Disusun Oleh :
FITRALOKA ARUM SARI 0734010186
JURUSAN TEKNIK INFORMATIKA FAKULTAS TEKNIK INDUSTRI
UNIVERSITAS PEMBANGUNAN NASIONAL “VETERAN” JAWA TIMUR
Puji syukur penulis panjatkan kehadirat Allah SWT yang telah melimpahkan rahmatnya kepada penulis sehingga penulis dapat menyelesaikan Tugas Akhir dengan baik dan benar.
Penyusun menyadari bahwasanya dalam menyelesaikan Skripsi ini telah mendapat banyak bantuan dan dukungan dari berbagai pihak, untuk itu pada kesempatan yang berharga ini, penyusunmengucapkanterimakasihkepada :
1. Bapak Ir. Sutiyono,MT selaku Dekan FTI, Universitas Pembangunan Nasional “Veteran” Jawa Timur.
2. Ibu Dr.Ir. Ni Ketut Sari,MT selaku Ketua Program Studi Teknik Informatika Universitas Pembangunan Nasional “Veteran” Jawa Timur.
3. Ibu Prof.Dr.Ir.Sri Redjeki,MT selaku Dosen Pembimbing I Skripsi atas segala do’a restu, arahan, ilmu, dan bimbingan-bimbingan yang telah diberikan selama penyelesaian Skripsi.
4. Bapak S.Kom selaku Dosen Pembimbing II Skripsi atas segala do’a restu, arahan, ilmu, dan bimbingan-bimbingan yang telah diberikan selama penyelesaian Skripsi.
5. Bapak Basuki Rahmat, S.Si, MT, Ibu Rr. Ani Dijah Raharjoe, ST, M.Cs, Bapak Rizky Parlika, S.Kom selaku Dosen Penguji Seminar TA yang banyak memberi masukan yang berguna kepada penulis selama revisi.
8. Keluarga Adi Hermawan, yang selalu membantu pengerjaan aplikasi ini dan memberikan masukkan guna untuk memperlancar skripsi
9. Kakak-kakakku mas Gambar, mas Erik dan adik tersayang Trias, terima kasih atas do’a serta dukungannya selama proses mengerjakan Skripsi ini dan aku sayang kalian semua.
10.KeluargaLulukSuharwati, yang maumeminjamkan print untukpenyusunpakaimencetakskripsiinidandoa yang selaluterpanjatkan.
11.Teman- temanTeknikInformatikaangkatan 2011 rhina, lian, april, nanda, novita, hayu, chanif, faiq, didit, aldo, novihendra, sanggra, rizal, atik,widya, adidll. TemanbermainRandie, fika, tya, upid, andreas, novi, irul, erlindadansemua orang yang berhubunganbaikdenganpenyusun yang tidakbisadisebutkansatupersatuterimakasihatasdo’adandukungannyaselamaini sertaterimakasihataspertemanannya.
12.Enrique Iglesiasdan Bruno Mars yang
lagunyaselalumenemanipenyusundalampembuatanskripsiini.
13.Yang paling berjasatapitidakmerasa paling berjasa My Laptop Asus yang seringpenyusunmaki di kalaaplikasimengalami error. Super Terimakasih.
Pembimbing I : Prof.Dr.Ir.Sri Redjeki,MT Pembimbing II : Faisal Muttaqin,S.Kom Penyusun : Fitraloka Arum Sari
ABSTRAK
Pengguna Komputer dan berbagai aplikasinya banyak menyebabkan terjadinya
penumpukan data dalam jumlah cepat yang sering kali menimbulkan kendala dalam mencari data
yang dibutuhkan secara cepat, tepat dan tidak dapat dilakukan karena harus mencari secara
manual atau satu per satu sehingga membutuhkan waktu cukup lama.
Kendala tersebut dapat bertambah apabila data yang dicari terletak di dalam jaringan
komputer lokal sehingga lokasi data semakin tersebar, yang menyebabkan bertambahnya dan
tenaga.
Untuk mengefisienkan hal tersebut diperlukan suatu aplikasi yang dapat melakukan
pencarian secara cepat dan akurat dalam menemukan kembali data yang dibutuhkan, yang
mampu mencari data di komputer stand alone maupun dalam jaringan komputer lokal.
KATA PENGANTAR
Alhamdulillah, Penulis bersyukur kepada Allah SWT atas semua Rahmat, Berkah, dan Ridho-Nya yang telah diberikan kepada penulis sehingga dapat menyelesaikan Skripsi yang berjudul “Membuat aplikasi temu kembali infor masi menggunakan model r uang vektor ” ini dengan baik.
Skripsi merupakan salah satu syarat bagi mahasiswa untuk menyelesaikan program studi Sarjana Strata Satu (S1) di Jurusan Teknik Informatika Fakultas Teknologi Industri Universitas Pembangunan Nasional “Veteran” Jawa Timur.
Melalui Skripsi ini penyusun merasa mendapatkan kesempatan besar untuk memperdalam ilmu pengetahuan yang diperoleh selama di bangku perkuliahan. Namun, penyusun menyadari bahwa Skripsi ini masih jauh dari sempurna. Oleh karena itu penyusun sangat mengharapkan saran dan kritik dari para pembaca untuk pengembangan aplikasi lebih lanjut.
Surabaya, 5 Juni 2012
ABSTRAK i
2.1 Konsep Dasar Sistem Informasi ... 9
2.1.1 Pengertian Sistem Kembali Informasi ... 9
2.2 Pembobotan Kata ... 15
2.2.1 Pemodelan Ruang Vektor . ... 16
2.3 Text Mining ... 18
2.4 Pengembangan Perangkat Lunak ... 19
2.5 Pengujian Perangkat Lunak ... 20
2.6 Data Flow Diagram ... 21
2.7 Definisi Pemprograman Delphi ... 21
BAB III ANALISIS DAN PERANCANGAN SISTEM ... 30
3.1 Analisis Sistem ... 30
3.2 Analisis Kebutuhan ... 30
3.2.1 Fungsi Perangkat Lunak ... 30
4.1 Lingkungan pemprograman ... .... 44
4.1.1 Lingkungan perangkat keras ... . 44
4.1.2 Lingkungan perangkat Lunak ... 44
4.2 Implementasi Arsitektur ... 45
4.3 Implementasi Proses ... 45
4.3.1 Implementasi Koneksi Database ... 46
4.4 Implementasi Aplikasi Desain Antar Muka ... 46
5.2.1 Uji coba Tampilan Pencarian Lokasi File ... 56
5.2.2 Uji coba Tampilan Pencarian kata/ keyword ... 59
5.2.3 Uji coba Tampilan Perankingan ... 62
5.3 Form Halaman Database ... 64
BAB VI PENUTUP 64
6.1.Kesimpulan ... 66
6.2. Saran ... 66
Gambar 2.1 Komponen Sistem Temu-Kembali Informasi (Tarto, 2008)... 13
Gambar 2.2 Interaksi antara pengguna dengan sistem (Tarto, 2008)... 13
Gambar 2.3 proses filter dokumen 2 tingkat... 17
Gambar 2.4 Filter dokumen dengan model ruang vektor ... 18
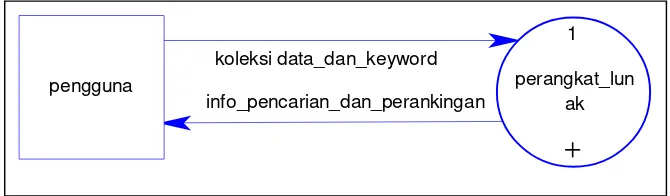
Gambar 3.1 Diagram Konteks ... 32
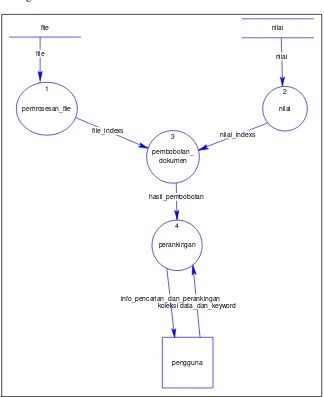
Gambar 3.2 Diagram Aliran Data Level 1 ... 33
Gambar 3.3 Rancangan antarmuka Utama perangkat Lunak ... 36
Gambar 3.4 Struktur Modul Perangkat Lunak ... 38
Gambar 3.5 Flowchart Perangkat Lunak ... 39
Gambar 3.6 Flowchart proses pencarian lokasi file ... 40
Gambar 3.7 flowchart proses pencarian nilai bobot dokumen ... 41
Gambar 3.8 flowchart perankingan ... 42
Gambar 4.1 Script Koneksi Database ... 46
Gambar 4.2 Tampilan Awal Aplikasi ... 47
Gambar 4.3 halaman hasil pencarian ... 48
Gambar 4.4 halaman pencarian lokasi file ... 49
Gambar 4.5 tampilan hasil daftar file dokumen... 49
Gambar 4.6 halaman hasil perhitungan bobot dan perankingan ... 50
Gambar 4.7 Form Halaman Setting Database ... 51
Gambar 4.8 Form tabel Database tfile ... 52
Gambar 4.9 Form tabel Database tnilai ... 52
Gambar 4.10 Hasil Pengujian ... 54
Gambar 5.1 Uji Coba Tampilan Aplikasi ... 56
Gambar 5.2 Uji Coba Tampilan Pencarian lokasi file ... 57
Gambar 5.5 Uji Coba Tampilan Pencarian Kata/Keyword ... 59
Gambar 5.6 Uji Coba Tampilan Hasil Pencarian Kata/Keyword ... 60
Gambar 5.6 Uji Coba Tampilan Hasil isi dari file ... 61
Gambar 5.7 Uji Coba Tampilan Hasil isi dari perankingan ... 62
Gambar 5.8 Perankingan ... 63
Gambar 5.9 Nilai Bobot ... 63
Gambar 5.10 Form Halaman Setting Database ... 64
Gambar 5.11 Form tabel Database tfile ... 65
P E N D A H U L U A N
1.1. Latar Belaka ng
Semakin canggihnya teknologi di bidang komputasi dan telekomunikasi pada masa kini, membuat informasi dapat dengan mudah didapatkan oleh banyak orang. Kemudahan ini menyebabkan informasi menjadi semakin banyak dan beragam. Informasi dapat berupa dokumen, berita, surat, cerita, laporan penelitian, data keuangan, dan lain-lain. Tidak dapat dipungkiri lagi informasi telah menjadi komoditi yang paling penting dalam dunia modern masa kini.
Seiring dengan perkembangan informasi,banyak pihak menyadari bahwa masalah utama telah bergeser dari cara mengakses informasi menjadi memilih informasi utama yang berguna secara selektif. Usaha untuk memilih informasi ternyata lebih besar dari sekedar mendapatkan akses terhadap informasi. Pemilihan atau penemuan kembali informasi ini tidak mungkin dilakukan secara manual karena kumpulan informasi yang sangat besar dan terus bertambah besar.
Mandala (2002,hal 1) menyatakan bahwa suatu sistem otomatis diperlukan informasi (information retrieval system) merupakan sistem yang digunakan untuk menemukan informasi yang relevan dengan kebutuhan dari penggunanua secara otomatis berdasarkan kesesuaian dengan query (masukan berupa ekspresi kebutuhan informasi oleh pengguna) dari suatu koleksi informasi.
Namun dari hasil temuan kembali dokumen, pengguna tidak dapat melihat peran dari query dalam proses pencarian dokumen tersebut, urutan dokumen yang di-retrieve dinilai tidak informatif berdasarkan tingkat kesesuaiannya dengan
query. Oleh karena itu digunakan model ruang vektor (vector space model) sistem temu kembali informasi. Menurut Arifin (dalam Salton, 1989) ’Salah satu model sistem temu kembali informasi yang paling sederhana namun paling produktif adalah model ruang vektor. Vektor model ini merepresentasikan term yang terdapat pada dokumen dan query. Elemen vektor tersebut adalah bobot term yang menjadi dasar penilaian dalam pemeringkatan dokumen. Hal yang perlu diperhatikan dalam penemuan kembali informasi model ruang vektor ini adalah pembobotan term (term weighting). Term dapat berupa kata, frase, atau unit hasil
indexing lain dalam suatu dokumen sebagai gambaran konteks dari dokumen tersebut. Karena tiap kata memiliki tingkat kepentingan yang berbeda dalam dokumen, maka diperlukan indikator yaitu term weight (bobot term) dalam proses pencocokan dan perankingan dokumen terhadap query.
Metode pembobotan yang umumnya diunggulkan dalam penelitian-penelitian untuk digunakan dalam model ruang vektor yaitu TF-IDF Term Frequency Inverse Document Frequency (Arifin, 2002). Menurut Arifin (dalam Salton, 1989) ‘Dalam perhitungan bobot term, sekalipun term frequency banyak digunakan, namun ia hanya mendukung proporsi jumlah dokumen yang dapat ditemukan-kembali oleh proses pencarian pada sistem Information Retrieval,
demikian akan diharapkan mampu mengelompokkan sejumlah dokumen yang memuatnya, sehingga berbeda dengan seluruh anggota koleksi dokumen lain yang tidak memilikinya. Kriteria ini dapat diakomodasi dengan menghitung invers frekuensi dokumen. Dengan digabungkannya kedua metode ini yaitu konsep frekuensi kemunculan term dalam sebuah dokumen dan inverse frekuensi dokumen yang mengandung kata tersebut, akan mampu meningkatkan proporsi jumlah dokumen yang dapat ditemukan kembali dan yang dianggap relevan secara sekaligus. Sehingga kriteria term yang paling tepat adalah term yang sering muncul dalam dokumen secara individu, namun jarang dijumpai pada dokumen lainnya.’ Menurut Defeng (dalam Robertson, 2004: 503) ’Metode TF-IDF merupakan suatu cara untuk memberikan bobot hubungan suatu kata (term) terhadap dokumen. Metode ini menggabungkan dua konsep untuk perhitungan bobot, yaitu frekuensi kemunculan sebuah kata di dalam sebuah dokumen tertentu dan inverse frekuensi dokumen yang mengandung kata tersebut. Frekuensi kemunculan kata di dalam dokumen yang diberikan menunjukkan seberapa penting kata itu di dalam dokumen tersebut. Frekuensi dokumen yang mengandung kata tersebut menunjukkan seberapa umum kata tersebut. Sehingga bobot hubungan antara sebuah kata dan sebuah dokumen akan tinggi apabila frekuensi kata tersebut tinggi di dalam dokumen dan frekuensi keseluruhan dokumen yang mengandung kata tersebut yang rendah pada kumpulan dokumen.
dengan menggunakan metode ini kadang belum tentu sesuai yang diinginkan, meskipun dalam dokumen yang diperoleh tersebut sudah mengandung kata kunci dalam masukan keyword. Salah satu penyebabnya adalah adanya berbagai konsep domain pengetahuan yang berbeda dalam kata kunci yang sama (problem semantik).
Penggunaan komputer dan berbagai aplikasinya banyak menyebabkan terjadinya penumpukan data dalam jumlah cepat yang sering kali menimbulkan kendala dalam mencari data yang dibutuhkan secara cepat, tepat dan tidak dapat dilakukan karena harus mencari secara manual atau satu per satu sehingga dapat membutuhkan waktu yang cukup lama.
Kendala tersebut dapat bertambah apabila data yang dicari terletak di dalam jaringan komputer lokal sehingga lokasi data semakin tersebar, yang menyebabkan bertambahnya waktu dan tenaga untuk mengefesienkan hal tersebut diperlukan suatu aplikasi yang dapat melakukakan pencarian secara cepat dan akurat dalam menemukan kembali data yang dibutuhkan, yang mampu mencari data di komputer stand alone maupun dalam jaringan komputer lokal.
Setiap paragraf latar belakang diatas dapat disimpulkan, maka dari itu penulis merasa perlu dibuat aplikasi temu kembali informasi dengan menggunakan model ruang vektor.
1.2. Per umusan Masalah
Adapun yang menjadi rumusan masalah dalam Tugas Akhir ini adalah: 1. Bagaimana merancang sistem yang dapat mencari data yang
2. Bagaimana cara kerja mesin pencari dalam melakukan pembobotan dokumen dengan menggunakan metode TF-IDF.
3. Bagaimana mesin pencarian dapat menghasilkan dokumen yang teranking berdasarkan query masukan oleh pengguna.
1.3. Batasan Masalah
Dalam penyusunan Tugas Akhir ini penulis memberikan batasan-batasan masalah sebagai berikut:
1. Data atau dokumen yang dicari hanya berformat teks (.txt). 2. Ukuran file dari data yang dicari tidak dibatasi ukurannya.
3. Pengindeksan data atau dokumen dilakukan berdasarkan perhitungan bobot.
4. Aplikasi yang dibuat menggunakan teknik pencarian Model Ruang Vektor yaitu suatu model yang digunakan untuk mengukur kemiripan antara isi suatu dokumen.
5. Pencarian kata/ keyword tidak bisa lebih dari satu kata.
6. Pencarian kata/ keyword tidak bisa mencari judul atau nama file/dokumen.
7. Aplikasi tidak bisa mencari tanda baca.
1.4 Tujuan
perncarian kata dengan melakukan pembobotan dokumen menggunakan metode TF-IDF. Aplikasi dapat menghasilkan dokumen yang di cari setelah melakukan pencarian kata dan pengguna dapat mengetahui proses dari pembobotan dokumen dan perankingan dengan menggunakan metode TF-IDF.
1.5 Manfaat
Manfaat penelitian Tugas Akhir akhir ini adalah mempermudah pengguna untuk mecari file yang diinginkan dengan cepat.dan mempermudah pengguna mendapatkan dokumen relevan berdasarkan query yang dimasukkan, serta telah teranking berdasarkan tingkat relevasianya.
1.6 Metodolologi Penelitian
Langkah-langkah dalam pengerjaan skripsi ini antara lain: 1. Studi literatur tentang:
Konsep/metode text mining, Metode pembobotan TF-IDF dan penerapannya teori search engine.
2. Perencanaan dan pembuatan perangkat lunak modul pemrosesan dokumen modul pemprosesan query modul matching (pencocokan).
3. Pengujian dan analisa perangkat lunak Pengujian program yang telah dibuat Analisa hasil output dari program
1.7 Sistematika Penulisan
Sistematika dalam penyusunan Tugas Akhir ini akan dijabarkan dalam setiap bab dengan pembagian sebagai berikut :
BAB I : PENDAHULUAN
Berisi tentang latar belakang diambilnya judul Skripsi “Implementasi Metode Term Frequency Inverse Document Frequency (TF-IDF) pada Sistem Temu Kembali Informasi” , rumusan masalah yang akan dikaji dalam Skripsi ini, ruang lingkup atau batasan masalah, tujuan dan manfaat dari pembuatan Skripsi ini, metodologi penelitian, dan sistematika penulisan Skripsi yang menjelaskan secara garis besar susbstansi yang diberikan pada masing-masing bab.
BAB II : TINJ AUAN PUSTAKA
Pada bab ini dijelaskan landasan teori yang berkaitan dalam penyelesaian masalah serta teori yang mendukung dalam pembuatan sistem. Teori-teori tersebut antara lain : Pengertian Sistem Kembali Informasi, Pemodelan Rung Vektor, Pengembangan Perangkat Lunak, Pengujian perangkat Lunak, Pengertian Delphi,
BAB III : ANALISIS DAN PERANCANGAN SISTEM
menggunkan metode Ruang Vektor, Perancangan Database
dan lain sebagainya.
BAB IV : IMPLEMENTASI PERANGKAT LUNAK
Pada bab ini akan dibahas tentang tampilan dari sistem yang telah dibuat dan dari implementasi ke bahasa pemrograman program yang telah dibuat.
BAB V : UJ I COBA DAN EVALUASI PROGRAM
Dalam bab ini berisi tentang uji coba pada sistem yang telah jadi dan mengadakan evaluasi atau pengecekkan terhadap sistem yang sudah berjalan.
BAB VI : PENUTUP
TINJ AUAN PUSTAKA
2.1 Konsep Dasar Sistem Infor masi
Dalam menyusun dan merancang sistem informasi, beberapa konsep dasar dapat dijadikan sebagai acuan dan landasan, dimana konsep tersebut merupakan teori yang berhubungan dengan perancangan sistem informasi dari pemecahan masalah.
2.1.1 Penger tian Sistem Kembali Infor masi
Pada awalnya, hiperteks dan temu-kembali informasi merupakan bidang penelitian yang berbeda satu dengan yang lain. Hiperteks berkisar pada masalah
Smeaton (1991) di dalam Ellist (1996) juga menyatakan bahwa hiperteks
dan temu-kembali informasi itu saling berelemen satu sama lain. Hiperteks
membutuhkan lebih banyak searching sedangkan temu-kembali informasi membutuhkan lebih banyak browsing. Hal yang dimaksud adalah hiperteks akan semakin baik jika disertai dengan fasilitas search, dan temu-kembali informasi membutuhkan browsing dalam melakukan pencarian yang efisien. Adapun maksud dari searching adalah berusaha mendapatkan atau mencapai tujuan spesifik sedangkan browshing adalah mengikuti suatu path sampai mencapai suatu yujuan. Menurut Brown (1988) didalam Agosti () 1993, browshing itu bisa diibaratkan dengan from where to what. Maksudnya adalah kita tahu dimana posisi kita salam database dan kita ingin tahu apa yang ada disana (database). Sedangkan Searching bisa diibaratkan dengan from wo where maksudnya kita tahu apa yang kita inginkan dan kita ingin menemukan dimana dia didalam database.
Penggabungan sistem temu-kembali ke dalam basis hiperteks lebih dikenal dengan nama search engine, dimana sistem ini dapat dibagi kedalam dua kategori berdasarkan sumber informasinya yaitu:
1. Worlswide Search Engine
2. Local Search Engine
Local Search Engine adalah suatu sistem temu-kembali informasi yang mengambil data-data dari server tertentu saja. Kata “local”, yang berarti lokal atau setempat, memberi penekanan akan lokasi sumber data yang akan digunakan. Local Search Engine tidak dirancang untuk mengarungi belantara internet seperti
worlwide search engine. Tujuan implementasi local search engine dimaksudkan untuk pencarian pada objek spesifil dam lebih kecil lingkupnya dibandingkan internet sendiri.
Mengenai pemilihan penerepan sistem temu-kembali berbentik local search engine atau worlwide search engine tergantung kepada masalah atau jenis informasi cara sistem pengindeksan dari temu-kembali. Sedangkan teknik
retrieval dan rancangan penerapan teknik pada hiperteks akan sama saja, baik pengindeksannya secara local search engine ataupun worldwide search engine.
Sistem Temu Kembali Informasi menerima query dari pengguna, kemudian melakukan perangkingan terhadap dokumen pada koleksi berdasarkan kesesuaiannya dengan query. Hasil perangkingan yang diberikan kepada pengguna merupakan dokumen yang menurut sistem relevan dengan query. Namun relevansi dokumen terhadap suatu query merupakan penilaian pengguna yang subjektif dan dipengaruhi banyak faktor seperti topik, pewaktuan, sumber informasi maupun tujuan pengguna. Menurut Lancaster (1979) Sistem Temu Kembali Informasi terdiri dari 6 (enam) subsistem, yaitu:
3. Subsistem kosa kata 4. Subsistem pencarian
5. Subsistem antarmuka pengguna-sistem 6. Subsistem penyesuaian.
Sementara itu Tague-Sutcliffe (1996) melihat Sistem Temu Kembali Informasi sebagai suatu proses yang terdiri dari 6 (enam) komponen utama yaitu:
1. Kumpulan dokumen 2. Pengindeksan
3. Kebutuhan informasi pemakai 4. Strategi pencarian
5. Kumpulan dokumen yang ditemukan 6. Penilaian relevansi
Secara garis besar komponen-komponen Sistem Temu Kembali dapat diilustrasikan seperti pada Gambar 2.4
Dalam proses pencarian informasi terjadi interaksi antara pengguna dengan sistem (mesin) baik secara langsung maupun tidak langsung. Secara umum interaksi antara pengguna dengan sistem dalam proses pencarian informasi dapat dinyatakan seperti pada Gambar 2.5.
Gambar 2.2 Interaksi antara pengguna dengan sistem (Tarto, 2008)
Sistem Temu Kembali Informasi didisain untuk menemukan dokumen atau informasi yang diperlukan oleh masyarakat pengguna. Sistem Temu Kembali Informasi bertujuan untuk menjembatani kebutuhan informasi pengguna dengan sumber informasi yang tersedia dalam situasi seperti dikemukakan oleh Belkin (1980) sebagai berikut:
1. Penulis mempresentasikan sekumpulan ide dalam sebuah dokumen menggunakan sekumpulan konsep.
3. Sistem temu kembali informasi bertujuan untuk mempertemukan ide yang dikemukakan oleh penulis dalam dokumen dengan kebutuhan informasi pengguna yang dinyatakan dalam bentuk pertanyaan (query).
Berkaitan dengan sumber informasi di satu sisi dan kebutuhan informasi pengguna di sisi yang lain, Sistem Temu Kembali Informasi berperan untuk: 1. Menganalisis isi sumber informasi dan pertanyaan pengguna.
2. Mempertemukan pertanyaan pengguna dengan sumber informasi untuk mendapatkan dokumen yang relevan.
Adapun fungsi utama Sistem Temu Kembali Informasi seperti dikemukakan oleh Lancaster (1979) dan Kent (1971) adalah sebagai berikut:
1. Mengidentifikasi sumber informasi yang relevan dengan minat masyarakat pengguna yang ditargetkan.
2. Menganalisis isi sumber informasi (dokumen)
3. Merepresentasikan isi sumber informasi dengan cara tertentu yang memungkinkan untuk dipertemukan dengan pertanyaan (query) pengguna. 4. Merepresentasikan pertanyaan (query) pengguna dengan cara tertentu yang
memungkinkan untuk dipertemukan sumber informasi yang terdapat dalam basis data.
5. Mempertemukan pernyataan pencarian dengan data yang tersimpan dalam basis data.
6. Menemu-kembalikan informasi yang relevan.
2.2. Pembobotan Kata
Setiap kata dalam vektor dapat diberikan bobot. Bobot dari sebuah kata menandakan tingkat kepentingan kata tersebut dalam dokumen. Pemberian bobot kata dapat dinyatakan dengan nilai tfidf (term frquency inverse document). Berikut ini adalah formula perhitungan tfidf :
Keterangan
• Wij adalah bobot kata i pada dokumen j • N adalah koleksi dokumen
• tfif adalah jumlah kehadiran kata i yang akan dihitung bobotnya dalam
dokumen j
• dfj adalah dokumen j yang mengandung kata yang akan dihitung bobotnya
• Rumusan Log disebut juga inverse document
Sebagai contoh :
Berikut ini adalah kata-kata yang ada dalam dokumen beserta frekuensinya :
Tabel 2.1. Contoh frekuensi kata dalam suatu dokumen
yang mengandung kata hukum, maka bobot kata hukum adalah w(hukum) = 4.Log(500/40)=4.3876
2.2.1 Pemodelan Ruang Vektor
Setiap kata dalam vektor dapat diberikan bobot. Bobot dari sebuah kata menandakan tingkat kepentingan kata tersebut dalam dokumen. Bagian penting dari penyelesaian masalah pencarian dokumen adalah: bagaimana dokumen-dokumen dalam sumber digital dibuat indeksnya dan bagaimana proses oencarian tersebut dilakukan. Untuk itu diusulkan proses filter/ penyaringan dokumen dalam dua tingkat. Dibawah ini contoh gambar proses filter dokumen 2 tingkat (gambar 2.3
Gambar 2.4 dibawah ini memperlihatkan bahwa terdapat tiga langkah operasi pada sistem temu kembali informasi. Langkah pertama dimulai dari koleksi dokumen dalam bentuk sumber digital (dapat dilihat dalam panah) sampai pada proses terbentuknya database indeks. Langkah kedua dimulai dari query pancarian dokumen oleh pengguna. Dalam query tersebut akan dilakukan formulasi term query, yaitu perhitungan bobot dari term-term query tersebut dengan menggunakan algoritma pembobotan TF-IDF. Sedangkan langkah ketiga proses perankingan dokumen dengan menggunakan algoritma model ruang vektor.
Gambar 2.4 Filter dokumen dengan model ruang vektor
2.3. Text Mining
berbeda-beda. Text Mining berbeda dari pencarian di web. Pada pencarian, pengguna biasanya mencari sesuatu yang sudah diketahui oleh mereka atau sudah pernah ditulis oleh orang lain.
Permasalahannya adalah bagaimana menyatukan semua data-data yang tidak diberhubungan dengan kebutuhan dengan kebutuhan pengguna tersebut agar dapat digunakan untuk mencari informasi yang sesuai dengan yang dicari. Text Mining tidak jauh berbeda dengan Data Mining yang membedakannya adalah pada sumber datanya, dimana Text Mining bersumber dari kumpulan dokumen atau Text.
2.4 Pengembangan Per angkat Lunak
Merupakan sebuah model chaos yang menggambarkan “perkembangan P/L sebagai sebuah kesatuan dari pemakai ke pengembang dan ke teknologi” disebut dengan “Prescriptive” karena menentukan sekumpulan elemen proses (aktivitas, aksi, tugas, produk kerja, jaminan kualitas dan lain-lain untuk setiap proyek), setiap model proses juga menentukan alur kerjanya.
Pada saat kerja bergerak maju menuju sebuah sistem yang lengkap, keadaan yang menggambarkan secara rekursif diaplikasikan kepada kebutuhan pemakai dan spesifikasi teknis perangkat lunak pengembang. Saat ini, prescriptive memberikan jawaban secara defnitive untuk masalah pengembangan perangkat lunak dalam setiap perubahan lingkungan komputasi.
Dalam pengerjaan pengembangan perangkat lunak, ada beberapa pertanyaan yang harus dijawab:
2. Apa saja karakteristik entitas yang digunakan untuk menyelesaikan persoalan tersebut?
3. Bagaimana entitas (dan solusinya) dapat direalisasikan? 4. Bagaimana entitas akan dibangun?
5. Pendekatan apa yang akan digunakan untuk mencegah terjadinya kesalahan desain dan pembuatan entitas?
6. Bagaimana entitas akan didukung selama mungkin, pada saat ada permintaan koreksi adaptasi dan pengembangan oleh user.
2.5 Pengujian Per angkat Lunak
Adanya beberapa inisiatif tersebut dapat dianggap sebagai asumsi awal bahwa perlu adanya Body of Knowledge yang dibuat oleh para praktisi software engineering. Body of Knowledge tersebut kalau dalan management proyek kemudian dikenal istilah project management Body of Knowledge atau yang disingkat dengan PMBOK maka dalam software engineering dikenal juga istilah yang identik, yaitu Software Engineering Body Of Knowledge atau SWEBOK. Tujuan dibuatnya Software Engineering Body Of Knowledge adalah untuk mengorganisir dan mengkatalogisasi knowledge dalam software engineering
secara sistematis, singkat dan deskripsi yang lengkap tentang software engineering itu sendiri.
SWEBOK sendiri lebih menitik berkan pada beberapa tema dalam
software engineering seperti berikut:
2. Mengklarifikasi serta memperjelas tempat dan ruang lingkup
software engineering dengan ilmu-ilmu lain seperti Computer science project management, computer engineering dan matematika.
3. Memberikan karakteristik kandungan knowledge dalam software engineering.
4. Menyediakan akses secara “tropical” pada SWEBOK.
5. Memberikan dasar untuk pengembangan kurikulum dan sertifikasi
software engineering
2.6. Data Flow Diagram
Data flow diagram atau yang disingkat dengan DFD merupakan
representatif dari sebuah sistem secara grafis yang digambarkan dengan sejumlah simbol tertentu utuk menunjukkan perpindahan data dalam proses suatu sistem. Dalam hal ini DFD menunjukkan perpindahan dan perubahan data dalam suatu sistem. DFD merupakan sau alat pemodelan proses dari sistem yang paling sering digunakan.
2.7. Definisi Pemr ogr aman Delphi
Anda bisa membuat program-program dengan tampilan yang menawan, Delphi hanya bisa bekerja di bawah System Microsoft Windows sedangkan untuk system yang lain seperti Linux atau Unix Delphi mempunyai saudara kembarnya yang bisa bekerja pada system tersebut yaitu KYLIX.
Adapun kelebihan dari bahasa pemprograman delphi yaitu perkembangan
Software Development Toold sangat pesat dengan persaingan yang sangat ketat. Masing-masing perangkat memiliki kelebihan dan kekurangan yang sangat tipis bila dibandingkan satu dengan yang lainnya. Pembahasan kelebihan deplhi disi bertujuan untuk melihat apa saja kekuatan dekphi yang bisa dimanfaatkan semaksimal mungkin.
Delphi termasuk Keluarga Visual sekelas Visual Basic, Visual C, artinya perintah-perintah untuk membuat objek dapat dilakukan secara visual. Pemrogram tinggal memilih objek apa yang ingin dimasukkan kedalam Form atau Windows, lalu tingkah laku objek tersebut saat menerima event tinggal dibuat programnya. Delphi merupakan bahasa berorentasi objek, artinya nama objek, properti dan prosedur dikemas menjadi satu kemasan (encapsulate).
Sebelum mempelajari ketiga struktur pemrograman ada baiknya kenali dahulu tampilan IDE, yang merupakan editor dan tools untuk membuat program Delphi. Pada IDE akan ditampilkan Form baru yang merupakan aplikasi / program window yang akan dibuat.
Pada pemrograman berbasis windows, kita akan diperhadapkan pada satu atau beberapa jendela. Jendela ini dalam Delphi disebut juga dengan form.
2.7.1 Kelebihan Pemr ogr aman Delphi
Bahasa pemrograman delphi sintak dasarnya menggunakan bahasa Pascal Basis Object Oriented Programming (OOP) dalam Delphi dapat mempermudah pengembang aplikasi dalam mebangun project yang dikelolanya. Berikut adalah kelebihan dari bahasa Pemrograman Delphi :
a. Komponen dapat dipakai ulang dan dapat dikembangkan Delphi mempermudah pembuatan program bagi komponen-komponen
Windows seperti label, button dan bahkan dialog dan lainnya. Komponen ini dapat diatur sesuai dengan kebutuhan kita si pembuat program.
b. Dapat mengakses VBX
Dengan Delphi kita dapat langsung mengakses komponen VBX yang sudah merupakan satu kesatuan dan dapat langsung digunakan .
c. Template Aplikasi dan Template Form
Dalam Delphi telah didefinisikan template aplikasi dan template Form yang dapat dipakai untuk membuat semua form aplikasi dengan lebih cepat.
d. Lingkungan Pengembang Delphi
e. Program Terkompilasi
Kebanyakan lingkungan pengembang visual pada windows menyatakan dapat mengkompilasi program. Namun sebenarnya mereka hanya dapat mengkompilasi sebagian program dan kemudian mengabungkan interpreter dan pcode dalam sebuah file. Dengan cara ini akan menghasilkan aplikasi dengan eksekusi yang lambat. Namun dengan pemrograman delphi output yang dihasilkannya merupakan file yang benar-benar terkompilasi tanpa interpreter dan pcode sehinga dapat berjalan lebih cepat. Program Delphi yang kecil dapat diserahkan dalam bentuk sebuah file EXE tanpa harus menyertakan file DLL.
f. Kemampuan mengakses data dalam berbagai macam format
Dalam Delphi terdapat BDE ( Borland Database Engine) yang digunakan untuk mengakses format file data yang ada. BDE telah melalui beberapa tahap pengembangan, yang sebelumnya BDE dikenal dengan ODAPI , kemudian IDAPI. Sekarang BDE sudah menjadi standar untuk akses semua jenis data yang ada saat ini. BDE juga dapat mengakses Database Client / Server seperti Sybase, SQL Server, Oracle dan Borland Interbase. Bila dibandingkan dengan microsoft ODBC , BDE lebih unggul dalam hal unjuk kerjannya, hal ini karena BDE memiliki bentuk yang lebih mendekati format database tujuannya.
2.7.2 Membuat Sebuah For m di Delphi
Development (RAD) Tool. Maksudnya adalah bagaimana menjadi perangkat yang mempercepat pengembangan aplikasi. Untuk RAD ini, delphi telah melakukannya dengan sangat baik, dimulai dari kemudahan penyusunan tampilan program. Aplikasi bisnis adalah aplikasi yang digunakan untuk membantu kegiatan bisnis atau operational perusahaan. Termasuk di dalamnya adalah aplikasi accounting, costumenrelationship, management, aplikasi kepegawaian (HRD) aplikasi pengelolaan pabrik, point of sales (POS). Bila ingin mengembangkan aplikasi jenis ini, perlu mempelajari lagi konsep database dari delphi. Kita harus mempunyai banyak sekali ppilihan database apa yang akan dihunakan. Misalkan MS SQL Server, Oracle, Firebird, PostgreSQL,MySQL. Saat anda pertama kali masuk ke Delphi, anda akan diperhadapkan pada sebuah form kosong yang akan dibuat secara otomatis. Form tersebut diberi nama Form1, form ini merupakan tempat bekerja untuk membuat antarmuka pengguna dalam Delphi.
2.7.3 Mengganti Nama For m dan Menambahkan J udul
Semua properti diurutkan berdasarkan alpabetik, dan dapat juga diurutkan berdasarkan kategori. Gantilah judul form dengan Hello melalui properti Caption, sedangkan nama form dengan nama form hello melalui properti Name. Caption digunakan untuk menyimpan keterangan yang dimunculkan pada form, sedangkan Name digunakan sebagai Nama dari objek tersebut. Isi dari properti Name harus diawali alpabet dan tidak menggunakan spasi atau tanda baca.
2.6. Gambar Jendela Object Inspector
2.8 Sejar ah Bor land Delphi
1. Delphi versi 1 (berjalan pada windows 3.1 atau windows 16 bit) 2. Delphi versi 2 (berjalan pada 95 atau delphi 32 bit)
Jendela Object Inspector
Properti Caption
Nilai / Isi Properti Nama Object
Tab Event
3. Delphi versi 3 (berjalan pada windows 95 keatas dengan tambahan fitur internet atau web)
4. Perkembanagn berikutnya diikuti dengan delphi versi 4, 5 dan 6 5. Versi terkini dari delphi adalah versi 7 dengan tambahan vitur.net
dengan tambahan file XML 32 bit.
2.8.1 Sequence Diagram
Sequence Diagram menjelaskan secara detil urutan proses yang dilakukan dalam sistem untuk mencapai tujuan dari use case. Interaksi yang terjadi antar class, operasi apa saja yang terlibat, urutan antar operasi, dan informasi yang diperlukan oleh masing-masing operasi.
2.8.2 Collaboration Diagram
Collaboration diagram dipakai untuk memodelkan interaksi antar objek di dalam sistem. Berbeda dengan sequence diagram yang lebih menonjolkan kronologis dari operasi-operasi yang dilakukan, collaboration diagram lebih fokus pada pemahaman atas keseluruhan operasi yang dilakukan oleh objek.
2.8.3 Class Diagram
Class diagram merupakan diagram yang selalu ada di permodelan sistem berorientasi objek. Class diagram menunjukkan hubungan antar class
2.9 MySQL
Pada awalnya, MySQL merupakan proyek internal sebuah firma asal Swedia, TcXDataKonsult.MySQL kemudian dirilis untuk publik pada tahun 1996. Karena MySQL menjadi sangat populer, pada tahun 2001 firma tersebut mendirikan sebuah perusahaan baru, MySQLAB, yang khusus menawarkan layanan dan produk berbasis MySQL (Gilmore, 2006).
Dari awal pembuatannya, para pengembang MySQL menitikberatkan pengembangan MySQL pada sisi performa dan skalabilitasnya. Hasilnya adalah sebuah perangkat lunak yang sangat teroptimasi, walaupun dari sisi fitur memiliki kekurangan dibandingkan solusi basis data kelas enterprise lain. Akan tetapi
MySQL menarik minat banyak pengguna. Saat ini, tercatat lebih dari lima juta basis data MySQL yang terpasang dan aktif di seluruh dunia. Beberapa perusahaan dan instansi penting dunia seperti Yahoo!, Google dan NASA menggunakan
MySQL untuk mengolah basis data mereka.
Ada beberapa kelebihan yang dimiliki MySQL sehingga dapat menarik banyak pengguna. Kelebihan tersebut yaitu:
1. Fleksibilitas Saat ini, MySQL telah dioptimasi untuk duabelas platform seperti
HP-UX, Linux, Mac OS X, Novell Netware, OpenBSD, Solaris, Microsoft
2. Performa Sejak rilis pertama, pengembang MySQL fokus kepada performa. Hal ini masih tetap dipertahankan hingga sekarang dengan terus meningkatkan fiturnya.
ANALISIS DAN PERANCANGAN SISTEM
3.1 Analisis Sistem
Berdasarkan rumusan masalah yang telah dijabarkan pada bab I, dibutuhkan suatu sistem perangkat lunak yang dapat digunakan untuk mengimplementasikan metode pembobtan dokumen Term Frequency Inverse Document Frequency (TF-IDF) dalam menghasilkan dokumen yang relevan dan terurut berdasarkan tingkat kerelevannya.
Untuk memudahkan didalam menentukan alur yang mungkin terjadi dalam sistem ini, ditentukan terlebih dahulu pengguna sistem ini. Pengguna sistem kemudian akan digambarkan sebagai entity dalam DFD. Pada sub bab berikut akan dibahas tentang pengguna sistem ini.
3.2 Analisis Kebutuhan
Dalam skripsi ini, akan dibangun sebuah perangkat lunak sistem temu kembali informasi yang mengimplementasikan metode pembobotan TF-IDF. Spesifikasi umum kebutuhan perangkat lunak terdiri dari fungsi perangkat lunak, tujuan perangkat lunak, batasan perangkat lunak serta model fungsionalitas perangkat lunak.
3.2.1 Fungsi Per angkat Lunak
1. Perangkat Lunak dapat berjalan dengan baik tanpa ada masalah pada saat dijalankan.
2. Perangkat Lunak dapat melakukan pencarian dokumen teks yang ada dalam sebuah lokasi yang telah ditentukan.
3. Perangkat Lunak dapat menampilkan hasil pencarian dokumen dalam bentuk list file.
4. Perangkat Lunak dapat melakukan pengelolaan keyword.
5. Perangkat Lunak dapat melakukan pengelolaan koleksi dokumen. 6. Perangkat Lunak dapat melakukan perankingan.
3.2.2 Tujuan Per angka t Lunak
Perangkat lunak yang dibuat memiliki tujuan sebagai berikut: 1. Memberikan penilaian terhadap aplikasi.
2. Menunjukkan kinerja yang didapat dari penggunaan metode pembobotan
TF-IDF.
3.2.3 Batasan Per angkat Lunak
3.3 Model Fungsional Per angkat Lunak
Model fungsional perangkat lunak memberikan gambaran umum mengenai proses-proses yang terjadi dalam perangkat lunak tanpa memberikan detail mengenai bagaimana proses-proses tersebut diimplementasikan. Model fungsional juga memberikan gambaran tentang aliran data yang terjadi antar proses-proses yang ada maupun antar proses dengan entitas luar, misalnya pengguna perangkat lunak.
3.3.1 Data Flow Diagr am
Aliran data tersebut akan mendefinisikan masukan dan keluaran yang terdapat pada masing-masing proses yang terjadi, sehingga hubungan antar proses dapat terlihat dengan jelas. Model fungsional yang akan digunakan adalah data flow diagram (DFD) atau disebut juga Diagram Aliran Data (DAD).
1. Diagram Aliran Data Level 0
Gambar 3.1 Diagram Konteks
2. Diagram Aliran Data Level 1
Gambar 3.2 Diagram Aliran Data Level 1
Proses yang dilakukan oleh perangkat lunak dapat dipecah menjadi beberapa sub proses, yaitu:
1. pengindeksan dokumen Kegiatan untuk menghasilkan file indeks. Sistem akan membuat suatu file yang berisi daftar term koleksi dokumen.
2. pemrosesan keyword Kegiatan ini bertujuan mengolah file menjadi
3. weighting (pembobotan dokumen) kegiatan ini bertujuan untuk menghasilkan keyword indeks2untuk kemudian dimatchingkan dengan file indeks, lalu dilengkapi dengan bobot untuk setiapsokumen yang memiliki keyword tersebut pada hasil akhir didapat bobot masing-masing dokumen terhadap keyword.
4. perankingan Kegiatan ini bertujuan menghasilkan daftar relevansi dokumen yang telah teranking menurut sistem.
3.4 Per ancangan Per a ngkat Lunak
Perancangan memiliki tujuan untuk menentukan kondisi akhir yang diharapkan dari perangkat lunak yang akan dibangun dan merumuskan cara yang harus dilakukan untuk memperoleh hasil tersebut. Pada perangkat lunak, tahap perancangan yang dilakukan mencakup perancangan arsitektur, perancangan data, perancangan antar muka perangkat lunak, dan perancangan prosedural.
3.4.1 Per ancangan Ar sitektur
Arsitektur sistem memiliki 4 proses utama yang dilakukan yaitu pengindeksan dokumen, pemrosesan keyword, pembobotan dokumen terhadap
keyword, dan perankingan. 1. pengindeksan dokumen
secara garis besar, metode pengindeksan dapat diurutkan sebagai berikut:
a. mengambil Keyword dari dokumen dengan mengabaikan tanda baca.
b. melakukan stemming terhadap Keyword tersebut
2. pemrosesan Keyword
Keyword yang diberikan oleh pengguna adalah sekumpulan kata yang menjadi kata kunci dari kebutuhan informasi pengguna. Proses-proses yang dilakukan untuk mengubah keyword tersebut adalah sebagai berikut: a. mengambil keyword dengan mengabaikan tanda baca.
b. melakukan stemming terhadap keyword tersebut
c. menampilkan hasil pengindeksan keyword ke dalam keyword indeks1 3. weighting (pembobotan dokumen)
Sistem menggunakan metode pembobotan TF-IDF untuk memperoleh kebutuhan informasi pengguna berupa dokumen yang relevan. Proses pembobotan dokumen ini menentukan seberapa besar tingkat relevansi suatu dokumen terhadap keyword. Proses-proses yang dilakukan untuk menentukan daftar dokumen relevan tersebut adalah sebagai berikut: daftar
file dokumen pada keyword indeks1 di-matchingkan dengan daftar term keyword pada file indeks, masing-masing term keyword yang terdapat dalam setiap dokumen dihitung bobotnya pada akhir proses semua bobot
term keyword di masing-masing dokumen tersebut dijumlahkan untuk menghasilkan bobot setiap dokumen.
3.4.2 Perancangan Data
Pengaruh struktur data pada struktur program dan kompleksitas prosedural menyebabkan perancangan data berpengaruh penting terhadap kualitas perangkat lunak. Tanpa melihat perancangan yang digunakan, data yang dirancang dengan baik dapat membawa kepada struktur program dan modularitas yang lebih baik, serta mengurangi kompleksitas prosedural (Pressman, 2002).
3.4.3 per ancangan Antar muka perangkat Lunak
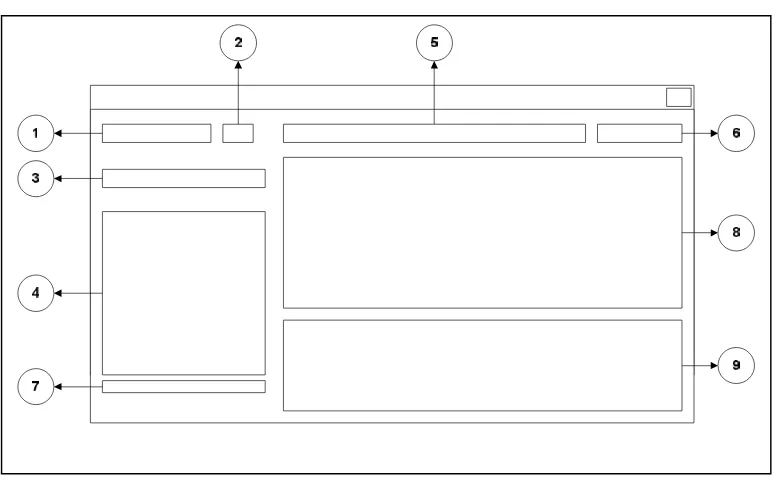
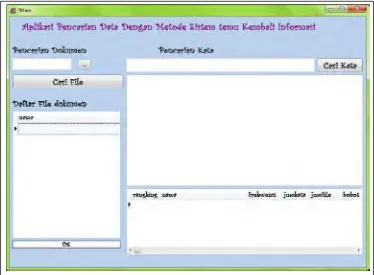
Untuk perangkat lunak ini, akan dibuat dua antarmuka yang terdiri atas sebuah antarmuka utama dan sebuah antarmuka tampilan. Rancangan layar utama pada perangkat lunak diperlihatkan oleh gambar 3.3 berikut:
Gambar 3.3 Rancangan antarmuka Utama perangkat Lunak
Keterangan untuk rancangan tampilan antarmuka dapat dilihat pada
Tabel 3.1 Keterangan Antar Muka Perangkat Lunak
No. Nama Tipe Keter a ngan
1 Lokasi Dokumen TEdit Menampilakan Lokasi Dokumen
2 Tombol Lokasi TButton
Tombol Menampilkan Lokasi Dokumen
3 Cari File TButton Tombol Menampilkan Dokumen
4 List Dokumen TDataGrid Menampilkan List Dokumen 5 Keyword TEdit Masukan Keyword
6 Cari Kata TButton Memproses pencarian kata 7 Prosentase Hasil TEdit Menampilkan prosentase hasil 8 Isi File TRichEdit Menampilkan isi Dokumen file 9 Ranking TDataGrid Hasil Perankingan
3.4.5 Perancangan Pr osedur al
Perancangan prosedural terjadi setelah perancangan arsitektur, data
dan antar muka perangkat lunak dibangun. Perangkat lunak disusun atas modul-modul
yang disesuaikan dengan diagram aliran data.
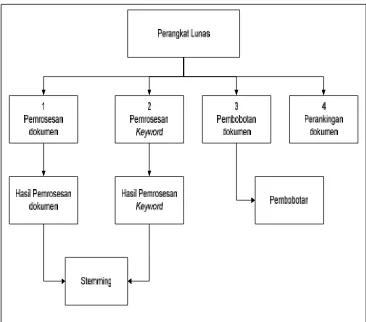
Perangkat lunak terbagi atas 4 modul utama, yaitu modul pemrosesan
dokumen, modul pemrosesan keyword, modul pembobotan dokumen, dan modul
perankingan. Masing-masing modul mewakili proses yang dilakukan pada diagram aliran
data level 1. Modul pemrosesan dokumen untuk proses “pengindeksan dokumen”, modul
untuk proses “pembobotan dokumen”, dan modul perankingan untuk proses “perankingan
dokumen”. Struktur rinci modul perangkat lunak dapat dilihat pada gambar 3.4 berikut.
Gambar 3.4 Struktur Modul Perangkat Lunak
3.4.6 Algor itma dan Flowchar t
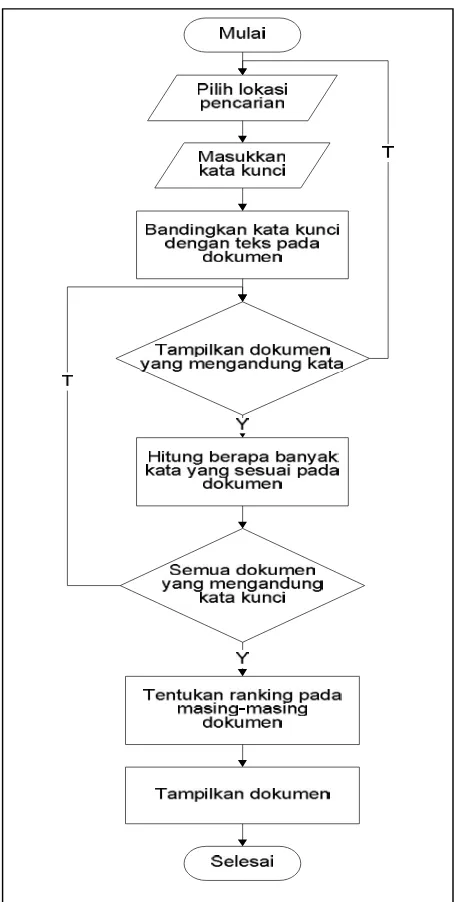
Gambar 3.5 Flowchart Perangkat Lunak
1. Pr oses Pencar ian Loka si file
Gambar 3.6 Flowchart proses pencarian lokasi file
Rincian prosesnya dipaparkan oleh algoritma berikut:
a. Mulai
b. Pilih lokasi file di drive komputer yang ada.
c. Hasil pencarian lokasi keyword yang berada di drive komputer.
d. Masukkan kata/ keyword yang ingin dicari
e. Menampilkan hasil pencarian kata/keyword yang ingin dicari.
2. Pr oses Pencar ian Nilai bobot dok umen
Proses ini digunakan untuk mencari hasil nilai bobot dokumen yang sebelumnya melakukan proses pencarian keyword.
Gambar 3.7 flowchart proses pencarian nilai bobot dokumen
Rincian prosesnya dipaparkan oleh algoritma berikut:
a. Mulai
b. Pilih lokasi file di drive komputer yang ada.
c. Hasil pencarian lokasi keyword yang berada di drive komputer.
e. Menampilkan hasil pencarian kata/keyword yang ingin dicari.
f. Menampilkan hasil nilai bobot dokumen
g. Berhenti
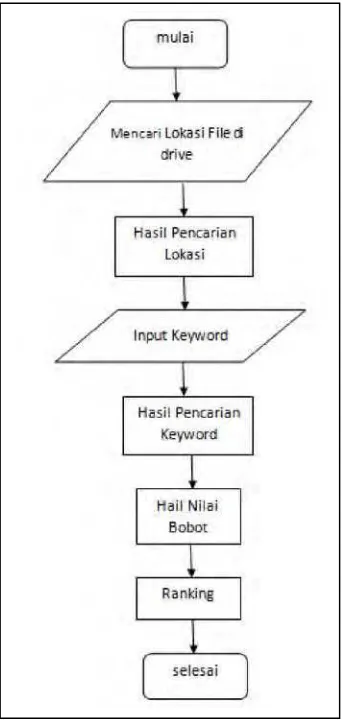
3. Pr oses Pencar ian r anking
Proses ini digunakan untuk mencari hasil perankingan dokumen yang sebelumnya melakukan proses pencarian keyword.
Rincian prosesnya dipaparkan oleh algoritma berikut:
a. Mulai
b. Pilih lokasi file di drive komputer yang ada.
c. Hasil pencarian lokasi keyword yang berada di drive komputer.
d. Masukkan kata/ keyword yang ingin dicari
e. Menampilkan hasil pencarian kata/keyword yang ingin dicari.
f. Menampilkan hasil nilai bobot dokumen
g. Menampilkan perankingan dokumen yang sebelumnya pencarian keyword.
BAB IV
IMPLEMENTASI PERANGKAT LUNAK
Pada bab ini akan membahas tentang implementasi program dari hasil analisa dan perancangan sistem pada bab III, serta bagaimana cara sistem tersebut dijalankan.
4.1 Lingkungan Pemr ogr aman
Lingkungan Implementasi dibagi menjadi 2, yaitu lingkungan perangkat keras dan lingkungan perangkat lunak.
4.1.1 Lingkungan Per angkat Ker as
Perangkat keras yang digunkan dalam implementasi adalah sebagai berikut:
1. Prosessor Intel Core i5
2. Memori 4 Gigabytes
3. Harddisk 500 GigaBytes
4. LCD WXGA 14”
4.1.2 Lingkungan Per angkat Lunak
Lingkungan perangkat lunak yang digunakan untuk pengimplementasian adalah sebagai berikut:
1. Windows 7 Ultimate sebagai sistem operasi.
3. Delphi 2010 sebagai editor program. 4. Xampp sebagai server database
4.2 Implementasi Ar sitektur
Arsitektur sistem dibagi dalam 4 proses utama, yaitu pemprosesan dokumen, pemprosesan query, weighting (pembobotan dokumen), dan perankingan. Semua proses utama dilakukan pada halaman utama. Hal ini dilakukan karena tiap proses utama terhubung dengan proses utama lainnya. 1. Pemprosesan dokumen
Proses ini akan diawali dengan menampilkan halaman yang meminta lokasi file koleksi dokumen dan query. Cari lokasi file di driver komputer, diproses dan akan menghasilkan berupa file indeks.
2. Weighting (pembobotan dokumen)
Proses ini akan menghasilkan nilai relevansi dokumen. 3. Perankingan
Proses perankingan menghasilkan daftar dokumen relevan yang telah berperingkat berdasarkan tingkat relevansinya.
4.3 Implementasi Pr oses
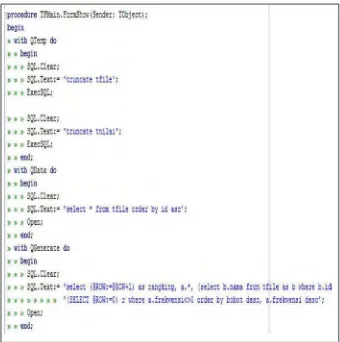
4.3.1 Implementasi Koneksi Database
Aplikasi ini menggunakan bahasa pemrograman Delphi 2010, server database menggunakan xampp dan database menggunakan phpMyadmin. terlihat pada Gambar 4.1.
Gambar 4.1 Script Koneksi Database
4.4 Implementasi Aplikasi Desain Antar Muka
Pada sub bab implementasi desain antarmuka dibuat dengan menggunakan
Jika program project1.exe dijalankan maka tampilan yang muncul adalah tampilan utama seperti pada gambar 4.2.
Gambar 4.2 Tampilan Awal Aplikasi
Gambar 4.3 dibawah ini adalah hasil setelah program dijalankan dari pencarian kata dan menghitung nilai bobot dokumennya.
Gambar 4.3 halaman hasil pencarian
Proses yang digunakan untuk mencari file dari suatu drive komputer dan hasil pencarian akan ditampilkan, terlihat pada gambar 4.4
Gambar 4.4 halaman pencarian lokasi file
Pada gambar diatas terlihat kotak berwarna merah, kotak tersebut adalah proses pencarian dokumen dan hasil pencariannya.
Proses perhitungan nilai bobot akan ditampilkan setelah keyword
dimasukkan kedalam kolom pencarian kata/ keyword dan perankingan, terlihat pada gambar 4.6.
Gambar 4.6 halaman hasil perhitungan bobot dan perankingan
Pada gambar diatas terlihat kotak berwarna merah, kotak tersebut adalah proses perthitungan suatu nilai bobot dari pencarian kata dan perankingan suatu
4.4.1 For m Halaman Database
Sebelum mengkoneksi sebuah database aplikasi ini membutuhkan sebuat
server database yang berfungsi sebagai penggabung sebuah aplikasi, xampp
mempunyai beberapa modul. Untuk aplikasi ini module yang digunakan adalah
MySql dan Apache. Telihat pada gambar
Gambar 4.7 Form Halaman Setting Database
Pada gambar diatas yang gunakan adalah apache dan mySql sebab mySql adalah database yang digunakan dalam aplikasi ini sedangkan apache untuk melihat hasil dari database yang digunakan dan untuk melihat dari localhost.
Setelah xampp dikoneksikan buka localhost/phpmyadmin pilih tabel
Gambar 4.8 Form tabel Database tfile
pilih tabel database, tabel nilaiakan menampilkan kolom seperti terlihat pada gambar 4.9
Gambar 4.9 Form tabel Database tnilai
4.5 Pengujian
sistem. Pada bagian ini akan dijelaskan mengenai pengujian dari penrangkat lunak.
Pengujian dilakukan terhadap fungsionalitas perangkat lunak. Pengujian fungsionalitas perangkat lunak bertujuan untuk mengetahui kesesuaian perangkat lunak dengan tujuan pembuatan perangkat lunak. Pengujian fungsionalitas perangkat lunak dilakukan di dalam lingkungan perangkat keras yang sama dengan lingkungan implementasi.
4.5.1 Tujuan Pengujian
Tujuan dari pelaksanaan pengujian sistem pencarian dokumen ini adalah meneliti performa dari sistem pencarian dokumen yang dibangun menggunakan metode Latent Semantic Indexing.
4.5.2 Pengujian Per ank ingan
Pengujian perankingan dilakukan untuk mengetahui apakah perankingan yang dilakukan terhadap dokumen sudah sesuai atau belum.
4.5.3 Kr iter ia Pengujian
4.5.4 Hasil Pengujian
Pengujian menunjukkan nilai relevansi dokumen-dokumen yang berhasil di-retrieve telah menghasilkan perangkingan yang sesuai. Pada beberapa
file terdapat kejadian dimana sistem me- retrieve dokumen-dokumen relevan dengan nilai relevansi yang sama. Untuk pengujian prtama dengan menggunakan kata kunci “pertandingan” mendapatkan 6 file yang ditemukan, seperti gambar 4.6.
UJ I COBA DAN EVALUASI PROGRAM
Pada bab ini membahas tentang ujicoba dan evaluasi program yang menerangkan bagaimana jalannya program secara detail dan akan dijelaskan pada sub bab dibawah ini :
5.1 Uji Coba Sistem
Pada bagian ini akan dijelaskan mengenai proses uji coba dari aplikasi yang telah dibuat berdasarkan dari desain sistem yang telah dijelaskan sebelumnya. Uji coba ini dilakukan untuk melihat dari aplikasi yang telah dibuat sesuai dengan yang diharapkan, mulai dari awal proses input (masukan) data yang dilakukan oleh pengguna sampai dengan mengetahui hasil nilai bobot. Uji coba yang akan dijalankan adalah sebagai berikut :
5.2 Uji Coba Halaman Utama
Jika sebelumnya telah dilakukan koneksi terhadap database dengan benar maka
hasil pembobotan dari metode TF-IDF. Berikut adalah tampilan utama seperti pada Gambar 5.1.
Gambar 5.1 Uji Coba Tampilan Aplikasi
5.2.1 Uji Coba Tampilan Pencar ian Loka si File
Langkah selanjutnya untuk menjalankan aplikasi ini adalah mencari lokasi
(.txt) dan sudah tersedia di kolom bawah sebelah kiri. Keterangan diatas bisa kita lihat Seperti pada gambar 5.2
Gambar 5.2 Uji Coba Tampilan Pencarian lokasi file
Berikut ini adalah keterangan untuk proses pencarian lokasi file/ dokumen di sebuah komponen drive komputer
a. Pilih lokasi dari drive komputer “ (C:), (D:), (E:) “.
b. Pilih lokasi folder yang mempunyai file/ dokumen .txt.
c. Folder tersebut double click
d. Pilih button cari file untuk mengetahui isi dalam folder tersebut, jika
file/ dokumen tersebut mengandung .txt otomatis akan muncul daftar
Keterangan diatas dapat dilihat seperti pada gambar 5.3.
Gambar 5.3 folder
5.2.2 Uji Coba Tampilan Penca r ian Kata/Keyword
Jika ingin melakukan proses pencarian kata/ keyword. Masukkan kata/
keyword yang akan dicari di kolom sebelah kanan seperti pada gambar 5.4.
Gambar 5.5 Uji Coba Tampilan Pencarian Kata/Keyword
Pada gambar diatas dan kotak warna merah adalah proses pencarian kata/
keterangan diatas bisa dapat dijabarkan dengan menggunakan gambar seperti pada gambar 5.6 seperti dibawah ini.
Gambar 5.6 Uji Coba Tampilan Hasil Pencarian Kata/Keyword
Berikut ini adalah keterangan untuk proses pencarian kata/ keyword dan hasil pencarian kata/ keyword
a. Masukkan kata/ keyword yang akan dicari dikolom atas sebelah kanan.
b. Pilih button cari kata.
c. Otomatis tampilan yang akan berubah sesuai kata kunci yang dicari.
Jika ingin mengetahui isi file/ dokumen yang sudah melalui hasil pencarian keyword, lihat pada gambar 5.6.
Gambar 5.6 Uji Coba Tampilan Hasil isi dari file
Berikut ini adalah keterangan untuk proses melihat isi dari file/ dokumen
a. Pilih file/ dokumen yang ingin lihat dari daftar file dokumen
b. Jika sudah menentukan file/ dokumen yang isinya ingin dilihat double click pada dokumen/ file yang dibuka.
c. Otomatis akan muncul hasil dari file/ dokumen yang sudah dipilih.
5.2.2 Uji Coba Tampilan Per ankingan
Proses perankingan yaitu proses pengurutan dari nilai yang terbesar atau
maximal sampai nilai yang terkecil atau minimal.seperti pada gambar 5.7
Gambar 5.7 Uji Coba Tampilan Hasil isi dari perankingan
Keterangan diatas dapat jabarkan dengan menggunakan gambar seperti pada gambar dibawah ini.
Gambar 5.8 Perankingan
Pada gambar 5.9 dibawah ini adalah hasil dari pembobotan dan gambar di ambil dari potongan yang berada di aplikasi. Pada kolom masing-masing mempunyai nilai yang berbeda-beda dan sudah terurut seperti frekwensi, jumlah kata, jumlah file dan nilai bobot dari setiap dokumen yang sudah dicari atau yang sudah melalui proses pencarian kata dan pencarian dokumen/ file.
Perhitungan nilai bobot dapat dilihat dari frekuensi, jumlah kata, jumlah file. Berikut ini penjelasan dari gambar diatas:
a. Frekwensi adalah adalah jumlah kehadiran kata i yang akan dihitung bobotnya dalam dokumen j
b. Jumlah kata adalah jumlah kata dalam satu file/ dokumen c. Jumlah file adalah jumlah file dalam satu folder
d. Nilai bobot adalah nilai bobot dokumen setelah memasukkan kata/
keyword.
5.2.3 Uji Coba Tampilan Kesalahan/Warning
Ujicoboba untuk kesalahan/ warning adalah tampilan aplikasi yang melakukan kesalahan saat ujicoba menjalankan suatu aplikasi. Dibawah ini ada
warning dari kesalahan.
Gambar 5.10 Warning folder
file/dokumen yang berformat (.txt) atau di folder tersebut hanya memiliki file/ dokumen lain seperti microsoft word (.doc), microsoft excel (.xls) atau power point (.ppt). maka aplikasi secara otomatis akan menampilkan warning/ kesalahan seperti gambar diatas.
Kesalahan/ warning yang lain terdapat di pencarian kata yaitu jika sudah menentukan lokasi file/dokumen di drive komputer lalu menginputkan secara langsung ke kolom keyword tanpa memilih button cari file dahulu secara langsung aplikasi akan menampilkan warning/kesalahan. Keterangan diatas dapat dijabarkan melalui gambar seperti gambar 5.11
Gambar 5.11 warning file
Kesalahan/ warning yang lain terdapat di pencarian kata yaitu warning
dari keyword yang tidak ditemukan, misalkan jika setelah menentukan lokasi
file/dokumen di drive komputer lalu memilih button cari file lalu folder tersebut terdapat file/dokumen yang berformat (.txt) otomatis akan menampilkan di daftar
file/dokumen yang berformat (.txt) di daftar file dokumen, jika menginputkan
menampilkan warning/kesalahan. Keterangan diatas dapat dijabarkan melalui gambar seperti gambar 5.12.
Gambar.5.12 warning pencarian kata
5.3 For m Halaman Database
Sebelum mengkoneksi sebuah database aplikasi ini membutuhkan sebuat
server database yang berfungsi sebagai penggabung sebuah aplikasi, xampp
mempunyai beberapa modul. Untuk aplikasi ini module yang digunakan adalah
MySql dan Apache. Telihat pada gambar 5.10
Setelah xampp dikoneksikan buka localhost/phpmyadmin pilih tabel
database, tabel file akan menampilkan kolom seperti terlihat pada gambar 4.6
Gambar 5.11 Form tabel Database tfile
pilih tabel database, tabel nilaiakan menampilkan kolom seperti terlihat pada gambar 4.7
BAB VI
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Skirpsi ini mengkaji pengimplementasian metode pembobotan Term Frequency Inverse Document Frequency (TF-IDF) pada sistem temu kembali informasi. Beberapa kesimpulan yang dapat ditarik dari skripsi adalah:
1. Metode pembobotan dokumen TF-IDF tidak selalu memberikan hasil performansi yang baik pada koleksi pengujian.
2. Metode pembobotan TF-IDF dalam beberapa contoh koleksi data uji menghasilkan nilai relevansi yang sama pada dokuen relevan yang berada setelah berhasil di retrieve sistem temu kembali informasi.
3. Dalam metode pembobotan TF-IDF, frekuensi kemunculan sebuah kata (term) dalam dokumen tidak memperngaruhi hasil perhitungan bobot dokumen oleh sistem (sifat monotonicity TF-IDF).
5.2 Sar an
Berikut ini adalah saran-saran yang mungkin dapat dilakukan untuk pengembangan skripsi ini:
2. Dilakukan pengembangan terhadap dokumen file yang tidak hanya search pada satu folder akan tetapi memakai sub folder dalam directory pencarian file tidak terpaku pada satu jenis file tetapi bisa lebih dari itu yaitu Ms Word(.doc), PDF.
Savoy, J “A Learning Scheme for Information Retrieval in Hypertext”. Information Processing & Management,30 (4), 515-533. 1933
Liddy, E.2001. How a Search Engine Works, Searcher 9(5). Information Today,Inc
Budhi Irawan, 2005, Jaringan Komputer,Graha Ilmu, Yogyakarta.
Agosti,Maristella.”Hypertext and Information Retrieval”. Information Processing & Management, 29(3), 283-285. 1993.
Dunlip, M.D. et.al. “Hypermedia and Free text Retrieval”. Information Processing & Management, 29(3),287-298. 1993.
Lucarella, D. “Information Retrieval From Hypertext: An Approach Using Plausible Inference”. Information Processing & Management, 29(3), 299-312. 1993.
Rada, Roy. Et al. “Retrieval Hierarchies in Hypertext”, Information Processing & Management, 29(3), 359-371.1993.
http://www.anneahira.com/xampp-adalah.htm