i
LAPORAN TUGAS AKHIR
IMPLEMENTASI DATA MINING UNTUK IDENTIFIKASI
POLA PENYAKIT ISPA DENGAN MENGGUNAKAN
ALGORITMA APRIORI (Studi Kasus Di UPTD Puskesmas Bae
Kabupaten Kudus)
Disusun Oleh:
Nama
:Abdul Mustakim
NIM
:A12.2011.04457
Program Studi
:Sistem Informasi - S1
FAKULTAS ILMU KOMPUTER
UNIVERSITAS DIAN NUSWANTORO
SEMARANG
2015
ii
IMPLEMENTASI DATA MINING UNTUK IDENTIFIKASI
POLA PENYAKIT ISPA DENGAN MENGGUNAKAN
ALGORITMA APRIORI (Studi Kasus Di UPTD Puskesmas Bae
Kabupaten Kudus)
Laporan ini disusun guna memenuhi salah satu syarat untuk menyelesaikan program studi Sistem Informasi S-1 pada Fakultas Ilmu Komputer
Universitas Dian Nuswantoro
Disusun Oleh:
Nama
:Abdul Mustakim
NIM
:A12.2011.04457
Program Studi
:Sistem Informasi - S1
HALAMAN JUDUL
FAKULTAS ILMU KOMPUTER
UNIVERSITAS DIAN NUSWANTORO
SEMARANG
2015
iii
PERSETUJUAN PROPOSAL TUGAS AKHIR
NB: Halaman ini tidak perlu dihapus dan dicetak Silakan download halaman ini di siadin setelah ujian
iv
NB: Halaman ini tidak perlu dihapus dan dicetak Silakan download halaman ini di siadin setelah ujian
v
PENGESAHAN DEWAN PENGUJI
NB: Halaman ini tidak perlu dihapus dan dicetak Silakan download halaman ini di siadin setelah ujian
vi
vii
PERNYATAANPERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
NB: Halaman ini tidak perlu dihapus dan dicetak Silakan download halaman ini di siadin setelah ujian
viii
Semarang, {Februari} {tanggal} Penulis
ix
*ABSTRAK/RINGKASAN
Dalam bidang kesehatan, ketersediaan data rekam medis sudah bukan lagi hal yang sulit diperoleh, namun sering kali data ini hanya diperlakukan sebagai rekaman tanpa pengolahan lebih lanjut, sehingga tidak mempunyai nilai guna lebih untuk keperluan masa mendatang. Berdasarkan rekap data rekam medis tahun 2013 menunjukkan penyakit ISPA menjadi penyakit paling banyak dialami oleh pengunjung UPTD Puskemas Bae, diperlukan solusi serta penanganan khusus untuk menangani masalah tersebut. Seperti mencari informasi mengenai pola penyakit tersebut, misalnya seberapa kuat hubungan persentase antara jenis kelamin, umur, alamat terhadap bulan periksa. Suatu teknologi yang dapat digunakan dalam pencarian pola atau hubungan asosiasi dari data yang bersekala besar adalah data mining association rule dengan algoritma apriori. Hasil pemrosesan data mining tersebut diharapkan dapat membantu mengetahui pola penyebaran penyakit ISPA dan menggunakannya sebagai referensi untuk melakukan sosialisasi atau penyuluhan mengenai gejala, bahaya serta dampak dari penyakit Ispa sehingga dapat dilakukan pencegahan lebih awal.
Kata kunci : Data Mining, Association Rule, Algoritma Apriori, Pola Penyakit
ABSTRACT
In the health sector, availability of medical records are no longer things that are difficult to obtain, but often this data is only treated as a recording without further processing so it does not have to be important value in the future. Based on recap medical records of 2013 show Acute Respiratory Infections (ARI) become most illnesses experienced by visitors UPTD Puskemas Bae, required special handling solutions as well as to address the problem, such as find the information about the pattern of the disease, such as how strong the relationship between the percentage of sex, age, address of the month check. A technology that can be used in searching pattern or relationship associations from large scale data is data mining association rule with apriori algorithm. The results of data mining processing is expected to help in determine the spread of Acute Respiratory Infections (ARI) and use it as a reference in socializing or counseling about the symptoms, dangers and impact of disease prevention ARI so it can be done earlier.
Keywords : Data Mining, Association Rule, Algorithm Apriori, Pattern Acute
xi DAFTAR ISI
Halaman Judul ... ii
Persetujuan Proposal Tugas Akhir ... iii
Persetujuan Laporan Tugas Akhir ... iv
Pengesahan Dewan Penguji ... v
Pernyataan Keaslian Tugas Akhir ... viv
Pernyataan Persetujuan Publikasi Karya IlmiahUntuk Kepentingan Akademis .... v
Ucapan Terimakasih ... vi
*Abstrak/Ringkasan ... vii
Abstract ... vx
Daftar Isi ... xi
Daftar Gambar... xv
Daftar Tabel ... xvi
Bab 1 Pendahuluan ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 2
1.3 Batasan Masalah ... 2
1.4 Tujuan Penelitian ... 3
1.5 Manfaat Penelitian ... 3
Bab 2 TINJAUAN PUSTAKA ... 5
2.1 Tinjauan Pustaka ... 5
2.2 Data Mining ... 6
2.2.1 Tahapan Proses Data Mining ... 7
2.3 Algoritma Apriori ... 11
2.4 Metode Pengembangan Sistem ... 1Error! Bookmark not defined. 2.5 Analisa Sistem ... 15
2.5.1 Pengertian Analisa Sistem ... 15
2.5.2 Tahap-tahap Analisis Sistem ... 16
2.5.3 Alat Bantu Analisis Sistem ... 17
2.6 Perancangan Sistem ... 18
2.6.1 Pengertian Perancangan Sistem ... 18
2.6.1 Alat Bantu Perancangan Sistem ... 19
2.6.3 Kamus Data (Data Dictionary) ... 22
2.7 PHP ... 22
2.7.1 Pengertian PHP ... 22
2.7.2 Cara Kerja PHP ... 23
Bab 3 METODE PENELITIAN ... 24
3.1 Objek Penelitian ... 24
3.2 Sumber Data ... 24
3.3 Metode Pengumpulan Data ... 24
3.4 Metode Analisis ... 25
3.5 Metode Pengembangan Sistem ... 26
Bab 4 HASIL DAN PEMBAHASAN ... 28
4.1 Hasil Penelitian ... 28
4.1.1 Mencari Atribut Pola Penyakit ISPA ... 28
4.1.2 Algoritm Apriori ... 29
4.2 Pengembangan Dan Analisa Sistem ... 39
xiii 4.2.2 Pemodelan Fungsi ... 40 4.2.3 Perancangan Database... 42 4.2.3.1 Tabel Periksa... 42 4.2.3.2 Tabel t_1_item_set_max ... 43 4.2.3.3 Tabel t_1_item_set_min ... 43 4.2.3.4 Tabel t_2_item_set_max ... 44 4.2.3.5 Tabel t_2_item_set_min ... 44 4.2.3.6 Tabel t_3_item_set_max ... 45 4.2.3.7 Tabel t_3_item_set_min ... 45 4.2.3.8 Tabel t_4_item_set_min ... 46 4.2.3.9 Tabel t_4_item_set_max ... 46 4.2.4 Kamus Data ... 47 4.2.5 Perancangan Aplikasi ... 49 4.2.5.1 Halaman Utama……… 49
4.2.5.2 Halaman Tampil Data Hasil Import Excel ke Database ... 50
4.2.5.3 Halaman Hasil Proses Data Mining ... 50
4.2.5.4 Halaman Lihat Perhitungan Data Mining ... 51
4.2.6 Pembahasan dan implementasi ... 51
4.2.6.1 Data Rekam Medis Puskesmas Tahun 2013………...51
4.2.6.2 Tampilan Halaman Utama ………...……… 52
4.2.6.3 Tampilan Hasil Import Data Excel ke Database …………...…..53
4.2.6.4 Tampilan Hasil Proses Data Mining ………...53
4.2.6.4 Tampilan Halaman Perhitungan ………...54
4.2.7 Pemeliharaan ... 55
5.1 Simpulan ... 57 5.2 Saran ... 58 DAFTAR PUSTAKA ... 59
xv
DAFTAR GAMBAR
Gambar 2.1 Bidang Ilmu Data Mining ... 6
Gambar 2.1 Tahap-Tahap Data Mining ... 7
Gambar 2.3 Model Waterfall ... 14
Gambar 4.1 Flow Chart Proses ... 39
Gambar 4.2 Context Diagram ... 40
Gambar 4.3 DFD Level-0 ... 41
Gambar 4.4 Halaman Depan ... 49
Gambar 4.5 Halaman Tampil Data Hasil Import Excel ke Database ... 50
Gambar 4.6 Halaman Hasil Proses Data Mining ... 50
Gambar 4.7 Halaman Lihat Perhitungan Data Mining ... 51
Gambar 4.8 Data Rekam Medis Puskesmas Tahun 2013 ... 52
Gambar 4.9 Tampilan Halaman Utama ... 52
Gambar 4.10 Tampilan Hasil Import Data Excel ke Database5Error! Bookmark not defined. Gambar 4.11 Tampilan Hasil Proses Data Mining ... 53
Gambar 4.12 Tampilan Perhitungan Iterasi 1 ... 54
Gambar 4.13 Tampilan Perhitungan Iterasi 2 ... 54
Gambar 4.14 Tampilan Perhitungan Iterasi 3 ... 55
DAFTAR TABEL
Tabel 2.1 Penelitian Terkait ... 4
Tabel 2.2 Simbol/Notasi Flowchart ... 17
Tabel 2.3 Simbol-simbol Konteks Diagram ... 20
Tabel 2.4 S Simbol-simbol ERD ... 21
Tabel 2.5 Simbol pada kamus data ... 22
Tabel 4.1 Kategori Pasien ... 28
Tabel 4.2 Transaksi Rekam Medis ... 31
Tabel 4.3 Transaksi Dalam Bentuk Tabular ... 32
Tabel 4.4 Kandidat Pertama (C1) ... 33
Tabel 4.5 Hasil pertama (L1) ... 34
Tabel 4.6 Kandidat Kedua (C2) ... 35
Tabel 4.7 Hasil Iterasi Kedua ... 36
Tabel 4.8 Kandidat Ketiga (C3) ... 36
Tabel 4.9 Hasil Iterasi Ketiga ... 37
Tabel 4.10 Kandidat Keempat (C4) ... 38
Tabel 4.11 Hasil Iterasi Keempat (L4) ... 38
Tabel 4.12 Hasil Support dan Confidence ... 38
Tabel 4.13 atribut tbl_periksa ... 43
Tabel 4.14 atribut t_1_item_set_max... 43
Tabel 4.15 atribut t_1_item_set_min ... 43
Tabel 4.16 atribut t_2_item_set_max... 44
xvii
Tabel 4.18 atribut t_3_item_set_max... 45
Tabel 4.19 atribut t_3_item_set_min ... 45
Tabel 4.20 atribut t_4_item_set_min ... 46
Tabel 4.21 atribut t_4_item_set_min ... 46
Tabel 4.22 Kamus data tabel tbl_periksa ... 47
Tabel 4.23 Kamus data t_1_item_set_ min ... 47
Tabel 4.24 Kamus data t_1_item_set_ max ... 47
Tabel 4.25 Kamus data t_ 2_item_set_ min ... 48
Tabel 4.26 Kamus data t_ 2_item_set_ max ... 48
Tabel 4.27 Kamus data t_ 3_item_set_ min ... 48
Tabel 4.28 Kamus data t_ 3_item_set_ max ... 48
Tabel 4.29 Kamus data t_4_item_set_ min ... 49
Tabel 4.30 Kamus data t_4_item_set_ max ... 49
1 1.1 Latar Belakang Masalah
Dalam bidang kesehatan ketersediaan data rekam medis sudah bukan lagi hal yang sulit diperoleh, namun data ini seringkali diperlakukan hanya sebagai rekaman tanpa pengolahan lebih lanjut sehingga tidak mempunyai nilai guna lebih untuk keperluan masa mendatang.
Analisa dari tiap koleksi data rekam medis tersebut akan menghasilkan pengetahuan atau informasi, misalnya berupa pola penyakit atau hubungan asosiasi yang terjadi pada data, UPTD Puskesmas Bae Kabupaten Kudus yang menjadi objek penelitian dari penulis mempunyai wacana untuk meningkatkan kualitas pelayanan kesehatan, salah satu masalah yang sering dialami adalah kurang tepatnya dalam hal pengambilan keputusan pengadaan obat yang berakibat tidak terpenuhinya persediaan obat bagi pasien.
Berdasarkan rekap data rekam medis UPTD Puskesmas Bae tahun 2013 menunjukan penyakit Infeksi Saluran Pernafasan Akut (ISPA) menjadi penyakit paling banyak dialami oleh masyarakat. Diperlukan solusi dan penanganan khusus untuk menangani masalah tersebut. Salah satunya yaitu mencari informasi mengenai pola penyakit tersebut, misalnya seberapa kuat hubungan persentase antara jenis kelamin, umur, alamat terhadap bulan periksa bagi yang terdiagnosa terkena penyakit Ispa. Dengan mengetahui pola penyakit Ispa pada masyarakat maka pihak UPTD Puskemas Bae mempunyai referensi untuk melakukan sosialisasi atau penyuluhan mengenai gejala, bahaya serta dampak dari penyakit Ispa sehingga dapat dilakukan pencegahan lebih awal.
Suatu teknologi yang dapat digunakan dalam pencarian pola atau hubungan asosiasi dari data yang bersekala besar adalah data mining. Data mining adalah analisis otomatis dari data yang berjumlah besar atau kompleks dengan tujuan
2
untuk menemukan pola atau kecenderungan yang penting yang biasanya tidak didasari keberadaanya[1].
Metode yang seringkali digunakan dalam teknologi data mining adalah metode asosiasi atau association rule. Association rule merupakan suatu prosedur untuk mencari hubungan antar item dalam suatu data set yang ditentukan[5]. Salah satu algoritma yang dapat digunakan untuk menemukan associan rule adalah algoritma apriori, Algoritma ini ditujukan untuk mencari kombinasi item-set yang mempunyai suatu nilai keseringan tertentu sesuai kriteria atau filter yang diinginkan. Hasil dari algoritma ini dapat digunakan untuk membantu dalam pengambilan keputusan pihak manajemen.
1.2 Rumusan Masalah
Mengacu pada latar belakang diatas, maka permasalahan dalam penelitian ini adalah bagaimana membuat suatu aplikasi untuk menghasilkan informasi yang berguna untuk menemukan pola penyebaran penyakit ISPA yang terdiagnosa di UPTD Puskesmas Bae dengan teknik Data Mining Association Rule menggunakan Algoritma Apriori
1.3 Batasan Masalah
Agar penelitian lebih fokus dan tidak meluas dari pembahasan yang dimaksud, dalam penelitian ini penulis membatasinya pada ruang lingkup penelitian sebagai berikut pada:
1. Membuat aplikasi untuk membantu pencarian pola penyakit Ispa dengan teknik Data Mining Association Rule menggunakan Algoritma Apriori. 2. Pengambilan data pada laporan rekam medis di UPTD Puskemas Bae tahun
2013.
3. Pencarian Pola Penyakit dikhususkan untuk mengetahui bulan periksa pasien. 4. Pembuatan aplikasi ini hanya sampai pada pengujian sistem, sehingga tidak
membahas mengenai jaringan dan konfigurasi dimana aplikasi ini diterapkan. 5. Aplikasi ini dibuat dengan bahasa pemrograman PHP berbasis website.
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1. Menghasilkan aplikasi untuk mendapatkan informasi pola penyakit ISPA dengan teknik Data Mining Association Rule menggunakan Algoritma Apriori.
2. Untuk dimanfaatkan UPTD Puskesmas Bae sebagai salah satu acuan pengambilan keputusan dalam meningkatkan kualitas pelayanan kesehatan, kebutuhan obat dan penyuluhan tentang penyakit ISPA.
1.5 Manfaat Penelitian
Adapun manfaat yang dihasilkan dari penelitian ini bagi pihak terkait adalah : 1. Bagi UPTD Puskesmas Bae
a. Membantu mengetahui pola penyakit ISPA yang diderita oleh masyarakat.
b. Membantu dalam pengambilan keputusan dan menjadi acuan dalam meningkatkan kualitas pelayanan kesehatan serta ketersediaan obat. c. Membantu memberikan referensi untuk melakukan sosialisasi atau
penyuluhan mengenai gejala, bahaya serta dampak dari penyakit ISPA sehingga dapat dilakukan pencegahan lebih awal.
2. Bagi Peneliti yaitu dapat mengembangkan ilmu pengetahuan yang diperoleh selama mengikuti perkuliahan dan mampu menerapkannya di lapangan. 3. Bagi Akademik yaitu menjadi tambahan sumbangsih ilmu pengetahuan
khususnya tentang manfaat data mining dalam menemukan, menggali, atau menambang pengetahuan dari data atau informasi yang kita miliki.
4 BAB 2
TINJAUAN PUSTAKA
2.1 Tinjauan Pustaka
Tinjauan pustaka merupakan paparan penelitian lain yang berkaitan dengan penelitian yang akan dilakukan. Tinjauan pustaka yang dituliskan meliputi masalah, atribut atau variabel, metode penyelesaian, dan hasil.
Tabel 2.1 Penelitian Terkait
No
Nama Peneliti dan Tahun
Masalah Metode Hasil
1. Dewi Kartika Pane, 2013
- Data penjualan tidak tersusun dengan baik, sehingga data tersebut hanya berfungsi sebagai arsip bagi perusahaan dan tidak dapat dimanfaatkan untuk pengembangan strategi pemasaran. Data mining association rule dengan menggunaka n algoritma apriori Berdasarkan penelitian merek produk elektronik yang paling banyak terjual adalah Acer dan Toshiba, dengan diketahuinya produk yang paling banyak terjual tersebut, sehingga perusahaan dapat menyusun strategi pemasaran untuk memasarkan produk dengan merek lain dengan meneliti apa kelebihan produk yang paling banyak terjual tersebut dengan produk
No
Nama Peneliti dan Tahun
Masalah Metode Hasil
lainnya dan dapat menambah persedian Acer dan Toshiba.
2. Tri Lestari, 2009
Bagaimana
mengembangkan sebuah aplikasi analisis keranjang belanja (market basket analysis) yang berkaitan dengan data transaksi
penjualan yang menggunakan teknik assosiatif ? Menngunaka n data mining analisis keranjang belanja serta Alat analisis yang digunakan adalah algoritma apriori. Penelitian ini memperlihatkan bahwa Analisis Keranjang Belanja tidak hanya digunakan untuk menentukan
kecenderungan
pelanggan dalam membeli barang-barang secara bersamaan, tetapi dapat digunakan untuk melihat kapan suatu barang dibeli pada jumlah yang paling besar.
6
2.2 Data Mining
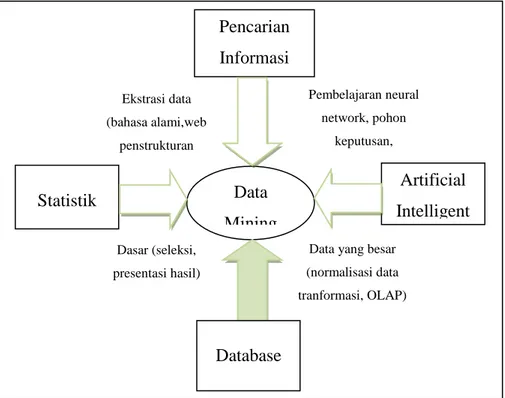
Data mining memiliki arti sebagai disiplin ilmu yang tujuan utamanya adalah untuk menemukan, menggali, atau menambang pengetahuan dari data atau informasi yang kita miliki [6]. Kegiatan inilah yang menjadi garapan atau perhatian utama dari disiplin ilmu data mining. Karena itu data mining sebenarnya memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent), machine learning, statistik dan basis data.
Kemajuan luar biasa yang terus berlanjut dalam bidang data mining didorong oleh beberapa faktor, antra lain [6] :
1. Pertumbuhan yang cepat dalam kumpulan data.
2. Penyimpanan data dalam data warehouse, sehingga seluruh perusahaan memiliki akses ke dalam database yang andal.
3. Adanya peningkatan akses data melalui navigasi web dan intranet.
4. Tekanan kompetisi bisnis untuk meningkatkan penguasaan pasar dalam globalisasi ekonomi. Data Mining Pencarian Informasi Artificial Intelligent Database Statistik Ekstrasi data (bahasa alami,web penstrukturan Pembelajaran neural network, pohon keputusan,
Data yang besar (normalisasi data tranformasi, OLAP) Dasar (seleksi,
presentasi hasil)
5. Perkembangan teknologi perangkat lunak untuk data mining (ketersediaan teknologi).
6. Perkembangan yang hebat dalam kemampuan komputasi dan pengembangan kapasitas media penyimpanan.
2.2.1 Tahapan Proses Data Mining
Gambar 2.2 Tahap-Tahap Data Mining (Fayyad, 1996)
Proses Knowledge discovery in databases (KDD) secara garis besar dapat dijelaskan sebagi berikut (Fayyad, 1996) :
1. Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-processing/Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi focus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga
8
dilakukan proses encrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau infomasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tegantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data Mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sengat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation/Evaluation
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
6. Presentasi pengetahuan (knowledge presentation)
Merupakan visualisasi dan penyajian pengetahuan mengenai teknik yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna. Tahap terakhir dari proses data mining adalah bagaimana memformulasikan keputusan atau aksi dari hasil analisa yang didapat.
2.2.2 Teknik-Teknik Data Mining
Fungsi atau sub kegiatan yang ada dalam data mining dalam rangka menemukan, menggali, atau menambang pengetahuan dari data atau informasi yang kita miliki, terdapat enam fungsi dalam data mining[Larose, 2005] yaitu :
1. Fungsi Deskripsi (description)
Terkadang peneliti dan analisis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat menemukan keterangan atau fakta bahwa siapa yang tidak cukup professional akan sedikit didukung dalam pemilihan presiden.
2. Fungsi Klasifikasi (classification).
Klasifikasi merupakan suatu perkerjaan menilai objek data untuk memasukkannya ke dalam kelas tertentu dari sejumlah kelas yang tersedia. Dalam klasifikasi ada dua pekerjaan utama yang dilakukan, yaitu pembangunan model sebagai prototype untuk disimpan sebagai memori dan penggunaan model tersebut untuk melakukan pengenalan/ klasifikasi/ prediksi pada suatu objek data lain agar diketahui di kelas mana objek data tersebut dalam model yang sudah disimpannya.
Sebagai contoh, pengklasifikasian jenis hewan, yang mempunyai sejumlah atribut. Dengan atribut tersebut, jika ada hewan baru, kelas hewannya bisa langsung diketahui.
3. Fungsi Estimasi (estimation).
Estimasi hampir sama dengan klasifikasi, kecuali variable target estimasi lebih kearah numeric daripada kearah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variable target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variable target dibuat berdasarkan nilai variable prediksi.
Sebagai contoh, estimasi nilai indeks prestasi kumulatif mahasiswa program pascasarjana dengan melihat nilai indeks prestasi mahasiswa tersebut pada saat mengikuti program sarjana.
4. Fungsi Prediksi (prediction).
Model Prediksi berkaitan dengan pembuatan sebuah model yang dapat melakukan pemetaan dari setiap himpunan variable ke setiap targetnya,
10
kemudian menggunakan model tersebut untuk memberikan nilai target pada himpunan baru yang didapat. Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil aka ada di masa mendatang. Sebagai contoh, prediksi nilai UN per siswa pada mata pelajaran matematika, bahasa Indonesia dan bahasa inggris.
Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
5. Fungsi Pengelompokan (cluster).
Pengklusteran merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Kluster sendiri adalah kumpulan record yang meiliki kemiripan satu dengan yang lainnya dan memiliki ketidakmiripan dengan record-record dalam kluster lain.
Algortima pengklasteran mencoba untuk melakukan pembagian terhadap keseluruhan data menjadi kelompok-kelompok yang memiliki kemiripan(homogen), yang mana kemiripan record dalam satu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan benilai minimal. Sebagai contoh di bidang kesehatan dapat digunakan untuk mengelompokan jenis-jenis makanan berdasarkan kandungna kalori, vitamin, dan protein.
6. Fungsi Asosiasi (association).
Analisis asosiasi atau association rule adalah teknik data mining untuk menemukan aturan asosiatif antara suatu kombinasi item. Metode Association Rule itu sendiri merupakan metode yang cukup populer dan biasanya digunakan untuk menemukan hubungan antara satu variabel dengan variabel yang lain dalam satu database yang cukup besar. Informasi yang dihasilkan dari data mining dengan metode Association Rule ini sendiri juga bisa dijadikan sebagai dasar untuk pengambilan keputusan. Metode data mining ini biasanya dipakai dalam data penjualan supermarket yang nantinya akan menunjukkan jika pelanggan membeli barang A dan barang B bersama-sama,
dia cenderung akan membeli barang C. Metode ini bisa diterapkan pada kasus yang diteliti oleh penulis, contohnya seberapa kuat persentase hubungan antara pasien yang didiagnosa terkena penyakit Ispa dan berjenis kelamin perempuan maka pasien tersebut berumur 65 tahun. Informasi ini bisa dijadikan sebagai alat bantu dalam mencari pola penyakit Ispa yang diderita oleh pasien di UPTD Puskesmas Bae Kabupaten Kudus. Association rule mining meliputi dua tahap, yaitu:
a. Mencari kombinasi yang paling sering terjadi dari suatu itemset (frequent itemset).
b. Mendefinisikan Association Rule dari frequent itemset yang telah dibuat sebelumnya.
Kekuatan aturan asosiasi dapat diukur dengan support dan confidence. Support (nilai penunjang) adalah persentase kombinasi item tersebut dalam database, sedangkan confidence (nilai kepastian) adalah kuatnya hubungan antar-item dalam aturan asosiasi.
Penggunaan metode Association Rule ini biasanya diikuti dengan penggunaan algoritma yang efisien, misalnya algoritma apriori dan algoritma eclat untuk dapat menemukan semua itemset yang sering muncul dalam database.
2.3 Algoritma Apriori
Algoritma Apriori termasuk jenis aturan asosiasi pada data mining. Selain apriori yang termasuk pada golongan ini adalah metode generalized rule induction dan Algoritma Hash Based. Analisis asosiasi atau association rule mining adalah teknik data mining untuk menemukan aturan asosiatif antara suatu kombinasi item [1].
Algoritma Apriori adalah algoritma untuk menemukan pola frekuensi tinggi. Pola frekuensi tinggi adalah pola-pola item di dalam suatu database yang memiliki frekuensi atau support di atas ambang batas tertentu yang disebut dengan istilah minimum support atau threshold. Pola frekuensi tinggi ini digunakan untuk menyusun aturan assosiatif dan juga beberapa teknik data mining.
12
Algoritma Apriori dibagi menjadi beberapa tahap yang disebut iterasi. Tiap iterasi menghasilkan pola frekuensi tinggi dengan panjang yang sama dimulai dari pertama yang menghasilkan pola frekuensi tinggi dengan panjang satu. Di iterasi pertama ini, support dari setiap item dihitung dengan menscan database. Setelah support dari setiap item didapat, item yang memiliki support diatas minimum support dipilih sebagai pola frekuensi tinggi dengan panjang 1 atau sering disingkat 1-itemset. Sedangkan k-itemset berarti satu set yang terisi dari k item. Iterasi kedua menghasilkan 2-itemset yang tiap setnya memiliki dua item. Pertama dibuat kandidat 2-itemset dari kombinasi semua 1-itemset. Kemudian tiap kandidat 2-itemset ini dihitung support nya dengan menscan database. Support disini artinya jumlah transaski dalam database yang mengandung kedua item dalam kandidat 2-itemset, setelah support dari semua kandidat 2-itemset didapat, kandidat 2-itemset yang memenuhi syarat minimum support dapat ditetapkan sebagai 2-itemset yang juga merupakan pola frekuensi tinggi dengan panjang 2. Untuk selanjutnya pada iterasi ke-k dapat dibagi lagi menjadi beberapa bagian : Pembentukan kandidat itemset
Kandidat k-itemset dibentuk dari kombinasi (k-1)-itemset yang didapat dari iterasi sebelumya. Satu ciri dari algoritma apriori adalah adanaya pemangkasan kandidat k-itemset ang subset-nya yang berisi k-q item tidak termasuk dalam pola frekuensi tinggi dengan panjang k-1.
Penghitungan support dari setiap kandidat k-itemset
Support dari tiap kandidat k-itemset didapat dengan menscan database untuk menghitung jumlah transaksi yang memuat semua item didalam kandidat k-itemset tersebut. Ini adalah juga cirri dari algoritma apriori dimana diperlukan penghitungan dengan scan seluruh database sebanyak k-itemset terpanjang. Tetapkan pola frekuensi tinggi
Pola frekuensi tinggi yang memuat itemset ditetapkan dari kandidat k-itemset yang supportnya lebih besar dari minimum support. Bila tidak didapat pola frekuensi tinggi baru maka seluruh proses dihentikan. Bila tidak, maka k ditambah satu dan kembali ke bagian 1.
Karena analisis asosiasi menjadi terkenal karena aplikasinya untuk menganalisis isi keranjang belanja dipasar swalayan,analisis asosiasi juga sering disebut market basket analysis. Metodologi dasar analisis asosiasi terbagi menjadi dua tahap: 1. Analisis pola frekuensi tertinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database. Nilai support sebuah item diperoleh dengan rumus sebagai berikut.
Support A = Transaksi mengandung A Transaksi
Sementara itu, nilai support dari 2 item diperoleh dari rumus berikut. Support A,B =P A∩B
Support A,B = Σ Transaksi mengandung A dan B Σ Transaksi
2. Pembentukan Aturan Asosiasi
Setelah semua pola frekuensi tinggi ditemukan, barulah dicari aturan asosiasi yang memenuhi syarat minimum untuk confidence dengan menghitung confidence A → B.
Nilai confidence dari aturan A → 𝐵 diperoleh dari rumus berikut.
Confidence = P(B|A) Σ Transaksi mengandung A dan B Σ Transaksi mengandung A
2.4 Metode Pengembangan Sistem
Metodologi yang penulis gunakan adalah metodologi waterfall sehingga model inilah yang akan dibahas, berikut adalah tahapan dari model waterfall yaitu :
14
1. Sistem Engineerinng
Pada tahap ini, penulis memulai pekerjaan dengan mendefinisikan dan mengumpulkan semua bahan-bahan seperti teori-teori yang di butuhkan dalam membentuk suatu informasi yang akan digunakan pada tahapan selanjutnya.
2. Analys
Pada tahap ini dilakukan analisis kebutuhan dari software yang akan dirancang dan dibuat, meliputi analisis fungsi/proses yang dibutuhkan, analisis output, analisis input, dan analisis kebutuhan.
3. Design
Pada tahap ini, dilakukan perancangan software yang bertujuan untuk memberikan gambaran apa yang seharusnya di kerjakan oleh software dan bagaimana tampilannya, meliputi rancangan output, rancangan input, rancangan struktur data yang digunakan, rancangan struktur software dan rancangan algoritma software. Tahapan ini membantu dalam menspesifikasikan kebutuhan dan arsitektur software secara keseluruhan. 4. Coding
Pada tahap ini, dilakukan proses coding atau pembuatan software. Pembuatan software dipecah menjadi beberapa modul yang nantinya akan
digabungkan dalam tahap berikutnya. Selain itu dalam tahap ini juga dilakukan untuk mengetahui apakah sudah memenuhi fungsi yang diinginkan atau belum.
5. Testing
Dalam tahap ini dilakukan pengabungan modul-modul yang telah di buat dan dilakukan pengujian atau testing. Pengujian ini dilakukan untuk mengetahui apakah software yang dibuat telah sesuai dengan desainnya dan apakah masih terdapat kesalahan atau tidak.
6. Maintenance
Tahap ini merupakan tahapan akhir dalam model waterfall. software yang sudah jadi dijalankan serta dilakukan pemeliharaan (Maintenance). Pemeliharaan ini termasuk memperbaiki kesalahan yang tidak ditemukan pada langkah sebelumnya. Perbaikan Implementasi unit sistem dan peningkatan jasa sistem sebagai kebutuhan baru.
2.5 Analisa Sistem
2.5.1 Pengertian Analisa Sistem
Analisa sistem (sistem analysis) dapat didefinisikan sebagai penguraian dari suatu sistem informasi yang utuh ke dalam bagian-bagian konponenya dengan maksud untuk mengidentifikasi dan mengevaluasi permasalahan-permasalahan, kesempatan-kesempatan, hambatan-hambatan yang terjadi dan kebutuhan kebutuhan yang diharapkan sehingga dapat diusulkan perbaikan-perbaikannya [2]. Tahap ini dilakukan setelah tahap perencanaan sistem dan sebelum tahap desain sistem. Di dalam tahap analisis sistem terdapat langkah-langkah dasar yang harus dilakukan oleh analis sistem sebagai berikut ini.
1. Identify, yaitu mengidentifikasi masalah.
2. Understand, yaitu memahami kerja dari sistem yang ada. 3. Analyze, yaitu menganalsis sistem.
16
2.5.2 Tahap-tahap Analisis Sistem
Tahap–tahap analisis merupakan tahap yang kritis yang sangat penting, karena kesalahan di tahap ini akan menyebabkan kesalahan-kesalahan di tahap berikutnya. Tahap-tahap di dalam analisis sistem antara lain adalah sebagai berikut :
1. Identifikasi masalah
Analisis sistem harus mempunyai pengetahuan yang cukup tentang aplikasi yang dianalisis sehingga dapat mengidentifikasi penyebab terjadinya masalah, antara lain :
a. Mengidentifikasi penyebab masalah. b. Mengidentifikasi titik keputusan. 2. Memahami kinerja sistem
Langkah ini dapat dilakukan dengan memperlajari operasi dari sistem. Untuk itu diperlukan data yang diperolah melalui penelitian, dengan langkah-langkah sebagia berikut :
a. Menentukan jenis penelitian b. Merencanakan jadwal penelitian c. Membuat agenda wawancara
d. Membuat penegasan dan mengumpulkan hasil penelitian 3. Menganalisis hasil penelitian
Untuk menganalisi hasil peneltian dapat digunakan dengan pertanyaan. Menganalisis sistem dibagi menjadi dua, yaitu menganalisa berdsarkan prinsip penelitian dan menganalisis berdasarkan pokok-pokok analisis.
4. Membuat laporan
Mengambil keputusan dari hasil penelitian yang telah berjalan. Tujuan dari pembuatan laporan adalah :
b. Meluruskan kesalah pahaman mengenai analisa yang ditemukan dan dianalisis oleh analis sistem.
c. Meminta pendapat dan saran-saran dari pihak manajemen.
d. Meminta pihak manajemen untuk melakukan tindakan selanjutnya (dapat berupa meneruskan ke tahap desain sistem atau menggantikan proyek bila dipandang tidak layak).
2.5.3 Alat Bantu Analisis Sistem
Alat bantu analisis yang digunakan yaitu : System Flowchart. didefinisikan sebagai bagan yang menunjukkan arus pekerjaan secara keseluruhan dari sistem. Bagan ini menjelaskan urut-urutan dari prosedur-prosedur yang ada di dalam sistem. Bagan alir sistem menunjukkan apa yang dikerjakan di sistem.
Untuk menyajikan dokumen menggunakan simbol-simbol sebagai berikut :
Simbol Nama Fungsi
TERMINATOR Permulaan/Akhir Program
PREPARATION Proses Inisialisasi/Pemberian Harga Awal
INPUT/OUTPUT DATA
Proses input/output data, parameter, informasi
DECISION
Perbandingan pernyataan, penyeleksian data yang memberikan
plihan untuk langkah selanjutnya
OFF PAGE CONNECTOR
Penghubung bagian-bagian flowchart yang berada pada halaman yang
berbeda Tabel 2.1 Simbol/Notasi Flowchart (Jogianto hartono, 2005)
18
PROSES Proses perhitungan/proses
pengolahan data ON PAGE
CONNECTOR
Penghubung bagian-bagian yang berada pada satu halaman
GARIS ALIR
(FLOW LINE) Arah aliran program
2.6 Perancangan Sistem
2.6.1 Pengertian Perancangan Sistem
Desain sistem dapat diartikan sebagai berikut [2]:
1. Tahap setelah analisis dari siklus pengembangan sistem. 2. Pendefinisian dari kebutuhan-kebutuhan fungsional. 3. Persiapan untuk rancang bangun.
4. Menggambarkan bagaimana suatu sistem dibentuk
5. Sistem dibentuk dapat berupa penggambaran, rancangan, dan pembuatan sketsa atau pengaturan dari beberapa elemen yang terpisah dalam satu kesatuan yang utuh dan berfungsi.
6. Termasuk menyangkut mengkonfigurasi dari komponen-komponen perangkat lunak dan perangkat keras dari suatu sistem.
Tahap perancangan sistem ini mempunyai 2 (dua) tujuan utama, yaitu untuk memenuhi kebutuhan pemakai sistem dan untuk memberikan gambaran yang jelas rancang bangun yang lengkap kepada pemrogram komponen yang terlibat [2]. Untuk mencapai tujuan ini, analis sistem harus dapat mencapai sasaran–sasaran sebagai berikut :
1. Desain sistem harus berguna, mudah dipahami dan nantinya mudah digunakan. Ini berarti data harus mudah ditangkap, metode-metode harus mudah diterapkan dan informasi harus mudah dihasilkan serta mudah dipahami dan digunakan.
2. Desain sistem harus dapat mendukung tujuan utama perusahaan sesuai dengan yang telah didefinisikan pada tahap perencanaan sistem yang dilanjutkan pada tahap analisis sistem.
3. Desain sistem harus efisien dan efektif untuk dpat mendukung pengolahan transaksi, pelaporan manajemen dan mendukung keputusan yang akan dilakukan oleh manajemen, termasuk tugas-tugas yang lainnya yang tidak dilakukan oleh komputer.
4. Desain sistem harus dapat mempersiapkan rancang bangun yang terinci untuk masing-masing komponen dari sistem informasi yang meliputi data dan informasi, simpanan data, metode-metode, prosedur-prosedur, orang-orang, perangkat keras, perangkat lunak dan pengemdalian sistem.
2.6.2 Alat Bantu Perancangan Sistem 1. Contex Diagram
Context Diagram adalah Data Flow Diagram (DFD) tingkat atas, yaitu diagram yang paling tidak detail dari sebuah sistem informasi yang menggambarkan aluran - aluran data ke dalam dan ke luar sistem dan ke dalam dan ke luar entitas eksternal. Context Diagram mempunyai sejumlah karakteristik dalam sistem, yaitu[2]:
a. Kelompok pemakai, organisasi atau sistem lain dimana sistem melakukan komunikasi (sebagai terminator).
b. Data masuk, yaitu data yang diterima sistem dari lingkungan dan diproses dengan cara tertentu.
c. Data keluar, yaitu data yang dihasilkan sistem dan diberikan ke dunia luar.
20
d. Penyimpanan data (storage), yaitu digunakan secara bersama antara sistem dengan terminator. Data ini dapat dibuat oleh sistem dan digunakan oleh lingkungan atau sebaliknya.
e. Batasan, antara sistem dan lingkungan.
Simbol Nama Simbol dan Keterangan
Terminator
Menggambarkan asal data atau tujuan data.
Proses
Menggambarkan entitas atau proses aluran data masuk yang ditransformasikan ke aluran data keluar.
Aluran Data
Menggambarkan aluran data atau informasi dari atau ke sistem.
Penyimpanan
Dapat digunakan untuk mendefinisikan basis data atau seringkali mendefinisikan
bagaimana penyimpanan di
implementasikan dalam sistem komputer.
2. Data Flow Diagram ( DFD )
Diagram Flow Document ( DFD ) menunjukkan alur (Flow) didalam program atau prosedur sistem secara logika. Bagan alur terutama digunakan untuk alat bantu komunikasi dan dokumentasi. Hal yang harus diperhatikan dalam menggambarkan diagram alur :
a. Bagan alur sebaiknya digunakan dari atas ke bawah mulai dari bagian kiri suatu halaman.
b. Kegiatan didalam bagan alur harus ditunjukkan dengan jelas.
c. Harus ditunjukkan dimana kegiatan dimulai dan dimana kegiatan berakhir
d. Masing-masing kegiatan didalam suatu bagan alur sebaiknya digunakan suatu kata untuk mengawali suatu kegiatan.
e. Gunakan simbol-simbol bagan alur dalam Context Diagram. Simbol yang digunakan dalam DFD Levelled sama dengan simbol dalam Context Diagram.
3. Diagram Hubungan Entitas (Entity Relationship Diagram/ERD)
Model entity-relationship yang berisi komponen-komponen himpunan entitas dan himpunan relasi yang masing-masing dilengkapi dengan atribut-atribut yang mempresentasikan seluruh fakta dari dunia nyata yang kita tinjau, dapat digambarkan dengan lebih sistematis dengan mnggunakan Diagram Entity-Relationship (Diagram E-R). Adapun simbol - simbol yang digunakan dalam ERD (Entity Relationship Diagram ) adalah sebagai berikut :
Simbol Nama Simbol
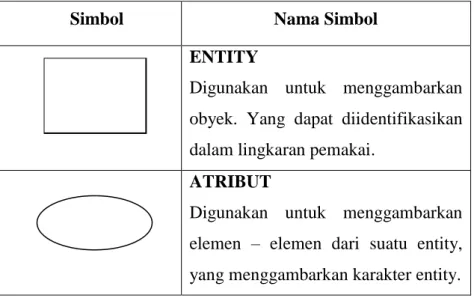
ENTITY
Digunakan untuk menggambarkan obyek. Yang dapat diidentifikasikan dalam lingkaran pemakai.
ATRIBUT
Digunakan untuk menggambarkan elemen – elemen dari suatu entity, yang menggambarkan karakter entity. Tabel 2.3 Simbol-simbol ERD (Jogianto, 2005)
22
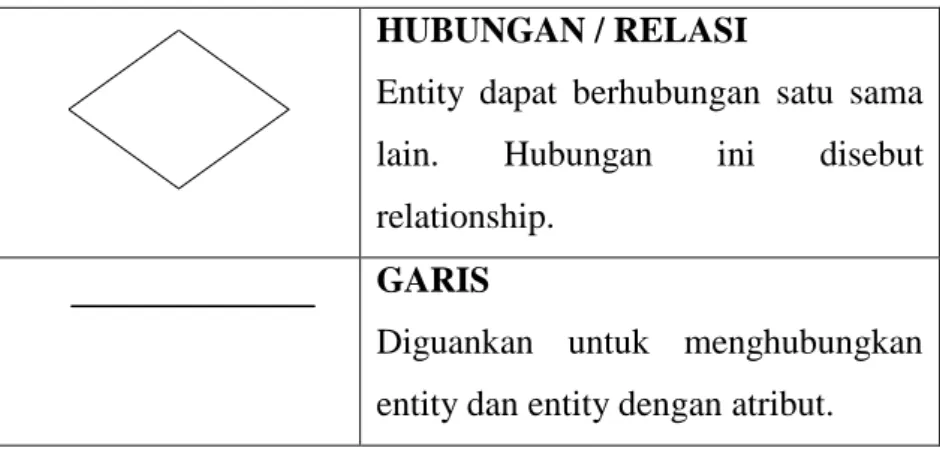
HUBUNGAN / RELASI
Entity dapat berhubungan satu sama lain. Hubungan ini disebut relationship.
GARIS
Diguankan untuk menghubungkan entity dan entity dengan atribut.
2.6.3 Kamus Data (Data Dictionary)
Kamus data (KD) atau Data Dictionary (DD) atau disebut juga dengan istilah sistem data dictionary adalah katalog fakta tentang data dan kebutuhan kebutuhan informasi dari suatu sistem informasi[2].
Sombol Keterangan
= Terbentuk dari, terdiri dari, artinya, atau sama dengan.
+ Dan
[] Salah satu dari
| Sama dengan simbol [ ]
{} Iterasi(elemen data daalam kurung beriterasi mulai minimum N kali dan Maksimum M kali)
() Optional (boleh ada atau tidak)
* Keterangan setelah tanda ini adalah komentar.
2.7 PHP
2.7.1 Pengertian PHP
Menurut dokumen resmi PHP, PHP merupakan singkatan dari PHP Hypertext Prepocessor. Ia merupakan bahasa berbentuk skrip yang ditempatkan dalam
server dan diproses di server. Hasilnyalah yang dikirmkan ke klien, tempat pemakai menggunakan browser[9].
Secara khusus, PHP dirancang untuk mebembentuk aplikasi web dinamis. Artinya, ia dapat membentuk suatu tampilan berdasarkan permintaan terkini. Toko Online, CMS, Forum, dan Website social networking adalah contoh aplikasi web yang bisa dibuat oleh PHP. PHP adalah bahasa scripting, bukan bahsa tag-based seperti HTML. PHP termasuk bahasa yang cross platform, ini artinya PHP bisa berjalan pada sistem opersasi yang berbeda-beda (Windows, Linux, ataupun Mac). Program PHP ditulis dalam file plain text(text biasa) dan mempunyai akhiran”.php” [9].
2.7.2 Cara Kerja PHP
Agar PHP dapat berjalan, PHP memebutuhkan sebuah perangkat lunak web server sebagai media untuk memproses file-file PHP dan mengirimkan hasil pemrosesan yang dilakukan oleh web server untuk di tampilan di perangkat lunak browser. Oleh karena itu PHP membutuhkan webserver utnuk memprosesnya. Web server itu sendiri adalah perangkat lunak yang diinstal pada komputer local maupun komputer lain yang berada di jaringan internet yang berfungsi melayani permintaan-permaintaan web dari client.
24 BAB 3
METODE PENELITIAN
3.1 Objek Penelitian
Penelitian tugas akhir ini dilakukan di UPTD Puskesmas Bae Kabupaten Kudus Jl. Colo Muria Km.5 Kec.Bae, Kudus - Jawa Tengah.
3.2 Sumber Data
Sumber data yang diperoleh dari : 1. Data Primer
Yaitu data yang diperoleh secara langsung dari sumber data rekam medis tersebut yang berhubungan dengan penelitian yang dilakukan. Dalam hal ini, data yang digunakan adalah data rekam medis periode 2013 yang terdiagnosa penyakit Ispa. Data yang berjumlah besar ini nantinya akan diolah denga menggunakan aplikasi association rule untuk menghasilkan informasi mengenai pola penyakit Ispa yang ada di lingkungan UPTD Puskesmas Bae Kabupaten Kudus.
2. Data Sekunder
Data yang diperoleh dari data peneliti dalam bentuk yang sudah jadi yang bersifat informasi dan kutipan, baik dari internet maupun literatur yang berkaitan dengan permasalahan yang dihadapi dan diteliti.
3.3 Metode Pengumpulan Data 1. Studi Pustaka
Studi pustaka yaitu merupakan metode pengumpulan data yang dilakukan dengan mencari, membaca dan mengumpulkan dokumen-dokumen sebagai referensi seperti buku, artikel, dan literatur-literatur tugas akhir yang berhubungan dengan topik yang dipilih yang berkaitan dengan objek penelitian. Studi pustaka digunakan oleh penulis untuk mendapatkan
tambahan informasi tentang metode yang digunakan penulis dalam pembuatan aplikasi data mining untuk mencari informasi pola penyakit Ispa di UPTD Puskesmas Bae Kabupaten Kudus.
2. Wawancara
Wawancara merupakan jenis pengumpulan data yang dilakukan dengan cara tanya jawab atau dengan cara percakapan langsung terhadap sumber-sumber data yang dibutuhkan dengan maksud tertentu. Percakapan ini dilakukan dua arah yaitu pewawancara dan responden. Adapun maksud dilakukan wawancara dalam penelitian ini adalah untuk mengkonstruksikan mengenai orang, kejadian, organisasi, perasaaan, motivasi, dan kepedulian memferivikasi, mengubah dan memperluas informasi yang diperoleh dari orang-orang lain atau narasumber. Dalam hal ini, data diperoleh melalui kegiatan tanya jawab dengan kepala UPTD Puskesmas Bae Kabupaten Kudus.
3.4 Metode Analisis
Berdasarkan data primer dan data sekunder yang telah didapatkan oleh peneliti, maka pembuatan metode Association Rule dan Algoritma Apriori.
1. Metode Association Rule
a. Mencari kombinasi yang paling sering muncul dari suatu itemset (frequent itemset).
b. Mendefinisikan Association Rule dari frequent itemset yang telah dibuat sebelumnya.
2. Algoritma Apriori
Dalam metodologi analisa asosiasi ini menggunakan : a. Analisis pola frekuensi tertinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database. Nilai support sebuah item diperoleh dengan rumus sebagai berikut.
26
Support A = Transaksi mengandung A Transaksi
Sementara itu, nilai support dari 2 item diperoleh dari rumus berikut. Support A,B =P A∩B
Support A,B = Σ Transaksi mengandung A dan B Σ Transaksi
b. Pembentukan Aturan Asosiasi
Setelah semua pola frekuensi tinggi ditemukan, barulah dicari aturan asosiasi yang memenuhi syarat minimum untuk confidence dengan menghitung confidence A → B.
Nilai Confidence dari aturan A → 𝐵 diperoleh dari rumus berikut
Confidence = P(B|A) Σ Transaksi mengandung A dan B Σ Transaksi mengandung A 3.5 Metode Pengembangan Sistem
Metodologi yang digunakan penulis dalam melakukan perancangan Sistem pada UPTD Puskesmas Bae Kabupaten Kudus ini yaitu dengan menggunakan model waterfall. Metode pengembangan sistem waterfall merupakan urutan kegiatan/aktivitas yang dilakukan dalam pengembangan sistem mulai dari rekayasa perangkat lunak, analisis kebutuhan, perancangan implementasi, pengkodean, pengujian, penerapan dan pemeliharaan.
1. Rekayasa perangkat lunak (system enginerring), melakukan pengumpulan data rekam medis dan penetapan kebutuhan semua elemen system.
2. Requirements analysis, melakukan analisis terhadap permasalahan yang dihadapi dan menetapkan kebutuhan perangkat lunak, fungsi performsi dan interfacing.
3. Design, menetapkan domain informasi untuk perangkat lunak, fungi dan interfacing yang sesuai dengan UPTD Puskesmas Bae Kabupaten Kudus.
4. Coding (imolementasi), pengkodean yang meng- implementasikan hasil desain ke dalam kode atau bahasa yang dimengerti oleh mesin komputer dengan menggunakan bahasa pemprograman PHP.
5. Testing (pengujian), kegiatan untuk melakukan pengetesan program yang sudah dibuat apakah udah benar atau belum di uji dengan cara manual. jika testing sudah benar maka program akan diterapkan di UPTD Puskesmas Bae Kabupaten Kudus.
6. Maintenance (pemeliharaan), menangani perangkat lunak yang sudah selesai supaya dapat berjalan lancar dan terhindar dari gangguan-gangguan yang dapat menyebabkan kerusakan.
28
BAB 4
HASIL DAN PEMBAHASAN
4.1 Hasil Penelitian
4.1.1 Mencari Atribut Pola Penyakit ISPA
Penyakit Infeksi Saluran Pernafasan Akut (ISPA) adalah infeksi saluran pernafasan yang berlangsung sampai 14 hari, yang dimaksud dengan saluran pernapasan adalah organ mulai dari hidung sampai gelembung paru, beserta organ-organ disekitarnya seperti : sinus, ruang telinga tengah dan selaput paru[8]. Penyakit ISPA ini disebabkan oleh virus dan bakteri, adapun tanda-tanda atau gejala penyakit ISPA adalah badan pegal, sakit kepala, batuk, nyeri tenggorokan, demam ringan, hidung beringus dan sering bersin.
Secara umum kondisi sanitasi rumah serta efek pencemaran udara terhadap saluran pernafasan dapat menyebabkan pergerakan silia hidung menjadi lambat dan kaku bahkan dapat berhenti sehingga tidak dapat membersihkan saluran pernafasan akibat iritasi oleh bahan pencemar. Akibatnya rentan tertular virus dan bakteri, hal ini akan memudahkan terjadinya infeksi saluran pernafasan.
Bedasarkan penjelasan diatas penulis menggunakan beberapa atribut yang tersedia dalam data rekam medis untuk menghubungkan atribut yang dapat digunakan dalam association rule yaitu jenis kelamin, umur, alamat, bulan periksa.
Mengingat banyaknya umur, untuk memudahkan pengelompokan maka akan dibuat kategori pasien bedasarkan umur sebagai berikut:
No Umur Kategori No Umur Kategori
1. Umur <5 Balita 6. Umur 36-45 Dewasa Akhir 2. Umur 6-11 Kanak-kanak 7. Umur 46-55 Lansia Awal
4. Umur 16-25 Remaja Akhir 9. Umur 65> Manula 5. Umur 26-35 Dewasa Awal
4.1.2 Algoritm Apriori
Algoritma Apriori adalah algoritma paling terkenal untuk menemukan pola frekuensi tinggi. Pola frekuensi tinggi adalah pola-pola item di dalam suatu database yang memiliki frekuensi atau support di atas ambang batas tertentu yang disebut dengan istilah minimum support. Pola frekuensi tinggi ini digunakan untuk menyusun aturan assosiatif dan juga beberapa teknik data mining lainnya. Algoritma apriori dibagi menjadi beberapa tahap yang disebut iterasi atau pass. Tiap iterasi menghasilkan pola frekuensi tinggi dengan panjang yang sama dimulai dari iterasi pertama yang menghasilkan pola frekuensi tinggi dengan panjang satu. Di iterasi pertama ini, support dari setiap item dihitung dengan men-scan database. Setelah support dari setiap item didapat, item yang memiliki support diatas minimum support dipilih sebagai pola frekuensi tinggi dengan panjang 1 atau sering disingkat 1-itemset. Singkatan k-itemset berarti satu set yang terdiri dari k item.
Iterasi kedua menghasilkan 2-itemset yang tiap setnya memiliki dua item. Pertama dibuat kandidat 2-itemset dari kombinasi semua 1-itemset. Lalu untuk tiap kandidat 2-itemset ini dihitung supportnya dengan men-scan database. Support disini artinya jumlah transaksi dalam database yang mengandung kedua item dalam kandidat 2-itemset. Setelah support dari semua kandidat 2-itemset didapatkan, kandidat 2-itemset yang memenuhi syarat minimum support dapat ditetapkan sebagai 2-itemset yang juga merupakan pola frekuensi tinggi dengan panjang 2 dan juga iterasi selanjutnya[1].
Bentuk aturan asosiasi biasanya dinyatakan seperti : [Laki-laki,10,Bae]->[Februari] (Support=15%, Confidence=75%) aturan tersebut berarti 15% dari
30
transaksi database adalah memuat atribut laki-laki, atribut 10, atribut Bae dan juga memuat Februari. Sedangkan kemungkinan munculnya keempat item tersebut secara bersamaan adalah 75% dari seluruh transaksi yang ada didatabase.
Dapat diartikan : ”jika seorang pasien yang didiagnosa penyakit berjenis kelamin laki-laki, berumur 10 tahun, beralamat di desa Bae maka mempunyai 75% kemungkinan pasien tersebut berobat pada bulan Februari”.
Analisa asosiasi didefinisikan suatu proses untuk menemukan semua aturan analisis yang memenuhi syarat minimum untuk support dan syarat minimum untuk confidence.
Metodelogi dasar analisis asosiasi di bagi menjadi dua tahap : 1. Analisis pola frekuensi tertinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai suport dalam database. Nilai support sebuah item diperoleh dengan rumus berikut :
Support (A) Transaksi mengandung A Transaksi
Melihat rumus diatas Support A dapat dimisalkan dengan atribut Laki-laki dan jika diterapkan sebagai berikut :
Support Laki-laki = Rekam Medis mengandung Laki-laki Transaksi
Transaksi dalam hal ini adalah transaksi data rekam medis pasien setiap mereka berobat di Puskesmas. Sementara itu nilai support dari 2 item diperoleh dari rumus berikut.
2. Pembentukan aturan asosiasi
Setelah pola frekuensi tinggi ditemukan barulah dicari aturan asosiasi yang memenuhi syarat minimum untuk confidence dengan menghitung confidence aturan asosiatif A→B
Nilai Confidence dari aturan A→B diperoleh dari rumus berikut.
𝑪𝒐𝒏𝒇𝒊𝒅𝒆𝒏𝒄𝒆 𝑃 𝐵 𝐴 =𝛴 𝑇𝑟𝑎𝑛𝑠𝑎𝑘𝑠𝑖 𝑚𝑒𝑛𝑔𝑎𝑛𝑑𝑢𝑛𝑔 𝐴 𝑑𝑎𝑛 𝐵 𝑡𝑟𝑎𝑛𝑠𝑎𝑘𝑠𝑖 𝑚𝑒𝑛𝑔𝑎𝑛𝑑𝑢𝑛𝑔 𝐴
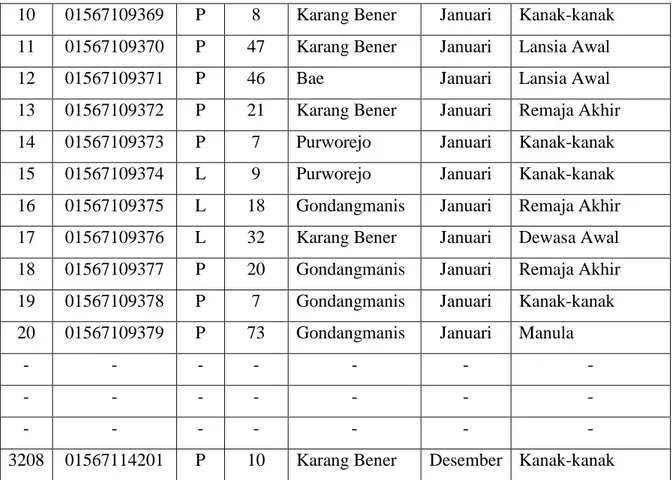
Sebagai analogi akan dilakukan penghitungan secara manual mengambil sempel 20 transaksi awal pada transaksi Rekam Medis tahun 2013 untuk mencari rule potensial Support dan Confidence. Berikut adalah data set yang sudah diseleksi berdasarkan atribut jenis kelamin, umur, alamat dan bulan periksa:
No NPJ JK Umur Alamat Bulan Kategori Pasien
1 01567109360 P 48 Bae Januari Lansia Awal
2 01567109361 P 48 Bae Januari Lansia Awal
3 01567109362 P 68 Bae Januari Manula
4 01567109363 L 5 Bae Januari Balita
5 01567109364 L 33 Gondangmanis Januari Dewasa Awal
6 01567109365 P 49 Bae Januari Lansia Awal
7 01567109366 L 30 Bae Januari Dewasa Awal
8 01567109367 P 37 Bae Januari Dewasa Akhir
9 01567109368 P 6 Bae Januari Kanak-kanak
32
10 01567109369 P 8 Karang Bener Januari Kanak-kanak 11 01567109370 P 47 Karang Bener Januari Lansia Awal
12 01567109371 P 46 Bae Januari Lansia Awal
13 01567109372 P 21 Karang Bener Januari Remaja Akhir 14 01567109373 P 7 Purworejo Januari Kanak-kanak 15 01567109374 L 9 Purworejo Januari Kanak-kanak 16 01567109375 L 18 Gondangmanis Januari Remaja Akhir 17 01567109376 L 32 Karang Bener Januari Dewasa Awal 18 01567109377 P 20 Gondangmanis Januari Remaja Akhir 19 01567109378 P 7 Gondangmanis Januari Kanak-kanak 20 01567109379 P 73 Gondangmanis Januari Manula
- - - -
- - - -
- - - -
3208 01567114201 P 10 Karang Bener Desember Kanak-kanak Apabila dibentuk dalam bentuk tabular, data transaksi tersebut akan tampak
seperti tabel 4.3 dibawah ini :
No L P 1 6 12 16 26 36 46 56 65 Gd Ba Kb Pr Jan (1) 1 0 1 0 0 0 0 0 0 1 0 0 0 1 0 0 1 2 0 1 0 0 0 0 0 0 1 0 0 0 1 0 0 1 3 0 1 0 0 0 0 0 0 0 0 1 0 1 0 0 1 4 1 0 1 0 0 0 0 0 0 0 0 0 1 0 0 1 5 1 0 0 0 0 0 1 0 0 0 0 1 0 0 0 1 6 0 1 0 0 0 0 0 0 1 0 0 0 1 0 0 1
8 0 1 0 0 0 0 0 1 0 0 0 0 1 0 0 1 9 0 1 0 1 0 0 0 0 0 0 0 0 1 0 0 1 10 0 1 0 1 0 0 0 0 0 0 0 0 0 1 0 1 11 0 1 0 0 0 0 0 0 1 0 0 0 0 1 0 1 12 0 1 0 0 0 0 0 0 1 0 0 0 1 0 0 1 13 0 1 0 0 0 1 0 0 0 0 0 0 0 1 0 1 14 0 1 0 1 0 0 0 0 0 0 0 0 0 0 1 1 15 1 0 0 1 0 0 0 0 0 0 0 0 0 0 1 1 16 1 0 0 0 0 1 0 0 0 0 0 1 0 0 0 1 17 1 0 0 0 0 0 1 0 0 0 0 0 0 1 0 1 18 0 1 0 0 0 1 0 0 0 0 0 1 0 0 0 1 19 0 1 0 1 0 0 0 0 0 0 0 1 0 0 0 1 20 0 1 0 0 0 0 0 0 0 0 1 1 0 0 0 1
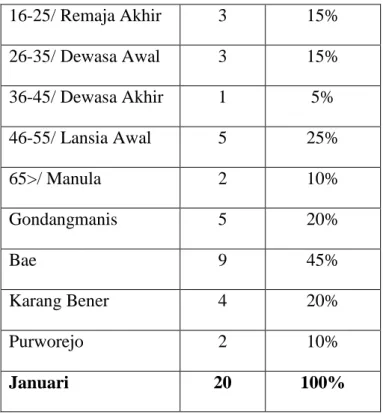
Dari data awal tersebut didapat kandidat pertama (C1) seperti pada tabel dibawah in:
Item set Count Support
Laki-laki 6 30%
Perempuan 14 70%
0-5/Balita 1 5%
6-11/Kanak-kanak 5 25%
34 16-25/ Remaja Akhir 3 15% 26-35/ Dewasa Awal 3 15% 36-45/ Dewasa Akhir 1 5% 46-55/ Lansia Awal 5 25% 65>/ Manula 2 10% Gondangmanis 5 20% Bae 9 45% Karang Bener 4 20% Purworejo 2 10% Januari 20 100%
Bila ditetapkan minimum transaksi (Threshold) adalah = 15%, maka kandidat yang nilainya kurang / dibawah dari 3 akan dihapus. Sehingga, didapat hasil seperti pada tabel dibawah ini :
Item set Count Support
Laki-laki 6 30% Perempuan 14 70% 6-11/ Kanak-kanak 5 25% 16-25/ Remaja Akhir 3 15% 26-35/ Dewasa Awal 3 15% 46-55/ Lansia Awal 5 25% Gondangmanis 5 20%
Karang Bener 4 20%
Januari 20 100%
Selanjutnya dicari kombinasi untuk 2 item dan didapat kandidat kedua (C2) seperti pada tabel dibawah ini :
Item set Count Support
Laki-laki, Kanak-kanak 1 5%
Laki-laki, Remaja Akhir 1 5%
Laki-laki, Dewasa Awal 3 15%
Laki-laki, Gondangmanis 2 10%
Laki-laki, Bae 3 15%
Laki-laki, Karang Bener 1 5%
Laki-laki, Januari 6 30%
Perempuan, Kanak-kanak 4 20%
Perempuan, Remaja Akhir 2 10%
Perempuan, Lansia Awal 5 25%
Perempuan, Gondangmanis 3 15%
Perempuan, Bae 6 30%
Perempuan, Karang Bener 3 15%
Perempuan, Januari 14 70%
Kanak-kanak, Gondangmanis 1 5%
36
Kanak-kanak, Januari 5 25%
- - -
Setelah ditetapkan minimum transaksi (Threshold) adalah 15%, maka didapat Support dan Confidence seperti pada tabel (L2) seperti pada tabel dibawah ini :
Item set Count Support Confidence
Laki-laki -> Dewasa Awal 3 15% 50%
Laki-laki -> Bae 3 15% 50%
Laki-laki -> Januari 6 30% 100%
Perempuan -> Kanak-kanak 4 20% 28%
Perempuan -> Lansia Awal 5 25% 35%
Perempuan -> Gondangmanis 3 15% 21%
Perempuan -> Bae 7 35% 50%
Perempuan -> Karang Bener 3 15% 21%
Perempuan -> Januari 14 70% 100%
Dari hasil kedua (L2) bisa didapat kandidat ketiga (C3) seperti pada tabel dibawah ini :
Item set Count Support
Laki-laki, Dewasa Awal, Bae 2 10%
Laki-laki, Dewasa Awal, Januari 3 15%
Tabel 4.7 Hasil Iterasi Kedua (L2)
Perempuan, Kanak-kanak, Bae 1 5% Perempuan, Kanak-kanak, Karang Bener 1 5%
Perempuan, Kanak-kanak, Januari 4 20%
Perempuan, Lansia Awal, Gondangmanis 2 10%
Perempuan, Lansia Awal, Bae 4 20%
Perempuan, Lansia Awal, Karang Bener 3 15%
Perempuan, Lansia Awal, Januari 4 20%
Perempuan, Gondangmanis, Januari 3 15%
Perempuan, Bae, Januari 7 35%
Perempuan, Karang Bener, Januari 3 15%
Setelah ditetapkan minimum transaksi (Threshold) 15%, maka didapat Support dan Confidence seperti pada tabel (L3) dibawah ini :
Item set Count Support Confidence
Laki-laki, Dewasa Awal -> Januari 3 15% 100%
Perempuan, Kanak-kanak -> Januari 4 20% 100%
Perempuan, Lansia Awal -> Bae 4 20% 80%
Perempuan, Lansia Awal -> Karang Bener 3 15% 60%
Perempuan, Lansia Awal -> Januari 4 20% 80%
Perempuan, Gondangmanis -> Januari 3 15% 100%
Perempuan, Bae -> Januari 7 35% 100%
Tabel 4.9 Hasil Iterasi Ketiga (L3)
38
Perempuan, Karang Bener -> Januari 3 15% 100%
Dari hasil ketiga (L3) bisa didapat kandidat keempat (C4) seperti pada tabel dibawah ini :
Item set Count Support
Perempuan, Lansia Awal, Bae, Januari 4 20%
Perempuan, Lansia Awal, Karang Bener, Januari 1 5%
Setelah ditetapkan minimum transaksi (Threshold) adalah 15%, maka didapat Support dan Confidence seperti pada tabel (L4) dibawah ini :
Item set Count Support Confidence
Perempuan, Lansia Awal, Bae -> Februari 4 20% 100%
Dari penghitungan manual diatas ditemukan rule potensial disetial iterasi, dapat dilihat besarnya nilai support dan confidence dari calon aturan asosiasi seperti tampak pada tabel dibawah ini :
iterasi Item set Count Support Confidence
2 Perempuan -> Januari 14 70% 100%
3 Perempuan, Bae -> Januari 7 35% 100%
4 Perempuan, Lansia Awal, Bae -> Februari
4 20% 100%
Tabel 4.10 Kandidat Keempat (C4)
Tabel 4.11 Hasil Iterasi Keempat (L4)
Dalam tahap ini yang dilakukan adalah menggambarkan bagaimana suatu sistem dibentuk dan mempersiapkan implementasi serta mendesain user interface yang digunakan untuk aplikasi program input dan output dari aplikasi tersebut.
tidak
ya
Gambar 4.1 Flow Chart Proses START
Input Data Rekam Medis Pesien Scan database End Input min. transaksi/threshold Support >= Min support? Delete item Hitung Confidence Scan database Output asosiation rule
40
4.2.2 Pemodelan Fungsi
Pemodelan fungsi digambarkan dengan Context Diagram, DFD (Data Flow Diagram) dan kamus data (Data Dictionary).
1. Context Diagram
Gambar 4.2 Context Diagram
Gambar 4.2 merupakan Context Diagram pada Aplikasi Data Mining yang terdiri dari 1 input dan 1 output. External entity berupa pengguna atau user dan 1 file data yaitu data rekam medis.
Threshold
Data rekam medis Data rekam medis Pola penyakit Proses Mining Data rekam medis Import Data
Data Rekam medis User
Tahapan proses Data Mining yang dipecah menjadi beberapa proses kecil guna menjelaskan fungsi dan arus data yang mengalur pada Aplikasi Data Mining. :
1. User
Dimulai user yang bertugas menginputkan data rekam medis dan menerima informasi berupa pola penyakit.
Membentuk aturan Pola Penyakit Membuat aturan Threshold Menampilkan data Input data Pembentukan frequensi tinggi Pembuatan database tbl_periksa T.item set_max Gambar 4.3 DFD Level-0 Generate frequent Itemsets Generate frequent Itemsets Import Data User
42
2. Import Data
Proses load data dari data rekam medis ke database data mining. Dalam hal ini data rekam medis berbentuk data file excel 2003 kemudian diimport menjadi sebuah database.
3. Mining Jenis kelamin, kategori pasien, alamat, bulan periksa a. Tahapan proses mining jenis kelamin
Proses ini merupakan proses mining untuk mengetahui pola penyakit ISPA dengan atribut laki-laki dan perempuan.
b. Tahapan proses mining Umur / Kategori Pasien
Proses ini merupakan proses mining untuk mengetahui hubungan pola penyakit ISPA dengan atribut Umur. Dengan penggolongan umur 1, 6, 12, 16, 26, 36. 46, 56, 65
c. Tahapan proses mining Alamat
Proses ini merupakan proses mining untuk mengetahui hubungan pola penyakit ISPA dengan atribut desa, misalnya Gondangmanis, Bae, Karang Bener, Panjang, Dersalam.
d. Tahapan proses mining Bulan Periksa
Proses ini merupakan proses mining untuk mengetahui hubungan pola penyakit ISPA dengan atribut bulan, meliputi 12 bulan Januari s/d Desember.
4.2.3 Perancangan Database
Setelah tahap perancangan sistem selesai dilakukan maka tahapan selanjutnya adalah melakukan perancangan basis data. Dalam aplikasi ini dibangun database dengan nama database data mining.
4.2.3.1 Tabel Periksa
Tabel periksa digunakan untuk menampung data rekam medis yang diimport dari data rekam medis yang berbentuk data file excel. Karena setelah proses Import data hanya terbentuk satu tabel yang sudah normal dan tidak memiliki dimensi
antar entitas. Adapun atribut tabel yang terbentuk.
Atribut Keterangan
id_tansaksi Sebagai kode unik di setiap transaksi npj Nomer kartu penjaskes pasien tanggal_periksa Nama Pasien
nama Nama pasien
umur Umur pasien
jenis_kelamin Jenis kelamin pasien bulan_periksa Bulan periksa pasien
desa Alamat pasien
kategori_pasien Jenis pasien berdasarkan umur
4.2.3.2 Tabel t_1_item_set_max
Tabel t_1_item_set_max digunakan untuk menampung iterasi pertama yang memenuhi treshold.
Atribut Keterangan
1_item_set
Sebagai field untuk menampung atribut pada iterasi pertama yang memenuhi threshold
Count
Field untuk menampung jumlah transaksi yang ada di dalam field 1_item_set
4.2.3.3 Tabel t_1_item_set_min
Tabel t_1_item_set_min digunakan untuk menampung iterasi pertama yang tidak memenuhi treshold.
Tabel 4.14 Tabel atribut t_1_item_set_max Tabel 4.13 Tabel atribut tbl_periksa