i
RDF RETRIEVAL UNTUK DOKUMEN BAHASA INDONESIA
DENGAN PEMBOBOTAN PER KONTEKS
REZA KEMAL ZAEN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2015
iii
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul RDF Retrieval untuk Dokumen Bahasa Indonesia dengan Pembobotan Per Konteks adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Desember 2015 Reza Kemal Zaen NIM G64110003
ABSTRAK
REZA KEMAL ZAEN. RDF Retrieval untuk Dokumen Bahasa Indonesia dengan Pembobotan Per Konteks. Dibimbing oleh JULIO ADISANTOSO.
Penelitian temu kembali informasi pada dokumen RDF sudah dilakukan. Akan tetapi, penelitian tersebut belum memperhatikan struktur dari dokumen RDF. Penelitian ini mengembangkan sistem temu kembali informasi pada dokumen RDF dengan memperhatikan struktur dokumen yaitu dengan membedakan bobot pada setiap konteks (tag) yang ada pada dokumen RDF. Pembobotan yang digunakan adalah tf-idf. Bobot yang dihasilkan pada setiap konteks dikalikan dengan suatu koefisien dengan nilai 0.2, 0.4, 0.6, 0.8, atau 1.0. Sistem temu kembali informasi yang dibangun dievaluasi dengan menggunakan 29 kueri. Penelitian ini menghasilkan nilai average precision (AVP) sebesar 0.89721. Nilai tersebut lebih tinggi 1.91% jika dibandingkan dengan sistem temu kembali informasi yang tidak membedakan bobot per konteks.
Kata kunci: pembobotan konteks, RDF, temu kembali informasi.
ABSTRACT
REZA KEMAL ZAEN. RDF Retrieval of Document Bahasa Indonesia Using Context Weighting. Supervised by JULIO ADISANTOSO.
Research on information retrieval using RDF document has been conducted, but the study did not consider the structure of RDF documents. This research develops an information retrieval system for RDF documents to distinguish weights of each context in an RDF document. The weighting used is tf-idf. Weights in each context are multiplied by a coefficient with a value of 0.2, 0.4, 0.6, 0.8, or 1.0. The information retrieval system is evaluated by using 29 queries. As the result of this experiment, an average precision value of 0.89721 was obtained. The value increased by 1.91% compared with the information retrieval system without context weighting.
iii Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
RDF RETRIEVAL UNTUK DOKUMEN BAHASA INDONESIA
DENGAN PEMBOBOTAN PER KONTEKS
REZA KEMAL ZAEN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2015
Penguji :
1 Ahmad Ridha, SKom MS 2 Dr. Irman Hermadi, SSi MS
v Judul Skripsi : RDF Retrieval untuk Dokumen Bahasa Indonesia dengan
Pembobotan Per Konteks Nama : Reza Kemal Zaen
NIM : G64110003
Disetujui oleh
Ir. Julio Adisantoso, MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga tugas akhir ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan September 2014 ini ialah temu kembali informasi, dengan judul RDF Retrieval untuk Dokumen Bahasa Indonesia dengan Pembobotan Per Konteks.
Terima kasih penulis ucapkan kepada Bapak Ir. Julio Adisantoso M.Kom selaku pembimbing yang telah membantu penulis dalam menyusun tugas akhir ini. Ungkapan terima kasih juga disampaikan kepada ayah, ibu, kakak, adik, serta seluruh keluarga, atas segala doa dan dukungan yang selalu diberikan. Begitu pula rasa terima kasih penulis ungkapkan kepada Rizki dan Luthfi selaku teman seperjuangan dalam menyelesaikan tugas akhir ini serta teman-teman Ilmu Komputer angkatan 48 atas kebersamaan, dukungan semangat yang diberikan kepada penulis.
Semoga tugas akhir ini dapat bermanfaat.
Bogor, Desember 2015
vii
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi PENDAHULUAN 1 Latar Belakang 1 Perumusan Masalah 1 Tujuan Penelitian 2 Manfaat Penelitian 2Ruang Lingkup Penelitian 2
METODE 2
Dokumen RDF 3
Penyimpanan Dokumen pada Sesame 3
Proses Indexing 4
Pencarian Dokumen 4
Evaluasi Sistem 5
HASIL DAN PEMBAHASAN 6
Dokumen RDF 6
Penyimpanan Dokumen pada Sesame 7
Proses Indexing 7
Pencarian Dokumen 8
Evaluasi Sistem 8
Temu Kembali Informasi Dokumen RDF Gen 12
SIMPULAN DAN SARAN 13
Simpulan 13
Saran 14
DAFTAR PUSTAKA 14
LAMPIRAN 15
DAFTAR TABEL
1 Relevant dan retrieved dokumen 5
2 Hasil pencarian dokumen RDF 9
3 Hasil interpolasi antara precision dan recall untuk setiap kombinasi pada sistem temu kembali yang membedakan bobot per konteks 10
4 Predikat pada dokumen RDF gen 12
DAFTAR GAMBAR
1 Diagram alur penelitian 2
2 Grafik perbandingan sistem temu kembali yang tidak membedakan bobot per konteks ( ) dengan yang membedakan bobot per
konteks( ) 11
3 Potongan dokumen RDF gen 12
4 Kueri SPARQL yang digunakan untuk parsing data RDF Tanaman
Obat 12
5 Kueri SPARQL yang digunakan untuk parsing data RDF Gen 13
DAFTAR LAMPIRAN
1 Contoh dokumen RDF tanaman obat 15
2 Daftar kombinasi koefisien bobot yang digunakan dalam penelitian 16
3 Daftar kueri dan dokumen relevan 17
4 Nilai precision berdasarkan 11 standar recall tanpa pembobotan per
konteks 18
5 Nilai precision berdasarkan 11 standar recall dengan pembobotan per
PENDAHULUAN
Latar BelakangSeiring dengan berkembangnya teknologi informasi mengakibatkan semakin bertambah banyaknya jumlah informasi. Bertambahnya jumlah informasi menimbulkan masalah bagaimana mendapatkan infomasi yang dibutuhkan secara cepat dan akurat. Temu kembali informasi (information retrieval) merupakan suatu bidang ilmu dalam ilmu komputer yang menjawab permasalahan tersebut. Tujuan dari sistem temu kembali informasi adalah mengembalikan informasi yang relevan dengan kueri dan informasi yang tidak relevan sesedikit mungkin (Baeza-Yates dan Ribeiro-Neto 1999).
Dalam pengembangan temu kembali informasi pada dokumen, format dokumen yang biasa digunakan adalah eXtensible Markup Language (XML). XML memiliki kemampuan untuk menyimpan data secara terstruktur serta sebagai format dalam pertukaran data. Selain XML, terdapat format data lain terstruktur yaitu Resource Description Framework (RDF). RDF merupakan model metadata dari bahasa yang direkomendasikan oleh W3C untuk membangun infrastruktur web semantik (Gutierrez et al. 2007). Dalam web semantik, RDF dapat merepresentasikan data berbasis ontologi. Penggunaan ontologi dalam temu kembali informasi memungkinkan untuk mendapatkan konsep dan relasi yang merepresentasikan pengetahuan dari suatu dokumen dalam domain yang spesifik, sehingga dokumen bisa diinterpretasikan bukan hanya secara sintak, tetapi juga secara semantik.
Penelitian di bidang temu kembali informasi pada dokumen RDF sudah banyak dilakukan, di antaranya adalah Minack (2008) yang melakukan penelitian dengan membuat full-text search pada dokumen RDF. Penelitian dokumen RDF lainnya dilakukan oleh Noviandi (2014) yaitu dengan membuat search engine dokumen RDF tanaman obat menggunakan Sesame dan Lucene. Pada penelitian tersebut, struktur konteks (tag) pada Dokumen RDF tanaman obat yang digunakan tidak diperhatikan sehingga bobot dari setiap konteks pada dokumen RDF tidak dibedakan.
Setiap konteks pada dokumen RDF memiliki tingkat kepentingan yang berbeda. Membedakan tingkat kepentingan dari setiap konteks yang ada pada dokumen RDF dapat dilakukan dengan memberikan bobot yang berbeda pada setiap konteks. Oleh karna itu, penelitian ini mengembangkan sistem temu kembali informasi pada dokumen terstruktur RDF dengan memperhatikan struktur dokumen yaitu dengan memberikan bobot pada setiap konteks yang ada pada dokumen RDF. Hasil penelitian ini diharapkan dapat memperbaiki nilai average precision pada temu kembali informasi dokumen RDF bahasa Indonesia.
Perumusan Masalah
Perumusan masalah dari penelitian ini adalah:
1 Bagaimana mengimplementasikan sistem temu kembali informasi dokumen RDF pada dokumen bahasa Indonesia dengan memperhatikan struktur dokumen?
2
2 Bagaimana kinerja sistem yang dibangun dalam mengembalikan jawaban yang relevan dari kumpulan dokumen RDF?
3 Apakah pemberian bobot pada konteks dapat memperbaiki kinerja sistem?
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1 Mengimplementasikan sistem temu kembali informasi RDF pada dokuman bahasa Indonesia dengan memperhatikan struktur dokumen.
2 Menelaah kinerja sistem yang dibangun dalam mengembalikan jawaban yang relevan dari kumpulan dokumen RDF.
Manfaat Penelitian
Hasil penelitian ini diharapkan dapat menbantu pengguna dalam menemukan dokumen RDF yang sesuai dengan kueri yang dimasukkan.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini antara lain:
1 Dokumen yang digunakan dalam penelitian adalah dokumen RDF tanaman obat yang masing-masing dokumen memiliki struktur yang sama.
2 Dokumen RDF tidak sampai membentuk ontologi.
METODE
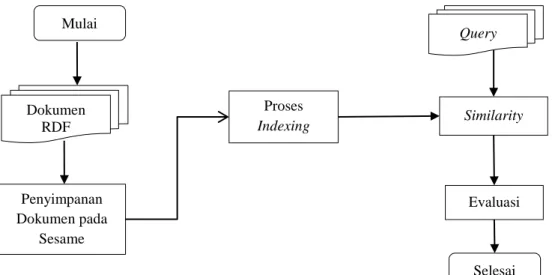
Secara garis besar penelitian dilakukan dalam beberapa tahap, yaitu perolehan dokumen RDF, menyimpan dokumen dalam aplikasi Sesame, proses indexing, pencarian dokumen, dan evaluasi sistem. Gambaran umum sistem yang dikembangkan dapat dilihat pada Gambar 1.
Gambar 1 Diagram alur penelitian Mulai Dokumen RDF Penyimpanan Dokumen pada Sesame Proses Indexing Similarity Evaluasi Selesai Query
3
3
Dokumen RDF
RDF merupakan bahasa yang digunakan untuk merepresentasikan metadata. RDF mendukung interoperabilitas antar-aplikasi yang mempertukarkan informasi yang bersifat machine undestandable pada web. Web semantik terdiri dari data yang ditulis dalam bahasa yang dapat dimengerti oleh mesin seperti RDF dan XML. RDF menggunakan graf untuk merepresentasikan kumpulan pernyataan. Simpul dalam graf mewakili suatu entitas, dan tanda panah mewakili relasi. Model konseptual pada RDF adalah graf dan untuk mempertukarkan metadata pada RDF digunakan sintaks dasar XML sehingga disebut juga RDF/XML (Manola dan Miller, 2004).
RDF dan XML merupakan model metadata dari bahasa yang direkomendasikan oleh W3C untuk membangun infrastruktur web semantik. Tetapi keduanya memiliki fungsi yang berbeda dalam infrastruktur semantik. XML berkaitan dengan format pertukaran data, sedangkan RDF berkaitan dengan konten informasi.
Pada RDF, sebuah deskripsi dari sumber direpresentasikan sebagai sejumlah triple, tiga bagian dari setiap triple disebut subjek, predikat, dan objek. Subjek dari triple adalah Uniform Resource Identifier (URI) yang mendefinisikan sumber. Objek dapat berupa nilai literal sederhana, seperti string, numerik, tanggal, atau URI dari sumberdaya lainnya yang berkaitan dengan subjek. Predikat mengindikasikan hubungan antara subjek dan objek.
Koleksi dokumen yang digunakan dalam penelitian ini adalah dokumen tanaman obat berbahasa Indonesia yang berjumlah 99 dokumen. Dokumen-dokumen tersebut berasal dari Laboratorium Temu Kembali Departemen Ilmu Komputer IPB. Koleksi dokumen tersebut memiliki struktur RDF yang seragam.
Koleksi dokumen tersebut memiliki struktur sebagai berikut: <rdf:Description rdf:about=" … "> <tanaman:id> ……….…….…… </tanaman:id> <tanaman:famili> ……….….…... </tanaman:famili> <tanaman:nama> ………..……… </tanaman:nama> <tanaman:latin> ………….……… </tanaman:latin> <tanaman:bagian> ………..……. </tanaman:bagian> <tanaman:manfaat> …….….… </tanaman:manfaat> <tanaman:kandungan> ….... </tanaman:kandungan> <tanaman:deskripsi> ……….. </tanaman:deskripsi> <tanaman:penyakit> ……….... </tanaman:penyakit> </rdf:Description>
Selain dokumen tanaman obat, digunakan juga dokumen RDF gen yang berasal dari ICS-FORTH (Institute of Computer Science - Foundation of Research Technology Hellas - Greece) dan dokumen tersebut diambil dari situs http:// 139.91.183.30:9090/RDF/VRP/Examples/go.rdf.
Penyimpanan Dokumen pada Sesame
Sesame merupakan aplikasi yang dikembangkan oleh Aduna yang menyediakan fungsi untuk parsing, menyimpan, dan kueri pada data RDF. Sesame menyediakan dua bahasa kueri yaitu SeRQL dan SPARQL. SeRQL dan
4
SPARQL merupakan bahasa kueri yang dikembangkan oleh Aduna yang digunakan untuk memanipulasi data dan parsing data RDF.
Koleksi dokumen RDF tanaman obat yang digunakan untuk penelitian disimpan di dalam aplikasi Sesame. Dokumen RDF tanaman obat disimpan pada aplikasi Sesame untuk di parsing menggunakan kueri SPARQL
Proses Indexing
Dalam sistem temu kembali informasi, dokumen yang ditemukembalikan akan melalui proses indexing sebelum dicocokkan dengan kueri. Beberapa tahapan dalam indexing pada di antaranya adalah tokenisasi, pembuangan stopwords, pemotongan imbuhan (stemming), pembobotan dan pembuatan indeks.
Tokenisasi berfungsi untuk memisahkan deretan kata di dalam kalimat, paragraf atau halaman menjadi token atau potongan kata tunggal dan pengubahan setiap kata menjadi huruf kecil. Stemming berfungsi untuk menghilangkan variasi morfologi kata dengan cara menghilangkan imbuhan pada setiap kata. Stopword merupakan proses penghilangan kata-kata umum yang tidak memiliki makna penting. Stopwords dibuang karena dianggap akan mengurangi akurasi dari informasi yang di temu-kembalikan (Manning et al. 2008).
Pembobotan pada Lucene menggunakan pembobotan tf-idf. Term frequency (tf) merupakan frekuensi kemunculan suatu term t pada dokumen d. Document frequency (df) merupakan banyaknya dokumen dalam korpus yang mengandung kata tertentu. Pembobotan tf-idf memberikan bobot term t dalam dokumen d dengan nilai (Manning et al. 2008)
wd,t = tft,d × idft
dengan tft,d merupakan frekuensi term t pada dokumen d, idf = 1+log(N/dft), N adalah jumlah dokumen dalam koleksi, dan dft adalah dokumen yang mengandung term t.
Pada penelitian ini, pembobotan dari setiap konteks yang ada pada dokumen RDF akan dibedakan. Bobot pada setiap konteks akan dikalikan dengan suatu nilai koefisien, nilai koefisien tersebut adalah 0.2, 0.4, 0.6, 0.8, dan 1.0. Terdapat 8 konteks pada dokumen RDF yang akan dikalikan dengan nilai koefisien. 8 konteks tersebut adalah ‘nama’, ‘famili’, ‘latin’, ‘bagian’, ‘manfaat’, ‘kandungan’, ‘deskripsi’, dan ‘penyakit’.
Pencarian Dokumen
Proses pencarian dapat dilakukan jika dokumen sudah terindeks. Proses pencarian dilakukan dengan mencari kata-kata dalam sebuah indeks untuk menemukan dokumen dimana dokumen-dokumen itu muncul. Pencarian dilakukan dengan menghitung nilai kemiripan kueri dengan dokumen. Lucene menggunakan model matematika Vector Space Model (VSM) untuk menentukan bahwa sebuah dokumen itu relevan terhadap sebuah informasi. Model ini akan menghitung derajat kesamaan antara setiap dokumen yang disimpan di dalam sistem dengan kueri yang diberikan oleh pengguna.
Dalam VSM terdapat beberapa ukuran kesamaan yang dapat digunakan di antaranya adalah inner, product, cosine, dice, jaccard, overlap dan asymmetric. Rahman (2006) membandingkan kinerja 4 ukuran kesamaan yaitu cosine, dice, (1)
5 5 (2) (3) (4) (5) jaccard, dan overlap, dan mendapatkan hasil bahwa cosine memiliki kinerja yang lebih baik dalam temu kembali informasi. Cosine menghitung nilai cosinus sudut antara 2 vektor. Jika terdapat dua vektor dokumen d dan kueri q, serta t term diekstrak dari koleksi dokumen maka nilai cosinus antara d dan q didefinisikan sebagai (Manning et al. 2008):
la
Lucene memodifikasi ukuran kesamaan cosine untuk mencari nilai scoring dan similarity menjadi:
la ( )
∑
dengan 𝑡𝑓 adalah frekuensi e pada dokumen, 𝑡𝑓 adalah frekuensi e pada kueri, |𝑞| adalah panjang vektor kueri, |𝑑| adalah panjang vektor dokumen, dan adalah nilai e yang diberikan terhadap e pada kueri dengan nilai e aul 1.
.
Evaluasi Sistem
Dua ukuran yang sering dipakai untuk mengukur efektifitas suatu sistem temu kembali informasi adalah recall dan precision. Recall adalah rasio antara dokumen relevan yang berhasil ditemukembalikan dari seluruh dokumen relevan yang ada di dalam sistem, sedangkan precision adalah rasio dokumen relevan yang berhasil ditemukembalikan dari seluruh dokumen yang berhasil ditemu-kembalikan (Manning et al. 2008).
Tabel 1 Relevant dan retrieved dokumen
Relevant Nonrelevant Retrieved True positives (tp) False positive (fp) Not retrieved False negatives (fn) True negatives (tn) Berdasarkan Tabel 1, nilai recall dan precision dapat ditulis sebagai:
e e all
dengan tp adalah dokumen relevan yang ditemukembalikan, fp adalah dokumen tidak relevan yang ditemukembalikan, fn merupakan dokumen relevan yang tidak ditemukembalikan, dan tn merupakan dokumen tidak relevan yang tidak
6
ditemukembalikan. tp+fp merupakan semua dokumen yang ditemukembalikan dan tp+fn merupakan semua dokumen yang relevan.
Pengujian sistem dilakukan dengan melakukan perhitungan terhadap recall dan precision dalam menentukan tingkat keefektifan proses hasil temu-kembali. Jumlah kueri yang digunakan yaitu 29 kueri yang didapatkan dari penelitian Herawan (2011). Dalam perhitungan precision, digunakan 11 titik recall standar, yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0. Hasil perhitungan recall dan precision untuk masing-masing koefisien bobot akan dibandingkan agar diketahui kombinasi koefisien bobot yang terbaik. Selain itu, nilai average precision juga dihitung.
Selain pada dokumen RDF tanaman obat, pembangunan sistem temu kembali informasi juga dilakukan pada data dokumen RDF gen. Akan tetapi, dalam pengembangannya tidak dilakukan pembobotan per konteks dan tahap evaluasi. Pengembangan sistem temu kembali dokumen RDF gen dilakukan untuk diketahui apakah sistem temu kembali dokumen RDF dapat diterapkan pada dokumen RDF lainnya.
HASIL DAN PEMBAHASAN
Dokumen RDFKoleksi dokumen yang digunakan dalam penelitian ini adalah dokumen tanaman obat berbahasa Indonesia yang berjumlah 99 dokumen. Dokumen-dokumen tersebut berasal dari Laboratorium Temu Kembali Departemen Ilmu Komputer IPB. Semua dokumen tanaman obat digabung dalam satu file dengan format RDF. Keloksi dokumen tersebut memiliki struktur tag yang seragam. Struktur tag yang digunakan dalam dokumen adalah:
<rdf:RDF> </rdf:RDF>, mewakili namespace untuk dokumen RDF.
<rdf:Description> </rdf:Description>, mewakili keseluruhan isi dari dokumen. Di dalamnya terdapat tag lain yang mewakili atribut dokumen.
<rdf:about> </rdf:about>, mewakili id dokumen atau merupakan subjek pada RDF.
<tanaman:id> </tanaman:id>, mewakili id dari tanaman obat.
<tanaman:famili> </tanaman:famili>, mewakili famili tanaman obat. <tanaman:nama> </tanaman:nama>, mewakili nama tanaman obat. <tanaman:latin> </tanaman:latin>, mewakili nama latin tanaman obat.
<tanaman:bagian> </tanaman:bagian>, mewakili bagian yang digunakan pada tanaman obat
<tanaman:manfaat> </tanaman:manfaat>, mewakili manfaat dari tanaman obat.
<tanaman:kandungan> </tanaman:kandungan>, mewakili kandungan dari tanaman obat.
<tanaman:deskripsi> </tanaman:deskripsi>, mewakili deskripsi dari tanaman obat.
7
7
<tanaman:penyakit> </tanaman:penyakit>, mewakili penyakit yang dapat disembuhkan oleh tanaman obat.
Pada field <tanaman:manfaat> dan <tanaman:kandungan> dibuat dalam bentuk rdf:Bag karena dokumen tanaman obat memiliki manfaat dan kandungan yang banyak. Rdf:Bag merupakan tipe data dari RDF yang mendefinisikan bentuk list. Contoh dokumen RDF yang digunakan dapat dilihat pada Lampiran 1.
Pada RDF, sebuah deskripsi dari sumber direpresentasikan sebagai sejumlah triple, tiga bagian dari setiap triple disebut subjek, predikat, dan objek. Contoh dokumen RDF tanaman obat (Lampiran 1) dapat didefinisikan menjadi:
tanaman_1 memiliki famili Pancdanaceae tanaman_1 memiliki nama Pandan Wangi
tanaman_1 memiliki latin Pandanaus amaryllifolius Roxb tanaman_1 memiliki bagian daun yang dapat dimanfaatkan
tanaman_1 memiliki manfaat rambut rontok, menghitamkan rambut, menghilangkan ketombe, lemah saraf, tidak nafsu makan, rematik, pegal linu, dan sakit disertai gelisah.
tanaman_1 memiliki kandungan alkaloida, saponin, flavonoida, tannin, polifenol dan zat warna.
tanaman_1 memiliki deskripsi Tumbuh di tempat yang agak lembap, tumbuh subur dari daerah pantai, daerah dengan ketinggian 500m dpl. Batang bulat dengan bekas duduk daun, bercabang, menjalar, akar tunjang keluar di sekitar pangkal batang dan cabang.
Penyimpanan Dokumen pada Sesame
Koleksi dokumen RDF tanaman obat yang digunakan untuk penelitian disimpan didalam aplikasi Sesame. Dokumen RDF tanaman obat disimpan pada aplikasi Sesame untuk di parsing menggunakan kueri SPARQL. Dokumen RDF tanaman obat disimpan pada repositori Sesame dengan nama tanaman-obat.
Proses Indexing
Proses indexing dilakukan dengan menggunakan fungsi yang ada pada Lucene. Pembobotan pada Lucene menggunakan pembobotan tf-idf. Bobot pada masing-masing konteks pada dokumen RDF dibedakan dengan cara mengalikan hasil pembobotan tf-idf dengan suatu nilai koefisien bobot. Nilai koefisien yang digunakan adalah 0.2, 0.4, 0.6, 0.8, dan 1.0. Nilai koefisien bobot tersebut dikombinasikan dengan 8 konteks yang ada pada dokumen RDF tanaman obat. Koefisien bobot diberikan pada setiap konteks. Pemberian koefisien bobot diawali pada konteks ‘deskripsi’. Konteks ‘deskripsi’ dikombinasikan dengan semua koefisien bobot yang digunakan. Koefisien bobot yang terbaik pada konteks ‘deskripsi’ kemudian digunakan pada pengombinasian koefisien bobot konteks lainnya. Penentuan koefisien bobot terbaik di lihat berdasarkan nilai average precision. Daftar hasil kombinasi koefisien bobot yang dilakukan pada penelitian dapat dilihat pada Lampiran 2.
8
Pencarian Dokumen
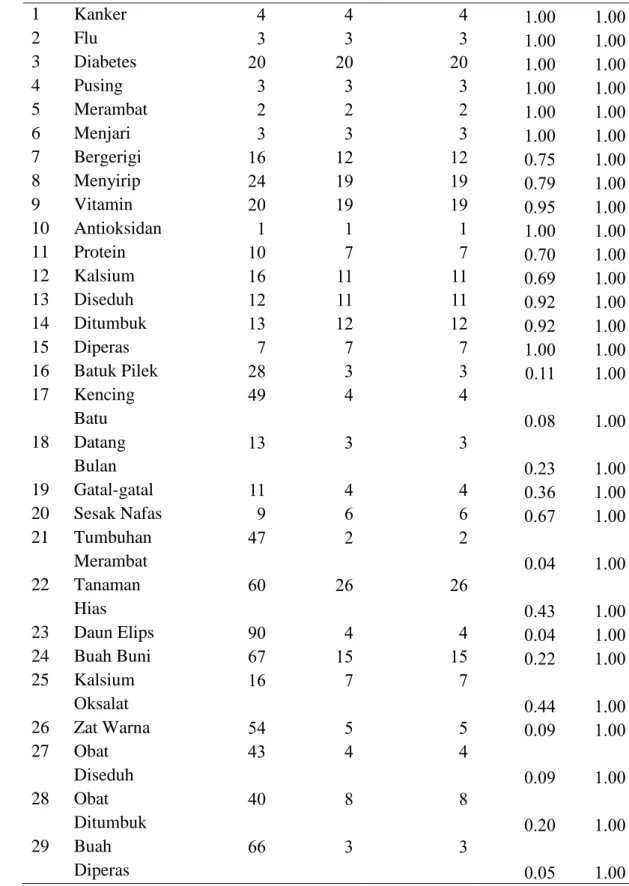
Pencarian Dokumen dapat dilakukan setelah proses indexing. Pencarian dokumen dilakukan dengan menggunakan 29 kueri yang terdiri dari 15 kata tunggal dan 14 frase. Kueri akan diproses oleh sistem kemudian sistem akan me-retrieve dan mengurutkan dokumen berdasarkan nilai kesamaan antara dokumen dengan kueri. Hasil pencarian dokumen dapat dilihat pada Tabel 2.
Nilai precision pada Tabel 2 didapat berdasarkan perhitungan Persamaan 4. Nilai precision didapat dengan membagi dokumen relevan yang ditemukembalikan dengan dokumen yang ditemukembalikan. Seperti contoh pada kueri ‘Bergerigi’ terdapat 12 dokumen relevan yang ditemukembalikan dan 16 dokumen yang ditemukembalikan. Berdasarkan Persamaaan 4 maka nilai precision untuk kueri ‘Bergerigi’ adalah 12 dibagi dengan 16 sehingga nilainya adalah 0.75.
Nilai recall pada Tabel 2 didapat berdasarkan perhitungan persamaan 5. Nilai recall didapat dengan membagi banyaknya dokumen relevan yang ditemukembalikan dengan banyaknya dokumen yang relevan. Seperti contoh pada kueri ‘Bergerigi’ terdapat 12 dokumen relevan yang ditemukembalikan dan 12 dokumen yang relevan. Berdasarkan Persamaaan 5 maka nilai recall untuk kueri ‘Bergerigi’ adalah 12 dibagi dengan 12 sehingga nilainya adalah 1.
Evaluasi Sistem
Pengujian sistem dilakukan dengan mengukur recall dan precision dalam proses hasil temu-kembali. Jumlah kueri yang digunakan yaitu 29 kueri yang terdiri dari 15 kata tunggal dan 14 frase (Lampiran 3). Dalam perhitungan precision, digunakan 11 titik recall standar, yaitu 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1. Nilai precision dari masing-masing kueri diinterpolasi maksimum pada 11 titik recall standar untuk menghitung nilai average precision (AVP). Nilai AVP dari sistem temu kembali yang tidak membedakan bobot per konteks dibandingkan sistem temu kembali yang membedakan bobot per konteks.
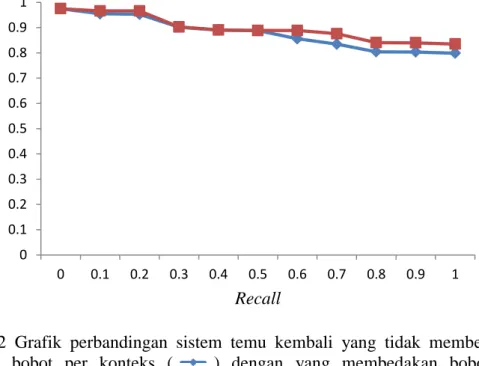
Sistem temu kembali yang tidak membedakan bobot per konteks memiliki nilai AVP sebesar 0.87809. Grafik hasil interpolasi antara precision dan recall pada sistem temu kembali yang tidak membedakan bobot per konteks dapat dilihat pada Gambar 2.
Perhitungan nilai AVP berdasarkan hasil interpolasi antara precision dan recall untuk setiap kombinasi (Lampiran 2) pada sistem temu kembali yang membedakan bobot per konteks ditunjukkan pada Tabel 3
Penentuan koefisien bobot dilakukan secara satu per satu untuk setiap konteks. Berdasarkan Tabel 3, Penentuan koefisien bobot diawali pada konteks ‘deskripsi’. Koefisien bobot terbaik pada konteks ‘deskripsi’ berdasarkan nilai average precision adalah 1. Koefisien bobot terbaik pada konteks ‘deskripsi’ kemudian digunakan dalam penentuan koefisien bobot terbaik pada konteks yang lainnya. Penentuan koefisien bobot pada konteks lainnya dilakukan sama seperti penentuan koefisien bobot pada konteks ‘deskripsi’.
9
9
Tabel 2 Hasil pencarian dokumen RDF
No. Kueri Dokumen di Retrieve Dokumen Relevan Dokemen Relevan yang di Retrieve Precision Recall 1 Kanker 4 4 4 1.00 1.00 2 Flu 3 3 3 1.00 1.00 3 Diabetes 20 20 20 1.00 1.00 4 Pusing 3 3 3 1.00 1.00 5 Merambat 2 2 2 1.00 1.00 6 Menjari 3 3 3 1.00 1.00 7 Bergerigi 16 12 12 0.75 1.00 8 Menyirip 24 19 19 0.79 1.00 9 Vitamin 20 19 19 0.95 1.00 10 Antioksidan 1 1 1 1.00 1.00 11 Protein 10 7 7 0.70 1.00 12 Kalsium 16 11 11 0.69 1.00 13 Diseduh 12 11 11 0.92 1.00 14 Ditumbuk 13 12 12 0.92 1.00 15 Diperas 7 7 7 1.00 1.00 16 Batuk Pilek 28 3 3 0.11 1.00 17 Kencing Batu 49 4 4 0.08 1.00 18 Datang Bulan 13 3 3 0.23 1.00 19 Gatal-gatal 11 4 4 0.36 1.00 20 Sesak Nafas 9 6 6 0.67 1.00 21 Tumbuhan Merambat 47 2 2 0.04 1.00 22 Tanaman Hias 60 26 26 0.43 1.00 23 Daun Elips 90 4 4 0.04 1.00 24 Buah Buni 67 15 15 0.22 1.00 25 Kalsium Oksalat 16 7 7 0.44 1.00 26 Zat Warna 54 5 5 0.09 1.00 27 Obat Diseduh 43 4 4 0.09 1.00 28 Obat Ditumbuk 40 8 8 0.20 1.00 29 Buah Diperas 66 3 3 0.05 1.00
10
Tabel 3 Hasil interpolasi antara precision dan recall untuk setiap kombinasi pada sistem temu kembali yang membedakan bobot per konteks
Koefisien Bobot Per Konteks
AVP
Deskripsi bagian kandungan nama latin famili penyakit manfaat
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.87809 0.8 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.87185 0.6 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.86903 0.4 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.86903 0.2 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.86903 1.0 0.8 1.0 1.0 1.0 1.0 1.0 1.0 0.87348 1.0 0.6 1.0 1.0 1.0 1.0 1.0 1.0 0.87348 1.0 0.4 1.0 1.0 1.0 1.0 1.0 1.0 0.87865 1.0 0.2 1.0 1.0 1.0 1.0 1.0 1.0 0.88975 1.0 0.2 0.8 1.0 1.0 1.0 1.0 1.0 0.88909 1.0 0.2 0.6 1.0 1.0 1.0 1.0 1.0 0.88975 1.0 0.2 0.4 1.0 1.0 1.0 1.0 1.0 0.88934 1.0 0.2 0.2 1.0 1.0 1.0 1.0 1.0 0.88828 1.0 0.2 0.6 0.8 1.0 1.0 1.0 1.0 0.88975 1.0 0.2 0.6 0.6 1.0 1.0 1.0 1.0 0.88975 1.0 0.2 0.6 0.4 1.0 1.0 1.0 1.0 0.88975 1.0 0.2 0.6 0.2 1.0 1.0 1.0 1.0 0.88975 1.0 0.2 0.6 1.0 0.8 1.0 1.0 1.0 0.88975 1.0 0.2 0.6 1.0 0.6 1.0 1.0 1.0 0.88975 1.0 0.2 0.6 1.0 0.4 1.0 1.0 1.0 0.88975 1.0 0.2 0.6 1.0 0.2 1.0 1.0 1.0 0.88975 1.0 0.2 0.6 1.0 1.0 0.8 1.0 1.0 0.88975 1.0 0.2 0.6 1.0 1.0 0.6 1.0 1.0 0.88975 1.0 0.2 0.6 1.0 1.0 0.4 1.0 1.0 0.88975 1.0 0.2 0.6 1.0 1.0 0.2 1.0 1.0 0.88975 1.0 0.2 0.6 1.0 1.0 1.0 0.8 1.0 0.88975 1.0 0.2 0.6 1.0 1.0 1.0 0.6 1.0 0.88975 1.0 0.2 0.6 1.0 1.0 1.0 0.4 1.0 0.88975 1.0 0.2 0.6 1.0 1.0 1.0 0.2 1.0 0.88975 1.0 0.2 0.6 1.0 1.0 1.0 1.0 0.8 0.89448 1.0 0.2 0.6 1.0 1.0 1.0 1.0 0.6 0.89721 1.0 0.2 0.6 1.0 1.0 1.0 1.0 0.4 0.89270 1.0 0.2 0.6 1.0 1.0 1.0 1.0 0.2 0.89254
Nilai koefisien bobot terbaik untuk masing-masing konteks berdasarkan Tabel 3 adalah 1.0 pada ‘deskripsi’, 0.2 pada ‘bagian’, 0.6 pada ‘kandungan’, 1.0
11
11
pada ‘nama’, 1.0 pada ‘latin’, 1.0 pada ‘famili’, 1.0 pada ‘penyakit’ dan 0.6 pada ‘manfaat’ dengan nilai AVP sebesar 0.89721. Nilai tersebut lebih tinggi 1.91% jika dibandingkan dengan sistem temu kembali informasi yang tidak membedakan bobot per konteks.
Pada konteks ‘nama’, ‘latin’, ‘famili’, dan ‘penyakit’, pemberian nilai koefisien bobot yang berbeda tidak mempengaruhi nilai AVP. Hal ini disebabkan kueri yang digunakan dalam pengujian tidak merepresentasikan isi dari ke empat konteks. Selain itu dapat juga disebabkan oleh isi dari konteks yang bersifat unik atau tidak ada pada konteks lain. Dalam penentuan koefisien bobot untuk kasus tersebut, koefisien bobot yang digunakan adalah 1.0. Pemberian koefisien bobot bernilai 1.0 dikarenakan nilai bobot jika dikalikan dengan koefisien 1.0 hasilnya akan tetap sama.
Berdasarkan Lampiran 4 dan 5, peningkatan nilai precision terjadi pada kueri ‘Daun Elips’, ‘Buah Buni’ dan ‘Buah Diperas’. Hal ini dikarenakan pemberian bobot yang berbeda pada konteks ‘deskripsi’, ‘bagian’, ‘manfaat’, dan ‘kandungan’. Seperti contoh pada kueri ‘Daun Elips’, pengguna menginginkan informasi daun yang memiliki bentuk elips, tetapi sistem akan menemukembalikan dokumen yang mengandung kata ‘Daun’ dan ‘Elips’. Kata ‘Daun’ terdapat pada konteks ‘bagian’ dan ‘deskripsi’ sedangkan kata ‘Elips’ terdapat pada konteks ‘deskripsi’, sehingga pemberian bobot yang lebih tinggi pada konteks ‘deskripsi’ dibandingkan dengan konteks ‘bagian’ dapat meningkatkan nilai precision.
Gambar 2 Grafik perbandingan sistem temu kembali yang tidak membedakan bobot per konteks ( ) dengan yang membedakan bobot per konteks( )
Gambar 2 menunjukan grafik perbandingan hasil interpolasi antara precision dan recall pada sistem temu kembali yang tidak membedakan bobot per konteks dengan sistem temu kembali pembobotan per konteks yang memiliki nilai AVP tertinggi. Nilai precision pada 11 standar recall untuk pembobotan per konteks yang memiliki nilai AVP tertinggi dapat dilihat pada Lampiran 5.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Pr ec isi on Recall
12
Temu Kembali Informasi Dokumen RDF Gen
Selain pada dokumen RDF tanaman obat, pembangunan sistem temu kembali informasi juga dilakukan pada data dokumen RDF gen. akan tetapi, dalam pengembangannya tidak dilakukan pembobotan per konteks dan tahap evaluasi. Pengembangan sistem temu kembali dokumen RDF gen dilakukan untuk diketahui apakah sistem temu kembali dokumen RDF dapat diterapkan pada dokumen RDF lainnya.
Untuk dapat membangun sistem temu kembali RDF gen diperlukan kueri SPARQL pada RDF gen agar dokumen RDF gen dapat di-parsing dengan menggunakan Sesame. Untuk mengetahui kueri SPARQL perlu diketahui terlebih dahulu predikat yang dimiliki dokumen RDF gen. Gambar 3 merupakan potongan dokumen RDF gen. Berdasarkan potongan dokumen tersebut, predikat yang digunakan pada RDF gen adalah sebagai berikut:
Tabel 4 Predikat pada dokumen RDF gen PREFIX Predikat Keterangan
go:
accession Menjelaskan id dari gen name Menjelaskan nama gen definition Menjelaskan definisi gen
Setiap predikat merupakan URI. Untuk mempermudah penulisan URI dalam kueri, PREFIX digunakan untuk mempersingkat penulisan URI. Contohnya URI http://139.91.183.30:9090/RDF/VRP/Examples/schema_go.rdfaccession menjadi go: accession.
Gambar 3 Potongan dokumen RDF gen
Gambar 4 Kueri SPARQL yang digunakan untuk parsing data RDF Tanaman Obat
<go:term rdf:ID="GO0004791" go:n_associations="0"> <go:accession>GO0004791</go:accession>
<go:name>thioredoxin reductase (NADPH)</go:name>
<go:definition>A flavoprotein catalyzing the reaction: NADPH + oxidised thoredoxin = NADP(+) + reduced thioredoxin.</go:definition> } </go:term> PREFIX tanaman:<http://localhost/tanaman-obat/rdf#> SELECT * WHERE {
?tanaman tanaman:nama ?nama . ?tanaman tanaman:habitus ?habitus . ?tanaman tanaman:penyakit ?penyakit . ?tanaman tanaman:famili ?famili . ?tanaman tanaman:bagian ?bagian . ?tanaman tanaman:latin ?latin .
?tanaman tanaman:deskripsi ?deskripsi . }
13
13
Gambar 4 merupakan kueri SPARQL yang digunakan pada dokumen RDF gen untuk melakukan parsing. Untuk dapat digunakan pada dokumen RDF gen kueri SPARQL tersebut harus disesuaikan. PREFIX pada dokumen RDF gen adalah go:<http://139.91.183.30:9090/RDF/VRP/Examples/schema_go.rdf>. Selain itu dilakukan juga penyesuaian pada predikat untuk mendapatkan hasil kueri yang diinginkan. Untuk mendapatkan hasil kueri dari accesion diperlukan URI predikat dari accession yaitu <http://139.91.183.30:9090/RDF/VRP/ Examples/schema_go.rdfaccession>. Penyesuaian Kueri SPARQL yang digunakan pada dokumen RDF gen dapat dilihat pada Gambar 5.
Gambar 5 Kueri SPARQL yang digunakan untuk parsing data RDF Gen Setelah kueri SPARQL didapat, proses parsing dapat dilakukan. Pencarian dokumen dilakukan dengan memasukkan kueri yang berkaitan dengan gen. Kueri akan diproses oleh sistem kemudian sistem akan me-retrieve dan mengurutkan dokumen berdasarkan nilai kesamaan antara dokumen dan kueri.
SIMPULAN DAN SARAN
SimpulanBerdasarkan penelitian yang dilakukan, dapat disimpulkan bahwa pemberian nilai koefisien bobot yang berbeda pada masing-masing konteks dalam dokumen RDF tanaman obat dapat meningkatkan nilai average precision (AVP). AVP pada hasil pencarian dengan tidak membedakan bobot masing-masing konteks bernilai 0.87809. Nilai AVP tertinggi pada hasil pencarian dengan membedakan bobot pada masing-masing konteks bernilai 0.8972 dengan nilai koefisien bobotnya yaitu 1.0 pada ‘deskripsi’, 0.2 pada ‘bagian’, 0.6 pada ‘kandungan’, 1.0 pada ‘nama’, 1.0 pada ‘latin’, 1.0 pada ‘famili’, 1.0 pada ‘penyakit’ dan 0.6 pada ‘manfaat’. Nilai AVP tersebut lebih tinggi 1.91% jika dibandingkan dengan sistem temu kembali informasi yang tidak membedakan bobot per konteks.
$sparql = "PREFIX go:<http://139.91.183.30:9090/RDF/VRP/Examples/schema_go.rdf> SELECT *
WHERE { ?go
<http://139.91.183.30:9090/RDF/VRP/Examples/schema_go.rdfaccession> ?accession ?go <http://139.91.183.30:9090/RDF/VRP/Examples/schema_go.rdfname> ?name ?go
<http://139.91.183.30:9090/RDF/VRP/Examples/schema_go.rdfdefinition> ?definition
14
Saran
Beberapa hal yang perlu dikembangkan dalam penelitian selanjutnya yang terkait dengan RDF Retrieval antara lain sebagai berikut:
1 Menggunakan jumlah koleksi dokumen yang lebih banyak.
2 Menggunakan ontologi pada dokumen RDF agar makna pada dokumen RDF dapat lebih spesifik.
3 Melakukan analisis perbandingan dengan metode pencarian koefisien bobot per konteks lainnya.
DAFTAR PUSTAKA
Baeza-Yates R, Ribeiro-Neto B. 1999. Modern Information Retrieval. Harlow (UK): Addison Wesley.
Gutierrez C, Hurtado C, Vaisman A. 2007. Introducing time into RDF. IEEE Trans. Knowl. Data Eng.. 19(2):207-218. doi:10.1109/tkde.2007.34.
Herawan Y, 2011. Ekstraksi ciri dokumen tumbuhan obat menggunakan chi-kuadrat dengan klasifikasi naive bayes [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Manning CD. Raghavan P, Schütze H. 2008. Introduction to Information Retrieval. New York (US): Cambridge University Press.
Manola F, Miller E. 2004. RDF Primer. http://www.w3.org/TR/2004/REC-rdf-primer-20040210/ [17 November 2014].
Minack E, Sauermann L, Grimnes Gunnar, Fluit C, Broekstra J. 2008. The Sesame LuceneSail: RDF Queries with Full-text Search. http://www.dfki.uni-kl.de/~sauermann/papers/Minack+2008.pdf [4 April 2015]
Noviandi L. 2014. Search engine dokumen RDF tanaman obat menggunakan Sesame dan Lucene [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Rahman A. 2006. Perbandingan kinerja beberapa ukuran kesamaan pada temu kembali informasi dokumen XML [skripsi]. Bogor (ID): Institut Pertanian Bogor.
15
15
LAMPIRAN
Lampiran 1 Contoh dokumen RDF tanaman obat <rdf:Description rdf:about="tanaman_1">
<tanaman:id>1</tanaman:id>
<tanaman:famili>Pancdanaceae</tanaman:famili> <tanaman:nama>Pandan Wangi</tanaman:nama>
<tanaman:latin>Pandanaus amaryllifolius Roxb</tanaman:latin> <tanaman:bagian>Daun</tanaman:bagian> <tanaman:manfaat> <rdf:Bag> <rdf:li>rambut rontok</rdf:li> <rdf:li>menghitamkan rambut</rdf:li> <rdf:li>menghilangkan ketombe</rdf:li> <rdf:li>lemah saraf (neurastenia)</rdf:li> <rdf:li>tidak nafsu makan</rdf:li> <rdf:li>rematik</rdf:li>
<rdf:li>pegal linu</rdf:li>
<rdf:li>sakit disertai gelisah</rdf:li> </rdf:Bag> </tanaman:manfaat> <tanaman:kandungan> <rdf:Bag> <rdf:li>alkaloida</rdf:li> <rdf:li>saponin</rdf:li> <rdf:li>flavonoida</rdf:li> <rdf:li>tannin</rdf:li> <rdf:li>polifenol</rdf:li> <rdf:li>zat warna</rdf:li> </rdf:Bag> </tanaman:kandungan>
<tanaman:deskripsi>Tumbuh di tempat yang agak lembap, tumbuh subur dari daerah pantai - daerah dengan ketinggian 500m dpl. Perdu tahunan, tinggi 1m-2m. Batang bulat dengan bekas duduk daun, bercabang, menjalar, akar tunjang keluar di sekitar pangkal batang dan cabang. Daun tunggal, duduk, dengan pangkal memeluk batang, tersusun berbaris tiga dalam garis spiral. Helai daun berbentuk pita, tipis, licin, ujung runcing, tepi rata, bertulang sejajar, panjang 40cm-80cm, lebar 3cm-5cm, berduri pada ibu tulang daun permukaan bawah bagian ujung-ujungnya, warna hijau. Bunga majemuk, bentuk bongkol, warnanya putih. Buahnya buah batu, menggantung, bentuk bola, diameter 4cm-7.5cm, dinding buah berambut, warnanya jingga</tanaman:deskripsi>
<tanaman:penyakit>Perawatan</tanaman:penyakit> </rdf:Description>
16
Lampiran 2 Daftar kombinasi koefisien bobot yang digunakan dalam penelitian deskripsi bagian kandungan nama latin famili penyakit manfaat
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.8 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.6 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.4 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.2 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.8 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.6 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.4 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.2 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.2 0.8 1.0 1.0 1.0 1.0 1.0 1.0 0.2 0.6 1.0 1.0 1.0 1.0 1.0 1.0 0.2 0.4 1.0 1.0 1.0 1.0 1.0 1.0 0.2 0.2 1.0 1.0 1.0 1.0 1.0 1.0 0.2 0.6 0.8 1.0 1.0 1.0 1.0 1.0 0.2 0.6 0.6 1.0 1.0 1.0 1.0 1.0 0.2 0.6 0.4 1.0 1.0 1.0 1.0 1.0 0.2 0.6 0.2 1.0 1.0 1.0 1.0 1.0 0.2 0.6 1.0 0.8 1.0 1.0 1.0 1.0 0.2 0.6 1.0 0.6 1.0 1.0 1.0 1.0 0.2 0.6 1.0 0.4 1.0 1.0 1.0 1.0 0.2 0.6 1.0 0.2 1.0 1.0 1.0 1.0 0.2 0.6 1.0 1.0 0.8 1.0 1.0 1.0 0.2 0.6 1.0 1.0 0.6 1.0 1.0 1.0 0.2 0.6 1.0 1.0 0.4 1.0 1.0 1.0 0.2 0.6 1.0 1.0 0.2 1.0 1.0 1.0 0.2 0.6 1.0 1.0 1.0 0.8 1.0 1.0 0.2 0.6 1.0 1.0 1.0 0.6 1.0 1.0 0.2 0.6 1.0 1.0 1.0 0.4 1.0 1.0 0.2 0.6 1.0 1.0 1.0 0.2 1.0 1.0 0.2 0.6 1.0 1.0 1.0 1.0 0.8 1.0 0.2 0.6 1.0 1.0 1.0 1.0 0.6 1.0 0.2 0.6 1.0 1.0 1.0 1.0 0.4 1.0 0.2 0.6 1.0 1.0 1.0 1.0 0.2
17
17
Lampiran 3 Daftar kueri dan dokumen relevan
No Kueri Dokumen Relevan
1 Kanker d15, d86, d88, d95 2 Flu d45, d65, d99 3 Diabetes d2, d5, d14, d18, d33, d37, d39, d54, d55, d58, d59, d70, d78, d79, d81, d85, d86, d95, d97, d99 4 Pusing d38, d76, d84 5 Merambat d3, d94 6 Menjari d6, d2, d99 7 Bergerigi d8, d17, d36, d52, d62, d64, d68, d69, d73, d85, d93, d94 8 Menyirip d8, d9, d19, d22, d25, d52, d57, d64, d69, d73, d80, d81, d87, d89, d94, d95, d96, d97, d98 9 Vitamin d18, d20, d23, d28, d34, d39, d44, d55, d59, d60, d64, d73, d77, d79, d84, d94, d95, d97, d99 10 Antioksidan d79 11 Protein d60, d64, d73, d94, d95, d97, d99 12 Kalsium d50, d60, d64, d68, d73, d78, d84, d85, d94, d97, d99 13 Diseduh d41, d53, d56, d60, d70, d80, d82, d83, d84, d85, d90 14 Ditumbuk d39, d40, d51, d55, d59, d66, d67, d68, d70, d71, d77, d86 15 Diperas d34, d40, d60, d64, d68, d77, d84 16 Batuk Pilek d45, d50, d65 17 Kencing Batu d47, d62, d85, d36 18 Datang Bulan d60, d54, d58 19 Gatal-gatal d48, d51, d52, d69 20 Sesak Nafas d7, d28, d29, d30, d34, d60 21 Tumbuhan Merambat d3, d94 22 Tanaman Hias d12, d21, d23, d24, d25, d32, d35, d37, d38, d50, d51, d52, d61, d63, d64, d65, d67, d69, d70, d71, d72, d73, d76, d77, d78, d86 23 Daun Elips d14, d29, d85, d86 24 Buah Buni d9, d13, d23, d26, d32, d53, d61, d64, d71, d73, d79, d80, d84, d89, d81 25 Kalsium Oksalat d20, d23, d50, d64, d73, d78, d94 26 Zat Warna d1, d31, d42, d66, d74 27 Obat Diseduh d80, d84, d60, d85 28 Obat Ditumbuk d39, d40, d51, d53, d55, d59, d68, d70 29 Buah Diperas d34, d60, d84
18
kueri Nilai precision pada 11 standar recall
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00 Kanker 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Flu 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Diabetes 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Pusing 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Merambat 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Menjari 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Bergerigi 1.00 0.75 0.75 0.75 0.75 0.75 0.75 0.75 0.75 0.75 0.75 Menyirip 1.00 1.00 1.00 1.00 1.00 0.94 0.94 0.94 0.90 0.90 0.86 Vitamin 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.95 0.95 0.95 Antioksidan 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Protein 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.88 0.88 0.88 Kalsium 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.83 0.83 0.73 Diseduh 1.00 1.00 1.00 0.92 0.92 0.92 0.92 0.92 0.92 0.92 0.92 Ditumbuk 1.00 1.00 1.00 0.92 0.92 0.92 0.92 0.92 0.92 0.92 0.92 Diperas 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Batuk Pilek 1.00 1.00 1.00 1.00 0.67 0.67 0.67 0.30 0.30 0.30 0.30 Kencing Batu 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.50 0.50 0.50 Datang Bulan 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Gatal-gatal 1.00 1.00 1.00 0.40 0.40 0.40 0.40 0.40 0.40 0.40 0.40 L ampi ra n 4 Nilai pr ec isi on be rda sa rka n 11 sta nda r re ca ll tanpa pe mbo botan pe r kon teks
19 L ampir an 4 L anjuta n
kueri Nilai precision pada 11 standar recall
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00 Sesak Nafas 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Tumbuhan Merambat 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Tanaman Hias 0.92 0.92 0.92 0.92 0.92 0.92 0.92 0.92 0.92 0.90 0.90 Daun Elips 1.00 1.00 1.00 1.00 1.00 1.00 0.06 0.06 0.06 0.06 0.06 Buah Buni 1.00 0.67 0.60 0.60 0.60 0.60 0.60 0.60 0.60 0.60 0.60 Kalsium Oksalat 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Zat Warna 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Obat Diseduh 1.00 1.00 1.00 0.29 0.29 0.29 0.29 0.29 0.29 0.29 0.29 Obat Ditumbuk 0.35 0.35 0.35 0.35 0.35 0.35 0.35 0.35 0.35 0.35 0.35 Buah Diperas 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.75 0.75 0.75 0.75
20
kueri Nilai precision pada 11 standar recall
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00 Kanker 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Flu 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Diabetes 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Pusing 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Merambat 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Menjari 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Bergerigi 1.00 0.75 0.75 0.75 0.75 0.75 0.75 0.75 0.75 0.75 0.75 Menyirip 1.00 1.00 1.00 1.00 1.00 0.94 0.94 0.94 0.90 0.90 0.86 Vitamin 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.95 0.95 0.95 Antioksidan 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Protein 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.88 0.88 0.88 Kalsium 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.83 0.83 0.73 Diseduh 1.00 1.00 1.00 0.92 0.92 0.92 0.92 0.92 0.92 0.92 0.92 Ditumbuk 1.00 1.00 1.00 0.92 0.92 0.92 0.92 0.92 0.92 0.92 0.92 Diperas 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Batuk Pilek 1.00 1.00 1.00 1.00 0.67 0.67 0.67 0.30 0.30 0.30 0.30 Kencing Batu 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.36 0.36 0.36 Datang Bulan 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Gatal-gatal 1.00 1.00 1.00 0.40 0.40 0.40 0.40 0.40 0.40 0.40 0.40 L ampir an 5 N ilai pre ci sion be rda sa rka n 11 sta n da r re call de n g an pe mbo bota n pe r kon teks pa d a AV P te rtingg i
21 L ampir an 5 L anjuta n
kueri Nilai precision pada 11 standar recall
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00 Sesak Nafas 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Tumbuhan Merambat 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Tanaman Hias 0.92 0.92 0.92 0.92 0.92 0.92 0.92 0.92 0.92 0.90 0.90 Daun Elips 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Buah Buni 1.00 1.00 1.00 0.63 0.61 0.61 0.61 0.61 0.61 0.61 0.60 Kalsium Oksalat 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Zat Warna 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Obat Diseduh 1.00 1.00 1.00 0.29 0.29 0.29 0.29 0.29 0.29 0.29 0.29 Obat Ditumbuk 0.35 0.35 0.35 0.35 0.35 0.35 0.35 0.35 0.35 0.35 0.35 Buah Diperas 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00
22
RIWAYAT HIDUP
Penulis dilahirkan di Bogor, Jawa Barat pada tanggal 6 Juni 1993 dari pasangan Zaenal Abidin dan Ane Rufaedah. Penulis merupakan anak ketiga dari empat bersaudara.
Tahun 2011 penulis lulus dari Madrasah Aliyah Negeri 2 Bogor dan pada tahun yang sama penulis diterima di Institut Pernatian Bogor melalui jalur Seleksi Nasional Masuk Perguruan Tinggi Negeri (SNMPTN) Undangan pada Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam (FMIPA) IPB.