Truecasing untuk Teks Bahasa Indonesia
Said Al Faraby dan Ade Romadhony
Fakultas Informatika
Universitas Telkom
Indonesia
{saidalfaraby,aderomadhony}@telkomuniversity.ac.id
Abstrak
Penggunaan huruf besar pada dokumen teks mengandung informasi penting tentang mak-na dari kata-kata yang terdapat di dalam dokumen tersebut. Kesalahan penulisan atau tidak adanya penanda huruf besar dapat men-imbulkan efek pada pemrosesan teks selan-jutnya. Sementara itu terdapat beberapa kon-disi di mana penulisan huruf besar tidak ditemui atau tidak dilakukan dengan tepat, antara lain pada teks informal dan teks tran-skrip berita. Truecasing adalah pekerjaan un-tuk memberikan penandaan huruf besar pada teks yang tidak mengandung informasi atau
mempunyai banyak kesalahan dalam
penggunaan huruf besar. Dengan diterap-kannya truecasing, kualitas dokumen teks akan meningkat karena akan dihasilkan data yang lebih bersih. Makalah ini memaparkan tentang truecasing untuk dokumen teks baha-sa Indonesia yang diimplementasikan dengan metode HMM.
1 Pendahuluan
Pemrosesan dokumen teks sangat bergantung pada kualitas perangkat pemroses bahasa yang digunakan. Perangkat pemroses bahasa umumnya mensyaratkan kondisi bahwa teks yang diproses adalah teks yang dituliskan dalam bentuk formal. Terdapat dua ke-lompok umum metode yang digunakan dalam perangkat pemroses bahasa, yaitu berbasis aturan dan berbasis pembelajaran atau statistika. Syarat bentuk dokumen formal tersebut disebabkan koleksi doku-men yang digunakan sebagai sumber pembelajaran mayoritas adalah dokumen formal. Oleh karena itu, ketidaksesuaian dalam aturan penulisan dapat me-nyebabkan kesalahan hasil pemrosesan perangkat pemroses bahasa.
Di sisi lain, dengan semakin berkembangnya media untuk menyebarkan informasi, semakin beragam pula gaya penulisan. Efek yang ditimbulkan antara lain adalah teks yang tidak bersih, misalnya penggunaan huruf besar yang tidak tepat. Sementara penggunaan
huruf besar pada suatu kata dapat menjadi fitur pent-ing dalam pekerjaan pemroses bahasa. Sebagai contoh pada pekerjaan Named Entity Recognition (NER). Pada pekerjaan NER, salah satu fitur penting adalah penggunaan huruf besar, karena menandakan bahwa kata yang dituliskan diawali atau seluruhnya menggunakan huruf besar adalah sebuah entitas pent-ing. Jika penggunaan huruf besar dalam teks tidak tepat, dapat menyebabkan perangkat untuk NER tidak menghasilkan keluaran yang benar.
Kasus lain di mana tidak terdapat informasi tentang penggunaan huruf besar adalah pada dokumen tran-skrip yang merupakan keluaran dari perangkat pem-roses suara dan mesin penerjemah. Perangkat pemros-es suara umumnya mengeluarkan teks dalam format huruf besar semua atau huruf kecil semua. Tentu saja kondisi tersebut menyebabkan perlunya pemrosesan lebih lanjut untuk menuliskan teks keluaran dengan informasi huruf besar yang tepat, seperti dilakukan oleh (Liang & Wu, 2003) dan (Tan & Bond, 2014). Berdasar latar belakang tersebut, dalam makalah ini diusulkan sebuah perangkat untuk menerapkan penggunaan huruf besar yang tepat dalam teks bahasa Indonesia. Penelitian sebelumnya tentang truecasing lebih banyak ditemui untuk diterapkan pada bahasa Inggris. Pada bahasa yang berbeda tentu aturan yang digunakan juga berbeda. Pekerjaan lain yang berhub-ungan erat dengan truecasing adalah pendeteksian ambiguitas pada kata, disambiguitas sense pada kata, dan spelling correction.
Sistem truecasing untuk bahasa Inggris antara lain dibahas pada (Lita, Ittycheriah, Roukos, & Kambhatla, 2003), diimplementasikan sebagai sebuah fasilitas anotasi pada perangkat Stanford NLP (Manning et al., 2014), serta truecaser khusus untuk media sosial (Nebhi, Bontcheva, & Gorrell, 2015). Pada penelitian (Lita et al., 2003), truecaser dibangun dengan pendefinisian model bahasa serta menggunakan metode HMM. Sementara pada perangkat Stanford NLP anotasi truecase diimple-mentasikan dengan metode CRF.
Persoalan truecasing diartikan sebagai proses restorasi penggunaan huruf besar yang benar pada kata dalam kalimat. Persoalan tersebut dipandang
sebagai persoalan sequence labeling atau klasifikasi. Oleh karena itu beberapa sistem truecaser menggunakan metode untuk sequence labeling seperti halnya HMM dan CRF, atau SVM untuk me-nyelesaikan persoalan klasifikasi.
Contoh pengaruh penggunaan huruf besar yang tidak tepat dalam pemrosesan teks untuk pekerjaan lain seperti pengenalan Named Entity dapat dilihat pada Gambar I. Pengenalan Named Entity dilakukan dengan perangkat Stanford CoreNLP1. Pada contoh tersebut, teks transkrip yang dituliskan dalam huruf besar semua menyebabkan pengenalan Named Entity tidak tepat. Terdapat Named Entity Organization yang tidak dapat dikenali, dan Named Entity Location yang salah dikenali sebagai Person. Jika teks tersebut dimodifikasi sehingga huruf besar digunakan secara tepat, semua Named Entity dapat dikenali dengan te-pat pula.
Mengenai truecasing untuk teks bahasa Indonesia sendiri sejauh ini belum ditemui penelitian sejenis. Begitu juga dengan efek yang ditimbulkan pada pekerjaan lainnya jika huruf besar tidak digunakan secara tepat. Sejauh ini hanya ditemui sistem NER bahasa Indonesia (InNER) (Budi, Bressan, Wahyudi, Hasibuan, & Nazief, 2005), namun tidak ditemukan penjelasan khusus tentang penggunaan fitur huruf besar.
2 Aturan Penggunaan Huruf Besar
Ba-hasa Indonesia
Bahasa Indonesia mempunyai aturan tersendiri dalam penggunaan huruf besar dalam teks. Aturan tersebut didefinisikan dalam Ejaan Yang Disempurnakan (EYD)2. Berdasarkan posisinya dalam kalimat, huruf besar digunakan pada awal kalimat dan pada awal kalimat setelah petikan langsung. Contoh penggunaan pada awal kalimat setelah petikan langsung adalah sebagai berikut: Ia menanyakan “Ada apa di dalam
sana ?”.
1 http://nlp.stanford.edu:8080/corenlp
2 http://www.balaibahasa.com/penulisan-huruf-kapital.html
Selain berdasarkan pada posisi, penggunaan huruf besar juga diterapkan pada kata-kata tertentu, yaitu: Kata dan ungkapan yang berhubungan dengan
agama, kitab suci, dan Tuhan, termasuk kata ganti untuk Tuhan.
Unsur-unsur nama orang
Nama bangsa, suku bangsa, dan bahasa Nama tahun, bulan, hari, dan hari raya Unsur-unsur nama peristiwa sejarah Unsur-unsur nama diri geografi
Unsur nama resmi negara, lembaga resmi, lem-baga ketatanegaraan, badan, dan nama dokumen resmi
Semua kata di dalam judul buku, majalah, surat kabar, dan makalah, kecuali kata tugas
Kata Anda yang digunakan dalam penyapaan Terdapat pula beberapa kondisi penggunaan huruf besar dengan syarat tertentu, yaitu bergantung pada kata setelahnya. Berikut adalah kondisi penggunaan huruf besar yang bergantung pada kata setelahnya: Huruf pertama nama gelar kehormatan,
ke-turunan, dan keagamaan yang diikuti nama orang. Nama jabatan dan pangkat yang merujuk kepada nama orang, nama instansi, atau nama tempat ter-tentu.
Huruf besar tidak dipakai sebagai huruf pertama nama diri geografi yang digunakan sebagai pen-jelas nama jenis.
Huruf besar tidak dipakai sebagai huruf pertama kata yang bukan nama resmi negara, lembaga resmi, lembaga ketatanegaraan, badan, dan nama dokumen resmi.
3 Deskripsi Sistem
Berdasarkan aturan penggunaan huruf besar bahasa Indonesia sesuai dengan EYD, dilakukan perancangan sistem untuk truecaser bahasa Indonesia. Persoalan
truecasing dipandang sebagai persoalan sequence labeling. Jenis label penggunaan huruf besar dalam
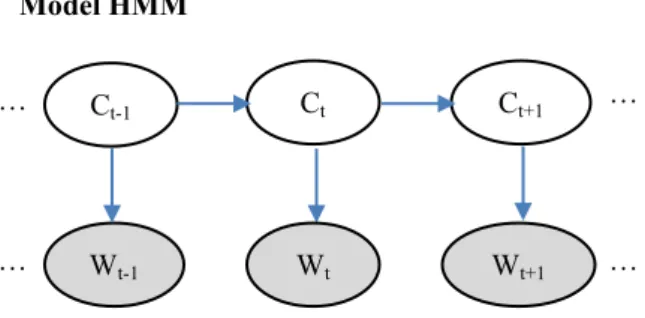
… Ct-1 Ct Ct+1 Wt Wt+1 Wt-1 … … …
Gambar 2 Representasi grafis HMM, dimana C ada-lah hidden variable dan W adaada-lah observable variable. kata dibagi menjadi empat kelas, yaitu: semua huruf dituliskan dalam huruf kecil (LC), huruf awal kata adalah huruf besar (UC), semua huruf dalam kata ada-lah huruf besar (AC), kata dituliskan dalam huruf be-sar dan kecil/campuran (MC).
Metode yang digunakan adalah Hidden Markov
Mod-el (HMM) karena merupakan salah satu metode
han-dal han-dalam persoalan sequence labeling (Nguyen & Guo, 2007). Fitur yang digunakan adalah:
Current word Previous word Next word
Fitur previous word digunakan untuk memberikan konteks pada current word, misalnya kata „terserah‟ di tengah kalimat biasanya dilabeli LC, namun jika
previous word-nya adalah „restoran‟ maka bisa jadi
„terserah‟ adalah nama restoran sehingga harus dila-beli UC. Begitu juga dengan fitur next word, digunakan karena berdasar aturan EYD tentang penggunaan huruf besar, terdapat beberapa poin aturan yang mensyaratkan kondisi kata setelahnya.
Model HMM
HMM adalah sebuah generative model yang secara natural biasa digunakan untuk permasalahan sequence
labeling (Rabiner, 1989). Ilustrasi generative process
dari HMM dapat dilihat pada Gambar 2.
Secara formal HMM adalah sebuah generative model yang didefinisikan melalui komponen berikut : 1. C : Hidden states dalam HMM. Untuk
permasa-lahan true casing S terdiri dari jenis casing yang mungkin, yaitu LC, CA, UC, MC.
2. W : Himpunan observations. Dalam hal ini W adalah token (kata) yang ada dalam pembelajaran set. Untuk Unknown token bias dihandle secara terpisah untuk menghindari zero probability. 3. T : State transition probabilities. Probabilitas
perpindahan antara suatu hidden state ke hidden state yang lain. mengindikasikan probabilitas
case akan diikuti oleh case dalam suatu ka-limat. Probabilitas ini didapatkan dari proses
pembelajaran HMM menggunakan data pembela-jaran.
4. E : Emission probabilities. merepresentasikan probabilitas munculnya observasi jika HMM sedang berada di state .
5. P(C) : Initial distribution. menyatakan probabilitas sekuens dimulai dengan casing Jika diberikan sebuah sekuen kata dengan panjang , maka tugas HMM adalah mencari sekuen hidden
states, yang dalam hal ini sekuen jenis case, yang
paling memungkinkan menghasilkan sekuen kata ter-sebut.
4 Eksperimen
Dataset yang digunakan pada eksperimen adalah artikel berita yang diperoleh dari media Kompas
online2. Penggunaan artikel berita surat kabar online sebagai sumber dataset berdasar asumsi bahwa penu-lisan teks telah mengikuti aturan EYD. Jumlah total artikel adalah 7525. Untuk baseline, dengan menga-dopsi metode pada penelitian sebelumnya (Lita et al., 2003), digunakan pendefinisian label penggunaan huruf besar berdasar peluang kemunculan terbesar. Terdapat dua skenario pengujian yang dilakukan, yai-tu skenario dengan data uji tanpa unknown words dan data uji dengan unknown words. Pada skenario per-tama, kasus yang muncul adalah pemberian label hu-ruf besar pada kata-kata yang mempunyai kemung-kinan dituliskan dengan cara yang berbeda. Misalnya kata “presiden” dapat dituliskan dengan diawali huruf besar, atau dengan huruf kecil semua. Sementara pada skenario kedua, akan diamati bagaimana performansi sistem dalam menangani kata-kata yang tidak muncul dalam data pembelajaran.
Pada skenario I, jumlah total artikel yang digunakan pada data pembelajaran untuk skenario pertama ada-lah 7255 artikel. Sejumada-lah 80% digunakan untuk proses pembelajaran dan 20% untuk data uji. Pada data pembelajaran, terdapat 3991 kata unik, dan 471 kata yang mempunyai variasi penggunaan huruf besar > 1. Variasi yang dijumpai hanya berupa kata ditulis-kan dalam huruf kecil semua atau diawali dengan huruf besar ( 2 variasi). Skenario II menggunakan data pembelajaran yang sama dengan Skenario I, na-mun untuk data uji terdapat 9 artikel dengan yang mengandung 845 unknown words.
Pada eksperimen yang telah dilakukan, dikembangkan 3 buah Model :
Unigram Model sebagai baseline
2 http://kompas.com
HMM1 Model, yaitu HMM dengan fitur/observasi hanya berupa current word,
HMM2 Model, yaitu HMM dengan
fitur/observasi previous word, current word, dan
next word.
Pengukuran performansi sistem dilakukan
menggunakan metriks precision, recall, dan
F-measure.
Untuk Matrik F-AVG dihitung dengan mempertim-bangkan persentase jumlah token tiap case, sehingga
Hasil eksperimen untuk skenario I dan II terdapat pada Tabel 1 dan Tabel 2. Untuk skenario I dimana tidak terdapat unknown words pada data uji, HMM1 dengan fitur hanya berupa current word lebih baik dari pada dua metode lainnya. HMM1 berhasil me-maksimalkan performansi pada label LC dan UC yang memberikan kontribusi terbesar pada data uji. Sedikit menarik bahwa HMM2 dengan fitur yang lebih kom-pleks menunjukkan performa yang sedikit inferior dibanding HMM1. Hal ini menunjukkan bahwa untuk data uji yang memiliki tingkat kesamaan kata yang tinggi (e.g tanpa unknown words), current word dan
case/label pada kata sebelumnya (implisit dari cara
kerja HMM), sudah cukup untuk melakukan prediksi. Untuk skenario II, dimana terdapat ±30% unknown
words, HMM2 memiliki F-AVG terbaik. Walaupun
nilai F1(LC) HMM2 sedikit lebih kecil dibanding
Unigram, namun HMM2 secara signifikan
mengungguli Unigram pada semua komponen UC yang memiliki kontribusi kedua terbesar pada data uji. Hal inilah yang pada akhirnya membuat HMM2 secara F-AVG lebih baik dibanding Unigram. Bisa dikatakan bahwa pada data uji yang memiliki banyak
unknown words, fitur tambahan seperti next word dan previous word lebih dibutuhkan untuk melakukan
prediksi yang lebih baik.
5 Pengembangan Selanjutnya
Berdasarkan hasil performansi eksperimen, terlihat bahwa sistem masih mempunyai kelemahan dalam menangani unknown words. Hal ini membuka peluang untuk pengembangan berupa penanganan kasus
known words. Metode lain yang dapat diterapkan
un-tuk persoalan pelabelan seperti klasifikasi dengan SVM dan sequence labeling dengan CRF juga dapat dikaji. Batasan dalam eksperimen berupa diabaikann-ya tanda baca juga membuat kasus penggunaan huruf besar dalam kalimat langsung belum dapat ditangani. Peluang pengembangan selanjutnya adalah penerapan
truecaser untuk pekerjaan lain seperti pengenalan Named Entity, ekstraksi informasi, dan mesin
pen-erjemah. Perkembangan pada media sosial juga mem-buat metode yang diterapkan pada teks dengan tata bahasa formal kemungkinan tidak sesuai jika diterap-kan pada teks informal. Perlu kajian lebih lanjut untuk
truecaser pada teks informal atau media sosial.
Referensi
Budi, I., Bressan, S., Wahyudi, G., Hasibuan, Z. A., & Nazief, B. A. (2005). Named entity recognition for the indonesian language: combining contextual, morphological and part-of-speech features into a knowledge engineering approach. Discovery Science (pp. 57–69). Springer. Liang, Y.-T., & Wu, J.-C. (2003). Restoration of Case Information
in All-Cap English Broadcast Transcription. ROCLING. Lita, L. V., Ittycheriah, A., Roukos, S., & Kambhatla, N. (2003).
Truecasing. Proceedings of the 41st Annual Meeting on Association for Computational Linguistics-Volume 1 (pp. 152–159). Association for Computational Linguistics. Model LC (76.43%) UC (18.89%) MC (3.77%) CA (0.19%) AVG F-P R F1 P R F1 P R F1 P R F1 Unig .8313 .9746 .8973 .7107 .2612 .382 1.0 .7944 .8854 1.0 0.5 .6667 .7926 HMM1 .8959 .8571 .8761 .7087 .3041 .4256 .188 .9065 .3114 .8235 .5385 .6512 .7629 HMM2 .9524 .8308 .8875 .7379 .541 .6243 .196 .9065 .3223 .2241 0.5 .3095 .8089
Tabel 2 Performansi tiap model dalam Precision, Recall, dan F-measure pada data uji untuk skenario II Model P LC (76.43%) R F1 P UC (18.89%) R F1 P MC (3.77%) R F1 P CA (0.19%) R F1 AVG
F-Unig .928 .9786 .9526 .9174 .7591 .8308 1.0 .9974 .9987 1.0 .9936 .9968 .9245
HMM1 .9862 .9904 .9883 .9582 .9393 .9486 .9955 .9989 .9972 .9921 .9964 .9943 .9740
HMM2 .9826 .9801 .9813 .9368 .9422 .9395 .9865 .9978 .9921 1.0 .9965 .9982 .9668
Manning, C. D., Surdeanu, M., Bauer, J., Finkel, J., Bethard, S. J., & McClosky, D. (2014). The Stanford CoreNLP natural language processing toolkit. Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations (pp. 55–60). Nebhi, K., Bontcheva, K., & Gorrell, G. (2015). ResToRinG
CaPitaLiZaTion in# TweeTs. Proceedings of the 24th International Conference on World Wide Web Companion (pp. 1111–1115). International World Wide Web Conferences Steering Committee.
Nguyen, N., & Guo, Y. (2007). Comparisons of sequence labeling algorithms and extensions. Proceedings of the 24th international conference on Machine learning (pp. 681– 688). ACM.
Rabiner, L. R. (1989). A tutorial on hidden Markov models and selected applications in speech recognition. Proceedings of the IEEE, 77(2), 257–286. IEEE.
Tan, L., & Bond, F. (2014). Manipulating Input Data in Machine Translation. Proceedings of the 1st Workshop on Asian Translation (WAT2014).