EVALUASI SISTEM TEMU KEMBALI INFORMASI MODEL RUANG VEKTOR
DENGAN PENDEKATAN USER JUDGEMENT
Didik Kurniawan
Jurusan Matematika Program Studi Ilmu Komputer FMIPA Universitas Lampung E-mail: [email protected]
ABSTACT
The performance measure of a back-finding system usually determined by precision values, recall, fall-out, F-measure, precision averages, precision mean and some other assesments. This research take a difference perspective to those mentioned method, i.e. by evaluating the system based on the user perspective. By analyzing the interaction between the users against system on a back-finding system, the information is build with vector space model indicated that the model satisfy the users toward the information needed by the back-finding system which is marked by the system is able to recover the document deemed relevant by the users in the sequence above the average score of the recalled document.
Keywords: information back-finding system, uses interaction ABSTAK
Ukuran performansi suatu sistem temu kembali informasi biasanya ditentukan oleh nilai-nilai presisi, recall, fall-out, F-messure, rata-rata presisi, nilai tengah rata-rata presisi dan beberapa penilaian lainnya. Penelitian ini mengambil sudut pandang berbeda dengan metode pengukuran tersebut, yaitu dengan melakukan evaluasi sistem dari sudut pandang pengguna. Dengan melakukan analisis interaksi pengguna terhadap sistem pada suatu sistem temu kembali informasi yang dibangun dengan model ruang vektor didapatkan bahwa model ini dapat memenuhi kebutuhan penguna akan informasi yang diinginkan dari sistem temu kembali informasi ditandai dengan sistem dapat mengembalikan dokumen yang dianggap relevan oleh pengguna pada urutan di atas rata-rata score dokumen yang direcall.
Kata kunci: sistem temu kembali informasi, interaksi pengguna 1. PENDAHULUAN
Secara teoritis sistem temu kembali informasi atau information retrieval merupakan cabang ilmu yang menfokuskan pada pencarian atau menemukan dokumen relevan sesuai dengan permintaan user terhadap kumpulan dokumen yang kompleks1-4). Salah satu aplikasi umum dari sistem temu kembali informasi adalah mesin pencari (search engine) yang terdapat di internet. Pengguna dapat mencari halaman-halaman web yang dibutuhkan melalui mesin tersebut.
Ukuran performansi suatu sistem temu kembali informasi ditentukan oleh nilai-nilai presisi, recall, fall-out, F-messure, rata-rata presisi, nilai tengah rata-rata presisi dan beberapa penilaian lainnya. Akan tetapi dalam penelirian ini tidak akan membahas tentang performansi kinerja sistem terhadap nilai-nilai pengukuran tersebut, akan tetapi lebih memfokuskan pada evaluasi sistem berdasarkan persepsi dari pengguna, dengan melakukan user judgement terhadap informasi yang dikembalikan oleh sistem berdasarkan kueri yang dimasukan.
Model-model sistem temu kembali informasi secara garis besar dibagi menjadi empat kategori, yaitu set theoritic models, algebraic models, probabilistic models dan machine learned ranking models. Pada penelitian dilakukan evaluasi terhadap model ruang vektor yang merupakan salah satu dari algebraic models. Model ini dipilih dengan beberapa pertimbangan, diantaranya5):
- Model sederhana yang berdasarkan aljabar linear
- Pengembalian informasi berdasarkan pembobotan term bukan binari
- Memungkinkan penghitungan tingkat kemiripan kueri dan dokumen secara kontinu - Memungkinkan perangkingan dokumen sesuai dengan tingkat relevansinya - Memungkinkan untuk melakukan pencocokan sebagian.
Tujuan melakukan penelitian ini adalah untuk mengetahui apakah informasi yang dikembalikan oleh sistem temu kembali informasi dengan menggunakan model ruang vektor dapat merangkingkan dokumen sesuai tingkat relevansinya berdasarkan persepsi pengguna. Selain itu juga dalam penelitian ini dilakukan analsisis interaksi pengguna terhadap sistem temu kembali informasi, tujuan dari analisis ini adalah menilai pengaruh model yang digunakan oleh sistem terhadap persepsi pengguna terhadap sistem.
Dengan melakukan penilaian yang dilakukan oleh pengguna, nantinya akan diketahui performansi sebuah sistem temu kembali informasi, yang dilihat dari informasi yang dikembalikan oleh sistem. Sehingga dapat menjadi pertimbangan untuk pengembangan suatu sistem temu kembal informasi yang baik6).
1.1. Sistem Temu Kembali Informasi
Information retrieval (IR) atau temu kembali informasi adalah menemukan materi (biasanya dokumen) dari sebuah kumpulan data yang tidak terstruktur (biasanya teks) untuk memenuhi kebutuhan informasi dari koleksi yang besar3).
Aplikasi yang melibatkan proses temu kembali informasi pada awalnya digunakan untuk membantu pustakawan untuk megorganisir koleksi referensi pustaka dan digunakan oleh paralegal. Sejak berkembangnya internet dan menyebabkan informasi yang terdapat di internet semakin lama semakin besar, maka aplikasi temu kembali informasi secara tidak disadari sering digunakan oleh hamper setiap user internet. Sebagai contoh aplikasi yang sering digunakan adalah mesin pencari (Search Engine) dan mesin pencari arsip email.
Kualitas relevansi hasil pencarian tanpa perangkingan dokumen ditentukan oleh dua nilai yaitu recall dan precision. Recall adalah perbandingan jumlah dokumen relevan yang terambil sesuai dengan query yang diberikan dengan total kumpulan dokumen yang relevan dengan query (Persamaan 1). Precision adalah perbandingan jumlah dokumen yang relevan terhadap query dengan jumlah dokumen yang terambil hasil pencarian (Persamaan 2). ) | ( ) ( # ) ( # rel ret P ri rir r= = ……… (1) ) | ( ) ( # ) ( # ret rel P ri rir p= = ……… (2) Dimana, r: recall p: precision
rir: relevan items retrieved ri: relevan items
ret: retrieved rel: relevan
Keterhubungan relevansi dokumen dengan eksekusi query dapat dilihat dari data yang terambil dan tidak, hubungan ini dibagi menjadi empat kondisi yaitu false negative , false positive, true negative dan true positve yang digambarkan dalam Tabel 1.
Tabel 1. Hubungan relevansi keterambilan dokumen
Relevan Tidakrelevan
Terambil True positve (tp) False negative (fn)
fn tp tp precision + = (4) Akurasi berdasarkan tabel di atas didapat dengan:
fn tn fn tp fp tp accuracy + + + + = ………(5)
Alasan untuk tidak menggunakan nilai akurasi sebagai parameter yang tepat untuk mengatasi masalah temu kembali informasi. Kenyataannya pada umumnuya terdapat 99.99% dokumen tidak relevan. Jika sistem dirancang untuk mendapatkan akurasi yang tinggi, maka sistem akan menganggap semua dokumen tidak relevan untuk setiap query.
Kedua nilai recall dan precision juga tidak menjamin dapat mengatasi masalah pada sistem temu kembali informasi. Sebagian user khususnya web surfer menginginkan menemukan dokumen relevan pada halaman pertama pencarian. Untuk itu diperlukan proses perangkingan dokumen sesuai dengan bobot relevansi terhadap query, pada sub judul berikutnya dibahas mengenai teori perangkingan dengan pembobotan dokumen.
1.2. Model Ruang Vektor
Model ruang vektor mempresentasikan sejumlah n term yang ada pada kamus term atau indeks term sebagai ruang vektor berdimensi n5). Sehingga query maupun dokumen merupakan vektor berdimensi n. Jika t mewakili setiap term dalam indeks term, maka query Q adalah vektor Q(t1,t2,...,tn) dengan t1 dimana i=1,2,3…,n merupakan term yang ada pada indeks term, dokumen D adalah vektor D(t1,t2,...,tn) untuk setiap Di dengan j=1,2,…,m. Dimana m merupakan banyak dokumen yang ada pada koleksi dokumen.
Sebagai contoh terdapat tiga buah term (t1,t2,dan t3 serta dua buah dokumen D1 dan D2 serta sebuah query Q. Masing-masing dokumen dan query direpresentasikan dalam persamaan berikut :
D1=2t1 + 3t2 + 5t3 D2=3t1 + 7t2 + 0t3 Q=0t1 + 0t2 + 2t3
Maka secara grafis dapat direpresentasikan pada Gambar 1
Gambar 1. Representasi dokumen dan query pada ruang vektor
Secara geometris, sudut yang merentang antara vektor Q dan vektor D dapat diukur. Semakin kecil sudut diantara keduanya, semakin tinggi derajat kesamaan. Cosinus dari sudut tersebut merupakan koefisien yang dapat mewakilinya, seperti tergambar dalam Gambar 2 berikut :
Gambar 2. Representasi grafis sudut vektor dokumen dan query
Jika Q adalah vektor query dan D adalah vektor dokumen, dimana vektor-vektor tersebut merupakan vektor dalam ruang dimensi-n, dan θ adalah sudut yang dibentuk oleh kedua vektor, maka :
Q • D = |Q||D|cos θ ………(6)
dimana Q • D adalah hasil inner product kedua vektor. Cos θ adalah Similarity Coefficient antara Q dan D.
D
Q
D
Q
•
=
θ
cos
………(7)Panjang dokumen cenderung mempunyai pengaruh terhadap nilai derajat kesamaan. Dokumen yang lebih panjang mengakibatkan mempunyai nilai yang lebih besar. Maka jarak Euclidean (panjang) kedua vektor dijadikan sebagai faktor pembagi atau faktor normal.
Menurut Euclid panjang vektor merupakan akar dari jumlah kuadran elemen-elemennya sehingga,
∑
==
n iQ
1 2 iQ
dan∑
==
n iD
1 2 iD
………(8) Perhitungan kesamaan kedua vektor adalah sebagai berikut :i i n i D Q D Q D Q D Q D Q D Q SC = = • =
∑
• =1 1 ) , cos( ) , ( ………(9) Dimana, SC = Similarity Coefficient (Derajat Kesamaan)2. METODE PENELITIAN
Metode yang digunakan untuk menganalisa sistem temu kembali informasi ini dengan merancang sebuah aplikasi sistem temu kembali dengan menggunakan model ruang vektor lalu menganalisis statistik log sistem. Log yang disimpan oleh sistem adalah, sebagai berikut:
1. Data-data statistik hasil pencarian yang meliputi kueri, jumlah data yang ditemukan, statistik deskriptif score dokumen terhadap kueri dan waktu yang dibutuhkan sistem untuk menemukan dokumen yang dianggap releval terhadap sistem.
2. Data penilaian user terhadap hasil pencarian yang dianggap relevan, dan 3. Data aktivitas perilaku pengguna sistem temu kembali informasi.
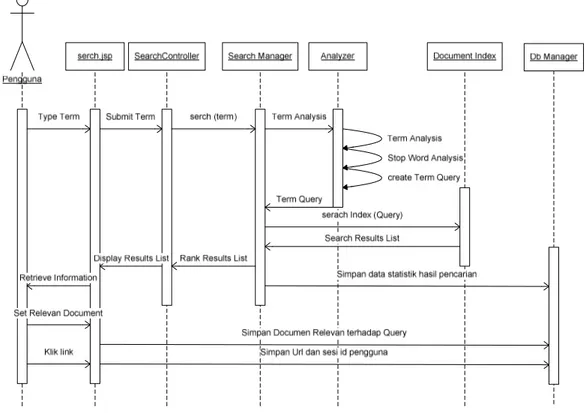
Gambar 3.1 merupakan diagram sequence yang menggambarkan kinerja sistem yang dibangun. Dari diagram ini, dapat dilihat aktivitas pengguna, meliputi:
1. Memasukan term atau kata kunci pencarian, lalu sistem merespon dengan class analyzer untuk membangun sebuah kueri standar yang dikenali sistem.
Gambar 3. Diagram sequence sistem temu kembali informasi
Dari data yang direkam oleh sistem ini, lalu akan dievaluasi kinerja sistem temu kembali model ruang vektor dengan menganalisis bagaimana sistem mengembalikan informasi kepada pengguna dengan melakukan perangkingan, apakah perangkingan yang dilakukan sistem ini sesuai dengan keinginan pengguna (relevan dari sudut pandang pengguna).
3. HASIL DAN PEMBAHASAN
Penelitian ini dilakukan di laboratium komputasi FMIPA Universitas Lampung, data yang diindek oleh sistem adalah konten dari website http://dwww.unila.ac.id yang di download dengan menggunakan webcrawler pada bulan April 2010. Field-field yang diindekan oleh sistem adalah content, path, dan title dari dokumen.
Dari proses pengindekan didapatkan data-data sebagai berikut, jumlah dokumen ada 2.299 dan jumlah term yang berbeda untuk semua dokumen ada 35.717 term. Dari ujicoba yang dilakukan pada bulan Mei 2010 selama 3 hari, pengguna disarankan untuk mengakses intranet pada ip 192.168.150.141 pada lingkungan jaringan FMIPA Universitas Lampung. dari analisis log penggunaan sistem setidaknya terdapat 35 sesi pengguna. Setelah user melakukan submit term pada halaman search.jsp, terdapat 27 sesi pengguna melakukan aktivitas dengan hasil pencarian dan sisanya apatis terhadap sistem. Dari 27 sesi pengguna yang mendapatkan hasil pencarian terdapat 17 sesi pengguna yang melakukan penandaan dokumen yang relevan dan pengguna melakukan submit kueri pada sistem sebanyak 4.46 kali dalam satu sesi7).
Berikut adalah hasil analisis dari kinerja sistem yang dibagi menjadi 3 bagian, statistik hasil pencarian, interaksi pengguna pada penandaan dokumen relevan dan interaksi pengguna saat menggunakan sistem.
Tabel 2. Statistik deskriptif hasil pencarian kueri pada sistem IR Jumlah Pencar ian numHits Score Mean Score Median Score Max Score Min Score Stdev Waktu (detik) MAX 24 1744 0.85 0.87 1 0.57 0.19 0.19 MIN 1 7.33 0.03 0.01 0.25 0 0.03 0.03 Rerata 4.46 618.92 0.16 0.13 0.66 0.07 0.1 0.1 Sim. Baku 5.29 598.12 0.15 0.16 0.23 0.11 0.04 48.58
Dilihat dari Tabel 2 didapatkan bahwa rata-rata score dokumen terhadap kueri yang didapat adalah 0.16, maksimum rata-rata score dokumen adalah 0.85 dan minimum rata-rata score dokumen adalah 0.03. Statistik ini menggambarkan respon sistem terhadap kueri yang diinputkan oleh pengguna. Semakin kecil score kueri pada suatu dokumen maka relevansi dokumen terhdap kueri akan semakin kecil.
Kata kunci term yang diinputkan user juga sangat beragam, hal ini diindikasikan nilai variasi atau simpangan baku nilai maksimum score sangat besar yaitu 0.66, jika dilihat dari skla score suatu dokumen antara 0 dan 1, maka simpangan baku nilai maksimum score dokumen ini relatif besar.
Keragaman koleksi dokumen digambarkan oleh nilai simpangan baku score dokumen terhadap kueri. Jika dilihat pada tabel yang sama keragaman dokumen terhadap kueri relatif kecil hal ini diindikasikan dengan nilai rata-rata simpangan baku score dokumen terhadap kueri yaitu sebesar 0.1.
Penandaan dokumen relvan oleh user
0 0.2 0.4 0.6 0.8 1 1.2 S e s i1 S e s i2 S e s i3 S e s i4 S e s i5 S e s i6 S e s i7 S e s i8 S e s i9 S e s i1 0 S e s i1 1 S e s i1 2 S e s i1 3 S e s i1 4 S e s i1 5 S e s i1 6 S e s i1 7 Sesi S c o re scoremax scoremean score Relevan
Gambar 4. Grafik posisi score dokumen yang dianggap relevan
Dilihat dari Gambar bahwa user menandai dokumen relevan relatif terhadap score kueri tersebut, ini diindikasikan bahwa dokumen yang dianggap relevan berada di atas score rata-rata, kecuali dua penandaan relevan oleh pengguna yang score-nya berada dibawah garis rata-rata score yaitu sesi 2 dan sesi 3. Ini mengindikasikan perangkingan yang dilakukan dengan metode ruang vektor dapat menghasilkan dokumen
0 3 6 9 12 15 18 21 24 27 30 Sesi T o ta l H it
Hit Menu Sistem Hit Hasil
Hit M enu Sistem 0 1 1 10 1 6 2 5 1 0 0 1 3 7 1 2 0 1 3 3 1 2 1 3 3 1 1 Hit Hasil 4 0 2 4 3 13 6 24 5 2 1 7 2 0 0 2 2 0 0 0 0 1 0 0 0 4 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
Gambar 5. Perbandingan jumlah hit dalam sistem IR
Dari data yang diperlihatkan Gambar 5 bahwa dari 142 hit dalam 27 sesi terdapat 57.75% hit yang mengakses hasil pencarian dan 42.25% hit yang mengakses menu sistem IR. Yang termasuk dalam menu disini adalah berupa komponen sistem IR, yaitu pencarian dasar, pencarian lanjut dan penelusuran halaman sistem IR.
Dari Gambar 5 didapatkan bahwa dari total 27 sesi pengguna, terdapat 9 sesi yang tidak melakukan hit hasil pencarian, hal ini mengindikasikan tidak menemukan dokumen relevan dalam daftar yang ditampilkan oleh sistem.
Rata-rata pengguna dalam setiap sesi melakukan hit sebanyak 5.26 kali. Dengan maksimum hit sebanyak 29 kali dan minimum 1 kali, jika dilihat dari jumlah hit dalam sistem temu kembali dapat diambil suatu hipotesis bahwa semakin besar jumlah hit rata-rata dalam setiap sesi menggambarkan kepuasan pengguna dalam sistem.
4. KESIMPULAN
Dari analisis yang dilakukan terhadap statistik log sistem temu kembali informasi dapat diambil kesimpulan sebagai berikut:
1. Dokumen relevan yang ditandai oleh pengguna sebagian besar di atas score rata-rata kueri terhadap dokumen yaitu 15 dari 17 sesi atau sebesar 88,24% sesi pengguna yang memilih dokumen relevan berada di atas score rata-rata. Hal ini mengindikasikan perangkingan yang dilakukan dengan model ruang vektor dapat memenuhi kebutuhan informasi bagi pengguna.
2. Pada evaluasi interaksi pengguna sistem temu kembali informasi yang dibangun dengan model ruang vektor didapatkan bahwa kecenderungan pengguna akan meninggalkan sistem ketika sudah mendapatkan dokumen yang dianggap relevan, hal ini ditandai dengan 57.75% pengguna memilih dokumen hasil penelusuran dibandingkan dengan 42.25 persen dimana pengguna melakukan penelusuran halaman hasil pencarian dan komponen pada sistem.
DAFTAR PUSTAKA
1. Hiemstra, D. 2001. Using Language Models for Information Retrieval, Center for telematics and Information Technology. AE Enschede. Netherlands.
3. Manning, C. D., Raghavan, P. and Schütze, H. 2008. Introduction to Information Retrieval, Cambridge University Press.
4. Grossman, D.A. and Ophir, H. 1998. Information retrieval: Algorithms and Heuristics, Kluwer Academic Publisher. Massachutetts. USA.
5. Salton , G., Wong , A., Yang. C. S. 1975. A vector space model for automatic indexing. Communications of the ACM, 18 (11): 613-620.
6. Shneiderman, B. 1998. Designing the User Interface: Strategies for Effective Human-Computer Interaction. Addison-Wesley Publishers.
7. Luhn, H. P. 1957. A statistical approach to mechanized encoding and searching of literary information. IBM Journal of Research and Development, 1(4). (p. 47, p. 76).