B A B I V
A N A L I S I S D I S K R I M I N A N
( D I S C R IM I N A N T A N A L Y S I S )
5 . 1 K o n s e p d a n P e n g e r t i a n D a s a r
Analisis Diskriminan adalah suatu metode statistika untuk mengklasifikasikan sejumlah obyek ke dalam beberapa kelompok berdasarkan kumpulan variabel bebas (Dillon dan Goldstein, 1984). Dalam upaya mengetahui keterkaitan antar variabel, kadang kita dihadapkan pada suatu masalah dimana variabel yang dilibatkan adalah variabel yang bersifat kualitataif, atau katagori. Bila variabel katagori tersebut adalah salah satu dari variabel bebas, maka analisis regresi multiple masih dapat digunakan, namun bagaimana kalau variabel katagori merupakan variabel terikat?. Contoh, bangkrut dan tidak bangkrutnya perusahaan dikaitkan dengan rasio-rasio keuangan. Bangkrut tidak bangkrutnya perusahaan merupakan variabel terikat.
Dalam upaya mengetahui atau melakukan analisis keterkaitan antara bangkrut tidak bangkrutnya perusahaan dengan rasio- rasio keuangan di mana rasio rasio keuangan merupakan variabel bebas, maka diperlukan analisis yang disebut analisis diskriminan dan analisis regresi logistic. Jadi analisis ini digunakan bila variabel terikat adalah variabel katagori (nonmetric/ nominal), sedangkan variabel bebas
A n a l i s i s D i s k r im i n a n Metode statistika untuk mengklasifikasikan sejumlah obyek ke dalam beberapa kelompok berdasarkan kumpulan variabel bebas. Digunakan bila variabel terikat adalah variabel katagori (nonmetric/ nominal), sedangkan variabel bebas adalah metric (interval atau rasio).
adalah metric (interval atau rasio). Dalam banyak kasus penelitian variabel terikat terdiri atas dua katagori (klasifikasi /grup) misalnya pria dan wanita, rendah dan tinggi, tempat A dan Bukan A, dan seterusnya.
Misalnya masyarakat dikelompokkan ke dalam dua kelompok, yaitu mereka yang mengunakan produk telkom (PT) dan yang tidak menggunakan(Non-PT). Kepada orang orang yang menggunakan dan yang tidak menggunakan produk diukur karakeristik/ variabelnya, yaitu, X1= pendapatan, X2= tingkat pendidikan , X3= usia. Dengan analisis diskriminan, akan dapat ditentukan variabel mana yang dapat menerangkan perbedaan ke dua kelompok ini, selain bisa juga memprediksi termasuk kelompok mana seseorang dengan karakteristik X1, X2 dan X3 tertentu.
5 . 2 T u j u a n
Tujuan utama dari analisis diskriminan adalah mengklasifikasikan suatu individu atau objek ke dalam satu dari beberapa kelompok yang telah diketahui sebelumnya dengan cara menemukan suatu pembatas yang mampu memaksimalkan rasio perbedaan (variability) antar kelompok dan di dalam kelompok itu sendiri. Dalam analisis diskriminan,
sebelum melakukan pengklasifikasian peneliti harus
mengetahui terlebih dahulu objek-objek mana yang masuk ke dalam kelompok 1, kelompok 2 dan seterusnya bergantung pada banyaknya kelompok. Dapat dikatakan bahwa kita ingin
T u j u a n Um um Mengklasifikasikan suatu individu atau objek ke dalam satu dari beberapa kelompok yang telah diketahui sebelumnya dengan cara menemukan suatu pembatas yang mampu memaksimalkan rasio perbedaan (variability) antar kelompok dan di dalam kelompok itu sendiri.
mengetahui apakah ada perbedaan yang jelas antar grup pada variabel dependen
Tujuan lain analisis diskriminan, yaitu :
1. Menentukan apakah ada perbedaan yang signifikan ntara rata-rata skore dari dua atau leboh kelompok. 2. Menentukan prosedur-prosedur untuk menelompokkan
individu-individu atau objek-objek ke dalam kelompok-kelompok berdasarkan skore-skore variabel.
3. Menentukan variabel predictor mana yang mempunyai
discriminating power atau daya beda yang besar untuk
membedakan dua atau lebih kelompok.
5 . 3 M o d e l A n a l i s i s D i s k r im i n a n
Analisis diskriminan adalah teknik statistik multivariat jika variabel tak bebas (respons) merupakan nominal, atau kategori, atau nonmetrik dan variabel bebas (prediktor) merupakan metrik, atau paling sedikit skala pengukurannya interval, atau bersifat kontinu. Pada contoh diatas, variabel respons adalah P T dan N o n - P T. Jika variabel tersebut dimisalkan
Y, maka variabel itu merupakan variabel nominal, dapat ditulis sebagai berikut :
Analisis diskriminan melibatkan kombinasi linier dari dua atau lebih variabel predictor yang membedakan antara
Li =
1, setiap individu ke-i yang PT
0, setiap individu ke-i yang Non-PT
T u j u a n I Menentukan apakah ada perbedaan yang signifikan ntara rata-rata skore dari dua atau leboh kelompok. T u j u a n I I Menentukan prosedur-prosedur untuk menelompokkan individu-individu atau objek-objek ke dalam kelompok-kelompok berdasarkan skore-skore variabel. T u j u a n I I I Menentukan variabel predictor mana yang mempunyai discriminating power atau daya
beda yang besar untuk
membedakan dua atau lebioh kelompok
kelompok. Secara teknis hal tersebut yaitu dengan cara memaksimumkan varians di antara kelompok (Between) relative terhadap varians di dalam kelompok (Within); hubungan ini dinyatakan sebagai rasio di antara-kelompok terhadap di dalam-kelompok. Kombinasi linier untuk analisis diskriminan dalam bentuk persamaan linier, yaitu :
1 1 2 2 3 3 ... p p
Lw X w X w X w X
Dalam hal ini, L = skore diskriminan, w = bobot (Weight) dan, X = variabel prediktor.
Analisis diskriminan adalah teknik statistik untuk menguji hipotesis bahwa vektor rata-rata dari dua atau lebih kelompok adalah sama. Sehingga analisis diskriminan, juga bisa melalui Manova. Selain itu, penyelesaian analisis diskriminan bisa melalui analsis regresi multipel.
Pengujian fungsi diskriminan bisa melalui jarak antara
the group centroid, yang dihitung dengan membandingkan
distribusi skore diskriminan dua atau lebih kelompok. Yang dimaksud dengan centroid adalah rata-rata skor diskriminan untuk setiap kelompok. Jika distribusi tersebut menunjukkan
overlapnya makin kecil, maka fungsi diskriminan memiliki discriminating power yang lebih baik. Demikian juga berlaku
sebaliknya.
Asumsi dasar analisis diskriminan, yaitu :
1. Variabel prediktor berdistribusi normal multivariat
A s um s i D a s a r I Variabel prediktor berdistribusi normal multivariat A s um s i D a s a r I I Matriks varians-kovarians untuk setiap kelompok adalah sama A s um s i D a s a r I I I Di antara variabel prediktor tidak ada multikolinearitas
2. Matriks varians-kovarians untuk setiap kelompok adalah sama
3. Di antara variabel prediktor tidak ada multikolinearitas
5 . 4 T a h a p a n A n a l i s i s
Proses dasar dari analisis diskriminan adalah pertama kita membagi objek-objek ke dalam dua atau lebih kelompok, setiap kelompok diamati dan diukur berbagai karakteristik yang diperlukan, selanjutnya kita dapat mengetahui dari pengamatan ciri-ciri atau karakteristik setiap kelompok. Sehingga apabila ada objek baru dengan karakteristik yang dipunyainya, obyek tersebut dapat diidentifikasi termasuk kelompok yang mana.
Model dari analisis diskriminan adalah
p p
X
X
X
y
1 1
2 2
...
untuk :y
: Variabel dependen (berupa data kategori)
: Koefisien bobot fungsi diskriminanX : Variabel Independen (berupa data interval atau rasio) Analisis diskriminan yang optimum adalah analisis diskriminan yang menghasilkan peluang kesalahan klasifikasi yang sekecil-kecilnya. Untuk hasil yang optimal diasumsikan bahwa (1)
p
buah variabel prediktor berdistribusi normalmultivariat dan (2) memiliki matriks varians dan kovarians yang sama dalam setiap G grupnya.
Secara Umum menurut penjabaran matematis cara
F i s h e r, prosedur perhitungan Analisis Diskriminan dimulai
dengan :
1. Membentuk sampel acak sebesar n1 darik1 (kelompok 1) dan sampel sebesar n2 dari k2(kelompok 2).
.
.
.
.
.
.
.
.
.
.
.
.
...
...
1 1 3 1 2 1 1 21 321 221 121 11 311 211 111 1 1 1 1 p n p p p n nX
X
X
X
X
X
X
X
X
X
X
X
X
. . . . . . . . . . . . ... ... 2 2 3 2 2 2 1 21 322 222 121 11 312 212 112 2 2 21 2 p n p p p n n X X X X X X X X X X X X X2. Dari data sampel itu dihitung vektor rata-rata sampel pada tiap kelompok.
11 21 1
1 X X ,..., Xp X
21 21 1
2 X X ,..., Xp X3. Menghitung matriks varians kovarians untuk masing-masing kelompok dan matriks varians kovarians sampel gabungannya adalah S dengan rumus :
Untuk masing-masing kelompok
1,2 1 2 , 1 2 , 1 ( )( ) 1 1 n i k jk j ij X X X X n S Untuk matriks varian-kovarian gabungan
)
2
(
)
1
(
)
1
(
2 1 2 2 1 1
n
n
S
n
S
n
S
4. Menurut aturan fisher Kemudian dicari adalah taksiran komposit linear dari x1,
x ,...,
2x
p adalah :x b y ' atau p pX X X y
1 1
2 2 ...
dimana badalah taksiran
, yang diperoleh darihubungan-hubungan yang menyangkut
diatas,dengan penggantian, yaitu
diganti denganpenaksirnya yaitu xi sedang
y
diganti denganpenaksirnya S.
Maka diperoleh
b
S
1(
x
1
x
2)
dimanaS
1 adalah invers dari matriks varians-kovarian sampel gabungan. 5. Setelah didapat fungsi diskriminannya langkahselanjutnya kita lakukan pengujian
6. Klasifikasi pengelompokkan menggunakan bayess, aturan titik tengah, aturan fisher.
5 . 5 P e n g u j i a n S i g n i f i k a n s i P e r b e d a a n
Salah satu tujuan dari analisis diskriminan adalah ingin mengetahui apakah ada perbedaan yang jelas antar grup pada variabel dependen.
Untuk hal tersebut dilakukan pengujian Signifikansi untuk mencari daya pembeda antara kelompok kelompok yang terlibat.
Jika fungsi diskriminan untuk dua kelompok K1 dan K2
adalah
y
b
'
x
maka selisih antara rata-rata nilai diskriminanadalah : ) ( ' ' ' 1 2 1 2 2 1 Y b x b x b x x Y
)
(
)'
(
x
1
x
2S
1x
1
x
2
besaran ruas kanan itu disebut jarak Mahalanobis antara x1 dan
2
x , dinyatakan dengan tanda :
) , ( 1 2 2 x x D atau D2
Ukuran statistik diatas dapat digunakan untuk menyelidiki apakah antara dua vektor rata-rata ada perbedaan yang signifikan, sebagai berikut :
H i p o t e s i s
2 1
:
Ho (tidak terdapat perbedaan)
2 1 1:
H (ada Perbedaan antara dua kelompok)
S t a t i s t i k u j i 2 2 1 2 1 2 1 ) 2 1
)
2
(
)
1
(
(
D
p
n
n
p
n
n
n
n
n
n
F
derajat bebas (p;n1 n2 p1), dimana
2
D adalah jarak Mahalanobis antara vektor rata-rata sampel, yaitu
) ( )' ( 1 2 1 1 2 2 x x S x x D
Kriteria uji bahwa
F
hitung lebih besar dariF
tabel maka tolakHo. Kesimpulan bahwa tolak Hoperbedaan rata-rata kedua kelompok berdasarkan fungsi diskriminan sangat signifikan.
Dalam hal ini,
'
2 1
1 2 1 2
D
X
X
S
X
X
Kriteria uji, tolah H0 jika Z > f pada taraf
tertentu.Analisis diskriminan dua kelompok pendekatan pemecahannya dapat melalui analisis regresi multipel. Variabel respons fungsi diskriminan dalam analisis regresi multipel [
C r a m e r (1967), K e n d a l l (1961), F i s h e r (1938) ], yaitu: 1 i
n
L
n
jika Xi dari kelompok 1=
n
2n
jika Xi dari kelompok 2Analisis varians atau anova dapat dilihat pada Tabel 5.1
T a b e l 5 . 1
m e l a l u i A n a l i s i s R e g r e s i M u l t i p e l S um b e r v a r i a s i J u m l a h k u a d r a t D e r a j a t b e b a s Regresi Kekeliruan
' 1 2 1 2n n
b X
X
n
' 1 2 1 21
n n
b X
X
n
k n - k - 1 Totaln n
1 2n
n - 1Jika hasil pengujian signifikansi, ada petunjuk kuat bahwa ada perbedaan kelompok. Hubungan antara D2 dengan koefisien
determinasi R2 diberikan sebagai
2 2 2 1 2 ( 2) 1 R n n D R n n 5 . 6 P e n g u j i a n v a r i a b e l p r e d i k t o r
Setelah semua variabel-variabel prediktor dapat membedakan populasi 1 dan 2 melalui pengujian hipotesis pada bagian sebelumnya, selanjutnya timbul pertanyaan seperti : Variabel-variabel mana saja yang ‘benar-benar’ dapat membedakan populasi 1 dan 2. Untuk menjawab pertanyaan tersebut, salah satunya dapat melalui pengujian secara
statistik. Metode yang dibahas diantaranya adalah melalui
Discriminant Loadings dan analisis diskriminan stepwise. 5 . 6 . 1 D i s c r im i n a n t L o a d i n g s
Discriminant Loadings adalah korelasi antara variabel
prediktor dengan fungsi diskriminan. Metode ini biasanya sering digunakan untuk analisis diskriminan multipel. Perumusannya dapat digunakan sebagai berikut :
( loading )j = R b*j
Dengan, R adalah matriks korelasi, b*j = C b j ; dan C adalah akar
pangkat dua dari elemen diagonal utama pada matriks S. Metode ini biasanya dilakukan melalui peragaan grafik.
5 . 6 . 2 A n a l i s i s D i s k r im i n a n S t e p w i s e
Analisis diskriminan stepwise pada prinsipnya hampir sama seperti dalam analisis regresi multipel. Dalam prinsip analisis stepwise dimulai dari model yang paling sederhana sampai kompleks. Kriteria variabel-variabel mana yang masuk dalam model yaitu didasarkan pada kepada nilai maksimum D2
( Jarak Mahalanobis ) atau nilai Lamda Wilks yang terkecil, atau nilai maksimum dari F ( F - t o e n t e r , F - t o r e m o v e ). Dengan
demikian akan didapat variabel-variabel prediktor mana yang secara simultan mempunyai Discriminating Power yang berarti.
5 . 7 C O N T O H A P L I K A S I S P S S D A N I N T E R P R E T A S I D i s c r im i n a n t L o a d i n g s Korelasi antara variabel prediktor dengan fungsi diskriminan..
Sebuah Perusahaan yang bergerak dalam penjualan Air Mineral mengumpulkan data sekelompok konsumen Air Mineral dengan variabel berikut :
Tipe Konsumen dari banyaknya air mineral yang diminum, dengan kode :
Kode 0 = SEDIKIT (konsumen yang termasuk tipe sedikit minum air mineral)
Kode 2 = BANYAK (konsumen yang termasuk tipe banyak minum air mineral)
Usia Konsumen (tahun)
Berat Badan Konsumen (kilogram)
Pendapatan Konsumen (ribuan Rupiah/bulan)
Jam Kerja Konsumen dalam sehari (jam)
Kegiatan Olahraga Konsumen dalam sehari (jam)
T a b e l 5 . 2 D a t a K o n s u m e n A i r M i n e r a l N am a M i n u m U s i a B e r a t T i n g g i I n c o m e J a m K e r j a O l a h r a g a RUSDI sedikit 40.00 65.00 154.00 680.00 5.33 3.0 NINA sedikit 30.00 70.00 157.00 700.00 5.30 3.6 LANNY sedikit 25.00 60.00 158.00 580.00 5.27 3.5 CITRA sedikit 26.00 75.00 160.00 600.00 5.33 3.0 DINA sedikit 40.00 50.00 159.00 700.00 5.50 3.5 SISKA banyak 28.00 62.00 158.00 440.00 5.00 2.2 LUSI sedikit 29.00 50.00 160.00 580.00 5.07 2.9 LENNY sedikit 40.00 52.00 165.00 800.00 5.13 4.0 RUDI banyak 35.00 68.00 150.00 700.00 5.17 3.5 ROBY sedikit 36.00 70.00 152.00 720.00 5.23 3.6 BAMBANG sedikit 39.00 50.00 154.00 780.00 5.33 3.9 YUNUS sedikit 30.00 62.00 155.00 600.00 5.30 3.0 LESTARI sedikit 34.00 60.00 157.00 680.00 5.27 2.9 ERNI banyak 35.00 51.00 160.00 700.00 5.33 4.0 ESTI banyak 29.00 62.00 165.00 580.00 5.50 3.5
HANY banyak 30.00 51.00 162.00 600.00 5.00 3.6 HESTY sedikit 35.00 80.00 157.00 700.00 5.33 3.9 SUSAN banyak 22.00 52.00 154.00 440.00 5.30 3.0 LILIS sedikit 40.00 72.00 155.00 800.00 5.27 3.4 LITA banyak 41.00 45.00 164.00 820.00 5.33 3.5 LINA sedikit 32.00 42.00 160.00 640.00 5.50 2.9 RANI sedikit 29.00 54.00 157.00 580.00 5.30 3.0 BOBY banyak 21.00 35.00 150.00 420.00 5.27 3.5 ANDRE banyak 25.00 50.00 154.00 500.00 5.07 2.5 HENGKY sedikit 30.00 60.00 158.00 600.00 5.20 3.0 HANA sedikit 45.00 40.00 159.00 900.00 5.13 4.5 ELI banyak 35.00 45.00 158.00 700.00 5.17 3.5 RENATA sedikit 35.00 42.00 152.00 700.00 5.23 3.5 DEWI banyak 30.00 51.00 156.00 600.00 5.30 3.0 JOHAN sedikit 24.00 75.00 154.00 480.00 5.13 2.4 GUNAWAN banyak 28.00 42.00 155.00 560.00 5.17 2.8 LINA banyak 27.00 51.00 157.00 540.00 5.23 2.7 VINA banyak 20.00 55.00 159.00 400.00 5.30 2.0 RINA sedikit 26.00 70.00 160.00 520.00 5.33 2.6 SUGENG sedikit 29.00 40.00 162.00 580.00 5.40 2.9 HANDOKO banyak 20.00 42.00 156.00 400.00 5.20 2.0 HERMAN banyak 35.00 51.00 153.00 700.00 5.10 3.5 SOBARI sedikit 31.00 70.00 162.00 620.00 5.40 3.1 RULLY banyak 34.00 55.00 164.00 680.00 5.47 3.4 BINSAR sedikit 28.00 52.00 160.00 560.00 5.33 2.8 FANNY banyak 29.00 51.00 165.00 580.00 5.50 2.9 FENNY banyak 21.00 40.00 162.00 420.00 5.40 2.1 YULITA sedikit 22.00 70.00 179.00 440.00 5.23 2.2 YULIA banyak 22.00 65.00 159.00 440.00 5.30 2.2 RICHARD sedikit 25.00 47.00 154.00 500.00 5.13 2.1 ROSSY banyak 30.00 40.00 158.00 600.00 5.27 2.2 LEONY sedikit 45.00 49.00 159.00 900.00 5.30 2.2 AGNES sedikit 35.00 59.00 156.00 700.00 5.20 2.5 DEDDY banyak 39.00 70.00 175.00 780.00 5.13 3.0 DODIK banyak 34.00 45.00 155.00 680.00 5.17 4.5 DIMAS banyak 24.00 58.00 160.00 480.00 5.33 2.4 KIKY sedikit 31.00 75.00 175.00 620.00 5.40 3.1 CONNY sedikit 32.00 70.00 156.00 640.00 5.20 3.2 MARY sedikit 35.00 59.00 160.00 700.00 5.33 3.5 SUSY banyak 38.00 70.00 174.00 760.00 5.40 3.8 USMAN banyak 20.00 46.00 163.00 400.00 5.43 2.0 SALIM banyak 25.00 55.00 168.00 500.00 5.13 2.5 JAMES banyak 29.00 49.00 153.00 580.00 5.10 2.9 JONI banyak 28.00 62.00 179.00 700.00 5.40 3.5 JONO sedikit 27.00 41.00 148.00 780.00 5.20 3.9 KRISTANTO sedikit 26.00 47.00 160.00 680.00 5.33 3.4 KARIM banyak 22.00 47.00 164.00 480.00 5.40 2.4 MELANI sedikit 20.00 49.00 157.00 760.00 5.43 3.8 RUSMIN banyak 24.00 48.00 178.00 400.00 5.13 2.0
SULASTRI sedikit 25.00 59.00 160.00 500.00 5.10 2.5 LILIANA banyak 32.00 48.00 162.00 420.00 5.30 2.1 PRIHARDI banyak 34.00 46.00 168.00 740.00 5.07 3.7 SUHARDI sedikit 32.00 45.00 159.00 700.00 5.10 3.5 SUSANA banyak 21.00 58.00 158.00 600.00 5.30 3.0 TITIK sedikit 37.00 47.00 159.00 720.00 5.07 3.6 TATIK banyak 35.00 46.00 175.00 700.00 5.30 3.5 NANIK sedikit 30.00 52.00 150.00 600.00 5.27 3.6 NINIK sedikit 36.00 44.00 162.00 720.00 5.30 3.5 NUNING banyak 39.00 55.00 162.00 780.00 5.20 2.5 GALA banyak 30.00 50.00 165.00 600.00 5.50 2.1
Berdasarkan data di atas, akan dilakukan analisis Diskriminan untuk mengetahui :
Apakah ada perbedaan yang signifikan antara mereka yang minum Air Mineral Dalam Kemasan (AMDK) dengan mereka yang sedikit meminumnya?
Jika ada perbedaan yang signifikan, variable apa saja yang membuat perilaku konsumen Air Mineral mereka berbeda?
Membuat model diskriminan dua factor (karena hanya ada mereka yang SEDIKIT dengan yang BANYAK) untuk kasus tersebut.
Menguji ketepatan model (fungsi) diskriminan
Untuk menganalisis data di atas melalui program SPSS maka diperlihatkan langkah-langkah sebagai berikut :
Dari SPSS Data Editor, setelah semua variabel masuk, tekan
Sehingga tampak tampilan seperti berikut :
Kemudian masukan variabel Minum ke kotak dialog G r o u p i n g
V a r i a b l e, dan sisanya ke kotak dialog I n d e p e n d e n t s..
Tekan D e f i n e R a n g e untuk memasukan nilai kategori pada
dependen variabel. Sehingga muncul tampilan berikut di bawah ini. Untuk nilai m i n i m u m masukan 0 dan m a x im um = 1.Lalu
C o n t i n u e.
Tekan S t a t i s t i c s untuk memilih output yang akan
ditampilkan, kemudian checklist beberapa pilihan seperti tampilan di bawah ini :
Perhatikan bagian tengah kotak dialog utama. Klik mouse pada pilihan Use stepwise method, maka secara otomatis icon M E T H O D
akan terbuka (aktif), kemudian isi beberpa pilihan sebagai berikut :
Kotak diaolog C L A S S I F Y adlah pelengkap dari pembuatan model
diskriminan, terutama cara penyajian model diskriminan, serta kelayakan model tersebut. Isi sesuai dengan tampilan berikut ini :
Lalu C o n t i n u e dan tekan O K sehingga muncul Output dan sbb:
Discriminant
Analysis Case Processing Summary
75 100.0 0 .0 0 .0 0 .0 0 .0 75 100.0 Unweighted Cases Valid Missing or out-of-range group codes
At least one missing discriminating variable Both missing or
out-of-range group codes and at least one missing discriminating variable Total Excluded Total N Percent Menunjukan ada tidaknya data yang hilang.
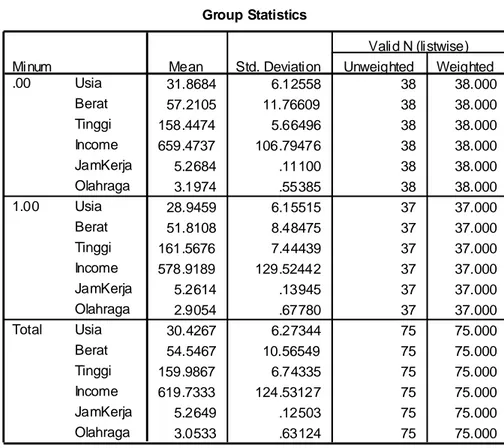
Tabel G R O U P S T A T I S T I C S pada dasarnya berisi data
desktriptif yang utama yakni rata-rata dan standar deviasi dari kedua grup konsumen. Misalnya pada tabel di atas kita dapat melihat bahwa konsumen yang termasuk tipe ‘sedikit’ (0) yang meminum air mineral mempunyai rata-rata berat badan 57,21 kilogram. Sedangkan mereka yang termasuk tipe ‘banyak’ 51,81 kilogram, dan seterusnya untuk deskripsi variabel lainnya. Group Statistics 31.8684 6.12558 38 38.000 57.2105 11.76609 38 38.000 158.4474 5.66496 38 38.000 659.4737 106.79476 38 38.000 5.2684 .11100 38 38.000 3.1974 .55385 38 38.000 28.9459 6.15515 37 37.000 51.8108 8.48475 37 37.000 161.5676 7.44439 37 37.000 578.9189 129.52442 37 37.000 5.2614 .13945 37 37.000 2.9054 .67780 37 37.000 30.4267 6.27344 75 75.000 54.5467 10.56549 75 75.000 159.9867 6.74335 75 75.000 619.7333 124.53127 75 75.000 5.2649 .12503 75 75.000 3.0533 .63124 75 75.000 Usia Berat Tinggi Income JamKerja Olahraga Usia Berat Tinggi Income JamKerja Olahraga Usia Berat Tinggi Income JamKerja Olahraga Minum .00 1.00 Total
Mean Std. Deviation Unweighted Weighted Valid N (listwise)
Menunjukan deskriptif data
Berdasarkan output di atas, diperoleh hasil analisis dengan menggunakan uji F sebagai berikut :
Variabel USIA, BERAT, TINGGI, INCOME, dan OLAHRAGA
mempunyai angka signifikansi dibawah 0,05 maka terdapat perbedaan antar group. Artinya, usia, berat, tinggi, income dan olahraga mempengaruhi banyak sedikitnya mereka yang mengkonsumsi air mineral.
Variabel JAM KERJA mempunyai angka Sig. 0,783 > 0,05.
Artinya, jumlah Jam Kerja seseorang tidak
mempengaruhi banyak sedikitnya konsumsi air mineral.
Dari enam variable di atas, terdapat lima variable yang berbeda secara signifikan untuk dua grup diskriminan, yaitu USIA, BERAT, TINGGI, INCOME dan OLAHRAGA. Dengan demikian, sedikit atau banyaknya konsumsi seseorang akan air mineral dipengaruhi oleh usia responden, berat dan tinggi badan responden, tingkat penghasilan dan kegiatan olahraga responden yang bersangkutan.
Tests of Equality of Group Means
.945 4.247 1 73 .043 .934 5.173 1 73 .026 .946 4.186 1 73 .044 .894 8.656 1 73 .004 .999 .059 1 73 .808 .946 4.183 1 73 .044 Usia Berat Tinggi Income JamKerja Olahraga Wilks' Lambda F df1 df2 Sig. Pengujian perbedaan antargrup
Namun, pada beberapa analisis diskriminan, sebuah variable yang tidak lolos uji tidak otomatis dikeluarkan. Seperti pada variable JAM KERJA, walaupun tidak lolos uji, namun seharusnya tetap disertakanpada analisis diskriminan selanjutnya. Karena, sesuai prinsip pada analisis multivariate, bahwa variable-variabel dianggap sebagai suatu kesatuan, dan bukan terpisah-pisah.
Jika analisis ANOVA dan angka Wilk’s Lambda menguji rata-rata dari setiap variable, maka Box’s M menguji varians dari setiap variable. Asumsi pada analisis diskriminan :
Varians variable bebas untuk tiap grup seharusnya sama. Jika demikan, seharusnya varians dari responden yang Sedikit mengkonsumsi air mineral sama dengan varians dari responden yang Banyak mengkonsumsi air mineral.
Varians di antara variabel-variabel bebas seharusnya juga sama. Jika demikian, seharusnya dari USIA sama dengan varians dari BERAT, OLAHRAGA dan sebagainya.
Dari kedua asumsi di atas, seharusnya group covariance
matrices adalah relative sama, yang diuji dengan alat Box’s M
dengan ketentuan : Test Results 28.145 1.222 21 19569.371 .220 Box's M Approx. df1 df2 Sig. F
HIPOTESIS :
H0 : group covariance matrices adalah relative sama
H1 : group covariance matrices adalah berbeda secara nyata
Kriteria uji :
Tolak H0 jika Sig. < 0,05. Terima dalam hal lainnya.
Dari table output terlihat bahwa angka Sig. (0,220) > 0,05 yang berarti group covariance matrices adalah sama. Artinya, data di atas sudah memenuhi asumsi analisis diskriminan.
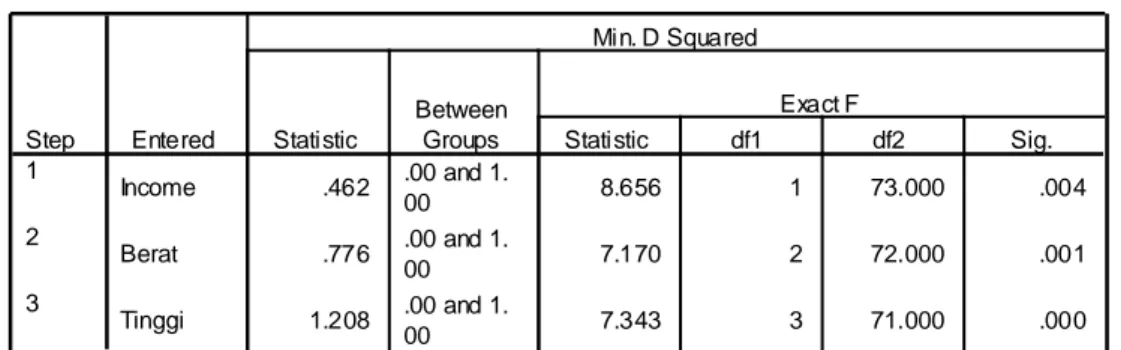
Stepwise Statistics
Tabel di atas menyajikan variabel mana saja dari lima variabel yang bisa dimasukan (entered) dalam persamaan diskriminan. Proses yang dilakukan adalah stepwise (bertahap), dimulau oleh variabel yang memiliki angka F statistik terbesar.
Pada tahap pertama angka F hitung variabel INCOME adalah yang terbesar, mencapai 8.656. Sehingga pada tahap pertama ini variabel INCOME terpilih. Selanjutnya pada tahap
Variables Entered/Removeda, b,c,d Income .462 .00 and 1. 00 8.656 1 73.000 .004 Berat .776 .00 and 1. 00 7.170 2 72.000 .001 Tinggi 1.208 .00 and 1. 00 7.343 3 71.000 .000 Step 1 2 3 Entered Statistic Between
Groups Statistic df1 df2 Sig.
Exact F Min. D Squared
At each step, the variable that maximizes the Mahalanobis distance between the two closest groups is entered.
Maximum number of steps is 12. a.
Maximum significance of F to enter is .05. b.
Minimum significance of F to remove is .10. c.
F level, tolerance, or VIN insufficient for further computation. d.
dua dan tiga diikuti oleh variabel BERAT dan TINGGI badan. Ketiga variabel ini memiliki angka signifikan lebih kecil dari 0.05. Dengan demikian, dari lima variabel yang dimasukan hanya ada tiga variabel yang signifikan. Dengan kata lain, variabel INCOME, BERAT, dan TINGGI secara signifikan mempengaruhi perilaku konsumen dalam mengkonsumsi sedikit atau banyaknya air mineral.
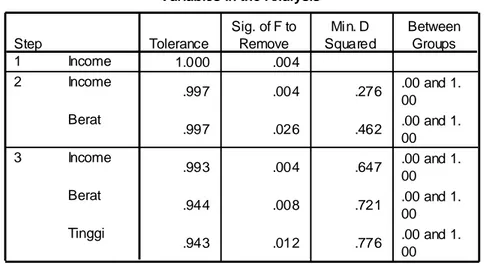
Tabel diatas sebenarnya hanyalah perincian (detail) dari proses stepwise pada tabel sebelumnya. Pada step 1, variabel INCOME adalah variabel pertama yang masuk ke dalam model diskriminan. Hal ini disebabkan variabel tersebut mempunyai angka SIG. OF F TO REMOVE yang paling sedikit, yakni 0,004 (jauh di bawah 0,05). Kemudian pada step 2, dimasukkan variabel kedua, yakni BERAT. Variabel tersebut memenuhi syarat, karena mempunyai angka SIG. OF F TO REMOVE di bawah 0,005, yakni 0,0026. pada step 3 atau terakhir, dimasukkan variabel ketiga, yakni TINGGI. Variabel tersebut juga memenuhi syarat, dengan angka SIG. OF F TO REMOVE di
Variables in the Analysis
1.000 .004 .997 .004 .276 .00 and 1. 00 .997 .026 .462 .00 and 1. 00 .993 .004 .647 .00 and 1. 00 .944 .008 .721 .00 and 1. 00 .943 .012 .776 .00 and 1. 00 Income Income Berat Income Berat Tinggi Step 1 2 3 Tolerance Sig. of F to Remove Min. D Squared Between Groups
bawah 0,05, yakni 0,012. perhatikan perubahan angka pada variabel BERAT seiring dengan masuknya variabel ketiga, yakni variabel TINGGI.
Pada step 0 (keadaan awal), kelima variabel secara lengkap ditayangkan dengan SIG. OF F TO REMOVE sebagai faktor penguji. Terlihat angka SIG. OF F TO REMOVE yang
Variables Not in the Analysis
1.000 1.000 .043 .227 .00 and 1. 00 1.000 1.000 .026 .276 .00 and 1. 00 1.000 1.000 .044 .223 .00 and 1. 00 1.000 1.000 .004 .462 .00 and 1. 00 1.000 1.000 .808 .003 .00 and 1. 00 1.000 1.000 .044 .223 .00 and 1. 00 .318 .318 .542 .484 .00 and 1. 00 .997 .997 .026 .776 .00 and 1. 00 .997 .997 .042 .721 .00 and 1. 00 1.000 1.000 .811 .465 .00 and 1. 00 .538 .538 .953 .462 .00 and 1. 00 .317 .316 .458 .812 .00 and 1. 00 .943 .943 .012 1.208 .00 and 1. 00 .996 .994 .926 .776 .00 and 1. 00 .537 .537 .876 .777 .00 and 1. 00 .316 .316 .524 1.238 .00 and 1. 00 .956 .905 .556 1.234 .00 and 1. 00 .523 .523 .798 1.213 .00 and 1. 00 Usia Berat Tinggi Income JamKerja Olahraga Usia Berat Tinggi JamKerja Olahraga Usia Tinggi JamKerja Olahraga Usia JamKerja Olahraga Step 0 1 2 3 Tolerance Min. Tolerance Sig. of F to Enter Min. D Squared Between Groups
terkecil adalah pada variabel INCOME (0,004). Maka variabel INCOME dikeluarkan dari step 0 tersebut, yang berarti variabel tersebut bukan termasuk variabel yang tidak dianalisis.
Pada step 1, sekarang terlihat ada empat variabel, dan proses pengujian terus berjalan, dengan pedoman angka SIG. OF F TO REMOVE harus di bawah 0,05 dan jika mungkin diambil angka yang terkecil. Terlihat variabel BERAT sekarang mempunyai angka SIG. OF F TO REMOVE terkecil (0,026), sehingga variabel tersebut dikeluarkan.
Pada step 2, sekarang terlihat ada tiga angka variabel, dan terlihat variabel TINGGI pada step ini mempunyai angka SIG. OF F TO REMOVE terkecil (0,012), sehingga variabel tersebut dikeluarkan.
Pada step 3, sekarang terlihat hanya ada dua variabel, dan terlihat kedua variabel tersebut mempunyai angka SIG. OF F TO REMOVE di atas 0,05 (yakni 0,524 untuk USIA dan 0,798 untuk OLAHRAGA). Oleh karena sudah tidak ada variabel yang memenuhi syarat, maka proses pengeluaran variabel berhenti, dan kedua variabel sisa tersebut tidak dikeluarkan, yang berarti keduanya termasuk pada VARIABLE NOT IN THE ANALYSIS, atau variabel yang tidak dianalisi lebih lanjut.
Wilks' Lambda 1 .894 1 1 73 8.656 1 73.000 .004 2 .834 2 1 73 7.170 2 72.000 .001 3 .763 3 1 73 7.343 3 71.000 .000 Step 1 2 3 Number of
Variables Lambda df1 df2 df3 Statistic df1 df2 Sig.
Wilk`s Lambda pada prinsipnya adalah varians total dalam dicriminant scores yang tidak bisa dijelaskan oleh perbedaan di antara grup-grup yang ada. Perhatikan tabel di atas yang terdiri atas tiga tahap (step), yang terkait dengan tiga variabel yang secara berurutan dimasukkan pada tahapan analisis sebelumnya.
Pada step 1, jumlah variabel yang dimasukkan ada satu (INCOME), dengan angka wilk`s Lambda adalah 0.894. hal ini berarti 89.4% varians tidak dapat dijelaskan oleh perbedaan antar grup-grup. Kemudian pada step 2, dengan tambahan variabel BERAT (lihat kolom NUMBER OF VARIABLES yang sekarang adalah 2), angka wilk`s Lambda turun menjadi 0,834. dan pada step 3, angka itu turun lagi menjadi 0,763. Penurunan angka wilk`s Lambda tentu baik bagi model diskriminan, karena varians yang tidak bisa dijelaskan juga semakin kecil (dari 89,4% menjadi 76,3%).
Dari kolom F dan signifikansinya, terlihat bik pada pemasukan variabel 1,2 dan kemudian 3, semuanya adalah signifikan secara statistik. Hal ini berarti ketiga variabel tersebut (INCOME, BERAT, dan TINGGI) memang berbeda untuk kedua tipe konsumen.
Canonical Correlation mengukur keeratan hubungan antara discriminant scores dengan grup (dalam hal ini, karena ada dua tipe konsumen, maka ada dua grup). Angka 0,487 menunjukkan keeratan yang cukup tiggi, dengan ukuran skala asosiasi antara 0 sampai 1.
Tabel diatas menyatakan angka akhir wilk`s Lambda, yang sebenarnya sama saja dengan angka terakhir dari step 3 pembuatan model diskriminan (lihat tabel terdahulu). Angka Chi-Square sebesar 19,321 dengan tingkat signifikansi yang cukup tinggi menunjukkan perbedaan yang jelas antara dua grup konsumen (mereka yang BANYAK minum dengan yang SEDIKIT minum).
Eigenvalues
.310a 100.0 100.0 .487
Function 1
Eigenvalue % of Variance Cumulative %
Canonical Correlation
First 1 canonical discriminant functions were used in the analysis. a. Wilks' Lambda .763 19.321 3 .000 Test of Function(s) 1 Wilks'
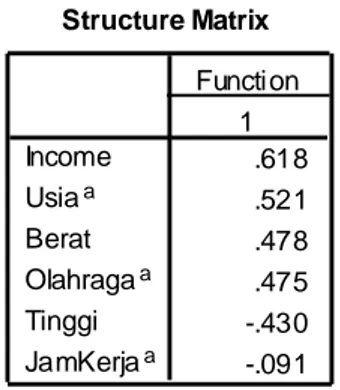
Tabel STRUCTURE MATRIX menjelaskan korelasi antara variabel independen dengan fungsi diskriminan yang terbentuk. Terlihat variabel USIA, BERAT dan seterusnya. Hanya disini variabel USIA dan OLAHRAGA tidak dimasukkan dalam model diskriminan (perhatikan tanda a di dekat variabel tersebut). Perhatikan tanda korelasi yang sama dengan tanda koefisien pada model Discriminant Scores.
Tabel diatas mempunyai fungsi yang hampir mirip dengan persamaan regresi berganda, yang dalam analisis diskriminan disebut sebagai FUNGSI DISKRIMINAN :
z Scores = 7,884 + 0,064 BERAT -0,093 TINGGI +0,006 INCOME.
Structure Matrix .618 .521 .478 .475 -.430 -.091 Income Usiaa Berat Olahragaa Tinggi JamKerjaa 1 Function
Pooled within-groups correlations between discriminating variables and standardized canonical discriminant functions Variables ordered by absolute size of correlation within function.
This variable not used in the analysis. a.
Canonical Discriminant Function Coefficients
.064 -.093 .006 7.884 Berat Tinggi Income (Constant) 1 Function Unstandardized coefficients
Kegunaan fungsi ini untuk mengetahui sebuah case (dalam kasus ini adalah seorang konsumen) masuk pada grup yang satu, ataukah tergolong pada grup yang lainnya.
Selain fungsi di atas, dengan dipilihnya FISHER FUNCTION COEFFICIENT pada proses analisis, maka akan terbentuk pula fungsi diskriminan Fisher (lihat pembahasan selanjutnya).
Oleh karena ada dua tipe konsumen, maka disebut Two-Group Discriminant, dimana grup yang satu mempunyai Centroid (Group Means) negatif, dan grup satunya lagi mempunyai Centroid (Group Means) positif. Angka pada tabel menunjukkan besaran Z yang memisahkan kedua grup tersebut.
Gambar :
Functions at Group Centroids
.542 -.557 Minum .00 1.00 1 Function
Unstandardized canonical discriminant functions evaluated at group means
Terlihat distribusi anggota grup dengan kode 0 (SEDIKIT) dan kode 1 (BANYAK), di mana dari 75 responden, 37 orang ada
3 2 1 0 -1 -2 8 6 4 2 0 Mean = 0.54 Std. Dev. = 0.968 N = 38 Minum = 0
Canonical Discriminant Function 1
3 2 1 0 -1 -2 -3 -4 14 12 10 8 6 4 2 0 Mean = -0.56 Std. Dev. = 1.032 N = 37 Minum = 1
pada grup BANYAK dan 38 orang ada pada grup SEDIKIT (komposisi anggota lihat penjelasan selanjutnya).
Tampilan gambar di atas akan digunakan untuk menentukan apakah seorang responden akan tergolong pada grup SEDIKIT atau BANYAK (lihat penjelasan bagian CASEWISE RESULT).
Classification Statistics
Tabel di atas memperlihatkan komposisi ke 75 responden yang dengan moel diskriminan menghasilkan 37 responden ada di grup BANYAK, sedang sisanya ada di grup SEDIKIT.
Sama seperti tampilan Unstandardized (Canonical) sebelumnya. Fungsi diskriminan dari Fisher pada prinsipnya membuat semacam persamaan regresi, dengan pembagian berdasar pada kode grup :
Mereka yang minum air mineral dalam kategori SEDIKIT :
Prior Probabilities for Groups
.500 38 38.000 .500 37 37.000 1.000 75 75.000 Minum .00 1.00 Total
Prior Unweighted Weighted Cases Used in Analysis
Classification Function Coefficients
.035 -.035 3.587 3.690 .036 .030 -297.882 -306.557 Berat Tinggi Income (Constant) .00 1.00 Minum
SCORE = -297,882 + 0,03506 BERAT +3,587 TINGGI +0,03007 INCOME
Mereka yang minum air mineral dalam kategori BANYAK: SCORE = -306,557 -0,03481 BERAT +3,690 TINGGI +0,03007
INCOME
Selisih di antara grup SEDIKIT dengan BANYAK adalah :
(-297,882+0,03506 BERAT+3,587 TINGGI+0,03641 INCOME) – (-306,557-0,03481BERAT+3,690 TINGGI+0,03007 INCOME)