PREDIKSI PINDAH JURUSAN PADA SMK MENGGUNAKAN
TEKNIK DATA MINING POHON KEPUTUSAN
Karwandi
1)Langgeng Listiyoko
2)Henderi
3)Sudaryono
4)1) 2)Business IntelligenceSTMIK Raharja
email : 1)[email protected], 2)[email protected] 3) 4)Magister Teknik Informatika STMIK Raharja
email : 3)[email protected], 4)[email protected]
ABSTRACT
Not all of class major in vocational school is the one primary choice. Therefore some exchange occasionally happened from one major to the other. This could be happened in early years of class since they have not specified yet. Data mining helps the officer to prevent any other problem regarding to class switches. Decision tree technique predicts a student will stay in the class or not. Thus, they can keep any spare specified tools for each major.
Key words
data mining, decision tree, major switch.
1. Pendahuluan
Data mining (DM) semakin hari kian menjadi kebutuhan dalam dunia bisnis demi menciptakan sebuah Business Intelligence (BI). Pada perkembangannya DM telah diimplementasikan dalam organisasi-organisasi yang tidak bergerak dalam dunia bisnis praktis. Meski demikian konsep DM dapat diterima dalam beberapa kasus yang dihadapi organisasi sosial yang tidak sepenuhnya berorientasi dalam memperoleh keuntungan semata.
Penelitian ini didasari oleh masalah yang dapat ditemui dalam proses penerimaan siswa baru (PSB) pada sebuah sekolah menengah kejuruan (SMK). Pada proses awal pendaftaran panitia memberikan kesempatan pendaftar untuk memilih dua jurusan. Sementara itu proses yang dilakukan dalam menentukan kelulusan calon siswa adalah membuat peringkat melalui serangkaian test yang dijalani masing-masing pendaftar.
Salah satu yang menarik adalah kasus pindah jurusan. Hal ini sangat mungkin terjadi dengan berbekal peringkat yang cukup dari pendaftar. Kasus ini sebenarnya dapat dengan mudah diselesaikan dengan memberikan pilihan mengundurkan diri, namun tentu keputusan panitia seperti ini tidak cukup bijaksana. Kasus ini dapat terjadi selama
proses pendaftaran, masa orientasi, bahkan setelah proses belajar mengajar berjalan di semester pertama.
Pendaftar yang ternyata lolos untuk pilihan kedua berpotensi WO dengan tidak melakukan pendaftaran ulang (heregistrasi). Jika ini yang terjadi, maka akan ada kekosongan kursi/kuota. Untuk selanjutnya kemungkinan akan berdampak pada biaya operasional belajar mengajar yang tidak optimal.
Dengan mempelajari pola yang didapat dari data histori tahun-tahun sebelumnya maka kejadian ini dapat diprediksikan lebih dini. Sejumlah pendaftar yang ditengarai WO akan diberikan pendekatan persuasif sehingga kepastian lanjut atau tidaknya proses PSB segera diketahui. Keputusan untuk menyiapkan calon siswa cadangan pun menjadi efektif. Prosedur mengenai penyiapan calon siswa cadangan tidak dibahas di sini.
Jika prediksi oleh data mining berjalan sebagaimana mestinya maka jumlah siswa yang diterima selama PSB dapat dipertanggungjawabkan oleh panitia kepada pengelola sebagai parameter keberhasilan kinerja tim.
2. Data Mining
Data mining merupakan sub sistem penting dalam KDD (Knowledge Discovering in Database) seperti dijelaskan Maimon et.al [7] seperti gambar 1 di bawah ini:
Langkah KDD :
a. Domain understanding b. Selection & Addition c. Preprocessing d. Transformation e. Data mining process f. Evaluating
g. Discovered knowledge
2.1 Domain understanding
Untuk dapat mengetahui permasalahan yang akan diselesaikan dapat dilakukan dengan memperhatikan aspek dampak. Dengan analisa kebutuhan data yang baik sangat mempengaruhi keberhasilan penelitian.
Penelitian ini diawali dengan mengumpulkan data yang akan digunakan sebagai data histori, didapat dari panitia PSB tahun-tahun sebelumnya. Data harus memuat setidaknya variable / atribut berikut ini:
a. Waktu pendaftaran b. Nilai ujian seleksi c. Pilihan 1
d. Pilihan 2 e. Pilihan lolos
f. Keputusan pindah jurusan g. Keputusan heregistrasi
Variable tersebut diperoleh setelah melakukan proses seleksi, cleansing, transforming, dan integrating menurut proses KDD. Sebagaimana gudang data, selama proses PSB direkam sejumlah informasi dari pendaftar untuk keperluan selama minimal 3 tahun ke depan (selama siswa terdaftar sebagai peserta didik pada SMK pada umumnya). Dalam memproses data history tidak semua atribut dilibatkan, namun tidak pula menutup kemungkinan muncul atribut baru. Atribut baru yang terbentuk merupakan produk dari kegiatan preprocessing.
Pada penelitian data mining kali ini tidak begitu memerlukan adanya sebuah data warehouse (DW). Data yang diperlukan masih dapat disediakan oleh local database yang juga berperan sebagai datamart, yaitu pada bagian PSB saja.
2.2 Seleksi
Data history yang diterima memiliki sejumlah atribut guna mendapatkan informasi yang dibutuhkan user. Namun demikian pada teknik data mining atribut tersebut tidak seluruhnya dibutuhkan. Data set yang diterima dari data mart harus diseleksi untuk memastikan hanya atribut yang dibutuhkan saja yang disimpan.
2.3Preprocessing
Maimon menjelaskan preprocessing sebagai kegiatan meningkatkan reliablity. Tahapan ini sangat penting dalam data mining. Keberhasilan suatu metode DM dalam menyelesaikan masalah sangat dipengaruhi seberapa tinggi kualitas data histori yang merupakan produk dari preprocessing. Dalam prosesnya, tak jarang tahapan ini melibatkan beberapa operasi dasar statistika yang banyak dijumpai pada program aplikasi spreadsheet (contoh Ms. Excel). Dalam rangka mempermudah penanganan data dilakukan proses seperti sorting, filtering, penghitungan mean, maksimum dan minimum.
Proses untuk mendapatkan data yang siap diolah dalam penelitian ini melibatkan juga cleaning, yakni membersihkan data set dari berbagai bentuk noises. Noises yang dijumpai berupa data tidak lengkap (misalnya pekerjaan orang tua dikosongkan untuk merepresentasikan “Buruh”), alamat tidak menyebutkan Kota, atau teknik penulisan angka desimal yang tidak konsisten.
Dengan beberapa proses dasar di atas maka dapat mempermudah kegiatan pemilihan variable/ atribut yang sesuai dengan kebutuhan. Selain itu kesalahan-kesalahan yang terjadi pada masing-masing rekord dapat segera diamati, misalnya data yang kurang lengkap, data tidak sesuai, dan dapat dibersihkan. Pada nilai atribut yang bertipe non numerik dapat diperiksa penyebarannya sehingga sangat membantu dalam pemeringkatan.
2.4 Transformation
Umumnya transformasi data mengubah nilai karakter menjadi numerik dengan cara memberikan peringkat. Dalam teknik pohon keputusan nilai atribut tidak harus berupa angka. Atribut nilai ujian seleksi perlu diubah menjadi nilai diskrit yaitu kategori nilai rendah, sedang, dan tinggi.
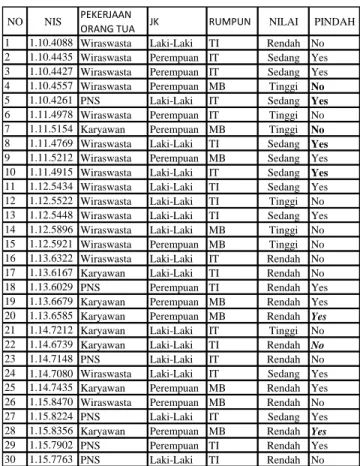
Sementara itu untuk mempermudah evaluasi, maka setiap jurusan yang lolos bagi setiap siswa dikelompokkan menurut rumpun atau paket keahlian. Tabel 1 adalah representasi data history yang telah melewati tahap transformasi.
Tabel 1. Data History
NO NIS PEKERJAAN
ORANG TUA JK RUMPUN NILAI PINDAH
1 1.10.4088 Wiraswasta Laki-Laki TI Rendah No 2 1.10.4435 Wiraswasta Perempuan IT Sedang Yes 3 1.10.4427 Wiraswasta Perempuan IT Sedang Yes 4 1.10.4557 Wiraswasta Perempuan MB Tinggi No
5 1.10.4261 PNS Laki-Laki IT Sedang Yes
6 1.11.4978 Wiraswasta Perempuan IT Tinggi No 7 1.11.5154 Karyawan Perempuan MB Tinggi No 8 1.11.4769 Wiraswasta Laki-Laki TI Sedang Yes 9 1.11.5212 Wiraswasta Perempuan MB Sedang Yes 10 1.11.4915 Wiraswasta Laki-Laki IT Sedang Yes 11 1.12.5434 Wiraswasta Laki-Laki TI Sedang Yes 12 1.12.5522 Wiraswasta Laki-Laki TI Tinggi No 13 1.12.5448 Wiraswasta Laki-Laki TI Sedang Yes 14 1.12.5896 Wiraswasta Laki-Laki MB Tinggi No 15 1.12.5921 Wiraswasta Perempuan MB Tinggi No 16 1.13.6322 Wiraswasta Laki-Laki IT Rendah No 17 1.13.6167 Karyawan Laki-Laki TI Rendah No
18 1.13.6029 PNS Perempuan TI Rendah Yes
19 1.13.6679 Karyawan Perempuan MB Rendah Yes 20 1.13.6585 Karyawan Perempuan MB Rendah Yes 21 1.14.7212 Karyawan Laki-Laki IT Tinggi No 22 1.14.6739 Karyawan Laki-Laki TI Rendah No
23 1.14.7148 PNS Laki-Laki IT Rendah No
24 1.14.7080 Wiraswasta Laki-Laki IT Sedang Yes 25 1.14.7435 Karyawan Perempuan MB Rendah Yes 26 1.15.8470 Wiraswasta Perempuan MB Rendah No
27 1.15.8224 PNS Laki-Laki IT Sedang Yes
28 1.15.8356 Karyawan Perempuan MB Rendah Yes
29 1.15.7902 PNS Perempuan TI Rendah Yes
30 1.15.7763 PNS Laki-Laki TI Rendah No
2. 5 Data mining process
Proses data mining sebagai inti dari KDD dimulai dengan menentukan tipe. Klasifikasi, assosiasi, prediksi adalah contoh tipe data mining dilihat dari fungsinya [12]. Adapundecision tree, clustering, a-priori, neural network adalah contoh tipe data mining dilihat dari teknik penyelesaiannya [1]. Teknik pohon keputusan (decision tree) sesuai untuk melakukan prediksi terhadap kelas dalam sejumlah data set. Proses selanjutnya adalah menentukan algoritma penyelesaian teknik pohon keputusan.
CART (Classification and Regression Tree) merupakan salah satu algoritma penyelesaian masalah oleh DM pada metode klasifikasi dengan pendekatan pohon keputusan (decision tree)[1]. Terdapat dua konsep pohon keputusan, yaitu pertumbuhan dan penyingkiran (growing and pruning)[7]. Adapun CART adalah algoritma klasifikasi yang menganut konsep pruning. CART sesuai untuk melakukan prediksi oleh karena kemampuannya untuk menciptakan pohon regresi, di mana setiap cabang memprediksi sebuah angka real
,
bukan suatu kelas [13]. Pada prinsipnya CART sangat efektif membentuk leaf atauTerdapat 2 pendekatan pohon keputusan, yakni prunned dan unprunned seperti tampak pada gambar 2. Gambar sisi kiri adalah unprunned sedangkan sisi kanan adalah prunned[2].
Gambar 2. Model decision tree
Algoritma pruning yang dianut CART bertujuan untuk meningkatkan akurasi dengan membuang cabang yang mengindikasikan adanya noise[3]. Untuk dapat mencapai efektifitasnya, maka ditentukan root node dengan cara menghitung.... penentuan root node ini mempengaruhi seberapa panjang cabang-cabang dapat terbentuk sebelum akhirnya diperoleh kesimpulan yang diidentifikasi sebagai leaf. Semakin sederhana pohon kesimpulan yang terbentuk menandakan tingginya efektifitas sebab jalur testing terhadap sample data cukup pendek.
Algoritma penyelesaian pohon keputusan dalam penelitian ini menganut tahapan sebagai berikut[6] : 1. Pilihatribut/ variabel sebagai akar. Akar didapat dari
nilai Gain yang tertinggi, dari atribut yang ada. Untuk menghitung Gain digunakan formula (1) di bawah ini.
………..(1) Keterangan
S : himpunan kasus A : atribut
n : jumlah partisi atribut A | Si | : jumlah kasus pada partisi ke-i | S | : jumlah kasus dalam S
Sedangkan formula untuk menghitung Entropy (2) adalah seperti berikut :
𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑆) = ∑𝑛𝑖=1−𝑝𝑖 ∗ log2𝑝𝑖(2) Keterangan :
S : himpunan kasus A : fitur
Tabel 2. Tabel Perhitungan Entropy dan Gain Ya Tidak Total 30 16 14 0.996792 1 Pekerjaan Ortu 0.013132 Wiraswasta 16 8 8 1 PNS 6 4 2 0.918296 Karyawan 8 4 4 1 2 Jenis Kelamin 0.030685 Laki-laki 16 7 9 0.988699 Perempuan 14 9 5 0.940286 3 Jurusan -0.42501 Teknik Industri 10 5 5 1 Teknologi Informasi 10 6 4 0.970951 Bisnis Managemen 10 5 5 1 4 Nilai 0.56531 Rendah 13 6 7 0.995727 Sedang 10 10 0 0 Tinggi 7 0 7 0 Keputusan Entrophy Gain Jumlah Node
Tabel 2 membantu peneliti untuk mendapatkan nilai entropy dan gain dengan formula yang diberikan[6]. Atribut dengan nilai gain tertinggi adalah kandidat node yang lolos.
2. Buat cabang untuk masing-masing nilai
Gambar 3. Pembentukan Node Pertama
Gambar 3 merupakan node pertama yang berhasil dibangun, yakni atribut “Nilai” oleh karena atribut ini memiliki nilai gain tertinggi diantara atribut lainnya. 3. Bagi kasus dalam cabang. Setiap atribut mewakili
sebuah kasus yang harus diselesaikan. Dalam data history yang dimiliki menunjukkan atribut “Nilai” seluruhnya bernilai “Yes” untuk nilai Sedang, dan seluruhnya bernilai “No” untuk nilai Tinggi. Sehingga kasus yang harus dibagi hanya untuk nilai Rendah. 4. Ulangi proses untuk setiap masing-masing cabang
sampai semua kasus pada cabang memiliki kelas yang sama.
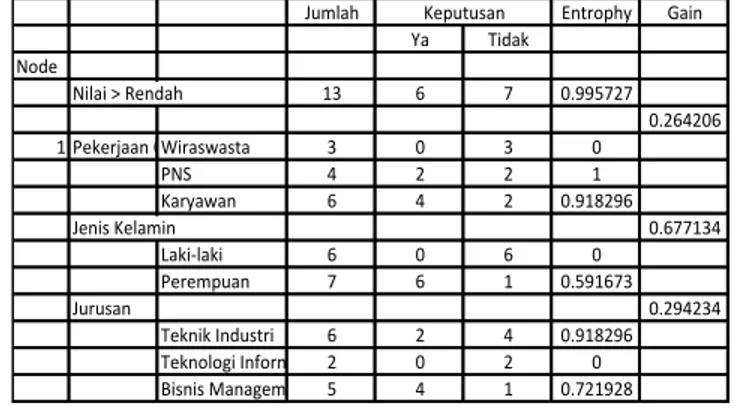
Tabel 3. Penentuan Node Kedua
Jumlah Entrophy Gain
Ya Tidak Node Nilai > Rendah 13 6 7 0.995727 0.264206 1 Pekerjaan OTWiraswasta 3 0 3 0 PNS 4 2 2 1 Karyawan 6 4 2 0.918296 Jenis Kelamin 0.677134 Laki-laki 6 0 6 0 Perempuan 7 6 1 0.591673 Jurusan 0.294234 Teknik Industri 6 2 4 0.918296 Teknologi Informasi 2 0 2 0 Bisnis Managemen 5 4 1 0.721928 Keputusan
Selanjutnya dengan bantuan tabel 3 dapat ditntukan kandidat node berikutnya, yaitu atribut “Jenis Kelamin”.
Tabel 4. Penentuan Node Ketiga
Jumlah Keputusan Entrophy Gain Ya Tidak Node Rendah>Perempuan 7 6 1 0.591673 1 Pekerjaan Ortu 0.591673 Wiraswasta 1 0 1 0 PNS 2 2 0 0 Karyawan 4 4 0 0 2 Jurusan 0.07601 Teknik Industri 2 2 0 0 Teknologi Informatika 0 0 0 0 Bisnis Management 5 4 1 0.721928
Dalam praktiknya, himpunan data yang dimiliki dapat dibagi menjadi dua masing-masing sebagai data learning dan data test dengan porsi tertentu.[10]. Dalam penelitian ini data learning akan diambil dari seluruh data history yang dimiliki. Data history disimpan dalam repositori dengan jumlah dan anggota tetap. Adapun data test adalah seluruh data baru yang diterima. Metode testing seperti ini juga telah dilakukan oleh [9].
2.5 Evaluasi
Evaluasi dilakukan pada setiap proses input-output. Pada tahap ini diperiksa apakah data history yang dimiliki telah melalui tahap preprocessing dengan baik sehingga siap untuk digunakan. Data history di penelitian ini juga mengalami transformasi, sehingga dengan proses evaluasi dapat diketahui efisiensi data bentukannya.
Dari proses prediksi yang telah dilakukan dapat dievaluasi sebagai berikut :
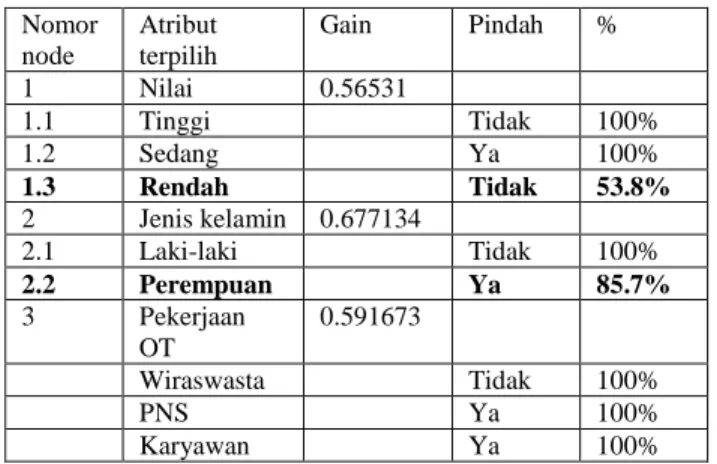
Tabel 5. Summary Penentuan Node Nomor node Atribut terpilih Gain Pindah % 1 Nilai 0.56531 1.1 Tinggi Tidak 100% 1.2 Sedang Ya 100% 1.3 Rendah Tidak 53.8% 2 Jenis kelamin 0.677134 2.1 Laki-laki Tidak 100% 2.2 Perempuan Ya 85.7% 3 Pekerjaan OT 0.591673 Wiraswasta Tidak 100% PNS Ya 100% Karyawan Ya 100%
Tabel 5 adalah summary penentuan masing-masing node. Atribut “Jurusan” tidak terpilih sebagai node. Hal ini terjadi karena pada node ketiga seluruh “leaf” telah diketahui dengan pasti nilai kelasnya, sehingga tidak perlu lagi menentukan node lain.
2.7 Discovered knowledge
Tahap terakhir KDD adalah mengoleksi knowledge sebagai hasil data mining. Pada penelitian pohon keputusan, knowledge yang diperoleh berupa sekumpulan rule yang dibangun dengan kalimat logika “jika maka” atau implikasi. Rule inilah yang digunakan sebagai tool prediksi.
3. Hasil dan Pembahasan
Hasil pemrosesan data history yang dimiliki menginformasikan bahwa prediksi kepindahan siswa dari jurusan yang telah diplot dapat diketahui pertama kali dari nilai ujian seleksi. Kemudian disusul dengan atribut yang lain yaitu jenis kelamin dan pekerjaan orang tua. Adapun atribut rumpun jurusan pada penelitian ini terbukti bukan suatu alasan mendasar yang dapat diprediksi.
Gambar 5 adalah hasil final pembentukan pohon keputusan untuk data history. Dari sini kemudian dapat dikoleksi rule sebagai hasil discovered knowledge. Rule tersebut adalah
1. Jika Nilai tinggi maka TIDAK pindah. 2. Jika Nilai sedang maka PINDAH.
3. Jika Nilai rendah dan Jenis Kelamin laki-laki maka TIDAK pindah.
4. Jika Nilai rendah dan Jenis Kelamin perempuan dan Pekerjaan Orang Tua wiraswasta maka TIDAK pindah.
5. Jika Nilai rendah dan Jenis Kelamin perempuan dan
6. Jika Nilai rendah dan Jenis Kelamin perempuan dan Pekerjaan Orang Tua PNS maka PINDAH.
Gambar 4. Pohon keputusan sempurna
Program aplikasi Rapidminer 5 menghasilkan pohon keputusan yang sama untuk data history yang dimiliki di penelitian ini (gambar 6). Prograrm ini mampu memberikan deskripsi laporan yang baik sebab telah menyertakan pi peluang setiap leaf yang terbentuk. Tampak pada gambar bahwa seluruh leaf memiliki probabilitas 100%, ditandai dengan homogenitas warna merah (class “Yes”) dan biru (class “No”). Hal ini menunjukkan tingkat confidence yang tinggi untuk setiap rule yang terbentuk..
Gambar 5. Pohon keputusan hasil Rapidminer 5.3
Laporan probabilitas masing-masing leaf/ rule yang terbentuk disajikan dalam tabel 4 berikut :
Tabel 6. Probabilitas leaf
No Rule Probabilitas Yes (%) Probabilitas No (%) 1 0 100 2 100 0 3 0 100 4 0 100 5 100 0 6 100 0
Visualisasi grafik dari tabel 4 di atas ditunjukkan pada grafik 1. Tampak dalam grafik bentuk batang yang homogen, artinya setiap kelas memiliki nilai yang sempurna (100%).
Grafik 1 Visualisasi Probabilitas Leaf
Sistem ini kemudian diuji untuk memprediksi setiap data uji yang diterima dengan metode seperti gambar 7berikut :
Gambar 6 Metode pengujian
Setiap data uji yang diberikan kemudian dibandingkan dengan rule yang telah dikoleksi. Kelas sebagai keputusan/ hasil prediksi segera diketahui sesaat setelah rule yang sesuai ditemukan.
Tabel 7. Tabel Confusion Matriks Pengujian Terhadap 600 Sample Baru
Sesungguhnya Total Yes No TRUE FALSE Yes Positif 74 260 334 No Negatif 85 181 266 Total 159 441 600 Precision 22.16% Recall 29.02% Accuracy 26.50% Sistem Prediksi Confusion
Tabel 6 adalah hasil pengujian sistem terhadap 600 sample baru yang diberikan. Dengan metode pengukuran Precision, Recall, dan Accuracy diketahui bahwa sistem belum mampu menunjukkan performa yang diharapkan. Hal ini diakibatkan minimnya data history sehingga kurang representatif untuk data uji.
4. KESIMPULAN
Dari penelitian ini dapat disimpulkan sebagai berikut :
Pohon keputusan membantu pengelola institusi memprediksi kepindahan jurusan seorang siswa SMK.
Prediksi yang diketahui lebih dini dapat digunakan sebagai pedoman mempersiapkan perubahan administrasi yang mungkin terjadi.
CART membantu user untuk menentukan kelas suatu obyek data yang kemudian diadopsi sebagai fungsi prediksi data mining.
5. SARAN
Saran untuk penelitian sejenis di masa yang akan datang adalah perlu adanya perhatian yang lebih baik dalam transformasi data numerik menjadi non numerik. Dalam menentukan rating di penelitian ini belum menganut kaidah statistik sepenuhnya.
REFERENSI
[1] Gorunescu, F., 2011, “Data Mining Concepts, Models and Techniques”, Springer, Berlin.
[2] Han, J., & Kamber, M., 2006,“Data Mining : Concepts and Techniques”, Elsevier, San Fransisco.
[3] Hand, D., Mannila, H., & Smyth, P., 2001, “Principles of Data mining”, MIT Press, London.
[4] Hermawati, F. A., 2013, “Data Mining”, Andi Publisher, Yogyakarta.
[5] Larose, D. T., 2005,“Discovering Knowledge in Data : An Introduction to Data Mining”, John Wiley & Sons, Inc., New jersey.
[6] Kusrini, Luthfi, E.T., 2009, “Algoritma Data Mining”, Andi Publisher.
[7] Maimon, O., & Rokach, L., 2010,“Data Mining And Knowledge Discovery Handbook (Second Edition)”, Springer, New York.
[8] Maurina, D., Fanani, A.Z., 2015, “Penerapan Data Mining Untuk Rekomendasi Beasiswa Pada SMA Muhammadiyah Gubug Menggunakan Algoritma C4.5”, Jurnal Udinus. [9] Meilani, B.D., Slamat, A.F., 2013, “Klasifikasi Data
Karyawan Untuk Menentukan Jadwal Kerja Menggunakan Metode Decision Tree”, Jurnal ITATS.
[10] Pratiwi,L.D.B., Wibowo,W., Zain,I., 2015, “Klasifikasi Nilai Peminat SBMPTN (Seleksi Bersama Masuk Perguruan Tinggi Negeri) ITS dengan Pendekatan CART”, Jurnal Sains dan Seni ITS Vol.4 No. 2 D193-198.
[11] Susanti, 2013, ”Klasifikasi Kredit Menggunakan Metode Decision Tree Pada Nasabah PD BPR BKK Gabus”, Jurnal Udinus.
[12] Susanto, S., & Suryadi, D., 2010,“Pengantar Data Mining Menggali Pengetahuan Dari Bongkahan Data”, Andi Publisher, Yogyakarta.
[13] Vercellis, C., 2009, “Business Intelligence : Data Mining And Optimization For Decision Making”, John Wiley & Son Ltd, Padstow. 0 50 100 150 1 2 3 4 5 6 Probabilitas No (%) Probabilitas Yes (%)