Vol 5, No 1 Maret 2022
Sistem Deteksi Kemiripan Teks Pada Berita Berbahasa Indonesia Menggunakan Algoritma
Ratcliff/Obershelp
Nurul Izzah#1, Novi Yusliani*2, Desty Roodiah*3
#Teknik Informatika, Univeristas Sriwijaya
Jl. Srijaya Negara Bukit Besar, Palembang 30128, Indonesia
Abstrak
—
Plagiarisme karya tulis sering sekali ditemukan diberbagai media, salah satunya yaitu internet. Pencegahan dapat dilakukan dengan membuat sistem cerdas yang mampu mendeteksi kemiripan teks. Salah satu algoritma yang digunakan untuk pembuatan sistem deteksi kemiripan teks adalah algoritma Ratcliff/Obershelp. Algoritma ini menggabungkan string dari 2 buah teks untuk mendapatkan panjang karakter total (sequence (string) matching).Hasilnya digunakan untuk mencari kata yang sama (sub- sequence) dan menghitung panjang karakternya.
Perhitungan nilai similarity dan persentasenya dilakukan untuk mengklasifikasikan jenis plagiarisme yang ada pada teks. Data yang digunakan berupa 8 teks berita berbahasa indonesia dengan sumber internet yang berbeda yang terbagi atas 2 topik dan menghasilkan persentase kesalahan rata – rata 0,26%.
Kata kunci
—
Algoritma Ratcliff/Obershelp, Internet, Plagiarisme, Sistem Deteksi Kemiripan Teks, Teks Berita Berbahasa Indonesia.I. PENDAHULUAN
Plagiarisme merupakan suatu tindakan copy dan paste dari produk intelektual orang lain yang disalahgunakan tanpa menyebutkan nama penulis, penemu, dan penggagas orisinal [1]. Tindakan plagiarisme diatur dalam UU nomor 19 tahun 2002 mengenai hak cipta. Proporsi plagiarisme dapat berupa kata, ide, sumber, dan kepengarangan [2]
yang terjadi dikarenakan kurangnya kreativitas masyarakat sehingga mendorong pelaku plagiarisme untuk menjiplak hasil karya orang lain. Dalam hal ini, karya tidak hanya sebatas pada dokumen, tetapi juga berupa desain, gambar, video, maupun kode program.
Salah satu contoh plagiarisme karya tulis adalah teks berita.
Teks berita merupakan sumber informasi yang dibutuhkan oleh sebagian besar masyarakat untuk
menarik serta memperluas wawasan dan memperkaya pengetahuan. Teks berita dapat diakses dengan mudah di berbagai media, salah satunya adalah internet. Namun, semakin banyak informasi yang beredar di internet mengakibatkan meningkatnya tindakan plagairisme tanpa adanya sitasi, sehingga membuat masyarakat lebih selektif dalam memilih informasi. Hal ini berdampak pada berkurangnya apresiasi terhadap hasil karya dan kreativitas dari si pencipta aslinya.
Upaya yang dilakukan untuk mencegah plagiarisme tidak cukup dengan mengingatkan bahwa tindakan tersebut melanggar hak cipta. Pencegahan dengan mendeteksi plagiarisme merupakan salah satu cara yang paling efektif untuk meminimalisirnya. Namun, pendeteksian sangat sulit dilakukan secara manual, sehingga diperlukan suatu sistem cerdas yang mampu mendeteksi kemiripan teks [3]. Sistem deteksi kemiripan teks dibangun dengan berbagai algoritma, salah satunya adalah algoritma Ratcliff/Obershelp [4], [5].
Algoritma Ratcliff/Obershelp merupakan algoritma yang digunakan untuk mencari sequence (string) matching, sub-string, dan melakukan perhitungan kemiripan string.
Algoritma ini dapat melakukan proses identifikasi kemiripan string yang akurat dengan jumlah string yang sangat banyak. Algoritma ini akan mendeteksi string yang sama pada dua buah teks yang berbeda. Namun proses stemming dalam tahapan pre-processing jarang dilakukan, sehingga mempengaruhi hasil dan keakuratan dari perhitungan algoritma ini.
Pada penelitian sebelumnya, hasil persentase nilai yang diperoleh dengan algoritma Ratcliff/Obershelp hampir mendekati nilai persentase yang telah diprediksi sebelumnya. Namun hasil yang dipeorleh kurang akurat karena kurangnya proses stemming pada tahapan pre- processing text, sehingga mempengaruhi hasil dari proses pendeteksian kemiripan teks menggunakan algoritma
nilai persentase, perhitungan nilai similarity, waktu eksekusi, dan nilai konsistensi yang lebih baik daripada algoritma Rabin Karp [5].
Berdasarkan hal tersebut, maka penelitian ini berfokus pada menghasilkan sebuah perangkat lunak yang dapat mendeteksi kemiripan teks pada teks berita berbahasa Indonesia menggunakan algoritma Ratcliff/Obershelp dan melakukan proses stemming dengan algoritma Nazief dan Adriani pada tahapan pre- processing text.
II. METODELOGI PENELITIAN
A. Pengumpulan Data
Jenis data yang digunakan pada penelitian ini adalah data primer berupa teks berita berbahasa Indonesia dengan sumber 8 website yang berbeda. Data dikumpulkan dengan metode observasi, kemudian di pilih berdasarkan topik tertentu dan disalin ke dalam file dengan format .txt.
B. Kerangka Kerja
Gambar dibawah ini menunjukkan tahapan penelitian yang dilakukan oleh peneliti.
Gambar 1. Diagram Kerangka Kerja
Gambar 1 merupakan tahapan penelitian yang diawali dengan memasukkan 2 data teks ke dalam sistem. Selanjutnya data akan melalui tahapan pre- processing text. Kemudian akan dilakukan pendeteksian kemiripan teks menggunakan algoritma Ratcliff/Obershelp pada data. Tahap yang terakhir
adalah melakukan klasifikasi jenis plagiarisme teks pada data berdasarkan nilai hasil persentase.
1. Pre-Processing Teks
Pre-processing merupakan tahapan yang dilakukan dalam proses pendeteksian kemiripan teks.
Data teks akan dibersihkan sehingga data menjad lebih terstruktur sebelum masuk ke tahap berikutnya [4]. Pada penelitian ini, proses pre-processing yang digunakan adalah case folding, punctuation, stemming, tokenization, dan whitespace removal.
Case folding merupakan proses perubahan huruf teks menjadi huruf kecil (lowercase) [6].
Punctuation merupakan proses penghapusan karakter, tanda baca, tanda hubung, simbol, angka, dan lain-lain dalam teks [6]. Stemming merupakan proses pencarian kata dasar dengan menghilangkan prefiks serta surfiks kata dan algoritma Nazief dan Adriani merupakan algoritma yang digunakan untuk stemming pada teks berbahasa Indonesia[7].
Tokenization merupakan proses pemisahan string ke dalam bentuk yang lebih kecil. Sedangkan whitespace removal merupakan proses penghapusan spasi, tab, dan baris baru dalam teks agar menjadi satu string yang utuh [4].
2. Algoritma Ratcliff/Obershelp
Algoritma Ratcliff/Obershelp merupakan algoritma yang melakukan proses yang sama untuk menentukan apakah dua pola atau dimensi pada suatu teks sama. Pada algoritma ini, setiap string teks akan dihitung sebagai 1 dimensi, sehingga algoritma akan mengembalikan nilai yang dapat digunakan sebagai persentase dari kesaman 2 string [4]. Proses yang dilakukan pada algoritma ini adalah sequence (string) matching, sub-sequence (sub- string), serta menghitung nilai dan persentase similarity string [4].
Sequence (string) Matching merupakan proses perhitungan panjang karakter yang ada pada masing – masing teks. Sub-Sequence (Sub-String) merupakan proses perhitungan dan pencarian Sub- Sequence (Sub-String) atau anchor (sub-string terpanjang) yang sama –sama dimiliki oleh kedua teks. Sedangkan Perhitungan nilai dan persentase similarity string merupakan proses yang dilakukan untuk mengetahui berapa besar nilai dan persentase kemiripan teks pada dua buah data. Rumus perhitungan nilai dan persentase similarity string dapat dilihat pada persamaan berikut.
S = (2 x KM) / ( |S1| + |S2| ) (1) Persentase Nilai Similarity String = S x 100% (2)
Keterangan :
S = Nilai similarity string
KM = Jumlah total karakter pada kata yang sama
|S1| = Panjang string1
|S2| = Panjang string2
3. Klasifikasi Jenis Plagiarisme
Klasifikasi Jenis Plagiarisme merupakan proses pengelompokan hasil deteksi kemiripan teks untuk mengetahui tingkatan plagiarisme pada sebuah teks yang dilakukan berdasarkan hasil persentase dari perhitungan nilai similarity string. Klasifikasi ini dikategorikan menjadi 5 jenis [8] seperti pada tabel 1.
TABELI
KLASIFIKASI JENIS PLAGIARISME
Persentase
Similarity Klasifikasi
0% Kedua teks sangat berbeda atau tidak memiliki kemiripan
< 15% Kedua teks memiliki sedikit kemiripan
15 - 50% Kedua teks memiliki tingkat kemiripan teks sedang
> 50% Kedua teks mendekati kemiripan teks 100% Kedua teks termasuk kemiripan teks
C. Pengujian
Pada penelitian ini, pengujian dilakukan sebanyak 3 skenario. Dimana pada tiap skenario akan dilakukan pengujian menggunakan 2 data teks. Pengujian ini akan menghasilkan persentase dan klasifikasi kemiripan teks.
Untuk menguji apakah hasil persentase telah benar, maka diperlukan suatu nilai pembanding sebagai nilai prediksi.
Nilai ini diperoleh dari hasil perhitungan cosine similarity[9]. rumus cosine similarity dapat dilihat pada persamaan berikut.
(3)
Keterangan : A = Vektor B = Vektor
Ai = Bobot term i dalam blok A Bi = Bobot term i dalam blok B i = jumlah term dalam teks n = jumlah vektor
Hasil persentase kemiripan teks kemudian dibandingkan dengan nilai prediksi untuk dihitung berapa persentase kesalahan pada tiap pengujiannya. Rumus persentase keksalahan dapat dilihat pada persamaan berikut [10].
%Kesalahan = [(Nilai Y–Nilai X) / Nilai Y] x
100% (4)
Keterangan :
Nilai Y = Nilai prediksi Nilai X = Nilai yang diperoleh
D. MetodePengembangan Perangkat Lunak
Penelitian ini menggunakan metode Rational Unified Process (RUP) dalam mengembangkan perangkat lunak.
Metode ini memiliki empat fase sebagai berikut.
1. Inception
Pada fase ini dilakukan proses pendeskripsian kebutuhan sistem, menganalisis dan mendesain sistem menggunakan use case diagram, serta melakukan pengujian atau validasi kesesuaian antara kebutuhan sistem dan use case diagram yang telah dirancang.
2. Elaboration
Pada fase ini dilakukan proses pendefinisian kebutuhan sistem, merancang skenario use case, activity diagram, sequence diagram, class diagram, serta perancangan antarmuka sistem.
3. Construction
Pada fase ini dilakukan proses implementasi dan pengembangan perangkat lunak dalam bentuk kode program.
4. Transition
Pada fase ini dilakukan proses pengujian atau validasi usability perangkat lunak menggunakan black box testing.
III. HASIL DAN ANALISIS
Pengujian perangkat lunak dilakukan dengan menggunakan 8 data teks berita berbahasa Indonesia dengan sumber yang berbeda dan terbagi atas 2 topik.
Pengujian dilakukan menggunakan 3 skenario dimana pada tiap skenario akan dilakukan pengujian menggunakan 2 data teks untuk mencari nilai persentase kemiripan teks dan klasifikasinya. Hasil pengujian akan ditampilkan dalam bentuk tabel dengan data nilai prediksi persentase, hasil persentase, klasifikasi, dan persentase kesalahan. Data prediksi persentase diperoleh dari hasil perhitungan cosine similariity. Data hasil persentase diperoleh dari nilai hasil perhitungan algoritma Ratcliff/Obershelp. Data klasifikasi diperoleh dari hasil klasifikasi jenis plagiarisme, dan data persentase kesalahan diperoleh dari perhitungan rumus persentase kesalahan.
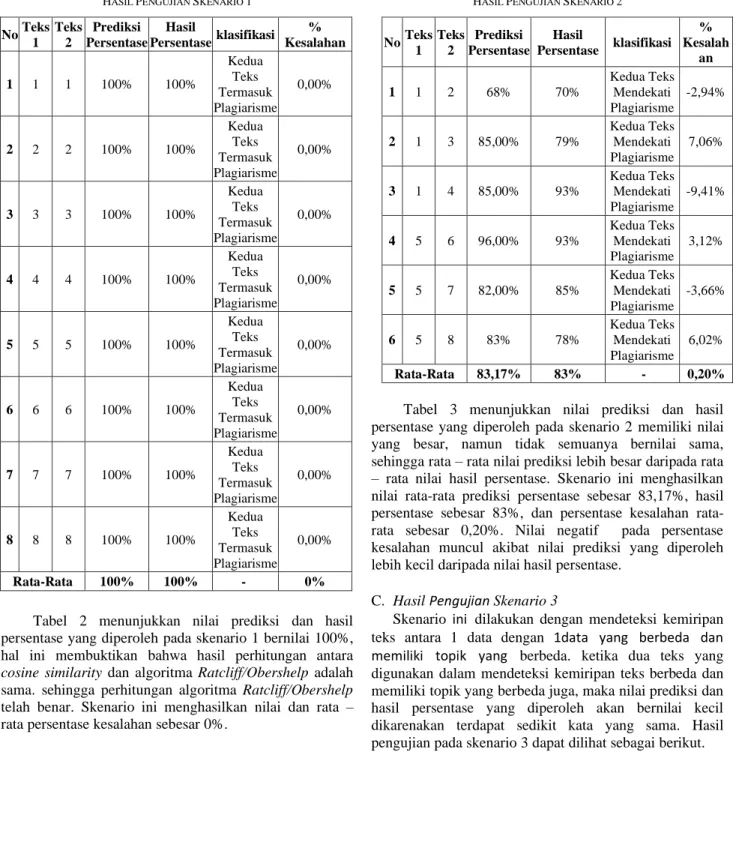
A. Hasil Pengujian Skenario 1
Skenario ini dilakukan dengan mendeteksi kemiripan teks antara 1 data dengan data itu sendiri. ketika dua teks yang digunakan dalam mendeteksi kemiripan teks sama, maka nilai prediksi dan hasil persentase yang seharusnya diperoleh adalah 100% dikarenakan semua kata dari kedua teks akan sama. Hasil pengujian pada skenario 1 dapat dilihat pada Tabel 2.
TABEL2 HASIL PENGUJIAN SKENARIO 1
No Teks 1
Teks 2
Prediksi Persentase
Hasil
Persentase klasifikasi % Kesalahan
1 1 1 100% 100%
Kedua Teks Termasuk Plagiarisme
0,00%
2 2 2 100% 100%
Kedua Teks Termasuk Plagiarisme
0,00%
3 3 3 100% 100%
Kedua Teks Termasuk Plagiarisme
0,00%
4 4 4 100% 100%
Kedua Teks Termasuk Plagiarisme
0,00%
5 5 5 100% 100%
Kedua Teks Termasuk Plagiarisme
0,00%
6 6 6 100% 100%
Kedua Teks Termasuk Plagiarisme
0,00%
7 7 7 100% 100%
Kedua Teks Termasuk Plagiarisme
0,00%
8 8 8 100% 100%
Kedua Teks Termasuk Plagiarisme
0,00%
Rata-Rata 100% 100% - 0%
Tabel 2 menunjukkan nilai prediksi dan hasil persentase yang diperoleh pada skenario 1 bernilai 100%, hal ini membuktikan bahwa hasil perhitungan antara cosine similarity dan algoritma Ratcliff/Obershelp adalah sama. sehingga perhitungan algoritma Ratcliff/Obershelp telah benar. Skenario ini menghasilkan nilai dan rata – rata persentase kesalahan sebesar 0%.
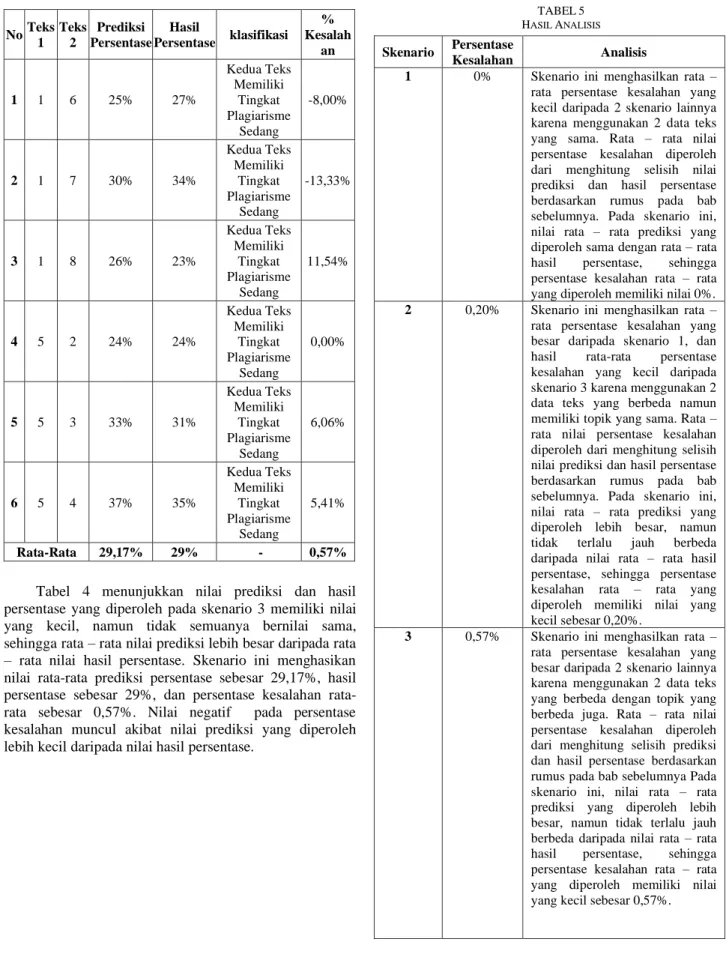
B. Hasil Pengujian Skenario 2
Skenario ini dilakukan dengan mendeteksi kemiripan teks antara 1 data dengan 1 data yang berbeda namun memiliki topik yang sama. ketika dua teks yang digunakan dalam mendeteksi kemiripan teks berbeda namun memiliki topik yang sama, maka nilai prediksi dan hasil persentase yang diperoleh akan bernilai besar dikarenakan terdapat banyak kata yang sama. Hasil pengujian pada skenario 2 dapat dilihat pada Tabel 3.
TABEL3 HASIL PENGUJIAN SKENARIO 2
No Teks 1
Teks 2
Prediksi Persentase
Hasil
Persentase klasifikasi
% Kesalah
an
1 1 2 68% 70%
Kedua Teks Mendekati Plagiarisme
-2,94%
2 1 3 85,00% 79%
Kedua Teks Mendekati Plagiarisme
7,06%
3 1 4 85,00% 93%
Kedua Teks Mendekati Plagiarisme
-9,41%
4 5 6 96,00% 93%
Kedua Teks Mendekati Plagiarisme
3,12%
5 5 7 82,00% 85%
Kedua Teks Mendekati Plagiarisme
-3,66%
6 5 8 83% 78%
Kedua Teks Mendekati Plagiarisme
6,02%
Rata-Rata 83,17% 83% - 0,20%
Tabel 3 menunjukkan nilai prediksi dan hasil persentase yang diperoleh pada skenario 2 memiliki nilai yang besar, namun tidak semuanya bernilai sama, sehingga rata – rata nilai prediksi lebih besar daripada rata – rata nilai hasil persentase. Skenario ini menghasilkan nilai rata-rata prediksi persentase sebesar 83,17%, hasil persentase sebesar 83%, dan persentase kesalahan rata- rata sebesar 0,20%. Nilai negatif pada persentase kesalahan muncul akibat nilai prediksi yang diperoleh lebih kecil daripada nilai hasil persentase.
C. Hasil Pengujian Skenario 3
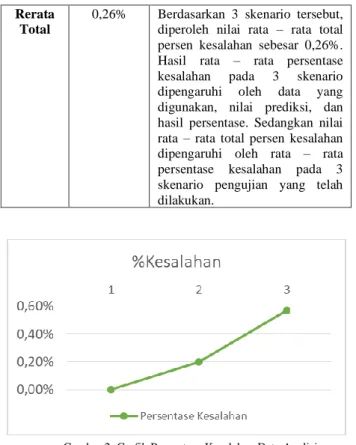
Skenario ini dilakukan dengan mendeteksi kemiripan teks antara 1 data dengan 1data yang berbeda dan memiliki topik yang berbeda. ketika dua teks yang digunakan dalam mendeteksi kemiripan teks berbeda dan memiliki topik yang berbeda juga, maka nilai prediksi dan hasil persentase yang diperoleh akan bernilai kecil dikarenakan terdapat sedikit kata yang sama. Hasil pengujian pada skenario 3 dapat dilihat sebagai berikut.
TABEL4 HASIL PENGUJIAN SKENARIO 3
No Teks 1
Teks 2
Prediksi Persentase
Hasil
Persentase klasifikasi
% Kesalah
an
1 1 6 25% 27%
Kedua Teks Memiliki
Tingkat Plagiarisme
Sedang
-8,00%
2 1 7 30% 34%
Kedua Teks Memiliki
Tingkat Plagiarisme
Sedang
-13,33%
3 1 8 26% 23%
Kedua Teks Memiliki
Tingkat Plagiarisme
Sedang
11,54%
4 5 2 24% 24%
Kedua Teks Memiliki
Tingkat Plagiarisme
Sedang
0,00%
5 5 3 33% 31%
Kedua Teks Memiliki
Tingkat Plagiarisme
Sedang
6,06%
6 5 4 37% 35%
Kedua Teks Memiliki
Tingkat Plagiarisme
Sedang
5,41%
Rata-Rata 29,17% 29% - 0,57%
Tabel 4 menunjukkan nilai prediksi dan hasil persentase yang diperoleh pada skenario 3 memiliki nilai yang kecil, namun tidak semuanya bernilai sama, sehingga rata – rata nilai prediksi lebih besar daripada rata – rata nilai hasil persentase. Skenario ini menghasikan nilai rata-rata prediksi persentase sebesar 29,17%, hasil persentase sebesar 29%, dan persentase kesalahan rata- rata sebesar 0,57%. Nilai negatif pada persentase kesalahan muncul akibat nilai prediksi yang diperoleh lebih kecil daripada nilai hasil persentase.
D. Hasil Analisis
TABEL5 HASIL ANALISIS
Skenario Persentase
Kesalahan Analisis
1 0% Skenario ini menghasilkan rata – rata persentase kesalahan yang kecil daripada 2 skenario lainnya karena menggunakan 2 data teks yang sama. Rata – rata nilai persentase kesalahan diperoleh dari menghitung selisih nilai prediksi dan hasil persentase berdasarkan rumus pada bab sebelumnya. Pada skenario ini, nilai rata – rata prediksi yang diperoleh sama dengan rata – rata hasil persentase, sehingga persentase kesalahan rata – rata yang diperoleh memiliki nilai 0%.
2 0,20% Skenario ini menghasilkan rata – rata persentase kesalahan yang besar daripada skenario 1, dan hasil rata-rata persentase kesalahan yang kecil daripada skenario 3 karena menggunakan 2 data teks yang berbeda namun memiliki topik yang sama. Rata – rata nilai persentase kesalahan diperoleh dari menghitung selisih nilai prediksi dan hasil persentase berdasarkan rumus pada bab sebelumnya. Pada skenario ini, nilai rata – rata prediksi yang diperoleh lebih besar, namun tidak terlalu jauh berbeda daripada nilai rata – rata hasil persentase, sehingga persentase kesalahan rata – rata yang diperoleh memiliki nilai yang kecil sebesar 0,20%.
3 0,57% Skenario ini menghasilkan rata – rata persentase kesalahan yang besar daripada 2 skenario lainnya karena menggunakan 2 data teks yang berbeda dengan topik yang berbeda juga. Rata – rata nilai persentase kesalahan diperoleh dari menghitung selisih prediksi dan hasil persentase berdasarkan rumus pada bab sebelumnya Pada skenario ini, nilai rata – rata prediksi yang diperoleh lebih besar, namun tidak terlalu jauh berbeda daripada nilai rata – rata hasil persentase, sehingga persentase kesalahan rata – rata yang diperoleh memiliki nilai yang kecil sebesar 0,57%.
Rerata Total
0,26% Berdasarkan 3 skenario tersebut, diperoleh nilai rata – rata total persen kesalahan sebesar 0,26%.
Hasil rata – rata persentase kesalahan pada 3 skenario dipengaruhi oleh data yang digunakan, nilai prediksi, dan hasil persentase. Sedangkan nilai rata – rata total persen kesalahan dipengaruhi oleh rata – rata persentase kesalahan pada 3 skenario pengujian yang telah dilakukan.
Gambar 2. Grafik Persentase Kesalahan Data Analisis
Tabel 5 dan gambar 2 menunjukkan data hasil analisis dan grafik persentase kesalahan pada 3 skenario.
Hasil akhir yang diperoleh dari rata – rata total persentase kesalahan adalah 0,26%. Pada tiap skenario, data yang digunakan untuk mendeteksi kemiripan teks sangat mempengaruhi nilai hasil persentase dan persentase kesalahan sistem. Semakin sama data dan topik yang digunakan, maka nilai prediksi dan hasil persentase yang diperoleh akan semakin besar dan hasil persentase kesalahan yang dihasilkan akan semakin kecil.
Sebaliknya, semakin berbeda data dan topik yang digunakan, maka nilai prediksi dan hasil persentase yang diperoleh akan semakin kecil dan hasil persentase kesalahan yang dihasilkan akan semakin besar.
IV. KESIMPULAN
Sistem deteksi kemiripan teks pada berita berbahasa indonesia berhasil dibangun menggunakan algoritma Ratcliff/Obershelp dan stemming dengan algoritma Nazief dan Adriani pada tahapan pre-processing text. Sistem ini menghasilkan nilai persentase kesalahan sebesar 0,26%
yang diperoleh dari rata – rata persentase kesalahan 3 skenario dengan menggunakan 8 teks berita berbahasa indonesia yang dibagi atas 2 topik yang berbeda dengan sumber internet. Pada masing – masing skenario terdapat rata – rata persentase kesalahan. Skenario 1 memiliki persentase kesalahan sebesar 0%, skenario 2 memiliki persentase kesalahan sebesar 0,20%, dan skenario 3 memiliki persentase kesalahan sebesar 0,57%.
ACKNOWLEDGMENT
Ucapan terima kasih kepada seluruh pihak dan peneliti pada bidang natural language processing yang telah memberikan referensi, motivasi, dan bimbingannya dalam penulisan jurnal ini.
REFERENSI
[1] M.A. Shadiqi, “Memahami dan Mencegah Perilaku Plagiarisme dalam Menulis Karya Ilmiah,” Buletin Psikologi, vol.27, no.1, pp.
30-42, 2019.
[2] Simarmata, J. 2019. Kita Menulis : Semua Bisa Menulis Buku.
[Online]. Available:
https://books.google.co.id/books?hl=id&lr=&id=UdjFDwAAQB AJ&oi=fnd&pg=PR13&dq=10+Jenis+Plagiarisme+Berdasarkan+
Aspek,+Pola+dan+Kesengajaan&ots=tBG3nlDHMC&sig=w- 0bAYtByKBCu6gMAnFl_RDCh0w&redir_esc=y#v=onepage&q
&f=false
[3] L. Sulistyaningsih, “Plagiarisme, Upaya Pencegahan, Penanggulangan, dan Solusinya,” Jurnal Pustaka Ilmiah, vol.3, no.1, 2017.
[4] Y.L. Joane, et al, “Aplikasi Deteksi Kemiripan Dokumen Teks Menggunakan Algoritma Ratcliff/Obershelp,” E-Journal Teknik Informatika, vol.11, no.1, 2017.
[5] B. Yusuf, “Perbandingan Algoritma Rabin-Karp dan Ratcliff/Obershelp untuk Menghitung Kesamaan Teks dalam Bahasa Indonesia,” Seminar Nasional APTIKOM (SEMANTIK), pp. 61-69, 2019.
[6] S. Mujilahwati, “Pre-Processing Text Mining Pada Data Twitter,”
Seminar Nasional Teknologi Informasi dan Komunikasi (SENTIKA), Yogyakarta, pp. 49-56, 2016.
[7] M.W. Sardjono, et al, “Pendeteksian Kesamaan Kata Untuk Judul Penulisan Berbahasa Indonesia menggunakan Algoritma Stemming Nazief-Adriani,” Universitas Gunadarma, Depok, pp.
138-146, 2018.
[8] S. Agustina, et al, “Anti Plagiarism Application with Algoritm Karp-Rabin at Thesis in Gunadarma University,” Universitas Gunadarma, depok. 2008.
[9] Firdaus, et al, “Implementasi Cosine Similarity Untuk Peningkatan Akurasi Pengukuran Kesamaan Dokumen Pada Klasifikasi Dokumen Berita Dengan K Nearest Neighbour,”
STMIK AKBA, pp. 69-74, 2019.
[10] F. Tsuneo, et al, Bab 1 : Pengukuran dan Kesalahan. Instrumentasi Elektronik dan Pengukuran, pp. 11-13, 2011.