Prosiding SEMINAR NASIONAL SAINSTEK 2018 ISSN: 2541-0636
Jimbaran, Bali – 26 Oktober 2018 | i
TIM PROSIDING
Penanggung Jawab: Drs. Ida Bagus Made Suaskara, M.Si. Pengarah:
Anak Agung Bawa Putra, S.Si., M.Si. Drs. I Wayan Santiyasa, M.Si.
Editorial Team Chief-in-Editor
Drs. I Made Satriya Wibawa, M.Si. Associate Editor
I Gede Nyoman Konsumajaya, S.H. Editorial Board:
Sony Heru Sumarsono, Ph.D. (ITB)
Imas Sukaesih Sitanggang, S.Si., M.Si. Ph.D. (IPB) Dr. Drs. I Made Sukadana, M.Si. (UNUD)
Dr. Drs. Anak Agung Ngurah Gunawan, M.Si. (UNUD) Dr. I Ketut Ginantra, S.Pd., M.Si. (UNUD)
Desak Putu Eka Nilakusmawati, S.Si., M.Si. (UNUD) Dewa Ayu Swastini, S.Farm., M.Farm., Apt. (UNUD) Dr. I Ketut Gede Suhartana, S.Kom., M.Kom. (UNUD)
Luh Putu Pebriyana Larasanty, S.Farm., M.Farm., Apt. (UNUD) Dr. I Wayan Gede Gunawan, S.Si., M.Si. (UNUD)
Dr. Dra. Ngurah Intan Wiratmini, M.Si. (UNUD) Sekretariat:
Dr. Sagung Chandra Yowani, S.Si., M.Si., Apt. Ni Luh Putu Rusmadewi, S.S.T.
Luh Putu Martiningsih, S.T.
I Gusti Ayu Agung Made Widiasih, S.Sos. Dra. Ni Wayan Satriasih
Ir. Ni Made Arini Desain Grafis:
I Komang Ari Mogi, S.Kom., M.Si. I Gede Artha Wibawa, S.T., M.Kom.
Prosiding SEMINAR NASIONAL SAINSTEK 2018 ISSN: 2541-0636
ii | Jimbaran, Bali – 26 Oktober 2018
KATA PENGANTAR
Puja dan puji syukur kita panjatkan kehadirat Ida Sanghyang Widhi Wasa/Tuhan Yang Maha Esa, karena atas berkat-Nyalah maka Prosiding Seminar Nasional Sains dan Teknologi (SAINSTEK) tahun 2018 dapat dilaksanakan sesuai dengan harapan.
Seminar Nasional Sains dan Teknologi ini mengambil tema “Penguatan Riset Perguruan Tinggi untuk Pengembangan Sains dan Teknologi yang Berkelanjutan” yang diselenggarakan oleh Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Udayana pada tanggal 26 Oktober 2018, bertempat di Universitas Udayana Kampus Bukit Jimbaran, Bali.
Sebagai lembaga pendidik, dimana salah satu tugas pokok dan fungsi dari civitas akademika adalah melakukan penelitian yang kemudian dipublikasikan untuk dapat disebarkan kepada masyarakat luas. Oleh karena itu Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Udayana melaksanakan kegiatan dalam bentuk seminar nasional Sains dan Teknologi tahun 2018.
Adapun tujuan dari Seminar Nasional SAINSTEK ini yaitu meningkatkan pengetahuan dan pemahaman tentang keilmuan sains dan teknologi dan meningkatkan kepedulian tentang pentingnya publikasi untuk para penelitian, baik yang memperoleh dana penelitian Unggulan Program Studi dan Unggulan Udayana, serta memberikan wahana dalam publikasi ilmiah bagi peneliti, dosen, dan mahasiswa, maupun civitas akademika dan masyarakat lain.
Peserta seminar nasional SAINSTEK ini dihadiri oleh dosen, mahasiswa, dan peneliti lain yang berjumlah 105 pemakalah dan 400 peserta dan tamu undangan. Invited speaker dalam seminar ini mengundang Sony Heru Sumarsono, Ph.D. (Institut Teknologi Bandung) dan Imas Sukaesih Sitanggang, S.Si., M.Si., Ph.D (Institut Pertanian Bogor). Atas nama panitia, kami mengucapkan terimakasih yang sebesar-besarnya atas kesediaan beliau semua hadir dalam Seminar ini.
Kami dari pihak panitia mengucapkan terima kasih kepada semua peserta dan pemakalah yang telah mengirimkan makalahnya untuk diterbitkan pada prosiding seminar nasional SAINSTEK tahun 2018. Terima kasih pula kepada Rektor Universitas Udayana, pihak Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Udayana, pihak sponsor dan panitia baik dari staf dosen, staf pegawai, panitia mahasiswa, serta semua pihak yang turut memberikan kontribusi atas suksesnya pelaksanaan kegiatan ini.
Ketua Panitia
Prosiding SEMINAR NASIONAL SAINSTEK 2018 ISSN: 2541-0636
Jimbaran, Bali – 26 Oktober 2018 | iii
DAFTAR ISI
TIM PROSIDING ……… ..………. i
KATA PENGANTAR ………... ii
DAFTAR ISI ……….……….. iii-iv
DAFTAR ARTIKE L
MONITORING JENIS DAN BIODIVERSITAS BURUNG DI KAMPUS UNUD BUKIT J IMBARAN, BALI
Anak Agung Gde Raka Dalem, Ida Bagus Made Suaskara, I Ketut Ginantra, I Ketut Muksin, dan Sang Ketut Sudirga ……….…….. 1-9 FRAKSINASI DAN AKTIVITAS ANTIOKSIDAN EKSTRAK ETIL
ASETAT MANGGIS (GARCINIA MANGOSTANA L.)
Ni Putu Ayu Dewi Wijayanti dan Ketut Widyani Astuti ……….. 10-14 FAKTOR-FAKTOR YANG MEMPENGARUHI KECENDERUNGAN
KONSUMEN TERHADAP SHOPEE DAN INSTAGRAM
Irena Nofrita, Ni Kadek Sriandani, Getser Surbakti, dan I P. W. Gautama ….….. 15-22 PERSEPSI KONSUMEN DALAM PEMILIHAN BUKU CETAK DAN
E-BOOK
Ni Kadek Nita Silvana Suyasa, Ni Made Dinda Pratiwi, Ni Made Sintya
Sugiarni, dan D.P.E. Nilakusmawati ……….…... 23-27 PENGUKURAN KEBERHASILAN PEMBELAJARAN SAINTIFIK PADA
MATA KULIAH ANALISIS DATA KATEGORIK SECARA KUALITATIF DAN KUANTITATIF
M. Susilawati ………... 28-32 PENCARIAN SUMBER AIR TANAH DENGAN METODE GEOLISTRIK
UNTUK PENGEMBANGAN PARIWISATA DI TAMAN HARMONI BALI BUKIT ASAH BUGBUG KARANGASEM
I Nengah Simpendan I Wayan Redana ……… 33-38
LOYALITAS KONSUMEN TERHADAP PASAR TRADISIONAL
Kimberly Rose, Made Ayugia Bunga Nirmala, I Gusti Ayu Suci Wiratni, dan
D.P.E. Nilakusmawati ………. 39-42
AUTOMATIC TEMPERATURE CONTROL SYSTEM ON AT89S51 MICROCONTROLLER BASED INCUBATOR
I Made Satriya Wibawa, I Ketut Putra, Bhakti Hardian Yusuf, dan Cici Izzah
Prosiding SEMINAR NASIONAL SAINSTEK 2018 ISSN: 2541-0636
iv | Jimbaran, Bali – 26 Oktober 2018
ANALISIS PREFERENSI KECENDERUNGAN PENGGUNA APLIKASI WHATSAPP DAN LINE
Ummu Kulsum, Namira, Wiwin Winda Sari, dan D.P. E. Nilakusmawati ………... 49-55 THE SPECIES, DIVERSITY INDEX AND STATUS OF BUTTERFLIES IN
JATILUWIH, TABANAN-BALI
Anak Agung Gde Raka Dalem and I Gusti Ayu Sugi Wahyuni ……… 56-62 KECENDERUNGAN PEMBELIAN TIKET PESAWAT DAN BOOKING
KAMAR HOTEL SECARA ONLINE
Febby Verennika, Indri Susanti Malo, Ainun Zamzam, dan I P. W. Gautama …. 63-72 ROLE EDUCATION OF SELF MANAGEMENT TO KNOWLEDGE LEVEL
IN DIABETES MELLITUS TYPE II PATIENT
Made Ary Sarasmita, I Gusti Ayu Artini Ekajaya Amandari, dan Sari Dewi ….. 73-77 PREFERENSI KONSUMEN MENGGUNAKAN MTIX/TIXID DALAM
MEMBELI TIKET BIOSKOP SECARA ONLINE
Sisilia Martina Utami Agustini, Putu Widya Astuti, Ayu Lestari Br Ginting, dan
D.P.E. Nilakusmawati ………. 78-82
MENGUKUR TINGKAT KEPUASAN PENGGUNA TERHADAP
LAYANAN APLIKASI GO-LIFE
Boby Al-Qurthuby, Agung Benny Butar-Butar, Feliks Andrea, dan Muhammad
Sultoni ………. 83-88
KUALITAS DAN STATUS MUTU PERAIRAN DANAU BATUR DAN DANAU BERATAN DI BALI
I Ketut Sundra ……….. 89-94 ALGORITMA K-NEAREST CLASSIFIER UNTUK KLASIFIKASI INDEKS
PEMBANGUNAN MANUSIA DI INDONESIA
I Gusti Ngurah Lanang Wijayakusuma ……… 95-107 PEMINDAIAN KETERBELITAN KUANTUM KELAS W DAN GHZ
MELALUI KRITERIA RANK PENYELARAS BERLAPIS
I N. Artawan dan N.L.P. Trisnawati ……… 108-114
MENGUNGKAP MUNCULNYA MATA AIR DI CANDIDASA
KARANGASEM BALI BERDASARKAN DATA GEOLISTRIK
I Nengah Simpen, Ni Nyoman Susi Kesuma Wardani, dan Ni Made Widya
Prosiding SEMINAR NASIONAL SAINSTEK 2018 : 95-107 ISSN: 2541-0636
95
ALGORITMA K-NEAREST NEIGHBORS CLASSIFIER UNTUK KLASIFIKASI INDEKS PEMBANGUNAN MANUSIA DI INDONESIA
I Gusti Ngurah Lanang Wijayakusuma
Program Studi Matematika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Udayana
Email: [email protected] ABSTRACT
Indonesia is a developing country, and to become one of the developed countries, certainly needed human resources that can compete. The quality of human resources in a country can be seen from the level of economic growth, equity and national stability. Success or failure of human resource development itself is measured by Human Development Ideks (IPM). One method that can be applied in classifying HDI is K- nearest Neighbors.
Keywords: k-nearest neighbors, Human Development Index, Classification
1. PENDAHULUAN
Indonesia saat ini merupakan negara berkembang, negara berkembang adalah negara yang sedang membangun jika dibandingkan dengan negara-negara yang ekonominya lebih maju (Ragnar Nurkse, 1992). Pembangunan dilakukan berdasarkan trilogi pembangunan. Tiga landasan dalam trilogi pembangunan meliputi pertumbuhan ekonomi, pemerataan dan stabilitas nasional. Kualitas dari sumber daya manusia memiliki peran yang paling utama dalam pembangunan ekonomi. Manusia sebagai pelaku proses serta menjadi modal dalam pembangunan. Indeks Pembangunan Manusia (IPM) merupakan suatu cara yang digunakan untuk mengukur berhasil tidaknya satu negara atau wilayah dalam bidang pembangunan manusia.
Indeks Pembangunan Manusia (IPM) mengukur capaian pembangunan manusia berbasis sejumlah komponen dasar kualitas hidup. Sebagai ukuran kualitas hidup, IPM dibangun melaluli pendekatan tiga dimensi dasar. Dimensi tersebut mencangkup umur panjang dan sehat, pengetahuan, dan kehidupan layak. Ketiga dimensi tersebut memiiki pengertian yang sangat luas karena terkait banyak faktor. Untuk megukur dimensi kesehatan, digunakan angka harapan hidup waktu lahir. Selanjutnya untuk mengukur dimensi pengetahuan digunakan gabungan indikator kemampuan angka melek huruf dan rata-rata lama sekolah. Adapun untuk mengukur dimensi hidup layak digunakan indikator kemampuan daya beli masyarakat terhadap sejumlah kebutuhan pokok yang dilihat dari rata-rata besarnya pengeluaran per kapita sebagai pendekatan pendapatan yang mewakili capaian pembangunan untuk hidup layak (BPS, 2015).
Sehingga didapatkan komponen Indeks Pembangunan Manusia (IPM) yang meliputi angka harapan hidup, angka melek huruf, rata-rata lama sekolah dan pengeluaran riil per kapita. Angka Harapan Hidup (AHH) pada waktu lahir yang merupakan rata-rata perkiraan banyak tahun yang dapat ditempuh oleh seseorang selama hidup. Angka melek huruf yang merupakan persentase penduduk usia 15 tahun keatas yang dapat membaca dan menulis huruf latin dan huruf lainnya. Selanjutnya rata-rata lama sekolah yang menggambarkan jumlah tahun yang digunakan oleh penduduk usia 15 tahun keatas dalam menjalani pendidikan formal. Dan yang terakhir pengeluaran riil per kapita yang disesuaikan.
Klasifikasi Indeks Pembangunan Manusia menurut (BPS, 2014) yang telah disusun, maka ditetapkan empat kelompok daerah. Pertama, daerah dengan tingkat pembangunan manusia yang rendah bila IPM-nya < 60. Daerah yang masuk kategori ini sama sekali atau
ALGORIT M A K-NEAREST NEIG HBOR S CLASSI FIER UNTU K KLASI FI KASI INDE KS PEMB ANG UN AN MANUSI A DI INDO N ESIA
I Gusti Ngurah Lanang Wijayakusuma
96
kurang memperhatikan pembangunan sumber daya manusia. Kedua, daerah dengan tingkat pembangunan manusia sedang jika IPM-nya berkisar antara 60 sampai 70. Daerah yang masuk kategori ini mulai memperhatikan pembangunan sumber daya manusianya. Ketiga, daerah dengan tingkat pembangunan manusia tinggi jika IPM-nya berkisar antara 70 sampai 80. Daerah yag masuk kategori ini sangat memperhatikan pembangunan sumber daya manusianya. Dan yang ke empat adalah daerah dengan tingkat pembangunan manusianya sangat tinggi dengan IPM > 80. Daerah yang masuk kategori ini adalah daerah yang sangat baik dalam membangun sumber daya manusianya.
k-nearset neighbor (k-NN) merupakan salah satu metode klasifikasi yang terdapat dalam machine learning dan termasuk dalam kelompok instace-beased learning. (k-NN) dilakukan dengan mencari dengan mencari k objek dalam data training yang paling dekat(mirip) dengan objek pada data testing (Wu, 2009). Data training diproyeksikan kedalam ruang yang berdimensi banyak, dimana masing-masing dimensi mempresentasikan fitur dari data. Dekat atau jauhnya tetangga/data bisa dihitung berdsarkan jarak Euclidean. k-nearset neighbor (k-NN) adalah metode yang sering digunakan dalam pengklasifikasian pada umumnya dan seringkali menghasilkan akurasi klasifikasi yang tinggi. Hal ini dperkuat oleh penelitian yang telah dilakukan oleh (Wali Ja‟far Shudiq, 2017) dengan judul ” Penerapan k-nearset neighbor berbasis algoritma genetika untuk klasifikasi mutu padi” pada penelitian ini (k-NN) mampu mengasilkan akurasi yang tinggi.
Dari penelitian tentang k-nearset neighbor tersebut, maka dalam penelitian ini akan meggunakan metode k-NN dengan K-nearest neighbors Classifier untuk pengklasifikasian Indeks Pembangunan Manusia Kabupaten/Kota se-Indonesia.
2. METODE PENELITIAN 2.1. Rumusan Masalah
Berdasarkan latar belakang masalah di atas, maka dapat ditemukan masalah yang akan diselesaikan dalam penelitian ini adalah :
1. Bagaimana metode K-nearest neighbors yang optimal untuk klasifikasi Indeks Pembangunan Manusia di Indonesia?
2. Apakah metode K-nearest neighbors dapat digunakan untuk melakukan klasifikasi Indeks Pembangunan Manusia?
2.2. Batasan Masalah
Untuk menghindari penyimpangan dari judul dan tujuan yang sebenarnya, maka penulis membuat batasan permasalahan pada penelitian ini, adapun batasan masalahnya adalah :
1. Penelitian yang dilakukan menggunakan data angka harapan hidup (tahun), harapan lama sekolah (tahun), rata-rata lama sekolah (tahun), pengeluaran perkapita disesuaikan, dan Indeks Pembangunan Manusia di Indonesia.
2. Data yang digunakan adalah data dari BPS Indonesia dari tahun 2013.
3. Output dari hasil penelitian merupakan hasil klasifikasi dalam bentuk grafik dan sistem yang dapat melakukan klasifikasi kabupaten/kota dalam waktu ke depan. 2.3. Manfaat Penelitia
1. Memperluas dan memperdalam pengetahuan dengan menerapkan ilmu pengetahuan yang diperoleh pada perkuliahan khususnya machine learning. 2. Dengan adanya penelitian dalam bidang klasifikasi IPM ini dapat membantu
pemerintah dalam menentukan kebijakan/keputusan yang tepat dan klasifikasi dengan tingkat kesalahan yang minim.
3. Mendapat pengetahuan tentang metode K-nearest neighbors yang merupakan salah satu metode machine learning.
Prosiding SEMINAR NASIONAL SAINSTEK 2018 : 95-107 ISSN: 2541-0636
97 2.4. Penelitian Sebelumnya
1. Penelitian oleh (BPS, 2014) dengan judul “Indeks Pembangunan Manusia (Human Development Index)”. Menjelaskan bagaimana mengelompokkan bobot IPM kedalam 4 kelompok daerah, yaitu kelompok daerah dengan IPM rendah, sedang, tinggi, dan sangat tinggi. Yang dimana daerah dengan tingkat pembangunan manusia yang rendah bila IPM-nya < 60. Daerah yang masuk kategori ini sama sekali atau kurang memperhatikan pembangunan sumber daya manusia. Kedua, daerah dengan tingkat pembangunan manusia sedang jika IPM-nya berkisar antara 60 sampai 70. Daerah yang masuk kategori ini mulai memperhatikan pembangunan sumber daya manusianya. Ketiga, daerah dengan tingkat pembangunan manusia tinggi jika IPM-nya berkisar antara 70 sampai 80. Daerah yag masuk kategori ini sangat memperhatikan pembangunan sumber daya manusianya. Dan yang ke empat adalah daerah dengan tingkat pembangunan manusianya sangat tinggi dengan IPM > 80. Daerah yang masuk kategori ini adalah daerah yang sangat baik dalam membangun sumber daya manusianya.
2. Penelitian oleh (BPS, 2015) dengan judul “Indeks Pembangunan Manusia Menurut Kabupaten/Kota”. Menjelaskan faktor-faktor yang mempengaruhi IPM, yang terdiri dari angka harapan hidup, angka melek huruf, rata-rata lama sekolah, dan pengeluaran riil per kapita yang disesuaikan. Angka Harapan Hidup (AHH) pada waktu lahir yang merupakan rata-rata perkiraan banyak tahun yang dapat ditempuh oleh seseorang selama hidup. Angka melek huruf yang merupakan persentase penduduk usia 15 tahun keatas yang dapat membaca dan menulis huruf latin dan huruf lainnya. Selanjutnya rata-rata lama sekolah yang menggambarkan jumlah tahun yang digunakan oleh penduduk usia 15 tahun keatas dalam menjalani pendidikan formal. Dan yang terakhir pengeluaran riil per kapita yang disesuaikan. 3. Penelitian oleh (Moh Yamin Darsyah dan Rochdi Wasono, 2013) dengan judul “Pendugaan IPM Kecil di Kota Semarang dengan Pendekatan Non Parametrik”. Menjelaskan Variabel penelitian yang digunakan dalam penelitian IPM meliputi Indeks Pembangunan Manusia (IPM) sebagai variabel respon (Y) serta angka harapan hidup, rata-rata lama sekolah, harapan lama sekolah dan pengeluaran perkapita yang disesuaikan sebagai variabel predictor (X).
2.5. K-nearest neighbors
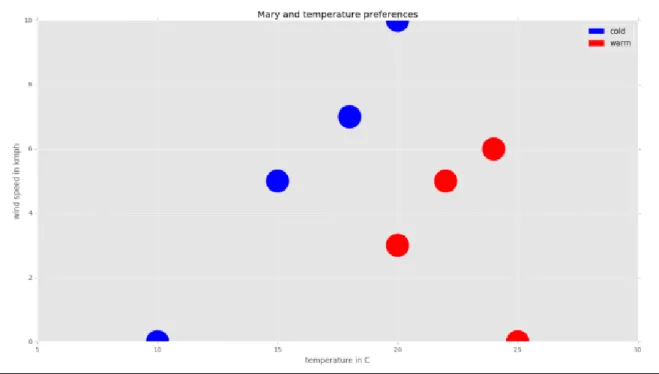
Tabel 1. Contoh data pembelajaran
Tempraure in Celcius Wind Speed in km/h Mary’S Percepton
10 0 Cold 25 0 Warm 15 5 Cold 20 3 Warm 18 7 Cold 20 10 Cold 22 5 Warm 24 6 Warm
Sumber : Data Science Algorithms in a Week
K-nearest neighborss atau k-NN adalah algoritma yang berfungsi untuk melakukan klasifikasi suatu data berdasarkan data pembelajaran (train data sets), yang diambil dari k tetangga terdekatnya (nearest neighbors). Dengan k merupakan banyaknya tetangga terdekat.
ALGORIT M A K-NEAREST NEIG HBOR S CLASSI FIER UNTU K KLASI FI KASI INDE KS PEMB ANG UN AN MANUSI A DI INDO N ESIA
I Gusti Ngurah Lanang Wijayakusuma
98
2.6. Klasifikasi Terdekat (Nearest Neighbor Classification)
Data baru yang diklasifikasi selanjutnya diproyeksikan pada ruang dimensi banyak yang telah memuat titik-titik c data pembelajaran. Proses klasifasikasi dilakukan dengan mencari titik c terdekat dari c-baru (nearest neighbor).
Gambar 1. Contoh proyeksi data pembelajaran
Teknik pencarian tetangga terdekat yang umum dilakukan dengan menggunakan formula jarak euclidean. Berikut beberapa formula yang digunakan dalam algoritma k-NN untuk mencari tetangga terdekat.
a) Euclidean Distance
Euclidean distance adalah formula untuk mencari jarak antara 2 titik dalam ruang dua dimensi.
b) Humming Distance
Hamming distance adalah cara mencari jarak antar 2 titik yang dihitung dengan panjang vektor biner yang dibentuk oleh dua titik tersebut dalam block kode biner.
c) Manhattan Distance
Manhattan distance atau taxicab geometri adalah formula untuk mencari jarak d antar 2 vektor p,q pada ruang dimensi n.
d) Minkowski Distance
Minkowski distance adalah formula pengukuran antar 2 titik pada ruang vektor normal yang merupakan hibridisasi yang mengeneralisasi euclidean distance dan mahattan distance. 2.7. Banyaknya k Tetangga Terdekat
Untuk menggunakan algoritma K-nearest neighborss, perlu ditentukan banyaknya k tetangga terdekat yang digunakan untuk melakukan klasifikasi data baru. Banyaknya k, sebaiknya merupakan angka ganjil, misalnya k = 1, 2, 3, dan seterusnya. Penentuan nilai k dipertimbangkan berdasarkan banyaknya data yang ada dan ukuran dimensi yang dibentuk oleh data. Semakin banyak data yang ada, angka k yang dipilih sebaiknya semakin rendah. Namun, semakin besar ukuran dimensi data, angka k yang dipilih sebaiknya semakin tinggi.
Prosiding SEMINAR NASIONAL SAINSTEK 2018 : 95-107 ISSN: 2541-0636
99 Algoritma K-nearest neighborss
i. Tentukan k bilangan bulat positif berdasarkan ketersediaan data pembelajaran ii. Pilih tetangga terdekat dari data baru sebanyak k
iii. Tentukan klasifikasi paling umum pada langkah (ii), dengan menggunakan frekuensi terbanyak
iv. Keluaran klasifikasi dari data sampel baru 2.8. K-Vold Cross Validation
K-Vold Cross-validation (CV) adalah metode statistik yang dapat digunakan untuk mengevaluasi kinerja model atau algoritma dimana data dipisahkan menjadi dua subset yaitu data proses pembelajaran dan data validasi / evaluasi. Model atau algoritma dilatih oleh subset pembelajaran dan divalidasi oleh subset validasi. Selanjutnya pemilihan jenis CV dapat didasarkan pada ukuran dataset. Biasanya K-Vold CV digunakan karena dapat mengurangi waktu komputasi dengan tetap menjaga keakuratan estimasi.
Misalkan 𝑡𝑙𝑘 dan 𝑦𝑙𝑘 (k = 1, 2, 3,…, 10 dan l = 1, 2, 3, … , Ncv) menjadi nilai target dan nilai prediksi pengamatandata l dalam subset k. Maka, kinerja model atau algortima dapat diperkirakan dengan mean square error cross-validaton (MSECV) sebagai berikut.
𝑀𝑆𝐸𝐶𝑉 = 1 10 1 𝑁𝑐𝑣 ∑ ∑(𝑡𝑙𝑘− 𝑦 𝑙𝑘)2 𝑁𝑐𝑣 𝑖=𝑙 10 𝑘=1
Kita menggunakan CV untuk memilih model yang sesuai dengan membandingkan nilai mean squared error dari cross-validation (MSECV). Model ini atau logaritma terbaik dipilih jika memiliki nilai MSECV terendah disbanding yang lain.
2.9. MSE
Mean Squared Error (MSE) adalah metode lain untuk mengevaluasi metode peramalan. Masing-masing kesalahan atau sisa dikuadratkan. Kemudian dijumlahkan dan ditambahkan dengan jumlah observasi. Pendekatan ini mengatur kesalahan peramalan yang besar karena kesalahan-kesalahan itu dikuadratkan. Metode itu menghasilkan kesalahan-kesalahan sedang yang kemungkinan lebih baik untuk kesalahan kecil, tetapi kadang menghasilkan perbedaan yang besar. 𝑀𝑆𝐸 = ∑ 𝑒𝑖 2 𝑛 = ∑(𝑋𝑖− 𝐹𝑖)2 𝑛
ALGORIT M A K-NEAREST NEIG HBOR S CLASSI FIER UNTU K KLASI FI KASI INDE KS PEMB ANG UN AN MANUSI A DI INDO N ESIA
I Gusti Ngurah Lanang Wijayakusuma
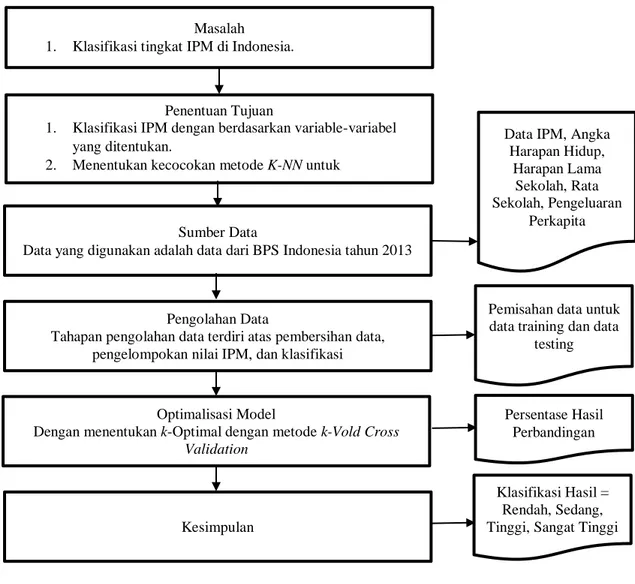
100 2.10. Kerangka Pemikiran
Gambar 1. Kerangka Pemikiran 2.11. Prosedur Penelitian
Penelitian ini pertama diawali dengan tahap identifikasi dan pengumpulan data, pencarian literatur, kemudian dilanjutkan dengan tahap persiapan dan seleksi data, pembentukan data baru, proses machine learning, dan yang terakhir adalah optimalisasi. a. Identifikasi dan Pengumpulan Data
Pada tahap ini dilakukan identifikasi terhadap penelitian yang akan dilakukan dan melakukan pengumpulan data yang sesuai dengan penelitian. Pada pengumpulan data, data yang digunakan adalah data IPM Seluruh Kabupaten/Kota di Indonesia pada tahun 2013. Data ini didapatkan dari data Badan Pusat Statistik Indnesia.
b. Pencarian Literatur
Tahap ini adalah mencari literatur dari buku-buku maupun jurnal penelitian terdahulu tentang Indeks Pembangunan Manusia serta beberapa faktor yang mempengaruhinya, metode machine learning yang digunakan yaitu K-nearest neighbors, dan algoritma untuk pencarian k-Optimal yaitu k-Vold Cross Validation.
Masalah 1. Klasifikasi tingkat IPM di Indonesia.
Penentuan Tujuan
1. Klasifikasi IPM dengan berdasarkan variable-variabel yang ditentukan.
2. Menentukan kecocokan metode K-NN untuk mengklasifikasi IPM.
Sumber Data
Data yang digunakan adalah data dari BPS Indonesia tahun 2013
Data IPM, Angka Harapan Hidup, Harapan Lama Sekolah, Rata Sekolah, Pengeluaran Perkapita Pengolahan Data
Tahapan pengolahan data terdiri atas pembersihan data, pengelompokan nilai IPM, dan klasifikasi
Pemisahan data untuk data training dan data
testing
Optimalisasi Model
Dengan menentukan k-Optimal dengan metode k-Vold Cross Validation Persentase Hasil Perbandingan Kesimpulan Klasifikasi Hasil = Rendah, Sedang, Tinggi, Sangat Tinggi
Prosiding SEMINAR NASIONAL SAINSTEK 2018 : 95-107 ISSN: 2541-0636
101 c. Persiapan dan Pemilihan Data
Melakukan persiapan terhadap data yang telah didapat seperti melihat struktur tabel yang ada pada database. Pemilihan data dilakukan karena tidak semua tabel serta data yang ada dalam database memiliki nilai, sehingga hanya data yang memiliki nilai yang akan digunakan.
d. Pembersihan Data
Tahap ini dilakukan untuk memastikan bahwa tidak ada data yang terduplikasi, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data. Data yang telah bersih dari kesalahan dapat mempermudah penelitian dan mencegah adanya kesalahan pada penelitian. e. Pembentukan Data Baru
Pembentukan data baru ini agar data yang didapat dan telah bersih dari kesalahan bisa dibentuk menjadi sebuah tabel baru yang sesuai dengan algoritma K-NN untuk melakukan klasifikasi IPM serta mencari k-Optimal pada algoritma K-NN. Serta pengelompokan data nilai IPM kedalam satuan rendah, sedang, tinggi, dan sangat tinggi dengan menggunakan bilangan numerik, seperti :
1 = Rendah 2 = Sedang 3 = Tinggi
4 = Sangat Tinggi
f. Proses Machine Learning
Tahap yang sangat penting dalam penelitian. Pada tahap ini ada beberapa tahap dilakukan yaitu:
1. Proses pencarian k-Optimal pada algoritma k-NN menggunakan metode k-Vold Cross Validation.
2. Setelah mendapatkan nilai k-Optimal, nilai tersebut digunakan untuk di uji akurasinya menggunakan data real sebanyak 511 buah dari data sehingga akan diketahui berapa banyak data yang memiliki banyak ketepatan klasifikasi.
3. Tahap terakhir adalah melakukan klasifikasi IPM dengan menggunakan algoritma k-NN dengan nilai k hasil dari k-Volds Cross Validation dengan variabel input yaitu Angka harapan hidup, harapan lama sekolah, rata sekolah, dan pengeluaran perkapita.
g. Evaluasi
Tahap ini adalah tahap dimana pola informasi yang dihasilkan dari proses machine learning ditampilkan dalam bentuk yang dapat dipahami oleh pihak yang berkepentingan.
3. HASIL DAN PEMBAHASAN 3.1. Hasil Penelitian
Data yang digunakan dalam penelitian ini adalah data sekunder dari Badan Pusat Statistik (BPS). Data yang diambil dalah data tentang indeks pembangunnan manusia, rata-rata lama sekolah, harapan lama sekolah, angka harapan hidup, dan pengeluaran perkapita yang disesuaikan dari tahun 2013. Jumlah data yang diteliti 511 data tiap variabel.
Variabel Penelitian merupakaan istilah yang sangat popular dalam melakukan penelitan. Dalam sebuah penelitian, umumnya memiliki 2 jenis variabel yaitu variabel respon dan variabel prediktor. Variabel penelitian yang digunakan dalam penelitian ini adalah Indeks Pembangunan Manusia (IPM) sebagai variabel respon serta angka harapan hidup, rata-rata lama sekolah, harapan lama sekolah dan pengeluaran perkapita yang disesuaikan sebagai variabel predictor merujuk pada penelitian Moh Yamin Darsyah dan Rochdi Wasono (2013). Varibel dalam penelitian ini terdiri atas dua bagian yaitu variabel respon (Y) dan variabel prediktor (X).Variabel Respon terdiri dari empat kategori yaitu:
ALGORIT M A K-NEAREST NEIG HBOR S CLASSI FIER UNTU K KLASI FI KASI INDE KS PEMB ANG UN AN MANUSI A DI INDO N ESIA
I Gusti Ngurah Lanang Wijayakusuma
102 x = 1 untuk daerah dengan IPM rendah x<60
x = 2 untuk daerah dengan IPM sedang x>=60 x<=70 x = 3 untuk daerah dengan IPM tinggi x>70 dan x<=80 x = 4 untuk daerah dengan IPM sangat tinggi x >80 3.2. Pembahasan
3.2.1. Pembersihan Data
Data yang digunakan merupakan data angka harapan hidup, rata sekolah, harapan lama sekolah, pengeluaran perkapita, dan indeks pembangunan manusia se-Indonesia dari data BPS tahun 2013. Di dalam data tersebut terdapat data-data yang tidak memiliki nilai. Seperti, Malinau, Bulungan, Kota Tarakan dan beberapa kota lainnya. Dari 554 kota terdapat 43 kota yang datanya tidak memiliki nilai.
Data yang di eliminasi adalah data rata-rata Indonesia, 34 Provinsi, dan 8 data kabupaten yang kosong (BULUNGAN, BUTON SELATAN, BUTON TENGAH, KOTA TARAKAN, MALINAU, MUNA BARAT, NUNUKAN ,TANA TIDUNG). Sehingga diperoleh 511 kota yang memiliki nilai setelah dilakukan pembersihan.
3.2.2. Pengelompokan Nilai Data IPM
Data IPM dari BPS merupakan data berupa nilai dengan range dari 0-100. Data tersebut kemudian diklasifikasikan sesuai dengan pengklasifikasian IPM menurut BPS menjadi 4 kategori, rendah, sedang, tinggi dan sangat tinggi.
Kemudian data di konversi kedalam variable numerik merujuk pada penelitian Moh Yamin Darsyah dan Rochdi Wasono (2013), yaitu :
x = 1 untuk daerah dengan IPM rendah x<60
x = 2 untuk daerah dengan IPM sedang x>=60 x<=70 x = 3 untuk daerah dengan IPM tinggi x>70 dan x<=80 x = 4 untuk daerah dengan IPM sangat tinggi x >80
Persiapan 554 data harapan hidup, rata sekolah, harapan lama sekolah, pengeluaran perkapita, dan indeks pembanguna n manusia se-Indonesia Eliminasi data 34 provinsi dan data rata-rata Indonesia Eliminasi data 8 kabupaten yang kosong 511 data kabupaten di Indonesia
Prosiding SEMINAR NASIONAL SAINSTEK 2018 : 95-107 ISSN: 2541-0636
103 3.2.3. Proses Klasifikasi Data
Berikut proses klasifikasi data yang telah disiapkan
Nilai IPM tersuai y = nilai IPM tersuai Data Indikator IPM
a = pengeluaran perkapita b = angka harapan hidup c = rata-rata sekolah d = harapan lama sekolan
Dataset
Pemecahan data urut
Data Nilai IPM x = nilai IPM Pengelompokan nilai IPM x<60: rendah x>=60 x<=70: sedang x>70 dan x<=80: tinggi x >80: sangat tinggi Transformasi dan pembagian data pembelajaran (train) dan data pengujian (test) rasio 4:1 k-Optimal k-NN Model Optimun Klasifikasi IPM Evaluasi MSE K-flod cross validations 1≤k-NN≤200 Dengan 5-Vold Cross validations Melakukan perhitung jarak k-tetangga terdekat
ALGORIT M A K-NEAREST NEIG HBOR S CLASSI FIER UNTU K KLASI FI KASI INDE KS PEMB ANG UN AN MANUSI A DI INDO N ESIA
I Gusti Ngurah Lanang Wijayakusuma
104 3.2.4. Klasifikasi Data Menggunakan k-NN
Data diklasifikasi dengan k-Nearest Neighbours dengan jumlah data pembelajaran adalah 80% (408) dari semua data. Setiap data IPM tersuai di proyeksikan dalam ruang dimensi 4 dengan sumbu angka harapan hidup (AHH), pengeluaran perpakita (PP), rata sekolah (RS), dan harapan lama sekola (HLS).
a. Melakukan proyeksi data pembelajaran
Catatan: Dilakukan untuk setiap data train b. Melakukan klasifik data train terdekat
Hal pertama yang dilakukan adalah dengan melakukan proyeksi data train ke dalam proyeksi data pembelajaran di ruang dimensi 4.
Test1 (w1, x1, y1, z1) IPM terdekat (wt, xt, yt, zt)
c. Menentukan jumlah k tetangga terdekat
Dalam penentuan k, digunakan nilai 1-200 dengan menggunakan k-Vold Cross Validations
d. Hasil klasifikasi data
Hasil klasifikasi ditentukan dengan dari kategori IPM terbanyak dari k IPM terdekatnya.
3.2.5. Penentuan Nilai k-Optimal
Penentuan nilai k-Optimal dilakukan untuk membuat nilai paling akurat. Metode yang digunakan dalam menentukan k-Optimal adalah metode k-Vold Cross Validation. Nilai k yang digunakan pada metode ini adalah 5. Metode ini membagi data menjadi 5 bagian yang dilakukan pengujian dengan rasio train: test = 8:2
Jarak sumbu PP (x) (w,x,y,z) Jarak sumbu AHH (w) Jarak sumbu RS (y) Jarak sumbu HLS (z)
Prosiding SEMINAR NASIONAL SAINSTEK 2018 : 95-107 ISSN: 2541-0636
105 Warna merah : data pembelajatan (train) Warna putih : data pengujian (test)
1 2 3 4 5
1 2 3 4 5
1 2 3 4 5
1 2 3 4 5
1 2 3 4 5
Setiap vold cross validation melakukan perhitung untuk l = 511, memperoleh 𝑀𝑆𝐸𝐶𝑉 = 1 5 1 511∑ ∑(𝑡𝑙 𝑘− 𝑦 𝑙𝑘)2 511 𝑖=1 5 𝑘=1
Dengan t nilai target dan y nilai klasifikasi model. Kemudian diperoleh MSE
𝑀𝑆𝐸𝑣𝑎𝑙 = 1 511∑ (𝑡𝑚 𝑣𝑎𝑙− 𝑦 𝑚𝑣𝑎𝑙)2 511 𝑚=1
Dengan tval nilai target valid dan yval nilai prediksi valid
Dengan melakukan proses di atas terhadap algoritma k-NN dengan banyak tetanga terdekatnya k 1-200. Diperoleh nilai MSE pada grafik berikut :
Dari grafik tersebut di dapat nilai k-Optimalnya adalah 22. Sehingga k yang akan digunakan dalam proses k-Neirest Neighbor Classifier adalah k=22. Dengan menggunakan k=22 diperoleh MSE 18,23%. Nilai ini cukup baik untuk melakukan klasifikasi data IPM, karena efesiensi waktu yang diberikan dapat mempercepat klasifikasi IPM yang tergolong lama.
ALGORIT M A K-NEAREST NEIG HBOR S CLASSI FIER UNTU K KLASI FI KASI INDE KS PEMB ANG UN AN MANUSI A DI INDO N ESIA
I Gusti Ngurah Lanang Wijayakusuma
106 3.2.6. Hasil Klasifikasi IPM
Dengan menggunakan k = 22 pada k-Nearest Neighbors, dibuat plot 2 dimensi. Ini menunjukkan sebaran IPM di Indonesia berdasarkan indikator-indikatornya dan daerah klasifikasi dari metode k-NN
***Catatan: Kesalahan klasifikasi ditunjukkan oleh adanya daerah klasifikasi yang memuat bukan IPM dari daerah tersebut. Dimana titik-titik tersebut merupakan data aktual (training).
Klasifikasi pada plot diatas menunjukkan semakin tinggi pengeluaran perkapita suatu kabupaten, maka IPM nya juga semakin tinggi. Namun untuk angka harapan hidup IPM rendah, sedang, dan tinggi secara umum hampir sama 57,5-70, walaupun terdapat pencilan terhadap IPM rendah AHH < 57,5. Sedangkan IPM tinggi AHH > 70.
Klasifikasi pada plot diatas secara umum menujukkan semakin tinggi rata-rata sekolah dan harapan lama sekolah berbanding lurus dengan tingkat IPM suatu kabupaten. Namun terdapat kesenjangan pada IPM sedang dimana daerah klasifikasi juga memuat banyak titik IPM tinggi dan rendah.
Keterangan titik IPM Merah : rendah Hijau : sedang Biru :Tinggi
Kuning: Sangat Tinggi Daerah klasifikasi IPM Merah : rendah
Hijau : sedang Biru :Tinggi
Kuning: Sangat Tinggi
Keterangan titik IPM Merah : rendah Hijau : sedang Biru :Tinggi Kuning: Sangat Tinggi Daerah klasifikasi IPM Merah : rendah Hijau : sedang Biru :Tinggi Kuning: Sangat Tinggi
Prosiding SEMINAR NASIONAL SAINSTEK 2018 : 95-107 ISSN: 2541-0636
107 4. SIMPULAN DAN SARAN
4.1. Simpulan
Model klasifikasi IPM di Indonesia dengan k-Nearest Neighbors yang optimal menggunakan pengujian k-Vold Cross Validations dengan kv = 5. Data yang di split yang menghasilkan rasio train:test = 4:1 yaitu 408 data train dan 103 data test. Diperoleh nilai k untuk tetangga terdekat 22 dengan pengujian pada interval kn 1-200. Hasil menunjukkan MSE= 18,23%. Hasil ini cukup baik untuk melakukan klasifiksi IPM di Indonesia.
Klasifikasi IPM kabupaten di Indonesia menggunakan k-Nearest Neighors dapat digunakan sebagai referensi untuk menentukan IPM suatu kabupaten/kota di masa depan. Hal ini disebabkan karena efesiensi waktu yang diberikan untuk melakukan klasifikasi IPM yang termasuk lama. Di tahun 2017 pemerintah Indonesia hanya dapat memberikan klasifikasi lengkap untuk tahun 2013, itu pun dengan 8 data kabupaten yang tidak valid.
4.2.Saran
Diharapkan penelitian ini dapat dijadikan referensi untuk melakuan klasifikasi IPM di Indonesia secara berkala. Serta dapat dijadikan referensi terkait untuk penelitian klasifikasi IPM selanjutnya.
DAFTAR PUSTAKA
[1] Natingga, Dávid. Data Science Algorithms in a Week. Livery Place. 2017: Packt
[2] Sutton, Oliver. Introduction to k Nearest Neighbour Classification and Condensed Nearest Neighbour Data Reduction. 2012: University of Leicaster
[3] BPS. Indeks Pembangunan Manusia (Human Development Index). 2014:BPS [4] BPS. Indeks Pembangunan Manusia Menurut Kabupaten/Kota. 2015:BPS
[5] Moh Yamin Darsyah dan Rochdi Wasono. Pendugaan IPM Kecil di Kota Semarang dengan Pendekatan Non Parametrik. 2013