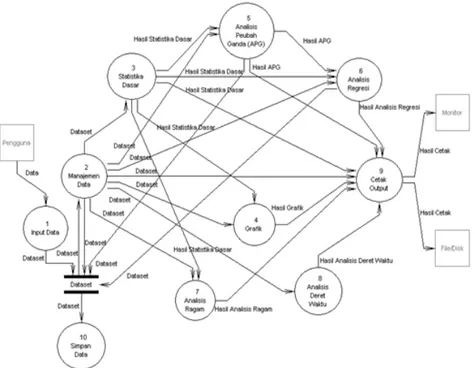
Gambar 3 Diagram aliran data level 1. menjadi input untuk proses 2. Proses 2
dapat didekomposisi menjadi Proses 2.1 Pilih Dataset Aktif, Proses 2.2 Edit Dataset Aktif, Proses 2.3 Kalkulator, Proses 2.4 Bangkitkan Bilangan Acak, dan Proses 2.5 Pilih Peubah. Setelah pengguna memilih peubah, maka dataset telah siap digunakan untuk analisis. Proses manajemen data ini ditampilkan pada Lampiran 2. Data yang telah diolah dalam sistem kemudian dapat disimpan melalui dua proses, yaitu Proses 10.1 Ekspor Dataset dan Proses 10.2 Simpan Dataset (Lampiran 3).
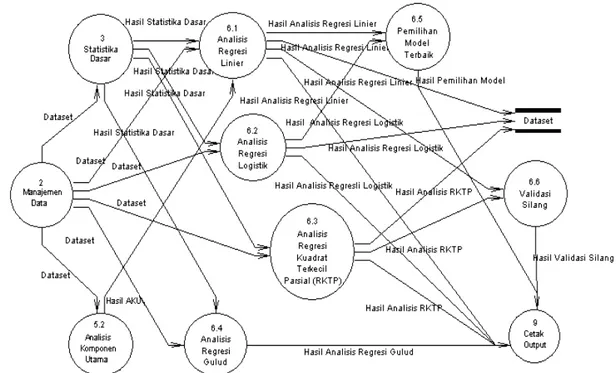
Aliran data pada Proses 5 Analisis Regresi dijelaskan oleh Gambar 4. Proses 6.2 Analisis Regresi Logistik didekomposisi lagi menjadi Proses 6.2.1 Regresi Logistik Biner, Proses 6.2.2 Regresi Logistik Ordinal, dan Proses 6.2.3 Regresi Logistik Multinomial (Lampiran 4). Kemudian Proses 6.2.1 dan Proses 6.2.2 akan masuk ke Proses 6.2.4 Fungsi Penghubung. Proses 6.2.4 ini didekomposisi kembali menjadi tiga fungsi penghubung, yaitu logit, probit dan complementary log-log yang disajikan dalam Lampiran 5. Setelah menentukan fungsi penghubung, data yang masuk dapat langsung dianalisis baik melalui prosedur pemilihan model regresi terbaik (stepwise, forward, dan
backward) ataupun tidak (Lampiran 6). Nilai sisaan, nilai peluang respons, dan nilai dugaan kategori respons hasil analisis regresi logistik kemudian disimpan dalam dataset. Proses 5.7 Analisis Regresi Kuadrat Terkecil Parsial didekomposisi kembali berdasarkan empat algoritma yang biasa digunakan, yaitu algoritma kernel, wide kernel, SIMPLS dan orthogonal scores atau biasa dikenal dengan NIPALS. Proses ini dijelaskan pada Lampiran 7. Analisis regresi komponen utama melibatkan keluaran dari analisis komponen utama yang merupakan bagian dari proses analisis peubah ganda. Nilai akar ciri dan vektor ciri yang dihasilkan dari analisis komponen utama akan digunakan dalam analisis regresi linier untuk melakukan analisis regresi komponen utama. Selanjutnya pengguna dapat langsung mencetak hasil analisis regresi kuadrat terkecil parsial dan hasil analisis regresi komponen utama atau melakukan Proses 6.6 Validasi Silang. Ada dua jenis validasi silang yang digunakan, yaitu buang satu amatan dan buang lebih dari satu amatan (Lampiran 8). Nilai dugaan respons, sisaan, skor X dan skor Y dari analisis regresi komponen utama dan analisis regresi kuadrat terkecil parsial tersimpan dalam dataset.
Gambar 3 Diagram aliran data level 1. menjadi input untuk proses 2. Proses 2
dapat didekomposisi menjadi Proses 2.1 Pilih Dataset Aktif, Proses 2.2 Edit Dataset Aktif, Proses 2.3 Kalkulator, Proses 2.4 Bangkitkan Bilangan Acak, dan Proses 2.5 Pilih Peubah. Setelah pengguna memilih peubah, maka dataset telah siap digunakan untuk analisis. Proses manajemen data ini ditampilkan pada Lampiran 2. Data yang telah diolah dalam sistem kemudian dapat disimpan melalui dua proses, yaitu Proses 10.1 Ekspor Dataset dan Proses 10.2 Simpan Dataset (Lampiran 3).
Aliran data pada Proses 5 Analisis Regresi dijelaskan oleh Gambar 4. Proses 6.2 Analisis Regresi Logistik didekomposisi lagi menjadi Proses 6.2.1 Regresi Logistik Biner, Proses 6.2.2 Regresi Logistik Ordinal, dan Proses 6.2.3 Regresi Logistik Multinomial (Lampiran 4). Kemudian Proses 6.2.1 dan Proses 6.2.2 akan masuk ke Proses 6.2.4 Fungsi Penghubung. Proses 6.2.4 ini didekomposisi kembali menjadi tiga fungsi penghubung, yaitu logit, probit dan complementary log-log yang disajikan dalam Lampiran 5. Setelah menentukan fungsi penghubung, data yang masuk dapat langsung dianalisis baik melalui prosedur pe milihan model regresi terbaik (stepwise, forward, dan
backward) ataupun tidak (Lampiran 6). Nilai sisaan, nilai peluang respons, dan nilai dugaan kategori respons hasil analisis regresi logistik kemudian disimpan dalam dataset. Proses 5.7 Analisis Regresi Kuadrat Terkecil Parsial didekomposisi kembali berdasarkan empat algoritma yang biasa digunakan, yaitu algoritma kernel, wide kernel, SIMPLS dan orthogonal scores atau biasa dikenal dengan NIPALS. Proses ini dijelaskan pada Lampiran 7. Analisis regresi komponen utama melibatkan keluaran dari analisis komponen utama yang merupakan bagian dari proses analisis peubah ganda. Nilai akar ciri dan vektor ciri yang dihasilkan dari analisis komponen utama akan digunakan dalam analisis regresi linier untuk melakukan analisis regresi komponen utama. Selanjutnya pengguna dapat langsung mencetak hasil analisis regresi kuadrat terkecil parsial dan hasil analisis regresi komponen utama atau melakukan Proses 6.6 Validasi Silang. Ada dua jenis validasi silang yang digunakan, yaitu buang satu amatan dan buang lebih dari satu amatan (Lampiran 8). Nilai dugaan respons, sisaan, skor X dan skor Y dari analisis regresi komponen utama dan analisis regresi kuadrat terkecil parsial tersimpan dalam dataset.
Gambar 3 Diagram aliran data level 1. menjadi input untuk proses 2. Proses 2
dapat didekomposisi menjadi Proses 2.1 Pilih Dataset Aktif, Proses 2.2 Edit Dataset Aktif, Proses 2.3 Kalkulator, Proses 2.4 Bangkitkan Bilangan Acak, dan Proses 2.5 Pilih Peubah. Setelah pengguna memilih peubah, maka dataset telah siap digunakan untuk analisis. Proses manajemen data ini ditampilkan pada Lampiran 2. Data yang telah diolah dalam sistem kemudian dapat disimpan melalui dua proses, yaitu Proses 10.1 Ekspor Dataset dan Proses 10.2 Simpan Dataset (Lampiran 3).
Aliran data pada Proses 5 Analisis Regresi dijelaskan oleh Gambar 4. Proses 6.2 Analisis Regresi Logistik didekomposisi lagi menjadi Proses 6.2.1 Regresi Logistik Biner, Proses 6.2.2 Regresi Logistik Ordinal, dan Proses 6.2.3 Regresi Logistik Multinomial (Lampiran 4). Kemudian Proses 6.2.1 dan Proses 6.2.2 akan masuk ke Proses 6.2.4 Fungsi Penghubung. Proses 6.2.4 ini didekomposisi kembali menjadi tiga fungsi penghubung, yaitu logit, probit dan complementary log-log yang disajikan dalam Lampiran 5. Setelah menentukan fungsi penghubung, data yang masuk dapat langsung dianalisis baik melalui prosedur pe milihan model regresi terbaik (stepwise, forward, dan
backward) ataupun tidak (Lampiran 6). Nilai sisaan, nilai peluang respons, dan nilai dugaan kategori respons hasil analisis regresi logistik kemudian disimpan dalam dataset. Proses 5.7 Analisis Regresi Kuadrat Terkecil Parsial didekomposisi kembali berdasarkan empat algoritma yang biasa digunakan, yaitu algoritma kernel, wide kernel, SIMPLS dan orthogonal scores atau biasa dikenal dengan NIPALS. Proses ini dijelaskan pada Lampiran 7. Analisis regresi komponen utama melibatkan keluaran dari analisis komponen utama yang merupakan bagian dari proses analisis peubah ganda. Nilai akar ciri dan vektor ciri yang dihasilkan dari analisis komponen utama akan digunakan dalam analisis regresi linier untuk melakukan analisis regresi komponen utama. Selanjutnya pengguna dapat langsung mencetak hasil analisis regresi kuadrat terkecil parsial dan hasil analisis regresi komponen utama atau melakukan Proses 6.6 Validasi Silang. Ada dua jenis validasi silang yang digunakan, yaitu buang satu amatan dan buang lebih dari satu amatan (Lampiran 8). Nilai dugaan respons, sisaan, skor X dan skor Y dari analisis regresi komponen utama dan analisis regresi kuadrat terkecil parsial tersimpan dalam dataset.
Gambar 4 Diagram aliran data level 2 proses 1. Implementasi Sistem
Implementasi sistem menggunakan program R.2.11.1 dan beberapa paket tambahan lainnya untuk menjalankan fungsi -fungsi pada Pakar 2.0. Tabel 1 menunjukkan paket-paket yang diperlukan untuk menjalankan Pakar 2.0. Paket standar adalah paket yang sudah tersedia dalam program R. Sedangkan paket tambahan adalah paket yang harus diunduh melalui http://CRAN.R-Project.org.
Tabel 1. Paket-paket yang dibutuhkan untuk menjalankan Pakar 2.0
No. Paket standar Paket tambahan
1. tcltk tkrplot 2. stats RODBC 3. foreign R2HTML 4. MASS car 5. nnet nortest 6. tseries 7. pls
Pakar 2.0 tersusun oleh pilihan menu di bagian atas dan jendela hasil di bagian bawah menu untuk menampilkan keluaran. Pakar 2.0 terdiri atas lima menu utama yaitu Menu File, Menu Edit, Menu Data, Menu Statistika, dan Menu Bantuan. Lingkungan utama dan skema menu Pakar 2.0 disajikan pada Lampiran 9.
Menu File
Menu File terdiri atas delapan submenu yaitu:
1. Buat Dataset Baru
Submenu ini digunakan untuk memasukkan data ke dalam sistem secara langsung. Sebelum membuat dataset baru, pengguna harus memberi nama untuk dataset tersebut.
2. Memuat Dataset
Submenu ini digunakan untuk memuat dataset yang telah disimpan dalam file R dengan ekstensi .rda atau .rdata. Namun fungsi ini tidak dapat digunakan untuk memuat dataset yang tersimpan pada paket R tambahan.
3. Impor Dataset
Submenu ini terdiri atas lima fungsi yaitu “SPSS”, “.csv (,)”, “.csv (;)”, “Ms. Excel” dan “Ms. Access”. Fungsi-fungsi tersebut memungkinkan pengguna untuk mengimpor dataset dari file SPSS (.sav dan .por), Ms. Excel (.xls, .xlsx, dan .csv), dan Ms. Access (.mdb dan .accdb). Impor data dengan ekstensi .csv dapat digunakan untuk mengimpor file dengan pembatas “,” dan “;”. Sebelum mengimpor data, pengguna harus memberi nama untuk dataset yang akan diimpor data tersebut. Gambar 4 Diagram aliran data level 2 proses 1.
Implementasi Sistem
Implementasi sistem menggunakan program R.2.11.1 dan beberapa paket tambahan lainnya untuk menjalankan fungsi -fungsi pada Pakar 2.0. Tabel 1 menunjukkan paket-paket yang diperlukan untuk menjalankan Pakar 2.0. Paket standar adalah paket yang sudah tersedi a dalam program R. Sedangkan paket tambahan adalah paket yang harus diunduh melalui http://CRAN.R-Project.org.
Tabel 1. Paket-paket yang dibutuhkan untuk menjalankan Pakar 2.0
No. Paket standar Paket tambahan
1. tcltk tkrplot 2. stats RODBC 3. foreign R2HTML 4. MASS car 5. nnet nortest 6. tseries 7. pls
Pakar 2.0 tersusun oleh pilihan menu di bagian atas dan jendela hasil di bagian bawah menu untuk menampilkan keluaran. Pakar 2.0 terdiri atas lima menu utama yaitu Menu File, Menu Edit, Menu Data, Menu Statistika, dan Menu Bantuan. Lingkungan utama dan skema menu Pakar 2.0 disajikan pada Lampiran 9.
Menu File
Menu File terdiri atas delapan submenu yaitu:
1. Buat Dataset Baru
Submenu ini digunakan untuk memasukkan data ke dalam sistem secara langsung. Sebelum membuat dataset baru, pengguna harus memberi nama untuk dataset tersebut.
2. Memuat Dataset
Submenu ini digunakan untuk memuat dataset yang telah disimpan dalam file R dengan ekstensi .rda atau .rdata. Namun fungsi ini tidak dapat digunakan untuk memuat dataset yang tersimpan pada paket R tambahan.
3. Impor Dataset
Submenu ini terdiri atas lima fungsi yaitu “SPSS”, “.csv (,)”, “.csv (;)”, “Ms. Excel” dan “Ms. Access”. Fungsi-fungsi tersebut memungkinkan pengguna untuk mengimpor dataset dari file SPSS (.sav dan .por), Ms. Excel (.xls, .xlsx, dan .csv), dan Ms. Access (.mdb dan .accdb). Impor data dengan ekstensi .csv dapat digunakan untuk mengimpor file dengan pembatas “,” dan “;”. Sebelum mengimpor data, pengguna harus memberi nama untuk dataset yang akan diimpor data tersebut. Gambar 4 Diagram aliran data level 2 proses 1.
Implementasi Sistem
Implementasi sistem menggunakan program R.2.11.1 dan beberapa paket tambahan lainnya untuk menjalankan fungsi -fungsi pada Pakar 2.0. Tabel 1 menunjukkan paket-paket yang diperlukan untuk menjalankan Pakar 2.0. Paket standar adalah paket yang sudah tersedi a dalam program R. Sedangkan paket tambahan adalah paket yang harus diunduh melalui http://CRAN.R-Project.org.
Tabel 1. Paket-paket yang dibutuhkan untuk menjalankan Pakar 2.0
No. Paket standar Paket tambahan
1. tcltk tkrplot 2. stats RODBC 3. foreign R2HTML 4. MASS car 5. nnet nortest 6. tseries 7. pls
Pakar 2.0 tersusun oleh pilihan menu di bagian atas dan jendela hasil di bagian bawah menu untuk menampilkan keluaran. Pakar 2.0 terdiri atas lima menu utama yaitu Menu File, Menu Edit, Menu Data, Menu Statistika, dan Menu Bantuan. Lingkungan utama dan skema menu Pakar 2.0 disajikan pada Lampiran 9.
Menu File
Menu File terdiri atas delapan submenu yaitu:
1. Buat Dataset Baru
Submenu ini digunakan untuk memasukkan data ke dalam sistem secara langsung. Sebelum membuat dataset baru, pengguna harus memberi nama untuk dataset tersebut.
2. Memuat Dataset
Submenu ini digunakan untuk memuat dataset yang telah disimpan dalam file R dengan ekstensi .rda atau .rdata. Namun fungsi ini tidak dapat digunakan untuk memuat dataset yang tersimpan pada paket R tambahan.
3. Impor Dataset
Submenu ini terdiri atas lima fungsi yaitu “SPSS”, “.csv (,)”, “.csv (;)”, “Ms. Excel” dan “Ms. Access”. Fungsi-fungsi tersebut memungkinkan pengguna untuk mengimpor dataset dari file SPSS (.sav dan .por), Ms. Excel (.xls, .xlsx, dan .csv), dan Ms. Access (.mdb dan .accdb). Impor data dengan ekstensi .csv dapat digunakan untuk mengimpor file dengan pembatas “,” dan “;”. Sebelum mengimpor data, pengguna harus memberi nama untuk dataset yang akan diimpor data tersebut.
4. Ekspor Dataset
Submenu ini terdiri atas empat fungsi yaitu “SPSS”, “.csv (,)”, “.csv (;)”, dan “Ms. Excel 2003”. Fungsi-fungsi tersebut memungkinkan pengguna untuk mengekspor dataset aktif ke file SPSS (.sps) dan Ms. Excel 2003 (.xls dan .csv). Ekspor data dengan ekstensi .csv dapat digunakan untuk mengekspor file dengan pembatas “,” dan “;”.
5. Simpan Dataset
Submenu simpan dataset digunakan untuk menyimpan dataset hasil input langsung atau dataset hasil pengolahan data dengan Pakar 2.0. Dataset tersebut akan tersimpan dengan ekstensi .rda atau .rdata.
6. Simpan Hasil
Submenu ini digunakan untuk menyimpan keluaran yang terdapat pada je ndela hasil dalam bentuk teks dengan ekstensi .txt. Selain itu hasil juga dapat disimpan dengan ekstensi .doc.
7. Hasil HTML
Submenu ini digunakan untuk menampilkan keluaran yang dicetak ke jendela hasil dalam format HTML. Fungsi ini aktif jika tombol cek “Tampilkan Output HTML” dan direktori folder terisi. Jika fungsi ini aktif maka setiap pengguna mencetak keluaran ke jendela hasil, keluaran tersebut juga akan ditampilkan oleh browser yang terdapat pada komputer pengguna.
8. Keluar
Submenu ini digunakan untuk keluar dari Pakar 2.0.
Menu Edit
Menu edit terdiri atas tujuh submenu untuk melakukan edit pada jendela hasil. Ketujuh submenu tersebut antara lain :
1. Cut
Submenu ini digunakan untuk mengirimkan objek yang terpilih pada jendela hasil ke clipboard sistem komputer dan menghapus objek yang terpilih pada jendela hasil.
2. Salin
Submenu ini digunakan untuk mengirimkan objek yang terpilih pada jendela hasil ke clipboard sistem komputer. Fungsi ini biasanya digunakan untuk menyalin objek yang terpilih. 3. Paste
Submenu ini digunakan untuk menampilkan objek yang ada pada clipboard sistem komputer ke jendela
hasil. Fungsi ini biasanya digunakan untuk menampilkan objek yang sudah disalin. 4. Hapus
Submenu ini digunakan untuk menghapus objek yang terpilih pada jendela hasil. 5. Undo
Submenu ini digunakan untuk mengembalikan tampilan jendela hasil ke tampilan sebelum tampilan terakhir. 6. Pilih Semua
Submenu ini digunakan untuk memilih semua objek yang ada pada jendela hasil. 7. Bersihkan Jendela
Submenu ini digunakan untuk menghapus semua objek yang ada pada jendela hasil. Untuk menggunakan fungsi pada menu edit, pengguna harus mengaktifkan kursor pada jendela hasil. Fungsi-fungsi dalam menu ini mempunyai kegunaan yang sama dengan fungsi klik kanan pada jendela hasil.
Menu Data
Menu data merupakan menu untuk memodifikasi, memilih, melihat, mengedit, dan mencetak dataset. Menu ini dapat dijalankan jika terdapat dataset aktif pada program. Submenu dalam menu data antara lain:
1. Pilih Dataset Aktif
Submenu pilih dataset aktif digunakan untuk memilih dataset mana yang akan digunakan, sehingga memungkinkan pengguna untuk memiliki lebih dari satu dataset dalam sistem.
2. Lihat Dataset Aktif
Submenu ini digunakan untuk melihat dataset aktif.
3. Edit Dataset Aktif
Submenu ini digunakan untuk mengedit data atau menambahkan data baru pada dataset aktif.
4. Kalkulator
Submenu kalkulator terdiri atas perhitungan aritmatika standar (+, -, *, /, ^), operator perbandingan (>, <, >=, <=, !=), operator logika (&, |), serta beberapa fungsi lain yang tersedia dalam program R. Submenu ini memungkinkan pengguna untuk melakukan modifikasi data.
5. Bangkitkan Bilangan Acak
Submenu ini digunakan untuk membangkitkan bilangan acak dari sebaran seragam, sebaran binomial, dan sebaran normal.
6. Cetak Dataset Aktif
Submenu ini digunakan untuk mencetak dataset aktif yang kemudian ditampilkan pada jendela hasil.
Menu Statistika
Menu statistika adalah menu utama dalam Pakar 2.0 yang berisi fungsi -fungsi untuk melakukan analisis regresi dan perhitungan statistika dasar. Menu ini terdiri atas dua submenu, yaitu statistika dasar dan analisis regresi. Submenu statistika dasar terdiri atas perhitungan korelasi, perhit ungan kovarian, dan uji kenormalan. Submenu analisis regresi terdiri atas sembilan sub-submenu, yaitu plot pengepasan garis, analisis regresi linier, analisis regresi bertatar, analisis regresi komponen utama, analisis regresi gulud, analisis regresi logistik biner, analisis regresi logistik ordinal, analisis regresi logistik multinomial, dan analisis regresi kuadrat terkecil parsial. Sesuai dengan ruang lingkup dalam karya ilmiah ini, maka yang akan dibahas lebih lanjut adalah enam sub -submenu terakhir:
1. Regresi Komponen Utama
Sub-submenu ini merupakan fungsi untuk mengatasi masalah multikolinieritas pada regresi linier berganda menggunakan analisis komponen utama. Sub -submenu ini memanfaatkan paket pls. Pengguna harus memasukkan peubah respons dan peubah prediktor terlebih dahulu. Peubah prediktor minimal terdiri atas dua peubah. Pengguna dapat menentukan berapa jumlah komponen yang akan disertakan dalam model dengan mengetikkan jumlah komponen yang diinginkan.
Input data yang digunakan adalah matriks X dan matriks Y. Matriks X adalah matriks yang setiap kolomnya merupakan peubah prediktor dan berukuran (n x p). Sedangakan matriks Y adalah matriks peubah respons berukuran (n x 1). Hasil dari fungsi ini adalah nilai proporsi keragaman, nilai loading, nil ai skor, RMSEP, R2, MSEP, koefisien regresi, serta plot-plot regresi komponen utama. Nilai skor X dari regresi komponen utama tersimpan dalam dataset aktif. Plot yang dihasilkan dalam fungsi ini antara lain plot R2, plot RMSEP, plot MSEP, plot prediksi, plot koefisien, plot skor, plot loading, biplot skor X vs loading X, dan biplot loading X vs loading Y. Kotak dialog untuk fungsi ini disajikan pada Lampiran 10. Berikut adalah sintaks R yang digunakan untuk melakukan analisis regresi komponen utama (misalka n jumlah komponen = 1):
rku <- mvr(Y ~ X, ncomp = 1, data = Data, scale =
TRUE, method = ”svdpc”)
Fungsi validasi silang digunakan untuk menentukan jumlah komponen yang optimum dalam model. Ada dua jenis validasi yang digunakan dalam analisis ini, yaitu validasi dengan membuang satu amatan dan validasi dengan membuang lebih dari satu amatan.
Buang satu amatan:
rku <- mvr(Y ~ X, ncomp = 1, data = Data, scale =
TRUE, method = ”svdpc”, validation = “LOO”)
Buang lebih dari satu amatan (misalkan 10 kelompok amatan):
val <- crossval(rku, ncomp = 1, segments = 10,
segment.type= c(“random”, “consecutive”,
“interleaved”))
Validasi silang akan menghasilkan nilai PRESS, RMSECV, dan R2 prediksi. Fungsi plot yang digunakan dalam analisis regresi komponen utama sama d engan fungsi plot pada analisis regresi kuadrat terkecil parsial.
Berikut adalah sintaks R yang digunakan untuk menampilkan plot -plot regresi komponen utama:
Plot R2:
plot(rku, estimate = “all”, “validation”, val.type = “R2”)
Plot RMSEP:
plot(rku, estimate = “all”, “validation”, val.type= “RMSEP”)
Plot MSEP:
plot(rku, estimate = “all”, “validation”, val.type = “MSEP”)
Plot prediksi: predplot(rku, ncomp=rku$ncomp) Plot koefisien: plot(rku, plottype = “coefficients”, ncomp = 1:rktp$ncomp, type = “l”) Plot skor:
plot(rku, plottype = “scores”,
comps = 1: rktp$ncomp) Plot loading:
plot(rku, plottype=“loadings”,
comps = 1: rktp$ncomp) Biplot skor X vs loading X:
biplot(rku, which = “x”)
Biplot loading X vs loading Y:
biplot(rku, which = “loadings”)
2. Regresi Gulud
Sub-submenu ini merupakan fungsi untuk mengatasi masalah multikolinieritas pada regresi linier berganda dengan menambahkan konstanta k pada diagonal utama matriks X’X. sub-submenu ini memanfaatkan paket MASS. Data yang
digunakan dalam analisis ini ha rus berskala interval atau rasio. Pengguna harus memasukkan peubah respons dan peubah prediktor terlebih dahulu. Untuk melakukan ridge trace, pengguna harus mengisis tombol cek pada “jejak gulud” dan mengisi nilai k awal, k akhir dan lebar grid yang ingin digunakan.
Fungsi ini menghasilkan koefisien regresi gulud, persamaan gulud, serta plot koefisien gulud. Kotak dialog untuk fungsi regresi gulud disajikan pada Lampiran 11. Berikut adalah sintaks R yang digunakan (misalkan nilai k awal=0, k akhir=0.1 dan lebar grid=0.01):
gulud <- lm.ridge(y ~ x1 + x2, data = Data, lambda = seq(0,0.1,0.01)) select(gulud)
Plot koefisien gulud:
matplot(lambda, t(koef), lwd = 2, type = "l", xlab =
expression(lambda), ylab = expression(hat(beta)))
3. Regresi Logistik Biner
Sub-submenu ini merupakan fungsi untuk melakukan analisis regresi logistik biner berdasarkan tiga jenis fungsi penghubung (logit, probit, da n complementary log-log). Sub-submenu ini memanfaatkan paket stats. Data respons yang digunakan dalam analisis ini harus memiliki dua kategori. Pengguna harus memasukkan peubah respons dan peubah prediktor terlebih dahulu. Kemudian pengguna harus memilih f ungsi penghubung yang ingin digunakan.
Fungsi ini menghasilkan tabel analisis deviance, uji Wald, uji G, tabel klasifikasi, prosedur regresi bertatar, serta nilai rasio odds khusus untuk fungsi penghubung logit. Kotak dialog untuk fungsi ini disajikan pada Lampiran 12. Berikut adalah sintaks R yang digunakan:
logistik <- glm(y ~ x1 + x2, data = Data, family
= binomial(“logit”, “probit”,“cloglog”))
summary(logistik)
anova(logistik, test = ”Chisq”)
Prosedur pemilihan model regresi terbaik menggunakan statistik AIC sebagai indikator. Berikut adalah sintaksnya: null <- glm(y ~ 1, data=Data,
family = binomial
(“logit”,“probit”, “cloglog”))
atas <- glm(y ~ x1 + x2, data = Data, family =binomial
(“logit”,“probit”,“clo glog”))
untuk stepwise:
step.AIC(null, scope = list(lower = null, upper = atas), direction = 'both') untuk forward:
step.AIC(null, scope = list(lower = null, upper = atas), direction = 'forward') untuk backward:
step.AIC(atas, direction = 'backward')
Tabel klasifikasi yang dihasilkan adalah tabulasi silang antara respons dengan dugaan kategori respons. Nilai peluang respons yang melebihi atau sama dengan batas cutoff akan dikategorikan sebagai kategori tinggi. Sedangkan nilai peluang respons yang kurang dari batas cutoff akan dikategorikan seba gai kategori rendah. Kategori tinggi dan rendah dalam fungsi ini disesuaikan berdasarkan abjad atau angka dari kategori yang dimasukkan oleh pengguna. Berikut adalah fungsi untuk membuat dugaan kategori respons pada regresi logistik biner:
y <- logistik$fitted n <- length(Data[,y]) Kategori <- 1:n for (i in 1:n) { if (y[i] >= cutoff) {Kategori[i] <- kategori2} else if (y[i] < cutoff) {Kategori[i] <- kategori1} }
4. Regresi Logistik Ordinal
Sub-submenu ini merupakan fungsi untuk melakukan analisis regresi logistik ordinal berdasarkan tiga jenis fungsi penghubung (logistic, probit, dan complementary log-log) dengan metode kemungkinan maksimum. Sub -submenu ini memanfaatkan paket MASS. Model regresi logistik ordinal yang digunakan adalah proportional odds. Data respons yang digunakan dalam analisis ini harus berskala ordinal dengan lebih dari dua kategori. Pengguna harus memasukkan peubah respons dan peubah prediktor terlebih dahulu. Kemudian pengguna harus memilih fungsi penghubung yang ingin digunakan.
Fungsi ini menghasilkan uji Wald, tabel klasifikasi, prosedur regresi bertatar, serta nilai rasio odds khusus untuk fungsi penghubung logit. Kotak dialog untuk fungsi ini disajikan pada Lampiran 13.
Berikut adalah sintaks R yang digunakan untuk melakukan analisis regresi logistik ordinal:
logistik <- polr(y ~ x1 + x2, data = Data, method
= c(“logistic”, “probit”,“cloglog”))
Sintaks regresi bertatar yang digunakan sama dengan sintaks regresi bertatar pada analisis regresi logistik biner.
5. Regresi Logistik Multinomial
Sub-submenu ini merupakan fungsi untuk melakukan analisis regresi logistik multiomial berdasarkan fungsi penghubung logit. Sub -submenu ini memanfaatkan paket nnet. Data respons yang digunakan dalam analisis ini harus berskala nominal dengan lebih dari dua kategori. Pengguna harus memasukkan peubah respons dan peubah prediktor terlebih dahulu.
Fungsi ini menghasilkan uji Wald, tabel klasifikasi, prosedur regresi bertatar, serta nilai rasio odds. Kotak dialog untuk fungsi ini disajikan pada Lampiran 14. Berikut adalah sintaks R yang digunakan: logistik <- multinom(y ~ x1 +
x2, data = Data)
summary(logistik, “Wald”=T)
Sintaks regresi bertatar yang digunakan sama dengan sintaks regresi bertatar pada analisis regresi logistik biner.
6. Regresi Kuadrat Terkecil Parsial
Sub-submenu ini merupakan fungsi untuk melakukan analisis regresi kuadrat terkecil parsial. Sub-submenu ini memanfaatkan paket pls. Fungsi ini digunakan ketika peubah-peubah prediktor saling berkorelasi tinggi atau ketika jumlah pengamatan lebih sedikit daripada jumlah peubah prediktor. Pengguna harus memasukkan peubah respons dan peubah prediktor terlebih dahulu. Peubah respons dapat berjumlah lebih dari satu peubah. Peubah prediktor minimal terdiri atas dua peubah. Pengguna dapat menentukan berapa jumlah komponen yang akan disertakan dalam model dengan mengetikkan jumlah komponen yang diinginkan. Selanjutnya pengguna harus memilih algoritma dan tipe validasi silang yang akan digunakan.
Input data yang digunakan adalah matriks X dan matriks Y. Matriks X adalah matriks yang setiap kolomnya merupakan peubah prediktor dan berukuran (n x p). Matriks Y adalah matriks yang setiap
kolomnya merupakan peubah respons dan berukuran (n x q). Hasil dari fungsi ini adalah nilai proporsi keragam an, nilai loading, nilai skor, RMSEP, R2, MSEP, koefisien regresi, serta plot -plot regresi kuadrat terkecil parsial. Nilai skor X dari regresi kuadrat terkecil parsial tersimpan dalam dataset aktif. Plot yang dihasilkan dalam fungsi ini antara lain plot R2, plot RMSEP, plot MSEP, plot prediksi, plot koefisien, plot skor, plot loading, biplot skor X vs loading X, biplot skor Y vs loading Y, biplot skor X vs skor Y, dan biplot loading X vs loading Y. Biplot antara skor Y vs loading Y serta skor X vs skor Y tidak dapat ditampilkan jika hanya terdapat satu komponen dalam model. Kotak dialog untuk fungsi ini disajikan pada Lampiran 15. Berikut adalah sintaks R yang digunakan (misalkan jumlah komponen = 1):
rktp <- mvr(Y ~ X, ncomp = 1, data = Data, scale = TRUE, method =
c(“oscorespls”,
“simpls”, “kernelpls”, “widekernelpls”))
Fungsi validasi silang digunakan untuk menentukan jumlah komponen yang optimum dalam model. Ada dua jenis validasi yang digunakan dalam analisis ini, yaitu validasi dengan membuang satu amatan dan validasi dengan membuang lebih dari satu amatan.
Buang satu amatan:
rktp <- mvr(Y ~ X, ncomp = 1, data = Data, scale = TRUE, method =
c(“oscorespls”,
“simpls”, “kernelpls”, “widekernelpls”), validation = “LOO”)
Buang lebih dari satu amatan (misalka n 10 kelompok amatan):
val <- crossval(rktp, ncomp = 1, segments = 10,
segment.type= c(“random”, “consecutive”,
“interleaved”))
Terdapat tiga cara untuk membangkitkan data yang akan dibuang dalam setiap kelompok amatan yaitu acak ( random), berurutan (consecutive), dan berselang-seling (interleaved). Validasi silang akan menghasilkan nilai PRESS, RMSECV, dan R2prediksi.
Berikut adalah sintaks R yang digunakan untuk menampilkan plot -plot regresi kuadrat terkecil parsial:
Plot R2:
plot(rktp, estimate = “all”, “validation”, val.type = “R2”)
Plot RMSEP:
plot(rktp, estimate = “all”, “validation”, val.type= “RMSEP”)
Plot MSEP:
plot(rktp, estimate = “all”, “validation”, val.type = “MSEP”)
Plot prediksi: predplot(rktp, ncomp=rktp$ncomp) Plot koefisien: plot(rktp, plottype = “coefficients”, ncomp = 1:rktp$ncomp, type = “l”) Plot skor:
plot(rktp, plottype = “scores”,
comps = 1: rktp$ncomp) Plot loading:
plot(rktp, plottype=“loadings”,
comps = 1: rktp$ncomp) Biplot skor X vs loading X:
biplot(rktp, which = “x”)
Biplot skor Y vs loading Y:
biplot(rktp, which = “y”)
Biplot skor X vs skor Y:
biplot(rktp, which = “scores”)
Biplot loading X vs loading Y:
biplot(rktp, which = “loadings”)
Menu Bantuan
Menu bantuan digunakan untuk memberikan informasi penggunaan Pakar 2.0. Menu ini terdiri atas dua submenu yaitu: 1. Bantuan Pakar 2.0
Submenu ini berisis dokumentasi tentang pengunaan Pakar 2.0.
2. Tentang Pakar 2.0
Submenu ini berisi informasi tentang versi Pakar 2.0 dan pengembangan Pakar 2.0.
Pengujian
Pengujian Pakar 2.0 dimulai dari implementasi fungsi-fungsi Pakar 2.0 hingga pengujian Pakar 2.0 secara menyeluruh. Ada beberapa data yang digunakan dalam pengujian ini. Data Winearoma.MTW yang berasal dari lembar kerja Minitab digunakan untuk menguji regresi kuadrat terkecil parsial dan regresi komponen utama. Data EXH_REGR.MTW digunakan untuk menguji regresi logistik biner. Data mlogit.csv digunakan untuk menguji regresi logistik multinomial dan diunduh dari http://www.ats.ucla.edu/stat/r/dae/mlogit.csv Data ologit.csv digunakan untuk menguji regresi logistik ordinal dan diunduh dari http://www.ats.ucla.edu/stat/r/dae/ologit.csv . Data longley yang berasal dari dataset R digunakan untuk menguji regresi gulud.
Tabel 2. Perbandingan keluaran Pakar 2.0 dengan Minitab, SAS, dan SPSS menggunakan metode blackbox Fungsi dalam Pakar 2.0 Perangkat Lunak Perbandingan Keluaran Regresi Komponen Utama Minitab -SAS Berbeda* SPSS -Regresi Gulud Minitab -SAS Berbeda SPSS -Regresi Logistik Biner Minitab Sama SAS Sama SPSS Sama Regresi Logistik Ordinal Minitab Berbeda* SAS Berbeda* SPSS Sama Regresi Logistik Multinomial Minitab Sama SAS Sama SPSS Berbeda* Regresi Kuadrat Terkecil Parsial Minitab Sama SAS Berbeda* SPSS
-*) berbeda tidak signifikan akibat adanya perbedaan kategori acuan yang digunakan dan perbedaan nilai desimal hasil iterasi.
Pengujian paket dilakukan dengan membandingkan keluaran Pakar 2.0 dengan keluaran dari perangkat lunak statistika lainnya yaitu Minitab, SAS, dan SPSS. Hasil perbandingan dari keempat perangkat lun ak tersebut ditampilkan pada Tabel 2. Berikut adalah penjelasan mengenai tabel perbandingan di atas:
1. Regresi Komponen Utama
Data yang digunakan untuk analisis regresi komponen utama adalah data terbakukan. Matriks yang digunakan dalam analisis ini adalah matriks kovarian. Terdapat perbedaan nilai loading antara Pakar 2.0 dengan SAS, namun kisaran nilai loading yang dihasilkan sama. Nilai loading dalam analisis ini adalah vektor ciri. Oleh sebab itu, perbedaan nilai loading antara kedua perangkat lunak dikarenakan nilai vektor ciri yang tidak unik. Hasil perbandingan antara Pakar 2.0 dan SAS dapat dilihat pada Lampiran 16. Berdasarkan hasil simulasi, analisis regresi komponen utama pada Pakar 2.0 mampu menganalisis hingga 5000 peubah prediktor.
2. Regresi Gulud
Perbandingan regresi gulud antara Pakar 2.0 dan SAS menunjukkan hasil yang berbeda. Hal ini disebabkan metode pendugaan koefisien regresi yang berbeda
antara kedua perangkat lunak. Hasil perbandingan regresi gulud dis ajikan pada Lampiran 17. Sedangkan perbandingan plot regresi gulud antara Pakar 2.0 dan SAS ditampilkan pada Lampiran 18. 3. Regresi Logistik Biner
Perbandingan analisis regresi logistik biner antara Pakar 2.0, Minitab, SPSS, dan SAS menunjukkan hasil yang sama untuk beberapa kasus uji. Tabel klasifikasi keluaran dari Pakar 2.0, SPSS dan SAS menunjukkan hasil yang sama. Hasil perbandingan regresi logistik biner dengan fungsi penghubung logit ditampilkan pada Lampiran 19. Sedangkan perbandingan tabel klasifikasinya ditampilkan pada Lampiran 20.
4. Regresi Logistik Ordinal
Perbandingan nilai koefisien regresi untuk analisis regresi ordinal antara Pakar 2.0, Minitab, SPSS, dan SAS menunjukkan hasil yang berbeda. Perbedaan tersebut terjadi pada peubah prediktor yang bernilai kategorik. Peubah pared dan public merupakan peubah kategorik dengan nilai 0 dan 1. Pakar 2.0 dan SPSS menggunakan 1 sebagai kategori acuan, sedangkan Minitab dan SAS menggunakan 0 sebagai kategori acuan, oleh sebab itu tanda koefisiennya menjadi berbeda. Nilai koefisien antara Pakar 2.0, Minitab, dan SAS berbeda dengan SPSS. Hal ini disebabkan oleh proses iterasi pada metode kemungkinan maksimum yang berbeda. Nilai rasio odds hasil keluaran Pakar 2.0 berbeda dengan Minitab dan SAS disebabkan oleh perbedaan tanda pada koefisien regresi. Hasil perbandingan regresi logistik ordinal dapat dilihat pada Lampiran 21.
5. Regresi Logistik Multinomial
Perbandingan analisis regresi multinomial antara Pakar 2.0, Minitab, SPSS, dan SAS menunjukkan hasil yang sama untuk beberapa kasus uji. Namun nilai dugaan koefisien SPSS sedikit berbeda dibandingkan hasil keluaran dari perangkat lunak lainnya. Hal ini disebabkan karena SPSS menggunakan kategori acuan dan proses iterasi pada metode kemungkinan maksimum yang berbeda dengan ketiga perangkat lunak lainnya. Hasil perbandingan regresi logistik multinomial dapat dilihat pada Lampiran 22.
6. Regresi Kuadrat Terkecil Parsial
Hasil perbandingan menggunakan algoritma NIPALS menunjukkan bahwa nilai loading keluaran Pakar 2.0 dan
Minitab sama, tetapi berbeda dengan SAS. Hal ini dikarenakan proses iterasi yang berbeda pada setiap perangkat lunak. Tabel hasil perbandingan antara Pakar 2.0, Minitab dan SAS dapat dilihat pada Lampiran 23. Berdasarkan hasil simula si, analisis regresi kuadrat terkecil parsial pada Pakar 2.0 mampu menganalisis hingga 5000 peubah prediktor.
Batasan dan Pemasangan Sistem Sistem ini mempunyai batasan -batasan tertentu yaitu:
1. Analisis regresi gulud hanya menghasilkan nilai koefisien regresi gulud dan plotnya, tidak menghasilkan nilai RMSE.
2. Analisis regresi logistik belum mampu melakukan pengaturan terhadap kategori acuan yang digunakan.
3. Plot regresi komponen utama dan plot regresi kuadrat terkecil parsial yang mampu ditampilkan dalam satu jendela grafik maksimum berjumlah sembilan plot.
4. Analisis regresi komponen utama dan analisis regresi kuadrat terkecil parsial belum menghasilkan nilai prediksi. 5. Ekspor dataset aktif pada Pakar 2.0 masih
terbatas pada file SPSS dan Ms. Excel 2003.
Pemasangan Pakar 2.0 diawali dengan pemasangan program R dan paket R lain yang dibutuhkan. Setelah itu, pasang paket Pakar 2.0 melalui menu “Packages > Install package(s) from local zip file …”. Untuk memuat Pakar 2.0 ketikkan pada R console sebagai berikut:
library(Pakar2) Pakar2()
KESIMPULAN DAN SARAN
KesimpulanPenelitian ini telah berhasil menyusun paket R dengan antarmuka user friendly sebagai pengembangan dari paket analisis regresi (Pakar) yang telah ada sebelumnya. Paket ini diberi nama Pakar 2.0. Fungsi -fungsi statistika dalam Pakar 2.0 mencakup fungsi kovarian, korelasi, uji kenomalan, plot pengepasan garis, analisis regresi linier , prosedur pemilihan model regresi terbaik, analisis regresi kuadrat terkecil parsial, analisis regresi logisitik (biner, ordinal, dan multinomial), analisis regresi komponen utama, dan analisis regresi gulud. Pakar 2.0 terdiri atas lima menu utama, yaitu Menu File,