Klasifikasi Emosi Untuk Teks Bahasa Indonesia Menggunakan
Metode Naive Bayes
I. Destuardi
1*, Surya Sumpeno
2Jurusan Teknik Elektro, Institut Teknologi Sepuluh Nopember (ITS), Surabaya, Indonesia* Email : [email protected]
Jurusan Teknik Elektro, Institut Teknologi Sepuluh Nopember (ITS), Surabaya, Indonesia2
Abstrak
Komunikasi dapat dilakukan dari informasi verbal dan non-verbal, verbal dapat berupa tulisan yang diperoleh dari kata, kalimat, paragraf dan sebagainya untuk penggalian informasi teksnya menggunakan klaisifikasi teks. Pada proses klasifikasi itu akan digunakan data set yang telah diketahui kelas emosinya yaitu jijik, malu, marah, sedih, senang, dan takut dengan menggunakan metode Naïve Bayes dan Naïve Bayes Multinomial. Akan dilihat sejauh mana kedua metode itu dapat mengklasifikasikan data emosi berbahasa indonesia. Hasil percobaan menunjukkan dengan metode Naive Bayes Multinomial mampu mengenali dokumen dengan tingkat akurasi 61.57% dengan rasio data 0.6 dengan melakukan perlakuan berbeda pada preprosessing data
Katakunci: klasifikasi teks, emosi, model multinomial, naïve bayes.
1. Pendahuluan
Kemunculan teknologi agen cerdas menyadarkan telah ada peluang untuk mengembangkan antarmuka sebagai perbaikan model interaksi antara manusia dan komputer; simulasi karakter virtual untuk aplikasi berbeda seperti hiburan, pendidikan dan sebagainya. Karakter yang hidup dipercaya dapat meningkatkan ketertarikan pada game komputer. Dewasa ini interaksi antara manusia dan komputer telah dilakukan melalui text, mouse atau keyboard bersamaan dengan cepatnya perkembangan komputer grafis dan teknologi pengenalan wicara membuat interaksi lebih adaptif, fleksibel dan berorientasi manusia [1]
Agen lama digagas dan lebih dari dua dekade, agen adalah segala tanggapan terhadap lingkungan melalui sensor dan bertindak sesuai lingkungan tersebut sebagai efeknya. Agen membutuhkan input dan output, input dapat berupa kamera, microphone sedangkan output hampir sama dengan manusia berupa suara atau gerakan isyarat [2].
Sebuah agen dapat dikatakan cerdas jika dilengkapi dengan emosi [3], sehingga agen perlu ditambahkan emosi. Komunikasi dapat dilakukan dari informasi verbal dan non-verbal, verbal dapat berupa tulisan yang diperoleh dari kata, kalimat, paragraf dan sebagainya. Non-verbal dapat sebuah isyarat tubuh [4] dalam beberapa studi tentang emosi dan interaksi manusia dan komputer di dasarkan pada analisis ekspresi wajah, meskipun demikian hampir semua fokus pada analisis data psikologi atau pengenalan wajah, penghilangan aspek komunikasi non-verbal [5]
Pengambil ekspresi wajah untuk mewakili suatu emosi sebagai contoh senyuman dapat
diartikan senang atau gembira, sedangkan agar tafsiran emosi menjadi lebih baik harus tetap memperhatikan informasi verbal. Dalam penelitian ini untuk mengenali komunikasi verbalnya dengan berbasis klasifikasi teks.
2. Psikologi dan emosi
Emosi dapat digambarkan sebagai keadaan yang pada umumnya disebabkan oleh suatu kejadian penting sebuah subyek yang meliputi (a) keadaan mental sadar yang dinyatakan dengan kemampuan mengenali, kualitas perasaan dan diarah untuk beberapa subyek, (b) gangguan jasmani pada beberapa organ tubuh, (c) pengenalan ekspresi pada wajah, suara dan isyarat tubuh, (d) kesiapan untuk melakukan tindakan tertentu. Karenanya emosi dalam sosio-biologi adalah kecenderungan mental (conative dan kognitif), keadaan, proses dan model komputasi harus spesifikasi semirip mungkin [6]
Sejumlah penelitian tentang emosi manusia telah dilakukan sehingga ada kesepakatan tentang emosi dasar [7]
1. Takut sebagai ancaman fisik atau sosial untuk diri sendiri
2. Marah sebagai ganjalan atau frustasi dari peran atau tujuan yang di rasakan orang lain
3. Jijik menggambarkan penghapusan atau jarak dari seseorang, obyek, atau menolak ide untuk diri sendiri dan menghargai peran dan tujuan
4. Sedih digambarkan sebagai kegagalan atau kerugian tentang peran dan tujuan 5. Senang digambarkan sebagai berhasil
atau bergerak menuju selesainya peran yang bernilai atau tujuan
3. Perbedaan perlakuan preprosesing
Di dalam klasifikasi teks untuk kategori artikel kata-kata seperti “tidak”, “bukan”, “tanpa” dianggap tidak penting sehingga di masukan dalam daftar kata yang bias dihilangkan (stopword), namun dalam hal ini (klasifikasi teks emosi) kata-kata “tidak”, ”bukan”, “tanpa” menjadi sangat berarti sehingga tidak boleh dihilangkan.
Perlakuan proses sebelum klasifikasi menjadi sangat penting supaya data yang akan diolah benar-benar mewakili maksud dari dokumen yang ditulis seringkali penggunaan kata “bukan”, “tanpa” dan “tidak” menjadi sangat penting, perbedaan arti “tanpa cinta” dan “tidak senang” dapat menempatkan dokumen dalam kelas berbeda sehingga tidak menutup kemungkinan dalam preprocessing ada modifikasi kata terlebih dahulu [8]
4. Representasi dokumen
Dalam teknik penggalian informasi representasi sebuah obyek di dasarkan pada seperangkat atribut yang digambarkan dalam sampel. Dokumen teks adalah sekumpulan kata sehingga diperlukan proses transformasi kedalam bentuk yang dapat di gunakan dalam proses klasifikasi. Dengan pemodelan dalam bentuk vector tiap dokumen C akan di buat vektor dalam term-space (kumplan kata yang terjadi di semua dokumen)
...(1)
adalah kejadian dari n kata dalam dokumen ada dua dasar untuk membuat vektor [9]
a. Biner – hanya berdasarkan pada ada tidaknya kata yang muncul dalam dokumen
b. Frekuensi – banyaknya kemunculan kata dalam dokumen
Penghitungan bobot dokumen diolah dalam bentuk vektor dengan term yang berhasil dikenali perhitungannya berdasar metode TFIDF yang merupakan integrasi Term Frequency (TF) dan
Inverse Document Frequency (IDF) dengan rumus
………(2)
Dimana
= jumlah term terjadi dalam dokumen
= jumlah dokumen di dalam C koleksi Pembobotan ini dapat diasumsikan lebih sering term terjadi dalam sebuah dokumen maka akan lebih mewakili isi dokumen [10]
5. Klasifikasi
Klasifikasi teks adalah proses pengelompokan dokumen kedalam kelas berbeda, dalam tahapannya tiap dokumen d
menunjuk pada satu kelas tertentu maka dibutuhkan proses untuk menggali informasi dari
dokumen tersebut. Sehingga dokumen tersebut harus dapat merepresentasikan dari kelasnya sehingga tiap kata yang muncul dalam dokumen mempunyai nilai.
5.1 Naïve Bayes
Klasifikasi–klasifikasi Bayes adalah klasifikasi statistik yang dapat memprediksi kelas suatu anggota probabilitas. Untuk klasifikasi Bayes sederhana yang lebih dikenal sebagai naïve Bayesian Classifier dapat diasumsikan bahwa efek dari suatu nilai atribut sebuah kelas yang diberikan adalah bebas dari atribut-atribut lain. Asumsi ini disebut class conditional independence yang dibuat untuk memudahkan perhitungan-perhitungan pengertian ini dianggap “naive”, dalam bahasa lebih sederhana naïve itu mengasumsikan bahwa kemunculan suatu term kata dalam suatu kalimat tidak dipengaruhi kemungkinan kata-kata yang lain dalam kalimat padahal dalam kenyataanya bahwa kemungkinan kata dalam kalimat sangat dipengaruhi kemungkinan keberadaan kata-kata yang dalam kalimat.
Dalam Naïve Bayes di asumsikan prediksi atribut adalah tidak tergantung pada kelas atau tidak dipengaruhi atribut laten
Gambar 1. Klasifikasi Naïve Bayes sebagai jaringan bayes dengan atribut prediksi (P1, P2, …….Pk) dan kelas (C)
C adalah adalah anggota kelas dan X adalah variabel acak sebuah vektor sebagai atribut nilai yang diamati. c mewakili nilai label kelas dan x mewakili nilai atribut vector yang diamati. Jika diberikan sejumlah x tes untuk klasifikasi maka probablitas tiap kelas untuk atribut prediksi vektor yang diamati adalah
……….(3)
X = x adalah mewakili kejadian dari Jumlah dari untuk semua kelas adalah 1
5.2 Naïve Bayes Flexibel
Algoritma Naïve Bayes Flexibel sebenarnya sama dengan Naïve Bayes perbedaannya pada penggunaan untuk perkiraan kepadatan pada atribut kontinyu, yang pada umumnya menggunakan Gaussian tunggal sebagai teknik menghitung variabel yang kontinyu
Berdasar dari persamaan Naïve Bayes untuk kepadatan tiap atribut kontinyu sebagai
untuk kernel Gaussian, jika menggunakan perkiraan
n
t
)
,...,
,
(
t
1t
2t
nC
=
C
P
1P
2P
k ) ( ) ( ) ( ) ( c C p c C x X p c C p x X c C p = = = = = = = k x k X x X x X1= 1∧ 2= 2∧... = j it
Nd
,
t
j p(C= cX= x) id
jNt
= = = ) (X xC c p g(x,µ
iσ
c) j j i j iNt
C
t
Nd
t
d
tfidf
j
i
w
(
,
)
=
(
,
)
=
,
.
log
kepadatan kernel adalah
…………...(4) Dimana i mencakup diatas titik pelatihan atribut X dalam kelas c, dan µi = xi dalam metode kernel
persamaan 4 ekivalen dengan rumus standar kernel
Dimana h = σ dan K =
Dalam Naïve Bayes dapat memperkirakan µi
dan σi serta menyimpannya sekali dan
menjumlahkan x pengamatan kemudian menjumlahkan kuadratnya kalau dalam statistik disebut distribusi normal. Untuk Bayes Flexibel menyimpan setiap atribut yang kontinyu selama pelatihan (training), Naïve Bayes melakukan evaluasi g sekali sedangkan Bayes Flexibel melakukan n evaluasi, satu per nilai pengamatan untuk X dalam kelas C[11].
5.3 Multinomial
Model multinomial mengambil jumlah kata yang muncul pada sebuah dokumen, dalam model multinomial sebuah dokumen terdiri dari beberapa kejadian kata dan di asumsikan panjang dokumen tidak bergantung pada kelasnya. Dengan menggunakan asumsi Bayes yang sama bahwa kemungkinan tiap kejadian kata dalam sebuah dokumen adalah bebas tidak terpengaruh dengan konteks kata dan posisi kata dalam dokumen.
Tiap dokumen di di gambarkan sebagai
distribusi multinomial kata, Nit dihitung dari jumlah
kemunculan kata wt yang terjadi dalam dokumen di . Maka kemungkinan sebuah dokumen
diberikan sebuah kelas adalah [12]
….(5)
Kemungkinan untuk tiap kata dapat ditulis
dimana dan
Disini perkiraan untuk kemungkinan untuk kata wt dalam kelas cj adalah
(6)
5.4 Evaluasi
Untuk mengevaluasi kesamaan diantara dokumen-dokumen dapat di ukur berdasar recall, precision dan F-measure. Dalam hasil klasifikasi (prediction class1) mempunyai kemungkinan yaitu memang benar dalam kelasnya (class1 true) atau salah, ikut kelas lainnya (class2 true) dalam hal ini parameter diatas akan digunakan untuk menghitung parameter evaluasi yaitu [13]:
1. Recall adalah tingkat keberhasilan mengenali suatu kelas yang harus dikenali
2. Precision adalah tingkat ketepatan hasil klasifikasi dari seluruh dokumen
Maka dapat di hitung Recall menyatakan jumlah pengenalan entitas bernilai benar yang dilakukan sistem dibagi dengan jumlah entitas yang seharusnya dapat dikenali sistem, untuk
Precision di hitung dari jumlah pengenalan yang bernilai benar oleh sistem dibagi dengan jumlah keseluruhan pengenalan yang dilakukan oleh sistem
F-measure merupakan nilai yang mewakili keseluruhan kinerja sistem dan merupakan penggabungan nilai recall dan precision dalam sebuah nilai [14] secara matematis untuk menghitung F-Measure/F1 dengan rumus [15]
……….(7)
6. Eksperimen 6.1 Data
Penelitian ini menggunakan 6 kelas emosi dasar yang diperoleh dari dataset ISEAR (International Survey on Emotion Antecedents and Reaction) berisikan 7.666 kalimat dan 1096 partisipan dari berbagai disiplin ilmu psikologi, ilmu sosial, seni, bahasa, ilmu alam, teknik, dan kesehatan. Berasal dari 16 negara lintas lima benua, Penelitian ISEAR tidak ditujukan pada klasifikasi teks namun mencoba mencari hubungan antara emosi dan perbedaaan budaya, gender, umur dan agama. Dataset tujuh jenis emosi yaitu jijik, malu, marah, sedih, senang, bersalah dan takut. Dalam penelitian ini ada beberapa hal yang perlu diperhatikan adalah
• Menggunakan date enam kelas meliputi jijik, malu, marah, sedih, senang dan takut
• Jumlah data yang digunakan untuk masing-masing kelas 200 kalimat
• Data dibagi dalam dua perlakuan
− Data adalah data asli tanpa modifikasi penambahan “not”
− DataNot adalah data modifikasi dengan menggabungkan kata dengan tidak misal: “tidak suka” menjadi “tidaksuka”
Data yang masih dalam bahasa Inggris diterjemahkan terlebih dahulu dalam bahasa Indonesia secara bebas tanpa mengurangi maksud kalimat aslinya serta dikelompokkan dalam kelas-kelas emosi seperti aslinya.
6.2 Strategi Stopword
Sebelum di lakukan percobaan terlebih dahulu kalimat akan dibagi menjadi dua mengingat kalimat yang digunakan lebih banyak berupa kalimat situasi maka ada beberapa kata yang tidak boleh di hilangkan sembarangan walaupun mungkin untuk klasifikasi teks lainnya boleh dihilangkan. Sebagai contoh “tidak gembira” tentu mempunyai arti berbeda dengan “gembira” karena “gembira” mempunyai kelas senang sedangkan “tidak gembira” tentu masuk kelas selain “senang” untuk alasan yang lain akan terjadi penghitungan kata “tidak” sendiri dan “senang” sendiri sehingga untuk mengatasi hal ini maka “tidak senang” akan ditulis menjadi
∑
=
=
=
i c ix
g
n
c
C
x
X
p
(
)
1
(
,
µ
,
σ
)
∏
= = v t it N j t i i j i N c w P d d P c d P it 1 ! ) ; ( ! ) ( ) ; ( θ θ∑
− − = = = xC c nhj
K xhi X p( ) ( ) 1 µ ) 1 , 0 , (x g ) ; ( θ θwtcj = Pwtcj 0≤ ≤1 j c wt θ∑ ∑
∑
= = = + + = = V s D i is j i D i it j i j j t c wt d c P N V d c P N c w P j 1 1 1 ) ( ) ( 1 ) ˆ ; ( ˆ θ θ call ecision call ecision F Re Pr Re * Pr * 2 1 = + 1 =∑
tθwtcj“tidaksenang”
6.3 Preprosessing
Sebelum data di vektorkan terlebih dahulu data diproses menggunakan lower case untuk mengubah semua huruf dalam dokumen menjadi huruf kecil hanya huruf ‘a’ sampai ‘z’ kemudian untuk semua karakter selain huruf akan delimiter
Klasifikasi
Dengan menggunakan 10 kali validasi silang (cross validation) percobaan pada tiap-tiap rasio data yang diambil pada data agar diperoleh data yang lebih valid, ada dua jenis metode klasifikasi data teks yang akan digunakan yaitu Naïve Bayes (NB) dan Multinomial Naïve Bayes (Multinomial NB)
Gambar 2 Precision versus recall menggunakan Data
dari hasil percobaan dengan menggunakan kedua metode naive bayes pada Data tidak terlihat menunjukkan perbedaan yang signifikan, tren kedua kurva juga cenderung berhimpit.
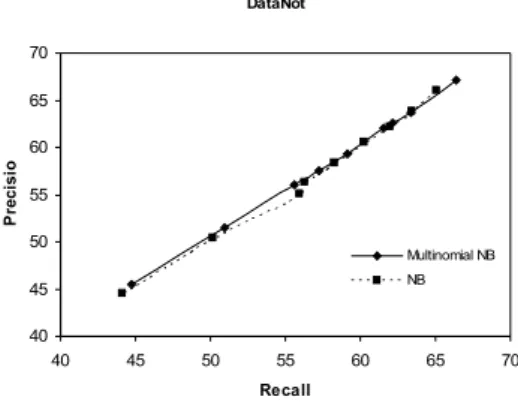
Gambar 3 Precision versus recall menggunakan DataNot
pada gambar 3 yang menggambarkan kurva recall dan precision menggunakan kedua metode pada DataNot mempunyai tren cenderung sama dan hanya sedikit perbedaan, walaupun dalam gambar kurva metode naïve bayes sedikit tidak stabil yaitu pada recall 50 sampai 55 mengalami penurunan.
Sehingga secara umum dapat di hipotesa penggunaan kedua metode pada kondisi perlakuan data yang berbeda mempunyai kecenderungan sama dan kalaupun terjadi
perbedaan tidak signifikan, hasil penggambaran kurva metode multinomial cenderung lebih stabil sehingga terlihat tren
Gambar 4 Akurasi penggunaan Data dan DataNot Dengan metode multinomial naïve bayes
Pada gambar 4 adalah hasil percobaan penggunaan Data dan DataNot yang diuji dengan metode multinomial naïve bayes, DataNot dapat memperbaiki tingkat keakurasian dari mesin learning semakin banyak komposisi data latihnya akurasinya juga meningkat pada rasio data 0.6 akurasi yang dicapai 61.57
Gambar 5 Akurasi penggunaan Data dan DataNot Dengan metode naïve bayes
Sedangkan bila menggunkan metode naïve bayes DataNot juga mengalami kenaikan tingkat akurasinya, bila diambil rasio data 0.6 pada gambar akan didapat tingkat akurasinya sekitar 60.28 sehingga bila dibandingakan menggunakan metode multinomial naïve bayes ternyata lebih baik 1.29
7. Kesimpulan dan rencana
Dari hasil percobaan yang dilakukan dapat ditarik kesimpulan bahwa :
1. Modifikasi data dapat meningkatkan kemampuan mesin mengklasifikasi data teks emosi berbahasa indonesia
2. Metode multinomial naïve bayes lebih baik dari metode naïve bayes untuk klasifikasi teks berbahasa Indonesia
3. Dengan rasio data 0,6 yang dihasilkan akurasi sebesar 61,57 untuk multinomial naïve bayes menggunakan DataNot
4. Hasil klasifikasi mengggunakan metode
Data 40 45 50 55 60 65 40 45 50 55 60 65 Recall P re ci si o n Multinomial NB NB DataNot 40 45 50 55 60 65 70 40 45 50 55 60 65 70 Recall P re ci si o n Multinomial NB NB 40 45 50 55 60 65 70 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Rasio Data A ku ra si Data DataNot 40 45 50 55 60 65 70 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Rasio Data A ku ra si Data DataNot
multinomial naïve bayes dan naïve bayes tidak memberikan perbaikan yang signifikan saat rasio data 0,4 untuk percobaan DataNot dan Data
5. Perlu penelitian mendalam dalam klasifikasi tanggapan emosi dengan menggunakan metoda lain
6. Penelitian dapat dikembangkan menjadi tanggapan dari hasil klasifikasi menggunakan animasi sederhana
DAFTAR PUSTAKA
[1] Casell, J., Sullivan, J., Prevost, S., and Churchill, E., (2000). Embodied Conversational Agent. MIT Press editors
[2] S.J Russell and P. Norvig, (2003). Artificial Intelligence: A Modern Approach. Prentice Hall, [3] Minsky, M.L., (1987). The Society of Mind
William Heinemann Ltd., London.
[4] P. Ekman, W. V Friesen, (1969). The repertoire of nonverbal behaviour. Semiotica, Vol.1, pp.49-98.
[5] Hazlett, R., (2003). Measurement of User Frustration: A Biologic Approach. Ext. Abstracts CHI 2003 (Florida, FL, April 5-10), ACM. Press, 734-735.
[6] Oatley, K. and Jenkins, J.M, (1996). Understanding Emotions, Blackwell.
[7] Power, M. and Dalgleish, T., (1997) Cognition and Emotion, LEA Press.
[8] Taner danisma and Adil Alpkocak., (2008). Feeler: Emotion Clasification of Text Using Vector, Proceedings of AISB 2008 Symposium on Affective Language in Human and Machine Volume 2.
[9] Machnik Lukasz, (2004). Document Clustering Techniques, Annales UMCS Informatica AI 2 p.401-411.
[10] Paralic, J. - Bednar, P. (2003). Text Mining for Documents Annotation and Ontology Support. A book chapter in: Intelligent Systems at the Service of Mankind, Springer Verlag. [11] George H. John and Pat Langley, (1995).
Estimating Continuous Distribution in Bayesian Classifiers, In Poceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence, Morgan Kaufmann Publishers, San Mateo.
[12] Andrew McCallum and Kamal Nigam, (1998). A Comparison of Event Models for Naive Bayes Text Classification, In AAAI/ICML-98
Workshop on Learning for Text Categorization, pp.41-48, Technical Report WS-98-05. AAAI Press.
[13] Agus Zainal Arifin dan Ari Novan Setiono, (2002). Klasifikasi Dokumen Berita Kejadian Berbahasa Indonesia dengan Algoritma Single Pass Clustering”, Proceeding of Seminar on Intelligent Technology and Its Applications (SITIA), Teknik Elektro, Institut Teknologi Sepuluh Nopember, 07 Mei.
[14] Minarsari Dewi, Indra Budi dan Petrus Mursanto, (2005). Identifikasi Titik Percabangan Pada Deskripsi Tekstual Use Case Menggunakan Entitas Bernama dengan
Metode Association Rules Mining, Seminar NAsional Ilmu Komputer dan Teknologi Informasi Universitas Kriten Satya Wacana. [15] Yang, Yiming, (1999). An evaluation of
statistical approaches to text categorization. Journal of Information Retrieval I, pp 69-90, Kluwer Academic Publishers, Netherlands.
Ket:
I. Destuardi (2207205717) Mahasiswa S2 Game Tech Jur Teknik Elektro ITS Dosen Pembimbing:
1. Moch. Hariadi, ST., MSc., PhD 2. Surya Sumpeno, ST., MSc