BAB 2
LANDASAN TEORI
2.1 Sistem
Kata sistem mempunyai beberapa pengertian, tergantung dari sudut pandang mana kata tersebut didefinisikan. Pendekatan sistem yang lebih menekankan pada elemen-elemen atau kelompoknya, yang dalam hal ini sistem itu didefinisikan sebagai suatu jaringan kerja dari prosedur-prosedur yang saling berhubungan, berkumpul bersama-sama untuk melakukan suatu kegiatan atau untuk menyelesaikan suatu aturan tertentu [4].
2.2 Informasi
Informasi adalah data yang sudah diolah menjadi sebuah bentuk yang berarti bagi pengguna, yang bermanfaat dalam pengambilan keputusan saat ini atau mendukung sumber informasi. Data belum memiliki nilai sedangkan informasi sudah memiliki nilai [4].
2.3 Analisis
Analisis dapat didefinisikan sebagai penguraian dari suatu sistem informasi yang utuh ke dalam bagian-bagian komponennya dengan maksud untuk mengidentifikasi dan
mengevaluasi permasalahan, kesempatan dan hambatan yang terjadi serta kebutuhan-kebutuhan yang diharapkan sehingga dapat diusulkan perbaikan-perbaikannya [4].
2.4 Query
Query adalah satu atau beberapa kata atau frase / kalimat yang di masukan / di ketikan oleh pengguna saat melakukan pencarian pada search engine (google atau search engine lainnya).
2.5 Search Engine
Search engine adalah aplikasi yang didesain untuk mencari informasi dari world wide web/ internet. Internet terdiri dari triliun data dan informasi dalam jutaan server dan lokasi yang tersebar luas. Search engine menkoleksi data, gambar, informasi dalam bentuk indeks. Informasi yang disajikan dalam bentuk daftar kepada pencari berdasarkan info yang diberikan oleh pencari.
Cara kerja search engine berdasarkan urutan berikut ini: 1. Web Crawling
2. Indexing 3. Searching
Web crawler (disebut juga spider) adalah program komputer yang melihat-lihat/browse halaman web serta mengikuti setiap link di halaman tersebut, dan kemudian menyimpannya dalam indeks di server search engine. Isi dari halaman tersebut dianalisa untuk mendapatkan index kata-kata dari judul, header, dan meta tag. Index memungkinkan hasil query yang sepandan dengan cepat.
Saat pengguna menuliskan pertanyaan (query) ke search engine, maka search engine akan searching (mengevaluasi) index dan memberikan daftar halaman web yang paling sesuai dengan pertanyaan (query), beserta ringkasan singkat yang terdiri dari judul dokumen dan sebagian dari teks.
2.6 Hostname
Nama dari komputer dalam Internet, digunakan untuk menunjukkan skema penamaan URL. Pemberian nama ini spesifik, untuk satu komputer tertentu saja dalam suatu jaringan .Karena sifatnya yang unik, maka dalam satu jaringan tidak boleh ada 2 atau lebih hostname yang sama. Jika terjadi penamaan yang sama, maka sistem akan memberitahukan bahwa telah terjadi duplikasi nama. Tapi jika komputer tidak saling terkoneksi ke jaringan memberikan nama komputer yang sama tidak masalah.
2.7 URL (Uniform Resource Locator)
Pengertian URL (Uniform Resource Locator) adalah rangkaian karakter menurut suatu format standar tertentu, yang digunakan untuk menunjukkan alamat suatu sumber seperti dokumen dan gambar di Internet.URL pertama kali diciptakan oleh Tim Berners-Lee pada tahun 1991 agar penulis-penulis dokumen dokumen dapat mereferensikan pranala ke World Wide Web.Sejak 1994, konsep URL telah dikembangkan menjadi istilah Uniform Resource Identifier (URI) yang lebih umum sifatnya.
URL/URI terdiri atas nama domain plus protocol yang digunakan untuk membuka domain tersebut. Sebagai contoh, edutechnolife.com adalah domain, sedangkan http://edutecnolife.com adalah URL/URI.
2.8 HTML (Hypertext Markup Language)
HTML merupakan standard bahasa yang digunakan untuk menampilkan document web, yang bisa anda lakukan [1] :
1. Mengontrol tampilan dari web page dan content-nya.
2. Mempublikasikan document secara online sehingga bisa di akses di seluruh dunia
3. Membuat online form yang bisa di gunakan untuk menangani pendaftaran, transaksi secara online.
4. Menambahkan object-object seperti image, audio, video dan juga java applet dalam document HTML.
Browser merupakan software yang di install di mesin client yang berfungsi untuk menterjemahkan tag-tag HTML menjadi halaman web. Browser yang sering di gunakan biasanya Internet Explorer, Netscape Navigator dan masih banyak yang lainya [8].
Program yang di gunakan untuk membuat document HTML, ada banyak HTML editor yang bisa anda gunakan diantaranya: Ms FrontPage, Dreamweaver, Notepad.
2.8.1 Tag-Tag HTML
Command HTML biasanya disebut TAG, TAG digunakan untukmenentukan tampilan dari document HTML.
<BEGIN TAG>..</END TAG>
Contoh: Setiap dokumen HTML di awali dan di akhiri dengan tag HTML. <HTML>
. . .
Tag tidak case sensitive, jadi bisa gunakan <HTML> atau <html> keduanya menghasilkan output yang sama.
Bentuk dari tag HTML sebagai berikut: <ELEMENT ATTRIBUTE = value>
1. Element - nama tag 2. Attribute - atribut dari tag 3. Value - nilai dari atribut. Contoh:
<BODY BGCOLOR=red>
BODY merupakan element, BGCOLOR(Background) merupakan atribut yang digunakan untuk memberikan suatu warna pada background HTML .
2.8.2 Struktur HTML Dokumen
Dokumen HTML bisa di bagi mejadi tiga bagian utama:
1. HTML
Setiap document HTML harus di awali dan di tutup dengan tag HTML <HTML>..</HTML>
Tag HTML memberi tahu browser bahwa yang di dalam kedua tag tersebut adalah dokumen HTML.
2. HEAD
Bagian header dari dokumen HTML di apit oleh tag <HEAD></HEAD> di dalam bagian ini biasanya dimuat tag TITLE yang menampilkan judul dari halaman pada title-nya browser.
Selain itu Bookmark juga megunakan tag TITLE untuk memberi mark suatu web site. Browser menyimpan “title” sebagai bookmark dan juga untuk keperluan pencarian (searching) biasanya title di gunakan sebagai keyword.
Header juga memuat tag META yang biasanya di gunakan untuk menentukan informasi tertentu mengenai document HTML, anda bisa menentukan author name, keywords, dan lainyan pada tag META.
Contoh:
<META name=”Author” contents=”Joe Ramone”> Author dari document tersebut adalah “Joe Ramone”
Atribut http-equiv dapat di gunkan untuk meletakkan nama HTTP Server atribut untuk menciptakan HTTP header.
Contoh:
<META http-equiv=”Expires” content=”Wed, 7 May 2003 20:30:40 GMT”>
yang akan menciptakan HTTP header : Expires: Wed, 7 May 2003 20:30:40 GMT
Sehingga jika documents di cached, HTTP akan megetahui kapan untuk meng-update document tersebut pada cache.
3. BODY
Document body di gunakan untuk menampilkan text, image link dan semua yang akan di tampilkan pada web page.
<html> <head>
<title>Welcome to HTML</title> </head>
<body bgcolor="red">
<p>Document HTML yang Pertama</p> </body>
</html>
2.9 Text Mining
Text mining mengembangkan banyak teknik seperti Data Mining, Information Retrieval, Machine Learning, dan sebagainya. Sumber data yang digunakan pada text mining adalah kumpulan teks yang memiliki format yang tidak terstruktur atau minimal semi terstruktur [10]. Text mining merupakan proses ekstraksi pola atau pengetahuan yang menarik dan baru dari digital library, pesan dalam email, dan halaman website. Saat ini bidang text mining semakin berkembang karena informasi yang tersedia sebagian besar tersimpan dalam koleksi dokumen dari berbagai sumber misalnya artikel berita, paper penelitian, buku-buku, majalah, koran, dan website. Pada penelitian skripsi ini, sumber data yang digunakan adalah website. Jika sumber data berbentuk paper maka harus diubah ke dalam data digital. Alasan lainnya adalah data yang diperoleh dari website sudah lebih banyak dan menggunakan dua bahasa.
2.10 Corpus
Corpus adalah repositori dari kumpulan materi bahasa alami, seperti teks, paragraf, dan kalimat dari satu atau banyak bahasa. Dua jenis corpora (jamak dari "corpus") telah digunakan dalam terjemahan query [12]:
1. Parallel Corpora
Parallel corpora terdiri dari teks yang sama di lebih dari satubahasa. Kesejajaran parallel corpus dijelaskan untuk menunjukkan secara tepatkalimat dari bahasa sumber sesuai dengan kalimat dari teks sasaran. Ketikamengambil teks dari parallel corpus, query dalam hal ini tidak perlu diterjemahkan, karena query bahasa sumber dapat dicocokkan dengan komponen bahasa sumber dari corpus, dan kemudian komponen bahasa target sejalan dengan itu dapat diambil dengan mudah. Parallel corpora dapat diisi menggunakan terjemahan manusia, situs Web dalam lebih dari satu bahasa atau menggunakan metode MT.
2. Comparable Corpora
Comparable corpora berisi teks di lebih dari satu bahasa. Teks-teks dalam bahasa masing-masing tidak terjemahan satu sama lain,tapi menutupi area topik yangsama, dan karenanya mengandungkosa kata yang setara. Sejumlah teknik statistik dapat digunakan untuk mendapatkan topik-spesifik (disebut teknis) kamus dwibahasa dari paralel corpora.
Corpus merupakan kumpulan teks berupa kata atau kalimat dalam ukuran besar dan terstruktur. Corpus dapat berisi text dalam satu bahasa (corpus monolingual) atau berbagai macam bahasa (corpus multilingual) dan dapat disimpan dalam bentuk file text. Salah satu kegunaan corpus yaitu sebagai data training untuk mendukung probabilistic
translation model yang dibutuhkan oleh Cross Language Information Retrieval (CLIR) dan Machine Translation (MT).
Dalam menerjemahkan suatu bahasa ke bahasa lain, mesin translasi membutuhkan kaidah penerjemahan. Corpus kerap sekali disamakan dengan dictionary [3]. Perbedaan diantara keduanya yaitu:
1. Berdasarkan kriteria isi, corpus lebih fleksibel dibanding dengan dictionary karena kriteria isi dari corpus tergantung user (independent), misalnya penggunaan corpus dapat dilakukan berdasarkan kata, kalimat, bunyi, atau arti. Sedangkan dictionary bersifat konsisten karena isinya tidak berubah, hanya berupa kata atau kalimat.
2. Berdasarkan fungsinya, corpus tidak digunakan untuk menerjemahkan suatu kata atau kalimat tetapi corpus digunakan sebagai data mentah atau row data yang digunakan oleh mesin translasi sedangkan dictionary dapat langsung digunakan oleh user untuk menerjemah kata sesuai dengan kebutuhan user.
Beberapa contoh corpus yang pernah dibangun menurut [7] diantaranya yaitu:
1. English - Norwegian corpus terdiri dari teks asli bahasa Inggris dan Norwegia yang diambil dari buku fiksi dan non-fiksi. Jumlah kata-kata di dalamnya mencapai 2,6 juta kata. Data pada corpus dikumpulkan sekitar tahun 1994 sampai 1997.
2. English – Swedish corpus memiliki kesamaan dengan English –Norwegian corpus yakni data pada corpus diambil dari buku fiksi dan non-fiksi. Jumlah kata-kata di dalamnya mencapai 2,8 juta kata. Data pada corpus dikumpulkan sekitar tahun 1997 sampai 2001.
3. Hunglishcorpus terdiri dari parallel text antara bahasa Hungarian dan bahasa Inggris yang datanya diambil dari literatur, buku agama, perundang-undangan, dokumentasi perangkat lunak, majalah, dan berita-berita.
4. English - Chinese corpus terdiri dari teks asli bahasa Inggris dan China. English - Chinese corpus dikembangkan oleh Wu Dekai sekitar tahun 1994. Corpus ini digunakan untuk men-train model translasi untuk menerjemahkan query pada Chinese-English Cross Language Information Retrival (CLIR).
French – English corpus terdiri dari teks asli bahasa Inggris dan Prancis. French-English corpus berisi kira-kira 50 juta kata. Tujuan dari French-English corpus adalah untuk men-train model translasi untuk menerjemahkan query pada French-English Cross Language Information Retrival (CLIR).
2.11 Parallel Text
Parallel text merupakan koleksi dari pasangan teks yang menunjukkan pasangan teks dari dua bahasa [5]. Dengan kata lain, parallel text merupakan kumpulan pasangan text dari dua bahasa yang memiliki makna yang sama. Pada [6] juga dijelaskan bahwa parallel text menunjukkan terjemahan yang mendekati aslinya.
2.11.1 Parallel Text pada English - Chinese Corpus
Tahapan yang dilakukan untuk menghasilkan corpus berisi parallel text untuk bahasa Cina dan bahasa Inggris yaitu [2]:
2.11.1.1 Fetching File Name
Fetching file name adalah proses mencari site yang memiliki parallel text. Proses dilakukan dengan mengirim query ke search engine. Isi dari query yang diberikan adalah namahostname, host:hostname, sebagai contoh www.wikipedia.com. Hasil akhir dari proses ini adalah alamat URL dari namahostname yang telah dikirimkan ke search engine.
2.11.1.2 Pair Scan
Setelah fetching filename, tahapan kedua yang dilakukan adalah pair scan. Pair scan merupakan proses mencari pasangan web page. Setiap pasangan web page memiliki dua bahasa. Untuk mencari pasangan web page, terdapat dua cara yang dapat dilakukan, yaitu:
1. Berdasarkan Nama Web Page
Pasangan web page mempunyai nama yang mirip bahkan sama. Biasanya perbedaannya terletak pada penamaan web page yang mencirikan bahasanya. Contoh, "file-ch.html" (Chinesse) vs. "file-eng.html" (English).
2. Berdasarkan Alamat URL
Pasangan web page mempunyai alamat url yang dapat mencirikan bahasanya. Sebagai contoh, .../Ch/.../file.html" vs. ".../Eng /.../file.html. Pola nama dari web page tersebut sering digunakan oleh webmaster untuk mengorganisasi web-nya, sehingga dapat diasumsikan bahwa pasangan webpage yang mempunyai polatersebut, memiliki parallel text.
Tahap ini dilakukan dengan menggunakan bantuan spider boot.Spiderbootakan menjelajahi setiap web page pada alamat URLyang diberikan oleh user. Hasil yang didapat adalah jumlah alamat URL dari pasangan web page.
2.11.1.3 Verified dan Download
Setelah pair scan selesai dilakukan, maka tahap selanjutnya adalah tahap verifikasi web page yaitu proses menentukan ukuran, bahasa dan karakter dari sebuah web page. Pasangan web page biasanya mempunyai size dan line of code yang hampir sama, sehingga apabila terdapat pasangan file yang mempunyai size dan line of code yang jauh berbeda maka akan di eliminasi. Setelah dilakukan verifikasi terhadap web page, maka web page akan diunduh (download). Hasil akhir dari tahap ini adalah seluruh pasangan web page pada site.
2.11.1.4 Parallel Text Alignment
Parallel text alignment merupakan proses menentukan parallel text dari pasangan web page yang telah diunduh. Cara yang dilakukan adalah dengan menggunakan HTML Structure and Alignment.
HTML Structure and Alignment merupakan proses mensejajarkan pasangan web page berdasarkan struktur HTML (Hypertext Markup Language). Hal ini dilakukan dengan cara memberikan penomoran pada setiap tag HTML dan setiap tag HTML pada web page untuk bahasa China dibandingkan dengan tag HTML yang ada pada web page untuk bahasa Inggris sesuai dengan nomor yang telah ditentukan.
1. Parallel Text Alignment berdasarkan Kesamaan Panjang Line Code
Pasangan web page dibagi berdasarkan panjang line code. Hal ini dilakukan dengan cara mengenali setiap tag HTML pada pasangan web page. Tag HTML yang dimaksud adalah tag yang memiliki penutup dan tag yang tidak memiliki penutup. Tag-tag ini mempengaruhi pemberian nomor (id) pada setiap bagian linecode yang sudah dibagi.Tahap selanjutnya adalah membandingkan line code dari pasangan web page dengan menghitung line code dari setiap nomor (id). Jika pada salah satu web page memiliki jumlah line code pada setiap nomor (id) tidak sama dengan jumlah line code pada pasangan web page-nya maka akan dilakukan penghitungan jumlah line code pada nomor (id) berikutnya hingga jumlah line code pada pasangan web page sama. Tahap terakhir adalah menghapus tag HTML pada setiap bagian yang sudah memiliki jumlah line code yang sama dan mengambil text dari kedua web page yang disebut dengan parallel text. Metode [9] ini dapat dilihat pada Gambar 2.1.
Gambar 2.1 Parallel Text Alignment berdasarkan Kesamaan Panjang Line Code
Pada Gambar 2.1, pengambilan parallel text pada <s id=0000> berhasil karena jumlah line code sama, hal yang sama terjadi pada <s id=0001>. Tetapi pada <s id=0002>, meskipun jumlah line codesama, parallel text yang didapatkan mulai menunjukkan kesalahan karena hasil perbandingan yang didapatkan berbeda. Hal ini dapat terlihat pada potongan codeEnglish<s id=0002>, <s id=0003>, dan <s id=0004> yang merupakan satu bagian yang memiliki line code yang sama dengan <s id=0002> pada bahasa Chinese.
Kelemahan pada parallel text alignment berdasarkan method kesamaan panjang line code adalah persamaan panjang baris code tidak selalu memberikan perbandingan parallel text yang sama sehingga cara ini kurang efektif.
2. Parallel Text Alignment berdasarkan Kesamaan Tag HTML
Permasalahan yang muncul dengan menggunakan metode panjang linecode dapat diatasi dengan menggunakan metode kesamaan tag HTML. Metode ini dilakukan dengan membandingkan code dari pasangan web page. Pemberian nomor (id) sama dengan metode panjang line code. Perbedaan ke dua metode tersebut terletak pada perbandingan nomor (id) pada pasangan web page.
Pada metode kesamaan tag HTML, code pada web page yang sudah diberi nomor (id) disesuaikan dengan nomor (id) yang sama pada pasangan web page-nya. Jika terdapat kesamaan tag HTML pada nomor (id) yang sama, maka diambil text yang berbeda dari pasangan web page yang merupakan parallel text. Sebaliknya, jika pada saat perbandingan, tag HTML pada nomor (id) yang sama berbeda maka akan dilakukan perbandingan pada nomor (id) berikutnya hingga memiliki tag HTML yang sama pada pasangan web page. Cara ini sangat efektif karena pembatas sudah jelas yaitu tag HTML. Contoh Parallel Text Alignment berdasarkan kesamaan tag HTML [9] dapat dilihat pada Gambar 2.2.
Gambar 2.2 Parallel Text Alignment berdasarkan Kesamaan Tag HTML
Pada Gambar 2.2, pengambilan parallel text pada nomor <s id=0000> dinyatakan berhasil karena adanya kesesuaian dari tag HTML dari potongan code, begitu juga pada <s id=0001> dan seterusnya.
2.11.2 Lexicon Evaluation
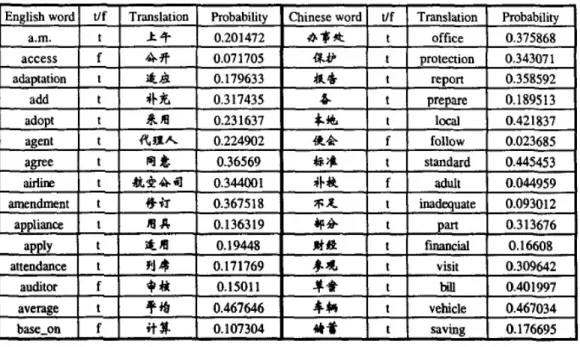
Untuk mengevaluasi ketepatan dari Inggris-Cina model terjemahan yang di-train pada Web Corpus, dilakukan pengujian terhadap dua contoh lexicon dari 200 kata, satu disetiap
Dilakukan pemeriksaan pada terjemahan yang paling mungkin untuk setiap kata. Lexicon Cina-Inggris ditemukan memiliki ketepatan 77%. Lexicon Inggris-Cina memiliki ketepatan lebih tinggi 81,5%. Bagian dari lexicon ditunjukkan pada Tabel 2.1 [9], dimana t/ f menunjukkan apakah terjemahan adalah benar atau salah. Ketepatan ini tampaknya cukup tinggi. Mereka cukup sebanding dengan yang diperoleh oleh Wu (1994) menggunakan panduan Cina-Inggris parallel corpus.
Tabel 2.1 Bagian dari Evaluation Lexicon
2.11.3 English-Chinese CLIR Result
Hasil yang diperoleh setelah melakukan training dari corpus Inggris-Cina dan perbandingan terhadap Mono-Lingual IR, Translation Model, Dictionary, dan gabungan dari Translation Model dan Dictionary, yaitu :
2.11.3.1 Hasil
Percobaan pada kedua corpora memberikan hasil yang ditunjukkan pada Tabel 4. Ketepatan IR satu bahasa diberikan sebagai patokan. Pada kedua E-C dan C-E CLIR, model terjemahan dicapai sekitar 40% dari ketepatan satu bahasa. Untuk membandingkan dengan pendekatan berbasis kamus, kami menggunakan kamus Cina-Inggris, CEDICT dan kamus online Inggris-Cina untuk menerjemahkan query.
Untuk setiap kata dari sumber query, semua kemungkinan terjemahan diberikan oleh kamus termasuk dalam terjemahan query. Kamus Cina-Inggris memiliki sekitar performansi sama dengan model terjemahan, sementara kamus Inggris-Cina memiliki ketepatan yang lebih rendah dibandingkan dengan model terjemahan.
Percobaan lain yaitu menggabungkan terjemahan yang diberikan oleh model terjemahan dan kamus. Dalam kedua C-E dan E-C CLIR, perbaikan signifikan dicapai (seperti yang ditunjukkan pada Tabel 2.2). Perbaikan menunjukkan bahwa terjemahan diberikan oleh model terjemahan dan kamus saling melengkapi untuk tujuan IR. Model terjemahan mungkin memberikan terjemahan yang tepat atau tidak benar tetapi keterhubungan kata. Meskipun kata-kata ini tidak benar dalam arti terjemahan, mereka sangat mungkin dihubungkan dengan subjek query dan dengan demikian membantu untuk tujuan IR. Pendekatan berbasis kamus memperluas query dimensi lain. Ini memberi semua kemungkinan terjemahan untuk setiap kata termasuk yang tidak terjawab oleh model terjemahan.
2.11.3.2 Perbandingan dengan Sistem MT
Satu keuntungan dari model terjemahan berbasis parallel text adalah bahwa lebih mudah untuk membangun sistem MT. Telah diteliti kinerja CLIR model terjemahan, selanjutnya akan membandingkannya dengan dua sistem MT yang ada. Kedua sistem diuji di E-C CLIR.
1. Sunshine Web Tran Server
Sistem online Inggris-Cina MT, untuk menerjemahkan 54 pertanyaan bahasa Inggris, diperoleh ketepatan rata-rata 0,2001, yang merupakan 50,3% dari ketepatan satu bahasa. Ketepatan lebih tinggi dari yang diperoleh dengan menggunakan model terjemahan (0,1804) atau kamus (0,1427) saja, tetapi lebih rendah dari ketepatan yang diperoleh dengan menggunakan mereka bersama-sama (0,2232).
2. Kwok Trans Perfect
Kwok (1999) meneliti kinerja CLIR dari perangkat lunak bahasa Inggris-Cina MT yang disebut TransPerfect, menggunakan kumpulan Cina yang sama seperti TREC yang digunakan dalam penelitian ini. Menggunakan perangkat lunak MT saja, Kwok mencapai 56% dari ketepatan satu bahasa. Ketepatan itu ditingkatkan menjadi 62% dengan memperbaiki terjemahan dengan kamus. Kwok juga mengadopsi pretranslation query ekspansi, ketepatan lebih ditingkatkan sampai 70% dari hasil satu bahasa. Dalam kasus ini, ketepatan terbaik E-C CLIR menggunakan model terjemahan (dan kamus) adalah 56,1%. Hal ini rendah dari yang dicapai dengan menggunakan KwokTransPerfect. Namun, perbedaannya tidak besar.
2.11.4 Parallel Text pada Prancis-Inggris Corpus
Tahapan yang diambil untuk menghasilkan corpus sederhana berisi parallel text bahasa Prancis dan bahasa Inggris yaitu:
2.11.4.1 Pemilihan Situs
Pemilihan site dilakukan dengan menggunakan search engine. Query yang dikirim ke search engine berisi hostname. Search engine akan mengembalikan daftar alamat url dari sekumpulan site.
Calon site dengan versi domain languange memiliki link yang menunjukan versi bahasa lain yang disebut link anchor text. Misalnya, dari site dengan versi Inggris, terdapat link ”en francais”, ”French”, atau ”French version”.... yang merupakan anchor text yang dapat menampilkan site dengan versi Prancis. Sebaliknya, web page dengan versi Prancis juga mempunyai link anchor text ”in English”, ”version anglaise”, dan lain-lain. Hal ini dapat digunakan sebagai kriteria pemilihan site. Jika terdapat site yang berisi link anchor text ke site yang sama dan memiliki dua arah link anchor text maka site disebut calon site dari parallel text.
2.11.4.2 Pemilihan Pasangan Web Page
Setiap pasangan web page memiliki dua bahasa. Untuk mencari pasangan web page terdapat dua cara yang dapat dilakukan, yaitu:
1. Berdasarkan Nama Web Page
Pasangan web page mempunyai nama yang mirip bahkan sama. Biasanya perbedaannya terletak pada penamaan web page yang mencirikan bahasanya. Contoh, ”file-fr.html” vs. ”file-en.html”, ”f-file.html” vs. ”e-file.html” dan lain-lain.
2. Berdasarkan Alamat URL
Pasangan web page mempunyai alamat url yang dapat mencirikan bahasanya. Sebagai contoh, ”eng/” v.s ”fr/”, sehingga dapat diasumsikan bahwa pasangan web page yang mempunyai pola tersebut, kemungkinan memiliki parallel text.
2.11.4.3 Verified dan Download
Setelah pemilihan pasangan web page selesai dilakukan, maka tahap selanjutnya adalah tahap verifikasi web page yaitu proses menentukan ukuran, bahasa dan karakter dari sebuah web page. Pasangan web page biasanya mempunyai size dan struktur teks HTML yang hampir sama, sehingga apabila terdapat pasangan web page yang mempunyai size dan struktur teks HTML yang jauh berbeda maka akan di eliminasi. Setelah dilakukan verifikasi terhadap web page, maka web page akan diunduh (download). Hasil akhir dari tahap ini adalah seluruh pasangan web page pada site.
2.11.4.4 Parallel Text Allignment
Tahap berikutnya adalah parallel text alignment. Tahap ini merupakan tahap untuk mendapatkan parallel text dari pasangan web page yang telah diunduh. Tahap ini menggunakan algoritma alignment yaitu algoritma untuk mensejajarkan calon teks. Jika
mungkin disejajarkan, maka kemungkinan parallel menjadi sangat tinggi. Akan tetapi proses ini akan memakan banyak waktu. Sehingga menggunakan cara lain yaitu metode text length. Metode ini merupakan salah satu kriteria untuk menentukan parallel text yaitu pasangan web page harus mempunyai panjang line of code yang sama. Terdapat 1000 pasangan web page yang dipilih secara acak di mana hasil yang menggunakan panjang hanya berbeda 2% dari yang diperoleh menggunakan algoritma alignment. Maka kriteria ini dipertimbangkan sebagai pengganti algoritma alignment yang bagus.
2.12 Cross Language Information Retrieval (CLIR)
Information Retrieval (IR) didefinisikan sebagai pengambilan dokumen dari koleksi teks (biasanya dari web) sebagai tanggapan untuk kata kunci spesifik atau query yang diberikan pada search engine [2]. Cross-Language Information Retrieval (CLIR) merupakan sistem temu balik informasi dari sebuah aplikasi ke user [9]. CLIR dapat meningkatkan pencarian dokumen atau informasi karena CLIR mengizinkan user memberikan query dalam bahasa tertentu yang selanjutnya query diterjemahkan ke bahasa lain sehingga mendapatkan dokumen sesuai dengan query dalam berbagai bahasa yang didukung oleh CLIR.
CLIR juga meliputi text, pengucapan, dan mungkin tanda bahasa tetapi kebanyakan menggunakan text untuk mencari informasi. Dalam menerjemahkan query, CLIR membutuhkan corpus yang berisi parallel text yang besar sebagai data training. Sistem CLIR yang telah digabungkan keterjemahan query untuk parallel corpora dapat menunjukkan hasil yang lebih baik sebagai parallel corpora memiliki konteks yang kaya untuk menutupi konteks yang lemah pada query [12].
2.13 Machine Translation (MT)
Machine Translation merupakan alat penerjemah otomatis pada sebuah teks dari satu bahasa ke bahasa lainnya. Mesin penerjemah statistik adalah sebuah pendekatan mesin penerjemah dengan hasil terjemahan dihasilkan atas dasar model statistik yang parameter-parameternya diambil dari hasil analisis corpus teks bilingual (atau paralel) [11]. Kualitas hasil terjemahan Bahasa Inggris-Bahasa Indonesia tersebut masih jauh dari sempurna dan memiliki nilai akurasi yang rendah. Untuk mendapatkan terjemahan yang baik maka digunakan pendekatan statistik. Pendekatan statistik yang digunakan adalah konsep probabilitas. Setiap pasangan kalimat (S,T) akan diberikan sebuah P(T|S) yang diinterpretasikan sebagai distribusi probabilitas yang sebuah penerjemah akan menghasilkan T dalam bahasa tujuan ketika diberikan S dalam bahasa sumber disebut juga probabilistic translation model.
2.14 Probabilistic Translation Model
Melalui probabilistic translation model, berarti mekanisme yang menggabungkan setiap kalimat dari sumber bahasa (query) S sebuah probability distribution pada p(T|S) pada kumpulan kalimat T dari target bahasa[7]. Dengan model ini, kita dapat menentukan terjemahan yang paling mungkin Ts dari S dan mengusulkannya kepada user. Secara kasar prinsip pelatihan model adalah sebagai berikut: terdapat sekumpulan teks dari sumber dan target bahasa, jika dua elemen tersebut muncul secara bersamaan dalam parallel text, maka mereka mempunyai kesempatan yang tinggi untuk menjadi terjemahan satu sama lain. Kumpulan kata ini adalah calon kata terjemahan terbaik dari sumber query S. Tujuan dari probabilistik model ini adalah untuk memberikan kemungkinan p(T|S) – kemungkinan memiliki kata t dari target bahasa dalam terjemahan dari sumber bahasa S.