Penerapan K-Means Untuk Pengelompokan Pengguna Internet
Berdasarkan Elapsed dan Byte Transferred
Artikel Ilmiah
Diajukan kepada Fakultas Teknologi Informasi
Untuk memperoleh Gelar Sarjana Komputer
Oleh:
Kushendra Satria Prabawa (672009121) Dr. Irwan Sembiring, S.T., M.Kom.
Program Studi Teknik Informatika Fakultas Teknologi Informasi Universitas Kristen Satya Wacana
Salatiga Desember 2015
Penerapan K-Means Untuk Pengelompokan Pengguna Internet
Berdasarkan Elapsed dan Byte Transferred
1)
Kushendra Satria Prabawa2) IrwanSembiring
Fakultas Teknologi Informasi Universitas Kristen Satya Wacana Jl. Diponegoro 52-60, Salatiga 50711, Indonesia
Email: 1)[email protected], 2)[email protected],
Abstract
Agencies providing Internet to its employees, to send and receive information.
Internet connection is provided is often misused to access websites that do not provide
benefits to the institution. Websites that do not provide these benefits need to be identified and then blocked access. This is done with the purpose so that the user can be more focused on productivity. The analysis process can be done by reading and processing the access log files contained on the Internet proxies, such as for example Squid. Process analysis was performed using data mining, by processing the file acces log using algorima K-Means Clustering based on elapsed and bytes transferred. The process analysis on the file is expected to provide an overview for the network administrator, about the Group's website as well as users anywhere who use its Internet access is high, and whether the available internet service actually used for the benefit of the Agency.
Keywords: Data mining, K-Means, elapsed, byte transferred, Acces log
Abstrak
Pada suatu instansi, Internet disediakan untuk mengirim dan menerima informasi. Koneksi Internet yang disediakan sering kali disalahgunakan untuk mengakses
website-website yang tidak memberikan manfaat bagi instansi tersebut. Website yang tidak
memberikan manfaat tersebut perlu dikenali kemudian diblokir aksesnya. Hal ini dilakukan dengan tujuan supaya pengguna dapat lebih terfokus pada produktivitasnya. Proses analisis dapat dilakukan dengan membaca dan mengolah file access log yang terdapat pada proxy Internet, seperti contohnya Squid. Proses analisis dilakukan dengan menggunakan data mining, tepatnya dengan mengolah file acces log tersebut menggunakan algorima K-Means Clustering berdasarkan elapsed dan byte transferred. Proses analisis pada file tersebut diharapkan dapat memberikan gambaran bagi administrator jaringan, tentang kelompok website maupun pengguna mana saja yang pemakaiannya akses internetnya tinggi, dan apakah layanan internet yang tersedia benar-benar digunakan untuk kepentingan instansi.
Kata Kunci: Data mining, K-Means, elapsed, byte transferred, Acces log
______________________________________ 1)
Mahasiswa Program Studi Teknik Informatika, Fakultas Teknologi Informasi, Universitas Kristen Satya Wacana
2)
1
1. Pendahuluan
Pada era digital saat ini, tidak bisa dibayangkan dunia tanpa komunikasi. Manusia memiliki kepentingan bertukar informasi untuk berbagai tujuan. Internet memiliki peran sebagai penyedia informasi dari berbagai titik di dunia, kepada tempat manapun di dunia. Informasi dapat diperoleh dengan mudah dan cepat.
Pada suatu instansi, Internet disediakan untuk mengirim dan menerima informasi. Koneksi Internet yang disediakan sering kali disalahgunakan untuk mengakses website yang tidak memberikan manfaat bagi instansi tersebut.
Website yang mengalihkan perhatian pengguna Internet, dapat menurunkan
kinerja pengguna tersebut, dan dapat mengganggu kinerja instansi.
Website yang tidak memberikan manfaat tersebut perlu dikenali kemudian
diblokir aksesnya. Hal ini dilakukan dengan tujuan supaya pengguna dapat lebih terfokus pada produktivitasnya. Pola penggunaan Internet tersebut perlu dianalisis untuk mengetahui seberapa besar persentase penggunaan data untuk mengakses
website-website tersebut.
Proses analisis dapat dilakukan dengan membaca dan mengolah file access
log yang terdapat pada proxy Internet, seperti contohnya Squid. Pada file tersebut
terdapat rekaman waktu akses, sumber dan tujuan akses, lama akses, dan besar data yang ditransmisikan. Proses analisis dilakukan dengan menggunakan data
mining, tepatnya dengan menggunakan algorima K-Means Clustering. Proses
analisis pada file tersebut diharapkan dapat memberikan gambaran bagi administrator jaringan, tentang kelompok website dan user mana saja yang mempunyai akses tinggi, dan apakah layanan internet yang tersedia benar-benar digunakan untuk kepentingan instansi.
Berdasarkan permasalahan tersebut, dilakukan penelitian untuk mengelompokkan pengunaan internet baik dari user maupun website yang dikunjungi. Analisis dilakukan untuk mengetahui seberapa besar throughput yang digunakan untuk kepentingan instansi. Analisis dilakukan dengan mengembangkan aplikasi berbasis desktop.
2. Tinjauan Pustaka
Pada penelitian Sutiknyo [1], diimplementasikan K-Means dalam proses penggolongan suara berdasarkan usia. Data suara dikumpulkan dengan proses sampling kemudian dianalisis dengan K-Means untuk dikelompokan dalam
cluster usia dewasa dan anak-anak. Pada saat ada sinyal baru yang masuk, maka
akan dibandingkan dengan data yang telah terklaster. Perbandingan dilakukan dengan menghitung titik tengah data baru, dengan titik tengah tiap cluster, sehingga diketahui cluster terdekat dengan data baru (sinyal suara baru) tersebut. Penelitian tersebut menghasilkan aplikasi penggolongan suara, yang berdasarkan pengujian, memiliki tingkat keberhasilan 100%.
Pada penelitian Rismawan [2], dibahas mengenai membangun suatu sistem untuk mengelompokkan data yang ada berdasarkan status gizi dan ukuran rangkanya dengan memasukkan parameter kondisi fisik dari orang tersebut. Pengelompokkan data dilakukan dengan menggunakan metode clustering
K-2
Means yaitu dengan mengelompokkan n buah objek ke dalam k kelas berdasarkan
jaraknya dengan pusat kelas. Dari hasil penelitian terhadap 20 data sampel diperoleh 3 kelompok mahasiswa berdasarkan nilai BMI dan ukuran rangka, yaitu : BMI normal dan kerangka besar, BMI obesitas sedang dan kerangka sedang, BMI obesitas berat dan kerangka kecil.
Data Mining [3] merupakan solusi yang mampu menemukan kandungan
informasi yang tersembunyi berupa pola dan aturan sekumpulan data yang besar agar mudah dipahami. Data Mining didefinisikan sebuah proses untuk menemukan hubungan, pola, dan tren baru yang bermakna dengan menyaring data yang sangat besar, yang tersimpan dalam penyimpanan. menggunakan teknik pengenalan pola seperti teknik statistik dan matematika. Data Mining dan
knowledge discovery in database (KDD) [4] merupakan istilah yang memiliki
konsep yang berbeda akan tetapi saling berkaitan karena data mining adalah bagian dalam proses knowledge discovery in database.
Salah satu metode yang diterapkan dalam KDD adalah clustering.
Clustering adalah membagi data ke dalam grup-grup yang mempunyai obyek
yang karakteristiknya sama [5]. Garcia-Molina [6] menyatakan clustering adalah pengelompokan item data ke dalam sejumlah kecil grup sedemikian sehingga masing-masing grup mempunyai sesuatu persamaan yang esensial. Clustering memegang peranan penting dalam aplikasi data mining, misalnya eksplorasi data ilmu pengetahuan, pengaksesan informasi dan text mining, aplikasi basis data spasial, dan analisis web.
Tan [7] membagi clustering dalam dua kelompok, yaitu hierarchical and
partitional clustering. Partitional Clustering [8] disebutkan sebagai pembagian
obyek-obyek data ke dalam kelompok yang tidak saling overlap sehingga setiap data berada tepat di satu cluster. Hierarchical clustering [9] adalah sekelopok
cluster yang bersarang seperti sebuah pohon berjenjang (hirarki). Algoritma clustering terbagi ke dalam kelompok besar seperti berikut: 1. Partitioning algorithms: algoritma dalam kelompok ini membentuk bermacam partisi dan
kemudian mengevaluasinya dengan berdasarkan beberapa kriteria. 2. Hierarchy
algorithms: pembentukan dekomposisi hirarki dari sekumpulan data
menggunakan beberapa kriteria. 3. Density-based [10] : pembentukan cluster berdasarkan pada koneksi dan fungsi densitas. 4. Grid-based: pembentukan
cluster berdasarkan pada struktur multiple-level granularity 5. Model-based:
sebuah model dianggap sebagai hipotesa untuk masing-masing cluster dan model yang baik dipilih diantara model hipotesa tersebut.
Algoritma K-Means adalah algoritma clustering yang paling popular dan banyak digunakan dalam dunia industri [5]. Algoritma ini disusun atas dasar ide yang sederhana. Algoritma K-Means merupakan model centroid. Model centroid adalah model yang menggunakan centroid untuk membuat cluster. Centroid adalah “titik tengah” suatu cluster yang berupa nilai. Centroid digunakan untuk menghitung jarak suatu obyek data terhadap centroid. Pada awalnya ditentukan berapa cluster yang akan dibentuk. Sembarang obyek atau elemen pertama dalam
cluster dapat dipilih untuk dijadikan sebagai titik tengah (centroid point) cluster.
Algoritma K-Means selanjutnya akan melakukan pengulangan langkah-langkah berikut sampai terjadi kestabilan (tidak ada obyek yang dapat dipindahkan): 1.
3
menentukan koordinat titik tengah setiap cluster, 2. menentukan jarak setiap obyek terhadap koordinat titik tengah, 3. mengelompokkan obyek-obyek tersebut berdasarkan pada jarak minimumnya. Gambar 1 menunjukkan diagram alir dari algoritma K-Means. Secara umum metode K-Means menggunakan algoritma sebagai berikut [11]:
1. Tentukan k sebagai jumlah cluster yang dibentuk.
Untuk menentukan banyaknya cluster k dilakukan dengan beberapa pertimbangan seperti pertimbangan teoritis dan konseptual yang mungkin diusulkan untuk menentukan berapa banyak cluster.
2. Bangkitkan k Centroid (titik pusat cluster) awal secara random. Penentuan centroid awal dilakukan secara random/acak dari objek-objek yang tersedia sebanyak k cluster, kemudian untuk menghitung
centroid cluster ke-i berikutnya,
3. Hitung jarak setiap objek ke masing centroid dari masing-masing cluster. Ada beberapa cara penghitungan jarak yang biasa digunakan yaitu :
Euclidean distance
Manhattan distance disebut juga taxicab
Chebichev distance
4. Alokasikan masing-masing objek ke dalam centroid yang paling terdekat.
Untuk melakukan pengalokasian objek kedalam masing-masing cluster pada saat iterasi secara umum dapat dilakukan dengan dua cara yaitu dengan hard k-means, dimana secara tegas setiap objek dinyatakan sebagai anggota cluster dengan mengukur jarak kedekatan sifatnya terhadap titik pusat cluster tersebut, cara lain dapat dilakukan dengan
fuzzy C-Means.
5. Lakukan iterasi, kemudian tentukan posisi centroid baru dengan menggunakan persamaan (1).
6. Ulangi langkah 3 jika posisi centroid baru tidak sama.
Pengecekan konvergensi dilakukan dengan membandingkan matriks
group assignment pada iterasi sebelumnya dengan matrik group assignment pada iterasi yang sedang berjalan. Jika hasilnya sama maka algoritma k-means cluster analysis sudah konvergen, tetapi jika
berbeda maka belum konvergen sehingga perlu dilakukan iterasi berikutnya.
4
Gambar 1 Alur algoritma K-Means [12]
Access log adalah file yang mencatat semua akses yang dilakukan terhadap web server. Data yang disediakan oleh web server logs berisi informasi tentang remotehost (ip address), rfc931, authuser, timestamp, request, status, dan size
serta jenis agen yang digunakan untuk mengakses website
Tabel 1 Format dan Contoh Access log
Field Keterangan Contoh
time Unix timestamp 1301572114
elapsed Durasi akses. Dalam milidetik 4014
client ip address Alamat IP komputer local 192.168.67.71
code/status Squid result code TCP_MISS/206
bytes Ukuran byte yang ditransmisikan 279858
method Metode yang digunakan untuk
mendapatkan objek GET
URL Alamat url yang diakses https://www.google.co.id/
rfc931 -
peerstatus/peerhost DIRECT/119.110.77.232
type Tipe data
application/x-rar-compressed 3. Metode dan Perancangan Sistem
Penelitian yang dilakukan, diselesaikan melalui tahapan penelitian yang terbagi dalam empat tahapan, yaitu: (1) Analisis kebutuhan dan pengumpulan
5
data, (2) Perancangan sistem, (3) Implementasi sistem yaitu Perancangan aplikasi/program, dan (4) Pengujian sistem serta analisis hasil pengujian.
Gambar 2 Tahapan Penelitian
Tahapan penelitian pada Gambar 2, dapat dijelaskan sebagai berikut.
Tahap pertama: yaitu melakukan analisis kebutuhan; Tahap kedua: yaitu
melakukan perancangan sistem yang meliputi perancangan proses K-Means, atribut-atribut yang digunakan di access log untuk diterapkan pada proses
clustering; Tahap ketiga: yaitu mengimplementasikan rancangan yang telah
dibuat di tahap dua ke dalam sebuah aplikasi/program sesuai kebutuhan sistem;
Tahap keempat: yaitu melakukan pengujian terhadap sistem yang telah dibuat,
serta menganalisis hasil pengujian tersebut, untuk melihat apakah aplikasi yang telah dibuat sudah sesuai dengan yang diharapkan atau tidak, jika belum sesuai maka akan dilakukan perbaikan.
Tentukan Pusat Cluster Awal Mulai K=jumlah cluster I = jumlah iterasi Access Log
Hitung Jarak tiap-tiap record terhadap tiap-tiap cluster
Hitung Ulang Titik Pusat masing-masing
cluster Jika Semua Iterasi selesai dijalankan Mulai Proses Iterasi FALSE Selesai TRUE
Masukkan tiap record ke dalam cluster terdekat
Gambar 3 Alur Proses Clustering Data Access log
Alur proses clustering pada penelitian ini ditunjukkan pada Gambar 3.
Access log yang diperoleh dari squid, disimpan dalam database, dengan tujuan
dapat diolah dan dibaca kembali. Proses clustering memerlukan dua variabel masukan, yaitu jumlah cluster dan dan jumlah iterasi yang harus dilakukan. Jumlah iterasi menentukan kondisi kapan proses clustering berhenti. Tiap cluster harus ditentukan titik pusat awal. Titik pusat ini berupa angka x dan y. X
6
mewakili nilai elapsed time, dan y menentukan byte transferred. Rumus untuk menentukan titik pusat awal cluster adalah sebagai berikut:
(1)
(2) Xi adalah titik pusat cluster ke i. Untuk menentukan titik tengah awal, maka diperlukan nilai “selisih”. Selisih, pada rumus 1 adalah nilai peningkatan dari satu cluster ke cluster berikutnya. Xmax adalah nilai x terbesar dalam kumpulan record. Xmin adalah nilai x terkecil dalam kumpulan record. Sebagai contoh, diketahui Xmin = 2, Xmax = 4, jumlah cluster = 5. Maka selisih yang diperoleh adalah (4-2)/5 = 0.4.
Rumus 2 digunakan untuk menentukan nilai titik pusat awal tiap-tiap
cluster. Jika selisih yang digunakan adalah 0.4, seperti diperoleh pada rumus 1,
maka titik pusat awal
cluster 0 adalah 2 + (0.4 x 0) = 2, cluster 1 adalah 2 + (0.4 x 1) = 2.4, cluster 2 adalah 2 + (0.4 x 2) = 2.8, cluster 3 adalah 2 + (0.4 x 3) = 3.2, dan cluster 4 adalah 2 + (0.4 x 4) = 3.6.
Pada tiap record, dihitung jarak antara record dengan titik tengah tiap-tiap
cluster. Rumus perhitungan jarak euclidean ditunjukkan pada rumus 3. Rumus 4
merupakan rumus perhitungan rata-rata (mean) digunakan untuk menghitung ulang titik pusat cluster. Rata-rata suatu cluster diperoleh dengan menjumlahkan nilai member pada cluster tersebut, dibagi dengan jumlah member di dalam
cluster itu. Rata-rata dihitung untuk tiap atribut, yaitu x untuk elapsed time, dan y
untuk byte transferred. Pada rumus 4 ditunjukkan rumus untuk atribut x (elapsed
time), yang juga dapat berlaku untuk atribut y (byte transferred)
(3)
(4)
Berikut diberikan contoh proses clustering terhadap data access log. Format data access log adalah sebagai berikut:
Tabel 2 Format Access log
Field Keterangan Contoh
Time Unix timestamp 1301572114
Elapsed Durasi akses. Dalam milidetik 4014
7
code/status Squid result code TCP_MISS/206
Bytes Ukuran byte yang ditransmisikan 279858
Method Metode yang digunakan untuk
mendapatkan objek GET
URL Alamat url yang diakses https://www.google.co.id/
rfc931 -
peerstatus/peerhost DIRECT/119.110.77.232
Type Tipe data application/x-rar-compressed
Setelah melalui proses pembersihan, dimisalkan hasil ringkasan access log adalah sebagai berikut:
Tabel 3 Contoh Hasil Ringkasan Access log
IP Elapsed (X) Byte Transferred (Y)
192.168.67.10 16335 3362067 192.168.67.16 25665 6042126 192.168.67.22 16677 3619241 192.168.67.23 17698 3723590 192.168.67.24 17643 3733322 192.168.67.28 18290 3648499 192.168.67.39 16507 3459869 192.168.67.41 17722 3769288 192.168.67.56 16706 3822160 192.168.67.57 16641 3625630
Data tersebut akan dikelompokkan dalam 3 cluster yaitu A, B, C, dengan jumlah iterasi adalah 2. Titik tengah tiap cluster yang dihasilkan dari perhitungan dengan rumus 1, dan rumus 2 yaitu:
A = (16335, 3362067), B = (19445, 4255420), dan C = (22555, 5148773). Hasil iterasi pertama adalah:
Tabel 4 Hasil Iterasi Pertama IP Elapsed (X) Byte Transferred (Y) A B C 192.168.67.10 16335 3362067 0 893358.4 1786717 192.168.67.16 25665 6042126 2680075 1786717 893358.4 192.168.67.22 16677 3619241 257174.2 636185 1529543 192.168.67.23 17698 3723590 361525.6 531832.9 1425191 192.168.67.24 17643 3733322 371257.3 522101.1 1415460 192.168.67.28 18290 3648499 286438.7 606922.1 1500280 192.168.67.39 16507 3459869 97802.15 795556.4 1688915 192.168.67.41 17722 3769288 407223.4 486135.1 1379493 192.168.67.56 16706 3822160 460093.1 433268.7 1326626 192.168.67.57 16641 3625630 263563.2 629796.2 1523154
Pada hasil iterasi pertama diperoleh keanggotaan pada cluster A sebanyak 8 anggota (192.168.67.10, 192.168.67.22, 192.168.67.23, 192.168.67.24,
8
192.168.67.28, 192.168.67.39, 192.168.67.41, 192.168.67.57), ditunjukkan dengan cetak tebal dan miring. Demikian juga pada cluster B ada 1 anggota (192.168.67.56, C ada 1 anggota (192.168.67.16). Angka pada tiap cluster adalah nilai jarak antara member dengan tiap cluster dengan menggunakan rumus
euclidean.
893358.4 adalah hasil perhitungan jarak menggunakan rumus 3 (Euclidean) yaitu (16335− 19445)2+ (3362067− 4255420)2. 16335 adalah nilai X pada member pertama, dan 3362067 adalah nilai Y pada member pertama. Angka 19445 dan 4255420 adalah titik tengah cluster B. Member dimasukkan pada cluster dengan nilai jarak terkecil.
Setelah itu, pada tiap cluster dihitung nilai rata-rata (means), untuk tiap
cluster, yaitu dengan menghitung rata-rata nilai X pada tiap member dan rata-rata
nilai Y pada tiap member cluster. Dari Iterasi pertama menghasilkan titik tengah
cluster baru yaitu:
A = (17189.1, 3617688), B = (16706, 3822160), dan C = (25665, 6042126) Hasil iterasi kedua adalah:
Tabel 5 Hasil Iterasi Kedua IP Elapsed (X) Byte Transferred (Y) A B C 192.168.67.10 16335 3362067 255622.7 460093.1 2680075 192.168.67.16 25665 6042126 2424453 2219984 0 192.168.67.22 16677 3619241 1635.024 202919 2422902 192.168.67.23 17698 3723590 105903 98574.99 2318550 192.168.67.24 17643 3733322 115634.6 88842.94 2308818 192.168.67.28 18290 3648499 30830.41 173668.2 2393638 192.168.67.39 16507 3459869 157820.7 362291.1 2582273 192.168.67.41 17722 3769288 151600.7 52881.76 2272852 192.168.67.56 16706 3822160 204472.3 0 2219984 192.168.67.57 16641 3625630 7960.643 196530 2416513
Hasil dari iterasi kedua ada beberapa member cluster A bergeser dan berpindah menjadi member di cluster B. Pada iterasi kedua ini jumlah member di cluster B yang pada iterasi pertama hanya mempunyai satu anggota, pada iterasi kedua bertambah menjadi 4 member, sedangkan cluster C tidak mengalami perubahan member. Hasil iterasi kedua dapat disimpulkan Cluster A adalah
cluster dengan kelompok IP yang memiliki waktu akses rendah, dan byte yang
dikirimkan rendah. Cluster B adalah cluster dengan waktu akses tinggi, tapi byte yang dikirimkan besar. Cluster C adalah cluster dengan nilai waktu tinggi dan
9
4. Hasil dan Pembahasan
Aplikasi yang dikembangkan dalam penelitian ini berupa aplikasi berbasis
desktop. Perangkat pengembangan yang digunakan adalah Visual Studio 2012
Express for Windows Desktop, dengan pustaka .Net Framework 4.5. Database yang digunakan adalah Microsoft SQL Server Express 2012.
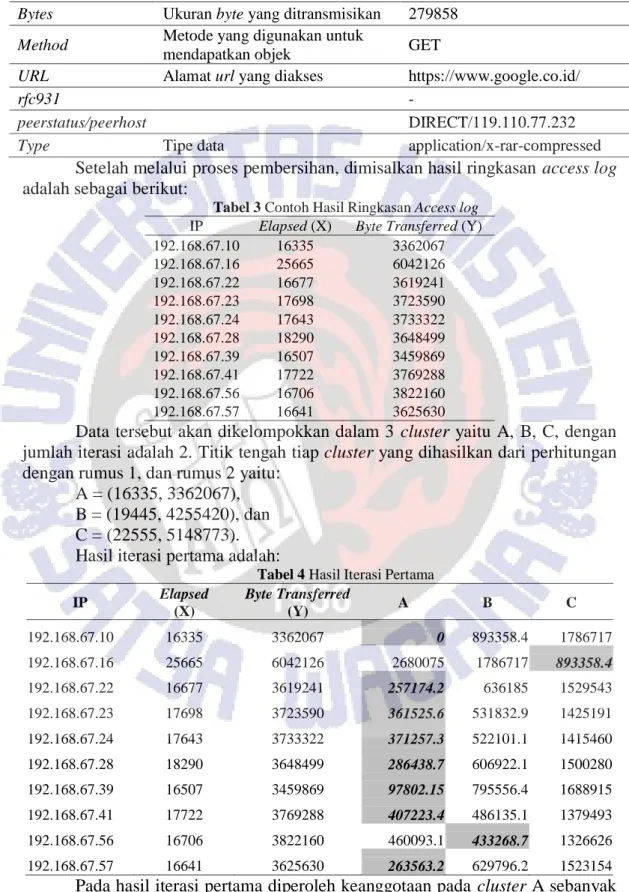
Gambar 4 Hasil Implementasi Clustering pada Aplikasi
Sesuai dengan perancangan, pada aplikasi dikembangkan fitur clustering dengan menggunakan algoritma K-Means berdasarkan remote host(destination) maupun local host. Pada Gambar 4, diatur untuk membentuk 4 cluster dengan
object Remote Host ( Destination) menggunakan iterasi 10. Data access log yang
diolah dibatasi oleh rentang waktu yaitu pada jam 7 pagi sampai dengan jam 16.
10
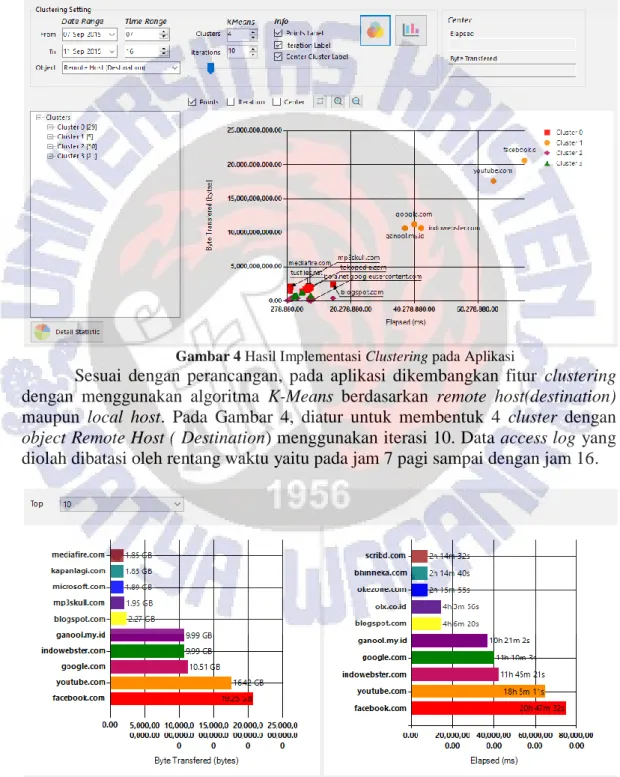
Gambar 5 menunjukkan form yang menampilkan grafik bar. Grafik ini merupakan ringkasan dari 10 website yang paling banyak menggunakan byte data dan waktu akses. Chart sebelah kiri merupakan daftar website dengan penggunaan
byte 10 terbesar. Chart sebelah kanan dihitung berdasarkan total waktu akses
(elapsed) dalam satuan detik. Kedua chart ini dimaksudkan untuk memberikan informasi secara visual, kepada administrator jaringan, sehingga dapat membantu dalam pengambilan keputusan pengaturan jaringan.
Tiap satu proses iterasi akan membentuk susunan cluster tersendiri. Seiring dengan banyaknya proses iterasi yang dilalui, maka pusat cluster akan semakin menyesuaikan. Titik tengah cluster akan bergeser berdasarkan anggota-anggota cluster yang dimiliki. Semakin lama, dalam satu cluster, akan terdapat anggota yang memiliki atribut-atribut yang berdekatan (mirip).
Gambar 6 Hasil Clustering Penggunaan Internet Pada Rentang Jam 7-16 dalam sepekan
Gambar 6 menunjukkan hasil clustering dari sample data access log, yang terkumpul sepanjang tanggal 7-11 September 2015, dalam rentang jam 7 sampai dengan 16. Hasil clustering membentuk 4 cluster. Cluster 1 merupakan kelompok
website yang paling banyak diakses, dalam hal waktu dan byte. Pada cluster ini
terdapat website populer yaitu youtube.com, facebook.com dan google.com.
Website-website media dan berita berada di cluster 0. Website-website pendidikan
masuk dalam cluster 2 dan cluster 3, yaitu cluster dengan penggunaan byte data dan waktu yang paling kecil.
11
Gambar 7 Ringkasan URL yang diakses oleh beberapa komputer
Pada iterasi terakhir, terdapat satu cluster dengan satu komputer yang memiliki nilai “byte transferred” dan “elapsed time” terbesar yaitu facebook.com. Ringkasan penggunaan byte data oleh komputer tersebut dapat dilihat pada fiter statistik data. Gambar 7 menunjukkan komputer mana saja yang mengakses
website facebook tersebut. Data tersebut jika disajikan dalam bentuk chart,
ditunjukkan pada Gambar 8. Visualisasi data ini bertujuan untuk mempermudah pemahamaan data.
12
Pada Gambar 8 ditunjukkan diagram pie untuk menampilkan 10 besar komputer yang mengakses facebook.com dengan byte transferred terbesar. Disini dapat dilihat penggunaan terbesar yang mengakses facebook.com adalah member dengan ip 192.168.67.254
Gambar 9 Hasil Implementasi Clustering pada Aplikasi berdasar local host
Pada Gambar 9 menunjukkan hasil clustering dari sample data access log berdasarkan local host, yang terkumpul sepanjang tanggal 7-11 September 2015, dalam rentang jam 7 sampai dengan 16. Hasil clustering membentuk 4 cluster.
Cluster 2 merupakan kelompok local host yang paling banyak menggunakan
akses internet, dalam hal waktu dan byte.
Gambar 10 Grafik Bar untuk 10 Local Host Paling Banyak Menggunakan byte data dan Waktu
13
Gambar 10 menunjukkan form yang menampilkan grafik bar. Grafik ini merupakan ringkasan dari 10 local host yang paling banyak menggunakan byte
data dan waktu akses. Chart sebelah kiri merupakan daftar local host dengan
penggunaan byte 10 terbesar. Chart sebelah kanan dihitung berdasarkan total waktu akses (elapsed) dalam satuan detik. Kedua chart ini dimaksudkan untuk memberikan informasi secara visual, kepada administrator jaringan, sehingga dapat membantu dalam pengambilan keputusan pengaturan jaringan.
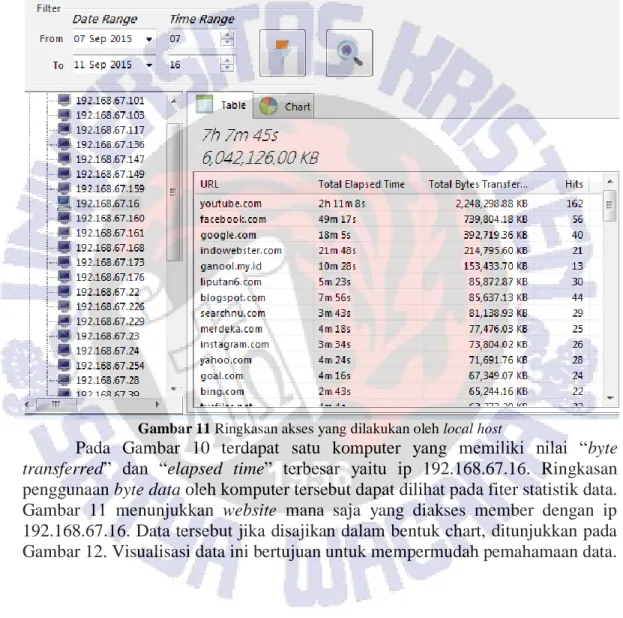
Gambar 11 Ringkasan akses yang dilakukan oleh local host
Pada Gambar 10 terdapat satu komputer yang memiliki nilai “byte
transferred” dan “elapsed time” terbesar yaitu ip 192.168.67.16. Ringkasan
penggunaan byte data oleh komputer tersebut dapat dilihat pada fiter statistik data. Gambar 11 menunjukkan website mana saja yang diakses member dengan ip 192.168.67.16. Data tersebut jika disajikan dalam bentuk chart, ditunjukkan pada Gambar 12. Visualisasi data ini bertujuan untuk mempermudah pemahamaan data.
14
Gambar 12 Ringkasan URL yang diakses oleh suatu komputer dalam bentuk diagram pie.
Pada Gambar 12 ditunjukkan diagram pie untuk menampilkan 10 besar website mana saja yang diakses oleh 192.168.67.16 dengan byte transferred terbesar. Disini dapat dilihat penggunaan terbesar yang diakses oleh alamat tersebut adalah mengakses youtube.com
5. Simpulan
Berdasarkan penelitian, pengujian dan analisis terhadap sistem, maka dapat diambil kesimpulan yaitu pengelompokan penggunaan internet dapat dianalisis dengan cara mengolah access log dari proxy server, kemudian diklasterkan dengan menggunakan algoritma K-Means. Hasil clustering menunjukkan kelompok-kelompok website yang paling sering diakses dan pengguna yang paling banyak menggunakan byte data pada rentang waktu tertentu. Rentang waktu ini dapat dispesifikasikan sampai dengan rentang per jam, sehingga dapat diketahui pola perilaku penggunaan pada jam kerja dan jam istirahat. Berdasarkan hasil clustering ini, administrator jaringan dapat melihat
website mana saja yang perlu dibatasi aksesnya, sehingga dapat memaksimalkan
penggunaan byte data internet untuk keperluan yang seharusnya. Pola titik tengah
cluster membentuk pola yang menunjukkan bahwa semakin besar waktu yang
digunakan untuk mengakses website tersebut, maka semakin besar pula data byte yang digunakan.
Saran yang dapat diberikan untuk penelitian dan pengembangan selanjutnya adalah algoritma untuk penelitian ini menggunakan salah satu algoritma clustering yaitu K-Means dengan menggunakan atribut elapsed dan byte
15
transferred dalam acceslog. Untuk penelitian selanjutnya dapat ditambahkan
atribut lainnya yaitu method yang terdapat pada file acceslog. Untuk penelitian selanjutnya, dapat dibandingkan dengan menggunakan algoritma asosiasi (Apriori), atau klasifikasi (KNN).
6. Daftar Pustaka
[1]. Sutiknyo, P. H. P. & Soelistijorini, R. 2011. Penggolongan Suara
Berdasarkan Usia Dengan Menggunakan Metode K-Means. EEPIS Final
Project
[2]. Rismawan & Kusumadewi. Aplikasi K-Means untuk Pengelompokan
Mahasiswa Berdasarkan Nilai Body Mass index (BMI) & Ukuran Kerangka. Yogyakarta: Seminar Nasional Aplikasi Teknologi Informasi
2008 (SNATI 2008) ISSN: 1907-5022; 2008.
[3]. Soumen Chakrabarti, Martin Ester, Usama Fayyad, Johannes Gehrke, Jiawei Han, Shinichi Morishita, Gregory Piatetsky-Shapiro, W. W. 2015.
Data Mining Curriculum. http://www.kdd.org/curriculum/index.html.
Diakses 5 Januari 2016.
[4]. Fayyad, U., Piatetsky-Shapiro, G. & Smyth, P. 1996. From data mining to
knowledge discovery in databases. AI magazine 17, 37.
[5]. Berkhin, P. 2004. Survey Of Clustering Data Mining Techniques. Accrue
Software, San Jose, CA, 2002.
[6]. Garcia-Molina, H. 2008. Database systems: the complete book. Pearson Education India.
[7]. Tan, P.-N., Steinbach, M. & Kumar, V. 2013. Data Mining Cluster
Analysis: Basic Concepts and Algorithms.
[8]. Popat, S. K. & Emmanuel, M. 2014. Review and Comparative Study of
Clustering Techniques. International Journal of Computer Science and
Information Technologies 5, 805–812.
[9]. Zhao, Y. & Karypis, G. 2002. Evaluation of hierarchical clustering
algorithms for document datasets. In Proceedings of the eleventh
international conference on Information and knowledge management, pp. 515–524.
[10]. Chen, Y. & Tu, L. 2007. Density-based clustering for real-time stream
data. In Proceedings of the 13th ACM SIGKDD international conference
on Knowledge discovery and data mining, pp. 133–142.
[11]. Agusta Y. K-Means-Penerapan, Permasalahan dan Metode Terkait. Denpasar, Bali: Jurnal Sistem dan Informatika (Februari 2007) Vol. 3:
47-60; 2007.
[12]. Andayani, S. 2007. Pembentukan Cluster dalam Knowledge Discovery in
Database dengan Algoritma K-means. SEMNAS Matematika dan
Pendidikan Matematika 2007 dengan tema Trend Penelitian Matematika dan Pendidikan Matematika di Era Global
![Gambar 1 Alur algoritma K-Means [12]](https://thumb-ap.123doks.com/thumbv2/123dok/2636173.3629578/11.893.152.758.173.998/gambar-alur-algoritma-k-means.webp)