Pemodelan
“The model should be complex
enough to fit the data well,”
“but simpler models
are easier to interpret”
tujuan tujuan
Study
Exploratory Exploratory Confirmatory
How Many Predictors
Can You Use?
Strategi pemilihan model
• Evaluasi variabel bebas :
Ideal : 10 respon untuk 1 prediktor
Example :
Jika n = 1000
hanya ada 30 pengamatan dengan Y = 1
Idealnya hanya ada≤ 3 prediktor
Prediktor yang banyak rentan dengan kasus
MULTIKOLINIERITAS
CONTOH KASUS
• Studi mengenai faktor yang mempengaruhi banyaknya satellite kepiting
betina.
• Berat
• Lebar cangkang
• Warna
1 = agak terang
2 = sedang
3 = agak gelap
4 = gelap
• Kondisi Capit
1 = kedua-duanya baik, 0 selainnya
2 = salah satunya cacat, 0 selainnya
X
Y
1 = memiliki satellite ≥ 1 0 = tidak memiliki satellite
Menggunakan peubah boneka
:
MODEL LOGITNYA :
Logit [P(Y=1)] = α +β
1Weight +β
2Width + β
3C
1+ β
4C
2+ β
5C
3+ β
6S
1+ β
7S
2X 1 = Berat
X2 = Lebar Cangkang
C1 = 1 untuk warna agak terang, 0 selainnya
C2 = 1 untuk warna sedang, 0 selainnya
C3 = 1 untuk warna agak gelap, 0 selainnya
S1 = 1 untuk kondisi capit yang kedua-duanya baik, 0 selainnya
S2 = 1 untuk kondisi capit yang salah satunya jelek, 0 selainnya
HASIL ANALISIS
Parameter Estimate SE Intercept -9.273 3.838 Color (1) 1.609 0.936 Color (2) 1.506 0.567 Color (3) 1.120 0.593 Spine (1) -0.400 0.503 Spine (2) -0.496 0.629 Weight 0.826 0.704 Width 0.263 0.195Testing Global Null Hypothesis: BETA=0
• Test Chi-Square DF Pr > ChiSq
Likelihood Ratio 40.5595 7 <.0001
Score 36.3085 7 <.0001
Wald 29.4758 7 0.0001
Uji likelihood-ratio (simultan)
• Hipotesis Uji
H
0
: β
1= · · · = β
7= 0.
H
1
: minimal ada β
i
≠ 0, i = 1, 2,…,7
• Statistik Uji
• G = −2(L
0
− L
1
) = 40.6
db = 7, Pvalue < 0.0001.
• Yang berarti tolak H
0
didapatkan kesimpulan
bahwa minimal ada 1 prediktor yang
mempengaruhi banyaknya satellite pada kepiting
betina.
UJI PARSIAL (WALD)
Parameter Estimate Std Error WaldChi Square Pr> Chisq
Intercept -9.273 3.838 5.835 0.0157 Color (1) 1.609 0.936 2.959 0.0854 Color (2) 1.506 0.567 7.063 0.0079 Color (3) 1.120 0.593 3.565 0.0590 Spine (1) -0.400 0.503 0.634 0.4259 Spine (2) -0.496 0.629 0.623 0.4301 Weight 0.826 0.704 1.379 0.2402 Width 0.263 0.195 1.813 0.1781
Uji Parsial
lanjutan
Catatan :
• Walaupun secara simultan hasilnya signifikan, tetapi
secara parsial hanya color yang sedang yang signifikan, ini
mengindikasikan adanya multikolinieritas.
• Telah diuji dan dibuktikan bahwa width berpengaruh
signifikan terhadap model, sehingga variabel width
digunakan untuk analisis. Sedangkan variabel weight
dibuang.
• weight and width have a strong correlation (0.887). For
practical purposes they are equally good predictors, but it
is nearly redundant to use them both.
SELEKSI MODEL
• Stepwise untuk menyeleksi variabel prediktor
yang masuk dalam model :
1.Forward : Menyeleksi satu persatu variabel
yang masuk dalam model secara sequential
2. Backward : Dimulai dengan memasukkan
semua variabel prediktor, kemudian dibuang satu
persatu secara sequential, sampai didapatkan
model yang paling layak digunakan
CONTOH KASUS : METODE BACKWARD
• Data Kepiting
Model Prediktor Deviance df AIC Model
Banding DevianceBeda 1 C*S+C*W+S*W 173.7 155 209.7 -2 C + S + W 186.6 166 200.6 (2)-(1) 12.9 (df=11) 3a C + S 208.8 167 220.8 (3a)-(2) 22.2 (df=1) 3b S + W 194.4 169 202.4 (3b)-(2) 7.8 (df=3) 3c C + W 187.5 168 197.5 (3c)-(2) 0.9 (df=2) 4a C 212.1 169 220.1 (4a)-(3c) 24.6 (df=1) 4b W 194.5 171 198.5 (4b)-(3c) 7.0 (df=3) 5 C = dark + W 188.0 170 194.0 (5)-(3c) 0.5 (df=2) 6 None 225.8 172 227.8 (6)-(5) 37.8 (df=2)
Memilih model
UJI signifikansi MODEL
:
Model 2 (C+S+W) Vs Model 1 (C*S+C*W+S*W) Beda Deviance = 186.6 - 173.7 = 12.9 db = 166-155 = 11, P-value = 0.30,
Tolak Ha : Tidak diperlukan interaksi pada semua factor dalam model
Hipotesis Ujinya :
Ho : model sederhana lebih baik
Ha : model Yang lebih Lengkap yang lebih baik
l. Model 4b (W) Vs Model 3c ( C+W) Beda deviance = 194.5 - 187.5 = 7.0 Db = 171-168 = 3, P-value = 0.07
Tolak Ha : untuk model ini tidak perlu memasukan variabel Color
MEMILIH model
lanjutan
• Akaike information criterion (AIC)
AIC =
-2 (log likelihood – jumlah parameter dalam model)
= -2 log likelihood + 2 (jumlah parameter dalam model)
Model C + W didapat -2 log likelihood = 187.5
Jumlah parameter 5 ( 1 intercept, width, dan 3 color),
AIC = 187.5 + 2(5) = 197.5
Model yang lebih sederhana
C = dark + W didapat -2 log likelihood = 188
Jumlah parameter 3 ( 1 intercept, color, width)
AIC = 188 + 2(3) = 194.0
TINGKAT KEBAIKAN PREDIKSI MODEL
• TABEL KLASIFIKASI
ŷ = 1 ketika π
i
> π
odan
ŷ =0 ketika π
i
≤ π
ountuk
beberapa nilaicut off pada
π
0
Untuk model (C + W)sebagai prediktor, dari
data 173 kepiting sebanyak 111 memiliki
satellite dengan proporsi sampel
= 111 / 173 = 0.64.
Uji Diagnostik
• Semakin sensitif uji diagnostik, semakin besar kemungkinan
Anda akan mengklasifikasikan individu dengan penyakit
sebagai positif.
• Semakin spesifik uji diagnostik, semakin besar kemungkinan
Anda akan mengklasifikasikan individu tanpa penyakit sebagai
negatif.
• Agar uji diagnostik untuk menjadi akurat, uji tersebut HARUS
sensitive DAN spesifik.
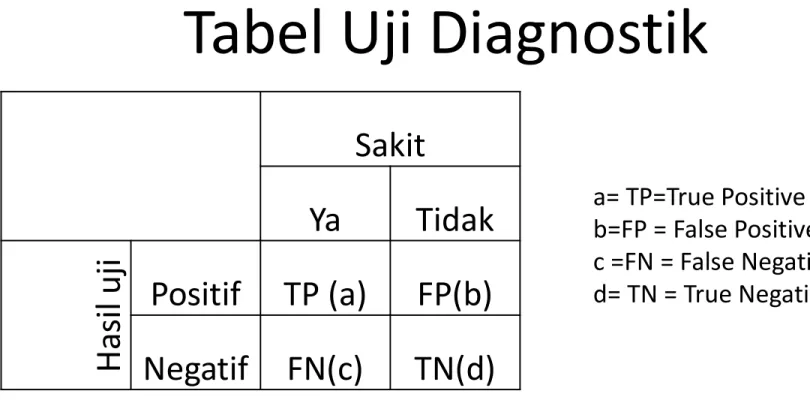
Tabel Uji Diagnostik
Sakit
Ya
Tidak
Ha
sil
u
ji
Positif TP (a) FP(b)
Negatif FN(c) TN(d)
a= TP=True Positive b=FP = False Positive c =FN = False Negative d= TN = True NegativeSensitivitas = proporsi pasien dengan penyakit yang memiliki hasil tes positif = a / (a + c) Spesifisitas = proporsi pasien tanpa penyakit yang memiliki hasil tes negatif = d / (b + d) Positif Predictive Value (PPV) = proporsi pasien dengan hasil tes positif yang memiliki penyakit = a / (a + b)
Negatif Nilai prediktif (NPV) = proporsi pasien dengan hasil tes negatif yang tidak memiliki penyakit = d / (c + d)
• A classification table has limitations: It
collapses continuous predictive values πˆ into
binary ones.
• The choice of π
0is arbitrary.
• Results are sensitive to the relative numbers
of times that y = 1 and y = 0.
PREDIKSI MODEL
TABEL KLASIFIKASI
lanjutan
• Sensitivitas =
• Spesifisitas =
• Ketika π
0
= 0.642
dugaan sensitivitasnya = 74 / 111 = 0.667 dan
dugaan spesifisitasnya = 42/62 = 0.677.
• Proporsi keseluruhan untuk kebenaran
klasifikasi
• = (74 + 42) / 173 = 0.671
y
ˆ
y
1
|
1
P
y
ˆ
y
0
|
0
P
Kurva ROC
• ROC menggambarkan hubungan antara
sensitivitas dan spesifisitas (lihat slide
berikutnya). ROC berhubungan sensitivitas
disumbu x dan 1-spesifisitas pada sumbu y.
Kurva ROC
(A receiver operating charateristic)
1 - Specificity
• Ketika π
0mendekati 0, hampir semua prediksi y = 1;
sensitivitas dekat 1, spesifisitas dekat 0, dan titik untuk (1
-spesifisitas, sensitivitas) memiliki koordinat dekat (1, 1).
• Ketika π
0mendekati 1, hampir semua prediksi y = 0;
sensitivitas dekat 0, spesifisitas dekat 1, dan titik untuk (1
-spesifisitas, sensitivitas) memiliki koordinat dekat (0, 0).
• Untuk spesifisitas, daya prediksi yang lebih baik adalah yang
memiliki sensitivitas lebih tinggi.
• When π0 = 0.642, specificity = 0.68, sensitivity = 0.67,
and the point plotted has coordinates (0.32, 0.67).
• The area under the ROC curve is identical to the value
of a measure of predictive power called the
concordance index.
• Consider all pairs of observations (i, j ) such that yi = 1
and yj = 0.
• The concordance index c estimates the probability that
the predictions and the outcomes are concordant,
which means that the observation with the larger y
also has the larger πˆ .
• A value c = 0.50 means predictions were no better
than random guessing. This corresponds to a model
having only an intercept term. Its ROC curve is a
straight line connecting the points (0, 0) and (1, 1).
• For the horseshoe crab data, c = 0.639 with color
alone as a predictor, 0.742 with width alone, 0.771
with width and color, and 0.772 with width and an
indicator for whether a crab has dark color.
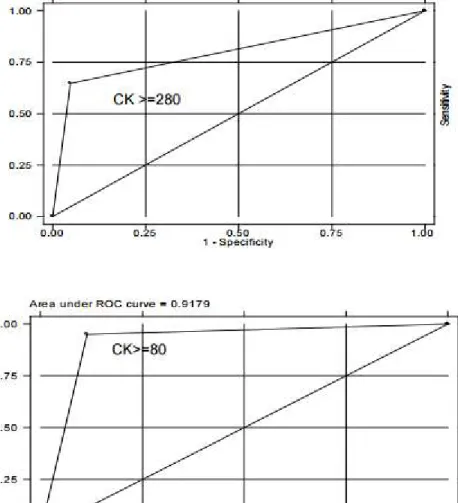
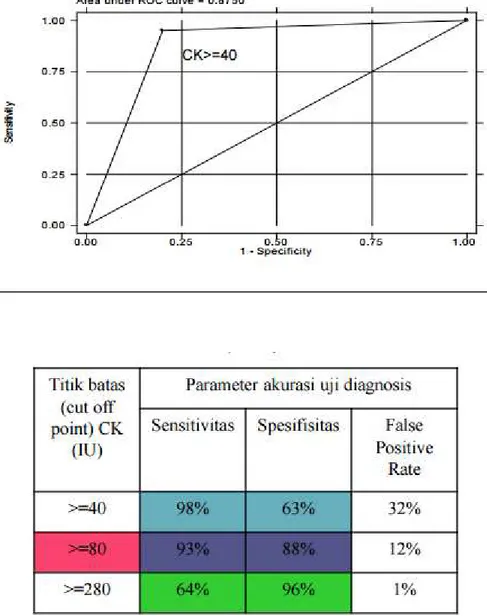
ilustrasi
Sumber: https://rossisanusi.files.wordpress.com
Gambar A menunjukkan bahwa dengan titik cut-off dari CK> = 280 IU,
sensitivitas sedikit rendah sementara spesifisitas tinggi.
Gambar B menunjukan bahwa dengan cut-off point >=80 IU, sensitivitas dan spesifisitas
Gambar C menunjukkan bahwa dengan cut-off point >=40 IU, sensitivitas tinggi dan
spesifisitas agak rendah. Intinya, cut-off point yang dipilih menentukan sensitivitas dan
spesififitas tes
Sumber: https://rossisanusi.files.wordpress.com
Ketepatan (akurasi) keseluruhan tes diagnostik dapat diterangkan oleh luasnya area di bawah kurva ROC; makin luas area makin bertambah baik hasil tesnya (terbaik adalah area ROC pada Gambar B).
Choose Sensitive or Specific Test?
• Sebuah uji yang ideal sangat sensitif dan spesifik. Namun, karena baik
sensitivitas dan spesifisitas yang dibingkai tabel kontingensi 2x2, kenaikan
sensitivitas akan menyebabkan penurunan spesifisitas, dan sebaliknya.
• Pilih tes yang sangat sensitif jika pengobatan yang efektif tersedia untuk
TP(mis tuberkulosis,syphillis, dll). Selain menjadi efektif, perawatan ini
mungkin murah, dan non-ekspansif, sehingga efek samping diabaikan.
• Di sisi lain, temuan FN akan merugikan pasien dan komunitas yang lebih
besar dan menempatkan mereka pada risiko tinggi untuksuatu penyakit
karena mereka tidak diobati dengan tersedia pengobatan yang efektif.
• Pilih uji yang sangat spesifik jika tes invasif, mahal, dan mengakibatkan
efek samping banyak (kemoterapi misalnya untuk kanker) untuk temuan
TN, sementara temuan FP akan menstigmatisasi pasien (mis HV / AIDS)
PEMERIKSAAN MODEL
• Uji Likelihood-ratio
yaitu : membandingkan model yang
sederhana dengan model yang lebih kompleks
Model kompleks kemungkinan mengandung
PERBANDINGAN MODEL
Mis : X = width sebagai prediktor
Modelnya :
logit[π(x)] = α + βx
Dibandingkan dengan unsur Kuadrat
Modelnya
: logit[ (x)] = α + β
1
x + β
2
x
2
Hipotesis Uji :
Ho :
β
2 =
0
• Statistik Uji :
• Uji Likelihood Ratio =0.83 dengan db=1,
P-Value = 0.36
Kesimpulan : Terima Ho yang artinya
Model sederhana lebih baik atau tidak perlu
menggunakan unsur kuadrat dalam model.
GOODNESS Of FIT dan DEVIANCE
• Deviance dapat dicari dengan rumus :
G
2
(M) = 2 observed [log(observed/fitted)]
Statistic pearson dengan rumus :
X
2
(M) =(observed − fitted)
2
/fitted
CONTOH KASUS
Suatu studi ingin mengetahui apakah AZT dapat memperlambat
gejala AIDS
• Peluang gejala AIDS-nya akan terus meningkat bagi subjek
yang menggunakan AZT secepatnya yaitu :
• Proporsi Ras putih yang menggunakan AZT
Proporsi = 14/107 = 0.131
Peluangnya = 0.131/(1 - 0.131) = 0.150
Karena ada 107veteran kulit putih yang menggunakan AZT
maka
Dugaannya : 107 (0.150) = 16
Dugaan veteran yang gejala AIDSnya tidak meningkat
= 107 (0.85) = 91.
• G
2
= 1.38 dan X
2
= 1.39.
• G
2
dan X
2
yang kecil mengindikasikan bahwa
CONTOH KASUS
Pelamar yang diterima (Y), gender (G) dan Departemen (D). nik adalah Jumlah
gender i dalam departemen k, Yik adalah jumlah pelamar yang lulus dan πik
adalah peluang sukses.
contoh departemen astronomi menerima 6 wanita dengan standar deviasi = 2.87 departemen memiliki standar residual yang paling besar yang diduga oleh model.
•the model may be inadequate, perhaps because a gender effect exists in
•some departments or because the binomial assumption of an identical probability •of admission for all applicants of a given gender to a department is unrealistic. Its •goodness-of-fit statistics are G2 = 44.7 and X2 = 40.9, both with df = 23. This