K-NEAREST NEIGHBOR DENGAN CORRELATION ATRIBUTE
EVAL UNTUK MEMPREDIKSI LUAS LAHAN PANEN
TANAMAN PADI DI KARAWANG
Sofi Defiyanti
1), Betha Nurina Sari
2), Vika Saraswati
3) 1)Fakultas Ilmu Komputer, Universitas Singaperbangsa Karawang, email: [email protected]
2)
Fakultas Ilmu Komputer, Universitas Singaperbangsa Karawang, email: [email protected] 3)
Fakultas Ilmu Komputer, Universitas Singaperbangsa Karawang, email: [email protected] Abstrak – Karawang dikenal dengan kota lumbung padi dikarenakan setengah dari jumlah wilayah kota merupakan lahan pertanian khususnya persawahan. Selain dikenal dengan kota lumbung padi, saat ini Karawang juga dikenal dengan sebutan kota industri, hal ini mengkhawatirkan beberap pihak akan alih fungsi lahan persawahan menjadi lahan yang lain. Maka dilakukan prediksi terhadap luas lahan panen padi dikabupaten karawang. Untuk dapat melakukan prediksi yang baik dibutuhkan atribut-atribut yang relevan yang didapat dari seleksi fitur dengan Correlation Attribute Eval. Terdapat 6 atribut yang relevan terhadap prediksi luas lahan panen padi di kabupaten karang yaitu atribut produksi, luas tanam, luas baku sawah, luas sawah, produktivitas dan wereng batang coklat. K-Nearest Neighbor dengan Correlation Attribute Eval mengalami peningkatan akurasi sebesar 0,37%.
Kata Kunci : K-Nearest Neigbor, Luas Lahan Panen, Correlation Atribute Eval
Abstract - Karawang is known as a rice granary town since the half of city area is agricultural land which
mainly becomes rice field. Besides, known as a rice granary city, Karawang is also recognized as an industrial city in this recent times. It turns into worried that some parties will change the function of paddy field into another land function. Therefore, predicting the rice harvest area in karawang regency is urgently required. In order to make good predictions, it is essential to choose the relevant attributes gained from the feature selection with Correlation Attribute Eval. There are 6 attributes that are relevant to the prediction of rice harvest area in reef district: production attribute, planting area, rice field area, paddy field area, productivity and brown planthopper. The K-Nearest Neighbor with Correlation Attribute Eval has an accuracy increasing of 0.37%. Keywords: K-Nearest Neighbor, Area of Harvested Land, Correlation Attribute Eval
1. PENDAHULUAN
Karawang dikenal dengan sebutan kota lumbung padi, karena luas lahan tanaman padi atau pertanian padi sawah yang hampir separuh dari luas wilayah kota karawang. Hingga tahun 2016, luas lahan sawah di Karawang berdasarkan Dinas Pertanian dan Kehutanan Karawang adalah 98.615 Hektar merupakan 56% dari luas kabupaten Karawang. Hal ini juga mendukung dengan 61,9% penduduknya bergerak di bidang usaha pertanian dengan presentase buruh tani sekitar 59,43%.
Selain dikenal dengan kota lumbung padi saat ini Karawang juga dikenal dengan kota industri, hal ini menyebabkan lahan yang semula digunakan untuk memproduksi padi berubah menjadi pemukiman warga, pabrik, pusat bisnis dan infrastruktur lainnya. Tercatata alih fungsi lahan pertanian di kabupaten Karawang mencapai 150 hektar pertahun. Hal ini menyebabkan luas tanam panen padi mulai terancam. Sehingga diperlukan cara untuk membantu para penentu kebijakan untuk dapat memprediksi luas lahan panen padi agar ketersediaan pangan tetap terjaga dan kabupaten Karawang tetap dikenal dengan kota lumbung padi.
Klasifikasi adalah salah satu teknik yang dapat digunakan untuk memprediksi nilai dari sekelompok
atribut dalam menggambarkan dan membedakan kelas data, klasifikasi merupakan metode pembelajaran[1].
K-Nearest Neighbor (KNN) adalah salah satu algoritma dalam teknik klasifikasi. K-NN adalah salah satu algoritma dengan akurasi yang tinggi dengan rasio kesalahan kecil[2]. Algoritma KNN adalah salah satu algoritma klasifikasi yang digunakan sebagian besar dalam aplikasi yang berbeda[3]. Salah satu kelemahan dari KNN adalah semua atribut dalam menghitung jarak antar record baru dan record yang tersedia dalam data training hal ini menjadi masalah dalam pemilihan atribut mana yang harus dipergunakan untuk mendapatkan hasil terbaik[4].
Seleksi fitur merupakan suatu proses pemilihan atribut yang dianggap relevan dalam proses klasifikasi. Banyaknya atribut mempengaruhi proses komputasi dan bahkan jika banyak atribut yang tidak relevan digunakan dalam proses klasifikasi maka akan mempengaruhi hasil akurasinya[5].proses dari seleksi fitur adalah membuang atribut yang tidak relevan dan berlebihan sehingga dapat membuat proses algoritma klasifikasi bekerja lebih cepat dan efektif serta memungkinkan peningkatan akurasi suatu algoritma.
Pada penelitian ini akan menambahkan seleksi fitur yaitu Correlation Atribute Eval pada algoritma
KNN untuk mengurangi permasalahan yang ada didalam algoritma KNN.
2. LANDASAN TEORI
2.1. K-Nearest Neighbor
K-Nearest Neighbor (K-NN) adalah metode klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut. KNN termasuk kelompok instance-based learning. Algoritma ini juga merupakan salah satu teknik lazy learning. Proses K-NN dilakukan dengan mencari kelompok k objek dalam data training yang paling dekat (mirip) dengan objek pada data baru atau data testing[6].
Langkah-langkah algoritma KNN adalah : 1. Menentukan parameter k, misalnya k=5 2. Menghitung jarak (similarity) diantara semua
training record dan objek baru
3. Pengurutan data berdasarkan nilai jarak dari nilai yang terkecil sampai terbesar
4. Pengambilan data sejumlah nilai k (misal k=5)
5. Menentukan label yang frequensinya paling sering diantara k training record yang paling dekat dengan objek[4].
2.2. Correlation Atribute Eval
CorrelationAttributeEval mengevaluasi fitur-fitur yang sangat berkorelasi dengan kelas target, namun tidak berkorelasi satu sama lain. Mengevaluasi nilai atribut dengan mengukur korelasi (Pearson) antara atribut dan kelas. Atribut nominal dianggap berdasarkan nilai dengan nilai dasar dan memperlakukan setiap nilai sebagai indikator. Korelasi keseluruhan untuk atribut nominal melalui bobot rata-rata atau weighted average.
3. HASIL DAN PEMBAHASAN
Hasil penelitian ini didapat dengan menggunakan metodelogi data mining yaitu CRIPS-DM (Cross industry Standard Process for Data Mining) dengan beberapa langkah yaitu : 1) Business Understanding (Pemahaman bisnis); 2) Data understanding (Pemahaman Data); 3) Data Preparation (Pengolahan Data); 4) Modelling (Pemodelan); 5) Evaluation (Evaluasi); dan 6) Deployment (Penyebaran).
3.1. Business Understanding (Pemahaman Bisnis)
Business Understanding terdiri dari beberapa tahapan yaitu determine business objective, assess the situation, dan determine the data mining goal.
Determine business objective (Menentukan Tujuan Bisnis) : memprediksi luas lahan panen padi sawah di kabupaten karang untuk dapat dipergunakan sebagai alat bantu penentu kebijakan dalam pengambilan kebijakan agar ketersediaan pangan tetap terjaga.
Assess the situation (Menilai Situasi) : Luas lahan panen padi merupakan luasan tanaman yang dipungut hasilnya setelah tanaman tersebut cukup umurnya. Luas lahan panen padi merupakan salah satu hal
penentu dalam produksi padi. Dengan semakin banyaknya alih fungsi lahan akan menyebabkan terganggunya jumlah produksi padi. Terdapat data luas lahan panen setiap tahunnya sehingga dapat dipergunakan sebagai informasi ataupun pengetahuan yang lebih bermanfaat.
Determine the data mining goal (Menentukan Tujuan Data mining) : menggunakan fitur seleksi Correlation Attribute Eval untuk menangani salah satu kekurangan dari algoritma K-NN dalam pemilihan atribut sehingga hasil akurasi dari algoritma K-NN dapat menjadi lebih baik.
3.2. Data understanding (Pemahaman Data)
Data Understanding terdiri dari beberapa tahapan didalamnya yaitu : Collect the initial data, Describe the data, Explore the data, Data Preparatioan dan Verify data quality.
Collect the initial data (pengumpulan data awal) : pengumpulan data didapat dari Dinas Pertanian Karawang mengenai data yang mempengaruhi luas lahan panen tanaman padi sawah. Data yang didapat dari tahun 2010-2015 yang terdiri dari data iklim, luas tanam, luas baku sawah, luas sawah, produksi, produktivitas, luas panen, organisme pengganggu tanaman (OPT) sebanyak jumlah kecamatan di kabupaten karawang.
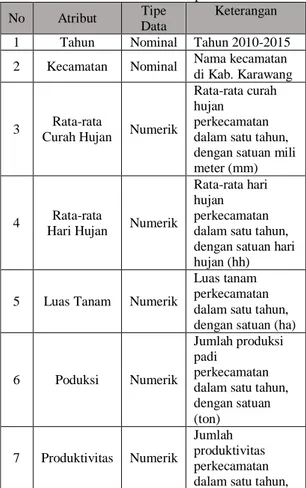
Describe the data (Mendeskripsikan data) : pemahaman data diolah dalam permasalahan prediski luas lahan panen tanaman padi dikarawang, deskripsi data yang dipereloeh dapat dilihat pada Tabel 1.
Tabel 1. Deskripsi data
No Atribut Tipe
Data
Keterangan
1 Tahun Nominal Tahun 2010-2015
2 Kecamatan Nominal Nama kecamatan
di Kab. Karawang
3 Rata-rata
Curah Hujan Numerik
Rata-rata curah hujan
perkecamatan dalam satu tahun, dengan satuan mili meter (mm)
4 Rata-rata
Hari Hujan Numerik
Rata-rata hari hujan perkecamatan dalam satu tahun, dengan satuan hari hujan (hh) 5 Luas Tanam Numerik
Luas tanam perkecamatan dalam satu tahun, dengan satuan (ha)
6 Poduksi Numerik
Jumlah produksi padi
perkecamatan dalam satu tahun, dengan satuan (ton) 7 Produktivitas Numerik Jumlah produktivitas perkecamatan dalam satu tahun,
dengan satuan (kw/ha) 8 Luas Baku
Sawah Numerik
Luas Baku sawah perkecamatan dalam satu tahun, dengan satuan (ha) 9 Luas Sawah Numerik
Luas sawah perkecamatan dalam satu tahun, dengan satuan (ha) 10 Luas Panen Numerik
Luas panen perkecamatan dalam satu tahun, dengan satuan (ha)
11 Organisme Pengganggu Tanaman (OPT) Numerik
Ada tujuh opt antara lain: penggerek batang, tikus, wereng batang coklat, hama putih palsu, bakteri hawar daun, siput murbai, dan blasit
Explore the data (mengekspolari data) : mencari atau mengetahui nilai maksimal, minimal, dan rata-rata atau mean. Sedangkan jumlah berapa banyak data dan keterangan untuk atribut nominal. Tahapan eksplorasi data berfungsi untung mengetahui karakteristik data yang akan digunakan.
Verify data quality (verifikasi kualitas data) : terdapat beberapa data yang tidak terdapat isinya atau kosong, salah satunya adalah data produksi. Didalam data produksi diisi dengan tanda (-) yang artinya tidak terdapat data atau kosong atau (missing value).
3.3. Data Preparation (Persiapan Data)
Data preparation mencakup semua kegiatan untuk membangun dataset yang akan dimasukan ke dalam alat pemodelan dari data mentah atau data awal. Fungsi utamanya khusus untuk alat pemodelan klasifikasi data. Pada data preparation terdiri dari beberapa tahapan yaitu select data, clean data, construct data, integrate data, dan format data.
Select Data (Pemilihan data) : pemilihan data dilakukan dari tahun 2010-2015 dengan atribut yang dipergunakan adalah rata-rata curah hujan, rata-rata hari hujan, luas sawah, luas baku sawah, luas tanam, produksi, produktivitas, pengerek batang, tikus, wereng batang coklat, hama putih palsu, bakteri hawar daun, siput murbai, blasit, dan luas lahan panen.
Clean data (pembersihan data): dari hasil tahapan sebelumnya diketahui bahwa terdapat beberapa data yang kosong atau terisi dengan tanda (-). Karena tidak diketahui bahwa data berisi apa. Maka pengisian data tetap di kosongkan.
Construct Data (membangun data) : Pengembangan dataset baru atau memproduksi atribut turunan melalui proses transformasi data (query) yang sesuai dengan kebutuhan pemodelan. Membangun data dilakukan perubahan data berupa luas lahan panen yang awalnya bernilai numerik diubah menjadi nominal yang nantinya luas lahan panen ini menjadi
class target. Terlebih dahulu melihat persentase nilai dari luas panen terhadap luas sawah perkecamatan dengan persamaan (1).
Luas Panen =Luas panen asli
Luas sawah × 100% (1)
Perubahan nilai dari bentuk numerik ke bentuk nominal dilakukan dengan persamaan (2).
I =nilai max − nilai min kelas interval
(2)
Keterangan :
I = Interval
Nilai Max = nilai tertinggi peratribut Nilai Min = nilai terendah peratribut
Kelas interval = jumlah kelas interval yang diinginkan, yaitu 3 (Tinggi, sedang, rendah)
Dan didapat kriteria luas lahan panen pada Tabel 2 dan gambar 1 merupakan proses menominalkan atribut class target luas lahan panen..
Tabel 2. Kriteria Class Target
Class target Rentang
Rendah Nilai < 1.73 Sedang 1,73 ≤ Nilai < 2,30
Tinggi Nilai ≥ 2,30
Gambar 1. Proses Menominalkan Class Target
Integrate Data (integrasi Data) : Pada tahap ini Tabel yang diintegrasikan adalah Tabel dari masing-masing atribut. Tabel tersebut kemudian dijadikan Tabel gabungan dari data yang akan digunakan sehingga memudahkan proses pemodelan yang melibatkan proses data mining.
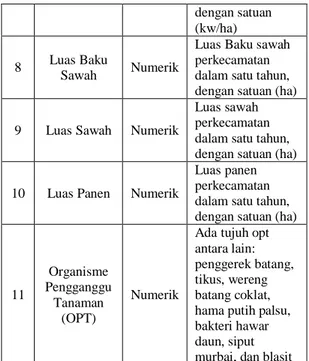
Format data : Tahap ini memproduksi dataset akhir yang siap ditambang atau diolah dalam tools pemodelan data mining.
Tabel 3. Dataset Final
Atribut Tipe Data Keterangan
Rata-rata Curah
Hujan Numerik
perkecamatan dalam satu tahun Rata-rata Hari Hujan Numerik perkecamatan
dalam satu tahun
Luas Tanam Numerik perkecamatan
Poduksi Numerik perkecamatan dalam satu tahun
Produktivitas Numerik perkecamatan
dalam satu tahun Luas Baku Sawah Numerik perkecamatan
dalam satu tahun
Luas Sawah Numerik perkecamatan
dalam satu tahun Penggerek batang Numerik perkecamatan
dalam satu tahun
Tikus Numerik perkecamatan
dalam satu tahun Wereng Batang
Coklat Numerik
perkecamatan dalam satu tahun Hama Putih Palsu Numerik perkecamatan
dalam satu tahun Bakteri Hawar Daun Numerik perkecamatan
dalam satu tahun
Siput Murbai Numerik perkecamatan
dalam satu tahun
Blasit Numerik perkecamatan
dalam satu tahun Luas Lahan Panen Nominal Merupakan Class Target
3.4. Modelling (pemodelan)
Modeling adalah fase yang secara langsung melibatkan teknik data mining. Pemilihan teknik data mining adalah pemilihan algoritma dan menentukan parameter dengan nilai yang optimal. Pada modeling terdiri dari beberapa tahapan yaitu select modeling techniques, generate test design, build model, dan asses model.
Select modeling techniques (Memilih Teknik Pemodelan): teknik klasifikasi yang dipilih adalah algoritma K-Nearest Neighbor (K-NN). Penelitian akan dibagi menjadi beberapa perlakuan khusus untuk meilihat efek dari seleksi fitur dengan Correlation Attribute Eval dengan yang tidak memakai fitur seleksi. Seperti pada gambar 2.
Gambar 2. Skenario Penelitian
Skenario yang dibuat adalah dengan menggunakan non seleksi fitur dan seleksi fitur. Jika menggunakan non seleksi fitur maka semua atribut akan dipergunakan, sementara jika
menggunakan seleksi fitur Correlation Attribute Eval maka atribut-atribut akan dikurangi satu persatu sesuai dengan rangking yang didapat oleh tiap atribut dalam seleksi fitur.
Correlation Attribute Eval menggunakan Korelasi Pearson, dengan persamaan (3).
𝑟 = 𝑛 ∑ 𝑥. 𝑦 − ∑ 𝑥 ∑ 𝑦 √(𝑛 ∑ 𝑥2− (∑ 𝑥)2)(𝑛 ∑ 𝑦2− (∑ 𝑦)2) (3) Keterangan : n : Jumlah data x : Atribut y : class target
Maka didapat hasil peringkat dari 14 atribut yang ada pada Tabel 4.
Tabel 4. Hasil Peringkat Seleksi fitur Correlation Attribute Eval
1 Produksi 2 Luas Tanam 3 Luas Baku sawah 4 Luas Sawah 5 Produktivitas 6 Wereng btanag coklat 7 Tikus
8 Hama Putih palsu 9 Siput Murbai 10 Pengerek Batang 11 Bakteri hawar daun 12 Blasit
13 Hari Hujan 14 Curah Hujan
Maka pengurangan setiap atribut akan dilakukan satu persatu sesuai dari peringkat yang terendah.
Algoritma K-NN menggunakan jumlah tetangga (k) yang digunakan yaitu dari k=1 sampai k=10.
Generate Test Design (menggunakan Desain Uji): Test pengujian atau atau tahap pembelajaran. Dalam tahap ini test pengujian dilakukan dengan menggunakan Test Options Cross-validation dengan jumlah Folds 10. Hal ini dilakukan karena data akan bergantian sebagai training set dan testting set. Build Model (Membangun Model): pembagunan model dibantu dengan menggunakan tools weka 3.8. didalam weka 3.8 algoritma K-NN menggunakan nama IBk dengan .
Asses Model (Menilai Model): penilaian model dilakukan dengan melihat nilai Acuracy yang diperoleh.
3.5. Evaluation (Evaluasi)
Tahap evaluation bertujuan agar hasil pada tahap modelling sesuai dengan sasaran yang ingin dicapai dalam tahap business understanting. Pada evaluation
Dataset Seleksi fitur Non-Seleksi K-NN Hasil kesimpulan
terdiri dari beberapa tahapan yaitu evaluate result, review process, dan determine next steps.
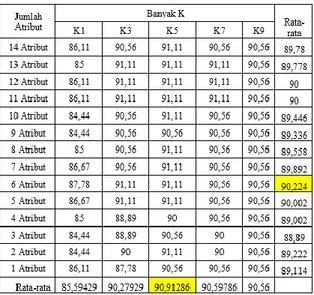
Evaluate result (Mengevaluasi hasil): hasil yang diperoleh dari keseluruhan tes yang dilakukan menggunakan seleksi fitur dan non-seleksi fitur dapat dilihat pada Tabel 5.
Pada Tabel 5 terdapat hasil dari beberapa skenario yang sudah dibuat. Percobaan non fitur seleksi menggunakan 14 atribut tanpa ada pengurangan atribut apapun. Maka pada Tabel 5 baris pertama merupakan hasil akurasi dari percobaan non seleksi fitur.
Selain itu terdapat percobaan dengan menggunakan seleksi fitur dengan pengurangan atribut satu persatu sesuai rangking yang telah dihitung dengan Correlation Attribute Eval. Pengurangan satu persatu atribut dilakukan dari ranking terbesar terlebih dahulu sampai kepada hanya tersisa satu buah atribut.
Tabel 5. Hasil akurasi K-NN
Review process (proses review) : Tahap review process memastikan tidak ada tahapan penting yang terlewatkan. Pada penelitian ini tahapan-tahapan yang sudah dilakuan antaralain Business Understanding (select modeling technique, generate test design, build model, dan asses model, data understanding (collect the initial data, describe the data, explore the data, data preparation, dan verify data quality), data preparation (select data, clean data, construct data, integrate data, dan format data), modeling (select modeling techniques, generate test design, build model, dan asses model), dan evaluation (evaluate result). Dari tahapan-tahapan yang telah dilakukan tidak ada tahapan penting yang terlewatkan dalam proses CRISP-DM.
Determine Next Steps (menentukan Tahap Berikutnya): berdasarkan hasil penelitian beberapa tahap sebelumnya diketahui bahwa algoritma K-NN dengan seleksi fitur ataupun non seleksi fitur dapat menghasilkan prediksi luas lahan panen padi di
Kab.Karawang. Hasil pada evaluasi tahap evaluasi menghasilkan nilai yang tertinggi untuk nilai akurasi. Karena tujuan bisnis dan tujuan data mining sudah tercapai maka akan lanjut ketahap selanjutnya yaitu Deployment (penyebaran).
3.6. Deployment (penyebaran)
Pada tahap deployment akan dilakukan pelaporan dari hasil penelitian yang telah dilakukan. Laporan hasil penelitian ini akan dipresentasikan dalam bentuk deskripsi agar mudah dipahami.
Algoritma K-NN dengan menggunaan seleksi fitur mengalami peningkatan akurasi. Pada Tabel 5 terlihat bahwa hasil dari algoritma K-NN non seleksi fitur memiliki akurasi lebih rendah jika dibandingkan dengan seleksi fitur Correlation Attribute Eval. Peningkatan akurasi tertinggi didapat pada atribut dengan jumlah 6 atribut dengan atribut produksi, luas tanam, luas baku sawah, luas sawah, produktivitas dan wereng batang coklat.
Seleksi fitur dapat digunakan untuk mengidentifikasi dan menghilangkan atribut dengan nilai yang tidak relevan atau berlebihan[7]. Seleksi fitur yang digunakan adalah Correlation Attribute Eval, seleksi fitur Correlation Attribute Eval dapat meningkatkan nilai akurasi.
4. KESIMPULAN
K-Nearest Neighbor dengan Correlation Attribute Eval sebagai seleksi fitur dalam memprediksi luas lahan panen padi di Kabupaten Karawang dapat menghilangkan atribut dengan nilai yang tidak relevan atau tidak terpakai bagi penentuan luas lahan panen padi di Kabupaten Karawang.
Correlation Attribute Eval sebagai fitur seleksi didapat hasil yang terbaik dari tingkat akurasinya yaitu dengan 6 buah atribut, yaitu atribut produksi, luas tanam, luas baku sawah, luas sawah, produktivitas dan wereng batang coklat. Artinya bahwa dalam memprediksi luas ahan panen padi di Kabupaten Karawang atribut yang sangat relevan adalah 6 atribut tersebut.
K-Nearest Neighbor dengan Correlation Attribute Eval mengalami peningkatan akurasi sebesar 0,37%.
DAFTAR REFERENSI
[1] K. Sani, W. W. Winarno, and S. Fauziati, “Untuk Authentication Uang Kertas ( Studi Kasus : Banknote Authentication ),” vol. 10, no. 1, pp. 1130–1139, 2016.
[2] Hutami and Erna, “Implementasi Metode K-Nearest Neighbor Untuk Prediksi Penjualan Furniture Pada CV.Octo Agung Jepara,” Univ. Dian Nuswantoro Semarang, 2016.
[3] M. Moradian and A. Baraani, “KNNBA: K-Nearest-Neighbor Based Association Algorithm,” J. Theor. Appl. Inf. Technol., 2009.
[4] H. Laily and R. Sucianna, Ghadati, “Penggabungan Algoritma Backward
Elimination Dan K-Nearest Neighbor Untuk Mendiagnosis Penyakit Jantung,” in Seminar Nasional Sains dan Teknologi (SNST), 2014, pp. 1–5.
[5] I. H. Witten, E. Frank, and M. A. Hall, Data Mining: Practical Machine Learning Tools and Techniques. Elsevier Science, 2011. [6] H. Leidiyana, “Penerapan algoritma k-nearest
neighbor untuk penentuan resiko kredit kepemilikan kendaraan bemotor,” J. Penelit. Ilmu Komputer, Syst. Embed. Log., vol. 1, no. 1, pp. 65–76, 2013.
[7] J. N. Ć, P. Strbac, and D. B. Ć, “TOWARD OPTIMAL FEATURE SELECTION USING RANKING METHODS AND
CLASSIFICATION ALGORITHMS,” vol. 21, no. 1, pp. 119–135, 2011.