perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
i
PENGELOMPOKAN PRODUKTIVITAS PADI DI INDONESIA
MENGGUNAKAN METRIK LOG-NORMALIZED PERIODOGRAM (LNP)
oleh
UMI MUSLIHAH
M0108110
SKRIPSI
ditulis dan diajukan untuk memenuhi sebagian persyaratan memperoleh gelar
Sarjana Sains Matematika
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SEBELAS MARET SURAKARTA
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
iii ABSTRAK
Umi Muslihah, 2013. PENGELOMPOKAN PRODUKTIVITAS PADI DI
INDONESIA MENGGUNAKAN METRIK LOG-NORMALIZED
PERIODOGRAM (LNP). Fakultas Matematika dan Ilmu Pengetahuan Alam,
Universitas Sebelas Maret Surakarta.
Padi merupakan makanan pokok sebagian besar masyarakat Indonesia. Oleh karena itu, produktivitas padi harus selalu ditingkatkan agar kebutuhan masyarakat bisa terpenuhi. Tidak semua provinsi di Indonesia mempunyai produktivitas padi yang sama, sehingga perlu dilakukan pengelompokan untuk mengetahui provinsi mana yang mempunyai produktivitas tinggi. Data produktivitas padi tersebut merupakan data runtun waktu, sehingga pengelompokannya tidak bisa menggunakan jarak Euclid, Mahalanobis dan Manhattan. Jarak yang bisa digunakan adalah jarak berdasar pada metrik log-normalized periodogram (LNP). Metrik LNP merupakan logaritma dari periodogram yang dinormalkan. Penelitian ini bertujuan untuk mengelompokkan produktivitas
padi di Indonesia menggunakan metrik LNP.
Data yang digunakan pada penelitian ini adalah produktivitas padi 26 provinsi di Indonesia. Pengelompokannya menggunakan metode complete linkage dengan jarak berdasar metrik LNP. Hasil penelitian menunjukkan bahwa pengelompokan produktivitas padi di Indonesia menggunakan metrik LNP menghasilkan 3 kelompok, yaitu kelompok dengan produktivitas cepat, tetap dan produktivitas yang negatif pada periode tertentu.
Kata Kunci: produktivitas, complete linkage, Log-Normalized Periodogram
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
iv ABSTRACT
Umi Muslihah, 2013. The Clustering of Paddy Productivity In Indonesia Using Log-Normalized Periodogram (LNP) Metric. Faculty of Mathematics and Natural Sciences, Sebelas Maret University.
Paddy is staple food of most Indonesian people. Therefore, the productivity
of paddy must be improved so that people’s needs can be fulfilled. Not all of the
provinces in Indonesia have the same paddy productivity, so it needs to cluster the provinces to know which province has high productivity. The paddy productivity data is time series data, so that clustering can not use Euclid, Mahalanobis and Manhattan distances. The distance that can be used is the distance based on Log-Normalized Periodogram (LNP) metric. Metric LNP is the logarithm of the normalized periodogram. This study aims to cluster the paddy productivity in Indonesia using the LNP metric.
The data used in this study are the paddy productivity of 26 provinces in Indonesia. The method that used to cluster is complete linkage with the distance based on LNP metric. The results showed that the clustering of paddy productivity in Indonesia using LNP metric produce 3 groups, i.e fast productivity, steady productivity, and negative productivity in some periods.
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
v MOTO
Setelah kesulitan pasti ada kemudahan
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
vi
PERSEMBAHAN
Karya ini kupersembahkan untuk
Bapak dan ibuku tercinta yang telah membimbingku dari kecil hingga saat ini
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
vii
KATA PENGANTAR
Segala puji syukur penulis panjatkan kepada Allah SWT yang telah
memberikan banyak kenikmatan kepada penulis sehingga penulis dapat
menyelesaikan skripsi ini dengan judul “PENGELOMPOKAN
PRODUKTIVITAS PADI DI INDONESIA MENGGUNAKAN METRIK
LOG-NORMALIZED PERIODOGRAM (LNP) ”. Sholawat serta salam semoga tercurah
limpahkan kepada suriteladan umat manusia yaitu Rasulullah Muhammad SAW,
keluarganya,sahabatnya, dan umatnya yang senantiasa istiqomah dijalan-Nya.
Pada kesempatan ini penulis juga mengucapkan terima kasih kepada
1. Dra. Etik Zukhronah, M.Si sebagai dosen Pembimbing I yang telah
memberikan bimbingan, arahan serta ide kepada penulis dalam menyelesaikan
skripsi ini.
2. Supriyadi Wibowo, M.Si sebagai dosen Pembimbing II yang telah
memberikan bimbingan dan arahan kepada penulis selama menyelesaikan
skripsi ini.
3. Semua pihak yang tidak dapat penulis sebutkan satu persatu yang telah
membantu dalam penyelesaian skripsi ini.
Semoga Allah SWT membalas semua kebaikan yang telah mereka berikan
selama ini dan semoga skripsi ini dapat memberikan manfaat.
Surakarta, Januari 2013
perpustakaan.uns.ac.id digilib.uns.ac.id
2.1.3. Fungsi Autokorelasi dan Fungsi Autokorelasi Parsial ... 5
2.1.4. Stasioner ... 6
2.1.5. Model Autoregressive Moving Average (𝐴𝑅𝑀𝐴) dan Integrated Autoregressive-Moving Average (𝐴𝑅𝐼𝑀𝐴) ... 7
2.1.6. Identifikasi Model ... 9
2.1.7. Estimasi Parameter Model ... 10
2.1.8. Uji Diagnostik Model ... 11
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
ix
2.1.10. Pengertian Analisis Spektrum ... 14
2.1.11. Periodogram ... 15
2.1.12. Penghalusan Spektrum (Spectrum Smoothing) ... 17
2.1.13. Jarak Berdasar pada Metrik Log-Normalized Periodogram ... 18
2.2. Kerangka Pemikiran ... 19
BAB III. METODE PENELITIAN ... 21
BAB IV. PEMBAHASAN 4.1. Kestasioneran Data ... 23
4.1.1. Identifikasi Model untuk Masing-Masing Provinsi ... 23
4.1.2. Estimasi Parameter Model untuk Masing-Masing Provinsi ... 25
4.1.3. Uji Diagnostik Model untuk Masing-Masing Provinsi ... 29
4.2. Hasil Pengelompokan Produktivitas Padi Di Indonesia ... 30
BAB V. PENUTUP 5.1. Kesimpulan ... 34
5.2. Saran ... 34
DAFTAR PUSTAKA ... 35
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
x
DAFTAR TABEL
Tabel 2.1 Karakteristik 𝐴𝐶𝐹dan 𝑃𝐴𝐶𝐹dalam Proses Stasioner untuk Model
𝐴𝑅, 𝑀𝐴 dan 𝐴𝑅𝑀𝐴. ... 9 Tabel 4.1 Model sementara produktivitas padi untuk masing-masing provinsi. 26
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
xi
DAFTAR GAMBAR
Gambar 4.1. Plot data asli Provinsi Nanggroe Aceh Darussalam. ... 24
Gambar 4.2. Plot data Provinsi Nanggroe Aceh Darussalam
setelah pembedaan ... 25
Gambar 4.3. Dendogram runtun waktu produktivitas padi di Indonesia
perpustakaan.uns.ac.id digilib.uns.ac.id
𝑄∗ : nilai Ljung-Box-Pierce
𝑥𝑡 : Observasi pada waktu 𝑡
𝑥𝑡+𝑘 : Observasi pada waktu 𝑡+𝑘 𝛾𝑘 : Fungsi autokovariansi
𝜔 : Frekuensi Fourier
𝑓 𝜔 : Spektrum
𝑃 𝜔𝑗 : Periodogram
𝑛 : Banyaknya observasi
𝑓 𝜔 : Spektrum sampel
𝑚𝑛 : Jumlah frekuensi yang digunakan dalam penghalusan
𝑊𝑛 𝑘 : Rangkaian fungsi pembobot spectral window
𝑊∗ 𝑘 : Fungsi pembobot lag window
𝑑𝐿𝑁𝑃 𝑥,𝑦 : Jarak berdasar pada metrik Log-Normalized Periodogram (LNP)
𝑁𝑃 𝜔𝑗 : Periodogram yang dinormalkan
perpustakaan.uns.ac.id digilib.uns.ac.id
Indonesia merupakan negara dengan luas wilayah 1.910.931,32 km2 (BPS,
2011). Wilayah Indonesia terdiri dari 33 provinsi yang tersebar di 6 pulau ( pulau
Sumatra, Jawa, Kalimantan, Nusa Tenggara, Kepulauan Maluku dan Papua).
Mata pencaharian sebagian besar penduduk Indonesia sebagai petani. Sektor
pertanian memiliki peran penting dalam perekonomian nasional, yaitu sebagai
sumber pendapatan, membuka lapangan kerja, mengentaskan kemiskinan dan
meningkatkan ketahanan pangan nasional. Komoditas padi merupakan salah satu
hasil pertanian yang sangat penting dan strategis kedudukannya.
Padi merupakan makanan pokok sebagian besar masyarakat Indonesia.
Kebutuhan beras akan bertambah seiring dengan laju pertumbuhan penduduk.
Besarnya tingkat konsumsi beras di Indonesia mengharuskan pemerintah untuk
mengimpor beras dari negara lain. Hal ini disebabkan produksi padi dalam negeri
belum bisa memenuhi kebutuhan masyarakat. Apabila Indonesia terus bergantung
pada negara lain tanpa mencari cara untuk memenuhi kebutuhan beras dalam
negeri maka suatu saat Indonesia akan dilanda kelaparan. Jika impor beras
dihentikan dan produktivitas padi dalam negeri tidak ada peningkatan, maka
kemungkinan Indonesia akan mengalami krisis pangan.
Oleh karena itu perlu dilakukan penelitian untuk mengetahui laju
produktivitas padi di Indonesia. Hal tersebut dapat dilakukan dengan cara
mengelompokkan produktivitas padi dari beberapa provinsi untuk mengetahui
kelompok laju produktivitas yang cepat, tetap dan produktivitas yang negatif.
Untuk mengetahui laju produktivitas padi diperlukan data dari beberapa periode
tertentu atau berupa data runtun waktu. Salah satu cara yang dapat digunakan
untuk mengelompokkan produktivitas padi adalah dengan analisis kluster.
Analisis kluster adalah suatu teknik pengelompokan obyek berdasarkan pada
kemiripannya, sehingga diperlukan suatu metode untuk mengukur kemiripan atau
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
2
yaitu ukuran kesamaan (similaritas). Ukuran kesamaan yang sering digunakan
adalah ukuran jarak. Menurut Dillon, et al. (1984), jarak yang bisa digunakan
antara lain jarak Euclid, jarak Mahalanobis dan jarak Manhattan (City Block).
Menurut Caiado (2006), ketiga jarak tersebut tidak dapat digunakan untuk data
runtun waktu. Jarak yang dapat digunakan untuk mengelompokkan data runtun
waktu diantaranya jarak berdasar pada metrik autocorrelations (ACF), partial
autocorrelations (PACF), inverse autocorrelations (IACF), dan log-normalized
periodogram (LNP). Namun metrik LNP lebih baik daripada metrik yang lain
dalam mengelompokkan data runtun waktu, hal ini dikarenakan metrik LNP dapat
membedakan dengan sempurna antar kelompok data runtun waktu. Karena data
produktivitas padi merupakan data runtun waktu maka dalam penelitian ini
menggunakan jarak yang berdasar pada metrik LNP.
Berdasarkan uraian di atas penulis tertarik untuk mengelompokkan
produktivitas padi di Indonesia menggunakan metrik LNP. Dengan adanya
pengelompokan produktivitas padi tersebut akan diketahui kelompok provinsi
mana yang mempunyai laju produktivitas padi yang cepat, tetap dan produktivitas
yang negatif, sehingga dapat membantu pemerintah dalam menentukan kebijakan
untuk memberikan perhatian khusus pada kelompok provinsi yang mempunyai
laju produktivitas padi yang negatif.
1.2Rumusan Masalah
Berdasarkan latar belakang masalah, maka rumusan masalahnya adalah
bagaimana pengelompokan produktivitas padi di Indonesia menggunakan metrik
LNP.
1.3Batasan Masalah
Penulis membatasi masalah dalam penelitian ini yaitu pengelompokan
produktivitas padi pada 26 provinsi di Indonesia mulai tahun 1970 sampai 2010
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
3
1.4Tujuan Penelitian
Berdasarkan perumusan masalah di atas, maka tujuan dari penelitian ini
adalah menentukan pengelompokan produktivitas padi di Indonesia menggunakan
metrik LNP.
1.5Manfaat Penelitian
Dengan penelitian ini diharapkan dapat memberikan pemahaman
mengenai analisis kluster pada data runtun waktu. Selain itu dapat menentukan
kelompok dan laju pertumbuhan produktivitas padi di Indonesia. Hal ini dapat
membantu pemerintah agar dapat meningkatkan produktivitas padi dan
memberikan perhatian khusus pada kelompok provinsi yang mempunyai laju
produktivitas padi yang negatif. Sehingga pertumbuhan produktivitas padi di
Indonesia untuk tahun selanjutnya meningkat dan dapat mencukupi kebutuhan
perpustakaan.uns.ac.id digilib.uns.ac.id
Pada bagian ini memuat beberapa hasil penelitian terdahulu dan teori yang
menjadi dasar dari penelitian penulis. Caiado (2006) memperkenalkan beberapa
jarak yang dapat digunakan untuk mengelompokkan data runtun waktu
diantaranya jarak yang berdasar pada metrik Autocorrelations (ACF), Partial
Autocorrelations (PACF), Inverse Autocorrelations (IACF) dan metrik
Log-Normalized Periodogram (LNP). Penelitian tersebut menunjukkan bahwa
pengelompokkan menggunakan metrik LNP memberikan hasil yang lebih baik
dari pada metrik yang lain. Hal ini dikarenakan metrik LNP dapat membedakan
dengan sempurna antara runtun waktu stasioner dan nonstasioner.
Penelitian ini memerlukan beberapa pengertian dasar antara lain
pengertian mengenai produktivitas, analisis runtun waktu, fungsi autokorelasi dan
fungsi autokorelasi parsial, stasioner, model Autoregressive Moving Average
(𝐴𝑅𝑀𝐴) dan Integrated Autoregressive-Moving Average (𝐴𝑅𝐼𝑀𝐴), analisis
kluster, analisis spektrum, periodogram, penghalusan spektrum, dan jarak
berdasar pada metrik LNP.
2.1.1 Produktivitas
Sejak awal perkembangannya sampai sekarang banyak definisi
produktivitas yang telah dikembangkan. Produktivitas merupakan istilah yang
seringkali dianggap sama dengan kata produksi. Pada kenyataannya, antara
produktivitas dan produksi mempunyai arti yang berbeda. Produksi merupakan
pengubahan bahan-bahan dari sumber-sumber daya menjadi barang dan jasa.
Menurut Pribadiyono (2006), produktivitas merupakan perubahan dalam suatu
produk yang dihasilkan dari penggunaan sumber daya. Tinggi rendahnya suatu
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
5
menghasilkan suatu produk atau jasa (output) (Bain, 1982). Oleh karena itu,
istilah produktivitas menggambarkan perbandingan antara keluaran (output) dan
masukan (input). Pada penelitian ini yang dimaksud input adalah luas panen dan
outputnya adalah produksi padi.
2.1.2 Analisis Runtun Waktu
Menurut Rosadi (2006), data runtun waktu adalah jenis data yang
dikumpulkan menurut urutan waktu dalam suatu rentang waktu tertentu. Data
dikumpulkan secara periodik misalnya dalam jam, hari, minggu, bulan, kuartal
dan tahun. Data runtun waktu dibangun oleh komponen trend, siklis, dan musiman
(untuk data bulanan). Berdasarkan konsep tersebut, analisis data runtun waktu
dapat dilakukan dalam dua domain, yaitu waktu dan frekuensi. Waktu
menentukan signifikansi autokorelasi, kestasioneran data, penaksiran parameter
regresi runtun waktu, dan peramalan. Sedangkan dalam frekuensi dapat ditentukan
frekuensi tersembunyi, yaitu frekuensi komponen siklis yang sulit diperoleh
dalam waktu tersebut, dengan tujuan untuk mengetahui kondisi tertentu pada data.
2.1.3 Fungsi Autokorelasi danFungsi Autokorelasi Parsial
Menurut Cryer (1986), fungsi autokorelasi (Autocorrelation Function
(𝐴𝐶𝐹)) pada selisih waktu (lag 𝑘) menyatakan hubungan keeratan antara nilai
𝑡+𝑘. Sedangkan fungsi autokorelasi parsial (Partial Autocorrelation Function
(𝑃𝐴𝐶𝐹)) digunakan untuk mengukur keeratan antara 𝑍𝑡 dan 𝑍𝑡−𝑘 apabila
pengaruh dari lag waktu 𝑡 = 1,2,3,…,𝑘 −1 dianggap terpisah. 𝑃𝐴𝐶𝐹 adalah
suatu fungsi yang menunjukkan besarnya korelasi parsial (hubungan linear secara
terpisah) antara pengamatan pada waktu sekarang (𝑡) dengan pengamatan pada
waktu-waktu sebelumnya (𝑡 −1,𝑡 −2,…,𝑡 − 𝑘). Menurut Cryer (1986), nilai
perpustakaan.uns.ac.id digilib.uns.ac.id
𝑃𝐴𝐶𝐹dinamakan korelogram (correlogram) dan dapat digunakan untuk
menentukan signifikansi autokorelasi dan kestasioneran data. Jika plot 𝐴𝐶𝐹
membangun sebuah histogram yang menurun (pola eksponensial), maka
autokorelasi signifikan atau data berautokorelasi. Sedangkan jika plot 𝑃𝐴𝐶𝐹
membangun histogram langsung terpotong pada lag ke-2, maka data tidak
stasioner. Ketika plot 𝐴𝐶𝐹 dan 𝑃𝐴𝐶𝐹 keduanya membentuk pola alternating
(tanda dan nilai autokorelasi berubah secara acak dan sesuai dengan berjalannya
nilai lag), hal ini mengindikasikan data tidak stasioner dalam variansi.
2.1.4 Stasioner
Beberapa model runtun waktu membutuhkan asumsi stasioner. Menurut
Mulyana (2004), stasioner merupakan kondisi yang diperlukan dalam analisis
runtun waktu karena dapat memperkecil kekeliruan model. Runtun waktu
stasioner adalah suatu runtun waktu yang mempunyai rata-rata dan variansi yang
tidak berubah dengan pergeseran waktu. Sedangkan data yang tidak stasioner
diklasifikasikan atas tiga bentuk yaitu
1. tidak stasioner dalam rata-rata hitung, hal ini terjadi jika trend tidak datar
(tidak sejajar sumbu waktu),
2. tidak stasioner dalam variansi, hal ini terjadi jika trend datar atau hampir datar
tetapi data tersebar membangun pola melebar atau menyempit yang meliput
secara seimbang trendnya (pola terompet),
3. tidak stasioner dalam rata-rata hitung dan variansi, hal ini terjadi jika trend
tidak datar dan data membangun pola terompet.
Proses stasioneritas dilakukan bergantung pada kondisi ketidakstasioneran
data, jika data tidak stasioner dalam
1. rata-rata hitung, maka proses stasioneritas adalah proses pembedaan
(differencing),
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
7
3. rata-rata hitung dan variansi, maka transformasi stabilisasi variansi harus
dilakukan terlebih dahulu, dan proses pembedaan dilakukan pada data hasil
transformasi.
Untuk melihat ketidakstasioneran data secara visual, tahap pertama dapat
dilakukan pada plot data berdasarkan urutan waktu. Jika belum mendapatkan
kejelasan, maka tahap berikutnya dilihat pada plot 𝐴𝐶𝐹 dan 𝑃𝐴𝐶𝐹. Pada plot
𝐴𝐶𝐹, jika data tidak stasioner maka plotnya akan membangun pola,
1. menurun, jika data tidak stasioner dalam rata-rata hitung (trend naik atau
turun),
2. alternating, jika data tidak stasioner dalam variansi,
3. gelombang, jika data tidak stasioner dalam rata-rata hitung dan variansi.
Selain itu, kestasioneran juga dapat diuji dengan unit root test. Menurut Tsay
(1999), hipotesis kestasioneran sebagai berikut,
𝐻0: 𝜙1 = 1 (data runtun waktu mempunyai unit root atau tidak stasioner)
𝐻1: 𝜙1 < 1 (data runtun waktu tidak mempunyai unit root atau stasioner).
Statistik uji menggunakan Augmented Dickey-Fuller atau rasio-𝑡,
𝐴𝐷𝐹 ≡rasio-t= 𝑠𝑑𝜙 1−1
atau p-value <𝛼 (tingkat signifikansi).
2.1.5 Model Autoregressive Moving Average (𝑨𝑹𝑴𝑨) dan Integrated
Autoregressive-Moving Average (𝑨𝑹𝑰𝑴𝑨)
Model runtun waktu stasioner meliputi proses Autoregressive untuk orde 𝑝
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
8
Autoregressive Moving Average untuk orde 𝑝 dan 𝑞 (𝐴𝑅𝑀𝐴(𝑝,𝑞)). Menurut
Cryer (1986), bentuk umum model Autoregressive (𝐴𝑅(𝑝)) sebagai berikut
𝑍𝑡 =𝜙1𝑍𝑡−1 +𝜙2𝑍𝑡−2+⋯+𝜙𝑝𝑍𝑡−𝑝 +𝑎𝑡,
Model tidak stasioner memiliki rata-rata dan variansi yang tidak konstan
sepanjang waktu. Hal itu disebabkan oleh variabel runtun waktu terdapat trend
perpustakaan.uns.ac.id digilib.uns.ac.id
mengidentifikasi model tersebut dengan menggunakan 𝐴𝐶𝐹 dan 𝑃𝐴𝐶𝐹.
Langkah-langkah yang dilakukan untuk identifikasi model adalah
1. Membuat plot data runtun waktu dan melihat karakter data untuk menentukan
perlu atau tidaknya dilakukan transformasi dan/atau proses pembedaan.
2. Menghitung nilai 𝐴𝐶𝐹 dan 𝑃𝐴𝐶𝐹 data asli (data sebelum dilakukan proses
transformasi) untuk mendapatkan informasi mengenai orde dari proses
pembedaan. Jika nilai 𝐴𝐶𝐹 membangun sebuah pola yang menurun secara
perlahan dan 𝑃𝐴𝐶𝐹 membangun pola yang nilainya terpotong secara
signifikan setelah lag-1 (perbedaan nilai antara 𝑃𝐴𝐶𝐹 lag-1 dengan lag-2 dan
sesudahnya sangat besar), maka hal ini perlu dilakukan pembedaan.
3. Menghitung nilai 𝐴𝐶𝐹 dan 𝑃𝐴𝐶𝐹 data hasil transformasi dan/atau pembedaan
(jika ada perlakuan transformasi dan/atau pembedaan), untuk memperkirakan
orde 𝐴𝑅 dan 𝑀𝐴 yang akan diambil.
Menurut Mulyana (2004), karakter plot 𝐴𝐶𝐹 dan 𝑃𝐴𝐶𝐹 dalam proses stasioner
untuk model 𝐴𝑅, 𝑀𝐴 dan 𝐴𝑅𝑀𝐴 dapat dilihat pada Tabel 2.1.
Tabel 2.1 Karakteristik 𝐴𝐶𝐹dan 𝑃𝐴𝐶𝐹dalam Proses Stasioner untuk Model
𝐴𝑅, 𝑀𝐴 dan 𝐴𝑅𝑀𝐴
Model 𝑨𝑪𝑭 𝑷𝑨𝑪𝑭
𝐴𝑅(𝑝) Turun secara eksponensial menuju
nol sejalan dengan bertambahnya 𝑘
Terpotong setelah lag 𝑝
𝑀𝐴(𝑞) Terpotong setelah lag 𝑞 Turun secara eksponensial
menuju nol sejalan dengan
bertambahnya 𝑘
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
10
2.1.7 Estimasi Parameter Model
Setelah identifikasi terhadap model, selanjutnya dilakukan estimasi
parameter. Menurut Cryer (1986), metode estimasi yang dapat digunakan untuk
model 𝐴𝑅𝐼𝑀𝐴(𝑝,𝑑,𝑞) adalah metode kuadrat terkecil (least square). Metode
kuadrat terkecil dilakukan dengan meminimumkan jumlah kuadrat residu. Jumlah
kuadrat residu pada model 𝐴𝑅𝐼𝑀𝐴(𝑝,𝑑,𝑞) dinyatakan dalam suatu fungsi
𝑆∗ 𝜙,𝜃 = 𝑛𝑡=1𝑎𝑡2. (2.3)
Model 𝐴𝑅𝐼𝑀𝐴(𝑝, 1,𝑞) pada persamaan (2.2) dapat dinyatakan sebagai
𝑎𝑡 = 𝑍𝑡 − 1 +𝜙1 𝑍𝑡−1− 𝜙2− 𝜙1 𝑍𝑡−2 − 𝜙3− 𝜙2 𝑍𝑡−3− ⋯
− 𝜙𝑝 − 𝜙𝑝−1 𝑍𝑡−𝑝 +𝜙𝑝𝑍𝑡−𝑝−1+𝜃1𝑎𝑡−1+𝜃2𝑎𝑡−2+⋯+𝜃𝑞𝑎𝑡−𝑞.
Jumlah kuadrat residu minimum ketika turunan parsial pertama pada persamaan
(2.3) sama dengan nol. Sehingga dengan menganggap turunan parsial pertama
terhadap 𝜙 dan 𝜃 sama dengan nol, diperoleh estimasi parameter 𝜙 dan 𝜃 .
Model 𝐴𝑅𝐼𝑀𝐴(1,1,1) dinyatakan sebagai
𝑍𝑡 = 1 +𝜙 𝑍𝑡−1+𝑎𝑡 − 𝜃1 𝑎𝑡−1. (2.4)
Persamaan (2.4) dapat ditulis ulang sebagai
perpustakaan.uns.ac.id digilib.uns.ac.id
Sedangkan langkah awal estimasi parameter 𝜃 adalah menentukan turunan parsial
pertama dari fungsi 𝑆∗ 𝜙,𝜃 pada persamaan (2.5) terhadap parameter 𝜃
Setelah diperoleh model 𝐴𝑅𝐼𝑀𝐴 yang cocok, kemudian dilakukan uji diagnostik
model.
2.1.8 Uji Diagnostik Model
Uji diagnostik model dilakukan untuk mengecek apakah asumsi model
terpenuhi. Dengan kata lain, uji diagnostik model bertujuan untuk mengetahui
apakah model layak digunakan atau tidak. Untuk mendapatkan model yang sesuai
seharusnya residu bersifat independen dan berdistribusi normal. Oleh karena itu
dilakukan uji independensi dan uji kenormalan terhadap residu. Menurut Pankratz
(1983), untuk mengetahui apakah residu bersifat independen maka perlu
dilakukan uji hipotesis sebagai berikut,
1. hipotesis
𝐻0 : 𝜌1 𝑎 =𝜌2 𝑎 = ⋯= 𝜌𝑘 𝑎 = 0
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
12
2. tingkat signifikansi 𝛼 %,
3. statistik uji yang digunakan adalah Ljung-Box Pierce
𝑄∗= 𝑛′ 𝑛′ + 2 𝑛′ −1 −1𝑟
jika 𝐻0 ditolak maka residu tidak bersifat independen.
Untuk memeriksa kenormalan residu dapat dilakukan dengan melihat plot
antara residu dengan normal-scorenya. Jika plot yang dihasilkan mendekati garis
lurus maka dapat dikatakan asumsi kenormalan sudah dipenuhi. Selain itu, dapat
dilihat dari nilai 𝑝 (𝑝-value) pada uji Kolmogorov-Smirnov. Hipotesis nol pada uji
Kolmogorov-Smirnov menyatakan data berdistribusi normal. Jika 𝑝-value lebih
besar dari tingkat signifikansi 𝛼% maka tidak menolak hipotesis nol yang berarti
bahwa asumsi kenormalan dipenuhi.
2.1.9 Analisis Kluster
Menurut Budhi, et al. (2008), analisis kluster adalah upaya menemukan
sekelompok obyek yang mewakili suatu karakter yang sama atau hampir sama
(similar) antara satu obyek dengan obyek yang lainnya pada suatu kelompok dan
memiliki perbedaan (nonsimilar) dengan obyek-obyek pada kelompok yang
lainnya. Pengelompokan data dapat dilakukan dengan dua macam metode yaitu
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
13
jumlah kelompok terlebih dahulu. Sedangkan metode hirarki digunakan bila
jumlah kelompok ditentukan dengan melihat gambar dendogram.
Pada penelitian ini digunakan metode pengelompokan hirarki. Metode hirarki
merupakan metode pengelompokan yang terstruktur dan bertahap berdasarkan
pada kemiripan sifat antar obyek. Kemiripan sifat tersebut dapat ditentukan dari
kedekatan jarak. Proses pengelompokan pada metode hirarki dengan membentuk
matriks jarak untuk masing obyek. Setelah itu menggabungkan
masing-masing obyek secara terstruktur berdasarkan kemiripan sifatnya. Metode
penggabungan yang biasa digunakan adalah single linkage, complete linkage, dan
average linkage. Menurut Rashidah, et al. (2011), metode complete linkage lebih
baik daripada metode single linkage, sehingga penelitian ini menggunakan metode
complete linkage. Single linkage pengelompokannya didasarkan pada jarak antara
anggota-anggota yang paling dekat, complete linkage pengelompokannya
didasarkan pada jarak terjauh antar anggota kluster, dan average linkage
pengelompokannya didasarkan pada jarak rata-rata antara pasangan-pasangan
anggota masing-masing pada himpunannya. Kelompok-kelompok tersebut
diidentifikasi pada setiap nilai jarak yang kemudian akan ditunjukkan dalam
pohon struktur yang dinamakan dendogram (Kakizawa, et al. 1998). Dendogram
menggambarkan penggabungan atau pembagian yang dibuat pada tingkat-tingkat
yang berurutan. Cabang-cabang dalam pohon menyajikan kluster. Banyaknya
kluster yang terbentuk dapat ditentukan bergantung pada subyektivitas peneliti
dengan melihat gambar dendogram. Kelompok yang terbentuk meliputi kelompok
cepat, tetap (konstan) dan negatif. Kelompok cepat yaitu kelompok yang
mempunyai plot data runtun waktu berfluktuasi secara tidak konstan di sepanjang
waktu, konstan yaitu tidak ada perubahan fluktuasi atau cenderung tetap pada plot
data di sepanjang waktu dan kelompok yang negatif yaitu mempunyai fluktuasi
yang besar pada periode tertentu.
Hal yang mendasar dalam analisis kluster adalah pemilihan metrik yang
relevan. Menurut Caiado (2006), jarak Euclid bukan metrik yang baik untuk
mengelompokkan runtun waktu karena merupakan invarian untuk perubahan
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
14
autokorelasi. Oleh karena itu, pada penelitian ini akan menggunakan jarak yang
berdasar pada metrik Log-Normalized Periodogram (LNP).
2.1.10 Pengertian Analisis Spektrum
Menurut Mulyana (2004), analisis spektrum adalah penaksiran dalam
kawasan frekuensi untuk menelaah periodesitas tersembunyi, yaitu periodesitas
yang sulit ditemukan dalam kawasan waktu. Analisis spektrum modern
didasarkan pada fenomena bahwa data runtun waktu merupakan hasil proses
stokastik, sehingga setiap data runtun waktu dapat disajikan dalam deret Fourier.
Spektrum dari proses stasioner adalah transformasi Fourier dari proses fungsi
autokovariansi. Transformasi Fourier adalah salah satu metode yang digunakan
dalam analisis runtun waktu yang merupakan metode nonparametrik berdasarkan
kawasan frekuensi. Transformasi Fourier tidak bisa merepresentasikan informasi
waktu dan frekuensi secara bersamaan. Hal ini menyebabkan transformasi Fourier
tidak dapat digunakan untuk menganalisis data-data yang tidak stasioner.
Sehingga jika data tidak stasioner maka distasionerkan melalui proses pembedaan.
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
15
2.1.11 Periodogram
Menurut Mulyana (2004), periodogram adalah fungsi spektrum kuasa atas
frekuensinya. Jika membangun fungsi spektrum kuasanya maka periodesitas data
dapat ditentukan. Misalkan terdapat deret Fourier untuk suatu proses 𝑥𝑡 yang
ortogonal dari fungsi trigonometri sebagai berikut
perpustakaan.uns.ac.id digilib.uns.ac.id
Sehingga dapat disimpulkan sebagai berikut
𝑎𝑗 =
Spektrum 𝑓 𝜔 yang didefinisikan pada persamaan (2.8), dapat diestimasi
dengan cara mengganti autokovariansi 𝛾𝑘 dengan 𝛾 𝑘. Oleh karena itu, spektrum
sampel diberikan oleh
𝑓 𝜔 = 𝑛−𝑘=1−(𝑛−1)𝛾 𝑘cos(𝜔𝑘)= 𝛾 0+ 2 𝑛−𝑘=11𝛾 𝑘cos(𝜔𝑘), (2.13)
dengan 𝛾 𝑘 = 1
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
17
Salah satu estimator spektrum adalah ordinat periodogram 𝑃 𝜔𝑗 . Anggap bahwa
𝜔 adalah frekuensi Fourier dari bentuk 𝜔𝑗 =2𝜋𝑗𝑛 untuk 𝑗 = 1,…, [𝑛/2]. Sehingga
diperoleh ordinat periodogram sebagai berikut
𝑃 𝜔𝑗 = 𝑛2 𝑎𝑗2+𝑏𝑗2
Dari persamaan (2.13) dan persamaan (2.14) diperoleh
𝑃 𝜔𝑗 = 2𝑓 𝜔𝑗 ,𝑗 = 1,…, 𝑛/2 ,
dan jika𝑛 genap, maka
𝑃 𝜔𝑛/2 =𝑛𝑎𝑛2/2 = 2𝑓 𝜔𝑛/2 .
Periodogram 𝑃 𝜔𝑗 sebanding dengan spektrum sampel 𝑓 𝜔𝑗 dan ditetapkan
untuk estimasi nonparametrik dari spektrum.
2.1.12 Penghalusan Spektrum (Spectrum Smoothing)
Spektrum sampel dari proses stasioner berfluktuasi selama interval
frekuensi kecil. Salah satu cara menurunkan variansi dari spektrum untuk
memperoleh estimasi penghalusan spektrum adalah dengan menghaluskan ordinat
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
18
𝑓 𝜔𝑗 = 𝑚𝑘=𝑛−𝑚𝑛𝑊𝑛 𝑘 𝑃(𝜔𝑗+𝑘),
dengan 𝑚𝑛 merupakan jumlah frekuensi yang digunakan dalam penghalusan,
𝑊𝑛 𝑘 adalah rangkaian fungsi pembobot yang memiliki sifat
𝑊𝑛 𝑘 = 1
halus (smoothed). Akibatnya, estimator mempunyai variansi yang lebih kecil,
tetapi kemungkinan bias besar. Oleh karena itu, harus menyeleksi fungsi
pembobot yang mempertimbangkan variansi yang lebih kecil dan dapat
menurunkan bias.
Spektrum 𝑓(𝜔) adalah transformasi Fourier dari fungsi autokovariansi 𝛾𝑘,
sehingga dapat mengestimasi spektrum dengan pembobotan sampel
autokovariansi sebagai berikut
𝑓 𝜔 = 𝑛−𝑘=1− 𝑛−1 𝑊∗ 𝑘 𝛾 𝑘𝑒−𝑖𝜔𝑘
= 𝑊∗ 0 𝛾 0+ 2 𝑘𝑛−=11𝑊∗ 𝑘 𝛾 𝑘𝑒−𝑖𝜔𝑘 , 0≤ 𝜔 ≤ 𝜋.
Fungsi pembobot 𝑊∗ 𝑘 disebut lag window dan erat kaitannya dengan spectral
window. Spectral window adalah transformasi Fourier dari lag window dan lag
window adalah invers transformasi Fourier dari spectral window. Oleh karena itu,
lag window dan spectral window merupakan pasangan transformasi Fourier,
dengan yang satu ditentukan oleh yang lain. Kedua istilah lag window dan
spectral window diperkenalkan oleh Blackman dan Tukey (1958).
2.1.13 Jarak Berdasar pada Metrik Log-Normalized Periodogram (LNP) Pada analisis data runtun waktu, data yang dianalisis harus merupakan data
stasioner, jika tidak stasioner harus distasionerkan dahulu melalui transformasi
atau pembedaan. Misalkan 𝑥𝑡, 𝑡= 1,2,…,𝑛𝑥 dan 𝑦𝑡, 𝑡 = 1,2,…,𝑛𝑦 merupakan
dua proses stasioner. Ordinat periodogram dari 𝑥𝑡 dan 𝑦𝑡 diberikan oleh
𝑃𝑥 𝜔𝑗 = 𝑛1 𝑛𝑡=1𝑥𝑡𝑒−𝑖𝑡𝜔𝑗
2
perpustakaan.uns.ac.id digilib.uns.ac.id
periodogram yang dinormalkan. Ketika variansi ordinat periodogram sebanding
dengan nilai spektrum pada frekuensi yang bersesuaian, maka dapat digunakan
log-normalized periodogram (LNP) dengan jarak sebagai berikut
𝑑𝐿𝑁𝑃 𝑥,𝑦 = log𝑁𝑃𝑥 𝜔𝑗 −log𝑁𝑃𝑦 𝜔𝑗
Berdasarkan tinjauan pustaka, dapat disusun suatu kerangka pemikiran
untuk mengelompokkan produktivitas padi berdasarkan provinsi di Indonesia.
Laju pertumbuhan produktivitas padi dapat diketahui dengan menganalisis data
produktivitas padi dari beberapa periode tertentu atau berupa data runtun waktu.
Pengelompokan dilakukan menggunakan analisis kluster. Karena penelitian ini
menggunakan data runtun waktu maka jarak yang digunakan untuk
pengelompokan adalah jarak yang berdasar pada metrik log-normalized
periodogram (LNP). Metrik LNP berasal dari logaritma periodogram yang
dinormalkan. Periodogram merupakan fungsi spektrum kuasa atas frekuensinya.
Jika dilakukan penaksiran pada fungsi spektrum kuasa dan nilai-nilai penaksirnya
dipetakan terhadap frekuensinya maka akan diperoleh sebuah garis spektrum.
periode-perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
20
periode data runtun waktu, sehingga nilai-nilai periodogram dapat digunakan
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
21 BAB III
METODE PENELITIAN
Pada penelitian ini menggunakan data sekunder yaitu mengambil data dari
Departemen Pertanian Indonesia (http://aplikasi.deptan.go.id). Data yang digunakan
adalah data produktivitas padi mulai tahun 1970 sampai 2010. Adapun tahap-tahap
penelitiannya adalah sebagai berikut,
1. mencari data sekunder yang akan digunakan
Data hanya terdiri dari data produktivitas padi pada 26 provinsi. Hal ini
disebabkan terdapat 7 provinsi yang memiliki data tidak lengkap.
2. menentukan model ARIMA
Dalam menentukan model ARIMA dilakukan melalui beberapa tahap. Adapun
tahap-tahapnya adalah
a. Tahap Indentifikasi Model
i. Membuat plot data runtun waktu
ii. Membuat plot fungsi autokorelasi
iii. Memeriksa apakah data telah stasioner terhadap mean dan variansi
dengan melihat plot data dan menggunakan uji Augmented Dickey
Fuller (ADF).
Jika data tidak stasioner terhadap variansinya maka dilakukan
transformasi yang sesuai sehingga diperoleh data yang stasioner
terhadap variansinya. Jika data tidak stasioner terhadap mean maka
dilakukan pembedaan untuk mean yang tidak stasioner.
iv. Membuat plot fungsi autokorelasi parsial,
v. Melakukan pendugaan model sementara melalui plot fungsi
autokorelasi dan fungsi autokorelasi parsial.
b. tahap estimasi parameter model
Setelah diduga model sementara, selanjutnya dapat diestimasi nilai parameter
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
22
c. tahap diagnostik model
i. Membuat plot fungsi autokorelasi sisa.
ii. Melakukan uji independensi nilai sisa.
iii. Melakukan uji kenormalan nilai sisa.
3. menentukan metrik LNP
Setelah diperoleh model yang stasioner, selanjutnya dapat ditentukan metrik
log-normalized periodogram (LNP).
4. menentukan jarak yang berdasar pada metrik LNP
5. melakukan analisis kluster dengan metode pengelompokan complete linkage atau
pengelompokan berdasarkan jarak terjauh.
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
23 BAB IV PEMBAHASAN
Pengelompokan produktivitas padi dilakukan menggunakan analisis
kluster. Analisis kluster merupakan suatu teknik pengelompokan yang didasarkan
pada kesamaan jarak. Jarak yang digunakan dalam penelitian ini adalah jarak yang
berdasar pada metrik log-normalized periodogram (LNP). Periodogram
merupakan fungsi spektrum kuasa atas frekuensinya dimana spektrum adalah
transformasi Fourier dari proses fungsi autokovariansi. Transformasi Fourier
hanya dapat digunakan untuk menganalisis data stasioner. Sehingga langkah
pertama yang dilakukan dalam penelitian ini adalah melihat kestasioneran dari
data.
4.1Kestasioneran Data
Pada umumnya data runtun waktu adalah tidak stasioner. Sedangkan
aspek-aspek Autoregressive (𝐴𝑅) dan Moving Average (𝑀𝐴) hanya mengacu pada
data stasioner sehingga data asli yang tidak stasioner harus distasionerkan terlebih
dahulu terhadap mean dan variansinya. Untuk menstasionerkan data dapat
dilakukan dengan transformasi atau pembedaan. Jika data tidak stasioner terhadap
rata-rata maka dilakukan pembedaan. Sedangkan jika data tidak stasioner terhadap
variansi maka dilakukan transformasi. Untuk memperoleh model pada kasus
produktivitas padi di Indonesia dilakukan tahap-tahap sebagai berikut.
4.1.1 Identifikasi Model untuk Masing-Masing Provinsi
Indentifikasi model untuk provinsi yang pertama yaitu Provinsi Nanggroe
Aceh Darussalam. Plot data runtun waktu produktivitas padi di Provinsi Nanggroe
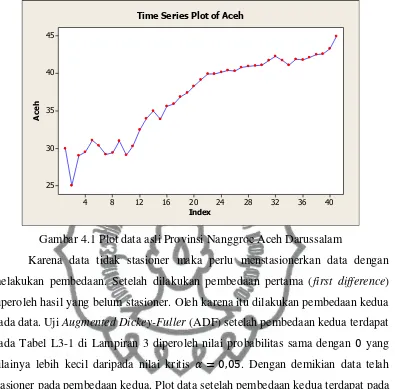
Aceh Darussalam pada tahun 1970 sampai 2010 terdapat pada Gambar 4.1.
Berdasarkan Gambar 4.1 tampak bahwa data tidak stasioner karena data
cenderung naik, hal ini menunjukkan bahwa data mengandung trend. Selain itu,
dengan menggunakan uji Augmented Dickey-Fuller (ADF) terdapat pada Tabel
L2-1 di Lampiran 2 diperoleh nilai probabilitas sebesar 0,8619 yang nilainya lebih
besar daripada nilai kritis 𝛼 = 0,05, sehingga dapat disimpulkan bahwa data tidak
perpustakaan.uns.ac.id digilib.uns.ac.id
Gambar 4.1 Plot data asli Provinsi Nanggroe Aceh Darussalam
Karena data tidak stasioner maka perlu menstasionerkan data dengan
melakukan pembedaan. Setelah dilakukan pembedaan pertama (first difference)
diperoleh hasil yang belum stasioner. Oleh karena itu dilakukan pembedaan kedua
pada data. Uji Augmented Dickey-Fuller (ADF) setelah pembedaan kedua terdapat
pada Tabel L3-1 di Lampiran 3 diperoleh nilai probabilitas sama dengan 0 yang
nilainya lebih kecil daripada nilai kritis 𝛼= 0,05. Dengan demikian data telah
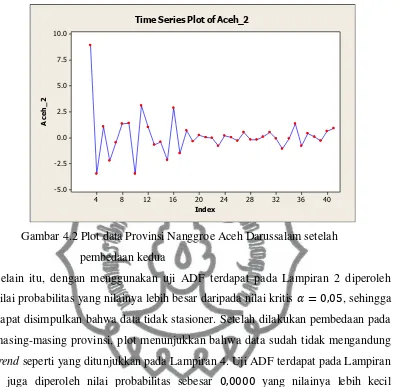
stasioner pada pembedaan kedua. Plot data setelah pembedaan kedua terdapat pada
Gambar 4.2. Berdasarkan Gambar 4.2 terlihat bahwa data sudah tidak mengandung
trend dan tersebar di sekitar nol maka dapat dikatakan bahwa data sudah stasioner.
Untuk mengidentifikasi model 𝐴𝑅 dan 𝑀𝐴 yang sesuai untuk data yang
sudah stasioner tersebut digunakan nilai fungsi autokorelasi (𝐴𝐶𝐹) dan fungsi
autokorelasi parsial (𝑃𝐴𝐶𝐹). Berdasarkan Lampiran 5 terlihat bahwa plot untuk
Provinsi Nanggroe Aceh Darussalam, nilai 𝐴𝐶𝐹 terputus setelah lag pertama dan
nilai PACF juga terputus setelah lag pertama maka berdasarkan Tabel 2.1 model
yang mungkin digunakan adalah model 𝐴𝑅𝐼(1,2), 𝐼𝑀𝐴(2,1),𝐴𝑅𝐼𝑀𝐴(1,2,1).
Analog untuk provinsi-provinsi lainnya dengan plot data asli ditunjukkan
pada Lampiran 1. Berdasarkan Lampiran 1, plot data asli untuk masing-masing
provinsi menunjukkan bahwa data tidak stasioner karena data cenderung naik. Hal
perpustakaan.uns.ac.id digilib.uns.ac.id
Gambar 4.2 Plot data Provinsi Nanggroe Aceh Darussalam setelah
pembedaan kedua
Selain itu, dengan menggunakan uji ADF terdapat pada Lampiran 2 diperoleh
nilai probabilitas yang nilainya lebih besar daripada nilai kritis 𝛼 = 0,05, sehingga
dapat disimpulkan bahwa data tidak stasioner. Setelah dilakukan pembedaan pada
masing-masing provinsi, plot menunjukkan bahwa data sudah tidak mengandung
trend seperti yang ditunjukkan pada Lampiran 4. Uji ADF terdapat pada Lampiran
3 juga diperoleh nilai probabilitas sebesar 0,0000 yang nilainya lebih kecil
daripada nilai kritis 𝛼= 0,05. Hal ini berarti bahwa data sudah stasioner.
4.1.2 Estimasi Parameter Model untuk Masing-Masing Provinsi Pada tahap identifikasi dipilih satu atau lebih model sementara yang
memberikan representasi yang sesuai dengan data. Untuk mendapatkan model
sementara, koefisien 𝐴𝑅 dan 𝑀𝐴 harus ditentukan terlebih dahulu. Berdasarkan
plot 𝐴𝐶𝐹 dan 𝑃𝐴𝐶𝐹 yang terdapat pada Lampiran 5 diperoleh model sementara
produktivitas padi di Indonesia pada masing-masing provinsi yang disajikan pada
Tabel 4.1.
Estimasi parameter model diperoleh dengan bantuan program. Estimasi
parameter model untuk provinsi Nanggroe Aceh Darussalam terdapat pada
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
26
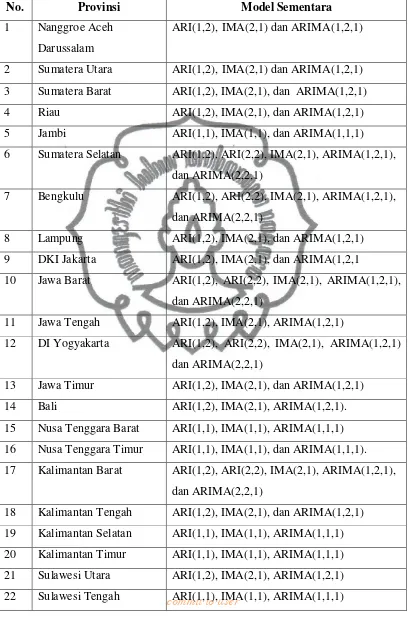
Tabel 4.1 Model sementara produktivitas padi untuk masing-masing provinsi
No. Provinsi Model Sementara
1 Nanggroe Aceh
Darussalam
ARI(1,2), IMA(2,1) dan ARIMA(1,2,1)
2 Sumatera Utara ARI(1,2), IMA(2,1) dan ARIMA(1,2,1)
3 Sumatera Barat ARI(1,2), IMA(2,1), dan ARIMA(1,2,1)
4 Riau ARI(1,2), IMA(2,1), dan ARIMA(1,2,1)
5 Jambi ARI(1,1), IMA(1,1), dan ARIMA(1,1,1)
6 Sumatera Selatan ARI(1,2), ARI(2,2), IMA(2,1), ARIMA(1,2,1),
dan ARIMA(2,2,1)
7 Bengkulu ARI(1,2), ARI(2,2), IMA(2,1), ARIMA(1,2,1),
dan ARIMA(2,2,1)
8 Lampung ARI(1,2), IMA(2,1), dan ARIMA(1,2,1)
9 DKI Jakarta ARI(1,2), IMA(2,1), dan ARIMA(1,2,1
10 Jawa Barat ARI(1,2), ARI(2,2), IMA(2,1), ARIMA(1,2,1),
dan ARIMA(2,2,1)
11 Jawa Tengah ARI(1,2), IMA(2,1), ARIMA(1,2,1)
12 DI Yogyakarta ARI(1,2), ARI(2,2), IMA(2,1), ARIMA(1,2,1)
dan ARIMA(2,2,1)
13 Jawa Timur ARI(1,2), IMA(2,1), dan ARIMA(1,2,1)
14 Bali ARI(1,2), IMA(2,1), ARIMA(1,2,1).
15 Nusa Tenggara Barat ARI(1,1), IMA(1,1), ARIMA(1,1,1)
16 Nusa Tenggara Timur ARI(1,1), IMA(1,1), dan ARIMA(1,1,1).
17 Kalimantan Barat ARI(1,2), ARI(2,2), IMA(2,1), ARIMA(1,2,1),
dan ARIMA(2,2,1)
18 Kalimantan Tengah ARI(1,2), IMA(2,1), dan ARIMA(1,2,1)
19 Kalimantan Selatan ARI(1,1), IMA(1,1), ARIMA(1,1,1)
20 Kalimantan Timur ARI(1,1), IMA(1,1), ARIMA(1,1,1)
21 Sulawesi Utara ARI(1,2), IMA(2,1), ARIMA(1,2,1)
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
27
23 Sulawesi Selatan ARI(1,2), IMA(2,1), ARIMA(1,2,1)
24 Sulawesi Tenggara ARI(1,2), ARI(2,2), IMA(2,1), ARIMA(1,2,1),
dan ARIMA(2,2,1)
25 Maluku ARI(1,2), ARI(2,2), IMA(2,1), ARIMA(1,2,1),
dan ARIMA(2,2,1)
26 Papua ARI(1,2), IMA(2,1), ARIMA(1,2,1)
Berdasarkan persamaan (2.1), estimasi parameter model provinsi Nanggroe Aceh
Darussalam dapat ditulis dengan
𝑍𝑡 = 2𝑍𝑡−1− 𝑍𝑡−2+ 0,017269−1,0099 𝑎𝑡−1.
Analog untuk provinsi yang lainnya dengan estimasi parameter model terdapat
pada Lampiran 6. Berdasarkan Lampiran 6 diperoleh persamaan estimasi
parameter untuk masing-masing provinsi yang ditunjukkan pada Tabel 4.2.
Tabel 4.2 Hasil Estimasi Model untuk Masing-masing Provinsi
No. Provinsi Nilai Estimasi
Parameter
2 Sumatera Utara ARIMA(1,2,1)
𝜙 = −0,5928 𝜃 = 0,3931
𝑍𝑡 = 1,4072𝑍𝑡−1+ 0,1856𝑍𝑡−2 −0,5928𝑍𝑡−3 −0,3931𝑎𝑡−1
3 Sumatera Barat ARIMA(1,2,1)
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
28
6 Sumatera Selatan ARIMA(2,2,1)
𝜙 1 =−0,4219
17 Kalimantan Barat IMA(2,1)
perpustakaan.uns.ac.id digilib.uns.ac.id
20 Kalimantan Timur ARI(1,1)
𝜙 = −0,5210
22 Sulawesi Tengah IMA(1,1)
𝜃 = 0,5675
𝑍𝑡 = 𝑍𝑡−1+ 0,7855−0,5675𝑎𝑡−1
23 Sulawesi Selatan IMA(2,1)
𝜃 = 0,9637
𝑍𝑡 = 2𝑍𝑡−1− 𝑍𝑡−2−0,9637𝑎𝑡−1
24 Sulawesi Tenggara IMA(2,1)
𝜃 = 0,9543
4.1.3 Uji Diagnostik Model untuk Masing-Masing Provinsi
Setelah dilakukan estimasi parameter untuk model 𝐴𝑅𝐼𝑀𝐴, langkah
selanjutnya adalah melakukan uji diagnostik dari kecukupan model tersebut. Pada
tahap diagnostik model akan diuji apakah residu bersifat independen dan
berdistribusi normal. Jika residu dari model tersebut telah bersifat independen dan
berdistribusi normal maka model tersebut sesuai dengan data.
Untuk menguji independensi residu dilakukan dengan memeriksa nilai
autokorelasi residu. Plot fungsi autokorelasi residu untuk masing-masing provinsi
terdapat pada Lampiran 7, dan terlihat bahwa nilai koefisien autokorelasi residu
berada di sekitar nol. Hal tersebut berarti residu saling independen. Uji
independensi residu dapat juga diketahui melalui uji Ljung-Box-Pierce. Uji
Ljung-Box-Pierce pada masing-masing provinsi pada Lampiran 8 menunjukkan
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
30
menunjukkan bahwa secara signifikan tidak menolak hipotesis nol yang berarti
residu saling independen.
Untuk menguji kenormalan residu dapat dilakukan dengan menggunakan
uji Kolmogorov-Smirnov. Berdasarkan Lampiran 9 diperoleh plot uji normalitas
pada semua provinsi menunjukkan residu tidak menolak hipotesis nol. Hal
tersebut berarti data berdistribusi normal pada tingkat signifikansi 5% sehingga
uji normalitas dipenuhi. Uji kenormalan residu juga dapat dilakukan dengan
melihat pola plot antara residu dengan normal scores. Berdasarkan Lampiran 9
menunjukkan plot untuk semua provinsi mendekati garis lurus yang berarti bahwa
residu berdistribusi normal. Karena residu dari model untuk semua provinsi telah
bersifat independen dan berdistribusi normal maka model tersebut sesuai dengan
data.
4.2 Hasil Pengelompokan Produktivitas Padi Di Indonesia
Setelah diperoleh model akhir untuk masing-masing provinsi, dicari nilai
periodogram untuk masing-masing provinsi dengan menggunakan rumus pada
persamaan (2.15) dengan hasil perhitungan terdapat pada Lampiran 10. Kemudian
dicari nilai periodogram yang dinormalkan untuk masing-masing provinsi dengan
menggunakan rumus pada persamaan (2.17). Setelah diperoleh periodogram yang
dinormalkan, kemudian dicari metrik log-normalized periodogram (LNP) yaitu
logaritma dari periodogram yang dinormalkan dengan hasil perhitungan terdapat
pada Lampiran 11. Dengan menggunakan persamaan (2.16), diperoleh jarak
antara ordinat LNP dengan hasil perhitungan terdapat pada Lampiran 12.
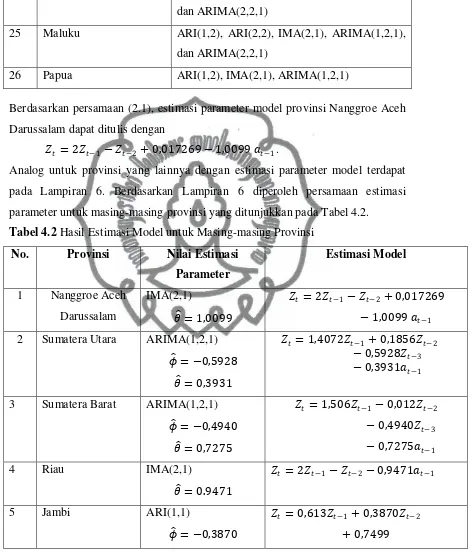
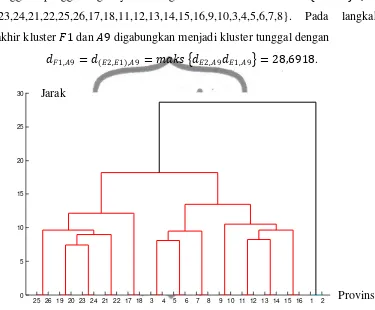
Selanjutnya mengelompokkan runtun waktu produktivitas padi di
Indonesia menggunakan metode complete linkage dengan jarak yang berdasarkan
metrik LNP. Dalam metode complete linkage, kluster-kluster digabungkan
berdasarkan jarak antara anggota-anggota yang paling jauh. Pada awalnya
banyaknya kluster sama dengan banyaknya obyek. Selanjutnya menggabungkan
obyek-obyek yang paling dekat atau paling mirip, berdasarkan hasil perhitungan
jarak didapatkan kluster awal dengan jarak antar obyek nol, yaitu 𝐴1={25,26}, 𝐴2
={23,24}, 𝐴3={21,22}, 𝐴4={19,20}, 𝐴5={17,18}, 𝐴6={15,16}, 𝐴7={13,14},
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
31
Langkah kedua dihitung jarak antara kluster awal dengan obyek-obyek yang lain,
diperoleh kluster yang paling mirip dengan jarak sebagai berikut
𝑑𝐴4,𝐴2 = 𝑚𝑎𝑘𝑠 𝑑19,20 23,𝑑 19,20 24 = 7,3904
dengan obyek yang belum tergabung, diperoleh kluster yang paling mirip dengan
jarak sebagai berikut
𝑑𝐵1,𝐴3 = 𝑑(𝐴4,𝐴2),𝐴3 = 𝑚𝑎𝑘𝑠 𝑑𝐴4,𝐴3,𝑑𝐴2,𝐴3 = 8,9615 𝑑𝐵2,𝐴12 = 𝑑(𝐴10,𝐴11),𝐴12 = 𝑚𝑎𝑘𝑠 𝑑𝐴10,𝐴12,𝑑𝐴11 ,𝐴12 = 9,4631
𝑑𝐵3,𝐴6 =𝑑(𝐴8,𝐴7),𝐴6 =𝑚𝑎𝑘𝑠 𝑑𝐴8,𝐴6,𝑑𝐴7,𝐴6 = 9,6470 .
Penggabungan tersebut menghasilkan kluster 𝐶1={𝐵1,𝐴3}={19,20,23,24,21,22},
𝐶2={𝐵2,𝐴12}={3,4,5,6,7,8} dan 𝐶3={𝐵3,𝐴6}={11,12,13,14,15,16}. Langkah
keempat menghitung jarak antara kluster 𝐶1, 𝐶2 dan 𝐶3 dengan obyek atau
kluster yang belum tergabung, diperoleh kluster yang paling mirip dengan
𝑑𝐶1,𝐴1 = 𝑑(𝐵1,𝐴3),𝐴1 = 𝑚𝑎𝑘𝑠 𝑑𝐵1,𝐴1,𝑑𝐴3,𝐴1 = 9,6656
kluster yang lain sehingga diperoleh kluster yang paling mirip dengan
𝑑𝐷1,𝐴5 =𝑑(𝐶1,𝐴1),𝐴5 = 𝑚𝑎𝑘𝑠 𝑑𝐶1,𝐴5𝑑𝐴1𝐴5 = 12,1563 𝑑𝐷2,𝐶2 = 𝑑(𝐶3,𝐴13 ),𝐶2 = 𝑚𝑎𝑘𝑠 𝑑𝐶3,𝐶2𝑑𝐴13,𝐶2 = 13,4820 . Penggabungan diatas menghasilkan kluster
𝐸1 = {𝐷1,𝐴5} = {19, 20,23,24,21,22,25,26,17,18} dan
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
32
Langkah berikutnya menghitung jarak antar kluster yang terbentuk sebelumnya
yaitu 𝐸1, 𝐸2 dan 𝐴9, diperoleh kluster yang paling mirip dengan
𝑑𝐸2,𝐸1 = 𝑑(𝐷2,𝐶2),𝐸1 =𝑚𝑎𝑘𝑠 𝑑𝐷2,𝐸1𝑑𝐶2,𝐸1 = 18,2074.
Sehingga penggabungannya menghasilkan kluster 𝐹1 = {𝐸2,𝐸1}={19,
20,23,24,21,22,25,26,17,18,11,12,13,14,15,16,9,10,3,4,5,6,7,8}. Pada langkah
terakhir kluster 𝐹1 dan 𝐴9 digabungkan menjadi kluster tunggal dengan
𝑑𝐹1,𝐴9 =𝑑(𝐸2,𝐸1),𝐴9 =𝑚𝑎𝑘𝑠 𝑑𝐸2,𝐴9𝑑𝐸1,𝐴9 = 28,6918.
Gambar 4.3 Dendogram runtun waktu produktivitas padi di Indonesia
menggunakan metrik LNP.
{19, 20,23,24,21,22,25,26,17,18}, 𝐸2 = {11,12,13,14,15,16,9,10,3,4,5,6,7,8},
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
33
pengelompokannya dibuat dalam bentuk dendogram yang terdapat pada Gambar
4.3.
Kelompok pertama terdiri dari provinsi Maluku, Papua, Kalimantan
Selatan, Kalimantan Timur, Sulawesi Selatan, Sulawesi Tenggara, Sulawesi
Utara, Sulawesi Tengah, Kalimantan Barat, dan Kalimantan Tengah. Kelompok
kedua terdiri dari provinsi Sumatera Barat, Riau, Jambi, Sumatera Selatan,
Bengkulu, Lampung, DKI Jakarta, Jawa Barat, Jawa Tengah, DI Yogyakarta,
Jawa Timur, Bali, Nusa Tenggara Barat, dan Nusa Tenggara Timur. Sedangkan
kelompok ketiga terdiri dari provinsi Nanggroe Aceh Darussalam dan Sumatera
Utara. Berdasarkan fluktuasi plot data runtun waktu yang sudah stasioner dari
masing-masing provinsi yang terdapat pada Lampiran 4, kelompok pertama
menunjukkan laju produktivitas padi yang cepat. Kelompok kedua menunjukkan
adanya laju produktivitas padi yang negatif pada beberapa periode. Kelompok
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
34 BAB V PENUTUP
5.1 Kesimpulan
Berdasarkan hasil pembahasan, dapat diperoleh kesimpulan bahwa laju
produktivitas padi di Indonesia dapat dikelompokkan menjadi 3 kelompok
provinsi. Kelompok pertama menunjukkan laju produktivitas padi cepat yang
terdiri dari provinsi Maluku, Papua, Kalimantan Selatan, Kalimantan Timur,
Sulawesi Selatan, Sulawesi Tenggara, Sulawesi Utara, Sulawesi Tengah,
Kalimantan Barat, dan Kalimantan Tengah. Kelompok kedua menunjukkan
adanya laju produktivitas padi yang negatif pada beberapa periode terdiri dari
provinsi Sumatera Barat, Riau, Jambi, Sumatera Selatan, Bengkulu, Lampung,
DKI Jakarta, Jawa Barat, Jawa Tengah, DI Yogyakarta, Jawa Timur, Bali, Nusa
Tenggara Barat, dan Nusa Tenggara Timur. Sedangkan kelompok ketiga
menunjukkan laju produktivitas padi tetap atau konstan yang terdiri dari provinsi
Nanggroe Aceh Darussalam dan Sumatera Utara.
5.2 Saran
Pada penelitian ini, pengelompokan dilakukan dengan menggunakan metrik
yang berdasar pada Log-Normalized Periodogram (LNP). Oleh karena itu dalam
penelitian lebih lanjut dapat digunakan metrik yang berdasar pada koefisien