Vektor dan Inverted Index
Fika Hastarita Rachman
Jurusan Teknik Informatika, Fakultas Teknik, Universitas Trunojoyo Madura Jl. Raya Telang PO.BOX 2 Kamal, Bangkalan, Madura 69192
ABSTRAK
Pertambahan data setiap tahun untuk dokumen naskah publikasi di salah satu program studi perguruan tinggi menjadi penyebab semakin dibutuhkannya sarana untuk pencarian data yang lebih cepat dan sesuai dengan keinginan pengguna. Pencarian yang telah digunakan masih bersifat word maching berdasarkan kata kunci pada judul ataupun penyusunnya. Hal ini menyebabkan munculnya dokumen yang hanya relevan berdasarkan judulnya atau penyusunnya saja, tetapi tidak berdasarkan isi dari dokumen tersebut. Sehingga banyak dokumen relevan yang tidak terpanggil. Penerapan sistem temu kembali informasi terhadap koleksi dokumen, diharapkan mampu menjawab kebutuhan tersebut. Penelitian ini melakukan kajian penerapan sistem temu kembali informasi dalam mesin pencarian abstrak naskah publikasi dengan menggunakan preprocessing, inverted index, pembobotan tf-idf dan model pencarian ruang vektor. Pada pengujian sistem diperoleh hasil bahwa sistem ini mampu menghasilkan dokumen pencarian dengan tingkat recall sebesar 84,7%, dan precision sebesar 39,7%. Hal ini berarti sistem mampu meningkatkan performa pencarian, terutama untuk hal kelengkapan perolehan dokumen yang diinginkan pengguna.
Kata kunci : sistem temu kembali informasi, recall, precision
ABSTRACT
Added publication manuscript documents each year in one departement of university is causes of the need to search data more quickly accordance with the user need. Search that has been used is still a word maching based on keywords in the title or composer. This led to the emergence of relevant documents only by their title or composer, but not based on the content of the document.Many relevant documents that not called. Application of information retrieval system on the document collection, expected to answer those needs. This study reviewing the application of information retrieval in search engines publication abstract using preprocessing, inverted index, tf-idf weighted and vector space model. The result of system testing is able to produce a document search with a recall rate of 84.7% and precision of 39.7%. This means that the system can improve the search performance, especially for the completeness acquisition documents of the user's need.
PENDAHULUAN
Seiring bertambahnya tahun, semakin banyak lulusan S2 dan semakin banyak pula Naskah Publikasi yang dihasilkan. Saat ini, beberapa Program Studi memiliki sarana untuk mempublikasikan Naskah Publikasi tersebut secara onlineSetelah menganalisa beberapa online library diperoleh hasil bahwa pencarian yang digunakan pada sistem terkomputerisasi tersebut masih bersifat data retrieval, dalam artian pencariannya masih terbatas menggunakan kata kunci (keyword) berdasarkan subyek, judul atau penyusun dari setiap dokumen. Pencarian tersebut memiliki kelemahan, yaitu dokumen yang dihasilkan dari pencarian terkadang tidak sesuai dengan yang diinginkan pengguna.
Sistem Temu Kembali Informasi dalam mesin pencarian dokumen mampu menghasilkan dokumen dengan tingkat relevansi yang tinggi. Adanya penelitian mengenai peningkatan performa Sistem Temu Kembali Informasi melalui stemming, menjadi salah satu objek penelitian. Pengaruh stemming Bahasa Indonesia terhadap peningkatan nilai recall hasil pencarian sistem temu kembali informasi dengan menggunakan mesin pencarian zettair telah dilakukan dan menghasilkan nilai recall yang tinggi [1]. Dalam proses pencariannya, Zettair menggunakan model pencarian boolean.
Sistem Temu Kembali Informasi terdiri dari beberapa sub bagian untuk menjalankan tugasnya. Dan masing-masing bagian memiliki beberapa model. Untuk model pencarian terdapat model klasik dan model terstruktur. Model klasik terdiri dari model teoritis (model boolean), model algebraic (model ruang vektor), dan probabilistik. Dengan adanya model-model tersebut, muncul pertanyaan penelitian: apakah stemming juga berpengaruh terhadap performa sistem dengan model pencarian ruang vektor diukur dari recall dan precision.
Sehingga pada penelitian ini dilakukan analisa terhadap sistem temu kembali informasi yang dibuat dengan model inverted index, model pencarian ruang vektor dengan adanya stemming. Mengacu pada keakuratan hasil penelitian terdahulu [2], maka algoritma stemming yang digunakan adalah algoritma stemming Nazief Andriani.
Dasar Teori
Teori yang digunakan adalah teori mengenai Sistem Temu Kembali Informasi, Pre Processing, Stemming Bahasa Indonesia, Model Pencarian Ruang Vektor dan Pengukuran Performa Sistem.
Sistem Temu Kembali Informasi
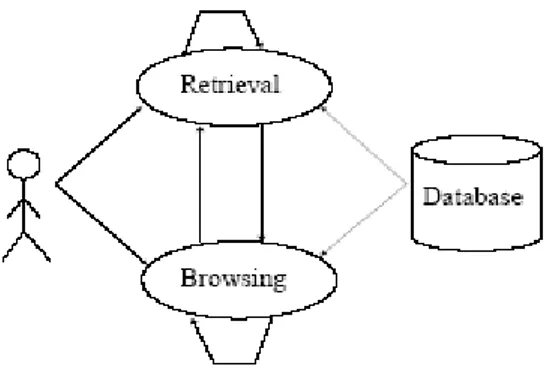
Di dunia informasi terdapat beberapa cara yang dapat dilakukan untuk proses pencarian dokumen. Gambar 2.1 mengilustrasikan interaksi pengguna dalam menemukan suatu informasi yang diinginkan. Terdapat 2 (dua) istilah yang biasanya dilakukan, yaitu data atau informasi retrieval dan browsing. Kedua istilah itu sama-sama menghasilkan suatu informasi dan biasanya dilakukan pada antarmuka web, tetapi berbeda proses.
Browsing adalah proses mencari informasi dari satu link ke link lainnya. Sedangkan data atau informasi retrieval adalah proses mencari informasi yang dimiliki suatu web page melalui query. Retrieval dan browsing dapat saling terkait dalam penggunaannya. Proses menghasilkan dokumen sesuai dengan query dari pengguna inilah yang disebut proses temu kembali informasi [3].
Gambar 1. Interaksi pengguna dengan Sistem Temu Kembali Informasi
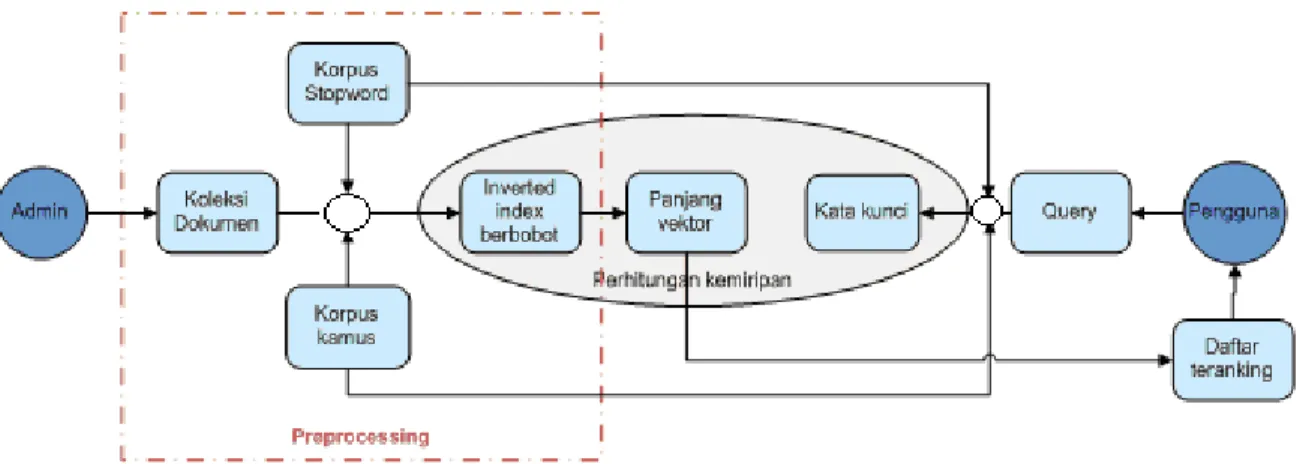
Proses yang dilakukan Sistem Temu Kembali Informasi secara umum terlihat pada Gambar 1. Pada gambar terlihat adanya beberapa tahapan proses yang akan dilalui mulai dari query pengguna sampai dengan hasil keluaran sistem.
Gambar 2. Tahapan proses sistem temu kembali informasi [3]
Proses retrieval merupakan proses kompleks yang dapat dibagi menjadi subproses. Terdapat dua buah alur operasi pada sistem temu kembali informasi. Alur pertama dimulai dari koleksi dokumen dan alur kedua dimulai dari query yang dimasukkan pengguna dalam sistem. Alur yang pertama tidak tergantung pada alur kedua, pemrosesan koleksi dokumen dilakukan sampai menghasilkan basis data indeks. Sedangkan alur kedua tergantung pada basis data indeks hasil pemrosesan yang pertama.
Sistem temu kembali informasi secara umum terdiri dari 2 (dua) tahapan besar yaitu indexing dan pencarian. Setelah menghimpun dokumen (dalam hal ini naskah publikasi dalam bentuk pdf dan abstrak dalam bentuk text) akan dilakukan proses preprocessing dilanjutkan dengan proses indexing, yaitu membangun suatu daftar indeks (inverted index).
Kemudian dilakukan proses pembobotan terhadap indeks tersebut. Term indeks dan bobot disimpan untuk selanjutnya diproses mencari kemiripan vektor dengan kata kunci yang dihasilkan dari proses indexing query. Hasil perhitungan kemiripan diranking untuk dikembalikan kepada pengguna. Rancangan arsitektur sistem untuk sistem temu kembali informasi terlihat pada Gambar 3. Dalam hal ini proses tokenisasi (tokenization), penghilangan stopword, stemming dan indexing masuk kedalam
tahapan preprocessing.
Dari arsitektur sistem secara keseluruhan, terdapat bagian yang digambarkan detail dalam bentuk flowchart, yaitu proses preprocessing (tokenisasi, stemming, inverted index, pembobotan tf-idf) dan proses pencarian menggunakan model pencarian ruang vektor / VSM (Vektor Space Model). Terdapat beberapa proses dalam pengolahan data abstrak dokumen. Proses penghilangan tanda baca menjadi spasi adalah proses penting, karena dalam pencarian tanda baca tidak digunakan. Proses tokenisasi juga harus dilakukan, sebab dalam proses ini dihasilkan token-token yang nantinya digunakan sebagai inputan dalam proses selanjutnya.
Dalam proses tokenisasi, data abstrak yang berbentuk teks dipisah dengan pemisah spasi menjadi term-term yang akan diolah selanjutnya. Penghilangan stopword dilakukan ketika termnya memiliki bentuk yang sama dengan list term stopword pada korpus stopword. Term yang tidak terkena proses stopword akan masuk dalam tahapan stemming, inverted index dan pembobotan tf-idf.
Gambar 3. Rancangan arsitektur sistem temu kembali informasi
Pre Processing
Proses text operation sebagai Preprocessing, karena dilakukan sebelum proses utama temu kembali informasi dilakukan [4]. Tujuan dari preprocessing adalah mengoptimalkan performa dari analisis data. Analisis data sangat bergantung pada preprocessing dan model representasi data. Ini adalah langkah yang paling penting sebelum menyimpan representasi dokumen untuk mengukur kemiripan.
Dalam preprocessing terdapat beberapa proses yang menggunakan istilah-istilah dalam system temu kembali informasi. Diantaranya stopword dan stemming. Stopwords adalah kata umum (common words) yang biasanya muncul dalam jumlah besar dan dianggap tidak memiliki makna [5]. Sedangkan stemming adalah proses untuk memecah setiap kata menjadi suatu bentuk kata dasar. Stem(akar kata) adalah bagian dari kata yang tersisa setelah dihilangkan imbuhan (awalan dan akhiran) dan sisipannya. Sebelum dilakukan proses pembuangan stopwords, dilakukan proses case folding, yaitu pengubahan semua huruf dalam dokumen menjadi huruf kecil [6].
Stemming Bahasa Indonesia
Ada banyak ragam pembentukan kata dalam Bahasa Indonesia. Sebagian besar kata dibentuk dengan cara menggabungkan beberapa komponen yang berbeda. Afiks (imbuhan) akan mengubah makna dan pembentukan kata. Prefiks (awalan) melekat di awal kata dasar, diantaranya: ber-, di-, ke-, me-, pe-, se-, ter-. Awalan yang mengalami peluluhan: meng-, mem-, meny-, per-, pem-, peng-, peny-. Untuk sufiks (akhiran), terdiri dari: -an, -kan, -i, -pun, -lah, -kah, -nya.
Dan untukkonfiks (awalan-akhiran), terdiridari: ke - an, ber - an, pe - an, peng - an, peny - an, pem - an, per - an, se – nya. Dalam penulisannya juga terdapat infiks (sisipan), reduplikasi dan kata-kata majemuk yang berafiks [7].
Algoritma Nazief dan Adriani [1], memiliki tahap-tahap sebagai berikut:
1. Cari kata yang akan distem dalam kamus. Jika ditemukan maka diasumsikan bahwa kata tesebut adalah root word. Maka algoritma berhenti.
2. Inflection Suffixes (lah”, kah”, ku”, “-mu”, atau “-nya”) dibuang. Jika berupa particles (“-lah”, “-kah”, “-tah” atau “-pun”) maka langkah ini diulangi lagi untuk menghapus Possesive Pronouns (ku”, “-mu”, atau “-nya”), jika ada.
3. Hapus Derivation Suffixes (i”, an” atau “-kan”). Jika kata ditemukan di kamus, maka algoritma berhenti. Jikatidakmakakelangkah 3a
a. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “-k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3b.
b. Akhiran yang dihapus (i”, an” atau “-kan”) dikembalikan, lanjut langkah 4. 4. Hapus Derivation Prefix. Jika pada langkah 3
ada sufiks yang dihapus maka pergi ke langkah 4a, jika tidak pergi ke langkah 4b. a. Periksa tabel kombinasi awalan-akhiran
yang tidak diijinkan. Jika ditemukan maka algoritma berhenti, jika tidak pergi ke langkah 4b.
b. For i = 1 to 3, tentukan tipe awalan kemudian hapus awalan. Jika root word
belum juga ditemukan lakukan langkah 5, jika sudah maka algoritma berhenti. Catatan: jika awalan kedua sama dengan awalan pertama algoritma berhenti. 5. Melakukan recoding.
6. Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal diasumsikan sebagai root word. Proses selesai.
Tabel 1. Kombinasi awalan akhiran yang tidak diijinkan
Tabel 2. Aturan tipe awalan untuk kata yang diawali dengan “Te-“
Tabel 3. Jenis awalan berdasarkan tipe awalannya
Model Ruang Vektor
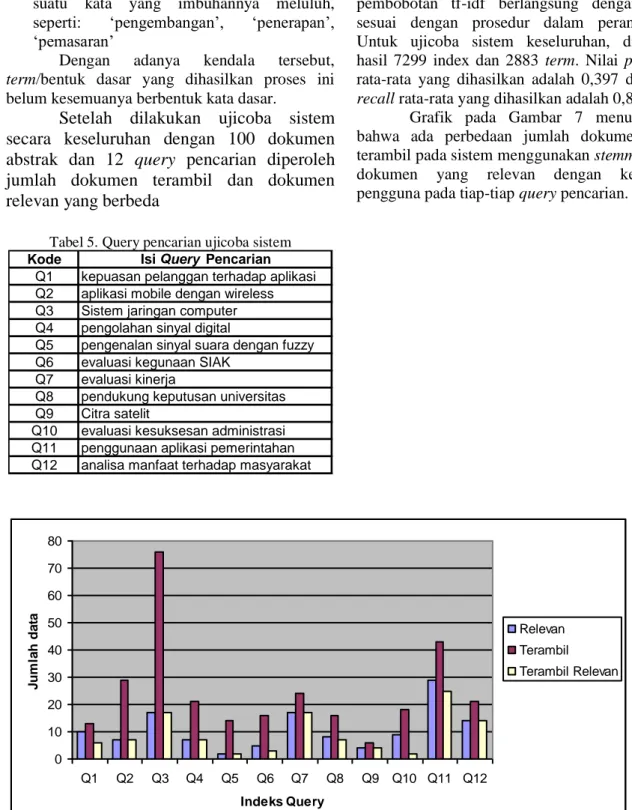
Model vektor adalah teknik standart dari sistem temu kembali informasi dimana dokumennya direpresentasikan dalam kata yang terkandung didalamnya. Model ruang vektor dibuat oleh Gerard Salton pada tahun 1960-an, model ini menkonversi teks dalam bentuk matrik dan vektor, kemudian digunakan teknik analisis matrik untuk menemukan relasi dan kunci dari koleksi dokumen yang sesuai dengan query yang dibutuhkan pengguna [8]. Representasi dokumen dan query dalam bentuk vektor dapat terlihat pada Gambar 4.
Gambar 4. Tampilan ruang vektor dari dokumen dan query
Kesamaan antar dokumen dapat diukur dengan fungsi similaritas (mengukur kesamaan) atau fungsi jarak(mengukur ketidaksamaan). Salah satu ukuran kemiripan teks yang populer [9] adalah cosine similarity. Ukuran ini menghitung nilai cosinus sudut antara dua vektor. Jika terdapat dua vektor dokumen dj dan queryq, serta t term diekstrak dari koleksi dokumen maka nilai cosinus antara dj dan q didefinisikan
sebagai:
t i iq t i ij t i iq ij j j j w w w w q d q d q d similarity 1 2 1 2 1 . ) . ( . . ) , (Pengukuran Performa Sistem
Nilai performansi sistem temu kembali informasi menunjukkan keberhasilan dari suatu sistem dalam mengembalikan informasi yang dibutuhkan oleh user. Pengukuran yang seringkali digunakan untuk mengukur performa kerja sistem temu kembali informasi adalah recall dan precision.
1. Precision (ketepatan)
Parameter ini menunjukkan tingkat ketepatan hasil pencarian terhadap suatu event.
2. Recall (kelengkapan)
Parameter ini menunjukkan tingkat keberhasilan mengenali suatu event dari seluruh event yang seharusnya dikenali.
METODE
Jalan penelitian yang dilakukan meliputi 5 tahapan yaitu tahap 1 pemahaman awal, tahap 2 perancangan sistem, tahap 3 pembuatan sistem, tahap 4 pengujian sistem, dan tahap 5 adalah dokumentasi. Gambaran detail alurnya terlihat pada diagram alir pada Gambar 5.
Dari analisa sistem diketahui terdapat beberapa masalah yang nantinya digunakan sebagai dasar pembuatan sistem. Diantaranya adalah:
Adanya dokumen tesis yang semakin bertambah setiap tahunnya sehingga dibutuhkan sistem pencarian dengan performa yang baik. Kurang optimalnya penggunaan website referensi bagi pengguna perpustakaan jurusan dari sisi pencarian dokumen yang dibutuhkan.
Dengan dukungan fasilitas website referensi, sumber daya yang dapat mengoperasikan komputer dengan baik (admin perpustakaan), dan sumber data digital yang ada, maka muncul peluang pengembangan sistem sekarang ke sistem baru melalui pembuatan mesin pencarian data digital dokumen dengan model sistem temu kembali informasi. Yang dijadikan sebagai sumber data digitalnya adalah data Tesis S2 salah satu perguruan tinggi negeri. Pengguna yang terlibat adalah pengguna umum sebagai pencari data dan administrasi perpustakaan yang berfungsi untuk manage data. Gambaran umum sistem secara keseluruhan terlihat pada Gambar 6.
Gambar 6. Gambaran umum sistem pencarian dokumen
Setelah dilakukan analisa sistem sebelumnya dan kelayakan sistem digunakan, maka terlihat bahwa dalam pembuatannya nanti diharapkan sistem memiliki kemampuan:
1. Sistem harus mampu melakukan preprocessing (case folding, tokenisasi, penghilangan stopword, dan stemming) data dokumen dalam bentuk digital untuk menghasilkan data indeks.
2. Sistem harus memiliki fasilitas input query dengan Bahasa Indonesia dan mampu untuk melakukan pencarian dokumen yang ada dalam koleksi dokumen.
3. Sistem harus mampu melakukan pembobotan/perankingan hasil dokumen pencarian.
4. Sistem harus memiliki fasilitas download dokumen hasil pencarian bagi anggota.
Kelengkapan fitur dalam sistem didukung oleh adanya kebutuhan pengguna dalam melakukan hal-hal tertentu. Daftar kebutuhan pengguna terlihat pada Tabel 4. Dalam tabel tersebut diuraikan kebutuhan-kebutuhan yang diinginkan oleh aktor pengguna sistem.
Tabel 4. Daftar Kebutuhan Pengguna
Aktor Requirement
Admin Dapat login dan logout dalam sistem
Dapat merubah password
Dapat menambahkan dokumen baru
Dapat mengedit info dokumen yang sudah ada
Dapat menghapus dokumen Anggota Dapat melakukan pencarian dokumen
Dapat membuka/mendownload dokumen yang dipilih dari daftar dokumen hasil pencarian
Pengguna Umum
Dapat melakukan pencarian dokumen
HASIL DAN PEMBAHASAN
Terdapat beberapa ujicoba yang dilakukan terhadap 100 dokumen abstrak naskah publikasi Tesis dengan 12 variasi query pencarian. Dalam ujicoba proses tokenisasi (tokenization), terdapat hasil tokenisasi berupa kata yang disimpan dalam suatu array dan telah terdefinisi pada program. Tokenisasi untuk naskah dokumen dilakukan pada saat dokumen mengalami proses penyimpanan ke dalam database.
Pada ujicoba proses stopword removal, proses berjalan lancar. Terbukti dengan adanya penghapusan kata yang sama dengan list stopword. data yang digunakan sebagai korpus adalah list stopword hasil penelitian Fadilah Z.Tala, sebanyak 364 kata.
Hasil ujicoba algoritma stemming membuktikan bahwa algoritma stemming
Nazief-Adriani, memiliki beberapa
kelemahan.Diantaranya:
1. Tidak adanya algoritma untuk mengatasi suatu kata yang bersisipan, seperti: ‟kinerja‟
2. Tidak adanya algoritma untuk mengatasi suatu kata yang imbuhannya meluluh, seperti: „pengembangan‟, „penerapan‟, „pemasaran‟
Dengan adanya kendala tersebut, term/bentuk dasar yang dihasilkan proses ini belum kesemuanya berbentuk kata dasar.
Setelah dilakukan ujicoba sistem
secara keseluruhan dengan 100 dokumen
abstrak dan 12 query pencarian diperoleh
jumlah dokumen terambil dan dokumen
relevan yang berbeda
Tabel 5. Query pencarian ujicoba sistem
Kode Isi Query Pencarian
Q1 kepuasan pelanggan terhadap aplikasi Q2 aplikasi mobile dengan wireless Q3 Sistem jaringan computer Q4 pengolahan sinyal digital
Q5 pengenalan sinyal suara dengan fuzzy
Q6 evaluasi kegunaan SIAK
Q7 evaluasi kinerja
Q8 pendukung keputusan universitas Q9 Citra satelit
Q10 evaluasi kesuksesan administrasi Q11 penggunaan aplikasi pemerintahan Q12 analisa manfaat terhadap masyarakat
Hasil ujicoba proses inverted index dan pembobotan tf-idf berlangsung dengan baik, sesuai dengan prosedur dalam perancangan. Untuk ujicoba sistem keseluruhan, diperoleh hasil 7299 index dan 2883 term. Nilai precision rata-rata yang dihasilkan adalah 0,397 dan nilai recall rata-rata yang dihasilkan adalah 0,847.
Grafik pada Gambar 7 menunjukkan bahwa ada perbedaan jumlah dokumen yang terambil pada sistem menggunakan stemming dan dokumen yang relevan dengan keinginan pengguna pada tiap-tiap query pencarian.
0 10 20 30 40 50 60 70 80 Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10 Q11 Q12 Indeks Query J um la h da ta Relevan Terambil Terambil Relevan
Gambar 7. Grafik perbandingan dokumen relevan terambil pada sistem
Dari hasil pengujian diketahui bahwa rata-rata waktu pencarian adalah ±20 detik. Setelah dianalisa dengan melakukan perhitungan nilai big O maka diperoleh hasil bahwa sistem memiliki nilai pertumbuhan data yang sebanding dengan nilai kuadratik jumlah dari token yang
akan diproses. Dengan kata lain perhitungan big O nya adalah O(n2), dengan n adalah jumlah token yang digunakan. Token adalah hasil dari proses tokenisasi yang masukannya berupa data dokumen teks.
Sehingga secara tidak langsung nilai kompleksitas waktu dari algoritma yang
digunakan sebanding dengan jumlah dokumen yang digunakan. Semakin banyak dokumen koleksi, maka semakin besar pula nilai kompleksitasnya.
Kata-kata dalam list stopword juga berpengaruh terhadap hasil pencarian. Hal ini terbukti ketika kata ‟sistem‟ dijadikan masukan, maka hasil keluaran adalah banyak dokumen,
sehingga berpengaruh juga terhadap pengukuran precision. Gambar 8 menggambarkan tampilan utama sistem pencarian yang berbasis sistem temu kembali informasi untuk pengguna umum. Terlihat fitur yang diberikan hanya fitur pencarian dan info-info umum.
Gambar 8. Tampilan bagi pengguna umum
Sedangkan tampilan utama untuk aktor admin tersedia beberapa fitur sesuai dengan fungsi dan kerja dari aktor tersebut, diantaranya: fitur tambah dokumen koleksi, list untuk naskah tesis, pencarian dokumen, tambah anggota dan lainnya.
SIMPULAN
1. Model sistem temu kembali informasi dengan penggunaan stemming, dan pencarian ruang vector, serta inverted index mampu menghasilkan dokumen yang dibutuhkan pengguna.
2. Penggunaan algoritma stemming dapat mempengaruhi nilai similarity vector yang diperoleh. Untuk penggunaan algoritma Nazief Adriani dalam sistem ini, diperoleh pengukuran recall (kelengkapan) sebesar 84,7% dan precision sebesar 39,7%. Hal ini berarti system mampu meningkatkan performa pencarian, terutama untuk hal
kelengkapan perolehan dokumen yang diinginkan pengguna berdasarkan query yang dimasukkan.
SARAN
Dalam pengembangan sistem selanjutnya diharapkan pengembang sistem mampu mengembangkan system ke arah yang lebih luas lagi.
1. Dalam proses pencarian Sistem Temu Kembali Informasi dibuat adanya klustering, sehingga hasil pencariannya lebih optimal dengan stopword list yang semakin luas sesuai dengan bidang dalam dokumen koleksi
2. Penggunaan stemming untuk dua atau lebih bahasa dalam penerapan Sistem Temu Kembali Informasi (misal: Inggris dan Indonesia), sehingga dokumen yang dijadikan korpus lebih luas.
3. Adanya proses kesamaan term, antara term yang dijadikan query dengan beberapa term yang memiliki arti yang sama, semisal: cinta
dengan love sehingga dapat meningkatkan performa pencarian
4. Adanya penelitian mengenai peningkatan kompleksitas algoritma (O(n)) terhadap performa kinerja Sistem Temu Kembali Informasi
5. Adanya penelitian dengan menggunakan algoritma stemming yang kompleks, yang mampu mengenali bentuk-bentuk kata berimbuhan, bersisipan, mengalami peluluhandan kata majemuk
DAFTAR PUSTAKA
[1] Mirna. A, Asian, J., Bobby N., Tahagoghi W., Hugh E., “Stemming Indonesian: A Confix-Stripping Approach”, Artikel ACM Transactions on Asian Language Information Processing, Vol.6, No.4, Artikel 13, Desember 2007.
[2] Lady, A., “Perbandingan Algoritma Stemming Porter dengan Algoritma Nazief & Adriani untuk Stemming Dokumen Teks Bahasa Indonesia “, Konferensi nasional Sistem dan Informatika, Bali, 2009.
[3] Ricardo Y. B., Berthier Ribeiro N.B, “Modern Information Retrieval”, ACM Press, New York, 1999.
[4] Nisa, N., “An Analysis of Hierarchical Clustering and Neural Network Clustering for Suggestion Supervisitors and Examiners”, Tesis S2 Universitas Teknologi Malaysia, 2005.
[5] Yudi, 2008, Stopword Untuk Bahasa Indonesia. URL :
http://yudiwbs.wordpress.com/2008/07/23/st op-words-untuk-bahasa-indonesia/, Tanggal akses: 14 Maret 2011.
[6] Wibisono, Y., Khondra, A., “Clustering Berita Berbahasa Indonesia”, KNSI, 2008. [7] Anonymous, Kamus Elektronik Indodic,
Pembentukan Kata-kata Bahasa Indonesia, URL: http://indodic.com/affixindo.html, Tanggal akses: 28 April 2011.
[8] Said, A., Mohammad, A., Rosni, N, Aini, “Modified Vector Space Model for Protein Retrieval”, IJCSNS International Journal of Computer Science and Network Security, 2007.
[9] Sandeep, T., Patel M., Jignesh, “ Estimating the Selectivity of tf-idf based Cosine Similarity Predicates”, Sigmod Record, Vol. 36 No.4, Desember, 2007.
![Gambar 2. Tahapan proses sistem temu kembali informasi [3]](https://thumb-ap.123doks.com/thumbv2/123dok/4143717.3072797/3.893.139.654.140.492/gambar-tahapan-proses-sistem-temu-kembali-informasi.webp)