45 BAB III PEMBAHASAN
Bab III merupakan pembahasan yang meliputi proses penelitian yaitu Fuzzy
Radial Basis Function Neural Network (FRBFNN), prosedur pembentukan model
FRBFNN, hasil model FRBFNN untuk deteksi dini kanker paru, dan ketepatan hasil deteksi dini kanker paru.
A. Fuzzy Radial Basis Function Neural Network (FRBFNN)
Fuzzy Radial Basis Function Neural Network (FRBFNN) merupakan model
yang terintegrasi dari Radial Basis Function Neural Network (RBFNN) dan logika
fuzzy. Model tersebut menerapkan konsep teori himpunan fuzzy pada input, output
dan lapisan tersembunyi. Penggunaan logika fuzzy yang diterapkan pada suatu jaringan saraf tiruan untuk mengantisipasi dalam mengolah informasi-informasi yang memiliki ketidakpastian atau bersifat ambigu. Model RBFNN telah banyak digunakan dalam menyelesaikan permasalahan-permasalahan seperti data mining, prediksi runtun waktu, pengolahan sinyal, sistem kontrol dan pengenalan pola.
Model FRBFNN melakukan pembelajaran jaringan secara hybrid dengan menggunakan pembelajaran tak terawasi (unsupervised learning) dan pembelajaran terawasi (supervised learning). Model FRBFNN menggunakan variabel input fuzzy yang didasarkan pada logika fuzzy, yaitu derajat keanggotaan masing-masing himpunan fuzzy yang merupakan hasil dari proses fuzzifikasi input fitur, sedangkan proses pengambilan keputusan diselesaikan dengan menggunakan pendekatan jaringan saraf tiruan.
46
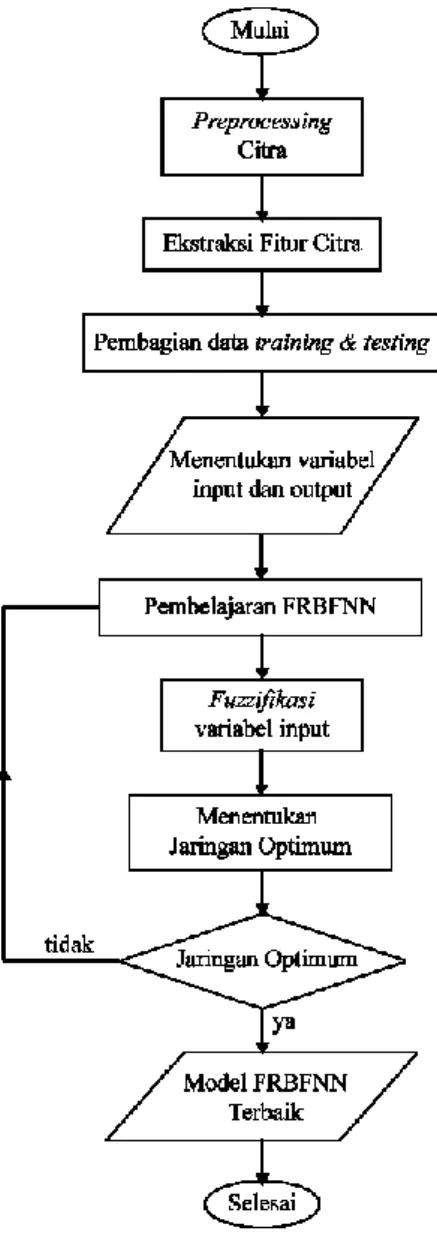
1. Arsitektur Fuzzy Radial Basis Function Neural Network (FRBFNN) Desain arsitekur model FRBFNN yang digunakan pada tugas akhir ini terdiri dari 4 lapisan, yaitu lapisan ke-1 sebagai lapisan input fitur, lapisan ke-2 sebagai lapisan input fuzzy dari input fitur, lapisan ke-3 sebagai lapisan tersembunyi dan lapisan ke-4 sebagai lapisan output. Desain dari arsitektur FRBFNN dapat dilihat pada Gambar 3.1.
-Gambar 3.1 Arsitektur Model FRBFNN
Pada lapisan ke-1 menuju lapisan ke-2 dilakukan fuzzifikasi untuk memperoleh derajat keanggotaan masing-masing input fitur yang digunakan pada neuron-neuron di lapisan ke-2. Pada lapisan ke-2 menuju lapisan ke-3 dilakukan
𝑥1 𝑥2 𝑥𝑝 𝑦1 𝜑1 𝜑2 𝜑3 𝜑𝑚 𝑏𝑖𝑎𝑠 𝜇1.1(𝑥1) ) 𝜇2.1(𝑥1) ) 𝜇𝑞.1(𝑥1) ) 𝜇1.2(𝑥2) ) 𝜇2.2(𝑥2) ) 𝜇𝑞.2(𝑥2) ) 𝜇1.𝑝(𝑥𝑝) ) 𝜇2.𝑝(𝑥𝑝) ) 𝜇𝑞.𝑝(𝑥𝑝) ) 𝑤1 ) 𝑤2 ) 𝑤3 ) 𝑤𝑚 ) 𝑤0 )
47
proses pembelajaran jaringan tak terawasi (unsupervised learning) sedangkan pada lapisan ke-3 menuju lapisan ke-4 dilakukan proses pembelajaran jaringan terawasi (supervised learning).
Pada model FRBFNN ini lapisan input fitur menerima sinyal dari 𝑥1, 𝑥2, … , 𝑥𝑝 kemudian pada masing-masing input fitur akan ditentukan derajat keanggotaan dengan menggunakan fungsi keanggotaan representasi kurva trapesium pada Persamaan (2.30), sedangkan pada lapisan input fuzzy menerima sinyal dari 𝜇1.1(𝑥1), 𝜇2.1(𝑥1), 𝜇3.1(𝑥1), 𝜇1.2(𝑥2), . . . , 𝜇𝑙.𝑖(𝑥𝑖), … , 𝜇𝑞.𝑝(𝑥𝑝) kemudian sinyal tersebut dikirimkan ke semua neuron pada lapisan tersembunyi. Diantara lapisan tersembunyi dan lapisan output terdapat m buah bobot 𝑤1, 𝑤2, 𝑤3, … , 𝑤𝑚 dan sebuah bobot bias 𝑤0. Selanjutnya, pada arsitektur FRBFNN menggunakan fungsi aktivasi 𝜑1, 𝜑2, 𝜑3, … , 𝜑𝑚 dari lapisan tersembunyi menuju lapisan output 𝑦1. Dalam arsitektur FRBFNN juga menambahkan satu neuron bias pada lapisan
tersembunyi. Dengan menambahkan bias pada lapisan tersembunyi diharapkan dapat mengoptimalkan kinerja jaringan saraf tiruan untuk mengolah informasi. 2. Fungsi Aktivasi Fuzzy Radial Basis Function Neural Network (FRBFNN)
Model FRBFNN menggunakan fungsi aktivasi yaitu fungsi radial basis pada setiap neuron di lapisan tersembunyi. Berikut ini beberapa fungsi radial basis yang dapat digunakan sebagai fungsi aktivasi (Orr, 1996: 40):
a. Fungsi Gaussian
𝜑[𝜇(𝑥)] = exp [−(𝜇(𝑥)−𝑐)2
48 b. Fungsi Cauchy 𝜑[𝜇(𝑥)] =[(𝜇(𝑥)−𝑐) 2+𝑟2]−1 𝑟 (3.2) c. Fungsi Multikuadratik 𝜑[𝜇(𝑥)] = √(𝜇(𝑥) − 𝑐)2+ 𝑟2 (3.3)
d. Fungsi Invers Multikuadratik
𝜑[𝜇(𝑥)] = 𝑟
√(𝜇(𝑥)−𝑐)2+𝑟2 (3.4)
dengan,
𝑟 = jarak maksimum variabel input ke pusat cluster 𝑐 = nilai pusat variabel input pada cluster
𝑥 = nilai input fitur
𝜇(𝑥) = derajat keanggotaan himpunan fuzzy dari input fitur 𝜑[𝜇(𝑥)] = fungsi aktivasi neuron tersembunyi
Output (𝑦) yang dihasilkan dari model FRBFNN merupakan kombinasi linear dari bobot (𝑤𝑗) dengan fungsi aktivasi (𝜑[𝜇(𝑥)]) dan bobot bias (𝑤0). Output (𝑦) dirumuskan sebagai berikut :
𝑦 = ∑𝑚𝑗=1𝑤𝑗𝜑𝑗[𝝁(𝑿)] + 𝑤0 (3.5) dengan, 𝜑𝑗[𝝁(𝑿)] = exp [−[𝝁(𝑿)−𝑪𝑗] 𝑇 [𝝁(𝑿)−𝑪𝑗] 𝑟𝑗2 ], [𝝁(𝑿)]𝑇 = [𝜇 1.1(𝑥1) 𝜇2.1(𝑥1) 𝜇3.1(𝑥1) . . . 𝜇𝑙.𝑖(𝑥𝑖) … 𝜇𝑞.𝑝(𝑥𝑝)], [𝑪𝒋]𝑇 = [𝑐(11) 𝑐(21) 𝑐(31) … 𝑐(𝑙𝑖) … 𝑐(𝑞𝑝)],
49
𝝁(𝑿) = vektor derajat keanggotaan himpunan fuzzy dari input fitur 𝑪𝑗 = vektor nilai pusat cluster ke-j
𝑤𝑗 = bobot dari neuron pada lapisan tersembunyi ke-𝑗 menuju neuron pada lapisan output,
𝑤0 = bobot bias pada lapisan tersembunyi menuju neuron pada lapisan output,
𝑟𝑗 = jarak maksimum pada cluster ke-𝑗, 𝑗 = 1,2,3, … , 𝑚,
𝑖 = 1,2,3, … , 𝑝. 𝑙 = 1,2,3, … , 𝑞.
3. Algoritma Pembelajaran FRBFNN
Proses pembelajaran model FRBFNN menggunakan jaringan hybrid, yaitu dengan menggabungkan antara pembelajaran tak terawasi (unsupervised learning) pada proses pengiriman sinyal lapisan input fuzzy menuju lapisan tersembunyi dan pembelajaran terawasi (supervised learning) untuk pemrosesan informasi dari lapisan tersembunyi menuju lapisan output.
Algoritma pembelajaran FRBFNN terbagi menjadi 4 tahapan yaitu menentukan input fuzzy pada lapisan fuzzy, input fuzzy pada lapisan fuzzy ditentukan melalui proses fuzzifikasi input fitur. Hasil dari proses fuzzifikasi dari input fitur yaitu derajat keanggotaan masing-masing himpunan fuzzy. Kedua, menentukan pusat (𝑐(𝑙𝑖)) dan jarak (𝑟𝑗) pada masing-masing fungsi basis, setiap pusat dan jarak tersebut ditentukan menggunakan salah satu metode clustering yaitu metode
50
yang dilakukan secara trial and error. Terakhir, menentukan bobot-bobot pada lapisan jaringan optimum, bobot ditentukan melalui dua pendekatan yaitu metode
global ridge regression dan metode algoritma backpropagation. Dari dua metode
tersebut akan dibandingkan, hasil yang terbaik yang akan digunakan pada model FRBFNN.
a. Proses Fuzzifikasi Input Fitur
Untuk menentukan input fuzzy pada lapisan input fuzzy dilakukan proses
fuzzifikasi. Fuzzifikasi adalah pemetaan himpunan tegas (crisp) ke himpunan fuzzy
yang diwakili oleh suatu derajat keanggotaan (Ross, 2010: 93). Berikut ini contoh proses fuzzifikasi menggunakan fungsi keanggotaan representasi kurva trapesium. Misalkan 𝑥1 = 0,6 dan himpunan semesta dari 𝑥 adalah 𝑈𝑥 = [0 1] akan dipetakan ke dalam 3 himpunan fuzzy. Perhitungan parameter-parameter pada fungsi keanggotaan trapesium untuk 𝑥1 pada himpunan A, himpunan B, dan himpunan C, dapat dirumuskan sebagai berikut,
Diketahui himpunan semesta 𝑈 = [𝑚𝑖𝑛 𝑚𝑎𝑥]
(𝑏 − 𝑎) = (𝑑 − 𝑐) =𝑚𝑎𝑥 −𝑚𝑖𝑛 4 (3.6) (𝑐 − 𝑏) =(𝑚𝑎𝑥−𝑚𝑖𝑛)−[2(𝑏−𝑎)] 2 (3.7) 𝑎𝐴 = 𝑚𝑖𝑛 − (𝑏 − 𝑎) − [1 2(𝑐 − 𝑏)] (3.8) dengan (𝑏 − 𝑎) = (𝑏𝐴− 𝑎𝐴) = ⋯ = (𝑏𝐶− 𝑎𝐶) = (𝑑𝐴− 𝑐𝐴) = ⋯ = (𝑑𝐶− 𝑐𝐶) = (𝑑 − 𝑐). 𝑎𝐵 = 𝑐𝐴, 𝑏𝐵 = 𝑑𝐴, 𝑎𝐶 = 𝑐𝐵, 𝑏𝐶 = 𝑑𝐵.
51
Menentukan parameter-parameter pada fungsi keanggotaan trapesium untuk himpunan A yaitu 𝑎𝐴, 𝑏𝐴, 𝑐𝐴, 𝑑𝐴 adalah sebagai berikut,
(𝑏 − 𝑎) = (𝑑 − 𝑐) =𝑚𝑎𝑥 − 𝑚𝑖𝑛 4 = 1 − 0 4 = 0,25 (𝑐 − 𝑏) =(𝑚𝑎𝑥 − 𝑚𝑖𝑛) − [2(𝑏 − 𝑎)] 2 = (1 − 0) − [2(0,25)] 2 = 0,25 𝑎𝐴 = 𝑚𝑖𝑛 − (𝑏 − 𝑎) − [ 1 2(𝑐 − 𝑏)] = 0 − 0,25 − ( 1 2× 0,25) = −0,375 𝑏𝐴 = 𝑎𝐴+ 0,25 = −0,125 𝑐𝐴 = 𝑏𝐴 + 0,25 = 0,125 𝑑𝐴 = 𝑐𝐴+ 0,25 = 0,375
Fungsi keanggotaan pada himpunan A untuk 𝑥 berdasarkan Persamaan (2.30) adalah sebagai berikut,
𝜇𝐴(𝑥) = { 0; 𝑥 ≤ −0,375 𝑎𝑡𝑎𝑢 𝑥 ≥ 0,375 𝑥 + 0,375 −0,125 + 0,375; −0,375 < 𝑥 < −0,125 1; −0,125 ≤ 𝑥 ≤ 0,125 0,375 − 𝑥 0,375 − 0,125; 0,125 < 𝑥 < 0,375
Perhitungan parameter-parameter fungsi keanggotaan pada himpunan B dan C analog dengan perhitungan parameter pada himpunan A, sehingga diperoleh fungsi keanggotaan untuk himpunan B dan C berdasarkan Persamaan (2.30) adalah sebagai berikut, 𝜇𝐵(𝑥) = { 0; 𝑥 ≤ 0,125 𝑎𝑡𝑎𝑢 𝑥 ≥ 0,875 𝑥 − 0,125 0,375 − 0,125; 0,125 < 𝑥 < 0,375 1; 0,375 ≤ 𝑥 ≤ 0,625 0,875 − 𝑥 0,875 − 0,625; 0,625 < 𝑥 < 0,875
52 𝜇𝐶(𝑥) = { 0; 𝑥 ≤ 0,625 𝑎𝑡𝑎𝑢 𝑥 ≥ 1,375 𝑥 − 0,625 0,875 − 0,625; 0,625 < 𝑥 < 0,875 1; 0,875 ≤ 𝑥 ≤ 1,125 1,375 − 𝑥 1,375 − 1,125; 1,125 < 𝑥 < 1,375
Perhitungan derajat keanggotaan pada masing-masing himpunan fuzzy adalah sebagai berikut,
𝜇𝐴(0,6) = 0 𝜇𝐵(0,6) = 1 𝜇𝐶(0,6) = 0
b. K-Means Clustering untuk Menentukan Pusat dan Jarak Fungsi Basis
Algoritma K-Means Clustering adalah algoritma klasterisasi yang mengelompokkan data berdasarkan titik pusat klaster (centroid) terdekat dengan data. Tujuan dari K-Means Clustering adalah mengelompokkan data dengan memaksimalkan kemiripan data dalam satu klaster dan meminimalkan kemiripan data antar klaster. Memaksimalkan kemiripan data didapat berdasarkan jarak terpendek antara data terhadap titik pusat (centroid) (Asroni & Adrian, 2015: 78).
Algoritma metode K-Means Clustering (Johnson & Wichern, 2007: 696): 1) Tentukan partisi awal data ke dalam m-cluster.
2) Tempatkan setiap data ke dalam cluster terdekat dengan menghitung jarak antar data dan tiap-tiap cluster (perhitungan jarak biasanya menggunakan jarak
euclidean). Persamaan jarak euclidean antara dua buah titik sebarang
𝐴(𝑥1, 𝑥2, … , 𝑥𝑛) dan 𝐵(𝑦1, 𝑦2, … , 𝑦𝑛) sebagai berikut: 𝑑(𝐴, 𝐵) = √(𝑥1− 𝑦1)2+ (𝑥
53
Hitung ulang kembali nilai pusat untuk cluster yang menerima data baru dan
cluster yang kehilangan data.
3) Ulangi kembali langkah ke-2 sehingga tidak terdapat data yang berpindah
cluster.
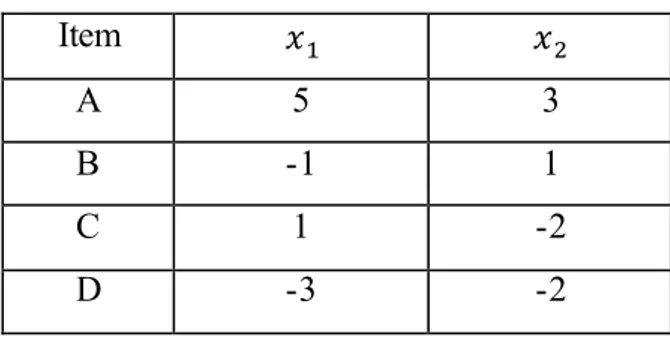
Contoh penggunaan metode K-Means Clustering: Misalkan terdapat dua variabel yaitu 𝑥1 dan 𝑥2 untuk masing-masing A, B, C, dan D. Data diberikan pada Tabel 3.1:
Tabel 3.1 Tabel Data Pengamatan
Item 𝑥1 𝑥2 A 5 3 B -1 1 C 1 -2 D -3 -2
Data pada Tabel 3.1 akan dikelompokkan menjadi 2 cluster (𝑚 = 2). Untuk mengimplementasikan K-Means Clustering dengan 2 cluster, pertama partisi item menjadi 2 cluster (AB) dan (CD), kemudian hitung pusat masing-masing cluster, seperti pada Tabel 3.2:
Tabel 3.2 Koordinat Pusat Cluster Partisi Pertama
Cluster Koordinat Pusat Cluster
𝑥1 𝑥2 (𝐴𝐵) 5 + (1) 2 = 2 3 + 1 2 = 2 (𝐶𝐷) 1 + (−3) 2 = −1 −2 + (−2) 2 = −2
54
Langkah selanjutnya adalah menghitung jarak euclidean pada Persamaan (3.9) untuk masing-masing item dari pusat cluster dan menempatkan kembali masing-masing item ke cluster terdekat. Jika terdapat item yang berpindah, maka pusat cluster dihitung kembali. Untuk koordinat ke-i, 𝑖 = 1,2, … , 𝑗 pusat cluster dihitung dengan cara:
1) Jika item ke-i ditambahkan ke dalam cluster 𝑥̅𝑖,𝑛𝑒𝑤 =
𝑛𝑥̅𝑖+𝑥𝑗𝑖
𝑛+𝑖 (3.10)
2) Jika item ke-i dihilangkan dari cluster
𝑥̅𝑖,𝑛𝑒𝑤 = 𝑛𝑥̅𝑖−𝑥𝑗𝑖
𝑛−𝑖 (3.11)
Dengan n adalah jumlah item pada cluster sebelumnya. Lalu, dilakukan perhitungan jarak euclidean tiap item terhadap masing-masing cluster dengan menggunakan Persamaan (3.9):
𝑑(𝐴, (𝐴𝐵)) = √(5 − 2)2+ (3 − 2)2= 3,162
𝑑(𝐴, (𝐶𝐷)) = √(5 + 1)2+ (3 + 2)2= 7,810
Karena jarak A dengan (AB) lebih dekat, sehingga A tetap pada cluster (AB). 𝑑(𝐵, (𝐴𝐵)) = √(−1 − 2)2+ (1 − 2)2 = 3,162
𝑑(𝐵, (𝐶𝐷)) = √(−1 + 1)2+ (1 + 2)2 = 3
Karena jarak B dengan (CD) lebih dekat, sehingga B berpindah ke cluster (CD). 𝑑(𝐶, (𝐴𝐵)) = √(1 − 2)2+ (−2 − 2)2= 4,123
𝑑(𝐶, (𝐶𝐷)) = √(1 + 1)2+ (−2 + 2)2= 2
Karena jarak C dengan (CD) lebih dekat, sehingga C tetap pada cluster (CD). 𝑑(𝐷, (𝐴𝐵)) = √(−3 − 2)2+ (−2 − 2)2 = 6,403
55 𝑑(𝐷, (𝐶𝐷)) = √(−3 + 1)2+ (−2 + 2)2 = 2
Karena jarak D dengan (CD) lebih dekat, sehingga D tetap pada cluster (CD). Berdasarkan perhitungan jarak di atas dilakukan pengelompokan kembali berdasarkan jarak minimum, diperoleh cluster yang baru yaitu (A) dan (BCD) dan menghitung kembali nilai pusat yang baru dengan Persamaan (3.10) dan (3.11) dengan nilai pusat baru pada Tabel 3.3:
Tabel 3.3 Koordinat Pusat Cluster Partisi Kedua
Cluster Koordinat Pusat Cluster
𝑥1 𝑥2 (𝐴) 2(2) − (−1) 2 − 1 = 5 2(2) − 1 2 − 1 = 3 (𝐵𝐶𝐷) 2(−1) + (−1) 2 + 1 = −1 2(−2) + 1 2 + 1 = −1
Pusat cluster baru yang terbentuk adalah 𝐴 (5,3) dan 𝐵𝐶𝐷 (−1,−1). Setelah diperoleh cluster dan pusat cluster yang baru dilakukan perhitungan jarak euclidean dan pengelompokan kembali. Pada contoh ini, perhitungan jarak euclidean dan pengelompokan kembali diperoleh hasil yang sama dengan sebelumnya (stabil) yaitu 𝐴 (5,3) dan 𝐵𝐶𝐷 (−1,−1). Selanjutnya, menghitung jarak maksimum tiap item terhadap cluster masing-masing:
𝑑(𝐴, (𝐴)) = √(5 − 5)2+ (3 − 3)2 = 0
𝑑(𝐵, (𝐵𝐶𝐷)) = √(−1 + 1)2+ (1 + 1)2 = 2
𝑑(𝐶, (𝐵𝐶𝐷)) = √(1 + 1)2 + (−2 + 1)2 = 2,236
56
Berdasarkan hasil perhitungan di atas, diperoleh jarak maksimum untuk tiap-tiap cluster adalah 0 untuk cluster (𝐴) dan 2,236 untuk cluster (𝐵𝐶𝐷).
c. Menentukan Jumlah Neuron pada Lapisan Tersembunyi
Jumlah neuron pada lapisan tersembunyi sama dengan banyaknya cluster yang digunakan pada proses clustering dengan K-Means Clustering. Untuk menentukkan jumlah neuron pada lapisan tersembunyi dari model FRBFNN dilakukan secara trial and error.
d. Menentukan bobot-bobot pada Jaringan Optimum
Penentuan bobot-bobot pada model FRBFNN yang digunakan pada tugas akhir ini menggunakan dua pendekatan yaitu mengestimasi bobot optimum menggunakan metode global ridge regression dan algoritma backpropagation. Berikut adalah estimasi bobot optimum dengan menggunakan metode global ridge
regression dan algoritma backpropagation:
1) Estimasi Bobot Optimum menggunakan Metode Global Ridge Regression Proses pembelajaran terawasi (supervised) pada model FRBFNN dari lapisan tersembunyi menuju lapisan output menggunakan metode Global Ridge
Regression. Metode Global Ridge Regression mengestimasi bobot dengan cara
menambahkan parameter regulasi yang bernilai positif (𝜆 > 0) pada Sum Square
Error (Orr, 1996:24). Estimasi bobot terbaik diperoleh dari hasil akhir dengan SSE
terkecil. Dengan menggunakan metode kuadrat terkecil (ordinary least square) akan diperoleh bobot optimum. Model linear yang digunakan adalah 𝑦 = ∑𝑚 𝑤𝑗𝜑𝑗[𝝁(𝒙)] + 𝑤0
𝑗=1
𝑆𝑆𝐸 = ∑𝑛 (𝑦𝑘− 𝑦̂𝑘)2
57 dengan
𝑛 = jumlah data pengamatan
𝑦̂𝑘 = hasil variabel output dari data ke-𝑘 𝑦𝑘 = target variabel output dari data ke-𝑘 𝑘 = 1,2,3, . . . , 𝑛.
Untuk menentukan nilai optimum bobot 𝑤𝑗, dapat ditentukan dengan
mendiferensialkan Persamaan (3.12) terhadap bobot-bobotnya sehingga diperoleh,
𝜕𝑆𝑆𝐸 𝜕 𝑤𝑗 = 2 ∑ (𝑦𝑘− 𝑦̂𝑘) 𝜕𝑦 𝜕𝑤𝑗 𝑛 𝑘=1 (3.13)
Berdasarkan Persamaan (3.5) diperoleh,
𝜕𝑦
𝜕𝑤𝑗 = 𝜑𝑗[𝝁(𝒙)] (3.14)
Persamaan (3.14) disubstitusikan ke Persamaan (3.13) dengan mengasumsikan bahwa 𝜕𝑆𝑆𝐸 𝜕 𝑤𝑗 = 0 diperoleh, 0 = 2 ∑𝑛 (𝑦𝑘− 𝑦̂𝑘)𝜑𝑗[𝝁(𝒙)] 𝑘 =1 (3.15) 0 = 2 ∑𝑛 𝑦𝑘𝜑𝑗[𝝁(𝒙)] 𝑘 =1 − 2 ∑𝑛𝑘=1𝑦̂𝑘𝜑𝑗[𝝁(𝒙)] (3.16) 2 ∑𝑛 𝑦̂𝑘𝜑𝑗[𝝁(𝒙)] 𝑘=1 = 2 ∑𝑛𝑘=1𝑦𝑘𝜑𝑗[𝝁(𝒙)] (3.17) ∑𝑛 𝑦̂𝑘𝜑𝑗[𝝁(𝒙)] 𝑘 =1 = ∑𝑛𝑘=1𝑦𝑘𝜑𝑗[𝝁(𝒙)] (3.18)
Karena, 𝑗 = 1,2, … , 𝑚 maka akan diperoleh m persamaan seperti Persamaan (3.18) untuk menentukan 𝑚 bobot. Untuk memperoleh penyelesaian tunggal, Persamaan (3.18) ditulis dalam notasi vektor diperoleh,
𝝋𝑗𝑇𝒚̂ = 𝝋 𝑗
58 𝝋𝑗 = [ 𝜑𝑗[𝝁(𝒙)]1 𝜑𝑗[𝝁(𝒙)]2 ⋮ 𝜑𝑗[𝝁(𝒙)]𝑛] ; 𝒚 = [ 𝑦1 𝑦2 ⋮ 𝑦𝑛 ] ; 𝒚̂ = [ 𝑦̂1 𝑦̂2 ⋮ 𝑦̂𝑛 ] [ 𝝋1𝑇𝒚̂ 𝝋2𝑇𝒚̂ ⋮ 𝝋𝑚𝑇𝒚̂] = [ 𝝋1𝑇𝒚 𝝋2𝑇𝒚 ⋮ 𝝋𝑚𝑇𝒚] 𝝋𝑇𝒚̂ = 𝝋𝑇𝒚 (3.20) dengan 𝝋 = [𝝋1 𝝋2 … 𝝋𝑚 𝝋𝑏𝑖𝑎𝑠] 𝝋 = [ 𝜑1[𝝁(𝒙)]1 𝜑1[𝝁(𝒙)]2 ⋮ 𝜑1[𝝁(𝒙)]𝑛 𝜑2[𝝁(𝒙)]1 𝜑2[𝝁(𝒙)]2 ⋮ 𝜑2[𝝁(𝒙)]𝑛 … … ⋱ … 𝜑𝑚[𝝁(𝒙)]1 1 𝜑𝑚[𝝁(𝒙)]2 1 ⋮ 1 𝜑𝑚[𝝁(𝒙)]𝑛 1 ]
Matriks 𝝋 adalah matriks desain. Komponen ke-k dari y saat bobot pada nilai optimum adalah (Orr, 1996: 43),
𝑦𝑘 = ∑𝑚 𝑤𝑗𝜑𝑗[𝝁(𝒙)] 𝑗=1 = 𝝋̅𝑘𝑇𝒘̂ (3.21) dengan 𝝋̅𝑘 = [ 𝜑1[𝝁(𝒙)]𝑘 𝜑2[𝝁(𝒙)]𝑘 ⋮ 𝜑𝑚[𝝁(𝒙)]𝑘 1 ] (3.22)
Akibat 𝝋𝒋 adalah salah satu kolom dari 𝝋 dan 𝝋̅𝒌𝑻 adalah satu baris dari 𝝋. Oleh
karena itu, berdasarkan Persamaan (3.21) diperoleh,
𝒚 = [ 𝑦1 𝑦2 ⋮ 𝑦𝑛 ] = [ 𝝋̅1𝑇𝒘̂ 𝝋̅2𝑇𝒘̂ ⋮ 𝝋̅𝑛𝑇𝒘̂ ] = 𝝋𝒘̂ (3.23)
59
Dengan mensubstitusikan Persamaan (3.23) ke Persamaan (3.20) maka,
𝝋𝑇𝝋𝒘̂ = 𝝋𝑇𝒚̂ (3.24) (𝝋𝑇𝝋)−1𝝋𝑇𝝋𝒘̂ = (𝝋𝑇𝝋)−1𝝋𝑇𝒚̂ (3.25)
𝒘̂ = (𝝋𝑇𝝋)−1𝝋𝑇𝒚̂ (3.26)
Selanjutnya pada persamaan SSE yaitu Persamaan (3.12) ditambahkan suatu parameter regulasi (𝜆 > 0) sehingga diperoleh suatu cost function sebagai berikut (Orr, 1996: 24): 𝐶 = ∑ (𝑦𝑘− 𝑦̂𝑘)2+ ∑ 𝜆 𝑗𝑤𝑗2 𝑚 𝑗=1 𝑛 𝑘 =1 (3.27) dengan
𝑘 = 1,2,3. . . , 𝑛, banyak data pengamatan 𝑦̂𝑘 = hasil variabel output dari data ke-𝑘 𝑦𝑘 = target variabel output dari data ke-𝑘 𝜆𝑗 = parameter regulasi
𝑤𝑗 = bobot dari neuron pada lapisan tersembunyi ke-j menuju neuron pada lapisan output
Dengan melakukan hal yang sama pada sebelumnya bobot yang optimum diperoleh dengan mendiferensialkan Persamaan (3.27) kemudian ditentukan penyelesaiannya untuk differensial sama dengan nol diperoleh (Orr, 1996: 41-43),
𝜕𝐶 𝜕𝑤𝑗 = 2 ∑ (𝑦𝑘− 𝑦̂𝑘) 𝑛 𝑘=1 𝜕𝑦 𝜕𝑤𝑗+ 2𝜆𝑗𝑤𝑗 (3.28) 𝜕𝐶 𝜕𝑤𝑗 = 2 ∑ 𝑦𝑘 𝑛 𝑘=1 𝜕𝑦 𝜕𝑤𝑗− 2 ∑ 𝑦̂𝑘 𝑛 𝑘 =1 𝜕𝑦 𝜕𝑤𝑗+ 2𝜆𝑗𝑤𝑗 (3.29)
60 Dengan mengasumsikan bahwa 𝜕𝐶
𝜕𝑤𝑗 = 0 pada Persamaan (3.29) sehingga akan
diperoleh, 0 = 2 ∑𝑛𝑘 =1𝑦𝑘 𝜕𝑦 𝜕 𝑤𝑗− 2 ∑ 𝑦̂𝑘 𝑛 𝑘 =1 𝜕𝑦 𝜕 𝑤𝑗+ 2𝜆𝑗𝑤𝑗 (3.30) 0 = ∑𝑛 𝑦𝑘 𝑘=1 𝜕𝑦 𝜕𝑤𝑗− ∑ 𝑦̂𝑘 𝑛 𝑘 =1 𝜕𝑦 𝜕 𝑤𝑗+ 𝜆𝑗𝑤𝑗 (3.31) ∑𝑛𝑘 =1𝑦̂𝑘 𝜕𝑦 𝜕𝑤𝑗 = ∑ 𝑦𝑘 𝑛 𝑘 =1 𝜕𝑦 𝜕 𝑤𝑗+ 𝜆𝑗𝑤𝑗 (3.32)
Berdasarkan Persamaan (3.5) bahwa 𝜕𝑦
𝜕𝑤𝑗 = 𝜑𝑗[𝝁(𝒙)], maka berdasarkan
Persamaan (3.32) diperoleh, ∑𝑛 𝑦̂𝑘
𝑘 =1 𝜑𝑗[𝝁(𝒙)] = ∑𝑛𝑘=1𝑦𝑘𝜑𝑗[𝝁(𝒙)] + 𝜆𝑗𝑤̂𝑗 (3.33)
Karena, 𝑗 = 1,2, … , 𝑚 maka akan diperoleh m persamaan seperti Persamaan (3.33) untuk menentukan 𝑚 bobot. Untuk memperoleh penyelesaian tunggal, Persamaan (3.33) ditulis dalam notasi vektor diperoleh,
𝝋𝑗𝑇𝒚̂ = 𝝋 𝑗 𝑇𝒚 + 𝜆 𝑗𝑤̂𝑗 (3.34) 𝝋𝑗 = [ 𝜑𝑗[𝝁(𝒙)]1 𝜑𝑗[𝝁(𝒙)]2 ⋮ 𝜑𝑗[𝝁(𝒙)]𝑛] ; 𝒚 = [ 𝑦1 𝑦2 ⋮ 𝑦𝑛 ] ; 𝒚̂ = [ 𝑦̂1 𝑦̂2 ⋮ 𝑦̂𝑛 ] [ 𝝋1𝑇𝒚̂ 𝝋2𝑇𝒚̂ ⋮ 𝝋𝑚𝑇 𝒚̂] = [ 𝝋1𝑇𝒚 𝝋2𝑇𝒚 ⋮ 𝝋𝑚𝑇 𝒚] + [ 𝜆1𝑤̂1 𝜆2𝑤̂2 ⋮ 𝜆𝑚𝑤̂𝑚 ] 𝝋𝑇𝒚̂ = 𝝋𝑇𝒚 + 𝚲𝒘̂ (3.35)
61 dengan 𝚲 = [ 𝜆1 0 … 0 0 𝜆2 … 0 ⋮ 0 ⋮ 0 ⋱ … ⋮ 𝜆𝑚+1 ] dan 𝝋 = [𝝋1 𝝋2 … 𝝋𝑚 𝝋𝒃𝒊𝒂𝒔] 𝝋 = [ 𝜑1[𝝁(𝒙)]1 𝜑1[𝝁(𝒙)]2 ⋮ 𝜑1[𝝁(𝒙)]𝑛 𝜑2[𝝁(𝒙)]1 𝜑2[𝝁(𝒙)]2 ⋮ 𝜑2[𝝁(𝒙)]𝑛 … … ⋱ … 𝜑𝑚[𝝁(𝒙)]1 1 𝜑𝑚[𝝁(𝒙)]2 1 ⋮ 1 𝜑𝑚[𝝁(𝒙)]𝑛 1 ]
Matriks 𝝋 adalah matriks desain. Komponen ke-k dari y saat bobot pada nilai optimum adalah (Orr, 1996: 43),
𝑦𝑘 = ∑𝑚 𝑤𝑗𝜑𝑗[𝝁(𝒙)] 𝑗=1 = 𝝋̅𝑘𝑇𝒘̂ (3.36) dengan 𝝋̅𝑘 = [ 𝜑1[𝝁(𝒙)]𝑘 𝜑2[𝝁(𝒙)]𝑘 ⋮ 𝜑𝑚[𝝁(𝒙)] 𝑘 1 ] (3.37)
Akibat 𝝋𝒋 adalah salah satu kolom dari 𝝋 dan 𝝋̅𝒌𝑻 adalah satu baris dari 𝝋. Oleh
karena itu, berdasarkan Persamaan (3.36) diperoleh,
𝒚 = [ 𝑦1 𝑦2 ⋮ 𝑦𝑛 ] = [ 𝝋̅1𝑇𝒘̂ 𝝋̅2𝑇𝒘̂ ⋮ 𝝋̅𝑛𝑇𝒘̂ ] = 𝝋𝒘̂ (3.38)
Dengan mensubstitusikan Persamaan (3.38) ke Persamaan (3.35) diperoleh,
𝝋𝑇𝝋𝒘̂ + 𝚲𝒘̂ = 𝝋𝑇𝒚̂ (3.39)
62
𝒘̂ = (𝝋𝑇𝝋 + 𝚲)−𝟏𝝋𝑇𝒚̂ (3.41)
𝒘̂ = (𝝋𝑇𝝋 + 𝜆𝑰
𝒎+𝟏)−𝟏𝝋𝑇𝒚̂ (3.42)
Persamaan (3.42) merupakan bentuk persamaan normal untuk bobot-bobot optimum yang diperoleh dari metode global ridge regression.
Selain itu, pada model FRBFNN menggunakan kriteria pemilihan model untuk memprediksi error. Model terbaik dipilih berdasarkan nilai prediksi error terkecil. Generalized Cross-Validation (GCV) merupakan salah satu kriteria pemilihan model. GCV melibatkakan semua penyesuaian rata-rata mse (mean
square error) pada data training (Orr, 1996: 20). Berikut ini rumus kriteria
pemilihan model dengan GCV.
𝜎̂𝐺𝐶𝑉2 = 𝑛𝒚̂𝑻𝑷2𝒚̂
(𝑡𝑟𝑎𝑐𝑒((𝑷))2 (3.43)
dan
𝑷 = 𝑰𝑛 − 𝝋(𝝋𝑇𝝋)−1𝝋𝑇 (3.44)
𝝋 = matriks fungsi aktivasi 𝑛 = banyak data pengamatan 𝑷 = matriks proyeksi
𝒚̂ = vektor hasil variabel output
2) Estimasi Bobot Optimum menggunakan Algoritma Backpropagation
Backpropagation merupakan algoritma pembelajaran terawasi (supervised learning). Pembelajaran backpropagation pada jaringan mampu mengatur
bobot-bobot jaringan sehingga diakhir pelatihan akan memberikan bobot-bobot yang baik. Pembelajaran backpropagation meliputi 3 fase. Fase pertama adalah fase maju
63
(feedforward). Pola masukan dihitung maju mulai dari lapisan input menuju lapisan
output. Pada model FRBFNN yang menjadi lapisan input dalam pembelajaran
backpropagation yaitu hasil fungsi aktivasi pada lapisan tersembunyi pada model
FRBFNN. Fase kedua adalah fase mundur. Selisih antara keluaran jaringan dengan target yang diinginkan merupakan kesalahan (error) yang terjadi. Fase ketiga adalah modifikasi bobot untuk menurunkan error yang terjadi.
Berikut ini adalah algoritma backpropagation yang digunakan pada model FRBFNN:
Langkah 0 : Inisialisasi semua bobot dengan bilangan acak terkecil.
Langkah 1 : Jika kondisi penghentian belum terpenuhi, maka lakukan langkah 2-7.
Langkah 2 : Untuk setiap nilai fungsi aktivasi 𝜑𝑗 pada lapisan tersembunyi lakukan langkah 3-6.
Fase Maju:
Langkah 3 : Setiap neuron input (𝜑𝑗, 𝑗 = 1,2,3, . . , 𝑚) menerima sinyal dan meneruskan ke neuron pada lapisan output.
Langkah 4 : Menghitung semua output jaringan di pada lapisan output (𝑦𝑘, 𝑘 = 1,2,3, … , 𝑛).
𝑦_𝑖𝑛𝑘 = ∑𝑚 𝜑𝑗𝑤𝑗
𝑗=1 + 𝑤0 (3.45)
𝑦𝑘 = 𝑓(𝑦_𝑖𝑛𝑘) (3.46) Fase Mundur:
Langkah 5 : Menghitung kesalahan (error) dari neuron output di masing-masing neuron output (𝑦𝑘, 𝑘 = 1,2,3, … , 𝑛)
64
𝛿𝑘= (𝑡𝑘 − 𝑦𝑘)𝑓′(𝑦_𝑖𝑛𝑘) (3.47) Menghitung perubahan bobot 𝑤𝑗
∆𝑤𝑗= 𝛼𝛿𝑘𝜑𝑗 (3.48) Menghitung perubahan bobot 𝑤0
∆𝑤0 = 𝛼𝛿𝑘 (3.49) dan mengirimkan 𝛿𝑘 ke neuron pada lapisan tersembunyi.
Memperbaharui Bobot dan Bias:
Langkah 6 : setiap neuron output (𝑦𝑘, 𝑘 = 1,2,3, . . . , 𝑛) memperbaharui bobot
dan biasnya (𝑘 = 1,2,3,. . . , 𝑛), (𝑗 = 0,1,2,3, … , 𝑚)
𝑤𝑗(𝑏𝑎𝑟𝑢) = 𝑤𝑗(𝑙𝑎𝑚𝑎) + ∆𝑤𝑗 (3.50) Langkah 7 : Kondisi pembelajaran berhenti.
B. Prosedur Pembentukan Model Fuzzy Radial Basis Neural Network (FRBFNN) dengan Preprocessing Citra untuk Deteksi Dini Kanker Paru
Berikut ini adalah prosedur pemodelan Fuzzy Radial Basis Function Neural
Network (FRBFNN) untuk deteksi dini kanker paru:
1. Preprocessing Citra
Preprocessing citra merupakan proses pengolahan citra yang bertujuan untuk
memperbaiki kualitas citra dengan menghilangkan noise, memperhalus citra, mempertajam citra, pemotongan citra, resize, menghilangkan background citra dan mengubah citra berwarna menjadi citra grayscale ataupun citra biner. Pada tugas akhir ini, preprocessing yang dilakukan adalah pemotongan citra, kemudian mengubah citra ke bentuk citra grayscale selanjutnya melakukan operasi
65
transformasi pada citra dengan menggunakan filter high frequency emphasis dan pada tahap akhir preprocessing citra dilakukan histogram equalization. Proses
preprocessing citra ini dilakukan dengan bantuan software Photoshop CS6 dan
program Matlab R2013a.
2. Ekstraksi Fitur pada Citra
Setelah melakukan preprocessing citra langkah selanjutnya yaitu melakukan ekstraksi fitur. Ekstraksi fitur merupakan satu karakteristik terpenting yang dapat digunakan untuk mengidentifikasi objek atau daerah suatu citra yang diamati. Gray
Level Co-occurrence Matrix (GLCM) adalah salah satu metode untuk
mengekstraksi second-order statistical. Terdapat 5 fitur yang digunakan pada tugas akhir ini yaitu energy (𝑥1), contrast (𝑥2), correlation (𝑥3), inverse difference
moment (𝑥4), entropy (𝑥5). Proses ekstraksi fitur ini dilakukan dengan
menggunakan bantuan program Matlab R2013a. 3. Pembagian Data
Pembagian data input pada jaringan saraf tiruan dibagi menjadi 2, yaitu data
training dan data testing. Data training digunakan untuk melatih jaringan dalam
mengenali informasi yang diberikan. Sedangkan, data testing merupakan data yang akan digunakan untuk menguji tingkat keakuratan model jaringan dalam mengolah informasi yang telah diberikan. Terdapat beberapa komposisi data training dan data
testing yang digunakan dalam jaringan saraf tiruan (Hota, Shrivas, & Singhai, 2013:
165):
a. 60% keseluruhan data sebagai data training dan 40% keseluruhan data sebagai data testing,
66
b. 75% keseluruhan data sebagai data training dan 25% keseluruhan data sebagai data testing,
c. 80% keseluruhan data sebagai data training dan 20% keseluruhan data sebagai data testing.
4. Menentukan Variabel Input dan Variabel Output
Variabel input model Fuzzy Radial Basis Function Neural Network (FRBFNN) yang digunakan pada lapisan input fitur adalah 5 fitur hasil ekstraksi citra yang diperoleh dari metode GLCM yaitu, Energy (𝑥1), Contrast (𝑥2),
Correlation (𝑥3), Inverse Difference Moment (𝑥4), Entropy (𝑥5). Sehingga banyak
neuron pada lapisan input adalah 5 neuron.
Variabel output pada model FRBFNN pada tugas akhir ini adalah hasil diagnosa citra radiography paru yaitu normal dan kanker. Sehingga banyak neuron pada lapisan output adalah 1 neuron. Target jaringan yang digunakan adalah diagnosa citra radiography paru yaitu normal dan kanker.
5. Pembelajaran Fuzzy Radial Basis Function Neural Network (FRBFNN) Pembelajaran FRBFNN terbagi menjadi 4 bagian. Pada bagian pertama, menentukan banyaknya neuron pada lapisan input fuzzy. Jumlah neuron pada lapisan input fuzzy ditentukan dengan melakukan proses fuzzifikasi. Pada proses
fuzzifikasi dilakukan dengan menggunakan beberapa fungsi keanggotaan. Pada
penelitian tugas akhir ini menggunakan fungsi keanggotan trapesium. Fungsi keanggotaan trapesium digunakan karena memberikan hasil terbaik dalam mendefinisikan himpunan fuzzy pada masing-masing input fitur.
67
Proses fuzzifikasi dilakukan pada masing-masing variabel input yaitu 𝑥1, 𝑥2, 𝑥3, 𝑥4, 𝑥5. Pada langkah awal proses fuzzifikasi yaitu mengidentifikasi himpunan semesta dari 𝑥1, 𝑥2, 𝑥3, 𝑥4, 𝑥5. Himpunan semesta pada variabel input yaitu nilai mininum dan nilai maksimum yang diperoleh dari 5 fitur hasil ekstraksi citra yang meliputi keseluruhan data training dan data testing. Setelah mengidentifikasi himpunan semesta pada variabel input, langkah selanjutnya yaitu menentukan parameter-parameter dari fungsi keanggotaan trapesium dan diperoleh derajat keanggotaan untuk tiap-tiap himpunan fuzzy. Masing-masing variabel input didefinisikan menjadi 3 himpunan fuzzy dengan fungsi keanggotaan trapesium. Proses mendefinisikan himpunan tegas ke himpunan fuzzy dilakukan dengan bantuan program Matlab R2013a.
function y = trapmf(x, params) dengan,
y = bilangan fuzzy, 𝑦 ∈ [0 1] x = bilangan crisp
params = parameter-parameter pada fungsi keanggotaan trapesium (𝑎, 𝑏, 𝑐, 𝑑)
Pada bagian kedua, menentukan pusat dan jarak pada fungsi aktivasi
gaussian. Penentuan pusat cluster dan jarak maksimum masing-masing cluster
menggunakan metode K-Means Clustering. Metode K-Means Clustering dilakukan dengan menggunakan bantuan software Minitab.
Pembelajaran FRBFNN pada bagian ketiga yaitu menentukan jumlah neuron pada lapisan tersembunyi. Jumlah neuron pada lapisan tersembunyi ditentukan
68
berdasarkan banyaknya cluster yang terbentuk pada metode K-Means Clustering. Pada lapisan tersembunyi FRBFNN menggunakan fungsi aktivasi, fungsi aktivasi yang digunakan berupa fungsi radial basis Gaussian. Pada tugas akhir ini aktivasi fungsi basis dilakukan dengan bantuan Matlab R2013a. Berikut ini fungsi
rbfDesign pada Matlab R2013a.
function H = rbfDesign(X, C, R, options) dengan,
H = matriks desain FRBFNN X = matriks data input
C = matriks pusat cluster
R = matrisk jarak input terhadap pusat cluster options = tipe fungsi aktivasi
Pada bagian keempat dari pembelajaran FRBFNN yaitu menentukan bobot-bobot yang menghubungkan antara lapisan tersembunyi dan lapisan output. Pada tugas akhir ini menggunakan dua pendekatan dalam menentukan bobot-bobot tersebut. Pada pendekatan yang pertama menggunakan metode global ridge
regression dengan pemilihan kriteria model menggunakan kriteria Global Cross-Validation (GCV). Metode global ridge regression dilakukan dengan bantuan
Matlab R2013a. Berikut ini fungsi globalRidge pada Matlab 2013a. function l = globalRidge(H, T, 0.05) dengan,
l = parameter regulasi H = matriks desain FRBFNN
69 T = matriks target data training 0.05 = nilai estimasi parameter regulasi
Pada pendekatan yang kedua yaitu menggunakan algoritma backpropagation. Input yang digunakan pada algoritma backpropagation adalah nilai-nilai fungsi aktivasi pada lapisan tersembunyi. Pada algoritma backpropagation juga menggunakan suatu fungsi aktivasi. Jenis fungsi aktivasi yang digunakan adalah fungsi identitas. Sebelum melakukan pembelajaran backpropagation, parameter-parameter pembelajaran perlu diatur terlebih dahulu. Terdapat beberapa fungsi pembelajaran yang dapat digunakan salah satunya adalah gradient descent with
momentum and adaptive learning rate (traingdx). Berikut ini parameter yang harus
diatur pada fungsi pembelajaran traingdx (Kusumadewi, 2004: 151-152): a. Maksimum Epoh
Maksimum epoh adalah jumlah epoh maksimum yang dilakukan selama proses pembelajaran. Iterasi akan dihentikan apabila nilai epoh melebihi maksimum epoh. Perintah pada Matlab R2013a adalah,
net.trainParam.epochs=MaxEpoh
Nilai maksimum epoh yang digunakan adalah 5000. Pemilihan nilai maksimum epoh sebesar 5000 untuk mempercepat proses pembelajaran.
b. Kinerja Tujuan
Kinerja tujuan adalah target nilai fungsi kinerja. Iterasi akan berhenti apabila nilai fungsi tujuan kurang dari atau sama dengan kinerja tujuan. Perintah pada Matlab R2013a adalah
70
Nilai kinerja tujuan yang digunakan adalah 1 × 10−2. Pemilihan nilai kinerja tujuan
sebesar 1 × 10−2 untuk memperoleh error model yang cukup kecil.
c. Maksimum Kenaikan Kinerja
Maksimum kenaikan kinerja adalah nilai maksimum kenaikan error yang diijinkan, antara error saat ini dan error sebelumnya. Jika perbandingan antara
error pembelajaran yang baru dengan error pembelajaran lama melebihi
maksimum kenaikan kinerja, maka bobot-bobot akan diabaikan. Sebaliknya, jika perbandingannya kurang dari maksimum kenaikan kinerja, maka bobot-bobot akan dipertahankan. Perintah pada Matlab R2013a adalah
net.trainParam.max_perf_inc=MaxPerfInc
Nilai maksimum kenaikan kinerja yang digunakan adalah 1,0. Pemilihan nilai maksimum kenaikan kinerja sebesar 1,0 untuk memperoleh bobot-bobot optimum. d. Learning rate
Learning rate adalah laju pembelajaran. Semakin besar nilai learning rate
akan berakibat pada semakin besarnya langkah pembelajaran. Jika learning rate diatur terlalu besar, maka algoritma akan menjadi tidak stabil. Perintah pada Matlab R2013a adalah
net.trainParam.lr=LearningRate
Nilai learning rate yang digunakan pada tugas akhir ini adalah 0,1. Pemilihan nilai
71 e. Rasio untuk menaikkan learning rate
Rasio ini berguna sebagai faktor pengali untuk menaikkan learning rate apabila learning rate yang ada terlalu rendah untuk mencapai kekonvergenan. Perintah pada Matlab R2013a adalah
net.trainParam.lr_inc=IncLearningRate
Nilai rasio yang digunakan adalah 1,2. Pemilihan nilai rasio kenaikan
learning rate sebesar 1,2 untuk mencapai kekonvergenan yang lebih cepat.
f. Rasio untuk menurunkan learning rate
Rasio ini berguna sebagai faktor pengali untuk menurunkan learning rate, apabila learning rate yang ada terlalu tinggi dan menuju ketidakstabilan. Perintah pada Matlab R2013a adalah
net.trainParam.lr_dec=DecLearningRate
Nilai rasio yang digunakan adalah 0,6. Pemilihan nilai rasio penurunan
learning rate sebesar 0,6 untuk mencapai kekonvergenan yang lebih cepat.
g. Momentum
Momentum adalah konstanta yang mempengaruhi besarnya perubahan bobot, yang bernilai antara 0 sampai 1. Jika nilai Momentum = 0, maka perubahan bobot hanya akan dipengaruhi oleh gradiennya. Jika nilai Momentum = 1, maka perubahan bobot akan sama dengan perubahan bobot selamanya. Perintah pada Matlab R2013a adalah
net.trainParam.mc=Momentum
Nilai momentum yang digunakan adalah 0,8. Pemilihan nilai momentum sebesar 0,8 untuk memperoleh bobot-bobot optimum.
72 h. Jumlah Epoh yang ditunjukkan
Parameter ini menunjukkan berapa jumlah epoh berselang yang akan ditunjukkan kemajuannya. Perintah pada Matlab R2013a adalah
net.trainParam.show=Epohshow
Nilai epoh yang akan ditunjukkan kemajuannya adalah 500. Pemilihan nilai epoh yang ditunjukkan sebesar 500 untuk melihat perubahan error setiap 500 epoh yang telah dijalankan.
6. Menentukan Jaringan Optimum
Jaringan optimum pada FRBFNN diperoleh dengan metode trial and error. Metode ini dilakukan untuk membandingkan nilai akurasi tertinggi yang diperoleh berdasarkan jumlah neuron pada lapisan tersembunyi. Jumlah neuron pada lapisan tersembunyi didapatkan dari banyaknya cluster yang digunakan pada metode
K-Means clustering.
Berdasarkan prosedur pendeteksian dini kanker paru menggunakan model FRBFNN adalah preprocessing citra radiography dengan cara melakukan operasi transformasi menggunakan filter high frequency emphasis dan histogram
equalization. Selanjutnya, melakukan ekstraksi fitur dengan menggunakan metode Gray Level Co-occurrence Matrix (GLCM) untuk memperoleh 5 parameter sebagai
input yaitu energy, contrast, correlation, inverse difference moment, dan entropy. Setelah itu, membagi data menjadi 2 bagian yaitu 80% dari keseluruhan data adalah data training dan 20% dari keseluruhan data adalah data testing. Variabel input yang digunakan adalah 5 parameter hasil ekstraksi fitur dan variabel output adalah diagnosa dari citra radiography. Pada pembelajaran FRBFNN terbagi menjadi 4
73
tahap, yaitu melakukan fuzzifikasi dari 5 parameter ekstraksi citra dengan menggunakan fungsi keanggotaan trapesium, menentukan nilai pusat dan jarak fungsi aktivasi gaussian dengan menggunakan K-Means clustering, menentukan jumlah neuron pada lapisan tersembunyi, dan menentukkan bobot-bobot jaringan dengan menggunakan dua pendekatan yaitu metode Global Ridge Regression dan algoritma Backpropagation, maka diperoleh diagram alir pada Gambar 3.2 untuk prosedur pemodelan FRBFNN dalam mendeteksi dini kanker paru sebagai berikut,
74
C. Hasil Model Fuzzy Radial Basis Function Neural Network (FRBFNN) dengan Preprocessing Citra untuk Deteksi Dini Kanker Paru
Fuzzy Radial Basis Function Neural Network (FRBFNN) adalah salah satu
model yang dapat digunakan untuk mendeteksi dini kanker paru. Pada tugas akhir ini menggunakan citra foto Radiography paru-paru yang diperoleh dari digital
image database yang tersedia pada Japanese Society of Radiography Technology
(JSRT). Masing-masing citra radiography berukuran 2048x2048 pixel dengan format Disk Image File (IMG). Data yang digunakan pada tugas akhir ini berjumlah 100 citra yang terdiri dari 48 citra radiography paru-paru normal dan 52 citra
radiography paru-paru kanker untuk data selengkapnya terdapat pada Lampiran (1)
halaman 115. Langkah-langkah mendeteksi dini kanker paru menggunakan model
Fuzzy Radial Basis Function Neural Network (FRBFNN) adalah sebagai berikut.
1. Preprocessing Citra
Preprocessing citra yang digunakan berupa pemotongan citra, kemudian
mengubah citra ke bentuk citra grayscale selanjutnya melakukan preprocessing citra pada domain frekuensi menggunakan filter high frequency emphasis dan pada tahap akhir preprocessing citra dilakukan histogram equalization. Selain itu, karena format citra berupa Disk Image File (IMG) dibutuhkan program bantuan yaitu
ImageJ untuk mengubah format citra ke bentuk Joint Photographic Experts Group
(JPEG atau JPG). a. Pemotongan Citra
Proses pemotongan citra radiography dilakukan dengan bantuan software Photoshop CS6. Hasil dari pemotongan citra radiography selengkapnya terdapat
75
pada Lampiran (1) halaman 115. Berikut ini adalah contoh hasil dari pemotongan citra yang dilakukan.
b. Perbaikan kualitas citra
Setelah melakukan pemotongan citra, citra yang telah dipotong akan dilakukan proses perbaikan kualitas citra. Proses ini meliputi filter high frequency
emphasis dan histogram equalization. Script M-File Matlab R2013a selengkapnya
dapat dilihat pada Lampiran (2) halaman 120. Pada Gambar 3.4(a) menunjukkan hasil setelah dilakukan pemotongan citra dan pada Gambar 3.4(b) menunjukkan spektrum fourier pada citra (a). Sedangkan pada Gambar 3.6(a) merupakan citra hasil filter high frequency emphasis dan pada Gambar 3.7(a) merupakan citra hasil dilakukan histogram equalization.
(a) (b)
Gambar 3.3 Pemotongan citra radiography N1.jpg; (a) N1.jpg sebelum dipotong, (b) N1.jpg setelah dipotong
(a) (b)
Gambar 3.4 Perbaikan kualitas citra radiography N1.jpg; (a) N1.jpg setelah dilakukan pemotongan citra; (b) Spektrum Fourier dari citra (a);
(c) Histogram dari citra (a).
76
2. Ektraksi Fitur pada Citra
Langkah selanjutnya setelah melakukan preprocessing citra radiography paru-paru adalah dilakukan ekstraksi fitur citra. Ekstraksi fitur yang digunakan adalah metode Gray Level Co-occurrence Matrix (GLCM). Proses ekstraksi citra dilakukan untuk memperoleh 5 parameter yang akan digunakan sebagai input pada jaringan. Script M-file Matlab R2013a untuk ekstraksi citra ini terdapat pada
(a) (b)
Gambar 3.5 Filter Highpass; (a) Filter Butterworth Highpass; (b) Filter
High Frequency Emphasis
(a) (b) (c)
Gambar 3.6 Perbaikan kualitas citra radiography N1.jpg; (a) N1.jpg setelah dilakukan Filter High Frequency Emphasis; (b) Spektrum Fourier
dari citra (a); (c) Histogram dari citra (a).
(a) (b)
Gambar 3.7 Perbaikan kualitas citra radiography N1.jpg; (a) N1.jpg setelah dilakukan Histogram Equalization; (b) Histogram dari citra (a).
77
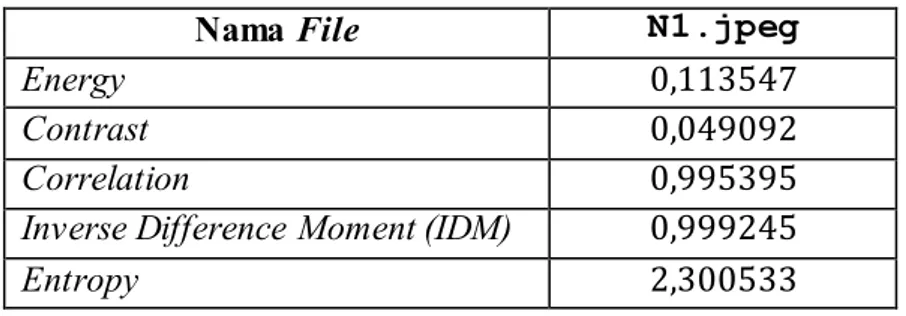
Lampiran (2) halaman 120, sedangkan untuk hasil ektraksi fitur citra secara lengkap terdapat pada Lampiran (3) halaman 121. Berikut adalah contoh hasil ekstraksi fitur citra radiography N1.jpg yang ditunjukkan pada Tabel 3.4.
Tabel 3.4 Hasil Ekstraksi Citra N1.jpg
Nama File N1.jpeg
Energy 0,113547
Contrast 0,049092
Correlation 0,995395
Inverse Difference Moment (IDM) 0,999245
Entropy 2,300533
3. Pembagian Data
Pada tugas akhir ini menggunakan pembagian data yaitu 80% dari data keseluruhan sebagai data training dan 20% dari data keseluruhan sebagai data
testing. Oleh karena itu, dari 100 data radiography dibagi menjadi data training
sebanyak 80 data dan data testing sebanyak 20 data. Hasil pembagian input terdapat pada Lampiran (4) halaman 125 dan Lampiran (5) halaman 129.
4. Menentukan Variabel Input dan Variabel Output
Variabel input pada model FRBFNN yang digunakan adalah hasil 5 parameter yang diperoleh dari ekstraksi fitur citra radiography. Parameter yang digunakan sebagai input adalah Energy (𝑥1), Contrast (𝑥2), Correlation (𝑥3),
Inverse Difference Moment (𝑥4), Entropy (𝑥5). Sehingga jumlah neuron pada lapisan input fitur sebanyak 5 neuron.
Variabel output pada model FRBFNN yang digunakan adalah hasil diagnosa dari citra radiography paru-paru, yaitu dengan satu variabel output, sehingga jumlah neuron pada lapisan output adalah satu neuron. Target jaringan yang
78
digunakan adalah diagnosa masing-masing citra radiography yaitu normal dan kanker, sehingga target dan output jaringan yaitu 1 untuk diagnosa citra
radiography normal, dan 2 untuk diagnosa citra radiography kanker. Variabel
output menggunakan satu variabel yang dibagi menjadi 2 selang untuk penentuan hasil diagnosa dengan kriteria pengelompokkan sebagai berikut,
a. Jika output (𝑦𝑘) bernilai 𝑦𝑘< 1,500 maka dianggap 1, sehingga hasil diagnosa normal.
b. Jika output (𝑦𝑘) bernilai 𝑦𝑘≥ 1,500 maka dianggap 2, sehingga hasil diagnosa kanker.
5. Pembelajaran FRBFNN
Pada tahap awal pembelajaran FRBFNN adalah melakukan proses fuzzifikasi pada masing-masing input fitur. Fuzzifikasi input fitur menggunakan fungsi keanggotaan trapesium. Sebelum melakukan fuzzifikasi dari 5 input fitur, terlebih dahulu mengidentifikasi himpunan semesta (𝑈) tiap-tiap input fitur. Selanjutnya, menentukan parameter-parameter pada masing-masing himpunan fuzzy. Hasil
fuzzifikasi input fitur berupa derajat keanggotaan dari masing-masing himpunan fuzzy. Hasil selengkapnya untuk derajat keanggotaan masing-masing himpunan fuzzy terdapat pada Lampiran (6) halaman 130 dan Lampiran (7) halaman134.
Berikut ini adalah himpunan semesta (𝑈) dan himpunan fuzzy dari 5 input fitur. a. Energy (𝑥1)
Himpunan semesta untuk input fitur energy (𝑥1) adalah nilai minimum dan nilai maksimum dari fitur energy yaitu 0,102417 dan 0,11606 maka himpunan semesta untuk fitur energy (𝑥1) adalah 𝑈𝑥
79
energy (𝑥1) didefinisikan menjadi 3 himpunan fuzzy yaitu 𝐴1, 𝐴2, dan 𝐴3. Berikut ini 3 himpunan fuzzy untuk input fitur energy (𝑥1),
𝜇𝐴 1(𝑥) = { 0; 𝑥 ≤ 0,09628 𝑎𝑡𝑎𝑢 𝑥 ≥ 0,1086 𝑥 − 0,09628 0,1017 − 0,09628; 0,09628 < 𝑥 < 0,1017 1; 0,1017 ≤ 𝑥 ≤ 0,1031 0,1086 − 𝑥 0,1086 − 0,1031; 0,1031 < 𝑥 < 0,1086 𝜇𝐴 2(𝑥) = { 0; 𝑥 ≤ 0,1031 𝑎𝑡𝑎𝑢 𝑥 ≥ 0,1154 𝑥 − 0,1031 0,1086 − 0,1031; 0,1031 < 𝑥 < 0,1086 1; 0,1086 ≤ 𝑥 ≤ 0,1099 0,1154 − 𝑥 0,1154 − 0,1099; 0,1099 < 𝑥 < 0,1154 𝜇𝐴3(𝑥) = { 0; 𝑥 ≤ 0,1099 𝑎𝑡𝑎𝑢 𝑥 ≥ 0,1222 𝑥 − 0,1099 0,1154 − 0,1099; 0,1099 < 𝑥 < 0,1154 1; 0,1154 ≤ 𝑥 ≤ 0,1167 0,1222 − 𝑥 0,1222 − 0,1167; 0,1167 < 𝑥 < 0,1222
Nilai fitur energy (𝑥1) berdasarkan hasil ekstraksi untuk citra N1.jpg adalah 𝑥1 = 0,113547. Maka, perhitungan derajat keanggotaan pada masing-masing himpunan fuzzy untuk fitur energy adalah sebagai berikut,
𝜇𝐴 1(0,113547) = 0; 𝜇𝐴 2(0,113547) = 0,1154−0,113547 0,1154−0,1099 = 0,336946; 𝜇𝐴 3(0,113547) = 0.113547−0,1099 0,1154 −0,1099 = 0,663054; b. Contrast (𝑥2)
Himpunan semesta untuk input fitur contrast (𝑥2) adalah nilai minimum dan nilai maksimum dari fitur contrast yaitu 0,038619 dan 0,107859 maka himpunan
80 semesta untuk fitur contrast (𝑥2) adalah 𝑈𝑥
2 = [0,038619 0,107859]. Input fitur
contrast (𝑥2) didefinisikan menjadi 3 himpunan fuzzy yaitu 𝐵1, 𝐵2, dan 𝐵3. Berikut ini 3 himpunan fuzzy untuk input fitur contrast (𝑥2),
𝜇𝐵 1(𝑥) = { 0; 𝑥 ≤ 0,007461 𝑎𝑡𝑎𝑢 𝑥 ≥ 0,06978 𝑥 − 0,007461 0,03516 − 0,007461; 0,007461 < 𝑥 < 0,03516 1; 0,03516 ≤ 𝑥 ≤ 0,04208 0,06978 − 𝑥 0,06978 − 0,04208; 0,04208 < 𝑥 < 0,06978 𝜇𝐵 2(𝑥) = { 0; 𝑥 ≤ 0,04208 𝑎𝑡𝑎𝑢 𝑥 ≥ 0,1044 𝑥 − 0,04208 0,06978 − 0,04208; 0,04208 < 𝑥 < 0,06978 1; 0,06978 ≤ 𝑥 ≤ 0,0767 0,1044 − 𝑥 0,1044 − 0,0767; 0,0767 < 𝑥 < 0,1044 𝜇𝐵 3(𝑥) = { 0; 𝑥 ≤ 0,0767 𝑎𝑡𝑎𝑢 𝑥 ≥ 0,139 𝑥 − 0,0767 0,1044 − 0,0767; 0,0767 < 𝑥 < 0,1044 1; 0,1044 ≤ 𝑥 ≤ 0,1113 0,139 − 𝑥 0,139 − 0,1113; 0,1113 < 𝑥 < 0,139
Nilai fitur contrast (𝑥2) berdasarkan hasil ekstraksi untuk citra N1.jpg adalah 𝑥2= 0,049092. Maka, perhitungan derajat keanggotaan pada masing-masing himpunan fuzzy untuk fitur contrast adalah sebagai berikut,
𝜇𝐵 1(0,049092) = 0,06978 − 0,049092 0,06978 − 0,04208 = 0,746848; 𝜇𝐵 2(0,049092) = 0,049092 − 0,04208 0,06978 − 0,04208 = 0,253152; 𝜇𝐵 3(0,049092) = 0;
81 c. Correlation (𝑥3)
Himpunan semesta untuk input fitur correlation (𝑥3) adalah nilai minimum dan nilai maksimum dari fitur correlation yaitu 0,989876 dan 0,996391 maka himpunan semesta untuk fitur contrast (𝑥3) adalah 𝑈𝑥
3 = [0,989876 0,996391]. Input fitur correlation (𝑥3) didefinisikan menjadi 3 himpunan fuzzy yaitu 𝐶1, 𝐶2, dan 𝐶3. Berikut ini 3 himpunan fuzzy untuk input fitur correlation (𝑥3),
𝜇𝐶 1(𝑥) = { 0; 𝑥 ≤ 0,9869 𝑎𝑡𝑎𝑢 𝑥 ≥ 0,9928 𝑥 − 0,9869 0,9896 − 0,9869; 0,9869 < 𝑥 < 0,9896 1; 0,9896 ≤ 𝑥 ≤ 0,9902 0,9928 − 𝑥 0,9928 − 0,9902; 0,9902 < 𝑥 < 0,9928 𝜇𝐶 2(𝑥) = { 0; 𝑥 ≤ 0,9902 𝑎𝑡𝑎𝑢 𝑥 ≥ 0,9961 𝑥 − 0,9902 0,9928 − 0,9902; 0,9902 < 𝑥 < 0,9928 1; 0,9928 ≤ 𝑥 ≤ 0,9935 0,9961 − 𝑥 0,9961 − 0,9935; 0,9935 < 𝑥 < 0,9961 𝜇𝐶3(𝑥) = { 0; 𝑥 ≤ 0,9935 𝑎𝑡𝑎𝑢 𝑥 ≥ 0,9993 𝑥 − 0,9935 0,9961 − 0,9935; 0,9935 < 𝑥 < 0,9961 1; 0,9961 ≤ 𝑥 ≤ 0,9967 0,9993 − 𝑥 0,9993 − 0,9967; 0,9967 < 𝑥 < 0,9993
Nilai fitur correlation (𝑥3) berdasarkan hasil ekstraksi untuk citra N1.jpg adalah 𝑥3= 0,995395. Maka, perhitungan derajat keanggotaan pada masing-masing himpunan fuzzy untuk fitur correlation adalah sebagai berikut,
𝜇𝐶 1(0,995395) = 0; 𝜇𝐶 2(0,995395) = 0,995395 − 0,9935 0,9961 − 0,9935 = 0,271218;
82 𝜇𝐶
3(0,995395) =
0,9961 − 0,995395
0,9961 − 0,9935 = 0,728782; d. Inverse Difference Moment (𝑥4)
Himpunan semesta untuk input fitur inverse difference moment (𝑥4) adalah nilai minimum dan nilai maksimum dari fitur inverse difference moment yaitu 0,998347 dan 0,999406 maka himpunan semesta untuk fitur contrast (𝑥4) adalah 𝑈𝑥
4 = [0,998347 0,999406]. Input fitur inverse difference moment (𝑥4) didefinisikan menjadi 3 himpunan fuzzy yaitu 𝐷1, 𝐷2, dan 𝐷3. Berikut ini 3 himpunan fuzzy untuk input fitur inverse difference moment (𝑥4),
𝜇𝐷 1(𝑥) = { 0; 𝑥 ≤ 0,9979 𝑎𝑡𝑎𝑢 𝑥 ≥ 0,9988 𝑥 − 0,9979 0,9983 − 0,9979; 0,9979 < 𝑥 < 0,9983 1; 0,9983 ≤ 𝑥 ≤ 0,9984 0,9988 − 𝑥 0,9988 − 0,9984; 0,9984 < 𝑥 < 0,9988 𝜇𝐷 2(𝑥) = { 0; 𝑥 ≤ 0,9984 𝑎𝑡𝑎𝑢 𝑥 ≥ 0,9994 𝑥 − 0,9984 0,9988 − 0,9984; 0,9984 < 𝑥 < 0,9988 1; 0,9988 ≤ 𝑥 ≤ 0,9989 0,9994 − 𝑥 0,9994 − 0,9989; 0,9989 < 𝑥 < 0,9994 𝜇𝐷 3(𝑥) = { 0; 𝑥 ≤ 0,9989 𝑎𝑡𝑎𝑢 𝑥 ≥ 0,9999 𝑥 − 0,9989 0,9994 − 0,9989; 0,9989 < 𝑥 < 0,9994 1; 0,9994 ≤ 𝑥 ≤ 0,9995 0,9999 − 𝑥 0,9999 − 0,9994; 0,9995 < 𝑥 < 0,9999
Nilai fitur inverse difference moment (𝑥4) berdasarkan hasil ekstraksi untuk citra N1.jpg adalah 𝑥4= 0,999245. Maka, perhitungan derajat keanggotaan pada masing-masing himpunan fuzzy untuk fitur inverse difference moment adalah sebagai berikut,
83 𝜇𝐷 1(0,999245) = 0; 𝜇𝐷 2(0,999245) = 0,9994 − 0,999245 0,9994 − 0,9989 = 0,310533; 𝜇𝐷3(0,999245) = 0,999245 − 0,9989 0,9994 − 0,9989 = 0,689467; e. Entropy (𝑥5)
Himpunan semesta untuk input fitur entropy (𝑥5) adalah nilai minimum dan nilai maksimum dari fitur entropy yaitu 2, 261654 dan 2,448185 maka himpunan semesta untuk fitur entropy (𝑥5) adalah 𝑈𝑥
5= [2,261654 2,448185]. Input fitur
entropy (𝑥5) didefinisikan menjadi 3 himpunan fuzzy yaitu 𝐸1, 𝐸2, dan 𝐸3. Berikut ini 3 himpunan fuzzy untuk input fitur entropy (𝑥5),
𝜇𝐸 1(𝑥) = { 0; 𝑥 ≤ 2,178 𝑎𝑡𝑎𝑢 𝑥 ≥ 2,346 𝑥 − 2,178 2,252 − 2,178; 2,178 < 𝑥 < 2,252 1; 2,252 ≤ 𝑥 ≤ 2,271 2,346 − 𝑥 2,346 − 2,271; 2,271 < 𝑥 < 2,346 𝜇𝐸 2(𝑥) = { 0; 𝑥 ≤ 2,271 𝑎𝑡𝑎𝑢 𝑥 ≥ 2,439 𝑥 − 2,271 2,346 − 2,271; 2,271 < 𝑥 < 2,346 1; 2,346 ≤ 𝑥 ≤ 2,364 2,439 − 𝑥 2,439 − 2,364; 2,364 < 𝑥 < 2,439 𝜇𝐸 3(𝑥) = { 0; 𝑥 ≤ 2,364 𝑎𝑡𝑎𝑢 𝑥 ≥ 2,532 𝑥 − 2,364 2,439 − 2,364; 2,364 < 𝑥 < 2,439 1; 2,439 ≤ 𝑥 ≤ 2,458 2,532 − 𝑥 2,532 − 2,458; 2,458 < 𝑥 < 2,532
84
Nilai fitur entropy (𝑥5) berdasarkan hasil ekstraksi untuk citra N1.jpg adalah 𝑥5= 2,300533. Maka, perhitungan derajat keanggotaan pada masing-masing himpunan fuzzy untuk fitur contrast adalah sebagai berikut,
𝜇𝐸1(2,300533) = 2,346 − 2,300533 2,346 − 2,271 = 0,606227; 𝜇𝐸 2(2,300533) = 2,300533 − 2,271 2,346 − 2,271 = 0,393773; 𝜇𝐸 3(2,300533) = 0;
Pada tahap kedua pembelajaran FRBFNN adalah proses pembelajaran tak terawasi (unsupervised learning). Proses pembelajaran tak terawasi pada model FRBFNN menggunakan metode K-Means Clustering. Setelah melakukan proses
clustering akan diperoleh nilai pusat dan jarak maksimum dari masing-masing cluster. Nilai pusat dan jarak maksimum digunakan dalam perhitungan fungsi
aktivasi pada lapisan tersembunyi. Nilai pusat dan jarak maksimum dari hasil proses Means Clustering terdapat pada Lampiran (8) halaman 135. Proses
K-Means Clustering dilakukan dengan bantuan software Minitab.
Selanjutnya, pada tahap ketiga pembelajaran FRBFNN adalah menentukan jumlah neuron pada lapisan tersembunyi. Jumlah neuron pada lapisan tersembunyi sama dengan jumlah cluster yang digunakan pada metode K-Means Clustering. Penentuan jumlah neuron pada lapisan tersembunyi secara trial and error.
Pada tahap keempat pembelajaran FRBFNN adalah menentukan bobot-bobot yang menghubungkan neuron pada lapisan tersembunyi menuju lapisan output. FRBFNN akan melakukan pembelajaran terawasi (supervised learning) untuk memperoleh bobot optimal. Metode global ridge regression dan algoritma
85
backpropagation merupakan dua metode pembelajaran terawasi yang digunakan
untuk menentukan bobot. Dari 2 metode pembelajaran terawasi yang digunakan akan dibandingkan dan hasil yang terbaik akan digunakan untuk menentukan bobot-bobot pada model FRBFNN.
6. Menentukan Jaringan Optimum
Proses selanjutnya adalah mengoptimalkan jaringan dan mengoptimalkan bobot-bobot pada jaringan. Untuk memperoleh jaringan yang optimum, dilakukan dengan menentukan banyak neuron pada lapisan tersembunyi secara trial and error. Jaringan optimum ditunjukkan dengan tingkat keakuratan model FRBFNN terbaik dalam mendeteksi dini kanker paru. Script M-file pemrograman Matlab R2013a untuk model FRBFNN terdapat pada Lampiran (9) halaman 136 dan Lampiran (10) halaman 138. Pada tugas akhir penelitian ini juga akan membandingkan hasil deteksi dini kanker paru menggunakan model RBFNN dan FRBFNN. Berikut ini hasil nilai persentase akurasi dari proses model RBFNN dan FRBFNN,
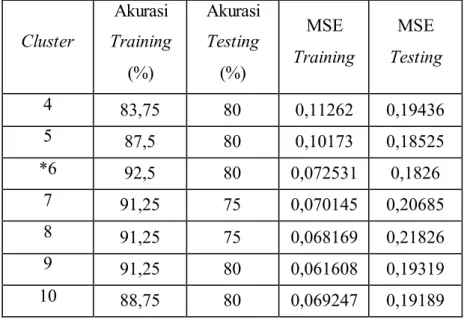
Tabel 3.5 Persentase Akurasi Model RBFNN Metode Global Ridge Regression
Cluster Akurasi Training (%) Akurasi Testing (%) MSE Training MSE Testing 4 83,75 80 0,11262 0,19436 5 87,5 80 0,10173 0,18525 *6 92,5 80 0,072531 0,1826 7 91,25 75 0,070145 0,20685 8 91,25 75 0,068169 0,21826 9 91,25 80 0,061608 0,19319 10 88,75 80 0,069247 0,19189
86 Cluster Akurasi Training (%) Akurasi Testing (%) MSE Training MSE Testing 11 88,75 80 0,066912 0,17408 12 90 80 0,070342 0,18854 13 90 80 0,067546 0,20454 14 90 80 0,067307 0,20196 15 91,25 80 0,073949 0,21452 16 91,25 80 0,073949 0,21452
Keterangan: *) Model Terbaik
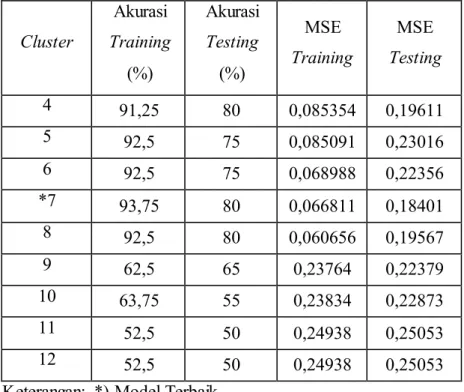
Pada Tabel 3.5 yang merupakan hasil persentase akurasi model RBFNN metode global ridge regression, terlihat bahwa persentase akurasi model tertinggi terdapat pada cluster 6 yaitu 92,5% untuk data training dengan nilai MSE sebesar 0,072531 dan 80% untuk data testing dengan nilai MSE sebesar 0,1826. Berdasarkan Tabel 3.5 menunjukkan bahwa persentase akurasi data training mengalami peningkatan pada cluster 4 sampai dengan 6, namun mulai menunjukkan penurunan pada cluster 6 sampai dengan 11. Sedangkan, nilai persentase akurasi pada data testing tidak menunjukkan kenaikan ataupun penurunan yang signifikan pada cluster 4 sampai dengan 16.
Pada model RBFNN metode global ridge regression nilai persentase akurasi data training dan testing terbaik diperoleh dengan cluster sebanyak 6, sehingga jaringan dengan jumlah neuron pada lapisan tersembunyi sebanyak 6 menghasilkan jaringan yang optimum.
87
Tabel 3.6 Persentase Akurasi Model RBFNN Metode Algoritma
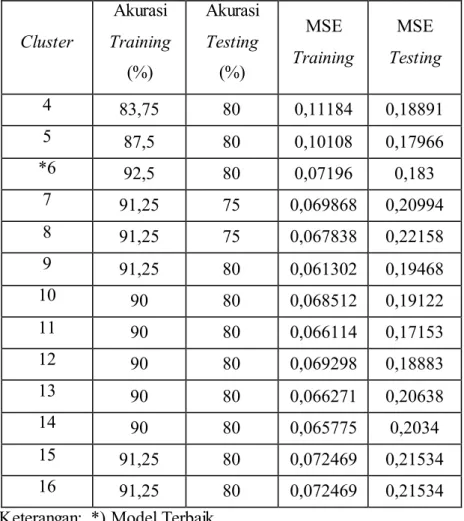
Backpropagation Cluster Akurasi Training (%) Akurasi Testing (%) MSE Training MSE Testing 4 83,75 80 0,11184 0,18891 5 87,5 80 0,10108 0,17966 *6 92,5 80 0,07196 0,183 7 91,25 75 0,069868 0,20994 8 91,25 75 0,067838 0,22158 9 91,25 80 0,061302 0,19468 10 90 80 0,068512 0,19122 11 90 80 0,066114 0,17153 12 90 80 0,069298 0,18883 13 90 80 0,066271 0,20638 14 90 80 0,065775 0,2034 15 91,25 80 0,072469 0,21534 16 91,25 80 0,072469 0,21534
Keterangan: *) Model Terbaik
Berdasarkan Tabel 3.6 yang merupakan hasil persentase akurasi model RBFNN metode algoritma backpropagation, terlihat bahwa persentase akurasi tertinggi terdapat pada cluster 6 yaitu 92,5% untuk data training dengan nilai MSE sebesar 0,07196 dan 80% untuk data testing dengan nilai MSE sebesar 0,183. Berdasarkan Tabel 3.6 menunjukkan bahwa persentase akurasi data training mengalami peningkatan pada cluster 4 sampai dengan 6, namun mulai menunjukkan penurunan pada cluster 6 sampai dengan 11. Sedangkan, nilai persentase akurasi pada data testing tidak menunjukkan kenaikan ataupun penurunan yang signifikan pada cluster 4 sampai dengan 16.
88
Pada model RBFNN metode algoritma backpropagation nilai persentase akurasi data training dan testing terbaik diperoleh dengan cluster sebanyak 6, sehingga jaringan dengan jumlah neuron pada lapisan tersembunyi sebanyak 6 menghasilkan jaringan yang optimum.
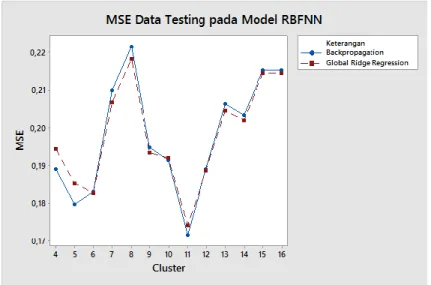
Pada Gambar 3.8 dan Gambar 3.9 menunjukkan grafik perbedaan MSE data
training pada model RBFNN dan MSE data testing pada model RBFNN.
Gambar 3.8 Perbedaan MSE Data Training pada Model RBFNN