i
MESIN PENCARI GAMBAR GEOMETRI BANGUN DATAR
MENGGUNAKAN
AGGLOMERATTIVE HIERARCHICAL
CLUSTERING
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh :
Astriana Krisma Risky 095314005
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
SEARCH ENGINE OF SHAPES GEOMETRY IMAGE BY
USING AGGLOMERATTIVE HIERARCHICAL
CLUSTERING
A THESIS
Presented as Partial Fulfillment of The Requirements To Obtain The Sarjana Komputer Degree
Informatics Engineering Study Program
By :
Astriana Krisma Risky 095314005
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
vii
Abstrak
Penelitian ini memiliki peranan dalam menampilkan nama, rumus, dan keterangan gambar bangun datar menggunakan Agglomerative Hierarchical Clustering. Dengan melalui beberapa proses preprocessing image sebelum dilakukan ekstrak fitur, kemudian dari matriks fitur yang ada dihitung jarak kedekatannya menggunakan Euclidean Distance dalam metode single, average dan complete linkage untuk 50 gambar bangun datar yang dibuat menggunakan aplikasi paint sebagai data training.
viii
Abstract
This research have a role to show the name, formula, and information about shapes image by using Agglomerative Hierarchical Clustering. Some preprocessing image process done before feature extraction, then the existing features of the matrix is computed the similarity with Euclidean Distance in single, average and complete linkage method to 50 shapes images are created using paint application as training data.
ix
KATA PENGANTAR
Puji syukur dan terima kasih kepada Tuhan Yang Maha Esa atas berkat yang diberikan kepada saya dalam proses penyusunan sampai dengan penyelesaian skripsi ini.
Skripsi ini disusun untuk memperoleh gelar sarjana komputer di Jurusan Teknik Informatika, Fakultas Sains dan Teknologi, Universitas Sanata Dharma, Yogyakarta. Skripsi ini juga disusun sebagai sumbangan sedikit pengetahuan, sehingga saya dapat memberikan sedikitnya kontribusi pada perkembangan ilmu pengetahuan berikutnya.
Ucapan terima kasih saya atas dukungan dan doa yang ditujukan kepada : 1. Paulina Heruningsih Prima Rosa, S.Si, M.Sc., selaku Dekan Fakultas Sains
dan Teknologi, Universitas Sanata Dharma.
2. Ridowati Gunawan, S.Kom, M.T., selaku Ketua Program Studi Teknik Informatika, Universitas Sanata Dharma dan dosen penguji skripsi.
3. Dr. C. Kuntoro Adi, S.J., M.A., M.Sc., selaku pembimbing skripsi.
4. Sri Hartati Wijono, S.Si, M.Kom., selaku dosen penguji skripsi dan Wakil Ketua Program Studi Teknik Informatika, Universitas Sanata Dharma.
5. Orang tua dan adik beserta keluarga tercinta yang selalu memberikan dukungan dan doa.
xi
PERNYATAAN KEASLIAN HASIL KARYA ... v
PERNYATAAN PERSETUJUAN PUBLIKASI ... vi
xii
1.7 Metode Penelitian ... 5
1.8 Sistematika Penulisan ... 6
BAB II ... 7
LANDASAN TEORI ... 7
2.1 Data Mining : Knowledge Discovery Database (KDD) ... 7
2.2 Tahapan DataMining ... 9
2.3 Pengelompokan Data Mining ... 11
2.4 Algoritma Clustering (ClusteringAlgorithm) ... 14
2.4.1 K-Means Clustering... 18
2.4.2 Clustering Hirarki (HierarchicalClustering) ... 19
2.5 Teknik Analisis Cluster Hirarki ... 20
2.6 Fungsi Jarak ... 25
2.7 Geometri ... 26
2.8 Sudut ... 26
2.9 Geometri Bangun Datar ... 27
2.9.1 Bagian-bagian Bangun Datar ... 27
2.9.2 Macam Bangun Datar ... 28
2.10 Cluster Validitas ... 37
2.11 Alat Ukur Akurasi ... 38
xiii
ANALISA DAN DESAIN ... 39
3.1 Deskripsi Umum Aplikasi ... 39
3.2 Data... 43
3.3 Ekstrak Fitur ... 44
3.4 Proses Agglomerative Hierarchical Clustering ... 47
3.5 Evaluasi Hasil ... 50
3.6 Model Use Case ... 51
3.6.1 Aktor dalam Use Case ... 51
3.6.2 Diagram Use Case ... 51
3.6.3 Definisi Use Case ... 52
3.6.4 Skenario Use Case ... 52
3.7 Desain Subsistem Manajemen Model ... 53
3.8 Desain Interface ... 54
BAB IV ... 55
IMPLEMENTASI ... 55
4.1 Ekstrak Fitur ... 55
4.1.1 Transformasi ke dalam citra biner ... 55
4.1.2 Resize dan crop citra menjadi lebih fokus ... 56
4.1.3 Rotasi gambar ... 58
xiv
4.2 Proses clustering menggunakan Agglomerative Hierarchical Clustering60
4.3 Menghitung validasi cluster ... 70
4.4 Uji Tunggal ... 70
BAB V ... 72
HASIL DAN PENGUJIAN... 72
5.1 Data Input Testing ... 72
5.2 Hasil Pengujian Sistem ... 73
5.2.1. Hasil transformasi ke dalam citra biner ... 73
5.2.2. Hasil resize dan crop citra menjadi lebih fokus ... 74
5.2.3. Hasil rotasi gambar ... 76
5.2.4. Hasil ekstrak fitur gambar bangun datar ... 78
5.2.5. Hasil clustering menggunakan Agglomerative Hierarchical Clustering ... 79
BAB VI ... 89
PENUTUP ... 89
6.1. Kesimpulan ... 89
6.2. Saran ... 90
DAFTAR PUSTAKA ... 91
xv
DAFTAR GAMBAR
Gambar 2.1.Data Mining : Proses KDD ... 9
Gambar 2.2.Dendrogram Hierarchical Clustering : Agglomerative, Divisive .. 21
Gambar 2.3. Hierarchical Clustering : Agglomerative, Single Linkage ... 23
Gambar 2.4. Hierarchical Clustering : Agglomerative, Complete Linkage ... 24
Gambar 2.5. Hierarchical Clustering : Agglomerative, Average Linkage ... 24
Gambar 2.6. Segitiga sama sisi ... 29
Gambar 2.7. Segitiga sama kaki ... 29
Gambar 2.8. Segitiga siku-siku ... 29
Gambar 2.9. Segitiga sembarang ... 30
Gambar 2.10. Segitiga tumpul ... 30
Gambar 2.11. Persegi ... 31
Gambar 2.12. Persegi panjang ... 31
Gambar 2.13. Jajargenjang ... 32
Gambar 2.14. Belah katupat ... 33
Gambar 2.15. Layang-layang ... 33
Gambar 2.16. Trapesium sembarang ... 34
Gambar 2.17. Trapesium siku-siku ... 34
Gambar 2.18. Trapesium sama kaki ... 34
Gambar 2.19. Lingkaran ... 35
Gambar 2.20. Elips ... 36
xvi
Gambar 3.1. Diagram alur proses pemodelan ... 40
Gambar 3.2. Diagram alur proses ekstrak fitur ... 40
Gambar 3.3. Diagram alur proses Agglomerative Hierarchical Clustering ... 40
Gambar 3.4.Flowchart Sistem Validasi Fitur ... 41
Gambar 3.5. Gambar file training ... 44
Gambar 3.6. Contoh pemotongan gambar ... 45
Gambar 3.7. Membagi menjadi 5x5 untuk ekstrak fitur ... 46
Gambar 3.8. Grafik model segitiga ... 48
Gambar 3.9. Grafik model segi empat... 49
Gambar 3.10. Grafik model lingkaran ... 49
Gambar 3.11. Use Case Diagram ... 51
Gambar 3.12. Desain Interface sistem ... 54
Gambar 4.1. Hasil Pemotongan gambar segitiga siku-siku ... 57
Gambar 4.2.Dendrogram hirarki hasil clustering ... 65
Gambar 4.3. Dendrogram masing-masing cluster dengan single linkage ... 67
Gambar 4.4. Dendrogram masing-masing cluster dengan complete linkage ... 68
Gambar 4.5. Dendrogram masing-masing cluster dengan average linkage ... 69
Gambar 4.6. Interface searching bangun datar untuk user ... 71
Gambar 5.1. Gambar data file testing atau pengujian ... 73
Gambar 5.2 Hasil transformasi citra biner jajargenjang ... 74
Gambar 5.3. Hasil transformasi citra biner segitiga ... 74
Gambar 5.4. Hasil transformasi citra biner lingkaran ... 74
xvii
Gambar 5.6. Hasil pemotongan gambar elips ... 76
Gambar 5.7. Hasil rotasi gambar segitiga ... 76
Gambar 5.8. Hasil rotasi gambar persegi ... 77
Gambar 5.9. Data gambar pengujian grup 1 ... 80
Gambar 5.10. Data gambar pengujian grup 2 ... 81
xviii
DAFTAR TABEL
Tabel 3.1.Confussion Matrix 3x3 ... 50
Tabel 3.2. Definisi Use Case ... 52
Tabel 3.3. Ilustrasi sorting ... 83
Tabel 5.1. Akurasi hasil Agglomerative Hierarchical Clustering ... 79
Tabel 5.2.Confussion matrix single linkage kelompok 1 ... 82
Tabel 5.3.Confussion matrix single linkage kelompok 2 ... 82
Tabel 5.4.Confussion matrix single linkage kelompok 3 ... 83
Tabel 5.5.Confussion matrix complete linkage kelompok 1... 84
Tabel 5.6.Confussion matrix complete linkage kelompok 2... 84
Tabel 5.7.Confussion matrix complete linkage kelompok 3... 85
Tabel 5.8.Confussion matrix average linkage kelompok 1 ... 86
Tabel 5.9.Confussion matrix average linkage kelompok 2 ... 86
Tabel 5.10.Confussion matrix average linkage kelompok 3 ... 87
Tabel 5.11. Hasil clustering data training ... 96
1
BAB I
PENDAHULUAN
Bab ini menjelaskan mengenai desain atau gambaran aplikasi yang akan dibuat dan dikembangkan mulai dari latar belakang penelitian, rumusan masalah, batasan-batasan masalah, tujuan penelitian, luaran, manfaat, metodologi penelitian dan sistematika penulisan.
1.1Latar Belakang
Matematika merupakan salah satu cabang ilmu yang sangat penting dan diajarkan mulai dari jenjang SD sampai dengan perguruan tinggi. Hingga sekarang, matematika dikategorikan sebagai mata pelajaran yang selalu ikut serta dalam daftar mata pelajaran yang diujikan secara nasional mulai jenjang SD hingga SMA. Bagi banyak orang, matematika berguna sebagai penunjang dalam mengembangkan ilmu-ilmu lainnya sehingga mampu berpikir logis, kritis, tekun, bertanggung jawab dan mampu menyelesaikan persoalan (Kultsum, 2009).Namun banyak yang menganggap matematika sulit dan bahkan menakutkan, maka banyak orang lebih mengabaikan dan justru tidak mengetahui dasar-dasar perhitungan matematika. Hal ini sangat memprihatinkan mengingat pengetahuan dasar matematika menjadi dasar perhitungan untuk tingkat yang lebih tinggi dalam berbagai bidang.
kita untuk berpikir logis, kerja yang sistematis, menghidupkan kreativitas serta dapat mengembangkan kemampuan berinovasi (Aisah, 2012). Penerapan bangun datar sangat banyak ditemukan dalam pembelajaran arsitektur suatu bangunan, desain gambar baik satu dimensi maupun tiga dimensi, dan ilmu lainnya yang membutuhkan dasar perhitungan mengenai bangun datar dan bangun ruang. Pembelajaran geometri bidang datar dimulai dengan menyelidiki keseluruhan atau garis besar atau bentuk bangunnya terlebih dahulu, kemudian baru ke unsur-unsur yang makin kecil dan sederhana. Misalnya dimulai dari bangun datar, dilanjutkan dengan sisi, sifat-sifat sejajar, tegak lurus, ukuran dan akhirnya titik sudut (Suharjana, 2008).
Geometri ruang telah diajarkan sejak SD, namun ternyata kemampuan siswa dalam menyelesaikan soal-soal dimensi dua masih rendah hanya karena penyajian dalam gambar mengharuskan bentuk persegi menjadi bentuk jajargenjang. Hasil survey Programme for International Student Assessment (PISA) 2000/2001 menunjukkan bahwa siswa lemah dalam geometri, khususnya dalam pemahaman ruang dan bentuk (Suwaji, 2008).
kemiripan antar obyek menggunakan Agglomerative Hierarchical Clustering karena akan mudah diketahui kedekatannya menggunakan bentuk hirarki. Tetapi sejauh mana peran dari Agglomerative Hierarchical Clustering dalam menampilkan model dan hasil pencarian yang relevan akan dilihat melalui evaluasi akurasi.
1.2Rumusan Masalah
Berdasarkan uraian latar belakang di atas, maka yang menjadi rumusan masalah dalam penelitian ini adalah :
Sejauh mana Agglomerative Hierarchical Clustering dapat menampilkan hasil pencarian yang relevan berupa nama, rumus, dan keterangan dari gambar bangun datar yang diinputkan dalam sebuah aplikasi mesin pencari?
1.3Batasan Masalah
Materi-materi tersebut meliputi bangun-bangun datar seperti segitiga, lingkaran, elips, persegi, persegi panjang, jajargenjang, belah ketupat,layang-layang, dan trapesium yang membahas berupa istilah, luas dan keliling, sifat-sifat bangun datar. Selain itu input gambar bangun datar dari gambar tangan manual atau buku materi pembelajaran baik diambil menggunakan kamera ataupun scanner, diharapkan memiliki tingkat kontras yang cukup baik (sisi terang atau gelap tidak mendominan terlalu banyak), sedikit noise, dan hanya terdiri dari 1 buah gambar dalam sekali input. Untuk hasil maksimal, digunakan gambar yang dibuat dengan aplikasi paint.
1.4Tujuan Penelitian
Untuk menyelesaikan masalah dan mewujudkan apa yang menjadi manfaat, maka tujuan dari penelitian ini adalah :
1. Merancang suatu cara pengenalan bangun datar dalam pendekatan Agglomerative Hierarchical Clustering.
2. Merancang sebuah prototype yang relevan sebagai mesin pencari untuk siswa siswi SMP.
3. Membangun sebuah aplikasi mesin pencari berdasarkan input gambar geometri bangun datar dengan hasil pencarian yang relevan menggunakan Agglomerative Hierarchical Clustering.
1.5Luaran
Dari penelitian ini, luaran yang diharapkan adalah sebuah aplikasi mesin pencari berdasarkan input gambar geometri bangun datar dengan hasil pencarian yang relevan menggunakan Agglomerative Hierarchical Clustering.
1.6Manfaat
Dalam penelitian ini, maanfaat yang ingin didapat antara lain :
1. Membantu siswa siswi tingkat SMP dalam pemahaman materi geometri yang cukup penting untuk terapan ilmu lain di jenjang yang lebih tinggi.
2. Membantu guru matematika dalam menyiapkan sebuah alat peraga pembahasan materi geometri.
3. Menampilkan hasil searching dari sebuah mesin pencari yang cukup relevan dengan gambar yang digunakan user sebagai input.
1.7Metode Penelitian
1.8Sistematika Penulisan
Sistematika penulisan yang digunakan dalam penelitian ini adalah : - BAB I PENDAHULUAN
Bab ini menjelaskan latar belakang penelitian, rumusan masalah, batasan-batasan masalah, tujuan penelitian, luaran, manfaat, metodologi penelitian dan sistematika penulisan.
- BAB II LANDASAN TEORI
Bab ini menjelaskan dasar-dasar teori yang dipakai sebagai referensi dan acuan dalam penelitian dan pembuatan aplikasi sebagai implementasi. - BAB III ANALISA DAN DESAIN
Bab ini menjelaskan mengenai metode yang dipakai dalam penelitian dan pembuatan aplikasi sebagai implementasi. Juga disebutkan pengertian dan hal-hal yang terkait dengan metode yang dipakai tersebut.
- BAB IV IMPLEMENTASI
Bab ini dapat berisi mengenai listing program dari hasil implementasi yang telah dibuat beserta penjelasan singkat dan output hasil dari implementasi tersebut.
- BAB V HASIL DAN PENGUJIAN
Bab ini berisi mengenai evaluasi dari hasil aplikasi yang telah diimplementasikan berupa nilai akurasi yang didapat dan analisanya.
- BAB VI PENUTUP
7
BAB II
LANDASAN TEORI
Bab ini menjelaskan mengenai dasar teori yang akan digunakan dalam implementasi meliputi pengertian data mining sebagai Knowledge Discovery Database secara umum, tahapan dalam data mining, cara pengelompokan data mining, pengertian algoritma clustering, teknik analisis dalam cluster hirarki, pengertian fungsi jarak, geometri, sudut, dan jenis-jenis geometri bangun datar, serta validasi cluster dan alat ukur akurasi.
2.1Data Mining : Knowledge Discovery Database (KDD)
database, data warehouse, atau penyimpanan informasi lainnya. Data mining berkaitan dengan bidang ilmu-ilmu lain, seperti database system, data warehousing, statistik, machine learning, information retrieval, dan komputasi tingkat tinggi. Selain itu, data mining didukung oleh ilmu lain seperti neural network, pengenalan pola, spatial data analysis, image database, signal processing (Han, 2006). Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Turban, dkk. 2005).
Masalah-masalah yang dapat diselesaikan dengan teknik data mining dapat dicirikan dengan (Piatetsky & Shapiro, 2006) :
- memerlukan keputusan yang bersifat knowlegde-based,
- mempunyai lingkungan yang berubah,
- metode yang ada sekarang bersifat sub-optimal,
- tersedia data yang bisa diakses, cukup dan relevan,
- memberikan keuntungan yang tinggi jika keputusan yang diambil tepat.
machine learning, statistik dan database. Beberapa metode yang sering disebut-sebut dalam literatur data mining antara lain clustering, classification, association rules mining, neural network, genetic algorithm dan lain-lain (Pramudiono, 2003).
2.2Tahapan DataMining
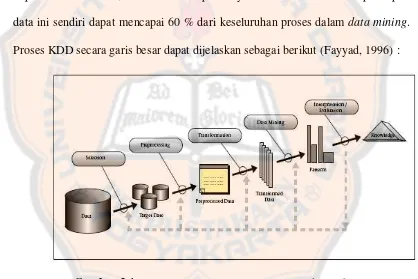
Data yang ada tidak dapat langsung diolah menggunakan sistem data mining. Data tersebut harus dipersiapkan terlebih dahulu agar hasil yang diperoleh dapat lebih maksimal, dan waktu komputasinya lebih minimal. Proses persiapan data ini sendiri dapat mencapai 60 % dari keseluruhan proses dalam data mining. Proses KDD secara garis besar dapat dijelaskan sebagai berikut (Fayyad, 1996) :
Gambar 2.1.Data Mining : Proses KDD (Fayyad, 1996)
- Seleksi Data (Data Selection)
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari database operasional.
- Pra-pemrosesan / Pembersihan (Pre-processing / Cleaning)
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
- Transformasi (Transformation)
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam database.
- Data mining
metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
- Interpretasi / Evaluasi (Interpretation / Evaluation)
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
2.3Pengelompokan Data Mining
Menurut Larose, data mining dapat dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu (Larose, 2005) :
1. Deskripsi (Description)
2. Estimasi (Estimation)
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih ke arah numerik daripada ke arah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel prediksi. Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.
3. Prediksi (Prediction)
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa datang. Contoh prediksi dalam bisnis dan penelitian adalah :
- prediksi harga beras dalam tiga bulan yang akan datang,
- prediksi persentase kenaikan kecelakaan lalu lintas tahun depan jika batas bawah kecepatan dinaikkan.
Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
4. Klasifikasi (Classification)
tinggi, pendapatan sedang, dan pendapatan rendah. Contoh lain klasifikasi dalam bisnis dan penelitian adalah :
- memperkirakan apakah suatu pengajuan hipotek oleh nasabah merupakan suatu kredit yang baik atau buruk,
- mendiagnosis penyakit seorang pasien untuk mendapatkan kategori penyakit apa.
5. Pengelompokan (Clustering)
Clustering merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Cluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan memiliki ketidakmiripan dengan record-record dalam cluster lain.
Pengelompokan berbeda dengan klasifikasi yaitu tidak adanya variabel target dalam pengelompokan. Pengelompokan tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target. Akan tetapi, algoritma pengelompokan mencoba untuk melakukan pembagian terhadap keseluruhan data menjadi kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan record dalam satu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal. Contoh pengelompokan dalam bisnis dan penelitian adalah :
- mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari suatu produk bagi perusahaan yang tidak memiliki dana pemasaran yang besar,
- untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap perilaku finansial dalam baik dan mencurigakan.
6. Asosiasi (Assosiation)
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja. Contoh asosiasi dalam bisnis dan penelitian adalah :
- menemukan barang dalam supermarket yang dibeli secara bersamaan dan barang yang tidak pernah dibeli secara bersamaan,
- meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang diharapkan untuk memberikan respons positif terhadap penawaran upgrade layanan yang diberikan.
2.4Algoritma Clustering (ClusteringAlgorithm)
Gagasan mengenai pengelompokan data, atau clustering, memiliki sifat yang sederhana dan dekat dengan cara berpikir manusia; kapanpun kepada kita dipresentasikan jumlah data yang besar, kita biasanya cenderung merangkumkan jumlah data yang besar ini ke dalam sejumlah kecil kelompok-kelompok atau kategori-kategori untuk memfasilitasi analisanya lebih lanjut. Selain itu, sebagian besar data yang dikumpulkan dalam banyak masalah terlihat memiliki beberapa sifat yang melekat yang mengalami pengelompokan-pengelompokan natural (Hammouda & Karray, 2003). Namun, penemuan pengelompokan-pengelompokan ini atau upaya untuk mengkategorikan data adalah bukan sebuah tugas yang sederhana bagi manusia kecuali data memiliki dimensionalitas rendah (dua atau tiga dimensi paling banyak). Inilah sebabnya mengapa beberapa metode dalam soft computing telah dikemukakan untuk menyelesaikan jenis masalah ini. Metode ini disebut “Metode-metode Pengelompokan Data” (Hammouda & Karray, 2003).
Algoritma-algoritma clustering digunakan secara ekstensif tidak hanya untuk mengorganisasikan dan mengkategorikan data, akan tetapi juga sangat bermanfaat untuk kompresi data dan konstruksi model. Melalui pencarian kesamaan dalam data, seseorang dapat merepresentasikan data yang sama dengan lebih sedikit simbol. Selain itu, jika kita dapat menemukan kelompok-kelompok data, kita dapat membangun sebuah model masalah berdasarkan pengelompokan-pengelompokan ini (Dubes & Jain, 1988).
sekumpulan record yang adalah sama dengan satu sama lain dan tidak sama dengan record dalam cluster lain. Clustering berbeda dari klasifikasi dimana tidak ada variabel target untuk clustering. Tugas clustering tidak mencoba untuk mengklasifikasikan, mengestimasi, atau memprediksi nilai variabel target (Larose, 2005). Bahkan, algoritma clustering berusaha mensegmentasikan seluruh kumpulan data ke dalam sub kelompok atau cluster-cluster homogen secara relatif. Dimana kesamaan record dalam cluster dimaksimalkan dan kesamaan dengan record diluar cluster ini diminimalkan.
Clustering sering dilaksanakan sebagai langkah pendahuluan dalam proses pengumpulan data, dengan cluster-cluster yang dihasilkan digunakan sebagai input lebih lanjut ke dalam sebuah teknik yang berbeda, seperti neural network. Karena ukuran yang besar dari banyak database yang dipresentasikan saat ini, maka sering sangat membantu untuk menggunakan analisa clustering terlebih dahulu, untuk mengurangi ruang pencarian untuk algoritma-algoritma downstream. Aktivitas clustering pola khusus meliputi langkah-langkah berikut (Dubes & Jain, 1988) :
- representasi pola (secara opsional termasuk ekstraksi dan/atau seleksi sifat),
- definisi ukuran kedekatan pola yang tepat untuk domain data,
- clustering pengelompokan,
- penarikan data (jika dibutuhkan),
- pengkajian output (jika dibutuhkan).
Beberapa informasi ini dapat tidak bisa dikontrol oleh praktisioner. Seleksi sifat (fitur) adalah proses pengidentifikasian subset fitur original yang paling efektif untuk digunakan dalam clustering. Ekstraksi fitur adalah penggunaan satu atau lebih transformasi dari sifat-sifat input untuk menghasilkan sifat-sifat baru yang lebih baik.
Pertimbangkan dataset X yang terdiri dari point-point data (atau secara sinonim, objek-objek, hal-hal, kasus-kasus, pola, tuple, transaksi) x
i = (xi1, …, xid) Є A dalam ruang atribut A, dimana i = 1, N, dan setiap komponen adalah sebuah atribut A kategori numerik atau nominal. Sasaran akhir dari clustering adalah untuk menentukan point-point pada sebuah sistem terbatas dari subset k, cluster. Biasanya subset tidak berpotongan (asumsi ini terkadang dilanggar), dan kesatuan mereka sama dengan dataset penuh dengan pengecualian yang memungkinkan outlier. C
i adalah sekelompok point data dalam dataset X, dimana X = Ci .. Ck .. C
outliers, Cj1 .. Cj2 = 0.
Menurut William (William, 2005), algoritma clustering terbagi ke dalam kelompok besar seperti berikut :
1. Partitioning algorithms: algoritma dalam kelompok ini membentuk
bermacam partisi dan kemudian mengevaluasinya dengan
berdasarkan beberapa kriteria.
2. Hierarchy algorithms: pembentukan dekomposisi hirarki dari
sekumpulan data menggunakan beberapa kriteria.
3. Density-based: pembentukan cluster berdasarkan pada koneksi dan
4. Grid-based: pembentukan cluster berdasarkan pada struktur
multiple-level granularity
5. Model-based: sebuah model dianggap sebagai hipotesa untuk
masing-masing cluster dan model yang baik dipilih diantara model hipotesa
tersebut.
2.4.1 K-Means Clustering
Algoritma K-Means adalah algoritma yang disusun atas dasar ide yang sederhana. Ada awalnya ditentukan berapa cluster yang akan dibentuk. Sembarang obyek atau elemen pertama dalam cluster dapat dipilih untuk dijadikan sebagai titik tengah (centroid point) cluster. Algoritma K-Means selanjutnya akan melakukan pengulangan langkah-langkah berikut sampai terjadi kestabilan (tidak ada obyek yang dapat dipindahkan) :
1. menentukan koordinat titik tengah setiap cluster,
2. menentukan jarak setiap obyek terhadap koordinat titik tengah,
data dan outlier). Selai itu juga bergantung pada pemilihan nilai awal centroid, tidak diketahui berapa banyak cluster k yang terbaik, dan hanya bekerja pada atribut numerik.
2.4.2 Clustering Hirarki (HierarchicalClustering)
Clustering Hirarki membangun sebuah Hirarki cluster atau dengan kata lain sebuah pohon cluster, yang juga dikenal sebagai dendrogram. Setiap node cluster mengandung cluster anak; cluster-cluster saudara yang membagi point yang ditutupi oleh induk mereka. Metode-metode clustering Hirarki dikategorikan ke dalam agglomeratif (bawah-atas) dan divisive (atas-bawah) (Jain & Dubes, 1988; Kaufman & Rousseeuw, 1990). Clustering agglomeratif dimulai dengan cluster satu point (singleton) dan secara berulang menggabungkan dua atau lebih cluster yang paling tepat. Cluster divisive dimulai dengan satu cluster dari semua point data dan secara berulang membagi cluster yang paling tepat. Proses tersebut berlanjut hingga kriteria penghentian (seringkali, jumlah k yang diperlukan dari cluster) dicapai. Kelebihan cluster Hirarki meliputi:
- fleksibilitas yang tertanam mengenai level granularitas,
- kemudahan menangani bentuk-bentuk kesamaan atau jarak,
- dapat digunakan pada tipe-tipe atribut apapun.
Kelemahan dari clustering Hirarki berhubungan dengan:
- ketidakjelasan kriteria terminasi,
Untuk clustering Hirarki, menggabungkan atau memisahkan subset dari point-point dan bukan point-point-point-point individual, jarak antara point-point-point-point individu harus digeneralisasikan terhadap jarak antara subset.
Ukuran kedekatan yang diperoleh disebut matrik hubungan. Tipe matrik hubungan yang digunakan secara signifikan mempengaruhi algoritma Hirarki, karena merefleksikan konsep tertentu dari kedekatan dan konektivitas. Matrik hubungan antar cluster utama (Murtagh 1985, Olson 1995) termasuk hubungan tunggal, hubungan rata-rata, dan hubungan sempurna. Semua matrik hubungan diatas dapat diperoleh sebagai jarak dari pembaharuan formula Lance-Williams (Lance & Williams, 1967).
D(C
i · · Cj , Ck = ɑ (i) d (Ci , Ck) + ɑ (k) d (Cj , Ck) + bd (Ci , Cj ) + c|d (Ci , Ck) –d(Cj , Cj)|
Dimana a, b, c adalah koefisien-koefisien yang sesuai dengan hubungan tertentu. Formula ini menyatakan sebuah matrik hubungan antara kesatuan dari dua cluster dan cluster ketiga dalam bentuk komponen-komponen yang mendasari.
Clustering Hirarki berdasarkan matrik hubungan mengalami kompleksitas waktu. Dibawah asumsi-asumsi yang tepat, seperti kondisi daya reduksi (metode-metode grafik memenuhi kondisi ini), (metode-metode-(metode-metode matrik hubungan memiliki kompleksitas (N2) (Olson 1995).
2.5Teknik Analisis Cluster Hirarki
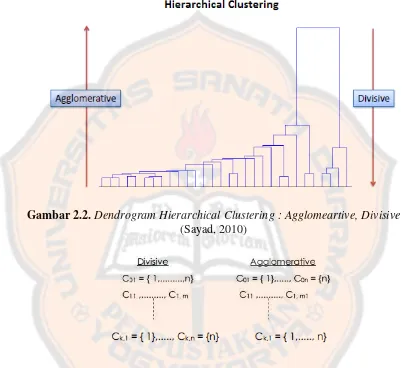
pertandingan). Dengan demikian proses pengelompokannya dilakukan secara bertingkat atau bertahap. Teknik analisis cluster hirarki dapat dibedakan ke dalam dua metode. Perbedaan kedua metode dapat dilihat di bawah :
Gambar 2.2.DendrogramHierarchical Clustering : Agglomeartive, Divisive (Sayad, 2010)
Metode Divisive dimulai dari satu cluster yang terdiri dari elemen x, sedangkan metode Agglomerative dimulai dari n cluster (Maulvi, 2009).
- Metode Agglomerative
ada atau bersama obyek lain dan membentuk cluster baru. Hal ini tetap memperhitungkan jarak kedekatan antar obyek. Proses akan berlanjut hingga akhirnya terbentuk satu cluster yang terdiri dari keseluruhan obyek. Diasumsikan jarak matrix (dij) pada setiap obyek C = { 1, ..., n}.
Menurut Kusrini (Kusrini, 2009), langkah-langkah dalam algoritma clustering hirarki agglomerative untuk mengelompokkan N objek (item/variabel) :
1. Mulai dengan N cluster, setiap cluster mengandung entitas tunggal dan sebuah matriks simetrik dari jarak (similarities) D = {dik} dengan tipe NxN.
2. Cari matriks jarak untuk pasangan cluster yang terdekat (paling mirip). Misalkan jarak antara cluster U dan V yang paling mirip adalah duv.
3. Gabungkan cluster U dan V. Label cluster yang baru dibentuk dengan (UV). Update entries pada matrik jarak dengan cara :
a. Hapus baris dan kolom yang bersesuaian dengan cluster U dan V b. Tambahkan baris dan kolom yang memberikan jarak-jarak antara cluster (UV) dan cluster-cluster yang tersisa.
Terdapat 3 metode dalam pembentukan cluster, yaitu :
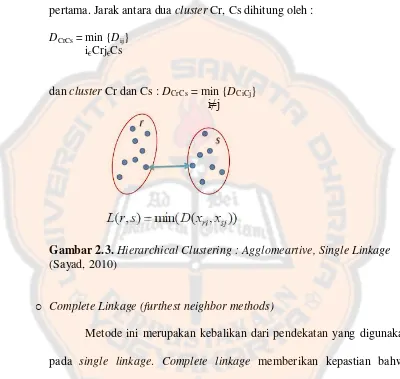
o Single Linkage (nearest neighbor methods)
Metode ini menggunakan prinsip jarak minimum yang di awali dengan mencari dua obyek terdekat dan keduanya membentuk cluster pertama. Jarak antara dua cluster Cr, Cs dihitung oleh :
DCrCs = min {Dij} i€Crj€Cs
dan cluster Cr dan Cs : DCrCs = min {DCiCj} i≠j
Gambar 2.3.Hierarchical Clustering : Agglomeartive, Single Linkage (Sayad, 2010)
o Complete Linkage (furthest neighbor methods)
Metode ini merupakan kebalikan dari pendekatan yang digunakan pada single linkage. Complete linkage memberikan kepastian bahwa semua item-item dalam satu cluster berada dalam jarak paling jauh ( similaritas terkecil) satu sama lain. Jarak dihitung menggunakan rumus :
Gambar 2.4.Hierarchical Clustering : Agglomeartive, Complete Linkage (Sayad, 2010)
o Average Linkage
Pada average linkage, jarak antara dua cluster didefinisikan sebagai jarak rata-rata antara setiap titik dalam satu cluster untuk setiap titik di cluster lain. Misalnya, jarak antara cluster "r" dan "s" di sebelah kiri adalah sama dengan panjang rata-rata setiap anak panah yang menghubungkan titik-titik satu cluster dengan yang lain.
2.6Fungsi Jarak
Untuk menghitung jarak kedekatan (similarity) obyek satu dengan yang lain, dapat digunakan Euclidean Distance. Dalam matematika (Rodiyansyah, 2010), Euclidean Distance adalah jarak antara dua titik yang dapat diukur dan dihasilkan oleh formula pytagoras. Euclidean vector atau sering hanya disebut dengan vector adalah obyek geometri yang memiliki panjang (magnitude) dan arah (direction). Sedangkan ruang vektor adalah sebuah structur matematika yang dibentuk oleh sekumpulan vektor. Vektor-vektor tersebut dapat ditambahkan, dikalikan dengan bilangan real dan lain-lain. Berikut merupakan penyelesaian dalam menghitung jarak antara vektor A dan vektor B. Panjang vektor A dan B dapat didefinisikan sebagai berikut:
Dengan demikian, untuk menghitung jarak antara kedua vektor tersebut menggunakan persamaan sebagai berikut :
(2.6.1) Sedangkan untuk n dimensi ruang vektor, jarak euclidean distance ditentukan dengan menggunakan persamaan sebagai berikut :
2.7Geometri
Kata “geometri” berasal dari bahasa Yunani yang berarti “ukuran bumi”.
Maksudnya mencakup segala sesuatu yang ada di bumi. Geometri adalah ilmu yang membahas tentang hubungan antara titik, garis, sudut, bidang dan bangun-bangun ruang. Mempelajari geometri penting karena geometri telah menjadi alat utama untuk mengajar seni berpikir. Geometri juga terdiri dari serangkaian pernyataan tentang titik-titik, garis-garis, dan bidang-bidang juga planar (proyeksi bidang) dan benda-benda padat. Geometri dimulai dari istilah-istilah yang tidak terdefinisikan, definisi-definisi, aksioma-aksioma, postulat-postulat dan selanjutnya teorema-teorema. Berdasarkan sejarah, geometri telah mempunyai banyak penerapan yang sangat penting, misalnya dalam mensurvei tanah, pembangunan jembatan, pembangunan stasiun luar angkasa dan lain sebagainya.
Geometri adalah sistem pertama untuk memahami ide. Dalam geometri beberapa pernyataan sederhana diasumsikan, dan kemudian ditarik menjadi pernyataan-pernyataan yang lebih kompleks. Sistem seperti ini disebut sistem deduktif. Geometri mengenalkan tentang ide konsekuensi deduktif dan logika yang dapat digunakan sepanjang hidup (Asmadi, 2011).
2.8Sudut
segitiga siku-siku 180o. Besar sudut pada persegi empat 360o. Untuk mengukur sudut dapat digunakan busur derajat. Macam besar sudutnya, yaitu :
- Sudut Lancip
Sudut yang besarnya lebih kecil dari 90odan lebih besar dari ∞.
- Sudut Siku-siku
Sudut yang besarnya 90o.
- Sudut Tumpul
Sudut yang besarnya lebih kecil dari 180o dan lebih besar dari 90o.
- Sudut Lurus
Sudut yang besarnya 180o.
- Sudut Lingkaran Penuh
Sudut yang besarnya 360o (Asmadi, 2011).
2.9Geometri Bangun Datar
2.9.1 Bagian-bagian Bangun Datar
Sedangkan garis (garis lurus) hanya mempunyai ukuran panjang, tetapi tidak mempunyai ukuran lebar. Nama dari sebuah garis dapat ditentukan dengan menyebutkan nama wakil garis itu dengan memakai huruf kecil g, h, k atau menyebutkan nama segmen dari titik pangkal ke titik ujung(Dwijoeas, 2008). Sebuah garis (garis lurus) dapat dibayangkan sebagai kumpulan dari titik-titik yang memanjang secara tak terhingga ke kedua arah(Asmadi, 2011).
Sebuah bidang (dimaksudkan adalah bidang datar), hanya dapat diperluas seluas-luasnya. Pada umumnya, sebuah bidang hanya dilukiskan sebagian saja yang disebut sebagai wakil bidang. Wakil suatu bidang mempunyai dua ukuran, yaitu panjang dan lebar. Gambar dari wakil bidang dapat berbentuk persegi atau bujur sangkar, persegi panjang, atau jajargenjang. Nama wakil bidang dituliskan di daerah pojok bidang dengan memakai huruf-huruf α, β, ϒ atau H, U, V, W atau dengan menyebutkan titik-titik sudut dari wakil bidang itu (Dwijoeas, 2008). Dikatakan juga bahwa sebuah bidang dapat dianggap sebagai kumpulan titik yang jumlahnya tak terhingga yang membentuk permukaan rata yang melebar ke segala arah sampai tak terhingga(Asmadi, 2011).
2.9.2 Macam Bangun Datar
2.9.2.1Segitiga
Bangun segitiga dilambangkan dengan ∆ (Rizki, 2008). Jumlah sudut pada segitiga besarnya 180⁰. Jenis-jenis segitiga :
a. Segitiga Sama Sisi
Gambar 2.6. Segitiga sama sisi mempunyai 3 sisi sama panjang.
mempunyai 3 sudut sama besar yaitu 60⁰. mempunyai 3 simetri lipat.
mempunyai 3 simetri putar. b. Segitiga Sama Kaki
Gambar 2.7. Segitiga sama kaki
mempunyai 2 sisi yang berhadapan sama panjang. mempunyai 1 simetri lipat.
mempunyai 1 simetri putar. c. Segitiga Siku-Siku
mempunyai 2 sisi yang saling tegak lurus. mempunyai 1 sisi miring.
salah satu sudutnya adalah sudut siku-siku yaitu 90⁰. tidak mempunyai simetri lipat dan putar.
untuk mencari panjang sisi miring digunakan rumus phytagoras :
d. Segitiga Sembarang
Gambar 2.9. Segitiga sembarang
Segitiga sembarang merupakan bangun geometri yang dibentuk oleh 3 buah garis saling bertemu dan membentuk 3 buah titik sudut. Bangun segitiga dilambangkan dengan ∆. Jumlah sudut
pada segitiga besarnya 1800.
e. Segitiga Tumpul
Gambar 2.10. Segitiga tumpul
a2 + b2 = c2
Segitiga tumpul merupakan bangun geometri yang dibentuk oleh 3 buah garis saling bertemu dan membentuk 3 buah titik sudut yang berbeda. Rumus keliling dan luas segitiga adalah sebagai berikut(Rizki, 2008) :
2.9.2.2Persegi
Gambar 2.11. Persegi
Persegi adalah bangun datar yang dibatasi 4 sisi yang sama panjang. Mempunyai 4 titik sudut. Mempunyai 4 sudut siku-siku 90⁰. Mempunyai 2 diagonal yang sama panjang. Mempunyai 4 simetri lipat. Mempunyai 4 simetri putar. Rumus keliling dan luas adalah sebagai berikut(Rizki, 2008) :
„
2.9.2.3Persegi Panjang
Gambar 2.12. Persegi panjang
Keliling = panjang sisi 1 + panjang sisi 2 + panjang sisi 3 Luas = alas x tinggi
2
Persegi panjang merupakan bangun datar yang mempunyai 4 sisi. Sisi yang berhadapan sama panjang dan sejajar. Sisi-sisi persegi panjang saling tegak lurus. Mempunyai 4 sudut siku-siku 90⁰. Mempunyai 2 diagonal yang sama panjang. Mempunyai 2 simetri lipat. Mempunyai 2 simetri putar. Rumus keliling dan luas adalah sebagai berikut :
Keliling = 2 x ( panjang + lebar ) Luas = panjang x lebar
2.9.2.4Jajargenjang
Gambar 2.13. Jajargenjang
Jajargenjang merupakan bangun datar yang mempunyai 4 buah sisi. Sisi yang berhadapan sejajar dan sama panjang. Dua sisi lainnya tidak saling tegak lurus. Mempunyai 4 sudut, 2 sudut berpasangan dan berhadapan. Sudut yang saling berdekatan besarnya 180⁰. Mempunyai 2 diagonal yang tidak sama panjang.
Tidak mempunyai simetri lipat dan simetri putar. Rumus keliling dan luas adalah sebagai berikut:
2.9.2.5Belah Ketupat
Gambar 2.14. Belah Ketupat
Belah ketupat merupakan bangun geometri yang dibatasi 4 sisi sama panjang. Mempunyai 4 titik sudut. Sudut yang berhadapan besarnya sama. Sisinya tidak tegak lurus. Mempunyai 2 diagonal yang berbeda panjangnya. Mempunyai 2 simetri lipat. Mempunyai 2 simeteri putar. Rumus keliling dan luas adalah sebagai berikut :
Keliling = 4 x sisi
Luas = ½ x diagonal 1 x diagonal 2
2.9.2.6Layang-layang
Gambar 2.15. Layang-layang
panjang. Mempunyai 4 buah sudut. Sepasang sudut yang berhadapan sama besar. Mempunyai 2 diagonal berbeda dan tegak lurus. Mempunyai 1 simetri lipat. Tidak mempunyai simetri putar. Rumus keliling dan luas adalah sebagai berikut[21] :
Keliling = 2 x ( sisi panjang + sisi pendek ) Luas = ( diagonal 1 x diagonal 2 ) / 2
2.9.2.7Trapesium
Trapesium adalah bangun segiempat dengan sepasang sisi berhadapan sejajar. Tiap pasang sudut yang sisinya sejajar adalah 180⁰. Jenis-jenis trapesium :
1. Trapesium Sembarang (mempunyai sisi-sisi yang berbeda)
Gambar 2.16. Trapesium sembarang
2. Trapesium Siku-Siku (mempunyai sudut siku-siku)
Gambar 2.17. Trapesium siku-siku
3. Trapesium Sama Kaki (mempunyai sepasang kaki sama panjang).
Rumus keliling dan luas adalah (Rizki, 2008) : Keliling = jumlah ke-empat sisinya
Luas = ( jumlah sisi sejajar x tinggi ) / 2
2.9.2.8Lingkaran
Gambar 2.19. Lingkaran
Lingkaran merupakan kurva tertutup sederhana beraturan. Jumlah derajat lingkaran sebesar 360⁰. Lingkaran mempunyai 1
titik pusat. Mempunyai simetri lipat dan simetri putar yang jumlahnya tidak terhingga. Istilah-istilah dalam lingkaran :
1. Diameter lingkaran (d) yaitu ruas garis yang menghubungkan dua titik pada busur lingkaran melalui titik pusat lingkaran. 2. Jari-jari lingkaran (r) yaitu ruas garis yang menghubungkan
titik pada busur lingkaran dengan titik pusat lingkaran.
3. Tali busur yaitu garis yang menghubungkan dua titik pada busur lingkaran dan tidak melewati titik pusat lingkaran.
4. Busur yaitu bagian lingkaran yang dibagi oleh tali busur.
6. Susut pusat yaitu sudut yang dibentuk oleh 2 buah jari-jari (Rizki, 2008).
Rumus Hubungan Diameter (d) dan Jari-Jari (r)(r) :
Rumus Hubungan Busur, Juring, dan Sudut Pusat :
Rumus Keliling Lingkaran : lingkarannya, tidak demikian dengan elips karena elips merupakan gambar yang menyerupai lingkaran yang salah satu jari-jarinya
Diameter (d) = 2 x jari-jari Jari-jari (r) = ½ diameter
telah dipanjangkan ke satu arah (sumbu-x atau sumbu-y). Elips adalah salah satu contoh dari irisan kerucut (Abdurahim, 2012).
Rumus keliling = 1/2π (a+b) Rumus Luas = π/4 x ab
2.10 Cluster Validitas
Cluster validitas adalah salah satu langkah yang paling penting dan mendasar dalam cluster analisa yang berhubungan dengan ekstrak fitur data. Hal ini bertujuan untuk mengevaluasi hasil pengelompokan dan pemilihan skema yang paling sesuai dengan data yang mendasarinya.
2.11 Alat Ukur Akurasi
Evaluasi sebuah model merupakan tahapan yang perlu dilakukan dalam sebuah penelitian untuk memperoleh informasi ketepatan (akurasi) algortima clustering yang digunakan. Menurut Kohavi dan Provost (Kohavi dan Provost, 1998), akurasi berhubungan mengenai prediksi tingkat kebenaran yang dibuat oleh model lebih dari satu set data. Akurasi biasanya diperkirakan dengan menggunakan set tes independen yang tidak digunakan setiap saat selama proses pembelajaran (training). Dalam penelitian kali ini, alat ukur akurasi yang digunakan adalah Confussion Matrix. Confussion Matrix (Kohavi dan Provost, 1998) adalah matriks yang berisi informasi aktual dan prediksi klasifikasi yang dilakukan oleh sistem klasifikasi. Kinerja sistem seperti ini biasanya dievaluasi dengan menggunakan data dalam matriks. Tabel berikut menunjukkan confussion matrix untuk mengklasifikasi dua kelas :
Gambar 2.21.Confussion Matrix (Kohavi dan Provost, 1998) Berikut istilah yang ditetapkan menurut Confussion Matrix di atas :
Akurasi (Accuracy) : (a+d)/(a+b+c+d) (2.10.1) True positive rate (Recall, Sensitivity) : d/(c+d) (2.10.2) True negative rate (Specificity) : a/(a+b) (2.10.3)
Precision : d/(b+d) (2.10.4)
False positive rate : b/(a+b) (2.10.5)
39
BAB III
ANALISA DAN DESAIN
Bab ini menjelaskan mengenai desain atau gambaran aplikasi yang akan dibuat dan dikembangkan mulai dari data, diagram use case, desain subsistem manajemen model dan desain interface.
3.1Deskripsi Umum Aplikasi
Aplikasi yang akan dibuat adalah aplikasi mesin pencari dengan input berupa gambar bangun datar. Gambar yang diinputkan akan melalui pemrosesan terlebih dahulu sebelum dibandingkan, antara lain proses thinning dan resize citra input sehingga ukuran gambar yang dibandingkan sama, dan binerisasi citra untuk memastikan nilai piksel dalam matriks hanya 0 dan 1. Dari proses tersebut akan didapatkan matriks feature untuk dibandingkan dengan feature yang sudah diekstrak dan disimpan.
Proses yang akan dilakukan sistem mulai dari data training sampai menjadi model adalah sebagai berikut :
Gambar 3.1. Diagram alur proses pemodelan
Sedangkan diagram untuk menggambarkan proses ekstrasi fitur adalah sebagai berikut :
Gambar 3.2. Diagram alur proses ekstrak fitur
Di bawah adalah diagram untuk menggambarkan proses clustering menggunakan Agglomerative Hierarchical Clustering:
Input
Sedangkan alur kerjaaplikasi interface untuk user dapat dilihat pada gambar flowchart sistem validasi feature di bawah :
Start
User menginputkan gambar bangun datar ke dalam aplikasi
pencarian dibandingkan feature model
hirarki clustering (segitiga, persegi dan lingkaran)
Sistem menghitung similaritas feature input dengan feature segitiga, persegi dan lingkaran. similaritas feature input dengan feature
macam-macam segitiga
Ya
Tidak
Sistem menghitung similaritas feature input dengan feature
macam-macam persegi
Sistem menghitung similaritas feature input dengan feature
macam-macam lingkaran
2
3
Gambar 3.4.Flowchart Sistem Validasi Fitur
Dari Gambar 3.4 dapat diketahui proses penyeleksian validasi feature input dengan data pemodelan yang telah dilakukan sistem pada interface user adalah sebagai berikut :
1. Gambar input user akan diresize dengan memfokuskan pada gambar input dari background yang kurang penting dan selanjutnya akan dibinerkan terlebih dahulu untuk memudahkan penghitungan similaritas menggunakan Euclidean Distance.
2. Sistem mengekstrak fitur dari gambar yang sudah di-thinning, resize dan dibinerkan dengan mendapatkan matriks hasil ekstrak fitur berupa jumlah total putih atau 1 dalam matriks berukuran 1 x 25.
2 3 4 dan rumus jenis segitiga dari hasil validasi nilai similarity
terbesar
Menampilkan keterangan dan rumus jenis persegi dari hasil validasi nilai similarity
terbesar
Menampilkan keterangan dan rumus jenis lingkaran dari hasil validasi nilai
similarity terbesar
3. Dari matriks fitur, gambar input tersebut dibandingkan dengan matriks fitur model segitiga, persegi dan lingkaran dengan menghitung jarak kedekatan matriks menggunakan Eucllidean Distance.
4. Dari hasil perhitungan similaritas sebelumnya, didapat hasil similaritas dari perhitungan jarak Euclidean dengan nilai terkecil yang kemudian dipakai untuk membandingkan matriks fitur input dengan jenis-jenis dari model (segitiga, persegi, atau lingkaran) yang didapat sebelumnya.
5. Sistem menampilkan hasil pencarian berupa keterangan dan rumus dari geometri bangun datar yang sesuai dengan hasil pengukuran similaritas terbesar jenis-jenis model.
3.2Data
Data yang akan digunakan oleh aplikasi ini meliputi jenis-jenis geometri bangun datar pada pelajaran Matematika tingkat Sekolah Menengah Pertama (SMP) dengan keterangan dan rumus dari bangun datar tersebut. Gambar bangun datar yang digunakan sebagai pemodelan cluster adalah gambar bangun datar yang dibuat menggunakan paint dengan jumlah gambar sebanyak 50. Sedangkan gambar lain yang digunakan sebagai testing adalah file gambar berekstensi *.jpg dari hasil gambar tangan di-scan, gambar scan dari buku materi dan beberapa sumber lain di internet.
Gambar 3.5. Gambar filetraining
3.3Ekstrak Fitur
Untuk dapat diproses menggunakan Agglomerative Hierarchical Clustering, setiap gambar akan melalui proses ekstrak fitur untuk mendapatkan informasi unik dari masing-masing gambar yang digunakan untuk membedakan gambar yang satu dengan yang lain. Proses ini merupakan proses terpenting dalam penelitian. Kualitas gambar antara lain kontras, pencahayaan, dan noise sangat berperan penting dalam ekstraksi fitur. Selain itu jumlah data bisa yang terlalu sedikit maupun banyak juga dapat mempengaruhi ketepatan anggota dari masing-masing cluster. Langkah untuk mendapatkan matriks fitur adalah sebagai berikut : 1. Load folder data gambar bangun datar bertipe .jpg.
2. Untuk masing-masing gambar dalam folder yang telah di-load, lakukan looping :
2. Ubah data matriks gambar ke dalam citra keabuan dengan fungsi rgb2gray.
3. Lakukan proses thresholding dengan fungsi graythresh. 4. Ubah citra ke dalam „black and white’ dengan fungsi im2bw.
5. Resize gambar input dengan crop gambar fokus setelah menemukan titik pertama setiap dari kiri ke kanan dan sebaliknya, juga setiap kolom dari atas ke bawah dan sebaliknya. Titik noise sangat mempengaruhi.
3. Putar gambar dengan fungsi imrotate supaya gambar yang didapatkan lebih dalam posisi normal. Langkah merotasi gambar sendiri adalah sebagai berikut: 1. Lakukan looping dari 1-180 dimana nilai ini adalah parameter yang
digunakan dalam fungsi imrotate (nilai derajat).
2. Untuk masing-masing nilai derajat, cari ukuran gambar dengan dimensi terkecil. Kemudian bandingkan dengan nilai dimensi gambar sebelum dirotasi. Nilai dimensi terkecil dianggap sebagai posisi normal dari gambar. Maka pilih gambar dengan nilai dimensi terkecil.
4. Lakukan looping masing-masing gambar untuk memindahkan gambar fokus yang telah dicrop ke dalam matriks berukuran maksimum panjang dan lebar supaya ukuran ekstrak fitur sama.
5. Untuk masing-masing gambar yang telah diproses dan di-resize, lakukan looping :
1. Bagi gambar menjadi 25 bagian : 5 baris dan 5 kolom, matriks 5x5.
1 2 3 4 5
6 7 8 9 10
11 12 13 14 15
16 17 18 19 20
21 22 23 24 25
Gambar 3.7. Membagi menjadi 5x5 untuk ekstrak fitur
2. Untuk sub bagian dari masing-masing bagian, jumlahkan nilai biner di setiap kolom dan barisnya setelah melalui proses thinning.
3. Jumlahkan kembali nilai jumlah biner setiap kolom dan baris yang sudah didapat sehingga didapat fitur berukuran 1 x 25.
4. Urutkan dari nilai ekstrak fitur terkecil yang didapat sampai nilai maksimal menggunakan fungsi sort. Didapatkan asumsi bahwa posisi sudut masing-masing gambar berbeda, sehingga dengan membuat urutan fitur secara acak melalui proses sorting didapatkan lebih banyak kemiripan. Ilustrasi sorting dapat dilihat pada Tabel 3.3 di lampiran. 5. Bagi nilai matriks ekstrak fitur yang sudah diurutkan dengan nilai
3.4Proses Agglomerative Hierarchical Clustering
Dari matriks fitur hasil proses ekstrak fitur untuk gambar training, untuik mengetahui 3 kelompok yang berbeda digunakan Agglomerative Hierarchical Clustering untuk mendapatkan model pengenalan segitiga, segi empat atau lingkaran. Langkah yang dilakukan adalah sebagai berikut :
1. Dari ekstrak fitur yang didapat, hitung jarak kedekatan setiap obyeknya menggunakan Euclidean Distance :
EuclideanDistance = sqrt(sum((obyek1-obyek2).^2))
2. Cari nilai jarak yang terkecil dari keseluruhan jarak antar obyek yang di dapat untuk mendapatkan similaritas terbesar dalam sebuah matriks jarak.
3. Gabungkan obyek dengan nilai jarak terbesar atau terjauh menggunakan metode complete linkage. Simpan ke dalam variabel bantu yang terdiri dari 3 kolom (kolom 1, 2 adalah obyek yang digabung, kolom 3 adalah jarak hasil obyek yang digabung).
4. Setelah didapat hubungan jarak antar obyek, tampilkan dalam bentuk dendrogram.
5. Didapat 3 kelompok cluster, segitiga, segi empat dan lingkaran.
1. Segitiga
0 0 0 0 0 0 0 0 0 0.03 0.05 0.07 0.10 0.47 0.48 0.55 0.57 0.60 0.61 0.62 0.62 0.62 0.93 0.97 1
2. Segi Empat
0 0 0 0 0 0 0 0 0 0.26 0.33 0.43 0.47 0.49 0.50 0.54 0.55 0.57 0.57 0.58 0.58 0.75 0.80 0.95 1
3. Lingkaran
0 0 0 0 0 0 0 0 0 0.44 0.44 0.45 0.45 1 1 1 1 1 1 1 1 1 1 1 1
Bila ditampilkan ke dalam grafik akan terlihat perbedaan antara model segitiga, segi empat dengan lingkaran :
1. Grafik model segitiga
2. Grafik model segi empat
Gambar 3.9. Grafik model segi empat 3. Grafik model lingkaran
Gambar 3.10. Grafik model lingkaran
3.5Evaluasi Hasil
Untuk mengetahui seberapa akurat proses modeling yang telah dilakukan, dapat dihitung menggunakan Confussion Matrix. Langkah untuk mendapatkan nilai akurasi sebagai evaluasi hasil adalah :
1. Bagi data model ke dalam beberapa kelompok atau grup. 2. Cari kombinasi dari beberapa kelompok atau grup tersebut.
3. Untuk masing-masing gabungan, hitung akurasi dari hasil conffusion matrix : Masukan jumlah data berupa informasi aktual dan prediksi yang dilakukan oleh sistem ke dalam Confussion Matrix 3x3 untuk mengenali model segitiga, segi empat atau lingkaran.
Tabel 3.1.Confussion Matrix 3x3
Aktual / Prediksi Segitiga Segi Empat Lingkaran
Segitiga A B C
Segi Empat D E F
Lingkaran G H I
Akurasi akan dihitung dengan menjumlahkan A, E, dan I yang akan dibagi dengan total data : (A+E+I)/(A+B+C+D+E+F+G+H+1).
Jika nilai akurasi mendekati 1, maka keakuratan sistem sangat baik. Jika dilihat dalam persen, maka nilai akurasi tersebut bisa dikalikan dengan 100%.
3.6Model Use Case
Use Case adalah salah satu diagram yang digunakan untuk mendeskripsikan siapa yang akan menggunakan sistem dan melalui cara apa pengguna (user) mengharapkan interaksi dengan sistem tersebut secara grafis. Use Case secara naratif digunakan secara tekstual untuk menggambarkan sekuensi langkah–langkah dari setiap interaksi.
3.6.1 Aktor dalam Use Case
Hanya terdapat satu aktor yang berperan sebagai pengguna Aplikasi searching dengan input gambar geometri bangun datar menggunakan Agglomerative Hierarchical Clustering ini, yaitu user yang meliputi siswa siswi Sekolah Menengah Pertama dan guru (khususnya mata pelajaran Matematika) sebagai alat peraga mengajar.
3.6.2 Diagram Use Case
Aplikasi Searching Gambar Geometri Bangun Datar Menggunakan Hierarchical Clustering
Agglomerative Single LinkageInput gambar geometri bangun datar
user
Klik tombol cari <<depends on>>
3.6.3 Definisi Use Case
Deskripsi : Aktor dapat melakukan input gambar untuk dilakukan proses pencarian keterangan, contoh soal, dan rumus yang sesuai.
S-02-02 Klik tombol cari Aktor : User
Deskripsi : Aktor klik tombol cari untuk melakukan proses pencarian.
3.6.4 Skenario Use Case
Nama Use Case : Input gambar geometri bangun datar
Aktor : User
Skenario:
Aksi Actor Reaksi Sistem
Skenario Normal 1. User meng-input-kan data berupa gambar pada kotak browse image.
2. Sistem menampilkan gambar input user.
Nama Use Case : Klik tombol cari
Aktor : User
Skenario:
Aksi Actor Reaksi Sistem
Skenario Normal 1. User melakukan klik pada tombol cari.
2. Sistem memvalidari matriks fitur gambar input dengan yang sudah disimpan.
3.Sistem menampilkan gambar yang telah diproses dan detailnya.
3.7Desain Subsistem Manajemen Model
Data set yang digunakan sebagai data training cluster pembuatan model dalam sistem aplikasi ini menggunakan data matriks fitur beberapa bangun datar. Untuk mendapatkan hasil pencarian digunakan teknik data mining yakni Agglomerative Hierarchical Clustering. Langkah-langkah perhitungannya adalah sebagai berikut :
1. Mengukur kedekatan gambar input dengan gambar model (segitiga, persegi, dan lingkaran) dengan menggunakan Euclidean Distance. Untuk perhitungan ini, digunakan matriks fitur yang berisi jumlah piksel putih atau biner 1 untuk masing-masing bagian menjadi 1x25.
2. Jika nilai similarity atau kedekatan antar obyek sudah didapat melalui perhitungan nomor 1, gambarkan ke dalam dendrogram.
3. Dari gambar dendogram hirarki clustering akan diambil 3 kluster untuk membedakan segitiga, segi empat dan lingkaran.
3.8Desain Interface
Desain interface diperuntukan bagi user untuk mempermudah interaksi dengan sistem. Berikut adalah tampilan halaman awal bagi user :
Dari gambar desain antarmuka tersebut, dapat dijelaskan bahwa pada bagian header akan diisi logo dan judul dari aplikasi tersebut. Sedangkan kotak dialog akan berisi nama data gambar yang diinputkan setelah user klik tombol browse dan gambar input akan ditampilkan pada kotak gambar input. Untuk memulai proses pencarian, user dapat klik tombol cari dan sistem akan menampilkan gambar setelah diproses dan hasil pencarian pada bagian content hasil pencarian. Sedangkan footer berisi tahun pembuatan dan inisial pembuat.
HEADER
browse cari
Content hasil pencarian footer
Gambar input Gambar stlh
diproses
55
BAB IV
IMPLEMENTASI
Pada bab ini berisi implementasi sistem dan interface. Implementasi menggunakan Matlab dan merupakan implementasi utama pembacaan citra bangun datar, implementasi metode Agglomerative Hierarchical Clustering sederhana untuk membantu membentuk cluster agar menjadi lebih cepat, dan implementasi interface yang merupakan hasil implementasi antarmuka untuk aplikasi searching gambar bangun datar yang dibuat.
4.1Ekstrak Fitur
Pada keseluruhan proses menggunakan bantuan Matlab meliputi pembacaan file, pemrosesan citra, ekstraksi fitur, pembentukan cluster, tampilan dendrogram dan interface sistem. Implementasi sistem berisi listing program dengan Matlab. Implementasi ini merupakan implementasi perancangan sistem yang telah dibuat pada bab sebelumnya. Pada proses ekstrak fitur, terdapat beberapa proses yang dilakukan, antara lain :
4.1.1 Transformasi ke dalam citra biner
im2bw untuk merubah citra ke dalam black and white atau biner. Berikut listing lengkap transformasi ke dalam citra biner :
4.1.2 Resize dan crop citra menjadi lebih fokus
Contoh hasil pemotongan gambar yang telah dilakukan adalah pada pemotongan gambar segitiga siku-siku di bawah :
Gambar 4.1. Hasil Pemotongan gambar segitiga siku-siku
gambar tampak lebih fokus dengan mengabaikan latar belakang. Pada proses pembentukan cluster, proses pemotongan gambar di atas dilakukan supaya gambar yang dibandingkan berukuran sama.
4.1.3 Rotasi gambar
Rotasi gambar yang memanfaatkan fungsi imrotate dilakukan supaya gambar yang didapatkan lebih dalam posisi normal. Didapatkan asumsi bahwa ada beberapa gambar dalam kondisi miring dan membuat ukuran dimensi gambar lebih besar. Sehingga dilakukan rotasi gambar untuk mendapatkan posisi yang benar untuk menghilangkan beberapa bagian yang kurang penting selain informasi dari gambar. Langkah merotasi gambar sendiri adalah sebagai berikut :
1. Lakukan looping dari 1-180 dimana nilai ini adalah parameter yang digunakan dalam fungsi imrotate (nilai derajat).
4.1.4 Proses Ekstrak fitur gambar bangun datar
Setelah melalui beberapa proses sebelumnya, proses ini merupakan proses terpenting dalam analisis citra untuk mengenali gambar yang akan dilakukan oleh komputer melalui piksel-piksel yang tersimpan dalam matriks. Selain obyek satu dengan lainnya harus terbedakan, kompleksitas komputasi juga perlu diperhatikan karena semakin rendah tingkat kompleksitas komputasi akan memberikan hasil yang lebih baik. Karena aplikasi yang dibuat merupakan aplikasi searching, maka harus diperhatikan kecepatan dan ketepatan dalam menampilkan hasil, sehingga fitur yang digunakan sedikit supaya menghemat waktu komputasi. Dalam kasus ini digunakan ekstraksi bentuk untuk membedakan bangun datar jenis segitiga, segi empat, dan lingkaran.
Pada proses ini dikenai thinning sebagai preprocessing untuk menghilangkan bagian atau piksel-piksel yang tidak perlu sehingga ukurannya lebih kecil dan menghasilkan informasi yang esensial. Pada listing program di atas, thinning dilakukan dengan bantuan function bwmorph :
4.2Proses clustering menggunakan Agglomerative Hierarchical Clustering
nilai jarak terbesar dan average linkage adalah dengan dengan mendefinisikan jarak rata-rata antar setiap titik dalam satu cluster untuk setiap titik di cluster lain. Ketiga metode tersebut akan coba diimplementasikan dibuat dalam beberapa function. Parameter function singleLinkage, completeLinkage, dan averageLinkage adalah nama variabel yang menyimpan matriks jarak yang sudah didapat.