BAB II
LANDASAN TEORI
2.1. Plagiarisme
Plagiarisme merupakan salah satu bentuk pencurian hak cipta dan menyatakan hal tersebut sebagai miliknya sendiri.Beberapa bentuk plagiarisme berdasarkan metode pengambilan data terbagi menjadi dua, yaitu offline plagiarism dan online plagiarism.Offline plagiarism merupakan bentuk plagiarisme dimana pengambilan data dilakukan dari sumber yang berupa hardcopy.Sedangkan, online plagiarism merupakan bentuk plagiarisme dimana pengambilan data dilakukan dari sumber yang berupa softcopy dan telah beredar di media internet.(Ercegovac & Richardson Jr., 2004)
Beberapa bentuk plagiarisme berdasarkan metode dalam melakukan plagiat dibedakan menjadi 2, yaitu Intrinsic Plagiarism dan External Plagiarism.External plagiarism merupakan bentuk plagiarisme dimana metode plagiat yang dilakukan berupa copy-paste atau mengkutip secara langsung dari sumber tanpa adanya perubahan dan tidak menyertakan bentuk umum dari pengkutipan yang seharusnya.Intrinsic Plagiarism merupakan bentuk plagiarisme dimana metode plagiat yang dilakukan berupa mengkutip secara tidak langsung dengan dilakukan perubahaan struktur maupun perubahan kata namun masih memiliki arti dan makna yang sangat dekat dengan sumber yang dikutip.
Ada 4 bentuk plagiarisme berdasarkan bentuk plagiarisme yang dilakukan khususnya Intrinsic Plagiarism, yakni Near Copies Plagiarism, Disguised Plagiarism,Translated Plagiarism dan Idea Plagiarism. Near Copiesmerupakan penyebutan untuk bentuk plagiarisme yang melakukan penyalinan hampir sama persis dengan sumber namun dilakukan penambahan dan perubahan sedikit pada struktur kalimat.Disguised
merupakan penyebutan untuk bentuk plagiarisme yang melakukan penyalinan disertai dengan adanya perubahan struktur kalimat dan pertukaran kata dengan sinonim kata dari sumber yang diambil dalam kadar yang hampir menyeluruh. Translated Plagiarism merupakan bentuk plagiarisme dimana kutipan dilakukan dengan mengkutip namun hasil kutipan diterjemahkan ke bahasa yang berbeda biasanya teknik ini disertai dengan adanya perubahan struktur pada pola kalimat sumber yang dikutip. Sedangkan, Idea Plagiarism merupakan bentuk plagiarisme dimana hasil kutipan mengambil ide dari sumber dengan ide yang persis sama namun dijelaskan kembali dengan kata-kata yang berbeda.(Meuschke & Gipp, 2013)
Ada 3 bentuk plagiarisme yang merupakan penjabaran lebih lanjut dilihat dari Disguised Plagiarism, yakni :(Meuschke & Gipp, 2013)
• Shake and Paste, merupakan bentuk plagiarisme dimana pengkutipan yang
dilakukan mengubah struktur kalimat namun pengubahan yang berlangsung hanya berfokus pada perubahan struktur kata.
• Paraphrasing, merupakan bentuk plagiarisme dimana pengkutipan yang
dilakukan mengubah struktur kalimat serta mengubah kata – kata yang digunakan dengan kata – kata yang bermakna sama untuk menyampaikan makna yang sama. • Technical Disguised, merupakan bentuk plagiarisme dimana metode ini
menganalisa kelemahan dari metode pendeteksi palgiarisme dan membuat plagiarisme dengan pola yang tidak dapat dideteksi oleh mesin tersebut.
2.2. Tata Bahasa (Grammar)
Tata bahasa atau Grammar merupakan pola penyusunan kalimat baku yang mengikuti standarisasi dalam hal ini khususnya bahasa Inggris. Pola penyusunan kalimat menentukan sebuah kalimat merupakan valid atau tidak.Valid disini mengartikan bahwa
kalimat tersebut tidak memiliki makna ganda atau ambigu.Dengan demikian dapat diperoleh kalimat yang valid dengan makna yang jelas.Hal ini diperlihatkan dari komponen penyusun kalimat tersebut. Dimana kalimat ini terdiri atas beberapa komponen sebagai berikut, subjek (subject), kata kerja atau predikat (verb), objek (object), komplemen (complement), dan kata keterangan (adverbial).
Subjek (Subject) merupakan kata atau kelompok kata (phrase) yang mencerminkan pihak yang memberikan aksi. Kata kerja atau predikat (Verb) merupakan kata kerja yang menunjukkan proses atau tindakan yang dinyatakan dalam kalimat tersebut. Objek (Object) merupakan kata atau kelompok kata (phrase) yang mencerminkan pihak yang menerima akibat dari tindakan yang dilakukan oleh subjek.Komplemen (complement)merupakan frase dari sebuah baik kata sifat maupun kata benda.Kata keterangan (adverbial) merupakan sebuah frase yang membentuk sebuah keterangan baik waktu, sifat, dan tempat.Beberapa pola pembentukan kata akan dijabarkan dibawah ini :
1. Subject + Verb + Adverbial The car is leaving shortly
2. Subject + Verb + Complement The rain is too heavy
3. Subject + Verb + Object I am shooting the duck
4. Subject + Verb + Object + Adverbial The airplane leaving Jakarta at 8 o’clock
Beberapa contoh diatas merupakan penggambaran beberapa pola dalam pembentukan sebuah kalimat.Unsur dasar yang perlu diperhatikan adalah subjek dan
predikat.Sebuah kumpulan kata baru dapat dikatakan kalimat apabila mengandung kedua unsur ini.(Eastwood, 2002; Thompson & Martinet, 1986)
2.2.1. Frase (Phrase)
Frase (Phrase) merupakan kumpulan kata yang tidak mengandung subject dan predikat tapi membentuk sebuah makna. Frase dibagi menjadi 5 macam, yakni Verb Phrase, Noun Phrase, Adjective Phrase, Adverb Phrase, dan Prepositional Phrase.(Eastwood, 2002; Thompson & Martinet, 1986). Dimana :
• Verb Phrase, merupakan frase yang terbentuk dari kata kerja (verb) yang
dilengkapi dengan kata kerja bantu (auxiliary verb). Misal :will be climbing.
• Noun Phrase, merupakan frase yang terbentuk dari kata benda (noun) yang
dilengkapi dengan kata sifat (adjective). Misal :a good fight.
• Adjective Phrase, merupakan frase yang terbentuk dari kata sifat (adjective) yang
dilengkapi dengan kata keterangan ukuran (adverb of degree). Misal :too late.
• Adverb Phrase, merupakan frase yang terbentuk dari kata keterangan yang
dilengkapi dengan kata keterangan ukuran. Misal :almost certainly.
• Prepositional Phrase, merupakan frase yang terbentuk dari kata depan
(preposition) dan dilengkapi dengan noun phrase. Misal :after lunch, on the aircraft.
Klausa (Clause) merupakan pembentukan anak kalimat atau kalimat dasar yang hanya terdiri dari subjek dan predikat yang nantinya akan dipakai dan terhubung dengan induk kalimat dengan menggunakan kalimat sambung.Klausa memiliki dua sifat utama, yakni ada yang tergantung dengan klausa utama (dependent tomain clause) dan ada yang tidak bergantung pada kalimat utama (independent to main clause).(Eastwood, 2002)
2.2.3. Sinonim (Synonym)
Sinonim (Synonym) merupakan padanan kata yang berbeda namun memiliki makna dan arti yang sama.Biasa padanan kata ini digunakan dalam memadukan kata yang sesuai dengan kalimat sehingga diperoleh makna yang lebih sesuai dengan bahasan penelitian. Seperti halnya pembuatan penelitian kedokteran akan cenderung menggunakan padanan kata yang lebih sesuai dan menggambarkan makna yang sesuai dengan bahasa kedokteran.(Eastwood, 2002)
2.2.4.
Bentuk Pasif (Passive Voice)
Bentuk pasif merupakan pembentukan sebuah kalimat dari kalimat aktif yang memiliki makna yang sama dari sebuah kalimat asalnya lainnya.Pada penelitian ini, pembentukan kalimat pasif difokuskan terhadap bentuk pasif dari kalimat pada bahasa inggris. Pembentukan kalimat pasif pada bahasa Inggris akan melakukan perubahaan pada jenis kata ganti orang yang digunakan (Promoun), bentuk kata kerja asal (Passive Verb), dan penambahan kata kerja bantu (Auxiliary / Helping Verb).
Pada pembentukan kalimat pasif perlu diperhatikan tenses (bentuk waktu) yang digunakan. Dikarenakan pada bahasa Inggris, tiap kalimat perlu diperhatikan bentuk waktu yang digunakan. Namun, struktur inti dari kalimat tetaplah sama, yakni subjek, kata kerja, objek, komplemen, dan kata keterangan.(Thompson & Martinet, 1986)
2.2.5. Junction Grammar (Grammar Tree)
Junction Grammar (Grammar Tree) merupakan metode yang digunakan dalam pemecahan struktur dari unsur – unsur penyusun sebuah kalimat ke dalam bentuk pohon. Unsur – unsur tersebut nantinya akan dipecah – pecah lagi secara mendalam untuk diketahui unsur dasar penyusunnya.Dari adanya penerapan Junction Grammar ditemukan bahwa struktur dasar dari sebuah kalimat bersumber dari potongan – potongan kata yang saling terhubung dalam bentuk frase dengan adanya aturan penulisan.
Perkembangan dari Junction Grammar (JG) berupa Tree Adjoining Grammar (TAG). TAG merupakan penerapan dari Junction Grammar yang diterapkan dengan menggunakan metode Natural Language Processing (NLP)dengan penerapanContext Free Grammar (CFG). TAG merupakan metode pengecekan grammar yang digunakan untuk menentukan benar tidaknya penulisan sebuah kalimat.(Millett & Lonsdale, 2004)
Gambar 2.1.Salah Satu Bentuk Grammar Tree.(Cohn, Blunsom, & Goldwater, 2010)
2.3. Natural Language Processing (NLP)
Natural Language Processing (NLP) merupakan teknik pemrosesan untuk mengolah kalimat ke dalam bentuk sebuah penjabaran unsur penyusun kalimat yang diproses per kata.Salah satu bentuk proses pengolahan kata adalah metode Chomsky
Normal Form (CNF). Metode ini mengolah kalimat per kata dimana masing – masing kata akan di analisa jenis katanya serta dilakukan fragmentasi hingga di dapat hasil berupa unsur inti dari kalimat tersebut. Hasil tersebut dapat digambarkan melalui Grammar Tree dimana unsur – unsur kalimat akan terpecah – pecah dan akan terlihat struktur inti dari kalimat. Penerapan NLP dapat dilihat pada metode – metode yang digunakan oleh mesin deteksi plagiarisme dimana metode yang digunakan berupa semantic analysis dan lexical analysis.(Mihalcea, Liu, & Lieberman, 2006)
Context Free Grammar (CFG) atau Right Linear Grammar merupakan salah satu bentuk penerapan dari Natural Language Processing (NLP) yang merupakan bentuk pengembangan dari Chomsky Normal Form (CNF) dimana setiap tokennon-terminal dapat diturunkan lagi.Dalam hal ini token non-terminal dapat digambarkan sebagai variabel dan token terminal sebagai konstan dalam perumpamaan bentuk persamaan aljabar.(Krulee, 1991; Collobert, Weston, Bottou, Karlen, Kavukcuoglu, & Kuksa, 2011)
2.4. Algoritma Deteksi Plagiarisme Dengan Penerapan Natural
Language Processing
2.4.1. Algoritma Deteksi Plagiarisme Berbasis Semantic Analysis
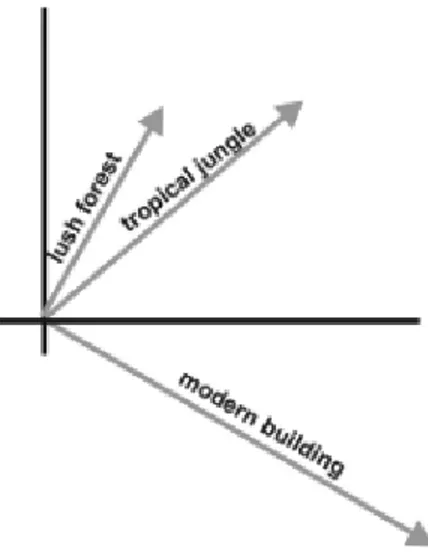
Algoritma deteksi plagiarisme berbasis semantic analysis merupakan bentuk penerapan natural language processing (NLP) dalam memproses pengolahan kata untuk deteksi plagiarisme dimana kalimat yang didapat diolah menjadi token – token yang memiliki sinonim diwujudkan sebagai token terminal yang bercabang untuk menunjukkan ada tidaknya kata yang memiliki makna yang sama atau sinonim dari kata tersebut. Salah satu metode yang paling terkenal dengan penerapan semantic analysis dalam mendeteksi plagiarisme adalah Latent Semantic Analysis (LSA). LSA memiliki beberapa karakteristik dalam melakukan proses pendeteksian dimana metode tersebut dilakukan dengan penurunan sinonim kata untuk melihat kemiripan plagiarisme.LSA
melakukan pengukuran kemiripan antara 2 kata dilakukan dengan mengukur nilai kosinus dari penggambaran dua buah vector yang merupakan pencerminan dari kata – kata yang dibandingkan.(Stamatatos, 2009; Mozgovoy, Kakkonen, & Cosma, Automatic Student Plagiarism Detection: Future Perpectives, 2010)
Gambar 2.2.Contoh penggambaran tiga kata – kata dalam vector oleh LSA. (Botana, Leon, Olmos, & Escudero, 2010)
Pada Gambar 2.2. digambarkan bahwa kata – kata yang memiliki makna yang cenderung mirip akan diletakkan pada satu kuadran yang sama dan kata yang memiliki makna sangat berbeda akan diletakkan pada kuadran yang berbeda. Semakin tinggi tingkat kemiripan makna dari kata – kata yang ada, maka semakin dekat garis vektor tersebut berada. Prosedur atau tahapan kerja dari algoritma LSA adalah sebagai berikut :
(1) Menganalisa isi dokumen dan membangun matriks dimensional dimana setiap baris merepresentasikan kata – kata yang unik dan setiap kolom mewakili sebuah dokumen, sebuah paragraph, sebuah kalimat, dsb. Perbandingan berdasarkan kolom bergantung pada kontex dari proses pengecekan yang akan dilakukan.
(2) Setelah pengukuran linguistik dari kata – kata tersebut berupa pengukuran bobot dari istilah – istilah kata yang terkait dengan kata tersebut, proses selanjutnya adalah penguraian matriks awal dengan Singular Vector Decomposition (SVD), teknik matematika untuk mengurai matriks X menjadi tiga matriks lainnya (diuraikan sebanyak dimensi k yang disesuaikan dengan konsep yang diberikan). Matriks vektor dari istilah – istilah digambarkan sebagai U, sebuah matriks singular digambarkan sebagai S, dan matriks vektor dari dokumen digambarkan sebagai V maka persamaan yang diberikan berupa X = USVT dimana matriks U-V dan S-V. Hal ini memungkinkan untuk melakukan perbandingan satu kata dengan kata lainnya (baik dari kumpulan kata, kalimat, paragraf, esai, dan ringkasan) dimana perbandingan kata – kata dilakukan dengan penggambaran vektor yang terletak berdampingan (Adjoining Vector) akan menyatakan kata dengan makna yang mirip.
Bentuk rumus pendekatan dalam melakukan perbandingan kosinus antara dua vektor tersebut diberikan dalam bentuk persamaan (1), dimana Vw1 merupakan representasi vektor dari kalimat yang ingin dibandingkan, Vw2 merupakan representasi vektor dari kumpulan kalimat atau dokumen yang akan dibandingkan serta k merupakan dimensi dari jumlah dokumen yang akan dibandingkan terhadap dokumen yang ada.Sedangkan, bentuk rumus pendekatan dalam melakukan pengukuran jarak antara dua vektor tersebut, diberikan dalam bentuk persamaan (2).
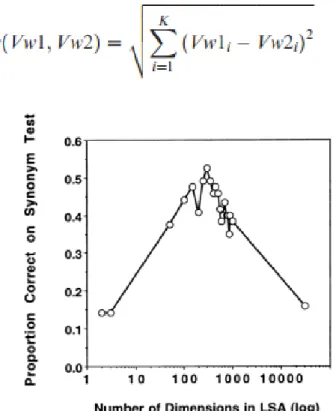
Gambar 2.2. Grafik Proporsional Cek Sinonim Dengan LSA. (Landauer, Foltz, & Laham, 1998)
Dari Gambar 2.2. dapat dilihat pola proporsional hasil dari penggunaan LSA dalam melakukan pengecekan sinonim kata dengan beragam jumlah. Hasil signifikan diberikan pada level dimensional 80 – 1200 dimensi.Namun, pada pola kalimat yang telah diubah strukturnya LSA tidak dapat memberikan hasil yang akurat.(Botana, Leon, Olmos, & Escudero, 2010; Landauer, Foltz, & Laham, 1998)
2.4.2. Algoritma Deteksi Plagiarisme Berbasis Lexical Analysis
Algoritma deteksi plagiarisme berbasis lexical analysismerupakan bentuk penerapan dari natural language processing (NLP) dalam memproses pengolahan kata untuk deteksi plagiarisme dimana kalimat yang didapat diolah menjadi token – token yang nantinya akan dilakukan pengecekan secara per tahap dengan mencocokkan kata per kata untuk melihat kata tersebut merupakan kata yang valid atau tidak dan merupakan kata yang sama dengan kata yang dikutip atau tidak.(Sebesta, 2006; Micol, Munoz,
&Ferrandez, 2011). Salah satu algoritma deteksi yang sering digunakan adalah character n-grams.Metode ini tahan terhadap gangguan berupa noise (karakter – karakter penyusun kata yang berupa latah yang mengganggu pola struktur kalimat). Dikarenakan metode ini biasa digunakan untuk menentukan konsistensi gaya penulisan kalimat yang beragam.Namun metode ini memiliki kelemahan dalam menentukan konsistensi plagiarisme pada kalimat pendek.Teknik ini melakukan perbandingan berdasarkan pemotongan kalimat menjadi potongan – potongan kata yang panjangnya disesuaikan pada kalimat dan dimulai dari awal karakter pada kalimat tersebut. Posisi pemotongan kata dari n-gram berikutnya akan dimulai dari posisi n-gram terakhir bergeser pada indeks terakhir yang dipotong sesuai dengan offset value. Parameter nbergantung pada divisi yang akan digunakan oleh metode n-gram.Sebagai contoh, jika n-gram dibuat dari penggabungan kata – kata maka offset merupakan nilai dari kata – kata yang dilewati ketika dibuat n-gramberikutnya. Jika n-gram dibuat dengan menggabungkan beberapa huruf tanpa memperhitungkan akhir dari kata maka offsetakan mewakili nilai dari huruf – huruf yang dilewati ketika n-gram berikutnya dibuat. Nilai divisi dari n-gram sangat beragam dibanding metode deteksi plagiarisme lainnya yang juga melakukan pendekatan terhadap pemotongan teks menjadi kumpulan n-gram, yang mana cara pemotongan dari n-gram terbagi menjadi 2,yakni :
• Overlapping n-grams, setiap n-gram dimulai pada posisi dimana potongan
tersebut memiliki kesamaan potongan kata (substring) dengan n-gram sebelumnya. Sebagai contoh, pemotongan kata “ABCDEBHAAC” menjadi n-grams dengan nilai n = 3 dan offset = 1 (nilai yang menentukan huruf yang akan dilewati). Dari pemotongan tersebut didapat kumpulan n-gram sebagai berikut : “ABC”, “BCD”, “CDE”, “DEB”, “EBH”, “BHA”, “HAA”, dan “AAC”.
• Non – Overlapping n-grams, Tidak ada n-gram yang dibuat dari huruf penyusun
atau potongan kata dari n-gram sebelumnya pada posisi yang sama.
Persamaan 3 dibawah ini akan mewujudkan cara kerja perbandingan untuk melakukan pendeteksian menggunakan metode n-gram.
Dimana A menggambar dokumen yang akan dibandingkan terhadap dokumen B yang dicurigai sebagai dokumen yang merupakan plagiat yang bentuk plagiarisme bersifat dikaburkan (intrinsic plagiarism).
Namun, metode n-gram tidak bekerja dengan baik pada kalimat yang pendek. Hal ini dikarenakan kedua kalimat akan dilakukan perbandingan antara segmentasi dari dua buah kalimat dan untuk mengidentifikasikan apakah paragraf yang dibandingkan memiliki gaya penulisan (style) yang berbeda atau tidak. (Chong & Specia, 2011; Stamatatos, 2009; Kucecka, 2011)
2.4.3. Algoritma Deteksi Plagiarisme Berbasis Syntactic Analysis.
Algoritma deteksi plagiarisme berbasis syntactic analysis merupakan bentuk penerapan dari natural language processing (NLP) dalam memproses pengolahan kata untuk deteksi plagiarisme dimana kalimat didapat diolah menjaditoken – tokenyang manatoken – token tersebut berupa potongan – potongan kata dari kalimat yang kemudian akan dilakukan pengecekan terhadap struktural dari pola penyusunan kalimat tersebut.Hal ini biasa digambarkan dengan penerapan context-free grammar (CFG). Hasil lebih lanjut dari proses ini digambarkan oleh context free grammar parse tree. Context free grammar parse tree memperlihatkan hasil pemotongan kalimat dalam bentuk pohon struktur tata
bahasa (Grammar Tree).Perbandingan kalimat ini dilakukan dengan menganalisa kemiripan makna kalimat dengan memproses pohon sintaks (syntactic dependency trees) antara dua dokumen yang dibandingkan.(Bose, 2004; Micol, Munoz, & Ferrandez, 2011; Stamatatos, 2009). Beberapa metode dibawah ini merupakan metode yang paling umum dalam melakukan penguraian kalimat (parsing) :
• Top – Down Parsing, proses penguraian kalimat yang dilakukan pada sebuah
parse tree dengan dimulai dari node S (sentence) dan diuraikan hingga ke tahapan terujung melalui pemecahan NP (Noun Phrase) dan VP (Verb Phrase).
• Bottom – Up Parsing, proses penguraian dimulai dari kata pertama pada kalimat
yang dibandingkan dan membangun sebuah tree yang bersumber dari kalimat dengan menggunakan aturan dari grammar yang diterapkan per kata.
• Depth – First Parsing, proses penguraian dilakukan dari tree yang telah ada yang
diuraikan secara mendalam hingga perlu dilakukan penambahan secara bertahap. • Repeated Parse Subtrees, proses penguraian dirancang untuk memecahkan
permasalahan ambiguitas dan untuk meningkatkan efisiensi dari algoritma penguraian lainnya. Proses penguraian dilakukan sebaliknya untuk mengecek kesalahan yang ada pada proses penguraian sebelumnya.
• Dynamic Programming Parsing Algorithms, menggunakan algoritma penguraian
secara sebagian untuk memecahkan masalah ambiguitas.
Salah satu bentuk algoritma yang merupakan penerapan dari metode ini adalah Part-Of-Speech (POS).Part-Of-Speech (POS) merupakan algoritma yang memecah-mecah atau menguraikan kalimat yang akan dibandingkan menjadi kata – kata yang dicerminkan oleh token – token dan akan dilihat dan disesuaikan berdasarkan polanya. Hal ini sangat diperlukan dalam menentukan ada tidaknya plagiarisme yang dilakukan
dengan merubah kalimat aktif menjadi pasif.Bentuk persamaan dari algoritma ini dapat digambarkan pada persamaan 4, yakni :
Pada persamaan tersebut terlihat bahwa kata yang mempunyai makna yang sama (sinonim) berdasarkan kode identik yang diberikan akan dibandingkan terhadap kata yang memiliki makna yang sama pada dokumen sumber. Hal ini juga berlaku sebaliknya apabila yang dilakukan adalah parafrase dengan cara merubah pola kata dan mengambil antonim dari kata tersebut.
Tabel 2.1.Tabel Contoh Perbandingan Antara Dua Kalimat yang Dilakukan Plagiarisme Parafrase.
Pada tabel 2.1.digambarkan bentuk sederhana dari proses perbandingan yang dilakukan dengan penerapan dari algoritma Part-Of-Speech (POS) antara dua kalimat. Kalimat pertama (S1) merupakan kalimat asli pada dokumen sumber, sedangkan kalimat 2 (S2) merupakan bentuk kalimat yang dilakukan plagiarisme parafrase dengan mengubah bentuknya menjadi pasif.Terlihat bahwa tiap unsur penyusun inti dari kalimat tersebut dipecah – pecah dan dianalisa tipe dari kata tersebut (tag) untuk kemudian dilakukan analisa deteksi plagiarisme.
Sentence 1 (S1) : The manlikes the woman Sentence 2 (S2) : The woman is like by the man
Word
S1 : Tag
S2 :
Tag S1 : Phrase S2 : Phrase
man NN NN NP PP
like VBZ VBZ VP PP
Namun, metode ini masih memiliki kekurangan jika plagiarisme yang dilakukan dalam bentuk parafrase. Dikarenakan dokumen yang melakukan parafrase cenderung akan memiliki struktur kalimat yang benar, namun dikarenakan penggunaan kata yang berbeda disertai dengan adanya perubahan struktur pola kalimat sehingga menyamarkan tindakan plagiarisme yang dilakukan. Untuk memperoleh hasil yang lebih akurat, penggunaan metode ini dapat didukung dengan penerapan metode semantic analysis.Hal ini membantu menemukan hasil plagiarisme meskipun telah dilakukan perubahan pola aktif ke pasif maupun sebaliknya yang disertai adanya parafrase.(L & R, 2013; Lin, Peng, Yen, & Lin, 2012)
2.4.4. Algoritma Deteksi Plagiarisme Berbasis Grammar Analysis.
Algoritma deteksi plagiarisme berbasis grammar analysis merupakan bentuk pengembangan dari metodesyntacticanalysis.Algoritma ini menggunakan penerapan context free grammar (CFG) dalam melakukan proses analisa deteksinya.Metode ini bertujuan untuk menganalisa jenis plagiarisme yang telah dikaburkan (bersifat parafrase).Beberapa bentuk algoritma yang menerapkan metode ini adalah algoritma Plag-Inn dan APL2.(Cebrián, Alfonseca, & Orte, 2009; Tschuggnall & Specht, 2013). Plag-Inn merupakan algoritma deteksi plagiarisme dimana pendekatan terhadap plagiarisme dilakukan dengan pengecekan grammardari penulis. Hal ini dilakukan untuk menganalisa kemungkinan terjadi plagiarisme. Proses algoritma Plag-Inndilakukan tanpa melakukan perbandingan dengan sebuah dokumen lain sebagai pembanding diawalnya hingga ditemukan kata yang dicurigai maka proses perbandingan dengan dokumen sumber dilakukan. Tahapan proses kerja dari algoritma ini adalah sebagai berikut :
(1) Awalnya, dokumen yang dilakukan proses pengecekan akan diuraikan menjadi kalimat – kalimat independen dengan menggunakan Sentence Boundary Detection Algorithm.
(2) Kemudian dari kalimat – kalimat yang telah diurah tersebut, akan dilakukan penguraian lagi dari kalimat terhadap grammar.
(3) Hasil dari penguraian kalimat berdasarkan grammar yang digunakan akan digambarkan ke dalam sebuah triangular distance matrix.
Dimana, distance di,j mencerminkan jarak antara kalimat satu dengan kalimat
lainnya atau dengan kata lain, setiap baris dari matriks tersebut merupakan perwujudan dari kalimat yang diparsing. Jarak (Distance) antar kalimat tersebut dihitung menggunakan pq-gram distance methods.
Persamaan 5 merupakan bentuk persamaan yang menunjukkan perhitungan untuk memperoleh distance dengan menggunakan metode pq-gram dari kata yang dibandingkan. Dimana T1 merupakan tree hasil parser kata yang dibandingkan terhadap T2 merupakan tree hasil parser dari kumpulan kata – kata dalam bahasa inggris. Dari perbandingan tersebut akan dilihat irisan dari kemiripan kata dalam kalimat tersebut yang dibandingkan terhadap gabungan kata. Hasil perbandingan tersebut nantinya akan dikalikan dengan 2 dan dikurangi dengan 1. Jika nilai yang diperoleh adalah 1 maka tidak terjadi
plagiat.Selain itu, menentukan keeretan hubungan kata dalam kalimat untuk memprediksi adanya plagiat.
Misal, kata yang dibandingkan adalah abcde terhadap defghij maka nilai distance yang diperoleh adalah 1 – 2 ( 2 / 12 ) = 0.777 dimana huruf yang sama ada 2 dan total huruf ada 12. Hal ini memperlihatkan semakin tinggi nilai jaraknya maka semakin rendah tingkat plagiat yang dilakukan.Contoh tersebut diwujudkan dalam bentuk perbandingan kata.(Augsten, Bohlen, & Gamper, 2005; Tschuggnall & Specht, 2013)
(4) Untuk memperkirakan terjadinya plagiarisme pada dokumen tersebut maka akan dilihat dari pola yang diberikan pada matriks D dengan perhitungan tiap baris untuk menghitung jarak median (median distance) pada kalimat tersebut. Hasil dari perhitungan tersebut akan dilanjutkan dengan perhitungan dari sebaran normal menggunakan metode Gaussian untuk memperoleh nilai mean (µ) dan standar deviasinya ( ). Penentuan kalimat yang dicurigai sebagai plagiat akan dilihat berdasarkan nilai standar deviasi yang diberikan oleh kalimat tersebut apabila μ .
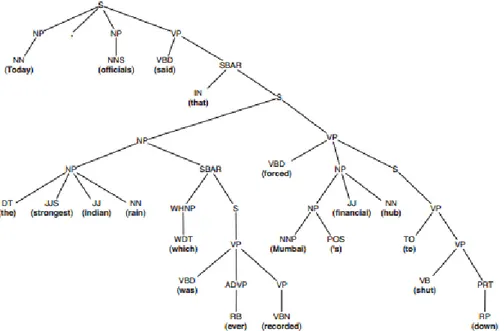
Gambar 2.4.Contoh hasil penguraian dari Plag-Inn.(Tschuggnall & Specht, 2013)
Pada gambar 2.4.diperlihatkan proses penguraian dengan menggunakan algoritma dari Plag-Inn dimana kata yang diuraikan berasal dari kalimat “Today, Officials said that the strongest indian rain which was ever recorded forced Mumbai’s financial hub to shut down”. Dari parsing tree diatas terlihat perbedaan yang jelas antara context free grammar umum dengan context free grammar yang telah dimodifikasi oleh Plag-Inn. Pada Plag-Inn parsing tree terlihat bahwa semua token yang merupakan penguraian dari kalimat akan diproses, sebandingnya pada CFG umumnya hanya unsur inti dari kalimat yang akan diproses. Namun, Algoritma Plag-Inn memiliki kelemahan, dikarenakan proses pendeteksian dilakukan berdasarkan grammar maka perbandingan terhadap dokumen sumber (reference corpus) hanya ketika ditemukan ada keganjilan pada grammar dalam dokumen tersebut. Hal ini menyebabkan proses pendeteksian menjadi tidak akurat apabila dilangsungkan terhadap dokumen yang melakukan plagiarisme namun memiliki struktur tata bahasa yang benar. Dikarenakan algoritma ini berfokus pada gaya penulisan dari
penulis untuk membentuk sebuah pola dalam menganalisa jika terjadi adanya plagiat.(Tschuggnall & Specht, 2013)
APL2 merupakan salah satu algoritma yang menganalisa plagiarisme berdasarkan grammarnamun memiliki pola analisa context free grammar(ditunjukkan pada gambar 2.5.) yang berbeda serta hasil dari penguraian tersebut akan digambarkan menggunakan Minimum Spanning Trees (MSTs). Algoritma ini melakukan proses pendeteksian dengan menghitung nilai rata – rata (means) dari kalimat tersebut berdasarkan pola grammar dari kalimat tersebut. Perbedaannya adalah pada algoritma ini dilakukan perbandingan dengan dokumen sumber (reference corpus).
Gambar 2.5.Pola Context Free Grammar pada Algoritma APL2. (Cebrián, Alfonseca, & Orte, 2009)
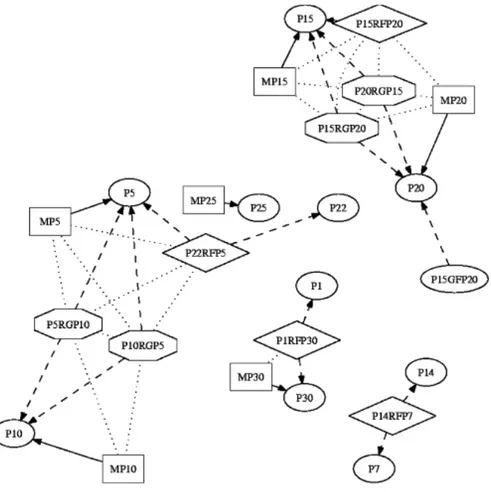
Gambar 2.6. Bentuk hasil proses penguraian dan pendeteksian yang digambarkan kedalam MST. (Cebrián, Alfonseca, & Orte, 2009)
Pada gambar 2.6.bentuk bulat mewakili perwujudan dokumen sumber, kotak mewakili perwujudan dokumen plagiat yang bersumber pada satu sumber, jajargenjang mewakili perwujudan dokumen plagiat yang bersumber pada lebih dari satu dokumen dan kurang dari empat, dan segienam mewakili perwujudan dokumen plagiat yang bersumber pada lebih dari empat sumber.Sedangkan garis merupakan bentuk perwujudan keeratan plagiat yang dilakukan, semakin solid garis yang ditunjukkan maka semakin mirip plagiat yang terjadi dihadapkan pada dokumen sumber.Namun kekurangan dari metode deteksi ini adalah keterbatasan penggunaan dimana algoritma ini cenderung digunakan dalam mendeteksi source code dari aplikasi yang ada.(Cebrián, Alfonseca, & Orte, 2009)