1
PENERAPAN ASSOCIATION RULE MINING UNTUK REKOMENDASI PENELUSURAN BUKU DENGAN ALGORITMA CT-PRO
Dwi Maryati Suryana, Sri Setyaningsih, Lita Karlitasari e-mail : [email protected]
Program Studi Ilmu Komputer Universitas Pakuan Jl. Pakuan PB 452, Bogor, Jawa Barat 16143
Abstrak
Perpustakaan Fakultas Matematika dan Ilmu Pengetahuan (FMIPA), memiliki sejumlah koleksi buku maupun media cetak lainnya, yang jumlahnya mencapai 2.632 buku. Sistem penelusuran buku yang tersedia sangat membantu pengunjung untuk mencari buku yang dibutuhkan. Terutama jika sistem tersebut memiliki fitur rekomendasi buku. Dalam pemberian rekomendasi buku digunakan salah satu teknik data mining, yaitu teknik association rule mining atau penggalian aturan asosiasi. Dalam pembangunan sistem rekomendasi ini, digunakan model KDD (Knowledge Discovery from Database). Data yang digunakan adalah data transaksi histori peminjaman buku dengan kategori “kimia”, selama 5 (lima) bulan terakhir, yaitu September 2014 – Februari 2015. Teknik penggalian aturan asosiari ini, memiliki 2 (dua) proses utama, yaitu : pencarian pola item yang sering muncul (frequent patterns) dan penentuan aturan (rule). Untuk menemukan frequent patterns, digunakan Algoritma CT-PRO. Nilai minimum support yang digunakan sebesar 1 dan 2. Setelah pola ditemukan, dihitung nilai confidence dari setiap pola tersebut. Nilai minimum confidence yang digunakan berkisar dari 10% sampai 100%. Aturan pemberian rekomendasi, didasarkan pada perhitungan nilai confidence ini. Perbandingan nilai minimum support menunjukkan, bahwa semakin besar nilai minimum support, maka semakin sedikit pola peminjaman yang dihasilkan, begitupun sebaliknya. Dalam perbandingan nilai minimum confidence menunjukkan, bahwa semakin besar nilai minimum confidence, maka semakin sedikit aturan rekomendasi yang diberikan.
Kata kunci : Perpustakaan, Sistem Rekomendasi, Knowledge Discovery from Database (KDD), Association Rule Mining, Algoritma CT-PRO
1. Pendahuluan
Data selalu menjadi bagian dari setiap aktivitas yang kita lakukan saat ini. “We’re living in data age” (Jiawei Han, 2012). Akibatnya, pertumbuhan data menjadi hal yang tak terelakkan lagi. Dari yang ukurannya byte hingga ke petabyte. Untuk mengolah jutaan, bahkan milyaran data yang tersimpan dalam suatu penyimpanan data elektronik, dibutuhkan tools yang sesuai. Pengolahan data disini bertujuan untuk menghasilkan informasi yang bisa membantu manajemen dalam mengambil keputusan. Dari dasar inilah, lahir
konsep data mining. Data mining adalah sebuah proses dasar dimana metode kecerdasan digunakan untuk menghasilkan pola data (Jiawei Han, 2012).
Perpustakaan Fakultas
Matematika dan Ilmu Pengetahuan Alam (MIPA) di Universitas Pakuan, memiliki statistik pengunjung 30 orang perhari pada tahun 2014. Jumlah buku yang tersedia mencapai 2.632 buku. Bagi pengunjung yang bertujuan mencari referensi dari suatu topik, sistem penelusuran buku yang telah tersedia di perpustakaan ini menjadi sasaran utama. Karena dalam
2
mencari referensi biasanya dibutuhkan lebih dari satu buku, maka suatu fasilitas rekomendasi buku dari sistem akan sangat membantu pengunjung.
Metode penggalian aturan asosiasi (association rule mining) merupakan salah satu metode dalam konsep data mining, yang bertujuan untuk mencari pola yang menarik dalam sejumlah transaksi. Pada umumnya algoritma yang digunakan dalam metode asosiasi ini adalah Apriori dan FP Growth. Algoritma FP Growth merupakan perbaikan dari algoritma Apriori dari segi kecepatan eksekusi. Namun, algoritma FP Growth membutuhkan banyak memori, sehingga muncul beberapa algoritma hasil pengembangan dari FP Growth. CT-PRO merupakan salah satunya. Pada penelitian ini, digunakan algoritma CT-PRO. Algoritma ini digunakan untuk mencari pola frekuensi (frequent pattern) dari transaksi peminjaman buku (buku apa saja yang dipinjam dalam suatu transaksi peminjaman). Dari pola frekuensi tersebut, dihasilkan rekomendasi buku lainnya dari suatu buku yang dicari user dalam sistem penelusuran buku.
Penelitian ini bertujuan untuk menerapkan metode association rule
mining untuk rekomendasi
penelusuran buku dengan
menggunakan algoritma CT-PRO. Manfaat dalam penelitian ini diharapkan :
a. Sebagai rujukan untuk menambah fitur rekomendasi pada sistem penelusuran buku yang telah ada, agar mempermudah pengunjung dalam mencari referensi yang berkaitan.
b. Memberikan pengetahuan mengenai penggunaan data
mining dengan teknik
association rule untuk memberikan rekomendasi buku melalui transaksi peminjaman. 2. Tinjauan Pustaka
Ada 2 (dua) proses utama dalam penggalian aturan asosiasi, yaitu :
a. pencarian pola (frequent pattern) dari sejumlah transaksi
b. penentuan kuatnya rule (aturan) dari pola yang dihasilkan.
Dalam association rule mining ada 2 (dua) hal yang mempengaruhi :
a. Support
Support adalah proporsi suatu item dalam semua transaksi. Support dirumuskan sebagai berikut :
( ) ∑ ∑ b. Confidence
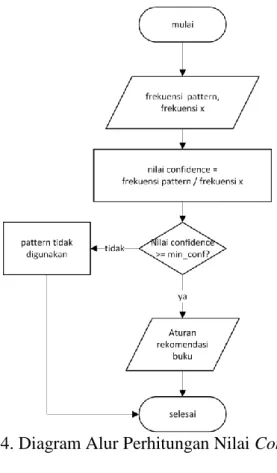
Confidence adalah hal yang mendasari aturan asosiasi, dengan konsep implikasi (x => y), atau “if ... then ...”. Besarnya nilai confidence suatu aturan (rule) dirumuskan sebagai berikut :
( ) ∑ ∑
Nilai minimum support dan minimum confidence bisa diatur oleh pengguna ataupun ahli yang berkaitan (Han, Jiawei. 2012).
Sucahyo, Gopalan (2004) telah melakukan penelitian yang berjudul CT-PRO: A Bottom-Up Non Recursive Frequent Itemset Mining Algorithm Using Compressed FP-Tree Data Structure. Pada penelitian ini, diperkenalkan algoritma baru sebagai pengembangan dari algoritma FP Growth, yaitu CT-PRO. Penulis juga melakukan perbandingan waktu eksekusi antara algoritma CT-PRO,
3
FP Growth dan Apriori. Pada perbandingan waktu tersebut menunjukkan, bahwa algoritma CT-PRO mempunyai waktu eksekusi paling sedikit.
Gupta (2011) telah melakukan penelitian yang berjudul FP-Tree Based Algorithms Analysis: FPGrowth, COFI-Tree and CT-PRO. Pada penelitian ini, penulis membandingkan ketiga algoritma yang berbasis FP Tree, yaitu algoritma FP Growth, COFI-Tree dan CT-PRO. COFI-Tree dan CT-PRO merupakan pengembangan dari algoritma FP Growth. Langkah – langkah ketiga algoritma ini dijelaskan melalui studi kasus yang sama. Perbandingan ketiga algoritma ini dinilai dari aspek struktur, pendekatan, teknik, utilisasi memori dan basis data.
Wandi, Hendrawan dan
Mukhlason (2012) telah melakukan
penelitian yang berjudul
Pengembangan Sistem Rekomendasi
Penelusuran Buku dengan
Penggalian Association Rule Menggunakan Algoritma Apriori (Studi Kasus Badan Perpustakaan dan Kearsipan Provinsi Jawa Timur). Pada penelitian ini, pemberian rekomendasi buku menggunakan aturan asosiasi dengan algoritma Apriori. Nilai minimum support 1,2,3,4 dan nilai minimum confidence 10% - 100%. Nilai minimum support dan confidence yang beragam itu
digunakan untuk melihat
perbandingan eksekusi waktu. 3. Metode Penelitian
Untuk penelitian ini digunakan model KDD (Knowledge Discovery from Database). Model ini memiliki 7 (tujuh) fase, yaitu : pembersihan data, penyatuan data, pemilihan data, transformasi data, penggalian data,
pengujian pola dan penyajian pengetahuan.
Berikut penjabaran untuk setiap fase dalam penelitian ini.
a. Pembersihan Data (Data Cleaning)
Pada tahap ini, dilakukan penghapusan untuk data yang mengganggu (noise) dan yang ridak relevan. Tahap ini sangat penting, karena hasil dati proses data mining ini tergantung pada kualitas data yang dipilih. Contoh hal yang
dilakukan pada tahap
pembersihan data adalah : menghapus record yang duplikat, atau record yang banyak mengandung missing value.
b. Penyatuan Data (Data Integration)
Tahap ini dilakukan untuk menyatukan data, apabila data tersebut berada dari berbagai lokasi penyimpanan data
(database atau data
warehouse).
c. Pemilihan Data (Data Selection)
Pada tahap ini dilakukan pemilihan data dari sejumlah data yang sudah dilakukan proses penyatuan data. Data yang dipilih adalah data yang berhubungan untuk proses data mining selanjutnya. Data yang tidak dibutuhkan bisa dihilangkan.
d. Transformasi Data (Data Transformation)
Pada tahap ini dilakukan penyesuaian format data dengan tahap selanjutnya yaitu penggalian data. Seperti mengubah format salah satu
4
bagian data atau mengubah
format data secara
keseluruhan, agar sesuai dengan tools yang akan digunakan pada saat proses perhitungan data mining. Dengan berakhirnya tahap ini, maka data sudah siap untuk diolah.
e. Penggalian Data (Data Mining)
Pada tahap ini, dilakukan pemilihan teknik data mining yang sesuai dengan tujuan penggalian data. Setelah itu, teknik tersebut diterapkan pada data yang sudah disiapkan sebelumnya. Hasil dari tahap ini berupa pola – pola data yang menarik.
f. Pengujian Pola (Pattern Evaluation)
Pada tahap ini, dilakukan pengujian terhadap pola – pola data yang ditemukan pada proses penggalian data. Karena, bisa jadi tidak semua pola benar – benar “menarik” jika berdasarkan suatu ukuran (measure). Jika memenuhi standar ukuran, maka pola tersebut digunakan sebagai pengetahuan (knowledge). g. Penyajian Pengetahuan
(Knowledge Presentation) Pada tahap ini, dirancang teknik – teknik visual untuk menyajikan pengetahuan dari proses data mining¸ agar mudah dimengerti oleh pengguna. Pada tahap ini pula, dilakukan implementasi terhadap perancangan tersebut ke dalam basis teknologi.
4. Hasil dan Pembahasan
Data yang dibutuhkan terdapat pada database perpustakan FMIPA
UNPAK. Untuk pemberian
rekomendasi buku, dibutuhkan data peminjaman dan data buku, atau tabel peminjaman dan tabel buku dari database untuk 5 (lima) bulan terakhir, yaitu September 2014 – Februari 2015.
Data yang tidak sesuai (missing values) dihilangkan, agar tidak menganggu keakuratan perhitungan. Pembersihan data yang dilakukan pada tabel peminjaman. Pada tabel tersebut terdapat 13% (23 records) dari total 178 records, yang tidak memiliki value pada field buku. Sehingga record tersebut dihilangkan. Untuk field buku tidak dilakukan pembersihan data.
Selanjutnya, dilakukan
penyeleksian data pada tabel peminjaman dan buku. Field yang tidak dibutuhkan pada kedua tabel tersebut akan dihapus. Berikut merupakan daftar field yang dihapus :
a. Tabel peminjaman : npm, tgl_tempo, tgl_perpanjang, kembali, id_petugas, telat, denda, bayar, sisa, angkatan dan kode_prodi.
b. Tabel buku : keterangan, kode_prodi, bahan_pustaka,
stok_rusak, tanggal,
sumber_buku, barcode.
Daftar buku dan peminjaman yang digunakan hanya yang berasal dari program studi kimia. Total buku ada 220 buku dan total peminjaman sebanyak 155 transaksi.
Penambahan data dilakukan
dengan menambah tabel
borrow_book. Tabel ini digunakan untuk merelasikan tabel peminjaman (borrows) dan tabel buku (books), karena pada tabel peminjaman yang diisi adalah kode buku. Sehingga
5
untuk mendapatkan judul buku harus melihat dari tabel buku.
Penyusunan (format) data juga perlu dilakukan untuk menyesuaikan tools yang digunakan dengan format data yang tersedia. Format database perpustakaan ini sudah dalam bentuk SQL (Structured Query Language), sesuai dengan tools database yang digunakan pada penelitian ini, yaitu MySQL.
Selanjutnya, dilakukan pemilihan teknik data mining. Teknik data mining yang digunakan yaitu association rule mining, untuk melihat hubungan menarik antar buku yang dipinjam. Hubungan yang menarik tersebut akan memberikan informasi berupa kecenderungan peminjam untuk meminjam buku A biasanya akan meminjam pula buku B. Dari situlah rekomendasi buku diberikan.
Secara umum, proses association rule mining terbagi 2 (dua), yaitu : pemilihan frequent patterns dan penentuan kuatnya suatu rule. Untuk menentukan frequent patterns, digunakan algoritma CT-PRO. Dan untuk menentukan kuatnya suatu rule, digunakan rumus nilai confidence. Agar pemahaman teknik ini lebih baik, dijabarkan langkah – langkah perhitungan menggunakan data sampel sebanyak 15 transaksi peminjaman dan nilai minimum support sebesar 2 (dua).
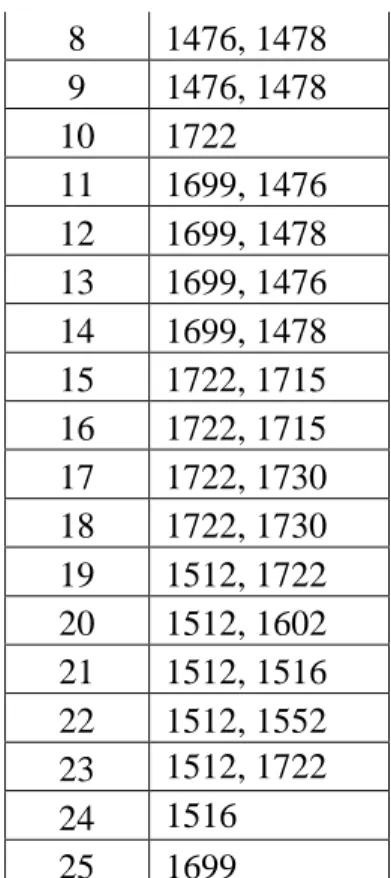
Tabel 1. Daftar Transaksi Peminjaman No Item 1 1512 2 1512 3 1476, 1516 4 1512, 1722 5 1512 6 1699, 1516 7 1699, 1516 8 1476, 1478 9 1476, 1478 10 1722 11 1699, 1476 12 1699, 1478 13 1699, 1476 14 1699, 1478 15 1722, 1715 16 1722, 1715 17 1722, 1730 18 1722, 1730 19 1512, 1722 20 1512, 1602 21 1512, 1516 22 1512, 1552 23 1512, 1722 24 1516 25 1699
Berikut merupakan langkah – langkah algoritma CT-PRO :
1. Hitung frekuensi item dari semua transaksi. item frequency 1476 5 1478 4 1512 9 1516 5 1552 1 1602 1 1699 7 1715 2 1722 8 1730 2
2. Hilangkan item yang nilanya dibawah min_sup. Item 1552 dan 1602 dieliminasi karena nilainya < min_sup.
3. Masukkan item ke dalam tabel global header. Disusun dari item frekuensi terbesar ke terkecil.
6
Tabel 2. Global Header index item frequency
1 1512 9 2 1722 8 3 1699 7 4 1476 5 5 1516 5 6 1478 4 7 1715 2 8 1730 2
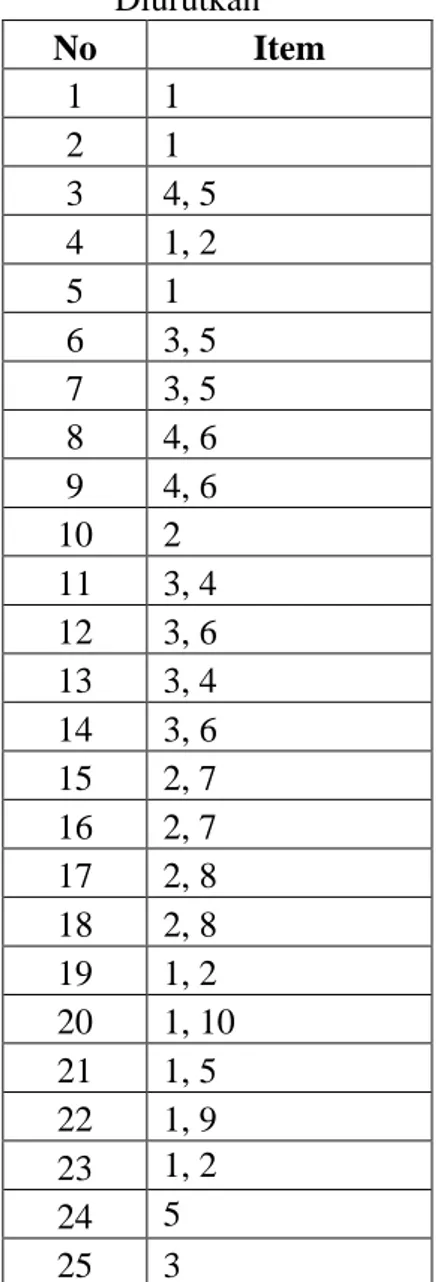
4. Urutkan item dalam setiap transaksi menurut indeks.
Tabel 3. Item Transaksi Diurutkan No Item 1 1 2 1 3 4, 5 4 1, 2 5 1 6 3, 5 7 3, 5 8 4, 6 9 4, 6 10 2 11 3, 4 12 3, 6 13 3, 4 14 3, 6 15 2, 7 16 2, 7 17 2, 8 18 2, 8 19 1, 2 20 1, 10 21 1, 5 22 1, 9 23 1, 2 24 5 25 3
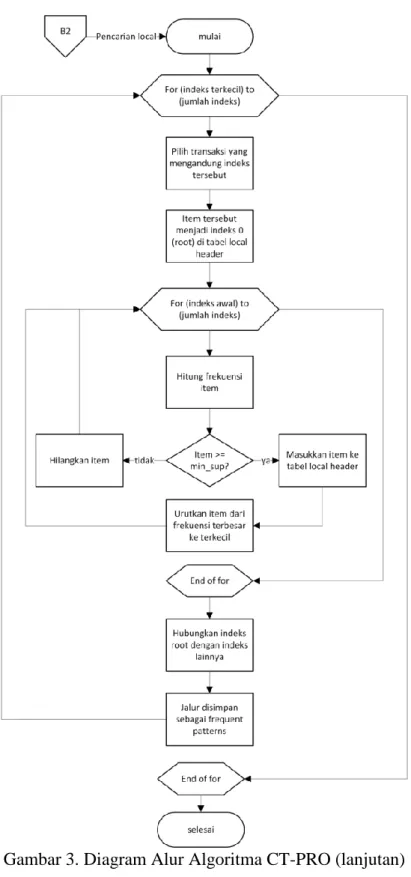
5. Lakukan pencarian frequent itemset secara lokal dari indeks terakhir, yaitu indeks 8.
5.1.Pilih transaksi yang mengandung indeks 8 (1730 = 2).
No. Transaksi Item
18 2, 8
19 2, 8
5.2.Hitung jumlah frekuensi indeks lain selain indeks 8.
index item frequency
2 1722 2
5.3.Hilangkan\ item yang
jumlahnya dibawah
min_sup. Buat tabel lokal indeks. Item disusun dari frekuensi terbesar ke terkecil. Item indeks 8 menjadi indeks 0.
index item frequency
0 1730 2
1 1722 2
5.4.Jika ada item lain selain indeks 0, gabungkan untuk mendapatkan frequent patterns lainnya.
frequent patterns :
index item frequency
0,1 1730, 1722 2
5.5.Lakukan pencarian
frequent patterns untuk indeks selanjutnya, yaitu indeks 7. Item indeks sebelumnya (item 1720) tidak dapat dibawa lagi ke pencarian selanjutnya. 6. Berikut hasil frequent patterns
7
Tabel 4. Hasil Frequent Patterns no item frequency 1 1730, 1722 2 2 1715, 1722 2 3 1478, 1699 2 4 1478, 1476 2 5 1516, 1699 2 6 1476, 1699 2 7 1722, 1512 3
Selanjutnya dilakukan pengujian untuk pola (patterns) yang ditemukan apakah benar – benar dapat digunakan untuk pemberian
rekomendasi buku. Untuk
menentukan kuat tidaknya suatu rule digunakan rumus confidence :
( ) ∑ ∑
Nilai minimum confidence (min_conf) untuk penelitian ini berkisar dari 10% - 100%. Untuk contoh perhitungan ini, misal nilai minimum confidence adalah 60%. Berikut merupakan hasil perhitungan nilai confidence untuk beberapa patterns : a. ( ) ∑ 1 x 100% = 100% b. ( ) ∑ 0.25 x 100% = 25% (tidak memenuhi nilai min_conf)
c. ( ) ∑ 1 x 100% = 100% d. ( ) ∑ 0.25 x 100% = 25% (tidak memenuhi nilai min_conf). Dan seterusnya.
Maka, pola (patterns) yang memenuhi nilai min_conf menjadi aturan (rule) dan dijadikan dasar pemberian rekomendasi. Sehingga bisa disimpulkan untuk hasil perhitungan ini :
a. Jika meminjam Kimia
Lingkungan (1730), maka juga meminjam Analisis Anorganik Kualitatif Makro dan Semikro (1722).
b. Jika meminjam Kimia
Lingkungan (1715), maka juga meminjam Kimia Anorganik Dasar (1722).
c. Dan seterusnya.
Tahap terakhir dari KDD adalah menerapkan aplikasi data mining yang telah dibuat ke lingkungan yang membutuhkan, agar dapat disajikan dengan tampilan yang memudahkan pengguna untuk memahami hasil pengetahuan (knowledge). Dalam studi kasus ini, hasil pengetahuan disajikan melalui media web, dalam bentuk sistem penelusuran buku yang
memuat fitur rekomendasi
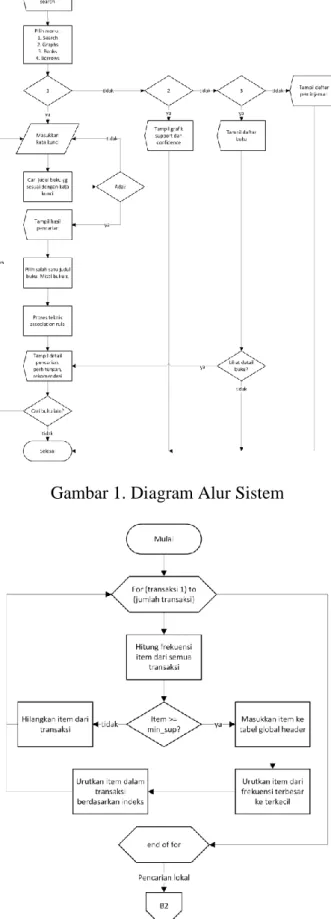
penelusuran. Berikut merupakan penggambaran sistem dan teknik association rule mining dalam bentuk diagram alur (flowchart) :
8
Gambar 1. Diagram Alur Sistem
9
10
Gambar 4. Diagram Alur Perhitungan Nilai Confidence
Berikut merupakan tampilan dari sistem rekomendasi buku, dari
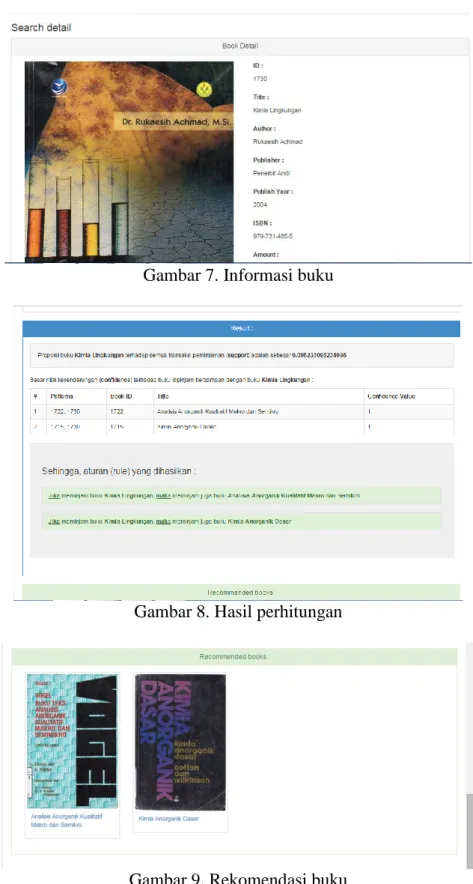
halaman pencarian, hasil pencarian, detail pencarian dan hasil perhitungan salah satu buku :
Gambar 5. Halaman Pencarian
11
Gambar 7. Informasi buku
Gambar 8. Hasil perhitungan
Gambar 9. Rekomendasi buku
Proses pencarian frequent patterns digunakan untuk mencari buku – buku yang sering dipinjam bersamaan, dengan menggunakan algoritma CT-PRO. Nilai minimum
support yang digunakan adalah 1 dan 2. Nilai minimum support didapat dari persebaran data transaksi peminjaman. Berikut merupakan hasil perbandingan nilai minimum support :
12
Tabel 5. Perbandingan jumlah item yang memenuhi nilai minimum
confidence Minimum Support Jumlah Item Persent ase 1 112 62% 2 42 38%
Tabel dan grafik perbandingan minimum support tersebut menunjukkan bahwa semakin besar nilai minimum support, maka semakin sedikit item yang dihasilkan. Begitupun sebaliknya.
Untuk proses penentuan aturan (rules), digunakan rumus nilai confidence. Nilai confidence digunakan untuk menentukan seberapa besar kecenderungan suatu item yang muncul bersamaan dengan item lainnya. Nilai minimum confidence yang digunakan berkisar antara 10% - 100%. Penentuan nilai minimum confidence ini berdasarkan penelitian yang dilakukan oleh Wandi, Hendrawan dan Mukhlason (2012) dengan studi kasus yang sama (lihat Daftar Pustaka). Berikut merupakan hasil perbandingan nilai confidence terhadap jumlah rules yang dihasilkan :
Tabel 6. Perbandingan total aturan yang memenuhi nilai
minimum confidence Minimum Confidence Jumlah rules 10% 13 20% 13 30% 10 30% 7 40% 5 50% 3 60% 3 70% 3 80% 3 90% 3 100% 3
Dari tabel minimum confidence menunjukkan bahwa, semakin besar nilai minimum confidence, maka semakin sedikit rules yang dihasilkan, begitupun sebaliknya. Artinya, semakin sedikit rules yang dihasilkan, maka semakin sedikit pula rekomendasi buku yang bisa diberikan dan sebaliknya.
Uji coba validasi ini dilakukan dengan membandingkan data peminjaman buku yang asli dengan hasil rekomendasi buku yang diberikan sistem. Berikut beberapa sampel buku yang direkomendasikan :
Tabel 7. Hasil uji coba validasi
No. Buku yang
direkomendasikan
Tanggal Peminjaman 1 Jika meminjam
Kimia Universitas Asas & Struktur E5 (1699), maka meminjam FESSENDEN FESSENDEN Kimia Organik (1516) 31-10-2014 2 Jika meminjam Kimia Lingkungan (1730), maka meminjam Kimia Anorganik Dasar (1715) 23-09-2014 05-01-2015 3 Jika meminjam Prinsip - Prinsip Kimia Modern (2741), maka meminjam Kimia Universitas Asas & Struktur E5 (1699) 31-12-2014 07-01-2015 4 Jika meminjam Analisa Kimia Kuantitatif (2757), 17-12-2014 29-12-2014
13 maka meminjam Konsep Dasar Kimia Analitik (1478) 5 Jika meminjam dasar-dasar kimia organik (2759), maka meminjam Fessenden & Fessenden Kimia Organik E3 (1552) 22-10-2014 30-10-2014
Berdasarkan data peminjaman di perpustakaan FMIPA UNPAK, buku yang paling banyak dipinjam adalah buku Konsep Dasar Kimia Analitik (1478), dengan frekuensi peminjaman sebanyak 12 kali.
5. Simpulan dan Saran
Penggalian aturan asosiasi (association rule mining) digunakan untuk melihat hubungan yang menarik diantara sejumlah transaksi. Proses dalam association rule mining ada 2 (dua), yaitu : pencarian pola dan menghitung kuatnya suatu aturan. Algoritma CT-PRO ini berguna untuk mencari buku saja yang sering dipinjam secara bersamaan. Untuk menyeleksi buku yang sering dipinjam, digunakan nilai minimum support. Selain, mencari pola buku yang dipinjam bersamaan, dihitung pula nilai confidence, untuk mengukur besar kecenderungan peminjaman suatu buku bersamaan dengan buku yang lainnya. Jika nilai confidence suatu pola memenuhi nilai minimum confidence, maka buku tersebut layak direkomendasikan.
Perbandingan nilai minimum support menunjukkan, bahwa semakin besar nilai minimum support, maka semakin sedikit pola peminjaman yang dihasilkan, begitupun sebaliknya. Dalam perbandingan nilai minimum confidence menunjukkan, bahwa semakin besar nilai minimum
confidence, maka semakin sedikit aturan rekomendasi yang diberikan.
Penerapan algoritma CT-PRO lebih efektif apabila diterapkan pada data yang mempunyai item lebih banyak pada setiap transaksi (item > 10 ). Sebagai pengembangan penelitian, dapat dilakukan perbandingan terhadap algoritma dalam association rules mining lainnya, seperti algoritma Apriori dan algoritma FP Growth terhadap studi kasus yang sama.
6. Ucapan Terima Kasih
Penulis mengucapkan terima kasih yang sebesar – besarnya kepada Perpustakaan Fakultas MIPA Universitas Pakuan, yang telah mengizinkan untuk melakukan penelitian. Penulis juga mengucapkan terima kasih kepada Ibu Sri Setyaningsih dan Ibu Lita Karlitasari, selaku dosen pembimbing. Juga kepada Bapak Soewarto Hardhienata, Ibu Eneng Tita Tosida, Bapak Iyan Mulyana, Ibu Arie Qur’ania, Ibu Prihastuti Harsani dan Ibu Tjut Awaliyah, sebagai dosen penguji. 7. Daftar Pustaka
1) Ahlemeyer-Stubbe, Andrea. Coleman, Shirley. 2014. A Practical Guide to Data Mining for Business and Industry. WILEY, United Kingdom. 2) Bell, Jason. 2015. Machine Learning:
Hands-On for Developers and Technical Professionals. John Wiley & Sons, Inc, Indiana Polis, Canada. 3) Brown, Meta S. 2014. Data Mining
For Dummies. John Wiley & Sons, Inc, New Jersey, Canada.
4) Gupta, Bharat. 2011. FP-Tree Based Algorithms Analysis: FPGrowth, COFI-Tree and CT-PRO. International Journal on Computer Science and Engineering (IJCSE). 3 : 2691 – 2699. 5) Han, Jiawei. Kamber, Micheline. Pei,
Jian. 2012. Data Mining Concepts and Techniques 3rd Edition. Morgan Kaufmann, USA.
14 6) Harrington, Peter. 2012. Machine
Learning in Action. Manning, Shelter Island, New York.
7) Sucahyo, Yudho Giri. Gopalan, Raj. P. 2004. CT-PRO: A Bottom-Up Non Recursive Frequent Itemset Mining Algorithm Using Compressed FP-Tree Data Structure.
8) Wandi, Nugroho. Hendrawan, Rully A. Mukhlason, Ahmad. 2012. Pengembangan Sistem Rekomendasi Penelusuran Buku dengan Penggalian Association Rule Menggunakan Algoritma Apriori (Studi Kasus Badan Perpustakaan dan Kearsipan Provinsi Jawa Timur). Jurnal Teknik Institut Teknologi Sepuluh November (ITS). 1 : A445 – A449.
9) http://www.sqldatamining.com/data- warehousing/steps-of-the-knowledge-discovery-in-databases-process