i
IDENTIFIKASI MAKNA KATA “SABAR” DALAM KARYA SASTRA MENGGUNAKAN SUPPORT VECTOR MACHINE (SVM) KERNEL
POLINOMIAL
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer Program Studi Teknik Informatika
Oleh:
Jonathan Widyo Wicaksono 125314098
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
IDENTIFICATION OF THE WORD “PATIENT” IN LITERATUR WORK USING POLYNOMIAL KERNEL SUPPORT VECTOR MACHINE (SVM)
A THESIS
Presented as Partial Fullfillment of Requirements to Obtain Sarjana
Komputer Degree in Informatics Engineering Study Program
By :
Jonathan Widyo Wicaksono 125314098
INFORMATICS ENGINEERING STUDY PROGRAM INFORMATICS ENGINEERING DEPARTMENT
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
YOGYAKARTA 2017
iii
HALAMAN PERSETUJUAN
SKRIPSI
IDENTIFIKASI MAKNA KATA “SABAR” DALAM KARYA SASTRA MENGGUNAKAN SUPPORT VECTOR MACHINE (SVM) KERNEL
POLINOMIAL
Oleh :
Jonathan Widyo Wicaksono NIM : 125314098
Telah disetujui oleh :
Dosen Pembimbing 1, Dosen Pembimbing 2,
Sri Hartati Wijono M.Kom. Dr. B. B. Dwijatmoko, M.A.
iv
HALAMAN PENGESAHAN
SKRIPSI
IDENTIFIKASI MAKNA KATA “SABAR” DALAM KARYA SASTRA MENGGUNAKAN SUPPORT VECTOR MACHINE (SVM) KERNEL
POLINOMIAL
Oleh :
Jonathan Widyo Wicaksono NIM : 125314098
Telah dipertahankan di depan Panitia Penguji Pada tanggal ……….
dan dinyatakan memenuhi syarat.
Susunan Panitia Penguji
Nama lengkap Tanda Tangan
Ketua : Puspaningtyas Sanjoyo Adi, S.T., M.T. ……….
Sekretaris : Alb. Agung Hadhiatma , M.T. ……….
Anggota 1 : Sri Hartati Wijono M.Kom. ……….
Anggota 2 : Dr. B. B. Dwijatmoko, M.A. ……….
Yogyakarta, ………. Fakultas Sains dan Teknologi
Universitas Sanata Dharma Dekan,
v
MOTO
“Semua Akan Selesai Pada Waktunya Hanya perlu
Bersabar dan Terus Berjuang”
“Kalau Sudah Basah Lebih Baik Basah-basahan Sekalian
Untuk Mendapatkan Hasil Terbaik”
vi
PERNYATAAN KEASLIAN
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, terkecuali yang sudah tertulis di dalam kutipan daftar pustaka, sebagaimana layaknya sebuah karya ilmiah.
Yogyakarta, ………. Penulis
vii
LEMBAR PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma : Nama : Jonathan Widyo Wicaksono
NIM : 125314098
Demi mengembangkan ilmu pengetahuan, saya memberikan kepada Perpusatakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul :
IDENTIFIKASI MAKNA KATA “SABAR” DALAM KARYA SASTRA MENGGUNAKAN SUPPORT VECTOR MACHINE (SVM) KERNEL
POLINOMIAL
Beserta perangkat yang diperlukan (bila ada). Dengan demikian, saya memberikan kepada Universitas Sanata Dharma hak untuk menyimpan, mengalihkan kedalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikannya secara terbatas dan mempublikasikannya di Internet atau media lain untuk kepentingan akademis tanpa perlu izin dari saya maupun memberi royalty kepada saya selama tetap mencantumkan nama saya sebagai penulis. Demikian pernyataan ini saya buat dengan sebenarnya.
Yang menyatakan,
viii
ABSTRAK
Kesabaran merupakan nilai hidup yang dijunjung tinggi bangsa Indonesia. Menurut Subandi (2011), kesabaran merupakan ajaran yang dijunjung oleh kelima agama besar di Indonesia ( Islam, Kristen, Katholik, Hindu, dan Budha). Lebih lanjut disebutkan oleh Subandi bahwa dalam Al Qur’an terdapat 44 ayat yang menggunakan kata sabar dan 14 ayat yang menggunakan kata kesabaran. Penelusuran dalam Alkitab (Bible) Bahasa Indonesia menunjukan 70 ayat yang mengandung kata sabar, kesabaran, dan kata lain dengan lema sabar. Subandi (2011) juga menyebutkan bahwa kesabaran merupakan bentuk pengendalian diri yang sangat penting dalam agama Budha dan Hindu.
Penelitian untuk mengidentifikasi makna sabar telah dilakukan oleh Dr. Benedictus Bherman Dwijatmoko, M.A yang menhasilkan klasifikasi atau pengelompokan makna kata sabar kedalam 6 enam kategori atau kelompok, yaitu giliran, keadaan, komunikasi, sifat, pekerjan, dan urutan tindakan.
Dalam skripsi ini identifikasi makna kata sabar dilakukan dengan menggunkan algoritma Support Vector Machine (SVM) dengan kernel Polinomial, yang hasilnya dibandingkan dengan hasil penelitian terdahulu oleh ahli untuk mendapatkan akurasi dari algoritma Support Vector Machine (SVM) dalam mengklasifikasikan makna kata sabar. Hasil akurasi yang didapat adalah 100% menggunakan data tranning 108 data dan test 108 data. 51.51% menggunakan data sebanyak 108 data yang di akurasikan menggunakan k-fold 5.
ix
ABSTRACT
Patience is a ‘value of life’ which is upheld by Indonesian. According to Subandi (2011), kesabaran “patience”is a teachings upheld by five major religions in Indonesia (Moeslem, Christianity, Catholic, Hinduism, and Buddhism). Furthermore, Subandi said there is 44 verses in Al-Quran using the word kesabaran
“patience” and 14 verses using the word kesabaran “patience”. In the holy bible,
there is 70 verses using the word kesabaran “patience”, sabar “patient”, etc. Subandi also said that kesabaran “patience” is an important ‘self-control’ in hinduism and buddhism.
A research to find the true meaning of kesabaran “patience” has been done by Dwijatmoko (2016), resulting in kesabaran “patience” classification in 6 categories, they are giliran “turn”, keadaan “situation”, komunikasi “communication”, sifat “character”, Pekerjaan “working”, and urutan tindakan “action sequence”.
In this thesis, identification of true meaning of sabar is done by Support Vector Machine (SVM) algorithm with Polynomial kernel, the results are compared to the old results done by expert to find an accurate result of Support Vector Machine (SVM) algorithm. The accuration result is 100% using 108 data train and 108 data test. 51.51% using 108 data which are accurated with 5 fold cross
validation.
x
KATA PENGANTAR
Puji dan syukur kepada Tuhan Yang Maha Esa atas segala berkat dan karunia-Nya, sehingga penulis dapat menyelesaikan tugas akhir yang berjudul “Identifikasi Makna Kata “Sabar” Dalam Karya Sastra Menggunkan Support
Vector Machine (SVM) kernel Polinomial “. Tugas akhir ini merupakan salah satu
mata kuliah wajib dan sebagai syarat akademik untuk memperoleh gelar sarjana komputer Program Studi Teknik Informatika Universitas Sanata Dharma Yogyakarta.
Penulis menyadari bahwa selama proses penelitian dan penyusunan laporan tugas akhir ini, banyak pihak yang telah membantu penulis, sehingga pada kesempatan ini penulis ingin mengucapkan terimakasih antara lain kepada :
1. Tuhan Yang Maha Esa, yang telah memberikan pertolongan dan kekuatan dalam proses pembuatan tugas akhir.
2. Ibu Sri Hartati Wijono M.Kom. dan Dr. B.B. Dwijatmoko, M.A selaku dosen pembimbing tugas akhir, atas kesabarannya dan nasehat dalam membimbing penulis, meluangkan waktunya, memberi dukungan, motivasi, serta saran yang sangat membantu penulis.
3. Sudi Mungkasi, Ph.D. selaku Dekan Fakultas Sains dan Teknologi, atas bimbingan, kritik dan saran yang telah diberikan kepada penulis.
4. Dr. Anastasia Rita Widiarti, M.Kom. selaku Ketua Program Studi Teknik Informatika, atas bimbingan, kritik dan saran yang telah diberikan kepada penulis.
5. Teman seperjuangan PEMEROLEHAN INFORMASI (Giri, Anjar, Xave).
6. Orang tua yang selalu memberi semangat Pudjono dan Ni Putu , serta kakak Elisabeth Lucia F. .
7. Teman begadang garap skripsi Eric.
8. Teman main DOTA (Bagus, Abed, Ricky, Alan, Ino, Koko, Mas Rio, Eric, Nikopil) .
xi
9. Teman-teman TI JARKOM 2012 yang memberi tempat untuk mengerjakan Skripsi.
10. Teman – teman Teknik Informatika semua angkatan dan khususnya TI angkatan 2012 yang selalu memberikan motivasi dan bantuan hingga penulis menyelesaikan tugas akhir ini.
Penulis menyadari bahwa masih banyak kekurangan dalam penyusunan tugas akhir ini. Saran dan kritik sangat diharapkan untuk perbaikan yang akan datang.
Yogyakarta ………
xii
DAFTAR ISI
IDENTIFIKASI MAKNA KATA “SABAR” DALAM KARYA SASTRA MENGGUNAKAN SUPPORT VECTOR MACHINE (SVM) KERNEL
POLINOMIAL ... i
IDENTIFICATION OF THE WORD “PATIENT” IN LITERATUR WORK USING POLYNOMIAL KERNEL SUPPORT VECTOR MACHINE (SVM) ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv MOTO ... v PERNYATAAN KEASLIAN ... vi ABSTRAK ... viii ABSTRACT ... ix KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR TABLE ... xv
DAFTAR GAMBAR ... xvi
BAB I ... 1 PENDAHULUAN ... 1 1.1. Latar Belakang ... 1 1.2. Rumusan Masalah ... 2 1.3. Tujuan ... 2 1.4. Batasan Masalah ... 2 BAB II ... 5 LANDASAN TEORI ... 5 2.1 Sabar ... 5 2.2 Information Retrieval ... 5 2.3 Text Prepocessing ... 5 2.2.1 Tokenizing ... 6 2.2.2 Filtering ... 7 2.2.3 Stemming ... 8 2.2.4 Pembobotan Kata ... 12
xiii
2.4 Support Vector Machine (SVM) ... 17
2.4.1 Multi Class SVM ... 20
2.5 Evaluasi Pengujian Sistem ... 23
BAB III ... 25
ANALISIS DAN DESAIN ... 25
3.1 Diskripsi sistem ... 25 3.2 Data ... 26 3.3 Penyimpanan Data ... 27 3.4 Pemetaan Data ... 28 3.2.1 Tokenizing ... 28 3.2.2 Stopword Filtering ... 28 3.2.3 Stemming ... 29
3.2.4 Computation of TF-IDF Feature ... 29
3.5 Mengunakan sistem ... 30
3.6 Struktur data ... 31
3.7 Desain Logikal (Logical Design) ... 31
3.4.1 DFD level 0 ... 31
3.4.2 Desain Proses PI (Pemerolehan Informasi) ... 32
3.4.3 Desain Proses SVM kernel Polinomial ... 33
BAB IV ... 34
IMPLEMENTASI SISTEM ... 34
4.1 Kebutuhan Perancangan Sistem ... 34
4.1.1 Hardware ... 34
4.1.2 Software ... 34
4.2 Implementasi Prepocessing Kalimat ... 34
4.2.1 Class Master ... 34
4.2.2 Class Kelas ... 36
4.2.3 Class Dokumen ... 37
4.2.4 Class Stopword ... 40
4.2.5 Class Mencari Bobot ... 42
4.3 Sistem Yang Digunakan Dari WEKA ... 45
xiv
4.3.2 Proses Input Bobot ... 48
4.3.3 Mengunkan WEKA ... 49 BAB V ... 50 ANALISIS HASIL ... 50 5.1 Skema Pengujian ... 50 5.2 Hasil Pengujian ... 51 5.2.1 Pengujian 1 ... 52 5.2.2 Pengujian 2 ... 52 5.3. Analisa Hasil ... 53 BAB VI ... 55
KESIMPULAN DAN SARAN ... 55
6.1 Kesimpulan ... 55
6.2 Saran ... 55
xv
DAFTAR TABLE
Table 2.1 Contoh hasil Tokenizing ... 6
Tabel 2.2 Daftar Stop Word ... 7
Tabel 2.3 Input dari hasil Tokenizing ... 7
Tabel 2.4 Hasil Output Filtering ... 8
Tabel 2. 5 Recoding ... 9
Tabel 2. 6 Kombinasi Awalan Akhiran yang Tidak Diijinkan ... 11
Tabel 2. 7 Contoh Input Proses Term Frequency (tf) / 𝒕𝒇𝒕, 𝒅 ... 13
Tabel 2. 8 Hasil Proses Term Frequency (tf) / 𝒕𝒇𝒕, 𝒅 ... 13
Tabel 2. 9 Contoh Input Proses Document Freuency (df) ... 14
Tabel 2. 10 Hasil Output Proses Document Freuency(df) ... 14
Tabel 2. 11 Input Proses Menghitung Invers Document Frecuency (idf) ... 15
Tabel 2. 12 Output Proses Invers Document Frecueny (idf) ... 16
Tabel 2. 13 Input Proses Mencari Nilai weight (w) ... 16
Tabel 2. 14 Hasil Output Proses Weight (w) ... 17
Tabel 2. 15 Fungsi kernel ... 19
Tabel 2. 16 Contoh 4 Class SVM biner dengan metode One-agains-all ... 20
Tabel 2. 17 Contoh 4 SVM biner dengan metode One-against-one ... 21
Tabel 2. 18 Contoh 6 SVM biner dengan metode DAGSVM ... 23
Tabel 3. 1 Tabel hasil dari TF-IDF dengan data sebenarnya 29
Tabel 3. 2 Nilai w tiap term 29 Table 5. 1 Data pengujin sebanyak 108 data 51
Table 5. 2 Data pengujin sebanyak 36 data 51
xvi
DAFTAR GAMBAR
Gambar 2. 1 Hyperplane melalui dua kelas linearly ... 18
Gambar 2. 2 Contoh Klasifikasi dengan metode One-against-all ... 21
Gambar 2. 3 Contoh klasifikasi dengan metode One-against-one ... 22
Gambar 2. 4 Contoh 6 SVM biner dengan metode DAGSVM ... 23
Gambar 3. 1 Skema Diskripsi Proses Klasifikasi SVM kernel Polinomial 26
Gambar 3. 2 Struktur Data 31 Gambar 3. 3 DFD Level 0 31 Gambar 3. 4 Diagram Alir Proses Pemerolehan Informasi 32 Gambar 3. 5 Diagram Alir Mengunkan sistem 33 Grafik 5. 1 Perbandingan hasil uji akurasi 54
1
BAB I
PENDAHULUAN
1.1. Latar Belakang
Kata “sabar” banyak diungkit dalam kehidupan berbangsa di Indonesia dan diajarkan oleh kelima agama besar di Indonesia (Islam, Katolik, Kristen, Hindu, Budha) menurut Subandi (2011). Subandi (2011) menyebutkan bahwa dalam Al Qur’an terdapat 44 ayat yang mengandung kata “sabar” dan 14 ayatt yang menggunakan kata “kesabaran”. Penelusuran dalam Alkitab (Bible) Bahasa Indonesia menunjukan 70 ayat yang mengandung kata “sabar” dan kata “kesabaran”. Kata “sabar” dalam ajaran Budha dan Hindu berguna dalam pengendalian diri, Subandi (2011) .
Sehingga B.B. Dwijatmoko melakukan penelitian untuk mengetahui atri dari kata “kesabaran” atau kata “sabar” dalam karya sastra Indonesia, dan hasil dari penelitian yang dilakukan mendapatkan hasil dimana kata “sabar” terbagi menjadi 6(enam) konsep yaitu : penerimaan kondisi yang harus dihadapi, penantian giliran, penerimaan urutan kegiatan, kesediaan menunggu dalam pembicaraan, sifat sabar, dan ketekunan dalam melakukan Pekerjaan. Data yang digunakan dalam penelitian oleh B.B Dwijatmoko berasal dari situs www.corci.org. Sebanyak 108 karya sastra. Distribusi data meliputi karya sastra mengandung kata “sabar” (81), kata “bersabar” (13), kata “kesabaran” (12), kata “penyabar” (1), dan kata “menyabarkan” (1). Data yang ada diatas disimpulan bahwa kata “sabar” memiliki 6 (enam) konsep dengan memakai pendekatan analisis wacana dan analisis wacana kritis (Fairclough, 1995 dan Wodak dan Meyer, 2001).
Diatas dapat didapatkan bahwa mengatagorikan kata “sabar” kedalam 6 (enam) kondisi menggunkan metode yang manual atau menggunakan analisis pendekatan. Melihat dari itu terlalu lama waktu yang
digunakan dalam menganalisis karya sastra Indonesia memerlukan waktu yang lama namun tepat sesuai dengan pendekatan manusia, dan sistem ini dibuat untuk membantu menguji apakah menggunkan metode klasifikasi SVM (Support Vector Machine) bisa mendapatkan ketepatan/ akurasi yang sama dengan yang menggunakan pendekatan analisis wacana dan analisis wacana kritis (Fairclough, 1995 dan Wodak dan Meyer, 2001).
1.2. Rumusan Masalah
Berdasarkan latar belakang diatas, maka rumusan masalah yang akan diselesaikan, yaitu :
1. Seberapa akurat klasifikasi SVM (Support Vector Machines) dalam mengklasifikasikan kata “sabar” dalam Karya Sastra. 2. Apakah SVM (Support Vector Machines) mampu untuk
mengklasifikasikan sebuah kata.
1.3. Tujuan
Tujuan dari penelitian ini adalah mengetahui akurasi dari SVM (Support Vector Machines) dalam mengkalsifikasi kata “sabar” dalam sebuah karya satra.
1.4. Batasan Masalah
Dalam sistem pengukur akurasi menggunakan metode SVM (Support Vector Machine), dilakukan beberapa batasan, sebagai berikut :
a. Sistem yang akan dibangun Menggunakan metode SVM (Support
Vector Machine) dengan kernel Polinimial di bantu dengan libary dari
WEKA.
b. Data karya sastra yang akan diklasifikasi hanya yang mengandung kata “sabar”.
c. Input sistem berupa karya sastra yang mengandung kata “sabar”. d. Output dari sistem adalah sebuah nilai akurasi dari metode SVM
1.5. Metode Penelitian
Metode penelitian yang digunakan dalam proses kalsifikasi Sastra Indonesi menggunakan metode SVM Kernel Polinomial :
1. Studi Literatur
Studi literatur tahapan dimana mencari dasar dari metode yang digunakan seperti SVM Kernel Polinomial yang bersumber dari buku, jurnal, dan website.
2. Pengumpulan Data
Pengumpulan data tahapan mengumpulkan bahan test dan bahan traning untuk dimasukan kedalam sistem untuk di uji kebenarnya.
3. Perancangan Sistem
Perancangan sistem adalah tahapan yang dibuat untuk menunjukan alur atau sebuah cerita dimana sistem yang akan dibuat bisa berjalan dan menghasilkan sebuah hasil yang dinginkan.
4. Pembuatan Sistem
Pembuatan sistem tahapan yang menjadikan sebuah rancangan yang sudah dibuat menjadi sebuah sistem yang dapat digunakan.
5. Implementasi Sistem
Implementasi sistem dengan cara menggunakan data yang sudah dicari. Data yang digunakan untuk implementasi sistem berupa data teks sumber dari corci.org.
6. Evaluasi
Evaluasi merupakan tahapan menganalisa hasil dari implementasi sistem yang sudah dibuat. Hasil dari analisa yang didapat dibuat kesimpulan.
1.6. Sistematika Penulisan
Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB I. Pendahuluan
Bab ini berisi latar belakang, rumusan masalah, tujuan, batasan masalah, dan sistematika penulisan.
BAB II. Landasan Teori
Bab ini berisi penjelasan tentang prinsip dan konsep dasar yang diperlukan untuk memecahkan masalah yang dibahas pada Bab
BAB III. Metodologi Penelitian
Bab ini berisi tentang metodologi penelitian yang akan dilakukan selama penelitian, terdiri dari : Tahap definisi ruang lingkup, analisis masalah, analisis kebutuhan, desain logikal, desain fisik dan integrasi dan tahap pembuatan sistem dan pengujian.
BAB IV. Analisis dan Perancangan Sistem
Bab ini akan menjelaskan deskripsi umum sistem, data, use case, desain database, desain proses, serta desain Graphical User Interface yang akan digunakan.
BAB V. Implementasi Sistem
Bab ini akan menjelaskan tentang implementasi sistem berdasarkan rancangan pada BAB IV.
BAB VI. Pengujian dan Analisis Hasil
Bab ini berisi pengujian terhadap sistem yang dibuat dan dilanjutkan dengan menganalisis hasil pengujian yang meliputi kelebihan dan kekurangan sistem yang dibuat.
BAB VII. Kesimpulan
Bab ini akan menjelaskan kesimpulan umum yang diperoleh dari pembuatan sistem serta rancangan pengembangan sistem ke depan.
5
BAB II
LANDASAN TEORI
Pada Bab II akan dijelaskan mengenai landasan teori yang digunakan untuk mendukung penelitian yang dilakukan penulis. Dalam Bab ini akan dijelaskan pengertian serta metode-metode yang digunakan oleh penulis.
2.1 Sabar
Kata “sabar” yang diteliti oleh B.B. Dwijatmoko dikarena sebagai sebuah gagasan yang penting sebagai untuk mempersatukan sebuah agama dan juga sebagai pengendali akan diri sendiri. Sabar yang teliti memiliki 6 konsep yaitu :
1. Penerimaan keadaan 2. Penantian giliran
3. Penerimaan urutan tindakan
4. Kesediaan menunggu dalam pembicaraan 5. Sifat sabar
6. Ketekunan dalam Pekerjaan
2.2 Information Retrieval
Sebuah proses untuk medapatkan sebuah informasi yang tepat dan sesuai yang akan di lakukan proses selanjutnya dalam proses Pemerolehan informasi (Mooers, 1951, hal. 25).
2.3 Text Prepocessing
Merupakan tahapan dalam mengelola sebuah data yang diinputkan kedalam program. Pada tahap text processing terdapat beberapa langkah, yaitu tokenizing, stopword filtering, stemming , computation of TF-IDF
2.2.1 Tokenizing
Proses yang dilakukan kepada sebuah kalimat yang masuk diubah kedalam bentuk kata-perkata dan juga menghilangkan tanda baca pada kalimat.
Input : Langkah untuk mengklasifikasi karya sastra menggunakan SVM : tekt Prepocesing , klasifikasi SVM.
Output :
Table 2.1 Contoh hasil Tokenizing Langkah untuk mengklasifikasi karya sastra menggunakan SVM tekt Prepocesing klasifikasi SVM
2.2.2 Filtering
Proses setelah tahap tokenizing dilakukan memerikasa kata yang seharusnya dihilangkan untuk efisiensi proses klasifikasi karena kata tersebut tidak banyak berpengaruh. Dafttar kata yang seharusnya dihilangkan disimpan dalam stopword list.
Daftar Stop Word :
Tabel 2.2 Daftar Stop Word
yang pernah sudah antara mampu setiap tetapi dan tentang untuk bisa ada di dari melakukannya seperti setelah mendapatkan lakukan jadi semua punya memang karena hampir telah baik Of juga mr lain mrs am …, dan lain-lain Input :
Tabel 2.3 Input dari hasil Tokenizing
Langkah untuk
mengklasifikasi karya
menggunakan SVM tekt Prepocesing klasifikasi SVM Output :
Tabel 2.4 Hasil Output Filtering
Langkah mengklasifikasi karya sastra menggunakan SVM tekt Prepocesing klasifikasi SVM 2.2.3 Stemming
Proses mengubah data yang sudah didapat dari tahap
Filtering diubah menjadi bentuk kata dasarnya seperti dalam kamus
besar bahasa indonesia. Proses ini menggunakan algoritma
stemming Nazief and Adriani’s dari Universitas Indonesia (1998).
Berikut ini urutan algoritman stemming Nazief and Adriani’s :
Cari kata yang sama antara data set dengan kamus jika sama diamsusikan bahwa kata tersebut adalah root word. Maka algoritma berhenti.
Inflection Suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”)
maka langkah ini diulangi lagi untuk menghapus Possesive
Pronouns (“-ku”, “-mu”, atau “-nya”), jika ada.
Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata ditemukan di kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a.
Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “-k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3b.
Akhiran yang dihapus (“-i”, “-an” atau “-kan”) dikembalikan, lanjut ke langkah 4.
Hapus Derivation Prefix. Jika pada langkah 3 ada sufiks yang dihapus maka pergi ke langkah 4a, jika tidak pergi ke langkah 4b. Periksa tabel kombinasi awalan-akhiran yang tidak diijinkan. Jika ditemukan maka algoritma berhenti, jika tidak pergi ke langkah 4b. For i = 1 to 3, tentukan tipe awalan kemudian hapus awalan. Jika root word belum juga ditemukan lakukan langkah 5, jika sudah maka algoritma berhenti. Catatan: jika awalan kedua sama dengan awalan pertama algoritma berhenti.
Melakukan Recoding dapat dilihat pada tabel 2.5
Tabel 2. 5 Recoding
Aturan Format Kata Pemenggalan
1 berV… ber-V... | be-rV...
2 berCAP…
ber-CAP... dimana C!=‟r‟ & P!=‟er‟
3 berCAerV... ber-CaerV... dimana C!=‟r‟ 4 belajar bel-ajar
5 beC1erC2...
be-C1erC2... dimana C1!={‟r‟|‟l‟}
6 terV... ter-V... | te-rV...
8 terCP...
ter-CP... dimana C!=‟r‟ dan P!=‟er‟
9 teC1erC2... te-C1erC2... dimana C1!=‟r‟ 10 me{l|r|w|y}V... me-{l|r|w|y}V...
11 mem{b|f|v}... mem-{b|f|v}... 12 mempe... mem-pe...
13 mem{rV|V}... me-m{rV|V}... |me-p{rV|V}… 14 men{c|d|j|z}... men-{c|d|j|z}...
15 menV... me-nV... | me-tV 16 meng{g|h|q|k}... meng-{g|h|q|k}... 17 mengV... meng-V... | meng-kV... 18 menyV... meny-sV...
19 mempV... mem-pV... dengan V!=‟e‟ 20 pe{w|y}V... pe-{w|y}V...
21 perV... per-V... | pe-rV...
22 perCAP
per-CAP... dimana C!=‟r‟ dan P!=‟er‟
23 perCAerV... per-CAerV... dimana C!=‟r‟ 24 pem{b|f|V}... pem-{b|f|V}...
25 pem{rV|V}... pe-m{rV|V}... | pe-p{rV|V}… 26 pen{c|d|j|z}... pen-{c|d|j|z}...
27 penV... pe-nV... | pe-tV... 28 peng{g|h|q}... peng-{g|h|q}... 29 pengV... peng-V... | peng-kV... 30 penyV... peny-sV...
31 pelV...
pe-lV... kecuali “pelajar” yang menghasilkan “ajar”
32 peCerV...
per-erV... dimana C!={r|w|y|l|m|n}
33 peCP...
pe-CP... dimana C!={r|w|y|l|m|n} dan P!=‟er‟ 34 terC1erC2... ter-C1erC2... dimana C1!=‟r‟
35 peC1erC2...
pe-C1erC2... dimana C1!={r|w|y|l|m|n}
a) Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal diasumsikan sebagai root word. Proses selesai. Tipe awalan ditentukan melalui langkah-langkah berikut:
1. Jika awalannya adalah: “di-”, “ke-”, atau “se-” maka tipe
awalannya secara berturut-turut adalah “di-”, “ke-”, atau “se-”.
2. Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-” maka
dibutuhkan sebuah proses tambahan untuk menentukan tipe awalannya.
3. Jika dua karakter pertama bukan “di-”, “ke-”, “se-”, “te-”,
“be-”, “me-”, atau “pe-” maka berhenti.
4. Jika tipe awalan adalah “none” maka berhenti. Jika tipe
awalan adalah bukan “none” maka awalan dapat dilihat pada Tabel 2.6. Hapus awalan jika ditemukan.
Tabel 2. 6 Kombinasi Awalan Akhiran yang Tidak Diijinkan
Awalan Akhiran yang tidak diijinkan
Be- -i
di- -an
Ke- -i ,-kan
Me- -an
2.2.4 Pembobotan Kata
Dalam menentukan bobot suatu kata tidak hanya berdasarkan frekuensi kemunculan kata di satu dokumen, tetapi juga memperhatikan frekuensi terbesar pada suatu kata yang dimiliki oleh dokumen yang bersangkutan. Hal ini untuk menentukan posisi relatif bobot dari kata dibanding dengan kata-kata lain di dokumen yang sama. Didalam memberikan bobot pada sebuah kata menggunakan teknik yang paling sering digunakan adalah TF/IDF (term frequency (tf), dan inverse dokumen frequency (idf)). Term
Frequency (tf) adalah jumlah kemunculan suatu kata dalam sebuah
dokumen dan Inverse document frequency (idf) adalah inverse
document frequency dari suatu kata keseluruhan dokumen yang
terkait. Rumus pembobotan (2.1) Salton (1989) adalah sebagai berikut:
(2. 1)
Dimana :
𝑤(𝑡, 𝑑) = bobot dari term(t)/kata dalam dokumen (d)
𝑡𝑓(𝑡,𝑑) =frekuensi kemunculan term(t)/kata dalam dokumen (d) 𝑖𝑑𝑓𝑡 = inverse document frequency dari kata t
𝑁 = jumlah seluruh dokumen terkait
𝑛𝑡= jumlah dokumen yang mengandung term (t) atau kata
Berikut ini tahapan pencarian data untuk setiap rumus diatas :
Menghitung Term Frequency (tf) atau 𝒕𝒇(𝒕,𝒅)
Ini mencari seberapa sering muncul kata yang sama dalam satu dokumen. Setiap kata yang muncul diberi nilai 1 dan bila ketemu kata yang sama lagi di tambah 1 lagi pada kata tersebut. Input :
𝑤(𝑡, 𝑑) = 𝑡𝑓𝑡,𝑑∗ 𝑖𝑑𝑓𝑡 = 𝑡𝑓(𝑡, 𝑑) ∗ 𝑙𝑜𝑔2(𝑁 𝑛𝑡)
Tabel 2. 7 Contoh Input Proses Term Frequency (tf) / 𝑡𝑓𝑡,𝑑 D1 D2 Langkah Karya klasifikasi Satra Karya Indonesia Sastra Klasifikasi Guna Enam SVM Kategori Teks Guna Prepocesing Metode klasifikasi SVM SVM Output :
Tabel 2. 8 Hasil Proses Term Frequency (tf) / 𝑡𝑓𝑡,𝑑
Term (t) D1 D2 Langkah 1 0 klasifikasi 1 1 Karya 1 1 Sastra 1 1 Guna 1 1 SVM 2 1 Teks 1 0 Prepocesing 1 0 klasifikasi 1 1 Indonesia 0 1 metode 0 1 Enam 0 1
Menghitung document frequency (df)
Merupakan banyaknya dokumen dimana suatu term(t) muncul. Sehingga apabila term (t) muncul lebih dari satu kali dalam satu dokumen tetap dihitung satu term(t) yang dimiliki oleh dokumen tersebut dan total dari document frequency (df) terbesar adalah banyanya total doumen apabila semua doumen memiliki term(t) yang sama dan jumlah terkecil dari document frequency (df) adalah 1 tidak bisa nol karena setiap doumen memiliki term(t) sendiri
Input :
Tabel 2. 9 Contoh Input Proses Document Freuency (df)
Term (t) D1 D2 Langkah 1 0 klasifikasi 1 1 Karya 1 1 Sastra 1 1 Guna 1 1 SVM 2 1 Teks 1 0 Prepocesing 1 0 klasifikasi 1 1 Indonesia 0 1 metode 0 1 Enam 0 1 Output :
Tabel 2. 10 Hasil Output Proses Document Freuency(df)
Term (t) df Langkah 1 klasifikasi 2 Karya 2
Sastra 2 Guna 2 SVM 2 Teks 1 Prepocesing 1 klasifikasi 2 Indonesia 1 metode 1 Enam 1
Menghitung invers document frequency (idf) / 𝒊𝒅𝒇𝒕
Sebagai proses untuk mencari nilai invers dari hasil
document frequency (df).
Input :
Tabel 2. 11 Input Proses Menghitung Invers Document Frecuency (idf)
Term (t) df Langkah 1 klasifikasi 2 Karya 2 Sastra 2 Guna 2 SVM 2 Teks 1 Prepocesing 1 klasifikasi 2 Indonesia 1 metode 1 Enam 1
Output :
Tabel 2. 12 Output Proses Invers Document Frecueny (idf)
Term (t) df idf Langkah 1 0.30103 klasifikasi 2 0 Karya 2 0 Sastra 2 0 Guna 2 0 SVM 2 0 Teks 1 0.30103 Prepocesing 1 0.30103 klasifikasi 2 0 Indonesia 1 0.30103 metode 1 0.30103 Enam 1 0.30103
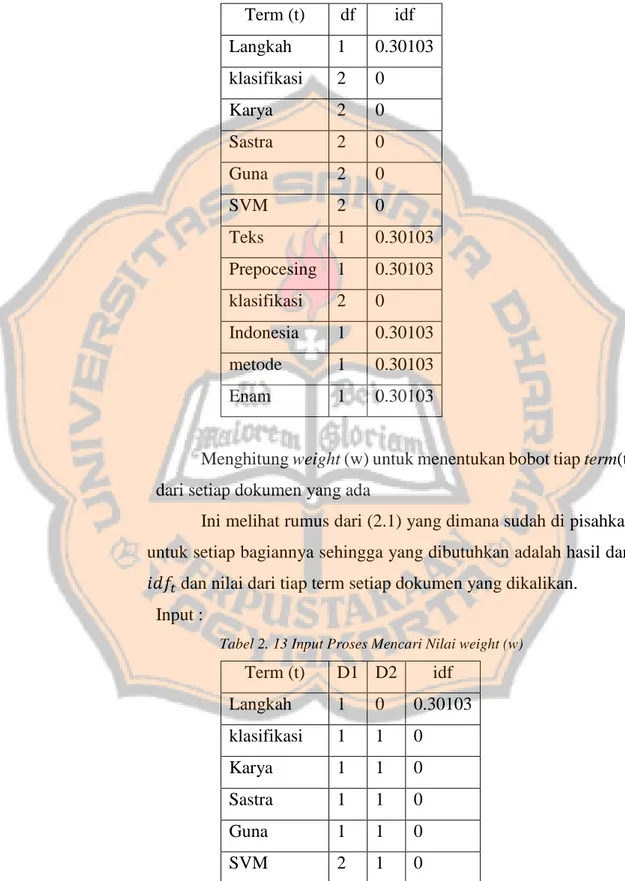
Menghitung weight (w) untuk menentukan bobot tiap term(t) dari setiap dokumen yang ada
Ini melihat rumus dari (2.1) yang dimana sudah di pisahkan untuk setiap bagiannya sehingga yang dibutuhkan adalah hasil dari 𝑖𝑑𝑓𝑡 dan nilai dari tiap term setiap dokumen yang dikalikan.
Input :
Tabel 2. 13 Input Proses Mencari Nilai weight (w)
Term (t) D1 D2 idf Langkah 1 0 0.30103 klasifikasi 1 1 0 Karya 1 1 0 Sastra 1 1 0 Guna 1 1 0 SVM 2 1 0
Teks 1 0 0.30103 Prepocesing 1 0 0.30103 klasifikasi 1 1 0 Indonesia 0 1 0.30103 Metode 0 1 0.30103 Enam 0 1 0.30103 Output :
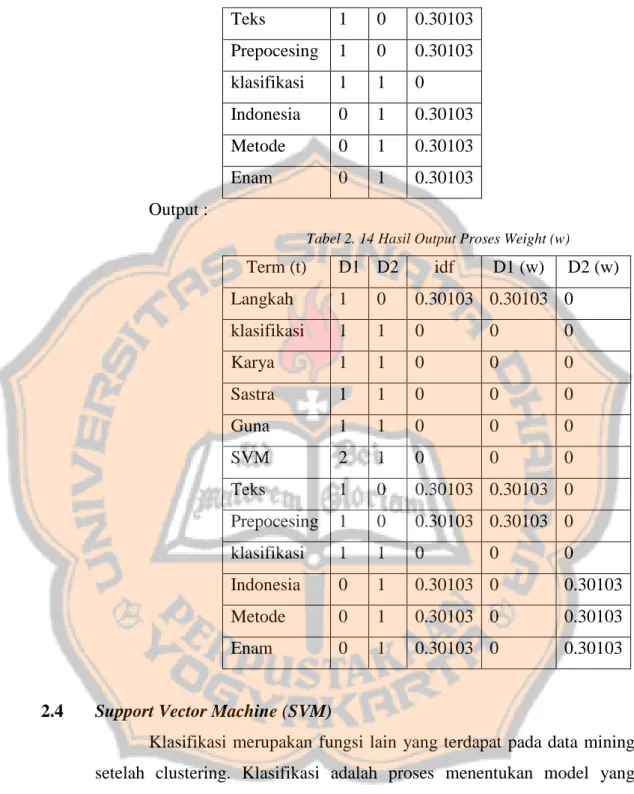
Tabel 2. 14 Hasil Output Proses Weight (w)
Term (t) D1 D2 idf D1 (w) D2 (w) Langkah 1 0 0.30103 0.30103 0 klasifikasi 1 1 0 0 0 Karya 1 1 0 0 0 Sastra 1 1 0 0 0 Guna 1 1 0 0 0 SVM 2 1 0 0 0 Teks 1 0 0.30103 0.30103 0 Prepocesing 1 0 0.30103 0.30103 0 klasifikasi 1 1 0 0 0 Indonesia 0 1 0.30103 0 0.30103 Metode 0 1 0.30103 0 0.30103 Enam 0 1 0.30103 0 0.30103
2.4 Support Vector Machine (SVM)
Klasifikasi merupakan fungsi lain yang terdapat pada data mining setelah clustering. Klasifikasi adalah proses menentukan model yang berguna untuk mendeskripsikan kelas tertentu, agar suatu objek dapat ditentukan kelasnya sesuai lebel (Han, Jiawei dan Micheline Kamber. 2006). Langkah yang pertama dalam mengklasifikasikan data adalah pengklasifikasian dari data training yang telah dibuat dari baris-baris data yang ada dalam database dan kelas label yang terkait. Setiap baris data disebut juga sebagai atribut kelas label. Atribut kelas label merupakan nilai
diskrit dan tidak terurut. Karena setiap baris data training sudah memiliki kelas label, proses ini juga dikenal dengan supervised learning. Langkah selanjutnya yaitu menggunakan model dari data training untuk menghitung akurasi yang dibandingkan dengan data tes. Data tes diperoleh dari baris-baris data yang dipilih secara acak. Akurasi merupakan presentase data tes yang diklasifikasikan secara benar menggunakan pengklasifikasi atau model dari data training.
Support Vector Machine (SVM) pertama kali diperkenalkan oleh
Vapni pada tahun 1992 SVM adalah metode pembelajaran data yang berusaha menemukan hyperplane terbaik antar kelas pada input space. Konsep dasar dan SVM adalah linear classfier, akan tetapi dikembangkan agar dapat bekerja pada permasalahan non-linear. Klasifikasi dalam SVM dapat melibatkan fungsi kemel tertentu agar dapat bekerja pada data dengan dimensi yang lebih banya.
Hyperplane pemisah terbaik antar kelas adalah sebuah garis pemisah
antar kedua kelas (lihat gambar 2.1). Hyperplane pemisah terbaik dapat dicari dengan mengukur margin atau Jarak hypmplane dengan pola terdekat dari masing-masing kelas dan mencari titik pemisahnya (Nupobo, dkk 2003). Data pada titik maksimal tersebutlah yang disebut sebagai support vector. Diketahui bahwa titik-titk maksimal tersebut membuat garis pemisah hyperplane yang lebih sempurna untuk memisahkan data.
Gambar 2. 1 Hyperplane melalui dua kelas linearly
Input data dapat berupa linear dan non linear. Jika input data berupa linear maka pemisahan hyperplane dapat diberikan dalam persamaan :
f(X) =w.x+b (2. 2)
dimana w adalah n-dimensi bobot vektor dan b adalah pengali skala atau nilai bias. Persamaan ini menemukan maksimum margin untuk memisahkan kelas dari kelas positif dari kelas negatif.
𝑥𝑖. 𝑤 + 𝑏 ≥ +1 𝑢𝑛𝑡𝑢𝑘 𝑦𝑖 = +1 (2. 3)
𝑥𝑖. 𝑤 + 𝑏 ≥ −1 𝑢𝑛𝑡𝑢𝑘 𝑦𝑖 = −1 (2. 4)
Pemillihan Parameter pada Support vector Machine
Untuk mendapatkan tingkat kinerja yang tinggi, beberapa parameter dari algoritma SVM harus diperbaiki (Maimon 2010), termasuk:
1. Pemilihan Fungsi Kernel
Tabel 2. 15 Fungsi kernel
Kernel Definisi Kernel
Linear 𝐾(𝑥, 𝑦) = 𝑥. 𝑦 Quadratic 𝐾(𝑥, 𝑦) = (𝑥. 𝑦)2 RBF
𝐾(𝑥, 𝑦) = 𝑒
−( ||𝑥−𝑦||2 2𝜎2 ) Polynomial 𝐾(𝑥, 𝑦) = (𝑥. 𝑦 + 𝑐)𝑑 Sigmoid (tangen hiperbolik) 𝐾(𝑥, 𝑦) = tanh (𝜎(𝑥. 𝑦) + 𝑐)2. Kinerja SVM tergantung pada pilihan fungsi kernel, besaran parameter kernel dan penentuan parameter C. Fungsi kernel yang berbeda memperoleh tingkat keberhasilan yang berbeda untuk berbagai jenis data aplikasi. Ketika nilai penentuan parameter C yang dipilih terlalu besar atau terlalu kecil, generalisasi SVM mungkin berkurang. Jika parameter kernel dan penentuan parameter yang tepat dipilih, kinerja SVM akan optimal.
3. Parameter Kernel(s) .
4. Parameter regularisasi (C, ν, ε) untuk tradeoff antara kompleksitas model dan akurasi mode.
2.4.1 Multi Class SVM
Mengklasifikasikan lebih dari dua kelas atau multi class SVM yaitu dengan menggabungkan beberapa SVM biner atau menggabungkan semua data yang terdiri dari beberapa kelas kedalam sebuah bentuk permasalahan optimasi. Dengan penggabungan kedua dimana menggabungkan beberapa kelas sekaligus mengalami optimasi yang lebih rumut.
Berikut ini adalah metode umum digunakan untuk mengimplementasikan multi class SVM (Krisantus 2007) :
1. Metode ”One-Against-All”
Dengan metode ini, dibangun k buah model SVM biner (k adalah jumlah kelas). Setiap model klasifikasi ke-i dilatih dengan menggunakan keseluruhan data, untuk mencari solusi permasalahan (2.5). Contohnya, terdapat permasalahan klasifikasi dengan 4 buah kelas. Untuk pelatihan digunakan 4 buah SVM biner seperti pada tabel 2.15 dan penggunannya dalam mengklasifikasi data baru dapat dilihat pada 5.
(2. 5)
Tabel 2. 16 Contoh 4 Class SVM biner dengan metode One-agains-all
y=1 y=-1 hipotesis
Kelas 1 Bukan kelas 1 f 1 (x) = (w1 )x + b1 Kelas 2 Bukan kelas 2 f 2 (x) = (w2 )x + b2 Kelas 3 Bukan kelas 3 f 3 (x) = (w3 )x + b3 Kelas 4 Bukan kelas 4 f 4 (x) = (w4 )x + b4
Gambar 2. 2 Contoh Klasifikasi dengan metode One-against-all
2. Metode ”One-Against-One” Membangun 𝑘(𝑘−1)
2 buah model klasifikasi biner ( adalah jumlah kelas). Setiap model klasifikasi dilatih pada data dari dua kelas. Untuk solusi kelas ke –i dan kelas ke-j (2.6)
(2. 6)
Selesai pengujian untuk menetukan data tes masuk kelas mana dilakukan pengujian dengan metode voting
Tabel 2. 17 Contoh 4 SVM biner dengan metode One-against-one
y=1 y=-1 hipotesis
Kelas 1 Kelas 2 f 12 (x) = (w12 )x + b12 Kelas 1 Kelas 3 f 13 (x) = (w13 )x + b13 Kelas 1 Kelas 4 f 14 (x) = (w14 )x + b14 Kelas 2 Kelas 3 f 23 (x) = (w23 )x + b23
Kelas 2 Kelas 4 f 24 (x) = (w24 )x + b24 Kelas 3 Kelas 4 f 34 (x) = (w34 )x + b34
Gambar 2. 3 Contoh klasifikasi dengan metode One-against-one
Jika data ke- i dimasukkan kedalam fungsi hasil pelatihan 𝑓12 (x) = (𝑤12 )x + b12dan hasilnya kelas i maka suara untuk kelas i ditambahkan satu ini bila kelas ke i lebih banyak dari kelas lainnya. Jika kelas ke i ada dua yang sama besar atau sama maka akan kelas lebih kecil adalah kelas milik data ke i tersebut. Dapat dilihat pada gambar 2.3 .
3. Metode DAGSVM (Directed Acyclic Graph Support Vector Machine)
Pelatihan dengan menggunakan metode ini sama dengan metode one-against-one, yaitu dengan membangun 𝑘(𝑘−1)
2 buah model klasifikasi SVM biner. Akan tetapi, pada saat pengujian digunakan binary
directed acyclic graph. Setiap node merupakan model
SVM biner dari kelas ke-i dan kelas ke-j. Pada saat memprediksi kelas data pengujian, maka hipotesis
dievaluasi mulai dari simpul akar, kemudian bergerak ke kiri atau ke kanan tergantung nilai output dari hipotesi.
Tabel 2. 18 Contoh 6 SVM biner dengan metode DAGSVM
y=1 y=-1 hipotesis Bukan Kelas 2 Bukan Kelas 1 f 12 (x) = (w12 )x + b12 Bukan Kelas 3 Bukan Kelas 1 f 13 (x) = (w13 )x + b13 Bukan Kelas 4 Bukan Kelas 1 f 14 (x) = (w14 )x + b14 Bukan Kelas 3 Bukan Kelas 2 f 23 (x) = (w23 )x + b23 Bukan Kelas 4 Bukan Kelas 2 f 24 (x) = (w24 )x + b24 Bukan Kelas 4 Bukan Kelas 3 f 34 (x) = (w34 )x + b34
Gambar 2. 4 Contoh 6 SVM biner dengan metode DAGSVM
2.5
Evaluasi Pengujian Sistem
Precision dan recall baik digunakan dalam mengevaluasi hasil dari suatu algoritma pengenalan pola. Precision adalah suatu ukuran keakuratan pola sedangkan recall adalah suatu ukuran kelengkapan (Dr. Kekre. HB, dkk, 2011) Precision pada dasarnya adalah sebuah ukuran dari pemerolehan dokumen yang relevan pada suatu pencarian.
Recall seperti yang disebutkan sebelumnya adalah ukuran suatu kelengkapan. Recall pada dasamya adalah probabilitas dari dokumen relevan yang dikembalikan dari suatu query. Pada binary classification, recall dapat juga disebut sensitivitas. Rumus perhitungan dari precision dan recall dapat dilihat sebagai berikut:
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = |{𝑑𝑜𝑘𝑢𝑚𝑒𝑛 𝑟𝑒𝑙𝑒𝑣𝑎𝑛} ∩ {𝑑𝑜𝑘𝑢𝑚𝑒𝑛 𝑑𝑖𝑝𝑒𝑟𝑜𝑙𝑒ℎ}| {𝑑𝑜𝑘𝑢𝑚𝑒𝑛 𝑑𝑖𝑝𝑒𝑟𝑜𝑙𝑒ℎ} (2. 7) 𝑟𝑒𝑐𝑎𝑙𝑙 = |{𝑑𝑜𝑘𝑢𝑚𝑒𝑛 𝑟𝑒𝑙𝑒𝑣𝑎𝑛} ∩ {𝑑𝑜𝑘𝑢𝑚𝑒𝑛 𝑑𝑖𝑝𝑒𝑟𝑜𝑙𝑒ℎ}| {𝑑𝑜𝑘𝑢𝑚𝑒𝑛 𝑟𝑒𝑙𝑒𝑣𝑎𝑛} (2. 8)
Dalam konteks klasifikasi, beberapa istilah seperti true positif (tp), false positif (fp, true negatif (tn) dan false negatif (fn) sering digunakan untuk membandingkan klasifikasi dari suatu objek dengan kelas yang sesungguhnya. perhitungan Precision dan recall bisasanya mengacu pada true positif dengan rumus perhitungan sebagai berikut :
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑡𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒 𝑡𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒 + 𝑓𝑎𝑙𝑠𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒 (2. 9) 𝑟𝑒𝑐𝑎𝑙𝑙 = 𝑡𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒 𝑡𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒 + 𝑓𝑎𝑙𝑠𝑒 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑒 (2. 10) 𝑎𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 𝑡𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒 𝑡𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒 + 𝑡𝑟𝑢𝑒 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑒 + 𝑓𝑎𝑙𝑠𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑓 + 𝑓𝑎𝑙𝑠𝑒 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑒 (2. 11)
25
BAB III
ANALISIS DAN DESAIN
Bab ini berisi analisis dan rancangan sistem yang digunakan dalam penelitian ini meliputi diskripsi sistem, data, penyimpanan data, struktur data, dari sistem.
3.1 Diskripsi sistem
Sistem yang dibangun merupakan sebuah sistem pemerolehan informasi, yang mempunyai fungsi untuk melakukan identifikasi makna kata sabar pada sebuah Karya Sastra Indonesia. Proses idenfikasi atau klasifikasi menggunakan metode Support Vector Machine (SVM) kenel
Polinomial.
Data yang digunakan berupa data yang berformat .txt, data tersebut dibagi menjadi dua bagian sebagai data test dan data trening. Kegunaan data traning sebagai sebuah data yang akan digunakan sebagai pembanding yang benar dimana pembandingnya adalah data test. Data traning merupakan data yang yang akan diklasifikasikan atau diproses dengan metode SVM kernel Polinomial. Sedang data test akan dibandingkan atau akan diuji dengan hasil dari data traning apakah data test tersebut dapat terklasifikasi dengan tepat atau tidak. Hasil akhirnya adalah berupa akurasi, hasil akurasi adalah perbandingan antara hasil data test yang sudah dianalisa dangan sistem dengan hasil data test sesuai dengan sumber. Dalam artian singkat apabila hasil dari sistem yang menguji data test dapat sama dengan hasil sumber makas sistem atau metode yang klasifikasi SVM kernel polinomial berhasil. Semua data yang akan diproses dengan sistem akan dilakukan
preprocessing dimana tahapan ini untuk memberikan bobot untuk setiap
kata yang akan diproses. Tahapannya adalah tokenisasi (pemenggalan kata dan penghapusan tanda baca), case folding (mengubah kata kedalam huruf kecil), stopword (penghapusan kata-kata yang tidak penting), stemming
(pengembalian kata ke bentuk dasar), dan menghitung tf (jumlah kemunculan kata yang sama dalam sebuah dokumen). Proses ini perlu dilakukan dikarena SVM menggunakan data yang memiliki nilai sedang kata tidak memiliki nilai sehingga pengganti nilai menggunakan bobot ini sama gunanya sebagai data yang memiliki nilai.
Gambar 3. 1 Skema Diskripsi Proses Klasifikasi SVM kernel Polinomial
Penghitungan akurasi melalui tahapan yang telah disediakan oleh
library WEKA. Metode yang digunakan dari WEKA menggunkan input
data yang telah diproses terdahulu oleh system.
3.2 Data
Dalam penelitian ini, sistem mengklasifikasikan makna kata sabar dalam karya sastra yang didefinisikan menggunakan metode SVM. Data diambil dari web corci.org sebagai data acuan dan data pendukung
penelitian ini. Data yang dipakai sebanyak 108 dokumen. Data ini dibagi menjadi data tranning dan data testing. Semua data disimpan dalam format .txt .
3.3 Penyimpanan Data
Media penyimpanan data yang digunakan berbentuk .txt , data yang disimpan hanya data yang akan dilakukan pengujian sedang proses hasil pengujian menggunakan arraylist tidak di simpan menggunakan .txt karena data hasil akan berbeda terus menerus setiap pengujia di ganti data uji. Data yang disimpan selain data uji .txt menyimpan kamus kata dasar dan juga stoplist.
3.3.1 Daftar media penyimpanan dalam .txt :
3.3.1.1 kata_dasar : Untuk menyimpan kata dasar dalam proses Stemming .
3.3.1.2 stopwordID : Digunakan dalam proses stopword ini berisi daftar dari apa saja kata yang tidak diijinkan keluar.
3.3.1.3 Bobot.txt : Menyimpan hasil dari bobot tiap term dan nama dokumen.
3.3.1.4 Term.txt : Menyimpan nama atribut yang dimiliki semua term yang ada.
3.3.2 Daftar media penyimpanan dalam arraylist :
3.3.2.1 ArrayList<Attribute> : Menyimpan data atribut 3.3.2.2 ArrayList<Prediction>: Menyimpan data hasil proses
akurasi SVM menggunkan WEKA
3.3.2.3 List<String> cls : Menyimpan data kategori yang digunakan
3.4 Pemetaan Data
Dalam proses pemetaan data ini merupakan proses yang dilakukan agar data siap diproses menggunakan sistem yang dibuat. Data akan diproses memalalui tahapan sebagai berikut ini :
3.2.1 Tokenizing
Sebuah proses untuk memberi tanda atau sekaligus menghilahkan tanda baca dalam sebuah artikel atau kalimat yang akan diproses.
Data sebelum proses :
“Hanya masalahnya sampai sekarang dia baru bisa memahami seorang perempuan saja namanya wanita yang sabar setiap bijaksana dan penuh kasih sayang.”
Data sesudah proses :
hanya masalahnya sampai sekarang dia baru bisa memahami perempuan saja namanya wanita yang sabar setia bijaksana penuh kasih sayang
3.2.2 Stopword Filtering
Adalah proses memerikasa kata yang seharusnya dihilangkan untuk efisiensi proses klasifikasi karena kata tersebut tidak banyak berpengaruh. Dafttar kata yang seharusnya dihilangkan disimpan dalam stopword list. Kata yang dapat dihilangkan misalnya adalah kata sambung yaitu : dan, yang, untuk , dsb
hanya masalahnya sampai sekarang baru bisa memahami perempuan nama wanita sabar setia bijaksana penuh kasih sayang
3.2.3 Stemming
Proses mengubah data yang sudah didapat dari token diubah menjadi bentuk kata dasarnya seperti dalam kamus besar bahasa indonesia
3.2.4 Computation of TF-IDF Feature
Tabel 3. 1 Tabel hasil dari TF-IDF dengan data sebenarnya
data tf baru 1 bijaksana 1 bisa 1 hanya 1 kasih 1 masalah 1 nama 1 paham 1 penuh 1 perempuan 1 sabar 1 sampai 1 sayang 1 sekarang 1 setia 1 wanita 1
Tabel 3. 2 Nilai w tiap term
Term tf DF IDF W 1 2 3 4 1 2 3 4 akan 2 1 0.60206 0 0 1.20412 0 akhir 2 1 0.60206 0 0 1.20412 0 antara 1 1 0.60206 0 0 0.60206 0 asih 1 1 0.60206 0 0.60206 0 0
hanya masalah sampai sekarang baru bisa nama paham perempuan wanita sabar setia bijaksana penuh kasih sayang
atap 1 1 0.60206 0 0.60206 0 0 bantal 1 1 0.60206 0 0 0.60206 0 baru 1 1 0.60206 0.60206 0 0 0 begini 1 1 0.60206 0 0 0 0.60206 benar 1 1 0.60206 0 0 0.60206 0 berpintu 1 1 0.60206 0 0.60206 0 0 bersih 1 1 0.60206 0 0.60206 0 0 biasa 2 1 0.60206 0 0 1.20412 0 bicara 1 1 0.60206 0 0 0.60206 0 bijaksana 1 1 0.60206 0.60206 0 0 0 bisa 1 4 2 0.30103 0.30103 0 1.20412 0 cinta 1 1 0.60206 0 0.60206 0 0 dengan 1 1 0.60206 0 0 0.60206 0 3.5 Mengunakan sistem
Dalam sistem yang dibuat oleh penulis menggunkan libary dari WEKA, di istem yang dibuat mengubah data input yang bisasanya digunakan oleh WEKA mengunakan format .csv menjadi format .txt. Dalam sistem yang dibuat data masukan akan dibuat menjadi dua .txt, yang satu berfungsi sebagai inisia term atau daftar kata unik sedang yang kedua sebagai informasi dari bobot tiap term di setiap dokumen yang ada.
Langkah pertama dalam membuat data inputan yaitu menggunakan proses preprosesing untuk mendapatkan term yang akan dimasukan kedalam .txt yang pertama yang digunakan dalam inisial term , selanjutnya sistem akan memproses nilai bobot atau w dari semua term yang didapat dari semua dokumen.
Setelah itu dilakukan proses sistem untuk menghitung akurasi yang sudah tersedia didalam libary WEKA. Penyesuai inputan kedalam proses ini mengunkan format yang sudah disesuaikan sehingga bisa diproses dengan sistem libary dari WEKA.
3.6 Struktur data
Struktur data dalam sistem akan memisahkan data yang termasuk treaning dan testing.
Gambar 3. 2 Struktur Data 3.7 Desain Logikal (Logical Design)
3.4.1 DFD level 0
3.4.2 Desain Proses PI (Pemerolehan Informasi)
3.4.3 Desain Proses SVM kernel Polinomial
Gambar 3. 5 Diagram Alir Mengunkan sistem
BAB IV
IMPLEMENTASI SISTEM
4.1 Kebutuhan Perancangan Sistem
Kebutuhan dalam mengimplementasikan sistem pendukung pengambilan keputusan pemilihan penerima beasiswa ini adalah :
4.1.1 Hardware
1. Procesor : Intel Core i3-4210U 1.7Ghz 2. Memori : 4 GB
3. Graphic Card : Nvidia GeForce 610M 2GB 4. Storage : 500GB
4.1.2 Software
1. IDE Netbeans 7.4
Sebagai IDE (Integrated Development Environment) untuk membuat atau mengembangkan perangkat lunak (software).
4.2 Implementasi Prepocessing Kalimat
Proses ini berfungsi untuk membantu proses dalam membaca dokumen dan juga sekaligus memproses dokumen menjadi data yang siap di klasifikasikan.
4.2.1 Class Master
Berfungsi sebagai fungsi untuk menyimpan dokumen yang sudah diproses dalam proses kata dasar dan pembatasan kata yang tidak diperlukan.
public class Master { List<Kelas> classes; List<Dokumen> documents; String stem, stopword; Set<String> terms; Dokumen testDoc;
public Dokumen getTestDoc() { return testDoc; }
public void setTestDoc(Dokumen testDoc) { this.testDoc = testDoc; d : documents) { d.setFileKamusStemWord(stem); } }
public String getStopword() { return stopword;
}
public String getStem() { return stem;
}
public void setStem(String stem) { this.stem = stem;
for (Dokumen d : documents) { d.setFileKamusStemWord(stem); }
}
public String getStopword() { return stopword;
}
public void setStopword(String stopword) { this.stopword = stopword;
for (Dokumen d : documents) {
d.setFileKamusStopWord(stopword); }
}
public void preprocess() { terms = new HashSet<>(); for (Dokumen d : documents) { d.Preprocessing();
terms.addAll(d.daftarKata); }
Map<String, Integer> tf = new HashMap<>(); for (final String term : terms) {
int freq = tf.containsKey(term) ? tf.get(term) : 0; for (Dokumen doc : documents) {
freq += Collections2.filter(doc.daftarKata, new Predicate<String>() {
@Override
public boolean apply(String input) { return term.equals(input); } }).size(); } tf.put(term, freq); } double f = 0;
for (Integer freq : tf.values()) { f += freq.doubleValue(); }
}
public Master(String path) {
File[] files = new File(path).listFiles(); documents = new ArrayList<>(files.length); classes = new ArrayList<>(files.length); for (File file : files) {
if (file.isDirectory()) { Kelas kelas = new Kelas(); kelas.setNama(file.getName()); classes.add(kelas);
4.2.2 Class Kelas
Memberi nama dalam setiap dokumen yang diambil sesuai dengan label.
File[] files = new File(path).listFiles(); documents = new ArrayList<>(files.length); classes = new ArrayList<>(files.length); for (File file : files) {
if (file.isDirectory()) { Kelas kelas = new Kelas(); kelas.setNama(file.getName()); classes.add(kelas);
File[] files2 = file.listFiles(); for (File file1 : files2) {
Dokumen doc = new Dokumen(file1); kelas.addDokumen(doc); documents.add(doc); } } else { documents.add(new Dokumen(file)); } } }
public Kelas getKelas(Dokumen d) { for (Kelas kelas : classes) {
if (kelas.getDaftarDokumen().contains(d)) { return kelas; } } return null; } }
List Code 4. 1 Class Master
public class Kelas { private String nama;
private List<Dokumen> daftarDokumen; public Kelas() {
daftarDokumen = new ArrayList<>(); }
public void setNama(String name) { nama = name;
}
public List<Dokumen> getDaftarDokumen() { return daftarDokumen;
}
public void addDokumen(Dokumen dokumen) { daftarDokumen.add(dokumen);
}
4.2.3 Class Dokumen
public void addDokumen(Dokumen dokumen) { daftarDokumen.add(dokumen);
}
public String getNama() { return nama;
} }
List Code 4. 2 Class Kelas
public class Dokumen {
List<String> kamusStopWord; Set<String> kamusKataDasar; String filename;
List<String> daftarKata;
private boolean tokenized, removedStopWords, stemmed; private String fileKamusStopWord, fileKamusStemWord; public String getFileKamusStopWord() {
return fileKamusStopWord; }
public void setFileKamusStopWord(String fileKamusStopWord) { this.fileKamusStopWord = fileKamusStopWord;
}
public String getFileKamusStemWord() { return fileKamusStemWord;
}
public void setFileKamusStemWord(String fileKamusStemWord) { this.fileKamusStemWord = fileKamusStemWord;
}
public Iterator<String> iterator() { return daftarKata.iterator(); }
public int size() {
return daftarKata.size(); }
public Dokumen(File file) { this(file.getPath()); }
public Dokumen(String path) { daftarKata = new ArrayList<>(); filename = path;
}
public void Tokenize() { if (tokenized) {
public Dokumen(String path) { daftarKata = new ArrayList<>(); filename = path;
}
public void Tokenize() { if (tokenized) { return; } try {
FileInputStream fis = new FileInputStream(filename); Scanner s = new Scanner(fis);
if (daftarKata == null) {
daftarKata = new ArrayList<>(); } else {
daftarKata.clear(); }
while (s.hasNext()) { String text = s.next();
String kata = text.replaceAll("[^a-zA-Z&&[^\\-]]", ""); //token.nextToken();
daftarKata.add(kata); }
tokenized = true;
} catch (FileNotFoundException ex) { tokenized = false;
Logger.getLogger(Dokumen.class.getName()).log(Level.SEVERE, null, ex);
} }
public void bacakamus(String path) { try {
FileInputStream fis = new FileInputStream(path); Scanner s = new Scanner(fis);
kamusKataDasar = new HashSet<>(); while (s.hasNext()) {
kamusKataDasar.add(s.next()); }
} catch (FileNotFoundException ex) {
Logger.getLogger(Tampilstopword.class.getName()).log(Level.SEVERE, null, ex);
} }
public void bacakamusstopword(String filename) { try {
FileInputStream FIS = new FileInputStream(filename); Scanner sc = new Scanner(FIS);
kamusStopWord = new ArrayList<>(); while (sc.hasNext()) {
kamusStopWord.add(sc.next()); }
} catch (FileNotFoundException ex) {
Logger.getLogger(Tampilstopword.class.getName()).log(Level.SEVERE, null, ex);
kamusStopWord = new ArrayList<>(); while (sc.hasNext()) {
kamusStopWord.add(sc.next()); }
} catch (FileNotFoundException ex) {
Logger.getLogger(Tampilstopword.class.getName()).log(Level.SEVERE, null, ex);
} }
public void hapusstopword() { if (removedStopWords) { return;
}
if (kamusStopWord == null) {
throw new IllegalStateException("Kamus stopword belum ada"); }
if (!tokenized) {
throw new IllegalStateException("Dokumen belum di-tokenize"); }
Iterator<String> i = daftarKata.iterator(); while (i.hasNext()) {
String token = i.next();
if (kamusStopWord.contains(token)) { i.remove(); } } removedStopWords = true; }
public void stem() { if (stemmed) { return; }
if (kamusKataDasar == null || kamusKataDasar.isEmpty()) { throw new IllegalStateException("Kamus kata dasar belum ada"); }
if (!removedStopWords) {
throw new IllegalStateException("Stopwords belum dibuang"); }
Lemmatizer stemmer = new DefaultLemmatizer(kamusKataDasar); for (int i = 0; i < daftarKata.size(); i++) {
String kata = daftarKata.get(i);
daftarKata.set(i, stemmer.lemmatize(kata)); }
stemmed = true; }
public void Preprocessing() { Tokenize(); bacakamusstopword(fileKamusStopWord); hapusstopword(); bacakamus(fileKamusStemWord); stem(); } }
4.2.4 Class Stopword
Berfungsi untuk memanggil kamus stopword bila belum tersedia sekaligus memproses dalam tahapan stopword.
bacakamusstopword(fileKamusStopWord); hapusstopword(); bacakamus(fileKamusStemWord); stem(); } }
List Code 4. 3 Class Dokumen
public class Tampilstopword {
public static void main(String[] args) { JFileChooser path = new JFileChooser();
FileFilter filter = (new FileNameExtensionFilter("Text files (*.txt)", "txt"));
path.addChoosableFileFilter(filter); path.setFileFilter(filter);
int result = path.showOpenDialog(null);
if (result == JFileChooser.APPROVE_OPTION) { File file = path.getSelectedFile();
Dokumen dok = new Dokumen(file); result = path.showOpenDialog(null); if (result == JFileChooser.APPROVE_OPTION) { dok.setFileKamusStopWord(path.getSelectedFile().getPath()); result = path.showOpenDialog(null); if (result == JFileChooser.APPROVE_OPTION) { dok.setFileKamusStemWord(path.getSelectedFile().getPath()); dok.Preprocessing(); System.out.println(dok.daftarKata); } } } }
public static List<String> Tokenize(String Teks) { StringTokenizer token = new
StringTokenizer(Teks.toString().toLowerCase(), " .,()?!-_+:;/*&^%$#@!~[]{}=()");
return Collections.list((Enumeration) token); }
public static List<String> bacakamusstopword(String filename) { try {
FileInputStream FIS = new FileInputStream(filename); Scanner sc = new Scanner(FIS);
List<String> hasil = new ArrayList<>(); while (sc.hasNext()) {
try {
FileInputStream FIS = new FileInputStream(filename); Scanner sc = new Scanner(FIS);
List<String> hasil = new ArrayList<>(); while (sc.hasNext()) {
hasil.add(sc.next()); }
return hasil;
} catch (FileNotFoundException ex) {
Logger.getLogger(Tampilstopword.class.getName()).log(Level.SEV ERE, null, ex);
return null; }
}
public static List<String> hapusstopword(List<String> hasiltoken, List<String> stopwords) {
List<String> hasilstopword = new ArrayList<>(hasiltoken); Iterator<String> i = hasilstopword.iterator();
while (i.hasNext()) { String token = i.next();
if (stopwords.contains(token)) { i.remove(); } } return hasilstopword; }
public static Set<String> bacakamus() { JFileChooser path = new JFileChooser(); int result = path.showOpenDialog(null);
if (result == JFileChooser.APPROVE_OPTION) { File filename = path.getSelectedFile();
FileInputStream fis = null; try {
fis = new FileInputStream(filename); } catch (FileNotFoundException ex) {
Logger.getLogger(Tampilstopword.class.getName()).log(Level.SEV ERE, null, ex);
}
Scanner s = new Scanner(fis);
Set<String> hasil = new HashSet<>(); while (s.hasNext()) { hasil.add(s.next()); } return hasil; } return null; }
public static List<String> stem(Dokumen Dokumen, Set<String> kamus) {
4.2.5 Class Mencari Bobot
Pemprosesan sebuah sistem untuk menentukan bobot di setiap
term yang didapat.
}
return hasil; }
return null; }
public static List<String> stem(Dokumen Dokumen, Set<String> kamus) {
Lemmatizer stemmer = new DefaultLemmatizer(kamus); List<String> hasil = new ArrayList<>(Dokumen.size()); for (String kata : Dokumen.daftarKata) {
hasil.add(stemmer.lemmatize(kata)); }
return hasil; }
}
List Code 4. 4 Class Tampil stopword
public class Mencari_bobot {
public static double dotproduct(double[] i, double[] j) { if (i.length != j.length) {
throw new IllegalArgumentException(); }
double hasil = 0;
for (int k = 0; k < i.length; k++) { hasil += i[k] * j[k];
}
return hasil; }
static class TermDocumentPair { public String term;
public Dokumen doc;
TermDocumentPair(String term, Dokumen doc) { this.term = term;
this.doc = doc; } }
private Set<String> allTerms;
private Map<TermDocumentPair, Integer> tableTF; private Map<String, Integer> tableDF;
private Master master; private Dokumen docTest; public Dokumen getDocTest() { return docTest;
}
public void setDocTest(Dokumen docTest) { this.docTest = docTest;
private Dokumen docTest; public Dokumen getDocTest() { return docTest;
}
public void setDocTest(Dokumen docTest) { this.docTest = docTest;
}
public Mencari_bobot(Master m) { master = m;
allTerms = m.terms;
int size = allTerms.size() * m.documents.size(); tableTF = new HashMap<>(size);
tableDF = new HashMap<>(size); docTest = m.getTestDoc(); }
public int getTermFrequency(String term, Dokumen doc) { TermDocumentPair key = new TermDocumentPair(term, doc); if (tableTF.containsKey(key)) {
return tableTF.get(key); } else {
int count = 0;
for (String kata : doc.daftarKata) { if (kata.equals(term)) { count++; } } tableTF.put(key, count); return count; } }
public int getDocumentFrequency(String term) { if (tableDF.containsKey(term)) {
return tableDF.get(term); } else {
int c = 0;
for (Dokumen d : master.documents) { if (d.daftarKata.contains(term)) { c++; } } tableDF.put(term, c); return c; } } //idf
private double idf1(String term) {
return Math.log(master.documents.size() / getDocumentFrequency(term));
}
private double idf2(String term) {
return 1d / (double) getDocumentFrequency(term); }
private double idf1(String term) {
return Math.log(master.documents.size() / getDocumentFrequency(term));
}
private double idf2(String term) {
return 1d / (double) getDocumentFrequency(term); }
private double idf3(String term) {
return Math.log(1000 / getDocumentFrequency(term)); }
public double getInverseDocumentFrequency(String term, int metode) { switch (metode) { case 1: return idf1(term); case 2: return idf2(term); case 3: return idf3(term); default:
throw new IllegalArgumentException(); }
} //bobot
public double getWeight(String term, Dokumen doc) { return getTermFrequency(term, doc) *
getInverseDocumentFrequency(term,1); }
public double getInnerProduct(String term, Dokumen doc) { return getWeight(term, doc) * getWeight(term, docTest); }