari pada ke arah kategori.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa mendatang.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. 5. Pengklusteran
Clustering merupakan suatu metode untuk mencari dan mengelompokkan data yang memiliki kemiripan karakteriktik (similarity) antara satu data dengan data yang lain. Clustering merupakan salah satu metode data mining yang bersifat tanpa arahan (unsupervised).
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam suatu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja [1].
Menurut Larose, data mining memeliki enam fase CRISP-DM (Cross Industry Standard Process for Data Mining), yaitu [1]:
1. Fase Pemahaman Bisnis ( Business Understanding Phase ) 2. Fase Pemahaman Data ( Data Understanding Phase ) 3. Fase Pengolahan Data ( Data Preparation Phase ) 4. Fase Pemodelan ( Modeling Phase )
5. Fase Evaluasi ( Evaluation Phase ) 6. Fase Penyebaran (Deployment Phase)
Naive Bayes adalah metode lama untuk klasifikasi sering dipakai lagi karena kesederhanaan dan stabilitasnya. Naive Bayes juga merupakan sebuah pengklasifikasian statistik yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class. Naive Bayes didasarkan pada teorema bayes yang memiliki kemampuan klasifikasi serupa decision tree dan neural network. Naive Bayes merupakan salah satu metode machine learning yang memanfaatkan perhitungan probabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi probabilitas di masa depan berdasarkan pengalaman di masa sebelumnya.
Teorema Bayes memiliki rumusan umum sebagai berikut [1]:
( | ) ( | ) ( ) ( )
Gambar 1. Rumusan Umum Teorema Bayes
Dimana :
X = data dengan class yang belum diketahui
9
P(C|X) = probabilitas hipotesis berdasarkan kondisi (posteriori probability)
P(C) = probabilitas hipotesis (prior probability)
P(X|C) = probabilitas berdasarkan kondisi pada hipotesis
P(X) = probabilitas C
P(X) untuk semua kelas adalah konstan, hanya membutuhkan P(X|C)P(C)
menjadi maksimal. Jika probabilitas priori kelas C tidak diketahui, maka biasanya diasumsikan bahwa probabilitas kelas-kelas ini adalah sama, yakni P(C1) = P(C2)
= ... = P(Cn), oleh karena pernyataan tersebut dikonversi untuk memaksimalkan
P(X|C). P(C) sering disebut sebagai kemungkinan data X ketika diberi C, sedangkan asumsi untuk memaksimalkan P(X|C) disebut kemungkinan maksimum. Jika tidak, maka perlu memaksimalkan P(X|C)P(C). Jika diketahui asumsi probabilitas tidak sama, maka probabilitas priori dari kelas dapat dihitung dengan P(C) = M / m, dimana M adalah jumlah sampel training di kelas C
sementara m adalah jumlah keseluruhan sampel training.
Confusion matrix memberikan keputusan yang diperoleh dalam traning dan
testing, confusion matrix memberikan penilaian performance klasifikasi berdasarkan objek dengan benar atau salah. [5] Confusion matrix berisi informasi aktual (actual) dan prediksi (predicted) pada sistem klasifikasi.
Tabel 1. Confusion Matrix
CLASSIFICATION PREDICTED CLASS
Class = Yes Class = No
Class = Yes A (True Positive-TP) B (False Negative-FN)
Class = No C (False Positive-FP) D (True Negative-TN)
Berikut adalah persamaan model confusion matrix untuk menghitung nilai
precision(pre), recall(rec) dan accuracy(acc).
pre = TP x 100%
Tahapan penelitian yang digunakan dalam Implementasi Algoritma Naive Bayes di Promosi Fakultas Teknologi Informasi Universitas Kristen Satya Wacana dapat dilihat pada Gambar 2.
10
Gambar 2. Tahapan Penelitian
Tahapan penelitian pada Gambar 2 dijelaskan sebagai berikut:
Tahap pertama adalah identifikasi masalah, pada tahap ini dilakkukan proses identifikasi masalah dengan melakukan wawancara dengan staf Biro Promosi FTI-UKSW. Dari wawancara yang telah dilakukan, didapatkan informasi bahwa pelaksanaan promosi di tiap-tiap daerah yang dilakukan setiap tahun dilakukan tanpa ada dasar alasan yang jelas, oleh karena itu pada penelitian ini akan dilakukan analisis terhadap data pelaksanaan promosi yang telah dilakukan untuk melihat efektifitas pelaksanaan promosi sebagai dasar pelaksanaan promosi pada suatu daerah.
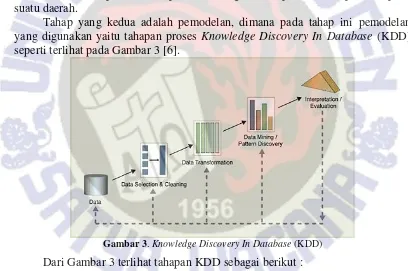
Tahap yang kedua adalah pemodelan, dimana pada tahap ini pemodelan yang digunakan yaitu tahapan proses Knowledge Discovery In Database (KDD) seperti terlihat pada Gambar 3 [6].
Gambar 3. Knowledge Discovery In Database (KDD)
Dari Gambar 3 terlihat tahapan KDD sebagai berikut :
Tahap pertama yaitu pengumpulan data. Pada tahap ini dilakukan pengumpulan data-data mentah yang akan digunakan untuk proses data mining. Data-data tersebut yaitu data Sekolah Menengah Tingkat Atas (SMTA) mahasiswa FTI-UKSW dari angkatan 2012 sampai 2017 yang diperoleh dari Biro Promosi dan Hubungan Luar UKSW dalam file excel. Data tersebut berisi atribut NIM, NAMA_SMTA, KOTA_SMTA, kota asal orang tua, serta program studi mahasiswa. Data mentah yang berikutnya yaitu data yang diperoleh dari perhitungan melalui google maps yang berupa data jarak antara FTI-UKSW (kota Salatiga) dengan daerah-daerah yang telah dilakukan promosi sebelumnya. Tabel 2 adalah data SMTA yang didapatkan dari BPHL UKSW.
Pemodelan
11
Tabel 2. Data SMTA Mahasiswa FTI-UKSW Dari Angkatan 2012 Sampai 2017
NIM NAMA_SMTA KOTA_SMTA KOTA_ORTU PRODI
672016040 SMK IPT Karangpanas, Sema
Kota Semarang Kab. Semarang TEKNIK INFORMATIKA 672016041 SMA Kristen 1, Salatiga Kota Salatiga Kota Salatiga TEKNIK
INFORMATIKA 672016042 SMK MUHAMADDIYAH,
SALATIGA
Kota Salatiga Kab. Semarang TEKNIK INFORMATIKA
.... .... .... .... ....
Tahap kedua yaitu tahap data selection & cleaning. Pada tahap ini dilakukan proses pemilihan dan pembersihan data terhadap data mentah yang diperoleh pada tahap sebelumnya melalui proses pre-processing atau biasa dikenal dengan proses normalisasi data. Normalisasi data dilakukan dengan menghapus data kosong di setiap atribut-atribut yang ada serta menghilangkan atribut yang tidak digunakan. Tabel 3 memperlihatkan hasil dari penghapusan beberapa atribut pada data SMTA.
Tabel 3. Hasil Data Selection & Cleaning pada Data SMTA
NIM KOTA_SMTA
672016040 Kota Semarang
672016041 Kota Salatiga
672016042 Kota Salatiga
.... ....
Tahap ketiga yaitu tahap Data Transformation. Berikut adalah tabel-tabel yang baru yang diperoleh dari tahap Data Transformation.
1) Tabel kota terdiri dari 4 atribut yaitu, atribut NO, KOTA_SMTA, JARAK yang digunakan untuk menampung data jarak antara Salatiga dengan daerah promosi sebelumnya dan atribut KETERANGAN yang digunakan untuk menampung keterangan nilai jarak, seperti dapat dilihat pada Tabel 4.
Tabel 4. Tabel Kota
2) Tabel mahasiswa memiliki atribut NIM, ID_KOTA, PRODI yang digunakan untuk menampung data mahasiswa dan PERIODE yang digunakan untuk menampung data periode promosi yang ada di database.
Tabel 5. Tabel Mahasiswa
NIM ID_KOTA PRODI PERIODE
672016040 1 TEKNIK INFORMATIKA 2016
672016041 2 TEKNIK INFORMATIKA 2016
12
3) Tabel periode memiliki atribut PRODI yang digunakan untuk menampung data periode promosi yang ada di database.
Tabel 6. Tabel Periode PERIODE
2017
2018 ....
4) Selanjutnya tabel efektifitas yang memiliki atribut KOTA_SMTA, JUMLAH MAHASISWA, PROMOSI FAKULTAS, JARAK, EFEKTIFITAS dan PELAKSANAAN PROMOSI yang digunakan untuk menampung data pelaksanaan promosi dari daerah promosi sebelumnya, seperti dapat dilihat pada Tabel 7.
Tabel 7. Tabel Efektifitas
ID_
JARAK EFEKTIFITAS PELAKSANAAN PROMOSI
Relasi dari tabel-tabel yang terbentuk, yaitu tb_mhs, tb_kota, tb_periode, tb_efektifitas terlihat pada Gambar 4.
Gambar 4. Database Relation
4. Hasil Pembahasan dan Implementasi
Output yang dihasilkan selanjutnya ditampilkan pada aplikasi berbasis
mobile yang berupa informasi efektifitas pelaksanaan promosi serta rekomendasi pelaksanaan promosi selanjutnya pada suatu daerah yang ditampilkan. Informasi tersebut diperoleh dari analisis menggunakan algoritma Naive Bayes pada data dari hasil proses transformasi atau dataset. Dengan menggunakan algoritma Naive Bayes dilakukan perhitungan pada data training, dimana pada penelitian ini yang digunakan sebagai tabel training adalah tb_efektifitas. Adapun variabel input
13
dan EFEKTIFITAS. Target output yang dihasilkan pada penelitian ini yaitu pelaksanaan promosi dengan classoutput adalah Ya dan Tidak.
Adapun proses perhitungan menggunakan algoritma Naive Bayes terlihat pada Gambar 5.
Gambar 5. Proses Perhitungan Algoritma Naive Bayes
Menghitung jumlah kelas dari pelaksanaan promosi berdasarkan klasifikasi yang terbentuk (prior probability).
1. C1 (Kelas PELAKSANAAN PROMOSI = “YA”) = jumlah data "YA" dibagi dengan keseluruhan jumlah data pada atribut PELAKSANAAN PROMOSI = 85/156 = 0,54
2. C2 (Kelas PELAKSANAAN PROMOSI = “TIDAK”) = jumlah data "TIDAK" dibagi dengan keseluruhan jumlah data pada atribut PELAKSANAAN PROMOSI = 71/156 = 0,46
Tahap untuk menghitung prior probability diimplementasikan dalam kode program seperti terlihat pada Kode Program 1.
Kode Program 1. Kode Program Menghitung Probabilitas “YA” dan “TIDAK”
1. (SELECT COUNT(id_efektifitas) FROM tb_efektifitas e2 WHERE 2. e2.PELAKSANAAN_PROMOSI='YA') AS 'strategi_ya',
3. (SELECT COUNT(id_efektifitas) FROM tb_efektifitas e2 WHERE 4. e2.PELAKSANAAN_PROMOSI='TIDAK') AS 'strategi_tidak',
5. (SELECT COUNT(PELAKSANAAN_PROMOSI) FROM pelaksanaan_promosi) AS 'strategi' 6. $prop_ya = $row2["strategi_ya"] / $row2["strategi"];
7. $prop_tidak = $row2["strategi_tidak"] / $row2["strategi"];
Kode program 1 pada baris 1 dan 2 digunakan untuk menghitung jumlah data "YA" pada atribut "PELAKSANAAN_PROMOSI" dan disimpan pada variabel “strategi_ya”, sedangkan pada baris 3 dan 4 digunakan untuk menghitung jumlah data "TIDAK" pada atribut "PELAKSANAAN_PROMOSI" dan disimpan pada variabel “strategi_tidak” dan pada baris 5-7 digunakan untuk menghitung
jumlah keseluruhan data yang ada pada pada atribut
"PELAKSANAAN_PROMOSI" yang kemudian dibagi jumlah seluruh data, kemudian disimpan dalam variabel “prop_ya” dan “prop_tidak”.
Menghitung probabilitas jumlah kasus yang sama pada setiap atribut dari kelas pelaksanaan promosi (YA/TIDAK) berdasarkan data testing.
14
7. P(EFEKTIFITAS = “TIDAK EFEKTIF” | Kelas PELAKSANAAN PROMOSI = “YA”) = 3/85 = 0.04
8. P(EFEKTIFITAS = “TIDAK EFEKTIF” | Kelas PELAKSANAAN PROMOSI = “TIDAK”) = 41/71 = 0.58
Menghitung probabilitas jumlah kasus yang sama pada setiap atribut dari kelas pelaksanaan promosi (YA/TIDAK) berdasarkan data training diimplementasikan dalam kode program seperti terlihat pada Kode Program 2.
Kode Program 2. Kode Program Menghitung Probabilitas “YA” Dan “TIDAK” Pada Setiap Atribut Naive Bayes
1. $jumlah_mahasiswa_ya = $row2["jml_mahasiswa_meningkat_ya"] / 2. $row2["strategi_ya"];
3. $jumlah_mahasiswa_tidak = $row2["jml_mahasiswa_ meningkat _tidak"] / 4. $row2["strategi_tidak"];
5. $promosi_fakultas_ya = $row2["promosi_fakultas_tidak_ya"] / 6. $row2["strategi_ya"];
7. $promosi_fakultas_tidak = $row2["promosi_fakultas_tidak_tidak"] / 8. $row2["strategi_tidak"];
9. $jarak_ya = $row2["jarak_jauh_ya"] / $row2["strategi_ya"];
10. $jarak_tidak = $row2["jarak_jauh_tidak"] / $row2["strategi_tidak"]; 11. $efektifitas_ya = $row2["efektifitas_tidak_efektif_ya"] /
12. $row2["strategi_ya"];
13. $efektifitas_tidak = $row2["efektifitas_tidak_efektif_tidak"] / 14. $row2["strategi_tidak"];
Kode Program 2 pada baris 1 sampai 4 digunakan untuk menghitung jumlah data mahasiswa dengan value “MENINGKAT” dibagi dengan variabel “strategi_ya” dan “strategi_tidak. Pada baris 5 sampai 8 digunakan untuk
menghitung jumlah data dengan value “YA” pada atribut
PROMOSI_FAKULTAS dibagi dengan variabel “strategi_ya” dan “strategi_tidak”. Pada baris 9 dan 10 digunakan untuk menghitung jumlah data dengan value“TIDAK” pada atribut JARAK dibagi dengan variabel “strategi_ya”
dan “strategi_tidak”. Pada baris 11 dan 14 digunakan untuk menghitung jumlah data dengan value“TIDAK EFEKTIF” pada atribut EFEKTIFITAS dibagi dengan
variabel “strategi_ya” dan “strategi_tidak”.
Perkalian seluruh probabilitas “YA” dan “TIDAK” setiap atribut dengan
15
Perkalian seluruh probabilitas “YA” dan “TIDAK” setiap atribut Naive Bayes
dengan prior probability diimplementasikan dalam kode program seperti terlihat pada Kode Program 3.
Kode Program 3. Kode Program Menghitung Perkalian Semua Hasil Variabel “strategi_ya” dan
“strategi_tidak”.
1. $ya = $jumlah_mahasiswa_ya * $promosi_fakultas_ya * $jarak_ya * 2. $efektifitas_ya * $prop_ya;
3. $tidak = $jumlah_mahasiswa_tidak * $promosi_fakultas_tidak * $jarak_tidak * 4. $efektifitas_tidak * $prop_tidak;
Kode program 3 pada baris 1 dan 2 digunakan untuk menghitung perkalian seluruh probabilitas “YA” setiap atribut Naive Bayes dan disimpan sebagai variabel “ya”. Sedangkan pada baris 3 dan 4 digunakan untuk menghitung perkalian seluruh probabilitas “YA” setiap atribut Naive Bayes dan disimpan sebagai variabel “tidak”.
Membandingkan hasil perkalian seluruh probabilitas “YA” dan “TIDAK” setiap atribut dengan prior probability
Karena hasil P (Ci) | Class Tahun Lulus = “yes”) P(X| Class Tahun Lulus = “yes”) lebih besar dariP (Ci) | Class Tahun Lulus = “no”) P(X| Class Tahun Lulus = “no”)maka keputusannya adalah “YA”
Tahap untuk membandingkan hasil perkalian seluruh probabilitas “YA” dan “TIDAK” setiap atribut dengan prior probability diimplementasikan dalam kode program seperti terlihat pada Kode Program 4.
Kode Program 4. Kode Program Membandingkan Hasil Kelas
1. if ($ya >= $tidak) { 2. $strategi = "YA"; 3. } else {
4. $strategi = "TIDAK"; }
5. $hasil["strategi_promosi"] = $strategi;
Kode program 4 merupakan kode program untuk membandingkan hasil dari tahap sebelumnya yaitu variabel “ya” dan “tidak”. Pada baris 1 digunakan untuk mengecek apakah variabel “ya” lebih dari sama dengan variabel “tidak”, jika ya maka mengeksekusi baris 2 dan menghasilkan output “YA”, apabila tidak maka baris 4 yang dieksekusi dan menghasilkan output “TIDAK”. Dan akhirnya pada
baris 5 digunakan untuk menyimpan hasil tersebut pada atribut “strategi_promosi” dalam tabel efektifitas di database.
16
Kode Program 5. Kode Program Java Script Objek Nation(JSON) 1. echo json_encode($data);
Output dari perhitungan diatas ditampilkan pada pada aplikasi yang berbasis
mobile, oleh karena itu dengan menggunakan JSON proses transfer data yang diinginkan jadi mudah.
Pada tahap Interpretation / Evaluation, data hasil perhitungan menggunakan algoritma Naive Bayes pada tahap data mining pada akhirnya ditampilkan pada aplikasi berbasis mobile sehingga staf Biro Promosi FTI-UKSW dapat melihat informasi efektifitas pelaksanaan promosi dari kota-kota yang dilakukan pada periode promosi sebelumnya dan pelaksanaan promosi yang dapat menjadi acuan staf Biro Promosi FTI-UKSW untuk melaksanakan promosi pada periode promosi selanjutnya.
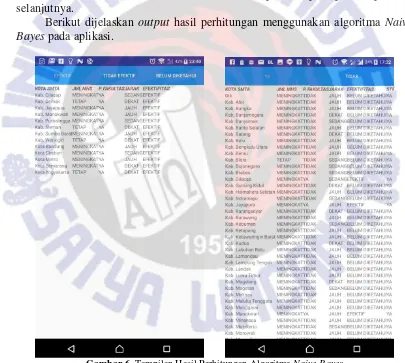
Berikut dijelaskan output hasil perhitungan menggunakan algoritma Naive Bayes pada aplikasi.
Gambar 6. Tampilan Hasil Perhitungan Algoritma Naive Bayes
17
mahasiswa “MENINGKAT” dan memiliki status “YA” pada promosi fakultasnya serta jarak antara Kabupaten Cilacap dengan Kota Salatiga yaitu SEDANG, menghasilkan value“EFEKTIF”.
Selanjutnya pada tabel informasi pelaksanaan promosi yang dibagi menjadi dua tab yaitu tab “YA” dan “TIDAK”. Kota Cilacap yang memperoleh value
“EFEKTIF” pada tabel informasi efektifitas, pada tabel informasi pelaksanaan promosi ini menghasilkan value“YA”.
Pada penelitian ini dilakukan pengujian untuk mengetahui pola atau cara kerja dari algoritma Naive Bayes dalam mengklasifikasikan data ke dalam kelas yang sudah ditentukan. Pada pengujian ini, menggunakan data latih dari yang diperoleh dari tabel informasi pelaksanaan promosi. Data uji untuk menguji tabel informasi pelaksanaan promosi menggunakan jumlah data yang sama dengan data latih. Cara kerja diperoleh dengan memberikan nilai pada confusion matrix untuk menghitung nilai precision, recall dan accuracy dari hasil pengujian. Berikut hasil pengujian dari beberapa percobaan.
1. Percobaan ke-1
Menggunakan data latih dan data uji sebanyak 31 data sampel informasi pelaksanaan promosi. Tabel 8 adalah perhitungan nilai precision, recall dan
accuracy dengan confusion matrix untuk percobaan ke-1.
Tabel 8. Confusion Matrix Percobaan Ke-1
Predicted Class pelaksanaan promosi. Tabel 9 adalah perhitungan nilai precision, recall dan
accuracy dengan confusion matrix untuk percobaan ke-2.
Tabel 9. Confusion Matrix Percobaan Ke-2
18
3. Percobaan ke-3
Menggunakan data latih dan data uji sebanyak 93 data sampel informasi pelaksanaan promosi. Tabel 10 adalah perhitungan nilai precision, recall dan
accuracy dengan confusion matrix untuk percobaan ke-3.
Tabel 10. Confusion Matrix Percobaan Ke-3
Predicted Class
Ya Tidak
Actual Class Ya 55 3
Tidak 0 35
Precision = 55 / (0+55) x 100% = 100,00%
Recall = 55 / (3+55) x 100% = 94,82%
Accuracy = (55+35) / 93 x 100% = 96,77%
4. Percobaan ke-4
Menggunakan data latih dan data uji sebanyak 124 data sampel informasi pelaksanaan promosi. Tabel 11 adalah perhitungan nilai precision, recall dan
accuracy dengan confusion matrix untuk percobaan ke-4.
Tabel 11. Confusion Matrix Percobaan Ke-4
Predicted Class
Ya Tidak
Actual Class Ya 67 6
Tidak 1 50
Precision = 67 / (1+67) x 100% = 98,53%
Recall = 67 / (6+67) x 100% = 91,78%
Accuracy = (67+50) / 124 x 100% = 94,35%
5. Percobaan ke-5
Menggunakan data latih dan data uji sebanyak 156 data sampel informasi pelaksanaan promosi. Tabel 12 adalah perhitungan nilai precision, recall dan
accuracy dengan confusion matrix untuk percobaan ke-5.
Tabel 12. Confusion Matrix Percobaan Ke-5
Predicted Class
Ya Tidak
Actual Class Ya 83 7
Tidak 2 64
19
Recall = 83 / (7+83) x 100% = 92,22%
Accuracy = (83+64) / 156 x 100% = 94,23%
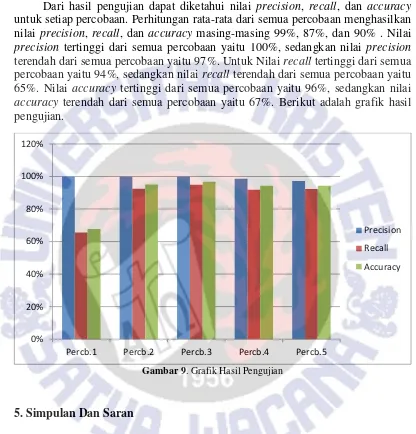
Dari hasil pengujian dapat diketahui nilai precision, recall, dan accuracy
untuk setiap percobaan. Perhitungan rata-rata dari semua percobaan menghasilkan nilai precision, recall, dan accuracy masing-masing 99%, 87%, dan 90% . Nilai
precision tertinggi dari semua percobaan yaitu 100%, sedangkan nilai precision
terendah dari semua percobaan yaitu 97%. Untuk Nilai recall tertinggi dari semua percobaan yaitu 94%, sedangkan nilai recall terendah dari semua percobaan yaitu 65%. Nilai accuracy tertinggi dari semua percobaan yaitu 96%, sedangkan nilai
accuracy terendah dari semua percobaan yaitu 67%. Berikut adalah grafik hasil pengujian.
Gambar 9. Grafik Hasil Pengujian
5.Simpulan Dan Saran
Berdasarkan penelitian yang telah dilakukan dapat disimpulkan bahwa analisa efektifitas pelaksanaan promosi dilakukan menggunakan algoritma Naive Bayes melalui tahapan Knowledge Discovery In Database (KDD). Dari dataset hasil transformasi data dilakukan perhitungan menggunakan algoritma Naive Bayes dan dihasilkan efektifitas pelaksanaan promosi serta rekomendasi untuk pelaksanaan promosi pada suatu daerah. Dari hasil pengujian dapat diketahui nilai
precision, recall, dan accuracy untuk setiap percobaan. Perhitungan rata-rata dari semua percobaan menghasilkan nilai precision, recall, dan accuracy masing-masing 99%, 87%, dan 90%.
Pengembangan yang dapat dilakukan pada penelitian ini di kemudian hari adalah menambahkan beberapa paramater atau atribut lain yang dapat mendukung proses analisis menjadi lebih baik. Untuk bagian tampilan di aplikasi mobile dapat
20
ditambahkan group by terhadap data hasil klasifikasi berdasarkan parameter yang lain agar informasi yang ditampilkan lebih informatif.
6. Daftar Pustaka
[1] Larose , Daniel T, 2005, Discovering Knowledge in Data: An Introduction to Data Mining, John Willey & Sons. Inc
[2] Fahrurozi, A. (2014). Klasifikasi Kayu Dengan Menggunakan Naive Bayes Classifier. KNM XVII ITS Surabaya. 2014.
[3] Listyaningrum, S. (2015). Penerapan Data Mining Untuk Analisis Karakteristik DPT Non-Participate sebagai Prediksi Partisipan Pemilu dengan Menggunakan Metode Naive Bayes Classifier. Universitas Dian Nuswantoro. Semarang.
[4] Nugroho, Y. S. (2014). Data Mining Menggunakan Algoritma Naive Bayes
Untuk Klasifikasi Mahasiswa Universitas Dian Nuswantoro. Universitas Dian Nuswantoro. Semarang.
[5] Ciptohartono, C. C. (2014). Algoritma Klasifikasi Naive Bayes Untuk Menilai Kelayakan Kredit.
[6] Ridwan, Mujib; Suyono, Hadi; Sarosa, M;. (2013). Penerapan Data Mining
Untuk Evaluasi Kinerja Akademik Mahasiswa Menggunakan Algoritma