Laporan Klasifikasi Data Mining Dan Data Warehouse
Oleh :
Adianzah Muhammad (14.01.53.0085) Dedi Setiyawan (14.01.53.0097)
Vio Binawan I (14.01.53.0105)
UNIVERSITAS STIKUBANK SEMARANG (UNISBANK) FALKUTAS TEKNOLOGI INFORMASI
BAB I PENDAHULUAN
1.1 Latar Belakang Masalah
Berkembangnya teknologi telah membuat banyak informasi bermunculan. Informasi-informasi tersebut tertuang dalam bentuk dokumen terutama dokumen digital. Semakin banyak informasi yang ada maka semakin banyak dokumen dokumen yang digunakan. Untuk bisa mengorganisir informasi-informasi tersebut dengan mudah, maka dibutuhkan klasifikasi dokumen secara otomatis. Salah satu metode yang dapat digunakan untuk klasifikasi adalah metode klasifikasi dengan Decision Tree, di mana metode dari Decision Tree yang umum dipakai adalah ID3. Decision Tree adalah sebuah pohon di mana setiap node cabang merupakan pilihan antara sejumlah alternatif, dan setiap simpul daun merupakan keputusan. Decision Tree biasanya digunakan untuk memperoleh informasi untuk tujuan pengambilan keputusan.
Decision Tree dimulai dengan root node yang digunakan untuk mengambil keputusan. Dari node ini, pengguna memisahkan tiap node secara rekursif menurut algoritma pelatihan Decision Tree. Hasil akhir adalah Decision Tree di mana tiap cabang merupakan skenario kemungkinan keputusan dan hasilnya Dalam penelitian yang akan dilakukan sebagai tugas akhir ini, penulis akan membuat sistem klasifikasi artikel secara otomatis dengan metode Decision Tree. Melalui program ini, artikel-artikel berita yang ada akan secara otomatis terklasifikasi sehingga mempermudah pengguna dalam melakukan pencarian artikel-artikel tersebut sesuai dengan kelas yang sudah ditentukan. Dari program yang akan dibuat ini, peneliti akan melakukan penelitian mengenai tingkat kinerja metode Decision Tree untuk klasifikasi artikel berita, sehingga dapat diketahui tingkat keakuratan metode yang digunakan untuk klasifikasi.
1.2 Rumusan Masalah
1. Bagaimana mengimplementasikan Decision Tree untuk klasifikasi ?
2. Berapa persen tingkat akurasi dari implementasi Decision Tree untuk klasifikasi?
3. Bagaimana pengaruh feature selection terhadap tingkat akurasi implementasi Decision Tree untuk klasifikasi?
1.3 Batasan Masalah
1. Artikel berita terbatas pada artikel olahraga, dan kelas-kelas untuk artikel tersebut dibagi menjadi: olahraga sepak bola, olahraga raket, olahraga otomotif, dan olahraga tinju.
2. Input data pelatihan berupa file plain-text (.txt).
3. Tidak melakukan stemming untuk token-token yang ada pada sistem yang akan dibangun.
1.4 Tujuan Penelitian
Tujuan dari penelitian yang akan dibangun adalah sebagai berikut:
1. Menerapkan metode Decision Tree untuk membangun sistem klasifikasi secara otomatis.
BAB II
TINJAUAN PUSTAKA
2.1 Kajian Deduktif
2.1.1 Pengertian Text Mining
Text mining adalah salah satu bidang khusus dari data mining . Sesuai
Tujuan dari text mining adalah untuk mendapatkan informasi yang berguna dari sekumpulan dokumen. Jadi, sumber data yang digunakan pada text mining adalah kumpulan teks yang memiliki format yang tidak terstruktur atau minimal semi terstruktur. Adapun tugas khusus dari text mining antara lain yaitu pengkategorisasian teks (text categorization) dan pengelompokan teks (text clustering).
2.1.2 Klasifikasi
Klasifikasi adalah salah satu teknik machine learning. Teknik ini termasuk ke dalam tipe supervised learning. Istilah dari klasifikasi didapat dari tujuan utama teknik ini untuk memprediksikan suatu kategori dari input data.
Sebelum proses prediksi dilakukan, langkah pertama yang dilakukan adalah proses pembelajaran. Proses pembelajaran fungsi target (model klasifikasi) yg memetakan setiap sekumpulan Atribut X (input) ke salah satu Class Y yang didefinisikan sebelumnya.
Proses pembelajaran memerlukan sebuah data, data yang digunakan adalah data latih / data training. Untuk data yang digunakan pada saat proses prediksi disebut dengan data uji / data testing.
Menurut definisi tersebut klasifikasi adalah teknik yang dilakukan untuk memprediksi class atau properti dari setiap instance data.
2.1.3 Decision Tree
pembagian hasil uji, dan node daun (leaf) merepresentasikan kelompok kelas tertentu. Level node teratas dari sebuah Decision Tree adalah node akar (root) yang biasanya berupa atribut yang paling memiliki pengaruh terbesar pada suatu kelas tertentu. Pada umumnya Decision Tree melakukan strategi pencarian secara top-down untuk solusinya. Pada proses mengklasifikasi data yang tidak diketahui, nilai atribut akan diuji dengan cara melacak jalur dari node akar (root) sampai node akhir (daun) dan kemudian akan diprediksi kelas yang dimiliki oleh suatu data baru tertentu.Secara singkat bahwa Decision Tree merupakan salah satu metode klasifikasi pada Text Mining. Klasifikasi adalah proses menemukan kumpulan pola atau fungsi-fungsi yang mendeskripsikan dan memisahkan kelas data satu dengan lainnya, untuk dapat digunakan untuk memprediksi data yang belum memiliki kelas data tertentu (Jianwei Han, 2001).
2.1.4 Naïve Bayes
Teorema Bayes dikemukakan oleh seorang pendeta presbyterian Inggris pada tahun 1763 yang bernama Thomas Bayes. Teorema Bayes digunakan untuk menghitung probabilitas terjadinya suatu peristiwa berdasarkan pengaruh yang didapat dari hasil observasi.Algoritma bayes mempelajari kejadian-kejadian dari rekaman database dengan cara memperhitungkan korelasi antara variabel yang dianalisa dengan variabel-variabel lainnya. Hasilnya adalah kita dapat memprediksi sesuatu, misalnya apakah seseorang berasal dari golongan tertentu berdasarkan variabel-variabel yang melekat padanya. Selain itu, naive bayes dapat juga menganalisa variabel-variabel yang paling mempengaruhinya dalam bentuk peluang. (Olson Delen, 2008)
2.2 KAJIAN INDUKTIF
faktor-faktor yang mempeengaruhi kelancaran kredit dan penilaiaan para nasabah dalam pemberian kredit dimasa yang akan datang apakah beresiko atau tidak, yang selama ini belum diterapkan oleh BPRS Berkah Dana Fadillah. Decission Tree dengan Algoritma C4.5 adalah metode yang akan diimplementasikan untuk menggali informasi potensial dalam menentukan resiko kredit nasabah berdasarkan kriteria Sandi BI, Tujuan Pembiayaan, Aktiva , Pasiva, Nilai Jaminan, dan Pendapatan dalam bentuk aturan dengan melihat riwayat kredit nasabah yang ada. Dari penelitian yang telah dilakukan pada 300 data nasabah dengan akurasi pengujian rule yang dihasilkan rata-rata diatas 50% serta tertinggi adalah 76.67% dengan jumlah aturan yang diperoleh adalah 30 buah aturan Model atau Aturan klasifikasi, aturan yang mengandung kelas aman sebanyak 19 aturan dan Beresiko sebanyak 11 aturan. Sehingga dengan tingginya tingkat akurasi dapat disimpulkan bahwa algoritma C4.5 memliki kinerja yang cukup baik dalam membentuk Rule.
Menurut penelitian yang dilakukan Suwanto Raharjo dan Edi Winarko (2014) dalam penelitiannya yang berjudul “Klasterisasi, Klasifikasi dan Peringkasan Teks Berbahasa Indonesia”, menjelaskan tentang studi pustaka penelitian di bidang klasterisasi dan klasifikasi dokumen teks berbahasa Indonesia menunjukan bahwa penelitian bidang pemrosesan dokumen telah dimulai pada tahun 2000. Terdapat berbagai metode data mining untuk melakukan pengelompokan dokumen digunakan seperti single pass filtering, Naive Bayes, Hirarki dan metode lainnya. Penelitian ini akan melakukan survei paper penelitian data mining teks berbahasa Indonesia. Dari paper yang didapatkan terlihat bahwa sebagian besar topik penelitian data mining bertujuan adalah untuk melakukan pengelompokan suatu berita baik online maupun cetak berdasar atas acuan tertentu, penelitian lain ditujukanuntuk mengolah teks di media sosial seperti twitter. Artikel ini akan memperlihatkan metode yang digunakan dan tujuan dari paper dalam bidang klasterisasi,klasifikasi danperingakasan dokumen berbahasa Indonesia.
2.3 Metode Penelitian
saat ini, pada penelitian ini kasus yang diambil adalah kesiapan siswa dalam menghadapi ujian nasional. Metode deskriptif mempunyai ciri-ciri sebagai berikut :
a. Berpusat pada penyelesaian masalah pada masa sekarang, dan pada masalah yang aktual.
b. Data yang terkumpul terlebih dulu disusun, dijelaskan dan dianalisa karena metode ini sering disebut metode analitik.
2.4 Desain Penelitian
Dalam penelitian ini penulis menggunakan model standarisasi data mining yaitu CRISP-DM (Cross Industry Standart Process for Data Mining), dengan langkah-langkah sebagai berikut:
2 . 3 .1 Pemahaman Data
(Data Understanding) Data yang digunakan dalam penelitian ini adalah sumber data primer.Data diperoleh dari lembaga kursus SMK Negeri 1 Dukuturi Semarang. Data yang dikumpulkan yaitu data nilai tryOut siswa.
2 . 3. 2 Pengolahan Data (Data Preparation)
a. Tahap Pertama, penentuan data yang akan diolah. Dari data yang telah diperoleh, tidak semua data akan diolah karena penelitian yang akan dilakukan memiliki batasan-batasan data yang akan digunakan.
b. Tahap Kedua, penanganan data missing value. Missing value adalah data yang tidak lengkap dikarenakan attribut tidak tercatat maupun attribut memang tidak dimiliki dsb. Penanganan missing value dilakukan dengan penghapusan record yang kosong.
c. Tahap Ketiga, menentukan atribut yang akan digunakan dari tahap pertama. Atribut yang akan digunakan adalah nama, nilai tryout yangn meliputi : nilai bahasa indonesia, nilai bahasa inggris, nilai matematika, nilai IPA, total nilai, rata-rata, Pramitya Lilimadani 45.
2 . 3 .3 Pemodelan (Modelling)
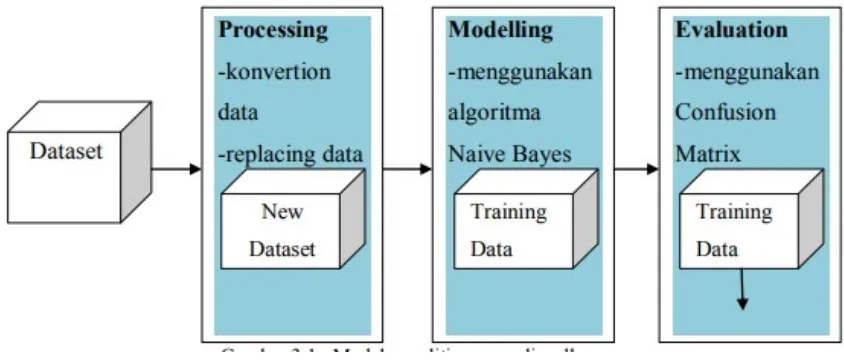
Metode yang akan digunakan dalam penelitian ini adalah Algoritma Naive Bayes Classification untuk melakukan pengukuran akurasi dalam penelitian ini akan menggunakan tools Rapid Miner. Brikut adalah gambaran pemodelan penelitian:
Gambar 3.1 : Model penelitian yang diusulkan
2 . 3 . 4 Evaluasi (Evaluation)
BAB III
METODE PENELITIAN
3.1 OBJEK PENELITIAN
3.2 METODE PENGUMPULAN DATA
Berikut ini adalah metode pengumpulan data dalam penelitian ini 3.2.1 Studi Literatur
Pengumpulan data dilakukan dengan cara mempelajari, meneliti dan menelaah berbagai literatur yang bersumber dari buku, situs internet, jurnal ilmiah, dan sumber – sumber lainnya yang berkaitan dengan penelitian yang dilakukan.
3.2.2 Package
Data penelitian diambil dari salah satu package Rgui
3.3 JENIS DATA
Konsep Data Dalam Decision Tree
• Data dinyatakan dalam bentuk tabel dengan atribut dan record.
• Atribut menyatakan suatu parameter yang dibuat sebagai kriteria dalam pembentukan tree. Misalkan untuk menentukan main tenis, kriteria yang diperhatikan adalah cuaca, angin dan temperatur. Salah satu atribut merupakan atribut yang menyatakan data solusi per-item data yang disebut dengan target atribut.
BAB IV
HASIL DAN PEMBAHASAN
4.1 IMPLEMENTASI
Instal package yang dibutuhkan pada R console Install.package(“party”)
Setelah menginstall package yang dibutuhkan kemudian jalankan librarynya library(party)
Gambar 4.1 R console setelah menginstall package dan menjalankan library
Selanjutnya jalankan perintah demi perintah script ke dalam R comsole # Print some records from data set readingSkills.
print(head(readingSkills))
# Create the input data frame. input.dat <- readingSkills[c(1:105),]
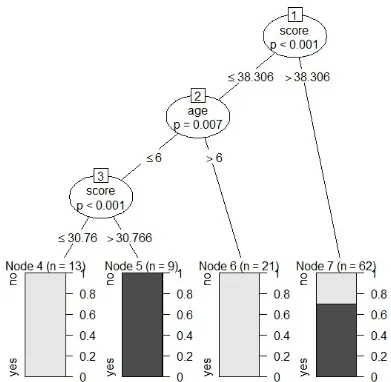
# Create the tree. output.tree <- ctree( nativeSpeaker ~ age + shoeSize + score, data = input.dat)
# Plot the tree. plot(output.tree)
# Save the file. dev.off()
BAB V
KESIMPULAN DAN REKOMENDASI
5.1. KESIMPULAN
Penelitian menggunakan metode klasifikasi decision tree ini cukup efektif untuk mengklasifikasi data sesuai kebutuhan.
Dari pohon keputusan yang ditunjukkan di atas dapat kita simpulkan bahwa siapa saja yang nilai readingSkills kurang dari 38,3 dan usia lebih dari 6 bukanlah Pembicara asli / penutur asli ( bahasa itu ).
5.2. REKOMENDASI
DAFTAR PUSTAKA
Hidayatsyah, M. R. (2013). Penerpan Metode Decision Tree Dalam Pemberian Pinjaman Kepada Debitur Dengan Algoritma C4.5. Pekanbaru: Universitas Islam Negeri Sultan Syarif Kasim Riau Pekanbaru.
http://fazri-indop.blogspot.co.id/2012/03/contoh-kasus-data-mining.html https://www.scribd.com/doc/216421345/Makalah-Data-Mining
https://howkind.wordpress.com/2012/12/19/makalah-algoritma-data-mining/ https://repository.widyatama.ac.id/xmlui/handle/123456789/2362