commit to user
PEMANFAATAN METADATA DALAM MENILAI
KESAMAAN PROPOSAL PENELITIAN
HALAMAN JUDUL
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Mencapai Gelar Strata Satu JurusanInformatika
Disusun Oleh :
LAHARDI ALKAWERO
M0508107
JURUSAN INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN
ALAM
UNIVERSITAS SEBELAS MARET
SURAKARTA
commit to user
ii
SKRIPSI
PEMANFAATAN METADATA DALAM MENILAI
KESAMAAN PROPOSAL PENELITIAN
HALAMAN PERSETUJUAN
Disusun oleh :
LAHARDI ALKAWERO M0508107
commit to user
iii
SKRIPSI
PEMANFAATAN METADATA DALAM MENILAI KESAMAAN PROPOSAL PENELITIAN
HALAMAN PENGESAHAN Disusun oleh :
LAHARDI ALKAWERO M0508107
telah dipertahankan di hadapan Dewan Penguji pada tanggal : 23 Januari 2013
Susunan Dewan Penguji
commit to user
iv
PEMANFAATANMETADATA DALAM MENILAI KESAMAAN PROPOSAL PENELITIAN
LAHARDI ALKAWERO
Jurusan Informatika.Fakultas Matematika dan Ilmu Pengetahuan Alam.
Universitas Sebelas Maret.
ABSTRAK
Penelitian ini bertujuan untuk mengetahui pemanfaatan metadata dalam
melakukan perhitungan kesamaan proposal penelitian. Masalah yang diteliti
adalah bagaimana memanfaatkan metadata untuk melakukan perhitungan
kesamaan teks antar dokumen proposal penelitian. Perhitungan kesamaan
dilakukan dengan metode Cosine Similarity dan pembobotan.Bobot dari metadata
menunjukkan tingkatan kepentingan metadata dalam dokumen. Pada penelitian
ini metadata dimanfaatkan sebagai solusi untuk tindakan awal dalam mendeteksi
secara cepat kesamaan teks pada dokumen penelitian. Hal ini menunjukkan bahwa
jika program yang dibuat pada penelitian ini digunakan, maka seorang reviewer
akan lebih mudah dalam melihat kesamaan dari banyak dokumen. Persetujuan
reviewer menunjukkan bahwa penggunaan metadata dengan pembobotan dalam
menghitung kesamaan dokumen proposal penelitian dapat diterima sebagai salah
satu alat bantu dalam menilai kesamaan secara cepat sebuah proposal penelitian.
Pemberian bobot yang berbeda besarnya pada setiap metadata dapat menjadi
solusi untuk memberikan tingkat kepentingan yang berbeda beda sesuai dengan
jenis skema. Hal ini menunjukkan bahwa pembobotan dapat mempengaruhi
proporsi nilai sebuah metadata untuk menunjukkan kepentingannya dalam sebuah
dokumen penelitian.
commit to user
v
THE USING OF METADATA IN ASSESSING THE SIMILARITY OF THE RESEARCH PROPOSAL
LAHARDI ALKAWERO
Department of Informatics. Mathematics and Natural Science Faculty.
Sebelas Maret University
ABSTRACT
This study aimed to examine the using of metadata in the calculation of the
similarity of research proposals. The problem studied is how to use metadata to
calculate similarities between the text of the research proposal document.
Similarity calculations done by using Cosine Similarity and weightings. The
weight of the metadata shows the level of importance in the document. In this
research, metadata is used as a solution to the initial action in the rapid detection
of text similarity of the research document. Itshows that if the program were made
in this study is used, then the reviewer will be easier to see the similarities of
many documents. Approval of reviewer suggests that the using of metadata with
weighting process in calculating the similarity of the research proposal documents
can be accepted as a tool in assessing similarities of research proposalsquickly.
Giving different weight to each metadata can be a solution to provide different
importancelevel according to the type of scheme. This shows that the weighting
can affect the proportion of the value of a metadata to indicate importance level in
a research document.
commit to user
vi
MOTTO
sesungguhnya
sesudah kesulitan itu ada kemudahan, Maka apabila kamu telah selesai (dari
sesuatu urusan), kerjakanlah dengan sungguh-sungguh (urusan) yang lain
(Q.S Alam Nasyrah : 5-7)
(Q.S Al-Baqarah : 214)
barangsiapa bertakwa kepada Allah niscaya dia akan mengadakan baginya
jalan keluar. Dan memberinya rezki dari arah yang tiada disangka-sangkanya.
dan barangsiapa yang bertawakkal kepada Allah niscaya Allah akan
mencukupkan (keperluan)nya. Sesungguhnya Allah melaksanakan urusan yang
(dikehendaki)Nya. Sesungguhnya Allah Telah mengadakan ketentuan bagi
tiap-tiap sesuatu
(Q.S At talaq : 2-3)
Banyak kegagalan dalam hidup ini dikarenakan orang-orang tidak menyadari
betapa dekatnya mereka dengan keberhasilan saat mereka
commit to user
vii
PERSEMBAHAN
Kupersembahkan karya ini kepada :
Ibu, Bapak serta kedua adik tercinta Asfarina Aulia dan Lazwardi Azhar
Nur Ahyuni, S.E. yang selalu memberi semangat
commit to user
viii
KATA PENGANTAR
Bismillahirrahmaanirrahiim
yang senantiasa memberikan nikmat dan karunia-Nya sehingga penulis dapat
menyelesaikan skripsi dengan judul Pemanfaatan Metadata Dalam Menilai
Kesamaan Proposal Penelitian, yang menjadi salah satu syarat wajib untuk
memperoleh gelar Sarjana Informatika di Universitas Sebelas Maret (UNS)
Surakarta.
Penulis menyadari akan keterbatasan yang dimiliki, begitu banyak
bimbingan, bantuan, serta motivasi yang diberikan dalam proses penyusunan
skripsi ini. Oleh karena itu, ucapan terima kasih penulis sampaikan kepada :
1. Ibu, Bapak, dan adik - adikku, serta teman-teman yang telah memberikan
banyak dukungan materi dan non materi sehingga penyusunan skripsi ini
dapat terselesaikan.
2. IbuDewi Wisnu Wardani, S. Kom. , MS. selaku Dosen Pembimbing I yang
penuh kesabaran membimbing, mengarahkan, dan memberi motivasi kepada
penulis selama proses penyusunan skripsi ini,
3. Ibu Sari Widya Sihwi, S.Kom., M.T.Iselaku Dosen Pembimbing II yang
penuh kesabaran membimbing, mengarahkan, dan memberi motivasi kepada
penulis selama proses penyusunan skripsi ini,
4. Bapak dan Ibu dosen serta karyawan di Jurusan Informatika FMIPA UNS
yang telah mengajar penulis selama masa studi dan membantu dalam proses
penyusunan skripsi ini,
5. Nur Ahyuni, S.E. sebagai sahabat terbaik yang telah banyak memberikan
motivasi dan inspirasi kepada penulis.
Surakarta, Januari 2013
commit to user
ix
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN PERSETUJUAN ... ii
HALAMAN PENGESAHAN ... iii
ABSTRAK ... iv
ABSTRACT ... v
MOTTO ... vi
PERSEMBAHAN ... vii
KATA PENGANTAR ... viii
DAFTAR ISI ... ix
DAFTAR TABEL ... xii
DAFTAR GAMBAR ... xiii
DAFTAR LAMPIRAN ... xiv
BAB IPENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 2
1.3 Batasan Masalah ... 2
1.4 Tujuan Penelitian ... 2
1.5 Manfaat Penelitian ... 3
1.6 Sistematika Penulisan ... 3
BAB IITINJAUAN PUSTAKA ... 4
2.1 Landasan Teori ... 4
2.1.1 Metadata ... 4
2.1.2 Information Retrieval ... 4
2.1.3 Text Processing ... 5
2.1.4 Indexing ... 6
commit to user
x
2.1.6 Term Frequency Inverse Document Frequency ... 8
2.2 Penelitian Sebelumnya ... 9
2.2.1 Text Similarity: An Alternative Way To Search MEDLINE ... 9
2.2.2 Similarity Measures For Text Document Clustering ... 9
2.2.3 A Wikipedia Based Multilingual Retrieval Model ... 9
2.2.4 Methods For Identifying Versione Dan Plagiarized Document ... 10
2.2.5 Inferring Similarity Between Music Objects With Application To Playlist Generation ... 10
2.2.6 From Context To Content: Leveraging Context To Infer Media Metadata ... 10
BAB IIIMETODE PENELITIAN... 11
3.1 StudiLiteratur ... 11
3.2 Observasi ... 11
3.3 Analisa Metadata ... 12
3.3.1 Metadata dan Pembobotan Tiap Skema ... 13
3.3.2 Data Set ... 15
3.4 Perancangan Dan Implementasi Algoritma Kesamaan Metadata ... 15
3.5 Pengujian ... 16
BAB IVHASIL DAN PEMBAHASAN ... 17
4.1 Perancangan Model dan Algoritma Kesamaan Metadata ... 17
4.2 Pengujian ... 22
4.3.1 Pengujian 1 ... 22
4.3.2 Pengujian 2 ... 23
4.3.3 Pengujian 3 ... 24
4.3.4 Pengujian 4 ... 25
4.3.5 Pengujian 5 ... 26
4.3.6 Pengujian 6 ... 28
4.3.7 Pengujian 7 ... 29
4.3.8 Pengujian 8 ... 30
commit to user
xi
4.3.10 Validasi Reviewer ... 32
BAB VPENUTUP ... 34
5.1 Kesimpulan ... 34
5.2 Saran ... 34
commit to user
xii
DAFTAR TABEL
Table 1. Tabel daftar metadata dan bobot pada skema Fundamental ... 13
Table 2. Tabel daftar metadata dan bobot dari skema Hibah Bersaing ... 14
Table 3. Tabel daftar metadata dan bobot dari skema Strategi Nasional ... 14
Table 4. Data Set ... 15
Table 5. Data Testing ... 15
Table 6. Daftar nilai kesamaan metadata ... 23
Table 7. Daftar nilai kesamaan metadata ... 24
Table 8. Daftar nilai kesamaan metadata ... 25
Table 9. Daftar nilai kesamaan metadata ... 26
Table 10. Daftar nilai kesamaan metadata ... 27
Table 11. Daftar nilai kesamaan metadata ... 28
Table 12. Daftar nilai kesamaan metadata ... 29
Table 13. Daftar nilai kesamaan metadata ... 31
Table 14. Daftar nilai kesamaan metadata ... 32
commit to user
xiii
DAFTAR GAMBAR
Gambar 1. Ilustrasi Algoritma Pembobotan TF-IDF ... 8
Gambar 2. Tahapan kerja pada penelitian ini... 11
Gambar 3. Cara pengambilan metadata dari dokumen penelitian ... 12
commit to user
xiv
DAFTAR LAMPIRAN
LAMPIRAN A Persetujuan pembobotan metadata oleh pihak LPPM UNS ... 39
LAMPIRAN B Tanggapan Reviewer... 40
commit to user
1
BAB I PENDAHULUAN
1.1 Latar Belakang
Pencarian informasi yang berupa tulisan seperti artikel, jurnal, dan buku
elektronik saat ini sangatlah mudah. Kemudahan akan pencarian informasi juga
menimbulkan masalah masalah yang terkait dengan keaslian isi atau ide dari
sebuah dokumen atau tulisan. Sebuah lembaga penelitian sudah semestinya
memiliki berbagai prosedur yang diterapkan untuk mencegah terjadinya tindakan
plagiat. Untuk itu, perlu adanya metode dan ukuran yang dapat menilai keaslian
atau kebaruan isi dari tulisan. Ukuran yang dapat digunakan adalah ukuran
kesamaan antar dokumen yang dihitung dengan berbagai metode. Salah satu
contohnya, kesamaan dokumen yang dihitung menggunakan pendekatan
kesamaan semantik(Broome, 2004)atau penelitian yang dilakukan dengan
menghitung kesamaan seluruh isi dokumen dengan melakukan text processing
dan menghitung kesamaannya menggunakan berbagai metode seperti Cosine,
Dice, Jaccard, Hellinger dan Harmonic(Hariharan, 2010).
Metode metode yang telah ada sudah banyak diterapkan dalam berbagai
kasus, salah satu kasusnya adalah mendeteksi adanya tindakan
plagiarisme(Hoada & Zobel, 2003). Meskipun dalam menilai tindakan
plagiarisme yang terjadi pada sebuah dokumen tidaklah mudah, namun metode
yang ada dapat diterapkan pada salah satu tahapan dalam menilai tindakan
plagiarisme yaitu pada tahap pengukuran kesamaan keseluruhan teks dengan
menggunakan metode Cosine Similarity(Hariharan, 2010).Selain menghitung
keseluruhan teks, metode yang ada juga telah digunakan untuk menghitung
kesamaan metadata, seperti kesamaan metadata untuk generate playlist lagu
lagu secara otomatis (Ragno et al., 2005)dan pengelompokkansecara otomatis
berdasarkan kesamaan metadata dari gambar yang diunggah(Davis et al., 2004).
Pada penelitian ini penulis meneliti bagaimana memanfaatkan metadata
untuk menghitung kesamaan dokumen proposal penelitian menggunakan metode
commit to user
standar sehingga bisa ditentukan bagian - bagian yang paling mewakili seluruh isi
dokumen. Bagian bagian tersebut akan dijadikan metadata yang dapat
digunakan dalam proses perhitungan kesamaan dokumen. Perhitungan kesamaan
yang dilakukan pun akan lebih efektif karena data yang digunakan hanyalah
metadata yang dianggap perlu dan mewakili isi dari dokumen, bukan seluruh isi
dari dokumen.
1.2 Rumusan Masalah
Berdasarkan latar belakang yang telah dijelaskan sebelumnya, maka
masalah yang akan diteliti adalah bagaimana memanfaatkan metadata dalam
melakukan perhitungan kesamaan antar dokumen proposal penelitian dengan
metode Cosine Similarity.
1.3 Batasan Masalah
Agar pembahasan terfokus pada permasalahan yang akan dibahas maka
penelitian ini terbatas pada :
Metadata dari dokumen penelitian yang akan digunakan sudah tersedia di
Lembaga Penelitian Dan Pengabdian Kepada Masyarakat Universitas Sebelas
Maret( LPPM UNS ).
Data dokumen yang diujikan adalah proposal penelitianLPPM UNS dengan
sumber dana dari Direktorat Jenderal Pendidikan Tinggi (Ditjen Dikti) khusus
skema Hibah Bersaing, Fundamental dan Strategis Nasional sejak tahun 2008
sampai 2011.
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah memanfaatkanmetadatadalam melakukan
perhitungan kesamaan antar dokumen proposal penelitian dengan metode Cosine
commit to user
3
1.5 Manfaat Penelitian
Diharapkan hasil penelitian ini dapat digunakan sebagai solusi alternatif
dalam membantu pihak lembaga penelitian yaitu LPPM UNS dalam menilai
kualitas sebuah proposal dengan menggunakan nilai kesamaan metadatadari
dokumen proposal penelitian. Hasil penelitian ini akan membantu reviewer dalam
menilai proposal yang akan diterima.
1.6 Sistematika Penulisan
Sistematika penyusunan laporan ini dibagi atas lima bab. Adapun bab-bab
tersebut adalah sebagai berikut :
BAB I PENDAHULUAN
Bab ini berisi uraian tentang latar belakang masalah, rumusan masalah, batasan
masalah, tujuan penelitian, manfaat penelitian, tinjauan pustaka, dan sistematika
penulisan laporan.
BAB II TINJAUAN PUSTAKA
Bab ini berisi teori-teori yang digunakan sebagai dasar pembahasan dari topik
laporan skripsi.
BAB III METODOLOGI
Bab ini berisi tahapan-tahapankerja yang digunakan sebagai acuan dalam
menyelesaikan skripsi.
BAB IV PEMBAHASAN
Bab ini berisi tentang eksperimen pengujian dari algoritma yang telah disusun
dengan menggunakan sejumlah sample datauntuk kemudian dilakukan analisis
terhadap hasil dari eksperimen yang telah dilakukan.
BAB V KESIMPULAN DAN SARAN
Bab ini berisi uraian tentang kesimpulan dan saran-saran sebagai bahan
commit to user
menggambarkan isi, format atau atribut dari catatan data atau sumber informasi.
Metadata didefinisikan secara umum sebagai data terstruktur tentang data. Namun
menurut Gililand dalam (Chuttur, 2011), proses pembuatan metadatadapat
melibatkan baik input subjektif maupun objektif sesuai dengan kebutuhan
pengguna.
Beberapa contoh metadata, yaitu pernyataan dari fakta tentang penulis,
tanggal pembuatan, versi, dan atribut lainnya umumnya dapat ditentukan secara
obyektif. Metadataobjektif juga dapat dihasilkan oleh mesin dalam kebanyakan
kasus, seperti metadata "properties" yang dihasilkan saat membuat sebuah file
dalam pengolah kata atau aplikasi spreadsheet.Metadata subjektif, adalah
metadata yang merujuk pada sudut pandang (penugasan kata kunci, ringkasan
konten dalam abstrak), atau karena secara khusus dimaksudkan untuk mewakili
evaluasi subjektif (review buku atau presentasi ). Bahkan elemen metadata yang
lebih formal menjadi subjektif bila digunakan dalam konteks budaya atau domain
yang merujuk pada interpretasi lokal. Sebagai contoh, karakteristik pedagogis
yang tergantung pada suatu filsafat pendidikan tertentu mungkin penting dalam
konteks tertentu, tapi tidak akan memiliki makna di luar konteks itu (Duval et al.,
2002).
2.1.2 Information Retrieval
Information retrievalsystem atau sistem temu kembali informasi berkaitan
dengan representasi, penyimpanan, pengorganisasian, dan pengaksesan informasi.
Sistem temu kembali informasi berbeda dengan sistem temu kembali data dalam
beberapa segi, antara lain spesifikasi query yang tidak lengkap dan tingkat
commit to user
5
dengan teks bahasa alami yang tidak selalu terstruktur dengan baik dan bersifat
ambigu(Baeza-Yates & Ribeiro-Neto, 1999).
Sistem temu kembali informasi bekerja berdasarkan query yang diberikan
pengguna yang menghasilkan daftar dokumen yang dianggap relevan. Tidak ada
jaminan bahwa seluruh materi yang ditemukembalikan tersebut relevan dengan
yang diinginkan pengguna dan belum tentu seluruh materi yang relevan dengan
permintaan pengguna berhasil ditemukembalikan (Adisantoso & Ridha, 2004).
2.1.3 Text Processing
Suatu dokumen tidak dapat dikenali langsung oleh suatu sistem temu
kembali informasi sehingga perlu dilakukan pemrosesan terlebih dahulu.
Beberapa pengolahan teks adalah sebagai berikut :
1.Tokenizing
Tokenizing adalah proses pengenalan token yang terdapat dalam rangkaian
teks(Grossman, 2001). Dalam pembuatan indeks istilah, dokumen dipecah
menjadi unit-unit yang lebih kecil misalnya berupa kata, frasa, atau kalimat. Unit
pemrosesan tersebut disebut token. Seringkali spasi digunakan sebagai pemisah
antar token (Jackson, 2002).
2.Stopword Removal
Stopword removal merupakan tahap pembuangan yang termasuk dalam
stoplist yaitu kata yang sering muncul dalam dokumen akan tetapi tidak memiliki
makna yang berarti dan tidak signifikan dalam membedakan dokumen atau query
misalnya
kata-Stopword removal bertujuan untuk mengurangi daftar kata indeks dan
mempercepat indexing(Grossman, 2001).
3.Stemming
Stemming adalah proses penghilangan prefiksdan suffiks dari kata untuk
mendapatkan kata dasarnya (Grossman, 2001). Dalam hal efisiensi, stemming
mengurangi jumlah kata-kata unik dalam indeks sehingga mengurangi kebutuhan
ruang penyimpanan untuk indeks dan mempercepat proses pencarian. Dalam hal
commit to user
kebentuk dasarnya. Kata bersama, kebersamaan, menyamai, akan diubah menjadi
kata dasarnya stemming dapat diukur
berdasarkan beberapa parameter, seperti kecepatan proses, keakuratan, dan
kesalahan.
2.1.4 Indexing
Indeks merupakan suatu daftar term. Tujuan penggunaan indeks adalah
untuk meningkatkan kecepatan dan efisiensi pencarian di dalam kumpulan
dokumen. Tanpa indeks, query pengguna harus secara sekuensial melakukan scan
terhadap kumpulan dokumen sehingga memerlukan waktu yang cukup lama
dalam menemukan dokumen mana yang relevan dengan term pencarian. Scan
secara sekuensial ini sangat tidak feasible(Grossman, 2001).
Inverted index terdiri dari dua bagian. Yang pertama adalah indeks dari kata
(secara umum disebut indeks kata, leksikon, atau kamus kata) yang menyimpan
daftar term yang berbeda yang ditemukan pada kumpulan dokumen. Untuk setiap
term terdapat daftar dokumen yang mengandungtermtersebut. Daftar dokumen ini
merupakan bagian kedua dari inverted index(Grossman, 2001). Berikut ini adalah
ilustrasi proses indexing dengan inverted index :
D1: The GDP increased 2 percent this quarter.
D2: The spring economic slowdown continued to spring downwards this
quarter.
Inverted index dari kedua dokumen tersebut adalah :
commit to user
7
spring [D2]
the [D1] [D2]
this [D1] [D2]
to [D2]
seperti yang terlihat diatas, term continued, economic, slowdown, spring dan to
hanya terdapat pada dokumen kedua. Term GDP, increased, percent, dan 2 hanya
terdapat pada dokumen pertama. Term quarter, the, dan this terdapat pada kedua
dokumen(Grossman, 2001).
2.1.5 Vector Space Model
Menurut Salton dalamArifin(2002), salah satu model sistem temu kembali
informasi yang paling sederhana namun paling produktif adalah model ruang
vektor. Vektor model ini merepresentasikan term yang terdapat pada dokumen
dan query. Term dapat berupa kata, frasa, atau unit hasil indexing lain dalam suatu
dokumen sebagai gambaran konteks dari dokumen tersebut. Karena tiap kata
memiliki tingkat kepentingan yang berbeda dalam dokumen, maka diperlukan
indikator yaitu termweight (bobot term) dalam proses pencocokan dan
perankingan dokumen terhadap query.
Menurut Munoz dalam Arifin(2002), dokumen dan term masing-masing
dapat direpresentasikan dengan model ruang vektor. Misal t1, t2, ..., tn
menyatakan term yang digunakan untuk mengindeks database yang terdiri dari
dokumen D1, D2, ...., Dm.maka dokumen Di dinyatakan dengan :
Di = (ai1, ai2, ..., ain) dimana aij = bobot term tj dalam dokumen Di.
Kobayashi dalam Arifin (2002)juga menambahkan terdapat beberapa
metode pembobotan term yaitu Binary Weighting, Term Frequency, Log
commit to user
2.1.6 Term Frequency Inverse Document Frequency
Metode pembobotan yang umumnya diunggulkan dalam
penelitian-penelitian untuk digunakan dalam model ruang vektor yaitu Term Frequency
Inverse Document Frequency (TF-IDF) Arifin (2002). Metode TF-IDF merupakan
suatu cara untuk memberikan bobot hubungan suatu kata (term) terhadap
dokumen. Metode ini menggabungkan dua konsep untuk perhitungan bobot yaitu
frekuensi kemunculan sebuah kata di dalam sebuah dokumen tertentu (term
frequency) dan inversidarifrekuensi dokumen yang mengandung kata tersebut
(inverse document frequency). Term frequency (TF) menunjukkan seberapa
penting kata tersebut didalam sebuah dokumen yang diberikan. Document
frequency (DF) menunjukkan seberapa umum kata tersebut.
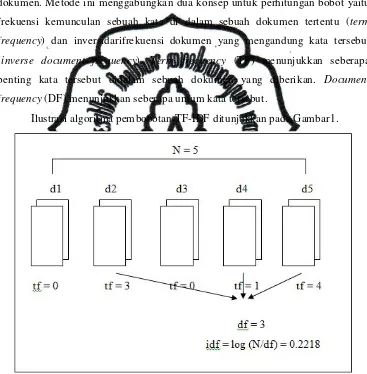
Ilustrasi algoritma pembobotan TF-IDF ditunjukkan pada Gambar1.
Gambar 1. Ilustrasi Algoritma Pembobotan TF-IDF(Harlian, 2006)
Keterangan :
d1, d2, d3, d4, d5 = dokumen
tf = banyaknya term yang dicari pada sebuah dokumen
N = total dokumen
commit to user
9
2.2 Penelitian Sebelumnya
Berikut ini adalah beberapa penelitian sejenis yang pernah dilakukan terkait
metadata dan informationretrievalsystem :
2.2.1 Text Similarity: An Alternative Way To Search MEDLINE (Lewis et al., 2006)
Artikel ini menerangkan bahwa metode cosine similarity adalah metode
yang paling banyak digunakan dalam perhitungan kesamaan vektor. tiga skema
pembobotan yang berbeda diterapkan dan diuji untuk mengukur pentingnya kata
kunci. Dalam pendekatan penilaian, setiap kata mendapatkan nilai m jika m kali
terjadi dalam sebuah teks (user query atau dokumen perpustakaan). Frekuensi
kemunculan dituliskan sebagai term frequency 1 (TF1) pembobotan, dan
diekspresikan dengan mendefinisikan kembali istilah xi sebagai jumlah
kemunculan kata i dalam query dan yi sebagai jumlah kejadian dari kata i dalam
teks perpustakaan. Pembobotan yang paling umum digunakan dalam literatur
information retrieval adalah TF * IDF.
2.2.2 Similarity Measures For Text Document Clustering (Huang, 2008)
Dalam artikel ini dijelaskan bahwa ketika dokumen direpresentasikan
sebagai sebuah vektor, similarity dari dua dokumen sesuai dengan korelasi antar
vektor. Hal ini diukur sebagai kosinus dari sudut antar vektor, yaitu yang disebut
Cosine Similarity. Cosine Similarityadalah salah satu yang paling popular untuk
mengukur kesamaan dan diterapkan untuk dokumen teks, seperti di banyak
aplikasi sistem temu kembali dan juga clustering.
2.2.3 A Wikipedia Based Multilingual Retrieval Model (Potthast et al., 2008)
Makalah ini memperkenalkan CL-ESA, model pengambilan baru
multibahasa untuk kesamaan analisis lintas bahasa. Model pengambilan
memanfaatkan keselarasan multi-bahasa dari Wikipedia: misalnya diberikan
commit to user
untuk d, di mana setiap dimensi i di d mengkuantifikasi kesamaan d terhadap
dokumen d * i dipilih dari "bagian-L" dari Wikipedia. Demikian juga, untuk d
dokumen kedua, ditulis dalam bahasa L maka L = L. Dibangun sebuah konsep
vektor d. Karena konsep kedua vektor d dan d* adalah koleksi-relatif representasi
d dan d* adalah language-independent, maka kesamaannya langsung dapat
dihitung dengan mengukur kesamaan kosinus.
2.2.4 Methods For Identifying Versione Dan Plagiarized
Documents (Hoada & Zobel, 2003)
Mudahnya perpindahan sebuah dokumen teks dari sebuah tempat
penyimpanan ke tempat lain menimbulkan besarnya resiko plagiarisme.
Perubahan yang terjadi pada isinya pun dapat terjadi dengan mudah pada proses
edit. Dalam makalah ini dilakukan penelitian untuk mengidentifikasi dokumen
yang terindikasi ada resiko tindakan plagiarisme. Salah satu metode yang
digunakan adalah metode kesamaan vektor yaitu Cosine Similarityyang dapat
digunakan pada tahap penilaian kesamaan. Dokumen yang memiliki tingkat
kesamaan cukup besar dapat dilakukan analisa selanjutnya untuk menilai apakah
ada tindakan plagiarisme diantara dokumen yang terindikasi.
2.2.5 Inferring Similarity Between Music Objects With Application To
Playlist Generation (Ragno et al., 2005)
Pada penelitian ini metadata digunakan untuk generate playlist lagu lagu
secara otomatis. Metadata yang dihasilkan oleh program pemutar file musik
digunakan dalam perhitungan kesamaan menggunakan Metode Cosine Similarity.
2.2.6 From Context To Content: Leveraging Context To Infer Media
Metadata (Davis et al., 2004)
Pada penelitian ini dijelaskan bahwa Perhitungan kesamaan metadata dapat
commit to user
11
BAB III
METODE PENELITIAN
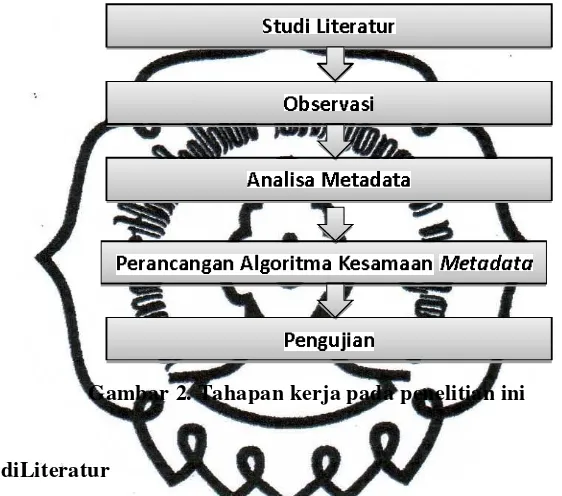
Tahapan kerja yang dilakukan dalam penelitian tugas akhir ini dapat dilihat pada
Gambar2
Gambar 2. Tahapan kerja pada penelitian ini
3.1StudiLiteratur
Studi literatur dilakukan penulis untuk memperdalam pengetahuan tentang
topik terkait dengan penelitian yang akan dilakukan yang meliputi metadata,
cosine similarity, text processing dan information retrieval.
3.2Observasi
Observasi dilakukan di lembaga penelitian yaitu LPPM UNS untuk
mengambil data dan mempelajari panduan penilaian sebuah dokumen proposal
penelitian. Pemilihan lembaga penelitian sebagai tempat observasi menjadi
penting karena akan mempengaruhi tahap analisa metadata. Dokumen penelitian
yang formatnya terstruktur dan memiliki panduan penulisan serta penilaian
membuat penulis memilih LPPM UNS sebagai tempat observasi dalam penelitian
commit to user
3.3Analisa Metadata
Pada tahap analisa metadata penulis meneliti data data yang telah
dikumpulkan pada tahap observasi. Setelah mengetahui data secara keseluruhan
barulah melakukan pemilihan metadata yang akan digunakan sebagai data
pengujian. Berikut ini adalah Gambar 3 sebagai ilustrasi pemilihan metadatadari
sebuah dokumen penelitian.
Gambar 3. Cara pengambilan metadata dari dokumen penelitian
Pada Gambar 3 dapat dilihat bahwa setiap bagian (judul, latar belakang,
rumusan masalah) akan digunakan sebagai metadata yang akan digunakan dalam
perhitungan kesamaan. Pemilihan metadata akan berbeda menyesuaikan skema
yang akan digunakan.
Hasil dari analisa metadata adalah daftar metadata serta bobotnya yang
mengacu pada panduan penelitian tahun 2011 serta disetujui oleh lembaga
penelitian.
Pemilihan metadata dan penentuan bobot didapatkan melalui diskusi dengan
commit to user
13
tahun. Skema yang diteliti adalah skema Fundamental, Hibah Bersaing dan
Strategi Nasional.
3.3.1 Metadata dan Pembobotan Tiap Skema
Setiap skema memiliki metadata dan cara pembobotan yang berbeda.
Penjelasan dilakukan melalui tabel untuk memudahkan pemahaman. Metadata
metadata yang digunakan dalam perhitungan
kesamaan.
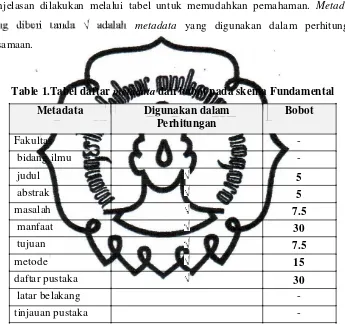
Table 1.Tabel daftar metadata dan bobot pada skema Fundamental Metadata Digunakan dalam
Perhitungan
Bobot
Fakultas -
bidang ilmu -
judul 5
abstrak 5
masalah 7.5
manfaat 30
tujuan 7.5
metode 15
daftar pustaka 30
latar belakang -
commit to user
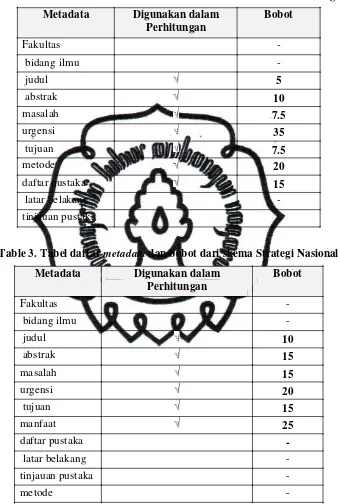
Table 2. Tabel daftar metadata dan bobot dari skema Hibah Bersaing Metadata Digunakan dalam
Perhitungan
daftar pustaka 15
latar belakang -
tinjauan pustaka -
Table 3. Tabel daftar metadata dan bobot dari skema Strategi Nasional Metadata Digunakan dalam
commit to user
15
3.3.2 Data Set
Data set yang digunakan untuk pengujian adalah metadata dokumen
proposal penelitian skema Fundamental, Hibah Bersaing dan Strategi Nasional
tahun 2008 sampai 2011 dengan rincian sebagai berikut :
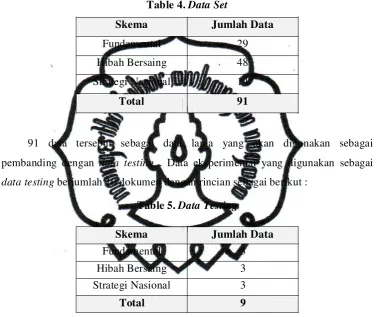
Table 4. Data Set
Skema Jumlah Data
Fundamental 29
Hibah Bersaing 48
Strategi Nasional 14
Total 91
91 data tersebut sebagai data lama yang akan digunakan sebagai
pembanding dengan data testing . Data eksperimental yang digunakan sebagai
data testing berjumlah 10 dokumen dengan rincian sebagai berikut :
Table 5. Data Testing
3.4Perancangan Dan Implementasi Algoritma Kesamaan Metadata
Pada tahap perancangan algoritma kesamaan metadata dibuat algoritma
yang dapat digunakan untuk menghitung kesamaan metadata. Algoritma yang
dihasilkan akan diterapkan pada kode program yang digunakan pada tahap
pengujian. Berikut ini adalah tahapan dalam merancang algoritma untuk
menghitung kesamaan metadata :
Menerapkan model matematika ke dalam kasus yang sedang diteliti.
Membuat kode semu dari algoritma.
Implementasi.
Skema Jumlah Data
Fundamental 3
Hibah Bersaing 3
Strategi Nasional 3
commit to user
Environtment / tools yang digunakan pada implementasi dari kode semu
menjadi kode program adalah sebagai berikut :
Bahasa pemrograman yang digunakan adalah java
Object relational mapping (ORM) framework yang digunakan adalah
Hibernate 3.6.10final.
Framework yang digunakan untuk menangani dependency injection dan
penanganan java object adalah Spring 3.0.5.
Application Programming Interface (API) yang digunakan untuk
penganganan text processing adalah Lucene 3.6.1.
3.5Pengujian
Pada tahap pengujian, seluruh data eksperimental diuji dengan
menggunakan program yang menerapkan algoritma yang telah dihasilkan pada
tahap perancangan algoritma. Pengujian dilakukan dengan tahap sebagai berikut :
Menentukan data set yang digunakan sebagai data pengujian. Data set terdiri
dari data lama dan data testing.
Menghitung kesamaan antara metadata dari setiap data testing dan metadata
dari seluruh data lama.
Melakukan validasi terhadap hasil persamaan yang akan dibantu oleh dua
orang reviewer dari LPPM UNS yaitu Prof.Dr.Okid Parama Astirin, M.S. dan
commit to user
17
BAB IV
HASIL DAN PEMBAHASAN
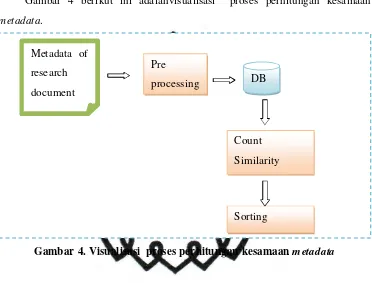
4.1Perancangan Model dan Algoritma Kesamaan Metadata
Gambar 4 berikut ini adalahvisualisasi proses perhitungan kesamaan
metadata.
Gambar 4. Visualisasi proses perhitungan kesamaan metadata
Dari Gambar 4dapat dilihat bahwa metadatadari dokumen penelitian
digunakan sebagai input. Sebelum dilakukan proses perhitungan kesamaan, input
yang berupa teks haruslah melalui tahap preprocessing ( text processing dan
indexing ) sebelum dilakukan proses perhitungan kesamaan metadata.Text
processing dilakukan dengan tambahan library dari apache.org yaitu Lucene
3.6.1.
Model kesamaan yang dimaksud adalah model matematika untuk
perhitungan kesamaan metadata. Dimisalkan jumlah metadata yang digunakan
pada perhitungan kesamaan dan pembobotan untuk sebuah skema
adalahnmetadata. Model matematika dari rumus cosine similarity dijelasan pada
persamaan (1). Metadata of
research
document
Pre
processing DB
Count
Similarity
commit to user
(1)
Dimana similarity adalah nilai kesamaan dari satu jenis metadata, misalkan
saja nilai kesamaan dari judul. A adalah vektor yang terbentuk dari salah satu
metadata sebuah dokumen dan B adalah vektor dari salah satu metadatadokumen
lainnya. A dan Badalah metadata dengan jenis yang sama, misalkan A
menyatakan judul maka B juga menyatakan judul. Ai adalah nilai dari index ke i
pada vektor A begitu juga dengan Bi. n menyatakan jumlah indeks dari vektor
yang terbentuk. Vektor vektor yang terbentuk berisi nilai hasil perhitungan
TF-IDF untuk setiap term atau kata yang ada dalam metadata.
Jika jumlah metadata dari sebuah dokumen adalah n, maka dapat dimodelkan
pada persamaan (2) .
(2)
Dimana sim_dok adalah nilai kesamaan total metadata - metadata dari dua dokumen. Namun karena bobot tiap metadata tidaklah sama, maka nilai
kesamaan totalnya dapat dimodelkan pada persamaan (3) .
(3)
Dimana Wiadalahbobot dari masing masing metadata. Nilai sim_dok inilahyang dijadikan nilai akhir dari kesamaan dua buah dokumen yang
dibandingkan. Setelah model matematika dari perhitungan kesamaan metadata
dibuat, tahap selanjutnya adalah pembuatan kode semu dan implementasi menjadi
kode program untuk pengujian.
Berikut ini adalah kodesemudari algoritma yang sudah dirancang . Kode
semu berikut digunakan untuk menghitung satu jenis metadata, jika terdapat
commit to user
19
//membuat vektor yang berisi kata-kata dari metadata lama dan baru
vektorLama; vektorBaru;
//membuat vektor baru yang berisi semua kata unique gabungan dari
vektorLama dan vektorBaru
vektorSemuaTerm ;
//membuat vektor yang berisi term frequency dari setiap kata yang ada
pada masing masing vektor (lama dan baru)
vektorTermFrequensiLama; vektorTermFrequensiBaru;
//mengisi term frequency untuk vektorTermFrequensiLama
//cek semua isi dari vektor yang berisi semua unique term
int j = 0;
for (cek semua isi dari vektorSemuaTerm) { double i = 0;
for (cek semua isi dari vektorLama) { if (isi termLama= isi termUniq) { i++;
}}
vektorTermFrequensiLama[j] = i;
//merubah isi vektor yang berisi term frequency menjadi TF-IDF dengan
cara dikalikan nilai IDF
dari setiap kata yang ada di vektor unique term
double idf = 0;
(cek semua isi dari index) { if(index=termUniq)) { idf = index.getIDF(); break;
} }
vektorTermFrequensiLama[j] = vektorTermFrequensiLama[j] * idf; j++;
commit to user
//mengisi term frequency untuk vektorTermFrequensiBaru
//cek semua isi dari vektor yang berisi semua unique term
j = 0;
(cek semua isi dari vektorSemuaTerm) { double i = 0;
(cek semua isi vektorBaru) {
if (ada yang sama dengan termUniq) {i++;}} vektorTermFrequensiBaru[j] = i;
double idf = 0;
(cek semua isi index) {
if(index=termUniq) {idf = index.getIDF(); break;
}}
vektorTermFrequensiBaru[j] = vektorTermFrequensiBaru[j] * idf; j++;
}
//hitung dot product
double dot = 0;
commit to user
21
//mencari panjang vektor dari vektor yang berisi nilai TF-IDF dari
vektor lama dan baru
double pjgVektorTFIDFLama= 0;
for (int i = 0; i < panjang vektorTermFrequensiLama; i++) { pjgVektorTFIDFLama+= pangkat(vektorTermFrequensiLama[i], 2); }
pjgVektorTFIDFLama= akar(pjgVektorTFIDFLama); double pjgVektorTFIDFBaru = 0;
for (int i = 0; i < panjang vektorTermFrequensiBaru; i++) { pjgVektorTFIDFBaru += pangkat(vektorTermFrequensiBaru[i], 2); }
pjgVektorTFIDFBaru = akar(pjgVektorTFIDFBaru);
double panjangTotal = pjgVektorTFIDFLama* pjgVektorTFIDFBaru; if (dot == 0 atau panjangTotal == 0) {
kembalikan nilai 0; }
//nilai kesamaan adalah dot product dari vektor lama dan baru di
bagi (panjang vektor lama dikali panjang vektor baru)
double sim = dot / panjangTotal;
//setelah dapat nilai kesamaannya, selanjutnya adalah mengalikannya
dengan bobot masing masing metadata. total kesamaan didapat dengan
commit to user
4.2 Pengujian
Keterangan pengujian adalah sebagai berikut :
1. Pengujian dilakukan per skema, maksudnya adalah setiap data testing akan
diujikan dengan seluruh data set yang skemanya sama dengan data testing.
2. Setelah data testing dibandingkan dengan seluruh data set, lalu dipilihlah data
dengan nilai kesamaan terbesar. Selanjutnya kumpulan data pengujian yang
memiliki nilai kesamaan terbesar akan ditunjukkan kepada reviewer LPPM
UNS untuk divalidasi apakah nilai kesamaan teks nya bisa diterima.
3. Data testing dituliskan sebagai data ke 1 sampai data ke 9. Iddata hasil
adalah nomer identitas dari data set dalam database. Id yang terpilih adalah Id
dari dokumen yang memiliki nilai kesamaan metadata paling besar dengan
data testing.
4.3.1 Pengujian 1
Keterangan pengujian
Jenis Skema : Hibah Bersaing
Judul Data Testing : Model Peningkatan Kompetensi Pemandu Wisata
Lokal Melalui Metode Tourism Interpretation Untuk
Mendukung Pengembangan Pariwisata Berbasis
Masyarakat Secara Berkelanjutan
Id Data Hasil : 88
Judul Data Hasil : Pengelolaan Kawasan Wisata Berbasis Masyarakat
Sebagai Upaya Penguatan Ekonomi Lokal Dan
Pelestarian Sumber Daya Alam Di Kabupaten
Karanganyar
commit to user
23
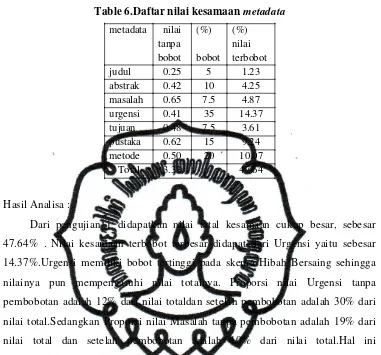
Table 6.Daftar nilai kesamaan metadata metadata nilai
14.37%.Urgensi memiliki bobot tertinggi pada skema Hibah Bersaing sehingga
nilainya pun mempengaruhi nilai totalnya. Proporsi nilai Urgensi tanpa
pembobotan adalah 12% dari nilai totaldan setelah pembobotan adalah 30% dari
nilai total.Sedangkan Proporsi nilai Masalah tanpa pembobotan adalah 19% dari
nilai total dan setelah pembobotan adalah 10% dari nilai total.Hal ini
menunjukkan bahwa dengan pembobotan Urgensi menjadi lebih penting dari pada
Masalah.
4.3.2 Pengujian 2
Keterangan pengujian
Jenis Skema : Hibah Bersaing
Judul Data Testing : Pemberdayaan Perempuan Pengrajin Batik Girli
Untuk Meningkatkan Perekonomian Keluarga Dan
Mengembangkan Desa Wisata Di Kabupaten Sragen
Id Data Hasil : 91
Judul Data Hasil : Model Pemberdayaan Perempuan Miskin Melalui
Pengembangan Kewirausahaan Keluarga Menuju
Ekonomi Kreatif Di Kabupaten Karanganyar
commit to user
Table 7.Daftar nilai kesamaan metadata metadata nilai
Dari pengujian 2 didapatkan nilai total kesamaan cukup besar, yaitu40.09
%. Nilai kesamaan terbobot terbesar didapat dari Pustakayaitu sebesar 14.93%.
Proporsi nilai Urgensi tanpa pembobotan adalah 11.5% dari nilai total dan setelah
pembobotan adalah 26% dari nilai total. Sedangkan Proporsi nilai Pustaka tanpa
pembobotan adalah 39% dari nilai total dan setelah pembobotan adalah 37% dari
nilai total. Nilai terbobot dari Pustaka lebih besar dari Urgensi karena karena nilai
kesamaannya adalah ±100%.
4.3.3 Pengujian 3
Keterangan pengujian
Jenis Skema : Hibah Bersaing
Judul Data Testing : Pengembangan Kanal Fleksibel Berbahan Beton
Memadat Mandiri Berserat Limbah Kaleng dan
Limbah Plastik
Id Data Hasil : 67
Judul Data Hasil : Rekayasa Beton Serat Performa Tinggi Dengan Serat
Baja Multi Dimensi
commit to user
25
Table 8.Daftar nilai kesamaan metadata metadata nilai
kesamaan terbobot terbesar didapat dari Urgensi yaitu sebesar 15.39%. nilai
kesamaan dari Urgensi sebelum dibobot mendekati 0.5 yang berarti cukup mirip.
Proporsi nilai Urgensi tanpa pembobotan adalah 20% dari nilai total dan setelah
pembobotan adalah 46% dari nilai total. Hal ini menunjukkan kepentingan dari
Urgensi yang tinggi dalam pada skema Hibah Bersaing.
4.3.4 Pengujian 4
Keterangan pengujian
Jenis Skema : Fundamental
Judul Data Testing : Pendidikan Ekologis Berbasis Mitos Masyarakat di
daerah Rawan Bencana di Tawangmangu, Kabupaten
Karanganyar, Jawa Tengah
Id Data Hasil : 94
Judul Data Hasil : Mitos Prabu Boko Dalam Menjaga Keseimbangan
Alam Di Dusun Pancot, Tawangmangu, Karangnyar
commit to user
Table 9.Daftar nilai kesamaan metadata metadata nilai
kesamaan terbobot terbesar didapat dari Manfaatyaitu sebesar 30.00%. Dengan
melihat pada nilai kesamaan per metadata pada Manfaat dan Tujuan didapatkan
nilai kesamaan sebesar 1 yang berarti sama persis. Dapat dilihat bahwa seluruh
metadata memiliki nilai kesamaan yang besar. Pustaka juga memiliki nilai
kesamaan yang besar. Dapat dilihat bahwa seluruh bagian metadata memiliki
nilai kesamaan yang cukup besar. Oleh karena itu, pengujian ini perlu diteliti lebih
lanjut oleh seorang reviewer.
4.3.5 Pengujian 5
Keterangan pengujian
Jenis Skema : Fundamental
Judul Data Testing : Digraf Eksentrik Dari Graf Friendship Dan Graf
Firecracker
Id Data Hasil : 27
Judul Data Hasil : Pelabelan L(D,2,1) Pada Graf Star, Graf Sun Dan
Graf Wheel Untuk Pola Penentuan Channel Stasiun
Radio
commit to user
27
Table 10.Daftar nilai kesamaan metadata Metadata nilai
yaitu28.41%. Nilai kesamaan terbobot terbesar didapat dari Manfaatyaitu sebesar
9.61%. sebelum pembobotan, nilai kesamaan yang terbesar adalah Judul yang
menunjukkan bahwa Judulnya cukup mirip. Namun Judul bukanlah aspek utama
dalam skema Fundamental. aspek utama dari skema Fundamental adalah Manfaat
dan Pustaka. Proporsi nilai Manfaat tanpa pembobotan adalah 15% dari nilai total
dan setelah pembobotan adalah 33% dari nilai total. Sedangkan proporsi nilai
Tujuan tanpa pembobotan adalah 21% dari nilai total dan setelah pembobotan
adalah 11% dari nilai total. Hal ini menunjukkan bahwa dengan pembobotan
commit to user
4.3.6 Pengujian 6
Keterangan pengujian
Jenis Skema : Fundamental
Judul Data Testing : Karakteristik Komposit Berpori Berbahan Dasar
Sampah Sebagai Alternatif Pengganti Core Komersial
Id Data Hasil : 26
Judul Data Hasil : Rekayasa Pengaturan Epoxy/Montmorilonite
Organoclay/ Serat Gelas Untuk Mendapatkan
Komposit Nano Dengan Karakteristik Struktur Mikro
Dan Sifat Mekanis Kualitas Tinggi
Tabel 11 Berikut ini menjelaskan nilai kesamaan tiap metadata secara detail.
Table 11.Daftar nilai kesamaan metadata Metadata nilai
kesamaan terbobot terbesar didapat dari Manfaatyaitu sebesar 21.47%.. Bobot
sebesar 30% diberikan pada Manfaat karena pada skema Fundamental manfaat
dianggap penting. Selain pada Manfaat, skema Fundamental juga berfokus pada
Pustaka sehingga diberikan bobot 30%. Pada pengujian ini nilai kesamaan
Pustaka hanya 0.10, sehingga seorang reviewer dapat melihat lebih teliti pada
commit to user
29
4.3.7 Pengujian 7
Keterangan pengujian
Jenis Skema : Strategis Nasional
Judul Data Testing : Manipulasi Pupuk Organik Untuk Meningkatkan
Efisiensi Pupuk Nitrogen Dan Kualitas Hasil
Tanaman Padi (Oryza Sativa L.)
Id Data Hasil : 80
Judul Data Hasil : Pengelolaan Tanaman Lorong Dan Tanaman Penutup
Tanah Sebagai Jaring Penyelamat Hara Dan
Pengendali Nitrifikasi Pada Kebun Kelapa Sawit
(Elaeis Guineensis Jacq.)
Tabel 12 Berikut ini menjelaskan nilai kesamaan tiap metadata secara detail.
Table 12.Daftar nilai kesamaan metadata Metadata nilai
yaitu26.86%. Nilai kesamaan terbobot terbesar didapat dari Tujuan yaitu sebesar
6.40%. Meskipun Tujuan memiliki kesamaan yang cukup besar, Tujuan bukanlah
aspek utama pada skema Strategis Nasional. Pada skema Strategis Nasional,
Manfaat dan Urgensi dianggap lebih penting. Sehingga bobot yang cukup besar
diberikan pada Manfaat dan Urgensi. Pada pengujian 7 nilai kesamaan Manfaat
commit to user
4.3.8 Pengujian 8
Keterangan pengujian
Jenis Skema : Strategis Nasional
Judul Data Testing : Pengentasan Kemiskinan Melalui Pendekatan
Pembangunan Sistem Nafkah Berkelanjutan
(Sustainable Livelihoods Approach-Sla)
Id Data Hasil : 52
Judul Data Hasil : Harmonisasi Kebijakan Pengentasan Kemiskinan Di
Indonesia Dengan Program Millennium Development
Goals Dalam Rangka Menciptakan Iklim Kondusif
commit to user
31
Tabel 13 Berikut ini menjelaskan nilai kesamaan tiap metadata secara detail.
Table 13.Daftar nilai kesamaan metadata Metadata nilai
sebesar 24.57%. Nilai kesamaan terbobot terbesar didapat dari Urgensi yaitu
sebesar 8.25%. Sebelum pembobotan nilai kesamaan yang terbesar adalah
Masalah, namun Masalah bukanlah aspek utama dalam skema Strategis Nasional
sehingga nilai terbobotnya tidak lebih besar dari Urgensi. Proporsi nilai Urgensi
tanpa pembobotan adalah 29% dari nilai total dan setelah pembobotan adalah 33%
dari nilai total. Sedangkan Proporsi nilai Masalah tanpa pembobotan adalah 30%
dari nilai total dan setelah pembobotan adalah 26% dari nilai total. Hal ini
menunjukkan bahwa dengan pembobotan Urgensi menjadi lebih penting dari pada
Masalah.
4.3.9 Pengujian 9
Keterangan pengujian
Jenis skema : Strategis Nasional
Judul data testing : Analisis Morfologi Tanaman Dan Kadar Protein Biji
Hubungannya Dengan Kualitas Hasil Olahan
Beberapa Varietas Kedelai Lokal Dan Impor
ID Data Hasil : 47
Judul data Hasil : Pencirian Tanaman Manggis (Garcinia Mangostana
L.) Di Jawa Sebagai Upaya Pemuliaan Dan
commit to user
Tabel 14 Berikut ini menjelaskan nilai kesamaan tiap metadata secara detail.
Table 14.Daftar nilai kesamaan metadata Metadata nilai
berarti bahwa dokumen testing tidak mirip dengan data set yang memiliki Id 47.
Nilai kesamaan terbobot terbesar didapat dari Masalah yaitu sebesar 1.64%. Pada
pengujian 9 tidak didapatkan dokumen yang cukup mirip dengan data testing,
kesimpulan tersebut dapat diambil dari hasil nilai total kesamaan yang didapatkan
sangat kecil.
4.3.10 Validasi Reviewer
Dari sembilan pengujian yang dilakukan didapatkan dua pengujian yang
menghasilkan nilai kesamaan yang besar. Data hasil pengujian yang terbesar
ditunjukkan kepada reviewer untuk divalidasi. Data yang diberikan adalah data
hasil pengujian 4 yang divalidasi oleh Prof.Dr.Okid Parama Astirin, M.S. dan data
hasil pengujian 2 yang divalidasi oleh Dr. Eddy Heraldy, M.Si. Daftar validasi
commit to user
33
Table 15. Tabel validasi pengujian yang dilakukan oleh reviewer
No. Pengujian
Reviewer Validasi
Pengujian 2 Prof.Dr. Okid Parama Astirin, M.S. disetujui
Pengujian 4 Dr. Eddy Heraldy, M.Si. disetujui
Maksud dari kata disetujui pada tabel 15 adalah hasil pengujian berupa nilai
kesamaan dan cara pembobotannya dapat diterima oleh reviewer. Lebih lanjut,
Metadata dapat digunakan sebagai tindakan awal dalam mendeteksi tindakan
plagiat dalam dokumen penelitian, yaitu pada tahap perhitungan kesamaan teks
dari dokumen penelitian.Lebih jelasnya, tanggapan dari reviewer dapat dilaihat
dari lampiran b. Hasil pengujian 2 dan pengujian 4 dapat dilihat pada bagian
commit to user
34
BAB V PENUTUP
5.1Kesimpulan
Pada penelitian ini metadata dimanfaatkan sebagai solusi untuk tindakan awal
dalam mendeteksi secara cepat kesamaan teks pada dokumen penelitian. Hal
ini menunjukkan bahwa jika program yang dibuat pada penelitian ini
digunakan, maka seorang reviewer akan lebih mudah dalam melihat kesamaan
dari banyak dokumen.Persetujuan reviewer menunjukkan bahwa penggunaan
metadata dengan pembobotan dalam menghitung kesamaan dokumen
proposal penelitian dapat diterima sebagai salah satu alat bantu dalam menilai
kesamaan secara cepat sebuah proposal penelitian.
Pemberianbobot yang berbeda besarnya pada setiap metadata dapat menjadi
solusi untuk memberikan tingkat kepentingan yang berbeda beda sesuai
dengan jenis skema.Hal ini menunjukkan bahwa pembobotan dapat
mempengaruhi proporsi nilai sebuah metadata untuk menunjukkan
kepentingannya dalam sebuah dokumen penelitian.
Untuk melihat atau menganalisa nilai kesamaan per metadata dapat dilihat
dari kolom nilai tanpa bobot, sedangkan untuk melihat atau menganalisa nilai
kesamaan dokumen secara keseluruhan dapat dilihat dari nilai terbobot.
5.2Saran
Penerapan algoritma natural language processing akan memperbaiki nilai
kesamaan karena sistem akan memiliki knowledge dari human expert, tidak
sebatas perbandingan teks yang membuat sistem tidak mengerti arti dari kata
kata yang dibandingkan.
Pengembangan algoritma penilaian akan lebih baik jika tidak sebatas
persamaan teks saja tetapi bisa memberi keputusan apakah ada tindakan