BAB II TINJAUAN PUSTAKA
2.1 Model Sirkulasi Umum
Model sirkulasi umum atau general circulation model (GCM) merupakan suatu penggambaran matematis dari sejumlah besar interaksi fisika, kimia, dan dinamika atmosfer bumi (Stroch, 1999). GCM ini menduga perubahan iklim dan disajikan tiga layer, yaitu layer horisontal dengan ukuran 100 hingga 600 km, 10 hingga 20 layer vertikal di atmosfer dan kadangkala 30 layer di samudra, seperti disajikan pada Gambar 1.
Gambar 1 Visualisasi Layering pada GCM (Sumber : IPPC, 2011)
Dengan resolusi yang begitu kasar, maka GCM tidak bisa menangkap fitur penting pada suatu area (region) tertentu yang menjadi fokus kajian dampak perubahan iklim. Namun demikian, GCM ini bisa digunakan untuk mengestimasi kepekaan iklim terhadap kondisi yang berbeda seperti perubahan gas rumah kaca (GRK). Oleh karena itu, model GCM memberikan beberapa keuntungan seperti tertera pada Sutikno, 2008, yaitu : (1) dapat digunakan untuk mengestimasi perubahan iklim global dalam merespon terhadap peningkatan konsentrasi GRK, (2) estimasi peubah iklim (curah hujan, suhu, kelembaban) secara fisik sesuai dengan model-model fisika, (3) estimasi peubah cuaca (angin, radiasi, penutupan awan, kelembaban tanah) yang berikutnya menjadi masukan bagi analisis
mengenai dampak, (4) mampu mensimulasi keragaman iklim siklus harian. Disamping kelebihan seperti disebutkan di atas, beberapa kelemahannya adalah : (1) resolusi terlalu kasar, sehingga terjadi gap antara hasil simulasi global, regional dan lokal, (2) model tersebut sulit mengkopel dengan model-model sirkulasi lautan, dan (3) proses-proses umpan balik atmosfer-biosfer tidak terpenuhi. Untuk menjembatani gap antara hasil global dengan regional dan lokal, maka diperlukan satu model yang dikenal dengan nama downscaling.
Dalam perkembangannya, model sirkulasi umum dikenal dengan nama model dinamik untuk memprediksi musim dan kondisi ENSO yang disebut model dinamik Coupled AO-GCM. Kedua model yang terpisah ini dipasangkan dan saling mempengaruhi satu sama lain. Saat model atmorfer bergerak dengan waktu, perubahan-perubahan pada angin rendah (dekat permukaan laut) berfungsi sebagai daya yang menggerakkan model lautan. Dengan bergeraknya model lautan dengan waktu, perubahan pada suhu lautan berfungsi sebagai mesin untuk model atmosfer melalui aliran panas dan uap air dari laut ke atmosfer. Luaran dari prakiraan musim disajikan dalam bentuk peluang yang diperoleh dari banyak model yang dikenal dengan ensemble model. Dalam hal ini Coupled AO-GCM dijalankan beberapa kali dengan nilai input awal yang sedikit berbeda.
2.2 Statistical Downscaling
Statistical Downscaling didefinisikan sebagai upaya menghubungkan antara sirkulasi peubah skala global (peubah penjelas) dan peubah skala lokal (peubah respon, Sutikno 2008). Gambar 2 memberikan ilustrasi proses downscaling.
Pendekatan statistical downscaling (SD) menggunakan data regional (statistic dynamical downscaling) atau global (statistical downscaling) untuk memperoleh hubungan fungsional antara skala lokal dengan skala global GCM, seperti model regresi. Pendekatan SD disusun berdasarkan adanya hubungan antara grid skala besar (prediktor) dengan grid skala lokal (respon) yang dinyatakan dengan model statistik yang dapat digunaan untuk menterjemahkan anomali-anomali skala global yang menjadi anomali dari beberapa peubah iklim lokal. Dalam hal ini SD merupakan suatu fungsi transfer yang menggambarkan
hubungan fungsional sirkulasi atmosfer global dengan unsur-unsur iklim lokal, yang bentuk umumnya adalah (Storch et al, 1993):
)
(
, , , ,p t q s g tf
X
Y
(1) Dengan :Y : Peubah-peubah iklim lokal X : Peubah-peubah luaran GCM t : Periode waktu
p : Banyaknya peubah Y q : Banyaknya peubah X s : Banyaknya lapisan atmosfer g : Banyaknya grid domain GCM
Gambar 2 Ilustrasi proses downscaling, (Sumber : Sutikno 2008)
Pada umumnya model SD melibatkan data deret waktu (t) dan data spasial GCM (g). Banyaknya peubah Y, peubah X, lapisan atmosfer dalam model dan autokorelasi serta kolinearitas pada peubah Y maupun X menunjukkan kompleksitas model.
Saat ini telah banyak dikembangkan model SD yang secara umum dikategorikan menjadi lima, yaitu teknik yang berbasis regresi atau klasifikasi,
berbasis model linear atau non linear, berbasis parametrik dan non parametrik, berbasis proyeksi dan seleksi, serta teknik berbasis model-driven atau data-driven. Pembedaan mengenai model yang dipergunakan sesuai kategori, disajikan secara detail pada Tabel 1. Suatu model perhitungan SD bisa termasuk ke dalam kombinasi ke lima kategori tersebut, sebagai contoh PCR termasuk kategori metode berbasis regresi, linear, parametrik, proyeksim dan data-driven.
Pengembangan model-model downscaling sangat diperlukan untuk pelaksanaan kegiatan kajian dampak keragaman dan perubahan iklim dan penyusunan strategi atau pembuatan keputusan baik pada tingkat pembuatan keputusan sampai petani.
Tabel 1 Kategori teknik downscaling (Sumber : Sutikno 2008)
2.3 Principal Component Analysis (PCA)
Salah satu tantangan dalam analisis peubah ganda adalah mereduksi dimesi dari himpunan data peubah ganda yang besar. Hal ini sering dilakukan dengan cara mereduksi himpunan peubah tersebut menjadi himpunan peubah yang lebih kecil atau himpunan peubah baru yang banyaknya lebih sedikit. Peubah-peubah baru tersebut merupakan fungsi dari Peubah-peubah asal atau Peubah-peubah asal itu sendiri yang memiliki proporsi informasi yang signifikan mengenai himpunan data tersebut (Dillon & Goldstein 1984).
PCA dapat mereduksi q peubah pengamatan menjadi k peubah baru yang saling ortogonal yang masing-masing k peubah baru tersebut merupakan kombinasi linear dari q peubah asal. Pemilihan k peubah baru sedemikian hingga keragaman yang dimiliki p peubah lama dapat diterangkan secara optimal oleh k peubah baru. PCA efektif jika antar q peubah asal memiliki korelasi yang cukup besar (Dillon & Goldstein 1984).
Ada beberapa fungsi dari penggunaan PCA diantaranya adalah (Dillon & Goldstein 1984):
1. Identifikasi peubah baru yang mendasari data peubah ganda, yang bercirikan: merupakan kombinasi linear peubah-peubah asal; jumlah kuadrat koefisien dalam kombinasi linear tersebut adalah satu;tidak berkorelasi;dan mempunyai ragam berurut dari yang terbesar ke yang terkecil.
2. Mengurangi banyaknya dimensi himpunan peubah yang biasanya terdiri atas peubah yang banyak dan saling berkorelasi menjadi peubah-peubah baru yang tidak berkorelasi dengan mempertahankan sebanyak mungkin keragaman dalam himpunan tersebut.
3. Memilih peubah asal yang banyak memberi kontribusi informasi atau menghilangkan peubah asal yang mempunyai kontribusi informasi relatif kecil.
Hasil PCA dapat digunakan untuk analisis lebih lanjut misalkan pengelompokkan (clustering) dan regresi komponen utama.
2.4 Support Vector Regression (SVR)
SVR merupakan penerapan support vector machine (SVM) untuk kasus regresi. Dalam kasus regresi output berupa bilangan riil atau kontinyu. SVR merupakan metode yang dapat mengatasi overfitting, sehingga akan menghasilkan performansi yang bagus (Smola dan Schölkopf, 2003).
Pada Gambar 3, dimisalkan diberikan data training
1 1 2 2
[( ,x y), (x y, ),..., ( ,x yl l)] dengan vektor input xi dan data output yi yang
SVR ingin menemukan suatu fungsi regresi f(x) yang dapat mengaproksimasi output ke suatu target aktual, dengan eror toleransi-ε, dan kompleksitas yang minimal. Fungsi regresi f(x) dapat dinyatakan dengan formula sebagai berikut (Smola dan Schölkopf, 2003):
( ) T ( )
f x w x b
(2) Dimana φ(x) menunjukkan suatu titik didalam ruang fitur berdimensi lebih tinggi, hasil pemetaan dari input vektor x di dalam ruang input yang berdimensi lebih rendah.
Gambar 3 Fungsi regresi pada SVR (Sumber : Smola dan Schölkopf 2003)
Koefisien w dan b diestimasi dengan cara meminimalkan fungsi resiko (risk function) yang didefinisikan dalam persamaan:
2 1 1 1 min , 2 w C i L y f xi i
(3a) yang memenuhi:
i i y w x b (3b)
i i , 1, 2,..., w x y b i Dimana,
0 ( , )0,untuk yang lain
i i i i i i y f x y f x L y f x (3c)
Faktor w2 dinamakan reguralisasi. Meminimalkan w 2 akan membuat suatu fungsi setipis mungkin, sehingga dapat mengontrol kapasitas fungsi. Empirical error diukur dengan ε-insensitive loss function yang diharuskan meminimalkan norm dari w agar mendapatkan generalisasi yang baik untuk fungsi regresi f(x) (Smola dan Schölkopf, 2003). Oleh karena itu diperlukan untuk menyelesaikan problem optimasi berikut:
2 2 1 min w (4a) yang memenuhi:
i i y w x b (4b)
i i , 1, 2,..., w x y b i Diasumsikan bahwa ada suatu fungsi f yang dapat mengaproksimasi semua titik
xi,yi
dengan presisi ε. Dalam kasus ini kita asumsikan bahwa semua titik ada dalam rentang f (feasible). Dalam hal ketidaklayakan (infeasible), dimana mungkin ada beberapa titik yang mungkin keluar dari rentang f , perlu ditambahkan variable slack ξ, ξ* untuk mengatasi masalah pembatasyang tidak layak (infeasible constraint) dalam problem optimasi seperti yang ditunjukkan pada Gambar 4.
Gambar 4 Penambahan variable slack pada SVR (Sumber : Smola dan Schölkopf 2003)
Selanjutnya problem optimasi di atas bisa diformulasikan sebagai berikut:
2 * 1 1 1 m i n , 2 l i i i w C x x l
(5a) yang memenuhi:
* * - - - £ , 1, 2, ..., - - £ , 1, 2, ..., , ³0 T i i i i i i i i y w j x b x Î i l wj x y b x Î i l x x (5b) Konstanta C>0 menentukan tawar menawar (trade off) antara ketipisan fungsi dan batas atas deviasi lebih dari yang masih dapat ditoleransi. Semua deviasi lebih besar daripada ε akan dikenakan pinalti sebesar C. Dalam SVR, εsetara dengan akurasi dari aproksimasi terhadap data training. Nilai ε yang kecil
terkait dengan nilai yang tinggi pada variable slack i(*) dan akurasi aproksimasi yang tinggi. Sebaliknya, nilai yang besar untuk ε berkaitan dengan nilai i(*) yang kecil dan aproksimasi yang rendah seperti yang diilustrasikan oleh Gambar 5.
Gambar 5 Ilustrasi proses SVR (Sumber : Smola dan Schölkopf 2003)
Nilai yang tinggi untuk variable slack akan membuat empirical error mempunyai pengaruh yang besar terhadap faktor regulasi. Dalam SVR, support vector adalah data training yang terletak pada dan diluar batas f dari fungsi keputusan, karena itu jumlah support vector menurun dengan naiknya ε (Smola dan Schölkopf, 2003).
Dalam formulasi dual, problem optimisasi dari SVR adalah sebagai berikut:
* * 1 1 * * 1 1 1 max , 2 i j i i j j i j i i i i i i i K x x y
(6a) yang memenuhi:
*
1 * 0 0 , 1, 2, ..., 0 , 1, 2, ..., i i i i i C i C i
(6b)j i x x
K , adalah dot-product kernel yang didefinisikan sebagai
i
j Tj
i x x x
x
K , . Dengan menggunakan langrange multiplier dan kondisi optimalitas, fungsi regresi secara eksplisit dirumuskan sebagai berikut:
*
1 - , i i i i f x K x x b
(7) 2.5 K-fold Cross ValidationK-fold cross validation merupakan salah satu variasi dari teknik cross validation. k-fold cross validation dilakukan untuk membagi training set dan test set. Inti validasi tipe ini adalah membagi data secara acak ke dalam k himpunan bagian. k-fold cross validation mengulang k-kali untuk membagi sebuah himpunan contoh secara acak menjadi k subset yang paling bebas, setiap ulangan disisakan satu subset untuk pengujian dan subset lainnya untuk pelatihan. Dari k himpunan bagian tersebut dipilih satu himpunan bagian menjadi data uji dan (k-1) dijadikan data latih. Proses ini dilakukan berulang sebanyak k, dimana setiap k himpunan bagian yang ada menjadi data uji dan sisanya menjadi data latih. Namun, secara teori tidak ada tolak ukur yang pasti untuk nilai k.
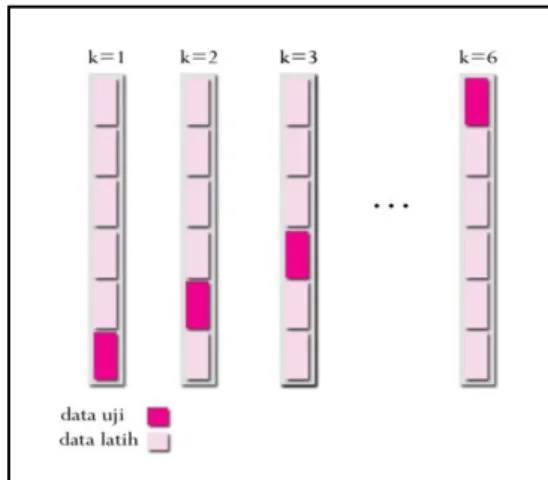
Keuntungan k-fold cross validation dibandingkan dengan variasi cross validation seperti Repeated random sub-sampling validation adalah semua data digunakan baik untuk data uji maupun data latih. Ilustrasi proses validasi dapat dilihat pada Gambar 6.
Gambar 6 Ilustrasi pembagian kelompok data latih dan uji pada k-cross validation (k=6).
2.6 Grid Search
Metode Grid search merupakan salah satu metode yang sederhana untuk mengatasi masalah pengoptimuman (Rao, 2009). Metode ini melibatkan penyusunan grid yang cocok dalam suatu ruang dimensi, mengevaluasi fungsi objektif dari seluruh titik grid, dan menemukan titik grid yang sesuai dengan fungsi objektif yang memiliki nilai optimum. Jika batas atas dan batas bawah dari variable ke- diketahui masing-masing sebagai dan , dapat dibagi range ( , ) ke dalam -1 bagian yang sama, sehingga ( ), ( ), … , ( )menunjukkan titik-titik grid sumbu ( = 1,2,3, … , ).
Gambar 7 Grid dengan = 4
Hal ini menunjukkan kepada total dari , , … , titik grid dalam dimensi ruang. Sebuah grid dengan = 4 ditunjukkan dalam 2 dimensi ruang seperti pada Gambar 7.
Sebagai contoh, akan dicari nilai optimum suatu model/fungsi dengan mencari kombinasi parameter-parameter yang memberikan atau dapat mengaprokmasi nilai terbaik (misalnya memiliki eror yang paling kecil). Ilustrasi metode grid search terlihat pada Gambar 8.
Gambar 8 Ilustrasi metode grid search.
Metode grid search memiliki cara kerja yang hampir serupa dengan percobaan secara manual menggunakan teknik trial dan eror. Mencoba kombinasi parameter satu persatu dan membandingkan nilai terbaik yang diberikan oleh parameter tersebut. Namun perbedaan metode grid search terletak pada proses perbandingan nilai yang tidak dilakukan di awal saat terpilihnya pasangan kombinasi parameter. Pasangan kombinasi dari parameter terlebih dahulu disimpan dalam grid-grid. Selanjutnya perbandingan nilai eror terkecil dilihat dari baris dan kolom pada grid tersebut. Baris ke-i dan kolom ke-j yang memiliki nilai terbaik merupakan kombinasi parameter ke-i dan parameter ke-j terpilih.