IV-1
IMPLEMENTASI DAN PENGUJIAN
Bab ini menjelaskan mengenai proses implementasi dan pengujian. Bagian implementasi meliputi lingkungan implementasi, spesifikasi dan batasan implementasi. Bagian pengujian meliputi tujuan dan lingkungan pengujian, hasil pengujian serta analisisnya.
4.1 Implementasi
Pada subbab ini dijelaskan mengenai lingkungan implementasi, spesifikasi dan batasan implementasi.
4.1.1 Lingkungan Implementasi
Lingkungan implementasi perangkat lunak terdiri dari dua bagian yaitu lingkungan perangkat keras dan lingkungan perangkat lunak.
4.1.1.1 Spesifikasi Perangkat Keras
Implementasi tugas akhir dilakukan dengan perangkat keras sebuah Personal Computer (PC) IBM Compatible. Spesifikasi detik dari PC yang digunakan adalah sebagai berikut.
1. Prosesor Intel Celeron 1400 MHz 2. RAM 512 MB
3. Harddisk 40 GB 4. Monitor LCD 15” 5. Keyboard dan Mouse
4.1.1.2 Spesifikasi Perangkat Lunak
Perangkat lunak yang digunakan pada tugas akhir ini adalah: 1. Sistem Operasi Windows XP Professional
4.1.2 Spesifikasi Produk
Spesifikasi produk adalah kebutuhan lingkungan operasi perangkat lunak aplikasi
clustering ini. Spesifikasi detil kebutuhan perangkat lunak tersebut adalah: 1. Prosesor 1400 MHz
2. RAM 512 MB 3. Monitor
4. Keyboard dan Mouse
4.1.3 Batasan Implementasi
Batasan yang didefinisikan untuk implementasi sistem clustering untuk data ekspresi gen adalah:
1. Hanya menerima masukan berupa data ekspresi gen berformat tab delimited text file.
2. Data ekspresi gen yang dibaca tidak dapat diubah untuk menjaga keaslian dan keabsahan data.
3. Cluster yang dihasilkan ditampilkan dalam format teks. 4. Tidak melakukan pengujian kompleksitas algoritma.
4.1.4 Implementasi Antar Muka
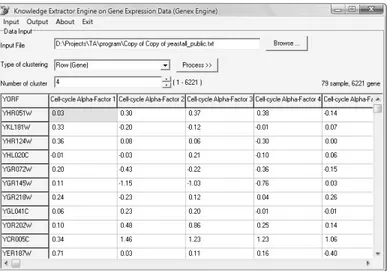
Implementasi antar muka data input dapat dilihat pada gambar IV-1, sedangkan penjelasan komponen – komponennya dapat dilihat pada tabel IV-1.
Tabel IV-1 Komponen Antarmuka Data Input
Elemen pada layar Keterangan
Editbox 1 Berisi path ke file data ekspresi gen (file masukan) Tombol Browse … Memilih file masukan
Combobox Memilih tipe clustering yang dilakukan
Editbox 2 Berisi jumlah cluster yang diinginkan Tombol Process Memproses data yang telah dimasukan
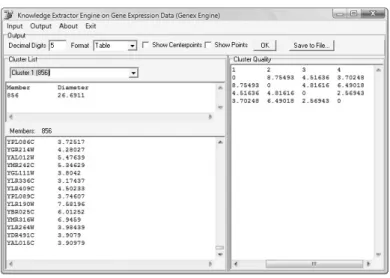
Implementasi antarmuka output dapat dilihat pada gambar IV-2, sedangkan penjelasan komponen – komponennya dapat dilihat pada tabel IV-2.
Gambar IV-2 Implementasi antarmuka output
Tabel IV-2 Komponen Antarmuka Output
Elemen pada layar Keterangan
Editbox 1 Berisi angka desimal yang diinginkan pada keluaran
Combobox 1 Memilih format keluaran
Check 1 Menampilkan titik tengah cluster pada keluaran
Check 2 Menampilkan titik masing – masing member pada keluaran
Tombol OK Menyimpan opsi keluaran
Tombol Save To File … Menyimpan hasil keluaran ke file Combobox 2 Memilih cluster yang ingin ditampilkan
Memo 1 Berisi data cluster yang dipilih
Memo 2 Berisi data anggota cluster yang dipilih
4.1.5 Implementasi Modul
Hasil implementasi modul perangkat lunak ini dapat dilihat pada Tabel IV-3. Tabel IV-3 Implementasi modul
Modul Keterangan
u_data.pas Mengatur segala sesuatu yang berkaitan dengan data, baik struktur maupun pemrosesannya
u_kmeans.pas Berisi algoritma K-means yang dipakai di aplikasi ini u_function.pas Berisi fungsi dan prosedur umum
u_interface.pas Mengatur segala sesuatu yang berkaitan dengan antarmuka aplikasi, merupakan modul utama
Representasi struktur data yang dipakai dalam aplikasi ini berupa list of list dengan
pointer. Hal ini dimaksudkan agar memori yang digunakan untuk pemrosesan tidak terlalu besar, sehingga dapat dipakai untuk data ekspresi gen yang besar. Selain itu penggunaan pointer juga dimaksudkan agar pengaksesan data baik data masukan maupun data pemrosesan dapat dilakukan dengan cepat. Pada list, pointer yang dipegang ada di depan (head) dan belakang (tail), hal ini dimaksudkan agar ketika memasukkan data, dapat diproses dengan lebih cepat.
Algoritma K-means diimplementasikan sesuai dengan algoritma yang didapat pada Bab 2. Tidak ada perubahan yang berarti pada implementasi, hanya disesuaikan dengan struktur data yang digunakan.
4.1.6 Interpretasi Hasil
Hasil dari aplikasi ini berupa cluster – cluster yang merepresentasikan hubungan antar anggotanya. Pengguna dapat memilih cluster yang ingin ditampilkan dan dapat melihat data inti cluster seperti jumlah anggota, diameter, dan titik tengah cluster. Selain itu ditampilkan pula data anggota masing – masing cluster tersebut, beserta jarak anggota ke titik tengah cluster dan jika diinginkan data titik anggota tersebut.
Untuk mengukur kualitas cluster yang dihasilkan ditampilkan pula jarak antara cluster
yang satu dengan cluster yang lain. Dari jarak antar cluster ini, dapat dibandingkan dengan diameter masing – masing cluster. Jika jarak antar cluster cukup lebar dan
diamater masing – masing cluster cukup kecil maka bisa dibilang hasilnya cukup baik. Tidak ada parameter pasti untuk mengukur perbandingan jarak antar cluster
dengan diameter cluster.
Jika kualitas cluster yang dihasilkan dirasa cukup baik, maka dapat disimpulkan bahwa anggota – anggota cluster tersebut memiliki hubungan yang cukup erat. Hal ini dapat digunakan oleh peneliti gen sebagai dasar untuk melakukan penelitiannya. Jika
clustering dilakukan terhadap gen, maka gen – gen yang berada dalam satu cluster
kemungkinan memiliki hubungan dalam proses metabolisme tubuh. Begitu pula jika dilakukan terhadap sampel, maka sampel – sampel yang berada dalam satu cluster
kemungkinan memiliki ciri yang sama berdasarkan kedekatan level gen mereka.
4.2 Pengujian
4.2.1 Tujuan Pengujian
Pengujian dilakukan terhadap aplikasi clustering untuk data ekspresi gen untuk mengetahui apakah implementasi algoritma dan keluarannya sudah memenuhi spesifikasi kebutuhannya.
4.2.2 Lingkungan Pengujian
Pengujian aplikasi dilakukan pada lingkungan yang sama dengan lingkungan implementasi. Keterangan detil lingkungan implementasi dapat dilihat pada subbab 4.1.1.
4.2.3 Skenario Pengujian dan Kriteria Keberhasilan
Data ekspresi gen yang dipakai dalam pengujian didapat dari Eisen Lab [EIS05] berupa data ekspresi gen organisme yeast (ragi) dan data ciri fisik iris dari kumpulan data WEKA. Pengujian dilakukan dalam 2 tahap sebagai berikut.
1. Pengujian validitas algoritma a. Tujuan
Memeriksa apakah implementasi algoritma K-means yang dipakai pada aplikasi clustering ini berfungsi dengan benar dan valid dengan membandingkan hasil keluaran dengan algoritma K-means pada aplikasi WEKA, yaitu aplikasi yang umum dipakai pada pembelajaran mesin (machine learning)
b. Skenario
- Menguji aplikasi dengan data iris yang sudah diketahui terbagi menjadi 3 grup dengan nilai K yang dimasukkan 3.
- Melakukan hal yang sama dengan aplikasi WEKA - Membandingkan hasil yang didapat antara kedua aplikasi c. Kriteria keberhasilan
- Menghasilkan keluaran yang minimal 95% sama dengan WEKA dengan data iris
2. Pengujian dengan data ekspresi gen a. Tujuan
Memeriksa apakah aplikasi dapat memproses data ekspresi gen dengan skala sedang, yaitu data ragi.
b. Skenario
- Menguji aplikasi dengan data ragi dengan nilai K sama dengan 91 sesuai dengan perkiraan jumlah cluster pada data tersebut [GAS02] serta tipe
clustering gen.
- Memeriksa cuplikan hasil keluaran, yaitu tiga cluster secara acak yang masing – masing berukuran kecil, sedang dan besar, dihitung dari statistik dengan membandingkan dengan data dari BioGrid, yaitu data keterkaitan antar gen yang merupakan hasil penelitian.
c. Kriteria keberhasilan
- Menghasilkan keluaran berupa cluster untuk data yang besar
- Menghasilkan cluster yang beberapa anggota – anggotanya memiliki keterkaitan
4.2.4 Hasil Pengujian
4.2.4.1 Hasil Pengujian Validitas Algoritma
Data iris yang dipakai berupa data 4 ciri fisik iris pada 150 sampel iris yang terbagi dalam 3 kelompok yaitu: iris setosa, iris virginica dan iris versicolor, masing – masing memiliki 50 anggota.
Hasil pengujian aplikasi dengan data iris dapat dilihat pada gambar IV-3. Sedangkan hasil WEKA terhadap data iris dapat dilihat pada gambar IV-4.
Gambar IV-3 Hasil aplikasi dengan data iris
Gambar IV-4 Hasil WEKA dengan data iris
Aplikasi ini menghasilkan 3 cluster dengan anggota masing – masing 50, 61 dan 39, sama dengan keluaran yang dihasilkan dengan WEKA. Cluster pertama diisi oleh iris setosa sedangkan cluster kedua dan ketiga diisi oleh gabungan iris virginica dan
versicolor. Dari hasil detil, terlihat bahwa hasil yang diperoleh dari aplikasi sama dengan hasil yang diperoleh dari WEKA dengan tingkat kesamaan 100% berdasarkan jumlah anggota cluster dan anggota – anggotanya.
4.2.4.2 Hasil Pengujian Dengan Data Ekspresi Gen
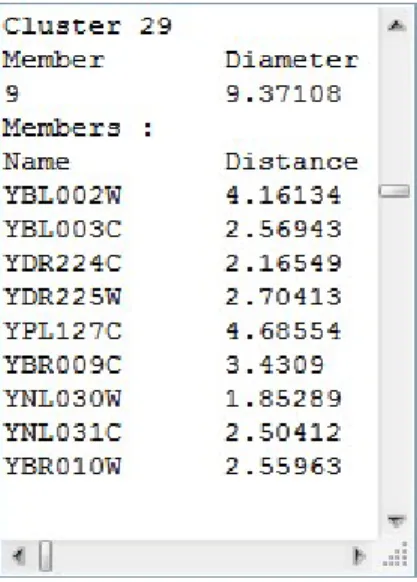
Cuplikan hasil pengujian aplikasi dengan data ekspresi gen dari organisme ragi untuk tipe clustering gen untuk contoh cluster kecil dapat dilihat pada gambar IV-5.
Gambar IV-5 Cuplikan hasil pengujian dengan data ragi (cluster kecil)
Dari data diatas diambil salah satu cluster kecil secara acak (nomor 29) kemudian diambil gen pertama (YBL002W) untuk dicari gen lainnya yang memiliki keterkaitan dengan gen tersebut. Dari web BioGrid [BIO08], didapatkan bahwa gen – gen yang memiliki keterkaitan dengan gen YBL002W adalah: YBL003C, YDR224C, YDR225W, YBR009C, YNL030W, YBR010W. Sementara untuk 2 gen lainnya yaitu YPL127C dan YNL031C belum ditemukan keterkaitan dengan gen YBL002W, sehingga dapat dilakukan penelitian oleh para ahli untuk menentukan kebenaran
cluster tersebut.
Untuk cuplikan contoh cluster yang berukuran sedang dapat dilihat pada gambar IV-6. Contoh cluster yang diambil adalah cluster nomor 21 yang memiliki 48 anggota. Setelah dicocokkan dengan data dari web BioGrid [BIO08], didapatkan bahwa hanya 20 dari 48 anggota yang saling berkaitan. Sedangkan untuk 28 anggota lainnya, belum ditemukan keterhubungannya. Hal tersebut dapat disebabkan oleh 2 hal, salah satunya
merupakan keterbatasan informasi dari BioGrid mengenai keterhubungan gen atau belum dilakukannya penelitian atas gen tersebut.
Gambar IV-6 Cuplikan hasil pengujian dengan data ragi (cluster sedang)
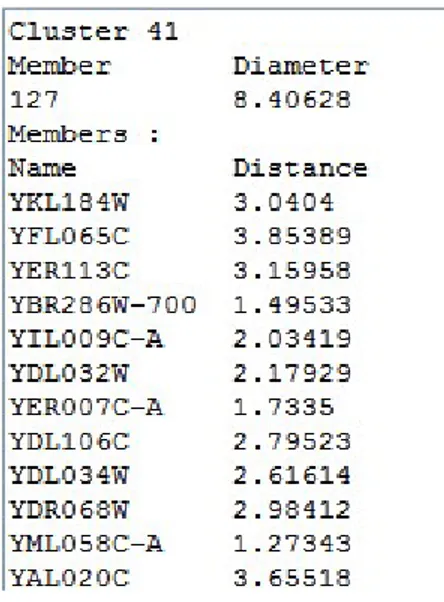
Cuplikan cluster terakhir yang berukuran besar dapat dilihat pada gambar IV-7. Contoh cluster yang diambil adalah cluster nomor 41 yang memiliki 127 anggota. Setelah diperiksa di web BioGrid [BIO08], ternyata hanya 43 anggota yang memiliki keterhubungan, sementara 84 anggota lainnya sebagian memiliki hubungan dengan anggota cluster yang lain, sebagian lagi tidak memiliki hubungan antar gen.
4.3 Analisis Hasil Pengujian
Dari pengujian dengan data iris dapat dilihat bahwa hasil dari aplikasi ini tidak berbeda dengan hasil dari aplikasi WEKA. Maka dapat diambil kesimpulan bahwa implementasi algoritma k-means pada aplikasi ini valid.
Setelah diuji dengan data ekspresi gen dari Eisen Lab kemudian dibandingkan dengan hasil penelitian yang diambil dari BioGrid, ternyata pada salah satu cluster yang berisi 9 anggota telah diketahui 7 dari 9 anggota tersebut memiliki keterkaitan, sedangkan untuk 2 anggota lainnya belum ditemukan adanya keterkaitan. Untuk cluster kedua yang berisi 48 anggota, 20 diantaranya memiliki keterhubungan satu sama lain. Dan untuk cluster berukuran besar (127 anggota), hanya 43 diantaranya yang memiliki hubungan antar gen. Gen – gen yang tidak terkait tersebut ada sebagian yang memiliki hubungan dengan cluster yang lain. Hal ini kemungkinan disebabkan diameter cluster
yang terlalu besar, sehingga jumlah anggotanya terlalu banyak dan kemungkinan anggota cluster lain masuk kedalam cluster tersebut pun semakin besar. Untuk gen – gen yang tidak ditemukan keterhubungannya, dapat dilakukan penelitian oleh ahli untuk memeriksa kebenaran hubungan gen – gen yang berada dalam satu cluster. Selain itu, pemilihan cluster pertama secara acak juga mempengaruhi keluaran. Jika pada awalnya, terdapat dua cluster yang memiliki titik tengah yang agak berdekatan, maka kedua cluster tersebut kemungkinan besar akan berpotongan dan anggota – anggotanya bisa masuk ke cluster yang lainnya.
Melihat hasil aplikasi dengan tingkat keberhasilan dibawah 50%, maka aplikasi dijalankan ulang dengan nilai k yang lebih besar. Hasil dari aplikasi dapat dilihat pada tabel IV-4. Nilai yang tertulis merupakan jumlah anggota yang saling terkait dari total jumlah anggota dalan satu cluster.
Tabel IV-4 Hasil aplikasi untuk dua nilai k
Nilai k Cluster 29 (YBL002W) Cluster 21 (YOR355W) Cluster 41 (YDL106C)
91 7 dari 9 20 dari 48 43 dari 127
150 7 dari 8 19 dari 39 37 dari 76
Dari hasil tersebut, ternyata dengan nilai k yang lebih besar, ukuran masing – masing
cluster menjadi lebih kecil, sehingga tingkat keterhubungan data menjadi semakin tinggi. Jadi dapat diambil kesimpulan bahwa penerapan algoritma k-means pada pengelompokan data ekspresi gen dapat dilakukan. Namun, sebaiknya clustering
dilakukan beberapa kali dengan data yang sama dengan percobaan nilai k yang berbeda – beda. Hal ini dilakukan dengan tujuan cluster yang dihasilkan lebih valid karena pemilihan cluster pertama kali dilakukan secara acak yang menyebabkan hasil yang dikeluarkan aplikasi sedikit berbeda untuk data masukan yang sama.