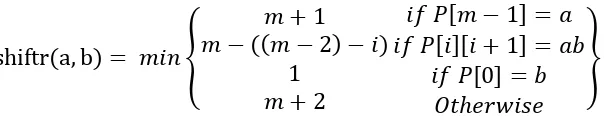BAB 2
LANDASAN TEORI
2.1 Sinonim kata 2.1.1. Definisi Sinonim
Menurut Chaer (2009), “Relasi makna adalah hubungan kemaknaan atau relasi semantik antara sebuah kata atau satuan bahasa lainnya dengan akta atau satuan bahasa lainnya lagi”. Hubungan relasi kemaknaan ini menyangkut hal misalnya sinonim. Secara etimologi, kata sinonimi atau disingkat sinonim berasal dari bahasa Yunani kuno, yaitu onoma yang berarti ‘nama’, dan syn yang berarti ‘dengan’. Untuk mendefinisikan sinonim, ada tiga batasan yang dapat dikemukakan. Batasan atau definisi itu ialah: (i) kata-kata dengan acuan ekstra linguistik yang sama, misalnya kata mati dan mampus; (ii) kata-kata yang mengandung makna yang sama, misalnya kata memberitahukan dan kata menyampaikan; dan (iii) kata-kata yang dapat disubtitusikan dalam konteks yang sama misalnya “ kami berusaha agar pembangunan berjalan terus. “, “ kami berupaya agar pembangunan berjalan terus.” Kata berupaya bersinonim dengan kata berusaha (Pateda, 2010).
2.1.2. Kemunculan Sinonim
Menurut Aminuddin (2008), ada lima cara yang dapat digunakan dalam
menentukan kemungkinan adanya sinonim. Kelima cara yang dimaksud adalah: 1. Seperangkat sinonim itu mungkin saja merupakan kata-kata yang
2. kata tersebut memiliki makna dasar berbeda-beda, kata-kata tersebut tidak dapat ditentukan sebagai sinonim.
3. Suatu kata yang semula dianggap memiliki kemiripan atau kesamaan makna, setelah berada dalam berbagai pemakaian ada kemungkinan membuahkan makna yang berbeda-beda. Kata bisa dan dapat, misalnya, meskipun secara leksikal merupakan sinonim, dalam konteks pemakaian “Saya nanti bisa datang” dan “Saya nanti dapat datang” tetap pula dapat dianggap sinonim. Sewaktu berada dalam konteks pemakaian “Bisa ular itu berbahaya”, kedua kata tersebut tidak dapat lagi disebut sinonim.
4. Suatu kata, apabila ditinjau berdasarkan makna kognitif, makna emotif, maupun makna evaluatif, mungkin aja akhirnya menunjukkan adaya karakteristik tersendiri meskipun dalam pemakaian sehari-hari semula dianggap memiliki kesinoniman dengan kata lainnya. Bentuk demikian misalnya dapat ditemukan dalam pasangan kata ilmu dan pengetahuan, mengamati dan meneliti serta antara mengusap dengan membelai. Apabila hal itu terjadi, maka kata-kata yang semula dianggap sinonim itu harus dianggap sebagai kata yang berdiri sendiri-sendiri.
5. Suatu kata yang semula memiliki kolokasi sangat ketat, misalnya antara kopi dengan minuman maupun pohon dengan batang, seringkali dipakai secara tumpang tindih karena masing-masing dianggap memiliki kesinoniman. Hal itu tentu saja tidak benar karena masing-masing kata tersebut jelas masih memiliki makna sendiri-sendiri. Sebab itu, pemakaian yang tumpang tindih dapat mengakibatkan adanya salah pengertian. 6. Kekurangtahuan terhadap nilai makna suatu kata maupun kelompok kata,
seringkali bentuk kebahasaan yang berbeda-beda begitu saja dianggap sinonim, misalnya antara bentuk kembali ke pangkuan ilahi dengan meninggalkan dunia kehidupan, antara merencanakan dengan menginginkan, serta antara gambaran dengan bayangan.
2.1.3. Jenis - jenis Sinonim
1. Kata dasar bersinonim dengan kata dasar.
cantik : anggun, ayu, elok hidup : jiwa, nyawa, tumbuh
2. Kata dasar tunggal bersinonim dengan kata majemuk
Gelandangan : tunawisma Pembantu : pramuwisma
3. Kata tunggal bersinonim dengan frasa
asmara : cinta berahi, cinta kasih muhibah : cinta kasih, rasa sahabat 4. Kata majemuk bersinonim dengan kata tunggal
awan hitam : mendung sakit hati : kecewa 5. Frase bersinonim dengan frase
tinggi hati : besar kepala merah jambu : merah muda
2.2. Stemming
2.2.1. Definisi Stemming
Stemming merupakan suatu proses yang terdapat dalam sistem IR yang mentransformasi
kata-kata yang terdapat dalam suatu dokumen ke kata-kata akarnya (root word) dengan
menggunakan aturan-aturan tertentu. Sebagai contoh, katabersama, kebersamaan, menyamai,
akan distem ke root word-nya yaitu “sama”. Proses stemming pada teks berbahasaIndonesia
berbeda dengan stemming pada teks berbahasa Inggris. Pada teks berbahasa Inggris, proses yang
diperlukan hanya proses menghilangkan sufiks. Sedangkan pada teks berbahasa Indonesia,
2.2.2. Metode Stemming
Metode stemming memerlukan input berupa term yang terdapat dalam dokumen. Sedangkan outputnya berupa stem. Ada tiga jenis metode stemming, antara lain : 1. Successor Variety (SV) : lebih mengutamakan penyusunan huruf dalam kata
dibandingkan dengan pertimbangan atas fonem. Contoh untuk kata-kata : corpus, able, axle, accident, ape, about menghasilkan SV untuk kata apple:
a. Karena huruf pertama dari kata “ apple” adalah “a”, maka kumpulan kata yang ada substring “a” diikuti “b”, “x”, “c”, “p” disebut SV dari “a” sehingga “a” memiliki 4 SV.
b. Karena dua huruf pertama dari kata “apple” adalah “ap”, maka kumpulan kata yang ada substring “ap” hanya diikuti “e” disebut SV dari “ap” sehingga “ap” memiliki 1 SV.
2. N-Gram Conflation : ide dasarnya adalah pengelompokan kata-kata secara bersama berdasarkan karakter-karakter (substring) yang teridentifikasi sepanjang N karakter.
3. Affix Removal (penghilangan imbuhan) : membuang prefix (awalan) dan suffix (akhiran) dari term menjadi suatu stem. Yang paling sering digunakan adalah algoritma Porter Stemmer karena modelnya sederhana dan efisien.
a. Jika suatu kata diakhiri dengan “ies” tetapi bukan “eies” atau “aies”, maka “ies” di-replace dengan “y”
b. Jika suatu kata diakhiri dengan “es” tetapi bukan “aes” atau “ees” atau “oes”, maka “es” di-replace dengan “e”
c. Jika suatu kata diakhiri dengan “s” tetapi bukan “us” atau “ss”, maka “s” di -replace dengan “NULL”
2.2.3. Porter Stemming
Porter Stemming merupakan salah satu teknik stemming yang umum digunakan. Algoritma Porter adalah cara pencarian root word (kata dasar) yang dilakukan secara stripping imbuhan dan akhiran tanpa memperhatikan sisipin dan tanpa pengecekan kamus kata dasar. Porter Stemmer for Bahasa Indonesia dikembangkan oleh Fadillah Z. Tala pada tahun 2003.
Awal mula Porter Stemmer for Bahasa Indonesia berdasarkan English Porter Stemmer yang dikembangkan oleh W.B. Frakes pada tahun 1992. Karena bahasa Inggris datang dari kelas yang berbeda, beberapa modifikasi telah dilakukan untuk membuat algoritma Porter dapat digunakan sesuai dengan bahasa Indonesia seperti pada gambar 2.1.
word
Remove Particle
Remove Possesive Pronoun
Remove 1st Order Prefix
Remove 2nd Order Prefix Remove Suffix
fall A rule if fired
Remove Suffix Remove 2nd Order Prefix A rule is fired
stem fall
Gambar 2.1. Desain Porter Stemmer (Tala, 2003)
Adapun tahap-tahap algoritma ini adalah : 1. Hapus partikel.
2. Hapus kata ganti kepunyaan. (-ku, -mu, -nya)
3. Hapus awalan pertama. Jika tidak ada, lanjutkan ke langkah 4a, jika ada hapus awalan dan lanjutkan ke langkah 4b.
b. Hapus akhiran, jika tidak ditemukan maka kata tersebut diasumsikan sebagai root word. Jika ditemukan maka lanjutkan ke langkah 5b.
5. a. Hapus akhiran. Kemudian kata akhir diasumsikan sebagai root word. b. Hapus awalan kedua. Kemudian kata akhir diasumsikan sebagai root word.
Ada lima kumpulan aturan pada algoritma Porter Bahasa Indonesia. Aturan tersebut dapat dilihat pada table 2.1 sampai table 2.5. Acuan pemotongan partikel pada infleksi kata bahasa Indonesia dapat dilihat pada tabel 2.1, acuan kata ganti milik orang pertama pada tabel 2.2, kumpulan imbuhan awalan bahasa Indoensia pada tabel 2.3 dan tabel 2.4, serta kumpulan akhiran bahasa Indoneisa dapat dilihat pada tabel 2.5.
Tabel 2.1 Aturan untuk Infection Particle (Tala, 2003)
Akhiran Replacement Additional Condition
Contoh
-lah Null null Pergilah
-kah Null null Mejakah
-tah null null Kursitah
-pun null null makanpun
Tabel 2.2 Aturan untuk Infection Possesive Pronoun(Tala, 2003)
Akhiran Replacement Additional Condition Contoh
-ku null null Pensilku
-mu null null Punyamu
-nya null null miliknya
Tabel 2.3 Aturan untuk First Order Derivational Prefix(Tala, 2003)
Awalan Replacement Addtional Condition Contoh
meng- null null Mengambil
meny- S V...* Menyelesaikan
men- null null Mendaki
mem- P V...* Mempunyai
me- null null Melarang
peng- null null Penghijauan
peny- null null Penyiksaan
pen- null null pendaki
pem- P V.... Pemahat
pem- null null Pembantu
di- null null Diberi
ter- null null terlepas
ke- null null kelaparan
Tabel 2.4 Aturan untuk Second Order Derivational Prefix(Tala, 2003)
Awalan Replacement Additional Condition Contoh
ber- null null Bersalah
bel- null Ajar Belajar
Tabel 2.4 Aturan untuk Second Order Derivational Prefix (lanjutan , Tala, 2003)
Akhiran Replacement Addtional Condition Contoh
per- null null Peralihan
pel- null ajar pelajar
pe- null null Pelatih
Tabel 2.5 Aturan untuk Derivation Suffix(Tala, 2003)
Akhiran Replacement Addtional Condition Contoh
-kan null Prefix bukan anggota ( ke, peng ) Salahkan
-an null Prefix bukan anggota ( di, meng, ter ) Makanan
-i null Prefix bukan anggota ( ber, ke, peng ) tandai
2.3. Stopword
2.3.1. Definisi Stopword
Penghilangan kata-kata yang frekuensinya terlalu banyak terdapat dalam dokumen. Frekuensi kata-kata yang terlalu banyak bukan merupakan kata kunci yang tepat. Faktanya sebuah kata yang frekuensi kemunculannya lebih banyak dari dokumen tidak berguna untuk tujuan retrieval. Kata-kata seperti itu dinamakan stopwords dan biasanya tidak dimasukkan ke dalam index terms. Kata depan dan kata penghubung biasanya menjadi kandidat sebagai stopwords.
2.4. Pattern matching
2.4.1. Definisi Pattern Matching
Pattern Matching adalah suatu teknik pencarian string yang berisi teks atau data biner dari sekumpulan karakter berdasarkan pola yang ingin dicari. Berhubung pengenalan pola (pattern recognition), pencocokan biasanya harus mempunyai nilai yang tepat atau sama.
Beberapa algoritma pencocokan pola yang sering digunakan antara lain Knuth-Moris-Pratt algorithm, Boyer-Moore, Rabin-Karp, Two Sliding Windows dan lain sebagainya.
2.4.2. Algoritma Two Sliding Windows (TSW)
Pada umumnya, algoritma TSW mendeteksi teks dari dua sisi secara bersamaan. Algoritma ini membagi teks menjadi dua bagian (windows) dan tiap bagian memiliki
panjang sebesar n/2 . Bagian kiri (left window) akan melakukan pemindaian dari kiri ke kanan dan bagian kanan (right window) melakukan pemindaian dari kanan ke kiri. Kemudian kedua windows tersebut bekerja bersamaaan secara paralel. Algoritma ini akan berhenti jika salah satu dari windows telah menemukan pola atau pola tersebut tidak ditemukan di dalam keseluruhan teks. Algoritma TSW mengimplementasikan ide dari algoritma Berry-Ravindran mengenai fungsi bad character shift untuk mendapatkan nilai shift pada saat fase pencarian. Disamping itu, algoritma BR juga digunakan oleh Hussain, et al (2010) untuk menentukan nilai pergeseran dan diterapkan pada algoritma pencarian Bidirectional. Perbedaan utama dari algoritma TSW dan algoritma BR antara lain :
1. TSW menggunakan dua slide sementara algoritma BR hanya menggunakan satu slide untuk melakukan pencarian teks.
2. TSW menggunakan dua array , tiap array merupakan array satu dimensi yang memiliki ukuran sebesar m – 1. Array tersebut digunakan untuk menyimpan nilai shift yang sudah terkalkulasi pada proses algoritma. Disamping itu, algoritma BR menggunakan array dua dimensi untuk menyimpan nilai shift pada pemrosesannya. Menggunakan array satu dimensi mempersingkat waktu pemrosesan dan mengurangi pemakaian memori yang diperlukan untuk
2.4.2.1. Pre-processing Phase
Fase pre-processing menghasilkan dua array berupa nextl dan nextr. Nilai dari nextl dihitung berdasarkan algoritma bad character Berry-Ravindran (BR). Nextl berisi nilai shift yang diperlukan untuk mencari teks pada sisi kiri. Untuk menghitungnya, algoritma ini mempertimbangkan dua karakter a dan b berturut-turut yang didapat sesaat setelah pergeseran window selesai. Nilai indeks dari dua karakter tersebut dari dihitung dari sebelah kiri (m+1) dan (m+2) .
Bad char shiftl a, b = � { − �+
+
� [ − ] = � [�][� + ] =
� [ ] = ℎ ��
}
Gambar 2.2. Bad charactershift a dan b pada nextl (Ravindran et al, 1999)
Sedangkan nilai nextr berisi nilai shift yang diperlukan untuk mencari teks pada sisi kanan dan menyimpan nilai indeks dua karakter tersebut dari teks sebelah kanan ( n-m-1) dan (n-m-2).
shiftr a, b = � {
+
− − − �
+
� [ − ] = � [�][� + ] =
� [ ] = ℎ ��
}
Gambar 2.3. Bad character shift a dan b pada nextr (Ravindran et al, 1999)
2.4.2.2. Searching Phase
2.5 Penelitian terdahulu
Berbagai penelitian telah dilakukan untuk menyelesaikan pencarian kata maupun persamaannya dengan algoritma pencarian antara lain :
1. Budhi et al. (2006) menggunakan algoritma Porter Stemmer for Bahasa Indonesia, untuk proses Stemmer pada langkah pre-processing yang merubah sebuah teks dalam bahasa Indonesia menjadi bentuk Compact Transaction. Compact Transaction digunakan sebagai masukan untuk proses Keyword-Based Association Analysis, sebuah metode Text Mining yang dikembangkan dari metode Market Basket Analysis, digunakan untuk membentuk rule-rule asosiasi dari data teks. Hasil pengujian terhadap kesalahan proses 'Stem' kata secara
otomatis cukup kecil, yaitu 2% sehingga dapat diatasi dengan cepat menggunakan pemeriksaan kembali secara manual terhadap hasil Stemmer.
2. Hudaib et al. (2008) melakukan penelitian untuk menerapkan dan membuat sebuah algoritma pattern matching yang cepat.Algoritma tersebut dinamakan algoritma two sliding windows. Penelitian dilakukan dengan menerapkan ide dari algoritma Berry-Ravindran untuk menentukan nilai pergeseran dan menggunakan dua sisi (window) untuk melakukan scanning karakter. Hasil pengujian menunjukkan bahwa performansi terbaik algoritma TSW apabila kata-kata tersebut berada di akhir sebuah dokumen.
3. Tahitoe & Diana (2010) melakukan penelitian terhadap algoritma Enhanced Confix Stripping Stemmer dan mendapati adanya kesalahan yang dilakukan oleh algoritma tersebut karena ECS Stemmer tidak mengajukan perbaikan terhadap permasalahan overstemming dan understemming. Oleh karena itu, diajukan perbaikan dengan menggunakan metode corpus based stemming. Hasil pengujian menunjukkan kesalahan stemming yang dilakukan oleh ECS Stemmer dapat diperbaiki dan penggunaan data fusion dan metode condorcet dapat mempersingkat waktu yang dibutuhkan untuk pembentukan relevan set dalam
4. Firdausiah et al. (2008) mencari sinonim kata berdasarkan pengukuran similaritas semantic berbasis WordNet pada sistem penilaian otomatis jawaban essay menggunakan ontologi moodle. Proses pencarian sinonim menghasilkan beberapa output sinonim berbeda pada level yang berbeda.
5. Putra, Hedryan K.(2013) menerepkan algoritma Karp Rabin dan metode pendekatan sinonim kata untuk mendapatkan tingkat duplikasi dengan tingkat ketelitian tinggi. Akurasi yang dihasilkan cukup tinggi karena pendeteksian dokumen diproses dengan membandingkan kata perkata yang terdapat di dalam dokumen dan membandingkan kata yang memiliki sinonim kata. Penjelasan penelitian sebelumnya dapat dilihat pada tabel 2.6.
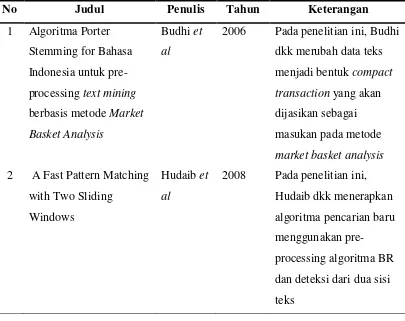
Tabel 2.6 Penelitian terdahulu yang berkaitan dengan pencarian sinonim kata
No Judul Penulis Tahun Keterangan
1 Algoritma Porter Stemming for Bahasa Indonesia untuk pre-processing text mining berbasis metode Market Basket Analysis
Budhi et al
2006 Pada penelitian ini, Budhi dkk merubah data teks menjadi bentuk compact transaction yang akan dijasikan sebagai masukan pada metode market basket analysis 2 A Fast Pattern Matching
with Two Sliding Windows
Hudaib et al
2008 Pada penelitian ini, Hudaib dkk menerapkan algoritma pencarian baru menggunakan pre-processing algoritma BR dan deteksi dari dua sisi
Tabel 2.6 Penelitian terdahulu yang berkaitan dengan pencarian sinonim kata (lanjutan)
No Judul Penulis Tahun Keterangan
3 Implementasi modifikasi Enhanced Confix
Stripping Stemmer
Tahitoe & Diana
2010 Pada penelitian ini, Tahitoe dan Diana menggunakan algoritma ECS dan memperbaiki kinerja algoritma tersebut dengan metode corpus
based stemming 4 Sistem Penilaian
Otomatis Jawaban Essay menggunakan Ontologi Moodle
Firdausiah et al