PENYUSUNAN PERANGKAT LUNAK R-STAT UNTUK PENDUGAAN
MODEL KALIBRASI
Oleh :
REVARIO OKTANO
G14101036
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Dan Katakanlah: "Bekerjalah kamu, Maka Allah dan rasul-Nya serta
orang-orang mukmin akan melihat pekerjaanmu itu, dan kamu akan
dikembalikan kepada (Allah) yang mengetahui akan yang ghaib dan yang
nyata", lalu diberitakan-Nya kepada kamu apa yang Telah kamu kerjakan.
<QS At-Taubah:105>
Untuk kedua orang tuaku..
Hanya Allah yang mampu membalas kasih sayang
yang telah dan akan selalu engkau berikan
ABSTRAK
REVARIO OKTANO. Penyusunan Perangkat Lunak R-Stat untuk Pendugaan Model Kalibrasi. Dibawah bimbingan Dr. Ir. Erfiani, M.Si dan Agus M Soleh, S.Si, MT.
Dalam pemodelan secara umum, permasalahan muncul jika banyak peubah p lebih besar dari jumlah amatan n dan antar peubah saling berkorelasi. Pemodelan akan menghasilkan dugaan parameter model yang tidak unik karena berasal dari sistem persamaan yang tidak konsisten. Hal ini diatasi antara lain dengan melakukan reduksi data sehingga diperoleh peubah baru p yang lebih kecil dari p serta menghilangkan kolinearitas antar peubah. Masalahnya kemudian adalah pada implementasi perangkat lunak. Dimensi peubah yang besar menyebabkan model terlalu rumit dan sulit dijadikan model umum, serta berakibat pada proses komputasi yang memakan waktu lama sehingga tejadi kendala proses (hang). Secara umum, hingga kini belum terdapat perangkat lunak yang khusus menangani permasalahan data besar dengan solusi model lengkap.
Penelitian ini dilakukan dengan tujuan mengembangkan program perangkat lunak yang memadai dalam penyusunan model kalibrasi untuk menduga peubah respon dari data dimensi besar dengan p >> n. Data yang digunakan dalam penelitian ini adalah data spektrum tanaman jahe dan temulawak dari beberapa daerah sentra tanaman obat pada penelitian Erfiani (2005). Proses pemodelan sendiri dilakukan setelah tahap pre-processing data. Metode yang digunakan dalam pre-processing adalah Analisis Komponen Utama, Metode Wavelet, Regresi Terpenggal, serta Koreksi Pencaran Multiplikatif. Sedangkan untuk pemodelan menggunakan Metode Bayes, Ordinary Least Square, Partial Least Square dan Neural-Network. Penelitian ini dikhususkan pada tahap penyusunan model. Perangkat lunak R-Stat adalah perangkat yang dirancang untuk dapat digunakan dalam menyusun model kalibrasi.
Model kalibrasi dapat diperoleh dengan terlebih dulu melakukan reduksi peubah agar diperoleh model yang baik, meski tanpa reduksi pemodelan juga dapat dilakukan secara langsung menggunakan Metode Bayes. Hal ini disebabkan pemodelan langsung akan membutuhkan proses komputasi yang lama dan kerja sistem yang berat. Program R-Stat menjadi salah satu perangkat yang dapat menampung dan mengatasi masalah komputasi pada data besar untuk pendugaan model kalibrasi.
PENYUSUNAN PERANGKAT LUNAK R-STAT UNTUK PENDUGAAN
MODEL KALIBRASI
Revario Oktano
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Sains
Pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
RIWAYAT HIDUP
Penulis dilahirkan di Pringsewu pada tanggal 9 Oktober 1983 sebagai anak pertama dari tiga bersaudara, putra dari pasangan Bejo Adhi Setyo dan Wati Prasetyo.
Penulis menyelesaikan pendidikan dasar di SDN 01 Baktirasa pada tahun 1995. Kemudian pada tahun 1998 penulis lulus dari SLTP Negeri 01 Palas. Setelah menyelesaikan studi di SMU Negeri 02 Bandar Lampung pada tahun 2001, penulis lulus seleksi masuk IPB pada tahun yang sama melalui jalur Ujian Masuk Perguruan Tinggi Negeri (UMPTN) pada Departemen Statistika Fakultas Matematika dan Ilmu Pengetahuan Alam.
Selama mengikuti perkuliahan, penulis pernah aktif di beberapa organisasi kampus, diantaranya adalah sebagai staf Divisi Kajian Strategis Himpunan Profesi Gamma Sigma Beta (GSB) dan menjadi Koordinator Departemen Komunikasi Ummat Keluarga Mahasiswa Muslim Statistika (KAMMUS). Penulis juga pernah aktif sebagai Koordinator Divisi Eksternal Dewan Perwakilan Mahasiswa FMIPA dan menjadi Pimpinan Redaksi majalah dakwah kampus Departemen Statistika NUANSA. Pada bulan Februari hingga April 2005 penulis diberi
Judul : Penyusunan Perangkat Lunak R-Stat untuk Pendugaan Model
Kalibrasi
Nama : Revario Oktano
NRP : G14101036
Menyetujui :
Pembimbing I,
Pembimbing II,
Dr. Ir. Erfiani, M.Si
NIP. 131878954
Agus M Soleh, S.Si, MT.
NIP. 132232455
Mengetahui :
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Dr. Ir. Yonny Koesmaryono, MS
NIP. 131473999
KATA PENGANTAR
Alhamdulillah. Segala puji dan rasa syukur penulis panjatkan kehadirat Allah SWT atas segala karunia-Nya sehingga karya ilmiah ini dapat terselesaikan. Shalawat serta salam semoga senantiasa tercurah kepada rasul mulia Muhammad saw.
Penulis persembahkan karya kecil ini bagi kedua orang tua, seluruh keluarga, para sahabat dan teman-teman yang selama ini dekat di hati penulis. Semoga bermanfaat dan menjadi kebanggaan.
Penulis juga menyadari bahwa masih banyak sekali kekurangan dalam penulisan karya ilmiah ini, oleh karena itu saran yang membangun selalu diharapkan sebagai sarana bagi penulis untuk memperbaiki diri dan meningkatkan pengetahuan di masa mendatang.
Terima kasih, kepada semua pihak yang telah berperan serta dalam penyusunan karya ilmiah ini yaitu kepada :
1. Ibu Dr. Ir. Erfiani, M.Si dan Bapak Agus M Soleh, S.Si, MT. Penulis banyak mendapat ilmu, bimbingan dan masukan dari beliau selama proses penyelesaian tugas akhir ini. 2. Dikti melalui program penelitian Hibah Pasca yang diketuai Bapak Dr. Ir. Khairil Anwar
Notodiputro, MS yang telah memberikan fasilitas dan bahan penelitian bagi penulis. 3. Ibu dan Ayah tercinta atas segenap do a, kasih sayang, kesabaran serta segala dukungan
yang telah dan terus-menerus diberikan sehingga mendorong penulis untuk memberikan yang terbaik bagi keduanya.
4. Adik-adik tercinta (Anggeng dan Puspa) yang membanggakan, atas do a, dukungan dan semangat yang selalu diberikan.
5. Saudara terdekat, yaitu teman-teman satu atap (Deny, Pipin, May, Tyo, Doni, Rendro, Asep, Ihyak, Icus dan Gatik). Terima kasih atas semua kenangan yang telah diberikan. Semoga suka-duka yang dilalui dapat terus berlanjut dan menjadi pelajaran berharga. 6. Seluruh sahabat dan saudara seperjuangan di STK 38, IM38, UNILA, juga kakak-kakak
dan adik-adik kelas, mudah-mudahan kebersamaan ini tetap Allah kekalkan.
7. Ibu Markonah, Bu Sulis, Pak Iyan, Bang Sudin, Mang Herman, Mang Usman, dan Kang Durrochman atas segala bantuan yang diberikan.
8. Semua pihak yang tidak mugkin disebutkan satu-persatu yang telah banyak membantu penulis selama ini.
Semoga semua amal baik dan bantuan yang telah diberikan kepada penulis mendapat balasan dari Allah SWT, dan semoga karya ilmiah ini bermanfaat bagi semua pihak yang membutuhkan .
Bogor, Juni 2006
DAFTAR ISI
Halaman
DAFTAR TABEL ... iii
DAFTAR GAMBAR ... iii
DAFTAR LAMPIRAN ... iii
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 1
TINJAUAN PUSTAKA Pre-processing Data Analisis Komponen Utama ... 1
Metode Wavelet ... 1
Regresi Terpenggal ... 1
Koreksi Pencaran Multiplikatif ... 2
Pemodelan Ordinary Least Square ... 2
Partial Least Square ... 2
Pendekatan Bayes ... 3
Neural Network ... 4
Model Dasar Kalibrasi ... 4
Kriteria Kebaikan Model ... 4
BAHAN DAN METODE Bahan ... 4
Metode ... 5
HASIL DAN PEMBAHASAN Pre-processing Data Analisis Komponen Utama ... 6
Metode Wavelet ... 6
Regresi Terpenggal ... 6
Koreksi Pencaran Multiplikatif ... 7
Pemodelan ... 7
Aplikasi Model dalam R ... 8
Output Pemodelan ... 9
Analisis Perangkat Lunak Evaluasi Sistem ... 10
Pemeliharaan Sistem ... 11
Kelebihan Sistem ... 11
Kekurangan Sistem ... 11
KESIMPULAN DAN SARAN Kesimpulan ... 11
Saran ... 11
DAFTAR PUSTAKA ... 11
DAFTAR TABEL
Halaman
1. Daerah identifikasi spektra gingerol ... 5
2. Daerah identifikasi spektra kurkumin ... 5
3. Perbandingan pengujian model ... 10
DAFTAR GAMBAR
Halaman 1. Ilustrasi Regresi Terpenggal dengan dua buah interval ... 22. Spektrum Gingerol ... 4
3. Spektrum Kurkumin ... 5
4. Diagram Alur Analisis ... 6
5. Spektrum Gingerol sebelum reduksi data ... 6
6. Spektrum Gingerol setelah reduksi data ... 6
7. Plot spektrum sampel pada data yang sudah dikoreksi ... 7
8. Metode Pemodelan 1 ... 7
9. Metode Pemodelan 2 ... 7
DAFTAR LAMPIRAN
Halaman 1. Contoh format baris dan kolom data input ... 132. Parameter input data jahe dan hasil output model Bayes ... 14
3. Output model OLS untuk gingerol dengan 4 komponen utama ... 16
4. Output dan perbandingan model PLS untuk gingerol ... 17
5. Pengujian iterasi dan output model Neural-Network ... 18
6. Langkah-langkah penggunaan perangkat lunak R-Stat ... 19
PENDAHULUAN
Latar Belakang
Dalam pembuatan model secara umum,
)
(
)
(
ny
1f
nx
pE
, permasalahan muncul jika jumlah data pengamatan (n) jauh lebih kecil dari banyak peubah (p) dan antar peubah saling berkorelasi. Proses pemodelan akan menghasilkan dugaan parameter yang tidak unik karena berasal dari sistem persamaan yang tidak konsisten (Atok 2005).Pengamatan secara umum pada data-data percobaan menunjukkan bahwa terdapat banyak kasus pemodelan dengan kondisi data seperti ini, salah satu contohnya adalah pada model pendugaan konsentrasi suatu senyawa aktif yang sering disebut model kalibrasi.
Mengatasi hal ini antara lain dilakukan dengan reduksi dimensi sehingga diperoleh peubah baru p yang jauh lebih kecil dari p dan antar peubah baru tidak saling berkorelasi. Kemudian model disusun berdasarkan peubah baru hasil reduksi. Hal ini dilakukan dengan memperhatikan ketepatan dan kesesuaian model yang digunakan dengan proses reduksi datanya.
Masalah lain model kalibrasi adalah pada implementasi perangkat lunak. Dimensi peubah yang besar menyebabkan model terlalu rumit dan sulit dijadikan model umum. Matriks data menjadi kendala karena besarnya jumlah kolom yang dapat menampung data pada perangkat lunak terbatas, sehingga perlu penanganan lebih lanjut yang tidak mudah dan kurang efisien. Akibat lain adalah lamanya waktu komputasi dan kendala proses (hang) tanpa peningkatan ketepatan pendugaan yang memadai.
Penelitian awal yang dilakukan oleh tim Hibah Pasca Program Pascasarjana IPB tahun 2003-2005 terhadap data percobaan tanaman obat menemui kendala dalam komputasi data untuk pendugaan model kalibrasi, yaitu masalah keterbatasan perangkat pemrosesan data serta waktu yang lama dalam pengolahan.
Secara umum hingga kini belum terdapat perangkat lunak yang khusus menangani masalah data besar dengan solusi model lengkap. Perangkat pengolahan yang umum digunakan hanya melakukan sebagian proses reduksi saja atau pemodelan saja tanpa proses awal serta analisis output yang tidak lengkap.
Oleh karena itu, diperlukan perangkat lain yang dapat menampung dan melakukan pengolahan dataset besar secara lebih efisien dan lebih stabil.
Tujuan
Tujuan penelitian ini adalah menyusun program perangkat lunak untuk pemodelan kalibrasi dalam menduga peubah respon dari data spektra tanaman.
TINJAUAN PUSTAKA
Pre-processing Data1. Analisis Komponen Utama (AKU)
Analisis Komponen Utama (AKU) adalah metode yang sering dipakai untuk tujuan pereduksian dimensi serta menghilangkan multikolinearitas pada data besar. AKU pada prinsipnya bertujuan mereduksi dimensi peubah asal menjadi dimensi yang lebih kecil namun mampu menjelaskan seluruh data (Johnson dan Wicher 2002).
Sistem kerja AKU adalah menguraikan matriks data hingga diperoleh r komponen utama yang bertindak sebagai peubah baru yang saling ortogonal, dengan jumlah komponen lebih kecil dari jumlah peubah asal (r << p) dan jumlah amatan (n > r).
2. Metode Wavelet
Metode Wavelet adalah salah satu metode yang digunakan untuk mereduksi data, dengan cara melakukan dekomposisi matriks peubah
T ip i i i
x
x
x
x
(
1,
2,
...
,
)
dalam sekumpulanfungsi basis. Ide dasar metode transformasi
wavelet adalah merepresentasikan suatu kurva
sebagai kombinasi linear kurva-kurva lain yang relatif lebih sederhana, yang disebut fungsi basis (Nason dan Silverman 1997).
Langkah umum penerapan metode
wavelet ini adalah dengan merepresentasikan
deret
x
sebagai jumlahan m bobot dari fungsi basis. Dengan memilih m yang jauh lebih kecil dari p, diharapkan hasil pemodelan peubah ganda masih cukup baik dan valid.Sunaryo (2005) menerapkan Wavelet pada data spektrum gingerol dan kurkumin untuk mendapatkan nilai koefisien yang digunakan dalam penentuan jumlah titik peubah yang direduksi. Hasil yang diperoleh dari 1866 titik data asal, baik untuk data gingerol maupun kurkumin, keduanya dapat direduksi menjadi 1024 titik.
3. Regresi Terpenggal (RT)
Jika (Xi, Yi), i=1, 2, ..., n adalah pasangan
data yang saling bebas, maka pada Regresi Terpenggal wilayah X dibagi menjadi dua
atau lebih interval/sekatan dengan tiap sekat memiliki fungsi tersendiri. Pada tiap sekatan hanya diambil dua titik yaitu titik awal dan titik akhir pengamatan. Titik akhir dari tiap sekatan disebut changepoints atau breakpoints (Küchenhoff & Wellisch dalam Erfiani 2005).
Ilustrasi sederhana dari model RT dengan dua buah sekatan tersaji pada Gambar 1, dengan adalah breakpoints.
Gambar 1. Ilustrasi RT dengan dua buah sekatan.
Erfiani (2005) melakukan penelitian dengan pendekatan Regresi Terpenggal untuk tujuan pemampatan data spektrum gingerol. Kesimpulan yang diperoleh adalah RT cukup baik dalam mereduksi data (dari 1866 titik mampu direduksi menjadi 86 titik, tergantung besaran koefisien determinasi standar yang digunakan) dengan tetap mempertahankan pola data asal.
Tetapi RT belum dapat menghilangkan kolinearitas antar peubah sehingga perlu penggabungan dengan metode lain untuk penyusunan model.
4. Koreksi Pencaran Multiplikatif (KPM)
Geladi (1986) mengembangkan metode Koreksi Pencaran Multiplikatif (Multi Scatter
Correction) pada data spektrum kimia untuk
tujuan mengoreksi posisi pencaran tiap contoh terhadap posisi rata-rata pencaran contoh.
Koreksi ini dilakukan dengan membuat persamaan regresi antara spektrum masing-masing contoh dengan rataannya. Bentuk persamaan garis regresi untuk masing-masing contoh tersebut sebagai berikut :
x
i=
0i + 1ix
j + ei dimana :i = 1, , n; j = 1, , p;
xi = amatan ke-i dan peubah ke-j 0i = pengaruh aditif contoh ke i 1i = pengaruh multiplikatif contoh ke i
n i ij j
x
n
x
11
Konstanta 0i dan 1i kemudian akan digunakan untuk mentransformasi data asli.
Bentuk transformasi tersebut dapat dituliskan sebagai persamaan: xij* = (xij - 0i) / 1i :
dimana :
xij* = data yang telah dikoreksi
xij = data yang belum dikoreksi
Arnita (2005) menggunakan pendekatan KPM untuk menyederhanakan model kalibrasi peubah ganda dan meningkatkan kelinieran model. Pemodelan ini hanya bertujuan melihat besar pergesaran spektra baik aditif atau multiplikatif terhadap rataannya namun tetap tidak mengeliminasi kolinearitas antar peubah.
Metode pre-processing yang digunakan dan aplikasinya dijelaskan lebih jauh lagi dalam penelitian Darmadi (in press).
Pemodelan 1. Ordinary Least Square (OLS)
Metode yang paling umum digunakan dalam menduga parameter adalah Metode Kuadrat Terkecil atau Ordinary Least Square (OLS). Tujuan OLS adalah menentukan penduga terbaik bagi parameter populasi yaitu dan . Sehingga diperoleh model dugaan residual dimana = Y - - X.
Kriteria optimasi model (atau pendugaan parameter) yang digunakan dalam OLS adalah dengan meminimumkan fungsi :
( 2) = ( Y - - X)2 jika parameter populasi tidak diketahui.
Jumlah dari kuadrat galat fungsi diatas disebut sebagai Jumlah Kuadrat Galat (JKG). JKG sebenarnya adalah kudrat jarak data pengamatan dengan garis regresi. Dengan pengukuran jarak, OLS pada prinsipnya mencari garis lurus yang terdekat dengan data. Dalam perhitungannya, prosedur OLS akan mengambil penduga parameter dan dengan JKG minimum (Ramanathan 1997). Salah satu asumsi utama yang harus dipenuhi dalam OLS adalah asumsi kebebasan galat.
Arnita (2005) menyimpulkan AKU dan model OLS mampu mengatasi permasalahan data besar dan korelasi antar peubah bebasnya
2. Partial Least Square (PLS)
PLS adalah metode lunak (soft method) karena didalam PLS pendugaannya tidak memerlukan asumsi sebaran dari peubah amatan (distribution free) serta ukuran contoh tidaklah harus berukuran besar (Chin 2000).
2
Kekhususan lain dari PLS adalah pada ujinya yang berperan mengukur kekuatan prediksi sehingga dapat memudahkan pengembangan metode respon yang baru.
Dalam regresi, jika peubah amatan semakin banyak atau lebih besar dari data pengamatan maka asumsi yang mendasari perhitungan menjadi semakin sulit terpenuhi, akibatnya model yang dibangun tidak dapat menjawab hubungan yang pasti antara peubah bebas dan peubah respon dengan hanya menggunakan Metode Kudrat Terkecil.
PLS adalah metode alternatif yang dalam perhitungannya tidak memerlukan asumsi yang ketat, baik mengenai sebaran peubah pengamatan maupun contoh. Oleh Joreskog dan Wold (1982) PLS dikembangkan sebgai metode umum untuk pendugaan model laten yang diukur secara tidak langsung oleh peubah penjelas.
PLS terdiri atas hubungan eksternal (outer
model atau model pengukuran) dan hubungan
internal (inner model atau model struktural). Hubungan tersebut didefinisikan sebagai dua persamaan linier yaitu model pengukuran yang menyatakan hubungan antara peubah laten dengan sekelompok peubah penjelas dan model struktural yaitu hubungan antar peubah-peubah laten (Chin 2000).
Persamaan model struktural yang menghubungkan peubah-peubah laten menurut Joreskog dan Wold (1982) adalah :
j i ji j j 0 ; i < j ; j = 1,2,...,J dimana :
j= peubah laten tak bebas ke-j i= peubah laten bebas ke-i (i j)
0
j = intersep model
ji= koefisien lintas peubah laten j= sisaan model struktural ke-j
cov i
,
i = 0 , untuk i < jsehingga peubah laten endogen (tak bebas) diasumsikan sebagai fungsi linear peubah laten eksogen (bebas).
3. Pendekatan Bayes
Dalam teori Berger (1985), dikemukakan bahwa pendekatan Bayes merupakan altematif untuk mengatasi masalah kolinearitas karena dalam pendekatan ini informasi baru ditambahkan ke dalam model dengan mengganggap bahwa parameter model berasal dari sebaran tertentu sehingga tidak bersifat
deterministik. Sebaran ini disebut sebaran prior yang mencerminkan keyakinan tentang besamya parameter tersebut. Jika parameter model yang ingin diduga adalah dengan y sebagai peubah acaknya, maka parameter dipilih yang memaksimumkan fungsi kepekatan bersyarat ( | y). Fungsi kepekatan bersyarat ini disebut fungsi posterior.
Secara umum, jika h( ) adalah sebaran prior dari dan statistik w = u(yl, y2,...,yp)
maka sebaran posteriornya adalah: ( | w)=
)
(
)
|
(
)
(
)
(
)
,
(
w
g
w
f
h
w
g
w
f
Dimana f(w| ) adalah fungsi kemungkinan dari w, f( ,w)adalah fungsi kepekatan bersama dari dan w. Nilai dipilih sedemikian sehingga diperoleh ( |w). Pemilihan h( ) yang tepat akan dapat memperbaiki fungsi f(w| ) sehingga ruang bagi nilai optimum menjadi terbatas.
Sebaran prior dapat diperoleh melalui dua pendekatan informative prior atau
non-informative prior. Pada non-informative prior,
parameter ditetapkan memiliki sebaran tertentu dengan kisaran nilai yang dapat diterima. Sedangkan non-informative prior, tidak ada informasi tambahan tentang parameter. Apabila prior pada
non-informative prior bernilai konstan maka
penduga parameter dengan pendekatan Bayes akan sama dengan penduga dengan metode kemungkinan maksimum.
Metode lain untuk menentukan sebaran prior yang cukup sederhana adalah dengan metode prior sekawan (conjugate prior). Prior sekawan ditentukan dengan memeriksa fungsi kemungkinan L( /y) = f(y/ ), dan memilih sebagai keluarga sekawan adalah kelompok sebaran yang sama dengan fungsi kemungkinannya. Sebagai contoh bila f(y/ ) menyebar normal maka L( /y) juga akan mengikuti sebaran normal.
Secara umum pendekatan Bayes akan menghasilkan nilai dugaan yang berbias, yaitu dipengaruhi oleh besar simpangan antara prior yang ditetapkan dengan nilai parameter yang sesungguhnya.
Meski demikian untuk penyusunan model kalibrasi pada data spektrum senyawa aktif tanaman jahe dan temulawak, Erfiani (2005) menemukan suatu pendekatan yang bersifat
robust (tidak dipengaruhi oleh penentuan
sebaran prior) yakni pendekatan Bayes dengan perilaku berhirarki dan acak.
4. Neural Network (NN)
Neural Network (NN) adalah suatu sistem
pemrosesan informasi yang mempunyai karakteristik-karakteristik kinerja tertentu yang mengambil analogi dari jaringan syaraf biologi (Fausett 1994). Neural Network telah digeneralisasi sebagai model matematik dari cara berpikir manusia, dengan didasarkan pada asumsi-asumsi sebagai berikut :
a. Pemrosesan informasi terjadi pada banyak elemen-elemen sederhana yang disebut dengan neuron atau node.
b. Sinyal-sinyal dikirim antar node melalui suatu koneksi (connection-links).
c. Setiap koneksi mempunyai bobot yang sesuai, tergantung tipe NN.
d. Setiap node menggunakan fungsi transfer yang mentransformasi jumlahan dari sinyal-sinyal input menjadi sinyal output. Proses pembentukan model dalam NN secara umum melalui 3 tahap : tahap training, validasi dan tahap testing (Bishop 1995).
Tahap training merupakan tahap dalam NN untuk menentukan bobot masing-masing node dengan mengacu pada selisih yang kecil antara target dan dugaan target. Tahap validasi untuk mencari kombinasi bobot neuron yang menghasilkan galat terkecil bagi data validasi sebagai representasi populasi. Metode ini sering disebut sebagai metode hold out (Bishop 1995). Tahap testing adalah tahap untuk menentukan kombinasi node yang menghasilkan dugaan paling mendekati nilai sebenarnya.
Salah satu keunggulan metode NN adalah terakomodasinya hubungan X dan Y yang tidak linear dalam model. Atok (2005) dalam kajian simulasinya memperoleh model terbaik dalam pemodelan kalibrasi melalui reduksi AKU adalah NN 2 lapis dengan 1 node pada lapis tersembunyi.
Model Dasar Kalibrasi
Secara umum, model kalibrasi adalah model yang menggunakan fungsi matematik dengan data empirik untuk menduga informasi Y yang tidak diketahui berdasarkan informasi pada X. Dalam bidang kimia, model kalibrasi menggambarkan suatu fungsi hubungan antara absorban (X) pada panjang gelombang yang dihasilkan spektrometer dengan konsentrasi (Y) larutan unsur atau senyawa yang dianalisis (Naes et al. 2002). Dengan model kalibrasi, konsentrasi larutan contoh dapat diketahui berdasarkan absorbannya.
Kriteria Kebaikan Model
Kriteria untuk melihat keterandalan model menurut Mattjik dan Sumertajaya (2002) antara lain adalah Jumlah Kuadrat Galat (JKG) dan Koefisien Determinasi (R2). Model yang baik mempunyai nilai JKG yang kecil dan R2 yang besar.
Selain itu dalam penelitian ini digunakan pula nilai Root Mean Square Error Prediction (RMSEP) dan MSEP dimana:
RMSEP = p N i p i i
y
N
y
1 2/
)
(
dengan
y
dan y adalah nilai dugaan dan pengukuran pada contoh pengujian serta Npadalah jumlah contoh pengujian (Naes et al. 2002). Model dikatakan baik jika memiliki nilai RMSEP atau MSEP yang kecil.
BAHAN DAN METODE
Bahan
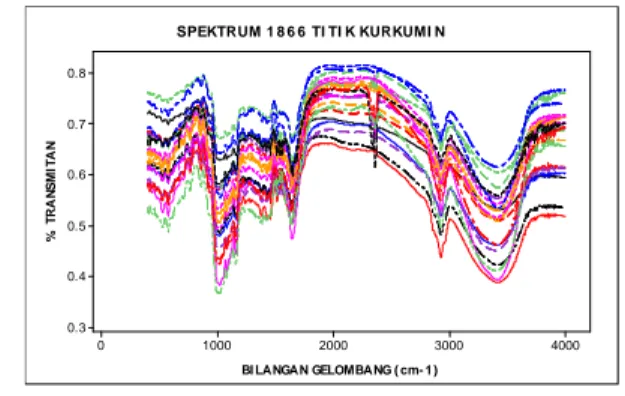
Data yang digunakan sebagai sampel penelitian adalah data spektrum dari senyawa aktif tanaman jahe yaitu gingerol sebanyak 20 sampel (Gambar 2) dan senyawa aktif tanaman temulawak yaitu kurkumin sebanyak 40 sampel (Gambar 3). Kedua senyawa ini menjadi senyawa penciri tanaman obat untuk jahe dan temulawak.
Data spektrum ini adalah hasil keluaran alat FTIR (Fourier Transform Infra Red), dengan rentang bilangan gelombang antara 400 - 4000cm-1
sebanyak 1866 titik peubah.
BILANGAN GELOMBANG (cm-1) % T R A N S M IT A N 4000 3000 2000 1000 0 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0.0
SPEKTRUM GI NGEROL PADA 1 8 6 6 TI TI K
Ket.: (s) kuat; (m) medium; (vs) sangat kuat
Data diperoleh dari lahan percobaan di beberapa daerah sentra tanaman obat di Jateng (Karanganyar), D.I.Y (Kulonprogo) dan Jabar (Bogor, Majalengka, dan Sukabumi) pada penelitian Erfiani (2005).
Selain pola data awal, perlu diperhatikan pula daerah identifikasi dari masing-masing senyawa aktif gingerol dan kurkumin. Hal ini terutama ditujukan pada reduksi dengan metode Wavelet, agar tidak ada informasi spektra transmitan utama yang hilang.
Tabel 1 dan Tabel 2 menyajikan daerah identifikasi menurut Socrates dalam Sunaryo (2005) untuk gingerol dan kurkumin
Tabel 1 Daerah identifikasi spektra gingerol
No Jenis vibrasi Bil. gelombng (cm-1) intensitas 1 Ikatan hidrogen O-H 3550-3230 m-s 2 C-H rentangan asimetri CH3-Ar 2935-2925 m-s 3 Aromatik -C=C- 1625-1590 v 4 - -keton tak jenuh 1700-1660 vs 5 R-O-Ar 1310-1210 1050-1010 m m 6 C-H ikatan luar Vinil R- CH=CH2- 990-980 910-230 m s 7 C-H ikatan luar o-subsitusi benzen 770-735 710-690 s s Tabel 2 Daerah identifikasi spektra kurkuminoid
No Jenis vibrasi Bil. gelombng (cm-1) intensitas 1 Ikatan hidrogen O-H 3600-3300 m-s 2 C-H Alkana 3000-2850 s 3 Aromatik C=C- rentangan 1660-1450 s 4 R-O-Ar 1300-1000 m 5 C=O keton 1820-1660 v 6 Sidik jari 900-700 s
Perangkat lunak dalam pemrosesan data menggunakan R-Language versi 2.2.1 dengan tambahan program R-D(COM) Server, paket BRugs, pls, pls.pcr, dan nnet (open source). Sebagai pembanding dan evaluator program digunakan SAS v8 serta Minitab 14. Desain program terapan menggunakan Visual Basic
6.0 (Enterprise Edition).
Perangkat lunak ini dirancang agar mampu menampung dan melakukan pengolahan data dengan berbagai metode pereduksian dan pemodelan dalam satu paket program serta melakukan perhitungan dengan waktu lebih singkat tanpa mengurangi akurasi model.
Perangkat terapan ini selanjutnya disebut sebagai program R-Stat. Di dalam perangkat ini disediakan metode reduksi dan pemodelan yang dapat langsung diaplikasikan pada data sampel spektrum.
Metode
Model kalibrasi yang akan disusun pada penelitian ini merupakan fungsi hubungan antara persen transmitan (X) yang dihasilkan FTIR dengan konsentrasi gingerol atau kurkumin (Y). Pendugaan model kalibrasi ini dilakukan menggunakan perangkat R-Stat.
Pemodelan kalibrasi pada R-Stat dibuat dan disesuaikan dengan tahap pre-processing (reduksi dan smoothing data) yang digunakan.
Secara garis besar, langkah-langkah yang dilakukan adalah sebagai berikut:
1. Eksplorasi data input 2. Pre-processing data.
Metode pre-processing yang digunakan adalah dengan AKU, metode Wavelet, RT (untuk reduksi peubah) maupun KPM (smoothing data)
3. Pemodelan data hasil reduksi
Pemodelan menggunakan metode kuadrat terkecil atau OLS, PLS, Neural Network, dan pendekatan Bayes.
4. Aplikasi dan evaluasi model. Evaluasi dilakukan dengan membandingkan besaran parameter hasil pendugaan model R-Stat dengan hasil dugaan perangkat evaluator. Langkah-langkah diatas secara lebih ringkas dijelaskan lewat Gambar 4.
Gambar 3. Spektrum Kurkumin BI LANGAN GELOMBANG ( cm- 1) % T R A N S M IT A N 4000 3000 2000 1000 0 0.8 0.7 0.6 0.5 0.4 0.3 SPEKTRUM 1 8 6 6 TI TI K KURKUMI N
HASIL DAN PEMBAHASAN
Dengan ukuran matriks data yang besar (1866 x 20 untuk gingerol dan 1866 x 40 untuk kurkumin), dapat dipastikan terdapat pautan linear antar peubah yang mencerminkan adanya korelasi yang tinggi. Terlebih pada data spektrum, nilai pengukuran dari suatu bilangan gelombang juga dipengaruhi nilai bilangan gelombang sebelumnya.
Matriks data yang besar menyebabkan kesulitan dalam proses komputasi model akibat kerja sistem yang berat dan memakan waktu yang lama. Oleh karena itu diperlukan proses awal atau pre-processing untuk mereduksi data menjadi lebih kecil sehingga memudahkan dalam pemodelan.
Pre-processing Data
1. Analisis Komponen Utama (AKU)
Penerapan reduksi AKU pada program umum pengolah data tidak dapat dilakukan karena kapasitas data besar tidak tertampung dan jumlah matriks baris dan kolom data yang tidak sama. Namun pada perangkat lunak R, dimensi data tidak menjadi masalah. Hasil keluaran AKU bahkan menampilkan akar ciri masing-masing peubah serta perhitungan skor komponen utama. Untuk penentuan berapa komponen yang digunakan diserahkan kenbali pada pengguna (user).
2. Metode Wavelet
Dari 20 sampel serbuk tanaman jahe dan 40 sampel serbuk temulawak dihasilkan data spektrum transmitan sebanyak 1866 titik. Dari 1866 titik diperoleh 1024 titik menggunakan reduksi Wavelet dengan tetap memperhatikan daerah identifikasi gingerol dan kurkumin.
Namun tiap senyawa tanaman yang berbeda memiliki daerah identifikasi yang berbeda pula, sehingga untuk penerapan pada data lain (selain gingerol dan kurkumin) masih harus ditentukan secara subyektif oleh peneliti.
Permasalahan lain yang timbul ternyata korelasi antar koefisien wavelet masih tinggi. Sehingga pemodelan dengan regresi ganda biasa dengan respon kadar gingerol atau kurkumin dan peubah bebas koefisien wavelet menjadi kurang valid, karena masih terjadi kasus multikolinearitas. Nilai VIF (Variance
Inflantion Factor) tiap peubah untuk data
gingerol antara 43,4 681,2 sedangkan untuk data kurkumin besarnya antara 16,9 - 25994,9.
3. Regresi Terpenggal (RT)
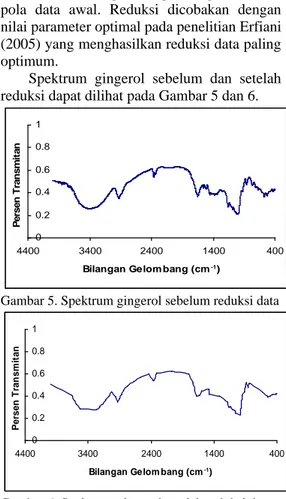
Berdasarkan pre-processing dengan RT pada spektrum gingerol diperoleh 86 titik hasil reduksi dengan tetap mempertahankan pola data awal. Reduksi dicobakan dengan nilai parameter optimal pada penelitian Erfiani (2005) yang menghasilkan reduksi data paling optimum.
Spektrum gingerol sebelum dan setelah reduksi dapat dilihat pada Gambar 5 dan 6.
0 0.2 0.4 0.6 0.8 1 400 1400 2400 3400 4400
Bilangan Gelom bang (cm-1)
P e rs e n T ra n s m it a n
Gambar 5. Spektrum gingerol sebelum reduksi data
0 0.2 0.4 0.6 0.8 1 400 1400 2400 3400 4400
Bilangan Gelom bang (cm-1)
P e rs e n T ra n s m it a n
Gambar 6. Spektrum gingerol setelah reduksi data
Namun metode Regresi Terpenggal tidak menghilangkan kolinearitas antar peubah, sehingga diperlukan metode tambahan (dengan penggabungan metode reduksi atau pemodelan) untuk memroses data yang masih berkorelasi.
4. Koreksi Pencaran Multiplikatif (KPM)
Selain reduksi, didalam pre-processing juga terdapat proses smoothing data. Proses
smoothing (pemulusan) ini bersifat optional
namun akan memberikan hasil reduksi yang lebih baik jika digabungkan dengan metode reduksi yang lain.
Gambar 7. Plot spektrum sampel pada data yang sudah dikoreksi.
Dari Gambar 7. terlihat bahwa spektrum pada data yang dikoreksi pencarannya lebih mendekati level idealnya, yaitu spektrum rata-rata seluruh sampel.
Reduksi KPM hanya bertujuan melihat besarnya pergeseran spektra sehingga tidak memerlukan asumsi yang umum berlaku dalam pembentukan model regresi, seperti autokorelasi. Adanya autokorelasi tidak mempengaruhi ketidakbiasan pendugaan parameter
B
tetapi akan menghasilkan ragam yang lebih kecil dari ragam sebenarnya, oleh karena itu pemenuhan asumsi terutama pada galatnya tidak diperlukan.Penjelasan lebih detail mengenai metode
pre-processing dan penerapan pada perangkat
lunak dijelaskan oleh Darmadi (in press).
Pemodelan
Proses pemodelan dilakukan setelah data terlebih dahulu direduksi atau setelah masalah kolinearitas antar peubah bebas dihilangkan.
Pemodelan data juga dilakukan dengan memperhatikan proses reduksi sebelumnya. Karena beberapa metode reduksi tidak dapat berdiri sendiri dalam menyelesaikan masalah kolinearitas, maka diperlukan penggabungan atau kombinasi antar metode reduksi. Namun kombinasi ini harus disesuaikan pula dengan pemodelan yang akan dibuat.
Dalam aplikasi model, proses reduksi dan
smoothing tidak harus berurutan. Artinya
smoothing bisa dilakukan lebih dulu sebelum
reduksi, maupun sebaliknya. Hal ini tidak mempengaruhi model asalkan reduksi tetap dilakukan.
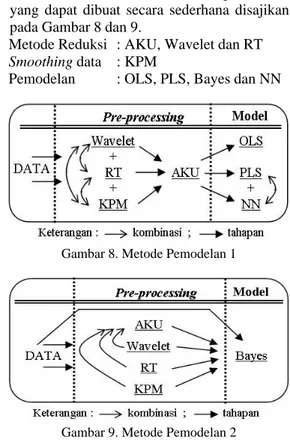
Kombinasi metode dan alur pemodelan yang dapat dibuat secara sederhana disajikan pada Gambar 8 dan 9.
Metode Reduksi : AKU, Wavelet dan RT
Smoothing data : KPM
Pemodelan : OLS, PLS, Bayes dan NN
Gambar 8. Metode Pemodelan 1
Gambar 9. Metode Pemodelan 2
a. Metode Pemodelan 1
Metode reduksi dengan Wavelet dan RT atau KPM saja atau sebaliknya belum bisa mengatasi masalah kolinearitas, karenanya harus terlebih dulu dikombinasikan dengan AKU. Selanjutnya baru dilakukan pemodelan menggunakan OLS, PLS atau NN. Atau dapat pula kombinasi NN dan PLS.
Penggabungan metode AKU dan OLS akan sama dengan proses Regresi Komponen Utama. Jika mengacu pada pre-processing yang sudah dilakukan, regresi komponen utama dengan OLS (contoh pengolahan pada spektrum gingerol) akan menghasilkan empat komponen utama dengan nilai RMSEP paling minimum yaitu 0,10961. Empat komponen ini memberikan sumbangan keragaman terbesar dengan kumulatif keragaman 97,2%. (Arnita 2005). Untuk pemodelan AKU dan PLS menghasilkan total keragaman yang dapat menjelaskan respon sebesar 65,07% untuk empat komponen utama yang diperoleh AKU.
Pada pemodelan NN permasalahan utama adalah dimensi peubah yang besar akan menyebabkan arsitektur model terlalu rumit dan sulit dijadikan model umum, selain waktu komputasi yang lama tanpa menghasilkan
peningkatan ketepatan pendugaan yang memadai. Untuk itu diperlukan reduksi data sebelum pemodelan.
Atok (2005) meneliti dan menyimpulkan bahwa kombinasi AKU + NN menghasilkan dugaan model terbaik yaitu NN 2 lapis dengan 1 node pada lapis tersembunyi, sehingga lebih disarankan AKU dalam pre-processing. b. Metode Pemodelan 2
Pemodelan dengan pendekatan Bayes tidak mensyaratkan adanya korelasi antar peubah atau bebas kolinearitas. Pendekatan Bayes bisa digunakan untuk semua jenis data, baik yang berkorelasi maupun tidak. Oleh karena itu, data sebenarnya dapat langsung dimodelkan tanpa melalui pre-processing.
Namun kendala yang muncul adalah dimensi data yang besar menyebabkan proses yang sangat lama serta kerja sistem yang berat (sangat berpengaruh pada kecepatan proses). Maka dari itu akan lebih efisien jika sebelum dimodelkan data terlebih dahulu melalui proses reduksi.
Dalam prakteknya, pendekatan Bayes dapat pula dikombinasi dengan pendekatan model lain. Atok (2005) juga menelaah penggunaan Bayes dan NN. Kombinasi model dilakukan dengan memperhatikan efisiensi dari segi pengolahan dan komputasi proses.
Efisiensi pengolahan dimaksudkan agar data tidak hanya direduksi terlebih dahulu menjadi dimensi yang lebih kecil namun juga dapat menghilangkan kolinearitas antar peubah. Sedangkan efisiensi komputasi menjadi pertimbangan agar proses pengolahan dapat dilakukan lebih cepat tanpa mengurangi akurasi hasil serta menghindari kendala proses
(hang) dalam perhitungan dan pemodelan.
Namun terdapat beberapa kombinasi pemodelan yang tidak disarankan untuk dilakukan karena alasan kurang efisien, yaitu: 1. KPM + Bayes
Pre-processing dengan metode KPM
hanya melakukan pemulusan data menuju pola rata-ratanya tetapi tidak mereduksi peubah. Penggabungan dengan Bayes akan mengembalikan ke permasalahan waktu pengolahan yang lama akibat data yang besar.
2. Wavelet +RT +AKU +PLS +Bayes +NN Pemodelan menggunakan hampir semua metode akan menjadi sangat tidak efisien karena selain mempengaruhi kecepatan proses (tanpa peningkatan akurasi model) juga menyebabkan kesulitan interpretasi parameter model output.
Serta metode-metode penggabungan lain yang mungkin dilakukan tetapi justru mengurangi efisiensi kerja dan keunikan model.
Aplikasi Model dalam R
Data awal yang menjadi input disimpan dalam format Comma Separated Value (CSV) agar dapat dibaca oleh R. Data input yang digunakan adalah data-data berdimensi besar dengan jumlah peubah (matriks kolom) lebih besar daripada jumlah data (baris data). Oleh karenanya, pada database sheet (umumnya menggunakan program Microsoft®
Office Excel) yang memiliki keterbatasan jumlah kolom, matriks data harus ditranspose terlebih dahulu dengan peubah respon disertakan pada baris/kolom paling akhir (contoh format data input pada Lampiran 1).
Sintaks perintah program dalam R juga bersifat case sensitive, artinya peka terhadap penggunaan abjad dan huruf balok. Apabila suatu variabel dideklarasi dengan abjad/huruf kecil, maka variabel ini hanya dapat dipanggil kembali dengan huruf yang sama.
Pemanggilan dan baca data dilakukan dengan perintah read.csv. Contoh perintah pemanggilan dan deklarasi data input:
InData <-read.csv(file=
"C:\\MyDoc\\data.csv",row.names=1) x <-t(InData[1:(nrow(InData)-1),]) y <-as.vector(InData
[nrow(InData),],mode="numeric")
Setelah masing-masing peubah didefinisikan kemudian baru dilakukan pemodelan menurut metodenya berdasarkan hasil pre-processing sebelumnya. Data atau hasil output disimpan juga dengan format CSV.
Seluruh metode pre-processing hanya memroses peubah bebas x. Variabel keluaran
pre-processing nantinya dideklarasi sebagai
variabel baru, misalkan xhasil. Pemodelan akan disusun dari informasi variabel xhasil
dan respon y dengan perintah sebagai berkut: a. Model OLS
ynew <-t(y)[,1:ncol(t(y))] ols1 <-lm(ynew ~ xhasil) anova(ols1);summary(ols1)
perintah lmmembuat model linear antara peubah ynew dan xhasil kemudian menampilkan hasil analisis ragam dan ringkasan output. (ynewadalah peubah y
opar <-par(mfrow =c(2,2), oma =c(0,0,1.1,0))
plot(ols1,las=1) ; par(opar)
baris perintah diatas menampilkan plot atau grafik dari model OLS keseluruhan. b. Model PLS
library(pls)
pls1 <-plsr(y ~ xhasil,ncomp=r) summary(pls1)
sebelum menyusun model PLS, paket pls harus diaktifkan terlebih dahulu dengan perintah library(pls). Kemudian baru dibuat pemodelan regresi parsial antara y
dan xhasil. Konstanta r adalah jumlah
komponen maksimum yang dimodelkan sesuai hasil pre-processing.
perintah terakhir menampilkan ringkasan hasil pemodelan. Untuk menampilkan plot koefisien PLS digunakan perintah:
coefplot(pls1, ncomp =1:r, legendpos = "bottomright")
c. Model Neural Network
library(nnet)
nhit <-nnet(xhasil[,1:r], y, size=1, linout=TRUE,
abstol=1.0e-3) summary(nhit)
paket nnet dipanggil untuk menyusun model Neural Network. Parameter yang digunakan dalam perintah nnet adalah parameter dengan nilai optimum untuk model terbaik dari penelitian Atok (2005) menggunakan reduksi AKU, yaitu NN 2 lapis dengan 1 node lapis tersembunyi. Parameter size menunjukkan jumlah node dalam lapis tersembunyi, linout
untuk output linear, dan abstol adalah tingkat kesalahan maksimal.
d. Model Bayes library(BRugs) modelCheck("jahemodel.txt") modelData("jahedata.txt") modelCompile(numChains=1) modelInits("jaheinit.txt") modelGenInits() modelUpdate(1000) samplesSet(c("JKG", "R2")) modelUpdate(1000) modBayes<-samplesStats("*"); modBayes
pada penelitian Erfiani (2005) pemodelan Bayes disusun dengan bantuan perangkat WinBugs. Di dalam bahasa R terdapat program OpenBugs yang algoritma dan strukturnya mirip dengan fungsi kerja pada WinBugs. Sehingga model Bayes juga dapat dibuat dalam lingkungan R dengan nilai-nilai parameter yang sama yang digunakan pula pada WinBugs. Fungsi program OpenBugs diaktifkan dengan memanggil paket BRugs. Proses pengecekan, input serta inisialisasi data dan iterasi menggunakan kriteria nilai parameter Bayes terbaik dari penelitian Erfiani (2005). Sedangkan baris perintah terakhir akan menampilkan output atau parameter output model (yaitu JKG dan R2 atau Koefisien Determinasi).
Contoh perintah diatas menggunakan data gingerol. Parameter model Bayes yang digunakan sebagai inisialisasi awal
(jahemodel, jahedata, jaheinit)
disajikan dalam Lampiran 2.
Output Pemodelan
Output perintah pemodelan menampilkan dugaan respon dan parameter masing-masing model (yaitu nilai kriteria kebaikan model) sebagai acuan untuk pendugaan respon sesuai pemodelan yang dilakukan.
Hasil output model OLS dan PLS antara lain menampilkan nilai RMSE, R2 dan R2 Adj. Selain itu dapat ditampilkan pula grafik atau plot data setelah pemodelan. Output model lengkap terdapat pada Lampiran 3 dan 4.
Parameter model Bayes yang ditampilkan adalah nilai JKG dan R2 (output model Bayes pada Lampiran 2). Sedangkan model Neural
Network menghasilkan node, koneksi serta
informasi bobot dan struktur model. Contoh output perintah model Neural Network adalah sebagai berikut: # weights: 7 initial value 5.545444 iter 10 value 1.400446 iter 20 value 1.322114 iter 30 value 1.321518 final value 1.321492 converged
a 4-1-1 network with 7 weights options were - linear output units b->h1 i1->h1 i2->h1 i3->h1 i4->h1 0.03 0.04 -0.53 0.14 -0.87 b->o h1->o
Keluaran awal model NN menunjukkan proses iterasi yang dilakukan sistem hingga mencapai kekonvergenan (proses ini tidak ditampilkan pada perangkat R-Stat). Secara
default, iterasi maksimum yang dilakukan
adalah 100 kali. Tapi pada sampel output ini, model sudah konvergen pada iterasi ke-30.
Hasil model NN yang diperoleh adalah NN (4,1,1) dengan 1 node lapis tersembunyi dan 7 pembobot. Ini berbeda dengan hasil yang diperoleh Atok (2005) yaitu NN (2,1,1). Tapi penelitian Atok dilakukan terhadap data simulasi dengan dimensi data yang berbeda dan tidak selalu mencapai kekonvergenan. Dalam penelitian tersebut juga disimpulkan bahwa perbedaan model disebabkan karena perbedaan dimensi data.
Karena iterasi dalam NN dilakukan acak, maka pengulangan proses akan menyebabkan perbedaan kecepatan konvergensi model dan nilai akhir namun tidak berpengaruh pada pendugaan model. Artinya dengan perintah yang sama, pengulangan proses menghasilkan jumlah iterasi dan nilai akhir yang berbeda-beda namun model yang diperoleh akan sama. Pembuktian iterasi NN pada Lampiran 5.
Meski beberapa model memiliki output parameter yang sama, namun tidak dapat dilakukan perbandingan hasil antar model karena perbedaan penafsiran parameter untuk setiap model yang berbeda.
Analisis Perangkat Lunak
R-Stat merupakan perangkat built-in
process yang tidak bisa berjalan sendiri,
melainkan juga harus dilengkapi metode
pre-processing data namun pembahasan disini
dikhususkan hanya pada tahap pemodelan. Pemodelan dalam perangkat lunak R-Stat menggunakan fungsi dan paket program yang tersedia dalam bahasa R.
Desain model dan tampilan menggunakan bahasa R dan Visual Basic. Tambahan perangkat R(D)COM Server diperlukan untuk menghubungkan keduanya sehingga perintah-perintah R dapat dijalankan di Visual Basic. Proses perhitungan pemodelan dilakukan oleh R dan hasilnya ditampilkan pada Visual Basic.
Untuk memanggil R pada Visual Basic dilakukan dengan baris perintah berikut:
Public x As StatConnector Set x = New StatConnector x.Init ("R")
Sedangkan untuk menuliskan perintah R pada VB menggunakan x.EvaluateNoReturn. Misal untuk memanggil paket nnet dalam R, pada VB dituliskan:
x.EvaluateNoReturn "library(nnet)"
Langkah-langkah penggunaan perangkat R-Stat dijelaskan dalam Lampiran 6.
1. Evaluasi Sistem
Pengujian dilakukan untuk mengetahui sejauh mana fungsi-fungsi yang dibuat sesuai dengan metode dan tujuan yang diterapkan.
Evaluasi atau pengujian sistem dilakukan dengan metode blackbox, dimana hasil output perhitungan R-Stat akan dibandingkan dengan output hasil perhitungan perangkat lunak yang digunakan sebelumnya (perangkat evaluator).
Pengujian sistem menggunakan bantuan perangkat keras komputer dengan spesifikasi:
a. Processor AMD Athlon XP~1,8GHz
b. Memori DDR 384 MB c. Harddisk 40 GB
Seluruh proses bekerja pada sistem operasi Microsoft®
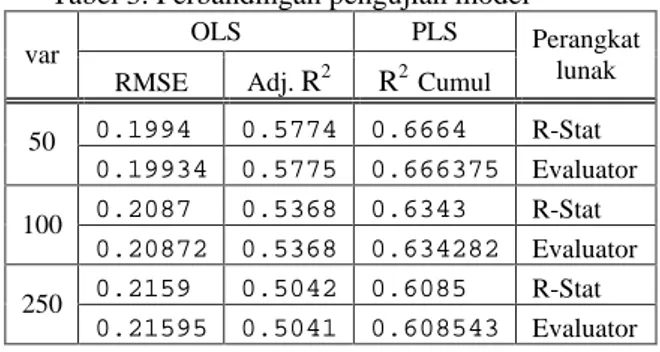
Windows XP Professional SP2. Pengujian menggunakan data gingerol dan kurkumin yang disekat-sekat menjadi partisi yang lebih kecil. Pengujian dilakukan pada partisi berukuran 50, 100 dan 250 variabel. Model yang diuji adalah model OLS dan PLS dengan reduksi komponen utama. Kriteria acuan untuk model OLS adalah nilai Adj.R2 (R2 terkoreksi) dan nilai RMSE sedangkan PLS menggunakan R2 komulatif, yaitu nilai R2 terbesar pada komponen model terakhir. Perangkat evaluator menggunakan SAS v8 untuk model OLS (regresi komponen utama) dan model PLS menggunakan Minitab 14.
Hasil pengujian pada Tabel 3 di bawah ini menunjukkan bahwa perangkat R-Stat mampu memberikan akurasi model yang sama dengan perangkat evaluator. Perbedaan sebesar 10e-4 lebih disebabkan pembulatan (hasil output pengujian secara lengkap pada Lampiran 7).
Tabel 3. Perbandingan pengujian model
OLS PLS
var
RMSE Adj. R2 R2 Cumul
Perangkat lunak 0.1994 0.5774 0.6664 R-Stat 50 0.19934 0.5775 0.666375 Evaluator 0.2087 0.5368 0.6343 R-Stat 100 0.20872 0.5368 0.634282 Evaluator 0.2159 0.5042 0.6085 R-Stat 250 0.21595 0.5041 0.608543 Evaluator
2. Pemeliharaan Sistem
Setelah pemodelan selesai dibuat dan mulai digunakan, maka dibutuhkan proses pemeliharaan agar program dapat berjalan dengan baik.
Bentuk pemeliharaan untuk program ini berupa penambahan fitur untuk menampilkan grafik dan bantuan yang lengkap, serta memperbaiki gangguan-gangguan yang ada baik dari segi tampilan maupun algoritma.
3. Kelebihan Sistem
Kelebihan dari perangkat R-Stat diantaranya: a. Efisien. R-Stat mampu menampung dan
melakukan pengolahan untuk menyusun model kalibrasi dengan beberapa metode sekaligus dalam satu paket program. b. Mampu menyusun model untuk data
dengan jumlah variabel yang besar. Perangkat R-Stat menyediakan kapasitas yang besar untuk menampung data, namun dalam proses pengolahan hingga pemodelan tergantung pada memori dan perangkat keras yang digunakan.
c. Memungkinkan pengembangan lebih lanjut. R-Stat menggunakan R dan Visual Basic sebagai pemrograman utama sehingga memudahkan pengembangan lebih lanjut sesuai kebutuhan data dan pengguna.
d. Hemat waktu dan biaya dibandingkan perhitungan model secara manual.
4. Kekurangan Sistem
Kekurangan dari perangkat R-Stat antara lain: a. Tampilan yang masih sedehana.
b. Komponen bantuan yang belum lengkap. c. Data input harus disimpan dalam fomat
CSV agar dapat dibaca.
d. Masih terdapat gangguan pada tampilan kursor saat data sedang diproses.
e. Karena menggunakan data sangat besar, seringkali perangkat membutuhkan waktu yang lama ketika menghitung.
f. Harus memasang perangkat tambahan untuk membantu proses yaitu paket-paket dalam R serta R (D)COM Server.
KESIMPULAN DAN SARAN
Kesimpulan
Pemodelan kalibrasi pada data berdimensi besar dilakukan dengan pre-processing data terlebih dahulu sebelum data dimodelkan.
Pre-processing bertujuan mereduksi dimensi
data dan menghilangkan kolinearitas antar peubah sehingga data mudah dimodelkan
Perangkat lunak R-Stat dikembangkan untuk tujuan pemodelan kalibrasi pada data berdimensi besar. R-Stat menggunakan model OLS, PLS, NN dan pendekatan Bayes dalam menyusun model kalibrasi.
Perangkat R-Stat lebih efisien digunakan karena dapat mencakup beberapa model dalam satu paket program. Selain itu juga mampu menghasilkan dugaan model dengan tingkat akurasi relatif sama dengan perangkat lunak statistik lain yang umum digunakan. Dalam pengembangan kasus pemodelan data yang lebih luas, perangkat R-Stat dapat dikembangkan lebih lanjut sesuai kebutuhan data dan pengguna.
Saran
Data spektrum senyawa aktif pada setiap tanaman obat bersifat spesifik dan khas sehingga untuk pemodelan pada data senyawa aktif lain sebaiknya memperhatikan pula karakteristik serta daerah identifikasi senyawa aktif yang diteliti.
Perangkat lunak R-Stat yang digunakan dalam pemodelan ini juga masih sederhana sehingga diperlukan pengembangan lebih lanjut dalam desain interface dan algoritma perhitungan serta informasi output yang lebih detail.
DAFTAR PUSTAKA
Arnita. 2005. Koreksi Pencaran Dalam Model Kalibrasi Peubah Ganda pada Data Senyawa Aktif Gingerol Serbuk Rimpang Jahe (Zingiber Officinale Roscue).
[Tesis]. Bogor: Program Pascasarjana, Institut Pertanian Bogor.
Atok RM. 2005. Jaringan Syaraf Tiruan untuk Pemodelan Kalibrasi dengan Prapemrosesan Analisis Komponen Utama dan Transformasi Fourier Diskret. [Tesis]. Bogor : Program Pasca Sarjana, Institut Pertanian Bogor.
Berger JO. 1985. Statistical Decision Theory
and Bayesian Analysis. 2nd Edition. New York: Springer-Verlag.
Bishop CM. 1995. Neural Networks for
Pattern Recognition. New York : Oxford
University Press Inc
Chin WW. 2000. Partial Least Squares for
Researchers: An Overview and Presentation of Recent Advances Using the PLS Approach. University of Houston
Darmadi RD. 2006. Penyusunan Perangkat Lunak R-Stat untuk Pre-Processing Model Kalibrasi. Institut Pertanian Bogor,
in press.
Erfiani. 2005. Pengembangan Model Kalibrasi dengan Pendekatan Bayes (kasus tanaman obat). [Disertasi]. Bogor: Program Pascasarjana, Institut Pertanian Bogor. Fausett L. 1994. Fundamentals of Neural
Networks: Architecture, Algorithms, and Applications. New Jersey : Prentice Hall
Geladi P, Kowalski BR. 1986. Partial Least
Square Regression. Tutorial. Analitica
Chimica Acta. 185: 1-17
Johnson RA, Wicher DW. 2002. Applied
Multivariate Statistical Analysis. 5th
Edition. NJ, USA: Prentice-Hall, Inc. Upper Saddle River.
Joreskog KG, Wold H. 1982. Systems Under
Indirect Observation. North Holland
Amsterdam.
Mattjik AA, Sumertajaya IM. 2002. Perancangan Percobaan : Dengan Aplikasi SAS dan Minitab. Ed. Ke-2. Bogor: IPB Press.
Naes T, Issakson T, Fearn T, Davies T. 2002.
Multivariate Calibration and Classification. United Kingdom: NIR
Publications Chichester.
Nason GP, Silverman BW. 1997. Wavelets for
Regression and other Statistical Problems. School of Mathematics, University of Bristol, UK.
Ramanathan R. 1997. Introductory Econometrics with Applications.
University of California-San Diego: The Dryden Press.
Sunaryo S. 2005. Model kalibrasi dengan Transformasi Wavelet sebagai Metode Pra-pemrosesan. [Disertasi]. Bogor: Program Pascasarjana, Institut Pertanian
Lampiran 2. Parameter input data jahe dan hasil output model Bayes 1. jahedata list(p = 14, N= 15, y = c( 0.53, 0.72, 0.58, 0.53, 0.52, 0.79, 0.78, 0.63, 0.78, 0.79, 1.26, 1.60, 1.18, 1.14, 1.07), x = structure(.Data = c(0.47253,0.29041,0.31688,0.21753,0.25393,0.22009,0.21148,0.388 56,0.37713,0.65655,0.62908,0.58359,0.47723,0.4722,0.50962, 0.47603,0.28579,0.31533,0.21139,0.25563,0.21993,0.20887,0.38551 ,0.37453, 0.64564,0.6302,0.57898, 0.47275,0.4693,0.5123, 0.47647,0.28275,0.314,0.20557,0.25577,0.21857,0.2052,0.38364, 0.37243,0.63984,0.63175,0.57553,0.47104,0.46794,0.51344, 0.56672,0.3546,0.4051,0.29131,0.32915,0.28759,0.26711,0.46795, 0.43497,0.69386,0.67472,0.62008,0.54909,0.53731,0.58624, 0.56274,0.3495,0.39983,0.28561,0.32426,0.28263,0.26202,0.46296, 0.4304,0.69062,0.67205, 0.61657,0.5447,0.53309,0.58325, 0.67551,0.55573,0.6187,0.51107,0.49047,0.43536,0.43565,0.65132, 0.60612,0.81641,0.73577,0.69682,0.68383,0.63573,0.6285, 0.6747,0.55584,0.61887,0.51176,0.49058,0.43533,0.43595,0.65182, 0.60626,0.81783,0.73522,0.6971,0.68425,0.63608,0.62835, 0.57868,0.39902,0.49078,0.33438,0.33912,0.27641,0.27514,0.51874 ,0.4743,0.74858,0.65828,0.5974,0.56572,0.52714,0.52937, 0.57792,0.3978,0.48961,0.33309,0.33811,0.27545,0.27411,0.51764, 0.47332,0.74788,0.65777,0.59672,0.56479,0.52632,0.52867, 0.43979,0.22404,0.31512,0.15845,0.20091,0.14318,0.13619,0.34674 ,0.33137,0.62805,0.55588,0.47425,0.40849,0.38333,0.40722, 0.43846,0.22253,0.31347,0.15712,0.19982,0.14214,0.13509,0.34515 ,0.32995,0.62669,0.55474,0.47294,0.40705,0.38209,0.40626, 0.33699,0.12572,0.20351,0.0835,0.13091,0.07792,0.06923,0.23675, 0.2355,0.51512,0.4652,0.37447,0.3046,0.28173,0.32147, 0.33755,0.12635,0.20427,0.08397,0.13132,0.07827,0.06962,0.23752 ,0.2362,0.51617,0.46572,0.37525,0.3054,0.28239,0.32194, 0.55615,0.39425,0.49631,0.3088,0.31221,0.24284,0.24461,0.50821, 0.47259,0.75379,0.62974,0.5599,0.55606,0.50592,0.48157 ), .Dim = c(14, 15)))
2. jahemodel
3. jaheinit
4. Output model Bayes
list( tau=10000000, beta.c=1, beta.tau=1 ) model; { for( i in 1 : N ) { for( j in 1 : p ) { bx[j , i] <- beta[j] * x[j , i] } } for( j in 1 : p ) { beta[j] ~ dnorm(beta.c,beta.tau) } for( i in 1 : N ) { y[i] ~ dnorm(mu[i],tau) } tau ~ dnorm(sigma,1.0E-3) sigma <- 1 / tau for( i in 1 : N ) { for( j in 1 : p ) { x[j , i] ~ dnorm( 0.0,1.0E-6)I(0,100) } } for( i in 1 : N ) {
mu[i] <- sum(bx[ , i]) }
for( i in 1 : N ) {
kuadrate[i] <- (y[i] - mu[i]) * (y[i] - mu[i]) }
JKG <- sum(kuadrate[]) for( i in 1 : N ) {
kuadraty[i] <- y[i] * y[i] }
JKT <- sum(kuadraty[]) - nyrataan2 R2 <- 1 - JKG / JKT
yrataan2 <- mean(y[]) * mean(y[]) nyrataan2 <- N * yrataan2
beta.c ~ dnorm( 0.0,1.0E-3) beta.tau ~ dgamma(0.01,0.001) }
mean sd MC_error val2.5pc median val97.5pc start sample JKG 0.3879 0.0937 0.011920 0.2664 0.3768 0.5756 1001 1000 R2 0.7305 0.0651 0.008279 0.6003 0.7387 0.8151 1001 1000
Lampiran 3. Output model OLS untuk gingerol dengan 4 komponen utama
Analysis of Variance Table Response: ynew
Df Sum Sq Mean Sq F value Pr(>F) outputx 4 1.16269 0.29067 6.9852 0.002206 ** Residuals 15 0.62419 0.04161 ---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Call:
lm(formula = ynew ~ outputx) Residuals:
Min 1Q Median 3Q Max -0.40943 -0.12890 0.04984 0.09600 0.34276 Coefficients:
Estimate Std. Error t value Pr(>|t|) (Intercept) 0.8360000 0.0456140 18.328 1.11e-11 *** outputxSkor 1 -0.0004878 0.0001968 -2.478 0.02559 * outputxSkor 2 0.0029638 0.0007755 3.822 0.00167 ** outputxSkor 3 0.0076024 0.0031193 2.437 0.02773 * outputxSkor 4 0.0017302 0.0039665 0.436 0.66891 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.204 on 15 degrees of freedom
Multiple R-Squared: 0.6507, Adjusted R-squared: 0.5575
Lampiran 4. Output dan perbandingan model PLS untuk gingerol Hasil Minitab
Number of components specified: 4
Model Selection and Validation for Validasi Components X Variance Error SS R-Sq 1 0.40036 0.954083 0.466062 2 0.76928 0.629608 0.647649 3 0.90974 0.624720 0.650385 4 1.00000 0.624192 0.650680 Hasil R-Stat
> pls.jh <- plsr(y ~ outputx, ncomp = 4) > summary(pls.jh)
Data: X dimension: 20 4 Y dimension: 20 1 Fit method: kernelpls
Number of components considered: 4 TRAINING: % variance explained
1 comps 2 comps 3 comps 4 comps X 96.15 99.71 99.89 100.00
Lampiran 5. Pengujian iterasi dan output model Neural-Network
> nhit <- nnet(outputx, y, size=1, linout=TRUE, abstol=1.0e-3) # weights: 7 initial value 12.256388 iter 10 value 1.328651 iter 20 value 1.327992 iter 30 value 1.234210 final value 1.234209 converged > summary(nhit)
a 4-1-1 network with 7 weights
options were - linear output units b->h1 i1->h1 i2->h1 i3->h1 i4->h1 0.45 0.47 -0.97 0.53 0.08 b->o h1->o
0.99 -0.33
> nhit2 <- nnet(outputx, y, size=1, linout=TRUE, abstol=1.0e-3) # weights: 7 initial value 16.251879 iter 10 value 1.234610 iter 20 value 1.234196 iter 30 value 1.233814 iter 40 value 1.096178 final value 1.094966 converged > summary(nhit2)
a 4-1-1 network with 7 weights
options were - linear output units b->h1 i1->h1 i2->h1 i3->h1 i4->h1 0.20 0.38 -0.24 -0.12 0.67 b->o h1->o
1.02 -0.37
> nhit3 <- nnet(outputx, y, size=1, linout=TRUE, abstol=1.0e-3) # weights: 7
initial value 12.338231 final value 1.234210 converged
> summary(nhit3)
a 4-1-1 network with 7 weights
options were - linear output units b->h1 i1->h1 i2->h1 i3->h1 i4->h1 0.14 -0.32 0.43 -0.22 0.35 b->o h1->o
0.65 0.33
> nhit4 <- nnet(outputx, y, size=1, linout=TRUE, abstol=1.0e-3) # weights: 7 initial value 7.702461 iter 10 value 1.107327 iter 20 value 1.094963 final value 1.094963 converged > summary(nhit4)
a 4-1-1 network with 7 weights
options were - linear output units b->h1 i1->h1 i2->h1 i3->h1 i4->h1 0.63 -0.28 0.28 -0.66 -0.54 b->o h1->o
Splash-screen program R-Stat ketika pertama kali
diaktifkan.
Jendela utama program R-Stat yang berisi tombol-tombol menu, yaitu:
1. Buka File, untuk mengambil atau membaca data input
2. Bantuan, menampilkan fungsi dan instruksi bantuan yang diperlukan dalam R-Stat
3. Grup Masukan, berisi menu Tampil X, Tampil Y, Simpan, Grafik dan Simpan Grafik
4. Prapemrosesan 5. Model
6. Tentang, berisi informasi utama mengenai program R-Stat, dan
7. Keluar Lampiran 6. Langkah-langkah penggunaan perangkat lunak R-Stat Buka program R-Stat dengan meng-klik dua kali ikon aplikasi R-Stat atau klik kanan pada ikon, pilih Open.
Klik pada menu Buka File, maka jendela Open akan muncul.
File of Type yang dapat dibaca oleh R-Stat adalah File dengan format CSV.
Jendela Peringatan akan muncul bila File data input tidak ditemukan dan atau jika tombol Cancel di-klik pada jendela Open.
Contoh hasil Prapemrosesan dengan AKU yang menampilkan Skor komponen utama.
Setelah data di-input maka R-Stat akan langsung mendefinisikan variabel ke dalam peubah X dan Y.
Oleh karenanya bentuk data input juga harus diperhatikan agar R-Stat tidak salah membaca variabel input.
Kemudian masing-masing variabel ini dapat ditampilkan (untuk memastikan data sudah terbaca) dengan meng-klik menu Tampil X. Begitu pula variabel Y dapat ditampilkan dengan menu Tampil Y.
Menutup jendela dilakukan dengan meng-klik pada menu File > Close. Jendela Masukan dapat digunakan apabila data telah di-input.
Pilihan Simpan hanya digunakan untuk menyimpan data input yang ditampilkan. Sedangkan untuk menyimpan Grafik digunakan menu Simpan Grafik. Grafik atau plot akan menampilkan grafik dari data input (bila ada).
Selanjutnya data yang telah di-input dapat langsung dilakukan pengolahan dengan meng-klik menu Prapemrosesan. Jendela Prapemrosesan berisi metode-metode yang digunakan dalam proses reduksi maupun pemulusan data. Selain itu terdapat pula pilihan untuk menampilkan hasil output, menyimpan kembali dalam file terpisah serta menu untuk menampilkan dan menyimpan grafik data hasil Prapemrosesan.
Kotak dialog Input Komponen muncul jika salah satu menu dalam Model dipilih. Disini user diminta memasukkan jumlah komponen hasil Prapemrosesan yang telah dilakukan sebelumnya.
Proses reduksi dan pemulusan diperlukan dalam pemodelan agar masalah data besar dan kolinearitas antar peubah dapat diatasi.
Menu Model berisi metode-metode dalam pemodelan yang digunakan menyusun model kalibrasi.
Didalamnya juga dilengkapi menu untuk menampilkan grafik untuk model OLS dan PLS. Sedangkan model Bayes dan Neural-Network tidak menghasilkan grafik atau plot dalam pengolahannya.
Output hasil pemodelan dapat disimpan pula secara terpisah dalam format CSV menggunakan menu Simpan Hasil. Grafik akan disimpan dalam format JPG.
Jendela Peringatan akan kembali muncul jika pada jendela Input Komponen user tidak memasukkan jumlah komponen dan memilih Cancel.
User dapat menggunakan kombinasi model
yang diperlukan sesuai kebutuhan dan kesesuaian dengan metode Prapemrosesan yang dilakukan.
Misalnya setelah pemodelan dengan Bayes, hasil output disimpan, kemudian kembali ke jendela model untuk memilih Neural-Network. Hasil yang disimpan adalah hasil akhir dari setiap pemodelan, sehingga untuk setiap model (jika melakukan kombinasi) akan diperoleh beberapa hasil output yang berbeda.
Menu Tentang akan memunculkan jendela About R-Stat yang berisi informasi tentang program R-Stat.
Contoh hasil pemodelan dan grafik PLS yang ditampilkan
Kotak dialog Save As menyimpan hasil pemodelan dengan format CSV.
Menutup jendela Model dan kembali ke jendela utama.
Bila masih terdapat hal yang kurang dimengerti pada jendela Model, pilihan Bantuan dapat digunakan.
Lampiran 7. Pengujian akurasi hasil perangkat R-Stat dan Evaluator
1. Iterasi untuk 50 variabel
Hasil Minitab (PLS)
PLS Regression: Y versus Skor 1, Skor 2, Skor 3, Skor 4
Number of components specified: 4 Analysis of Variance for Y
Source DF SS MS F P Regression 4 1.19073 0.297683 7.49 0.002 Residual Error 15 0.59615 0.039743
Total 19 1.78688
Model Selection and Validation for Y Components X Variance Error SS R-Sq 1 0.34837 0.779624 0.563695 2 0.61786 0.617788 0.654264 3 0.75867 0.596399 0.666235 4 1.00000 0.596147 0.666375 Hasil R-Stat (PLS)
Data: X dimension: 20 4 Y dimension: 20 1 Fit method: kernelpls
Number of components considered: 4 TRAINING: % variance explained
1 comps 2 comps 3 comps 4 comps X 99.986 100.00 100.00 100.00
y 8.375 16.99 63.92 66.64
Hasil SAS (OLS)
The REG Procedure Dependent Variable: Y Y Analysis of Variance Sum of Mean
Source DF Squares Square F Value Pr > F Model 4 1.19081 0.29770 7.49 0.0016 Error 15 0.59607 0.03974
Corrected Total 19 1.78688
Root MSE 0.19934 R-Square 0.6664 Dependent Mean 0.83600 Adj R-Sq 0.5775 Coeff Var 23.84504
Hasil R-Stat (OLS)
Analysis of Variance Table Response: ynew
Df Sum Sq Mean Sq F value Pr(>F) outputx 4 1.19073 0.29768 7.4902 0.001594 ** Residuals 15 0.59615 0.03974 ---
Residuals:
Min 1Q Median 3Q Max -0.28897 -0.07288 0.01148 0.11300 0.30874 Coefficients:
Estimate Std. Error t value Pr(>|t|) (Intercept) 0.8360000 0.0445775 18.754 8e-12 *** outputxSkor 1 0.0003304 0.0010125 0.326 0.748676 outputxSkor 2 0.0941880 0.0725534 1.298 0.213829 outputxSkor 3 1.7009091 0.3636653 4.677 0.000298 *** outputxSkor 4 1.0661428 0.6521408 1.635 0.122890 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.1994 on 15 degrees of freedom
Multiple R-Squared: 0.6664, Adjusted R-squared: 0.5774 F-statistic: 7.49 on 4 and 15 DF, p-value: 0.001594
2. iterasi untuk 100 variabel
Hasil Minitab (PLS)
PLS Regression: Y versus Skor 1, Skor 2, Skor 3, Skor 4
Number of components specified: 4 Analysis of Variance for Y
Source DF SS MS F P Regression 4 1.13339 0.283346 6.50 0.003 Residual Error 15 0.65349 0.043566
Total 19 1.78688
Model Selection and Validation for Y Components X Variance Error SS R-Sq 1 0.26602 0.683412 0.617539 2 0.57224 0.655728 0.633032 3 0.75529 0.653499 0.634279 4 1.00000 0.653495 0.634282 Hasil R-Stat (PLS)
Data: X dimension: 20 4 Y dimension: 20 1 Fit method: kernelpls
Number of components considered: 4 TRAINING: % variance explained
1 comps 2 comps 3 comps 4 comps X 99.952 99.99 100.00 100.00