BAB 4
PEMECAHAN MASALAH
4.1. Metodologi Pemecahan Masalah
Metodologi pemecahan masalah dari penelitian ini terangkum dalam gambar flowchart dibawah ini.
Tahap pertama adalah melihat distribusi data yang ada, normal atau tidak. Pengujian normalitas data menggunakan Tests of Normality dengan uji Kolmogorov-Smirnov dan Shapiro-wilk pada program SPSS. Normal atau tidaknya distribusi data dilihat dari tingkat signifikansi data sebagai penjabaran dari kemiringan (skewness) dan kelancipan (kurtosis) data. Tingkat signifikansi uji Kolmogorov-Smirnov dan Shapiro-wilk > 0,05 berarti distribusi data normal atau mendekati normal.
Tahap kedua adalah mengolah data dengan menggunakan six-Group of Stepwise Discriminant Analysis. Proses analisis diskriminan dalam penelitian ini sebagai berikut:
1. Memisahkan variabel-variabel yang menjadi variabel dependen dan variabel independen.
2. Membuat kategori untuk data yang akan digunakan pada variabel dependen. Dalam penelitian ini variabel dependen terdiri dari 6 (enam) grup yaitu kinerja keuangan pada industri Makanan dan Minuman (group 1), Tekstil dan Garmen (group 2), Plastik dan Kemasan (group 3), Logam dan Sejenisnya (group 4), Otomotif dan Komponennya (group 5), dan Properti dan Real Estat(group 6).
3. Menentukan metode untuk membuat fungsi diskriminan. Pada prinsipnya ada dua metode dasar yang digunakan, yaitu:
a. Simultaneous Estimation, dimana semua variabel dimasukkan secara bersama-sama kemudian dilakukan proses diskriminasi.
b. Stepwise Estimation, dimana variabel dimasukkan satu per satu kedalam model diskriminan. Pada proses ini ada kemungkinan satu atau lebih variabel independen yang dibuang dari model.
4. Menguji signifikansi dari fungsi diskriminan yang telah terbentuk, dengan menggunakan Wilk's Lamda, dan F test.
5. Melakukan pengklasifikasian data dari fungsi diskriminan dan group centroids yang terbentuk.
6. Menguji ketepatan klasifikasi secara individual dan keseluruhan berdasarkan fungsi diskriminan dan group centroids.
Penelitian ini menggunakan paket program komputer SPSS versi 13.0 dan Microsoft Excel for Windows untuk mempercepat dan menjamin ketelitian dalam pengolahan data serta pengujian.
4.2. Pengolahan Data dan Interpretasi Hasil Perhitungan 4.2.1. Klasifikasi Industri dan Anggotanya
Sampel dipilih dari enam industri yang terdaftar di Bursa Efek Jakarta (BEJ). Kemudian dari masing-masing industri dipilih perusahaan-perusahaan yang akan diambil sebagai sampel, yaitu perusahaan yang telah terdaftar di lantai bursa sejak tahun 1991 dan masih terdaftar hingga 2007.
Tabel 4.2 Klasifikasi Sampel pada Industri Tekstil dan Garmen
Tabel 4.3 Klasifikasi Sampel pada Industri Plastik dan Kemasan
Tabel 4.5 Klasifikasi Sampel pada Industri Otomotif dan Komponennya
Tabel 4.6 Klasifikasi Sampel pada Industri Properti dan Real Estat
4.2.2. Pengumpulan Data Keuangan dari Sampel
Pada tahap ini, dikumpulkan data rasio keuangan yang diambil dari sumber data Indonesian Capital Market Directory (ICMD) dari tahun 1991 sampai dengan ICMD tahun 2006 dengan beberapa perhitungan rasio keuangan lainnya yang tidak terdapat pada ICMD tersebut.
4.2.3. Pengolahan Data dan Interpretasi Hasil Perhitungan Periode 1991 – 1996 4.2.3.1. Proses Normalisasi dan Seleksi Data
Hasil pengujian data-data yang telah ditransformasi dapat dilihat pada tabel 4.7.
Tabel 4.7 Uji Normalitas
Kolmogorov-Smirnov(a) Shapiro-Wilk Jenis
Industri Statistic df Sig. Statistic df Sig.
CR Makanan dan minuman .430 7 .000 .590 7 .000
Tekstil dan garmen .243 11 .068 .877 11 .095
Plastik dan Kemasan .272 4 . .875 4 .319
Logam dan sejenisnya .342 5 .056 .822 5 .120
Otomotif dan komponennya .182 5 .200(*) .954 5 .763
Properti dan Real Estate .178 3 . 1.000 3 .960
CASH Makanan dan minuman .440 7 .000 .565 7 .000
Tekstil dan garmen .238 11 .083 .894 11 .155
Plastik dan Kemasan .282 4 . .867 4 .288
Logam dan sejenisnya .343 5 .054 .764 5 .040
Otomotif dan komponennya .214 5 .200(*) .923 5 .547
Properti dan Real Estate .254 3 . .964 3 .634
ITO Makanan dan minuman .294 7 .068 .727 7 .007
Tekstil dan garmen .173 11 .200(*) .967 11 .852
Plastik dan Kemasan .240 4 . .891 4 .389
Logam dan sejenisnya .175 5 .200(*) .971 5 .882
Otomotif dan komponennya .324 5 .093 .884 5 .329
Properti dan Real Estate .329 3 . .868 3 .291
TATO Makanan dan minuman .307 7 .044 .711 7 .005
Tekstil dan garmen .184 11 .200(*) .890 11 .140
Plastik dan Kemasan .379 4 . .770 4 .059
Logam dan sejenisnya .225 5 .200(*) .925 5 .560
Otomotif dan komponennya .300 5 .161 .857 5 .219
Properti dan Real Estate .280 3 . .938 3 .520
Tekstil dan garmen .327 11 .002 .586 11 .000
Plastik dan Kemasan .235 4 . .943 4 .671
Logam dan sejenisnya .279 5 .200(*) .876 5 .291
Otomotif dan komponennya .255 5 .200(*) .912 5 .477
Properti dan Real Estate .383 3 . .756 3 .013
DSO Makanan dan minuman .222 7 .200(*) .863 7 .162
Tekstil dan garmen .243 11 .070 .804 11 .011
Plastik dan Kemasan .350 4 . .830 4 .169
Logam dan sejenisnya .193 5 .200(*) .948 5 .723
Otomotif dan komponennya .255 5 .200(*) .897 5 .391
Properti dan Real Estate .256 3 . .962 3 .626
DR Makanan dan minuman .293 7 .069 .748 7 .012
Tekstil dan garmen .114 11 .200(*) .954 11 .695
Plastik dan Kemasan .286 4 . .829 4 .165
Logam dan sejenisnya .339 5 .061 .811 5 .099
Otomotif dan komponennya .203 5 .200(*) .908 5 .458
Properti dan Real Estate .338 3 . .852 3 .247
DER Makanan dan minuman .474 7 .000 .495 7 .000
Tekstil dan garmen .124 11 .200(*) .957 11 .734
Plastik dan Kemasan .267 4 . .904 4 .451
Logam dan sejenisnya .303 5 .150 .802 5 .085
Otomotif dan komponennya .284 5 .200(*) .770 5 .045
Properti dan Real Estate .366 3 . .796 3 .105
MARGIN Makanan dan minuman .303 7 .052 .791 7 .034
Tekstil dan garmen .143 11 .200(*) .967 11 .854
Plastik dan Kemasan .274 4 . .939 4 .650
Logam dan sejenisnya .211 5 .200(*) .935 5 .633
Otomotif dan komponennya .229 5 .200(*) .907 5 .449
Properti dan Real Estate .204 3 . .993 3 .843
BEP Makanan dan minuman .317 7 .032 .787 7 .030
Tekstil dan garmen .255 11 .044 .854 11 .048
Plastik dan Kemasan .283 4 . .863 4 .272
Otomotif dan komponennya .220 5 .200(*) .896 5 .390
Properti dan Real Estate .253 3 . .964 3 .637
ROA Makanan dan minuman .329 7 .021 .764 7 .018
Tekstil dan garmen .168 11 .200(*) .955 11 .710
Plastik dan Kemasan .192 4 . .978 4 .889
Logam dan sejenisnya .209 5 .200(*) .913 5 .483
Otomotif dan komponennya .141 5 .200(*) .994 5 .991
Properti dan Real Estate .311 3 . .898 3 .378
ROE Makanan dan minuman .317 7 .032 .755 7 .014
Tekstil dan garmen .160 11 .200(*) .970 11 .882
Plastik dan Kemasan .374 4 . .749 4 .038
Logam dan sejenisnya .204 5 .200(*) .902 5 .422
Otomotif dan komponennya .265 5 .200(*) .883 5 .321
Properti dan Real Estate .271 3 . .948 3 .560
EPS Makanan dan minuman .339 7 .015 .710 7 .005
Tekstil dan garmen .309 11 .004 .798 11 .009
Plastik dan Kemasan .202 4 . .972 4 .855
Logam dan sejenisnya .312 5 .124 .819 5 .115
Otomotif dan komponennya .235 5 .200(*) .899 5 .405
Properti dan Real Estate .374 3 . .778 3 .062
PER Makanan dan minuman .304 7 .049 .814 7 .056
Tekstil dan garmen .283 11 .014 .672 11 .000
Plastik dan Kemasan .264 4 . .893 4 .398
Logam dan sejenisnya .373 5 .022 .752 5 .031
Otomotif dan komponennya .448 5 .001 .631 5 .002
Properti dan Real Estate .290 3 . .925 3 .472
BVPS Makanan dan minuman .307 7 .046 .829 7 .079
Tekstil dan garmen .224 11 .128 .897 11 .172
Plastik dan Kemasan .313 4 . .908 4 .469
Logam dan sejenisnya .216 5 .200(*) .913 5 .486
Otomotif dan komponennya .128 5 .200(*) .996 5 .995
PBV Makanan dan minuman .153 7 .200(*) .944 7 .673
Tekstil dan garmen .265 11 .030 .830 11 .023
Plastik dan Kemasan .252 4 . .898 4 .423
Logam dan sejenisnya .277 5 .200(*) .835 5 .150
Otomotif dan komponennya .222 5 .200(*) .934 5 .626
Properti dan Real Estate .197 3 . .996 3 .873
Berdasarkan Tabel 4.7 dapat dilihat bahwa data-data mempunyai distribusi normal atau mendekati normal. Hal ini dapat diketahui dengan membandingkan tingkat signifikansi data yang lebih besar dari 0,05. Jika tingkat signifikansi semakin mendekati 0,200 pada uji Kolmogorov-Smirnov dan mendekati 0,990 pada uji Shapiro-Wilk berarti distribusi data sangat normal.
4.2.3.2. Metoda Six-Group of Stepwise Discriminant Analysis
Analisis diskriminan secara luas dipergunakan untuk mencapai dua tujuan: diskriminan dan klasifikasi. Pembedaan grup dicapai dengan fungsi diskriminan, sementara prediksi individu dilakukan dengan pedoman klasifikasi. Dengan kata lain, analisis diskriminan merupakan teknik statistik untuk mengklasifikasikan obyek ke dalam grup terpisah berdasarkan sejumlah variabel bebas. Tujuan utamanya adalah menemukan kombinasi linier dari sejumlah variabel bebas yang meminimalkan probabilitas kesalahan klasifikasi obyek ke dalam masing-masing grup. Analisis diskriminan dilakukan dalam penelitian ini, untuk memprediksi kinerja keuangan antar industri yaitu Makanan dan minuman, Tekstil dan garmen, Plastik dan Kemasan, Logam dan sejenisnya, Otomotif dan komponennya, Properti dan Real Estate.
Selanjutnya akan dibahas mengenai hasil Six-Group of Stepwise Discriminant Analysis pada penelitian ini. Dari data-data yang dimasukkan kedalam perhitungan analisis diskriminan empat grup, dihasilkan output seperti pada tabel berikut ini.
Tabel 4.8 Analysis Case Processing Summary
Unweighted Cases N Percent
Valid 35 100.0
Excluded Missing or out-of-range group codes 0 .0
At least one missing discriminating variable 0 .0
Both missing or out-of-range group codes and at least one missing
discriminating variable 0 .0
Total 0 .0
Total 35 100.0
Tabel diatas menjelaskan bahwa, dari 35 perusahaan semua data tidak terdapat data yang hilang atau tidak lengkap maka dapat dianalisis secara keseluruhan.
4.2.3.3. Penentuan variabel-variabel independen yang signifikan
Tabel 4.9 Tests of Equality of Group Means
Wilks' Lambda F df1 df2 Sig.
CR .652 3.094 5 29 .023 CASH .699 2.499 5 29 .053 ITO .525 5.245 5 29 .002 TATO .699 2.503 5 29 .053 FATO .789 1.555 5 29 .204 DSO .946 .333 5 29 .889 DR .816 1.311 5 29 .287 DER .844 1.076 5 29 .394 MARGIN .762 1.809 5 29 .142 BEP .750 1.937 5 29 .119 ROA .638 3.297 5 29 .018 ROE .702 2.464 5 29 .056 EPS .552 4.711 5 29 .003 PER .866 .899 5 29 .495 BVPS .818 1.290 5 29 .295 PBV .829 1.198 5 29 .335
Tabel diatas merupakan hasil pengujian untuk setiap variabel bebas yang ada. Dalam penelitian ini, keputusan untuk menentukan apakah sebuah variabel independen dapat atau tidak dapat digunakan sebagai model dalam memprediksi kinerja keuangan industri adalah dengan menggunakan F test atau uji F.
Dalam uji F, angka hasil perhitungan yang diperhatikan adalah tingkat signifikansi. Jika tingkat signifikansi > 0,05, berarti variabel tersebut tidak mampu melakukan perbedaan kinerja keuangan antar industri dan jika tingkat signifikansi < 0,05, berarti variabel tersebut mampu melakukan perbedaan kinerja keuangan antar industri. Hasil yang didapat pada tabel 3 adalah uji F dari CR,ITO,ROA,EPS memiliki tingkat signifikansi < 0,05 berarti empat variabel independen tersebut dapat membedakan kinerja keuangan antar industri. Variabel-variabel yang tidak lolos tahap ini berjumlah 12 variabel yaitu CASH, TATO, DSO,DR, DER, BEP, MARGIN, ROE, PER, BVPS dan PBV.
Pada bagian selanjutnya akan disajikan, variabel-variabel mana saja dari enam belas variabel yang dihasilkan dari perhitungan sebelumnya, yang bisa dimasukkan (entered) kedalam fungsi diskriminan.
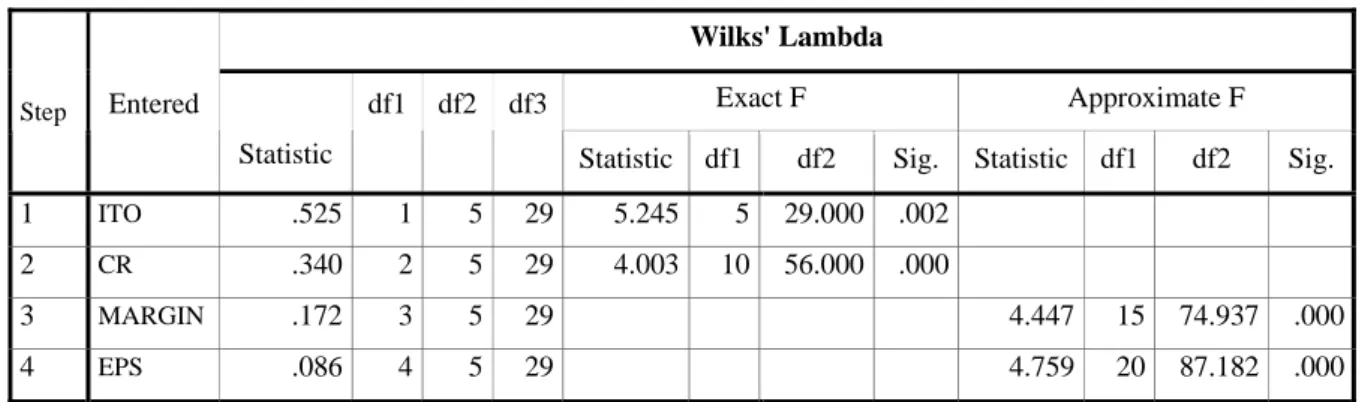
Tabel 4.10 Variables Entered/Removeda,b,c,d Wilks' Lambda Exact F Approximate F Step Entered Statistic df1 df2 df3
Statistic df1 df2 Sig. Statistic df1 df2 Sig.
1 ITO .525 1 5 29 5.245 5 29.000 .002
2 CR .340 2 5 29 4.003 10 56.000 .000
3 MARGIN .172 3 5 29 4.447 15 74.937 .000
4 EPS .086 4 5 29 4.759 20 87.182 .000
At each step, the variable that minimizes the overall Wilks' Lambda is entered. a Maximum number of steps is 32.
b Minimum partial F to enter is .01 c Maximum partial F to remove is .05.
Tahap-tahap pemasukan variabel bebas adalah sebagai berikut:
1. Pada tahap pertama, angka lamda variabel ITO adalah yang terbesar, mencapai 0.525, maka pada tahap pertama ini, variabel ITO terpilih.
2. Pada tahap kedua, angka lamda variabel CR adalah kedua terbesar, mencapai 0.340, maka pada tahap kedua ini, variabel CR terpilih.
3. Pada tahap ketiga, angka lamda variabel MARGIN adalah ketiga terbesar, mencapai 0.172, maka pada tahap ketiga ini, variabel MARGIN terpilih.
4. Pada tahap keempat, angka lamda variabel EPS adalah keempat terbesar, mencapai 0.086, maka pada tahap keempat ini, variabel EPS terpilih.
Jika kita perhatikan dari empat variabel di atas, keempatnya mempunyai tingkat signifikansi dibawah 0,05. Dengan demikian, hanya ada empat variabel yang signifikan. Dengan kata lain, bahwa ITO, CR, Margin dan EPS dapat mempengaruhi kinerja keuangan keenam industri yaitu Makanan dan minuman, Tekstil dan garmen, Plastik dan Kemasan, Logam dan sejenisnya, Otomotif dan komponennya, Properti dan Real Estate secara signifikan.
4.2.3.4 Penentuan fungsi diskriminan
Canonical Correlation merupakan alat ukur untuk mengukur keeratan hubungan antara discriminant score dengan grup yang diteliti.
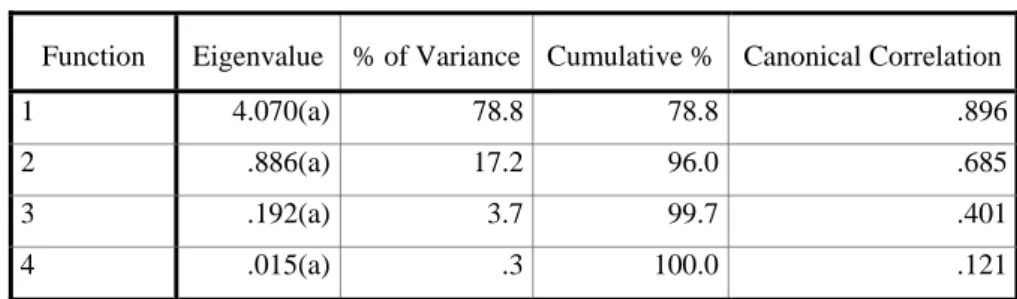
Tabel 4.11 Eigenvalues
Function Eigenvalue % of Variance Cumulative % Canonical Correlation
1 4.070(a) 78.8 78.8 .896
2 .886(a) 17.2 96.0 .685
3 .192(a) 3.7 99.7 .401
4 .015(a) .3 100.0 .121
a) First 4 canonical discriminant functions were used in the analysis.
Berdasarkan Tabel 4.11 ini menjelaskan ke 16 variabel bebas terlebih dahulu dikelompokkan ke dalam 4 faktor yang diinterpretasikan pada tabel 4.11 di atas. Korelasi
89.6% pada fungsi 1 menunjukkan keeratan hubungan yang cukup tinggi antara variabel-variabel independen yang dihasilkan fungsi/ faktor tersebut dengan kinerja keuangan keenam industri yang diteliti. Korelasi tersebut semakin mengecil pada fungsi 2,3 dan 4 yaitu sebesar 68.5% ,40.1% dan 12.1%. Namun, secara kumulatif, jika keempat fungsi/ faktor tersebut dimasukkan, maka kesemuanya akan mewakili varians yang terjadi hingga mencapai level 100%. Jika satu faktor yag digunakan, maka 78.8% varians dari variabel tak bebas (jenis industri) dapat dijelaskan oleh model diskriman yang terbetuk. Jika dua faktor yang digunakan, maka 96% varians dari variabel tak bebas (jenis industri) dapat dijelaskan oleh model diskriman yang terbetuk. Jika tiga faktor yang digunakan, maka 99.7% varians dari variabel tak bebas (jenis industri) dapat dijelaskan oleh model diskriman yang terbetuk, dan jika semua faktor yang digunakan, maka 100% varians dari variabel tak bebas (jenis industri) dapat dijelaskan oleh model diskriman yang terbetuk. Dengan demikian, maka akan digunakan 4 faktor untuk analisis selanjutnya.
Tingkat signifikansi yang menunjukkan perbedaan yang jelas dan nyata kinerja keuangan antar empat industri yang diteliti, dapat dilihat berikut ini:
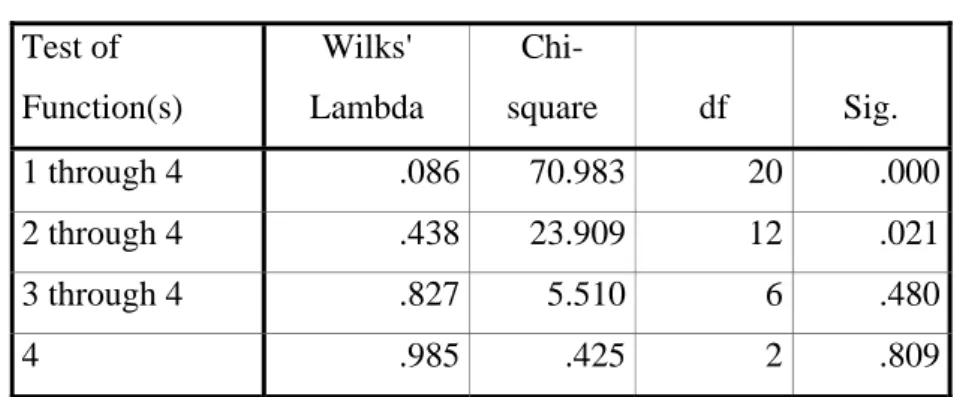
Tabel 4.12. Wilks' Lambda Test of Function(s) Wilks' Lambda Chi-square df Sig. 1 through 4 .086 70.983 20 .000 2 through 4 .438 23.909 12 .021 3 through 4 .827 5.510 6 .480 4 .985 .425 2 .809
Tabel di atas menyatakan nilai Chi-Square untuk baris 1 (fungsi 1 sampai 4) yaitu sebesar 70.983, baris 2 (fugsi 2 sampai 4) sebesar 23.909, baris 3 (fungsi 3 dan 40 sebesar 5.10 dan baris 4 (hanya fungsi 4) sebesar 0.425. Hipotesis penelitian yaitu:
H0: Tidak ada perbedaan yang signifikan kinerja keuangan antar enam industri yaitu Makanan dan minuman, Tekstil dan garmen, Plastik dan Kemasan, Logam dan sejenisnya, Otomotif dan komponennya, Properti dan Real Estate.
H1: Ada perbedaan yang signifikan kinerja keuangan antar enam industri yaitu industri Makanan dan minuman, Tekstil dan garmen, Plastik dan Kemasan, Logam dan sejenisnya, Otomotif dan komponennya, Properti dan Real Estate.
Dimana H0 diterima jika tingkat signifikansi > 0,05 atau H1 diterima jika tingkat signifikansi < 0,05. Ternyata dari tabel 4.8, hanya fungsi 1 dan 2 memiliki tingkat signifikansi < 0,05, hal ini berarti hanya baris 1 dan 2 yang mampu membedakan kinerja keuangan keempat industri sedangkan 3 dan 4 memiliki nilai signifikansi > 0.05.
Untuk memberikan arti yang lebih mendalam tentang korelasi, digunakan structure matrix.
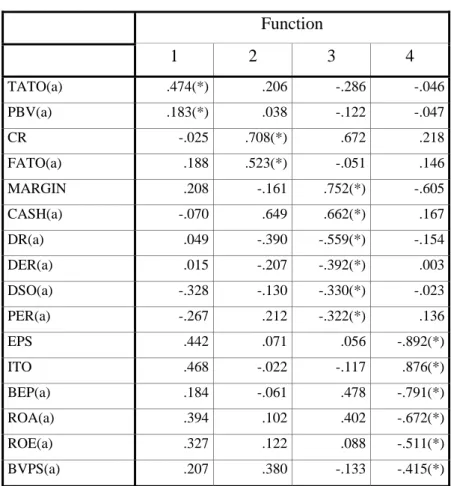
Tabel 4.13 Structure Matrix Function 1 2 3 4 TATO(a) .474(*) .206 -.286 -.046 PBV(a) .183(*) .038 -.122 -.047 CR -.025 .708(*) .672 .218 FATO(a) .188 .523(*) -.051 .146 MARGIN .208 -.161 .752(*) -.605 CASH(a) -.070 .649 .662(*) .167 DR(a) .049 -.390 -.559(*) -.154 DER(a) .015 -.207 -.392(*) .003 DSO(a) -.328 -.130 -.330(*) -.023 PER(a) -.267 .212 -.322(*) .136 EPS .442 .071 .056 -.892(*) ITO .468 -.022 -.117 .876(*) BEP(a) .184 -.061 .478 -.791(*) ROA(a) .394 .102 .402 -.672(*) ROE(a) .327 .122 .088 -.511(*) BVPS(a) .207 .380 -.133 -.415(*)
Pooled within-groups correlations between discriminating variables and standardized canonical discriminant functions
Variables ordered by absolute size of correlation within function.
* Largest absolute correlation between each variable and any discriminant function a This variable not used in the analysis.
Dari analisis sebelumnya, diperoleh hanya 4 variabel yang membedakan perilaku yaitu ITO, CR, Margin dan EPS. Sedangkan dari analisis Wilks Lambda, diperoleh perlunya 4 faktor untuk merigkas ke enam variabel tak bebas (jenis industri). Dari kedua hal tersebut, analisis selanjutnya akan menentuka variabel mana yang akan masuk ke faktor mana. Dasar pemasukan variabel dilihat pada besar korelasi kanonikal, dengan korelasi terbesar masuk ke faktor yang bersangkutan.
Variabel yang memiliki korelasi terbesar pada fungsi/faktor 1 dan termasuk dalam model adalah ITO sebesar 47.4%, dan variabel yang memiliki korelasi cukup penting pada fungsi/ faktor 2 dan termasuk dalam model adalah CR sebesar 70.8% .Sedangkan variabel yang memiliki korelasi terbesar pada fungsi/ faktor 3 dan termasuk dalam model adalah MARGIN sebesar 75.2% dan yang termasuk dalam model memiliki nilai korelasi terbesar pada fungsi/ faktor 4 adalah EPS sebesar 89.2%. Dengan demikian, faktor 1 berisi ITO, faktor 2 berisi CR, faktor 3 berisi MARGIN, sedangkan faktor 4 berisi EPS. Variabel-variabel lain tidak termasuk dalam model diskriminan (tanda a).
Tabel 4.14 Canonical Discriminant Function Coefficients Function 1 2 3 4 CR -.044 1.357 .391 .110 ITO .462 -.085 .035 .224 MARGIN 2.121 -17.012 17.733 .814 EPS .003 .002 -.002 -.002 (Constant) -3.290 -1.001 -2.142 -.658 Unstandardized coefficients
Tabel 4.14 di atas meghasilkan kesimpulan yang sama dengan analisis pada tabel 4.14, terdapat 4 variabel yang membedakan perilaku yaitu CR, ITO, MARGIN, dan EPS
dengan variabel ito dimasukkan pada fungsi 1, variabel CR dimasukkan pada fungsi 2, variabel MARGIN pada fungsi 3 dan variabel EPS pada fungsi 4.
Tabel di atas mempunyai fungsi yang sama persis dengan persamaan regresi berganda, yang dalam analisis diskriminan disebut sebagai fungsi diskriminan. Fungsi diskriminan atau persamaan Z Score yang diperoleh berdasarkan tabel di atas adalah:
Z Score 1 = – 3,290 - 0.044 CR + 0.462 ITO + 2,121 MARGIN + 0,003 EPS ...(1)
Z Score 2 = – 1,001 + 1,357 CR – 0,085 ITO – 17,012 MARGIN + 0,002 EPS ...(2)
Z Score 3 = – 2,142 + 0,391 CR + 0,035 ITO - 17,733 MARGIN - 0,002 EPS ...(3)
Z Score 4 = – 0,658 + 0,110 CR + 0,224 ITO + 0,814 MARGIN - 0,002 EPS ...(4)
Kegunaan dari fungsi ini adalah untuk mengetahui atau menggolongkan apakah sejumlah data (4 variabel independen) yang akan diteliti mampu memprediksi kinerja keuangan industri Makanan dan Minuman (grup 1), Tekstil dan Garmen (grup 2), Plastik dan Kemasan (grup 3), Logam dan sejenisnya (grup 4), Otomotif dan Komponennya (grup 5) dan Properti dan Real Estate(group 6).
4.2.3.5. Klasifikasi data berdasarkan hasil model diskriminan
Data atau perusahaan yang diobservasi termasuk kedalam salah satu industri jika jarak Squared Mahalanobis Distance to Centroid (D2) industri tersebut paling kecil dibandingkan jarak D2 kelima industri lainnya. Kemudian data hasil model diskriminan tersebut akan dibandingkan dengan data aktualnya.
Untuk dapat menentukan Squared Mahalanobis Distance to Centroid (D2), dibutuhkan data dari Functions at Group Centroids (tabel 4.11) dan Z Score dari ketiga fungsi.
Berikut adalah Tabel 4.15 Functions at Group Centroids.
Tabel 4.15 Functions at Group Centroids Function Industri
1 2 3 4
Makanan dan minuman 3.639 .026 .090 -.014
Tekstil dan garmen -1.012 -.218 -.136 -.142
Plastik dan Kemasan -.768 -1.270 -.045 .171
Logam dan sejenisnya -1.076 -.566 .598 .056
Otomotif dan komponennya -.396 .699 -.720 .114 Properti dan Real Estate -1.305 2.211 .549 .044
Unstandardized canonical discriminant functions evaluated at group means
Formula Squared Mahalanobis Distance to Centroid (D2) untuk tiga fungsi diskriminan adalah:
D2 = (Z1 – C1)2 + (Z2 – C2)2 + (Z3 – C3)2 + (Z4 – C4)2 Dimana: Zi = nilai Z score pada fungsi i; i = 1, 2, 3,4
Ci = nilai group centroids pada fungsi i; i = 1, 2, 3,4 Contoh perhitungan D2 sebagai berikut:
4 rasio dari data aktual 1 Makanana & minuman (data 1 dari 35 data) adalah:
Rasio CR ITO MARGIN EPS
Data 1 1.58 0.95 15.43 0.75
Maka;
Z 1 = – 3,290 - 0.044 CR + 0.462 ITO + 2,121 MARGIN + 0,003 EPS = 14.37
Z 2 = – 1,001 + 1,357 CR – 0,085 ITO – 17,012 MARGIN + 0,002 EPS = -261,431
Z 3 = – 2,142 + 0,391 CR + 0,035 ITO - 17,733 MARGIN - 0,002 EPS = -275,112
Z 4 = – 0,658 + 0,110 CR + 0,224 ITO + 0,814 MARGIN - 0,002 EPS = 12,287
dan, Nilai Group Centroids untuk industri Makanan dan minuman adalah: Function
INDUSTRI 1 2 3 4
Makanan dan minuman 3.639 .026 .090 -.014
Maka; C1 = 3.639 C2 = 0.026 C3 = 0.090 C4 = -0.014 Sehingga nilai: D2 = (Z1 – C1)2 + (Z2 – C2)2 + (Z3 – C3)2+ (Z4 – C5)2 D2 = 144362.4 Makanan dan minuman
Dengan cara yang sama, diperoleh:
D2 = 144235.1 pada industri tekstile dan garmen D2 = 143721.6 pada industri Plastik dan kemasan D2 = 144454.7 pada industri logam dan sejenisnya D2 = 144369.3 pada industri Otomotif dan komponennya D2 = 145891.7 pada industri Properti dan real estate
Karena nilai D2 terkecil (jarak terpendek antara Z score dan group centroids) adalah 143721.6 pada industri plastik dan kemasan, maka grup prediksi berdasarkan model diskriminan adalah grup 3 (industri Plastik dan kemasan).
Tabel 4.15 Functions at Group Centroids di atas juga menjelaskan mengeai pengelompokkan ke enam grup industri dalam fungsi 1, 2, 3 atau 4. Dasar pengelompokkan berdasarkan angak pada tabel ( tanda (-) dan (+) diabaikan.
1. Untuk kelompok jenis industri Makanan dan Minuman, angka terbesar ada di fungsi/ faktor 1 (3.639), maka jenis industri makanan dan minuman dimasukkan ke faktor 1.
2. Untuk kelompok jenis industri Tekstil dan Garment, angka terbesar ada di fungsi/ faktor 1 (-1.012), maka jenis industri tekstil dan garment dimasukkan ke faktor 1.
3. Untuk kelompok jenis industri Plastik dan Kemasan, angka terbesar ada di fungsi/ faktor 2 (-1.270), maka jenis industri Plastik dan Kemasan dimasukkan ke faktor 2.
4. Untuk kelompok jenis industri Logam dan sejenisnya, angka terbesar ada di fungsi/ faktor 1 (-1.076), maka jenis industri Logam dan sejenisnya dimasukkan ke faktor 1.
5. Untuk kelompok jenis industri Otomotif dan komponennya, angka terbesar ada di fungsi/ faktor 3 (-0.720), maka jenis industri Otomotif dan komponennya dimasukkan ke faktor 3.
6. Untuk kelompok jenis industri Properti dan Real Estate, angka terbesar ada di fungsi/ faktor 1 (2.221), maka jenis industri Properti dan Real Estate dimasukkan ke faktor 2.
Dengan demikian, jenis industri makanan minuman, tekstil dan garment, logam dan sejenisnya, terdapat pada faktor 1 (ITO). Jenis industri plastik dan kemasan serta properti dan real estate, terdapat pada faktor 2 (CR). Jenis industri otomotif dan komponennya terdapat pada faktor 3 (MARGIN) dan tidak ada satu jenis industri pun yang terdapat pada faktor 4 (EPS).
Interpretasi selengkapnya mengenai tanda negatif dan positif adalah sebagai berikut:
1. Jenis usaha makanan dan minuman mempunyai tanda + pada fungsi 1, hal ini menandakan bahwa jika ingin berinvestasi pada jenis industri makanan dan minuman, perlu memperhatikan faktor ITO yang positif
2. Jenis usaha tekstil dan garment mempunyai tanda - pada fungsi 1, hal ini menandakan bahwa jika ingin berinvestasi pada jenis industri tekstil dan garment, perlu memperhatikan faktor ITO yang negatif.
3. Jenis usaha logam dan sejenisnya mempunyai tanda - pada fungsi 1, hal ini menandakan bahwa jika ingin berinvestasi pada jenis industri logam dan sejenisnya, perlu memperhatikan faktor ITO yang negatif
4. Jenis usaha plastik dan kemasan mempunyai tanda - pada fungsi 2, hal ini menandakan bahwa jika ingin berinvestasi pada jenis industri plastik dan kemasan, perlu memperhatikan faktor CR yang negatif
5. Jenis usaha properti dan real estate mempunyai tanda + pada fungsi 2, hal ini menandakan bahwa jika ingin berinvestasi pada jenis industri otomotif properti dan real estate, perlu memperhatikan faktor CR yang positif
6. Jenis usaha otomotif dan komponennya mempunyai tanda - pada fungsi 3, hal ini menandakan bahwa jika ingin berinvestasi pada jenis industri otomotif dan komponennya, perlu memperhatikan faktor MARGIN yang negatif.
4.2.3.6 Ketepatan Klasifikasi Hasil Model Diskriminan dengan Data Aktual
Setelah model diskriminan (fungsi diskriminan dan group centroids) diperoleh, dan proses klasifikasi dilakukan, maka selanjutnya menentukan seberapa jauh ketepatan klasifikasi model diskriminan terhadap data aktual industri. Atau dengan kata lain, berapa persenkah tingkat kemungkinan terjadi misklasifikasi pada proses pengklasifikasian antara data aktual dengan hasil model diskriminan di atas.
Berdasarkan Tabel 4.16, hasil ketepatan klasifikasi yang diperoleh akan dijelaskan di bawah ini.
Tabel 4.16 Classification Resultsa
Predicted Group Membership
Industri Makanan dan minuman Tekstil dan garmen Plastik dan Kemasan Logam dan sejenisnya Otomotif dan komponennya Properti dan Real Estate Total
Makanan dan minuman 6 0 0 0 0 1 7 Tekstil dan garmen 0 5 2 2 2 0 11 Plastik dan Kemasan 0 2 2 0 0 0 4 Logam dan sejenisnya 0 3 0 2 0 0 5 Otomotif dan
komponennya 0 1 0 0 4 0 5 Count
Properti dan Real Estate 0 1 0 0 0 2 3
Makanan dan minuman 85.7143 0 0 0 0 14.2857 100 Tekstil dan garmen 0 45.4545 18.1818 18.1818 18.1818 0 100
Plastik dan Kemasan 0 50 50 0 0 0 100 Logam dan sejenisnya 0 60 0 40 0 0 100 Otomotif dan
komponennya 0 20 0 0 80 0 100 Original
%
Properti dan Real Estate 0 33.3333 0 0 0 66.6667 100
a 60.0% of original grouped cases correctly classified.
Pada bagian Count, terlihat bahwa jumlah data awal yang tergolong kedalam industri Makanan dan Minuman (grup 1) adalah 7 data, kemudian setelah dilakukan perhitungan menjadi 6 data. Dengan kata lain, ketepatan klasifikasi kinerja keuangan industri Makanan dan minuman adalah 85.71% (bagian %).
Data yang pada awalnya tergolong kedalam industri Tekstil dan Garmen (grup 2) sebanyak 11 data, setelah dilakukan perhitungan berubah menjadi 5 data. Dengan kata lain, ketepatan klasifikasi kinerja keuangan industri tekstil dan garmen adalah 45.45%.
Sedangkan jumlah data awal yang tergolong kedalam industri Pelastik dan kemasan (grup 3) adalah 4 data, setelah dilakukan perhitungan berubah menjadi 2 data. Dengan kata lain, ketepatan klasifikasi kinerja keuangan industri pelastik dan kemasan adalah 50%.
Kemudian untuk industri logam dan sejenisnya(grup 4), data awalnya sebanyak 5 data, tetapi setelah dilakukan perhitungan berubah menjadi 2 data. Dengan kata lain, ketepatan klasifikasi kinerja keuangan industri logam dan sejenisnya adalah 40%.
Sedangkan jumlah data awal untuk industri otomotif dan komponennya (grup 5) sebanyak 5 data, setelah dilakukan perhitungan berubah menjadi 4 data,dengan kata lain ketepatan klasifikasi kinerja keuangan industri otomotif dan komponennya adalah 80%.
Dan untuk data awal industri properti dan real estate (grup 6) adalah 3 data, tetapi setelah dilakukan perhitungan berubah menjadi 2 data, dengan katalain ketepatan klasifikasi kinerja keuangan untuk industri real estate adalah 66.66%.
Dari data tersebut diatas dapat diperoleh informasi bahwa prosentase ketepatan klasifikasi secara keseluruhan dari model yang dihasilkan adalah:
6 5 2 2 4 2 100% 60% 35 + + + + + ⎛ ⎞× = ⎜ ⎟ ⎝ ⎠
Prosentase ketepatan klasifikasi kinerja keuangan sebesar 60.0% adalah cukup tinggi karena diatas 50%, maka model diskriminasi tersebut cukup valid untuk digunakan dalam penelitian ini.
4.2.3.7. Penggunaan model diskriminan untuk kasus lain
Setelah terbukti bahwa model diskriminan yang telah dibuat dalam penelitian ini mempunyai ketepatan prediksi yang tinggi, maka model diskriminan tersebut bisa digunakan untuk memprediksi sebuah kasus, cukup dari empat (4) rasio saja yaitu CR, ITO, MARGIN dan EPS.
Kemudian dari empat rasio tersebut dilakukan klasifikasi grup, apakah tergolong kedalam klasifikasi kinerja keuangan grup tertentu, yaitu industri Makanan dan minuman, tekstil dan garmen, pelastik dan kemasan, logam dan sejenisnya, automotiv dan komponennya atau properti dan real estate.
4.2.3.8. Analisis Deskriptif dari empat Variabel Independen Signifikan
Pada bagian ini ditampilkan empat (4) rasio keuangan yang signifikan yaitu CR, ITO, MARGIN dan EPS. Keempat rasio di atas mampu membedakan kinerja keuangan antar enam industri yaitu industri makanan dan minuman, tekstil dan garmen, plastik dan kemasan, logam dan sejenisnya, automotiv dan komponennya dan properti dan real estate.
Tabel 4.17 Group Statistics Group Statistics
Valid N (listwise) Industri
Mean Std.
Deviation Unweighted Weighted
Makanan dan minuman CR 1.7557 .95194 7 7.000
ITO 8.5800 4.76271 7 7.000
MARGIN .1600 .08103 7 7.000
EPS 991.3571 693.11126 7 7.000
Tekstil dan garmen CR 1.5682 .45064 11 11.000
ITO 3.0818 .92075 11 11.000
MARGIN .0964 .05372 11 11.000
EPS 263.5445 271.54202 11 11.000
Plastik dan Kemasan CR 1.0700 .38944 4 4.000
ITO 4.0600 1.15300 4 4.000
MARGIN .1025 .04193 4 4.000
EPS 174.5000 240.17128 4 4.000
Logam dan sejenisnya CR 1.8020 .86543 5 5.000
ITO 3.2400 1.17852 5 5.000 MARGIN .1260 .09182 5 5.000 EPS 193.8340 111.18926 5 5.000 Otomotif dan komponennya CR 1.8060 .54811 5 5.000 ITO 4.4500 1.97430 5 5.000 MARGIN .0580 .02950 5 5.000 EPS 291.4320 126.93849 5 5.000
Properti dan Real Estate CR 3.3533 1.80539 3 3.000
ITO 2.8167 1.15362 3 3.000 MARGIN .0933 .03512 3 3.000 EPS 231.7800 148.93961 3 3.000 Total CR 1.7691 .91686 35 35.000 ITO 4.4886 3.10713 35 35.000 MARGIN .1083 .06609 35 35.000 EPS 390.2331 458.90681 35 35.000
4.2.4. Pengolahan Data dan Interpretasi Hasil Perhitungan Periode 2000 – 2005 4.2.4.1. Proses Normalisasi dan Seleksi Data
Hasil pengujian data-data yang telah ditransformasi dapat dilihat pada tabel 4.18. Tabel 4.18 Uji Normalitas
Kolmogorov-Smirnov(a) Shapiro-Wilk Industri
Statistic df Sig. Statistic df Sig. CR Makanan dan minuman .259 7 .172 .834 7 .087 Tekstil dan garmen .145 11 .200 .966 11 .842
Plastik dan Kemasan .320 4 . .870 4 .298
Logam dan sejenisnya .309 5 .135 .786 5 .062 Otomotif dan
komponennya
.306 5 .143 .839 5 .163
Properti dan Real Estate .352 3 . .826 3 .177 CASH Makanan dan minuman .333 7 .018 .667 7 .002 Tekstil dan garmen .204 11 .200 .936 11 .477
Plastik dan Kemasan .331 4 . .820 4 .142
Logam dan sejenisnya .298 5 .168 .863 5 .240 Otomotif dan
komponennya
.220 5 .200 .893 5 .370
Properti dan Real Estate .264 3 . .955 3 .589 ITO Makanan dan minuman .229 7 .200 .785 7 .029 Tekstil dan garmen .122 11 .200 .960 11 .768
Plastik dan Kemasan .330 4 . .883 4 .350
Logam dan sejenisnya .239 5 .200 .957 5 .789 Otomotif dan
komponennya
.244 5 .200 .889 5 .350
Properti dan Real Estate .385 3 . .751 3 .001 TATO Makanan dan minuman .223 7 .200 .933 7 .580 Tekstil dan garmen .175 11 .200 .905 11 .211
Plastik dan Kemasan .176 4 . .995 4 .980
Logam dan sejenisnya .226 5 .200 .961 5 .812 Otomotif dan
komponennya
.153 5 .200 .988 5 .973
FATO Makanan dan minuman .163 7 .200 .944 7 .677 Tekstil dan garmen .440 11 .000 .477 11 .000
Plastik dan Kemasan .224 4 . .953 4 .737
Logam dan sejenisnya .300 5 .162 .854 5 .209 Otomotif dan
komponennya
.344 5 .053 .737 5 .022
Properti dan Real Estate .328 3 . .871 3 .298 DSO Makanan dan minuman .201 7 .200 .955 7 .779 Tekstil dan garmen .225 11 .124 .822 11 .018
Plastik dan Kemasan .226 4 . .975 4 .873
Logam dan sejenisnya .266 5 .200 .829 5 .137 Otomotif dan
komponennya
.179 5 .200 .947 5 .719
Properti dan Real Estate .365 3 . .797 3 .107 DR Makanan dan minuman .269 7 .135 .820 7 .064 Tekstil dan garmen .120 11 .200 .963 11 .811
Plastik dan Kemasan .292 4 . .891 4 .387
Logam dan sejenisnya .209 5 .200 .976 5 .912 Otomotif dan
komponennya
.196 5 .200 .930 5 .598
Properti dan Real Estate .292 3 . .923 3 .463 DER Makanan dan minuman .237 7 .200 .779 7 .025 Tekstil dan garmen .184 11 .200 .902 11 .195
Plastik dan Kemasan .168 4 . .997 4 .989
Logam dan sejenisnya .180 5 .200 .984 5 .954 Otomotif dan
komponennya
.282 5 .200 .767 5 .042
Properti dan Real Estate .314 3 . .893 3 .363 MARGI
N
Makanan dan minuman .214 7 .200 .948 7 .713
Tekstil dan garmen .206 11 .200 .931 11 .424
Plastik dan Kemasan .194 4 . .965 4 .808
Logam dan sejenisnya .237 5 .200 .950 5 .740 Otomotif dan
komponennya
Properti dan Real Estate .175 3 . 1.000 3 1.000 BEP Makanan dan minuman .158 7 .200 .926 7 .519 Tekstil dan garmen .173 11 .200 .926 11 .371
Plastik dan Kemasan .226 4 . .936 4 .630
Logam dan sejenisnya .216 5 .200 .956 5 .783 Otomotif dan
komponennya
.213 5 .200 .963 5 .826
Properti dan Real Estate .351 3 . .828 3 .183 ROA Makanan dan minuman .229 7 .200 .838 7 .095 Tekstil dan garmen .131 11 .200 .961 11 .787
Plastik dan Kemasan .255 4 . .934 4 .616
Logam dan sejenisnya .261 5 .200 .940 5 .668 Otomotif dan
komponennya
.193 5 .200 .959 5 .804
Properti dan Real Estate .235 3 . .978 3 .716 ROE Makanan dan minuman .306 7 .047 .835 7 .090 Tekstil dan garmen .335 11 .001 .624 11 .000
Plastik dan Kemasan .309 4 . .863 4 .272
Logam dan sejenisnya .381 5 .017 .756 5 .034 Otomotif dan
komponennya
.294 5 .182 .849 5 .192
Properti dan Real Estate .299 3 . .915 3 .434 EPS Makanan dan minuman .327 7 .023 .773 7 .022 Tekstil dan garmen .201 11 .200 .937 11 .484
Plastik dan Kemasan .402 4 . .689 4 .009
Logam dan sejenisnya .256 5 .200 .946 5 .706 Otomotif dan
komponennya
.336 5 .067 .778 5 .053
Properti dan Real Estate .178 3 . .999 3 .956 PER Makanan dan minuman .148 7 .200 .955 7 .777 Tekstil dan garmen .293 11 .009 .708 11 .001
Plastik dan Kemasan .323 4 . .870 4 .299
Logam dan sejenisnya .234 5 .200 .900 5 .411 Otomotif dan
komponennya
Properti dan Real Estate .338 3 . .853 3 .247 BVPS Makanan dan minuman .202 7 .200 .907 7 .374 Tekstil dan garmen .208 11 .199 .879 11 .101 Plastik dan Kemasan .136 4 . 1.000 4 .999 Logam dan sejenisnya .206 5 .200 .967 5 .855 Otomotif dan
komponennya
.302 5 .152 .807 5 .093
Properti dan Real Estate .258 3 . .960 3 .615 PBV Makanan dan minuman .263 7 .153 .812 7 .054 Tekstil dan garmen .488 11 .000 .401 11 .000
Plastik dan Kemasan .298 4 . .926 4 .572
Logam dan sejenisnya .443 5 .002 .633 5 .002 Otomotif dan
komponennya
.305 5 .145 .851 5 .197
Properti dan Real Estate .376 3 . .773 3 .051
Berdasarkan Tabel 4.18 dapat dilihat bahwa data-data mempunyai distribusi normal atau mendekati normal. Hal ini dapat diketahui dengan membandingkan tingkat signifikansi data yang lebih besar dari 0,05. Jika tingkat signifikansi semakin mendekati 0,200 pada uji Kolmogorov-Smirnov dan mendekati 0,990 pada uji Shapiro-Wilk berarti distribusi data sangat normal.
4.2.4.2. Metoda Six-Group of Stepwise Discriminant Analysis
Analisis diskriminan secara luas dipergunakan untuk mencapai dua tujuan: diskriminan dan klasifikasi. Pembedaan grup dicapai dengan fungsi diskriminan, sementara prediksi individu dilakukan dengan pedoman klasifikasi. Dengan kata lain, analisis diskriminan merupakan teknik statistik untuk mengklasifikasikan obyek ke dalam grup terpisah berdasarkan sejumlah variabel bebas. Tujuan utamanya adalah menemukan kombinasi linier dari sejumlah variabel bebas yang meminimalkan probabilitas kesalahan klasifikasi obyek ke dalam masing-masing grup. Analisis diskriminan dilakukan dalam penelitian ini, untuk memprediksi kinerja keuangan antar industri yaitu Makanan dan minuman, Tekstil
dan garmen, Plastik dan Kemasan, Logam dan sejenisnya, Otomotif dan komponennya, Properti dan Real Estate.
Selanjutnya akan dibahas mengenai hasil Six-Group of Stepwise Discriminant Analysis pada penelitian ini. Dari data-data yang dimasukkan kedalam perhitungan analisis diskriminan empat grup, dihasilkan output seperti pada tabel berikut ini.
Tabel 4.19 Analysis Case Processing Summary
Unweighted Cases N Percent
Valid 35 100.0
Excluded Missing or out-of-range group codes 0 .0 At least one missing discriminating variable 0 .0 Both missing or out-of-range group codes and at least one
missing discriminating variable 0 .0
Total 0 .0
Total 35 100.0
Tabel diatas menjelaskan bahwa, dari 35 perusahaan semua data tidak terdapat data yang hilang atau tidak lengkap maka dapat dianalisis secara keseluruhan
4.2.4.3. Penentuan variabel-variabel independen yang signifikan
Tabel 4.20 Tests of Equality of Group Means Wilks' Lambda F df1 df2 Sig. CR .606 3.765 5 29 .009 CASH .713 2.338 5 29 .067 ITO .761 1.826 5 29 .139 TATO .619 3.564 5 29 .012 FATO .847 1.045 5 29 .410 DSO .918 .516 5 29 .762
DR .784 1.595 5 29 .193 DER .855 .985 5 29 .444 MARGIN .513 5.513 5 29 .001 BEP .493 5.960 5 29 .001 ROA .660 2.982 5 29 .027 ROE .856 .972 5 29 .451 EPS .682 2.707 5 29 .040 PER .811 1.348 5 29 .273 BVPS .867 .887 5 29 .502 PBV .846 1.053 5 29 .406
Tabel diatas merupakan hasil pengujian untuk setiap variabel bebas yang ada. Dalam penelitian ini, keputusan untuk menentukan apakah sebuah variabel independen dapat atau tidak dapat digunakan sebagai model dalam memprediksi kinerja keuangan industri adalah dengan menggunakan F test atau uji F.
Dalam uji F, angka hasil perhitungan yang diperhatikan adalah tingkat signifikansi. Jika tingkat signifikansi > 0,05, berarti variabel tersebut tidak mampu melakukan perbedaan kinerja keuangan antar industri dan jika tingkat signifikansi < 0,05, berarti variabel tersebut mampu melakukan perbedaan kinerja keuangan antar industri. Hasil yang didapat pada tabel 3 adalah uji F dari CR, TATO, MARGIN, BEP, ROA, EPS memiliki tingkat signifikansi < 0,05 berarti enam variabel independen tersebut dapat membedakan kinerja keuangan antar industri. Variabel-variabel yang tidak lolos tahap ini berjumlah 10 variabel yaitu CASH, ITO, FATO, DSO, DR, DER, ROE, PER, BVPS dan PBV.
Pada bagian selanjutnya akan disajikan, variabel-variabel mana saja dari enam belas variabel yang dihasilkan dari perhitungan sebelumnya, yang bisa dimasukkan (entered) kedalam fungsi diskriminan.
Tabel 4.21 Variables Entered/Removeda,b,c,d Wilks' Lambda Exact F Approximate F Step Entered Statistic df1 df2 df3
Statistic df1 df2 Sig. Statistic df1 df2 Sig.
1 CR .606 1 5 29 3.765 5 29.000 .009
2 MARGIN .396 2 5 29 3.300 10 56.000 .002
3 ROA .251 3 5 29 3.249 15 74.937 .000
4 MARGIN .346 2 5 29 3.918 10 56.000 .000
5 ROA .185 3 5 29 4.210 15 74.937 .000
At each step, the variable that minimizes the overall Wilks' Lambda is entered. a Maximum number of steps is 32.
b Minimum partial F to enter is .01 c Maximum partial F to remove is .05.
d F level, tolerance, or VIN insufficient for further computation.
Tahap-tahap pemasukan variabel bebas adalah sebagai berikut:
1. Pada tahap pertama, angka lamda variabel CR adalah yang terbesar, mencapai 0.606, maka pada tahap pertama ini, variabel CR terpilih.
2. Pada tahap kedua, angka lamda variabel MARGIN adalah kedua terbesar, mencapai 0.396, maka pada tahap kedua ini, variabel MARGIN terpilih.
3. Pada tahap ketiga, angka lamda variabel ROA adalah ketiga terbesar, mencapai 0.251, maka pada tahap ketiga ini, variabel ROA terpilih.
4. Pada tahap keempat, angka lamda variabel MARGIN adalah terbesar, mencapai 0.346, maka pada tahap keempat ini, variabel MARGIN terpilih kembali.
5. Pada tahap lima, angka lamda variabel ROA adalah terbesar, mencapai 0.185, maka pada tahap lima ini, variabel ROA terpilih kembali.
Jika kita perhatikan dari tiga variabel di atas, ketiganya mempunyai tingkat signifikansi dibawah 0,05. Dengan demikian, hanya ada tiga variabel yang signifikan. Dengan kata lain, bahwa CR, MARGIN dan ROA dapat mempengaruhi kinerja keuangan keenam industri yaitu Makanan dan minuman, Tekstil dan garmen, Plastik dan Kemasan, Logam dan sejenisnya, Otomotif dan komponennya, Properti dan Real Estate secara signifikan.
4.2.4.4. Penentuan fungsi diskriminan
Canonical Correlation merupakan alat ukur untuk mengukur keeratan hubungan antara discriminant score dengan grup yang diteliti.
Tabel 4.22 Eigenvalues
Function Eigenvalue % of Variance Cumulative %
Canonical Correlation
1 1.411(a) 58.4 58.4 .765
2 .614(a) 25.4 83.9 .617
3 .389(a) 16.1 100.0 .529
a First 3 canonical discriminant functions were used in the analysis.
Berdasarkan Tabel 4.11 ini menjelaskan ke 16 variabel bebas terlebih dahulu dikelompokkan ke dalam 3 faktor yang diinterpretasikan pada tabel 4.22 di atas. Korelasi 76.5% pada fungsi 1 menunjukkan keeratan hubungan yang cukup tinggi antara variabel-variabel independen yang dihasilkan fungsi tersebut dengan kinerja keuangan keenam industri yang diteliti. Korelasi tersebut semakin mengecil pada fungsi 2 dan3 yaitu sebesar 61.7% dan 52.9%. Namun, secara kumulatif, jika keempat fungsi/ faktor tersebut dimasukkan, maka kesemuanya akan mewakili varians yang terjadi hingga mencapai level 100%. Jika satu faktor yag digunakan, maka 58.4% varians dari variabel tak bebas (jenis industri) dapat dijelaskan oleh model diskriman yang terbetuk. Jika dua faktor yang digunakan, maka 83.9% varians dari variabel tak bebas (jenis industri) dapat dijelaskan oleh model diskriman yang terbetuk. Jika tiga faktor yang digunakan, maka 100% varians dari variabel tak bebas (jenis industri) dapat dijelaskan oleh model diskriman yang terbetuk. Dengan demikian, maka akan digunakan 3 faktor untuk analisis selanjutnya. Tingkat signifikansi yang menunjukkan perbedaan yang jelas dan nyata kinerja keuangan antar enam industri yang diteliti, dapat dilihat berikut ini:
Tabel 4.23 Wilks' Lambda Test of Function(s) Wilks' Lambda Chi-square df Sig. 1 through 3 .185 49.777 15 .000 2 through 3 .446 23.821 8 .002 3 .720 9.699 3 .021
Tabel di atas menyatakan nilai Chi-Square untuk baris 1 (fungsi 1 sampai 3) yaitu sebesar 49.777, baris 2 (fugsi 2 sampai 3) sebesar 23.821, dan baris 3 (hanya fungsi 3) sebesar 9.699. Hipotesis penelitian yaitu:
H0: Tidak ada perbedaan yang signifikan kinerja keuangan antar enam industri yaitu Makanan dan minuman, Tekstil dan garmen, Plastik dan Kemasan, Logam dan sejenisnya, Otomotif dan komponennya, Properti dan Real Estate.
H1: Ada perbedaan yang signifikan kinerja keuangan antar enam industri yaitu industri Makanan dan minuman, Tekstil dan garmen, Plastik dan Kemasan, Logam dan sejenisnya, Otomotif dan komponennya, Properti dan Real Estate.
Dimana H0 diterima jika tingkat signifikansi > 0,05 atau H1 diterima jika tingkat signifikansi < 0,05. Ternyata dari tabel 4.8, fungsi 1,2 dan 3 memiliki tingkat signifikansi < 0,05, hal ini berarti fungsi 1,2 dan 3 yang mampu membedakan kinerja keuangan keenam industri.
Untuk memberikan arti yang lebih mendalam tentang korelasi, digunakan structure matrix.
Tabel 4.24 Structure Matrix
Function 1 2 3 MARGIN .703(*) .503 .503 TATO(a) -.488(*) .031 .124 ITO(a) .488(*) .046 -.048 CR .342 .791(*) -.507
DR(a) -.115 -.693(*) .234 CASH(a) .491 .677(*) -.435 DER(a) .011 -.654(*) .028 DSO(a) -.007 -.312(*) -.078 BVPS(a) -.033 .183(*) -.008 EPS(a) -.087 .322 .748(*) ROA -.149 .674 .723(*) BEP(a) .485 .432 .600(*) ROE(a) -.389 .499 .503(*) FATO(a) -.199 .269 -.390(*) PER(a) -.042 -.072 -.360(*) PBV(a) .077 -.043 .157(*)
Pooled within-groups correlations between discriminating variables and standardized canonical discriminant functions.
Variables ordered by absolute size of correlation within function.
* Largest absolute correlation between each variable and any discriminant function a This variable not used in the analysis.
Dari analisis sebelumnya, diperoleh hanya 3 variabel yang membedakan perilaku yaitu CR, ROA, dan MARGIN. Sedangkan dari analisis Wilks Lambda, diperoleh perlunya 3 faktor untuk merigkas ke enam variabel tak bebas (jenis industri). Dari kedua hal tersebut, analisis selanjutnya akan menentuka variabel mana yang akan masuk ke faktor mana. Dasar pemasukan variabel dilihat pada besar korelasi kanonikal, dengan korelasi terbesar masuk ke faktor yang bersangkutan.
Variabel yang memiliki korelasi terbesar pada fungsi 1 dan termasuk dalam model adalah MARGIN sebesar 70.3%, dan variabel yang memiliki korelasi cukup penting pada fungsi 2 dan termasuk dalam model adalah CR sebesar 79.1% .Sedangkan variabel yang memiliki korelasi terbesar pada fungsi 3 dan termasuk dalam model adalah ROA sebesar 72.3%. Variabel-variabel lain tidak termasuk dalam model diskriminan (tanda a).
Tabel 4.25 Canonical Discriminant Function Coefficients
Function 1 2 3 CR -.039 .898 -.845 MARGIN 19.649 -3.690 7.485 ROA -.215 .174 .126 (Constant) -1.029 -2.288 .032 Unstandardized coefficients
Tabel 4.25 di atas meghasilkan kesimpulan yang sama dengan analisis pada tabel 4.25, terdapat 3 variabel yang membedakan perilaku yaitu CR, MARGIN, dan ROA dengan variabel MARGIN dimasukkan pada fungsi 1, variabel CR dimasukkan pada fungsi 2 dan variabel ROA pada fungsi 3.
Tabel di atas mempunyai fungsi yang sama persis dengan persamaan regresi berganda, yang dalam analisis diskriminan disebut sebagai fungsi diskriminan. Fungsi diskriminan atau persamaan Z Score yang diperoleh berdasarkan tabel di atas adalah:
Z Score 1 = – 1.029 - 0.039 CR + 19.649 MARGIN – 0.215 ROA ...(1) Z Score 2 = – 2.288 + 0.898 CR – 3.690 MARGIN + 0.174 ROA...(2) Z Score 3 = 0.032 – 0.845 CR + 7.485 MARGIN + 0.126 ROA...(3)
Kegunaan dari fungsi ini adalah untuk mengetahui atau menggolongkan apakah sejumlah data (3 variabel independen) yang akan diteliti mampu memprediksi kinerja keuangan industri makanan & minuman (grup 1), Tekstil dan garmen (grup 2), Plastik dan Kemasan
(grup 3), Logam dan sejenisnya (grup 4), Otomotif dan komponennya (grup 5) dan Properti dan Real Estate (group 6).
4.2.4.5. Klasifikasi data berdasarkan hasil model diskriminan
Data atau perusahaan yang diobservasi termasuk kedalam salah satu industri jika jarak Squared Mahalanobis Distance to Centroid (D2) industri tersebut paling kecil dibandingkan jarak D2 kelima industri lainnya. Kemudian data hasil model diskriminan tersebut akan dibandingkan dengan data aktualnya.
Untuk dapat menentukan Squared Mahalanobis Distance to Centroid (D2), dibutuhkan data dari Functions at Group Centroids (tabel 4.26) dan Z Score dari ketiga fungsi.
Tabel 4.26 Functions at Group Centroids Function Industri 1 2 3 Makanan dan minuman -.666 .894 .714
Tekstil dan garmen -.007 -.878 .119 Plastik dan Kemasan .168 .085 .359 Logam dan
sejenisnya -.700 -.358 -.360 Otomotif dan
komponennya -.505 .700 -1.129 Properti dan Real
Estate 3.365 .451 -.100
Unstandardized canonical discriminant functions evaluated at group means
Formula Squared Mahalanobis Distance to Centroid (D2) untuk tiga fungsi diskriminan adalah:
Dimana: Zi = nilai Z score pada fungsi i; i = 1, 2, 3
Ci = nilai group centroids pada fungsi i; i = 1, 2, 3 Contoh perhitungan D2 sebagai berikut:
3 rasio dari data aktual 1 Makanana & minuman (data 1 dari 35 data) adalah:
Rasio CR MARGIN ROA
Data 1 3.19 0.06 11.22 Maka; Z 1 = – 1.029 - 0.039 CR + 19.649 MARGIN – 0.215 ROA = -2.38 Z 2 = – 2.288 + 0.898 CR – 3.690 MARGIN + 0.174 ROA = 2.30 Z 3 = 0.032 – 0.845 CR + 7.485 MARGIN + 0.126 ROA = -0.80
dan, Nilai Group Centroids untuk industri Makanan dan minuman adalah: Function
INDUSTRI 1 2 3
Makanan dan minuman -.666 .894 .714
Maka; C1 = -0.666 C2 = 0.894 C3 = 0.714 Sehingga nilai: D2 = (Z1 – C1)2 + (Z2 – C2)2 + (Z3 – C3)2 D2 = 7.21 Makanan dan minuman Dengan cara yang sama, diperoleh:
D2 = 16.58 pada industri tekstile dan garmen D2 = 12.74 pada industri Plastik dan kemasan
D2 = 10.08 pada industri logam dan sejenisnya D2 = 6.18 pada industri Otomotif dan komponennya D2 = 36.91 pada industri Properti dan real estate
Karena nilai D2 terkecil (jarak terpendek antara Z score dan group centroids) adalah 6.18 pada pada industri Otomotif dan komponennya, maka grup prediksi berdasarkan model diskriminan adalah grup 5 (otomotif dan komponennya).
Tabel 4.26 Functions at Group Centroids di atas juga menjelaskan mengeai pengelompokkan ke enam grup industri dalam fungsi 1, 2, atau 3. Dasar pengelompokkan berdasarkan angak pada tabel ( tanda (-) dan (+) diabaikan.
1. Untuk kelompok jenis industri makanan dan minuman, angka terbesar ada di fungsi/ faktor 2 (0.894), maka jenis industri makanan dan minuman dimasukkan ke faktor 2.
2. Untuk kelompok jenis industri tekstil dan garment, angka terbesar ada di fungsi/ faktor 2 (-0.878), maka jenis industri tekstil dan garment dimasukkan ke faktor 1.
3. Untuk kelompok jenis industri Plastik dan Kemasan, angka terbesar ada di fungsi/ faktor 3 (0.359), maka jenis industri Plastik dan Kemasan dimasukkan ke faktor 3.
4. Untuk kelompok jenis industri Logam dan sejenisnya, angka terbesar ada di fungsi/ faktor 1 (-0.700), maka jenis industri Logam dan sejenisnya dimasukkan ke faktor 1.
5. Untuk kelompok jenis industri Otomotif dan komponennya, angka terbesar ada di fungsi/ faktor 3 (-1.129), maka jenis industri Otomotif dan komponennya dimasukkan ke faktor 3.
6. Untuk kelompok jenis industri Properti dan Real Estate, angka terbesar ada di fungsi/ faktor 1 (3.365), maka jenis industri Properti dan Real Estate dimasukkan ke faktor 1.
Dengan demikian, jenis industri logam dan sejenisnya serta properti dan real estate terdapat pada faktor 1 (MARGIN). Jenis industri makanan dan minuman serta tekstil dan garment terdapat pada faktor 2 (CR). Jenis industri plastik dan kemasan serta otomotif dan komponennya terdapat pada faktor 3 (ROA).
Interpretasi selengkapnya mengenai tanda negatif dan positif adalah sebagai berikut:
1. Jenis usaha makanan dan minuman mempunyai tanda + pada fungsi 2, hal ini menandakan bahwa jika ingin berinvestasi pada jenis industri makanan dan minuman, perlu memperhatikan faktor MARGIN yang positif
2. Jenis usaha tekstil dan garment mempunyai tanda - pada fungsi 2, hal ini menandakan bahwa jika ingin berinvestasi pada jenis industri tekstil dan garment, perlu memperhatikan faktor CR yang negatif.
3. Jenis usaha logam dan sejenisnya mempunyai tanda - pada fungsi 1, hal ini menandakan bahwa jika ingin berinvestasi pada jenis industri logam dan sejenisnya, perlu memperhatikan faktor MARGIN yang negatif.
4. Jenis usaha plastik dan kemasan mempunyai tanda + pada fungsi 3, hal ini menandakan bahwa jika ingin berinvestasi pada jenis industri plastik dan kemasan, perlu memperhatikan faktor ROA yang positif.
5. Jenis usaha properti dan real estate mempunyai tanda + pada fungsi 1, hal ini menandakan bahwa jika ingin berinvestasi pada jenis industri otomotif properti dan real estate, perlu memperhatikan faktor MARGIN yang positif
6. Jenis usaha otomotif dan komponennya mempunyai tanda - pada fungsi 3, hal ini menandakan bahwa jika ingin berinvestasi pada jenis industri otomotif dan komponennya, perlu memperhatikan faktor ROA yang negatif.
4.2.4.6 Ketepatan klasifikasi hasil model diskriminan dengan data aktual
Setelah model diskriminan (fungsi diskriminan dan group centroids) diperoleh, dan proses klasifikasi dilakukan, maka selanjutnya menentukan seberapa jauh ketepatan klasifikasi model diskriminan terhadap data aktual industri. Atau dengan kata lain, berapa persenkah tingkat
kemungkinan terjadi misklasifikasi pada proses pengklasifikasian antara data aktual dengan hasil model diskriminan di atas.
Berdasarkan Tabel 4.27, hasil ketepatan klasifikasi yang diperoleh akan dijelaskan di bawah ini.
Tabel 4.27 Classification Resultsa
a 45,7 % of original grouped cases correctly classified.
Predicted Group Membership
Industri Makanan dan minuman Tekstil dan garmen Plastik dan Kemasan Logam dan sejenisnya Otomotif dan komponenny a Properti dan Real Estate Total Makanan dan minuman 3 0 1 1 2 0 7 Tekstil dan garmen 2 5 1 3 0 0 11 Plastik dan Kemasan 1 0 1 2 0 0 4 Logam dan sejenisnya 0 1 0 3 1 0 5 Otomotif dan komponennya 0 0 0 3 2 0 5 Count Properti dan Real Estate 0 0 1 0 0 2 3 Makanan dan minuman 42.9 .0 14.3 14.3 28.6 .0 100.0 Tekstil dan garmen 18.2 45.5 9.1 27.3 .0 .0 100.0 Plastik dan Kemasan 25.0 .0 25.0 50.0 .0 .0 100.0 Logam dan sejenisnya .0 20.0 .0 60.0 20.0 .0 100.0 Otomotif dan komponennya .0 .0 .0 60.0 40.0 .0 100.0 Original % Properti dan Real Estate .0 .0 33.3 .0 .0 66.7 100.0
Pada bagian Count, terlihat bahwa jumlah data awal yang tergolong kedalam industri Makanan dan minuman (grup 1) adalah 7 data, kemudian setelah dilakukan perhitungan menjadi 3 data. Dengan kata lain, ketepatan klasifikasi kinerja keuangan industri Makanan dan minuman adalah 42,9% (bagian %).
Data yang pada awalnya tergolong kedalam industri Tekstil dan garmen (grup 2) sebanyak 11 data, setelah dilakukan perhitungan berubah menjadi 5 data. Dengan kata lain, ketepatan klasifikasi kinerja keuangan industri tekstil dan garmen adalah 45.5%.
Sedangkan jumlah data awal yang tergolong kedalam industri Pelastik dan kemasan (grup 3) adalah 5 data, setelah dilakukan perhitungan berubah menjadi 1 data. Dengan kata lain, ketepatan klasifikasi kinerja keuangan industri pelastik dan kemasan adalah 25%.
Kemudian untuk industri logam dan sejenisnya(grup 4), data awalnya sebanyak 4 data, tetapi setelah dilakukan perhitungan berubah menjadi 3 data. Dengan kata lain, ketepatan klasifikasi kinerja keuangan industri logam dan sejenisnya adalah 60%.
Sedangkan jumlah data awal untuk industri Automotiv dan komponennya (grup 5) sebanyak 5 data, setelah dilakukan perhitungan berubah menjadi 2 data, dengan kata lain ketepatan klasifikasi kinerja keuangan industri otomotif dan komponennya adalah 40%.
Dan untuk data awal industri properti dan real estate (grup 6) adalah 3 data, tetapi setelah dilakukan perhitungan berubah menjadi 2 data, dengan katalain ketepatan klasifikasi kinerja keuangan untuk industri real estate adalah 66.7%.
Dari data tersebut diatas dapat diperoleh informasi bahwa prosentase ketepatan klasifikasi secara keseluruhan dari model yang dihasilkan adalah:
7 5 1 3 2 2 100% 45.7% 35 + + + + + ⎛ ⎞× = ⎜ ⎟ ⎝ ⎠
Prosentase ketepatan klasifikasi kinerja keuangan sebesar 45.7% adalah cukup karena mendekati 50%, maka model diskriminasi tersebut cukup valid untuk digunakan dalam penelitian ini.
4.2.4.7. Penggunaan model diskriminan untuk kasus lain
Setelah terbukti bahwa model diskriminan yang telah dibuat dalam penelitian ini mempunyai ketepatan prediksi yang tinggi, maka model diskriminan tersebut bisa
digunakan untuk memprediksi sebuah kasus, cukup dari tigs (3) rasio saja yaitu CR, MARGIN dan ROA.
Kemudian dari tiga rasio tersebut dilakukan klasifikasi grup, apakah tergolong kedalam klasifikasi kinerja keuangan grup tertentu, yaitu industri Makanan dan minuman, tekstil dan garmen, pelastik dan kemasan, logam dan sejenisnya, otomotif dan komponennya atau properti dan real estate.
4.2.4.8. Analisis Deskriptif dari empat Variabel Independen Signifikan
Pada bagian ini ditampilkan tiga (3) rasio keuangan yang signifikan yaitu CR, MARGIN dan ROA. Ketiga rasio di atas mampu membedakan kinerja keuangan antar enam industri yaitu industri makanan dan minuman, tekstil dan garmen, plastik dan kemasan, logam dan sejenisnya, otomotif dan komponennya, dan properti dan real estate.
Tabel 4.28 Group Statistics Group Statistics Valid N (listwise) Industri Mean Std. Deviation Unweighted Weighted Makanan dan minuman CR 2.0371 .93690 7 7.000 MARGIN .1400 .06218 7 7.000 ROA 10.7643 5.51734 7 7.000
Tekstil dan garmen CR 1.2609 .34128 11 11.000
MARGIN .0936 .05697 11 11.000
ROA 3.5873 5.07034 11 11.000
Plastik dan Kemasan CR 1.8825 .97123 4 4.000
MARGIN .1400 .09866 4 4.000
ROA 6.9050 3.78823 4 4.000
Logam dan sejenisnya CR 1.6320 .56167 5 5.000
MARGIN .0640 .02510 5 5.000 ROA 4.0360 1.04412 5 5.000 Otomotif dan komponennya CR 2.7800 1.49910 5 5.000
MARGIN .0820 .03834 5 5.000
ROA 4.5700 1.83441 5 5.000
Properti dan Real Estate CR 3.3167 1.29307 3 3.000 MARGIN .2800 .11000 3 3.000 ROA 4.5700 1.05162 3 3.000 Total CR 1.9334 1.05294 35 35.000 MARGIN .1183 .08209 35 35.000 ROA 5.6906 4.73195 35 35.000