47
Penggunaan Twitter untuk Mendeteksi Banjir Melalui
Pendekatan Text Mining dan Evaluasinya
Wida Widiastuti
Badan Pusat StatistikABSTRAK
Pada waktu terjadi bencana alam, informasi yang up-to-date sangat diperlukan untuk mengidentifikasi wilayah yang membutuhkan penanganan segera. Berkembangnya teknologi komunikasi via internet memungkinkan orang untuk bertukar informasi secara cepat melalui media sosial. Bentuk komunikasi real-time seperti ini memberikan potensi besar untuk memperoleh informasi yang cepat saat terjadinya bencana. Salah satu aplikasi media sosial yang populer di Indonesia adalah Twitter. Pemerintah DKI Jakarta pernah memanfaatkan aplikasi ini untuk mengumpulkan informasi saat terjadinya banjir di Jakarta. Mengingat konten yang ditulis dalam Twitter bersifat bebas, maka untuk memperoleh informasi yang benar masih memerlukan proses lanjutan. Penelitian ini mencoba membangun suatu program dengan algoritma penyaringan informasi bencana banjir melalui pendekatan Text Mining. Pendekatan tersebut menggunakan bantuan Natural Language Processing untuk menyaring konten terkait banjir. Proses ini menghasilkan tidak hanya informasi lokasi banjir tetapi juga informasi ketinggiannya. Pada akhirnya, hasil akhir proses ini dapat menguji sejauh mana kebenaran informasi banjir yang dikirim para volunteers via Twitter. Cara pengujian dilakukan dengan dua cara; pertama dengan membandingkan pola sebaran spasial antara lokasi pengiriman Twitter setelah proses penyaringan dengan peta banjir yang diperoleh Badan Penanggulangan bencana Daerah Jakarta, kedua dengan melakukan uji F-measure untuk mengukur akurasi antara prediksi dan kondisi sehingga dapat diketahui kualitas program yang dibangun. Uji F-measure menunjukkan program Text Mining yang dibangun untuk menyaring informasi yang relevan adalah 90%, sedangkan hasil overlay antara layer koordinat Twitter dan peta banjir jakarta diperoleh 57% Tweet yang relevan berada pada lokasi banjir.
Kata kunci: banjir, Twitter, Text Mining ,Natural Language Processing, spasial
1. PENDAHULUAN
Kebutuhan informasi yang real-time saat terjadinya bencana sangat dibutuhkan untuk penangangan wilayah yang membutuhkan bantuan segera. Informasi ini dapat dengan cepat diperoleh dari masyarakat yang lebih mengetahui kondisi sebenarnya di lapangan. Seperti contoh, saat bencana gempa bumi di Haiti masyarakat berperan sebagai relawan yang menyediakan informasi mengenai situasi saat itu [1]. Sebagaimana disebutkan oleh [2], saat bencana banjir, teknologi internet menyediakan kemungkinan untuk mengumpulkan informasi in-situ seperti lokasi dan ketinggian air. Informasi ini memberikan keuntungan dalam memonitor kondisi secara cepat.
Munculnya situs social networking atau media sosial seperti Twitter memberikan potensi besar untuk mengumpulkan informasi terkini dari pengguna internet, karena sifatnya yang mobile dan ada dimana-mana [3]. Lebih lanjut, fitur geolokasi yang terdapat di Twitter berguna untuk siapapun yang ingin berbagi posisi geografis ketika melaporkan suatu lokasi kejadian.
Seperti halnya data yang digunakan pada penelitian ini, yaitu menggunakan pesan teks di Twitter atau biasa disebut Tweet saat bencana banjir Jakarta pada akhir tahun 2014 dan awal tahun 2015. Pada saat itu, pemerintah DKI Jakarta memiliki akun resmi Twitter @petajkt untuk memperoleh informasi banjir dan untuk berkomunikasi dengan warga Jakarta saat terjadi banjir. Kemudian, informasi via Twitter tersebut dipetakan melalui suatu sistem yang disebut “peta Jakarta” (http://petajakarta.org).
Saat pengumpulan data dengan hanya mengandalkan jumlah laporan Twitter saja belum cukup. Karena menyederhanakan hubungan antara banyaknya jumlah Twitter dengan area yang terkena dampak paling parah dapat menyebabkan kekurangan bantuan bagi area yang tidak banyak mengirimkan laporan [4]. Selain itu, sifat alami Twitter yang rentan gangguan dan tidak terstruktur akan berdampak terhadap kredibilitas informasinya [5], karena informasi tersebut diperoleh dari siapapun dengan berbagai motivasi yang berbeda.
informasi. Proses ekstrasi sejumlah besar teks yang tidak terstruktur dapat dilakukan dengan pendekatan Text Mining yang bertujuan untuk menemukan informasi relevan terkait dengan bencana banjir. Salah satu komponen Text Mining untuk menyaring informasi dari Twitter dapat dikerjakan dengan Natural Language Processing [6]. Lebih lanjut, proses linguistik ini memungkinkan untuk mengekstrak lokasi nama yang tercantum dalam pesan Twitter [7]. Mengidentifikasi suatu entitas lokasi dapat dikenali menggunakan suatu pendekatan Natural Language Processing yang disebut Named Entity Recognition (NER) [8].
Pertukaran informasi antara warga yang terdampak dan badan penanggulangan bencana selama terjadinya bencana adalah optimalisasi peran Twitter sebagai platform komunikasi. Warga terdampak berperan tidak hanya sebagai pencari informasi tetapi juga sebagai sensor yang berkontribusi di lapangan [9], sehingga badan penanggulangan bencana memperoleh informasi terkini secara periodik.
Tujuan umum dari penelitian ini adalah melakukan penggalian teks (Text Mining) untuk menyaring konten Twitter terkait lokasi banjir dan ketinggiannya menggunakan pendekatan Natural Language Processing. Selanjutnya, dari tujuan umum tersebut diharapkan dapat menjawab dua pertanyaan penelitian sebagai berikut:
A. Bagaimana hasil perbandingan antara informasi lokasi banjir yang diperoleh dari Twitter dengan sebaran spasial lokasi banjir dari pemerintah terkait?
B. Bagaimana hasil evaluasi dari proses Text Mining dalam penyaringan konten Twitter terkait lokasi banjir dan ketinggiannya?
2. METODE PENELITIAN
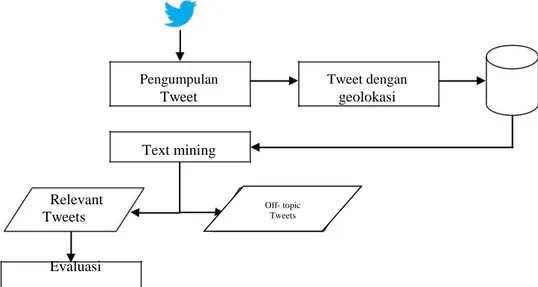
Secara umum, alur kerja penelitian ini terdiri dari tiga proses; pengumpulan data Twitter, Text Mining, dan evaluasi hasil. Pertama, pengumpulan data didesain untuk mengambil pesan teks Twitter yang ber-geolokasi. Untuk keperluan penelitian ini menggunakan data pada periode musim penghujan Desember 2014 hingga Maret 2015 yang terkait dengan banjir Jakarta. Kedua, Text Mining menggunakan Natural Language Processing (NLP) bertujuan mengekstrak informasi mengenai lokasi banjir atau ketinggian banjir. Berdasarkan konten tersebut suatu Tweet dapat dikelompokkan kedalam Tweet yang relevant atau Tweet yang off-topic. Ketiga, evaluasi hasil dari Text Mining tersebut menggunakan pendekatan perbandingan spasial dan menggunakan perhitungan F-measure (F1 score). Proses pengumpulan data dan Text Mining menggunakan suatu algoritma yang dibangun dengan bantuan; bahasa pemrograman Python, Twitter search API (Application Programming Interface), dan database PostgreSQL. Sedangkan untuk pemetaan hasil menggunakan aplikasi Quantum GIS. Untuk lebih jelasnya, alur kerja dari penelitian ini dapat dilihat pada gambar dibawah:
Pengumpulan Tweet Text mining Tweet dengan geolokasi Relevant Tweets Evaluasi
Gambar 1. Alur kerja penelitian
Off- topic Tweets
49
Dalam NLP, suatu metode yang memungkinkan untuk mengekstrak entitas suatu set teks disebut Name Entity Recognition (NER) [10]. Entitas yang paling umum adalah; orang, organisasi, dan lokasi. Dalam kasus ini, konten lokasi adalah entitas yang dibutuhkan untuk diidentifikasi.
Strategi untuk memperoleh entitas berbeda di setiap sistem. Tahapan utama metode NER adalah tokenization dan identifikasi kata-kata menggunakan Part Of Speech (POS) Tagging [11]. Tag adalah suatu deskriptor yang disematkan kedalam token (kata). Setiap kata dalam sebuah Tweet ditandai menurut kategori leksikalnya. Contohnya, A untuk adjektif, N untuk Noun atau kata benda, P untuk preposisi, dan lain-lain. Seperti halnya pada [12] mendesain suatu set Indonesian Part of Speech (POS) tag untuk menetapkan tag atau deskriptor dari 10.000 kalimat.
Tahapan pertama dalam proses ekstraksi adalah normalisasi untuk menghilangkan gangguan atau noise dari suatu konten Tweet. Proses normalisasi tersebut diantaranya; perubahan teks menjadi lower case, perubahan kata -kata yang tidak diperlukan (contoh: URL, prefix @, hashtag), dan penghapusan tanda baca. Proses dalam program dilakukan dengan bantuan ekspresi regex1) pada bahasa pemrograman python.
Tahapan kedua adalah identifikasi entitas lokasi. Cara yang paling mudah untuk mengidentifikasinya adalah menggunakan suatu kamus nama lokasi atau toponimi. Daftar toponimi ini diperoleh nama jalan dan nama lokasi. Untuk menemukan nama lokasi yang cocok dengan toponimi, program membaca baris-per baris dengan bantuan ekspresi regex kemudian mengkonversikannya kedalam tag lokasi.
Tahapan ketiga adalah tokenization . Tujuannya adalah untuk mengidentifikasi kata kunci terkait banjir, nama lokasi, dan ketinggian air menggunakan suatu set kata kunci kemudian merubahnya kedalam tag banjir, lokasi, dan ketinggian. Dalam proses ini, suatu kata yang berpotongan dengan kata kunci terkait dengan ketinggian banjir dikonversi kedalam angka (numerik), mengingat seringkali seseorang mengekspresikan ketinggian banjir menggunakan ukuran bagian tubuh manusia, contohnya; setinggi paha, setinggi lutut, dan sejenisnya.
Tahapan keempat adalah Part Of Speech (POS) tagging menggunakan suatu korpus berupa kumpulan set tag hasil riset dari [12]. Korpus digunakan untuk memberikan tag atau label selama proses POS. Hasil proses merupakan bagian kalimat yang dikonversi kedalam suatu tag. Sebelum proses POS, kata-kata yang tidak memiliki makna diidentifikasi sebagai “stopword”.
Tahapan kelima adalah identifikasi entitas lokasi menggunakan pendekatan rule assigment. Tahapan ini mensiasati jika ada entitas lokasi yang tidak teridentifikasi menggunakan toponimi. Proses ini menggunakan bantuan kata kunci Preposisi yang biasanya menunjukkan suatu lokasi. Kemudian, suatu Preposisi diikuti oleh serangkaian tag Noun (NN) akan diidentifikasi sebagai entitas lokasi. Sebagai contoh Tweet berikut;
banjir sepaha orang dewasa di jl. budi mulia gunung sahari @petajkt #banjir.
“jl. budi mulia gunung sahari” adalah satu set nama lokasi. POS mengidentifikasinya sebagai PREP NN NN NN NN. Dalam rule assignment, jika suatu preposisi diikuti oleh tag Noun, maka diidentifikasi sebagai satu entitas lokasi.
Tahapan terakhir dari Text Mining ini adalah identifikasi Tweet yang relevan menggunakan pendekatan rule assignment. Jika dalam suatu Tweet terdapat kata kunci terkait banjir dan entitas lokasi atau ketinggian banjir, maka Tweet tersebut diidentifikasi sebagai Tweet relevan. Lebih jelasnya dapat dilihat contoh berikut:
Tweet asli :
@petajkt #banjir banjir sepaha orang dewasa, Jl. Satria 2 Jelambar JakBar pic.twitter.com/CmdYPd4A7l
Tweet setelah tahapan proses Text Mining:
ATUSER KEYFLOOD KEYFLOOD DEEPVAL NN RB LOCNAME 2 LOCNAME LOCNAME URL Mengingat Tweet tersebut berisi kata kunci banjir dan lokasi, maka dikategorikan sebagai Tweet yang relevan. Potongan pengkodean rule assignment adalah sebagai berikut:
1). Regex : Regular Expression, adalah sederetan karakter yang mendefinisikan pola pencarian teks.
tweetsplit = tweet.split() #remaining words resrelevant = None
if (('KEYFLOOD' in tweetsplit) and (('LOCNAME' in tweetsplit) or
('KEYHEIGHT' in tweetsplit )) or ('DEEPVAL' in tweetsplit)):
resrelevant = 'y'
else:
resrelevant = 'n'
Untuk mengevaluasi program Text Mining yang telah dibangun, pengukuran F-measure test dilakukan. Seperti yang diadaptasi dari [12], F-measure (F1 score) adalah suatu metode untuk mengukur akurasi dari suatu prediksi dan kondisi. Dalam kasus ini, prediksi adalah hasil yang diperoleh dari proses Text Mining, dan kondisi adalah hasil yang diperoleh dari cek manual. F-measure mempertimbangkan precision dan recall yang diperoleh dari suatu klasifikasi kontingensi (kemungkinan) biner seperti yang terlihat pada tabel 1. Sel dari tabel kontingensi menunjukkan prediksi yang benar atau salah. Sel hijau merujuk prediksi yang benar dan sel merah merujuk prediksi yang salah.
Tabel 1: Tabel Kontingensi
Condition positive Condition negative
Predicted positive True positive False positive
(Type I error)
Predictive negative False negative True negative
(Type II error)
Precision (p) atau disebut sebagai Positive Predictive Value adalah jumlah hasil True Positive dibagi dengan jumlah keseluruhan Predicted Positive. Recall atau disebut True Positive Rate adalah jumlah True Positive dibagi dengan jumlah seluruh Condition Positive. Dengan kata lain, Precision adalah untuk mengukur kualitas dari program dan Recall adalah untuk mengukur kelengkapan hasil program tersebut.
Evaluasi bertujuan untuk mengukur rata-rata antara Precision dan Recall. Karenanya, berdasarkan parameter ini, F-measure dilakukan untuk menghitung taksiran rata-rata keduanya. Rumus F-measure ditunjukkan dengan persamaan berikut:
F-measure = 2 x precision x recall precision + recall
3. HASIL DAN PEMBAHASAN
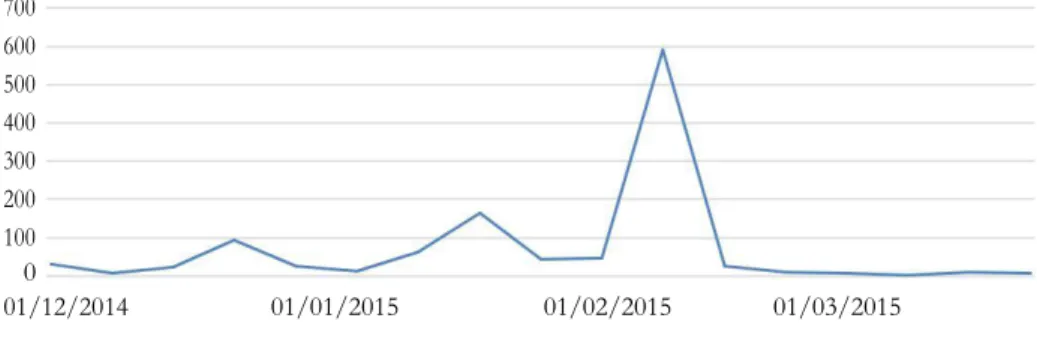
Program yang dibangun berhasil mengumpulkan 5.281 Tweet dari bulan Desember 2014 sampai bulan Maret 2015 baik Tweet bergeolokasi maupun tidak bergeolokasi. Mengingat penenilitian ini hanya mempertimbangkan Tweet bergeolokasi, maka jumlah Tweet berkurang menjadi 1.159 Tweet. Gambar dibawah menunjukkan aktifitas Tweet dalam kurun waktu tersebut. Kenaikan aktivitas Tweet seiringan dengan naiknya jumlah pengungsi banjir dibulan yang sama [13].
51 700 600 500 400 300 200 100 0 01/12/2014 01/01/2015 01/02/2015 01/03/2015 Minggu
Gambar 2. Grafik aktivitas Tweet per minggu
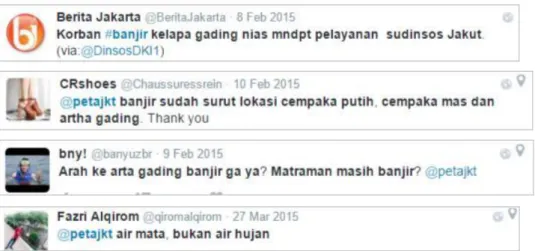
Pada musim penghujan, secara aktif akun @petajkt mengajak warga Jakarta melaporkan jika terjadi banjir dilingkungannya melalui Twitter. Contoh undangan tersebut bisa dilihat di gambar 3. Kemudian, masyarakat yang terdampak banjir dapat melaporkan keadaannya dengan mengaktifkan geolokasi agar bisa dipetakan kedalam sistemnya. Contoh laporan masyarakat tersebut dapat dilihat di gambar 4. Akan tetapi, banyaknya Tweet yang masuk tidak lepas dari noise atau gangguan. Noise tersebut berasal dari Tweet yang tidak ada kaitannya dengan banjir seperti terlihat di gambar 5. Tweet dengan noise dikelompokkan kedalam off-topic Tweets. Dari total Tweet yang terkumpul, proses Text Mining mengelompokkan relevant Tweets sebanyak 534 Tweet dan off-topic Tweet sebanyak 625 Tweet.
Gambar 3. Undangan pelaporan banjir
Gambar 4. Laporan masyarakat yang terdampak banjir
Gambar 5. Noise Tweet
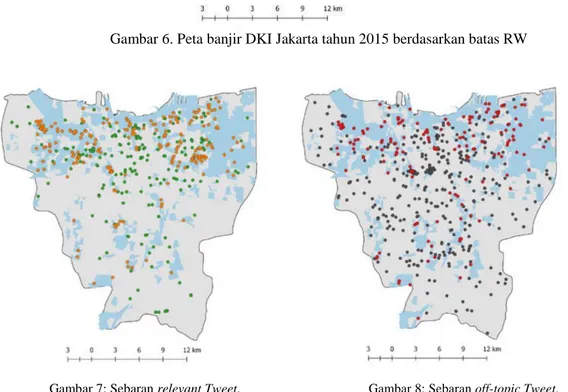
Untuk melihat pola spasial dari Tweet yang dihasilkan, dilakukan perbandingan antara sebaran Tweet hasil Text Mining dengan peta banjir DKI Jakarta di tahun yang sama. Peta banjir yang digunakan adalah tahun 2015 bersumber dari SDI (Spatial Data Infrastructure) BPPD DKI Jakarta (dapat dilihat digambar 6). Area banjir ditentukan berdasarkan laporan masing-masing ketua RW, sehingga deliniasi batas banjir sesuai dengan deliniasi batas RW yang dilaporkan. Hal ini mengakibatkan ketidak pastian (uncertainty) batas banjir yang sebenarnya.
Pertampalan antara sebaran titik relevant Tweet dengan peta banjir menunjukkan pola yang serupa. Hal ini bisa dilihat di gambar 7, dimana sebaran titik geolokasi Tweet banyak menyebar dilokasi banjir. Ini menunjukkan bahwa informasi yang dilaporkan melalui Twitter jika dilakukan proses penyaringan akan menghasilkan data yang cukup valid. Sebaliknya, gambar 8 menunjukkan sebaran Tweet yang off-topic cenderung lebih menyebar diseluruh wilayah.
Gambar 6. Peta banjir DKI Jakarta tahun 2015 berdasarkan batas RW
Gambar 7: Sebaran relevant Tweet. Gambar 8: Sebaran off-topic Tweet. Titik oranye adalah Tweet yang berada didalam area Titik merah adalah Tweet yang berada didalam area
banjir, titik hijau adalah Tweet yang berada diluar banjir, titik hitam adalah Tweet yang berada diluar area
area banjir banjir
Untuk mengevaluasi program Text Mining yang dibuat, pengukuran F-measure dilakukan terhadap relevant Tweet dan off-topic Tweet. Hasil yang diperoleh dapat dilihat di tabel 2, tabel menunjukkan bahwa nilai True Positivenya cukup besar, sehingga perhitungan Precision dan Recallnya pun tinggi.
Tabel 2: Tabel Kontingensi antara Tweet yang relevan dan Tweet yang off-topic
Teridentifikasi Tidak Teridentifikasi
relevant Tweet relevant Tweet
Tweet yang memiliki informasi relevan 495 63
53 Perhitungan Precision, recall, dan F-measure:
Precision = 495/(495+63) = 89% Recall = 495/(495+39) = 92% F-measure = 90%
Seperti yang terlihat pada tabel 2, error yang teridentifikasi dikelompokkan kedalam dua kondisi; kondisi False Negative (FN) adalah dimana Tweet tidak mempunyai informasi relevan (off-topic) tetapi teridentifikasi oleh program sebagai Tweet yang relevant. Kemudian, kondisi False Positive (FP) adalah dimana Tweet memiliki informasi yang relevan tetapi teridentifikasi oleh program sebagai Tweet yang off-topic.
Setelah dilakukan pengecekan, FN disebabkan oleh dua faktor; pertama, program mengidentifikasi suatu kata sebagai kata kunci banjir dan entitas lokasi. Akan tetapi, pada kenyataannya Tweet tersebut terkait evakuasi, pembaharuan informasi, dan menanyakan informasi seperti terlihat pada gambar 9.a, 9.b,dan 9.c. Kedua, program mengidentifikasi suatu kata terkait kata kunci banjir dan ketinggian banjir, tetapi pada kenyataannya Tweet terebut berupa noise seperti terlihat pada gambar 9.d.
a
b
c
d
Gambar 9: Tweet penyebab False Negative
4. KESIMPULAN
Besarnya jumlah data yang diperoleh dari hasil penelitian menunjukkan adanya potensi yang cukup tinggi untuk memperoleh informasi dari masyarakat melalui Twitter disaat terjadinya bencana banjir. Akan tetapi, kesadaran pentingnya geolokasi untuk memetakan sebaran Twitter tersebut masih sangat rendah. Hal ini dapat dilihat dari jumlah Tweet yang bergeolokasi tidak sampai 50% dari jumlah total Tweet yang dikumpulkan.
Perbandingan sebaran Tweet hasil penyaringan dengan peta sebaran lokasi banjir memperlihatkan bahwa Tweet yang memiliki konten relevan terhadap informasi banjir menunjukkan sebaran yang sama dengan lokasi banjir. Sebaliknya, Tweet yang tidak memiliki konten relevan terhadap informasi banjir (off-topic Tweet) memiliki sebaran yang cenderung menyebar dan tidak terklaster pada lokasi banjir.
Dalam rangka menyaring informasi Twitter, hasil evaluasi Text Mining menggunakan uji F-measure menunjukkan bahwa algoritma yang dibangun memiliki kualitas yang baik dalam mengklasifikasi konten Tweet yang relevan dan yang off-topic. Hal ini dapat dilihat dari nilai Precision sebesar 89%, Recall sebesar 92% dan nilai F-measure sebesar 90%. Hasil keseluruhan dari penelitian ini dapat disimpulkan bahwa informasi banjir yang diperoleh dari Twitter jika dilakukan proses penyaringan dengan benar akan memberikan sumber informasi yang dapat diandalkan.
5. DAFTAR PUSTAKA
[1] Oliver, D., Tiwari, R., Evans, M., & Shekhar, S. (2014). Disaster Response and Relief, VGI Volunteer Motivation. Encyclopedia of Social Network Analysis and Mining, 370–380. [2] Poser, K., & Dransch, D. (2010). Volunteered Geographic Information for Disaster Management With Application To Rapid Flood Damage Estimation. Geomatica, 64(1). [3] Bruns, A., & Liang, Y. (2012). Tools and methods for capturing Twitter data during natural disasters. First Monday, 17(4).
[4] Shelton, T., Poorthuis, A., Graham, M., & Zook, M. (2014). Mapping the data shadows of Hurricane Sandy: Uncovering the sociospatial dimensions of “big data”. Geoforum, 167-179. [5] Flanagin, A., & Metzger, M. (2008). The credibility of volunteered geographic information. GeoJournal, 3-4.
[6] Klein, B., & Castanedo, F. (2013). Emergency Event Detection in Twitter Streams Based on Natural Language Processing. UCAmI, Springer LNCS, 239–246.
[7] Li, C. (2014). Fine-grained location extraction from tweets with temporal awareness. Proceedings of the 37th international ACM SIGIR conference on Research & development in information retrieval, 43-52.
[8] Liu, X., Zhang, S., Wei, F., & Zhou, M. (2011). Recognizing Named Entities in Tweets. n Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL), 359–367.
[9] Goodchild, M. (2007). Citizens as sensors: The world of volunteered geography. GeoJournal, 211–221.
[10] Jung, J. (2012). Online named entity recognition method for microtexts in social networking services: A case study of twitter. Expert Systems with Applications, 8066–8070. [11] Gimpel, K., Schneider, N., O’Connor, B., Das, D., Mills, D., Eisenstein, J., et al. (2011). Part-of-speech tagging for Twitter: annotation, features, and experiments. Human Language Technologies, 42–47.
[12] Dinakaramani, A., Rashel, F., Luthfi, A., & Manurung, R. (2014). Designing an Indonesian Part of speech Tagset and Manually Tagged Indonesian Corpus.
[13] Powers, D. (2011). Evaluation: From precision, recall and f-measure to roc.,
informedness, markedness & correlation. Journal of Machine Learning Technologies, 37 – 63.
[14] BPBD Jakarta. (2016, Januari 21). Rekapitulasi Kejadian Banjir Bulan Februari_2015. Retrieved from http://bpbd.jakarta.go.id:
http://bpbd.jakarta.go.id/assets/attachment/document/Rekapitulasi_Kejadian_Banjir_Bulan_Febr uari_2015.pdf