31 Jurnal Nasional JMII 2016
ANALISIS TEXT-MINING DENGAN METODE DENSITY-BASED
CLUSTERING PADA PESAN MEDIA SOSIAL UNTUK
PEMETAAN LOKASI KECELAKAAN
NurjayantiFakultas Teknis, Jurusan Teknik Informatika Universitas Widyatama
Jalan Cikutra No. 204A, Bandung, Indonesia [email protected]
Abstrak
Salah satu fungsi media sosial adalah untuk berbagi pesan atau kabar berita dari satu pengguna kepada pengguna media sosial lainnya. Adanya kesadaran atau perhatian (awareness) masyarakat terhadap kejadian nyata seperti kecelakaan menjadi pemicu bagi masyarakat untuk menggunggah kabar berita tersebut ke media sosial. Pesan pada media sosial yang diunggah seringkali menyebutkan lokasi kejadian tersebut.
Proses deteksi kejadian secara real-time lengkap dengan informasi geospatial merupakan dasar dalam membuat pemetaan lokasi kecelakaan ini. Yang disebut kejadian pada penelitian ini adalah pesan media sosial yang memiliki topik “kecelaakan alat transportasi”. Dengan menggunakan text-mining, pesan tersebut dapat diproses untuk diperoleh infomasi geospatial yang kemudian dapat
divisualisasikan kedalam peta. Algoritma yang digunakan pada text-mining dengan metode
density-based clustering yaitu algoritma DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
Algoritma DBSCAN menggunakan dua parameter yaitu radius masing-masing anggota cluster dengan inti cluster Eps ( ) dan MinPts (Minimal Points) yang memberikan batasan jumlah minimum anggota
cluster dalam Eps. Ektraksi lokasi kemudian
dilakukan pada cluster yang dihasilkan proses
clustering. Visualisasi peta dilakukan terhadap lokasi cluster yang diekstrak menggunakan metode NER rule-based dan parsing lokasi ke Google Maps
Geocoding API. Kata kunci :
geospatial, text-mining, density-based clustering,
DBSCAN, NER rule-based
Abstract
Social media has a function as messages or news feed sharing platform between users, either in the form of texts, images, photos, or videos. The public awareness on real-time events such as accidents become a trigger for users to upload the news feed into social media. Messages on social media often mentioned the location where the event happened.
The process of events detection in real-time and geospatial information is the basis for mapping event location. An event in this study is a message on social media which has “transportation accident” as the topic. The social media messages can be processed to obtain geospatial information by using text-mining and then visualized into a map. The algorithm used in the text-mining with density-based clustering method is DBSCAN (Density-Based Spatial Clustering of Applications with Noise) algorithm. DBSCAN algorithm uses two parameters: the radius of each cluster member to the cluster core (ε) and MinPts (Minimal Points) which provides a minimum number of cluster members in Eps. Extraction locations then performed on each cluster that produced from clustering. Mapping visualization is done against cluster locations that are extracted using NER rule-based method and parsing to Google Maps Geocoding API.
Keywords :
geospatial, text-mining, density-based clustering,
32 Jurnal Nasional JMII 2016
I. P
ENDAHULUANProses deteksi kejadian secara real-time lengkap dengan informasi geospatial merupakan dasar dalam membuat pemetaan lokasi. Yang disebut kejadian pada penelitian ini adalah pesan media sosial yang memiliki topik “kecelaakan alat transportasi”.
Algoritma yang akan digunakan pada
text-mining dengan metode density-based clustering yaitu
algoritma DBSCAN (Density-Based Spatial
Clustering of Applications with Noise). Algoritma
DBSCAN menggunakan dua parameter yaitu radius masing-masing anggota cluster dengan inti cluster ( ) dan MinPts (Minimal Points) yang memberikan batasan jumlah minimum anggota cluster dalam Eps.
II. L
ANDASANT
EORIa. Text-mining dan Data Mining
Data mining dapat lebih dikarakterisasi sebagai
ekstraksi dari implisit, yang sebelumnya tidak diketahui, dan informasi yang berpotensi berguna dari data [12]. Informasi pada data mining diperoleh dari data implisit: data tersebut tersembunyi, tidak dikenali, dan sulit diekstrak tanpa sumber daya untuk teknik otomatis data mining. Sementara text-mining, informasi yang diekstrak adalah jelas dan eksplisit disebutkan dalam teks [10].
b. Vector Space Model (VSM)
Vector Space Model adalah teknik pada teks clustering yang digunakan untuk pembobotan dengan
merepresentasikan teks sebagai kumpulan titik di suatu ruang vektor. Dalam VSM, teks direpresentasikan dalam bentuk vektor (t1, t2, ... ti) dimana setiap ti mewakili sebuah kata. Kumpulan teks kemudian direpresentasikan dalat satu set vektor yang dapat digambarkan dalam bentuk matriks sebagai berikut. Perhitungan bobot pada VSM dapat menggunakan TF-IDF (Term Frequency – Inverse
Document Frequency) dimana dari matriks diatas
bobot direpresentasikan oleh setiap elemen xji [5]. Perhitungan bobot dengan TF-IDF dapat dilihat pada persamaan 1:
c. Analisa Cluster
Analisa cluster atau clustering adalah proses pembagian atau pengelompokan (partitioning) satu set objek data kedalam beberapa subset yang disebut
cluster. Objek dalam sebuah cluster bisa memiliki
kemiripan satu dengan yang lainnya atau ketidakmiripan dengan objek pada cluster lain [5]. Density-Based Clustering
Density-based clustering adalah metode clustering yang dapat digunakan untuk mencari clusters yang betuknya berubah-ubah (arbitary shape) yang dimodelkan berupa daerah yang padat
(dense regions) pada ruang data yang dipisahkan oleh daerah yang jarang (sparse regions) [5].
Algoritma DBSCAN: Density-Based Spatial Clustering of Applications with Noise
Algoritma DBSCAN digunakan pada spatial
database yang memuat noise. Density dari objek
dapat diukur dari banyaknya objek yang dekat ke . DBSCAN mencari objek inti (core objects) yaitu objek yang memiliki daerah sekitar yang padat (dense
neighborhoods). DBSCAN menghubungkan (density-connected) objek inti dan daerah sekitarnya untuk
membentuk daerah padat sebagai cluster. Sementara objek yang bukan anggota cluster dianggap sebagai
noise [5]. Berikut contoh pseudocode algoritma
DBSCAN.
Algoritma II.1 DBSCAN: a density-based clustering algorithm
Input :
D: a data set containing n objects : the radius parameter, and MinPts : the neighborhood density threshold
Output: A set of density-based clusters Method:
(1) mark all objects as unvisited; (2) do
(3) randomly select an unvisited object p;
(4) mark p as visited;
(5) if the -neighborhood of p has at least MinPts objects
(6) create a new cluster C, and add p to C;
(7) let N be the set of objects in the -neighborhood of p;
33 Jurnal Nasional JMII 2016
(9) if p’ is unvisited
(10) mark p’ as visited;
(11) if the -neighborhood of p’
has at least MinPts points,
(12) add those points to N;
(13) if p’ is not yet member of
any cluster, add p’ to C;
(14) end for;
(15) output C;
(16) else mark p as noise;
(17) until no object is unvisited; Evaluasi Clustering
Silhoutte coefficient merupakan metode evaluasi cluster secara internal dimana menggabungkan
konsep cohesion (bagaimana relasi kedekatan/ kepadatan objek dalam cluster) dan separation (seberapa baiknya masing-masing cluster terpisah antara satu dan lainnya).
Silhoutte coefficient didefinisikan sebagai
berikut pada persamaaan 2.
Dimana a(o) adalah rata-rata jarak objek o ke objek lain dalam cluster dan b(o) adalah minimal jarak rata-rata dari objek o ke objek lain dalam
cluster berbeda. Nilai silhoutte coefficient adalah
antara -1 dan 1. Kondisi yang baik adalah jika nilai
silhoutte coefficient mendekati 1, yang menunjukan cluster dimana objek o berada padat dan jauh terpisah
dari cluster lainnya.
d. Named Entity Recognition
Named Entity Recognition (NER) merupakan sub-tasks dari Information Extraction (IE) [6]. NER
merupakan bagian penting dari Natural Language
Processing (NLP). NER bertugas untuk mencari dan
menklasifikasi nama (entitas) dalam teks yang ditulis dengan bahasa natural.
III. A
NALISIS DANP
ERANCANGANa. Sumber Data
Jenis data yang digunakan adalah teks tweet pada Twitter yang berisi informasi kecelakaan dimana teks menggunakan bahasa Indonesia. Pengambilan teks tweet dibatasi parameter kata kunci dan bahasa. Data yang dipilih berasal dari
banyak pengguna Twitter. Attribut yang dipilih adalah teks tweet dengan jumlah maksimal karakter per teks adalah 140 karakter.
Tabel 1 Daftar Kata Kunci Pencarian Data
Kata
Kunci Format Parameter
kecelakaan kecelakaan, kecelakaan mobil, kecelakaan motor, kecelakaan kendaraan tabrakan tabrakan, tabrakan mobil, tabrakan motor, tabrakan kendaraan, menabrak
Metode scrapping web digunakan pada pengambilan data secara langsung dari halaman Twitter Search. Implementasi program akan mengakses URL https://twitter.com/i/search/timeline.
Proses dimulai dengan mengirimkan query
permintaan pencarian teks tweet. Apabila respon yang dikirimkan kembali oleh Twitter adalah sukses, teks tweet kemudian diekstrak dari informasi yang diterima. Teks tweet yang diekstrak tersebut kemudian disimpan sebagai data mentah (raw data). Sementara jika gagal permintaan akan dikirimkan kembali oleh sistem.
b. Tahapan Penelitian
Berikut gambaran alur kerja atau tahapan penelitian implementasi text-mining dengan metode
density-based clustering pada media sosial yang akan
dilakukan. Tahapan penelitian diatas sebagai berikut: 1. Raw Data, pada tahap ini data penelitian
dikumpulkan kemudian disimpan dan disebut sebagai data mentah (raw data).
2. Preprocessing, data mentah diolah pada tahap
preprocessing sehingga sesuai dan siap diproses
oleh text-mining, yaitu pada tahap implementasi
density-based clustering.
3. Data after preprocessing merupakan data yang diperoleh dari tahap preprocessing.
4. Density-Based Clustering, tahap implementasi metode density-based clustering pada data hasil
preprocessing. Pada proses clustering, jarak
antar teks dihitung menggunakan fungsi
Euclidean Distance kemudian proses clustering
dilakukan dengan algoritma DBSCAN.
5. Extract locations, ektraksi informasi lokasi dari teks pada cluster dengan menggunakan NER
rule-based untuk memilih teks yang diperkirakan
mengandung informasi lokasi secara eksplisit. Kata hasil keluaran NER kemudian di parsing
34 Jurnal Nasional JMII 2016
menggunakan Google Maps Geocoding API untuk meminta informasi geocoding.
6. Data from text-mining, data hasil keluaran penerapan metode density-based clustering. 7. Analysis & evaluation, analisa dan evaluasi hasil
keluaran metode density-based clustering dan hasil ekstraksi lokasi dari setiap cluster yang dihasilkan proses clustering.
8. Result, data yang sudah dievaluasi kemudian diproses untuk dibuat kedalam visualisasi pemetaan atau geospatial. Pada tahap ini dibuat hasil dan kesimpulan dari penelitian.
9. Mapping, tahap menampilkan visualisasi pemetaan lokasi kecelakaan. Pemetaan dilakukan dengan bantuan Google Maps Geocoding API. Tahapan Preprocessing
Pada tahap preprocessing dihasilkan data set yang siap untuk diproses oleh metode density-based
clustering. Tahapan preprocessing terdiri dari sub
tahap yaitu text-preprocessing dan pembobotan kata.Pada text-preprocessing dilakukan case folding dan tokenizing pada data mentah yang dikumpulkan. Proses processing diawali dengan inisialisasi tabel
hash yaitu tabel yang digunakan untuk menyimpan
frekuensi kemunculan kata pada sejumlah data yang akan diproses oleh clustering.Teks pada data yang dihasilkan tahap text-preprocessing dipecah ke dalam bentuk kata kemudian dihitung bobot untuk kata tersebut. Pembobotan kata akan menghasilkan nilai TF-IDF setiap kata pada teks. Persamaan untuk menghitung TF-IDF yang digunakan sebagai berikut.
Tahapan Implementasi DBSCAN
Hasil pembobotan kata yang sudah dilakukan kemudian digunakan dalam proses density-based
clustering. Algoritma DBSCAN yang akan
diimplementasikan akan membuat cluster sesuai dengan parameter masukan, yaitu dan MinPts.
Parameter dan MinPts akan mempengaruhi jumlah cluster yang terbentuk. DBSCAN akan membuat suatu daerah yang berpusat di dengan radius sebesar , sehingga anggota cluster adalah objek-objek dalam radius dari objek pusat .
Perhitungan jarak objek p ke objek pusat dapat menggunakan pengukuran numerik yaitu menggunakan Euclidean Distance. Berikut rumus
Euclidean Distance:
Tahapan Visualisasi Pemetaan
Visualisasi dilakukan terhadap setiap cluster yang dihasilkan DBSCAN. Adapun tahapan pada visualisasi pemetaan antara lain:
1. Tahap ekstraksi lokasi masing-masing cluster dengan menggunakan NER rule-based.
2. Visualisasi dengan menggunakan Google Maps Geocoding API dimana parameter yang digunakan adalah kata pada setiap cluster. Dengan menggunakan geocoding akan
dihasilkan koordinat geografis (dalam latitude dan longitude) yang kemudian dapat digunakan sebagai titik lokasi pada Google Maps.
Respon status yang diberikan geocoding pada permintaan (request) yang dikirimkan terdiri dari kode berikut: [4]
Tabel 2 Respon Status Geocoding
Status Keterangan
OK
menunjukan tidak ada error terjadi. Alamat berhasil diuraikan dan paling sedikit satu geocode dikembalikan. ZERO_RESULTS
menunjukan geocode berhasil tetapi mengembalikan hasil kosong. Hal tersebut mungkin jika geocoder memberikan alamat yang tidak ada (not existing address).
OVER_QUERY_LIMIT menunjukan bahwa permintaan melebihi kuota
REQUEST_DENIED menunjukan bahwa permintaan ditolak
INVALID_REQUEST umumnya menunjukan bahwa query (address, components atau latlng) hilang
UNKNOWN_ERROR
menunjukan bahwa permintaan tidak dapat diproses karena server error. Pemintaan munkin berhasil diproses jika dikirim ulang.
IV. I
MPLEMENTASID
ANA
NALISISPreprocessing
Penelitian implementasi density-based clustering dilakukan terhadap 50 pesan teks dari
35 Jurnal Nasional JMII 2016
Twitter. Preprocessing dimulai dengan
text-preprocessing yang terdiri dari tahap case folding dan tokenizing. Setelah text-preprocessing selesai
kemudian dilanjutkan dengan tahap pembobotan kata. Data hasil text-preprocessing dibentuk kedalam vektor yang direpresentasikan dengan kata. Kemudian dihitung frekuensi kemunculan setiap kata tersebut. Berikut contoh data pada tabel hasil perhitungan bobot yang dilakukan oleh sistem.
Tabel 3 Pembobotan Kata
Terms F term on text Total text with terms Total Text TFIDF
arah 1 9 50 0.745
Perhitungan untuk kata “arah” pada teks kesatu muncul sebanyak 1 kali dalam teks ke-1 dimana dari 50 teks yang diuji kata muncul pada 9 teks. Sehingga perhitungannya adalah sebagai berikut.
(5) Density-based Clustering dengan DBSCAN
Setiap teks adalah objek yang akan diuji kedekatannya oleh DBSCAN dalam proses
clustering. Pada tahap awal, DBSCAN akan
menandai semua objek sebagai “unvisited” dan kemudian memilih secara random satu objek untuk diuji kedekatannya dengan menggunakan fungsi pengukuran jarak yaitu Euclidean Distance. Berikut hasil clustering untuk dan minpts = 1 untuk 50 teks yang diuji.
Tabel 4 Contoh Hasil Clustering
ID Teks Cluster
1 gunakan jalur sesuai ketentuan jangan melawan arus karena rawan kecelakaan kesadaran kita keselamatan semua pictwittercomuzyzwcnq
7 2 gunakan jalur sesuai ketentuan jangan melawan
arus krn rawan kecelakaan kesadaran kita keselamatan semua pictwittercomlitosjblr
7
Iterasi pengujian pada teks dilakukan sampai semua teks dikunjungi (visited). Misal jika objek berikutnya yaitu teks-1 dan teks-2 yang akan diuji dimana teks-1 adalah objek pusat cluster C1 maka
perhitungan jaraknya adalah:
Tabel 5 Contoh Perhitungan Bobot
p Term TFIDF1 TFIDF2
x J i 1 arus 1.097 1.097 0 2 gunakan 1.222 1.222 0 3 jalur 1.097 1.097 0 4 jangan 1.097 1.097 0 5 karena 1.398 0 1.954404 6 kecelakaan 0.009 0.009 0 7 kesadaran 1.398 1.398 0 8 keselamatan 1.398 1.398 0 9 ketentuan 1.398 1.398 0 10 kita 1.398 1.398 0 11 melawan 1.398 1.398 0 12 pictwittercomuzyzwcnq 1.699 0 2.886601 13 rawan 0.854 0.854 0 14 semua 1.398 1.398 0 15 sesuai 1.398 1.398 0 16 pictwittercomlitosjblr 0 1.699 2.886601 ∑ 7.727606
Teks-2 karena berada didalam radius yaitu
sehingga teks-2 adalah anggota cluster C1.
36 Jurnal Nasional JMII 2016
semua noise akan diuji, termasuk objek r apakah berada dalam radius untuk clusteratau tidak. Visualisasi Pemetaan
Data yang dihasilkan DBSCAN kemudian diproses pada tahap preprocessing visualiasi yaitu dengan menghitung frekuensi kemunculan kata dalam sebuah cluster. Kemudian dilakukan pengecekan apakah kata dapat diidentifikasi oleh Google Maps Geocoding. Berikut contoh tabel hasil pengecekan lokasi menggunakan Google Maps Geocoding, informasi yang diberikan terdiri dari status, longitude, latitude, dan alamat.
Pengujian dan Analisis
Jumlah cluster yang dihasilkan dari proses
density-based clustering menunjukan jumlah
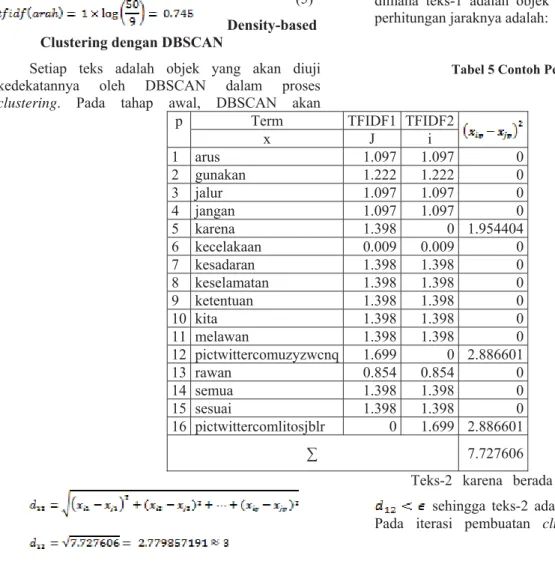
kejadian (event) yaitu kecelakaan yang terjadi. Pada percobaan menggunakan nilai diantara 1 sampai 10 untuk data 50 teks tweet yang diambil secara
real-time pada tanggal 21 Juni 2016 diperoleh jumlah
kejadian sebagai berikut.
Gambar 1 Grafik Jumlah Kejadian (Event) Kecelakaan yang Terjadi
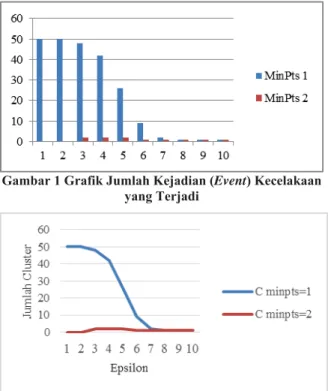
Gambar 2 Grafik Keterhubungan Nilai Epsilon, MinPts, dan Jumlah Cluster
Dari grafik pada gambar 2 dapat dilihat bahwa jumlah cluster yang dihasilkan dari proses clustering dipengaruhi oeh nilai dan MinPts. Pada percobaan yang dilakukan jumlah cluster paling banyak pada nilai MinPts = 1 dan dimana sebuah cluster paling sedikit memiliki anggota 1 teks tweet dan jarak antara teks dengan inti cluster . Sementara jumlah cluster yang paling sedikit pada pada nilai dimana berarti jarak antara teks dengan inti
cluster . Sehingga dapat disimpulkan bahwa
semakin kecil nilai dan MinPts maka jumlah
cluster semakin banyak. Dan sebaliknya semakin
besar nilai dan MinPts maka jumlah cluster semakin sedikit.
Pengujian hasil keluaran sistem dilakukan pada 6 skenario pengujian. Dimana pengujian dilakukan dengan variasi parameter ϵ dan MinPts untuk melihat jumlah cluster yang dihasilkan. Evaluasi clustering dilakukan dengan menghitung nilai Silhoutte
Coefficient. Nilai Silhoutte Coefficient adalah antara
-1 dan -1. Kondisi yang baik adalah jika nilai Silhoutte
Coefficient mendekati 1, yang menunjukan cluster
dimana teks tweet berada padat dan jauh terpisah dari cluster lainnya. Berikut nilai Silhoutte
Coefficient pada masing-masing skenario pengujian.
Tabel 6 Hasil Evaluasi Clustering
MinPts Jumlah Cluster Jumlah Teks dalam Cluster Silhoutte Coefficient 5 1 26 50 0.055 6 1 9 50 0.142 7 1 2 50 0.254 3 2 2 4 0.532 4 2 2 10 0.522 5 2 2 26 0.126
Dari hasil evaluasi clustering diatas diperoleh nilai Silhoutte Coefficient yang paling mendekati 1 adalah hasil clustering pada skenario 4 yaitu 0.532 dengan 3, MinPts = 2 dan jumlah cluster 2. Dimana nilai Silhoutte Coefficient pada skenario 4 menunjukan bahwa teks dalam cluster memiliki
density yang baik dan memiliki kemiripan atau
37 Jurnal Nasional JMII 2016
Nilai Silhoutte Coefficient pada skenario 1 sebesar 0.055 dengan 5, MinPts = 1 dan jumlah
cluster 26 adalah nilai yang paling mendekati -1.
Sehingga pada skenario 1 teks dalam cluster memiliki density yang kurang baik dan memiliki kemiripan atau kesamaan kejadian yang lebih rendah. Setelah dilakukan evaluasi clustering, kemudian dilakukan analisa terhadap informasi lokasi yang ditemukan pada hasil clustering. Pengujian informasi lokasi dilakukan dengan membandingkan hasil keluaran sistem dengan hasil observasi pada informasi lokasi yang eksplisit ada pada teks dalam
cluster.
Tabel 7 Hasil Pengujian Lokasi pada Cluster
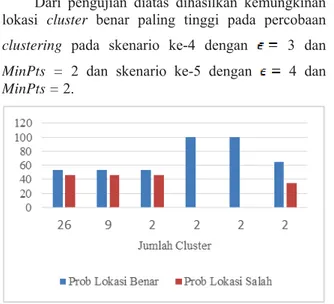
Jumlah Cluster Silhoutte Coefficient Jumlah Lokasi Ditemukan Jumlah Lokasi Benar Jumlah Lokasi Salah Probalitas Lokasi Benar Probalitas Lokasi Salah 26 0.055 26 14 12 0.538 0.462 9 0.142 26 14 12 0.538 0.462 2 0.254 26 14 12 0.538 0.462 2 0.532 2 2 0 1 0 2 0.522 5 5 0 1 0 2 0.126 17 11 6 0.647 0.353
Dari pengujian diatas dihasilkan kemungkinan lokasi
cluster benar paling tinggi pada percobaan clustering
pada skenario ke-4 dengan 3 dan MinPts = 2 dan skenario ke-5 dengan 4 dan MinPts = 2.
Dari pengujian diatas dihasilkan kemungkinan lokasi cluster benar paling tinggi pada percobaan
clustering pada skenario ke-4 dengan 3 dan MinPts = 2 dan skenario ke-5 dengan 4 dan MinPts = 2.
Gambar 3 Grafik Hubungan Jumlah Cluster dan Probalitas Lokasi
Pada skenario pengujian 4 dan 5 probalitas lokasi benar lebih tinggi dibandingkan dengan hasil skenario 3 dan 6 walaupun jumlah cluster sama. Hal ini dipengaruhi juga nilai Silhoutte Coefficient pada skenario 4 dan 5 yang paling mendekati 1. Dimana dapat disimpulkan bahwa pada skenario ke 4 dan 5, teks pada cluster memiliki kemiripan atau kesamaan kejadian lebih tinggi sehingga probalitas lokasi kejadian yang ditemukan juga lebih tinggi.
V. K
ESIMPULANDari penelitian yang dilakukan dapat diambil kesimpulan sebagai berikut:
1. Density-based clustering menggunakan
algoritma DBSCAN dapat digunakan untuk mendeteksi dan mengelompokan kejadian (event) nyata yang diunggah user melalui pesan pada media sosial. DBSCAN membuat sejumlah cluster berdasarkan paramater
masukan yaitu dan MinPts.
2. Identifikasi dan ekstraksi informasi geospatial atau lokasi dari suatu event pada sebuah cluster dapat menggunakan Google Maps Geocoding API, dimana parameter pencarian yang digunakan adalah kata pada teks anggota
cluster. Informasi koordinat geografis yang
38 Jurnal Nasional JMII 2016
titik lokasi pada visualisasi pemetaan lokasi kecelakaan.
3. Nilai parameter dan MinPts mempengaruhi jumlah cluster yang dihasilkan proses
clustering. Semakin kecil nilai dan MinPts
maka jumlah cluster semakin banyak. Dan sebaliknya semakin bear nilai dan MinPts maka jumlah cluster semakin sedikit.
4. Nilai silhoutte coefficient pada evaluasi
clustering mempengaruhi probalitas lokasi
benar dari cluster. Jika nilai silhoutte coefficient mendekati 1 maka probalitas lokasi benar semakin tinggi dan jika nilai silhoutte
coefficient mendekati -1 maka probalitas lokasi
benar semakin rendah.
5. Hasil keluaran sistem sudah dapat memberikan informasi lokasi kecelakaan. Informasi lokasi berupa daftar kemungkinan lokasi yang ada secara eksplisit dalam teks pesan media sosial pada setiap cluster. Akan tetapi hasil keluaran belum dapat disajikan dengan baik untuk publik karena lokasi yang ditemukan belum spesifik menyebutkan suatu lokasi dengan detail.
R
EFERENSI[1]. Chung-Hong, L. (2012). Mining spatio-temporal information on microblogging streams using a density-based online clustering method. 39(10).
[2]. Data Mining. (n.d.). Retrieved March 20, 2015, from Oracle:
http://www.oracle.com/technetwork/database/o ptions/advanced-analytics/odm/index.html [3]. Ester, M., Kriegel, H.-P., Sander, J., & Xu, X.
(n.d.). A density-based algorithm for
discovering clusters in large spatial databases with noise.
[4]. Google Maps APIs. (n.d.). Retrieved May 20,
2016, from Google Developers:
https://developers.google.com/maps/documenta tion/geocoding
[5]. Han, J., Kamber, M., & Pei, J. (2012). Data Mining Concepts and Techniques, Third Edition. USA: Elsevier Inc.
[6]. Konkol, M. (2012). Named Entity Recognition. Pilsen: University of West Bohemia.
[7]. Krstajic, M., Rohrdantz, C., Hund, M., & Weiler, A. (2012). Getting There First: Real-Time Detection of Real-Word Incidents on Twitter. Proceedings of the 2nd IEEE Workshop on Interactive Visual Text Analytics -IEEE VisWeek 2012. Seattle, WA, USA: Konstanzer Online Publications System. [8]. Kusrini, & Luthfi, E. T. (2009). Algoritma Data
Mining. Yogyakarta: ANDI.
[9]. Sebastiani, F. (2002). Machine learning in
automated text categorization. ACM
Computing, 34, 1-47.
[10]. The Streaming APIs | Twitter Developers. (n.d.). Retrieved 05 01, 2016, from Twitter: https://dev.twitter.com/streaming/overview [11]. Witten, I. (2005). Text mining. In M. Singh,
Practical handbook of internet computing. Boca Raton, Florida: Chapman & Hall/CRC Press. [12]. Witten, I. a. (2000). Data mining: Practical
machine learning tools and techniques. San Francisco, CA: Morgan Kaufmann.