Pada era globalisasi saat ini, pertumbuhan data yang sangat banyak seringkali terlalu
luas dan tidak menghasilkan suatu informasi yang jelas, apalagi pengetahuan. Penambangan
data akan mengubah data yang sangat tidak informatif tersebut menjadi sebuah informasi yang
berguna ataupun dapat pula menjadi suatu pengetahuan. Dalam penambangan data, ada suatu
teknik untuk mencari data yang tidak konsisten ataupun data yang berbeda dari data yang
lainnya, biasa dikenal dengan deteksi outlier. Teknik ini dapat digunakan untuk menganalisis
berbagai bidang, salah satunya adalah bidang pendidikan.
Maka dari itu, penelitian ini melakukan deteksi outlier dengan menggunakan algoritma
Influenced Outlierness (INFLO). Algoritma ini dikemukakan oleh Jin et.al. pada tahun 2006,
mengusulkan deteksi outlier berdasarkan influence space. Data yang digunakan adalah nilai
ujian SMA dari Provinsi DIY tahun 2011 – 2014.
Penelitian ini menghasilkan sistem alat bantu deteksi menggunakan algoritma INFLO.
Pengujiannya ada 5 metode. Hasil yang didapat dari seluruh pengujian adalah sistem ini dapat
digunakan untuk mendeteksi outlier data nilai ujian SMA tersebut.
In the current era of globalization, the growth of data very much often too broad and
did not produce a clear information, let alone knowledge. Data mining will change very
uninformative data into a useful information or can also be a knowledge. In data mining, there
is a technique to look for inconsistent data or data that is different from other data, commonly
known as outlier detection. This technique can be used to analyze a wide range of fields, one
of which is education.
Therefore, this study did outlier detection algorithms using Influenced Outlierness
(INFLO). This algorithm proposed by Jin et al in 2006, the outlier detection based influence
space. The data used is the high school test scores of DIY Province in 2011-2014.
This research resulted in the detection system uses an algorithm tools INFLO. There
are 5 methods of testing. The results of all testing is these systems can be used to detect a data
outlier high school test scores.
HALAMAN JUDUL
DETEKSI OUTLIER UNTUK NILAI UJIAN
SEKOLAH MENENGAH ATAS (SMA) MENGGUNAKAN ALGORITMA
INFLUENCED OUTLIERNESS (INFLO)
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh :
Maria Renia Octaviani
115314010
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
HALAMAN JUDUL (BAHASA INGGRIS)
OUTLIER DETECTION FOR THE HIGH SCHOOL EXAM USING INFLUENCED OUTLIERNESS (INFLO) ALGORITHM
A Final Project
Presented as Partial Fullfillment of the Requirements
To Obtain the Sarjana Komputer Degree
In Informatics Engineering Study Program
By :
Maria Renia Octaviani
115314010
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
iii
HALAMAN PERSETUJUAN
SKRIPSI
DETEKSI OUTLIER UNTUK NILAI UJIAN
SEKOLAH MENENGAH ATAS (SMA) MENGGUNAKAN ALGORITMA
INFLUENCED OUTLIERNESS (INFLO)
Oleh :
Maria Renia Octaviani
115314010
Telah Disetujui Oleh :
Dosen Pembimbing
iv
HALAMAN PENGESAHAN SKRIPSI
DETEKSI OUTLIER UNTUK NILAI UJIAN
SEKOLAH MENENGAH ATAS (SMA) MENGGUNAKAN ALGORITMA
INFLUENCED OUTLIERNESS (INFLO)
Yang dipersiapkan dan disusun oleh :
Maria Renia Octaviani
115314010
Telah dipertahankan di depan Panitia Penguji
Pada tanggal …… ……… 2015
Dan dinyatakan memenuhi syarat
Susunan Panitia Penguji
Tanda Tangan
Ketua : P.H. Prima Rosa, S.Si., M.Sc. ………
Sekretaris : Sri Hartati Wijono, S.Si., M.Kom. ………
Anggota : Ridowati Gunawan, S.Kom., M.T. ………
Yogyakarta, …… ……… 2015 Fakultas Sains dan Teknologi
Universitas Sanata Dharma
Dekan,
v
HALAMAN PERSEMBAHAN
“Karena Tuhanlah yang memberikan hikmat,
dari mulut-Nya datang pengetahuan dan
kepandaian”
( Amsal 2 : 6 )
Karya ini kupersembahkan kepada :
Tuhan Yesus Kristus
Bunda Maria
Keluarga
vi
HALAMAN PERNYATAAN
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak
memuat karya atau bagian karya orang lain, kecuali yang telah saya sebutkan dalam
kutipan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, … ……… 2015
Penulis,
vii ABSTRAK
Pada era globalisasi saat ini, pertumbuhan data yang sangat banyak
seringkali terlalu luas dan tidak menghasilkan suatu informasi yang jelas, apalagi
pengetahuan. Penambangan data akan mengubah data yang sangat tidak informatif
tersebut menjadi sebuah informasi yang berguna ataupun dapat pula menjadi suatu
pengetahuan. Dalam penambangan data, ada suatu teknik untuk mencari data yang
tidak konsisten ataupun data yang berbeda dari data yang lainnya, biasa dikenal
dengan deteksi outlier. Teknik ini dapat digunakan untuk menganalisis berbagai
bidang, salah satunya adalah bidang pendidikan.
Maka dari itu, penelitian ini melakukan deteksi outlier dengan
menggunakan algoritma Influenced Outlierness (INFLO). Algoritma ini
dikemukakan oleh Jin et.al. pada tahun 2006, mengusulkan deteksi outlier
berdasarkan influence space. Data yang digunakan adalah nilai ujian SMA dari
Provinsi DIY tahun 2011 – 2014.
Penelitian ini menghasilkan sistem alat bantu deteksi menggunakan
algoritma INFLO. Pengujiannya ada 5 metode. Hasil yang didapat dari seluruh
pengujian adalah sistem ini dapat digunakan untuk mendeteksi outlier data nilai
ujian SMA tersebut.
viii ABSTRACT
In the current era of globalization, the growth of data very much often too
broad and did not produce a clear information, let alone knowledge. Data mining
will change very uninformative data into a useful information or can also be a
knowledge. In data mining, there is a technique to look for inconsistent data or data
that is different from other data, commonly known as outlier detection. This
technique can be used to analyze a wide range of fields, one of which is education.
Therefore, this study did outlier detection algorithms using Influenced
Outlierness (INFLO). This algorithm proposed by Jin et al in 2006, the outlier
detection based influence space. The data used is the high school test scores of DIY
Province in 2011-2014.
This research resulted in the detection system uses an algorithm tools
INFLO. There are 5 methods of testing. The results of all testing is these systems
can be used to detect a data outlier high school test scores.
ix
HALAMAN PERSETUJUAN PUBLIKASI KARYA ILMIAH
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPERLUAN KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswi Universitas Sanata Dharma :
Nama : Maria Renia Octaviani
Nomor Mahasiswa : 115314010
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan
Universitas Sanata Dharma karya ilmiah saya yang berjudul :
DETEKSI OUTLIER UNTUK NILAI UJIAN
SEKOLAH MENENGAH ATAS (SMA) MENGGUNAKAN ALGORITMA
INFLUENCED OUTLIERNESS (INFLO)
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan
kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan,
mengalihkan dalam bentuk media lain, mengelolanya di internet atau media lain
untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun
memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai
penulis.
Demikian pernyataan ini saya buat dengan sebenarnya
Dibuat di Yogyakarta
Pada tanggal … ……… 2015 Yang menyatakan,
x
KATA PENGANTAR
Puji dan syukur kepada Tuhan Yang Maha Esa, karena pada akhirnya
penulis dapat menyelesaikan penelitian tugas akhir ini yang berjudul “Deteksi Outlier Untuk Nilai Ujian Sekolah Menengah Atas (SMA) Menggunakan Algoritma Influenced Outlierness (INFLO)”.
Dalam menyelesaikan seluruh penyusunan tugas akhir ini, penulis tak lepas
dari doa, bantuan, dukungan, dan motivasi dari banyak pihak. Oleh karena itu,
penulis ingin mengucapkan banyak terima kasih kepada :
1. Ibu Paulina Heruningsih Prima Rosa, S.Si., M.Sc. selaku Dekan Fakultas Sains
dan Teknologi dan juga selaku Dosen Penguji.
2. Ibu Ridowati Gunawan, S.Kom., M.T. selaku Ketua Program Studi Teknik
Informatika dan juga selaku Dosen Pembimbing Skripsi yang telah memberikan
waktu, bimbingan, dan motivasi kepada penulis.
3. Ibu Sri Hartati Wijono, S.Si., M.Kom. selaku Dosen Penguji.
4. Bapak Henricus Agung Hernawan, S.T., M.Kom. selaku Dosen Pembimbing
Akademik.
5. Seluruh dosen, sekretariat, laboran, dan perpustakaan yang telah membimbing
dan membantu selama proses perkuliahan di Universitas Sanata Dharma.
6. Bapak Bambang Kuncoro dari Seksi Data dan Teknologi Informasi Dinas
Pendidikan, Pemuda, dan Olah Raga Provinsi DIY yang telah bersedia
memberikan data penelitian.
xi
8. Nenek Soejani tercinta yang telah mendoakan, mendukung, memotivasi penulis
dari awal bersekolah hingga dapat menyelesaikan tugas akhir ini.
9. Andreas Widiyatmoko yang selalu mendoakan, dan ada dalam suka duka.
10.Erlita Octaviani dan Daniel Tomi Raharjo yang telah memberikan banyak
bantuan dalam memberikan pandangan dan refrensi kepada penulis saat
penyusunan tugas akhir ini.
11.Teman-teman TI 2011 terutama Winda, Elsa, Orin, Danik, Ronald, Arie, Pandu
W., Benny, Ega yang sudah menemani dan mendukung selama ini.
12.Mbak Ari selaku kakak dari seluruh anak Kost Wisma Dara dan teman-teman
kost (Nova, Yolanda, Nona, Claudia, Cik Angel, Elsa, Winda, Merna, Ratna,
dan semuanya) yang sudah menjadi teman kost terbaik.
13.Semua pihak yang sudah mendukung secara langsung ataupun tidak langsung,
mohon maaf saya tidak dapat menyebutkan satu per satu.
Penulis berharap penelitian ini dapat menjadi pengetahuan baru yang
berguna bagi para pembaca. Penelitian ini tidak luput dari kekurangan, oleh karena
itu, penulis mengharapkan saran dan kritik untuk perbaikan hingga akhirnya
penelitian ini menjadi lebih baik.
Yogyakarta, … ……… 2015
Penulis,
xii DAFTAR ISI
Halaman
HALAMAN JUDUL ... i
HALAMAN JUDUL (BAHASA INGGRIS) ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
HALAMAN PERSEMBAHAN ... v
HALAMAN PERNYATAAN ... vi
ABSTRAK ... vii
ABSTRACT ... viii
HALAMAN PERSETUJUAN PUBLIKASI KARYA ILMIAH ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xviii
DAFTAR TABEL ... xxi
DAFTAR RUMUS ... xxiii
DAFTAR LAMPIRAN ... xxiv
BAB I PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Rumusan Masalah... 5
1.3. Batasan Masalah ... 5
xiii
1.5. Manfaat Penelitian ... 6
1.6. Metodologi Penelitian... 6
1.7. Sistematika Penulisan ... 9
BAB II LANDASAN TEORI ... 11
2.1. PENAMBANGAN DATA ... 11
2.1.1. Pengertian Penambangan Data ... 11
2.1.2. Asal Usul Penambangan Data ... 11
2.1.3. Fungsi dalam Penambangan Data ... 12
2.1.4. Knowledge Discovery in Databases (KDD) ... 14
2.2. DETEKSI OUTLIER ... 16
2.2.1. Pengertian Outlier... 16
2.2.2. Macam Pendekatan Outlier ... 16
2.3. INFLUENCED OUTLIERNESS (INFLO)... 18
2.3.1. Deteksi Outlier dengan Algoritma INFLO ... 18
2.3.2. Contoh Deteksi Outlier dengan Algoritma INFLO ... 22
BAB III METODOLOGI PENELITIAN ... 27
3.1. SUMBER DATA ... 27
3.2. PENGOLAHAN DATA ... 28
3.2.1. Data Cleaning... 28
3.2.2. Data Integration ... 28
3.2.3. Data Selection... 28
3.2.4. Data Transformation ... 29
xiv
3.2.6. Pattern Evaluation ... 41
3.2.7. Knowledge Presentation ... 42
BAB IV ANALISIS DAN PERANCANGAN SISTEM ... 43
4.1. IDENTIFIKASI SISTEM ... 43
4.1.1. Diagram Use Case ... 44
4.1.2. Narasi Use Case ... 45
4.2. PERANCANGAN SISTEM SECARA UMUM ... 45
4.2.1. Input Sistem ... 45
4.2.2. Proses Sistem ... 46
4.2.3. Output Sistem ... 47
4.3. PERANCANGAN SISTEM ... 48
4.3.1. Diagram Aktivitas... 48
4.3.2. Diagram Kelas Analisis ... 48
4.3.3. Diagram Sequence ... 50
4.3.4. Diagram Kelas Desain ... 50
4.3.5. Rincian Algoritma per Method ... 51
4.3.5.1. Kelas KontrolKoneksiDatabase ... 51
4.3.5.2. Kelas KontrolKoneksiTable ... 53
4.3.5.3. Kelas KontrolSeleksiAtributTableModel ... 54
4.3.5.4. Kelas Kontrol_INFLOTableModel ... 55
4.3.5.5. Kelas Kontrol_INFLO ... 55
4.4. PERANCANGAN STRUKTUR DATA ... 67
xv
4.4.2. Matriks Dua Dimensi... 69
4.5. PERANCANGAN ANTARMUKA ... 70
4.5.1. Perancangan Halaman Awal ... 70
4.5.2. Perancangan Halaman Preprocess ... 71
4.5.3. Perancangan Halaman Pilih Database ... 72
4.5.4. Perancangan Halaman Pilih Table ... 73
4.5.5. Perancangan Halaman Deteksi Outlier ... 74
4.5.6. Perancangan Halaman Bantuan ... 75
4.5.7. Perancangan Halaman Tentang ... 76
BAB V IMPLEMENTASI PENAMBANGAN DATA ... 77
5.1. IMPLEMENTASI ANTARMUKA ... 77
5.1.1. Implementasi Halaman Awal ... 77
5.1.2. Implementasi Halaman Preprocess ... 78
5.1.2.1. Preprocess ‘Pilih File’ ... 79
5.1.2.2. Preprocess ‘Pilih Database’ ... 81
5.1.2.3. Seleksi Atribut pada Halaman Preprocess ... 84
5.1.3. Implementasi Halaman Deteksi Outlier ... 88
5.1.4. Implementasi Halaman Bantuan ... 93
5.1.5. Implementasi Halaman Tentang ... 94
5.1.6. Implementasi Keluar dari Sistem ... 95
5.2. IMPLEMENTASI KELAS... 95
5.2.1. Implementasi Kelas Model ... 96
xvi
5.2.3. Implementasi Kelas View ... 96
5.3. IMPLEMENTASI STRUKTUR DATA ... 97
5.3.1. Implementasi Kelas Vertex ... 97
5.3.2. Implementasi Kelas Graph ... 99
BAB VI PENGUJIAN DAN ANALISIS HASIL PENGUJIAN ... 101
6.1. RENCANA PENGUJIAN ... 101
6.1.1. Hasil Pengujian Black Box ... 105
6.1.1.1. Pengujian Memasukkan Data ... 105
6.1.1.2. Pengujian Koneksi ke Database ... 106
6.1.1.3. Pengujian Seleksi Atribut ... 109
6.1.1.4. Pengujian Deteksi Outlier ... 110
6.1.1.5. Pengujian Penyimpanan Hasil ... 112
6.1.2. Kesimpulan Hasil Pengujian Black Box ... 113
6.1.3. Hasil Pengujian Efek Perubahan Atribut ... 114
6.1.3.1. Pengujian Data Nilai Akhir (NA) IPA Tahun 2014 ... 114
6.1.3.2. Pengujian Data Nilai Sekolah (NS) IPA Tahun 2014 ... 115
6.1.3.3. Pengujian Data Nilai Ujian Nasional (UN) IPA Tahun 2014 ... 116
6.1.4. Kesimpulan Hasil Pengujian Efek Perubahan Atribut .. 117
xvii
6.1.6. Kesimpulan Hasil Pengujian Perbandingan Perhitungan
Manual dan Hasil Deteksi Sistem ... 119
6.1.7. Hasil Pengujian Akurasi ... 119
6.1.8. Kesimpulan Hasil Pengujian Akurasi ... 130
6.1.9. Hasil Pengujian Waktu Kinerja Sistem ... 131
6.1.10. Kesimpulan Hasil Pengujian Waktu Kinerja Sistem ... 132
6.2. KELEBIHAN DAN KEKURANGAN SISTEM ... 133
6.2.1. Kelebihan Sistem ... 133
6.2.2. Kekurangan Sistem ... 134
BAB VII PENUTUP ... 135
7.1. KESIMPULAN ... 135
7.2. SARAN ... 136
DAFTAR PUSTAKA ... 137
xviii
DAFTAR GAMBAR
Halaman
Gambar 2.1 Asal Usul Penambangan Data ... 12
Gambar 2.2 Proses Knowledge Discovery in Databases ... 14
Gambar 4.1 Graf... 67
Gambar 4.2 Graf Tidak Berarah... 68
Gambar 4.3 Rancangan Graf ... 68
Gambar 4.4 Perancangan Halaman Awal ... 70
Gambar 4.5 Perancangan Halaman Preprocess ... 71
Gambar 4.6 Perancangan Halaman Pilih Database ... 72
Gambar 4.7 Perancangan Halaman Pilih Table ... 73
Gambar 4.8 Perancangan Halaman Deteksi Outlier ... 74
Gambar 4.9 Perancangan Halaman Bantuan ... 75
Gambar 4.10 Perancangan Halaman Tentang ... 76
Gambar 5.1 Implementasi Halaman Awal ... 77
Gambar 5.2 Implementasi Halaman Preprocess ... 78
Gambar 5.3 Implementasi Kotak Dialog Pilih File yang Salah ... 79
Gambar 5.4 Implementasi Pesan Salah Memilih File ... 80
Gambar 5.5 Implementasi Kotak Dialog Pilih File yang Benar ... 80
Gambar 5.6 Proses Setelah Memasukkan Data dari Pilih File... 81
Gambar 5.7 Implementasi Halaman Pilih Database ... 81
xix
Gambar 5.9 Pesan Koneksi Database Berhasil ... 83
Gambar 5.10 Implementasi Halaman Pilih Table ... 83
Gambar 5.11 Proses Setelah Memasukkan Data dari Pilih File... 84
Gambar 5.12 Data dari Masukkan File ataupun Database ... 84
Gambar 5.13 Informasi Data yang Dimasukkan ... 84
Gambar 5.14 Seleksi Atribut ... 85
Gambar 5.15 Tandai Semua Atribut ... 85
Gambar 5.16 Batal Seleksi Atribut ... 86
Gambar 5.17 Hapus Tanda Beberapa Atribut ... 86
Gambar 5.18 Hasil Seleksi Atribut ... 87
Gambar 5.19 Implementasi Halaman Deteksi Outlier ... 88
Gambar 5.20 Isian Nilai 'k' yang Benar ... 88
Gambar 5.21 Pesan Isian Nilai 'k' yang Salah ... 89
Gambar 5.22 Hasil Proses Deteksi Outlier ... 89
Gambar 5.23 Rincian Hasil Deteksi Outlier ... 90
Gambar 5.24 Informasi Hasil Outlier... 90
Gambar 5.25 Isian Batasan Outlier yang Benar ... 90
Gambar 5.26 Pesan Isian Batasan Outlier yang Salah ... 91
Gambar 5.27 Hasil Deteksi Outlier dengan Batasan ... 91
Gambar 5.28 Cara Penyimpanan Hasil Deteksi ... 91
Gambar 5.29 Kotak Dialog Penyimpanan ... 92
Gambar 5.30 Pesan Penyimpanan Berhasil ... 92
xx
Gambar 5.32 Implementasi Halaman Bantuan ... 93
Gambar 5.33 Cara Melihat Informasi Sistem ... 94
Gambar 5.34 Implementasi Halaman Tentang... 94
Gambar 5.35 Cara Keluar dari Sistem ... 95
Gambar 5.36 Kotak Dialog Konfirmasi Keluar ... 95
Gambar 6.1 Grafik Pengujian Data Nilai Akhir (NA) IPA Tahun 2014 ... 114
Gambar 6.2 Grafik Pengujian Data Nilai Sekolah (NS) IPA Tahun 2014... 115
Gambar 6.3 Grafik Pengujian Data Nilai Ujian Nasional (UN) IPA Tahun 2014
... 116
xxi
DAFTAR TABEL
Halaman
Table 3.1 Tabel Atribut Data ... 27
Table 3.2 Tabel Seleksi Atribut ... 29
Table 3.3 Tabel Data Terseleksi... 30
Table 3.4 Tabel Jarak Antar Obyek ... 31
Table 3.5 Tabel NN dengan Jarak Antar Obyeknya ... 33
Table 3.6 Tabel K-Distance ... 35
Table 3.7 Tabel NN ... 36
Table 3.8 Table RNN ... 36
Table 3.9 Tabel IS ... 37
Table 3.10 Tabel Density ... 38
Table 3.11 Tabel Rata-rata Density Tiap Obyek ... 39
Table 4.1 Tabel Kelas Analisis ... 48
Table 4.2 Contoh Matriks Dua Dimensi (Awal Pembuatan Graf) ... 69
Table 4.3 Contoh Matriks Dua Dimensi (Setelah Terbentuk Edge) ... 70
Table 5.1 Tabel Implementasi Kelas Model ... 96
Table 5.2 Tabel Implementasi Kelas Controller ... 96
Table 5.3 Tabel Implementasi Kelas View ... 96
Table 6.1 Tabel Rencana Pengujian Black Box ... 102
Table 6.2 Tabel Pengujian Memasukkan Data ... 105
xxii
Table 6.4 Tabel Pengujian Seleksi Atribut ... 109
Table 6.5 Tabel Pengujian Deteksi Outlier ... 110
Table 6.6 Tabel Pengujian Penyimpanan Hasil ... 112
Table 6.7 Tabel Pengujian Data Nilai Akhir (NA) IPA Tahun 2014... 114
Table 6.8 Tabel Pengujian Data Nilai Sekolah (NS) IPA Tahun 2014 ... 115
Table 6.9 Tabel Pengujian Data Nilai Ujian Nasional (UN) IPA Tahun 2014 ... 116
Table 6.10 Tabel Data untuk Perbandingan Perhitungan Manual dan Sistem .... 117
Table 6.11 Tabel Hasil Perhitungan Manual... 118
Table 6.12 Tabel Hasil Perhitungan Sistem ... 119
Table 6.13. Tabel Confusion Matrix Data Nilai UN IPA Tahun 2014 ... 120
Table 6.15. Tabel Rincian Hasil Perbandingan Deteksi Sistem dan Pengguna Data
Nilai UN IPA Tahun 2014 ... 121
Table 6.14. Tabel Confusion Matrix Data Nilai UN IPS Tahun 2014 ... 125
Table 6.16. Tabel Rincian Hasil Perbandingan Deteksi Sistem dan Pengguna Data
Nilai UN IPS Tahun 2014 ... 126
xxiii
DAFTAR RUMUS
Halaman
Rumus 2.1. Rumus Menghitung Jarak Euclidean…………..……….... 19
Rumus 2.2. Rumus Menghitung K-Distance dan Mencari Nearest Neighbors
(NN)………. 19
Rumus 2.3. Rumus Menghitung Influence Space(IS)……...…………. 20
Rumus 2.4. Rumus Menghitung Reverse Nearest Neighbors (RNN)…. 20
Rumus 2.5. Rumus Menghitung Local Density………..…………. 21
Rumus 2.6. Rumus Menghitung Influenced Outlierness (INFLO)
Simple………...…………... 21
Rumus 2.7. Rumus Menghitung Average Density……...………. 21
Rumus 2.8. Rumus Menghitung Influenced Outlierness (INFLO) Complete
xxiv
DAFTAR LAMPIRAN
Halaman
LAMPIRAN 1 : DIAGRAM USE CASE 140
LAMPIRAN 2 : DESKRIPSI USE CASE 141
LAMPIRAN 3 : NARASI USE CASE 142
LAMPIRAN 4 : PROSES UMUM SISTEM 146
LAMPIRAN 5 : DIAGRAM AKTIVITAS 147
LAMPIRAN 6 : DIAGRAM KELAS ANALISIS 151
LAMPIRAN 7 : DIAGRAM SEQUENCE 152
LAMPIRAN 8 : DIAGRAM KELAS DESAIN 156
LAMPIRAN 9 : DIAGRAM KELAS 157
LAMPIRAN 10 : LISTING PROGRAM 163
LAMPIRAN 11 : HASIL DETEKSI OUTLIER DARI SISTEM 294
LAMPIRAN 12 : DIAGRAM (BOX AND WHISKER PLOTS) 344
LAMPIRAN 13 : SURAT IJIN SURVEY TUGAS AKHIR 346
1
1. BAB I PENDAHULUAN
1.1. Latar Belakang
Pada era globalisasi saat ini, pertumbuhan data sudah semakin pesat.
Data muncul dari segala jenis bidang. Namun, data yang sangat banyak
tersebut seringkali terlalu luas dan tidak menghasilkan suatu informasi yang
jelas, apalagi pengetahuan. Semakin bertambah banyaknya jumlah data,
maka terlalu banyak ruang untuk data yang sebenarnya tidak terpakai dalam
analisis tertentu. Untuk itu, dibutuhkan sebuah alat untuk menambang suatu
kumpulan data yang sangat banyak tersebut sehingga menjadi sebuah
informasi yang berguna. Suatu alat penambangan data akan mengubah data
yang sangat banyak dan tidak informatif tersebut menjadi sebuah informasi
yang berguna ataupun dapat menjadi suatu pengetahuan. Dapat disimpulkan
bahwa penambangan data merupakan serangkaian proses untuk menggali
data menjadi output yang tidak hanya sekedar informasi, tetapi juga sebuah
pengetahuan yang tersembunyi untuk membantu pengambilan suatu
keputusan (Han & Kamber, 2006).
Penambangan data sendiri sebenarnya memiliki teknik yang disebut
dengan Knowledge Discovery in Database (KDD). KDD sendiri masih
memiliki beberapa proses di dalamnya, yaitu data cleaning, data
integration, data selection, data transformation, data mining, pattern
Dalam penambangan data, sudah banyak teknik ataupun metode
yang sering digunakan. Salah satunya adalah teknik untuk mencari data
yang tidak konsisten ataupun data yang berbeda dari data yang lainnya.
Teknik ini biasa disebut dengan deteksi anomali data atau outlier detection
(Han & Kamber, 2006). Outlier sendiri merupakan sebuah observasi yang
menyimpang begitu banyak dari pengamatan lain untuk membangkitkan
kecurigaan bahwa objek tersebut dihasilkan oleh mekanisme yang berbeda
(Hawkins, 1980).
Banyak algoritma penambangan data yang mencoba untuk
meminimalkan pengaruh outlier. Masalah deteksi outlier dapat dilihat
sebagai dua submasalah. Pertama, menentukan data yang dapat dianggap
tidak konsisten dalam satu set data yang diberikan. Lalu yang kedua
menemukan metode yang efisien untuk menemukan data yang outlier
(berbeda dengan data yang lain). Dengan demikian, deteksi outlier
merupakan salah satu tugas penambangan data yang menarik (Han &
Kamber, 2006).
Menurut Kriegel et al. (2010), deteksi outlier memiliki 6 macam
pendekatan, yaitu statistical test, depth-based approaches, deviation-based
approaches, distance-based approaches, density-based approaches, dan
high-dimentional approache. Algoritma klasterisasi sendiri sementara
membuang outlier sebagai suatu noise, namun dapat dimodifikasi untuk
menyertakan deteksi outlier sebagai hasil dari eksekusi mereka. Secara
pendekatan ini memang benar-benar outlier. Namun dari sekian banyak
algoritma outlier yang ada, tidak semuanya dapat cocok untuk digunakan
dalam menganalisis outlier. Data yang memiliki dimensi tinggi merupakan
salah satu hambatan dari algoritma outlier yang ada. Salah satu algoritma
baru yang biasa digunakan untuk mendeteksi outlier adalah algoritma yang
bernama Influenced Outlierness (INFLO) yang dikemukakan oleh Jin et al
pada tahun 2006. Algoritma INFLO ini juga merupakan salah satu algoritma
deteksi outlier dengan pendekatan berbasis density-based yang
menggunakan Symmetric Neighborhood Relationship.
Teknik deteksi outlier ini dapat digunakan untuk menganalisis
berbagai bidang, salah satunya adalah bidang pendidikan. Salah satu isu
tentang pendidikan di Indonesia adalah mengenai Ujian Nasional (UN).
Penyelenggara UN adalah Badan Standar Nasional Pendidikan (BNSP)
yang bekerja sama dengan Kementerian Pendidikan dan Kebudayaan,
Kementerian Agama, Kementerian Dalam Negeri, Kepolisian Republik
Indonesia, Perguruan Tinggi Negeri, dan Pemerintah Daerah, yang dalam
pelaksanaannya terdiri atas Penyelenggara UN Tingkat Pusat,
Penyelenggara UN Tingkat Provinsi, Penyelenggara UN Tingkat
Kabupaten / Kota, dan Penyelenggara UN Tingkat Sekolah / Madrasah.
Menurut Prosedur Operasi Standart Ujian Nasional Tahun 2014 (POS UN
2014), kelulusan peserta didik dari UN ditentukan dari Nilai Akhir (NA)
yang merupakan gabungan nilai Ujian Nasional (UN) dengan Nilai Sekolah
juga merupakan gabungan nilai US dengan nilai rata – rata raport semester
3, 4, dan 5 (untuk tingkat Sekolah Menengah Atas) dengan bobot 60% nilai
US dan 40% nilai rata – rata raport.
Sekolah Menengah Atas (SMA) merupakan salah satu tingkatan
sekolah yang menarik dan memiliki beberapa hal untuk dianalisa. Hal ini
karena SMA merupakan jenjang sekolah terakhir sebelum menuju ke
tingkat yang lebih tinggi (Perguruan Tinggi). SMA sendiri memiliki
beberapa jurusan, seperti Ilmu Pengetahuan Alam (IPA), Ilmu Pengetahuan
Sosial (IPS), Bahasa, dan Agama.
Maka dari itu, penelitian ini akan melakukan deteksi outlier pada
nilai ujian SMA dari salah satu provinsi di Indonesia, yaitu Provinsi Daerah
Istimewa Yogyakarta (DIY). Pemilihan provinsi-provinsi tersebut dengan
alasan, yaitu berdasarkan provinsi letak Universitas Sanata Dharma
Yogyakatya (DIY). Nilai ujian yang diteliti adalah nilai ujian nasional, nilai
ujian sekolah, dan nilai akhir SMA dari jurusan IPA dan IPS karena
mayoritas SMA di Indonesia adalah jurusan IPA dan IPS. Nilai yang
dipergunakan adalah nilai ujian tahun 2011-2014.
Penelitian ini diharapkan dapat menghasilkan suatu informasi atau
bahkan pengetahuan baru dari kejadian langka dari data nilai ujian SMA
yang ada. Hasil yang didapatkan nantinya akan menampilkan sekolah mana
dari provinsi tertentu yang outlier atau berbeda dari sekolah – sekolah
lainnya yang ada dalam provinsi tersebut. Selain itu juga dapat terlihat
nilai NA. Selain itu, nantinya diharapkan dari hasil outlier yang didapatkan,
akan dapat menganalisa lebih lanjut pemasalahan UN yang terjadi di
Indonesia.
1.2. Rumusan Masalah
Rumusan masalah pada penelitian ini adalah sebagai berikut :
1. Bagaimana mendeteksi outlier data rata-rata nilai ujian nasional, nilai
ujian sekolah, dan nilai akhir dari Sekolah Menengah Atas (SMA) yang
ada di Provinsi Daerah Istimewa Yogyakarta (DIY) dengan
menggunakan algoritma Influenced Outlierness (INFLO)?
2. Apakah algoritma Influenced Outlierness (INFLO) dapat mendeteksi
outlier data rata – rata nilai ujian nasional, nilai ujian sekolah, dan nilai
akhir dari Sekolah Menengah Atas (SMA) yang ada di Provinsi Daerah
Istimewa Yogyakarta (DIY)?
1.3. Batasan Masalah
Batasan masalah pada penelitian ini adalah sebagai berikut :
1. Algoritma deteksi outlier yang digunakan adalah Influenced Outlierness
(INFLO).
2. Data yang digunakan adalah data nilai ujian nasional, nilai ujian
sekolah, dan nilai akhir untuk tahun ajaran 2011-2014.
3. Sekolah yang diteliti adalah Sekolah Menengah Atas (SMA) jurusan
1.4. Tujuan Penelitian
Tujuan dari penelitian ini adalah sebagai berikut :
1. Mendeteksi outlier data rata – rata nilai ujian nasional, nilai ujian
sekolah, dan nilai akhir dari Sekolah Menengah Atas (SMA) yang ada
di Provinsi Daerah Istimewa Yogyakarta (DIY) dengan menggunakan
algoritma Influenced Outlierness (INFLO).
2. Menganalisa kemampuan algoritma Influenced Outlierness (INFLO)
dalam mendeteksi outlier dari data rata – rata nilai ujian nasional, nilai
ujian sekolah, dan nilai akhir dari Sekolah Menengah Atas (SMA) yang
ada di Provinsi Daerah Istimewa Yogyakarta (DIY).
1.5. Manfaat Penelitian
Manfaat dari penelitian ini adalah sebagai berikut :
1. Memberikan pengetahuan baru mengenai cara mendeteksi outlier
dengan menggunakan algoritma Influenced Outlierness (INFLO).
2. Memberikan informasi mengenai anomali data yang ada dalam nilai –
nilai ujian Sekolah Menengah Atas (SMA).
1.6. Metodologi Penelitian
Metodologi penelitian yang digunakan dalam menyelesaikan tugas akhir ini
adalah sebagai berikut :
Metodologi pertama yang digunakan adalah studi pustaka.
Tahap ini merupakan proses mengumpulkan informasi berupa algoritma
yang digunakan untuk mendeteksi outlier dari berbagai macam referensi
yang tersedia (buku, karya ilmiah, ataupun artikel lainnya yang banyak
terdapat pada internet). Selanjutnya adalah mempelajari dan
menganalisa dari informasi yang didapat sehingga menentukan untuk
memilih algoritma Influenced Outlierness untuk penelitian deteksi
outlier pada nilai ujian siswa Sekolah Menengah Atas.
2. Metode Knowledge Discovery in Database (KDD)
Metodologi kedua ini adalah teknik penambangan data yang
dituliskan oleh Jiawei Han, Micheline Kamber, dan Jian Pei pada
bukunya Data Mining : Concepts and Techniques. Teknik KDD
mencakup beberapa proses, yaitu :
a. Data Cleaning
Tahap ini merupakan proses dimana data yang tidak
dibutuhkan / pengganggu (noise) dan data yang tidak
konsisten akan dihapus.
b. Data Integration
Tahap ini merupakan proses dimana
bermacam-macam data dari berbagai sumber akan digabungkan
menjadi satu kesatuan.
Tahap ini merupakan proses dimana untuk
melakukan analisis, data relevan akan diperoleh dari
database.
d. Data Transformation
Tahap ini merupakan proses dimana data diubah
(transformasi) atau digabungkan sehingga menjadi tepat
untuk ditambang dengan misalnya melakukan operasi
penjumlahan atau penggabungan.
e. Data Mining
Tahap ini merupakan proses pokok dimana metode
cerdas dilaksanakan untuk menggali pola dari data.
f. Pattern Evaluation
Tahap ini merupakan proses indentifikasi pola yang
sungguh menarik menampilkan basis pengetahuan dalam
suatu ukuran ketertarikan.
g. Knowledge Presentation
Tahap ini merupakan proses dimana teknik
menampilkan suatu gambaran dan pengetahuan digunakan
untuk menampilkan hasil tambang dari pengetahuan kepada
pengguna.
3. Analisis dan Evaluasi
Metode ketiga ini adalah melakukan analisis dalam menentukan
Outlierness (INFLO) dari data-data yang dipergunakan. Data yang
terdeteksi sebagai outlier adalah yang memiliki hasil INFLO menjauhi
angka “1”.
Setelah itu akan dilakukan evaluasi dari hasil analisa yang
didapat, yaitu informasi baru mengenai hasil sekolah-sekolah yang
terdeteksi sebagai outlier dari provinsi tertentu. Hasil evaluasi dapat
dijadikan permulaan untuk perbaikan dari sekolah yang terdeteksi
outlier tersebut.
1.7. Sistematika Penulisan
Sistematika penulisan tugas akhir ini adalah sebagai berikut :
a. BAB I : PENDAHULUAN
Bab pertama ini berisi latar belakang penelitian, rumusan masalah,
tujuan penelitian, batasan masalah, metodologi yang digunakan dalam
penelitian, dan sistematika penulisan tugas akhir.
b. BAB II : LANDASAN TEORI
Bab kedua ini berisi dasar-dasar teori penambangan data yang
digunakan dalam penelitian tugas akhir ini.
c. BAB III : METODOLOGI PENELITIAN
Bab ketiga ini berisi metodologi dari penelitian tugas akhir ini.
d. BAB IV : ANALISIS DAN PERANCANGAN SISTEM
Bab keempat ini berisi analisa dan perancangan dari sistem yang
e. BAB V : IMPLEMENTASI PENAMBANGAN DATA
Bab kelima ini berisi implementasi sistem yang dibangun.
f. BAB VI : PENGUJIAN DAN ANALISIS HASIL PENGUJIAN
Bab keenam ini berisi pengujian dan analisis hasil pengujian dari sistem
yang dibangun.
g. BAB VII : PENUTUP
Bab terakhir ini berisi kesimpulan dan saran dari sistem ini yang berguna
11
2. BAB II
LANDASAN TEORI
2.1. PENAMBANGAN DATA
2.1.1. Pengertian Penambangan Data
Menurut Tan et.al (2006), penambangan data adalah
teknologi yang memadukan metode analisis data tradisional dengan
algoritma yang canggih untuk memproses volume data yang besar.
Dalam bukunya disebutkan bahwa penambangan data adalah proses
menemukan informasi yang berguna dari repositori data yang besar
secara otomatis.
Namun tidak semua tugas menemukan informasi dapat
dicari menggunakan penambangan data. Meski tugas-tugas seperti
yang penting dan mungkin melibatkan pengguanaan algoritma yang
canggih dan struktur data, tetap harus mengandalkan teknik ilmu
komputer tradisional dan fitur yang jelas dari data. Hal ini perlu
dalam membuat struktur indeks untuk secara efisien mengatur dan
mengambil informasi. Meskipun demikian, teknik penambangan
data telah digunakan untuk meningkatkan sistem pencarian
informasi.
2.1.2. Asal Usul Penambangan Data
Menurut Tan et al. (2004), penambangan data menarik ide
basis data. Teknik tradisional mungkin tidak cocok karena data yang
sangat besar, data yang berdimensi tinggi, dan sifat heterogen, sifat
data yang didistribusikan. Hal ini dapat digambarkan seperti gambar
berikut ini :
Gambar 2.1 Asal Usul Penambangan Data
2.1.3. Fungsi dalam Penambangan Data
Menurut Han et al. (2012), penambangan data memiliki
beberapa fungsi yang menerapkan metode yang dapat dikategorikan
menjadi 2 bagian besar, yaitu metode deskriptif dan metode
prediktif. Metode deskriptif bertugas mengkarakterisasikan suatu
sifat dari data target. Sedangkan metode prediktif bertugas membuat
suatu prediksi masa depan yang dicari melalui data saat ini.
Fungsi yang terdapat dalam penambangan data ada 4, yaitu :
a. Asosiasi
Asosiasi dalam penambangan data merupakan aturan dalam
satu set transaksi yang akan memprediksi terjadinya item
berdasarkan item lainnya dalam transaksi tersebut. (Tan et al.
b. Klasifikasi
Menurut Tan et al. (2004), dalam koleksi catatan (training
set), setiap record berisi satu set atribut dimana salah satu atribut
adalah suatu kelas. Saat ingin menentukan klasifikasi training
set tersebut, dapat dengan mencari model untuk masing-masing
atribut kelas sebagai fungsi dari nilai-nilai atribut yang lainnya.
Tujuannya agar record yang sebelumnya tak terlihat dapat
ditujukan dalam kelas tersebut seakurat mungkin. Satu set tes
digunakan untuk menentukan akurasi dari suatu model.
Biasanya, kumpulan data yang diberikan dibagi menjadi training
set dan set test. Training set digunakan untuk membangun model
dan set test digunakan untuk memvalidasinya.
c. Klastering
Klastering merupakan fungsi untuk menemukan suatu kelompok
obyek sehingga obyek - obyek dalam kelompok akan mirip (atau
terkait) satu sama lain dan berbeda dari (atau tidak terkait
dengan) obyek - obyek di kelompok lainnya. (Tan et al. 2004)
d. Analisis Outlier
Menurut Tan et al. (2004), outlier merupakan himpunan titik
data yang jauh berbeda dari sisa data. Ada jauh lebih banyak
pengamatan "normal" dibandingkan pengamatan "normal"
adalah metode yang digunakan tanpa pengawasan, dan seperti
layaknya “mencari jarum dalam tumpukan jerami”.
2.1.4. Knowledge Discovery in Databases (KDD)
Penambangan data tidak dapat terpisahkan dari proses
knowledge discovery in databases atau biasa disebut dengan KDD.
Proses KDD merupakan sebuah proses mengubah data mentah
menjadi suatu informasi yang berguna. KDD sendiri masih memiliki
beberapa proses di dalamnya, yaitu data cleaning, data integration,
data selection, data transformation, data mining, pattern
evaluation, dan knowledge presentation (Han & Kamber, 2006).
1. Data Cleaning
Tahap ini merupakan proses dimana data yang tidak
dibutuhkan / pengganggu (noise) dan data yang tidak
konsisten akan dihapus.
2. Data Integration
Tahap ini merupakan proses dimana bermacam-macam
data dari berbagai sumber akan digabungkan menjadi
satu kesatuan.
3. Data Selection
Tahap ini merupakan proses dimana untuk melakukan
analisis, data relevan akan diperoleh dari database.
4. Data Transformation
Tahap ini merupakan proses dimana data diubah
(transformasi) atau digabungkan sehingga menjadi tepat
untuk ditambang dengan misalnya melakukan operasi
penjumlahan atau penggabungan.
5. Data Mining
Tahap ini merupakan proses pokok dimana metode
cerdas dilaksanakan untuk menggali pola dari data.
6. Pattern Evaluation
Tahap ini merupakan proses indentifikasi pola yang
sungguh menarik menampilkan basis pengetahuan dalam
7. Knowledge Presentation
Tahap ini merupakan proses dimana teknik menampilkan
suatu gambaran dan pengetahuan digunakan untuk
menampilkan hasil tambang dari pengetahuan kepada
pengguna.
2.2. DETEKSI OUTLIER
2.2.1. Pengertian Outlier
Outlier memiliki beberapa pengertian dari beberapa sumber.
Menurut Hawkins (1980), outlier adalah sebuah pengamatan yang
menyimpang begitu banyak dari pengamatan lain untuk
membangkitkan kecurigaan bahwa itu dihasilkan oleh mekanisme
yang berbeda. Menurut Barnet & Lewis (1994), outlier adalah
observasi (atau bagian dari pengamatan) yang tampaknya tidak
konsisten dengan sisa set data. Menurut Moore & McCabe (1999),
outlier adalah pengamatan yang terletak di luar pola keseluruhan
distribusi. Menururt Chen, Tan & Fu (2003), outlier adalah catatan
data yang tidak mengikuti derai dalam aplikasi.
2.2.2. Macam Pendekatan Outlier
Menurut Kriegel et. al. (2010), outlier memiliki beberapa
pendekatan, yaitu Model-based Approaches, Proximity-based
Pendekatan model-based memiliki beberapa metode, yaitu
statistical test; depth-based approaches yang memiliki contoh
algoritma ISODEPTH (Ruts & Rousseeuw, 1996) dan FDC
(Johnson et al., 1998); dan yang terakhir adalah deviation-based
approaches.
Pendekatan proximity-based juga memiliki beberapa
metode, yaitu Distance-based Approaches yang memiliki contoh
algoritma DB-outliers (Knorr & Ng, 1997), index-based (Knorr &
Ng, 1998), nested-loop based (Knorr & Ng, 1998), dan grid-based
(Knorr & Ng, 1998); Density-based Approaches memiliki contoh
algoritma local outlier factor / LOF (Breunig et al., 1999), (Breunig
et al., 2000), influenced outlierness / INFLO (Jin et al., 2006), dan
local outlier correlation integral / LOCI (Papadimitriou et al.,
2003).
Pendekatan terakhir adalah high-dimensional Approaches
yang memiliki contoh algoritma angle-based Outlier Degree /
ABOD (Kriegel et al., 2008), grid-based subspace outlier detection
(Aggrawal & Yu, 2000), dan subspace outlier degree / SOD
2.3. INFLUENCED OUTLIERNESS (INFLO)
2.3.1. Deteksi Outlier dengan Algoritma INFLO
Deteksi outlier seringkali lebih menarik daripada deteksi
yang pada umumnya. Hal ini karena outlier mengandung informasi
yang berguna dengan mendasari perilaku abnormal atau berbeda
dari data ataupun informasi lainnya. Pada penelitian ini akan
mendeteksi outlier dengan menggunakan algoritma Influence
Outlierness atau biasa disebut dengan INFLO. Teori ini
dikemukakan oleh Jin et.al. pada tahun 2006.
Algoritma ini mengusulkan deteksi outlier berdasarkan
relasi dari lingkungan simetris karena mengingat sebuah obyek
dalam memperkirakan distribusi kepadatan tetangganya dipengaruhi
oleh suatu tetangga atau dapat disebut dengan nearest neighbors
(NN) dan tetangga sebaliknya atau juga dapat disebut dengan
reverse nearest neighbors (RNN). Hubungan simetris antara NN
dan RNN akan membuat pengukuran outlierness menjadi lebih kuat.
Mendeteksi sebuah obyek apakah merupakan suatu outlier
atau hanya anggota suatu cluster, dilihat dari hasil Influenced
Outlierness (INFLO). Semakin tinggi INFLO, maka kemungkinan
besarnya obyek tersebut adalah outlier. Namun jika INFLO semakin
rendah, maka kemungkinan obyek tersebut hanya merupakan
1. Menghitung Jarak Menggunakan Euclidean Distance
Tahap ini adalah menghitung jarak (distance) dari suatu obyek p
dan q di suatu database D. Rumus menghitung jarak d(p, q)
dapat dirumuskan sebagai berikut :
,
= √∑
� �−
�... (2.1)
Keterangan :
d = jarak antar obyek
pi= obyek “p” ke - i
qi= obyek “q” ke - i
2. Menghitung K-Distance dan Mencari Nearest Neighbors (NN)
Tahap ini adalah mencari tetangga terdekat dari obyek p
sekaligus mencari k-distance yang dinotasikan sebagai d(p,q)
yaitu jarak terbesar dari jarak antara obyek p dengan k tetangga
terdekatnya dalam suatu database D, dengan ketentuan sebagai
berikut :
a. Setidaknya obyek k dalam ′∈ � menyatakan bahwa
, ′ ≤ , .
b. Setiap obyek (k – 1) dalam ′∈ � menyatakan bahwa
, ′ ≤ , .
c. K-NN dari obyek p adalah sebuah kumpulan obyek X dalam
database D dimana , � ≤ ��� , atau dapat
� = {� ∈ � \ { } | , � ≤ � � } ... (2.2)
Keterangan :
NN = tetangga terdekat
k-dist = nilai k-distance dari suatu obyek
3. Mencari Influence Space (IS)
Tahap ini adalah mencari hubungan tetangga simetris dari suatu
obyek. IS merupakan gabungan dari NN (Nearest Neighbors)
dan RNN (Reverse Nearest Neighbors) yang dapat dirumuskan
sebagai berikut :
�
�=
�∪
� ... (2.3)RNN merupakan inverse dari tetangga suatu obyek yang dapat
juga dicari dengan rumus sebagai berikut :
�
= { | ∈ �, ∈
�}
... (2.4)Keterangan :
NN = tetangga terdekat
RNN = reverse dari tetangga terdekat
IS = gabungan NN dan RNN
4. Menghitung Local Density
Tahap ini adalah mencari inverse dari k-distance obyek p, yang
�
=
�� ... (2.5)
Keterangan :
k-dist = nilai k-distance dari suatu obyek
den = nilai density dari suatu obyek
5. Menghitung Influenced Outlierness (INFLO)
Tahap ini adalah menghitung INFLO dari suatu obyek, yang
dapat dirumuskan sebagai berikut :
� ��
�=
������ � ... (2.6)dimana
�
���(�
�) =
∑ ∈ � � �| � � | ... (2.7)
Jadi dari rumus 2.6 dan 2.7 jika digabungkan menjadi :
� ��
�=
∑ ∈ � � �
| � � |
� ………. (2.8)
Keterangan :
IS = influence space (jumlah obyek gabungan NN dan RNN)
den = nilai density dari suatu obyek
den-avg = rata-rata nilai density obyek IS dari suatu obyek
6. Memberikan Kesimpulan
Jika hasil INFLO dari suatu obyek jauh melebihi 1, maka obyek
tersebut termasuk outlier. Namun jika hasil INFLO dari suatu
obyek mendekati 1, maka obyek tersebut hanya merupakan
anggota suatu cluster.
2.3.2. Contoh Deteksi Outlier dengan Algoritma INFLO
Contoh mendeteksi outlier menggunakan algoritma
Influenced Outlierness (INFLO) dalam sebuah himpunan D yang
memiliki 5 obyek, yaitu p1, p2, p3, p4, dan p5. Dari keempat obyek
tersebut ditentukan nilai k (jumlah tetangga) adalah 2.
1. Nilai masing-masing obyek
p1 9,5
p2 8,85 p3 9,35 p4 8,45 p5 7,95
2. Jarak antar obyek
p1 p2 p3 p4 p5
p1 0 8,05823 11,6939 14,9646 17,3998 p2 8,05823 0 8,03197 11,6929 14,9277 p3 11,6939 8,03197 0 8,01639 11,6861 p4 14,9646 11,6929 8,01639 0 7,96571 p5 17,3998 14,9277 11,6861 7,96571 0
p1 p2 p3 p4 p5 p1 0 p1 8,05823 p1 11,6939 p1 14,9646 p1 17,3998 p2 8,05823 p2 0 p2 8,03197 p2 11,6929 p2 14,9277 p3 11,6939 p3 8,03197 p3 0 p3 8,01639 p3 11,6861 p4 14,9646 p4 11,6929 p4 8,01639 p4 0 p4 7,96571 p5 17,3998 p5 14,9277 p5 11,6861 p5 7,96571 p5 0
Setelah diurutkan :
p1 p2 p3 p4 p5
p1 0 p2 0 p3 0 p4 0 p5 0
p2 8,05823 p3 8,03197 p4 8,01639 p5 7,96571 p4 7,96571 p3 11,6939 p1 8,05823 p2 8,03197 p3 8,01639 p3 11,6861 p4 14,9646 p4 11,6929 p5 11,6861 p2 11,6929 p2 14,9277 p5 17,3998 p5 14,9277 p1 11,6939 p1 14,9646 p1 17,3998
3. Mencari �
p1 p2 p3 p4 p5
p1 0 p2 0 p3 0 p4 0 p5 0
p2 8,05823 p3 8,03197 p4 8,01639 p5 7,96571 p4 7,96571 p3 11,6939 p1 8,05823 p2 8,03197 p3 8,01639 p3 11,6861 p4 14,9646 p4 11,6929 p5 11,6861 p2 11,6929 p2 14,9277 p5 17,3998 p5 14,9277 p1 11,6939 p1 14,9646 p1 17,3998
� = 2 tetangga terdekat dari masing-masing obyek.
� = {p2, p3}
� = {p3, p1}
� = {p4, p2}
� = {p5, p3}
� = {p4, p3}
Sebelum mencari � � , karena � � = � ∪ � ,
terlebih dahulu mencari � , seperti berikut :
p1 p2 p3 p4 p5
p1 0 p2 0 p3 0 p4 0 p5 0
p2 8,05823 p3 8,03197 p4 8,01639 p5 7,96571 p4 7,96571 p3 11,6939 p1 8,05823 p2 8,03197 p3 8,01639 p3 11,6861 p4 14,9646 p4 11,6929 p5 11,6861 p2 11,6929 p2 14,9277 p5 17,3998 p5 14,9277 p1 11,6939 p1 14,9646 p1 17,3998
� = {p2}
� = {p3, p1}
� = {p4, p2}
� = {p5, p3}
� = {p4}
Lalu hasil Influence Space (IS) menjadi seperti berikut :
p1 p2 p3 p4 p5
p1 0 p2 0 p3 0 p4 0 p5 0
p2 8,05823 p3 8,03197 p4 8,01639 p5 7,96571 p4 7,96571 p3 11,6939 p1 8,05823 p2 8,03197 p3 8,01639 p3 11,6861 p4 14,9646 p4 11,6929 p5 11,6861 p2 11,6929 p2 14,9277 p5 17,3998 p5 14,9277 p1 11,6939 p1 14,9646 p1 17,3998
5. Menghitung k-distance
��� = nilai terbesar (maksimal) dari tetangga terdekat dari
��� = 11,6939
��� = 8,05823
��� = 8,03197
��� = 8,01639
��� = 11,6861
6. Menghitung Local Density
� = 1 / 11,6939 = 0,08551
� = 1 / 8,05823 = 0,1241
� = 1 / 8,03197 = 0,1245
� = 1 / 8,01639 = 0,12474
� = 1 / 11,6861 = 0,08557
7. Menghitung Influenced Outlierness (INFLO)
� �� � =
, + ,
, = 1,45355
� �� � =
, + ,
, = 0,84618
� �� � =
, + ,
, = 0,99934
� �� � =
, + ,
, = 0,84202
� �� � =
, + ,
8. Memberikan Kesimpulan
Hasil INFLO dari masing-masing obyek, terlihat bahwa hasil INFLO
tersebesar adalah milik obyek p1 dan p5 dengan hasilnya
masing-masing 1,45355 dan 1,45636. Maka dari itu, obyek p1 dan p5 yang terdeteksi sebagai outlier. Obyek p1 terdeteksi karena nilainya adalah
9,5 yang dimana nilai tersebut adalah nilai tertinggi dari semua obyek,
sedangkan obyek p5 terdeteksi karena nilainya adalah 7,95 yang dimana
27
3. BAB III
METODOLOGI PENELITIAN
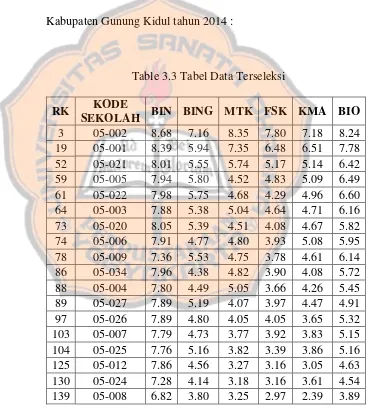
3.1. SUMBER DATA
Data yang digunakan untuk penelitian berupa file yang memiliki
ekstensi .xls yang diperoleh dari 2 sumber. Sumber yang pertama adalah
Seksi Data dan Teknologi Informasi Dinas Pendidikan, Pemuda, dan Olah
Raga (DIKPORA) Provinsi Daerah Istimewa Yogyakarta (DIY). Lalu
sumber yang kedua adalah dari website e-Reporting Ujian Nasional milik
Pusat Penilaian Pendidikan
http://118.98.234.22/sekretariat/hasilun/index.php/hasilun.
Data sumber merupakan data nilai Ujian Nasional (UN), Nilai
Sekolah (NS), dan Nilai Akhir (NA) dari tahun 2011 – 2014. Pada penelitian
ini hanya untuk SMA jurusan Ilmu Pengetahuan Alam (IPA) dan Ilmu
Pengetahuan Sosial (IPS).
Table 3.1 Tabel Atribut Data
Nama Atribut Keterangan
RANKING Urutan Ranking
NAMA_SEKOLAH Nama Sekolah
JENIS_SEKOLAH Jenis Sekolah (SMA / MA) STATUS_SEKOLAH Status Sekolah (Swasta / Negeri)
Jumlah
PESERTA Jumlah Peserta
L Jumlah Peserta yang Lulus
3.2. PENGOLAHAN DATA 3.2.1. Data Cleaning
Tahap pertama adalah membersihkan data dari noise seperti
data yang tidak terisi ataupun data yang tidak konsisten. Data yang
ada tidak memiliki noise sehingga tahap ini tidak dilakukan.
3.2.2. Data Integration
Tahap selanjutnya adalah melakukan penggabungan data
dari berbagai macam sumber. Data yang ada juga sudah terdapat
dalam 1 file sehingga tahap ini juga tidak dilakukan.
3.2.3. Data Selection
Tahap selanjutnya adalah seleksi data dari atribut yang tidak
terpakai. Proses seleksi ini dilakukan dengan memilih atribut yang
relevan untuk digunakan dalam penelitian, dan menghapus atribut Mata
Ujian
BIN Nilai Bahasa Indonesia
BING Nilai Bahasa Inggris
MTK Nilai Matematika
FSK / EKO
Nilai Fisika / Nilai Ekonomi KMA /
SOS
Nilai Kimia / Nilai Sosiologi BIO /
GEO
Nilai Biologi / Nilai Geografi
TOTAL Total Nilai
yang tidak relevan. Atribut yang dapat dilanjutkan untuk penelitian
adalah :
Table 3.2 Tabel Seleksi Atribut
Nama Atribut Keterangan
RANKING Ranking se-DIY
KODE_SEKOLAH Kode Sekolah
BIN Nilai Bahasa Indonesia
BING Nilai Bahasa Inggris
MTK Nilai Matematika
FSK / EKO
Nilai Fisika / Nilai Ekonomi KMA /
SOS
Nilai Kimia / Nilai Sosiologi BIO /
GEO
Nilai Biologi / Nilai Geografi
3.2.4. Data Transformation
Tahap selanjutnya adalah proses transformasi data dengan
melakukan normalisasi perbedaan range. Proses normalisasi
dilakukan dengan menggunakan rumus min-max normalization
seperti berikut :
′
=
�− � ����− � �
(�
���− �
� �) + �
� �…(3.1)Keterangan :
v = nilai sebelum ternormalisasi
v’ = nilai setelah ternormalisasi
minA = nilai minimal dari atribut A
� � � = nilai minimal terbaru dari atribut A
� ��� = nilai minimal terbaru dari atribut A
Pada penelitian ini, atribut yang digunakan sudah memiliki
data yang memiliki range yang sama, yaitu 0 – 10, sehingga tahap
ini tidak dilakukan. Berikut adalah data nilai Ujian Nasional
Kabupaten Gunung Kidul tahun 2014 :
Table 3.3 Tabel Data Terseleksi
RK KODE
3.2.5. Data Mining
Tahap selanjutnya adalah melakukan penambangan data yang
juga terdiri dari beberapa tahapan. Pada proses saat ini digunakan
aplikasi Microsoft Excel.
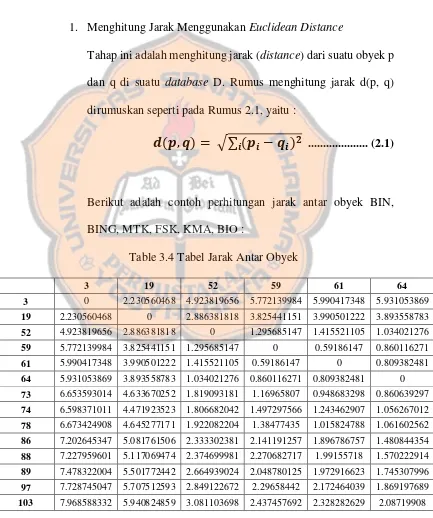
1. Menghitung Jarak Menggunakan Euclidean Distance
Tahap ini adalah menghitung jarak (distance) dari suatu obyek p
dan q di suatu database D. Rumus menghitung jarak d(p, q)
dirumuskan seperti pada Rumus 2.1, yaitu :
,
= √∑
� �−
� ... (2.1)Berikut adalah contoh perhitungan jarak antar obyek BIN,
BING, MTK, FSK, KMA, BIO :
Table 3.4 Tabel Jarak Antar Obyek
3 19 52 59 61 64
3 0 2.230560468 4.923819656 5.772139984 5.990417348 5.931053869
19 2.230560468 0 2.886381818 3.825441151 3.990501222 3.893558783
52 4.923819656 2.886381818 0 1.295685147 1.415521105 1.034021276
59 5.772139984 3.825441151 1.295685147 0 0.59186147 0.860116271
61 5.990417348 3.990501222 1.415521105 0.59186147 0 0.809382481
64 5.931053869 3.893558783 1.034021276 0.860116271 0.809382481 0
73 6.653593014 4.633670252 1.819093181 1.16965807 0.948683298 0.860639297
74 6.598371011 4.471923523 1.806682042 1.497297566 1.243462907 1.056267012
78 6.673424908 4.645277171 1.922082204 1.38477435 1.015824788 1.061602562
86 7.202645347 5.081761506 2.333302381 2.141191257 1.896786757 1.480844354
88 7.227959601 5.117069474 2.374699981 2.270682717 1.99155718 1.570222914
89 7.478322004 5.501772442 2.664939024 2.048780125 1.972916623 1.745307996
97 7.728745047 5.707512593 2.849122672 2.29658442 2.172464039 1.869197689
104 8.08233877 6.074635792 3.208644574 2.507468843 2.286853734 2.199136194
125 9.21180764 7.193622175 4.326176141 3.676492894 3.496355245 3.330555509
130 9.261414579 7.196596418 4.357751714 3.710606419 3.560210668 3.37372198
139 10.29342994 8.263237864 5.429742167 4.937296831 4.783764208 4.488685776
73 74 78 86 88 89
3 6.653593014 6.598371011 6.673424908 7.202645347 7.227959601 7.478322004
19 4.633670252 4.471923523 4.645277171 5.081761506 5.117069474 5.501772442
52 1.819093181 1.806682042 1.922082204 2.333302381 2.374699981 2.664939024
59 1.16965807 1.497297566 1.38477435 2.141191257 2.270682717 2.048780125
61 0.948683298 1.243462907 1.015824788 1.896786757 1.99155718 1.972916623
64 0.860639297 1.056267012 1.061602562 1.480844354 1.570222914 1.745307996
73 0 0.834026378 0.865621164 1.230772115 1.282770439 1.067426812
74 0.834026378 0 1.078007421 1.09945441 1.071587607 1.471393897
78 0.865621164 1.078007421 0 1.469387628 1.40648498 1.558043645
86 1.230772115 1.09945441 1.469387628 0 0.503487835 1.427094951
88 1.282770439 1.071587607 1.40648498 0.503487835 0 1.374881813
89 1.067426812 1.471393897 1.558043645 1.427094951 1.374881813 0
97 1.369890507 1.73781472 1.723571873 1.068456831 1.282692481 0.999699955
103 1.493619764 1.810938983 1.842118346 1.281288414 1.427795504 0.88391176
104 1.476787053 1.881249585 1.684280262 1.506817839 1.510099334 0.9226592
125 2.673854895 2.973835907 2.911940933 2.289432244 2.358686075 1.946458322
130 2.74457647 2.856588875 2.88925596 2.317433926 2.321723498 1.949179314
139 3.972908255 4.114948359 4.022623522 3.342274675 3.329129015 3.180597428
97 103 104 125 130 139
3 7.728745047 7.968588332 8.08233877 9.21180764 9.261414579 10.29342994
19 5.707512593 5.940824859 6.074635792 7.193622175 7.196596418 8.263237864
52 2.849122672 3.081103698 3.208644574 4.326176141 4.357751714 5.429742167
59 2.29658442 2.437457692 2.507468843 3.676492894 3.710606419 4.937296831
61 2.172464039 2.328282629 2.286853734 3.496355245 3.560210668 4.783764208
64 1.869197689 2.08719908 2.199136194 3.330555509 3.37372198 4.488685776
73 1.369890507 1.493619764 1.476787053 2.673854895 2.74457647 3.972908255
74 1.73781472 1.810938983 1.881249585 2.973835907 2.856588875 4.114948359
78 1.723571873 1.842118346 1.684280262 2.911940933 2.88925596 4.022623522
86 1.068456831 1.281288414 1.506817839 2.289432244 2.317433926 3.342274675
88 1.282692481 1.427795504 1.510099334 2.358686075 2.321723498 3.329129015
89 0.999699955 0.88391176 0.9226592 1.946458322 1.949179314 3.180597428
97 0 0.414125585 0.839464115 1.514958745 1.722411101 2.753870004
103 0.414125585 0 0.68571131 1.319166403 1.397998569 2.576800342
125 1.514958745 1.319166403 1.289340917 0 0.917932459 1.636734554
130 1.722411101 1.397998569 1.476550033 0.917932459 0 1.509668838
139 2.753870004 2.576800342 2.647319399 1.636734554 1.509668838 0
2. Menghitung K-Distance dan Mencari Nearest Neighbors (NN)
Tahap ini adalah menentukan tetangga terdekat (NN) dengan
asumsi jumlah tetangga terdekat (k) = 7. Caranya adalah dengan
mengurutkan jarak masing-masing obyek ke obyek lainya dari
nilai terkecil ke terbesar, lalu memilih 7 jarak terdekat, yaitu
yang mengandung nilai terkecil. Selanjutnya adalah menghitung
k-distance dari masing-masing obyek tersebut dengan mencari
nilai maksimal dari keseluruhan nilai jarak obyek dengan ke-7
tetangga terdekatnya.
Berikut adalah tetangga terdekat (NN) masing-masing obyek
dengan jarak antar obyeknya :
Table 3.5 Tabel NN dengan Jarak Antar Obyeknya
3 19 52 59
3 0 19 0 52 0 59 0
19 2.230560468 3 2.230560468 64 1.034021276 61 0.59186147
52 4.923819656 52 2.886381818 59 1.295685147 64 0.860116271
59 5.772139984 59 3.825441151 61 1.415521105 73 1.16965807
64 5.931053869 64 3.893558783 74 1.806682042 52 1.295685147
61 5.990417348 61 3.990501222 73 1.819093181 78 1.38477435
74 6.598371011 74 4.471923523 78 1.922082204 74 1.497297566
73 6.653593014 73 4.633670252 86 2.333302381 89 2.048780125
61 64 73 74