ANALISIS DAN IMPLEMENTASI DATA CLUSTERING DENGAN MENGGUNAKAN ALGORITMA INCREMENTAL GENETIK K-MEANS
Tyas Ayu Landiastuti¹, Arie Ardiyanti Suryani², Intan Nurma Yulita³
¹Teknik Informatika, Fakultas Teknik Informatika, Universitas Telkom
Abstrak
Data merupakan sumber penting yang dapat diolah menjadi suatu informasi yang berguna.Untuk menghasilkan informasi yang berguna data harus diolah dengan baik.Data mining merupakan proses mengolah data menjadi suatu informasi. Dalam data mining terdapat berbagai macam teknik untuk mengolah data, salah satunya adalah clustering.Clustering merupakan proses pengelompokan data berdasarkan kesamaan karakteristik yang dimiliki data, sehingga dihasilkan beberapa cluster dengan karakteristik yang berbeda. Untuk mengukur kesamaan antardata dapat digunakan pengukuran jarak untuk data bertipe numerik, misalnya Euclidean distance.Euclidean distanceakan sangat mudah digunakan dan berkeja sangat baik ketika data bertipe numerik, tetapi tidak dapat digunakan ketika data bertipe categori atau campuran. Di dunia nyata banyak data yang betipe kategori maupun campuran.Pada Tugas Akhir ini akan dilakukan clustering data bertipe campuran dengan menggunakn Incremental Genetic K-means Algorithm (IGKA).
Pada Tugas Akhir ini perhitungan jarak akan dilakukan secara terpisah untuk data numerik dan kategori. Algoritma Incremental Genetic K-means dimulai dengan inisialisasi individu sejumlah populasi P secara random, lalu dilakukan perhitungan fitness dan seleksi, kemudian individu yang terseleksi akan dimutasi. Setelah tahap mutasi selesai, maka semua individu masuk ke tahap k-means. Proses ini akan terus berjalan sampai akhir iterasi atau jika pusat sudah tidak berubah. Dari hasil pengujian dan analisa didapatkan bahwa jumlah klaster dapat mempengaruhi silhouette coefficient. Semakin besar jumlah klaster maka silhouette coefficient akan semakin besar.
Kata Kunci : data mining, Clustering, IGKA, data bertipe campuran
Abstract
Data is an important resource that can be processed into an useful information. To generate the data to be an information, the data must be processed properly. Data mining is a process to find an interesting information from very large data. In data mining there are many techniques to process the data, one of which is clustering. Clustering is the process of grouping the data based on characteristics of data into cluster(group) that has a same characteristics (similarity) in the same cluster and has a different characteristics (dissimilarity) with object in the other cluster. To measure the similarity between the data, the distance measurement can be used for numeric data type, such as Euclidean distance. Euclidean distance is very easy to be use and working good when the type of data is numeric, but when the type of data is categorical or mixed, Euclidean distance is cannot be used. In real world, a lot of data is categorical or mixed. In this Final project will be implemented clustering mixed type data with Incremental Genetic K-means Algorithm. In this Final Project the distance will be calculated separately for numerical and categorical data. Incremental Genetic K-means Algorithm starts with the randomized initialization of population, and calculate the fitness function and selection, then the individual who are selected will be transferred with mutation operator. After the mutation phase all individuals will be processed with k-means operator. This process will continue until the end of iteration or until the center of each cluster has not changed. From result and the analysis found that the number of clusters can affect the silhouette coefficient. The larger number of clusters will make the silhouette
coefficient tends to increasingly rise.
Keywords : data mining, clustering, IGKA, mixed data type
Powered by TCPDF (www.tcpdf.org)
1. Pendahuluan
1.1 Latar Belakang
Data merupakan sumber yang penting yang dapat diolah menjadi suatu informasi. Data tersebut harus diolah dengan baik agar dapat menghasilkan suatu informasi yang berguna dan dapat dimanfaatkan[8].Data mining merupakan proses memperoleh informasi dari suatu data yang diolah sedemikian rupa.Terdapat beberapa teknik dalam
data mining salah satunya adalah clustering. Teknik klaster termasuk teknik yang sudah
cukup dikenal dan banyak dipakai dalam data mining[8].
Clustering merupakan proses pengelompokan data dengan melihat kesamaan
karakteristik yang dimiliki data tersebut, sehingga dihasilkan beberapa klaster dengan kriteria data tertentu. Banyak algoritma yang digunakan dalam teknik clustering ini, tetapi beberapa algoritma hanya dapat menangani data yang bersifat numerical saja maupun categorical saja, tidak menangani data yang campuran antara keduanya. Pada kehidupan nyata banyak data yang berupa numerical dan categorical contohnya pada data bank atau data kesehatan. Pada data bank maupun data kesehatan terdapat atribut berupa jenis kelamin, merokok atau tidak merokok, yang termasuk categorical dan atribut umur, salary, yang termasuk data numerical[7]. Oleh karena itu dibutuhkan algoritma yang dapat menangani data dengan dua variabel tersebut. Salah satu algoritma tersebut adalah Genetic K-Means. Algoritma ini merupakan hasil penggabungan antara
Genetic Algorithm dan K-Means Algorithm. Penggabungan ini mengkombinasikan
kekuatan sifat natural pada algoritma genetik dengan performansi yang tinggi pada algoritma k-means[7].
Algoritma Genetic K-Means(GKA) sendiri telah mengalami pengembangan yaituFast Genetic K-means Algorithm(FGKA) dan Incremental Genetic K-Means
Algorithm(IGKA). Kedua algoritma tersebut dapat bekerja lebih cepat dari pada
algoritma GKA. FGKA dapat menghasilkan waktu 20 kali lebih cepat dari pada GKA. Akan tetapi meskipun FGKA melebihi GKA secara signifikan, FGKA memiliki kekurangan potensial. FGKA memiliki performansi yang bagus hanya jika probabilitas mutasi besar, sedangkan jika mutasi probabilitasnya kecil maka akan menyebabkan biaya yang mahal dalam perhitungannya[7].Sedangkan IGKA merupakan pengembangan dari FGKA untuk menangani probabilitas mutasi yang kecil. IGKA menghitung nilai Total Within-Clusters Variation(TWCV) dan menentukan titik pusat
clustersecara bertahap(incremental) dengan kondisi probabilitas mutasi yang kecil,
sehingga dapat mengurangi biaya pada proses mutasi. Pada tugas akhir ini akan digunakan Incremental Genetic K-Means Algorithm yang merupakan pengembangan dari Genetic K-Means Algorithm(GKA)dalam melakukan klasterisasi terhadap data dengan variabel campuran.
2
1.2 Perumusan Masalah
Berdasarkan latar belakang yang telah dipaparkan di atas, maka permasalahan yang diangkat pada tugas akhir ini adalah sebagai berikut:
1. Parameter inputan apa saja yang dapat mempengaruhi hasil klaster secara signifikan? 2. Bagaimana pengaruh masing-masing parameter input terhadap akurasi hasil klaster
algoritma Incremental Genetik K-means dalam klasterisasi data?
3. Bagaimana mengimplementasikan IGKA untuk melakukan klasterisasi data dengan tipedata campuran, categorical dan numerical.
1.3 Batasan Masalah
Adapun batasan masalah pada tugas Akhir ini, yaitu:
1. Data yang digunakan pada tugas akhir ini merupakan data yang memiliki tipe data campuran,categorical dan numerical.
2. Dataset yang digunakan merupakan dataset pada KEEL dataset Repository. 3. Proses diskritisasi menggunakan diskrtitisasi pada weka.
4. Proses sampling menggunakan resample pada weka.
1.4 Tujuan
Tujuan yang ingin dicapai dalam penelitian tugas akhir ini adalah
1. Membuat implementasi Incremental Genetic K-means Algorithm untuk Clustering data dengan tipe data campuran.
2. Menganalisaperformansi Incremental Genetic K-Means Algorithm terhadap kualitas hasil klaster.
1.5 Metodologi Penyelesaian Masalah
Metodologi yang akan digunakan untuk menyelesaikan permasalahan pada tugas akhir ini adalah sebagai berikut:
1. Studi Literatur : metodologi penyelesaian masalah dimulai dari mengumpulkan referensi yang berhubungan dan dapat membantu penyelesaian tugas akhir ini.
2. Tahap Implementasi : terdiri dari mempersiapkan data, preprocessing data lalu mengelompokan data dengan berbagai kombinasi parameter input dan attribut dan akan diambil kombinasi yang dapat memberikan hasil yang terbaik.
3. Tahap Analisis: menganalisis hasil clustering dengan berbagai kombinansi parameter inputan berupa probabilitas mutasi, jumlah klaster, ukuran populasi dan jumlah maksimum generasi yang digunakan dalam menentukan pengelompokan data.
3
4. Tahap Pembuatan Laporan: pada tahap ini akan dilakukan pembuatan laporan tugas akhir dan pengumpulan dokumentasi serta lampiran-lampiran yang diperlukan.
Powered by TCPDF (www.tcpdf.org)
30
5. Kesimpulan dan Saran
5.1 Kesimpulan
Berdasarkan pengujian yang telah dilakukan pada Tugas Akhir ini, dapat disimpulkan bahwa:
1. Perubahan jumlah klaster berpengaruh terhadap kualitas klaster, silhouette
coefficient. Berdasarkan pengujian yang dilakukan,semakin besar jumlah klaster
maka nilai silhouette coefficientcenderung semakin meningkat.Jumlah klaster yang dapat diinputkan berada pada range 2 sampai dengan sebanyak jumlah data. Dari hasil percobaan nilai SC akan menurun sampai pada titik tertentu nilai jumlah klaster, titik ini berbeda-beda pada setiap dataset. Pada data besar seperti
Adult sekitar 11000 data, algoritma ini dapat bekerja optimal mulai dari klaster 2
sampai dengan 30 sedangkan untuk data kecil seperti Acute Inflammation, algoritma dapat bekerja optimal dari klaster 2 sampai dengan 7.
2. Parameter nilai probabilitas mutasitidak berpengaruh terhadap silhouette
coefficient (SC).Pada suatu kasus dengan jumlah data yang kecil dan probabilitas
mutasi yang besar, nilai SC akan menurun, karena individu illegal. Probabilitas mutasi harus bernilai kecil, yaitu sekitar satu per jumlah data. Probabilitas mutasi berpengaruh pada waktu eksekusi, semakin besar probabilitas mutasi maka semakin banyak gen yang dimutasi sehingga waktu yang dibutuhkan akan semakin besar.Berdasarkan pengujian, algoritma ini dapat bekerja optimal ketika probabilitas mutasi berada pada range 0 sampai dengan 0.1.
3. Parameter ukuran populasi tidak berpengaruh secara langsung terhadap
silhouette coefficient. Ukuran populasi mempengaruhi banyaknya ruang solusi
yang dibentuk, semakin banyak ruang solusi yang dibentuk maka kemungkinan mencapai optimum global semakin besar dan waktu yang dibutuhkan akan semakin besar.Pada suatu kasus ketika ukuran populasi kecil (< 15) nilai SC akan mennurun, karena terjebak pada optimum local ataupun individu illegal. Berdasarkan pengujian, untuk data besar seperti dataset Adult algoritma ini berkerja optimal ketika ukuran populasi 10 sampai dengan 30. Sedangkan untuk data kecil seperti Acute Inflammation algoritma ini bekerja optimal ketika ukuran populasi 12 sampai dengan 200.
5.2 Saran
Saran yang mungkin perlu diperhatikan untuk pengembangan Tugas Akhir ini, yaitu:
1. Perlu adanya pengembangan terhadap teknik diskritisasi yang dilakukan untuk menghitung jarak data yang bertipe kategori.
Powered by TCPDF (www.tcpdf.org)
31
Daftar Pustaka
[1] Ahmad, Amir and Lipika Dey. 2007. A k-mean clustering algorithm for mixed
numeric and categorical data. ScienceDirect: Data & Knowledge Engineering
63(2007) 503-527.
[2] Ahmad, Amir and Lipika Dey. 2007. A method to compute distance between two
categorical values of same attribute in unsupervised learning for categorical data set. ScienceDirect: Pattern Recognition Letters28(2007) 110-118.
[3] Cox, Earl. 2005. Chapter9: Fundamental Concepts of Genetic Algorithms, Fuzzy
Modelling and Genetic Algorithms for Data Mining and Exploration. Morgan
Kaufmann.
[4] Krishna, K and M. Narasimha Murty. Genetic K-Means Algorithm. IEEE Transactions On System, Man, and Cybernetics-Part B: Cybernetics, Vol. 29 No. 3, June 1999.
[5] Lu, Yi, Shiyong Lu, Farshad Fotohui, Youping Deng, and Susan J. Incremental
Genetic K-means Algorithm and its Application in Gene Expression Data Analysis.
[6] Lu, Yi, Shiyong Lu, Farshad Fotouhi, Youping Deng, and Susan J. Brown.
FGKA: A Fast Genetic K-means Clustering Algorithm.
[7] Roy, Dharmendra K and Lokesh K Sharma. 2010. Genetic k-Means Clustering
Algorithm For Mixed Numerical And Categorical Data Sets. International
Journal og Artificial Intelligence & Aplication. Vol.1, No.2, April 2010.
[8] Santosa, Budi. 2007. Data Mining : Teknik Pemanfaatan Data untuk Keperluan
Bisnis. Yogyalkarta: Graha Ilmu.
[9] Suyanto. 2005. Algoritma Genetika dalam MATLAB. Yogyakarta: Andi. [10] Suyanto. 2008. Evolutionary Computation. Bandung: Informatika.
[11] Tan, Pang Ning, Michael Steinbach and Vipin Kumar. 2006. Chapter 8: Cluster
Analysis, Introduction to Data Mining. Addison Wesley.
32
Lampiran
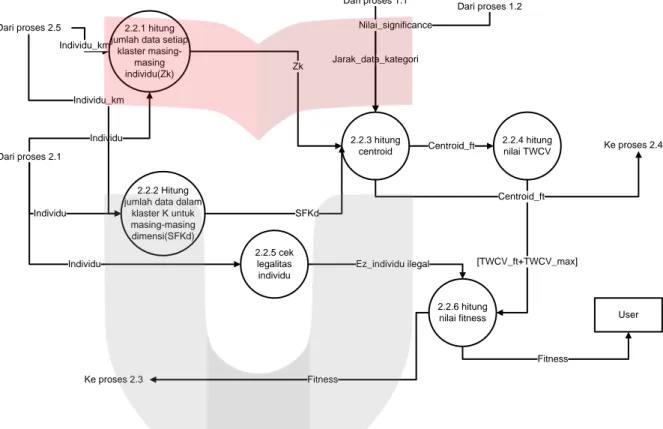
DFD Level 3 Hitung Nilai Fitness
2.2.3 hitung centroid Dari proses 2.1 Dari proses 1.2 2.2.4 hitung nilai TWCV Centroid_ft 2.2.5 cek legalitas individu Individu 2.2.6 hitung nilai fitness [TWCV_ft+TWCV_max] Ez_individu ilegal User Ke proses 2.3 Centroid_ft Ke proses 2.4.3 Dari proses 2.5 Individu_km 2.2.1 hitung jumlah data setiap
klaster masing-masing individu(Zk)
2.2.2 Hitung jumlah data dalam
klaster K untuk masing-masing dimensi(SFKd) Zk Individu SFKd Jarak_data_kategori Nilai_significance Individu Individu_km Dari proses 1.1 Fitness Fitness
Gambar Lampiran.1DFD Level 3 Hitung Fitness
DFD Level 3 Proses Seleksi
Dari proses 2.2 2.3.1 hitung probabilitas seleksi Fitness Prob_sel 2.3.3 memilih individu dengan merandom nilai 0-1 Ke proses 3 Dari proses 2.1 Individu Individu_seleksi
Gambar Lampiran.2DFD Level 3 Proses Seleksi
Powered by TCPDF (www.tcpdf.org)