PENGENALAN TULISAN TANGAN AKSARA SUNDA
MENGGUNAKAN KOHONEN NEURAL NETWORK
Mubarok
Ilmu Komputer
Universitas Pendidikan Indonesia Jl. Dr. Setiabudhi 229 Bandung
ayox060457@yahoo.co.id
Lala Septem Riza MT.
Ilmu Komputer
Universitas Pendidikan Indone sia Jl. Dr. Setiabudhi 229 Bandung
lala_s_riza@yahoo.com
Dr. Wawan Setiawan M.Kom.
Ilmu Komputer
Universitas Pendidikan Indonesia Jl. Dr. Setiabudhi 229 Bandung
pik@upi.edu
ABSTRAK
Aksara Sunda merupakan ciri khas dan warisan leluhur dari suku Sunda yang perlu dilestarikan keberadaannya. Aksara Sunda telah ada sejak 5 abad yang lalu. Saat ini aksara Sunda telah memiliki standar dari Unicode. Oleh karena itu, penulis mengembangkan model dan perangkat lunak p engenalan tulisan tangan aksara Sunda secara real time. Real time atau online merupakan cara pengenalan dari OCR (Optical Character Recognize). Aksara Sunda yang digunakan dalam peneltian ini adalah aksara Sunda Ngalagena yang memiliki 23 jenis karakter. Model dan perangkat lunak yang dibangun menggu nakan feature extraction zoning dan mempertimbangkan panjang guratan. Algoritma yang digunakan adalah algoritma kohonen neural network. Kohonen neural network termasuk unsupervised learning (pembelajaran tak terawasi) dengan mempelajari himpunan distribusi pola-pola tanpa informasi kelas. Dari hasil pengujian dengan guratan normal didapat akurasi tertinggi sebesar 77,39% dengan akurasi rata-rata sebesar 75,36%. Pengujian terhadap guratan noise diperoleh akurasi sebesar 76,52% dengan akurasi rata-rata sebesar 75,36%.
ABSTRACT
Sundanese script is typical and Sundanese heritage of the need to preserve its existence. Sundanese script has been around since the 5th century ago. Currently Sundanese script has the Unicode standard. Therefore, the authors develop ed a model and handwriting recognition software Sundanese script in real time. Real time or online is a way of introduction of OCR ( Optical Character Recognize). Sundanese script used in this research is Ngalagena Sundanese script that has 23 types of char acters. Models and software that is built using feature extraction to zoning and consider the long strokes. The algorithm used is the Kohonen neural network algorithm. Kohonen neural network, including unsupervised learning (unsupervised learning) by studying the distribution patterns of the set without class information. From the test results obtained with normal strokes in the highest accuracy of 77.39% with an average accuracy of 75.36%. Tests on the stroke of noise obtained accuracy of 76.52% with an average accuracy of 75.36%.
Kategori dan Deskripsi Subjek
D.3.3 [Kecerdasan Buatan]: Pengenalan Tulisan Tangan Aksara Sunda; menghitung akurasi sistem.
Ketentuan Umum
Teori
Kata Kunci
Unicode aksara Sunda, Kohonen Neural Network, Unsupervised learning, OCR—Online
1.
PENDAHULUAN
Perkembangan teknologi saat ini mempunyai peranan penting dalam kehidupan manusia. Teknologi merupakan hasil dari pemikiran dan ide manusia. Teknologi diciptakan bukan untuk mempersulit, melainkan untuk membantu dan mempermudah kehidupan manusia serta dapat “memanusiakan” manusia.
Kecanggihan teknologi telah membuat banyak perubahan pada diri manusia. Salah satu kecanggihan teknologi tersebut adalah komputer dengan input-an dari keyboard. Dahulu komputer merupakan alat hitung dan alat ketik. Namun seiring dengan berjalan waktu, komputer telah berubah menjadi alat yang dapat melakukan berbagai proses antara lain menghitung, menyimpan data, mengolah data, pengolahan citra atau gambar, sistem pakar, sistem cerdas, game dan sebagainya.
Perkembangan teknologi saat ini tidak hanya terpaku pada teknologi dengan input-an dari keyboard. Saat ini telah diciptakan teknologi dengan input-an berupa touchscreen atau menulis langsung pada layar tanpa menggunakan bantuan keyboard. Namun, dalam aplikasin ya belum terdapat konten berupa aksara -aksara kuno seperti -aksara Sunda.
Oleh karena itu, penulis dalam paper ini mencoba mengembangkan model dan aplikasi dengan aksara Sunda sebagai studi kasus serta menggunak an algoritma kohonen .
Kohonen atau Self Organizing Map (SOM) pertama kali
dikenalkan oleh Teuvo Kohonen pada awal tahun 1980 -an. Metode kohonen termasuk unsupervised learning dengan memperlajari himpunan distribusi pola -pola tanpa informasi kelas.
Aksara Sunda merupakan studi kasus dalam penelitian ini. Saat ini penelitian mengenai pengenalan tulisan tangan aksara Sunda masih relatif sedikit, karena aksara Sunda di gunakan hanya pada kalangan tertentu (misalnya masyarakat Jawa Barat). Aksara Sunda telah ada sejak 5 abad yang lalu yang merupakan hasil karya ortografi masyarakat Sunda. Saat ini aksara Sunda telah memiliki standar dari Unicode.
Penelitian ini diharapkan dapat menjadi langkah awal dalam pengembangan aplikasi selanjutnya yang menggunakan karakter aksara Sunda, dan juga diharapkan dapat melestarikan kebudayaan Sunda.
2.
PENGEMBANGAN SISTEM MODEL
2.1 Pengenalan Aksara Sunda
aksara Sunda adalah hasil karya ortografi masyarakat Sunda. Aksara Sunda sudah ada sejak sekitar abad 5 M yang lalu pada masa Kerajaan Tarumanagara. Hal itu tampak pada prasasti-prasasti dari zaman itu yang sebagian besar telah dibicarakan oleh Kern (1917) dalam buku yang berjudul Versvreide Geschriften; Inschripties van den Indichen Archipel. Karya tersebut memuat cukup lengkap data-data inskripsi dan facsimile disertai peta arkeologis yang cukup jelas [2]
Secara umum lambang aksara Sunda dapat digolongkan ke dalam kelompok aksara swara, aksara Ngalagena, aksara khusus, aksara rarangken, pasangan, dan angka [2].
Berikut ini adalah daftar aksara Sunda Ngalagena yang telah distandardisasi Unicode:
Tabel 2.1 Daftar aksara Sunda Ngalagena (http://www.unicode.org/charts/PDF/U1B80.pdf ) [2] KODE KARAKTER NAMA AKSARA SUNDA 1B8A k KA 1B8B q QA 1B8C g GA 1B8D g NGA 1B8E c CA 1B8F j JA 1B90 z ZA 1B91 j NYA 1B92 t TA 1B93 d DA 1B94 n NA 1B95 p PA 1B96 f FA 1B97 v VA 1B98 b BA 1B99 m MA 1B9A y YA 1B9B r RA 1B9C l LA 1B9D w WA 1B9E s SA 1B9F x XA 1BA0 h HA
Dilihat dari kebiasaan cara penulisan , berikut adalah cara panulisan aksara Sunda Ngalagena:
Gambar 2.1 Cara penulisan Aksara Sunda Ngalagena [2]
2.2 OCR (Optical Character Recognize)
Optical Character Recognition (OCR) merupakan sistem yang dapat mengenali tulisan baik itu tulisan cetak (ketik, scan) maupun tulisan tangan. Untuk mengenali tulisan, O CR memiliki 2 cara, yaitu off-line dan on-line. Off-line merupakan cara pengenalan tulisan dengan input-an berupa gambar hasil scan. Sedangkan on-line adalah cara pengenalan tulisan dengan mengenali tulisan tangan langsung dengan input-an berupa coretan atau guratan tulisan yang ditulis real time pada media penulisan digital.
Secara umum tahapan pengenalan tulisan sistem OCR
on-line dapat dilihat pada gambar berikut:
Gambar 2.2 Tahapan sistem OCR on-line [4] 2.3 Image Processing
Image prosesing memiliki beberapa tipe untuk memproses gambar, namun dalam penelitian ini yang digunakan dalam proses pengolahan gambar antara lain segmentasi dan
scalling, Online input Feature extraction Classifier/Clustering Classifier/Clustering Result Image processing
2.3.1 Segmentasi
Bertujuan untuk men-segmen atau capture gambar agar dapat dilakukan proses pemotongan gambar [1]. Proses segmentasi dilakukan dengan mencari batas daerah gambar yang akan di-capture, mulai dari batas atas, batas bawah, batas kanan dan batas kiri.
Proses segmentasi diawali dengan men-scan gambar dari kiri ke kanan dan dari atas ke bawah. Proses scan adalah untuk mengetahui awal terdapatnya pi ksel hitam sampai selanjutnya bertemu pada pixel hitam yang terakhir pada gamabr. S etelah proses scan selesai, selanjutnya melakukan pengkotakan atau pembatasan daerah gambar ya ng memiliki pixel hitam.
2.3.2 Scalling
scalling adalah proses untuk mengubah ukuran suatu image [1]. Scalling merupakan proses menormalisasikan ukuran
sehingga ukuran yang di peroleh selalu sama walaupun ukuran tulisan atau gambar tidak sama (besar atau k ecil). Dalam penelitian ini ukuran gambar dari hasil scalling di-set ke dalam dimensi 11x11.
.
2.4 Feature Extraction
Feature extraction bertujuan untuk mendapatkan karakteristik suatu karakter yang membedakannya dari karakter lain, yang disebut dengan feature [5]. Pada penelitian ini feature
extraction yang digunakan adalah zoning. Zoning merupakan salah satu Feature Extraction dari tipe statistical feature. Metode zoning adalah membagi karakter menjadi N x M
wilayah. Dari setiap wilayah, feature diekstraksi untuk membentuk feature vector. Tujuan zoning yaitu memperoleh
karakteristik lokal disamping karakteristik global.
Gambar 2.3 Metode Zoning [7]
Untuk mendapatkan karakteristik karakter, digunakan pula menghitung panjang guratan. Hasil dari penghitungan panjang guratan adalah angka desimal yang dikonversi ke biner(0,1) sebanyak 12 digit. Jadi, hasil dari feture extraction (zoning dan hitung panjang guratan) adalah sebanyak 133 digit .
Berikut adalah contoh dari hasil feature extraction (zoning dan hitung panjang guratan).
Tabel 2.2 contoh hasil feature extraction
Guratan Feature extraction Hasil 1111111100000000011000000000100000000 0110000000011000000001100000000110000 0000010000000001100000000010000000001 11 11111111 000110010110 001111111100010000000000100000000011 000000000100001111101000000001010000 000011100000000110000000001100000000 011 1111111111 001011101010 Guratan Feature extraction Hasil 11111110000 0000011000000000100000000 0110000000001000000 00011011111000100 00001 0001000000100110000001001000000 0100111111111 000110110010
Gambar berikut adalah gambaran mengenai proses penghitungan panjang guratan.
Gambar 2.4 Hitung panjang guratan [7]
Gambar 2.4 menjelaskan mengenai bagaiman a representasi dari penghitungan panjang guratan.
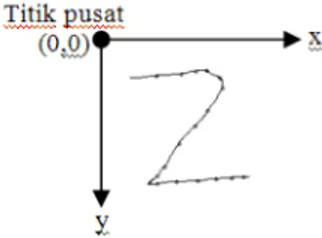
Sebelum melangkah jauh pada proses penghitungan panjang guratan, terlebih dahulu penulis mencerita bagaiman a representasi image pada aplikasi yang dibangun. Terlihat pada gambar 2.4 titik pusat (0,0) terdapat di atas. Panjag dari sumbu x adalah semakin ke kanan nilai x akan sema kin besar. Sedangkan pada sumbu y, semakin ke bawah maka nilai y akan semakin bertambah. Ini berpeangaruh pada penghitungan panjang guratan yang mana pada proses penghitungan panjang guratan akan membutuhkan koordinat (x,y) untuk mendapat hasil penghitunga n akhir.
Proses penghitungan panjang guratan dimulai dari awal dilakukannya pengguratan (pertama kali mouse diguratkan) dilakukan sampai terus menerus hingga berakhirnya di lakukannya guratan. Proses penghitungan guratan menggunakan
eucledian distance. Berikut adalah rumus eucledian distance yang
digunakan.
………(2.1)
.
2.5 Kohonen
Kohonen atau Self Organizing Map (SOM) pertama kali
dikenalkan oleh Teuvo Kohonen pada awal tahun 1980 -an. Metode kohonen termasuk unsupervised learning dengan memperlajari himpunan distribusi pola -pola tanpa informasi kelas.
Algoritma kohonen yang digunakan adalah sebagai berikut:
Gambar 2.6 Alur algoritma kohonen (modifikasi)[5]
3.
PENGUJIAN
Pengujian dilakukan dengan menggunakan perang kat lunak yang telah dibuat dengan skenario sebagai berikut:
1. Pengujian untuk mengetahui akurasi pengenalan tulisan tangan aksara Sunda Ngalagena dengan menggunakan algoritma kohonen neural network
2. Pengujian untuk mengetahui akurasi pengenalan tulisan tangan aksara Sunda Ngalagena dengan menggunakan algoritma kohonen neural network dengan noise.
3.1 Akurasi Pengenalan Tulisan Tangan Aksara Sunda Ngalagena Dengan Guratan Normal
Sebelum melakukan proses pelatihan dan pengenalan, nilai parameter yang digunakan dalam algoritma kohonen meliputi bobot(acak) dengan bilangan random antara 0 dan 1,
learning rate = 0.5, pengurang learning rate = 0.3, MaxEpoch =
1000.
Proses pengujian akurasi dilakukan sebanyak 3 kali dengan jumlah data training masing-masing 230, 460, dan 690. Pengujian dilakukan oleh tiga penguji yang berbeda dan memiliki karkateristik penulisan yang berbeda. Data uji yang dimasukkan oleh setiap penguji berjumlah 115 per data training. Untuk data
training 230, data uji yang digunakan berjumlah 345 (dari 3
penguji) begitu pun untuk data training 460 dan 690, data uji yang digunakan berjumlah 345. Berikut adalah contoh penulisan guratan normal yang digunakan dalam pengujian.
Gambar 3.1 Contoh penulisan guratan normal
Tabel berikut memperlihatkan akurasi pengenalan dengan guratan normal.
Tabel 3.1 Akurasi pengenalan dengan guratan normal
No Pengujian Jumlah Data Pengenalan Akurasi
Training Uji Benar Salah
1 1 230 345 267 78 77,39% 2. 2 460 345 259 86 75,07% 3 3 690 345 254 91 73,62% Rata-rata 75,36%
Dari tabel 3.1 dapat dilihat bahwa hasil akurasi tertinggi sebesar 77,39% dan rata-rata akurasi sebesar 75,36%. Dari hasil pengamatan, hasil akurasi yang didapat dipengaruhi ol eh mood penguji yang pada saat itu dirasa kurang menikmati pengujian yang terlalu lama dan banyak data yang diuji. Juga dipengaruhi oleh hasil ekstraksi ciri dan cluster yang dihasilkan yang berakibat pada pengenalan sering mengalami kesalahan. Tidak hanya itu hasil yang didapat juga dipengaruhi oleh kualitas data
sample yang digunakan.
3.2 Akurasi Pengenalan Tulisan Tangan Aksara Sunda dengan Noise
Nilai parameter yang digunakan dalam pengujian ini sama dengan pengujian dengan guratan normal yakni bobot (a cak),
learning rate = 0.5, pengurang learning rate = 0.3 dan MaxEpoch
= 1000.
Proses pengujian akurasi dilakukan sebanyak 3 kali dengan jumlah data training masing-masing 230, 460, dan 690. Pengujian dilakukan oleh seorang penguji. Data uji yang
Mulai Data hasil feature extraction Inisialisasi 1.Bobot (acak) 2.Learning rate (α) 3.Pengurang learning rate 4.MaxEpoch Berhenti = salah Selesai
Hitung kedekatan dengan:
Tentukan indeks j sedemikian sehingga
djminimum
Modifikasi bobot dengan:
Modifikasi learning rate dengan: Data
berjumlah 115 per data training. Berikut adalah contoh sampel tulisan tangan dengan noise.
Gambar 3.2 Contoh penulisan dengan noise
Tabel berikut memperlihatkan akurasi pengenalan dengan guratan normal.
Tabel 3.3 akurasi pengenalan tulisan tangan dengan noise
No Pengujian Jumlah Data Pengenalan Akurasi
Training Uji Benar Salah
1 1 230 115 88 27 76,52% 2. 2 460 115 88 27 76,52% 3 3 690 115 84 31 73,04% Rata-rata 75,36% Dari tabel 3.2 didapat hasil akurasi tertinggi sebesar 76,52% dan akurasi rata-rata sebesar 75,36%. Hasil yang dicapai ini dipengaruhi oleh noise yang dilakukan pada waktu pengujian sehingga saat dilakukan ekstraksi ciri tidak dapat menghasilkan ciri yang sesuai atau yang seharusnya pada penulisan normal.
4
KESIMPULAN
Dari pembahasan dan analisis pengujian di atas dapat disimpulkan bahwa model dan aplikasi yang dikembangkan telah mampu menjalankan proses pengenalan tulisan tangan aksara Sunda dengan akurasi tertinggi pada pengujian guratan normal adalah sebesar 77,30% dan rata -rata akurasi sebesar 75,36% sedangkan pada pengujian menggunakan noise didapat akurasi tertinggi sebesar 76,52% dengan rata -rata akurasi sebesar 75,36%
5.
DAFTAR PUSTAKA
[1] Asworo. 2010. Perbandingan antara metode kohonen
Neurall network dan learning vector Quan tization pada sistem pengenalan Tulisan tangan secara real time .
Surabaya: Institut Teknolo gi Sepuluh November. [Online]. Tersedia:
http://digilib.its.ac.id/bookmark/9299/real [26 Mei 2010]
[2] Baidillah, Idin, dkk. 2008. Direktori Aksara Sunda untuk Unicode. [Online]. Tersedia :
http://sabilulungan.org/aksara/.../Direktori_Aksara_Sun
da_untuk_ Unicode.pdf [14 Maret 2010]
[3] Heaton, Jeff. 2005. Introduction to Neural Networks
with Java. New York: Heaton Research, Inc.
[4] Karundeng, brian,dkk. An Evaluation Of Feature Extraction Algorithms For Automatic Language Transcription System For Ancient Handwriting Javanese Manuscripts. Jakarta: Swiss German University.
[5] Kusumadewi, Sri. 2009. Pengenalan Artificial Neural
Network. Handout kuliah. Bandung: Institut Teknologi
Bandung.
[6] Siong, Ang Wie., Resmana. 1999. Pengenalan Citra Objek Sederhana Dengan Menggunakan Metode Jaringan Saraf Tiruan Som. Prosiding Seminar Nasional I Kecerdasan Komputasional Universitas Indonesia, 20 -21 Juli 1999. Surabaya: Universitas Kristen Petra. [Online]. Tersedia:
http://fportfolio.petra.ac.id/user_files/91
-024/som-image-recog.doc [27 Februari 2010]
[7] Vamvakas, Giorgos. Optical Character Recognition for
Handwritten Characters . Athens: Institute of Informatics and Telecommunications.
![Tabel 2.1 Daftar aksara Sunda Ngalagena (http://www.unicode.org/charts/PDF/U1B80.pdf ) [2] KODE KARAKTER NAMA AKSARA SUNDA 1B8A k KA 1B8B q QA 1B8C g GA 1B8D g NGA 1B8E c CA 1B8F j JA 1B90 z ZA 1B91 j NYA 1B92 t TA 1B93 d DA 1B94 n NA 1B95 p PA 1B96 f FA 1](https://thumb-ap.123doks.com/thumbv2/123dok/4171189.2840349/2.918.487.816.118.407/tabel-daftar-aksara-sunda-ngalagena-unicode-karakter-aksara.webp)
![Gambar 2.6 Alur algoritma kohonen (modifikasi)[5]](https://thumb-ap.123doks.com/thumbv2/123dok/4171189.2840349/4.918.95.445.142.909/gambar-alur-algoritma-kohonen-modifikasi.webp)
