BAB 2
LANDASAN TEORI
2.1. Algoritma
Istilah algoritma (algorithm) berasal dari kata “algoris” dan “ritmis”, yang pertama kali diungkapkan oleh Abu Ja‟far Mohammed Ibn Musa al Khowarizmi (825 M) dalam buku Al-Jabr Wa-al Muqabla. Dalam bidang pemrograman algoritma didefenisikan sebagai suatu metode khusus yang tepat dan terdiri dari serangkaian langkah yang terstruktur dan dituliskan secara matematis yang akan dikerjakan untuk menyelesaikan suatu masalah dengan bantuan komputer. (Jogiyanto, 2005).
Istilah algoritma digunakan dalam ilmu komputer untuk menggambarkan metode pemecahan masalah yang terbatas, deterministik, dan efektif yang cocok untuk implementasi sebagai program komputer. (Sedgewick. 2011).
Terdapat beberapa defenisi yang diberikan untuk kata algoritma antara lain (Priyatna. 2015) :
a. Algoritma adalah sekelompok aturan untuk menyelesaikan perhitungan yang dilakukan oleh tangan atau mesin.
b. Algoritma adalah langkah demi langkah sebuah prosedur berhinggga yang dibutuhkan untuk menghasilkan sebuah penyelesaian.
c. Algoritma adalah urutan langkah-langkah perhitungan yang mentrasformasikan dari nilai masukan menjadi keluaran.
d. Algoritma adalah urutan operasi yang dilakukan terhadap data yang terorganisasi dalam struktur data.
e. Algoritma adalah sebuah program abstrak yang dapat dieksekusi secara fisik oleh mesin.
2.2. Algoritma Pencocokan String
Algoritma pencocokan string (string matching) merupakan komponen dasar dalam pengimplementasian berbagai perangkat lunak praktis yang sudah ada. String matching digunakan untuk menemukan satu atau lebih string yang disebut dengan pattern (string yang akan dicocokkan ke dalam text) dalam string yang disebut dengan text (string yang di-input). (Charras. 1997).
Algoritma yang dianggap memiliki hasil yang paling baik dalam praktiknya merupakan algoritma yang bergerak mencocokan string dari arah kanan ke kiri. Untuk mengetahui manakah algoritma yang mampu mencari string paling cepat, maka muncullah ide untuk meneliti kemampuan dari algoritma-algoritma ini. (Sagita. 2013). String adalah rangkaian karakter selama Σ alphabet yang terbatas. Misalnya, ATCTAGAGA adalah string lebih . Masalah pencocokan string adalah untuk menemukan semua kejadian dari string P yang disebut pola, di string T pada alphabet yang sama yang disebut teks. Mengingat string x, y, dan z kita mengatakan bahwa x adalah awalan dari xy, akhiran dari yx, dan faktor yxz. (Navarro. 2002).
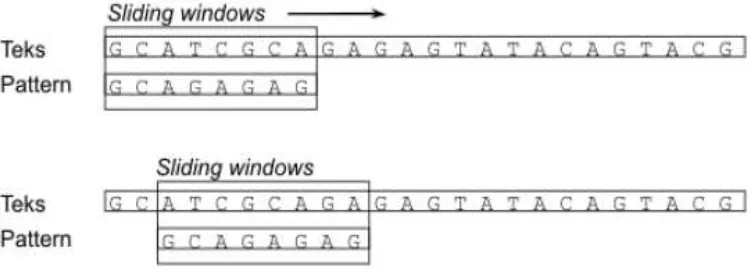
Exact string matching, yaitu pencocokan sebuah string secara sangat tepat dengan susunan karakter dalam string yang dicocokkan baik dalam jumlah maupun urutan karakter dalam stringnya. Pada proses pencocokan string, digunakan sebuah window yang akan bergeser di text. Window itu memiliki panjang yang sama dengan panjang pattern. Pada awal proses pencocokan string, window diletakkan pada ujung kiri text, lalu karakter-karakter pada window dibandingkan dengan karakter-karakter pada pattern, kemudian window akan digeser ke kanan di text dengan jarak tertentu, dan pergeseran tersebut baru akan berhenti bila window tersebut sampai pada ujung kanan text atau sampai pattern ditemukan cocok. (Charras. 1997).
Gambar 2.1 Mekanisme Sliding Windows
Algoritma pencocokan string dapat diklasifikasikan menjadi tiga bagian menurut pencariannya, (Charras. 1997) :
a. Kategori pertama, arah yang paling alami dalam pencocokan string yaitu dari kiri ke kanan. Algoritma kategori ini melakukan pencocokan string dimulai dari karakter paling kiri pattern seperti yang ditunjukkan pada Gambar 2.2. Beberapa algoritma yang termasuk dalam kategori ini adalah algoritma brute force, algoritma Karb-Rabin, dan algoritma Knuth-Morris-Pratt.
Gambar 2.2 Pencocokan dari Karakter Paling kiri ke Paling Kanan Pattern
b. Kategori kedua, algoritma yang melakukan pencocokan dari kanan ke kiri karakter pada pattern seperti yang dapat dilihat pada Gambar 2.3. Algoritma yang termasuk dalam kategori ini umumnya dikatakan sebagai algoritma yang menghasilkan hasil terbaik pada praktekmya, yaitu algoritma Boyer-Moore.
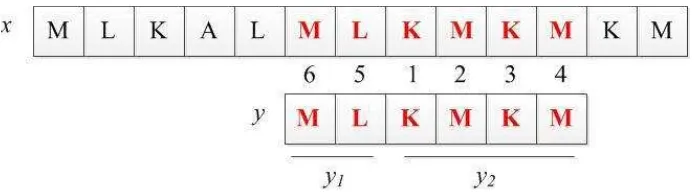
c. Kategori ketiga yaitu pencocokan dari dua arah yang telah ditentukan oleh tiap algoritma tertentu. Salah satunya seperti yang diterapkan oleh Galil-Seiferas dan
Crochemore-Perrin dalam algoritma Two Way, mereka membagi pattern y menjadi
dua bagian yaitu y = y1y2. Seperti yang dapat kita lihat pada Gambar 2.4, pertama kali,
pencarian terjadi pada y2 yang dilakukan dari karakter paling kiri ke kanan, apabila
selama pencarian pertama tidak terjadi ketidakcocokan atau pattern y2cocok dengan
text selanjutnya pada pencarian kedua algoritma akan memeriksa pada y1 yang
dilakukan dari kanan ke kiri seperti yang ditunjukkan pada Gambar 2.5.
Gambar 2.4 Pencocokan Patterny2 Dimulai dari Karakter Paling Kiri
Gambar 2.5 Pencocokan Patterny1 Dimulai dari Karakter Paling Kanan
2.3. Algoritma Galil-Seiferas
Algoritma Galil-Seiferas merupakan algoritma yang menggunakan konstanta k oleh Galil dan Seiferas dinyatakan bernilai 4. Fungsi reach jangkauan untuk 0 ≤ i <m sebagai berikut:
(i) = i + max {i ' ≤ m - i: x [0 .. i '] = x [i +1 .. i' + i +1]}.
searching dilakukan pencarian pada teks T untuk menemukan setiap v dan ketika ditemukan akan dilanjutkan dengan pencarian terhadap u tepat disebelahnya pada T. (Charras. 1997).
Implementasi dalam fase preprocessing
(fungsi newP1, newP2 dan mengurai) adalah untuk menemukan uv faktorisasi sempurna x dimana u = x[0....s-1] dan v = x[s....m-1]. Fungsi newP1 menemukan periode awalan terpendek x[s...m-1]. Fungsi newP2 menemukan periode awalan terpendek kedua dari x[s...m-1] dan fungsi parse terhadap s. Sebelum memanggil fungsi pencarian kita memiliki:
a. x[s...m-1] memiliki paling banyak satu periode awalan;
b. Jika x[s...m-1] tidak memiliki masa awalan, maka panjangnya adalah p1;
c. x[s...s+p1+q1-1] memiliki periode terpendek panjang p1;
d. x[s...s+p1+q1] tidak memiliki periode panjang p1;
Gambar 2.6 Faktorisasi Sempurna x
Pola x adalah dari bentuk x[0...s-1] x[s...m-1] dimana x[s...m-1] adalah dari bentuk z z’ z” dengan z dasar, |z|=p1.z’ awalan z, z’ tidak awalan z dan | z z '| =
p1+q1.
Pada Gambar 2.4 terlihat bahwa ketika mencari
x[s...m-1] di y, jikax[s...s+p1+q1-1] telah dicocokkan pergeseran panjang p1 dapat dilakukan dan
perbandingan yang dilanjutkan dengan x[s+q1]. Sebaliknya jika terjadi
ketidakcocokan dengan x[s+q] dengan q ≠ p1 + q1 maka pergeseran panjang q/k1
dapat dilakukan dan perbandingan yang dilanjutkan dengan x[0]. Hal ini memberikan jumlah linier keseluruhan perbandingan karakter teks.
Tahap preprocessing dari algoritma Galil-Seiferas di Ο(m) waktu dan kompleksitas ruang konstan. Fase pencarian di Ο(n) kompleksitas waktu. Paling banyak 5n perbandingan karakter teks dapat dilakukan selama fase ini.
void newP1() {
void GS(char *argX, int argM, char *argY, int argN) { x = argX;
Gambar 2.7 Fase Pencarian dengan Algoritma Galil-Seiferas.
2.4. Algoritma Not So Naϊve
Algoritma Not So Naϊve bekerja dimana selama fase pencarian dalam perbandingan karakter yang dibuat diatur dalam susunan sebagai berikut: 1, 2,...., m-2, m-1, 0. Untuk setiap upaya dimana jendela diposisikan pada faktor teks:
y [j .. j + m -1]: jika x [0] = x [1] dan x [1] y [j+1]
dari jika x [0] x [1] dan x [1] = y [j+1]
pola digeser oleh 2 posisi pada akhir upaya dan dengan 1 sebaliknya. Dengan demikian tahap preprocessing dapat dilakukan dalam ruang dan waktu yang konstan. Tahap pencarian algoritma Not So Naïve memiliki kasus kuadrat terburuk tapi itu sedikit (dengan koefisien) sub-linear dalam kasus rata-rata. (Charras. 1997).
Contoh :
Fase Pre-processing
k=1 and =2 Fase Searching
2.5. Kompleksitas Algoritma
Algoritma merupakan salah satu cabang ilmu komputer yang membahas prosedur penyelesaian suatu permasalahan. Dalam beberapa konteks, algoritma merupakan spesifikasi urutan langkah untuk melakukan pekerjaan tertentu. Algoritma adalah prosedur komputasi yang terdefenisi dengan baik yang menggunakan beberapa nilai sebagai masukan dan menghasilkan beberapa nilai sebagai masukan dan menghasilkan beberapa nilai yang disebut keluaran. (Munir. 2007).
Adanya algoritma yang baik maka komputer bisa menyelesaikan perhitungan dengan cepat dan benar. Sebaliknya jika algoritma kurang baik maka penyelesaian lambat dan bahkan tidak didapat solusi yang diharapkan. Baik buruknya sebuah algoritma dapat dibuktikan dari kompleksitas waktu yang digunakan.
Kompleksitas dari suatu algoritma merupakan seberapa banyak komputasi yang dibutuhkan algoritma tersebut untuk menyelesaikan masalah. Secara informal, algoritma yang dapat menyelesaikan suatu permasalahan dalam waktu yang singkat memiliki kompleksitas yang rendah, sementara algoritma yang membutuhkan waktu lama untuk menyelesaikan masalahnya mempunyai kompleksitas yang tinggi. (Azizah. 2013).
Dua hal penting untuk mengukur efektivitas suatu algoritma yaitu kompleksitas ruang (keadaan) dan kompleksitas waktu. Kompleksitas ruang berkaitan dengan sistem memori yang dibutuhkan dalam eksekusi program. Kompleksitas waktu dari algoritma berisi ekspresi bilangan dan jumlah langkah yang dibutuhkan sebagai fungsi dari ukuran permasalahan. Analisa asimtotik menghasilkan notasi Ο (Big O) dan dua notasi untuk komputer sain yaitu ϴ (Big Theta) dan (Big Omega). (Purwanto. 2008).
8.4.1. Big-O (O)
Secara informal, O(g(n)) adalah himpunan semua fungsi yang lebih kecil atau dengan urutan yang sama dengan g(n) (hingga beberapa konstanta, sampai n ke tak terhingga). Sebuah fungsi t(n) dikatakan bagian dari Ο((g(n)) yang dilambangkan dengan t(n) Є Ο(g(n)), jika t(n) batas atasnya adalah beberapa konstanta g(n) untuk semua n besar, jika terdapat konstanta c positif dan beberapa bilangan bulat tidak negatif n0 seperti
t(n) ≤ cg(n) untuk semua n≥n0 . ( Levitin. 2011).
8.4.2. Big Omega ( )
(g(n)) merupakan himpunan semua fungsi dengan tingkat pertumbuhan lebih besar atau sama dengan g(n) (hingga beberapa konstanta, sampai n ke tak terhingga). Sebuah fungsi t(n) dikatakan bagian dari (g(n)), dilambangkan dengan t(n) Є (g(n)), jika t(n) batas bawahnya adalah beberapa konstanta positif dari g(n) untuk semua n besar. Terdapat konstanta c positif dan beberapa bilangan bulat tidak negatif n0 seperti t(n) ≥ cg(n), (untuk setiap n ≥ n0). (Levitin. 2011).
8.4.3. Big Theta (ϴ)
ϴ(g(n)) adalah himpunan semua fungsi yang memiliki tingkat pertumbuhan yang sama dengan g(n) (hingga beberapa konstanta, sampai n ke tak terhingga). Sebuah fungsi t(n) dikatakan bagian dari ϴ(g(n)), dilambangkan dengan t(n) Є ϴ(g(n)), jika t(n) batas atas dan bawahnya adalah beberapa konstanta positif g(n) untuk semua n yang besar, yaitu jika ada beberapa konstanta positif c1 dan c2 serta beberapa bilangan
bulat non-negatif n0 seperti c2g(n) ≤ t(n) ≤ c1g(n) untuk semua n ≥ n0. (Levitin. 2011).
2.6. Kamus
perkataan dan juga contoh penggunaan bagi kata tersebut. Kamus disusun sesuai dengan abjad dari A-Z dengan tujuan memudahkan pengguna kamus dalam mencari istilah yang diinginkannya dengan cepat dan mudah.
Secara fisik, kamus terbagi menjadi dua jenis yaitu kamus yang berbentuk buku dan kamus elektronik (digital). Kamus berbentuk buku terdiri dari puluhan bahkan ratusan lembar halaman kata. Berbeda dengan kamus buku yang cenderung besar dan tebal, kamus elektronik atau kamus digital merupakan sebuah fasilitas yang membantu pengguna mencari kata dengan cara mengetikkan kata yang diinginkan pada kolom pencarian. Penggunaan kamus elektronik atau kamus digital ini lebih efisien dalam hal waktu dibandingkan dengan kamus buku. (Tania. 2015).
Kamus digital lebih mengutamakan pada fasilitas pengolah kata elektronis, yaitu sebuah fasilitas yang memungkinkan aplikasi pengolah kata memeriksa ejaan dari dokumen yang diketik. Hal ini dapat meminimumkan kemungkina salah eja atau salah ketik. Pengguna kamus elektronis atau kamus digital dalam aplikasi pemrosesan teks merupakan hal yang tidak dapat dihindarkan. Kamus merupakan basis pemeriksaan, basis pengetahuan, bahkan sebagai basis penyelidikan (Pasaribu. 2013).
2.7. Hukum
Hukum merupakan sistem yang terpenting dalam pelaksaan atas rangkaian kekuasaan kelembagaan. Menurut Prof. E. Utrecht, defenisi hukum adalah himpunan petunjuk hidup yang mengatur tata tertib dalam suatu masyarakat dan seharusnya ditaati oleh anggota masyarakat yang besangkutan, oleh karena pelanggaran terhadap petunjuk hidup itu dapat menimbulkan tindakan dari pemerintah masyarakat itu.
(Djindang. 1989).
menonjolkan kepentingan pribadinya atau kepentingan kelompoknya. Inti tujuan hukum adalah agar tercipta kebenaran dan keadilan.