i
PEMANFAATAN GUDANG DATA UNTUK KEPERLUAN ONLINE
ANALYTICAL PROCESSING (OLAP) DAN PENAMBANGAN DATA
(Studi Kasus: PT. ASDP Indonesia Ferry (Persero) Cabang Kupang)
Skripsi
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Oleh:
Loudya Ester Rosalina Kapa 085314054
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
THE UTILIZATION OF DATA WAREHOUSE FOR ONLINE ANALYTICAL PROCESSING(OLAP) AND DATA MINING PURPOSES
(Case Study: PT. ASDP Indonesia Ferry (Persero) Cabang Kupang)
A Thesis
Presented as Partial Fulfillment of the Requirements To Obtain the Sarjana Komputer Degree
By:
Loudya Ester Rosalina Kapa 085314054
INFORMATICS ENGINEERING STUDY PROGRAM FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
v
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, kecuali yang telah dsebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 20 February 2013 Penulis,
vi
LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma : Nama : Loudya Ester Rosalina Kapa
Nomor Mahasiswa : 08 5314 054
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul :
Pemanfaatan Gudang Data Untuk Keperluan Online Analytical Processing (OLAP) dan Penambangan Data
Studi Kasus : PT. ASDP Indonesia Ferry (Persero) Cabang Kupang
beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikannya secara terbatas, dan mempublikasikannya di Internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini yang saya buat dengan sebenarnya.
Dibuat di Yogyakarta
Pada tanggal : 22 Februari 2013 Yang menyatakan
vii
HALAMAN PERSEMBAHAN
Karya ini saya persembahkan kepada :
TUHAN YESUS, tanganMU yang setia menuntun ku, Engkau
Penopang dan Harapan ku
Bapa & Mama tercinta
Adik-adik ku sayang, Cory dan Anto
Keluarga Besar
viii M O T T O
~~~
Janganlah takut, sebab Aku menyertai engkau, janganlah bimbang, sebab Aku ini Allahmu;
Aku akan meneguhkan, bahkan akan menolong engkau; Aku akan memegang engkau dengan tangan kanan-Ku yang membawa kemenangan.
Yesaya 41:10
~~~
I hear no voice
I feel no touch
I see no glory bright
But yet I know that
“GOD is near”
In the darkness as in light
ix
KATA PENGANTAR
Segala puji syukur penulis panjatkan kepada Allah Bapa di Surga, karena berkat dan penyertaan-Nya penulis dapat menyelesaikan penyusunan Skripsi yang berjudul “Pemanfaatan Gudang Data untuk keperluan Online Analytical
Processing (OLAP) dan Penambangan Data (Studi Kasus: PT. ASDP Indonesia Ferry (Persero) Cabang Kupang)”.
Skripsi ini disusun sebagai salah satu syarat untuk memperoleh gelar sarjana strata satu pada Program Studi Teknik Informatika Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
Pada saat pengerjaan skripsi ini penulis banyak mendapatkan bantuan dari berbagai pihak, oleh karena itu penulis ingin mengucapkan terima kasih kepada : 1. Ibu Ridowati Gunawan, S.Kom, M.T. selaku Ketua Prodi Teknik Informatika
sekaligus dosen pembimbing, yang telah memberikan kebaikan, arahan, bimbingan, serta meluangkan waktu sehingga penulis dapat menyelesaikan skripsi ini.
2. Ibu P.H Prima Rosa, S.Si., M.Sc. selaku Dekan Fakultas Sains dan Teknologi dan sekaligus sebagai dosen penguji yang telah memberikan kritik dan saran untuk penyempurnaan skripsi ini
x
4. Bapak Hermin, selaku Supervisor Lintasan, yang telah mengizinkan penulis untuk melakukan studi kasus
5. Kedua orang tua, Bapak Morizon B.D Kapa dan Ibu S.Leonora Welkis yang telah memberikan dukungan doa, semangat, motivasi , perhatian, yang selalu sabar membimbing penulis sehingga penulis dapat membuktikan kepada keluarga bahwa penulis berhasil menyelesaikan skripsi ini. Kalian luar biasa. 6. Adik-adik tercinta, Cory dan Anto, yang selalu mendukung dalam doa serta
memberi semangat kepada penulis.
7. Keluarga Besar di Kupang, Opa Tom, Opa Benja, Opa Sabu, bapa Min, Be‟a Teli, bapa Herman, mama Ren, dan semua saudara yang selalu memberikan semangat dan doa bagi penulis. Kak Rose, Kak Ani, Rino, kak Adi, kak Jimmy, kak Cindi, dan semua keluarga yang selalu memberi support yang luar biasa kepada penulis.
8. Saudara sekaligus sahabat Carla R.G. Pekujawang S.Kom, Hety, Yanti, Juan, Didi „Dircya‟, Nitha, Dirk, Ivanna „Boim‟, Ryan, Debby Kristiana Dima yang
selalu memberikan senyum, doa, dan motivasi kepada penulis.
9. Sahabat-sahabat seperjuangan, Lucy, Devi, Angga, Siska, Surya, Petra, Pucha, Endro, Ithak, Ochak, Reza, Wulan, Densi, Ilana, Suci, Roy, Linardi, Tista serta sibling Bebeth, Agnes, Gadis, dan Ade, yang membantu penulis saat mengalami kesulitan dalam pengerjaan skripsi, dan memberikan semangat, tawa, dan doa.
xi
11. Teman-teman kos Intan, Ce Pipi dan Niken, yang memberikan motivasi dan doa kepada penulis. Teman-teman kos Puri Liberti, Anyho, dan semuanya yang begitu mendukung penulis dalam setiap keceriaan dan motivasi yang kalian berikan.
12. Teman-teman GSM (kak Santi, Novita, Winnie „Jaja‟, Kia, Galuh, Caca, Dea) yang mendukung dalam doa dan bersedia meluangkan waktu memberi support kepada penulis.
13. Semua pihak yang telah membantu dan memberikan dukungan kepada penulis yang tidak dapat disebutkan satu per satu.
Dengan kerendahan hati, penulis menyadari bahwa skripsi ini masih jauh dari sempurna, oleh karena itu berbagi saran, kritik, dan masukan sangat diharapkan demi perbaikan skripsi ini di kemudian hari. Akhir kata, penulis berharap semoga skripsi ini dapat bermanfaat.
xii
DAFTAR ISI
HALAMAN JUDUL ……….. i
HALAMAN JUDUL INGGRIS ……….... ii
HALAMAN PERSETUJUAN ……….. iii
HALAMAN PENGESAHAN ……… iv
HALAMAN KEASLIAN KARYA ………... v
LEMBAR PERNYATAAN PERSETUJUAN ……….. vi
xiii 2.3 Metode Analisis Asosiasi ………....
2.4 Algoritma Apriori ………
9
ANALISIS DAN PERANCANGAN SISTEM ………. 30
3.1 Identifikasi Masalah ………. 3.2 Arsitektur Sistem ………. 3.3 Analisis Kebutuhan ………. 3.4 Pembersihan Data ……… 3.5 Transformasi Data ……… 3.6 Pembuatan Gudang Data ………. 3.6.1 Membaca data legacy ……….
3.6.2 Memindahkan data ke server gudang data ……….
3.7 Pemanfaatan Gudang Data ………..
3.7.1 Pembuatan OLAP ………...
3.7.2 Penerapan Algoritma Apriori ………..
xiv
3.8 Analisis Kebutuhan ………..
3.8.1 Use Case ……….
3.8.2 Narasi Use Case ………...
3.8.3 Desain Antar Muka ………
3.9 Kebutuhan Komponen dan Kebutuhan Sistem ……….
51
IMPLEMENTASI DAN ANALISIS SISTEM ……….. 63
4.1 Implementasi Arsitektur Gudang Data ……… 4.2 Langkah Pembuatan Gudang Data ……….. 4.2.1 Membaca data legacy ……….
4.2.2 Memindahkan data ke server gudang data ………. 4.3 Penggunaan Gudang Data ……… 4.3.1 Gudang data untuk keperluan OLAP………. 4.3.2 Gudang data untuk penerapan algoritma Apriori ………. 4.4 Implementasi Antar Muka Pengguna ………..
4.4.1 Halaman Login ……….
4.4.2 Halaman utama ……….
4.4.3 Halaman Laporan Produksi ……… 4.4.4 Halaman Laporan Pendapatan..……… 4.4.5 Halaman Transformasi Data ……….. 4.4.6 Halaman Aturan Asosiasi ………..
63 5.1 Penyelesaian Rumusan Masalah ……….
5.2 Pengujian Cube ……… 5.3 Kelebihan dan Kelemahan Sistem ………...
xv
Perbedaan OLTP dan OLAP ………
Rekapitulasi jenis lintasan ………
Contoh data rekapitulasi ………...
Contoh data dari atribut ……… Narasi use case login……….
Narasi use case melihat laporan rekapitulasi………
Narasi use case melihat laporan produksi ………
Narasi use case melihat laporan pendapatan ………
Narasi use case transfer data produksi dan pendapatan... Narasi use case cari aturan asosiasi ………..
Penjelasan spesifikasi pembentukan tabel master………... Penjelasan pembentukan tabel dimensi_lintasan ………….
Penjelasan pembentukan tabel dimensi_kapal ……….
Penjelasan pembentukan tabel dimensi_tiket……… Penjelasan pembentukan fact_rekapitulasi ………..
Penjelasan pembentukan fact_laporan_produksi ………...
Penjelasan pembentukan fact_laporan_pendapatan ……...
Skema MDX cube Rekapitulasi Pelayanan ………..
xvi
Definisi skema LaporanRekapitulasi.xml ……… Tabel kode perintas file Automatisasi_data.bat………
Query sql untuk scanning database ……….
Listing Program untuk halaman login ………
Fungsi Login pada Control.jsp ……… Fungsi Login pada kelas Login.jsp ……….
Struktur halaman Laporan Rekapitulasi.jsp ……….. Struktur halaman Laporan Produksi.jsp ……….
Struktur halaman Laporan Pendapatan.jsp ……….
Listing Program untuk Halaman Transformasi data……..
Fungsi Transformasi pada Control.jsp ………
Method runBat pada kelas Tools.java ……….. Listing Program halaman pola asosiasi ………..
xvii
Arsitektur Gudang Data ………...
Arsitektur Sistem ………..
Pembentukan master_operasional ……… Pembentukan tabel dimensi_lintasan ………... Pembentukan tabel dimensi_kapal ………... Pembentukan tabel dimensi_tiket ………. Pembentukan tabel dimensi_waktu ……….. Pembentukan tabel fact_rekapitulasi ……… Pembentukan tabel fact_laporan_produksi ……….. Pembentukan tabel fact_laporan_pendapatan ………..
Star schema laporan_rekapitulasi ……….
Star schema laporan_produksi ……….
Star schema laporan_pendapatan ……….
Diagram Use Case ………
xviii
Star schema cube Rekapitulasi Pelayanan ………. Struktur pembentukan dimensi_lintasan ……… Struktur pembentukan dimensi_kapal ……… Struktur pembentukan dimensi_tiket ……….. Struktur pembentukan dimensi_waktu ………..
Star Schema cube Laporan Produksi ……….
Struktur pembentukan dimensi_waktu ……….. Struktur pembentukan dimensi_lintasan ……… Struktur pembentukan dimensi_kapal ……… Struktur pembentukan dimensi_tiket ………..
Star Schema cube Laporan Pendapatan ……….
xx
ABSTRAK
PEMANFAATAN GUDANG DATA UNTUK KEPERLUAN ONLINE
ANALYTICAL PROCESSING (OLAP) DAN PENAMBANGAN DATA (Studi Kasus: PT. ASDP Indonesia Ferry (Persero) Cabang Kupang)
Loudya Ester Rosalina Kapa Universitas Sanata Dharma
Yogyakarta 2013
Saat ini perusahaan harus pandai dalam mengelola data yang dimiliki untuk menjadi informasi yang berguna. informasi tersebut dapat membantu perusahaan dalam upaya peningkatan kualitas. Pada proses pengolahan data dapat digunakan sebuah teknik yaitu gudang data.
Pada tugas akhir ini diimplementasikan teknik gudang data yang berfungsi untuk OLAP (Online Analytical Processing) dan penerapan algoritma data mining yakni algoritma apriori. Teknologi gudang data ini membantu Supervisor Lintasan PT. ASDP Ferry Kupang dalam pembuatan laporan bulanan produksi dan pendapatan menggunakan teknologi OLAP. Selain itu gudang data ini dimanfaatkan untuk proses penambangan data untuk menemukan asosiasi antara hari, lintasan, dan pendapatan di PT. ASDP Ferry Kupang.
xxi
ABSTRACT
THE UTILIZATION OF DATA WAREHOUSE FOR ONLINE ANALYTICAL PROCESSING (OLAP) AND DATA MINING PURPOSES
(Case Study: PT. ASDP Indonesia Ferry (Persero) Cabang Kupang)
Loudya Ester Rosalina Kapa Universitas Sanata Dharma
Yogyakarta 2013
Today a company should capable on managing the data to be the useful information. Based on the information, it may help the company to develop the quality. In processing of data, it could use a technique called Data Warehouse.
In this final paper, the technique of warehouse is used for OLAP and the algorithm application of data mining called Apriori Algorithm. The technology of data warehouse would help the Route Supervisor of PT. ASDP Ferry Kupang on making the month production report and the income of using technology OLAP (Online Analytical Processing). Besides, Warehouse will be applied on data mining algorithm to get the information about association between day, route, and income in PT ASDP Ferry Kupang.
Keyword : Data Warehouse, OLAP, Apriori Algorithm, Production, Income
1
BAB I
PENDAHULUAN
1.1 Latar Belakang Masalah
Dewasa ini, peranan teknologi informasi sangat penting bagi banyak perusahaan dalam berbagai bidang. Perusahaan harus pandai dalam memanfaatkan sumber daya yang telah dimiliki baik itu data dan informasi. Pengolahan data menjadi informasi yang berguna ditinjau dari kualitas informasi yang dihasilkan. Proses pengolahan data dapat diterapkan di berbagai media, seperti pada database operasional, aplikasi operasional, atau menggunakan teknologi gudang data. Semakin baik kualitas informasi yang dihasilkan berpengaruh terhadap strategi dan keberhasilan perusahaan.
perolehan data dan informasi yang lengkap dan akurat. Untuk itu PT. ASDP Indonesia Ferry (Persero) cabang Kupang memerlukan sebuah teknologi informasi yang dapat mengintegrasikan, menyimpan data dalam jumlah besar serta menyediakan data dan informasi yang akurat bagi perusahaan guna menunjang proses analisa. Teknologi tersebut dinamakan Gudang Data.
Gudang data merupakan sekumpulan data yang berorientasi pada subjek, terintegrasi, memiliki rentang waktu, dan koleksi datanya tidak mengalami perubahan dalam mendukung pengambilan keputusan manajerial [2]. Gudang data memungkinkan integrasi berbagai jenis data dari berbagai macam aplikasi atau sistem. Beberapa manfaat dari gudang data adalah OLAP dan Penambangan Data [4]. OLAP mendayagunakan konsep data multi dimensi dan memungkinkan para pemakai menganalisa data sampai mendetail. Penambangan Data menggali pengetahuan dan informasi dari gudang data.
pendapatan yang diterima setiap bulan. Penerapan algoritma Apriori untuk menemukan asosiasi antara hari, lintasan, dan pendapatan sehingga membantu pihak Supervisor Lintasan dalam pengembangan pelayanan PT. ASDP Ferry Kupang.
1.2 Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan diatas, permasalahan yang diselesaikan dalam penelitian ini yakni : Bagaimana membuat gudang data yang dapat dipergunakan untuk sistem database Online Analytical Processing (OLAP) dan penambangan data dengan algoritma apriori untuk menunjang proses analisa pelayanan PT. ASDP Indonesia Ferry cabang Kupang ?
1.3 Tujuan Penelitian
Sesuai dengan rumusan masalah diatas, maka tujuan yang mendasari penelitian ini antara lain :
1. Membangun sistem database Online Analytical Processing
(OLAP) dari gudang data pelayanan ASDP sehingga diperoleh informasi pelayanan yang dapat membantu
2. Menerapkan algoritma Apriori dari gudang data yang terbentuk untuk menemukan asosiasi antara hari, lintasan, dan pendapatan di PT. ASDP Indonesia Ferry Cabang Kupang.
1.4 Kegunaan
Adapun kegunaan dari aplikasiyang akan dibangun adalah sebagai berikut :
Bagi penulis :
1. Menyelesaikan Tugas Akhir sebagai syarat kelulusan tingkat strata satu.
2. Mengetahui mengenai pelayanan operasional di PT. ASDP Indonesia Ferry (Persero) Cabang Kupang
3. Dapat membuat suatu gudang data pelayanan ASDP yang sudah terintegrasi dengan teknologi Online Analytical Processing
(OLAP) dan teknik penambangan data dengan algoritma Apriori
Bagi Supervisor Lintasan PT. ASDP Indonesia Ferry (Persero) Cabang Kupang :
2. Membantu kegiatan evaluasi produksi dan pendapatan lintasan yang dikelola oleh PT. ASDP Indonesia Ferry (Persero) Cabang Kupang
1.5 Batasan Masalah
Adapun batasan-batasan masalah dalam penelitian ini adalah :
a. Penelitian ini menggunakan data produksi dan pendapatan PT. ASDP Indonesia Ferry (Persero) Cabang Kupang tahun 2010 dan 2011 b. Gudang data yang terbentuk dimanfaatkan untuk sistem On-Line
Analytical Processing (OLAP) dan teknik penambangan data dengan algoritma apriori
c. Pada proses penambangan data dengan algoritma apriori, atribut yang diambil dari tabel master dalam gudang data hanya terdiri dari hari, lintasan, dan pendapatan
1.6 Metodologi Penelitian
Bagian ini bertujuan untuk menguraikan langkah-langkah peneliti dalam melaksanakan penelitian tugas akhir. Langkah-langkahnya antara lain:
1. Identifikasi Masalah
Melakukan wawancara kepada pihak yang terkait untuk mendapatkan informasi kebutuhan yang diperlukan.
Setelah data diperoleh dari pihak PT. ASDP Ferry Kupang, data kemudian dipersiapkan untuk proses pembuatan gudang data. Pertama yang dilakukan adalah pembersihan (cleaning) data. Informasi yang tidak dibutuhkan dihapus untuk mempercepat pemrosesan.
3. Transformasi Data
Pada tahap ini dilakukan transformasi terhadap data dengan cara mengubah metadata dari setiap atribut dan menambahkan data tertentu sehingga membuat data menjadi lebih mudah untuk digunakan dan dinavigasikan.
4. Pembentukan Gudang Data (Data Warehousing)
Setelah data di transformasikan, data dari sumber dipindahkan ke gudang data. Gudang data yang terbentuk dimanfaatkan untuk 2 proses antara lain:
a. Online Analytical Processing (OLAP)
Pembuatan sistem Online Analytical Processing (OLAP) dilakukan dengan cara :
1. Memecah gudang data ke dalam tabel dimensi dan tabel fakta
2. Pembuatan cube menggunakan skema multidimensi yaitu Skema Bintang (Star Schema). Penggunaan Star Schema
b. Penerapan Algoritma Apriori
Gudang data yang terbentuk diterapkan algoritma apriori untuk menemukan keterkaitan antara hari, lintasan, dan pendapatan dalam membantu analisis pelayanan PT. ASDP Ferry Indonesia Kupang
5. Evaluasi dan Presentasi pola
Pada tahap ini hasil direpresentasikan kepada pengguna akhir dalam bentuk yang dapat dipahami.
1.7 Sistematika Penulisan
Sistematika penulisan merupakan uraian susunan penulisan Tugas Akhir yang akan dibuat secara teratur dan sistematis yang dijalankan dalam beberapa bab dan subbab sehingga pada akhir penulisan akan memberikan gambaran secara menyeluruh. Sistematika penulisan disusun dengan urutan sebagai berikut.
BAB I. PENDAHULUAN
Bab ini berisi latar belakang penulisan tugas akhir, rumusan masalah, batasan masalah, metodologi penelitian, dan sistematika penulisan.
BAB II. LANDASAN TEORI
penambangan data menggunakan metode analisis asosiasi dengan algoritma Apriori.
BAB III : ANALISIS DAN PERANCANGAN SISTEM
Dalam bab ini akan diidentifikasikan masalah yang akan diselesaikan serta tahap tahap penyelesaian masalah tersebut dengan menggunakan algoritma apriori. Dalam bab ini pula akan dijelaskan pembuatan gudang data dan perancangan program implementasi penambangan data dengan algoritma apriori.
BAB IV. IMPLEMENTASI SISTEM
Bab ini berisi implementasi sistem yang meliputi implementasi data, implementasi use case, implementasi gudang data dan algoritma Apriori.
BAB V. ANALISA HASIL DAN PEMBAHASAN
Bab ini berisi analisa hasil program dan pembahasan masalah berdasarkan hasil yang telah didapat secara keseluruhan.
BAB VI. KESIMPULAN DAN SARAN
BAB II
LANDASAN TEORI
2.1Gudang Data
2.1.1 Definisi Gudang Data
Gudang Data merupakan koleksi data yang mempunyai sifat berorientasi subjek, terintegrasi, rentang waktu dan tidak mengalami perubahan dari koleksi data dan mendukung proses pengambilan keputusan [1].
Menurut Connolly dan Begg, gudang data adalah koleksi data yang mempunyai sifat berorientasi pada subjek, terintegrasi, memiliki rentang waktu, dan koleksi datanya tidak mengalami perubahan dalam mendukung pengambilan keputusan ditingkatan manajerial.
Tujuan utama gudang data untuk mengintegrasi data yang dimiliki perusahaan ke dalam sebuah repository yang akan memudahkan pengguna untuk menjalankan query, menghasilkan laporan, dan menampilkan analisa sehingga memudahkan perusahaan dalam mengambil keputusan.
2.1.2 Komponen Gudang Data
Ada banyak komponen yang terdapat dalam gudang data[2], diantaranya :
1. Penyimpan data
penyimpanan data operasional dimana data yang disimpan adalah tunggal untuk suatu aplikasi tertentu. Fungsi dari penyimpanan data operasional dalam gudang data adalah sebagai sumber aliran data mentah. Organisasi dalam penyimpanan data ini pada umumnya berorientasi subyek, dan berfokus pada pelanggan, produk, order, kebijakan hal lain diseputarnya. Penyimpanan data ini sering juga disebut sebagai gudang data secara fisik.
2. Data Mart
Data Mart adalah bagian dari gudang datadimana hanya data yang relevan saja yang dipelihara. Data Mart sering dilihat sebagai cara untuk meningkatkan masukan ke dalam bidang dari gudang data dan membuat seluruh kesalahan menjadi kecil. Data Mart biasanya digunakan oleh firma untuk memperkecil biaya dan memperkecil skala.
3. Metadata
Metadata merupakan salah satu contoh dari gudang data secara logikal. Yang digunakan untuk memperoleh informasi dan mengakses data secara aktual. Sistem legacy pada umumnya tidak menyimpan
lebih memperhatikan informasi yang disimpan tentang gudang dari pada informasi yang disediakan oleh gudang.
4. Sistem pendukung keputusan dan sistem informasi eksekutif. Keduanya bukanlah bagian dari gudang data akan tetapi aplikasi - aplikasinya digunakan untuk gudang data.
2.1.3 Karakteristik Gudang Data
Karakteristik gudang data[2]
1. Subject Oriented (Berorientasi subject)
Gudang Data berorientasi subject artinya Gudang Data didesain untuk menganalisa data berdasarkan subject-subject tertentu dalam organisasi,bukan pada proses atau fungsi aplikasi tertentu. Gudang Data diorganisasikan disekitar subjek-subjek utama dari perusahaan(customers, products dan sales) dan tidak diorganisasikan pada area-area aplikasi utama (customer invoicing,stock control dan
sales product). Hal ini dikarenakan kebutuhan dari gudang Data untuk menyimpan data-data yang bersifat sebagai penunjang suatu keputusan, dari pada aplikasi yang berorientasi terhadap data. Jadi dengan kata lain, data yang disimpan adalah berorientasi kepada subjek bukan terhadap proses.
2. Integrated (Terintegrasi)
tidak bisa dipecah-pecah karena data yang ada merupakan suatu kesatuan yang menunjang keseluruhan konsep gudang data itu sendiri. Syarat integrasi sumber data dapat dipenuhi dengan berbagai cara sepeti konsisten dalam penamaan variable,konsisten dalam ukuran variable,konsisten dalam struktur pengkodean dan konsisten dalam atribut fisik dari data. Contoh pada lingkungan operasional terdapat berbagai macam aplikasi yang mungkin pula dibuat oleh pengembang yang berbeda. Oleh karena itu, mungkin dalam aplikasi-aplikasi tersebut ada variable yang memiliki maksud yang sama tetapi nama dan format nya berbeda. Variable tersebut harus dikonversi menjadi nama yang sama dan format yang disepakati bersama. Dengan demikian tidak ada lagi kerancuan karena perbedaan nama, format dan lain sebagainya. Barulah data tersebut bisa dikategorikan sebagai data yang terintegrasi karena kekonsistenannya.
3. Time-variant (Rentang Waktu)
4. Non-Volatile
Karakteristik keempat dari gudang data adalah non-volatile, maksudnya data pada gudang data tidak di-update secara real time
tetapi di refresh dari sistem operasional secara reguler. Data yang baru selalu ditambahkan sebagai suplemen bagi database itu sendiri dari pada sebagai sebuah perubahan. Database tersebut secara terus-menerus menyerap data baru ini, kemudian secara incremental disatukan dengan data sebelumnya. Berbeda dengan database operasional yang dapat melakukan update, insert dan delete terhadap data yang mengubah isi dari database sedangkan pada gudang data hanya ada dua kegiatan memanipulasi data yaitu loading data (mengambil data) dan akses data (mengakses gudang data seperti melakukan query atau menampilan laporan yang dibutuhkan, tidak ada kegiatan updating data).
2.1.4 Arsitektur Gudang Data
Sumber data untuk mendukung pembuatan gudang data berupa data transaksi sehari-hari. Data tersebut dapat disimpan dalam berbagai media seperti
file excel , OLTP, dan sebagainya. Sebelum data di pindahkan ke gudang data, terlebih dahulu dilakukan proses ETL (Extract, Transform, Load). Setelah gudang data terbentuk dilanjutkan dengan proses OLAP dan Data Mining. OLAP menyediakan data secara multidimensi sehingga memudahkan pengguna dalam proses analisa dan pelaporan. Data mining menggali informasi berharga lainnya dari gudang data yang telah terbentuk.
2.1.5 Manfaat Gudang Data
Berikut ini manfaat yang bisa dilakukan dengan adanya gudang data, yaitu [4]:
a. Pembuatan laporan merupakan salah satu kegunaan gudang data yang paling umum dilakukan. Dengan menggunakan query sederhana didapatkan laporan perhari, perbulan, pertahun atau jangka waktu kapanpun yang diinginkan
b. On-Line Analytical Processing (OLAP).
dimensi, maka data yang berupa fakta yang sama bisa dilihat dengan menggunakan fungsi yang berbeda. Fasilitas lain yang ada pada sofware OLAP adalah fasilitas rool-up dan drill- down. Drill-down adalah kemampuan untuk melihat detail dari suatu informasi dan roll-up adalah kebalikannya
c. Penambangan Data (Data mining)
Data mining merupakan proses untuk menggali (mining) pengetahuan dan informasi baru dari data yang berjumlah banyak pada gudang data, dengan menggunakan kecerdasan buatan (Artificial Intellegence), statistik dan matematika. Data mining merupakan teknologi yang diharapkan dapat menjembatani komunikasi antara data dan pemakainya.
d. Proses informasi executive
2.1.6 Langkah Pembuatan Gudang data
Adapun langkah-langkah dalam pembuatan gudang dataantara lain:
1. Membaca data legacy
Memperhatikan bagian-bagian data yang perlu untuk dibersihkan 2. Memindahkan data dari sumber ke server gudang data
Membuat standarisasi format dan copy-kan data dari sumber sekaligus data dibuat bersih (clean).
3. Memecah gudang data dalam tabel fakta dan tabel dimensi.
Tabel fakta dan tabel dimensi disusun menurut kebutuhan subyek
2.1.7 Online Analytical Processing (OLAP)
Online Analytical Processing (OLAP) adalah sintetis dinamis, analisis dan konsolidasi dari sekumpulan besar data multi-dimensi [3]. OLAP memungkinkan pengguna untuk mendapatkan pengertian dan pengetahuan yang mendalam mengenai berbagai aspek dari data perusahaan dengan akses yang cepat, konsisten, interaktif melalui kemungkinan variasi view
dari data. Penjelasan mengenai perbedaan OLTP dan OLAP tampak pada tabel 2.1 [7].
Tabel 2.1 Perbedaan OLTP dan OLAP
Fitur OLTP OLAP
Karakteristik Proses operasional Proses Informasi
Fungsi Menangani transaksi sehari-hari
Kebutuhan informasi jangka panjang, pendukung keputusan Desain Database Berorientasi pada aplikasi Star/Snowflake Schema
Data Data up-to-date Data histori
Unit Kerja Transaksi sederhana Complex query
2.1.8 Extract, Transform, Load (ETL)
ETL merupakan singkatan dari extract, transform, load yang berfungsi untuk melakukan ekstraksi data dari data source, dan kemudian melakukan transformasi data, sebelum mengirimkannya ke data store
tujuan. Extract adalah suatu pengambilan atau perpindahan data yang dilakukan dari suatu tempat data awal ke tempat data sementara. Kemudian transform adalah suatu perubahan bentuk yang dilakukan untuk memenuhi kebutuhan. Sedangkan load adalah suatu pengiriman atau perpindahan data dari tempat data sementara atau variabel tertentu ke tempat penampungan akhir sebelum data tersebut ditampilkan atau diolah kembali.
dan membuat index dari data itu untuk menjamin kualitas dari data lalu menerbitkannya.
2.1.9 Dimensional modeling
2.1.9.1Tabel Fakta (Fact Table)
Tabel fakta merupakan tabel utama dalam model dimensional dimana ukuran dari performa suatu bisnis disimpan [7] . Fakta berisi nilai dari sebuah kejadian atau transaksi tertentu misalnya penyimpanan uang di bank, penjualan produk, pesanan, dan sebagainya. Tabel fakta umumnya mengandung angka dan data history yang terdiri dari foreign key yang merupakan primary key dari beberapa dimension table yang saling berhubungan. Tabel fakta sering disebut juga dengan major table.
2.1.9.2Tabel Dimensi
Tabel dimensi digunakan untuk menyempurnakan data yang ada pada tabel fakta atau menjelaskannya dengan lebih detil [7]. Datanya berupa karakter. Setiap tabel dimensi menyimpan baris dari data dengan informasi berupa karakter yang menjelaskan field yang berhubungan dengan tabel fakta dengan lebih detil.
fakta bisa memiliki banyak baris data untuk beberapa transaksi bagi item data yang sama.
2.1.9.3Cube, Dimension, Measure,Member
Teknologi OLAP menganut multi dimensional modeling, artinya dapat melihat analisis pengukuran dengan pandangan berbagai dimensi. Di dalam konsep ini perlu mengenal berbagai istilah yang berkaitan dengan OLAP [8]:
1. Cube adalah struktur multi dimensional konseptual, terdiri dari dimension dan measure dan biasanya mencakup pandangan bisnis tertentu.
2. Dimension adalah struktur view / sudut pandang yang menyusun cube. Dimensi dapat terdiri dari berbagai level.
3. Measure : nilai pengukuran
4. Member adalah isi / anggota dari suatu dimension / measure tertentu
2.1.9.4Skema Bintang (Star Schema)
Gambar 2.1 Star Schema dari PHI-Minimart
2.1.9.5Surrogate key
Surrogate key adalah key / kolom data di tabel dimensi yang menjadi primary
key dari tabel tersebut. Nilai ini biasanya berupa nilai sekuensial dan tidak
memiliki arti dari proses bisnis darimana sumber data berasal [10].
2.2Penambangan Data (Data Mining)
“Penambangan data adalah proses pengolahan informasi dari sebuah
database yang besar, meliputi proses ekstraksi, pengenalan, komprehensif, dan penyajian informasi sehingga dapat digunakan dalam pengambilan keputusan bisnis yang krusial “ (Connolly dan Begg 2004, p1233).
Sedangkan menurut Han dan Kamber (2006, p7)., “Penambangan
yang sangat besar. “. Penambangan Data merupakan suatu langkah dalam
knowledge discovery in database (KDD).
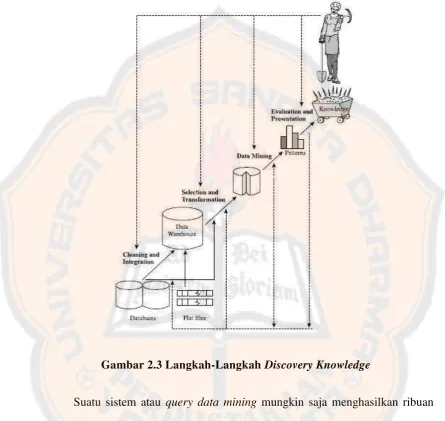
Langkah-langkah dalam menemukan pengetahuan (discovery knowledge) meliputi :
1. Data cleaning
Menghilangkan noise dan data yang tidak konsisten
2. Data integration
Menggabungkan berbagai sumber data
3. Data Selection
Menerima data yang berhubungan dnegan analisa dari database
4. Data transformation
Mengubah data ke bentuk yang sesuai untuk mining dengan melakukan agregasi atau summary
5. Data mining
Melakukan proses mining untuk mengekstrak data
6. Pattern evaluation
Mengidentifikasi pola yang menggambarkan pengetahuan (knowledge)
Menampilkan mined knowledge kepada pengguna
Gambar 2.3 Langkah-Langkah Discovery Knowledge
Suatu sistem atau query data mining mungkin saja menghasilkan ribuan pola, namun tidak semua pola tersebut adalah pola yang menarik atau penting. Ukuran suatu pola yang menarik atau penting adalah jika pola tersebut mudah dimengerti oleh manusia, bermanfaat, valid / benar pada data baru atau data tes dan membenarkna beberapa hipotesis.
digunakan untuk analisa data menggunakan teknik penambangan data sedangkan OLAP adalah basisdata yang khusus digunakan untuk menunjang proses pengambilan keputusan (decision making). Teknologi yang ada di gudang data dan OLAP dimanfaatkan penuh untuk melakukan penambangan data.
Gambar 2.4 Data Mining dan teknologi basisdata lainnya
2.3Metode Analisis Asosiasi
Salah satu metode dalam penambangan data adalah metode analisis asosiasi (association analysis). Metode analisis asosiasi merupakan metode yang bertujuan untuk menemukan aturan (association rule) antar item dalam suatu himpunan data (dataset), yaitu dengan membuat korelasi antar item yang dikelompokan ke dalam transaksi kemudian mengambil kesimpulan berdasarkan hubungan yang terbentuk dari sekumpulan data tersebut. Kumpulan item data ini sering disebut itemset.
analisis asosiasi bertujuan untuk menemukan semua aturan yang terdapat pada basisdata dengan minsup (minimum support) dan mincof (minimum confidence) yang melebihi batas tertentu. Suatu aturan asosiasi dirasa valid
apabila mempunyai nilai confidence / nilai kepastian ≥ 50% (Lopez-Cozar, 2000).
Support dari aturan adalah rasio dari record yang mengandung dengan total record dalam basisdata. Untuk mendapatkan nilai support
dapat menggunakan rumus :
...(2.1) Sedangkan Minsup (minimum support) menandakan ambang batas (threshold) yang menentukan apakah sebuah itemset akan digunakan pada perhitungan selanjutnya untuk pencarian aturan asosiasi.
Confidence dari aturan asosiasi adalah rasio dari record yang mengandung dengan total record yang mengandung . Untuk mendapatkan nilai confidence dapat menggunakan rumus :
.......(2.2) Atau dapat ditulis sebagai berikut:
Misalnya terdapat himpunan data transaksi D sebagai berikut [13]:
Tabel 2.2 Contoh Tabel Transaksi D
TID Itemset
1 Bread, Milk
2 Bread, Diaper, beer, Eggs
3 Milk, Diaper, Beer, Coke
4 Bread, Milk, Diaper, Coke
5 Bread, Milk, Diaper, Coke
Misalkan akan dihasilkan rule : {Milk, Diaper}→Beer Maka support menjadi
Confidence menjadi
Secara umum yang dilakukan dalam proses pencarian aturan asosiasi ini dapat dibagi menjadi 2 tahapan, yang terdiri dari :
o Pencarian frequent itemset
Yaitu proses pencarian semua itemset yang memiliki nilai support ≥
minsup. Itemset ini disebut frequent itemset atau large itemset ( l-itemset). Dalam tugas akhir ini proses pencarian frequent itemset
menggunakan algoritma apriori.
o Pembentukan strong association rule
aturan asosiasi yang memiliki nilai confidence minconf. Aturan asosiasi dapat ditemukan dari setiap frequent itemset.
2.4Algoritma Apriori
Algoritma Apriori merupakan algoritma untuk mencari frequent itemset yang berdasarkan prinsip apriori, yaitu jika suatu itemset merupakan
frequent itemset maka semua subset-nya akan berupa frequent itemset (Tan, et.al. 2006). Pembentukan frequent itemset dilakukan dengan mencari semua kombinasi item-item yang memiliki support yang lebih besar atau sama dengan minsup yang telah ditentukan. Pseudocode untuk pencarian frequent itemset menggunakan algoritma apriori adalah sebagai berikut (Gunawan, 2003) [11] :
= candidate itemset untuk ukuran k
= frequent itemset / large itemset untuk ukuran k = {candidate 1-itemset}
= {large 1-itemset}
for ( ) do begin
// new candidate
for all transaction do begin
//candidate contained in
for all candidates do
end
end
Algoritma diatas dapat dijelaskan sebagai berikut :
a. Pada iterasi pertama dihitung jumlah kemunculan setiap item dalam transaksi untuk menentukan large 1-itemset. Pada iterasi selanjutnya akan dihasilkan candidate k-itemset Ck menggunakan
frequent(k-1)-itemset yang ditemukan pada iterasi sebelumnya. Candidate generation
diimplementasikan menggunakan sebuah fungsi yang disebut apriori-gen. Apriori-gen digunakan untuk menghasilkan candidate itemset yang menyebabkan tidak seluruh itemset diolah pada proses selanjutnya, hanya yang memenuhi persyaratan saja yaitu sesuai dengan support
yang telah ditentukan. Hal ini mempersingkat waktu proses pencarian seluruh aturan asosiasi.
b. Setelah itu, dilakukan penelusuran dalam basisdata untuk menghitung
support bagi setiap candidate itemset dalam Ck . Untuk setiap transaksi
t, dicari semua candidate itemset t dalam set Ck yang terkandung dalam transaksi tersebut. Kumpulan dari semua candidate itemset dalam Ck yang terkandung dalam transaksi t disebut Ct dan ditulis dengan notasi
c. Selanjutnya nilai support dari semua candidate k-itemset dalam Ct dinaikkan. Penelusuran dilanjutkan pada transaksi berikutya sampai semua transaksi dalam basisdata ditelusuri. Lalu akan dilakukan eliminasi candidate itemset yang memiliki nilai support lebih kecil dari
disimpan dalam Lk yang akan digunakan untuk membentuk large
(k+1)-itemset. Algoritma berakhir ketika tidak ada large itemset baru yang dihasilkan.
Pencarian frequent itemset menggunakan algoritma apriori memiliki 2 karakteristik penting yaitu :
1. Apriori merupakan algoritma level-wise dimana proses pada algoritma ini membangkitkan frequent itemset per level, dimulai dari level 1-itemset sampai ke itemset terpanjang dan candidate level yang baru, dibentuk dari frequent itemset yang ditemukan di level sebelumnya lalu menentukan nilai supportnya.
2. Algoritma ini menggunakan strategi generate and test untuk menemukan frequent itemset. Pada tiap iterasi, candidate itemset
yang baru, dihasilkan dari frequent itemset yang ditemukan pada iterasi sebelumnya. Nilai support tiap candidate dihitung dan di bandingkan kembali dengan ambang batas minsupnya. Jumlah
iterasi yang dibutuhkan algoritma ini adalah , dimana kmaxmerupakan ukuran maksimum dari frequent itemset.
support-nya untuk menemukan frequent itemset pada level tersebut. Sedangkan strategi perhitungan nilai support dilakukan dengan horizontal counting, dengan cara membaca transaksi satu persatu, jika ditemukan
BAB III
ANALISIS DAN PERANCANGAN SISTEM
3.1 Identifikasi Masalah
PT. ASDP Indonesia Ferry (Persero) Cabang Kupang menangani pelayaran antar pulau di daerah Nusa Tenggara Timur. Data transaksi operasional pelayaran di tiap lintasan meliputi kapal yang beroperasi, jenis tiket yang terdiri dari tiket penumpang, tiket kendaraan, dan tiket barang serta produksi dan pendapatan. Data operasional produksi dan pendapatan yang dimiliki oleh PT. ASDP Kupang ini masih tercatat secara manual dalam bentuk file excel sehingga pihak Supervisor mengalami kesulitan dalam menganalisa data tersebut. Jadi untuk memudahkan menganalisa data tersebut maka digunakan teknik gudang data untuk merangkum transaksi sehingga mudah dianalisa.
3.2 Arsitektur Sistem
excel Gudang data Pemanfaatan
Gudang data
Gambar 3.1 Arsitektur Sistem
3.3 Analisis Kebutuhan
Supervisor Lintasan PT. ASDP Ferry Cabang Kupang ingin mengetahui informasi produksi dan pendapatan pada PT. ASDP Indonesia Ferry (Persero) Cabang Kupang. Informasi yang diinginkan meliputi informasi lintasan yang dikelola, kapal yang sering beroperasi, jenis tiket yang ditawarkan, besar produksi, dan besar pendapatan yang diterima tiap bulan. Informasi dibutuhkan untuk membuat rekap produksi dan pendapatan berbagai lintasan yang dikelola oleh PT. ASDP Kupang. Selain itu dengan teknik penambangan data menghasilkan informasi berharga mengenai keterkaitan antara hari, lintasan, pendapatan. Hasil asosiasi teknik penambangan data membantu pihak ASDP menyusun strategi untuk peningkatan kualitas pelayanan perusahaan.
3.4 Pembersihan Data
3.5 Transformasi Data
Pada tahap ini dilakukan pengubahan data ke dalam format yang sesuai untuk proses dalam gudang data. Terdapat pengubahan metadata dari setiap atribut sehingga mudah dinavigasikan. Atribut yang dimiliki data transaksi antara lain kode_tiket, jenis_tiket, tarif, nama_kapal, tanggal, produksi, pendapatan. Terdapat beberapa atribut yang dipecah antara lain kode_tiket dan jenis_tiket. Kode_tiket dibagi menjadi 2 antara lain id_kategori_tiket, yang menampung kategori tiket yaitu id tiket kategori penumpang, id tiket kategori kendaraan, dan id tiket kategori barang. Kategori_tiket menampung 3 kategori tiket yaitu penumpang, kendaraan, dan barang. Jenis tiket dibagi menjadi 2 yaitu id_tiket dan nama tiket. Berdasarkan pemecahan data tersebut dihasilkan atribut baru yaitu no, tanggal_opr, lintasan, kapal, id_kategori_tiket, id_tiket, kategori_tiket, tiket, produksi, dan pendapatan. Pada proses transformasi ini sebelum data dimasukkan ke gudang data akan diubah meta data dari tiap atribut sehingga memudahkan untuk proses selanjutnya.
3.6 Pembuatan Gudang Data
3.6.1 Membaca data legacy
Sumber data yang ada berupa data transaksi setiap lintasan. Data transaksi ini masih berbentuk file excel. Struktur data dari rekapitulasi tiap jenis lintasan seperti pada tabel 3.1
Tabel 3.1 Rekapitulasi jenis lintasan
JenisLintasan Tabel jenis lintasan pada tiap layanan PK NO URUT NO URUT sebagai primary key
Berisi NO URUT transaksi Berisi kode tiket pelayaran
Berisi jenis tiket lintasan, yang terdiri dari tiket penumpang, tiket kendaraan, dan tiket barang Berisi tarif tiket dari lintasan
Berisi nama kapal yang beroperasi Berisi nama lintasan yang dikelola Berisi tanggal operasi kapal Berisi jumlah tiket yang dibeli
Berisi pendapatan dari penjualan jenis tiket
TANGGAL, PRODUKSI, PENDAPATAN. Contoh data jenis lintasan seperti pada tabel 3.2
Tabel 3.2 Contoh data rekapitulasi Lintasan
NO URUT 1
KODE TIKET 4101010301
JENIS TIKET EKONOMI – DEWASA
TARIF 29700
NAMA KAPAL CUCUT
NAMA LINTASAN KUPANG-ROTE
TANGGAL 01/01/2010
PRODUKSI 153
PENDAPATAN 4.544.100
3.6.2 Memindahkan data dari sumber ke server gudang data
master_operasional
Gambar 3.2 Pembentukan master_operasional ke gudang data
Gambar 3.2 merupakan proses pembentukan tabel master_operasional. Tabel master_operasional berasal dari data operasional pada file excel. Tabel ini akan digunakan untuk proses selanjutnya yaitu OLAP dan Penambangan Data.
3.7Pemanfaatan Gudang Data
3.7.1 Pembuatan OLAP
Setelah tabel master_operasional terbentuk ke dalam gudang data maka dilanjutkan proses OLAP dan penerapan algoritma Apriori. Dalam proses pembentukan OLAP akan digunakan sebuah schema multidimensional yaitu Star Schema. Schema ini digunakan karena lebih efisien dan sederhana dalam pembuatan query serta mudah diakses oleh pengguna. Dalam star schema terdapat tiga tabel fakta dan beberapa tabel dimensi guna pemrosesan query yang lebih ringan.
1. Informasi rekapitulasi jumlah produksi dan besar pendapatan yang diperoleh setiap bulannya pada tahun 2010 dan 2011 untuk setiap lintasan, kapal dan tiket.
2. Informasi jumlah produksi untuk setiap lintasan, kapal, dan tiket tiap bulannya pada tahun 2010 dan 2011.
3. Informasi besar pendapatan yang diperoleh untuk setiap lintasan, kapal, dan tiket tiap bulannya pada tahun 2010 dan 2011.
Dalam proses pembuatan OLAP, gudang data yang terbentuk dipecah menjadi beberapa tabel dimensi dan tabel fakta. Pembentukan tabel dimensi dan tabel fakta antara lain:
1. Tabel Dimensi merupakan tabel yang berisi data yang menunjukkan tinjauan dari berbagai perspektif. Penjelasan dari masing-masing tabel dimensi dijelaskan sebagai berikut:
a. Tabel dimensi_lintasan
Gambar 3.3 Pembentukan tabel dimensi_lintasan
master_operasional. Pada tabel dimensi_lintasan ini memiliki
primary key sk_lintasan dan field lainnya yaitu lintasan.
b. Tabel dimensi_kapal master_operasional
PK no
tanggal_opr lintasan kapal
id_kategori_tiket kategori_tiket id_tiket tiket produksi pendapatan
dimensi_kapal
PK sk_kapal
kapal
Gambar 3.4 Pembentukan tabel dimensi_kapal
Gambar 3.4 merupakan proses pembentukan tabel dimensi_kapal. Table dimensi_kapal berasal dari tabel master_operasional. Pada tabel dimensi_kapal ini memiliki
primary key sk_kapal dan field lainnya yaitu kapal.
master_operasional
Gambar 3.5 Pembentukan tabel dimensi_tiket
Gambar 3.5 merupakan proses pembentukan tabel dimensi_tiket. Table dimensi_tiket berasal dari tabel master_operasional. Pada tabel dimensi_tiket ini memiliki primary key sk_tiket dan field lainnya yaitu id_kategori_tiket, kategori_tiket, id_tiket, dan tiket.
d. Tabel dimensi_waktu
Gambar 3.6 merupakan proses pembentukan tabel dimensi_waktu. Table dimensi_waktu berasal dari tabel master_operasional. Pada tabel dimensi_tiket ini memiliki primary key sk_waktu dan field lainnya yaitu day, month, year.
2. Tabel fakta yang terbentuk dari perancangan gudang data ini merupakan tabel yang berhubungan dengan pelayanan operasional di PT. ASDP Indonesia Ferry Cabang Kupang. Pembentukan tabel fakta dapat dijelaskan sebagai berikut :
a. Tabel fact_rekapitulasi
master_operasional
Gambar 3.7 Pembentukan tabel fact_rekapitulasi b. Tabel fact_laporan_produksi
master_operasional
Gambar 3.8 Pembentukan tabel fact_laporan_produksi
c. Tabel fact_laporan_pendapatan
master_operasional
Gambar 3.9 Pembentukan tabel fact_laporan_pendapatan
Proses pembentukan OLAP ASDP ini memerlukan 3 cube yaitu
cube laporan_rekapitulasi, cube laporan_produksi, dan cube
laporan_pendapatan. Cube laporan_rekapitulasi merupakan cube yang digunakan untuk melihat hasil rekapitulasi semua data produksi dan pendapatan yang dilihat dari perspektif waktu, lintasan, kapal, dan tiket.
untuk melihat laporan besar pendapatan pelayan operasional PT. ASDP Ferry Cabang Kupang yang dilihat dari perspektif waktu, lintasan, kapal, dan tiket. Ketiga cube ini berhubungan dengan tabel dimensi. Berikut ini penjelasan mengenai cube dalam pembentukan OLAP
1. Cube laporan_rekapitulasi
Cube laporan_rekapitulasi dengan star schema laporan_rekapitulasi. Pada star schema laporan_rekapitulasi memilki tabel fakta yaitu fact_rekapitulasi dan tabel dimensi yaitu tabel dimensi_waktu, dimensi_lintasan, dimensi_kapal, dan dimensi_tiket. Nilai pengukuran dalam cube adalah jumlah produksi dan besar pendapatan pelayanan operasional PT. ASDP Ferry Cabang Kupang. Star schema
master_operasional
Gambar 3.10 Star Schema laporan_rekapitulasi 2. Cube laporan_produksi
Cube laporan_produksi dengan star schema laporan_produksi. Pada
master_operasional
Gambar 3.11 Star Schema laporan_produksi 3. Cube laporan_pendapatan
master_operasional
Gambar 3.12 Star Schema laporan_pendapatan
3.7.2 Penerapan Algoritma Apriori
perhitungan association rule pengguna menentukan dataset atau parameter yang akan digunakan dalam proses.
Data set yang digunakan berasal dari gudang data yang telah terbentuk yakni dari tabel master_operasional. Atribut yang dipakai untuk proses asosiasi adalah hari, lintasan, dan pendapatan.
Tabel 3.3 Contoh data dari atribut
Hari Lintasan Pendapatan
Sabtu AIMERE_KUPANG 21.324.000
Rabu AIMERE_KUPANG 11.602.000
Rabu AIMERE_KUPANG 13.336.900
Selasa AIMERE_WAINGAPU 7.835.100
Kamis AIMERE_WAINGAPU 4.457.300
Sabtu AIMERE_WAINGAPU 3.710.100
Jumat BARANUSA_KALABAHI 851.000
Minggu BARANUSA_LEWOLEBA 408.000
Senin BARANUSA_LEWOLEBA 513.000
Selasa ENDE_KUPANG 9.895.700
Senin ENDE_KUPANG 11.968.800
..dst ..dst ..dst
Data atribut pendapatan dilakukan partisi sebanyak 5 partisi antara lain SANGAT TINGGI, TINGGI, CUKUP, RENDAH, SANGAT RENDAH. Kriteria pendapatan sangat tinggi > 30 juta, tinggi berkisar antara 19 juta sampai dengan 29,9 juta, kriteria cukup berkisar antara 9 juta hingga 18,9 juta, kriteria rendah berkisar 1,2 juta hingga 8,9 juta, dan kriteria sangat rendah < 1,19 juta.
. Selanjutnya pengguna menentukan nilai minimum support dan
100%. Setelah menentukan nilai minimum support dan minimum confidence yang akan digunakan dalam proses, baru dilakukan proses perhitungan association rule. Setelah proses perhitungan selesai, system akan menampilkan rule yang dihasilkan dan nilai confidencenya. Rule ini menunjukkan hasil asosiasi antara hari, lintasan, dan pendapatan.
Proses perhitungan association rule terdiri dari beberapa tahap antara lain
1. Sistem men-scan database untuk mendapatkan kandidiat 1-itemset (himpunan item yang terdiri dari 1 item) dan menghitung nilai
supportnya.. Support dari suatu itemset (S) merupakan presentase dari transaksi dalam T yang mengandung S. Kemudian nilai support tersebut dibandingkan dengan minimum support yang telah ditentukan. Jika nilainya lebih besar atau sama dengan minimum support maka itemset tersebut trmasuk dalam large itemset.
2. Itemset yang tidak termasuk dalam large itemset tidak diikutkan dalam iterasi selanjutnya (di-prune)
mendapatkan Lk seperti pada itersi sebelumnya system akan menghapus (prune) kombinasi itemset yang tidak termasuk dalam large itemset.
4. Setelah dilakukan operasi join, maka pasangan itemset baru dari hasil proses join tersebut juga dihitung supportnya.
5. Proses pembentukan kandidat yang terdiri dari proses join dan prune akan terus dilakukan hingga himpunan kandidat itemsetnya null, atau sudah tidak ada lagi kandidat yang akan dibentuk.
6. Setelah itu, dari hasil frequent itemset tersebut dibentuk association rule
yang memenuhi nilai support dan confidence yang telah ditentukan.
7. Pada pembentukan association rule nilai yang sama dianggap satu nilai
8. Association rule yang terbentuk harus memenuhi nilai minimum yang telah ditentukan
9. Untuk setiap large itemset L, dicari himpunan bagian L yang tidak kosong. Untuk setiap himpunan bagian tersebut, dihasilkan rule dengan bentuk a
3.8 Analisis Kebutuhan
3.8.1 Use Case
Diagram use case ini dapat menggambarkan kebutuhan dari Supervisor Lintasan PT. ASDP terhadap sistem yang akan dibangun. Gambar 3.13 merupakan gambar diagram use case untuk aplikasi gudang data PT. ASDP Kupang.
Melihat laporan rekapitulasi
Melihat laporan produksi <<depends on>>
Cari aturan asosiasi Supervisor Lintasan
Login
Melihat laporan pendapatan
Transfer data produksi dan pendapatan
3.8.2 Narasi Use Case
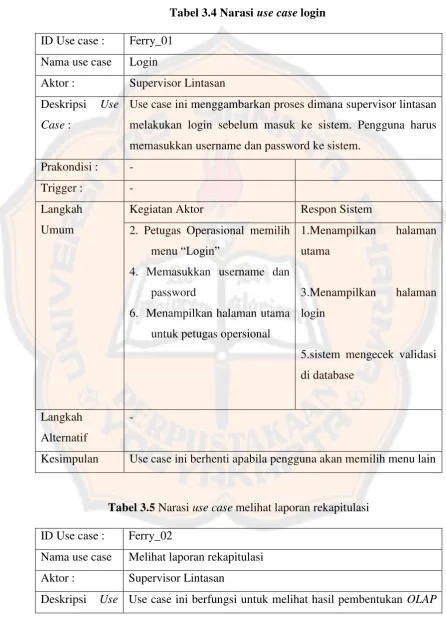
Tabel 3.4 Narasi use case login
ID Use case : Ferry_01 Nama use case Login
Aktor : Supervisor Lintasan Deskripsi Use
Case :
Use case ini menggambarkan proses dimana supervisor lintasan melakukan login sebelum masuk ke sistem. Pengguna harus memasukkan username dan password ke sistem.
Prakondisi : - Trigger : - Langkah
Umum
Kegiatan Aktor Respon Sistem
2. Petugas Operasional memilih menu “Login”
4. Memasukkan username dan password
6. Menampilkan halaman utama untuk petugas opersional
1.Menampilkan halaman utama
3.Menampilkan halaman login
5.sistem mengecek validasi di database
Langkah Alternatif
-
Kesimpulan Use case ini berhenti apabila pengguna akan memilih menu lain
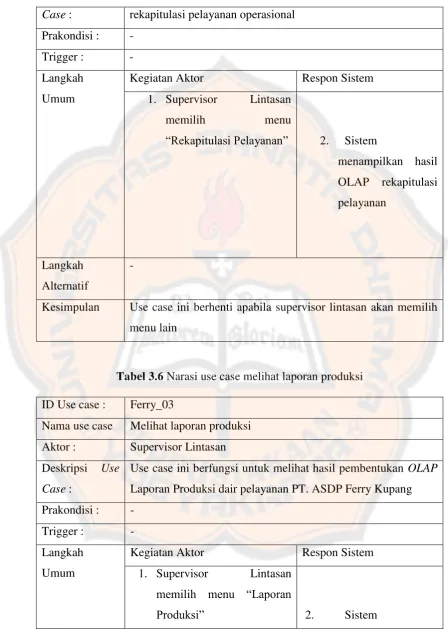
Tabel 3.5 Narasi use case melihat laporan rekapitulasi ID Use case : Ferry_02
Nama use case Melihat laporan rekapitulasi Aktor : Supervisor Lintasan
Case : rekapitulasi pelayanan operasional Prakondisi : -
Trigger : - Langkah
Umum
Kegiatan Aktor Respon Sistem
1. Supervisor Lintasan
memilih menu
“Rekapitulasi Pelayanan” 2. Sistem
menampilkan hasil
Kesimpulan Use case ini berhenti apabila supervisor lintasan akan memilih menu lain
Tabel 3.6 Narasi use case melihat laporan produksi ID Use case : Ferry_03
Nama use case Melihat laporan produksi Aktor : Supervisor Lintasan Deskripsi Use
Case :
Use case ini berfungsi untuk melihat hasil pembentukan OLAP
Laporan Produksi dair pelayanan PT. ASDP Ferry Kupang Prakondisi : -
Trigger : - Langkah
Umum
Kegiatan Aktor Respon Sistem
1. Supervisor Lintasan memilih menu “Laporan
menampilkan hasil
Kesimpulan Use case ini berhenti apabila supervisor lintasan akan memilih menu lain
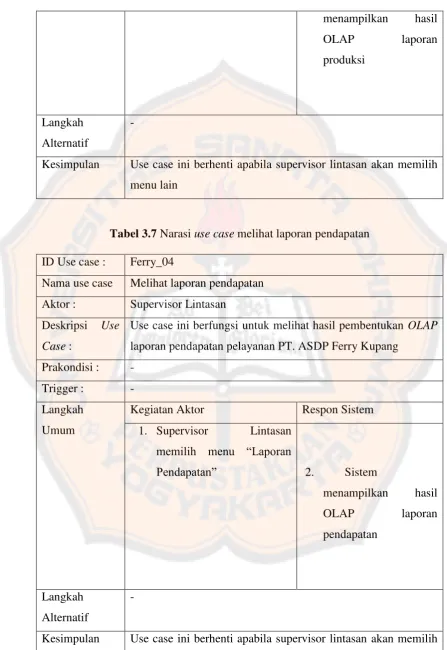
Tabel 3.7 Narasi use case melihat laporan pendapatan ID Use case : Ferry_04
Nama use case Melihat laporan pendapatan Aktor : Supervisor Lintasan
Deskripsi Use Case :
Use case ini berfungsi untuk melihat hasil pembentukan OLAP
laporan pendapatan pelayanan PT. ASDP Ferry Kupang Prakondisi : -
Trigger : - Langkah
Umum
Kegiatan Aktor Respon Sistem
1. Supervisor Lintasan memilih menu “Laporan
Pendapatan” 2. Sistem
menampilkan hasil
menu lain
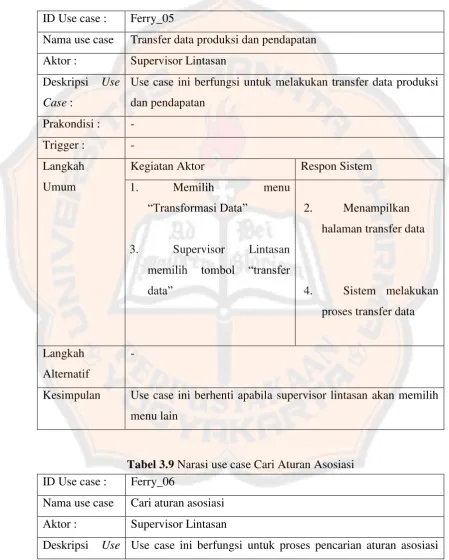
Tabel 3.8 Narasi use case transfer data produksi dan pendapatan ID Use case : Ferry_05
Nama use case Transfer data produksi dan pendapatan Aktor : Supervisor Lintasan
Deskripsi Use Case :
Use case ini berfungsi untuk melakukan transfer data produksi dan pendapatan
Prakondisi : - Trigger : - Langkah
Umum
Kegiatan Aktor Respon Sistem
1. Memilih menu
“Transformasi Data”
3. Supervisor Lintasan memilih tombol “transfer data”
2. Menampilkan halaman transfer data
4. Sistem melakukan proses transfer data
Langkah Alternatif
-
Kesimpulan Use case ini berhenti apabila supervisor lintasan akan memilih menu lain
Tabel 3.9 Narasi use case Cari Aturan Asosiasi ID Use case : Ferry_06
Nama use case Cari aturan asosiasi Aktor : Supervisor Lintasan
Case : antara hari, lintasan, dan pendapatan Prakondisi : -
Trigger : - Langkah
Umum
Kegiatan Aktor Respon Sistem
1. Supervisor Lintasan memilih menu “Aturan Asosiasi”
3. Supervisor lintasan memasukkan support dan confidence
2.sistem menampilkan halaman aturan asosiasi
5.Sistem melakukan proses association dengan algoritma apriori
6.Menampilkan hasil perhitungan apriori
Langkah Alternatif
-
Kesimpulan Use case ini berhenti apabila supervisor lintasan akan memilih menu lain
3.8.3 Desain Antar Muka
itu juga GUI yang terbentuk disediakan untuk layanan perhitungan asosiasi kapal yang beoperasi di PT. ASDP Ferry Kupang. Berikut ini rancangan antar muka yang disediakan dalam aplikasi
1. Halaman Login
Halaman login digunakan untuk memasukkan username dan
password pengelola sistem ini yakni Supervisor Lintasan. Halaman ini memiliki dua tombol yaitu Login dan Batal. Tombol logi digunakan untuk melakukan proses login untuk masuk ke halaman utama sistem. Tampilan halaman login dapat dilihat pada gambar 3.14
Username
Password
Login
PT. ASDP INDONESIA FERRY KUPANG
Gudang Data Pemantauan Pelayanan Operasional
Batal
Gambar 3.14 Halaman Login
2. Rancangan layar menu
sistem secara langsung akan menampilkan hasil mondrian rekapitulasi pelayanan. Tampilan rancangan menu dapat dilihat pada gambar 3.15
PT. ASDP Indonesia Ferry (Persero) Cabang Kupang
Rekapitulasi Pelayanan
Laporan Produksi
Laporan Pendapatan
Mondrian Rekapitulasi Pelayanan
Logout
Aturan Asosiasi Transformasi Data
Gambar 3.15 Halaman Home
3. Halaman Laporan Produksi
Halaman ini menampilkan hasil data analisis produksi PT. ASDP Ferry Kupang. Tampilan halaman laporan produksi ini tampak pada gambar 3.16
PT. ASDP Indonesia Ferry (Persero) Cabang Kupang
Rekapitulasi Pelayanan
Laporan Produksi
Laporan Pendapatan
Mondrian Laporan Produksi
Logout
Aturan Asosiasi Transformasi Data
4. Halaman Laporan Pendapatan
Halaman ini menampilkan hasil data analisis pendapatan PT. ASDP Ferry Kupang. Tampilan halaman laporan pendapatan ini tampak pada gambar 3.17
PT. ASDP Indonesia Ferry (Persero) Cabang Kupang
Rekapitulasi Pelayanan
Laporan Produksi
Laporan Pendapatan
Mondrian Laporan Pendapatan
Logout
Aturan Asosiasi Transformasi Data
Gambar 3.17 Halaman Laporan Pendapatan 5. Halaman Transformasi Data
PT. ASDP Indonesia Ferry (Persero) Cabang Kupang
Rekapitulasi Pelayanan
Laporan Produksi
Laporan Pendapatan
Transfer Data Produksi dan Pendapatan
Logout
Aturan Asosiasi Transformasi Data
Transfer Data
Gambar 3.18 Halaman Transfer Data
6. Halaman Aturan Asosiasi
PT. ASDP Indonesia Ferry (Persero) Cabang Kupang
Rekapitulasi Pelayanan
Laporan Produksi
Laporan Pendapatan
Logout
Aturan Asosiasi
Transformasi Data
Minimum support
Minimum confidence
Hasil
confirm
Gambar 3.19 Halaman Hasil Perhitungan Asosiasi Kapal
3.9Kebutuhan Komponen dan Kebutuhan Sistem
Adapun kebutuhan komponen yang menunjang terbentuknya gudang data ini antara lain:
a. Pentaho merupakan komponen utama untuk melakukan eksekusi terhadap kettle, Mondrian, jpivot, dan schema workbench untuk mendukung fungsi-fungsi yang telah disediakan
b. Kettle merupakan komponen yang dibutuhkan untuk melakukan ETL (Extract, Transform, Load) data
d. Schema Workbench merupakan komponen yang digunakan untuk membuat file skema mondrian dalam format XML untuk memetakan kubus, dimensi, dan measure dengan tabel relasi
BAB IV
IMPLEMENTASI DAN ANALISIS SISTEM
Pada bab ini akan dijelaskan mengenai implementasi pembuatan gudang data dan pembahasannya. Pembuatan gudang data mengacu pada kebutuhan informasi yang dibutuhkan Supervisor Lintasan.
4.1 Implementasi Arsitektur Gudang Data
Pada bab sebelumnya telah dibahas mengenai rancangan arsitektur gudang data. Gudang data yang terbentuk akan dimanfaatkan untuk kebutuhan OLAP dan teknik Penambangan Data dengan algoritma Apriori. Arsitektur sistem tampak pada gambar 4.1
Clean Extract Transform Load Refresh
Gudang Data Pelayanan Produksi
ASDP Kupang
OLAP
Data Mining – Algoritma
Apriori
Report
Pola asosiasi antar kapal di tiap lintasan
Gambar 4.1 Arsitektur Sistem
Untuk mendukung arsitektur sistem diperlukan beberapa spesifikasi
software dan hardware yang mendukung yaitu:
digunakan pada satu tempat yaitu Kantor Pelayanan PT. ASDP Ferry Kupang
2. Gudang data pelayanan operasional PT. ASDP Ferry Kupang menggunakan jaringan LAN (Local Area Network).
3. Sistem yang dibangun menggunakan media antara lain:
Database MySQL
Bahasa pemrograman JAVA
Tools : Kettle, Schema-Workbench, Mondrian, Apache Tomcat, Netbeans IDE 6.7 untuk pemrograman Java dan mySQL Connector untuk terhubung dengan program java
4. Spesifikasi hardware yang digunakan untuk pembuatan sistem antara lain:
Processor : Intel Pentium Dual Core 1,86GHz
Memory : 2 GB
4.2 Langkah Pembuatan Gudang Data
4.2.1 Membaca Data Legacy
Sumber data yang digunakan dalam pembuatan gudang data ini berbentuk file excel. Data yang diperoleh adalah rekapitulasi produksi dan pendapatan tiap bulan di tahun 2010 dan 2011. Berdasarkan data tersebut diketahui bahwa PT. ASDP Indonesia Ferry Cabang Kupang mengelola banyak lintasan antara lain AIMERE-KUPANG, AIMERE-WAINGAPU,
BARANUSA-KALABAHI, BARANUSA-LEWOLEBA,
KALABAHI-KUPANG, KALABAHI-LARANTUKA, KALABAHI-LEWOLEBA, KALABAHI-TELUK GURITA, KUPANG-AIMERE, KUPANG-ENDE, KUPANG-KALABAHI, KUPANG-LARANTUKA,
KUPANG-LEWOLEBA, KUPANG-ROTE, KUPANG-SABU,
KUPANG-WAINGAPU, KALABAHI,
LARANTUKA-KUPANG, LARANTUKA-LEWOLEBA,
LARANTUKA-WAIWERANG, LEWOLEBA-BARANUSA, LEWOLEBA-KALABAHI,
LEWOLEBA-KUPANG, LEWOLEBA-WAIWERANG,
ROTE-KUPANG, SABU-ROTE-KUPANG, SABU-WAINGAPU, TELUK
GURITA-KALABAHI, WAINGAPU-AIMERE, WAINGAPU-ENDE,
WAINGAPU-KUPANG, WAINGAPU-SABU,
WAIWERANG-LARANTUKA, dan WAIWERANG-LEWOLEBA. Kapal-kapal yang beroperasi di PT. ASDP Indonesia Ferry Cabang Kupang antara lain KMP. ILE APE, KMP. BALIBO, KMP. CUCUT, KMP.ROKATENDA, KMP.UMA KALADA, KMP.ILE MANDIRI, dan KMP. NAMPARNOS. Transaksi operasional terdapat 3 jenis kategori tiket yang disediakan oleh PT. ASDP Indonesia Ferry Cabang Kupang yakni tiket Penumpang, tiket Kendaraan, dan Tiket Barang. Tiket Penumpang terdiri dari tiket eksekutif, tiket bisnis, dan tiket ekonomi. Tiket Kendaraan terdiri dari beberapa golongan kendaraan lain antara lain :
Golongan I, merupakan golongan kendaraan sejenis Sepeda pancal.