Disusun oleh:
Kata Pengantar
Teori bahasa dan automata merupakan salah satu mata kuliah yang wajib di jurusan-jurusan informatika maupun ilmu komputer. Salah satunya pada STMIK Asia Malang. Mata kuliah ini mempelajari tentang notasi-notasi bahasa yang digunakan dalam komputer. Bahasan dalam mata kuliah ini akan banyak diimplementasikan pada teknik kompilasi. Oleh sebab itu akan terasa manfaatnya pada saat anda mempelajari tentang kompilasi.
Penulis mencoba menyajikan sesuatu dengan cara sesederhana mungkin dengan bahasa yang mudah diterima sehingga mengurangi kesulitan mahasiswa pada perkuliahan ini. Penulis mengharapkan pembaca bisa menangkap materi dan persoalan-persoalan yang diberikan. Diharapkan pembaca dapat menikmati permasalahan tanpa memandangnya sebagai sesuatu yang sulit. Sesuai dengan namanya, mata kuliah ini hanya memuat teori saja, tanpa memuat hal-hal praktis yang dapat diterapkan langsung dalam praktek.
Penulis menyadari bahwa maíz banyak kekurangan di sini, baik kesalahan pengetikan maupun kekurangtepatan dalam penjelasan. Penulis dengan senang hati akan menerima saran dan kritik membangun dari pembaca, dapat disampaikan melalui e-mail [email protected].
Tidak lupa penulis mengucapkan terima kasih yang tak terhingga lepada ALLAH SWT atas segala berkahnya, Ibunda tercinta yang akhir-akhir ini sering missed, Suamiku tercinta yang kadang-kadang juga nyebelin, dan calon ’dede’ dalam perutku yang akan menjadi semangat sepanjang hidupku. Serta semua saudaraku, sahabatku serta rekan – rekan kerja di ASIA Malang.
Malang, Agustus 2008
Daftar Isi Kata Pengantar ... i Daftar Isi ... ii Bab I : Pengantar ... 1 1.1 Teori Pengantar ... 1 1.1.1 Teori Himpunan ... 1
1.1.2 Fungsi dan Relasi... 4
1.1.3 Teori Pembuktian... 4
1.1.4 Graph dan Tree ... 5
1.2 Kompilasi ... 7 1.2.1 Bahasa Pemrograman ... 7 1.2.2 Translator ... 7 1.2.3 Interpreter ... 8 1.2.4 Assembler ... 8 1.2.5 Compiler ... 9
Bab II : Konsep Bahasa Automata ... 13
2.1 Konsep Bahasa dan Automata ... 13
2.1.1 Teori Bahasa ... 13
2.1.2 Automata ... 13
2.1.3 String ... 14
2.1.4 Operasi Dasar String ... 14
2.1.5 Sifat-sifat Operasi String ... 16
2.2 Grammar dan Bahasa ... 17
2.2.1 Definisi ... 17 2.2.2 Simbol ... 17 2.2.3 Aturan Produksi ... 18 2.2.4 Grammar ... 18 2.2.5 Klasifikasi Chomsky ... 19 2.2.6 Analisa Grammar ... 21
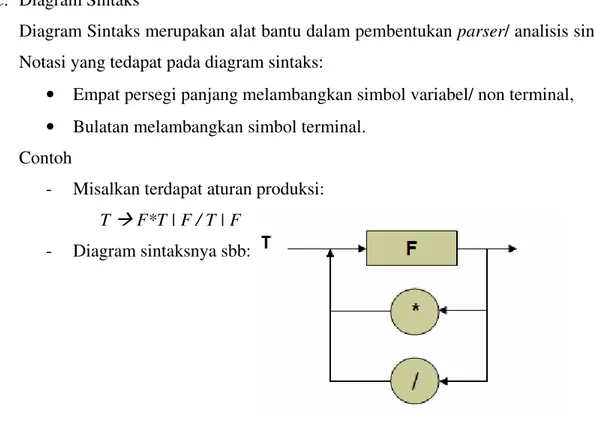
3.1 Definisi Formal ... 24
3.2 Fungsi Transisi ... 25
3.3 Jenis-jenis FSA ... 25
3.4 Deterministic finite automata (DFA) ... 26
3.5 Non deterministik finite automata (NFA) ... 27
3.6 Ekuivalen ... 29
3.7 Indistinguishable ... 29
3.8 Distinguishable ... 29
3.9 Prosedur menentukan pasangan status indistinguishable ... 30
3.10 Prosedur Reduksi DFA ... 30
Bab IV : Ekuivalensi NFA ke DFA ... 32
4.1 Algoritma Ekivalensi NFA ke DFA ... 32
4.2 NFA dengan ε-move ... 34
4.3 Ekuivalensi NFA dengan ε-move ke NFA tanpa ε-move ... 34
4.4 Penggabungan FSA ... 35
Bab V : Ekspresi Reguler ... 37
5.1 Bahasa regular ... 37
5.2 Sifat Bahasa Reguler ... 38
5.3 Konversi ekspresi reguler ke FSA ... 39
5.4 DFA dan Tatabahasa Reguler ... 39
5.5 Penerapan ekspresi regular ... 41
5.6 Pumping Lemma... 41
Bab VI : FSA dengan Output ... 43
6.1 Mesin Moore ... 43
6.2 Mesin Mealy ... 44
6.3 Ekuivalensi mesin Moore dengan mesin Mealy ... 45
Bab VII : Bahasa Bebas Konteks ... 47
7.1 Tata Bahasa Bebas Konteks ... 47
7.2 Leftmost dan Rightmost Derivation ... 48
7.3 Pohon Urai ... 49
7.5 Ambiguitas pada Tatabahasa dan Bahasa ... 50
7.6 Pumping Lemma untuk bahasa bebas konteks ... 50
7.7 Sifat - sifat tertutup bahasa bebas konteks ... 51
7.8 Substitusi ... 52
7.9 Tatabahasa Bebas Konteks dan Bahasa Pemrograman ... 52
Bab VIII : Penyederhanaan Tata Bahasa Bebas Konteks ... 53
8.1 Penghilangan Produksi Useless ... 53
8.2 Penghilangan Produksi Unit ... 55
8.3 Penghilangan Produksi ... 57
8.4 Pengembangan praktek ... 58
Bab IX : Bentuk Normal Chomsky ... 60
9.1 Pengertian ... 60
9.2 Aturan Produksi ... 60
9.3 Pembentukan CNF ... 60
9.4 Bagan Tahapan Pembentukan CNF ... 61
9.5 Algoritma CYK untuk Tata Bahasa Bebas Konteks ... 63
Bab X : Penghilangan Rekursif Kiri ... 69
10.1 Aturan Produksi Rekursif ... 69
10.2 Pohon Penurunan ... 69
10.3 Tahapan Penghilangan Rekursif Kiri ... 70
Bab XI : Bentuk Normal Greibach ... 73
11.1 Pengertian Bentuk Normal Greibach ... 73
11.2 Pembentukan GNF dengan Substitusi ... 73
Bab XII : Pushdown Automata (PDA) ... 77
12.1 Pendahuluan ... 77
12.2 Transisi ... 77
12.3 Definisi Formal PDA ... 78
Bab XIII : Mesin Turing ... 83
13.1 Sejarah ... 83
13.2 Mekanisme TM ... 83
13.4 Ilustrasi TM sebagai sebuah ‘mesin’ ... 84
13.5 Ilustrasi TM sebagai sebuah Graf berarah ... 84
Bab XIV : Aplikasi FSA dan CFG pada Pengembangan Kompilator ... 87
14.1 Scanner ... 87
14.2 Parser ... 87
14.3 Tool bantuan untuk konstruksi Scanner dan Parser... 88
14.4 Implementasi Scanner dan Parser ... 90
Bab I
PENGANTAR
1.1. Teori Pengantar 1.1.1. Teori Himpunan
Definisi sebuah himpunan adalah kumpulan obyek atau simbol yang memiliki sifat yang sama. Anggota himpunan disebut elemen
Contoh:
Terdapat sebuah himpunan X = {1, 2, 4}, maka 1 ∈ X 1 merupakan elemen dari himpunan X 3 ∈ X 3 bukan elemen dari himpunan X
A. Himpunan Sama
Himpunan dikatakan sama bila memuat elemen - elemen yang sama. Contoh :
Terdapat beberapa himpunan, X = {1, 2, 4} Y = {4, 1, 2} Z = {1, 2, 3} Maka, X = Y X Z
B. Himpunan Bagian (Subset)
Himpunan bagian adalah jika semua elemen dari himpunan A adalah elemen dari himpunan B.
Contoh :
Terdapat beberapa himpunan, A = {1, 2, 3}
Maka,
A ⊆ B dan C ⊆ B, maka A = C C. Himpunan Kosong
Himpunan kosong atau null (ø) merupakan bagian dari semua himpunan. Contoh : Terdapat himpunan, A = {1, 2, 3} B = {1, 2, 3, 4} C = {1, 2, 3} Maka, Ø ⊆ A Ø ⊆ B Ø ⊆ C
D. Operasi – operasi himpunan
1. Gabungan (Union), dinyatakan dengan ∪ Misal, A = {1, 2, 3}
B = {2, 4} Jika P = A ∪ B, maka
P = {x | x ∈ A atau x ∈ B} P = {1, 2, 3, 4}
Bisa dianalogikan dengan penjumlahan A ∪ B = A ∨ B = A + B
2. Irisan (Intersection), dinyatakan dengan ∩ Misal, A = {1, 2, 3} B = {2, 4} C = {10, 11} Jika P = A ∩ B, maka P = {x | x ∈ A dan x ∈ B} P = {2}
A ∩ C = Ø, disebut saling lepas (disjoint) Bisa dianalogikan dengan perkalian
3. Komplemen, adalah semua elemen yang tidak menjadi elemen himpunan tersebut. Semua himpunan yang dibahas diasumsikan merupakan bagian dari suatu himpunan semesta (Universal).
Jadi komplemen A = ¬A = U – A Misal A = {1, 2, 3}
B = {2, 4} C = {10, 11} Maka, A – B = {1, 3}
B – C = Ø
E. Beberapa ketentuan pada operasi himpunan o Ø ∪ A = A o Ø ∩ A = Ø o A ⊆ B A ∩ B = A o A ⊆ B A ∪ B = B o A ∩ A = A o A ∪ A = A o Komunikatif, A ∪ B = B ∪ A A ∩ B = B ∩ A o Assosiatif, A ∪ ( B ∪ C ) = (A ∪ B) ∪ C A ∩ ( B ∩ C ) = (A ∩ B) ∩ C o Distributif, A ∩ ( B ∪ C ) = (A ∩ B) ∪ ( A ∩ C) A ∪ ( B ∩ C ) = (A ∪ B) ∩ ( A ∪ C) o Hukum DeMorgan, A – B = A ∩ ¬B ¬(A ∩ B) = ¬A ∪ ¬B o ¬(A ∪ B) = ¬A ∩ ¬B o ¬(¬A) = A o ¬Ø = U o ¬U = Ø
1.1.2. Fungsi dan Relasi
Suatu fungsi adalah sebuah relasi yang memenuhi suatu kriteria. Contoh:
f : A B dan g : A B, maka
f = g f(x) = g(x) untuk semua x di dalam A
Beberapa ketentuan fungsi 1. f(Ø) = Ø
2. f({x}) = {f(x)} untuk semua x ∈ A 3. X ⊆ Y ⊆ A f(x) ⊆ f(y)
4. X ⊆ Y ⊆ B f-1(x) ⊆ f-1(y)
5. X ⊆ B dan Y ⊆ B f-1(x-y) = f-1(x) - f-1(y)
Kombinasi
Fungsi dapat dikombinasikan dengan cara komposisi, dinotasikan dengan o Misal: f(x) = 2x + 1 g(x) = x2 Maka, g o f(x) = g(2x + 1) = (2x + 1)2 = 4x2 + 4x + 1 1.1.3. Teori Pembuktian
Pembuktian menggunakan prinsip induksi matematika. Langkah-langkah dalam melakukan pembuktian :
o Tunjukkan hal itu berlaku untuk semua P0, disebut basis step. o Tunjukkan hal itu berlaku untuk Pn+1, disebut induction step. o Maka dapat ditarik kesimpulan hal tersebut berlaku untuk semua n Contoh Pembuktian
S(n) = 1 + 2 + …. + n = n(n+1)/2, n bilangan bulat positif S(0) = 0(0+1)/2 = 0 (terbukti)
S(i) = 1 + 2 + …. + i = i(i+1)/2 (anggap benar) Akan dibuktikan S(i+1) juga benar
S(i+1) = (i+1)((i+1)+1)/2 = 1+2+….+i+(i+1) = i(i+1)/2 + (i+1) = (i+1)(i/2+1) = (i+1)(i+2)/2 = (i+1)((i+1)+1)/2 (terbukti) Jadi, S(n) benar
1.1.4. Graph dan Tree
Suatu graph adalah himpunan vertex (titik) yang tidak kosong dengan setiap sisi (edge) menghubungkan 2 buah titik.
G = ( V , E ); V = vertex / titik E = edge / sisi
|V(G)| = banyak titik pada graph G = E+1 |E(G)| = banyak sisi pada graph G = V-1 Contoh sebuah Graph
Istilah-istilah dalam teori graph
o Lup/ gelung, adalah sisi yang menghubungkan titik dengan titik itu sendiri. o Titik terminal, adalah titik yang berderajat 1
o Derajat, adalah banyaknya sisi dalam 1 titik o Titik terasing, adalah titik yang berderajat nol
V2 V1 V3 V4 V5 V6 V7 V8 V9
o Adjantcy/ berdekatan, adalah bila titik-titik terhubung langsung oleh suatu sisi.
o Incident/ bersisian, adalah bila titik tidak terhubung langsung.
o Lintasan/ Path, adalah urutan titik dan sisi dalam suatu graph terhubung. o Jalan/ Trail, adalah urutan titik dan sisi dalam graph yang tidak mengulang
sisi.
o Sikel, adalah path yang dimulai dan diakhiri pada titik yang sama.
o Graph terhubung, adalah graph yang semua titiknya dihubungkan oleh sisi.
o Graph sederhana, adalah graph yang tidak ada simpul/ lup.
o Graph berarah/ directed graph, adalah graph yang sisinya mempunyai arah.
o Graph tidak berarah/ undirected graph
o Graph komplit, adalah graph yang semua titik-titiknya terhubung langsung (lema jabat tangan)
- Jumlah sisi |E(G)| = degV(G)/2 - Derajat max = V-1
|E(G)| = 6/2 = 3 Deg = 3-1 = 2
o Euler
- Lintasan Euler, adalah lintasan yang melalui semua sisi tepat 1 kali dalam graph.
- Sirkuit Euler, adalah lintasan Euler yang berangkat dan berakhir pada titik yang sama.
o Hamilton
- Lintasan hamilton, adalah lintasan yang melalui semua titik tepat 1 kali dalam graph.
- Sirkuit hamilton, adalah lintasan hamilton yang berangkat dan berakhir pada titik yang sama.
v1 v
2
1.2. Kompilasi
1.2.1. Bahasa Pemrograman
1. Bahasa mesin merupakan bentuk terendah dari bahasa komputer. Instruksi direpresentasikan dalam kode numerik.
2. Bahasa Assembly merupakan bentuk simbolik dari bahasa mesin. Kode misalnya ADD, MUL, dsb
3. Bahasa tingkat tinggi (user oriented) lebih banyak memberikan fungsi kontrol program, kalang, block, dan prosedur.
4. Bahasa problem oriented sering juga dimasukkan sebagai bahasa tingkat tinggi, misalnya SQL, Myob, dsb.
1.2.2. Translator
Translator melakukan pengubahan source code/ kode program kedalam target code/ object code. Interpreter dan Compiler termasuk dalam kategori translator.
Bahasa Pemrograman Bahasa mesin Bahasa Assembly Bahasa Tingkat tinggi Bahasa Problem Oriented
1.2.3. Interpreter 1.2.4. Assembler Source Code Object Code Assembl
er Lingke Target File
r
.ASM .OBJ .EXE / .COM
Proses Sebuah Kompilasi pada Bahasa Assembler
Translator
Interpreter
Compiler
Tidak membangkitkan object code.
Source code dan data diproses bersamaan. Contoh: BASICA, SPSS, DBASE III.
Source Code adalah bahasa tingkat tinggi. Object Code adalah bahasa mesin atau assembly. Source code dan data diproses tidak bersamaan. Contoh: PASCAL, C.
Assembler
Source Code adalah bahasa Assembly
Object Code adalah bahasa mesin.
Analisa Leksikal Analisa Sintaks Intermediate Program Interpretas i Pengelolaan Tabel Progra m Penanganan Kesalahan Hasil Operasi
Keterangan :
• Source Code adalah bahasa Assembler, Object Code adalah bahasa Mesin. • Object Code dapat berupa file object (.OBJ), file .EXE, atau file .COM • Contoh : Turbo Assembler (dari IBM) dan Macro Assembler (dari Microsoft).
1.2.5. Compiler
Kompilator (compiler) adalah sebuah program yang membaca suatu program yang ditulis dalam suatu bahasa sumber (source language) dan menterjemah-kannya ke dalam suatu bahasa sasaran (target language).
Proses kompilasi dapat digambarkan melalui sebuah kotak hitam (black box) berikut :
A. Fase Compiler
Proses kompilasi dikelompokkan ke dalam dua kelompok besar : 1. Analisis (front-end) :
a. program sumber dipecah-pecah dan dibentuk menjadi bentuk antara (inter-mediate representation)
b. Language Independent 2. Sintesis (back-end) :
a. membangun program sasaran yang diinginkan dari bentuk antara b. Language dependent
B. Blok Diagram Compiler
Keterangan
1. Program Sumber : ditulis dalam bahasa sumber (Pascal, Assembler, dsb) 2. Program Sasaran : dapat berupa bahasa pemrograman lain atau bahasa
mesin pada suatu komputer.
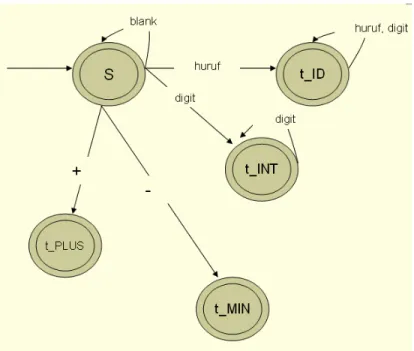
3. Penganalisa Leksikal : membaca program sumber, karakter demi karakter. Sederetan (satu atau lebih) karakter dikelompokkan menjadi satu kesatuan mengacu kepada pola kesatuan kelompok karakter (token) yang ditentukan dalam bahasa sumber. Kelompok karakter yang membentuk sebuah token dinamakan lexeme untuk token tersebut. Setiap token yang dihasilkan disimpan di dalam tabel simbol. Sederetan karakter yang tidak mengikuti pola token akan dilaporkan sebagai token tak dikenal (unidentified token).
4. Penganalisa sintaks : memeriksa kesesuaian pola deretan token dengan aturan sintaks yang ditentukan dalam bahasa sumber. Sederetan token yang tidak mengikuti aturan sintaks akan dilaporkan sebagai kesalahan sintaks (sintax error). Secara logika deretan token yang bersesuaian dengan sintaks tertentu akan dinyatakan sebagai pohon parsing (parse tree). Penganalisa Leksikal (scanner) Penganalisa Sintaks (parser) Penganalisa Semantik Pembangkit Kode antara Pembentuk kode Pengoptimal kode Program Sumber Program Sasaran TABEL SIMBOL ANALISA SINTESA
5. Penganalisa semantik : memeriksa token dan ekspresi dari batasan-batasan yang ditetapkan. Batasan-batasan-batasan tersebut misalnya :
a. panjang maksimum token identifier adalah 8 karakter, b. panjang maksimum ekspresi tunggal adalah 80 karakter, c. nilai bilangan bulat adalah -32768 s/d 32767,
d. operasi aritmatika harus melibatkan operan-operan yang bertipe sama.
Melakukan analisa semantik, biasanya dalam realisasi akan digabungkan Dengan intermediate code generator (bagian yang berfungsi membangkitkan kode antara).
6. Pembangkit kode antara : membangkitkan kode antara (intermediate code) berdasar-kan pohon parsing. Pohon parse selanjutnya diterjemahkan oleh suatu penerjemah yang dinamakan penerjemah berdasarkan sintak (syntax-directed translator). Hasil penerjemahan ini biasanya merupakan perintah tiga alamat (three-address code) yang merupakan representasi program untuk suatu mesin abstrak. Perintah tiga alamat bisa berbentuk quadruples (op, arg1, arg2, result), tripels (op, arg1, arg2). Ekspresi dengan satu argumen dinyatakan dengan menetapkan arg2 dengan - (strip, dash)
7. Pembentuk Kode : membangkitkan kode objek dalam bahasa target tertentu (misalnya bahasa mesin).
8. Pengoptimal Kode : Melakukan optimasi (penghematan space dan waktu komputasi), jika mungkin, terhadap kode antara sehingga dapat memperkecil hasil dan mempercepat proses.
9. Tabel : Menyimpan semua informasi yang berhubungan dengan proses kompilasi.
C. Pembuatan Compiler
Pembuatan kompilator dapat dilakukan dengan: 1. Bahasa Mesin
2. Bahasa Assembly
Bahasa Assembly bisa dan biasa digunakan sebagai tahap awal pada proses pembuatan sebuah kompilator.
3. Bahasa Tingkat Tinggi lain pada mesin yang sama Proses pembuatan kopilator akan lebih mudah.
4. Bahasa tingkat tinggi yang sama pada mesin yang berbeda
Misal, pembuatan kompilator C untuk DOS, berdasar C pada UNIX. 5. Bootstrap
Pembuatan kompilator secara bertingkat.
Keterangan :
o Pembentukan file Executable berdasar dari beberapa Source Code. o Source Code dapat terdiri dari satu atau lebih behasa
pemrograman.
D. Penggunaan Compiler selain untuk programming o Mentranslasikan javadoc ke html.
o Mendapatkan hasil dari SQL query (query optimization). o Printer parsing PostScript file.
o Screen Scrapping. o Konversi LaTeX ke PDF. Source Code 1 Source Code 2 Source Code n Object Code 1 Object Code 2 Object Code n Compiler 1 Compiler 2 Compiler n Lingker Executable Library Object Code
Bab II
KONSEP BAHASA AUTOMATA
2.1 Konsep Bahasa dan Automata 2.1.1 Teori Bahasa
Teori bahasa membicarakan bahasa formal (formal language), terutama untuk kepentingan perancangan kompilator (compiler) dan pemroses naskah (text processor). Bahasa formal adalah kumpulan kalimat. Semua kalimat dalam sebuah bahasa dibangkitkan oleh sebuah tata bahasa (grammar) yang sama. Sebuah bahasa formal bisa dibangkitkan oleh dua atau lebih tata bahasa berbeda. Dikatakan bahasa formal karena grammar diciptakan mendahului pembangkitan setiap kalimatnya. Bahasa manusia bersifat sebaliknya; grammar diciptakan untuk meresmikan kata-kata yang hidup di masyarakat. Dalam pembicaraan selanjutnya ‘bahasa formal’ akan disebut ‘bahasa’ saja.
2.1.2 Automata
Automata adalah mesin abstrak yang dapat mengenali (recognize), menerima (accept), atau membangkitkan (generate) sebuah kalimat dalam bahasa tertentu. Automata berkaitan dengan teori mesin abstrak, yaitu mesin sekuensial yang menerima input, dan mengeluarkan output, dalam bentuk diskrit.
Contoh :
o Mesin Jaja / vending machine o Kunci kombinasi
o Parser/compiler
Teori Otomata dan bahasa formal berkaitan dalam hal, yaitu:
o Pembangkitan kalimat/ generation : menghasilkan semua kalimat dalam bahasa L berdasarkan aturan yang dimilikinya.
o Pengenalan kalimat/ recognition : menentukan suatu string (kalimat) termasuk sebagai salah satu anggota himpunan L.
2.1.3 String 2.1.3.1 Definisi
Simbol adalah sebuah entitas abstrak. Sebuah huruf atau sebuah angka adalah contoh simbol.
String adalah deretan terbatas (finite) simbol-simbol. Sebagai contoh, jika a, b, dan c adalah tiga buah simbol maka abcb adalah sebuah string yang dibangun dari ketiga simbol tersebut.
Alfabet adalah hinpunan hingga (finite set) simbol-simbol 2.1.3.2 Panjang String
Definisi 1: sebuah string dengan panjang n yang dibentuk dari himpunan A adalah barisan dari n simbol. Misalnya a1a2...an ; ai ∈ A
Jika w adalah sebuah string maka panjang string dinyatakan sebagai w dan didefinisikan sebagai cacahan (banyaknya) simbol yang menyusun string tersebut.
Sebagai contoh, jika w = abcb maka w = 4 2.1.3.3 String Hampa :
Definisi 2 : String kosong/ String hampa (null string), dilambangkan dengan ε (atau ^) adalah untaian dengan panjang 0 dan tidak berisi apapun.
String hampa adalah sebuah string dengan nol buah simbol. Maka panjang string hampa ε = 0.
String hampa dapat dipandang sebagai simbol hampa karena keduanya tersusun dari nol buah simbol.
2.1.4 Operasi Dasar String
Diberikan dua string : x = abc, dan y = 123
o Prefik string w adalah string yang dihasilkan dari string w dengan menghilangkan nol atau lebih simbol-simbol paling belakang dari string w tersebut.
o ProperPrefix string w adalah string yang dihasilkan dari string w dengan menghilangkan satu atau lebih simbol-simbol paling belakang dari string w tersebut.
Contoh : ab, a, dan adalah semua ProperPrefix(x)
o Postfix (atau Sufix) string w adalah string yang dihasilkan dari string w dengan menghilangkan nol atau lebih simbol-simbol paling depan dari string w tersebut.
Contoh : abc, bc, c, dan adalah semua Postfix(x)
o ProperPostfix (atau PoperSufix) string w adalah string yang dihasilkan dari string w dengan menghilangkan satu atau lebih simbol-simbol paling depan dari string w tersebut.
Contoh : bc, c, dan adalah semua ProperPostfix(x) o Head string w adalah simbol paling depan dari string w.
Contoh : a adalah Head(x)
o Tail string w adalah string yang dihasilkan dari string w dengan menghilangkan simbol paling depan dari string w tersebut.
Contoh : bc adalah Tail(x)
o Substring string w adalah string yang dihasilkan dari string w dengan menghilangkan nol atau lebih simbol paling depan dan/atau simbol-simbol paling belakang dari string w tersebut.
Contoh : abc, ab, bc, a, b, c, dan adalah semua Substring(x)
o ProperSubstring string w adalah string yang dihasilkan dari string w dengan menghilangkan satu atau lebih simbol-simbol paling depan dan/atau simbolsimbol paling belakang dari string w tersebut.
Contoh : ab, bc, a, b, c, dan adalah semua Substring(x)
o Subsequence string w adalah string yang dihasilkan dari string w dengan menghilangkan nol atau lebih simbol-simbol dari string w tersebut.
Contoh : abc, ab, bc, ac, a, b, c, dan adalah semua Subsequence(x)
o ProperSubsequence string w adalah string yang dihasilkan dari string w dengan menghilangkan satu atau lebih simbol-simbol dari string w tersebut. Contoh : ab, bc, ac, a, b, c, dan adalah semua Subsequence(x)
o Concatenation adalah penyambungan dua buah string. Operator concatenation adalah concate atau tanpa lambang apapun.
Contoh : concate(xy) = xy = abc123
o Alternation adalah pilihan satu di antara dua buah string. Operator alternation adalah alternate atau |.
Contoh : alternate(xy) = x|y = abc atau 123 o Kleene Closure : x* = |x|xx|xxx|… = |x|x2|x3|… o Positive Closure : x+= x|xx|xxx|… = x|x2|x3|…
2.1.5 Sifat-sifat Operasi String
o Tidak selalu berlaku : x = Prefix(x)Postfix(x) o Selalu berlaku : x = Head(x)Tail(x)
o Tidak selalu berlaku : Prefix(x) = Postfix(x) atau Prefix(x) Postfix(x) o Selalu berlaku : ProperPrefix(x) ProperPostfix(x)
o Selalu berlaku : Head(x) Tail(x)
o Setiap Prefix(x), ProperPrefix(x), Postfix(x), ProperPostfix(x), Head(x), dan Tail(x) adalah Substring(x), tetapi tidak sebaliknya
o Setiap Substring(x) adalah Subsequence(x), tetapi tidak sebaliknya o Dua sifat aljabar concatenation :
a. Operasi concatenation bersifat asosiatif : x(yz) = (xy)z b. Elemen identitas operasi concatenation adalah : x = x = x o Tiga sifat aljabar alternation :
a. Operasi alternation bersifat komutatif : x|y = y|x b. Operasi alternation bersifat asosiatif : x|(y|z) = (x|y)|z
c. Elemen identitas operasi alternation adalah dirinya sendiri : x|x = x o Sifat distributif concatenation terhadap alternation : x (y|z) = xy|xz o Beberapa kesamaan :
a. Kesamaan ke-1 : (x*)* = (x*) b. Kesamaan ke-2 : |x+= x+| = x*
c. Kesamaan ke-3 : (x|y)* = |x|y|xx|yy|xy|yx|… = semua string yang merupakan concatenation dari nol atau lebih x, y, atau keduanya.
2.2 Grammar dan Bahasa 2.2.1 Definisi
Tata Bahasa (grammar) bisa didefinisikan secara formal sebagai kumpulan dari himpunan-himpunan variabel, simbol-simbol terminal, simbol awal, yang dibatasi oleh aturan-aturan produksi.
Bahasa adalah himpunan kalimat-kalimat. Anggota bahasa bisa tak hingga kalimat. Kalimat adalah deretan hingga (string) yang tersusun atas simbol-simbol terminal. Sentensial adalah string yang tersusun atas simbol terminal atau simbol-simbol non terminal atau campuran keduanya.
Kalimat adalah merupakan sentensial, sebaliknya belum tentu.
Derivasi adalah proses pembentukan sebuah kalimat atau sentensial. Sebuah derivasi dilambangkan sebagai : α β.
2.2.2 Simbol
A. Simbol Terminal
Pengertian terminal berasal dari kata terminate (berakhir), maksudnya derivasi berakhir jika sentensial yang dihasilkan adalah sebuah kalimat (yang tersusun atas simbol-simbol terminal itu).
Simbol terminal adalah simbol yang tidak dapat diturunkan lagi. Simbol-simbol berikut adalah simbol terminal :
- huruf kecil awal alfabet, misalnya : a, b, c - simbol operator, misalnya : +, −, dan × - simbol tanda baca, misalnya : (, ), dan ;
- string yang tercetak tebal, misalnya : if, then, dan else.
B. Simbol Non Terminal
Pengertian non terminal berasal dari kata not terminate (belum/tidak berakhir), maksudnya derivasi belum/ tidak berakhir jika sentensial yang dihasilkan mengandung simbol non terminal.
Simbol variabel /non terminal adalah simbol yang masih bisa diturunkan. Simbol-simbol berikut adalah simbol non terminal :
- huruf besar awal alfabet, misalnya : A, B, C - huruf S sebagai simbol awal
- string yang tercetak miring, misalnya : - expr dan stmt
Huruf besar akhir alfabet melambangkan simbol terminal atau non terminal, misalnya : X, Y, Z.
Huruf kecil akhir alfabet melambangkan string yang tersusun atas simbol-simbol terminal, misalnya : x, y, z.
Huruf yunani melambangkan string yang tersusun atas simbol-simbol terminal atau simbol-simbol non terminal atau campuran keduanya, misalnya : α, β, dan γ.
2.2.3 Aturan Produksi
Aturan produksi men-spesifikasikan bagaimana suatu tatabahasa melakukan transformasi suatu string ke bentuk lainnya. Melalui aturan produksi didefinisikan suatu bahasa yang berhubungan dengan tata bahasa tersebut. Sebuah produksi dilambangkan sebagai α → β (bisa dibaca menghasilkan ),
artinya : dalam sebuah derivasi dapat dilakukan penggantian simbol α dengan simbol β.
Simbol α dalam produksi berbentuk α → β disebut ruas kiri produksi sedangkan simbol β disebut ruas kanan produksi.
Contoh aturan produksi :
T → a , dibaca: T menghasilkan a
E → T | T+E, dibaca: E menghasilkan T atau E menghasilkan T+E merupakan pemendekan dari aturan produksi :
E → T E → T+E 2.2.4 Grammar
Grammar G didefinisikan sebagai pasangan 4 tuple : VT, VN, S, dan P.
- VT : himpunan simbol-simbol terminal (alfabet) kamus.
- VN : himpunan simbol-simbol non terminal.
- S∈ VN : simbol awal (atau simbol start)
- P : himpunan produksi. Contoh Grammar :
1. G1 : VT = {I, Love, Miss, You}, VN = {S,A,B,C},
P = {S → ABC, A→ I, B→ Love | Miss, C→ You} S ABC IloveYou L(G1)={IloveYou, IMissYou} 2. G2 : VT = {a}, VN = {S}, P = {S → aSa} S aS aaS aaa L(G2) ={an n 1}
L(G2)={a, aa, aaa, aaaa,…}
2.2.5 Klasifikasi Chomsky
Noam Chomsky melakukan penggolongan tingkatan bahasa berdasarkan aturan produksinya yang disebut dengan Hierarki Chomsky (1959). Berdasarkan komposisi bentuk ruas kiri dan ruas kanan produksinya (α → β), Noam Chomsky mengklasifikasikan 4 tipe grammar.
Tipe sebuah grammar (atau bahasa) ditentukan dengan aturan sebagai berikut : A language is said to be type-i (i = 0, 1, 2, 3) language if it can be specified
by a type-i grammar but can’t be specified any type-(i+1) grammar.
Klasifikasi Chomsky
1. Grammar tipe ke-0 : Unrestricted Grammar (UG) Ciri : α, β ∈ (VTVN)*, α > 0
Mesin automata : Mesin Turing Aturan Produksi : tidak ada batasan
Contoh : Bahasa manusia/bahasa alami, misalnya Abc → De
2. Grammar tipe ke-1 : Context Sensitive Grammar (CSG) Ciri : α, β ∈ (VTVN) *, 0 < α ≤ β
Mesin automata : Linier Bounded Automata Aturan Produksi : | | | |
Contoh : Ab → DeF, CD → eF, S →
* |s| = 1, | | = 0, ada perkecualian sehingga S → dianggap memenuhi context sensitive grammar.
3. Grammar tipe ke-2 : Context Free Grammar (CFG) Ciri : α ∈ VN, β ∈ (VTVN)*
Mesin automata : PDA
Aturan Produksi : berupa sebuah simbol variable Contoh : B → CDeFg, D → BcDe
4. Grammar tipe ke-3 : Regular Grammar (RG)
Ciri : α ∈ VN, β ∈ {VT, VTVN} atau α ∈ VN, β ∈ {VT, VNVT}
Mesin automata : FSA meliputi DFA & NFA Aturan Produksi :
- adalah sebuah simbol variable
- maksimal memiliki sebuah symbol variabel yang bila ada terletak di posisi paling kanan
Mesin Pengenal Bahasa
Kelas Bahasa Mesin Pengenal Bahasa
Unrestricted Grammar (UG) Mesin Turing (Turing Machine), TM Context Sensitive Grammar (CSG) Linear Bounded Automaton, LBA Context Free Gammar (CFG) Pushdown Automata, PDA Regular Grammar, RG Finite State Automata, FSA
Keterkaitan Bahasa
2.2.6 Analisa Grammar
A. Analisa Penentuan Type Grammar
1. Grammar G1 dengan P1 = {S → aB, B → bB, B → b}.
Ruas kiri semua produksinya terdiri dari sebuah VN, maka G1
kemungkinan tipe CFG atau RG. Selanjutnya karena semua ruas kanannya terdiri dari sebuah VT atau string VTVN maka G1 adalah RG (3).
2. Grammar G2 dengan P2 = {S → aAb, B → aB}.
Ruas kiri semua produksinya terdiri dari sebuah VN maka G2
kemungkinan tipe CFG atau RG. Selanjutnya karena ruas kanannya mengandung string yang panjangnya lebih dari 2 (yaitu aAb) maka G2
bukan RG, dengan kata lain G2 adalah CFG (2).
Ruas kirinya mengandung string yang panjangnya lebih dari 1 (yaitu aAb) maka G3 kemungkinan tipe CSG atau UG. Selanjutnya karena semua ruas
kirinya lebih pendek atau sama dengan ruas kananya maka G3 adalah CSG
(1).
4. Grammar G4 dengan P4 = {S → aAb, B → aB}.
Ruas kiri semua produksinya terdiri dari sebuah VN maka G4 kemungkinan
tipe CFG atau RG. Selanjutnya karena ruas kanannya mengandung string yang panjangnya lebih dari 2 (yaitu aAb) maka G4 bukan RG, dengan kata
lain G4 adalah CFG (2).
B. Derivasi Kalimat dan Penentuan Bahasa
Tentukan bahasa dari masing-masing gramar berikut : 1. G1 dengan P1 = {1. S → aAa, 2. A → aAa, 3. A → b}.
Jawab :
Derivasi kalimat terpendek : Derivasi kalimat umum :
S aAa (1) S aAa (1)
aba (3) aaAaa (2)
…
anAan (2) anban (3)
Dari pola kedua kalimat disimpulkan : L1 (G1) = {anban n ≥ 1}
2. G2 dg P2 = {1. S → aS, 2. S → aB, 3. B → bC, 4. C → aC, 5. C → a}.
Jawab :
Derivasi kalimat terpendek : Derivasi kalimat umum :
S aB (2) S aS (1) abC (3) … aba (5) an-1S (1) anB (2) anbC (3) anbaC (4)
…
anbam-1C (4)
anbam (5)
Dari pola kedua kalimat disimpulkan : L2 (G2)={anbam n ≥1, m≥1}
C. Menentukan Grammar Sebuah Bahasa
1. Tentukan sebuah gramar regular untuk bahasa L1 = { an n ≥ 1}
Jawab : P1 (L1) = {S → aSa}
2. Tentukan sebuah gramar bebas konteks untuk bahasa : L2 : himpunan bilangan bulat non negatif ganjil
Jawab :
Langkah kunci : digit terakhir bilangan harus ganjil. Vt={0,1,2,..9}
Vn ={S,G,J}
P = {S HT|JT|J; T GT|JT|J; H 2|4|6|8; G 0|2|4|6|8;J 1|3|5|7|9} P={S GS|JS|J; G 0|2|4|6|8;J 1|3|5|7|9}
Buat dua buah himpunan bilangan terpisah : genap (G) dan ganjil (J) P2(L2) = {S → JGSJS, G → 02468, J → 13579}
Bab III
FINITE STATE AUTOMATA
Finite State Automata/ FSA adalah mesin yang dapat mengenali bahasa reguler tanpa menggunakan storage (memory). FSA tidak memiliki tempat penyimpanan (memory), tetapi hanya bisa mengingat state terkini saja.
FSA disebut juga dengan Automata Hinga (AH). FSA/ AH sangat berhubungan dengan Regular Grammar. Dan merupakan kelas mesin dengan kemampuan-kemampuan yang paling terbatas.
FSA memiliki state yang berhingga banyaknya dan dapat berpindah dari satu state ke state lainnya berdasar input dan fungsi transisi. Sejumlah status dapat didefinisikan pada mesin untuk “mengingat” beberapa hal secara terbatas.
Manfaat nyata:
1. Software untuk mendesain dan mengecek perilaku sirkuit digital. Contoh: mesin ATM.
2. Bagian“Lexical Analyzer” dari berbagai kompiler yang berfungsi membagi teks input menjadi logical unit seperti Keyword, Identifier, dan pungtuasi.
3. Search engine menscan web, dan menemukan kata, frase atau pola yang tepat.
3.1 Definisi Formal
Definisi 1: FSA didefinisikan sebagai pasangan 5 tupel : (Q, , , S, F). Q : himpunan hingga state
: himpunan hingga simbol input (alfabet)
: fungsi transisi, menggambarkan transisi state FSA akibat pembacaan simbol input. Fungsi transisi ini biasanya diberikan dalam bentuk tabel. S ∈ Q : state AWAL
F ⊂ Q : himpunan state AKHIR
Mekanisme kerja FSA dapat diaplikasikan pada: elevator, text editor, analisa leksikal, pencek parity.
3.2 Fungsi Transisi
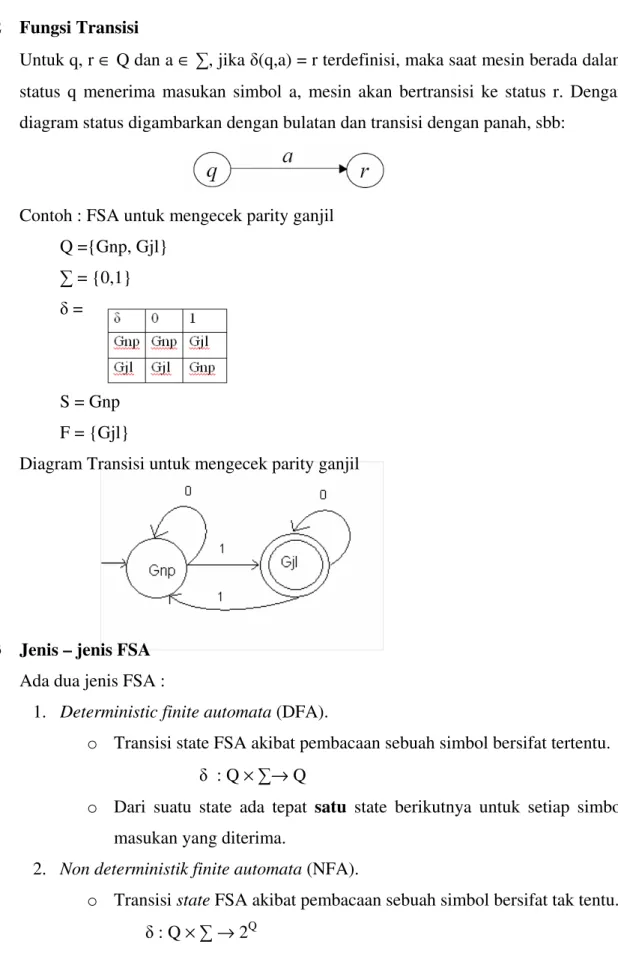
Untuk q, r ∈ Q dan a ∈ , jika (q,a) = r terdefinisi, maka saat mesin berada dalam status q menerima masukan simbol a, mesin akan bertransisi ke status r. Dengan diagram status digambarkan dengan bulatan dan transisi dengan panah, sbb:
Contoh : FSA untuk mengecek parity ganjil Q ={Gnp, Gjl}
= {0,1} =
S = Gnp F = {Gjl}
Diagram Transisi untuk mengecek parity ganjil
3.3 Jenis – jenis FSA Ada dua jenis FSA :
1. Deterministic finite automata (DFA).
o Transisi state FSA akibat pembacaan sebuah simbol bersifat tertentu. : Q × → Q
o Dari suatu state ada tepat satu state berikutnya untuk setiap simbol masukan yang diterima.
2. Non deterministik finite automata (NFA).
o Transisi state FSA akibat pembacaan sebuah simbol bersifat tak tentu. : Q × → 2Q
q1 q2 q3 1 0 0 1 1 0 0 1 start q0
o Dari suatu state ada 0, 1 atau lebih state berikutnya untuk setiap simbol masukan yang diterima.
3.4 Deterministic finite automata (DFA)
DFA disebut juga dengan Automata Hingga Deterministik (AHD). AHD sering digambarkan dengan dua cara :
• Table Transisi State • Transisi Digraph Contoh DFA :
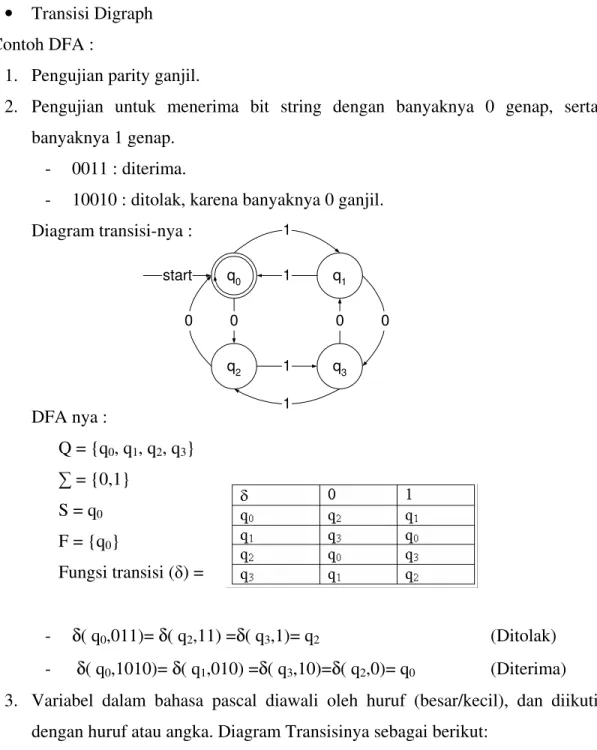
1. Pengujian parity ganjil.
2. Pengujian untuk menerima bit string dengan banyaknya 0 genap, serta banyaknya 1 genap.
- 0011 : diterima.
- 10010 : ditolak, karena banyaknya 0 ganjil. Diagram transisi-nya : DFA nya : Q = {q0, q1, q2, q3} = {0,1} S = q0 F = {q0} Fungsi transisi ( ) = - δ( q0,011)= δ( q2,11) =δ( q3,1)= q2 (Ditolak) - δ( q0,1010)= δ( q1,010) =δ( q3,10)=δ( q2,0)= q0 (Diterima)
3. Variabel dalam bahasa pascal diawali oleh huruf (besar/kecil), dan diikuti dengan huruf atau angka. Diagram Transisinya sebagai berikut:
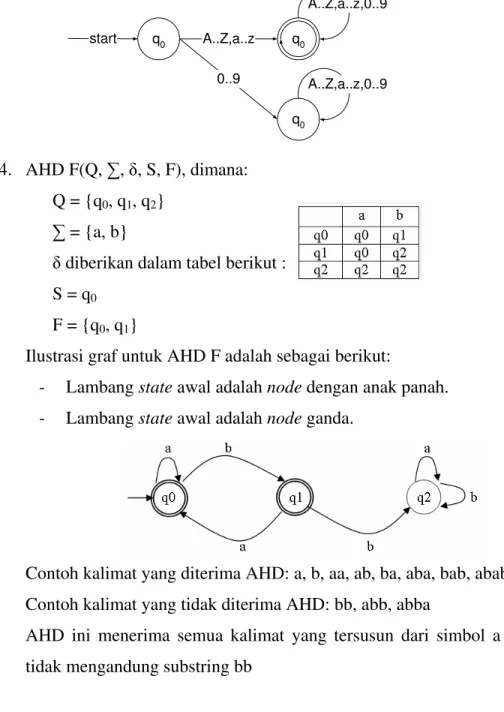
q0 A..Z,a..z start q0 q0 0..9 A..Z,a..z,0..9 A..Z,a..z,0..9 4. AHD F(Q, , , S, F), dimana: Q = {q0, q1, q2} = {a, b}
diberikan dalam tabel berikut : S = q0
F = {q0, q1}
Ilustrasi graf untuk AHD F adalah sebagai berikut:
- Lambang state awal adalah node dengan anak panah. - Lambang state awal adalah node ganda.
Contoh kalimat yang diterima AHD: a, b, aa, ab, ba, aba, bab, abab, baba Contoh kalimat yang tidak diterima AHD: bb, abb, abba
AHD ini menerima semua kalimat yang tersusun dari simbol a dan b yang tidak mengandung substring bb
3.5 Non deterministik finite automata (NFA)
Disebut juga Automata Hingga Non Deterministik (AHN). Fungsi transisi dapat memiliki 0 atau lebih fungsi transisi.
Sebuah kalimat di terima NFA jika :
- Salah satu tracing-nya berakhir di state AKHIR, atau
- Himpunan state setelah membaca string tersebut mengandung state AKHIR
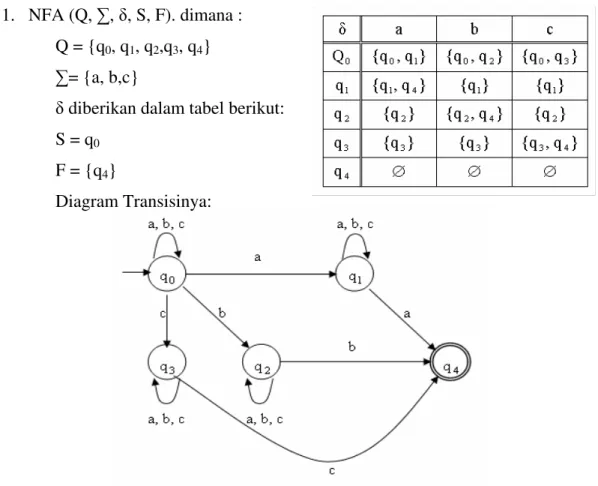
q2 q0 q1 q4 q3 0,1 0,1 0 0 1 1 0,1 Contoh NFA: 1. NFA (Q, , , S, F). dimana : Q = {q0, q1, q2,q3, q4} = {a, b,c}
diberikan dalam tabel berikut: S = q0
F = {q4}
Diagram Transisinya:
Kalimat yang diterima NFA di atas : aa, bb, cc, aaa, abb, bcc, cbb Kalimat yang tidak diterima NFA di atas : a, b, c, ab, ba, ac, bc
2. G = ({q0 , q1 , q2 , q3, q4 }, {0,1}, δ , q0 , {q2, q4}}
Diagram transisi:
Mengecek, apakah string 01001 diterima oleh mesin NFA di atas:
3.6 Ekuivalen
Definisi 2: Dua buah FSA disebut ekuivalen apabila kedua FSA tersebut menerima bahasa yang sama.
Contoh : FSA yang menerima bahasa {an | n≥0 }
3.7 Indistinguishable
Definisi 3: Dua buah state dari FSA disebut indistinguishable (tidak dapat dibedakan) apabila :
- δ(q,w)∈F sedangkan δ(p,w)∉F dan
- δ(q,w) ∉F sedangkan δ(p,w) ∈F untuk semua w ∈ Σ*
3.8 Distinguishable
Definisi 4: Dua buah state dari FSA disebut distinguishable (dapat dibedakan) bila terdapat w ∈ Σ* sedemikian hingga:
- δ(q,w)∈F sedangkan δ(p,w)∉F dan
- δ(q,w) ∉F sedangkan δ(p,w) ∈F untuk semua w ∈ Σ*
q0 q0 q0 q0 q0 q0 q3 q1 q3 q3 q1 q4 q4 0 1 0 0 1 0 1 0 0 1 0 1 q4 a a q4 q4 a
q0 q1 q2 q3 q4 0 1 0 0 0 1 1 1 0,1
3.9 Prosedur menentukan pasangan status indistinguishable 1. Hapus semua state yang tak dapat dicapai dari state awal.
2. Catat semua pasangan state (p,q) yang distinguishable, yaitu {(p,q) | p ∈ F ∧ q ∉ F}
3. Untuk setiap pasangan (p,q) sisanya,
4. untuk setiap a∈ Σ, tentukan δ(p,a) dan δ(q,a) Contoh:
- Hapus state yang tidak tercapai (tidak ada)
- Pasangan distinguishable (q0,q4), (q1,q4), (q2,q4), (q3,q4).
- Pasangan sisanya (q0,q1), (q0,q2), (q0,q3), (q1,q2) (q1,q3) (q2,q3)
- Catatan : jumlah pasangan seluruhnya :
3.10 Prosedur Reduksi DFA
1. Tentukan pasangan status indistinguishable.
2. Gabungkan setiap group indistinguishable state ke dalam satu state dengan relasi pembentukan grup secara berantai : Jika p dan q indistingishable dan jika q dan r indistinguishable maka p dan r indistinguishable, dan p,q serta r
indistinguishable semua berada dalam satu grup. 3. Sesuaikan transisi dari dan ke state-state gabungan.
10 ! 3 ! 2 ! 5 2 5 = = C
Contoh :
- pasangan status indistinguishable (q1,q2), (q1,q3) dan (q2,q3).
- q1,q2,q3 ketiganya dapat digabung dalam satu state q123
- Menyesuaikan transisi, sehingga DFA menjadi
q0 0,1 q123 1 q4
Bab IV
Ekuivalensi NFA ke DFA
4.1 Algoritma Ekivalensi NFA ke DFA
a. Buat semua state yang merupakan subset dari state semula. Jumlah state menjadi 2Q
b. Telusuri transisi state–state yang baru terbentuk, dari diagram transisi. c. Tentukan state awal : {q0}
d. Tentukan state akhir adalah state yang elemennya mengandung state akhir. e. Reduksi state yang tak tercapai oleh state awal.
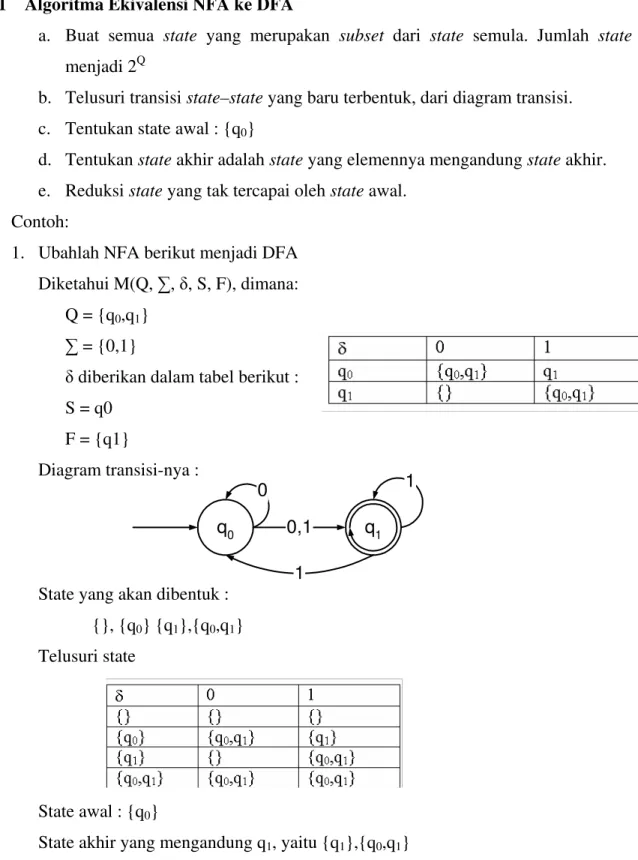
Contoh:
1. Ubahlah NFA berikut menjadi DFA Diketahui M(Q, , , S, F), dimana:
Q = {q0,q1}
= {0,1}
diberikan dalam tabel berikut : S = q0
F = {q1}
Diagram transisi-nya :
State yang akan dibentuk : {}, {q0} {q1},{q0,q1}
Telusuri state
State awal : {q0}
State akhir yang mengandung q1, yaitu {q1},{q0,q1}
q0 0,1 q1
0 1
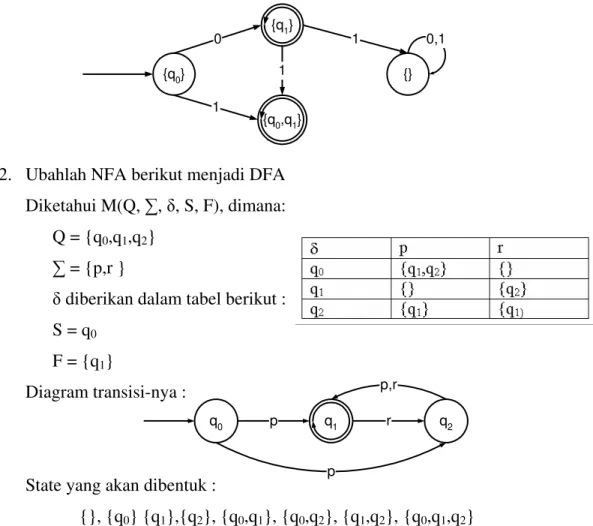
2. Ubahlah NFA berikut menjadi DFA Diketahui M(Q, , , S, F), dimana:
Q = {q0,q1,q2}
= {p,r }
diberikan dalam tabel berikut : S = q0
F = {q1}
Diagram transisi-nya :
State yang akan dibentuk :
{}, {q0} {q1},{q2}, {q0,q1}, {q0,q2}, {q1,q2}, {q0,q1,q2}
Telusuri state
State awal : {q0}
State akhir yang mengandung q1, yaitu {q1},{q1,q2}
Reduksi {q0,q1} {q0,q2} {q0,q1,q2 } sehingga FSA menjadi :
{q0} 0 1 1 0,1 {q1} {q0,q1} 1 {} q0 p r p,r p q2 q1 {q0} p p r r {q1,q2} {q1} p,r p r
q0 q4 q1 ε b q2 ε ε q3 b b
4.2 NFA dengan εεεε-move
Def 1. ε-move adalah suatu transisi antara 2 status tanpa adanya input. Contoh transisi antara status q1 ke q2
Def 2. ε-closure adalah himpunan state yang dapat dicapai dari suatu state tanpa adanya input. Contoh gambar :
- ε-closure(q0) = [q0,q1,q3]
- ε-closure(q1) = [q1,q3]
- ε-closure(q3) = [q3]
4.3 Ekuivalensi NFA dengan εεεε-move ke NFA tanpa εεεε-move Algoritma:
a. Buat tabel transisi NFA dengan ε-move b. Tentukan ε-closure setiap state
c. Carilah fungsi transisi/ tabel transisi yang baru, rumus : δ’(state,input) = ε-closure(δ(ε-closure(state,input))
d. Tentukan state akhir ditambah dengan state yang ε-closure nya menuju state akhir, rumusnya : F’ = F ∪ {q | (ε-closure(q) ∩ F ≠ ∅}
Contoh : Tabel transisi-nya q0 ε q1 q3 q2 a b
ε-closure dari FSA tersebut - ε-closure(q0) = [q0,q1]
- ε-closure(q1) = [q1]
- ε-closure(q2) = [q2]
- ε-closure(q3) = [q3]
Cari tabel transisi yang baru (δ’) :
Hasilnya menjadi :
4.4 Penggabungan FSA
Bila diketahui L1 adalah bahasa yang diterima oleh M1 dan L2 adalah bahasa yang
diterima oleh M2 maka :
a. FSA M3 yg dapat menerima L1+L2 dibuat dengan cara
- Tambahkan state awal untuk M3, hubungkan dengan state awal M1 dan
state awal M2 menggunakan transisi ε
- Tambahkan state akhir untuk M3, hubungkan dengan state-state akhir q0 q2 a b q3 q1 a b
b. FSA M4 yg dapat menerima L1L2 dibuat dengan cara
- State awal M1 menjadi state awal M4
- State-state akhir M2 menjadi state-state akhir M4
- Hubungkan state-state akhir M1 dengan state awal M2 menggunakan
transisi ε Contoh : - FSA M1 dan M2 - FSA M3 - FSA M4 qA1 qA0 0 1 q B1 qB0 1 1 0 qA0 0 1 qB0 1 1 0 qS ε ε qA1 qB1 ε ε qF qA0 0 1 qA1 qB0 qB1 1 1 0 ε
Bab V Ekspresi Reguler
5.1 Bahasa regular
Bahasa disebut reguler jika terdapat FSA yang dapat menerimanya. Bahasa reguler dinyatakan secara sederhana dengan ekspresi reguler/regular expression (RE). Contoh penerapan : searching string pada file
Hubungan RE dan NFA : Setiap RE ada satu NFA dengan ε-move yang ekuivalen. Konversi bentuk dari ekspresi regular menjadi bentuk DFA:
RE -> NFA dengan ε Move -> DFA
Definisi ekspresi reguler
Jika Σ merupakan himpunan simbol, maka
- ∅ , ε , dan a ∈ Σ adalah ekspresi reguler dasar
- Jika r dan t masing masing merupakan ekspresi reguler maka komposisi berikut merupakan ekspresi reguler :
Ekspresi Makna
r+t himpunan string gabungan R∪T
rt operasi penyambungan string thd himpunan r* Kleene closure dari R
(r) r
Contoh ekspresi reguler
- (0+1)* : himpunan seluruh string yang dapat dibentuk dari simbol ‘0’ dan ‘1’ - (0+1)*00(0+1)* : himpunan string biner yang mengandung paling sedikit satu
substring ‘00’
- (0+1)*00 : himpunan string biner yang diakhiri dengan ‘00’
1. Tentukan bahasa reguler yang dibentuk oleh r = (aa)* Jawab:
L(r) = L( (aa)* )
= {ε, aa, aaaa, aaaaaa, ... } = { a2n | n ≥ 0 }
menyatakan himpunan string a dengan jumlah genap
2. Tentukan ekspresi reguler pembentuk bahasa pada Σ = {0,1}, yaitu L(r) = { w ∈ Σ* | w memiliki substring ‘00’}
Jawab: r = (0+1)*00(0+1)*
5.2 Sifat Bahasa Reguler
a. Tertutup terhadap operasi himpunan sederhana
Jika L1 dan L2 adalah bahasa reguler, maka L1∪L2, L1∩L2, L1L2, ~(L1) dan L1*
adalah bahasa reguler juga
b. Tertutup terhadap homomorphic image
- Jika L1 adalah bahasa reguler, maka homomorphic image h(L1) adalah bahasa
reguler juga.
- Dimisalkan Σ dan Γ adalah alfabet, maka fungsi homomorphic dinyatakan dengan h : Σ → Γ
- Jika w = a1 a2 ... an, maka h(w) = h(a1) h(a2 ) ... h(an)
- Jika L adalah bahasa pada Σ maka homomorphic image bahasa L adalah h(L)= { h(w) | w∈L}
Contoh:
Dimisalkan Σ = {a,b} dan Γ = {a,b,c} dan didefinisikan h(a) = ab dan h(b) =bbc homomorphic image bahasa L = {aa,aba } adalah :
5.3 Konversi ekspresi reguler ke FSA
Contoh : Tentukan FSA untuk ekspresi reguler r = 0(1 | 23)*
5.4 DFA dan Tatabahasa Reguler
5.4.1 Tatabahasa Linier kiri dan linier kanan
Suatu tatabahasa G(T,N,S,P) disebut linier kiri jika seluruh aturan produksinya berbentuk A → xB dengan A, B ∈ N dan x ∈ T*
Suatu tatabahasa G(T,N,S,P) disebut linier kanan jika seluruh aturan produksinya berbentuk A → Bx dengan A, B ∈ N dan x ∈ T*
Contoh :
- Tatabahasa G = { {a,b}, {S}, S, P } dengan aturan produksi P adalah S → abS |a adalah tatabahasa linier kanan /regular
- Tatabahasa G = {{a,b}, {S, S1,S2}, S, P } dengan aturan produksi P
adalah S → S1ab, S1→ S1ab | S2, S2→ a
adalah tatabahasa linier kiri /reguler
- Tatabahasa G = {{a,b}, {S, A, B}, S, P } dengan aturan produksi P adalah S → A, A → aB | ε, B → Ab, adalah bukan tatabahasa regular.
5.4.2 Konversi DFA ke tatabahasa linier
Setiap DFA dapat diubah menjadi tatabahasa yang memiliki aturan produksi yang linier. Aturan pengubahan ini adalah sebagai berikut :
- setiap transisi status δ(A,a)=B diubah menjadi aturan produksi A → aB - setiap status akhir P diubah menjadi aturan produksi Pε→
Contoh FSA berikut
Tatabahasa linier untuk FSA tersebut yaitu
G = ({a,b}, {S,S1,S2,S3}, S, P ) dengan aturan produksi P adalah :
S → S1, S1 → aS2, S1 → bS3, S3 → ε
5.4.3 Konversi tatabahasa linier ke DFA
- setiap aturan produksi A → aB diubah menjadi transisi status δ(A,a)=B - setiap aturan produksi A → a diubah menjadi δ(A,a)=SF
- untuk a ∈ T* dengan |a|>1 dapat dibuat state tambahan - setiap aturan produksi A → B diubah menjadi δ(A,ε)=B Contoh: Tata bahasa G = ({a,b}, {V0,V1}, V0, P ) dengan P:
V0 →aV1 q0 ε q1 q3 q2 a b
V1 →abV0 | b
Mesin FSA nya menjadi
5.5 Penerapan ekspresi regular
Digunakan untuk memerinci unit-unit leksikal sebuah bahasa pemrograman (token). Contoh:
- ekspresi reguler ‘bilangan real positif’ (0+1+...+9)(0+1+...+9)*.(0+1+...+9) (0+1+...+9)*
- ekspresi reguler ‘bilangan bulat’ (‘+’ + ’-‘ + λ) (0+1+...+9)(0+1+...+9)* - Editor text
5.6 Pumping lemma
Apabila suatu bahasa merupakan bahasa reguler maka akan dapat diterima oleh mesin DFA M=(Q,Σ,δ,q0,F), dgn sejumlah state n. Apabila string w dengan |w| ≥ n diinputkan dalam DFA, maka pasti ada simpul k dalam DFA yang dikunjungi lebih dari satu kali. Apabila string diantara simpul k yang sama tersebut ‘dipompa’, maka sisanya pasti masih diterima oleh DFA tersebut.
Contoh : Bahasa yang menerima ekspresi reguler 0(10)*11
Ambil string w∈L , dengan |w|≥ n: w= 01011 q0 0 q1 1 q2 0 q1 1 q3 1 q4 V0 a b a V1 Vf b q0 0 1 1 q1 q4 0 q3 1 q2
simpul q1 dikunjungi 2 kali. String diantara simbol q1 tersebut dapat
‘dipompa’ keluar menjadi q0 0 q1 1 q3 1 q4
string 011 tersebut masih dapat diterima oleh FSA.
Secara formal,
Misal L adalah sebuah bahasa reguler infinite, maka terdapat sebuah konstanta n dengan sifat bahwa jika w adalah sebuah string dalam L yang panjangnya lebih besar atau sama dengan n maka kita bisa menulis w = uvx sedemikian sehingga uvix ∈ L untuk semua i ≥ 0. dengan |v|≥1 dan |uv| ≤ n .
Notasi matematisnya
Penjelasan,
Untuk memperlihatkan bahwa suatu bahasa infinite tidak reguler, maka kita tunjukkan bahwa untuk nilai n yang cukup besar, sekurang-kurangnya satu untai yang panjangnya n atau lebih besar gagal untuk dapat ‘dipompa’
Contoh : L = {ai^2 | i≥1} {a1, a4,a9, a16, ...}
{a , aaaa , aaaaaaaaa , aaaaaaaaaaaaaaaa, ... }
Suatu string dalam L harus mempunyai panjang yang berupa nilai kuadrat (1,4,9,16, ..., n2, ...). Misal bahwa L adalah bahasa reguler.
Perhatikan bahwa terdapat sebuah nilai n sedemikian sehingga an^2 ∈L, Menurut pumping lemma dapat kita tuliskan an^2 = uvx, sedemikian hingga
- 1 ≤|v|≤ n - (∀i) (uviw ∈ L)
karena |v| ≥1 maka jelas bahwa |uvw|<|uv2w|<|uv2w|< ...
ambil i = 2 maka kita dapatkan n2 = |uvw| < |uv2w| ≤ n2 + n < (n+1)2 Jelas bahwa n2 < |uv2w| < (n+1)2
Panjang |uv2w| bukan merupakan kuadrat sempurna, karena berada diantara 2 nilai kuadrat sempurna yang berurutan.Berarti uv2w ∉ L
Jadi disimpulkan bahwa L = {ai^2 | i≥1} bukan merupakan bahasa reguler.
( )( )( )
(
∃)
(
= ∧ ≤ ∧ ≥ ∧( )
∀(
∈)
)
≥ ∧ ∈ ∀ ∃ ∀ L w uv i v n uv uvw z w v u n z L z z n L i 1 , ,Bab VI FSA dengan Output
Konsep FSA dengan output
FSA: merupakan accepter, dapat menerima atau tidak. FSA dengan output : transducer
- Mesin Moore :output berasosiasi dengan state - Mesin Mealy :output berasosiasi dengan transisi
6.1 Mesin Moore M = (Q,Σ,δ,S,∆,λ)
Q : himpunan state
Σ : himpunan simbol input δ : fungsi transisi
S : state awal S ∈Q ∆ : himpunan output
λ : fungsi output untuk setiap state Contoh:
Mesin moore untuk memperoleh modulus 3 pada suatu bilangan biner: M = (Q,Σ,δ,S,∆,λ) Q : q0,q1,q2 Σ : [0,1] S : q0 ∆ : [0,1,2] λ(q0) =0 λ(q1) =1 λ(q2) =2 Prinsip:
1012 =5 10102 = 2*5 =10
- jika i diikuti dengan 1, maka hasilnya 2i+1 1012=5 10112 = 2*5+1 =11
- jika i/3 mempunyai sisa p, maka untuk input berikutnya bernilai 0 maka 2i/3 mempunyai sisa 2p mod 3
a. untuk p=0 maka 2p mod 3 = 0 b. untuk p=1 maka 2p mod 3 = 2 c. untuk p=2 maka 2p mod 3 = 1
- jika i/3 mempunyai sisa p, maka untuk input berikutnya bernilai 1 maka (2i+1)/3 mempunyai sisa (2p+1) mod 3
a. untuk p=0 maka (2p+1) mod 3 = 1 b. untuk p=1 maka (2p+1) mod 3 = 0 c. untuk p=2 maka (2p+1) mod 3 = 2 - Sehingga didapat mesin FSA sbb :
- Contoh :
a. input 5 (1012) , state terakhir q2/2 , 5 mod 3 = 2
b. input 10 (10102) ,state terakhir q1/1, 10 mod 3=1
6.2 Mesin Mealy M = (Q,Σ,δ,S,∆,λ)
Q : himpunan state
Σ : himpunan simbol input δ : fungsi transisi
S : state awal S ∈Q ∆ : himpunan output
λ : fungsi output untuk setiap transisi Contoh:
Mesin Mealy untuk mendeteksi ekspresi reguler (0+1)*(00+11)
q0/0 1 0 0 q1/1 1 q2/2 0 1
Jawab : M = (Q,Σ,δ,S,∆,λ) Q : q0,q1,q2 Σ : [0,1] S : q0 ∆ : [0,1,2] λ(q0,0) =T λ(q0,1) =T λ(q1,0) =Y λ(q1,1) =T λ(q2,0) =T λ(q2,1) =Y
6.3 Ekuivalensi mesin Moore dengan mesin Mealy 6.3.1 Mesin Moore ke mesin Mealy
Jml state = jml state sebelum * jml output
6.3.2 Mesin Mealy ke mesin Moore
- Menambah label output pada transisi - Menghapus label output pada state
q0 0/T 1/T 0/T q1 1/T q2 0/Y 1/Y q0T 0 q1T 0 q2T 1 1 q0Y 0 q1Y q2Y 0 1 0 1 0 1
Contoh kasus 1:
Tentukan FSA dari rangkaian sirkuit berikut ini. Asumsi bahwa terdapat waktu yang cukup untuk perambatan sinyal menuju kondisi yang stabil.
Contoh kasus 2
Kelereng dijatuhkan dari A atau B. Percabangan x1,x2 dan x3 menentukan
saluran mana yang akan dilewati kelereng (kiri / kanan). Ketika percabangan dilewati, kelereng berikutnya akan melewati dengan saluran berbeda.
Buatlah FSA nya
q0 1/1 0/2 0/1 q1 1/0 q2 0/0 1/2 input x F y2 y1 A B C D X1 X2 X3
Bab VII
Bahasa Bebas Konteks
7.1 Tata Bahasa Bebas Konteks Deskripsi bahasa alami
<kalimat> → <subjek> <predikat> <subjek> → <kata benda>
<predikat> → <kata kerja> <kata benda> → kucing <kata kerja> → berlari <kata kerja> → menyapu Contoh kalimat yang dapat dihasilkan
kucing berlari
kucing menyapu (sintaks yes, semantik no)
Dalam tatabahasa bebas konteks
- Ruas kiri dari aturan produksi terdiri dari SATU simbol non terminal
- Ruas kanan dapat berupa string yang dibentuk dari simbol terminal dan non terminal.
Contoh
1. S →aSb | ε
Kalimat-kalimat yang dibangkitkan dari aturan produksi itu adalah ε,ab,aabb,aaabbb,... , an
bn 2. A →0A0
A →1A1 A→a
Kalimat-kalimat yang dibangkitkan dari aturan produksi itu adalah a,01a10, 1001a1001 , 110a011 βaβR
Bahasa yang dihasilkan oleh tatabahasa dengan aturan produksi di atas: L = {w ∈ (a + b)* |na(w) =nb(w) }
7.2 Leftmost dan Rightmost Derivation
Suatu penguraian/ penurunan dikatakan leftmost derivation bila setiap tahapan penurunan variabel / non terminal terkiri yang diuraikan.
Apabila setiap tahapan penurunan variabel / non terminal paling kanan yang diuraikan disebut rightmost derivation.
Contoh 1:
- G = ({A,B,S}, {a,b},S,P} dengan aturan produksi P : S → AB
A→ aaA | λ B→Bb | λ
- Menspesifikasikan bahasa L(G) = {a2nbm | n≥0 , m≥0}
- Leftmost derivation untuk menghasilkan string aab S AB aaAB aaB aaBb aab - Righmost derivation untuk menghasilkan string aab
S AB ABb aaABb aaAb aab Contoh 2:
- G = ({A,B,S}, {a,b},S,P} dengan aturan produksi P : S → aAB
A→ bBb B→ A | λ
- Leftmost derivation untuk menghasilkan string abbbb
S aAB abBbB abAbB abbBbbB abbbbB abbbb - Righmost derivation untuk menghasilkan string aab
7.3 Pohon urai
Untuk menampilkan penguraian, dapat dilakukan dengan membentuk pohon urai (urutan penguraian tidak terlihat). Pohon urai untuk contoh sebelumnya :
7.4 Parsing dan Keanggotaan
Untuk menentukan apakah string w berada di L(G), dengan cara secara sistematis membangun semua kemungkinan penurunan, dan mencocokkan hasilnya apakah ada yang sama dengan string w. (disebut exhaustive search parsing)
Contoh : Menentukan apakah string ab berada pada bahasa yang dibentuk oleh grammar dengan aturan produksi S → SS | aSb | bSa | λ
Untuk penguraian pertama 1. S SS 2. S aSb 3. S bSa 4. S λ
Penguraian nomor 3 dan 4 tidak perlu dilanjutkan.
Penguraian 1 membentuk: Penguraian 2 membentuk:
1a. S SS SSS 2a. S aSb aSSb
1b. S SS aSbS 2b. S aSb aaSbb
1c. S SS bSaS 2c. S aSb abSab
1d. S SS S 2d. S aSb ab S a b B b B A b B b A λ λ
7.5 Ambiguitas pada Tatabahasa dan Bahasa
Tatabahasa bebas konteks G disebut ambigu jika terdapat beberapa w ∈ L(G) yang mempunyai paling sedikit dua buah pohon penurunan.
Contoh pada tatabahasa dengan aturan produksi S → SS | aSb | λ string aabb mempunyai 2 pohon penurunan :
7.6 Pumping Lemma untuk bahasa bebas konteks
Jika suatu rangkaian simbol /string yang cukup panjang yang merupakan sebuah bahasa bebas konteks, maka kita dapat menemukan dua substring yang jaraknya berdekatan yang jika dipompa, string baru yang diperoleh merupakan bahasa bebas konteks juga.
Secara formal, lemma diatas dinyatakan dengan
Syarat “ kedua lokasi berdekatan” dinyatakan dengan kondisi |vwx| ≤ n
Jika salah satu v atau x diambil sebagai string kosong, maka lemma diatas berubah menjadi lemma untuk bahasa regular.
Contoh tatabahasa dengan aturan produksi: S →uAy
A → vAx A → w
maka aturan derivasinya b S a S b S a λ b S a S b S a λ S S λ
( )( )( )
(
)
( )
∀(
∈)
≥ ∧ ≤ ∧ = ∃ ≥ ∧ ∈ ∀ ∃ ∀ L y wx uv i vx n vwx uvwxy z y x w v u n z L z z n L i i 1 , , , ,S uAy uwy
S uAy uvAxy uvwxy
S uAy uvAxy uvvAxxy uvvwxxy sehingga untuk setiap i ≥0 , uvi
wxiy ∈ L
7.7 Sifat - sifat tertutup bahasa bebas konteks 1. Gabungan dua CFL merupakan CFL juga
Jika diketahui dua buah CFG G1= (N1,T1,S1,P1) dan G2=(N2,T2,S2,P2) yang
menghasilkan bahasa L1 dan L2 , maka CFG L1 ∪ L2 dapat dibentuk dengan
cara :
- Menggabungkan kedua himpunan dan menambahkan satu simbol variabel baru S.
- Menggabungkan kedua himpunan simbol terminal.
- Menggabungkan kedua himpunan aturan produksi dan menambahkan satu aturan produksi baru S → S1|S2 yang digunakan untuk memilih salah satu
simbol awal S1 atau S2 dari simbol awal baru S.
G3 = (N1∪N2∪{S},T1∪T2 ,S,P1∪P2 ∪{S→S1|S2}}
2. Penyambungan dua CFL merupakan CFL juga
Jika diketahui dua buah CFG G1= (N1,T1,S1,P1) dan G2=(N2,T2,S2,P2) yang
menghasilkan bahasa L1 dan L2 , maka bahasa L1L2 dapat dibentuk oleh :
G4 = (N1∪N2∪{S},T1∪T2 ,S,P1∪P2 ∪{S→S1S2}}
3. Kleene Klosure dari CFL adalah CFL juga.
Kleene Klosure dari tatabahasa G=(N,T,S1,P) adalah
G5 = (N ∪ {S} , T , S , P ∪ {S → S1S | ε } )
4. Bahasa bebas konteks tertutup terhadap substitusi
Contoh:
La = {0 n1n | n ≥1 } dan Lb = { wwR | w ∈ (0+2)* }
dihasilkan oleh tatabahasa Ga dengan aturan produksi Sa → 0Sa1 | 01
7.8 Substitusi
Didefinisikan tatabahasa G dengan aturan produksi S → aSbS | bSaS | ε
jika f adalah substitusi f(a)= La dan f(b) = Lb maka f(L) adalah bahasa yang
dihasilkan oleh tatabahasa dengan aturan produksi S → SaSSbS | SbSSaS | ε
Sa → 0Sa1 | 01
Sb → 0Sb0 | 2Sb2 | ε
7.9 Tatabahasa Bebas Konteks dan Bahasa Pemrograman
Tatabahasa bebas konteks digunakan untuk mendefinisikan sintaks bahasa pemrograman menggunakan notasi BNF (Backus-Naur Form)
- variabel / non terminal : <...> - terminal : tanpa tanda
- ← diganti dengan ::= Contoh statemen if then else
< if_statement> ::= if <expression> <then_clause>
Bab VIII
Penyederhanaan Tata Bahasa Bebas Konteks
Tujuan
Melakukan pembatasan sehingga tidak menghasilkan pohon penurunan yang memiliki kerumitan yang tidak perlu atau aturan produksi yang tidak berarti.
Contoh
1. S AB | a A a
Aturan produksi S AB tidak berarti karena B tidak memiliki penurunan 2. S A
A B B C C D D a | A
Memiliki kelemahan terlalu panjang jalannya padahal berujung pada S a, produksi D A juga menyebabkan kerumitan.
Cara Penyederhanaan:
1. Penghilangan produksi useless (tidak berguna) 2. Penghilangan produksi unit
3. Penghilangan produksi
8.1 Penghilangan Produksi Useless
Di sini produksi useless didefinisikan sebagai produksi yang memuat simbol variabel yang tidak memiliki penurunan yang akan menghasilkan terminal-terminal seluruhnya. Produksi yang tidak akan pernah dicapai dengan penurunan apapun dari simbol awal, sehingga produksi itu redundan (berlebih)
Prinsipnya
Setiap kali melakukan penyederhanaan diperiksa lagi aturan produksi yang tersisa, apakah semua produksi yang useless sudah hilang.
Contoh :
1. S aSa | Abd | Bde A Ada
B BBB | a Maka,
- Simbol variabel A tidak memiliki penurunan yang menuju terminal, sehingga bisa dihilangkan.
- Konsekuensinya, aturan produksi S Abd tidak memiliki penurunan Penyederhanaan menjadi: S aSa | Bde B BBB | a 2. S Aa | B A ab | D B b | E C bb E aEa Maka,
- Aturan produksi A D, simbol variabel D tidak memiliki penurunan. - Aturan produksi C bb, Penurunan dari simbol S, dengan jalan manapun
tidak akan pernah mencapai C
- Simbol variabel E tidak memiliki aturan produksi yang menuju terminal - Konsekuensi no (3) Aturan produksi B E, simbol variabel E tidak
memiliki penurunan. Maka produksi yang useless:
A D C bb E aEa B E Penyederhanaannya menjadi: S Aa | B A ab B b 3. S aAb | cEB
A dBE | eeC B ff
C ae D h Analisa :
- Aturan produksi S cEB, A dBE dapat dihilangkan (E tidak memiliki penurunan)
- Aturan produksi D h, redundan Sisa aturan produksi
S aAb A eeC B ff C ae Hasil penyederhanaan : S aAb A eeC C ae Analisis lagi B ff juga redundan,
8.2 Penghilangan Produksi Unit
Produksi dimana ruas kiri dan kanan aturan produksi hanya berupa satu simbol variabel, misalkan: A B, C D. Keberadaannya membuat tata bahasa memiliki kerumitan yang tak perlu. Penyederhanaan dilakukan dengan melakukan penggantian aturan produksi unit.
Contoh : 1. S Sb S C C D C ef D dd
Dilakukan penggantian berturutan mulai dari aturan produksi yang paling dekat menuju ke penurunan terminal-terminal (‘=>’ dibaca ‘menjadi’):
C D => C dd S C => S dd | ef
Sehingga aturan produksi setelah penyederhanaan: S Sb S dd | ef C dd C ef C dd 2. S A S Aa A B B C B b C D C ab D b
Penggantian yang dilakukan : C D => C b
B C => B b | ab, karena B b sudah ada, maka cukup dituliskan B ab A B => A ab | b
S A => ab | b
Sehingga aturan produksi setelah penyederhanaan: S ab | b S Aa A ab | b B ab B b C b C ab D b
8.3 Penghilangan Produksi
Produksi adalah produksi dalam bentuk , atau bisa dianggap sebagai produksi kosong (empty). Penghilangan produksi dilakukan dengan melakukan penggantian produksi yang memuat variabel yang bisa menuju produksi , atau biasa disebut nullable.
Prinsip penggantiannya bisa dilihat kasus berikut: S bcAd
A
A nullable serta A satu-satunya produksi dari A, maka variabel A bisa ditiadakan, hasil penyederhanaan tata bahasa bebas konteks menjadi: S bcd Contoh:
1. Tetapi bila kasusnya: S bcAd
A bd |
A nullable, tapi A bukan satu-satunya produksi dari A, maka hasil penyederhanaan: S bcAd | bcd A bd 2. S Ab | Cd A d C
Variabel yang nullable adalah variabel C. Karena penurunan C merupakan penurunan satu-satunya dari C, maka kita ganti S Cd menjadi S d. Kemudian produksi C kita hapus.
Setelah penyederhanaan menjadi: S Ab | d
A d
3. Contoh tata bahasa bebas konteks: S AaCD
A CD | AB B b | C d | D
Variabel yang nullable adalah variabel B, C, D.
Kemudian dr A CD, maka variabel A juga nullable ( A ). Karena D hanya memilki penurunan D , maka kita sederhanakan dulu:
S AaCD => S AaC A CD => A C D kita hapus
Selanjutnya kita lihat variabel B dan C memiliki penurunan , meskipun bukan satu-satunya penurunan, maka dilakukan penggantian:
A AB => A AB | A | B S AaC => S AaC | aC | Aa | a B dan C kita hapus Setelah penyederhanaan: S AaC | aC | Aa | a A C | AB | A | B B b C 8.4 Pengembangan praktek
Ketiga penyederhanaan tersebut dilakukan bersama pada suatu tata bahasa bebas konteks, yang nantinya menyiapkan tata bahasa bebas konteks tersebut untuk diubah kedalam suatu Bentuk Normal Chomsky (BNF)
Urutan penghapusan aturan produksi : - Hilangkan produksi
- Hilangkan produksi unit - Hilangkan produksi useless Contoh:
A Bb | B AB | d C de Jawab:
- Hilangkan produksi , sehingga menjadi: S A | AA | C | bd
A Bb B B | AB | d C de
- Selanjutnya penghilangan produksi unit menjadi: S Bb | AA | de | bd
A Bb B AB | d C de
Penghilangan produksi unit bisa menghasilkan produksi useless. - Terakhir dilakukan penghilangan produksi useless:
S Bb | AA | de | bd A Bb
B AB | d
- Hasil akhir aturan produksi tdk lagi memiliki produksi , produksi unit, maupun produksi useless.
Bab IX
Bentuk Normal Chomsky
9.1 Pengertian
Bentuk normal Chomsky / Chomsky Normal Form (CNF) merupakan salah satu bentuk normal yang sangat berguna untuk tata bahasa bebas konteks (CFG). CNF dapat dibuat dari sebuah tata bahasa bebas konteks yang telah mengalami penyederhanaan yaitu penghilangan produksi, useless, unit, dan .
Dengan kata lain, suatu tata bahasa bebas konteks dapat dibuat menjadi CNF dengan syarat tata bahasa bebas konteks tersebut :
o Tidak memiliki produksi useless o Tidak memiliki produksi unit o Tidak memiliki produksi
9.2 Aturan produksi
Aturan produksi dalam CNF ruas kanannya tepat berupa sebuah terminal atau dua variabel. Misalkan: o A BC o A b o B a o C BA | d 9.3 Pembentukan CNF
Langkah-langkah pembentukan CNF secara umum sbb: 1. Biarkan aturan produksi yang sudah dalam CNF.
2. Lakukan penggantian aturan produksi yang ruas kanannya memuat simbol terminal dan panjang ruas kanan > 1.
3. Lakukan penggantian aturan produksi yang ruas kanannya memuat > 2 simbol variabel.
4. Penggantian-penggantian tersebut bisa dilakukan berkali-kali sampai akhirnya semua aturan produksi dalam CNF.
5. Selama dilakukan penggantian, kemungkinan kita akan memperoleh aturan-aturan produksi baru, dan juga memunculkan simbol-simbol variabel baru.
9.4 Bagan Tahapan Pembentukan CNF
Contoh (kita anggap CFG sudah mengalami penyederhanaan ) 1. S bA | aB
A bAA | aS | a B aBB | bS | b
- Aturan produksi yang sudah dalam CNF: A a
B b
- Dilakukan penggantian aturan produksi yang belum CNF S bA => S P1A S aB => S P1B A bAA => S P1AA => A P1P3 A aS => A P2S B aBB => B P2BB => B P2P4 B bS => B P1S
P1 b
P2 a
P3 AA
P4 BB
- Hasil akhir aturan produksi dalam CNF : A a B b S P1A S P2B A P1P3 A P2S B P2P4 B P1S P1 b P2 a P3 AA P4 BB 2. S aB | CA A a | bc B BC | Ab C aB | b
- Aturan produksi yang sudah dalam CNF : S CA
A a B BC C b
- Penggantian aturan produksi yang belum dalam CNF : S aB => S P1B
A bc => S P2P3