Network Layer Implemented Anycast Load Balancing
Ricardo Lopes Pereira
IST, Inesc-ID
[email protected]
Teresa Vaz˜ao
IST, Inesc-ID
[email protected]
Abstract
This paper presents a server selection method where the server selection is performed by the network, at the first router from the client. This method, usable in networks un-der single administrative control, combines network metrics (such as traffic or latency) with common server load bal-ancing metrics (such as load, CPU utilisation or response time), allowing network conditions to be taken into account when selecting the server which will handle the request.
The performance of this technique was compared, by means of simulations, to that of widely used techniques such as random, round robin and least loaded server selection.
1
Introduction
Despite the advent of the Personal Computers (PC) and distributed computing, the client/server model still plays a major role today. Many applications, such as Database servers and Web Services, remain centralised due to their nature. The ubiquity of the Internet or intranets, coupled with the emergence of the web browser as a human inter-face, also dictates that many applications are developed us-ing the web server centric paradigm. However, this cen-tralised approach has its weaknesses, as it presents a single point of failure. The concentration of all clients on the same server may also result in slow response times due to server overload, large network delays or congestion along the path from client to server.
Replicating the application across several servers will eliminate the single point of failure. Server load can be mit-igated by placing the application on a set of servers located in the same Local Area Network (LAN). Network latency and congestion may be avoided by placing servers across a Wide Area Network (WAN), closer to the clients. The two methods can be combined by spreading several clusters across a WAN.
For each of these approaches, different load balancing methods are used to distribute the clients’ requests [1]. WAN load balancing techniques may take into account not
only server availability but also the network distance and conditions along the paths from client to server and vice-versa. This is also what routing protocols such as Open Shortest Path First (OSPF) do, compute shortest paths. As-signing each server the same anycast address [13] allows each router to know the path towards the nearest server. When clients use the anycast address to reach servers, the network layer will automatically forward packets to the nearest server (according to the routing metrics) [8]. This method is successfully being used today in the Internet to distribute User Datagram Protocol (UDP) queries by the Domain Name System (DNS) root servers [6].
This paper presents a transparent load balancing tech-nique usable on networks under common administrative control, which aims at providing unmodified clients with better reply times while maximising the total number of re-quests handled by the set of servers. This method, which was named Network layer implemented Anycast Load Bal-ancing (NALB), combines network proximity and server load information in order to achieve dynamic load balanc-ing resortbalanc-ing to anycast addresses and link cost variation in already deployed routing protocols. This technique was val-idated by means of simulation using the HyperText Trans-fer Protocol (HTTP) protocol, although it may be applied to other applications such as DNS, Simple Mail Transfer Protocol (SMTP) or proxy servers.
Section 2 details the anycast concept, its strengths and limitations. Section 3 presents the proposed load balanc-ing scheme, which was compared with others by means of simulations, whose results are provided in section 4. The conclusions are presented in section 5.
2
IP Anycast
of a packet, never as the source [7].
Given several servers sharing the same anycast IP ad-dress and a proper routing infrastructure in place, clients should be directed to the nearest server (in number of hops or other routing metric).
2.1
Current combined anycast load
bal-ancing methods
Different research proposals appeared combining any-cast load balancing methods.
Ticket based probing combines anycast with server load information by sending probes to several anycast servers. They reply indicating their status (load). The status infor-mation combined with the reply time provides server and network information which is used to select the server [3]. This method, however, is not transparent, requiring clients to be modified. Most importantly, it requires routers to be modified, for probe packets to reach several anycast servers. These demands complicate its deployment in a legacy net-work.
Instead of leaving to the client the decision of which server to use, [10] proposes to restore it to the network, by using an active network. Active networks use routers capa-ble of running user supplied code on each packet. In this approach, routers communicate with the servers, gathering load information, which may eventually be piggybacked on traffic from the servers. This information is then used to forward packets destined to the anycast server address. The router chooses the best server and changes the packet’s tar-get address from the anycast address to the best server’s uni-cast address. When packets arrive in the opposite direction, the source address is changed, from the server’s unicast ad-dress to the anycast one. This solution requires an active network, the development of a communication protocol be-tween servers and routers and uses anycast addresses as the source of packets, which IPv6 disallows.
A different approach consists in the utilisation of rout-ing protocols which determine anycast routes usrout-ing network metrics as well as server state information [9]. This method requires routers to collect and propagate server’s state in-formation. Legacy routers would have to be upgraded to support these routing protocols.
2.2
Anycast addressing and routing
Anycast addresses can not be aggregated with other ad-dresses as they may be dispersed by several subnetworks and their worldwide deployments would result in the explo-sion of the number of routing entries carried by each router. Nevertheless, they can be successfully used under sin-gle administrative control and several anycast intra-domain routing protocols have been proposed. Single-path routing
anycast (SPRA) directs packets to the nearest server; it can be performed on small or confined networks using tradi-tional routing protocols as OSPF [15]. Multi-path routing distributes packets among all servers within the same dis-tance. Multi-path or global scale deployment of single-path routing requires specialised routing protocols [4, 17].
2.3
Maintaining TCP connections
Stateful connection methods, such as TCP, expect end-points to remain the same throughout the life-time of the connection, but anycast routing does not ensure that packets from the same connection will always reach the same server. Routing tables may change due to topology changes or due to the introduction or removal of anycast servers. Several proposals address the lack of stateful transport support by anycast, either by adding support applications, modifying Transmission Control Protocol (TCP) or using IPv6 packet headers.
A support application may be used to inform the client of the unicast address of an anycast server [17]. A UDP ser-vice, running at each anycast server on a well known port would receive UDP probe packets from the clients, which would use the anycast address as destination. The server would respond with a UDP message indicating its unicast address, which the client would then use to establish the TCP connection. Should several anycast servers respond, only the first one would be used. This method requires modifications to the clients and may not be used by legacy clients. Clients will also require a mechanism to know when a target address is an anycast address. This method adds a round-trip to the connection establishment process.
A client could also determine the server’s unicast address by sending a ping (ICMP ECHO request) to the anycast ad-dress. The server would then respond (ICMP ECHO reply) using its unicast address [11].
Modifications to the TCP protocol would enable it to overcome anycast limitations [13]. Just like in standard TCP, clients would send a SYN packet to the server’s any-cast address. However, the SYN-ACK response would ar-rive not from the anycast address but from the server’s uni-cast address, which would be used from then on. A differ-ent proposal is to extend TCP’s three-way handshake to a five-way handshake, creating a first phase where the unicast address of the server is determined [17]. These methods do not require the client to know, beforehand, when the address is an anycast one. Large scale TCP implementation substi-tution, albeit simpler than legacy applications modification, still represents a monumental endeavour.
ex-tension header allows the client to perceive the original ad-dress as anycast and allows it to match the SYN-ACK to its TCP connection. The ensuing packets will use the unicast address. This method requires a special TCP implementa-tion.
The IPv6 source route option has also been used to pro-vide connection capabilities to anycast [5]. The client sends a normal SYN packet to the anycast address. The server responds with a SYN-ACK using its anycast address as source, but providing a route option header with its unicast address. The client may then, if and only if the packet is properly authenticated, reverse the route header, forward-ing the next packets to the server’s unicast address [7]. The server, upon receiving the packets at its unicast address, for-wards them to the anycast address, according to the route header. The closest interface to the server with the anycast address will always belong to the server. Other than the added size, the use of the source route option will not over-load the intermediate routers, as the route option header will only be processed at the hosts. Assuming the IPv6 source route option to be honoured at the TCP layer, this method would only require modifications to the servers’ software as well as an authentication infrastructure in place. However, this method infringes on IPv6 as the server sends packets originated in its anycast address.
2.4
IP Anycast evaluation
In a network under single administrative control, cur-rent intra-domain routing protocols, such as OSPF, provide single-path anycast routing, by considering that paths to dif-ferent servers sharing the same anycast address are difdif-ferent paths to the same server. Routing table dimension is not a problem as the number of anycast addresses used will be limited. This enable anycast use with stateless protocols such as DNS.
The deployment of one of the methods described in sec-tion 2.3 on a single owner intranet is viable, enabling TCP connections. Strict standard compliance may also be over-looked if the anycast methods are confined to the intranet.
In these conditions, SPRA load balancing is possible, di-recting clients to the nearest server, while also minimising network traffic. The possibility of transparently using any-cast without requiring client modifications makes it an at-tractive option. However, [2] shows that scheduling each client to the nearest server (networkwise) may cause un-balanced servers, resulting in higher response times, due to large variations in each network region’s traffic, attributable to population distribution, time zones and hour of day. The load unbalance caused by SPRA will prevent servers from being used to the fullest and will increase the response time for clients assigned to overloaded servers. A better result may be achieved by combining the network metrics used by
the routing protocols with server status information.
3
Network layer implemented Anycast Load
Balancing
3.1
NALB architecture
NALB is an intra-domain architecture that provides load balancing by using a routing protocol that combines both network and server status information. NALB can also be combined with network QoS conditions should the intranet run a QoS enabled routing protocol [16].
Anycast addresses are assigned to the servers of a NALB domain and these servers will run the routing protocol, an-nouncing a route to the anycast address. However, when receiving a packet for this address, a server will process it as his.
The announced cost of the link to the anycast address will vary, according to the server state. Should the server be overloaded, the cost will be very high. Should it be idle, the cost would drop. When all the servers are idle, or equally loaded, clients will use their nearest server. When a server becomes overloaded, it will announce a higher cost to the anycast address, causing the routing protocol to con-sider it to be more “distant”. This will result in a number of clients now having a different nearest server, effectively being transfered from the overloaded server.
Server failure is automatically supported as down servers will stop announcing their routes to the anycast address, be-ing removed from the anycast group by the routbe-ing protocol.
3.2
Routing metrics
Different types of metrics may be used to measure the server status, namely: CPU usage, run queue length, num-ber of clients, transfer rate or a combination. However, should the load metric used be relative to each server’s per-formance (like CPU usage) and not absolute (such as num-ber of requests being served), the NALB method will auto-matically allow servers with different capacities to be used. The load metrics used, as well as the link cost variation, should be fine-tuned for best results experimentally. Fur-thermore, the link cost should only be increased when the load crosses a threshold, as assigning a client to a more dis-tant server to avoid a mildly loaded server might prove a bad move.
3.3
Application examples
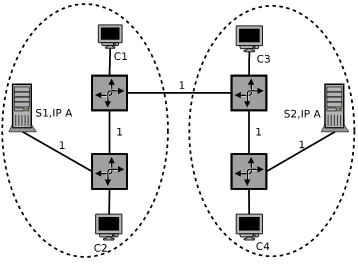
Figure 1 presents a situation where two anycast servers provide service to four clients. Servers S1 and S2 each have their own unicast address but both share the anycast address A. Routers are connected by links with a unitary cost. In this situation, both servers are under low load, announcing a cost of one towards the anycast address. The dashed lines encompass the clients closest to each server: clients C1 and C2 will use server S1, clients C3 and C4 will use server S2. Figure 2 portrays a scenario where S1 is under heav-ier load than S2. S1 reacts by increasing the announced route cost towards the anycast address. As a result, C1 will now be closer to S2 and will use this server for future re-quests. S1 will reduce the number of potential clients to one whereas S2 will now have to handle three clients. Clients are diverted from the server with the highest load to the least loaded one.
4
Simulation results
The proposed method was compared with traditional HTTP load balancing methods via simulation, performed using the 2.0.0 version of the SSFNet network simula-tor [12]. The simulasimula-tor was modified to implement CPU processing delays, traditional load balancing algorithms, anycast and the proposed method (including server perfor-mance measurement).
The load balancing alternatives used were: SRPA, source IP address hashing, random, round robin and least loaded. The utilisation of a single server, with capacity equal to the sum of that of all servers, was also tested in order to provide a baseline for comparison.
4.1
Simulation scenario
The core network of a large American ISP, with points-of-presence in 25 cities, was used. It spans four time zones,
Figure 1. Two servers with equal load
Figure 2. Left server under heavier load
making it a good candidate for a dynamic load balancing technique.
To each of the 25 core routers, a network island was attached. Network islands are all identical, each having 20 HTTP clients connected at 100Mb/s, 30 at 10Mb/s and 40 at 1Mb/s. Servers, connected to the core routers using 100Mb/s links, were placed on opposite sides of the net-work.
The OSPFv2 routing protocol was used. A stateful con-nection mechanism for anycast was assumed to be in place. HTTP 1.1 with persistent connections and no pipelining was used.
Whenever a client established a connection, the schedul-ing algorithm was used by it to choose a server.
Round robin state is kept globally. When a client chooses server 1, the next client will choose the second server and vice-versa. The least loaded algorithm is perfect, in the sense that it has instant up-to-date knowledge of the servers’ status. The least loaded server is considered to be the one with the smallest CPU run queue, to which clients have in-stant access with no network overhead.
As the server selection is performed at the client, no dispatching overhead is included. Traditional dispatching mechanisms such as DNS, server redirection or triangula-tion will add further overhead to traditriangula-tional load balancing techniques which does not affect SPRA or NALB. In these simulations, this overhead is not accounted for, providing traditional load balancing techniques with an advantage.
The routing protocol uses link costs proportional to the link delay, which in turn is proportional to its distance. With NALB, servers generate new route announcements every 15 minutes. CPU utilisation is measured in 5 minute intervals. CPU’s utilisation moving average is used as the server’s load metric. The route to the anycast address will present a cost of 1 whenever this average is inferior to 50% and a cost from 1 to 25 when the moving average raises above this figure. The longest core links present a cost of 30.
Simula-tions were run over a 24 hour period, after a 2 hour warm-up period. The client generated traffic was defined as an office work day, with low traffic during the night and lunch time, and high activity during work hours (9 to 13 and 15 to 19).
Clients are simulated to perform as real persons. They access the web site in sessions, which occur from time to time. During each session they will visit several pages, tak-ing some time to read each one before movtak-ing to the next one. Each web page will be constituted by an HTML object and several binary objects such as images, each with its own size. For each object request the server will require some CPU time. Servers assign 5ms CPU time slices to each re-quest using a round robin scheduler. Replies are only sent to the clients after the request has received the required CPU time. Clients timeout a request when the reply is not fully received within 20 minute.
Simulations were performed with 100Kb/s, 1Mb/s and 10Mb/s links connecting the core routers. No traffic other than OSPF’s and HTTP’s existed. Links with 100Kb/s are insufficient to respond to the demands of the clients, be-coming the bottleneck. In this case, the load balancing mechanism has to overcome the network limitations. Over-dimensioned 10Mb/s links guarantee traffic to flow swiftly across the network, making servers the bottleneck. Here the load balancing mechanism has to divert clients to the least loaded server. 1Mb/s links provide a test where both server CPU and network capacity are at a premium.
4.2
Results analysis
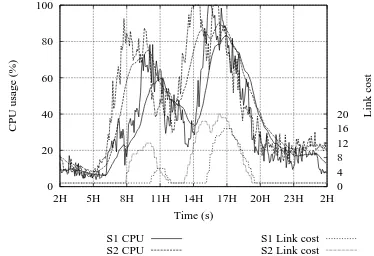
The existence of different timezones, each with a dif-ferent number of clients, results in unbalanced traffic gen-eration across the network. Fig. 3 shows how the load is distributed across both servers when using SPRA. The thin lines represent CPU usage while the thick lines represent the moving average. At the beginning of the day, clients in the east start peaking and, being closest to server 2, will cause it to have a higher load than server 1. Server 2 re-mains the most loaded one during the day as it is closer to a larger number of clients than server 1. Towards the end of the day, the roles are inverted. Server 2’s load starts to de-crease as the end of the day approaches. On the other hand, server 1 still has a significant number of clients due to the 3 hour difference from the east to the west of the network, and becomes the most loaded server. On the whole, server 2 has to support a significantly larger load.
Using NALB the load gap between servers is reduced as can be observed in Fig. 4. The thin lines at the bottom represent the link cost, which is read against the right verti-cal axis. At around 8h, server 2 crosses the CPU utilisation threshold, prompting the cost of its link to the anycast ad-dress to raise. As a result, the routing algorithm will deter-mine that the shortest path to the anycast address for some
0
S2 CPU S1 Link costS2 Link cost
Figure 3. CPU usage using SPRA and 10Mb/s
of the network islands now passes through server 1. Conse-quently, server 1 has an increase in traffic when compared to the previous SPRA scenario. Server 2’s traffic also in-creases more gradually. The same effect is visible during the afternoon period. This enables the set of servers to ser-vice a greater number of requests, as shown in table 1.
NALB also fares well when compared to the classical load balancing methods. Table 1 shows the number of re-quests successfully satisfied by each method during the af-ternoon peak. Similar results were observed when consid-ering the entire duration of the simulation.
When the core network bandwidth is limited to only 100Kb/s, it becomes the bottleneck. Under this scenario,, server capacity is not an issue. NALB and SPRA behave ex-actly the same as CPU utilisation remains below 50%, pre-venting servers from announcing higher route costs. Any-cast assigns each client to the closest server, limiting each request’s traffic to part of the network. Client locality re-duces global traffic, enabling a better utilisation of the avail-able bandwidth. As a result, anycast is capavail-able of answering a significantly larger number of requests.
0
Table 1. Successful requests from 14 to 17
Link speed
Scheduler 100Kb/s 1Mb/s 10Mb/s
NALB 64915 159382 180793
SPRA 64915 152610 178207
IP hash 56941 129092 178159
least loaded 50622 115548 181115
random 60984 123908 179102
round robin 57980 125208 181255 single server 40986 90458 179291
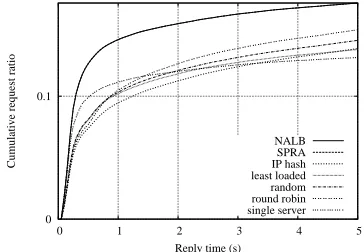
Reply time is also better, as shown in Fig. 5. For each load balancing method, the graphic shows the Cumulative Distribution Function (CDF) of the reply time.
Due to the bandwidth limitations, no method is able to serve more than 20% of the requests in under 5 seconds. NALB and SPRA, whose lines overlap, show a clear advan-tage over the other protocols.
IP hash, random and round robin present similar results as they all distribute clients over the two servers in almost uniform ways.
The selection of the least loaded server will allocate most of the traffic to the first server, as server analysis is always performed in the same order, and run queue length will be zero. As a consequence, the network surrounding server 1 will be more loaded, decreasing its response capacity. Therefore, it will not perform as well as the other methods. The worst performance results from using a single server. As all packets must cross the core links surround-ing the server, these will become overloaded. Nevertheless, as the server’s CPU has double the capacity of all others, the processing time is shorter, resulting in a large number of successful replies under 1 second.
When 1Mb/s links are used in the core, CPU also be-comes scarce in the face of the large number of requests. In
0.1
0
0 1 2 3 4 5
Cumulative request ratio
Reply time (s) NALB
SPRA IP hash least loaded random round robin single server
Figure 5. Request reply time using 100Kb/s
this situation, although SPRA performs the second best, it is outperformed by NALB. The SPRA method’s performance is limited by the CPU shortage during peak hours. The NALB method is capable of serving a larger number of re-quests by diverting clients from the loaded server to the least loaded one. However, this comes at a price. Fig. 6 shows that the reply time using NALB is slightly higher than that of SPRA. The diverted clients get access to a server which provides faster response times but the path has higher delay. Network bandwidth is still a bottleneck, as can be ob-served by the relative performance of the other methods, which are similar to those attained using 100Kb/s links.
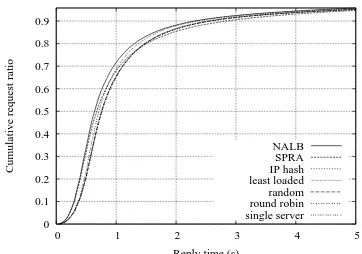
10Mb/s links allow the network not to obstacle per-formance. Server CPU speed becomes the single bottle-neck. In these simulations, each server represents what, in a real deployment, would be a cluster of servers. Therefore, servers are quick to respond to requests, and are only over-loaded during the peak hours of the day, as may be observed in Fig. 3 and 4. This results in very homogeneous results for the several methods used. Reply time is also very similar, as shown in Fig. 7.
SPRA no longer performs significantly better than tra-ditional methods with regard to the number of successful replies. NALB, however, by diverting further away clients to a least loaded server is capable of providing nearby clients with a fast response time, while only making far away clients move to the least loaded server. Clients ther away from the loaded server may not be much fur-ther away from the new server, suffering little impact from the move, while releasing some capacity on the overloaded server. This explains the better response time of NALB.
The Least loaded method performs comparably to NALB in terms of number of replies, but presents worse reply times, due to client to server paths. Round robin also per-forms very well as it provides the most uniform client dis-tribution. Using a single server, with double the capacity, does not turn out to be a problem as the network is capable of forwarding all traffic easily.
0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0
0 1 2 3 4 5
Cumulative request ratio
Reply time (s) NALB
SPRA IP hash least loaded random round robin single server
0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0
0 1 2 3 4 5
Cumulative request ratio
Reply time (s) NALB
SPRA IP hash least loaded random round robin single server
Figure 7. Request reply time using 10Mb/s
5
Conclusion
In this paper a load balancing method that combines net-work proximity and server load information is presented. This is accomplished by combining anycast mechanisms with varying link costs, forcing the routing protocol to for-ward clients’ packets to the best server. This method was compared to ideal implementation of traditional load bal-ancing methods and single path routing anycast using sim-ulation. The results suggest that it performs as well as or better than the other methods under different network con-ditions. It also proved robust, providing consistent results under the different scenarios.
Although this method is not yet applicable to the Inter-net at large, it could be deployed on large corporate or ISP networks. The method is completely distributed, supports servers with different capacities and can overcome server failure.
The proposed load balancing method was used in HTTP load balancing simulations, yet nothing prevents it from be-ing applied to other applications.
Though simulations suggest this method to be better than traditional ones, further work could be performed to over-come some of its limitations. Anycast methods allow pack-ets from client to server to travel the shortest path. However, in Web applications, the bulk of the traffic is in the opposite direction. A server which is more distant from the client might present a shorter path in the reverse direction.
More complex server load metrics could be used, other than CPU usage. Running queue length, connected clients, bandwidth being consumed or a combination of these could be tested.
Currently each server/cluster works independently, alter-ing its link cost without regardalter-ing the other servers’ state. Cooperation between the servers could be established to better balance the load.
The simulations were performed using a single server at each location. In a real deployment several servers would be
used, in a cluster. Only one of them would run the routing protocol, requiring knowledge of the others’ state to pro-duce an aggregate link cost. Resilience would have to be introduced into the protocol for this server to be replaced by one of the others should it fail.
References
[1] V. Cardellini, M. Colajanni, and P. S. Yu. Dynamic load bal-ancing on web-server systems. 3(3):28–39, May-June 1999. [2] V. Cardellini, M. Colajanni, and P. S. Yu. Geographic load balancing for scalable distributed Web systems. In Proc. 8th
International Symposium on Modeling, Analysis and Simu-lation of Computer and Telecommunication Systems, pages
20–27, San Francisco, CA, 2000.
[3] H. Chang, W. Jia, and L. Zhang. Distributed server selection with imprecise state for replicated server group. In Proc.
7th International Symposium on Parallel Architectures, Al-gorithms and Networks, pages 73–78, May 2004.
[4] S. Doi, S. Ata, H. Kitamura, and M. Murata. IPv6 anycast for simple and effective service-oriented communications. 42(5):163–171, May 2004.
[5] R. Engel, V. Peris, and D. Saha. Using IP anycast for load distribution and server location. In Proc. 3rd Global Internet
Mini-Conf., pages 27–35, Nov. 1998.
[6] T. Hardie. Distributing authoritative name servers via shared unicast addresses. IETF RFC3258, Apr. 2002.
[7] R. Hinden and S. Deering. Internet Protocol, Version 6 (IPv6) Specification. IETF RFC2460, Dec. 1998.
[8] R. M. Hinden. IP next generation overview. Commun. ACM, 39(6):61–71, 1996.
[9] C.-Y. Lin, J.-H. Lo, and S.-Y. Kuo. Load-balanced anycast routing. In Proc. Tenth International Conference on Parallel
and Distributed Systems, pages 701–708, July 2004.
[10] H. Miura, M. Yamamoto, K. Nishimura, and H. Ikeda. Server load balancing with network support: Active anycast. In H. Yasuda, editor, IWAN, volume 1942 of Lecture Notes
in Computer Science, pages 371–384. Springer, 2000.
[11] M. Oe and S. Yamaguchi. Implementation and Evaluation of IPv6 Anycast. In Proc. 10th Annual Internet Soc. Conf., 2000.
[12] A. Ogielski, D. Nicol, J. Cowie, et al. SSFNet network sim-ulator.
[13] C. Partridge, T. Mendez, and W. Milliken. Host anycasting service. IETF RFC1546, Nov. 1993.
[14] S. Shah and D. Sanghi. Host Anycast Support in IPv6. In Proc. of 5th Int’l Conf. on Advanced Computing
(AD-COMP), Dec. 1997.
[15] K. H. Tan, M. Yaacob, T. C. Ling, and K. K. Phang. IPv6 single-path and multi-path anycast routing protocols perfor-mance analysis. In ISICT ’03: Proceedings of the 1st
in-ternational symposium on Information and communication technologies, pages 555–560. Trinity College Dublin, 2003.
[16] Z. Wang. Internet QoS: Architectures and Mechanisms for
Quality of Service. Morgan Kaufmann, Mar. 2001.